
Spaudible is an offline search engine that helps you discover new music acoustically similar to your favorite songs. It achieves this by converting your input song into a mathematical vector (i.e. a song "fingerprint"), comparing this vector against a quarter billion other song vectors, and returning a playlist of songs that scored the highest in similarity.
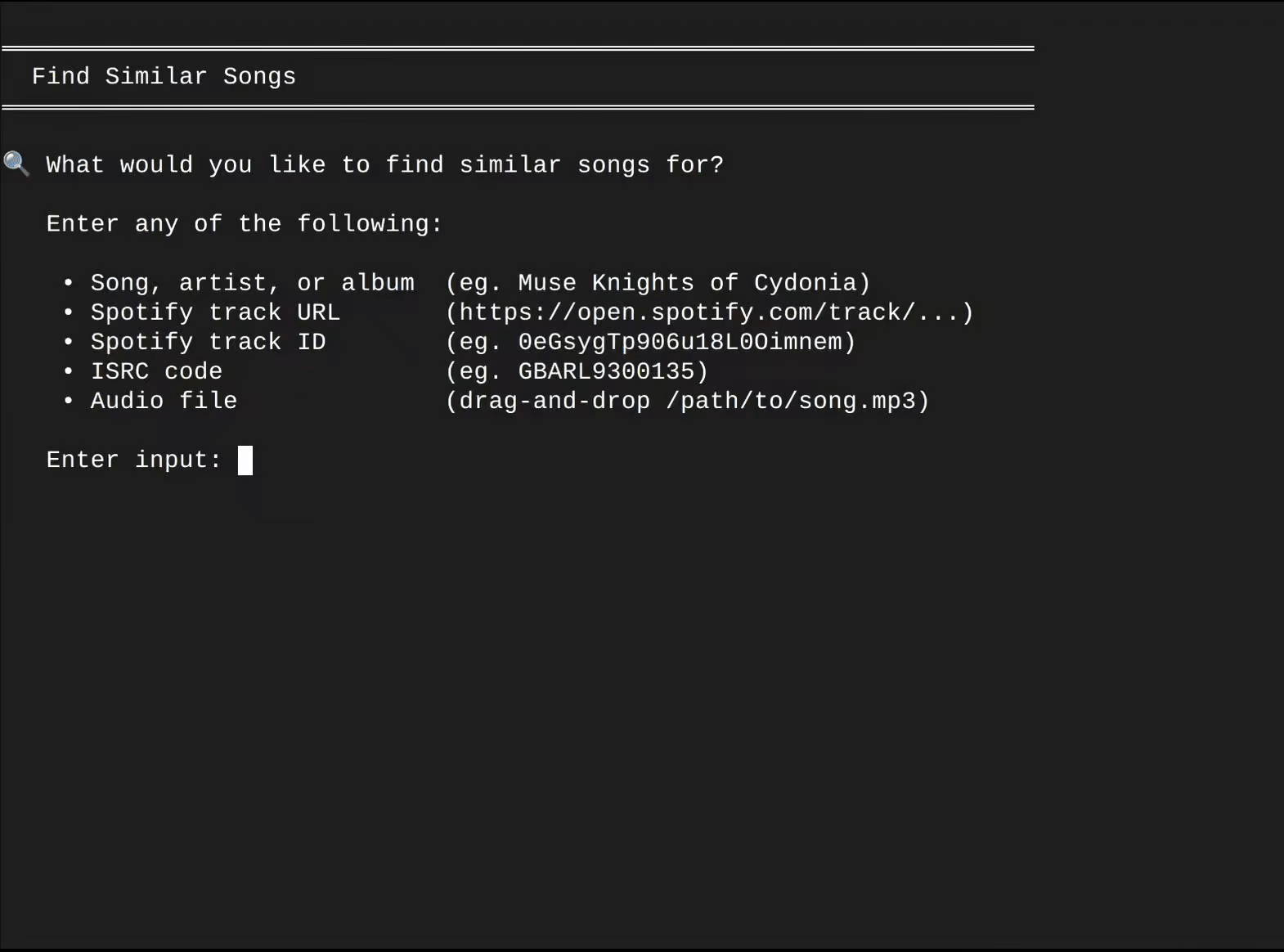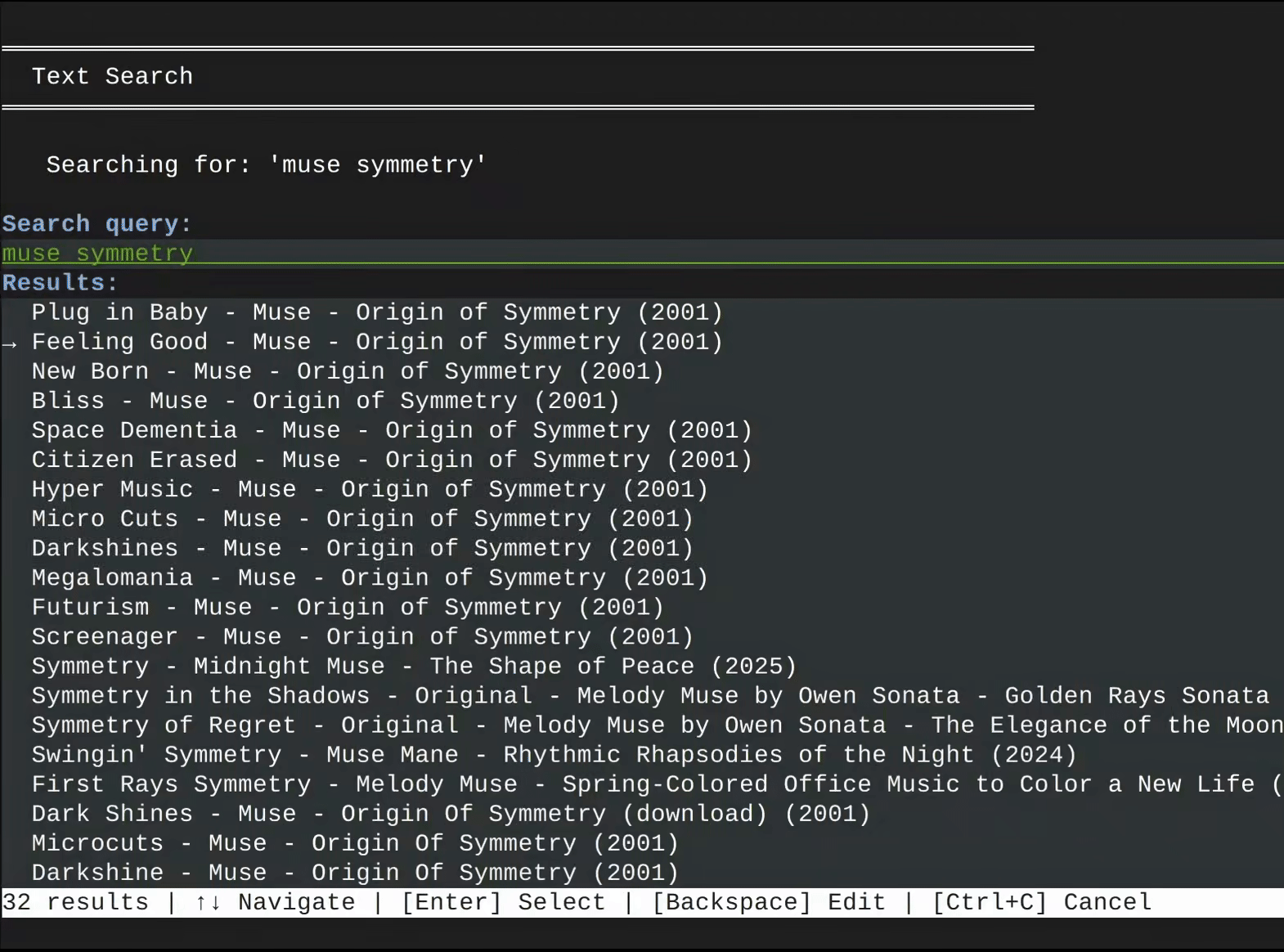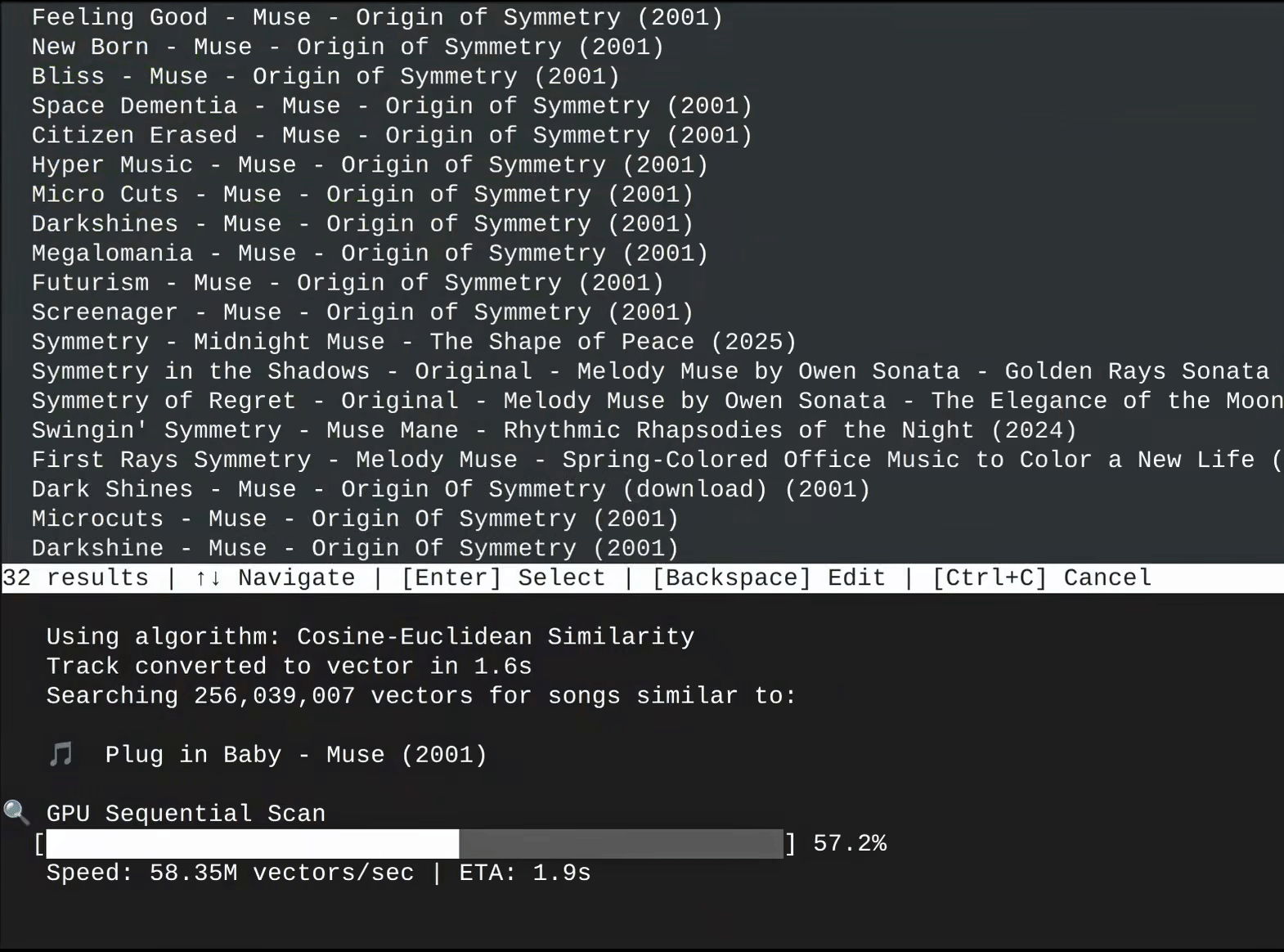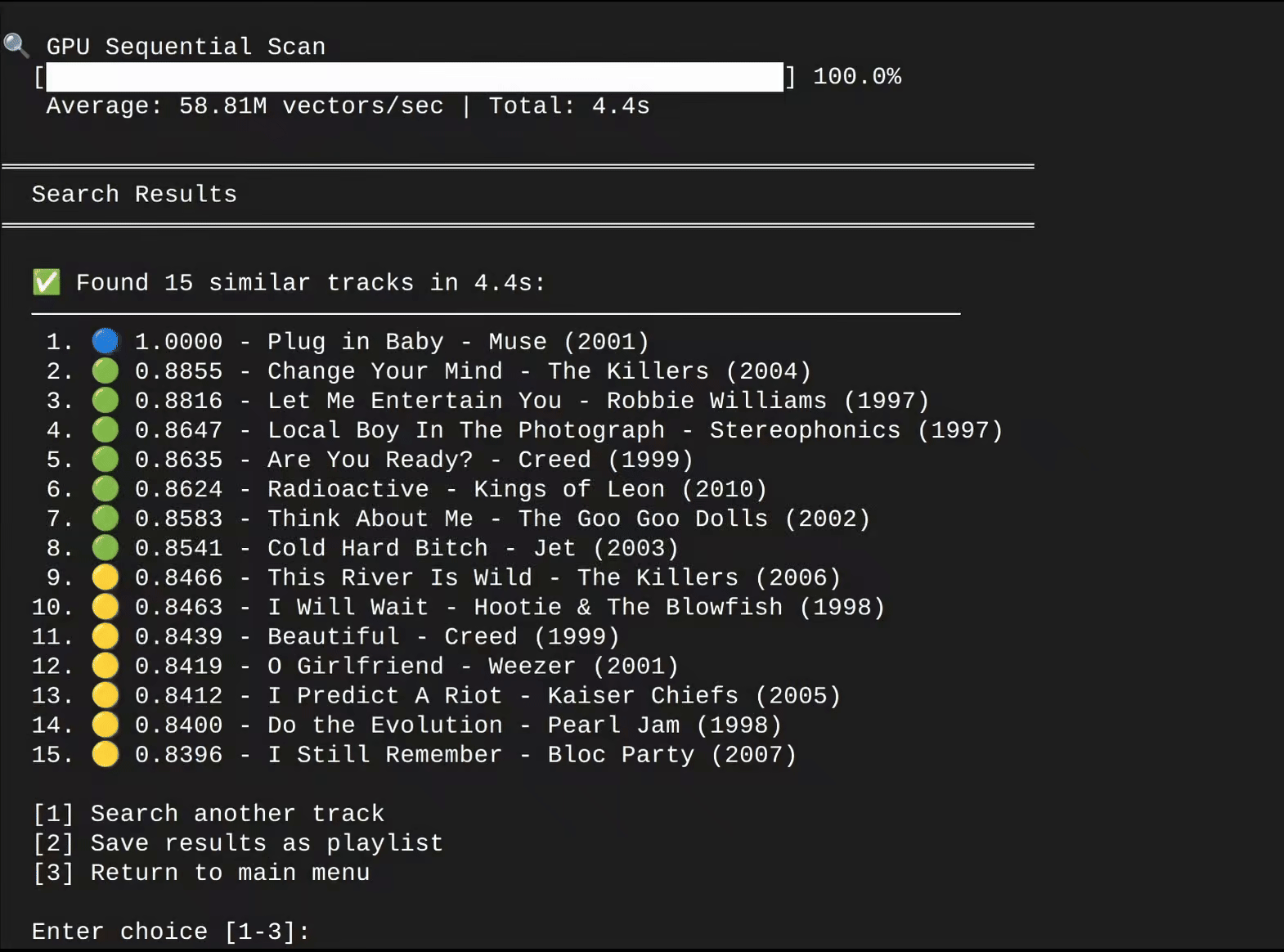
On a modern PC with an Nvidia GPU, finding similar songs takes only a few seconds. This is possible thanks to the CUDA-accelerated PyTorch library, which rapidly computes vector similarities in parallel across a custom-built vector cache. Even on systems without Nvidia hardware, Spaudible falls back to an efficient Numba-accelerated CPU pipeline that completes similarity searches within minutes.
| Component | Recommended Specs |
|---|---|
| SSD | ≥ 230 GB free disk space* |
| RAM | ≥ 8 GB |
| CPU | Multi-core |
| GPU | Nvidia RTX (optional) |
| OS | Windows, Linux, or macOS |
* In order for Spaudible to perform similarity searches and deliver well-formatted results completely offline, it needs to store the attributes of over 256 million songs locally. During setup, extracting the compressed attribute databases will temporarily cause the disk usage to peak around 230 GB, after which it'll settle down to 215 GB once the compressed files are automatically deleted and the setup completes.
Furthermore, performing a large number of vector comparisons in a short timespan demands fast vector data access, which is why storing the binary vector files on an SSD is strongly recommended to avoid the considerable bottleneck that an HDD would create.
Full breakdown of storage needs (click to expand)
166.9 GBfor uncompressed Spotify databases containing song metadata, which are used to interpret the results of the vector-based similarity searches in a human-readable way54.4 GBof temporary free space to extract the otherwise compressed Spotify databases33.3 GBfor the binary vector cache of song attributes and indexes4.9 GBfor a semantic index to enable fast text-based song queries~8 GBfor Python's virtual environment (eg. CUDA binaries)
Here's how to get Spaudible running on your computer:
-
Download and extract this repository to a folder on your PC.
You can use this link (which you can also find by clicking the green
Codebutton at the top of this page, and clickingDownload ZIP):Alternatively, if you have
gitinstalled on your system, you can open a terminal in the directory where you want to run Spaudible, and type this command to clone the repo:git clone https://github.com/Daveofthecave/spaudible.git
-
Refer to the following platform-specific instructions:
-
Simply double-click
spaudible.bat. If you get a Windows SmartScreen prompt, clickMore infoand thenRun anyway. -
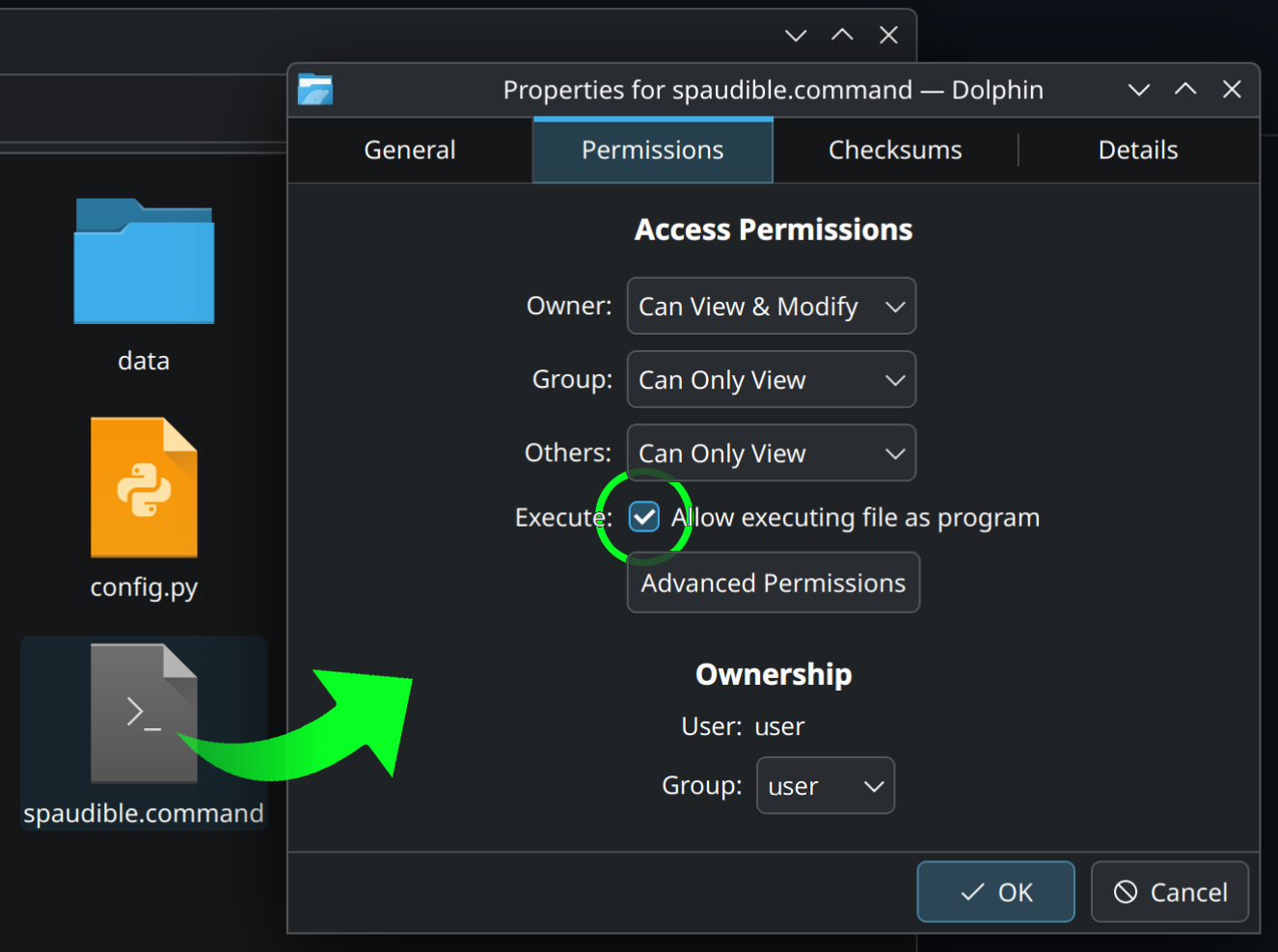
- Right-click on
spaudible.command, and clickProperties. - Click on the
Permissionstab in the window that pops up. - Check the box that says
Allow executing file as program. - Click
OK(if applicable) and close the Properties window.
- Double-click
spaudible.commandto set up the environment and launch Spaudible.
- Right-click on
-
Simply double-click
spaudible.command. If Gatekeeper prompts you about an unidentified developer, right-clickspaudible.command, clickOpen, and then clickOpenagain in the confirmation window.Note
Spaudible's launcher has not yet been tested on macOS, so results may vary. Given the universality of Python, however, Spaudible itself should have no problem running on macOS, provided its virtual environment is correctly set up. Due to a long-standing rift between Apple and Nvidia, modern versions of macOS lack support for Nvidia GPUs, which means CUDA-accelerated GPU mode won't work for song similarity searches.
-
The spaudible.bat and spaudible.command launchers automatically download the correct Python environment and required libraries through an open-source package manager called uv, which simplifies and speeds up the installation process across all platforms.
Every song has its own set of unique attributes; for example:
- Genre (eg. rock, classical, jazz)
- Tempo (eg. 120 bpm)
- Key (eg. C major, F♯ minor)
- Release year (eg. 2007)
One way to determine how similar two songs are to each other is to compare their attributes. If two songs share similar genres, tempos, keys, release years, and other attributes, we can conclude that those songs are indeed similar. On the contrary, if two songs have completely different genres, tempos, etc., we can conclude that they aren't very similar at all.
We humans naturally compare songs in a similar way, although these comparisons usually happen subconsciously and instantaneously. Hard rock "feels" very different from classical music, and a fast tempo "feels" more danceable than a slow tempo.
A computer, however, only understands numbers. If we'd want the computer to determine how similar two songs are, we would need to translate the attributes of those songs into its native language – numbers. This translation process is called "encoding".
Some song attributes are easier to encode than others. Tempo and release year, for instance, already exist as numbers, which makes things a lot easier. Genre and key, on the other hand, are usually represented with words, letters, and/or symbols. Translating these non-numeric attributes to numbers in a meaningful way is slightly trickier. That being said, there are many reasonable ways to do so.
Example
In Spaudible's case, for example, it groups musical keys together by the number of accidentals (sharps or flats), from 0 to 6, and then divides by 6 to obtain a normalized value between 0 and 1. This way, keys with fewer sharps or flats get a value closer to 0, and keys with many sharps or flats get a value closer to 1. Of course, there are many other ways to encode a key (eg. chromatically, by circle of fifths, etc.), but Spaudible uses this particular encoding to avoid overfitting while maintaining enharmonic synergy.
Once we figure out how we want to encode our song attributes, we need an efficient way to store them. One of the most common ways of storing a group of similar items is in a list. Computer scientists often like to use the term "array", while mathematicians are more partial to the term "vector", but in the end, both terms describe a collection of items.
That being said, while there may be overlap in semantics, there remain subtle (and often not-so-subtle) distinctions among certain terms that may help us in tackling our similarity problem.
Thinking of a list of numbers as a "vector" carries with it certain mathematical connotations that turn out to be useful for us. In math, a vector is a special list of numbers that has both direction and magnitude (length). Think of it like a container that stores numbers in an organized way, one after the other. Just like we can perform arithmetic and algebra on individual numbers, we can also do math on vectors – groups of numbers. This is essentially what linear algebra is; algebra on a "line" of numbers.
We can visualize vectors as arrows of varying lengths pointing in particular directions.
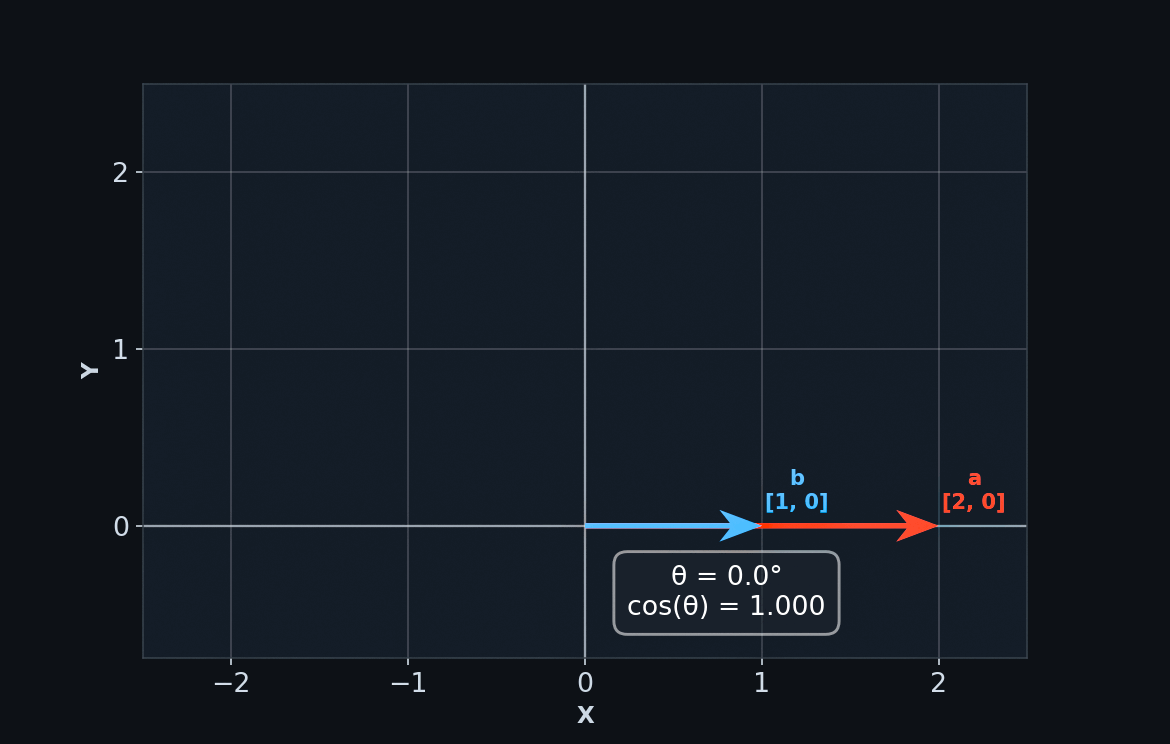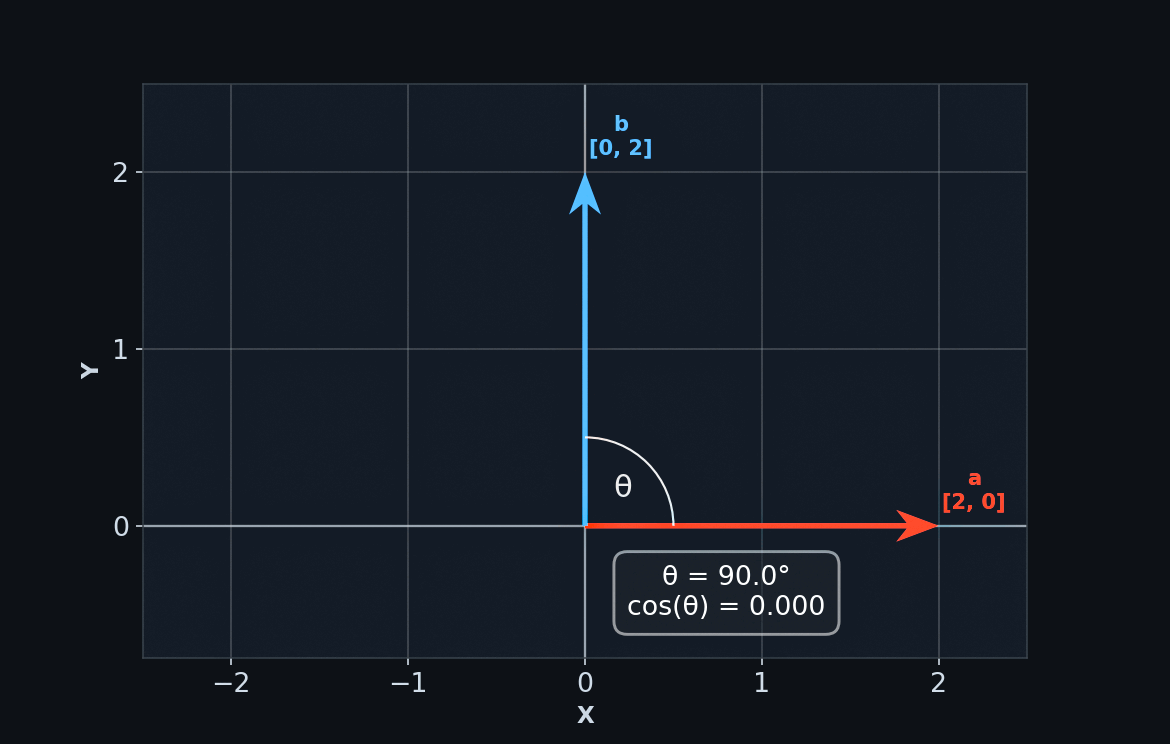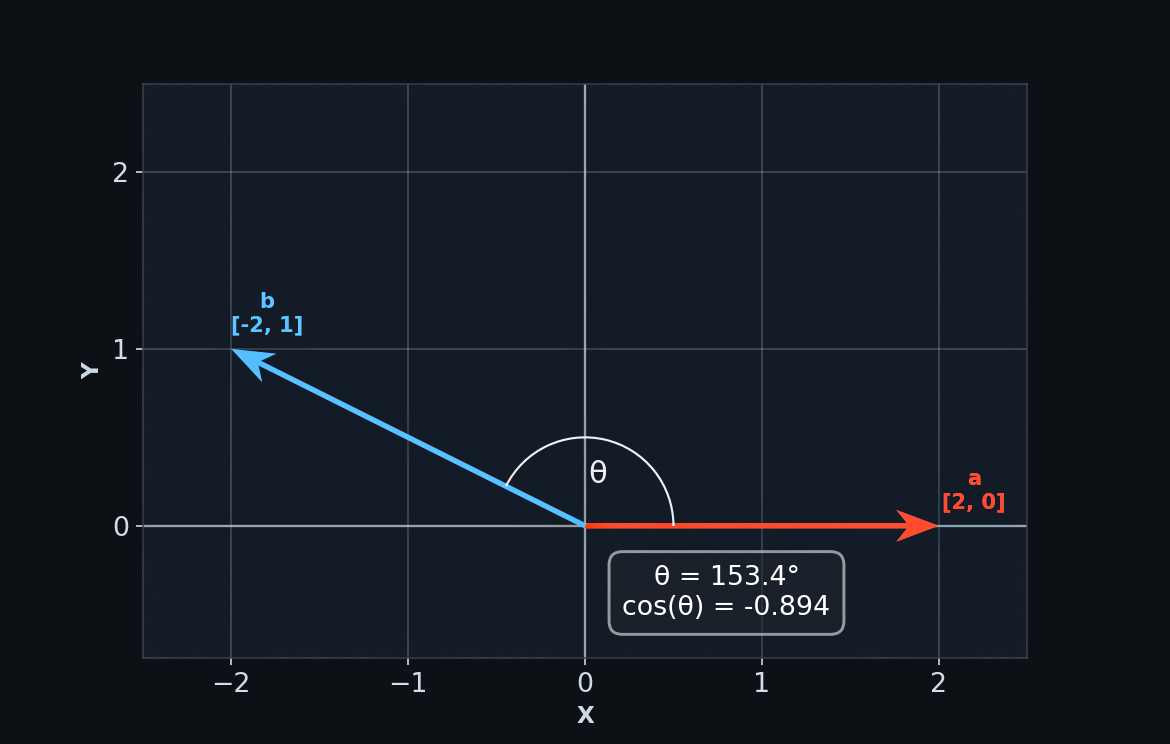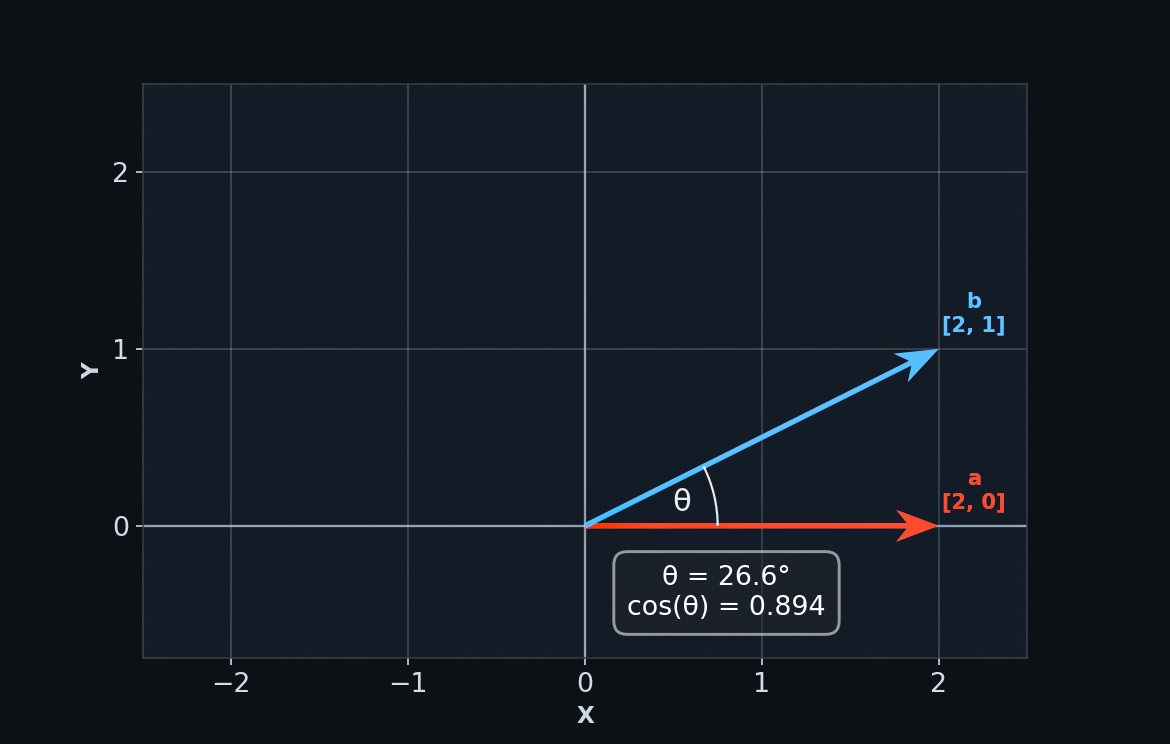
Some vectors point in similar directions, while others point in opposite directions. Where a vector points is defined by its components – the individual numbers that make up the vector. A vector's dimension (eg. 2D, 3D, ...) is determined by how many components it has.
We can tell how closely aligned two vectors are by calculating their cosine similarity. In other words, what is the cosine of the angle between them? Cosine behaves like a percentage. It can tell you, for example, that "vector b is 95% aligned with vector a."
Turns out this is pretty useful for our song comparison problem! Since we've determined that we can convert any song into a vector by treating each song attribute as a vector component, this means we can take advantage of these powerful vector operations to determine how similar two songs are!
This is exactly what Spaudible does under the hood.
But rather than using 2-dimensional vectors like in the animation above, where each vector can only encode 2 song attributes, we use 32-dimensional vectors that encode 32 attributes per song. This significantly increases the accuracy of our comparisons, since we have more data points to compare.
Using a preprocessed binary cache of 32D song vectors, in tandem with Spotify's databases that hold attributes to over 256 million songs, Spaudible takes a song the user provides, converts it into a vector, and then applies cosine similarity (or a related algorithm) between the user's song vector and the quarter billion other vectors sitting in the cache. Rather than going through the entire vector cache one-by-one, Spaudible splits up this job across the CPU's cores, or, better yet, across the GPU's more numerous CUDA cores. Since it doesn't matter in which order we conduct our similarity calculations, we leverage the power of parallel processing to reach our final result faster.