A comprehensive .NET MAUI plugin that provides ML inference capabilities with support for multiple backends including ONNX Runtime, CoreML, and platform-native acceleration.


{kind=link}
{kind=link}
graph TB
A["IMLInfer Interface"] --> B["OnnxRuntimeInfer"]
A --> C["CoreMLInfer (iOS/macOS)"]
A --> D["MLKitInfer (Android) - Coming Soon"]
A --> E["WindowsMLInfer (Windows) - Coming Soon"]
B --> F["Cross-Platform ONNX Models"]
C --> G["Apple Vision/CoreML Models"]
D --> H["TFLite/MLKit Models"]
E --> I["Windows ML Models"]
B -.->|Uses| J["CoreML EP (iOS/macOS)"]
B -.->|Uses| K["NNAPI EP (Android)"]
B -.->|Uses| L["DirectML EP (Windows)"]
style A fill:#4CAF50,stroke:#2E7D32,color:#fff
style B fill:#2196F3,stroke:#1565C0,color:#fff
style C fill:#FF9800,stroke:#E65100,color:#fff
style D fill:#9C27B0,stroke:#4A148C,color:#fff
style E fill:#00BCD4,stroke:#006064,color:#fff
Legend:
- Green: Unified interface for all backends
- Blue: ONNX Runtime (cross-platform, default)
- Orange: CoreML native (iOS/macOS only)
- Purple: ML Kit/TensorFlow Lite (Android - coming soon)
- Cyan: Windows ML (Windows - coming soon)
- Dotted arrows: Execution provider integration
- 🧠 Multiple ML Backends: ONNX Runtime, CoreML (iOS/macOS), ML Kit (Android - coming soon)
- 🏗️ Platform-Specific Optimizations: Leverages native ML acceleration on each platform
- iOS/macOS: CoreML execution provider & Apple Neural Engine
- Android: NNAPI execution provider
- Windows: DirectML execution provider
- 📱 Cross-Platform: Supports Android, iOS, macOS Catalyst, and Windows
- 🔧 Dependency Injection: Easy integration with .NET DI container
- 🛠️ Utility Classes: Helper classes for tensor operations and model management
- 📦 NuGet Package: Available as a ready-to-use NuGet package
- 🔍 Git LFS Support: Proper handling of large ML model files
- 🧪 Comprehensive Tests: Full unit test coverage
<PackageReference Include="Plugin.Maui.ML" Version="1.0.0" />// In your MauiProgram.cs
public static class MauiProgram
{
public static MauiApp CreateMauiApp()
{
var builder = MauiApp.CreateBuilder();
builder
.UseMauiApp<App>()
.ConfigureFonts(fonts =>
{
fonts.AddFont("OpenSans-Regular.ttf", "OpenSansRegular");
});
// Register ML services with platform-optimized defaults
builder.Services.AddMauiML(config =>
{
config.EnablePerformanceLogging = true;
config.MaxConcurrentInferences = 2;
});
// Or specify a backend explicitly
// builder.Services.AddMauiML(MLBackend.CoreML); // iOS/macOS only
return builder.Build();
}
}public class MainPage : ContentPage
{
private readonly IMLInfer _mlService;
public MainPage(IMLInfer mlService)
{
_mlService = mlService;
InitializeComponent();
}
private async void OnPredictClicked(object sender, EventArgs e)
{
try
{
// Check which backend is being used
Console.WriteLine($"Using backend: {_mlService.Backend}");
// Load your model (ONNX or platform-specific format)
await _mlService.LoadModelFromAssetAsync("my-model.onnx");
// Prepare input tensors
var inputData = new float[] { 1.0f, 2.0f, 3.0f, 4.0f };
var inputTensor = TensorHelper.CreateTensor(inputData, new int[] { 1, 4 });
var inputs = new Dictionary<string, Tensor<float>>
{
["input"] = inputTensor
};
// Run inference
var results = await _mlService.RunInferenceAsync(inputs);
// Process results
foreach (var output in results)
{
var outputData = TensorHelper.ToArray(output.Value);
Console.WriteLine($"Output '{output.Key}': [{string.Join(", ", outputData)}]");
}
}
catch (Exception ex)
{
await DisplayAlert("Error", ex.Message, "OK");
}
}
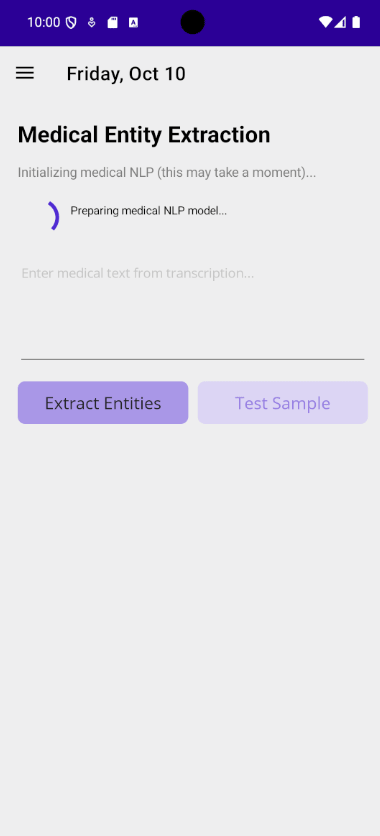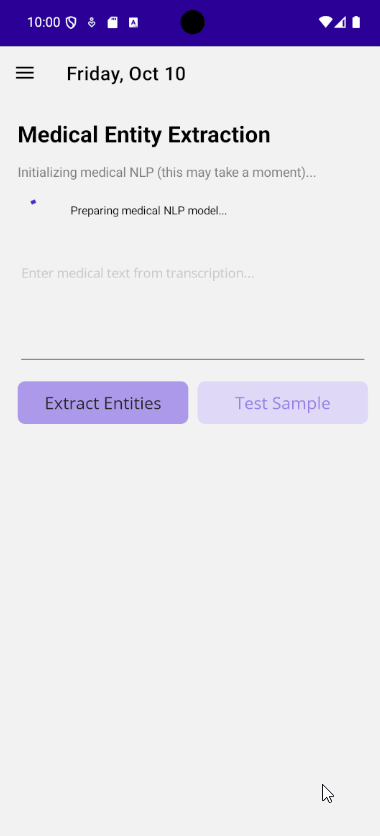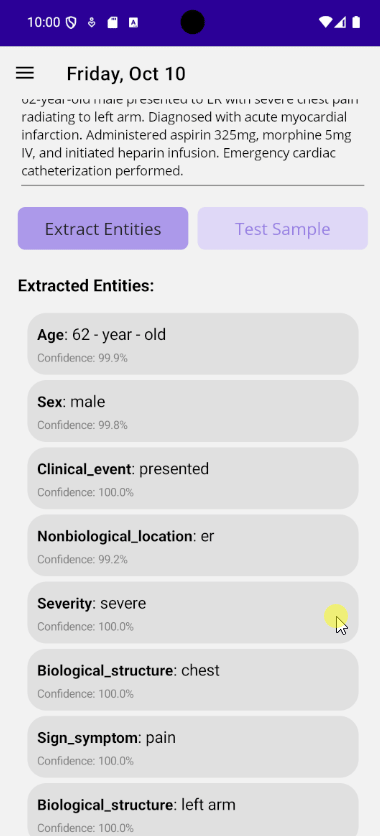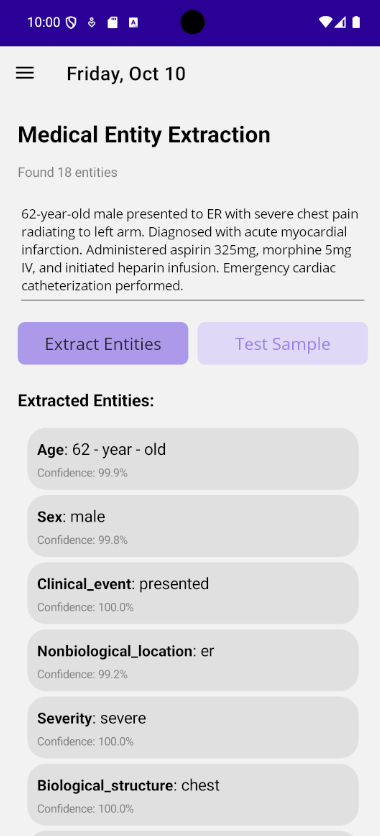
}Before using Plugin.Maui.ML, you'll need ONNX model files. You can:
- Download pre-converted ONNX models from Hugging Face Model Hub
- Convert existing models (PyTorch, TensorFlow, etc.) to ONNX format
We provide the HFOnnxTool to make this easy:
# Download a model that already has ONNX files
cd tools/HFOnnxTool
dotnet run -- fetch --repo sentence-transformers/all-MiniLM-L6-v2 --output ./models
# Or convert a model to ONNX format
dotnet run -- convert --repo d4data/biomedical-ner-all --task token-classification --output ./onnx📖 See the HFOnnxTool Guide for detailed instructions on:
- Using the
inspect,fetch, andconvertcommands - Working with specific models like biomedical NER and sentence transformers
- Python setup for model conversion
- Troubleshooting common issues
| Backend | Platforms | Status | Hardware Acceleration |
|---|---|---|---|
| ONNX Runtime | All | ✅ Stable | CoreML (iOS/macOS), NNAPI (Android), DirectML (Windows) |
| CoreML | iOS/macOS | ✅ Stable | Apple Neural Engine (A12+, M1+) |
| ML Kit | Android | 🚧 Coming Soon | NNAPI, GPU delegates |
| Windows ML | Windows | 🚧 Coming Soon | DirectML, DirectX 12 |
// Automatic platform-optimized selection (recommended)
builder.Services.AddMauiML();
// Explicit backend
builder.Services.AddMauiML(MLBackend.CoreML); // iOS/macOS only
// Configuration-based
builder.Services.AddMauiML(config =>
{
config.PreferredBackend = MLBackend.CoreML; // Falls back to default if not available
});
// Runtime selection
IMLInfer onnxInfer = new OnnxRuntimeInfer();
#if IOS || MACCATALYST
IMLInfer coreMLInfer = new CoreMLInfer();
#endif| Backend | Formats | Notes |
|---|---|---|
| ONNX Runtime | .onnx |
Cross-platform, largest model zoo |
| CoreML | .mlmodel, .mlmodelc |
Native iOS/macOS format |
| ML Kit | .tflite |
Android-optimized |
See Platform Backend Documentation for detailed information about backends, model conversion, and performance optimization.
The main interface for ML inference operations.
MLBackend Backend { get; }- Get the current backend typebool IsModelLoaded { get; }- Check if a model is currently loaded
-
Task LoadModelAsync(string modelPath, CancellationToken cancellationToken = default)- Load a model from a file path
-
Task LoadModelAsync(Stream modelStream, CancellationToken cancellationToken = default)- Load a model from a stream
-
Task LoadModelFromAssetAsync(string assetName, CancellationToken cancellationToken = default)- Load a model from MAUI assets
-
Task<Dictionary<string, Tensor<float>>> RunInferenceAsync(Dictionary<string, Tensor<float>> inputs, CancellationToken cancellationToken = default)- Run inference with float inputs
-
Task<Dictionary<string, Tensor<float>>> RunInferenceLongInputsAsync(Dictionary<string, Tensor<long>> inputs, CancellationToken cancellationToken = default)- Run inference with Int64 inputs (e.g., token IDs)
-
Dictionary<string, NodeMetadata> GetInputMetadata()- Get input metadata for the loaded model
-
Dictionary<string, NodeMetadata> GetOutputMetadata()- Get output metadata for the loaded model
-
void UnloadModel()- Dispose of the loaded model and release resources
Helper utilities for working with tensors.
-
static Tensor<float> CreateTensor(float[] data, int[] dimensions)- Create a tensor from a float array
-
static Tensor<float> CreateTensor(float[,] data)- Create a tensor from a 2D float array
-
static Tensor<float> CreateTensor(float[,,] data)- Create a tensor from a 3D float array
-
static float[] ToArray(Tensor<float> tensor)- Convert tensor to float array
-
static string GetShapeString(Tensor<float> tensor)- Get tensor shape as a string
-
static Tensor<float> Reshape(Tensor<float> tensor, int[] newDimensions)- Reshape a tensor to new dimensions
-
static Tensor<float> Normalize(Tensor<float> tensor)- Normalize tensor values to 0-1 range
-
static Tensor<float> Softmax(Tensor<float> tensor)- Apply softmax function to tensor
Configure the ML services with MLConfiguration:
builder.Services.AddMauiML(config =>
{
config.UseTransientService = false; // Use singleton (default)
config.EnablePerformanceLogging = true;
config.MaxConcurrentInferences = Environment.ProcessorCount;
config.DefaultModelAssetPath = "models/default-model.onnx";
config.PreferredBackend = MLBackend.CoreML; // Optional: specify preferred backend
});PreferredBackend: Preferred ML backend (default: null = platform default)UseTransientService: Whether to use transient service lifetime (default: false, uses singleton)EnablePerformanceLogging: Enable performance logging (default: false)MaxConcurrentInferences: Maximum number of concurrent inference operations (default: processor count)DefaultModelAssetPath: Default model asset path (default: null)
- NNAPI Support: Automatic Neural Network API acceleration on supported devices (Android 8.1+)
- Asset Loading: Load models directly from Android assets folder
- Check Capabilities:
PlatformMLInfer.IsNnapiAvailable()
- CoreML Integration: Automatic CoreML acceleration via ONNX Runtime
- Pure CoreML Support: Use native
.mlmodelfiles withCoreMLInfer - Neural Engine: Support for Apple Neural Engine on A12+ and M1+ chips
- Bundle Resources: Load models from iOS/macOS app bundles
- Check Capabilities:
PlatformMLInfer.IsNeuralEngineAvailable()
- DirectML Support: Hardware acceleration via DirectML on compatible GPUs
- Package Resources: Load models from Windows app packages
- Check Capabilities:
PlatformMLInfer.IsDirectX12Available(),PlatformMLInfer.GetSystemInfo()
Check out the sample projects in the samples/ directory:
- ConsoleApp: Basic console application demonstrating plugin usage
- MauiSample: Full MAUI app with UI examples
- Comprehensive examples showing different model types and backends
Run the comprehensive test suite:
dotnet test tests/Plugin.Maui.ML.Tests/The test suite includes:
- Unit tests for all core functionality
- Backend-specific tests
- Platform-specific integration tests
- Performance benchmarks
- Memory leak detection
- Use singleton service lifetime for better performance (default)
- Backend Selection:
- ONNX Runtime: Best for cross-platform compatibility
- CoreML: Best for iOS/macOS-only apps needing maximum performance
- Hardware Acceleration: Automatically enabled on all platforms
- Memory Management: Use
UnloadModel()when done with a model - Async Operations: All inference operations are async to avoid blocking UI
// Check backend capabilities
#if IOS
if (Platforms.iOS.PlatformMLInfer.IsNeuralEngineAvailable())
{
Console.WriteLine("Running on Apple Neural Engine!");
}
#endif
// Profile inference time
var sw = Stopwatch.StartNew();
var result = await _mlService.RunInferenceAsync(inputs);
sw.Stop();
Console.WriteLine($"Inference took: {sw.ElapsedMilliseconds}ms");- Platform Backend Guide - Detailed guide on backends and model conversion
- HFOnnxTool Guide - Guide for downloading and converting Hugging Face models to ONNX
- API Reference - Complete API documentation
- Examples - Sample code and applications
-
Model Loading Errors
- Ensure the model file path is correct
- Verify the model format matches the backend (ONNX for OnnxRuntime, .mlmodel for CoreML)
- Check file permissions
-
Backend Not Available
- Some backends are platform-specific
- Check
_mlService.Backendto see what's being used - Use
MLPlugin.Defaultfor automatic platform selection
-
Memory Issues
- Use
UnloadModel()when done with a model - Consider using transient services for memory-sensitive scenarios
- Monitor memory usage with large models
- Use
-
Platform-Specific Issues
- iOS: Ensure CoreML execution provider is available (iOS 11+)
- Android: Check NNAPI availability with
IsNnapiAvailable() - Windows: Verify DirectML support with
IsDirectX12Available()
We welcome contributions! Please see our Contributing Guide for details.
This project is licensed under the MIT License - see the LICENSE file for details.
- Built on top of Microsoft ONNX Runtime
- CoreML support via Apple's Core ML framework
- Inspired by the .NET MAUI community plugins
- Thanks to all contributors and users