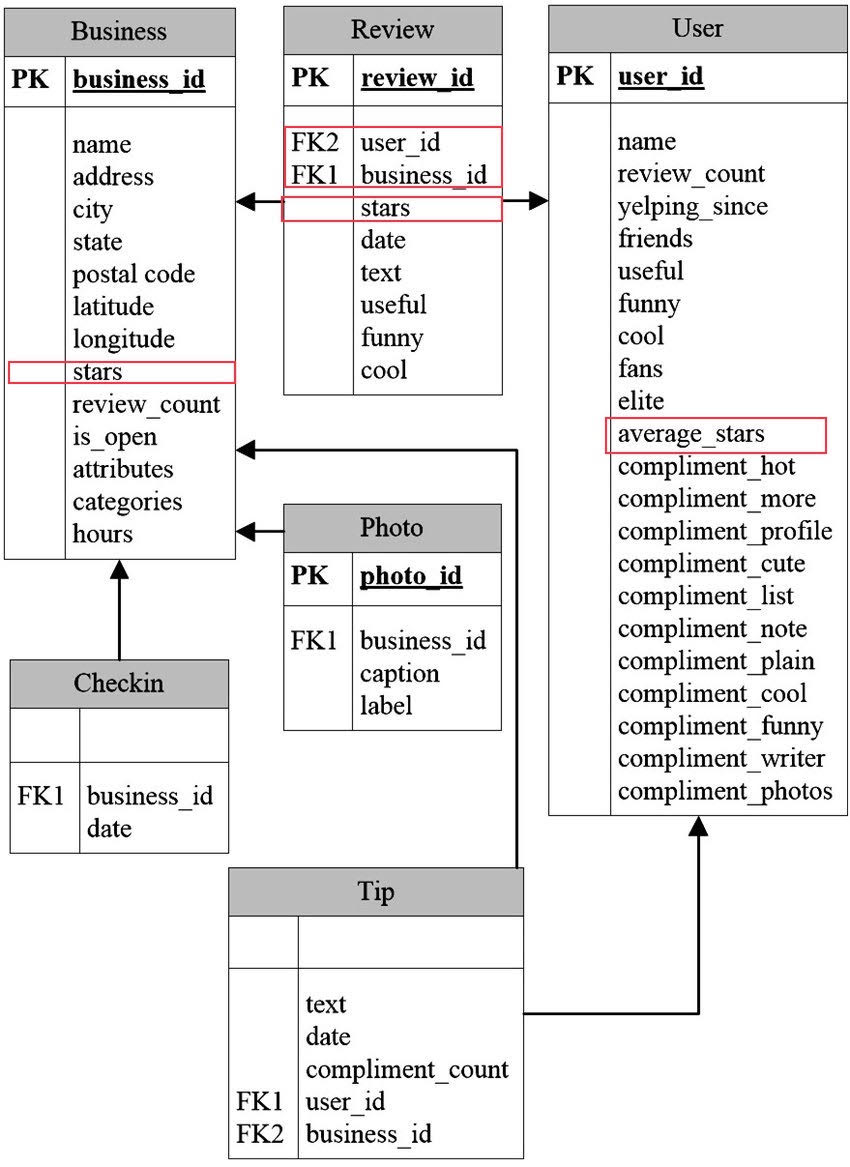
Pulled 10GB ofYelp Business data through the terminal via Kaggle API. The data was then pushed to and AWS S3 Bucket bucket for storage and analyzed on a Elastic MapReduce Cluster on a Jupyter Notebook using PySpark

| Name | Name | Last commit date | ||
|---|---|---|---|---|
Pulled 10GB ofYelp Business data through the terminal via Kaggle API. The data was then pushed to and AWS S3 Bucket bucket for storage and analyzed on a Elastic MapReduce Cluster on a Jupyter Notebook using PySpark