[toc]
-
为方便后续的数据计算和数据分析和统计有效信息,针对每一则租房信息设计了
RentHouseItem:class RentHouseItem(scrapy.Item): city = scrapy.Field() # 城市英文缩写 name = scrapy.Field() # 租房信息标题 district = scrapy.Field() # 行政区名字 street = scrapy.Field() # 街道/板块名字 community = scrapy.Field() # 小区名字 price = scrapy.Field() # 价格 元/月 square = scrapy.Field() # 面积 平方米 price_per_m2 = scrapy.Field() # 单位面积的价格 元 direction = scrapy.Field() # 朝向 layout = scrapy.Field() # 房型
此类型数据位于
original_data文件夹中。 -
同时,为统计每个城市的板块信息以及方便构造爬虫所需的url,针对每个城市设计了
RentHouseURLs:class RentHouseURLs(scrapy.Item): city = scrapy.Field() # 城市 district = scrapy.Field() # 行政区 area = scrapy.Field() # 街道/板块 url = scrapy.Field() # 该板块的第一页url total = scrapy.Field() # 总数据量 pages = scrapy.Field() # 总页数
此类型数据位于
url_data文件夹中。
位于项目的processed_data文件夹中。
renting_data.csv:合并了抓取的所有原始数据,在此基础上将数值转换为了常数类型,并且提取了每条数据的居室信息,方便后续进行居室和价格关系的分析。renting_layout_sta.csv:将居室的信息进行处理,将大于等于四居室的数据合并为4居室及以上,并统计了每个城市每种居室的价格平均值、中位数及最大最小值。renting_price_sta.csv:统计了各城市的月租平均值、中位数及最大最小值,方便后续画图。street_price文件夹:统计了各城市各街道的月租平均值,方便后续画图。house_data_tables:用于存放可视化图表。分为整体的表格和各城市的板块价格分析的表格。
- 使用Scrapy爬虫框架:
- 在
WebScraper/items.py中,定义了抓取的数据结构。 - 当 Spider 发起请求时,Scrapy 的调度器(Scheduler)会接收这些请求并将它们排入请求队列中。这些请求根据优先级和其他因素由调度器传递给下载器(Downloader)。
- Scrapy 会从请求队列中取出请求,通过下载器发送 HTTP 请求并获取响应。
- 在
- 编写了下载中间件,位于
WebScraper/middlewares.py中,主要目的是应对网站的反爬措施。下载中间件在下载器和 Spider 之间充当中间层。它可以对请求或响应进行处理,例如添加代理、修改请求头、处理重定向等。 - 编写了两个爬虫,位于
WebScraper/spiders文件夹中。lianjia.py:从之前保存的url文件中拿到每个板块的url,向该url发送请求。url_spider.py:抓取每个城市每个板块第一页的url。
- 编写管道用于保存数据,位于
WebScraper/pipelines.py中,两个管道分别对应两个spider,将数据以json文件的形式保存。
DataProcess.py:用于将original_data中的原始数据进行加工和清洗,根据需求转为不同的csv文件。DataDrawer.py:访问processed_data中的处理过的数据,进行进一步的分析和提取,根据需求转换为可视化图表。
-
通过递归请求获取城市不同板块的url
- 在给定的城市英文代号中,首先通过调用
start_requests函数进行请求,通过回调函数get_district获取该城市所有的行政区英文代号,然后通过这个信息构造新的url,向该url发起请求,并将已知信息通过meta传递; - 接着通过回调函数
get_area获取该行政区所有的板块的英文代号,然后通过这个信息又构造新的url,向该url发起请求,并将已知信息通过meta传递; - 最后通过回调函数
parse_url,使用获取的信息构建RentHouseURLs类型的数据,通过yield语句返回,最终保存在url_data中。 - 所有的信息都通过
Xpath的方式获取。
- 在给定的城市英文代号中,首先通过调用
-
核心代码
def start_requests(self): for name in self.city_names: # 每个城市的起始url yield SeleniumRequest(url=f"https://{name}.lianjia.com/zufang/", cookies=self.cookies, callback=self.get_district, meta={'city_name': name})
def get_district(self, response): # 通过Xpath获取区列表 ... # 构造每个区的起始url district_url = f"https://{city_name}.lianjia.com/zufang/{dis_str}/" yield SeleniumRequest(url=district_url, cookies=self.cookies, callback=self.get_area, meta={ 'city_name': city_name, 'district_name': dis_name })
def get_area(self, response): # 获取当前界面的a标签列表 area_href_list = response.xpath('//*[@id="filter"]/ul[4]/li/a') city_name = response.meta['city_name'] dis_name = response.meta['district_name'] for area in area_href_list[1:]: # 通过a标签中的链接获取到板块的英文代码,用于构造板块起始url area_str = area.xpath('./@href').get().strip().split('/')[2] area_url = f"https://{city_name}.lianjia.com/zufang/{area_str}/pg1" area_name = area.xpath('./text()').get() # 返回最终数据 yield SeleniumRequest(url=area_url, cookies=self.cookies, callback=self.parse_url, meta={ 'city_name': city_name, 'district_name': dis_name, 'area_name': area_name, 'url': area_url, })
-
获取url_data中的信息并构造url
首先通过
url可获取该板块第一页的url,通过pages则可以获取一共有多少页,从而构造pages个url,每个url的结尾从pg1到pg{pages}。这样做可以避免递归发请求,导致很多难以debug的错误和重复,同时也避免空的页导致爬虫效率低或数据出错。核心代码:
def start_requests(self): # 打开url的json文件 ... # 获取url信息 total = int(entry['total']) pages = int(entry['pages']) base_url = entry['url'] # 如果 total 为 0,跳过这个 entry if total == 0: continue # 构造分页 URL,从 pg1 到 pg{pages} for page in range(1, pages + 1): url = base_url.replace('pg1', f'pg{page}') yield scrapy.Request(url, callback=self.parse, meta={'city': entry['city'], 'district': entry['district'], 'area': entry['area']})
-
处理数据
通过回调函数
parse,通过Xpath获取数据,并对数据进行第一次简单处理。- 遇到广告时跳过,遇到空页也跳过;
- 遇到包含“仅剩两间”这样的数据也跳过,因为这类数据的信息不完整。具体实现是看html元素中是否包含
span[@class="room__left"]这类标签。 - 获取完面积和价格这两个信息后,直接计算出单位面积的价格,避免后续的大量计算;如果价格是一个区间,则取其平均数。
- 所有信息均通过Xpath获取
使用获取的信息构建
RentHouseItem类型的数据,通过yield语句返回,最终保存在url_data中。核心代码:
def parse(self, response): # 超出页数范围,会有这个标签 page_empty = bool(response.xpath('//div[@class="content__empty1"]')) if not page_empty: content_list = response.xpath('//*[@id="content"]/div[1]/div[1]/div') for content in content_list: # 去除广告 ad = content.xpath('.//p[@class="content__list--item--ad"]/text()').get() if ad: continue # 跳过一些不规范的数据 room_left = content.xpath('.//p[@class="content__list--item--des"]//span[@class="room__left"]') if room_left: continue # 构造要返回的数据 house = RentHouseItem() price = content.xpath('./div/span/em/text()').get() # 如果是价格区间,则取其平均数 if '-' in price: start, end = map(int, price.split('-')) price = str((start + end) / 2) # 处理其他常规数据 ... yield house
在爬取数据的过程中如果只采用简单的构造请求header,将会频繁触发重定向和人机验证界面,因此最终采取了随机user-agent和使用代理ip池的策略来应对反爬。在中间件中进行了实现:
-
随机user-agent
这里列举了一系列可用的User-Agent放在
agents列表里面,然后每次请求随机取出一个def process_request(self, request, spider): request.headers['User-Agent'] = random.choice(self.agents)
-
代理ip
向网上找到的提供代理ip的服务器发送请求,将收到的代理ip return:
def get_proxy(self): try: response = requests.get('https://share.proxy.qg.net/get?key=DADEA1E5&num=2') if response.status_code == 200: res_data = response.json() if res_data['code'] == "SUCCESS": return [p['server'] for p in res_data['data']] else: self.logger.error(f"代理池返回错误: {res_data}") time.sleep(2) # 暂停 2 秒后重试 except requests.RequestException: time.sleep(2) # 请求异常时重试
然后每60s更新一次代理ip,将ip存进列表proxies:
def update_proxies(self): self.proxies = [] self.proxies = self.get_proxy() def cron_update_proxies(self): sched = BlockingScheduler() sched.add_job(self.update_proxies, 'interval', seconds=60) sched.start()
每次向链家发送请求的时候,都从proxies中随机取出一个ip:
def process_request(self, request, spider): if len(self.proxies) == 0: self.update_proxies() time.sleep(1) proxy = random.choice(self.proxies).strip() # 随机取出一个ip request.meta['proxy'] = "https://" + proxy # 请求使用此代理ip request.meta['dont_redirect'] = True return None
遇到请求失败的处理:就算失败了也不能丢弃掉请求,一直请求到成功为止,就不会漏掉请求
def process_response(self, request, response, spider): if not response.text: print("wrong response") if response.status != 200: if response.status == 302: self.proxies = [] return request else: return response def process_exception(self, request, exception, spider): if str(exception).find('407') != -1: self.update_proxies() return request else: return request
这一步是处理刚才爬虫爬下来的原始数据,将数据进行处理后转为csv文件保存到processed_data文件夹。
-
清洗并合并数据
由于爬取下来的数据内,有许多重复数据,还有许多脏数据,所以进行数据清洗是很有必要的。
异常值处理:
- 去除车库相关的房屋信息:通过检查房屋名称中是否包含关键词” 车库”,将包含该关键词的记录从数据中剔除。 去除未知户型的房屋信息:通过检查房屋户型中是否包含关键词” 未知”,将包含该关键词的记录从数据中剔除。
- 去除单价异常值:将单价小于等于 2 的记录从数据中剔除。
- 去除面积异常值:将面积小于 10 平方米或大于 2000 平方米的记录从数据中剔除。
最终将五个城市的数据分别保存在csv文件中,五个城市的数据合并在一起保存在一个csv中。经过统计发现爬下来的有效数据有302965条。
# 异常值判断函数 def is_valid(item): # 车库和未知户型去除 if item["name"] and "车库" in item["name"]: return False if item["layout"] and "未知" in item["layout"]: return False # 单价异常值去除 if item["price_per_m2"] <= 2: return False # 面积异常值去除 if item["square"] < 10 or item["square"] > 2000: return False # 总价格异常值去除 if item["price"] < 100: return False return True
数据去重:
通过读取每个 JSON 文件,并使用
unique_data集合进行去重操作,确保输出文件中的数据是唯一 的,并保存每个城市分别的数据以及五个城市合并起来的数据:for name in city_names: unique_data = set() # 用于去重后的数据存储 data = pd.read_json(f'original_data/{name}.json') # 数据清洗和去重处理 # 过滤异常值 cleaned_data = data[data.apply(is_valid, axis=1)] # 将每一行的数据转化为元组,添加到集合中实现去重 for index, row in cleaned_data.iterrows(): row_tuple = tuple(row.values) # 获取整行的值作为元组 unique_data.add(row_tuple) # 将元组添加到集合中去重 cleaned_data = pd.DataFrame( list(unique_data), columns = cleaned_data.columns ) # 转换回DataFrame格式 # 导出每个城市的处理后的数据 cleaned_data.to_csv(f'processed_data/{name}.csv', index=False) # 将清洗后的数据合并到整体数据中 merged_data.append(cleaned_data) # 合并所有城市的数据 combined_df = pd.concat(merged_data, ignore_index=True) # 导出数据到csv文件 combined_df.to_csv('processed_data/renting_data.csv')
-
计算各城市的租金统计数据
访问刚才合并好的csv文件
renting_data.csv,将数据按照城市分组,计算价格(元/月)和单价(元/㎡)这两列的均价、最高价、最低价、中位数,并保存到文件renting_price_sta.csv。df = pd.read_csv('processed_data/renting_data.csv') # 删除包含缺失值(NaN)的特定列的行 df.dropna(subset=['价格(元/月)', '单价(元/㎡)'], inplace=True) # 按城市分组,计算统计信息 summary = df.groupby('城市').agg( 租金均价=('价格(元/月)', 'mean'), 租金最高价=('价格(元/月)', 'max'), 租金最低价=('价格(元/月)', 'min'), 租金中位数=('价格(元/月)', 'median'), 单位面积租金均价=('单价(元/㎡)', 'mean'), 单位面积租金最高价=('单价(元/㎡)', 'max'), 单位面积租金最低价=('单价(元/㎡)', 'min'), 单位面积租金中位数=('单价(元/㎡)', 'median') ).reset_index()
-
计算5个城市居室的情况
访问刚才合并好的csv文件
renting_data.csv,将数据按照城市和居室进行分组,并且将四居室及其以上合并为一列。计算价格(元/月)这一列的均价、最高价、最低价、中位数,并保存到文件renting_layout_sta.csv。df = pd.read_csv('processed_data/renting_data.csv') # 将四居室以上合并为 "四居室以上" df['居室'] = df['居室'].apply(lambda x: 4.0 if x >= 4 else x) grouped = df.groupby(['城市代号', '城市', '居室']) # 计算均价、最高价、最低价、中位数 summary = grouped['价格(元/月)'].agg( avg='mean', max='max', low='min', mid='median' ).reset_index()
-
计算5个城市不同板块的均价
访问刚才整理好的五个城市分别的数据,将数据按
街道这一列分组,计算这个街道的均价。# city_name是该城市的英文代号 df = pd.read_csv(f'processed_data/{city_name}.csv') grouped = df.groupby(['城市代号', '城市', '街道', '区域']) # 计算均价 summary = grouped['价格(元/月)'].agg(avg='mean').reset_index() summary = summary.round({'avg': 2}) summary.to_csv(f'processed_data/street_price/{city_name}.csv')
基于 pyecharts 和一些数据分析库(如 pandas 和 matplotlib)生成可视化图表。
-
单位月租和整体月租的分析
从文件
renting_price_sta.csv中读取各城市的房租价格数据,生成两个柱状图,一个展示各城市的租金统计,另一个展示单位面积的租金统计。最终这两个图表会组合在一个Grid图表中并保存为 HTML 文件。# 设置X轴和Y轴 data_types = ['租金均价', '租金最高价', '租金最低价', '租金中位数'] shanghai = [float(df.loc[df['城市'] == '上海', col].values[0]) for col in data_types] beijing = [float(df.loc[df['城市'] == '北京', col].values[0]) for col in data_types] dali = [float(df.loc[df['城市'] == '大理', col].values[0]) for col in data_types] guangzhou = [float(df.loc[df['城市'] == '广州', col].values[0]) for col in data_types] shenzhen = [float(df.loc[df['城市'] == '深圳', col].values[0]) for col in data_types] bar_all.add_xaxis(data_types) bar_all.add_yaxis("上海", shanghai, color='#1f77b4') bar_all.add_yaxis("北京", beijing, color='#ff7f0e') bar_all.add_yaxis("大理", dali, color='#2ca02c') bar_all.add_yaxis("广州", guangzhou, color='#d62728') bar_all.add_yaxis("深圳", shenzhen, color='#9467bd')
-
5个城市不同居室的房租情况
从文件
renting_layout_sta.csv中读取各城市不同居室的房租价格数据,将数据通过城市:{居室: 价格}的字典的形式存储在city_data中# 初始化 city_data 为字典,确保每个城市每个居室类型都是字典 city_data = {city: {layout: {} for layout in layout_types} for city in cities} for city in cities: for layout in layout_types: for data_type in data_types: # 获取对应的价格数据 price_value = df.loc[( df['城市代号'] == city) & (df['居室'] == layout), data_type ].values if price_value: # 确保存储在字典中 city_data[city][layout][data_type] = float(price_value[0])
将其转化为三维柱状图,展示不同户型(如一居、二居、三居等)在不同城市的月租价格分布。
# 计算三维柱状图的坐标 # (i-1)*5+n表示第i种户型的x轴坐标,m表示y轴坐标 for i in range(1, 5): n = 0 # 用于控制 y 轴位置 for city in cities: tmp = city_data[city][float(f'{i}.0')] m = 0 for key in tmp: data.append( [(i-1)*5+n,m,tmp[key] if key != '最高租金' else int(tmp[key]/10) ] ) m += 1 n += 1 # 创建三维柱状图 bar3d = Bar3D( init_opts=opts.InitOpts( width='1500px',height='750px',page_title="不同户型的月租分析" )) # 为三维柱状图填充数据 bar3d.add( series_name='月租金', data=data, xaxis3d_opts=opts.Axis3DOpts( type_='category', data=label, axislabel_opts=opts.LabelOpts( interval=0, rotate=45 ) ), yaxis3d_opts=opts.Axis3DOpts( name='数据类型', type_='category', data=['最小值', '平均值', '中位数', '最大值'], textstyle_opts=opts.TextStyleOpts( font_weight='bold', font_size=13 ) ), zaxis3d_opts=opts.Axis3DOpts( name='月租金', type_='log', textstyle_opts=opts.TextStyleOpts( font_weight='bold', font_size=13 ) ) )
-
5个城市的街道价格分析
循环读取
street_price/{city_code}.csv文件中的数据,获取该城市每个街道的均价。这里用到了两个工具函数:-
generate_color(max_value):根据数据类型的最大值来产生颜色,不同的均价对应不同的颜色。 -
WebScraper/geo.py:调用腾讯位置服务的接口,通过城市/区/街道的信息来获取该街道的点坐标,并存储到文件夹original_data/pos中,为后续画图做准备。def get_one_point(city_info): url = 'https://apis.map.qq.com/ws/geocoder/v1' city = city_info['城市'] params = { 'address': f"{city}市{city_info['区域']}区{city_info['街道']}", 'key': 'IRFBZ-F2CKZ-VR4XH-ZMLT5-YAMDK-EZFWY' }
最终使用
Geo地图组件来展示不同街道的平均月租价格。这个图表会根据每个街道的地理坐标绘制,并通过颜色映射显示租金的高低。for data in pos_data: g.add_coordinate(data['street'], data['y'], data['x']) # 添加数据到Geo图 g.add('', data_pair, type_=GeoType.EFFECT_SCATTER, symbol_size=5) g.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 颜色映射 max_price = max(price for _, price in data_pair) pieces = generate_color(max_price) g.set_global_opts( visualmap_opts=opts.VisualMapOpts(is_piecewise=True, pieces=pieces), title_opts=opts.TitleOpts( title=f'{city_name}市不同板块平均月租分布图(元/月)', pos_left='5%' ) )
-
-
5个城市的不同朝向的价格分析
循环访问文件
processed_data/{city_code}.csv,分析每个城市不同朝向directions = ["北", "东北", "东", "东南", "南", "西南", "西", "西北"]
对房租单价的影响,通过雷达图展示各城市不同朝向的平均房租单价,将五个城市的雷达图曲线叠加。
# 统计每个城市的朝向的单价 for city_code in city_codes: ori_prices = defaultdict(list) df = pd.read_csv(f'processed_data/{city_code}.csv') # 计算平均值,将南 北这样的朝向算进朝南和朝北 for _, row in df.iterrows(): price_per_m2 = row['单价(元/㎡)'] # 提取单价 if isinstance(row['朝向'], str) and row['朝向'] != 'nan': oris = row['朝向'].split() else: continue # 如果是 NaN 或无效值,跳过 for ori in oris: if ori in directions: ori_prices[ori].append(price_per_m2) # 将单价装入对应的朝向 orientation_avg = { orientation: round(sum(prices) / len(prices), 2) for orientation, prices in ori_prices.items() } max_item = max(orientation_avg.values()) if max_item > max_radar: max_radar = max_item ori_avgs.append({city_code: orientation_avg})
-
5个城市的人均gdp和单位面积租金分布的关系
访问
original_data/gdp获取城市人均gdp和人均工资性收入,分析各城市的人均 GDP 与单位面积租金的关系,生成一个包含柱状图和额外坐标轴的复合图表,横坐标为城市,柱状图展示单位面积租金,额外坐标轴则显示人均 GDP 、工资数据以及人均工资和单位面积月租平均数的比例。用折线图展示gdp、工资和比例数据。这样做更能直观展示四者的关系。# 初始化柱状图 b = Bar(init_opts=opts.InitOpts(width='1400px', height='550px', page_title='人均gdp和单位面积租金分布关系分析')) b.add_xaxis([city_names[city_code] for city_code in city_codes]) b.add_yaxis('单位面积月租金中位数', data['mid'], itemstyle_opts=opts.ItemStyleOpts(color='#f882b1'), z = 0) b.add_yaxis('单位面积月租金平均数', data['avg'], itemstyle_opts=opts.ItemStyleOpts(color='#ed9d5f'), z = 0) # 添加额外的坐标轴 b.extend_axis( yaxis=opts.AxisOpts(name='人均GDP', name_textstyle_opts=opts.TextStyleOpts(font_weight='bold'), position="right", axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color="#B22222"))) ) b.extend_axis( yaxis=opts.AxisOpts(name='人均工资', max_=max(salary), name_textstyle_opts=opts.TextStyleOpts(font_weight='bold'), position="right", offset=60, axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color="#5d2673"))) ) b.extend_axis( yaxis=opts.AxisOpts(name='工资/房租', max_=int(max(ratio)) + 1000, min_=int(min(ratio)) - 100, name_textstyle_opts=opts.TextStyleOpts(font_weight='bold'), position="left", offset=100, axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color="#322816"))) ) # 初始化折线图并添加数据 l = Line(init_opts=opts.InitOpts(width='1100px', height='550px')) l.add_xaxis([city_names[city_code] for city_code in city_codes]) l.add_yaxis('人均GDP', y_axis = gdp, yaxis_index=1, itemstyle_opts=opts.ItemStyleOpts(color='#B22222'), label_opts=opts.LabelOpts(font_weight='bold'), symbol_size=15, symbol='circle', linestyle_opts=opts.LineStyleOpts(width=2, type_="dashed")) l2 = Line(init_opts=opts.InitOpts(width='1100px', height='550px')) l2.add_xaxis([city_names[city_code] for city_code in city_codes]) l2.add_yaxis('人均工资性收入', y_axis = salary, yaxis_index=2, itemstyle_opts=opts.ItemStyleOpts(color='#5d2673'), label_opts=opts.LabelOpts(font_weight='bold'), symbol_size=15, symbol='circle', linestyle_opts=opts.LineStyleOpts(width=2, type_="dashed")) # 叠加折线图到柱状图上 b.overlap(l) b.overlap(l2)
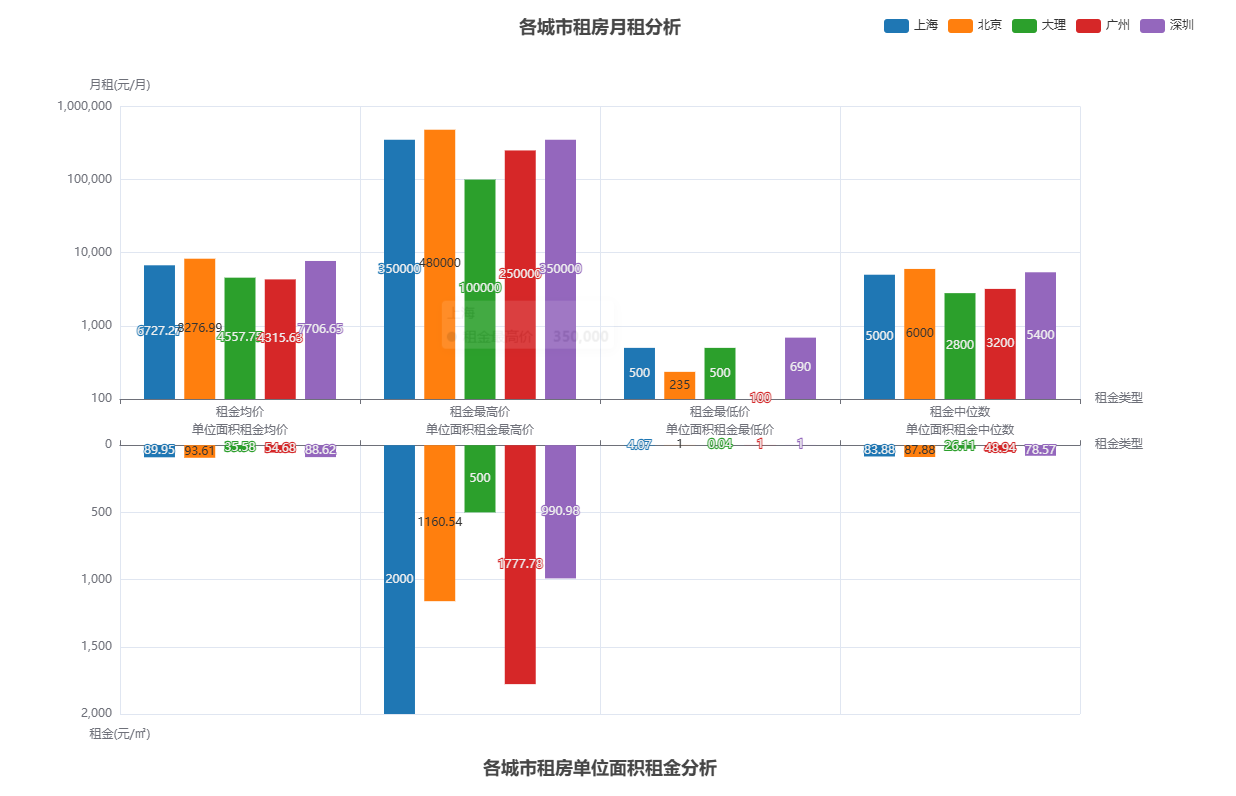
-
均价比较
北京、上海、广州和深圳的房租均价较高,可能是由于这些城市是一线城市,经济发展水平较高, 人口密度大,对房屋需求量大,而房源相对较少,导致房租水平相对较高。
-
最高价比较
北京、上海、深圳的最高租金明显高于其他城市,可能是由于这些城市的地理位置和经济实力,吸引了更多高端房源和高收入人群,推高了房租的最高价格。并且这三个地区存在大量高端房源,如豪华公寓、别墅等,这些房源的租金极高,拉高了租金最高价。同时,这些城市的核心地段、稀缺景观资源附近的房屋租金也非常高。
-
最低价比较
广州的最低租金明显低于其他城市,可能是因为外地过来务工的人比较多,贫富差距较大,必须有低价房源来满足这些人的需求。且广州发展并不平衡,许多老城区有很多低价房源。
-
中位数比较
北京、上海和深圳的中位数较高,可能是由于这些城市的房屋供需关系紧张, 房租上涨的影响较大,使得房租的中位数相对较高。而广州和大理的中位数较低,可能是由于这些城市的经济发展水平相对较低,房屋供需关系相对平衡,房租水平相对较低。
-
单位面积租金比较
可以看出单位面积的各项指标基本跟均价的各项指标对应。
北京、上海和深圳的单位面积租金较高,可能是由于就业机会多,每年都有大量的外来人口涌入这三个城市。人口的持续增长导致了住房需求的刚性增加。特别是对于年轻人和新就业者来说,租房是他们解决居住问题的主要方式,这就使得租赁市场供不应求,租金不断上涨。
广州的单位面积租金较低,可能是由于该城市的土地资源相对充足,房屋供应相对较多,相对降低了单位面积租金。大理的单位面积租金最低,可能是由于该城市的经济发展水平较低,土地资源相对充裕,房屋供应相对充足,导致单位面积租金较低。
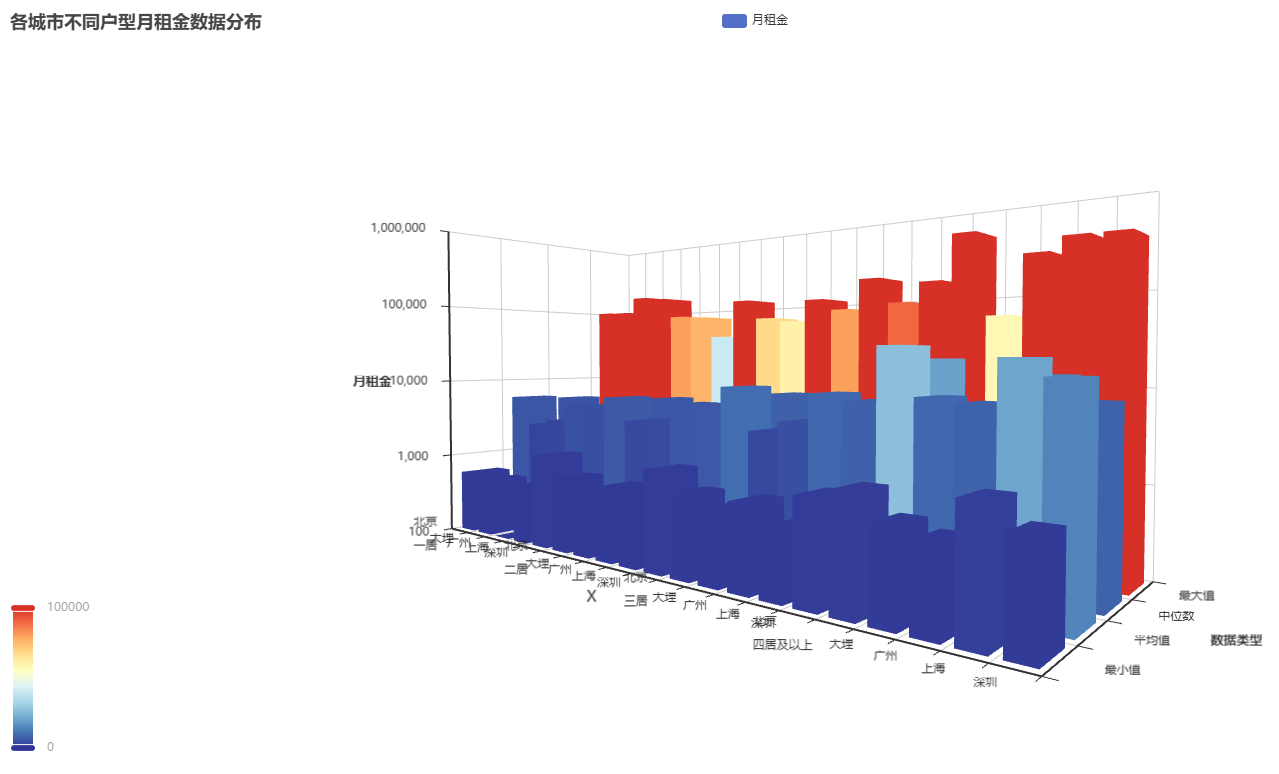
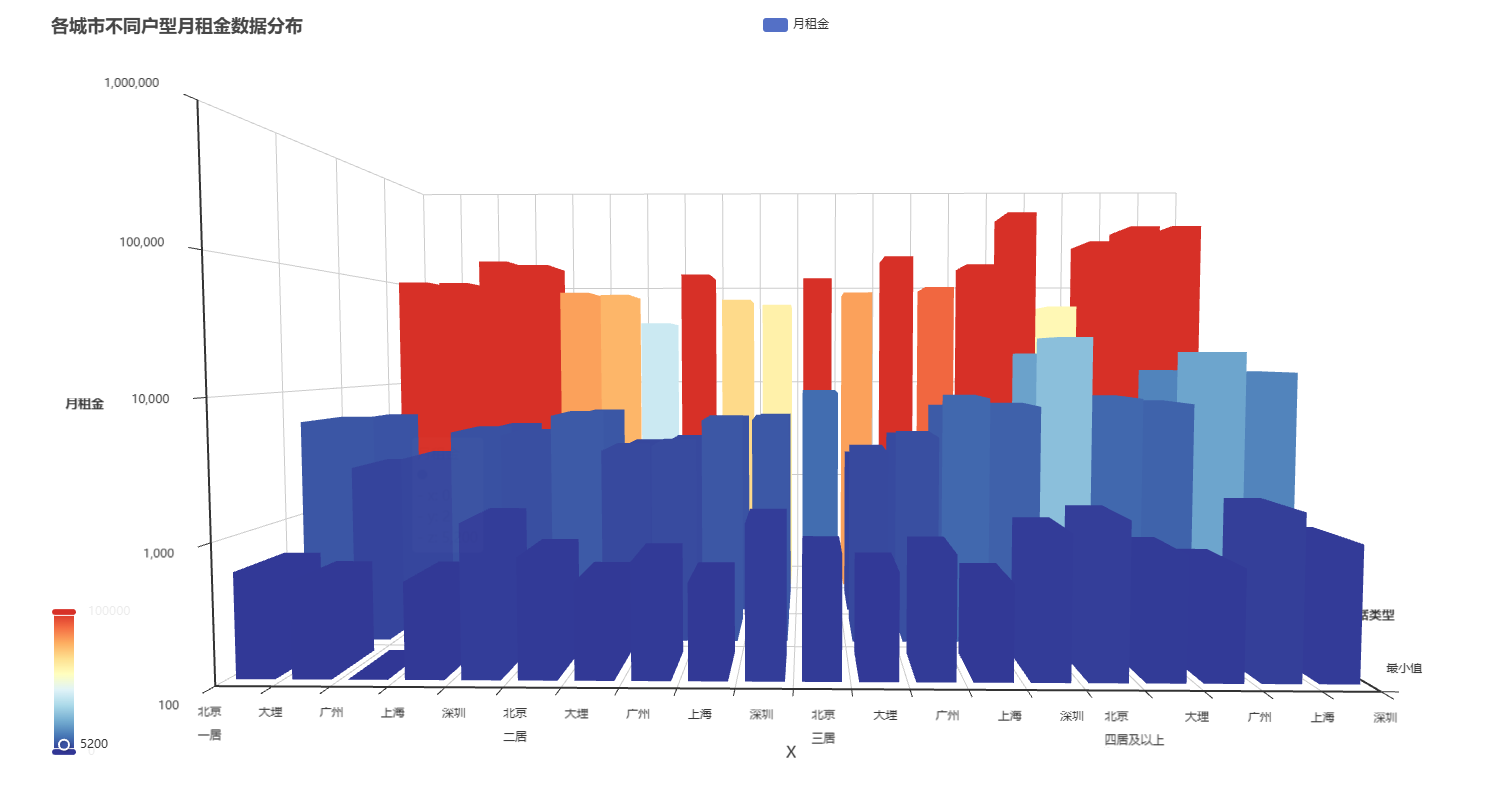
-
均价比较
北京和上海的一居、二居和三居均价都高于其他城市。这可能是由于北京和上 海作为中国的首都和经济中心,吸引了大量的人才和资源,导致房屋租金水平相对较高。
-
最高价差异
一居室中,几个地区的房租最高值差异不明显,可能是一居室的房屋面积相对较小,功能相对单一,无论在一线城市还是大理这样的城市,其基本配置(如卧室、卫生间等)相差不大。而且一居室的目标租户群体通常是单身人士或年轻情侣,对房屋的品质和配套设施要求相对较为一致,这使得各地区一居室的最高房租值较为接近。
而在二居、三居、四居及以上的情况中,就可以看出北京、上海、广州、深圳这几个一线城市的房租均价明显高于大理了,原因是一线城市人口密集,经济发达,大量的外来人口涌入导致对住房的需求旺盛。而且在这些城市,较大户型的房屋通常会被家庭所选择,家庭对房屋的地段、周边配套(如教育资源、医疗资源等)、房屋品质等有较高要求,愿意支付较高的租金来获取更好的居住环境。大理作为旅游城市和相对休闲的城市,人口密度较低,对大户型房屋的需求主要来自当地居民,而当地居民的收入水平和对租金的承受能力相对一线城市居民较低,因此大户型房屋租金较低。
-
最低价差异
广州的房屋租金最低价相对较低,这可能与广州的经济发展水平和房屋供应相对充足有关。广州作为中国南方重要的商贸中心和制造业基地,房屋供应相对充足,导致租金竞争较为激烈,价格相对较低。并且广州很多城中村和老城区,经济发展不平衡,外地来务工的人很多,这也导致有许多低价房源。
-
中位数差异
在几种居室中,北京和上海的房租中位数都明显高于其他地区,这可能是因为北京上海是我国最重要的两个经济城市,且这两个地方面积小土地贵,导致房租普遍偏高。
-
居室比较
- 如果只看最低价,会发现其实一居二居三居以及四居以上的最低价差距并不明显,说明主导最低价格的还是城市经济水平而不是居室的多少;
- 如果只看中位数,会发现一居二居三居的中位数差异都不明显,只有四居中的一线城市的中位数明显高于一到三居,可能是因为对于一居到三居户型,由于其需求群体广泛且房屋供应相对充足,市场价格分布较为均匀,导致中位数差异不大。而四居室通常是较为高端的户型,一线城市有更多高收入人群有能力且有需求租赁这种大户型,推高了四居室的租金中位数。
- 如果只看最高价,会发现一居二居的最高价差异不明显,而三居四居的价格普遍高于一居二居,但是对大理来说这种影响还是不明显。说明居室数量主要影响一线城市的房租最高价。可能是因为三居、四居房屋能满足家庭等更多人口的居住需求,在一线城市中,这类户型的高端房源(如豪华装修、核心地段等)能支撑较高的租金价格。大理由于城市特性,对大户型高端房源的需求较少,所以大户型租金价格上涨幅度不大;
- 值得注意的是大理的一居室价格最高价很高,可能是因为大理是一个旅游城市,旅游人群普遍租住一居室,其中一居室的高档房源较多,因此最高价较高。
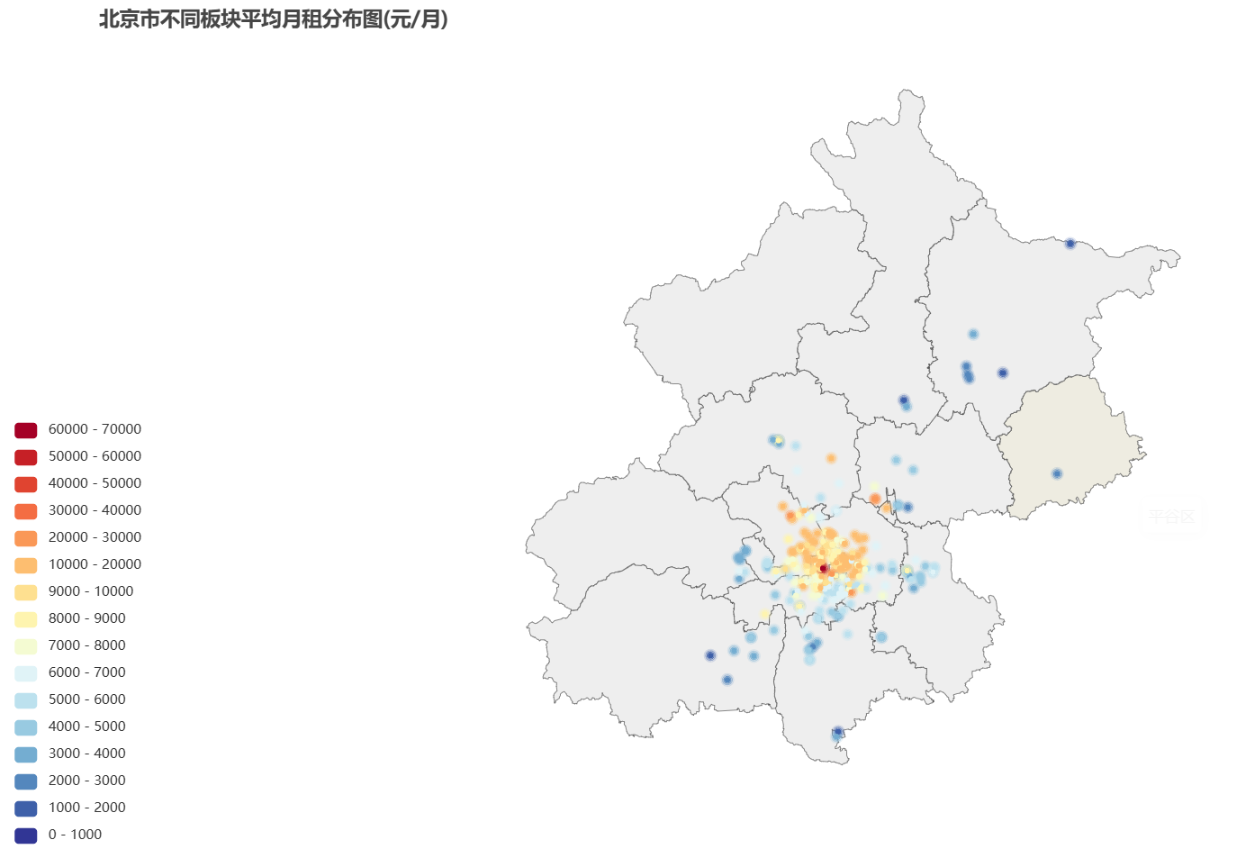
该统计结果为一个html动图,将光标移至点的位置会显示板块名称。
-
北京
文件位置:house_data_tables/street_price/bj.html
可以看出月租均价最贵的板块是西城区的西单。中央别墅区、东大桥、朝阳公园等核心区域租金较高,而延庆、密云、平谷等远郊区县租金较低。中央别墅区、东大桥、朝阳公园等核心区域租金高涨,主要原因是这些区域地段优越,交通便利,配套设施完善,吸引了大量高端人才和企业入驻。
由此图可以看出北京的贵价房源多集中在西城、东城、朝阳、海淀的板块,并且分布数量也是这几个区域最多,呈现一个分布和价格都不均匀且集中的形式。北京市各版块租金水平与经济发展水平密切相关,经济发展水平较高的区域,租金水平也较高,从这个图也可以看出北京的经济发展并不平衡。
-
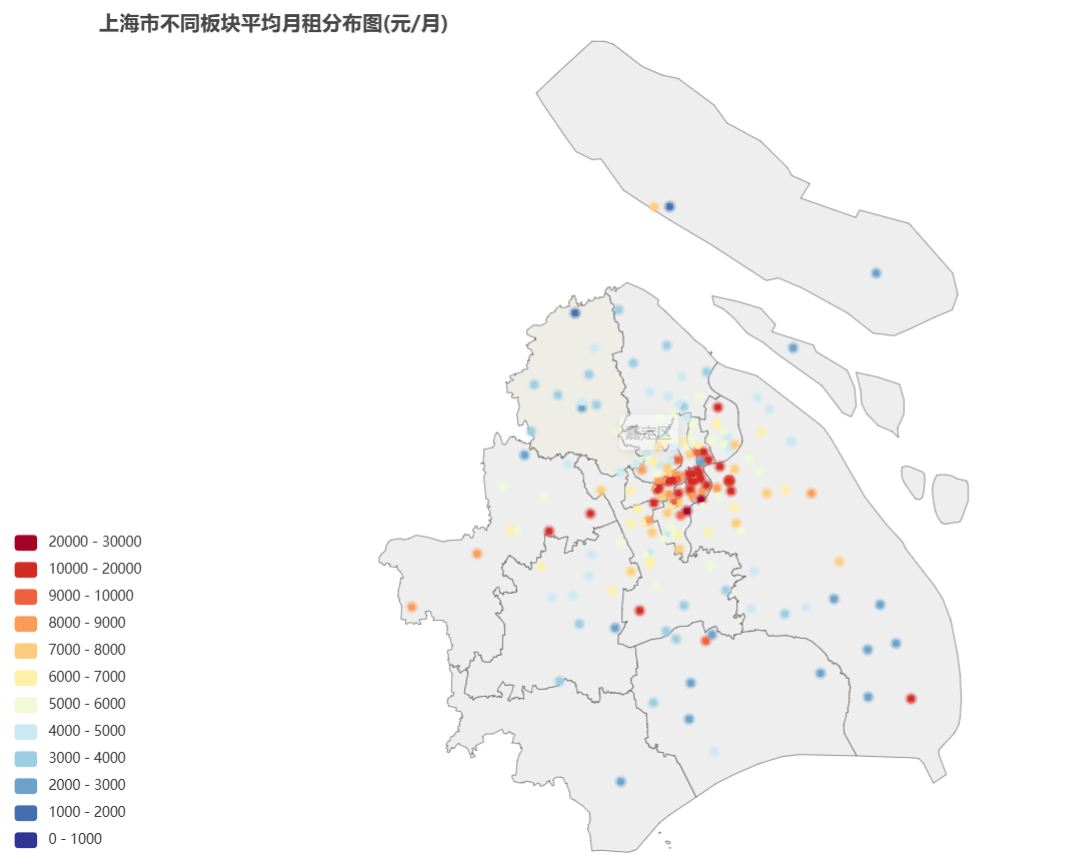
上海
文件位置:house_data_tables/street_price/sh.html
可以看出月租均价最贵的板块是黄浦区的黄浦滨江。黄浦滨江、徐汇滨江、新天地等核心区域租金较高,而崇明新城、车墩、柘林等远郊区县租金较低。黄浦滨江、徐汇滨江、新天地等核心区域租金高涨,主要原因是这些区域地段优越,交通便利,配套设施完善,吸引了大量高端人才和企业入驻。崇明新城、车墩、柘林等远郊区县租金较低,主要原因是这些区域距 离市中心较远,交通不便,配套设施不完善,吸引力较弱。
由此图可以看出上海的贵价房源多集中在黄浦、徐汇和长宁的板块,并且数量上也集中在这几个区,说明这几个区的经济较发达,是上海的核心区域。
-
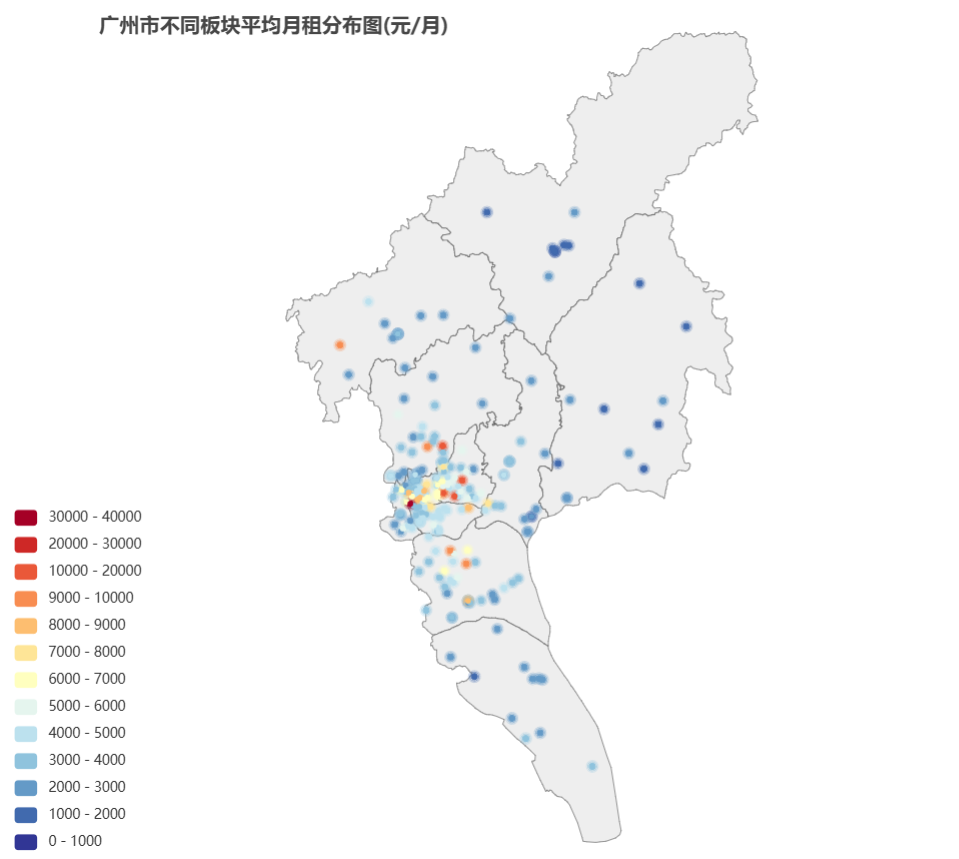
广州
文件位置:house_data_tables/street_price/gz.html
可以看出月租均价最贵的板块是荔湾区的沙面。黄埔村、沙面、二沙岛等核心区域租金较高,而增城碧桂园、石滩镇、福和镇等远郊区县租金较低。黄埔村、沙面、二沙岛等核心区域租金高涨,主要原因是这些区域地段优越,交通便利,配套设施完善,吸引了大量高端人才和企业入驻。并且沙面岛是旅游景区,景区的房租普遍较高。增城碧桂园、石滩镇、福和镇等远郊区县租金较低,主要原因是这些区域距离市中心较远,交通不便,配套设施不完善,吸引力较弱。
由此图可以看出广州的贵价房源多集中在天河、越秀、沙面和海珠的板块,且数量上也集中在这几个区,说明这几个地区是广州的核心区域。而对比其他城市,也可以看出其实广州比其他一线城市的房租低。
-
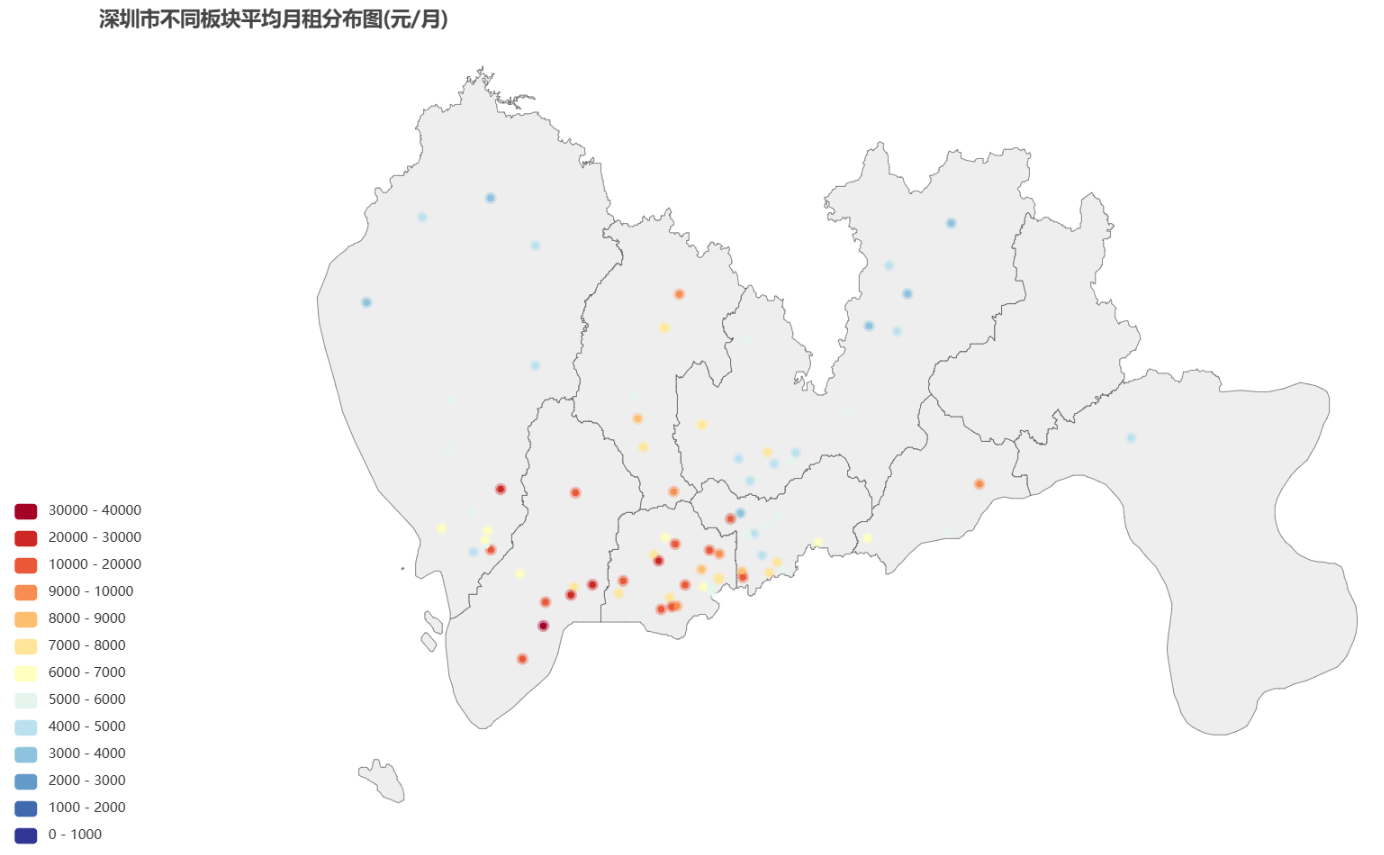
深圳
文件位置:house_data_tables/street_price/sz.html
可以看出深圳月租均价最贵的板块是南山区的深圳湾。深圳湾、香蜜湖、曦城等核心区域租金较高,而坪山、坪地、清水河等远郊区县租金较低。深圳湾、香蜜湖、曦城等核心区域租金高涨,主要原因是这些区域地段优越,交通便利,配套设施完善,吸引了大量高端人才和企业入驻。坪山、坪地、清水河等远郊区县租金较低,主要原因是这些区域距离市中心较远,交通不便,配套设施不完善,吸引力较弱。
由此图可以看出深圳的贵价房源多集中在南山区和福田区的板块,数量上多分布在南山区、福田区、罗湖区的板块。说明南山区和福田区经济较发达,房租较高,也许有很多人选择在房租较低的罗湖区租房。
-
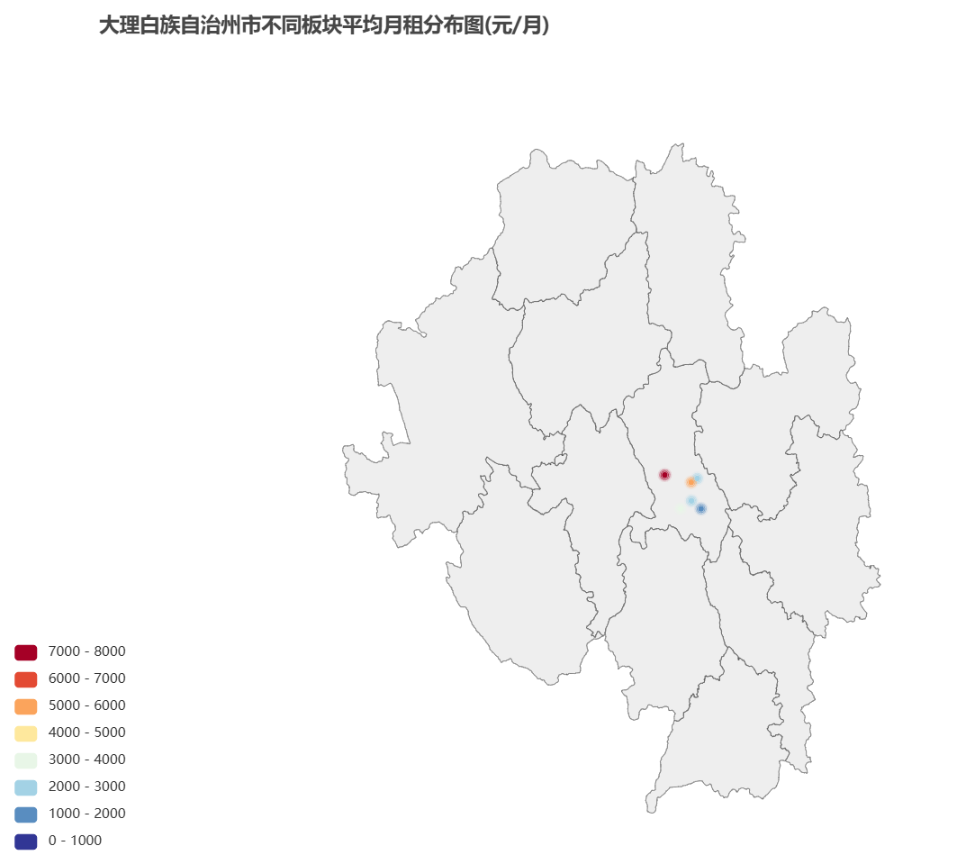
大理
文件位置:house_data_tables/street_price/dali.html
可以看出大理月租均价最贵的板块是大理市的古城,这里也是大理旅游景点中最中心的一个。古城和海东的房租均价较高,而下北关区和市区的房租均价较低。大理是一个旅游城市,因此靠近旅游景点的板块房租价格偏高,而虽然市区是经济发展的中心,却因为远离旅游景点房租反而偏低。
可以看出大理的房源明显少于其他几个一线城市,这也应证了大理的经济发展水平较低,甚至有的区没有租房的业务。
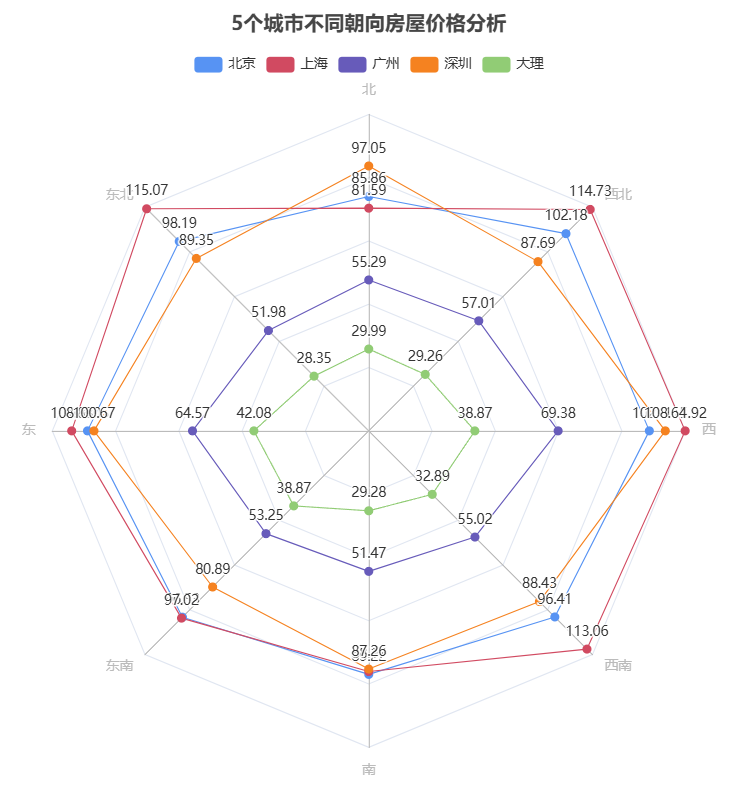
-
不同城市的房租情况
由不同城市的雷达图曲线可以看出,北京、上海、深圳的单位面积平均租金是明显高于广州和大理的。而大理的单位面积平均租金是最低的,但是其他三个一线城市在不同朝向上却存在价格高低差异。
-
不同朝向的情况
由雷达图可以看出,所有城市的朝西、朝东的房子单位面积平均租金都较高。早晨阳光充足,房间能够在一天的开始就获得较好的采光。对于大多数人来说,早晨的阳光能带来舒适感,而且朝东的房间在夏季可以避免下午强烈的西晒,相对较为凉爽,因此朝东的房间租金高。
虽然会有西晒问题,但在冬季,下午的阳光可以让房间更加温暖。并且,对于一些喜欢欣赏日落景色的租户来说,朝西的房子有一定的吸引力,因此朝西的房间租金高。大多数城市的主要道路和商业设施布局会考虑到朝向和采光。朝东和朝西的房屋往往更容易临近主要道路和商业区域,交通便利性和周边配套设施较为完善,这也会提升房屋的租金价值。
而不同城市之间还是存在一些差异,下面分析差异和原因:
- 北京:朝东北、东、西、西北、西南的单位面积租金较高,而其他方向较低;
- 上海:朝东北、东、西、西北、西南的单位面积租金较高,而其他方向较低,与北京一致;
- 北京和上海的气候条件较为相似,冬季寒冷,夏季炎热。在这种气候条件下,东北、东、西、西北、西南方向的房屋能够在不同季节获得较好的采光和通风条件。
- 广州:朝东、西、北、西北的单位面积租金较高,而其他方向较低;
- 广州气候较为炎热潮湿。朝东和朝西的房屋能够获得较好的采光和通风,有助于缓解潮湿闷热的感觉。而朝北的房屋在夏季相对凉爽,冬季广州气温相对较高,对阳光的依赖度较低,因此朝北房屋租金也较高。
- 深圳:朝东、西、北、东北、西北的单位面积租金较高,而其它方向较低;
- 深圳是新兴的现代化城市,其城市规划和经济发展对房屋租金有重要影响。东、西、北、东北、西北方向的房屋可能更靠近新兴的商业区、科技园区和交通要道,这些区域的高需求推高了房屋租金。
- 大理:朝东、西、东南的单位面积租金较高,而其他方向较低。
- 大理是著名的旅游城市,其独特的自然景观是吸引游客和居民的重要因素。朝东和朝西的房屋可能能够更好地欣赏到洱海的湖景或苍山的山景,同时东南方向可能能够获得较好的采光和景观视野,因此这些朝向的房屋租金较高。
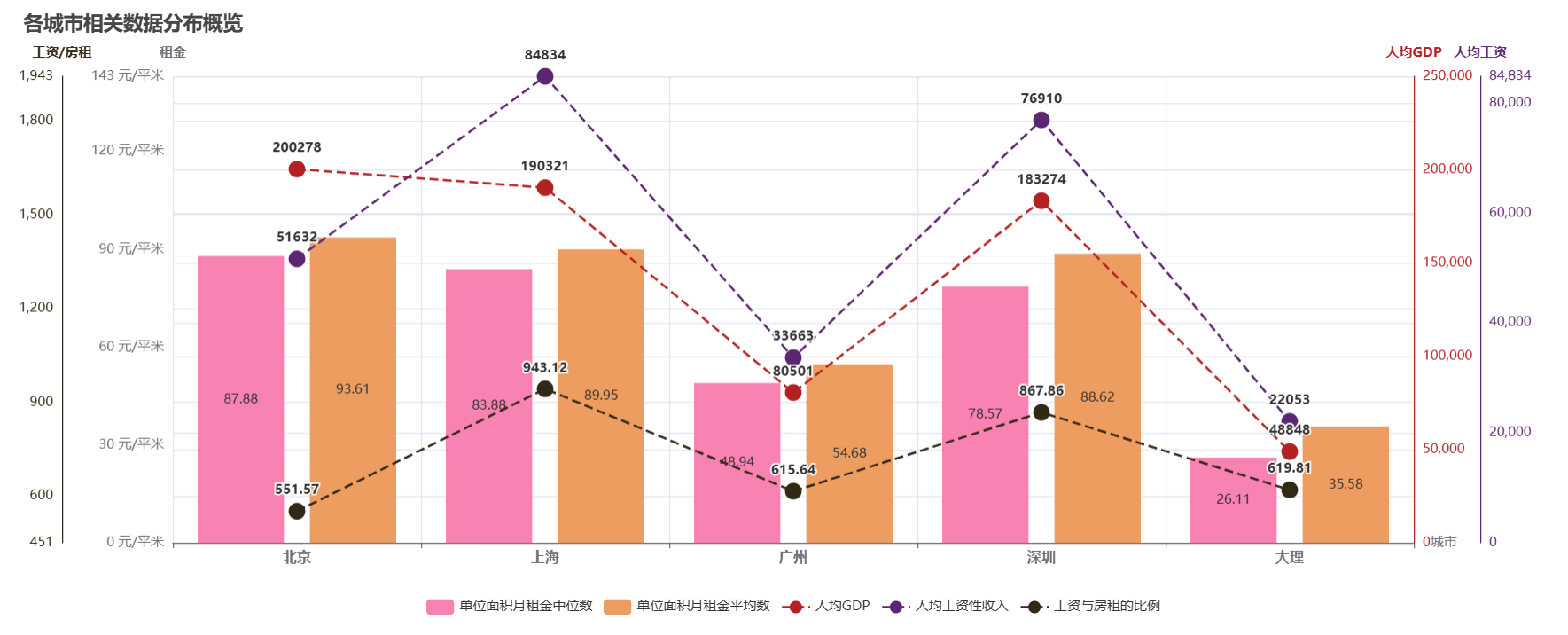
通过柱状图和折线图的对比可以看出,各城市的单位面积月租金中位数、平均数基本和人均GDP以及人均工资性收入呈正相关。除北京外,人均GDP也和人均工资性收入呈正相关;而北京的人均GDP高于上海和深圳,人均工资性收入却低于上海和深圳。
-
经济发展水平与购买力
在经济发达的城市,人均 GDP 和人均工资性收入较高,居民的购买力更强。这使得他们能够承受更高的租金,从而推高了房屋租赁市场的价格。例如,上海、深圳等高收入城市,人们愿意为更好的居住环境支付更高的租金。
高收入人群对居住品质的要求也更高,他们往往倾向于租赁地理位置优越、房屋条件好的房源,进一步拉高了租金中位数和平均数。
-
城市吸引力与人口流入
人均 GDP 和人均工资性收入高的城市通常具有更多的就业机会和优质的公共资源(如教育、医疗等),这会吸引大量人口流入。人口的增加导致对住房的需求上升,在房屋供应相对稳定的情况下,租金自然上涨。例如,一些新兴产业集中的城市,每年都会有大量年轻人涌入寻找工作机会,他们需要租房居住,促使租金水平与当地经济指标同步上升。
-
北京人均 GDP 高于上海和深圳,但人均工资性收入低于上海和深圳的原因
北京的经济结构中,政府机关、事业单位、国有企业以及大量的科研机构占比较大。这些单位虽然创造了较高的 GDP,但部分岗位的工资水平可能相对较为平均,没有像上海和深圳的一些行业那样存在高额的工资激励。上海是重要的金融中心,金融行业的高收入人群较多;深圳则是科技创新的前沿阵地,聚集了大量的高科技企业,这些企业往往通过股权激励等方式为员工提供高额收入,拉高了人均工资性收入。
-
租房负担分析
黑色折线的计算方式是人均工资性收入/单位面积租金平均数,该比例与租房负担呈负相关。由图可以看出,上海、深圳虽然房价高,但是该比例值大,所以租房负担其实很轻;而北京的租房负担最大;大理的租房负担第二大,但其实大理作为旅游城市,来租房的多是外地人,而这里是用本地人的工资来衡量负担的,因此大理的情况比较特殊。