This project implements a Convolutional Neural Network (CNN) for binary image classification. The model features automated data preprocessing, GPU optimization, and comprehensive evaluation metrics.
Both C++ and Python implementations, using Tensorflow and Torchlib (PyTorch) respectively are provided.
It was originally made in python using Tensorflow, but was recently ported to C++, see: C++ Port
Image scaling is performed using:
Where
-
$X$ is the input image pixel matrix values
And
-
$H$ is the height (number of rows) -
$W$ is the width (number of columns) -
$3$ is the constant number of channels (RGB)
Each pixel at position
Here's a representation of what this looks like:
[[[ 0 61 82]
[ 2 63 81]
[ 1 64 79]
...
[ 0 0 0]
[ 0 0 0]
[ 0 1 0]]
[[ 2 64 83]
[ 2 64 81]
[ 1 64 78]
...
[ 0 0 0]
[ 0 1 0]
[ 1 1 1]]
...
[[ 0 1 0]
[ 0 0 0]
[ 0 0 0]
...
[ 34 22 62]
[ 35 24 63]
[ 37 24 64]]]The model uses three key metrics:
- Binary Accuracy:
- Precision:
- Recall:
Where:
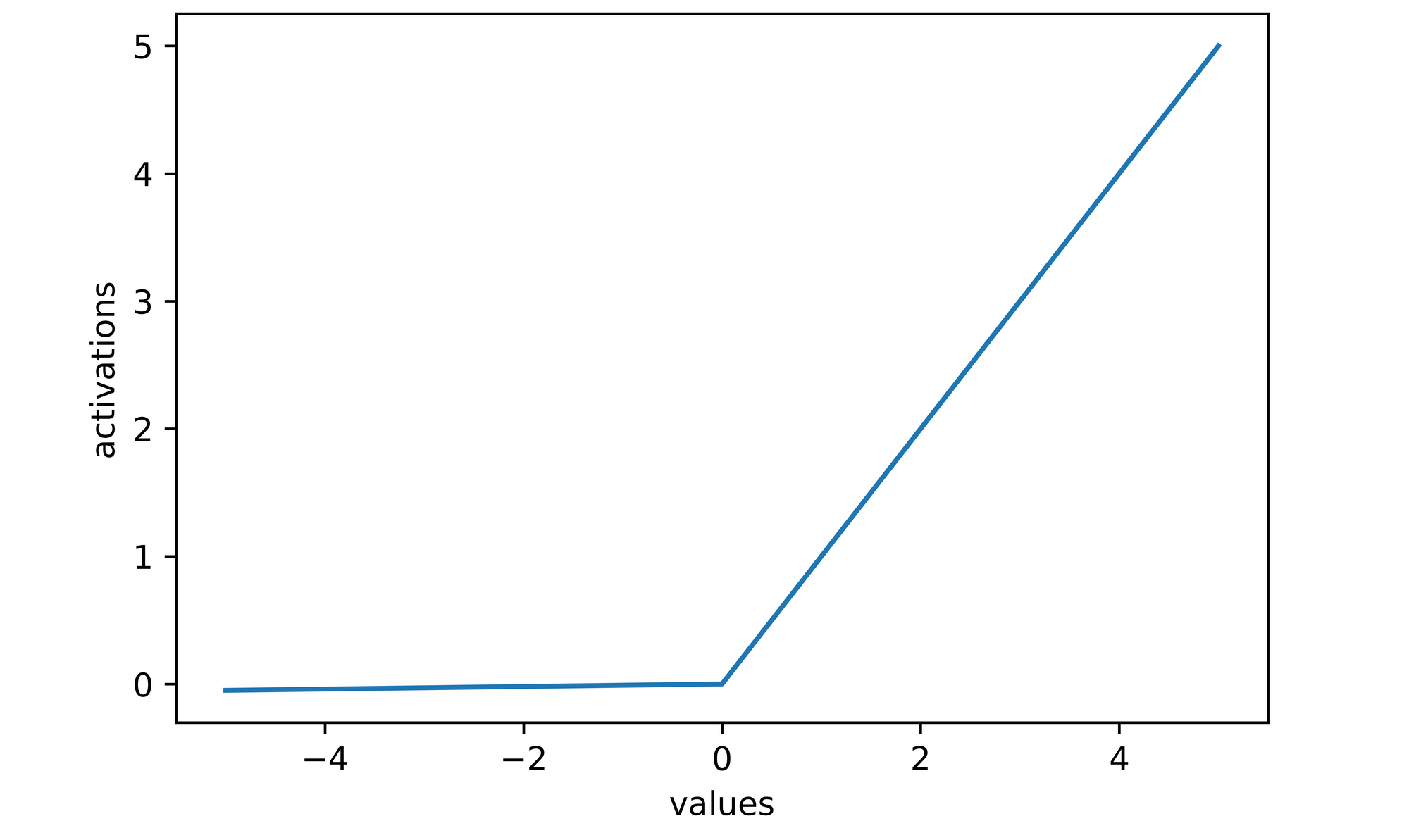
1. ReLU
The model applies the Rectified Linear Unit (ReLU) activation function
to all hidden layers, except for the last dense layer.
The ReLU function is defined as:
Properties:
- Domain:
$x \in \mathbb{R}$ - Range:
$[0, \infty)$
The function essentially outputs
Plotting this function out:
2. Sigmoid
On the final output dense layer, a single neuron, applies a sigmoid activation function.
The benefits of this methodology are described later on.
Generally speaking, its because it provides a clear binary output.
The Sigmoid function is defined as:
Where:
Applying these to the equation:
Plotting this function out:
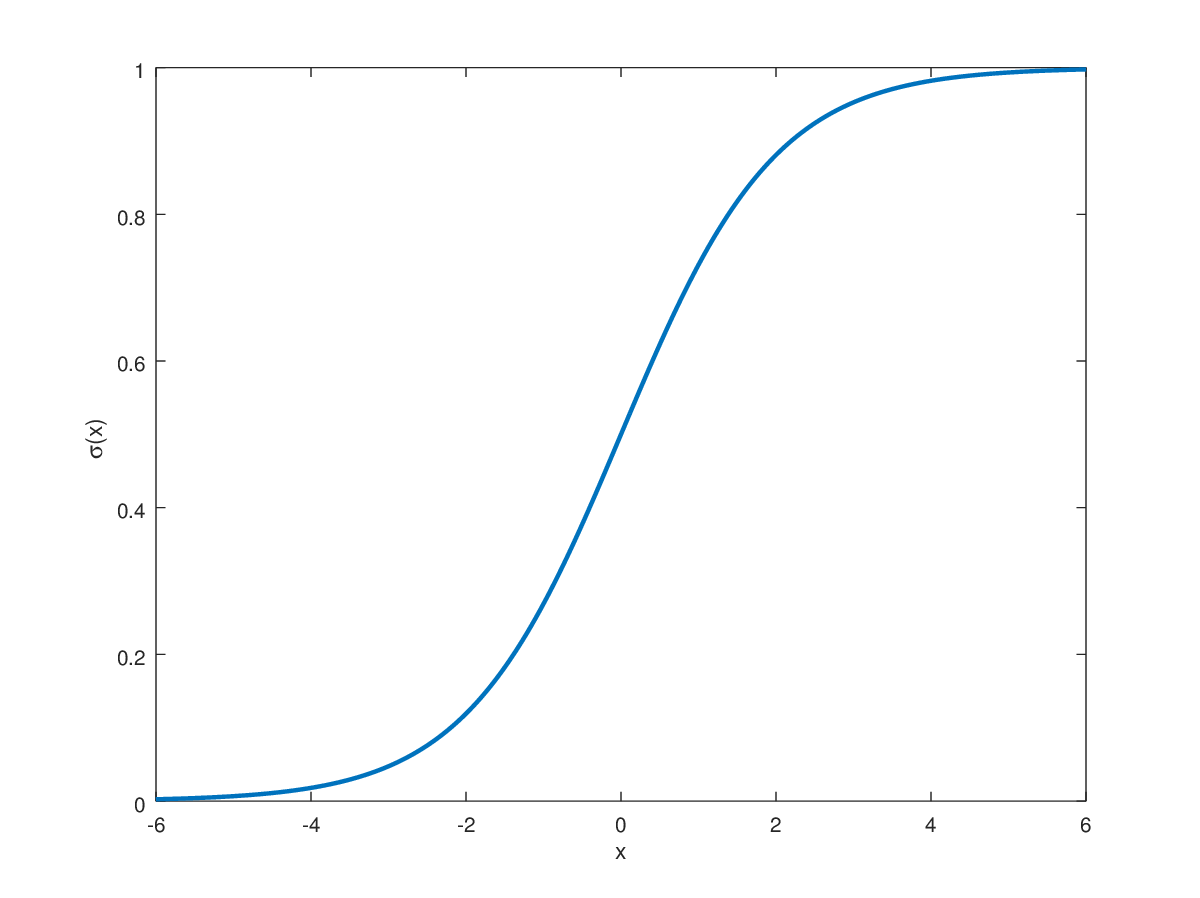
By visualizing the function, we can see that it's perfect to solve a binary problem
since it represents an output range of
This prospect makes the function perfect to provide a clear binary output.
The model makes use of the Adam Optimizer, which is a powerful optimization algorithm that combines the benefits of SGD
(Stochastic Gradient Descent) with momentum and adaptive learning rates. It adjusts learning rates dynamically for each parameter.
The algorithm updates the weights using the following equations:
Where:
-
$\mathbf{m}_t$ : First moment estimate -
$\mathbf{v}_t$ : Second moment estimate -
$\beta_1, \beta_2$ : Exponential decay rates (typically$\beta_1=0.9$ ,$\beta_2=0.999$ ) -
$\alpha$ : Learning rate -
$\epsilon$ : Small constant for numerical stability ($\approx 10^{-8}$ ) -
$\theta$ : Model parameters -
$J(\theta)$ : Objective function
Logic Flow:
flowchart LR
H[Compute Gradients] --> I[Update Momentum]
H --> J[Update Velocity]
I --> K[Bias Correction]
J --> K
K --> L[Parameter Update]
The model makes use of the BCE loss function, which is the standard loss function used in binary classification problems.
It measures how well the model's predicted probability distribution matches the actual labels.
It is defined as:
For binary classification with predicted probability
Properties:
- Domain:
$y \in {0,1}, \hat{y} \in (0,1)$ - Range:
$[0, \infty)$
Derivative with respect to logits:
Logic Flow:
flowchart LR
M[True Label y] --> O[Compute Loss]
N[Predicted ŷ] --> O
O --> P[Backpropagate]
This function works well due to:
- Probability-Based Loss
$\rightarrow$ Since BCE is based on log probabilitiy, it ensures that predictions are as close to$0$ or$1$ as possible. - Penalization of Incorrect Confident Predictions
$\rightarrow$ Large penalties for being confidently wrong (i.e., predicting$0.99$ when the true label is$0$ ). - Handling Imbalanced Datasets Well
$\rightarrow$ If class distribution is skewed BCE still provides meaningful gradients.
Conv2D:
The Conv2D layer applies a 2D convolution operation to the input. This is a sliding window (kernel/filter) operation that extracts local patterns or features from the input (such as edges, textures, etc. in images).
We define the Conv2D layer as:
Where:
-
$X$ is the input tensor -
$W_1$ is the kernel matrix -
$b_1$ is the bias term
We define the kernel as:
The following is the convolution function applying ReLU activation function:
Where:
-
$x_{i+m,j+n,c}$ is the input -
$w_{m,n,c,j}$ are the kernel weights -
$b_k$ is the bias for each output channel$k$
MaxPooling2D:
The MaxPooling2D layer reduces the spatial dimensions of the input by taking the maximum value from a defined region (typically a window of size
It can be defined as follows:
Where:
-
$f_1(i,j)$ refers to the result of the convolution from the previous layer (i.e., the$f_1(X)$ output). -
$W_{m,n}$ refers to the pooling window centered at the position$(m,n)$ . - The operation takes the maximum values of the window
$W$ over each channel.
Simplifying:
Which means that for each position
The function can be more formally expressed as:
Consider the same for the other two convolution blocks,
except the amount of neurons and parameters change.
Flatten:
A Flatten layer is used to convert a multi-dimensional tensor into a one-dimensional vector, while retaining the batch size.
The mathematical operation for flattening is relatively simple:
It takes an input tensor of shape:
Where
The flattening combines the dimensions
If
Where:
-
$i$ is the index of the flattened vector, starting from 0. - The values
$X_{i,d_1,d_2,...,d_n}$ are taken in a row-major order (i.e., elements are flattened by traversing all dimensions in sequence).
Therefore, given a batch size of
Dense Layer:
The Dense (fully connected) layer connects each neuron from the previous layer to every neuron in the current layer.
The dense layer computes the output
Where:
-
$X$ is the input tensor -
$W$ is the weights matrix -
$b$ is the bias vector
Including a non-linear activation function
Given our known input tensor:
And applying our known constants:
Output Layer:
The final output layer is also a Dense layer, however to get our desired binary output,
we apply the sigmoid activation function (rather than ReLU):
Where:
- The sigmoid function is defined as:
-
$\mathbf{W}_5$ is defined as:
To demonstrate a proof of concept, the model was trained on pneumonia xrays.
This model can be used in medical applications, however the architecture
can be trained on any data, and can provide applications in all fields
You can find the dataset here: Dataset
- Accuracy: 99.91%
- Loss: 0.3%
- Epochs: 30
To see the training logs and results, view the TensorBoard logfile: TensorBoardLog
To view the log:
tensorboard --logdir=./logs/


The trained and compiled model can be found at:
trained/Pneumonia_Model.h5
Applying what was previously discussed,
the model expects an image of shape:
Plugging in these constants:
Hidden Layers
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 254, 254, 16) | 448 |
| max_pooling2d (MaxPooling2D) | (None, 127, 127, 16) | 0 |
| conv2d_1 (Conv2D) | (None, 125, 125, 32) | 4,640 |
| max_pooling2d_1 (MaxPooling2D) | (None, 62, 62, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 60, 60, 16) | 4,624 |
| max_pooling2d_2 (MaxPooling2D) | (None, 30, 30, 16) | 0 |
| flatten (Flatten) | (None, 14400) | 0 |
| dense (Dense) | (None, 256) | 3,686,656 |
| dense_1 (Dense) | (None, 1) | 257 |



- Model Type: Sequential
- Total Model Size: 14.1MB
- Total Parameters: 3,396,627
- Trainable Parameters: 3,396,625
- Non-Trainable Parameters: 0
- Optimized Parameters: 2
The model was recently ported to C++ using TorchLib. It was originally implemented in python using Tensorflow. There are some minor differences, particularly in how the data is prepared (i.e. data directory cleaning).
- GPU memory optimization
- Automated image format validation
- Data scaling and preprocessing
- Train-test-validation split (70-20-10)
- TensorBoard logging support
- Model persistence (Save & Load)
from model.model import Model
from model.data import Data
import tensorflow as tf
# Create data pipeline
data = Data('category_a', 'category_b')
# Create and train OR load model
model = Model(data)
# Evaluate on test data
precision, recall, accuracy = model.evaluate_model(test_data)
# Read and process image
img = tf.io.read_file(image_path)
img = tf.image.decode_image(img, channels=3)
resize = tf.image.resize(img, (256, 256))
# Predict image class
pred = model.predict(np.expand_dims(resize/255, 0))[0][0]
# Determine image category
is_category_a: bool = pred < 0.5Please note there are extensive steps required in order to setup a LibTorch project,
please keep this in mind before attempting to implement this example.
int main(void)
{
try
{
// Create dataset
Dataset dataset("path/to/categoryA", "path/to/categoryB");
// Create model
Model::CNN model;
// Train model
Model::train(model, dataset, 32, 30);
std::cout << "Training completed successfully!" << std::endl;
// For inference later
model->eval();
torch::NoGradGuard no_grad;
// Example of loading an image for inference
torch::Tensor img = load_single_image("path/to/test/image.jpg");
torch::Tensor output = model->forward(img.unsqueeze(0));
float prediction = output.item<float>();
std::cout << "Prediction: " << prediction << std::endl;
}
catch (const std::exception& e)
{
std::cerr << "Error: " << e.what() << std::endl;
return 1;
}
return 0;
}- Images must be in supported formats: JPEG, JPG, BMP, PNG
- Input shape:
(256, 256, 3) - Images are automatically scaled to
[0,1]
data/
├── category_a/
│ ├── image1.png
│ └── image2.png
└── category_b/
├── image3.png
└── image4.png
Feel free to rename the child directories to whatever you'd like. Later, They are expected as arguments in the model.
- Optimizer: Adam
- Loss: Binary Cross Entropy
- Training epochs: 30
- Batch size: 32
- Train-Test-Val split: 70%-20%-10%
Models are automatically saved to:
// For Tensorflow
trained/model.h5
// For LibTorch
trained/model.ptTensorBoard logs are stored in:
logs/
This project uses the GNU GENERAL PUBLIC LICENSE v3.0 license
For more info, please find the LICENSE file here: License