



Fast Belote Contree game environment for reinforcement learning. Rust core with Python bindings.
Live demo: avok.me/colver/ — running on a Raspberry Pi.
- ~1.4M rollouts/sec single-threaded (play phase), ~895K rollouts/sec on a full deal
- 56-byte
Copygame state for fast MCTS cloning - Six AI agents — DMC Q-network, IS-DD with belief network, DD oracle, Smart/Naive IS-MCTS, and heuristic
- NN bidding — "Bid a Dede" (v2), a Dueling DQN trained on DD-solved deals with suit augmentation, used by all agents
- Belief network — NN-based card location prediction for IS-DD search
- Web interface — play against AI, spectate, analyze, and solve problems (FastAPI + WebSocket)
- Python bindings via PyO3 —
Envclass with full type stubs, installable from PyPI - Zero dependencies in the core (only
randbehind a feature flag)
Play against AI agents directly in your browser at avok.me/colver/, or run it locally:
uv run python -m colver.web
# Or: uv run colver-web
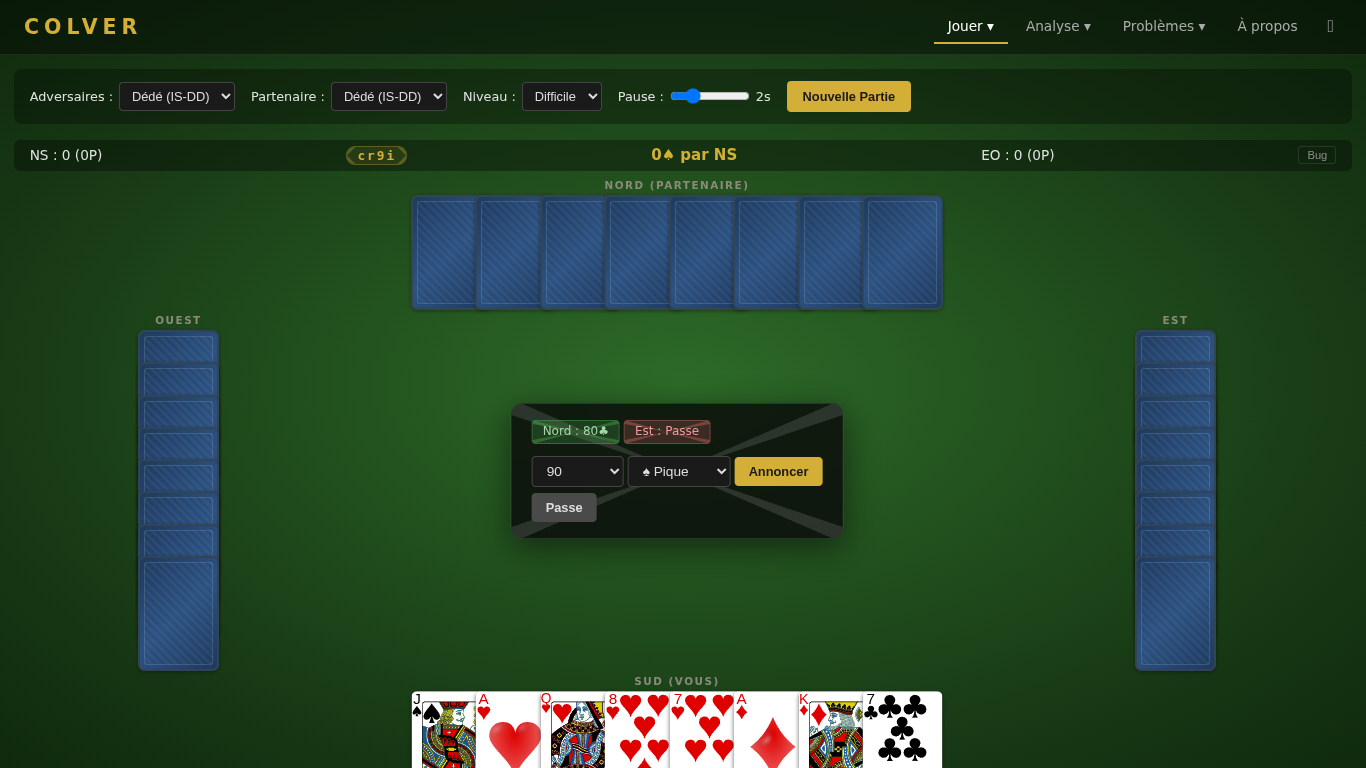
# Open http://localhost:8000Humain vs IA — Play as South against AI opponents. Choose the agent for your opponents (East/West) and your partner (North) independently. The game follows official FFB Belote Contree rules: bidding with coinche/surcoinche, then 8 tricks. Cards are played instantly on click; the pause slider controls AI thinking delay.
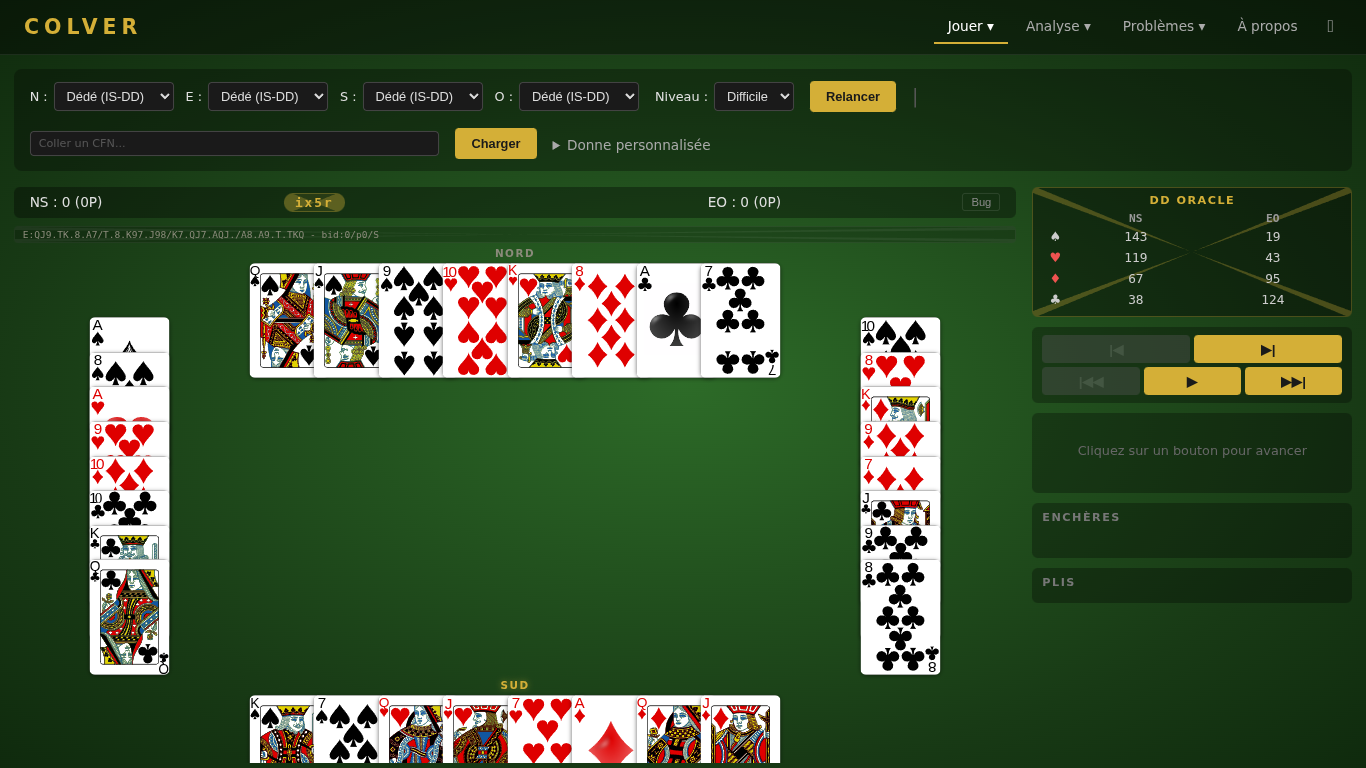
IA vs IA — Spectate AI vs AI matches with all hands visible. Assign a different agent to each of the 4 seats. Step through actions, play full tricks, or use auto-play. The stats panel shows Q-values, DD scores, or hand evaluations for each decision. Paste a CFN string to load a specific position.
Rejouer — Browse and replay past games (played or spectated). Click an entry to step through it with navigation controls.
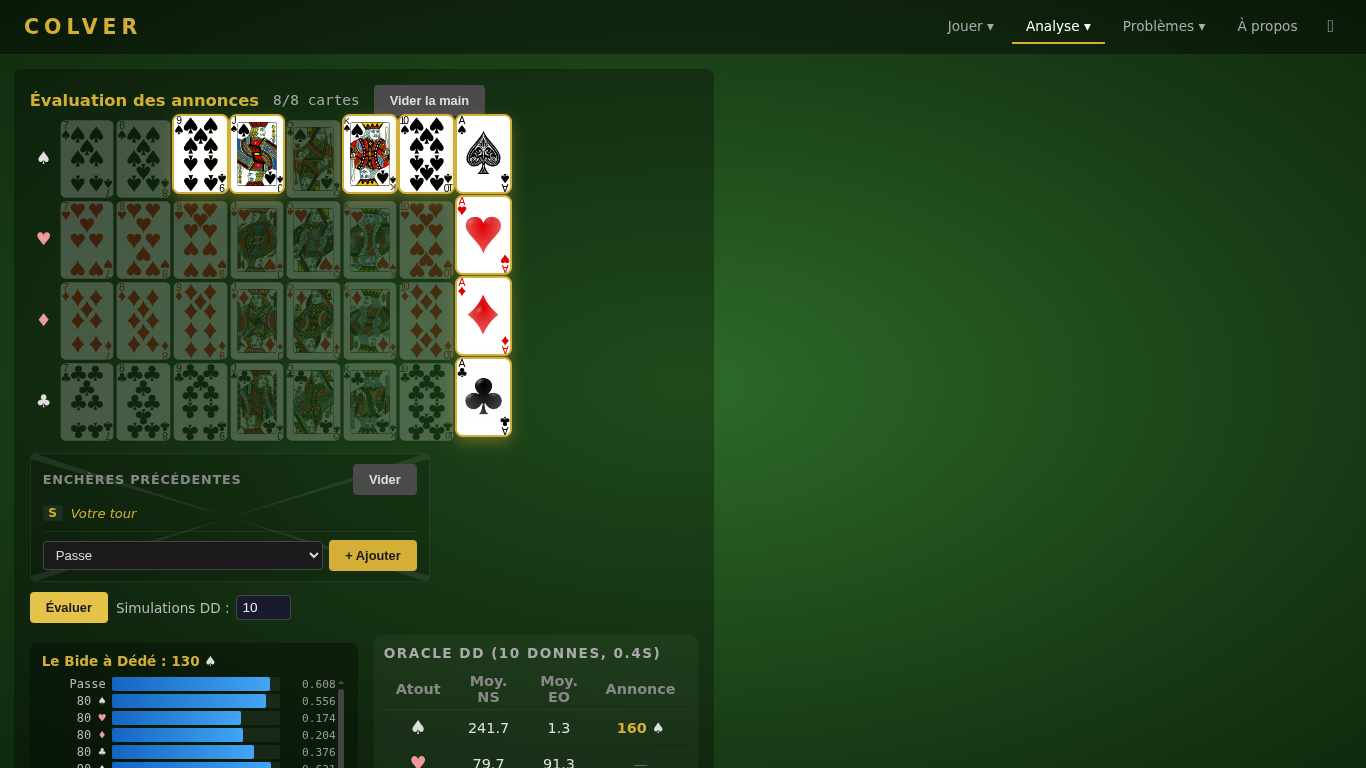
Annonces — Compose an 8-card hand, choose your position in the bidding round, and see what Bid a Dede (the NN bidder) would bid — with Q-values for every legal action.
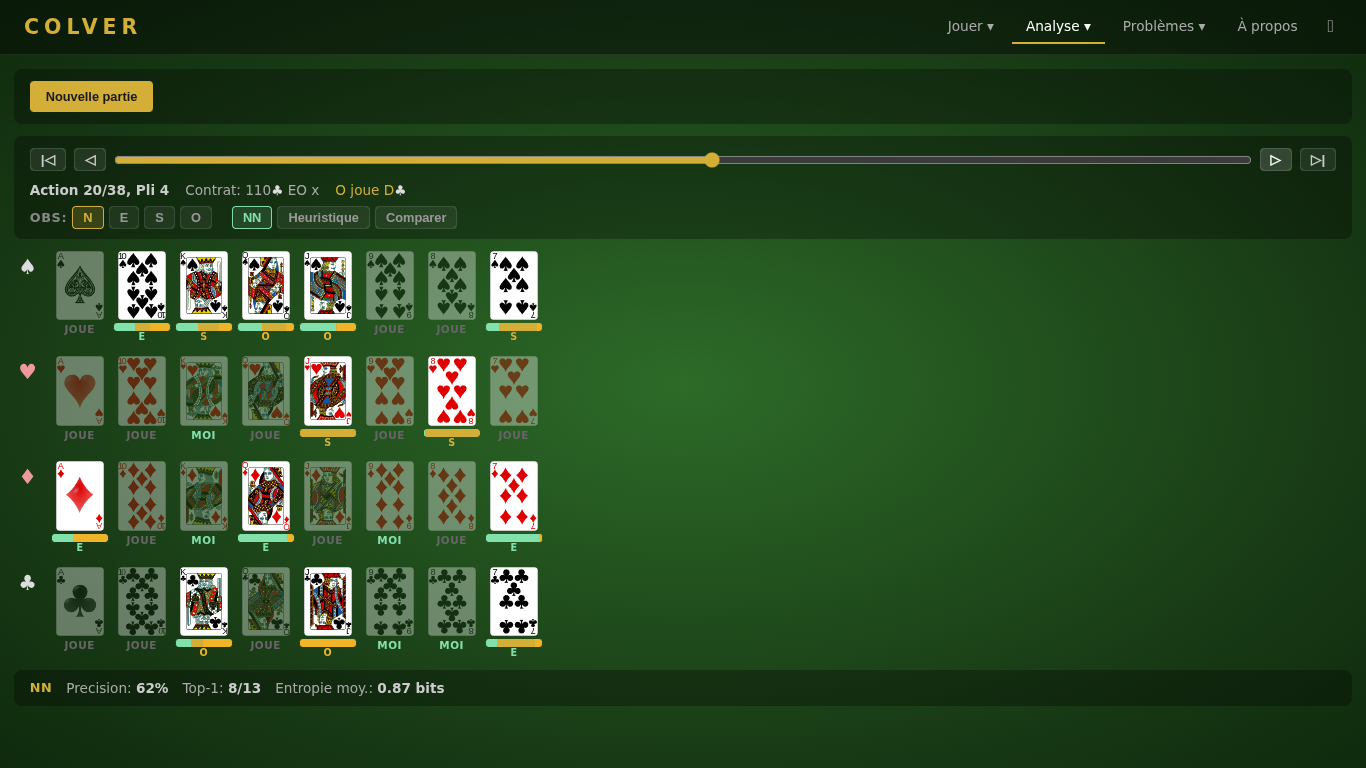
Croyances — Visualize how the belief network and heuristic model predict card locations as a game progresses. Generate a random game, step through it, and see per-card probability bars with ground truth overlay and accuracy stats. Switch observer perspective (N/E/S/W) and compare NN vs heuristic predictions side by side.
Problemes d'annonce — Bidding practice problems. See a hand and bidding history, then find the right bid. The AI evaluates your answer against the NN bidder's recommendation.
Problemes de jeu — Card play practice problems. See a mid-game position and find the best card. Compare your choice to the DD solver's optimal play.
Requires Rust 1.70+ and Python 3.10+.
# Tests (357 tests)
cargo test -p colver-core
# Performance benchmark
cargo run -p colver-core --bin bench --release
# MCTS vs random demo
cargo run -p colver-core --bin mcts_demo --release -- 100
# Smart IS-MCTS vs random + vs naive demo
cargo run -p colver-core --bin smart_ismcts_demo --release -- 100
# Python bindings (via uv)
uv sync
uv run python3 -c "import colver; env = colver.Env(); print(env.reset())"
# Web interface (play against AI)
uv run python -m colver.web
# DMC training (Q-network)
PYTHONPATH=scripts/training uv run python scripts/training/train_dmc.py --num-envs 256 --steps 20000000
# DMC evaluation vs IS-MCTS
uv run python scripts/analysis/eval_dmc.py models/dmc_final.pt --baseline smart --time-ms 20 --both-sidesPerfect-information double-dummy solver that sees all 4 hands — it cheats. Alpha-beta with transposition tables, PVS, killer moves, and card equivalence pruning. Computes the exact optimal card in ~7ms (median). Useful as an upper bound.
Information Set Double-Dummy search. Maintains a probabilistic belief model over hidden cards — updated after every action via hard constraints (voids, trump ceiling) and soft inference (bidding signals, play patterns). Optionally augmented with a belief network (NN-based card location prediction, 330→512→512→128, ~2MB). Samples plausible opponent hands weighted by these beliefs, then solves each world exactly with the alpha-beta DD solver. IS-DD sounds like "is Dede" — hence the name.
DouZero-style reinforcement learning agent. A Q-network picks card plays with a single forward pass — no search tree. Default play model, trained 50M steps with Bid a Dede frozen (triforge play-only phase).
Architecture: ResNet Dueling DQN 411→1024→1024→1024→32 with LayerNorm and skip connections (~2.6M parameters). Uses canonical suit encoding (no augmentation needed). Inference in pure Rust (~1ms/decision, no PyTorch needed). Strongest overall agent.
The previous model DouDou35 (415→1024³→32, legacy obs, 35M steps) is still supported for backward compatibility. DouDou = a reference to DouZero.
Smart IS-MCTS (smart_ismcts.rs) — Belief-weighted Information Set MCTS with heuristic card beliefs. Naive IS-MCTS (naive_ismcts.rs) — Ensemble determinization without beliefs. Both are configurable and documented in docs/SMART_ISMCTS.md.
Dueling DQN (108→512→512→512→43) trained on DD-solved deals with 24x suit augmentation. Default bidder for all agents. Beats the best heuristic bidder 70-76% across all play engines. BidNet::load auto-detects hidden size (tries 256, 512, 1024).
The previous model Bid a Doudou (v1, 114→256→256→43, trained with DouZero self-play) is still supported.
| Agent | Type | Speed/move | Notes |
|---|---|---|---|
| Oracle (DD) | DD solver (cheats) | ~7ms | Perfect info upper bound |
| Dede (IS-DD) | DD solver + beliefs | ~20ms | Strongest search-based |
| DouDou50 | Q-network (ResNet) | <1ms | Strongest overall, no search |
| Smart IS-MCTS | Search + beliefs | ~9ms | Configurable budget |
| Naive IS-MCTS | Search | ~8ms | Configurable budget |
Note: Search-based agents get stronger with more time budget. The DMC agent uses no search — one forward pass per decision.
Workspace: colver-core (pure Rust) + colver-py (PyO3/NumPy FFI) + colver-web (FastAPI/WebSocket)
Bitmask system: Card = u8 (0-31), CardSet = u32 (bitmask). Layout: Spades[0-7], Hearts[8-15], Diamonds[16-23], Clubs[24-31]. Within each suit: 7, 8, 9, J, Q, K, 10, A (plain strength order). Trump strength: J > 9 > A > 10 > K > Q > 8 > 7.
GameState is Copy and ≤96 bytes (compile-time enforced) for fast MCTS cloning. Contains hands, current trick, contract, points/tricks per team, bidding state, played cards bitmask, void tracking, and belote tracking.
| Phase | Actions | Encoding |
|---|---|---|
| Bidding | 43 total | 0=PASS, 1-36=bids (9 values x 4 suits), 37-40=capot x 4, 41=COINCHE, 42=SURCOINCHE |
| Playing | 32 total | Card index 0-31 directly |
Bidding → Playing → Done. Bidding ends after 3 consecutive passes, a surcoinche, or 4 passes (void deal). Playing runs 8 tricks of 4 cards. Card point total = 152; with dix de der = 162 (normal) or 252 (capot).
import colver
print(colver.__version__) # "0.3.2"
# Single environment
env = colver.Env()
obs, legal_actions = env.reset()
obs, reward, done, legal_actions = env.step(action)
env.current_player() # 0-3
env.phase() # 0=Bidding, 1=Playing, 2=Done
env.legal_action_mask() # numpy array (43,)
env.rewards() # [NS_score, EW_score]
env.bid_improved() # improved_bid action
env.deal_outcome() # [NS_outcome, EW_outcome] binary
env.get_observation() # 415-float observation vector
env.action_naive_ismcts(20) # naive IS-MCTS action (20ms)
env.action_smart_ismcts(20) # smart IS-MCTS action (20ms)
# DMC Q-network (if model weights downloaded)
model = colver.model_path() # ~/.cache/colver/models/dmc_final.bin
if model:
env.load_dmc_model(str(model))
result = env.action_dmc_with_stats() # {"best_action": 5, "q_values": [...]}| Workload | Throughput | Latency |
|---|---|---|
| Play-phase rollout | 1.4M/sec | ~720 ns |
| Full-deal rollout | 895K/sec | ~1118 ns |
| MCTS game (1000 iter) vs random | — | 8 ms |
| Smart IS-MCTS game (20x50) vs random | — | 9 ms |
| DMC Q-Network inference | — | <1 ms |
The Docker image lets you deploy the web interface on any machine, including a Raspberry Pi (ARM64).
# Build and run
docker build -t colver .
docker run -p 8000:8000 colver
# Or with Docker Compose
docker compose up -d
# Cross-build for Raspberry Pi (ARM64)
docker buildx build --platform linux/arm64 -t colver .The image is ~257 MB (no PyTorch dependency). All agents run in pure Rust and work on all architectures.
Implements Belote Contree with 4 suits (Spades, Hearts, Diamonds, Clubs). Scoring mode: "points faits + points demandes". See REGLES-DE-LA-BELOTE-CONTREE.pdf for the full FFB rulebook.
- Kocsis, L. & Szepesvari, C. (2006). Bandit Based Monte-Carlo Planning. ECML.
- Cowling, P.I., Powley, E.J. & Whitehouse, D. (2012). Information Set Monte Carlo Tree Search. IEEE Transactions on Computational Intelligence and AI in Games.
- Zha, D. et al. (2021). DouZero: Mastering DouDiZhu with Self-Play Deep Reinforcement Learning. ICML.
- Auer, P., Cesa-Bianchi, N. & Fischer, P. (2002). Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning.
Thanks to Ronan Guillou, seasoned coinche player, for his advice on the game and for being the first tester — his good sense guided many UI decisions.