A production-grade LangGraph state machine that automatically generates, executes, self-heals, and evaluates API test suites in response to pull requests — without human input on the happy path.
The framework uses a Hierarchical Supervisor-Worker pattern with an embedded Planner-Executor-Critic evaluation layer.
The top level is a LangGraph StateGraph that acts as the supervisor: it owns all routing decisions and enforces the pipeline topology via conditional edges. Individual agents (workers) are pure functions — they receive state, call a single LLM with with_structured_output(), and return a partial state dict. Workers never call other workers and never make routing decisions. This is the Supervisor-Worker split.
The Planner-Executor-Critic layer sits inside the execution/healing loop:
- Planner —
SpecParserAgentreads the OpenAPI spec and theChangeManifestto produceTestScenarios(what to test) - Executor —
TestGeneratorAgent+execute_teststurn scenarios into running code and produce anExecutionReport - Critic —
CoverageEvaluatorAgentscores the results against the changed surface area and either gates the merge or triggers a second planning cycle viaaugment_tests
- Zero-configuration test generation — reads the PR diff and OpenAPI spec; generates pytest and Playwright scripts without any human-authored test templates.
- Parallel fan-out / fan-in —
retrieve_history(ChromaDB) andgenerate_tests(GPT-4o) run concurrently;store_testswaits for both branches before proceeding. - Five-type self-healing — rule-based classifier (zero LLM tokens on high-confidence failures) with GPT-4o fallback for ambiguous cases.
- LLM-as-Judge coverage scoring — four weighted dimensions produce a 0–10 score; the judge's arithmetic is recomputed server-side and never trusted.
- Human-in-the-Loop checkpoint —
interrupt_before=["human_review"]writes full state to SQLite before suspending; the pipeline can resume from a different process. - Bounded retry loops — self-heal retries up to 3×; coverage augmentation up to 2× additional cycles; both limits are enforced by the router, not the agents.
- Structured observability — three append-only JSONL files with per-file threading locks; LangSmith tracing optional.
- ChromaDB test memory — successful test scripts stored with cosine similarity retrieval (threshold ≥ 0.75) as few-shot context for the next run.
The AQAF pipeline is orchestrated as a LangGraph state machine, ensuring a structured and auditable flow from PR analysis to final merge gate.
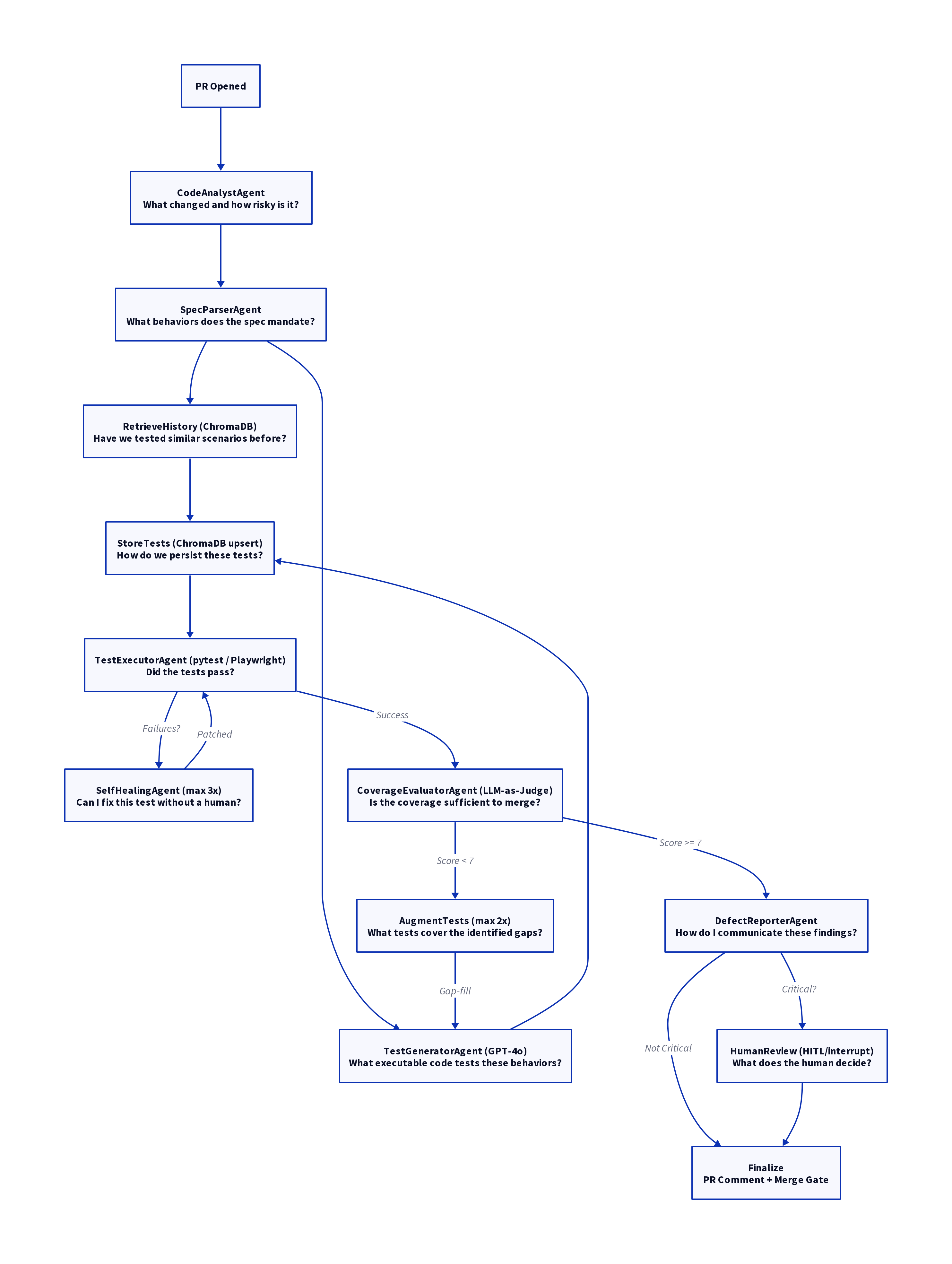
The framework is composed of 12 specialized agents, each with a distinct role in the pipeline.
| # | Agent | Answers the question | Input | Output | Auto-healable |
|---|---|---|---|---|---|
| 1 | CodeAnalystAgent | What changed and how risky is it? | PR diff (head/base SHA) | ChangeManifest — affected files, endpoints, risk score 0–1 |
N/A |
| 2 | SpecParserAgent | What behaviors does the spec mandate? | OpenAPI spec + ChangeManifest |
List[TestScenario] — scenario per endpoint × scenario type |
N/A |
| 3 | RetrieveHistory (no LLM) | Have we tested similar scenarios before? | List[TestScenario] |
List[TestScript] from ChromaDB (top-5 per scenario, similarity ≥ 0.75) |
N/A |
| 4 | TestGeneratorAgent | What executable code tests these behaviors? | List[TestScenario] + historical few-shot context |
List[TestScript] — full pytest / Playwright source files |
N/A |
| 5 | StoreTests (no LLM) | How do we persist these tests for future runs? | List[TestScript] |
ChromaDB upsert; writes chromadb_id back onto each TestScript |
N/A |
| 6 | TestExecutorAgent (no LLM) | Did the tests pass? | List[TestScript] (file paths) |
ExecutionReport — pass/fail/error counts + per-test TestResult |
N/A |
| 7 | SelfHealingAgent | Can I fix this test without a human? | Failing TestResult list + original TestScript |
Patched TestScript + RepairAttempt record; sets human_escalation_required if needed |
Yes (ASSERTION, SCHEMA, SELECTOR) |
| 8 | CoverageEvaluatorAgent | Is the coverage sufficient to merge? | ExecutionReport + ChangeManifest + TestScenarios |
CoverageReport — four dimension scores + MergeRecommendation |
N/A |
| 9 | TestGeneratorAgent (gap-fill mode) | What tests cover the identified gaps? | CoverageReport.gaps |
Additional List[TestScript] appended to state |
N/A |
| 10 | DefectReporterAgent | How do I communicate these findings? | ExecutionReport + CoverageReport |
List[Defect] + optional Jira ticket keys |
N/A |
| 11 | HumanReview (HITL) | What does the human decide? | Full pipeline state (via interrupt()) |
commit_status: success / failure / pending |
N/A |
| 12 | Finalize (no LLM) | How do I publish the result? | Final state | GitHub PR comment + commit status update | N/A |
# Clone
git clone https://github.com/yourusername/autonomous-qa-agent-framework
cd autonomous-qa-agent-framework
# Create virtual environment
python -m venv venv
source venv/bin/activate # or venv/Scripts/activate on Windows
# Install dependencies
pip install -r requirements.txt
# Install Playwright browsers
playwright install chromium
# Install package in dev mode
pip install -e .Create a .env file in the project root:
# LLM Configuration (Vocareum OpenAI Proxy)
OPENAI_API_KEY=voc-...
OPENAI_BASE_URL=https://openai.vocareum.com/v1
# LangSmith Observability (optional)
LANGCHAIN_API_KEY=your-langsmith-key
LANGCHAIN_TRACING_V2=true
LANGCHAIN_PROJECT=qa-agent
# GitHub Integration
GITHUB_TOKEN=your-github-token
USE_LIVE_GITHUB=false # set true for real PR integration
# Jira Integration
JIRA_URL=https://your-company.atlassian.net
JIRA_USERNAME=your-email
JIRA_API_TOKEN=your-jira-token
USE_LIVE_JIRA=false # set true for real ticket creation
# ChromaDB
CHROMA_HOST=localhost
CHROMA_PORT=8000- Mock Mode:
python main.py --mock- Runs the full pipeline with mock data and no credentials needed. - Real PR Mode:
python main.py --repo owner/repo --pr 123 --spec ./openapi.yaml- Runs against a real PR. - Resume Mode:
python main.py --resume --thread-id <thread-id>- Resumes after human-in-the-loop interruption. - Verbose Logging:
python main.py --mock --log-level DEBUG- Runs with detailed debug logs.
62 passed in 214.50s
test_analyst.py: 10 passed (PR diff parsing, risk scoring)test_parser.py: 12 passed (OpenAPI spec parsing, scenario generation)test_generator.py: 10 passed (pytest/Playwright code generation)test_self_heal.py: 15 passed (rule-based vs LLM healing)test_evaluator.py: 10 passed (coverage scoring, merge recommendation)test_pipeline_e2e.py: 5 passed (full end-to-end integration tests)
MIT