If you’re into AI, you’ve probably heard of DeepSeek R1. It’s currently trending in the LLM space and outperforming both open and closed-source models.
To make everything easy we will use hand-drawn flowcharts and simple calculations to help clarify your concepts from the ground up.
In fact, we’ll use the string What is 2 + 3 * 4? throughout this blog as an example to walk you through each component of the DeepSeek tech report.
- Quick Overview
- How DeepSeek V3 (MOE) Thinks?
- DeepSeek V3 as the Policy Model (Actor) In RL Setup
- How GRPO Algorithm Works?
- Objective Function of GRPO
- Reward Modeling for DeepSeek R1 Zero
- Training Template for Reward
- RL Training Process for DeepSeek R1 Zero
- Two main problems with R1 Zero
- Cold Start Data
- Supervised Fine-Tuning
- Reasoning-Oriented RL
- Rejection Sampling
- RL for All Scenarios
- Distillation
So, before going into the technical details, a quick overview is that DeepSeek-R1 isn’t trained from scratch, like, from nothing. Instead, they started with a pretty smart LLM they already had DeepSeek-V3 but they wanted to make it a reasoning superstar.
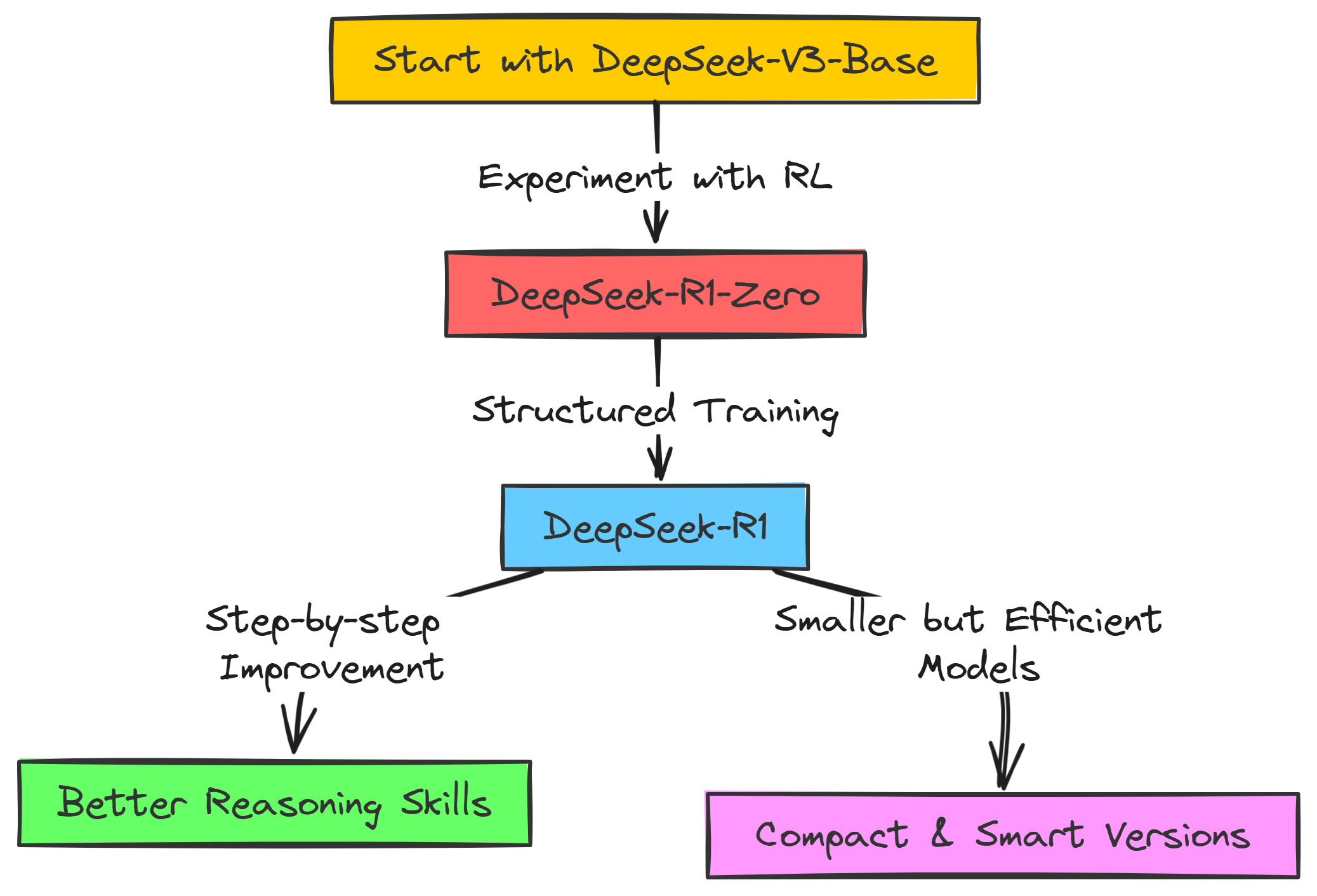
To do that, they used Reinforcement Learning, or RL for short where you reward the LLM when it does something good for reasoning while punish it otherwise.
But it’s not just one simple training session. It’s like a whole bunch of steps, a pipeline they call it. They first tried just pure RL to see if reasoning would pop up by itself that was DeepSeek-R1-Zero, kinda an experiment. Then for the real DeepSeek-R1, they made it more organized with different stages. They give it some starting data to get it going, then do RL, then more data, then more RL… it’s like leveling up, step by step!
The whole point is to make these language models way better at thinking through problems and giving you smart answers, not just spitting out words.
So yeah, that’s the super short version before we look into the crazy details of each step.
As I previously said, DeepSeek R1 training is not built from scratch but they use DeepSeek V3 as a base model. So we need to understand how V3 works and why it is called MOE?
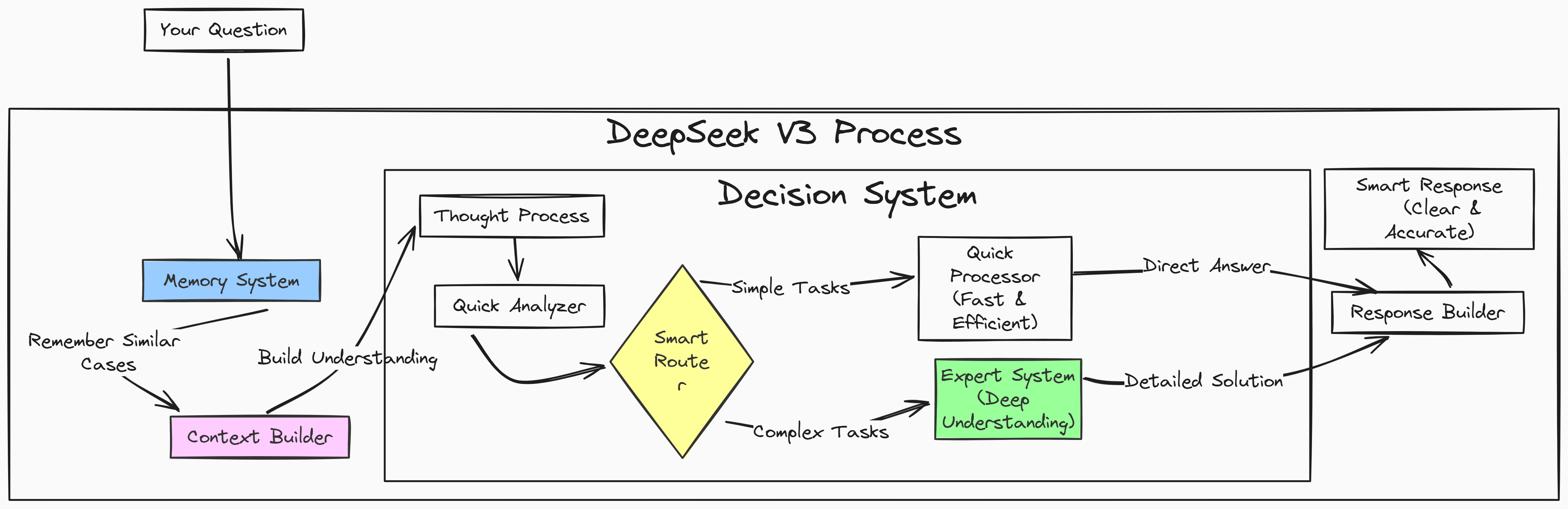
DeepSeek V3 operates with two main paths. When you input a question, it first goes through a memory system that quickly builds context by finding relevant information. Think of it as quickly recalling similar situations you’ve encountered before.
It’s main strength lies in its decision making system. After understanding your input, it uses a smart router that decides between two paths: a quick processor for straightforward tasks (like simple questions or common requests) and an expert system for complex problems (like analysis or specialized knowledge).
This router is what makes the DeepSeek V3 a mixture of experts model (MOE)
because it dynamically directs each request to the most suitable expert component for efficient processing.
Simple questions get quick, direct answers through the fast path, while complex queries receive detailed attention through the expert system. Finally, these responses are then combined into clear, accurate outputs.
Now that we have looked into an overview of how DeepSeek v3 thinks, and it is a starting point for the DeepSeek R1 implementation, by a starting point I meant that it has created the DeepSeek R1 zero version, an initial version which has some errors in it before the final version was created.
The initial version (R1 Zero) was created using Reinforcement Learning where DeepSeek v3 acts as an RL agent (actor who takes action). Let’s first visualize how it works.
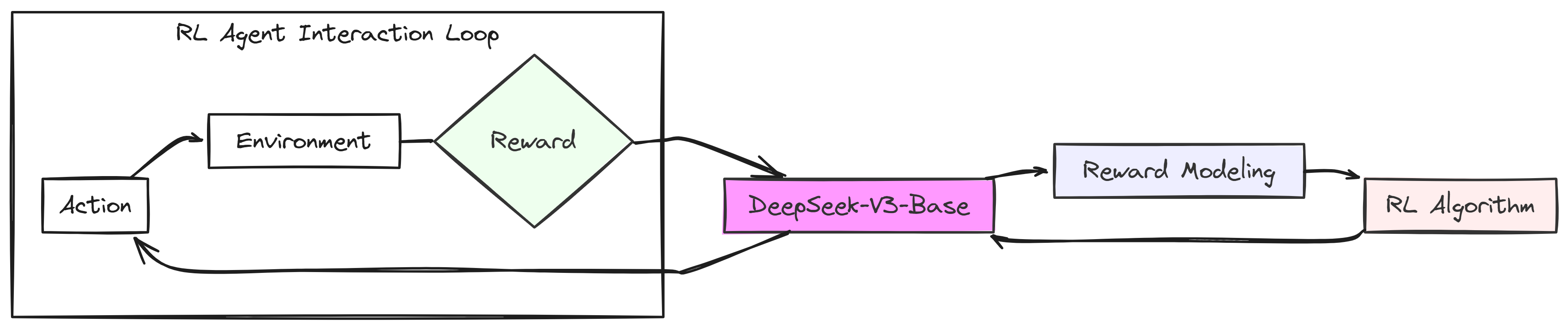
The RL agent (DeepSeek V3) starts by taking an Action, which means it generates an answer and some reasoning for a given problem that’s put into its Environment. The Environment, in this case, is simply the reasoning task itself.
After taking an action, the Environment gives back a Reward. This Reward is like feedback, it tells DeepSeek V3 base model how good its action was. A positive Reward means it did something right, maybe got the answer correct or reasoned well. This feedback signal then goes back to DeepSeek-V3-Base, helping it learn and adjust how it takes actions in the future to get even better Rewards.
In the upcoming sections, we’ll discuss this RL setup with reward model and the RL algorithm they used and try to solve it using our text input.
Training LLMs is extremely computationally expensive and RL adds even more complexity.
So, there are many RL algos available, but traditional RL use something called a “critic to help the main decision making part (“actor” i.e., DeepSeek V3) as you already know. This critic is usually just as big and complex as the actor itself, which basically doubles the amount of computational cost.
However, GRPO does things differently because it figures out a baseline, a kind of reference point for good actions directly from the results it gets from a group of actions. Because of this, GRPO doesn’t need a separate critic model at all. This saves a lot of computation and makes things more efficient.
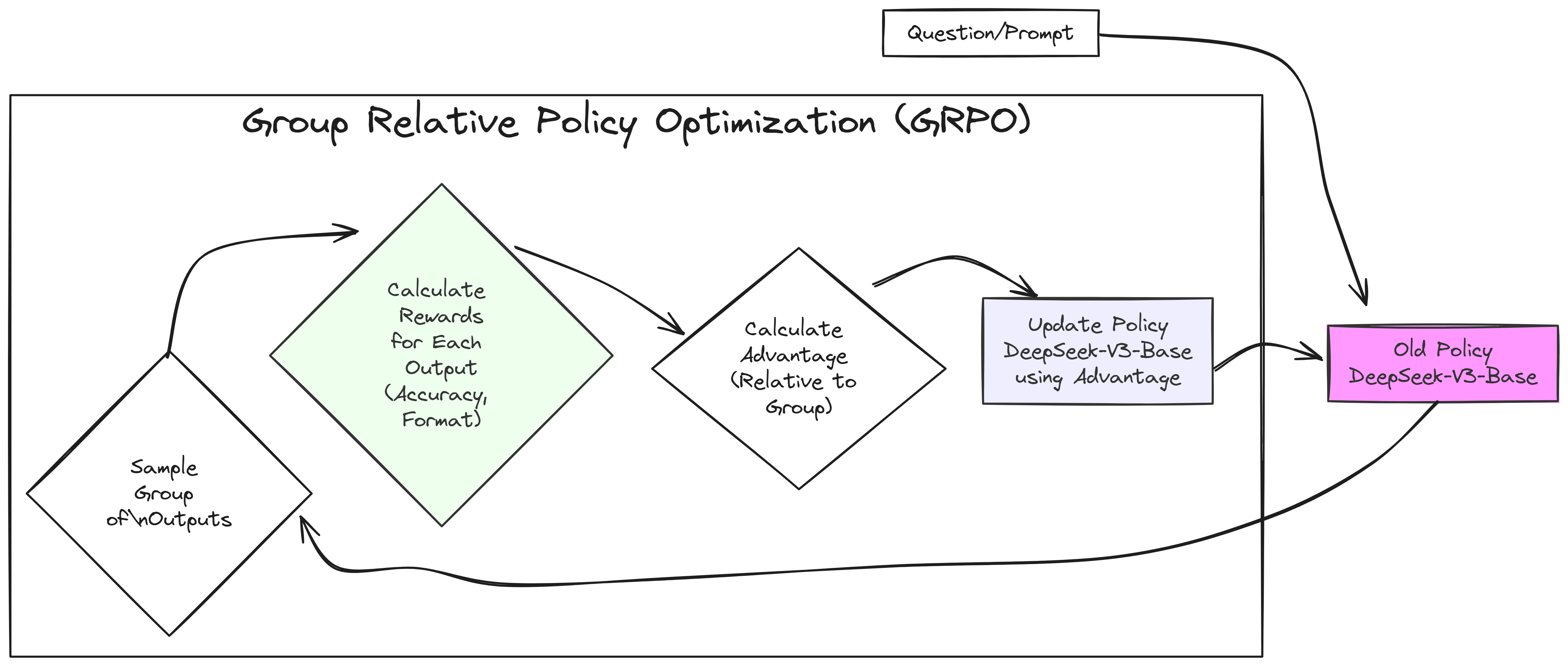
It starts with a question or prompt given to a model, called the “Old Policy”. Instead of just getting one answer, GRPO instructs the Old Policy to generate a group of different answers to the same question. Each of these answers is then evaluated and given a reward score, reflecting how good or desirable it is.
GRPO calculates an “Advantage for each answer by comparing it to the average quality of the other answers within its group. Answers better than average get a positive advantage, and worse ones get a negative advantage. Crucially, this is done without needing a separate critic model.
These advantage scores are then used to update the Old Policy, making it more likely to produce better-than-average answers in the future. This updated model becomes the new “Old Policy” and the process repeats, iteratively improving the model.
Obviously, behind this GRPO, there is complex math 💀 In one word, we can call it the objective function behind GRPO.
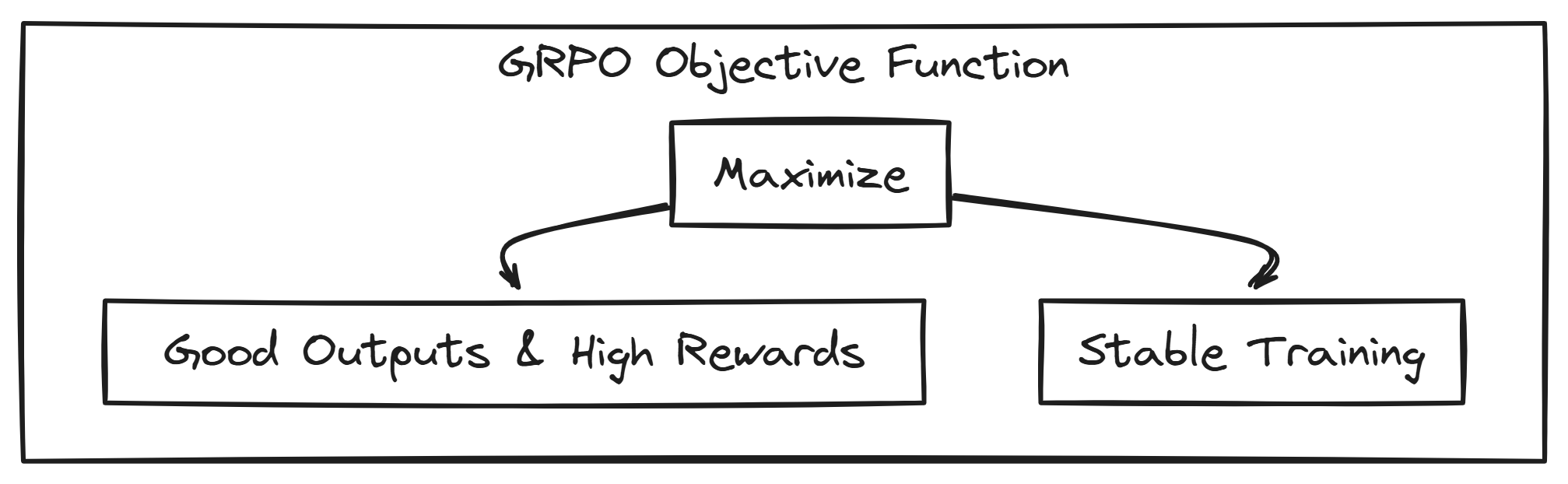
GRPO’s objective function has two goals, one is to give good outputs (high rewards) while also ensuring the training process is stable and doesn’t go out of control. The original function is scary but we will rewrite it into more simpler form without loosing its actual meaning.

Let’s break it down piece by piece. First AverageResult[…] or 1/n[…] refers to evaluating what happens on average across many different situations. We present a model with various questions. For each question, the model generates a group of answers. By looking at these answers across many questions and their respective groups of answers, we can calculate an average result.
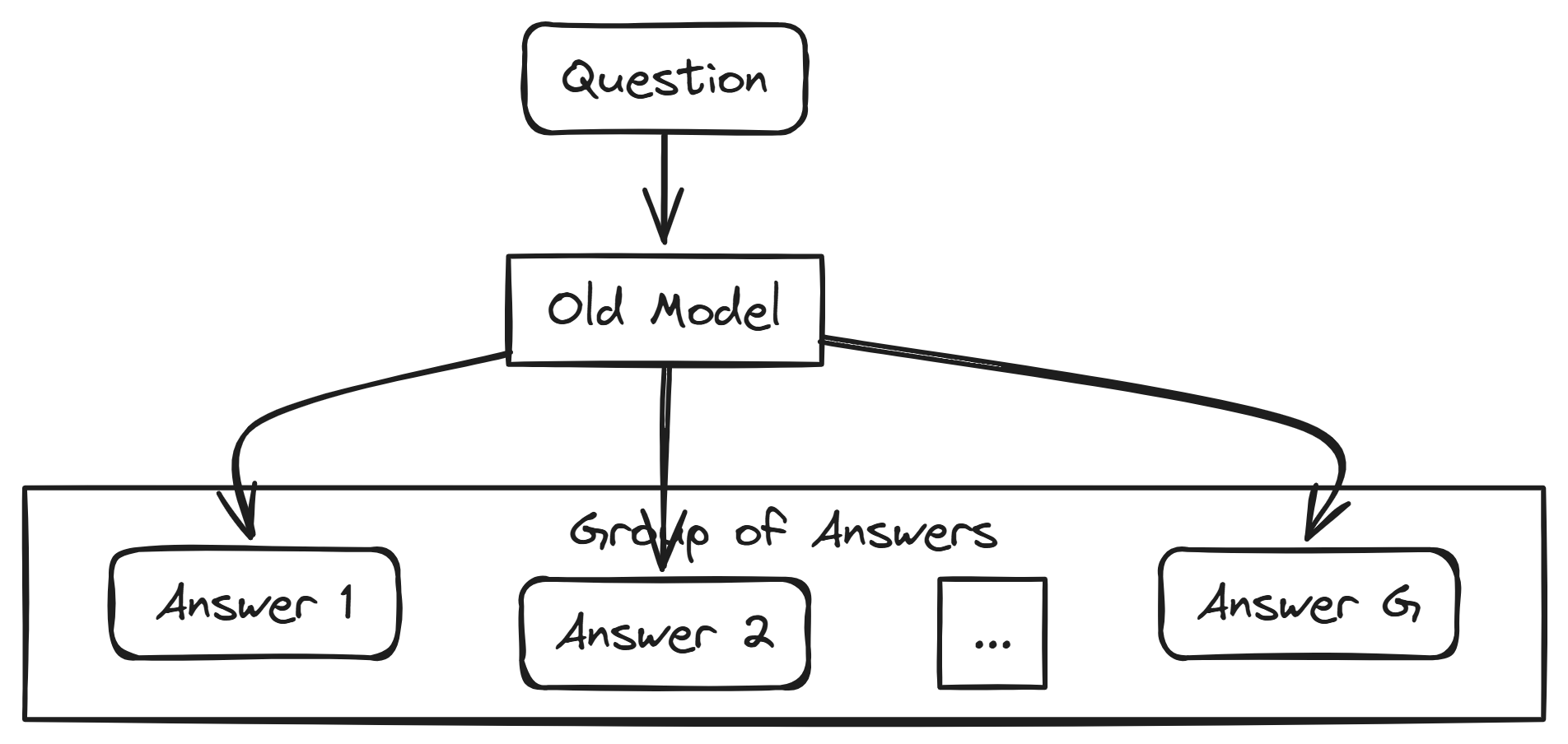
In the process, the question is fed to an old model, which produces multiple answers (e.g., Answer 1, Answer 2, …, Answer G). These answers form a group, and by evaluating this group across different questions, we derive the average outcome.
SumOf[..] or ∑[…] refers to performing a calculation for each individual answer in a group of answers (e.g., Answer 1, Answer 2, …, Answer G), and then adding the results of all those calculations together.
Then comes the RewardPart. This is the part that rewards the model for giving good answers. It’s a bit more complex inside, so let’s zoom in:

ChangeRatio tells us whether the chance of giving this answer increased or decreased with the new model. Specifically, it looks at:
-
Chance of Answer with New Model: How likely the new model is to give a particular answer.
-
Chance of Answer with Old Model: How likely the old model was to give the same answer.
Next, the Advantage score tells how much better or worse an answer is compared to other answers in the same group. It’s calculated as:
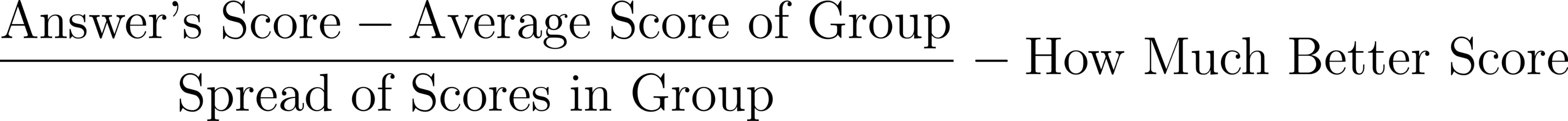
-
Answer’s Score: The reward given to the specific answer.
-
Average Score of Group: The average reward score of all answers in the group.
-
Spread of Scores in Group: How much variation exists in the scores of answers in the group.
The Advantage score tells us if an answer is better than average within the group, and how much better it is.
LimitedChangeRatio is a modified version of the ChangeRatio. It ensures that the ChangeRatio doesn’t swing too far, keeping the model’s learning stable. The limit is determined by a small value called Epsilon, h which make sure that the change isn’t too drastic.
Finally, the **SmallerOf[ … ] ** function picks the smaller value between two options:
-
ChangeRatio × Advantage: The change in likelihood of an answer, multiplied by its advantage score.
-
LimitedChangeRatio × Advantage: Same, but with a limited change ratio.
By selecting the smaller value, the model ensures that the learning process stays smooth and doesn’t overreact to large changes in performance. The result is the “good answer reward” which encourages the model to improve without overcompensating.
Finally, we subtract StayStablePart. This is about keeping the new model from changing too wildly from the old one. It’s not very complex but let’s zoom in it:

DifferenceFromReferenceModel measures how much the New Model differs from the Reference Model (which is often the Old Model). Essentially, it helps evaluate the changes that the new model has made compared to the previous one.
The Beta value controls how much the model should remain close to the Reference Model. A larger Beta means the model will prioritize staying closer to the old model’s behavior and output, preventing too much deviation. Let’s visualize it:

So in short StayStablePart makes sure the model learns gradually and doesn’t make crazy jumps.
Now that we have understand the the main theoretical concepts, let’s use our text input to learn how this reward modeling is working that created R1 Zero.
Remember, for R1 Zero, they kept things simple and direct. Instead of using a fancy neural network to judge the answers (like they might in later stages), they used a rule-based reward system.
For our math problem: “What is 2 + 3 * 4?”
The system knows the correct answer is 14. It will look at the output generated by DeepSeek V3 (our RL agent) and specifically check inside the <answer> tags.

If the <answer> tag contains “14” (or something numerically the same), It gets a positive reward, let’s say +1. If it’s wrong, it gets 0 reward, or possibly even a negative reward (though the paper focuses on 0 for simplicity at this stage).
But DeepSeek R1 Zero also needed to learn to structure its reasoning properly and for that <think> and <answer> tags can be used, there’s a smaller reward for getting the format right.
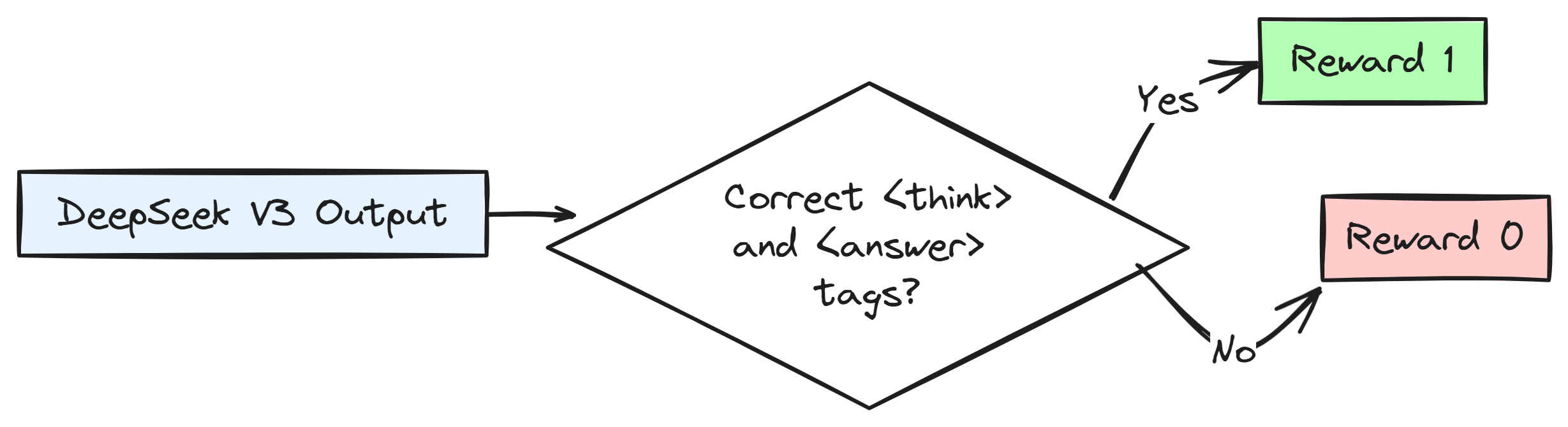
Check if the model output correctly encloses the reasoning process within … and the final answer within ….
DeepSeek R1 paper explicitly mentions avoiding neural reward models for
DeepSeek-R1-Zero to prevent reward hacking and reduce complexity in this
initial exploratory phase
For the reward model to be effective, researchers designed a specific training template. This template acts as a blueprint, instructing DeepSeek-V3-Base on how to structure its responses during the Reinforcement Learning process.
Let’s look at the original template and break it piece by piece:
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {prompt}. Assistant:
The {prompt} is where we plug in our math problem, like What is 2 + 3 * 4?. The important part is those <think> and <answer> tags. This structured output is super important for researchers to peek into the model’s reasoning steps later on.
When we train DeepSeek-R1-Zero, we feed it prompts using this template. For our example problem, the input would look like:
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: What is 2 + 3 * 4?. Assistant:
And we expect the model to generate an output that conforms to the template, like:
<think>
Order of operations:
multiply before add. 3 * 4 = 12. 2 + 12 = 14
</think>
<answer>
14
</answer>Interestingly, the DeepSeek team intentionally kept this template simple and focused on structure, not on telling the model how to reason.
Although the paper doesn’t specify the exact initial dataset for RL pre-training, we assumed that it should be be reasoning focused.
The first step they did was to generate multiple possible outputs using the old policy which is the DeepSeek-V3-Base model before reinforcement learning updates. In one training iteration, we are assuming GRPO samples a group of G = 4 outputs.
For example, the model produces the following four outputs for our text input What is 2 + 3 * 4?
-
o1: 2 + 3 = 5, 5 * 4 = 20 20 (Incorrect order of operations)
-
o2: 3 * 4 = 12, 2 + 12 = 14 14 (Correct)
-
o3: 14 (Correct, but missing tags)
-
o4: ...some gibberish reasoning... 7 (Incorrect and poor reasoning)

Each output will be evaluated and assigned a reward based on correctness and reasoning quality.
To guide the model towards better reasoning, rule-based reward system comes into play. Each output is assigned a reward based on:
-
Accuracy Reward: Whether the answer is correct.
-
Format Reward: Whether the reasoning steps are correctly formatted with
<think>tags.
Suppose the rewards are assigned as follows:
| Output | Accuracy Reward | Format Reward | Total Reward |
|---|---|---|---|
| o1 (Incorrect reasoning) | 0 | 0.1 | 0.1 |
| o2 (Correct with reasoning) | 1 | 0.1 | 1.1 |
| o3 (Correct but missing tags) | 1 | 0 | 1.0 |
| o4 (Incorrect and poor reasoning) | 0 | 0.1 | 0.1 |
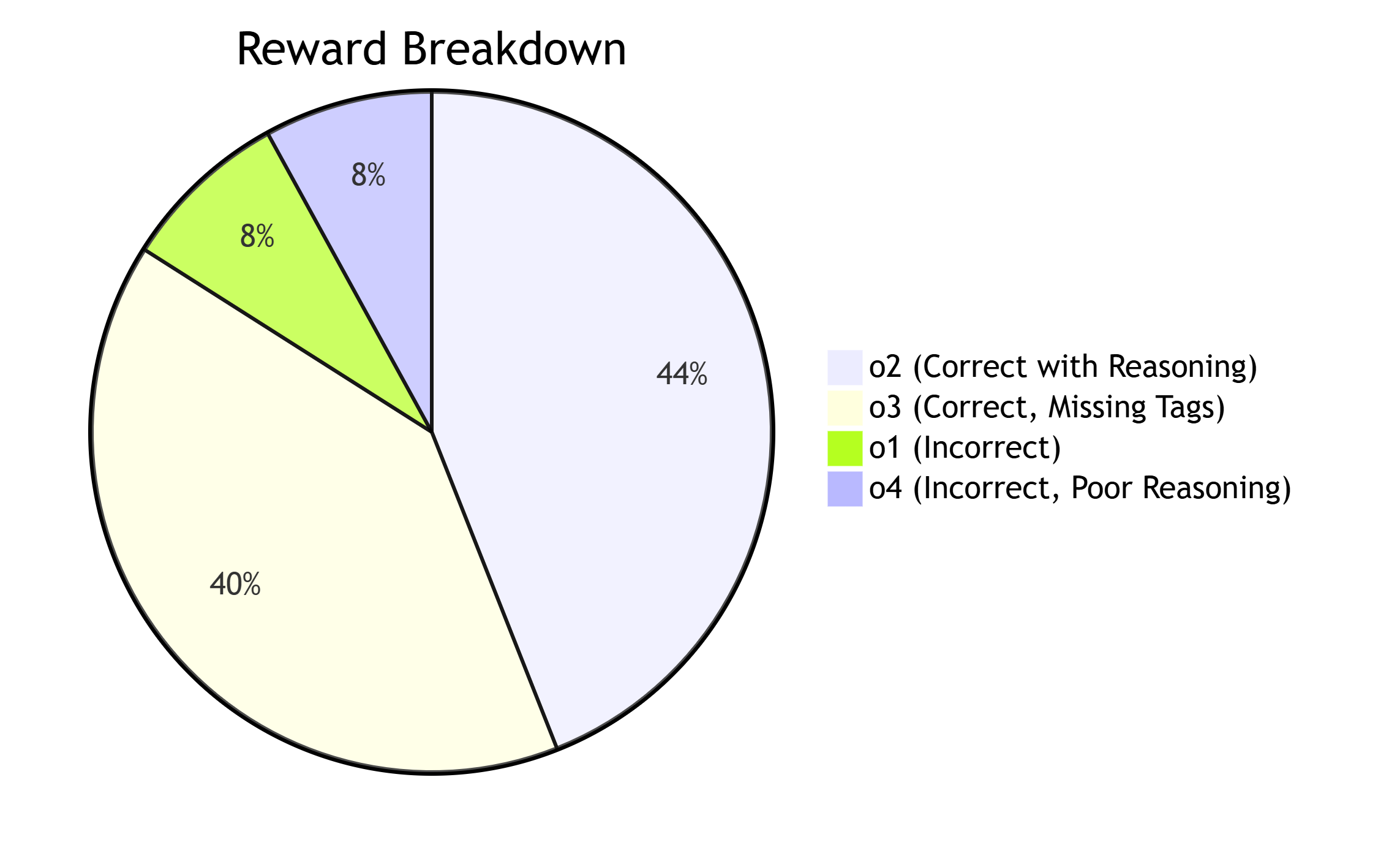
The model should learn to favor outputs with higher rewards while reducing the probability of generating incorrect or incomplete outputs.
To determine how much each output improves or worsens model performance, we compute the advantage using the reward values. The advantage helps in optimizing the policy by reinforcing better outputs.
For that, let’s calculate the mean first reward.

Standard Deviation (approximated) = 0.5 Now to calculate the advantage of each output.

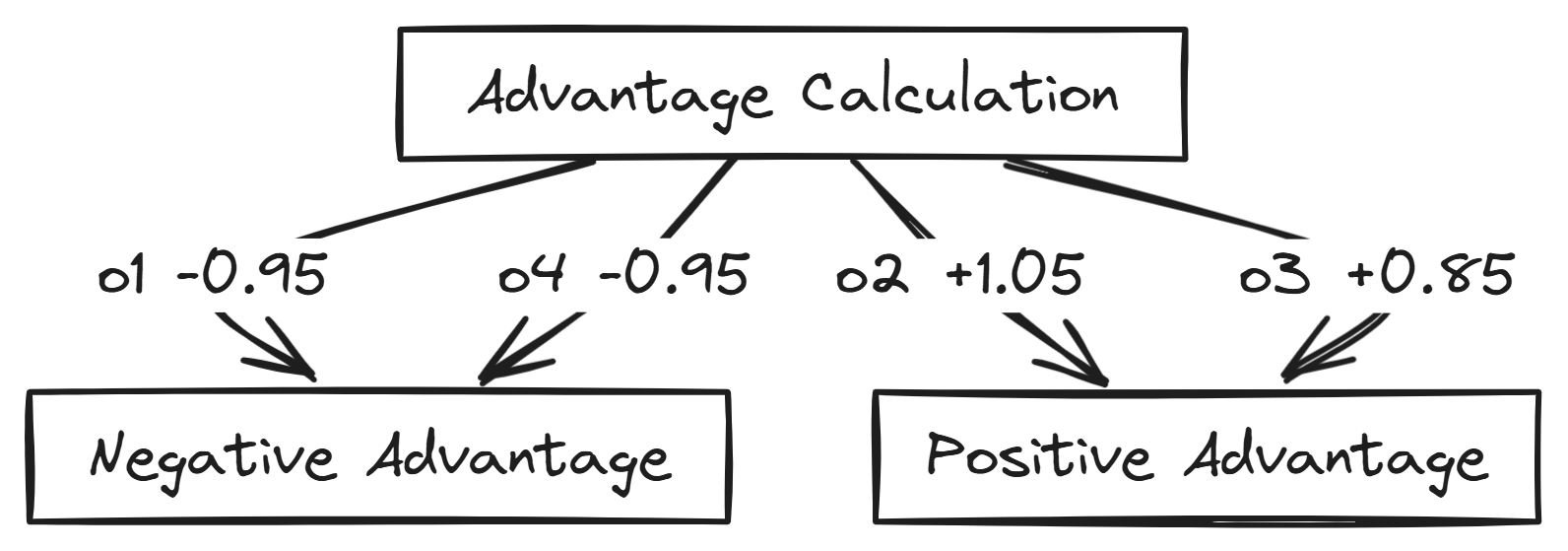
Outputs o2 and o3 receive positive advantages, meaning they should be encouraged. Outputs o1 and o4 receive negative advantages, meaning they should be discouraged.
GRPO then uses the calculated advantages to update the policy model (DeepSeek-V3-Base) to *increase *the probability of generating outputs with high advantages (like o2 and o3) and decrease the probability of outputs with low or negative advantages (like o1 and o4).
Update adjusts the model weights based on:
-
Policy Ratios: Probability of generating an output under the new vs. old policy.
-
Clipping Mechanism: Prevents overly large updates that could destabilize training.
-
KL-Divergence Penalty: Ensures that updates do not deviate too far from the original model.
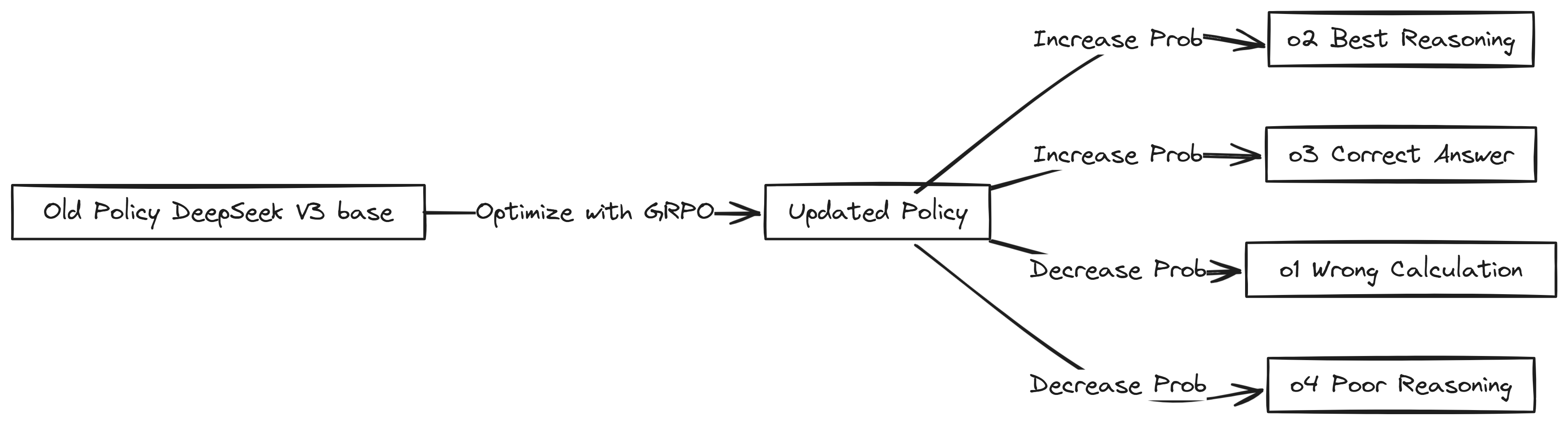
This ensures that in the next iteration, the model will be more likely to generate correct reasoning steps while reducing incorrect or incomplete responses.
So RL is an iterative process. The steps above are repeated thousands of times using different reasoning problems. Each iteration gradually improves the model’s ability to:
-
Perform correct order of operations
-
Provide logical reasoning steps
-
Use the proper format consistently
The overall training loop looks like this:

Over time, the model learns from its mistakes, becoming more accurate and effective at solving reasoning problems. 🚀
After DeepSeek-R1 Zero was created using RL training process on V3 model, Researches saw the trained model performed really well on reasoning tests, even scoring similarly to more advanced models like OpenAI-01–0912 on tasks like AIME 2024. This showed that using reinforcement learning (RL) to encourage reasoning in language models is a promising approach.
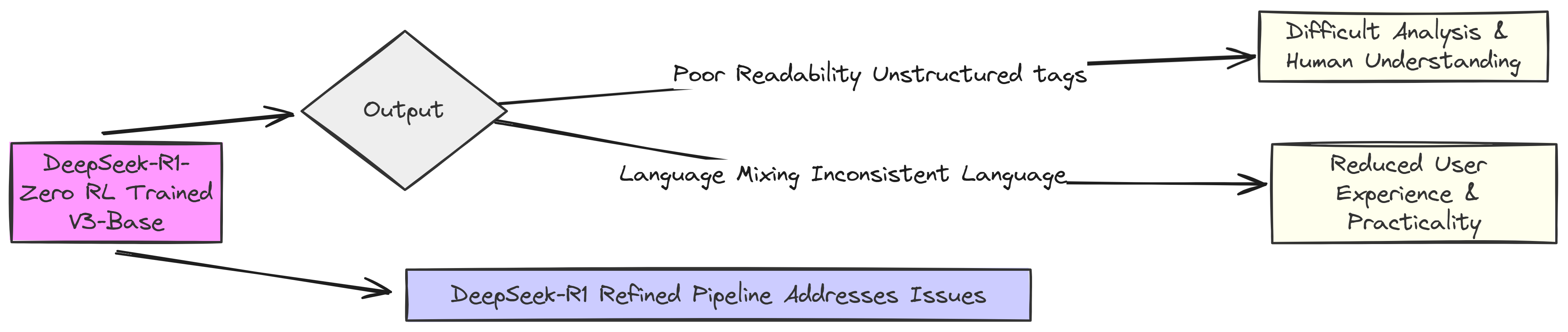
But they also noticed DeepSeek-R1-Zero had some key issues that needed fixing for real world use and wider research.
Researchers of DeepSeek states that the template is intentionally simple and structurally focused. It avoids imposing any content-specific constraints on the reasoning process itself. For example, it doesn’t say:
-
“You must use step-by-step reasoning” (It just says “reasoning process” leaving it open to the model to define what that means).
-
“You must use reflective reasoning”
-
“You must use a specific problem-solving strategy”
The main problem was that the reasoning processes inside the <think> tags were hard to read, making it tough for humans to follow and analyze.
Another issue was language mixing, when asked multi-lingual questions, the model sometimes mixed languages in the same response, leading to inconsistent and confusing outputs. If you asked it questions in, say, Spanish. Suddenly, its “thinking” would be a jumbled mix of English and Spanish, not exactly polished! These problems, messy reasoning and language confusion, were the clear roadblocks.
These are the two main reasons they transformed their initial R1 Zero Model into the R1
In the next section, we’ll go over how they improved their R1 zero model to the R1 model, which boosted its performance and helped it outperform all other models, both open-source and closed.
So to fix R1 Zero issues and really get DeepSeek reasoning properly, researchers performed a Cold Start Data Collection and included Supervised Fine Tuning.
You can think of it as giving the model a good foundation in reasoning before the really intense RL training. Basically, they wanted to teach DeepSeek-V3 Base what good reasoning looks like and how to present it clearly.
They gave DeepSeek-V3 Base a few examples of questions along with really detailed, step-by-step solutions, called Chain-of-Thought (CoT). The idea was for the model to learn by example and start imitating this step-by-step reasoning style.
Let’s visually understand this example based learning:
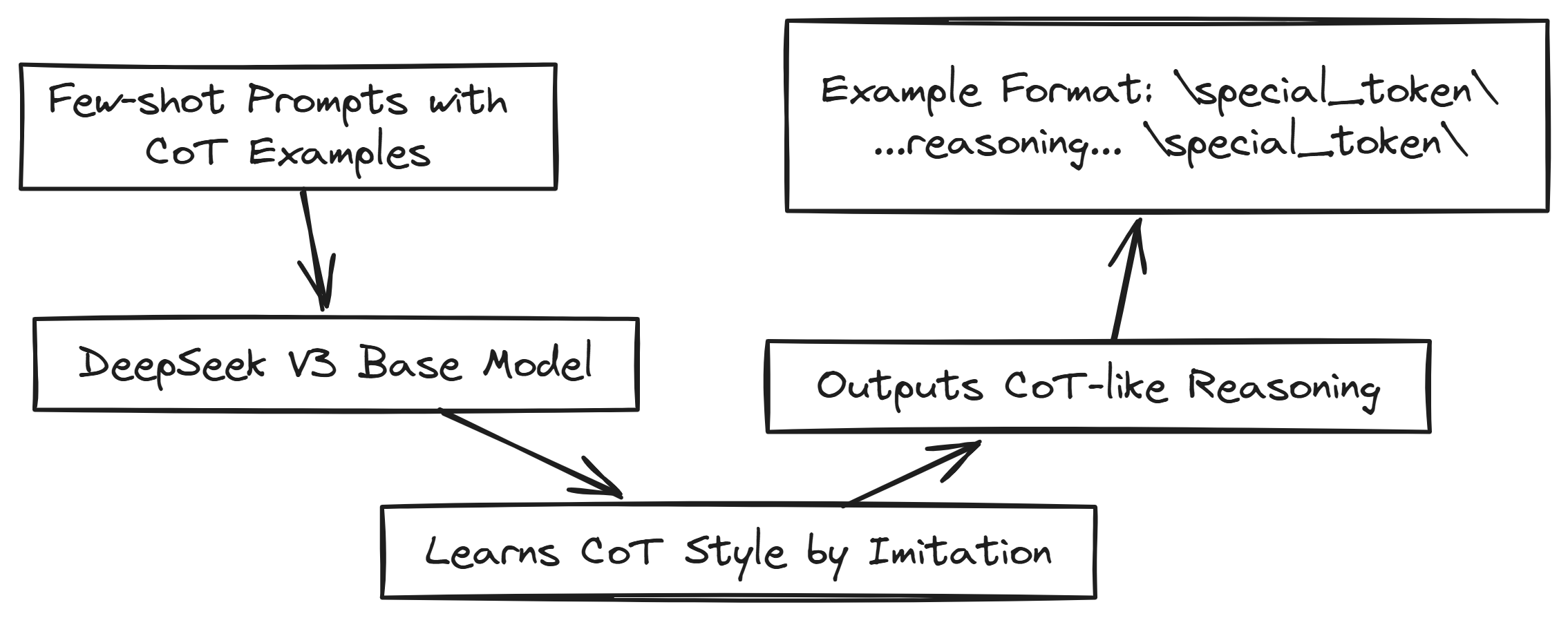
For our example problem What is 2 + 3 * 4?, they might show prompts like this:
Problem Examples with Solutions:
Problem: What's the square root of 9 plus 5?
Solution: | special_token | First, find the square root of 9, which is 3.
Then, add 5 to 3. 3 + 5 equals 8. | special_token | Summary: The answer is 8.
Problem: Train travels at 60 mph for 2 hours, how far?
Solution: | special_token | Use the formula: Distance = Speed times Time.
Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles.
| special_token | Summary: Train travels 120 miles.
Problem: What is 2 + 3 * 4?
Solution:
Those | special_token | things are just markers to separate the reasoning steps from the summary, making it clear for the model to learn the structure.
After seeing these examples, the model should learn to give answers in a similar format, like this for What is 2 + 3 * 4?
| special_token | Following order of operations (PEMDAS/BODMAS),
do multiplication before addition. So, first calculate 3 * 4 = 12.
Then, add 2 to 12. 2 + 12 = 14. | special_token | Summary: The answer is 14.
Another way they gathered data was by directly prompting the model to not only solve problems but also to explicitly show its reasoning step-by-step and then double-check its answer.
This was meant to promote more careful and thoughtful problem-solving.
For What is 2 + 3 * 4? the prompt could be:
Problem: Solve this, show reasoning step-by-step, and verify:
What is 2 + 3 * 4?
And they do expect an output that includes both reasoning steps and a verification part:
| special_token | Reasoning: To solve 2 + 3 * 4, I need to use order of
operations. Multiplication comes before addition.
Step 1: Calculate 3 * 4 = 12.
Step 2: Add 2 to the result from step 1: 2 + 12 = 14.
Verification: Checking order of operations again, yes, multiplication
is before addition. Calculation looks right.
| special_token | Summary: The answer is 14.
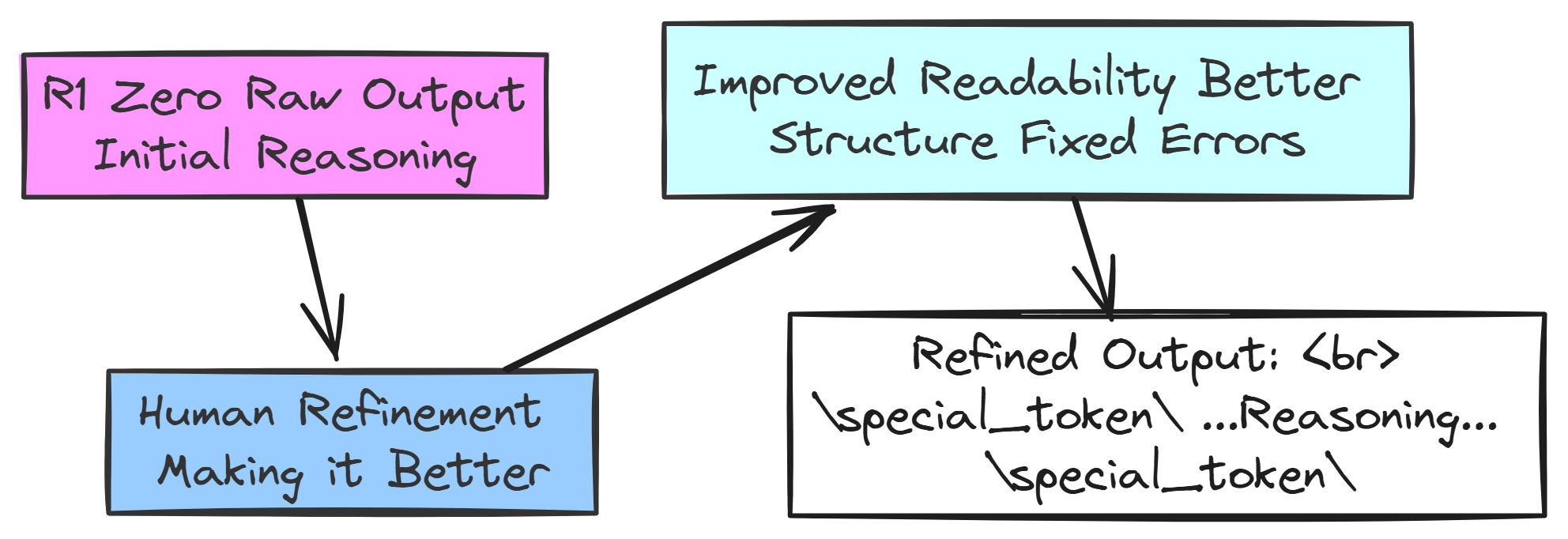
They even used the outputs from the already trained R1 Zero model. Even though R1 Zero had issues, it could reason a bit. So, they took R1 Zero’s outputs and had humans annotators to make them better cleaner, more structured, and correcting any errors.
For example, a messy R1 Zero output might be:
<think> ummm... multiply 3 and 4... get 12... then add 2...</think>
<answer> 14 </answer>Humans would then refine it to be much clearer and better formatted:
| special_token | Reasoning: To solve this, we use order of operations,
doing multiplication before addition.
Step 1: Multiply 3 by 4, which is 12.
Step 2: Add 2 to the result: 2 + 12 = 14.
| special_token | Summary: The answer is 14.
Visualizing the refinement process works like this:
The Cold Start Data they ended up with was really good because:
-
High-Quality Reasoning Examples: Each example showed good, step-by-step reasoning.
-
Consistent, Readable Format: The | special_token | format made everything uniform and easy to process.
-
Human-Checked: They made sure to filter out any bad examples, so the data was clean and reliable.
After getting this Cold Start Data they did Supervised Fine-Tuning (SFT).
The core idea of SFT Stage 1 is to use supervised learning to teach DeepSeek-V3-Base how to produce high-quality, structured reasoning outputs.
Basically we’re showing the model many examples of good reasoning and asking it to learn to imitate that style.
For SFT, we need to format our Cold Start Data into input-target pairs. For each reasoning problem in our dataset, we create a pair like this:
**Input = **The prompt or problem description itself
User: What is 2 + 3 * 4? Assistant:
This is what we feed into the model and our t**arget **is the corresponding well-structured reasoning and answer
| special_token | According to the order of operations (PEMDAS/BODMAS) ...
Summary: The answer is 14.This is the ideal output we want the model to learn to generate.
We’re telling the model:
When you see this input (the question), we want you to produce
this target output (the good reasoning and answer)
Instead of explaining it in detailed text and make it difficult for you to understand let’s visualize it first to have an easier SFT explanation
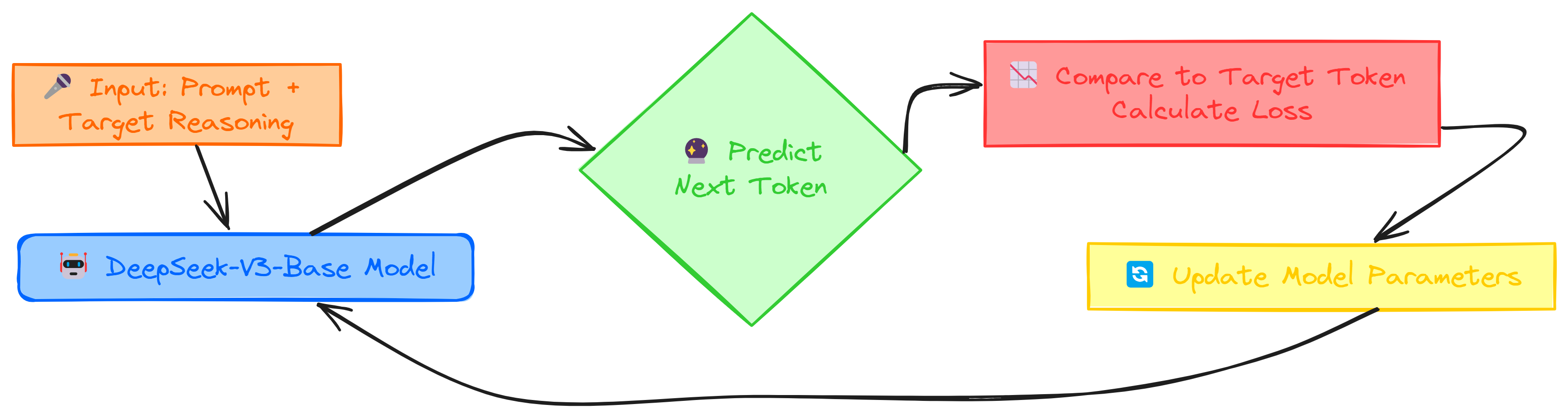
The fine-tuning process starts with Input: Prompt + Target Reasoning, where we provide a question and a structured reasoning example. This trains the model (DeepSeek-V3-Base Model) to generate well-structured responses.
In Predict Next Token, the model generates the next word in the reasoning sequence. This is compared to the actual next token in Compare to Target Token (Calculate Loss) using a loss function. A higher loss means the prediction was further from the correct token.
In Update Model Parameters, backpropagation and an optimizer adjust the model’s weights to improve its predictions. This process loops back, repeating over many input-target pairs, gradually improving the model structured reasoning skills with each iteration.
They have given DeepSeek V3 a reasoning education in SFT but to really sharpen its reasoning skills researchers introduced Reasoning oriented Learning!
This is where we take the SFT Fine-tuned DeepSeek-V3 model and push it to become even better through Reinforcement Learning.
They did used the same GRPO algorithm but the real upgrade in this stage was the Reward System. They added something new and super important Language Consistency Rewards!
Remember how R1 Zero sometimes got confused with languages and started mixing them up? To fix that, They added reward specifically for keeping the language consistent. The idea is simple, if you ask a question in English, we want the reasoning and answer to also be in English.
Let’s visualize this Language Consistency Reward calculation:
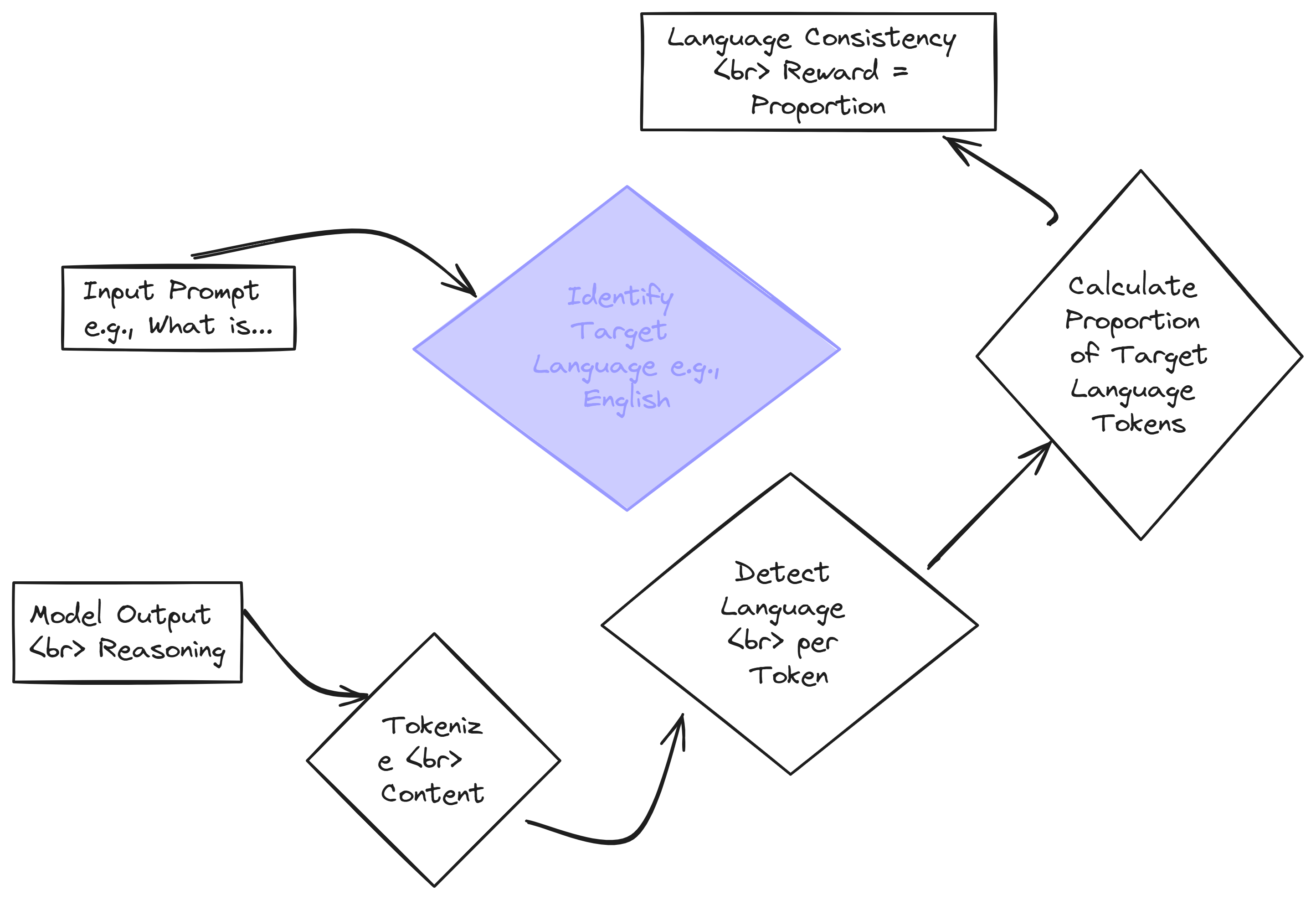
To understand the above diagram, let’s revisit our example outputs **o1 **and **o2 **from before, and see how the rewards change with this new Language Consistency Reward. We’ll assume the target language is English for simplicity.
Let’s look at how these rewards play out with our example outputs. Consider the first output, o1, which incorrectly calculates “2 + 3 * 4” but presents its flawed reasoning in English:
<think> 2 + 3 = 5, 5 * 4 = 20 </think> <answer> 20 </answer>
For this, the accuracy reward is naturally 0 because the answer is wrong. However, since the reasoning is assumed to be 100% in the target language (English, for this example), it receives a language consistency reward of 1.
When we calculate the total reward for RL Stage, we combine these. If we assign a weight of 1 to the accuracy reward and a smaller weight, say 0.2, to the language consistency reward, the total reward for o1 becomes.
Total Reward = (1 * Accuracy Reward) + (0.2 * Language Consistency Reward)
(1 * 0) + (0.2 * 1) = 0.2
Now consider output o2, which correctly solves the problem and also reasons in English:
<think> 3 * 4 = 12, 2 + 12 = 14 </think> <answer> 14 </answer>This output earns a perfect accuracy reward of 1 for the correct answer. Assuming its reasoning is also 100% English, it also gets a language consistency reward of 1. Using the same weights as before, the total reward for o2 is
(1 * 1) + (0.2 * 1) = 1.2
Notice how the language consistency reward slightly boosts the total reward even for the correct answer, and even provides a small positive reward for the incorrect answer o1, as long as it maintains language consistency.
This RL training loop follows the same DeepSeek R1 Zero training loop we saw ealier:
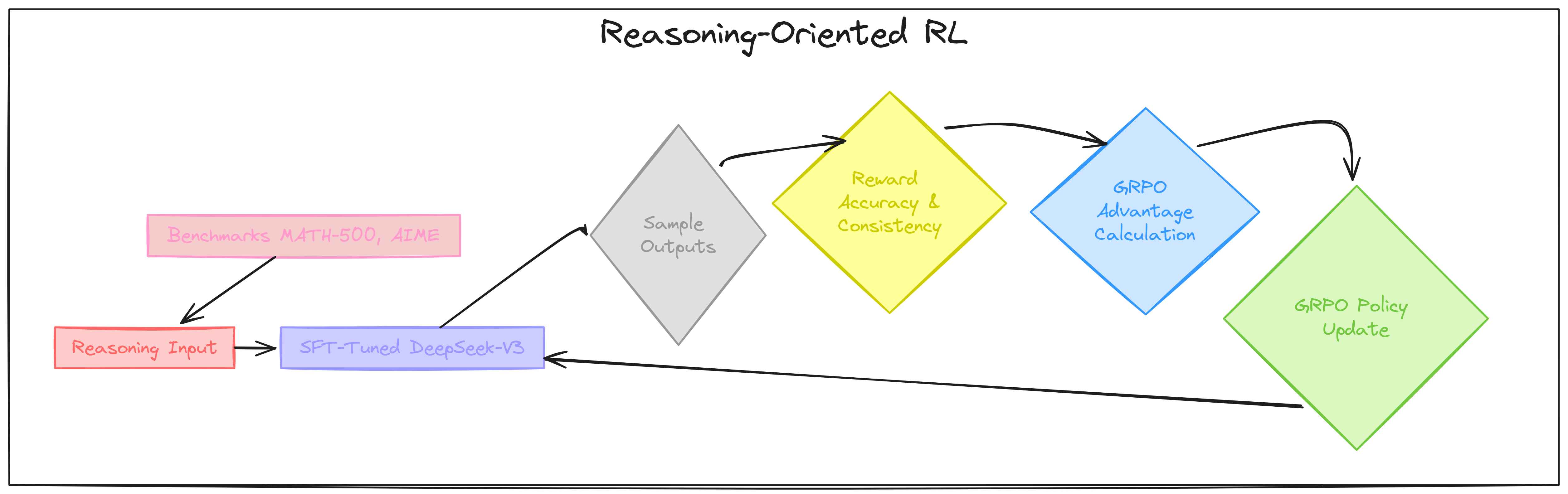
-
Generate multiple outputs.
-
Refine rewards, including Language Consistency.
-
Use GRPO for advantage estimation.
-
Train the model to favor high-advantage outputs.
-
Repeat the process!
For the reasoning data, DeepSeek team wanted to get the absolute best examples to further train the model. To do this, they used a technique called Rejection Sampling.
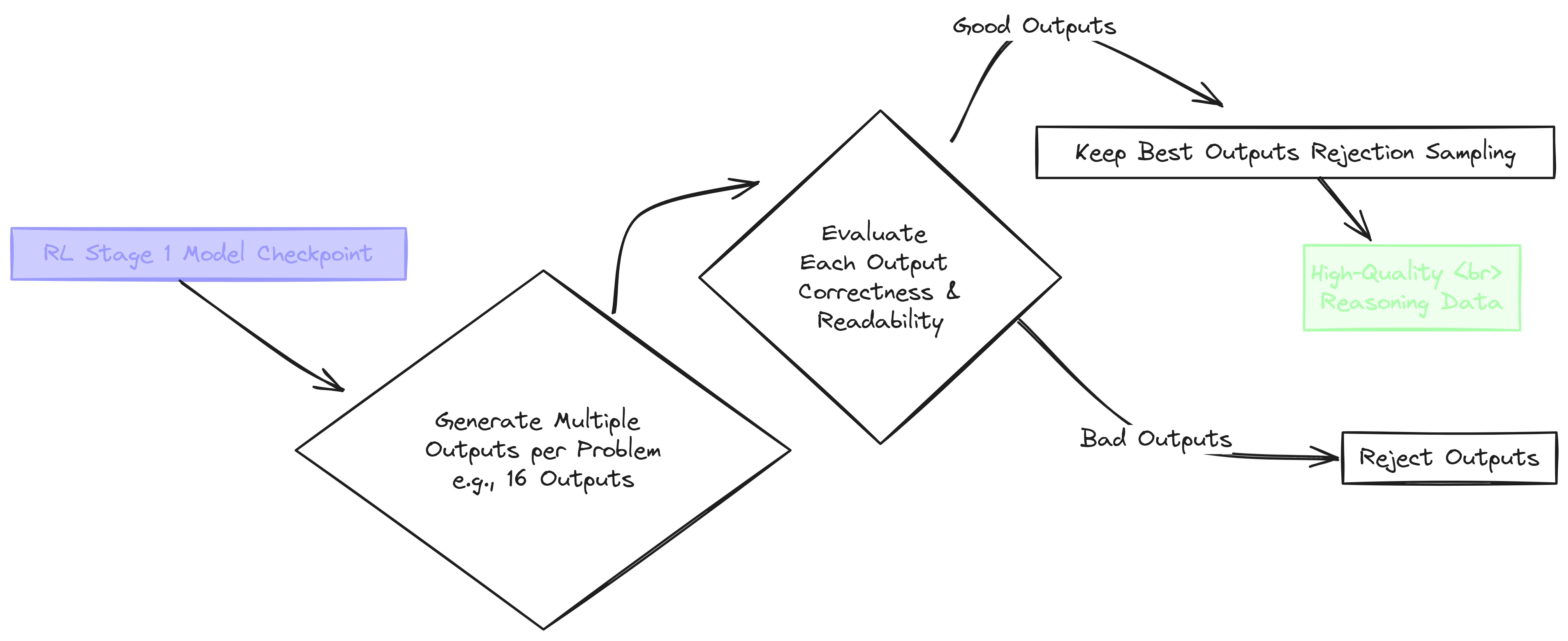
To refine reasoning data, DeepSeek used Rejection Sampling. For “What is 2 + 3 * 4?”, they’d generate many outputs from the previous stage model. Imagine getting outputs like 20 (wrong) and 14 … (right, reasoned).
They’d then evaluate each output for correctness (answer “14”) and readability of reasoning. Only the best outputs correct and well-reasoned are kept, while others are rejected.
For complex reasoning, a Generative Reward Model used in judging reasoning quality. Strict filters remove mixed languages, rambling reasoning, or irrelevant code. This process yields ~600k high-quality reasoning samples.
Alongside refined reasoning data, they added Non-Reasoning Data (~200k samples) for general skills: writing, QA, translation, etc., sometimes with Chain-of-Thought for complex tasks.
Finally, SFT Stage 2 trains the previous model checkpoint on the combined dataset (refined reasoning + non-reasoning) using next-token prediction. This stage further improves reasoning using top-tier examples from rejection sampling and generalizes the model for broader tasks, maintaining user-friendliness.
“What is 2 + 3 * 4?” now a perfectly refined reasoning example, becomes part of this training data.
This is Rejection Sampling, we’re rejecting the subpar samples and
keeping only the best to generate a high quality training data
We have got DeepSeek V3 reasoning, speaking consistently, and even handling general tasks pretty well after SFT Stage 2! But to truly make it a top-tier AI assistant, researched did that final touch alignment with human values. That’s the mission of Reinforcement Learning for All Scenarios (RL Stage 2)! Think of it as the final polish to make DeepSeek R1 truely safe.

For our example “What is 2 + 3 * 4?” while accuracy rewards still reinforce correct answers, the reward system now also considers:
-
Helpfulness, evaluating if the summary (if generated) provides useful context beyond just the answer.
-
Harmlessness, checking the entire output for safe and unbiased content. These are often assessed by separate reward models trained on human preferences.
The final reward signal becomes a weighted combination of accuracy, helpfulness, and harmlessness scores.
Now, the training data consists of
-
diverse mix, including reasoning problems
-
general QA prompts
-
writing tasks
-
and preference pairs where humans indicate which of two model outputs is better in terms of helpfulness and harmlessness.
The training process follows an iterative RL loop (likely using GRPO) to optimize the model based on a combined reward signal from this diverse data.
After many iterations of training, the model is refined to strike a good balance between reasoning performance and alignment (helpfulness/harmlessness). Once this balance is achieved, the model is evaluated on popular benchmark datasets and surpasses the performance of other models.
Their final checkpoint, highly optimized version is then named DeepSeek-R1
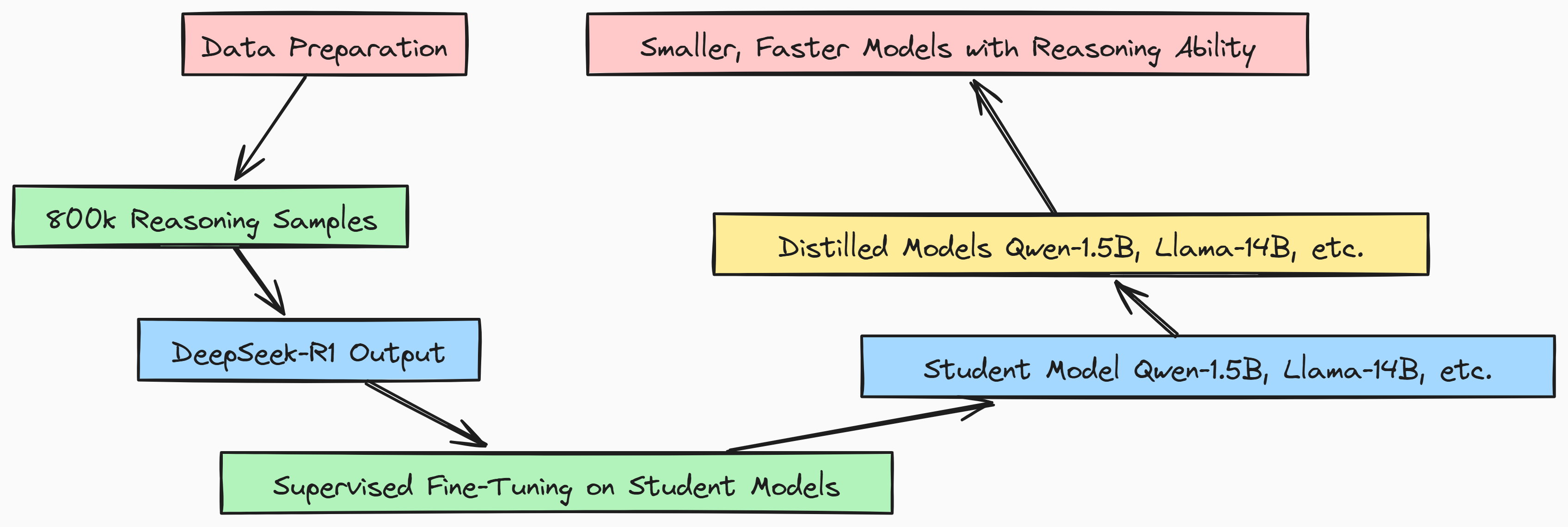
After DeepSeek team able to create a well performing DeepSeek R1 they further distilled their bigger into smalled models for the community with improved performance, This is how the distillation process works:
-
Data Preparation: Gather 800k reasoning samples.
-
DeepSeek-R1 Output: For each sample, the output from the teacher model (DeepSeek-R1) is used as the target for the student model.
-
Supervised Fine-Tuning (SFT): The student models (e.g., Qwen-1.5B, Llama-14B) are fine-tuned on these 800k samples to match the DeepSeek-R1 output.
-
Distilled Models: The student models are now distilled into smaller versions but retain much of DeepSeek-R1’s reasoning capability.
-
Result: You get smaller, faster models with good reasoning abilities, ready for deployment.
explained with ❤️ by Fareed Khan