A flexible, transparent entity linking system that leverages Named Entity Recognition (NER) class probabilities, contextual embeddings, and DBpedia knowledge-graph features to disambiguate and link mentions in text.
Keywords: entity linking, NER, NED, knowledge graphs, DBpedia, embeddings, Flask
-
Multiple NER Models: Choose from three NER models trained using SpanMaker framework:
-
Type-Aware Disambiguation: Optional embedding features based on predicted NER types.
-
Feature-Rich Ranking: Combines string similarity, popularity, context embeddings, position, and type embeddings in an XGBoost model.
-
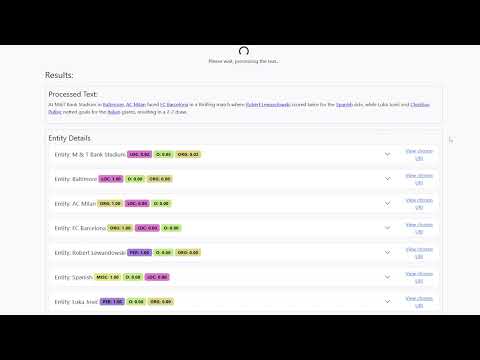
Interactive GUI:
- Highlighted, clickable entity mentions
- Accordion view of NER probabilities and candidate details
- Dynamic thumbnails from Wikipedia Commons
-
Configurable: select one of the available NER models and toggle using type-score features during NED.
-
Input & Configuration
- User enters text.
- Selects NER model and whether to use type-score features.
-
NER Stage
- Text is sent via AJAX to the Flask backend.
- The chosen transformer model produces entity spans and class probabilities.
-
Candidate Retrieval
- For each span, up to 10 candidates are fetched from the KB.
-
Feature Extraction
- Compute Levenshtein, popularity, context similarity, position, and optional type-embedding scores.
-
Ranking & Selection
- Feature vector is scaled and passed through a pretrained XGBoost pipeline.
- Best candidate index is returned; others are ranked for inspection.
-
Interactive Display
- Frontend highlights mentions, shows NER-class badges, and an accordion of candidate cards with details.
- Python 3.8+
pip- Virtual environment (recommended)
git clone https://github.com/Danzigerrr/ProbNEL.git
cd ProbNEL
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\\Scripts\\activate # Windows
pip install -r requirements.txtcd App/NEL_project
python flask_app.pyOpen your browser at http://127.0.0.1:5000/NEL_app.
- Paste text.
- Select NER model and toggle “Use type-score features.”
- Click Process text with DBpedia.
- View highlighted entities in text and expand accordions to inspect probabilities, ontology types, scores, and thumbnails.
Send a POST to /NEL_app with form-encoded parameters:
| Parameter | Description |
|---|---|
user_input |
Raw text |
knowledge_graph |
dbpedia |
ner_model |
Full NER model identifier |
use_types_score |
0 or 1 |
Response is JSON with text, entities, probabilities, and candidates.
Candidate selector is an XGboost model which select the best candidate among the 10 candidates fetched from DBpedia for a recognized named entity in text. The code used for trainig and evaluation of differnt configurations of candidate selector model is presented in Candidate_selector.ipynb.
In order to reuse the feature scores calcualted for each candidate in trainig and test datasets two zip files containig the calculted scores was created.
Code for downloading and unzipping these zip files is included in Candidate_selector.ipynb in the Download and extract cached calculations and requests from zip files section.
ProbNEL integrates fine-grained NER outputs and context-aware scoring to disambiguate entity mentions. Experimental results on two widely used benchmarks demonstrate the effectiveness of this approach:
| Test Dataset | Baseline Accuracy (Surface-Form - Only NED) | ProbNEL Accuracy (Full System - End-to-End Entity Linking) |
|---|---|---|
| AIDA | 64.8% | 86–90% |
| ACE2004 | 72.0% | 86–90% |
The baseline uses only surface form matching, whereas ProbNEL combines contextual similarity, entity popularity, position in DBpedia results, and multiple type-embedding scores derived from predicted NER class distributions. These scores are used as features in an XGBoost classifier trained on annotated datasets.
- AIDA-YAGO-CoNLL: 230 documents, 4463 annotated mentions
- ACE2004: 119 documents, 257 annotated mentions
By leveraging both structured type knowledge and deep contextual embeddings, ProbNEL significantly improves disambiguation accuracy. The system generalizes well across formal and informal texts, making it suitable for downstream applications such as question answering, information retrieval, and knowledge graph population.
This project is licensed under the GNU GPL v3.0. See LICENSE for details.