{kind=link}
#Visual story telling part 1: green buildings
green = read.csv('https://raw.githubusercontent.com/jgscott/STA380/master/data/greenbuildings.csv', header=T)#Let us use the log response
rent_all <- log(green$Rent)
#subset of dataset for simplicity, dont do this try to include all in dataset
all_sub <- green[,-c(0,1,2,3)] # lose lmedval and the room totals
n = dim(all_sub)[1] #Sample size
tr = sample(1:n, #Sample indices do be used in training
size = 3000, #Sample will have 5000 observation
replace = FALSE) #Without replacement
#Create a full matrix of interactions (only necessary for linear model)
#Do the normalization only for main variables.
xxall_rent_sub <- model.matrix(~., data=data.frame(scale(all_sub)))[,-1] # the . syntax multiplies data by each long and lat, and then by both
allData = data.frame(rent_all,all_sub)
#Two models initially, sets the scope/boundaries for search
null = lm(rent_all~1, data=allData[tr,]) #only has an intercept
full = glm(rent_all~., data=allData[tr,]) #Has all the selected variables
#Let us select models by stepwise
regBack = step(full, #Starting with the full model
direction="backward", #And deleting variables
k=log(length(tr))) #This is BIC## Start: AIC=-2358.4
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + Energystar + green_rating + net +
## amenities + cd_total_07 + hd_total07 + total_dd_07 + Precipitation +
## Gas_Costs + Electricity_Costs + cluster_rent
##
##
## Step: AIC=-2358.4
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + Energystar + green_rating + net +
## amenities + cd_total_07 + hd_total07 + Precipitation + Gas_Costs +
## Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - green_rating 1 74.704 -2366.32
## - Energystar 1 74.705 -2366.27
## - Precipitation 1 74.707 -2366.23
## - net 1 74.709 -2366.13
## - LEED 1 74.711 -2366.05
## - stories 1 74.724 -2365.53
## - renovated 1 74.801 -2362.48
## - class_b 1 74.853 -2360.39
## <none> 74.702 -2358.40
## - Gas_Costs 1 74.928 -2357.40
## - leasing_rate 1 74.970 -2355.75
## - amenities 1 75.016 -2353.91
## - class_a 1 75.042 -2352.91
## - empl_gr 1 75.160 -2348.23
## - Electricity_Costs 1 75.629 -2329.71
## - age 1 75.747 -2325.07
## - cd_total_07 1 78.743 -2209.63
## - hd_total07 1 79.122 -2195.32
## - cluster_rent 1 81.261 -2115.95
## - Rent 1 194.819 486.28
##
## Step: AIC=-2366.32
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + Energystar + net + amenities +
## cd_total_07 + hd_total07 + Precipitation + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - Precipitation 1 74.709 -2374.14
## - net 1 74.712 -2374.03
## - Energystar 1 74.714 -2373.92
## - LEED 1 74.721 -2373.66
## - stories 1 74.726 -2373.44
## - renovated 1 74.803 -2370.39
## - class_b 1 74.855 -2368.31
## <none> 74.704 -2366.32
## - Gas_Costs 1 74.932 -2365.28
## - leasing_rate 1 74.971 -2363.70
## - amenities 1 75.021 -2361.74
## - class_a 1 75.044 -2360.83
## - empl_gr 1 75.162 -2356.15
## - Electricity_Costs 1 75.631 -2337.63
## - age 1 75.748 -2333.05
## - cd_total_07 1 78.746 -2217.53
## - hd_total07 1 79.123 -2203.32
## - cluster_rent 1 81.273 -2123.51
## - Rent 1 194.835 478.51
##
## Step: AIC=-2374.14
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + Energystar + net + amenities +
## cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - net 1 74.717 -2381.83
## - Energystar 1 74.719 -2381.73
## - LEED 1 74.725 -2381.49
## - stories 1 74.734 -2381.14
## - renovated 1 74.807 -2378.25
## - class_b 1 74.868 -2375.81
## <none> 74.709 -2374.14
## - leasing_rate 1 74.980 -2371.36
## - amenities 1 75.022 -2369.70
## - Gas_Costs 1 75.026 -2369.55
## - class_a 1 75.056 -2368.34
## - empl_gr 1 75.325 -2357.70
## - age 1 75.769 -2340.20
## - Electricity_Costs 1 75.799 -2339.05
## - cd_total_07 1 78.819 -2222.77
## - hd_total07 1 79.137 -2210.79
## - cluster_rent 1 81.899 -2108.67
## - Rent 1 194.843 470.63
##
## Step: AIC=-2381.83
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + Energystar + amenities + cd_total_07 +
## hd_total07 + Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - Energystar 1 74.728 -2389.4
## - LEED 1 74.734 -2389.2
## - stories 1 74.740 -2388.9
## - renovated 1 74.814 -2386.0
## - class_b 1 74.876 -2383.5
## <none> 74.717 -2381.8
## - leasing_rate 1 74.989 -2379.0
## - amenities 1 75.027 -2377.5
## - Gas_Costs 1 75.040 -2377.0
## - class_a 1 75.069 -2375.9
## - empl_gr 1 75.331 -2365.5
## - age 1 75.786 -2347.5
## - Electricity_Costs 1 75.799 -2347.1
## - cd_total_07 1 78.821 -2230.7
## - hd_total07 1 79.140 -2218.7
## - cluster_rent 1 81.902 -2116.6
## - Rent 1 194.927 463.9
##
## Step: AIC=-2389.4
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + LEED + amenities + cd_total_07 + hd_total07 +
## Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - LEED 1 74.745 -2396.72
## - stories 1 74.754 -2396.35
## - renovated 1 74.824 -2393.59
## - class_b 1 74.889 -2391.00
## <none> 74.728 -2389.40
## - leasing_rate 1 75.008 -2386.26
## - amenities 1 75.041 -2384.94
## - Gas_Costs 1 75.042 -2384.92
## - class_a 1 75.103 -2382.50
## - empl_gr 1 75.335 -2373.31
## - Electricity_Costs 1 75.807 -2354.73
## - age 1 75.809 -2354.64
## - cd_total_07 1 78.823 -2238.62
## - hd_total07 1 79.162 -2225.86
## - cluster_rent 1 81.907 -2124.43
## - Rent 1 195.248 460.81
##
## Step: AIC=-2396.72
## rent_all ~ empl_gr + Rent + leasing_rate + stories + age + renovated +
## class_a + class_b + amenities + cd_total_07 + hd_total07 +
## Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - stories 1 74.772 -2403.65
## - renovated 1 74.842 -2400.87
## - class_b 1 74.908 -2398.25
## <none> 74.745 -2396.72
## - leasing_rate 1 75.026 -2393.54
## - amenities 1 75.054 -2392.45
## - Gas_Costs 1 75.065 -2392.02
## - class_a 1 75.127 -2389.56
## - empl_gr 1 75.350 -2380.72
## - age 1 75.828 -2361.90
## - Electricity_Costs 1 75.834 -2361.68
## - cd_total_07 1 78.851 -2245.59
## - hd_total07 1 79.186 -2232.96
## - cluster_rent 1 81.908 -2132.38
## - Rent 1 195.652 458.94
##
## Step: AIC=-2403.65
## rent_all ~ empl_gr + Rent + leasing_rate + age + renovated +
## class_a + class_b + amenities + cd_total_07 + hd_total07 +
## Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - renovated 1 74.861 -2408.14
## - class_b 1 74.928 -2405.46
## <none> 74.772 -2403.65
## - leasing_rate 1 75.040 -2401.00
## - amenities 1 75.056 -2400.37
## - Gas_Costs 1 75.094 -2398.86
## - class_a 1 75.127 -2397.55
## - empl_gr 1 75.393 -2387.05
## - age 1 75.881 -2367.85
## - Electricity_Costs 1 75.888 -2367.55
## - cd_total_07 1 78.982 -2248.65
## - hd_total07 1 79.512 -2228.74
## - cluster_rent 1 82.073 -2134.40
## - Rent 1 196.119 458.04
##
## Step: AIC=-2408.14
## rent_all ~ empl_gr + Rent + leasing_rate + age + class_a + class_b +
## amenities + cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - class_b 1 75.040 -2409.01
## <none> 74.861 -2408.14
## - leasing_rate 1 75.145 -2404.85
## - amenities 1 75.171 -2403.83
## - Gas_Costs 1 75.198 -2402.77
## - class_a 1 75.262 -2400.23
## - empl_gr 1 75.468 -2392.09
## - age 1 75.923 -2374.20
## - Electricity_Costs 1 76.047 -2369.36
## - cd_total_07 1 79.128 -2251.16
## - hd_total07 1 79.788 -2226.45
## - cluster_rent 1 82.106 -2141.20
## - Rent 1 196.122 450.07
##
## Step: AIC=-2409.01
## rent_all ~ empl_gr + Rent + leasing_rate + age + class_a + amenities +
## cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## <none> 75.040 -2409.0
## - class_a 1 75.266 -2408.1
## - Gas_Costs 1 75.383 -2403.4
## - leasing_rate 1 75.388 -2403.3
## - amenities 1 75.404 -2402.6
## - empl_gr 1 75.671 -2392.1
## - Electricity_Costs 1 76.217 -2370.7
## - age 1 76.353 -2365.4
## - cd_total_07 1 79.395 -2249.1
## - hd_total07 1 79.911 -2229.8
## - cluster_rent 1 82.222 -2145.0
## - Rent 1 197.141 457.5
regForward = step(null, #The most simple model
scope=formula(full), #The most complicated model
direction="both", #Add or delete variables
k=log(length(tr))) #This is BIC## Start: AIC=-4747.59
## rent_all ~ 1
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2976/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + Rent 1 513.67 98.05 -10140.8
## + cluster_rent 1 386.29 225.43 -7663.1
## + Electricity_Costs 1 111.46 500.25 -5290.9
## + total_dd_07 1 93.10 518.62 -5183.6
## + hd_total07 1 46.65 565.07 -4928.3
## + class_a 1 37.37 574.35 -4879.8
## + cd_total_07 1 26.08 585.64 -4821.9
## + leasing_rate 1 25.36 586.36 -4818.2
## + age 1 16.67 595.04 -4774.5
## + renovated 1 11.41 600.30 -4748.3
## + class_b 1 10.18 601.54 -4742.1
## + amenities 1 4.14 607.57 -4712.5
## + green_rating 1 2.62 609.09 -4705.0
## + net 1 2.32 609.40 -4703.5
## + Energystar 1 2.26 609.45 -4703.3
## + stories 1 1.70 610.01 -4700.5
## <none> 611.71 -4700.2
## + LEED 1 0.41 611.30 -4694.2
## + Gas_Costs 1 0.15 611.56 -4693.0
## + empl_gr 1 0.08 611.63 -4692.6
## + Precipitation 1 0.00 611.71 -4692.2
##
## Step: AIC=-10240.28
## rent_all ~ Rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2976/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + cluster_rent 1 9.83 88.22 -10447.2
## + total_dd_07 1 9.81 88.24 -10446.4
## + hd_total07 1 5.84 92.20 -10315.6
## <none> 98.26 -10240.3
## + age 1 3.26 94.79 -10233.3
## + Electricity_Costs 1 2.15 95.89 -10198.9
## + class_a 1 2.01 96.03 -10194.6
## + cd_total_07 1 1.33 96.71 -10173.5
## + leasing_rate 1 0.98 97.06 -10162.7
## + Precipitation 1 0.77 97.28 -10156.1
## + amenities 1 0.55 97.50 -10149.4
## + class_b 1 0.36 97.68 -10143.9
## + Gas_Costs 1 0.25 97.80 -10140.3
## + Energystar 1 0.23 97.81 -10139.9
## + green_rating 1 0.23 97.81 -10139.8
## + renovated 1 0.16 97.89 -10137.5
## + empl_gr 1 0.12 97.92 -10136.5
## + stories 1 0.10 97.95 -10135.8
## + net 1 0.01 98.04 -10133.0
## + LEED 1 0.01 98.04 -10132.9
## - Rent 1 516.46 614.72 -4747.6
##
## Step: AIC=-10545.3
## rent_all ~ Rent + cluster_rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2976/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + total_dd_07 1 5.762 82.453 -10640.2
## + age 1 4.213 84.003 -10584.8
## + hd_total07 1 3.479 84.737 -10558.9
## <none> 88.523 -10545.3
## + class_a 1 2.760 85.455 -10533.8
## + amenities 1 1.312 86.903 -10483.8
## + Precipitation 1 1.159 87.057 -10478.5
## + leasing_rate 1 0.808 87.408 -10466.6
## + cd_total_07 1 0.614 87.601 -10460.0
## + green_rating 1 0.573 87.642 -10458.6
## + Energystar 1 0.530 87.685 -10457.1
## + class_b 1 0.472 87.743 -10455.2
## + Gas_Costs 1 0.374 87.842 -10451.8
## + Electricity_Costs 1 0.218 87.998 -10446.5
## + empl_gr 1 0.184 88.031 -10445.4
## + renovated 1 0.106 88.109 -10442.8
## + LEED 1 0.045 88.170 -10440.7
## + stories 1 0.041 88.174 -10440.6
## + net 1 0.008 88.207 -10439.5
## - cluster_rent 1 9.736 98.259 -10240.3
## - Rent 1 138.464 226.987 -7728.4
##
## Step: AIC=-10737.11
## rent_all ~ Rent + cluster_rent + total_dd_07
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2976/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + age 1 3.178 79.276 -10749.2
## <none> 82.819 -10737.1
## + class_a 1 2.624 79.829 -10728.5
## + amenities 1 2.019 80.434 -10706.0
## + Electricity_Costs 1 1.833 80.620 -10699.1
## + leasing_rate 1 1.051 81.402 -10670.4
## + stories 1 0.508 81.945 -10650.6
## + class_b 1 0.398 82.055 -10646.6
## + empl_gr 1 0.395 82.058 -10646.5
## + green_rating 1 0.355 82.098 -10645.1
## + Energystar 1 0.317 82.136 -10643.7
## + renovated 1 0.065 82.388 -10634.6
## + cd_total_07 1 0.059 82.394 -10634.3
## + hd_total07 1 0.059 82.394 -10634.3
## + LEED 1 0.054 82.399 -10634.2
## + net 1 0.028 82.426 -10633.2
## + Gas_Costs 1 0.025 82.428 -10633.1
## + Precipitation 1 0.000 82.453 -10632.2
## - total_dd_07 1 5.704 88.523 -10545.3
## - cluster_rent 1 5.772 88.591 -10543.0
## - Rent 1 138.937 221.756 -7790.4
##
## Step: AIC=-10843.71
## rent_all ~ Rent + cluster_rent + total_dd_07 + age
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2976/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## <none> 79.715 -10843.7
## + Electricity_Costs 1 1.795 77.481 -10809.3
## + amenities 1 0.996 78.279 -10778.8
## + class_a 1 0.720 78.556 -10768.3
## + leasing_rate 1 0.669 78.606 -10766.4
## + cd_total_07 1 0.584 78.692 -10763.2
## + hd_total07 1 0.584 78.692 -10763.2
## + renovated 1 0.387 78.889 -10755.7
## + empl_gr 1 0.224 79.052 -10749.6
## + stories 1 0.189 79.087 -10748.3
## + Gas_Costs 1 0.131 79.145 -10746.1
## + green_rating 1 0.059 79.217 -10743.4
## + Energystar 1 0.044 79.232 -10742.8
## + class_b 1 0.038 79.238 -10742.6
## + LEED 1 0.037 79.239 -10742.5
## + net 1 0.002 79.274 -10741.2
## + Precipitation 1 0.000 79.275 -10741.2
## - age 1 3.104 82.819 -10737.1
## - total_dd_07 1 4.671 84.386 -10680.9
## - cluster_rent 1 6.635 86.350 -10611.9
## - Rent 1 131.645 211.360 -7926.4
#the total number of degree days (either heating or cooling) in the building's region in 2007.# Extract the buildings with green ratings
green_only = subset(green, green_rating==1)#Let us use the log response
green_rent <- log(green_only$Rent)
#subset of dataset for simplicity, dont do this try to include all in dataset
green_rent_sub <- green_only[,-c(0,1,2,3)] # lose lmedval and the room totals
n = dim(green_rent_sub)[1] #Sample size
tr = sample(1:n, #Sample indices do be used in training
size = 300, #Sample will have 5000 observation
replace = FALSE) #Without replacement
#Create a full matrix of interactions (only necessary for linear model)
#Do the normalization only for main variables.
xxgreen_rent_sub <- model.matrix(~., data=data.frame(scale(green_rent_sub)))[,-1] # the . syntax multiplies data by each long and lat, and then by both
greenData = data.frame(green_rent,green_rent_sub)
#Two models initially, sets the scope/boundaries for search
null = lm(green_rent~1, data=greenData[tr,]) #only has an intercept
full = glm(green_rent~., data=greenData[tr,]) #Has all the selected variables
#Let us select models by stepwise
regBack = step(full, #Starting with the full model
direction="backward", #And deleting variables
k=log(length(tr))) #This is BIC## Start: AIC=-363.05
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + green_rating +
## net + amenities + cd_total_07 + hd_total07 + total_dd_07 +
## Precipitation + Gas_Costs + Electricity_Costs + cluster_rent
##
##
## Step: AIC=-363.05
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + green_rating +
## net + amenities + cd_total_07 + hd_total07 + Precipitation +
## Gas_Costs + Electricity_Costs + cluster_rent
##
##
## Step: AIC=-363.05
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + net +
## amenities + cd_total_07 + hd_total07 + Precipitation + Gas_Costs +
## Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - Precipitation 1 3.5320 -368.75
## - net 1 3.5321 -368.74
## - LEED 1 3.5325 -368.70
## - leasing_rate 1 3.5326 -368.70
## - Gas_Costs 1 3.5328 -368.68
## - stories 1 3.5358 -368.43
## - Energystar 1 3.5383 -368.22
## - class_b 1 3.5428 -367.84
## - class_a 1 3.5443 -367.72
## - renovated 1 3.5468 -367.51
## - amenities 1 3.5514 -367.12
## <none> 3.5320 -363.05
## - empl_gr 1 3.6273 -360.84
## - Electricity_Costs 1 3.6756 -356.91
## - age 1 3.7146 -353.78
## - cluster_rent 1 3.9247 -337.44
## - cd_total_07 1 4.0012 -331.70
## - hd_total07 1 4.1182 -323.14
## - Rent 1 8.9326 -93.18
##
## Step: AIC=-368.75
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + net +
## amenities + cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - net 1 3.5321 -374.44
## - LEED 1 3.5325 -374.41
## - leasing_rate 1 3.5326 -374.40
## - Gas_Costs 1 3.5337 -374.31
## - stories 1 3.5358 -374.13
## - Energystar 1 3.5385 -373.91
## - class_b 1 3.5429 -373.53
## - class_a 1 3.5445 -373.40
## - renovated 1 3.5469 -373.20
## - amenities 1 3.5514 -372.82
## <none> 3.5320 -368.75
## - empl_gr 1 3.6715 -362.95
## - Electricity_Costs 1 3.6999 -360.66
## - age 1 3.7158 -359.39
## - cluster_rent 1 3.9274 -342.94
## - cd_total_07 1 4.0082 -336.89
## - hd_total07 1 4.1221 -328.57
## - Rent 1 8.9934 -96.87
##
## Step: AIC=-374.44
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + amenities +
## cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - LEED 1 3.5326 -380.10
## - leasing_rate 1 3.5327 -380.09
## - Gas_Costs 1 3.5339 -380.00
## - stories 1 3.5358 -379.83
## - Energystar 1 3.5387 -379.59
## - class_b 1 3.5431 -379.22
## - class_a 1 3.5447 -379.09
## - renovated 1 3.5471 -378.89
## - amenities 1 3.5515 -378.52
## <none> 3.5321 -374.44
## - empl_gr 1 3.6732 -368.51
## - Electricity_Costs 1 3.7004 -366.32
## - age 1 3.7158 -365.09
## - cluster_rent 1 3.9274 -348.64
## - cd_total_07 1 4.0226 -341.53
## - hd_total07 1 4.1251 -334.05
## - Rent 1 9.0068 -102.13
##
## Step: AIC=-380.1
## green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + Energystar + amenities +
## cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - leasing_rate 1 3.5332 -385.76
## - Gas_Costs 1 3.5346 -385.64
## - stories 1 3.5363 -385.50
## - class_b 1 3.5436 -384.89
## - class_a 1 3.5452 -384.75
## - renovated 1 3.5478 -384.53
## - amenities 1 3.5522 -384.16
## - Energystar 1 3.5612 -383.41
## <none> 3.5326 -380.10
## - empl_gr 1 3.6740 -374.15
## - Electricity_Costs 1 3.7015 -371.94
## - age 1 3.7160 -370.78
## - cluster_rent 1 3.9274 -354.34
## - cd_total_07 1 4.0262 -346.96
## - hd_total07 1 4.1260 -339.69
## - Rent 1 9.0365 -106.86
##
## Step: AIC=-385.76
## green_rent ~ empl_gr + Rent + stories + age + renovated + class_a +
## class_b + Energystar + amenities + cd_total_07 + hd_total07 +
## Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - Gas_Costs 1 3.5351 -391.30
## - stories 1 3.5368 -391.16
## - class_b 1 3.5442 -390.53
## - class_a 1 3.5460 -390.39
## - renovated 1 3.5495 -390.09
## - amenities 1 3.5530 -389.80
## - Energystar 1 3.5618 -389.06
## <none> 3.5332 -385.76
## - empl_gr 1 3.6747 -379.80
## - Electricity_Costs 1 3.7015 -377.64
## - age 1 3.7212 -376.07
## - cluster_rent 1 3.9274 -360.05
## - cd_total_07 1 4.0271 -352.60
## - hd_total07 1 4.1274 -345.30
## - Rent 1 9.0415 -112.39
##
## Step: AIC=-391.3
## green_rent ~ empl_gr + Rent + stories + age + renovated + class_a +
## class_b + Energystar + amenities + cd_total_07 + hd_total07 +
## Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - stories 1 3.5384 -396.73
## - class_b 1 3.5463 -396.06
## - class_a 1 3.5480 -395.92
## - renovated 1 3.5508 -395.69
## - amenities 1 3.5555 -395.30
## - Energystar 1 3.5697 -394.11
## <none> 3.5351 -391.30
## - empl_gr 1 3.6747 -385.50
## - Electricity_Costs 1 3.7056 -383.02
## - age 1 3.7212 -381.76
## - cluster_rent 1 3.9550 -363.67
## - cd_total_07 1 4.1571 -348.87
## - hd_total07 1 4.1591 -348.73
## - Rent 1 9.1204 -115.52
##
## Step: AIC=-396.73
## green_rent ~ empl_gr + Rent + age + renovated + class_a + class_b +
## Energystar + amenities + cd_total_07 + hd_total07 + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - class_b 1 3.5508 -401.39
## - class_a 1 3.5518 -401.31
## - renovated 1 3.5530 -401.21
## - amenities 1 3.5641 -400.28
## - Energystar 1 3.5748 -399.39
## <none> 3.5384 -396.73
## - empl_gr 1 3.6750 -391.18
## - Electricity_Costs 1 3.7129 -388.13
## - age 1 3.7241 -387.24
## - cluster_rent 1 3.9578 -369.16
## - cd_total_07 1 4.1575 -354.55
## - hd_total07 1 4.1608 -354.31
## - Rent 1 9.3379 -114.22
##
## Step: AIC=-401.39
## green_rent ~ empl_gr + Rent + age + renovated + class_a + Energystar +
## amenities + cd_total_07 + hd_total07 + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - class_a 1 3.5518 -407.01
## - renovated 1 3.5631 -406.07
## - amenities 1 3.5724 -405.29
## - Energystar 1 3.5842 -404.31
## <none> 3.5508 -401.39
## - empl_gr 1 3.6775 -396.68
## - age 1 3.7277 -392.66
## - Electricity_Costs 1 3.7471 -391.12
## - cluster_rent 1 3.9689 -374.03
## - cd_total_07 1 4.1662 -359.63
## - hd_total07 1 4.2058 -356.82
## - Rent 1 9.4061 -117.77
##
## Step: AIC=-407.01
## green_rent ~ empl_gr + Rent + age + renovated + Energystar +
## amenities + cd_total_07 + hd_total07 + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - renovated 1 3.5636 -411.73
## - amenities 1 3.5725 -410.99
## - Energystar 1 3.5857 -409.90
## <none> 3.5518 -407.01
## - empl_gr 1 3.6779 -402.36
## - age 1 3.7435 -397.10
## - Electricity_Costs 1 3.7472 -396.81
## - cluster_rent 1 3.9725 -379.47
## - cd_total_07 1 4.1702 -365.05
## - hd_total07 1 4.2084 -362.34
## - Rent 1 9.5318 -119.53
##
## Step: AIC=-411.73
## green_rent ~ empl_gr + Rent + age + Energystar + amenities +
## cd_total_07 + hd_total07 + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - amenities 1 3.5886 -415.36
## - Energystar 1 3.6010 -414.34
## <none> 3.5636 -411.73
## - empl_gr 1 3.6890 -407.17
## - age 1 3.7514 -402.18
## - Electricity_Costs 1 3.7671 -400.94
## - cluster_rent 1 3.9822 -384.45
## - cd_total_07 1 4.1969 -368.85
## - hd_total07 1 4.2463 -365.38
## - Rent 1 9.5593 -124.37
##
## Step: AIC=-415.36
## green_rent ~ empl_gr + Rent + age + Energystar + cd_total_07 +
## hd_total07 + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - Energystar 1 3.6165 -418.76
## <none> 3.5886 -415.36
## - empl_gr 1 3.7033 -411.72
## - age 1 3.7752 -406.01
## - Electricity_Costs 1 3.8161 -402.81
## - cluster_rent 1 4.0380 -386.02
## - cd_total_07 1 4.2336 -371.97
## - hd_total07 1 4.2768 -368.96
## - Rent 1 9.5610 -130.02
##
## Step: AIC=-418.76
## green_rent ~ empl_gr + Rent + age + cd_total_07 + hd_total07 +
## Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## <none> 3.6165 -418.76
## - empl_gr 1 3.7259 -415.62
## - age 1 3.7837 -411.04
## - Electricity_Costs 1 3.8323 -407.26
## - cluster_rent 1 4.0672 -389.58
## - cd_total_07 1 4.2357 -377.53
## - hd_total07 1 4.2770 -374.64
## - Rent 1 9.6322 -133.53
regForward = step(null, #The most simple model
scope=formula(full), #The most complicated model
direction="both", #Add or delete variables
k=log(length(tr))) #This is BIC## Start: AIC=-553.32
## green_rent ~ 1
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 297/300 rows from a combined fit
## Df Sum of Sq RSS AIC
## + Rent 1 40.380 5.642 -1165.74
## + cluster_rent 1 35.285 10.737 -974.65
## + total_dd_07 1 10.720 35.302 -621.14
## + Electricity_Costs 1 7.482 38.540 -595.07
## + hd_total07 1 4.375 41.648 -572.05
## + cd_total_07 1 3.665 42.357 -567.03
## + class_b 1 1.707 44.315 -553.61
## + class_a 1 1.658 44.364 -553.28
## <none> 46.022 -548.08
## + net 1 0.665 45.357 -546.70
## + leasing_rate 1 0.630 45.392 -546.48
## + Precipitation 1 0.454 45.568 -545.33
## + Gas_Costs 1 0.420 45.603 -545.10
## + amenities 1 0.309 45.714 -544.38
## + age 1 0.219 45.803 -543.80
## + stories 1 0.186 45.837 -543.58
## + empl_gr 1 0.138 45.884 -543.27
## + renovated 1 0.056 45.966 -542.74
## + Energystar 1 0.015 46.007 -542.48
## + LEED 1 0.004 46.019 -542.40
##
## Step: AIC=-1180.55
## green_rent ~ Rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 297/300 rows from a combined fit
## Df Sum of Sq RSS AIC
## + total_dd_07 1 0.950 4.692 -1214.81
## + cluster_rent 1 0.810 4.832 -1206.05
## + hd_total07 1 0.519 5.124 -1188.67
## <none> 5.644 -1180.55
## + age 1 0.264 5.378 -1174.26
## + Precipitation 1 0.195 5.447 -1170.51
## + cd_total_07 1 0.125 5.517 -1166.69
## + Gas_Costs 1 0.115 5.527 -1166.15
## + Electricity_Costs 1 0.070 5.573 -1163.72
## + amenities 1 0.065 5.578 -1163.46
## + empl_gr 1 0.062 5.580 -1163.32
## + stories 1 0.058 5.584 -1163.11
## + LEED 1 0.056 5.586 -1163.01
## + Energystar 1 0.045 5.597 -1162.41
## + class_b 1 0.026 5.616 -1161.42
## + class_a 1 0.025 5.617 -1161.36
## + net 1 0.017 5.626 -1160.91
## + leasing_rate 1 0.000 5.642 -1160.06
## + renovated 1 0.000 5.642 -1160.06
## - Rent 1 40.899 46.542 -553.32
##
## Step: AIC=-1228.78
## green_rent ~ Rent + total_dd_07
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 297/300 rows from a combined fit
## Df Sum of Sq RSS AIC
## + cluster_rent 1 0.4453 4.247 -1238.72
## + Electricity_Costs 1 0.3208 4.371 -1230.14
## <none> 4.715 -1228.78
## + age 1 0.2045 4.487 -1222.34
## + empl_gr 1 0.1689 4.523 -1220.00
## + amenities 1 0.0624 4.630 -1213.08
## + class_b 1 0.0477 4.644 -1212.14
## + class_a 1 0.0474 4.645 -1212.12
## + Gas_Costs 1 0.0097 4.682 -1209.72
## + Precipitation 1 0.0035 4.688 -1209.33
## + cd_total_07 1 0.0030 4.689 -1209.30
## + hd_total07 1 0.0030 4.689 -1209.30
## + renovated 1 0.0023 4.690 -1209.25
## + stories 1 0.0012 4.691 -1209.19
## + LEED 1 0.0003 4.692 -1209.13
## + Energystar 1 0.0003 4.692 -1209.12
## + net 1 0.0002 4.692 -1209.12
## + leasing_rate 1 0.0001 4.692 -1209.11
## - total_dd_07 1 0.9286 5.644 -1180.55
## - Rent 1 31.3563 36.072 -624.08
##
## Step: AIC=-1253.43
## green_rent ~ Rent + total_dd_07 + cluster_rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 297/300 rows from a combined fit
## Df Sum of Sq RSS AIC
## + Electricity_Costs 1 0.3399 3.9067 -1257.80
## <none> 4.2615 -1253.43
## + age 1 0.2400 4.0066 -1250.30
## + empl_gr 1 0.1399 4.1067 -1242.97
## + class_b 1 0.0603 4.1863 -1237.27
## + class_a 1 0.0570 4.1896 -1237.04
## + Gas_Costs 1 0.0471 4.1995 -1236.33
## + amenities 1 0.0331 4.2135 -1235.35
## + Precipitation 1 0.0200 4.2267 -1234.42
## + stories 1 0.0190 4.2276 -1234.35
## + renovated 1 0.0039 4.2428 -1233.29
## + cd_total_07 1 0.0012 4.2454 -1233.10
## + hd_total07 1 0.0012 4.2454 -1233.10
## + leasing_rate 1 0.0011 4.2455 -1233.10
## + LEED 1 0.0002 4.2465 -1233.03
## + net 1 0.0001 4.2465 -1233.03
## + Energystar 1 0.0000 4.2466 -1233.02
## - cluster_rent 1 0.4538 4.7153 -1228.78
## - total_dd_07 1 0.5917 4.8532 -1220.13
## - Rent 1 6.0523 10.3138 -993.98
##
## Step: AIC=-1267.83
## green_rent ~ Rent + total_dd_07 + cluster_rent + Electricity_Costs
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 297/300 rows from a combined fit
## Df Sum of Sq RSS AIC
## <none> 3.9853 -1267.83
## + age 1 0.1806 3.7261 -1266.15
## + empl_gr 1 0.1083 3.7984 -1260.45
## + class_a 1 0.0270 3.8797 -1254.16
## + class_b 1 0.0248 3.8819 -1253.99
## + Precipitation 1 0.0222 3.8845 -1253.79
## - Electricity_Costs 1 0.2762 4.2615 -1253.43
## + amenities 1 0.0092 3.8976 -1252.79
## + renovated 1 0.0057 3.9010 -1252.53
## + stories 1 0.0050 3.9017 -1252.48
## + Energystar 1 0.0047 3.9020 -1252.45
## + LEED 1 0.0038 3.9030 -1252.38
## + leasing_rate 1 0.0030 3.9038 -1252.32
## + cd_total_07 1 0.0021 3.9046 -1252.26
## + hd_total07 1 0.0021 3.9046 -1252.26
## + Gas_Costs 1 0.0004 3.9063 -1252.12
## + net 1 0.0001 3.9067 -1252.10
## - cluster_rent 1 0.4902 4.4754 -1238.74
## - total_dd_07 1 0.8607 4.8459 -1214.88
## - Rent 1 6.1982 10.1835 -992.09
#Step: AIC=-1319.5 green_rent ~ Rent + total_dd_07 + Electricity_Costs + cluster_rentnot_green = subset(green, green_rating==0)
dim(not_green)## [1] 7209 23
#Let us use the log response
not_green_rent <- log(not_green$Rent)
#subset of dataset for simplicity, dont do this try to include all in dataset
not_green_sub <- not_green[,-c(0,1,2,3)] # lose lmedval and the room totals
n = dim(not_green_sub)[1] #Sample size
tr = sample(1:n, #Sample indices do be used in training
size = 3000, #Sample will have 5000 observation
replace = FALSE) #Without replacement
#Create a full matrix of interactions (only necessary for linear model)
#Do the normalization only for main variables.
xxnot_green_sub <- model.matrix(~., data=data.frame(scale(not_green_sub)))[,-1] # the . syntax multiplies data by each long and lat, and then by both
notgreenData = data.frame(not_green_rent,not_green_sub)
#Two models initially, sets the scope/boundaries for search
null = lm(not_green_rent~1, data=notgreenData[tr,]) #only has an intercept
full = glm(not_green_rent~., data=notgreenData[tr,]) #Has all the selected variables
#Let us select models by stepwise
regBack = step(full, #Starting with the full model
direction="backward", #And deleting variables
k=log(length(tr))) #This is BIC## Start: AIC=-2270.29
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + green_rating +
## net + amenities + cd_total_07 + hd_total07 + total_dd_07 +
## Precipitation + Gas_Costs + Electricity_Costs + cluster_rent
##
##
## Step: AIC=-2270.29
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + green_rating +
## net + amenities + cd_total_07 + hd_total07 + Precipitation +
## Gas_Costs + Electricity_Costs + cluster_rent
##
##
## Step: AIC=-2270.29
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + Energystar + net +
## amenities + cd_total_07 + hd_total07 + Precipitation + Gas_Costs +
## Electricity_Costs + cluster_rent
##
##
## Step: AIC=-2270.29
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + LEED + net + amenities +
## cd_total_07 + hd_total07 + Precipitation + Gas_Costs + Electricity_Costs +
## cluster_rent
##
##
## Step: AIC=-2270.29
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + net + amenities + cd_total_07 +
## hd_total07 + Precipitation + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - net 1 77.398 -2277.67
## - stories 1 77.400 -2277.58
## - leasing_rate 1 77.413 -2277.10
## - renovated 1 77.547 -2271.96
## - Precipitation 1 77.567 -2271.20
## <none> 77.382 -2270.29
## - amenities 1 77.627 -2268.91
## - class_b 1 77.704 -2265.95
## - empl_gr 1 77.824 -2261.36
## - class_a 1 77.960 -2256.15
## - age 1 78.317 -2242.59
## - Electricity_Costs 1 78.576 -2232.76
## - Gas_Costs 1 78.590 -2232.24
## - hd_total07 1 82.118 -2101.74
## - cd_total_07 1 82.767 -2078.36
## - cluster_rent 1 90.388 -1816.56
## - Rent 1 192.838 435.44
##
## Step: AIC=-2277.67
## not_green_rent ~ empl_gr + Rent + leasing_rate + stories + age +
## renovated + class_a + class_b + amenities + cd_total_07 +
## hd_total07 + Precipitation + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## - stories 1 77.416 -2285.00
## - leasing_rate 1 77.429 -2284.48
## - renovated 1 77.563 -2279.36
## - Precipitation 1 77.583 -2278.59
## <none> 77.398 -2277.67
## - amenities 1 77.645 -2276.22
## - class_b 1 77.716 -2273.48
## - empl_gr 1 77.841 -2268.70
## - class_a 1 77.968 -2263.87
## - age 1 78.330 -2250.11
## - Gas_Costs 1 78.597 -2239.99
## - Electricity_Costs 1 78.640 -2238.36
## - hd_total07 1 82.204 -2106.63
## - cd_total_07 1 82.842 -2083.67
## - cluster_rent 1 90.448 -1822.59
## - Rent 1 193.246 433.71
##
## Step: AIC=-2285
## not_green_rent ~ empl_gr + Rent + leasing_rate + age + renovated +
## class_a + class_b + amenities + cd_total_07 + hd_total07 +
## Precipitation + Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - leasing_rate 1 77.451 -2291.64
## - Precipitation 1 77.586 -2286.48
## - renovated 1 77.589 -2286.34
## <none> 77.416 -2285.00
## - amenities 1 77.697 -2282.21
## - class_b 1 77.750 -2280.21
## - empl_gr 1 77.866 -2275.77
## - class_a 1 78.124 -2265.92
## - age 1 78.343 -2257.61
## - Gas_Costs 1 78.597 -2247.99
## - Electricity_Costs 1 78.642 -2246.31
## - hd_total07 1 82.317 -2110.57
## - cd_total_07 1 82.843 -2091.62
## - cluster_rent 1 90.539 -1827.62
## - Rent 1 193.932 436.24
##
## Step: AIC=-2291.64
## not_green_rent ~ empl_gr + Rent + age + renovated + class_a +
## class_b + amenities + cd_total_07 + hd_total07 + Precipitation +
## Gas_Costs + Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - Precipitation 1 77.629 -2292.83
## - renovated 1 77.631 -2292.74
## <none> 77.451 -2291.64
## - amenities 1 77.764 -2287.69
## - class_b 1 77.818 -2285.59
## - empl_gr 1 77.897 -2282.58
## - class_a 1 78.223 -2270.16
## - age 1 78.384 -2264.08
## - Gas_Costs 1 78.667 -2253.34
## - Electricity_Costs 1 78.682 -2252.78
## - hd_total07 1 82.323 -2118.34
## - cd_total_07 1 82.924 -2096.73
## - cluster_rent 1 90.757 -1828.46
## - Rent 1 194.344 434.53
##
## Step: AIC=-2292.83
## not_green_rent ~ empl_gr + Rent + age + renovated + class_a +
## class_b + amenities + cd_total_07 + hd_total07 + Gas_Costs +
## Electricity_Costs + cluster_rent
##
## Df Deviance AIC
## - renovated 1 77.793 -2294.57
## <none> 77.629 -2292.83
## - amenities 1 77.919 -2289.74
## - class_b 1 78.034 -2285.39
## - class_a 1 78.404 -2271.31
## - empl_gr 1 78.532 -2266.47
## - age 1 78.654 -2261.86
## - Electricity_Costs 1 78.689 -2260.52
## - Gas_Costs 1 78.803 -2256.24
## - hd_total07 1 82.651 -2114.53
## - cd_total_07 1 83.431 -2086.61
## - cluster_rent 1 91.370 -1816.48
## - Rent 1 194.364 426.83
##
## Step: AIC=-2294.57
## not_green_rent ~ empl_gr + Rent + age + class_a + class_b + amenities +
## cd_total_07 + hd_total07 + Gas_Costs + Electricity_Costs +
## cluster_rent
##
## Df Deviance AIC
## <none> 77.793 -2294.57
## - amenities 1 78.127 -2289.86
## - class_b 1 78.270 -2284.41
## - age 1 78.658 -2269.71
## - class_a 1 78.673 -2269.15
## - empl_gr 1 78.678 -2268.94
## - Electricity_Costs 1 78.933 -2259.34
## - Gas_Costs 1 79.002 -2256.72
## - hd_total07 1 83.116 -2105.87
## - cd_total_07 1 83.719 -2084.40
## - cluster_rent 1 91.401 -1823.49
## - Rent 1 194.491 420.78
regForward = step(null, #The most simple model
scope=formula(full), #The most complicated model
direction="both", #Add or delete variables
k=log(length(tr))) #This is BIC## Start: AIC=-4798.99
## not_green_rent ~ 1
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2972/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + Rent 1 487.50 111.89 -9730.6
## + cluster_rent 1 378.32 221.07 -7706.8
## + Electricity_Costs 1 129.23 470.16 -5464.1
## + total_dd_07 1 80.41 518.98 -5170.5
## + hd_total07 1 41.17 558.21 -4953.9
## + class_a 1 34.46 564.92 -4918.4
## + cd_total_07 1 22.01 577.37 -4853.6
## + leasing_rate 1 21.22 578.17 -4849.5
## + age 1 16.53 582.86 -4825.5
## + class_b 1 9.70 589.69 -4790.9
## + renovated 1 9.07 590.32 -4787.7
## + stories 1 4.24 595.15 -4763.5
## <none> 599.39 -4750.4
## + amenities 1 1.22 598.17 -4748.5
## + net 1 0.79 598.60 -4746.3
## + Precipitation 1 0.38 599.00 -4744.3
## + Gas_Costs 1 0.25 599.13 -4743.7
## + empl_gr 1 0.06 599.32 -4742.7
##
## Step: AIC=-9841.71
## not_green_rent ~ Rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2972/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + cluster_rent 1 19.52 92.37 -10292.3
## + total_dd_07 1 13.52 98.36 -10105.5
## + hd_total07 1 8.27 103.62 -9950.8
## + Electricity_Costs 1 5.27 106.62 -9866.0
## <none> 112.22 -9841.7
## + age 1 3.22 108.67 -9809.3
## + class_a 1 2.10 109.79 -9778.9
## + cd_total_07 1 1.87 110.02 -9772.7
## + Precipitation 1 0.91 110.98 -9746.9
## + leasing_rate 1 0.63 111.26 -9739.3
## + class_b 1 0.16 111.73 -9726.8
## + empl_gr 1 0.14 111.75 -9726.3
## + renovated 1 0.13 111.76 -9726.0
## + amenities 1 0.10 111.79 -9725.3
## + stories 1 0.08 111.81 -9724.7
## + net 1 0.02 111.86 -9723.3
## + Gas_Costs 1 0.00 111.89 -9722.6
## - Rent 1 492.06 604.28 -4799.0
##
## Step: AIC=-10399.65
## not_green_rent ~ Rent + cluster_rent
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2972/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## + total_dd_07 1 6.300 86.071 -10494.3
## + age 1 4.001 88.370 -10415.9
## + hd_total07 1 3.851 88.520 -10410.9
## <none> 92.927 -10399.7
## + class_a 1 3.120 89.251 -10386.4
## + Precipitation 1 1.230 91.141 -10324.2
## + amenities 1 1.104 91.267 -10320.0
## + cd_total_07 1 0.696 91.675 -10306.8
## + Electricity_Costs 1 0.443 91.928 -10298.6
## + leasing_rate 1 0.425 91.946 -10298.0
## + class_b 1 0.253 92.118 -10292.5
## + empl_gr 1 0.203 92.168 -10290.8
## + stories 1 0.170 92.201 -10289.8
## + Gas_Costs 1 0.021 92.350 -10285.0
## + renovated 1 0.013 92.358 -10284.7
## + net 1 0.013 92.359 -10284.7
## - cluster_rent 1 19.293 112.220 -9841.7
## - Rent 1 130.928 223.854 -7770.1
##
## Step: AIC=-10599.07
## not_green_rent ~ Rent + cluster_rent + total_dd_07
## Warning in add1.lm(fit, scope$add, scale = scale, trace = trace, k = k, : using
## the 2972/3000 rows from a combined fit
## Df Sum of Sq RSS AIC
## <none> 86.719 -10599.1
## + class_a 1 3.130 82.941 -10596.3
## + age 1 2.993 83.078 -10591.4
## + amenities 1 1.669 84.402 -10544.5
## + Electricity_Costs 1 1.448 84.623 -10536.7
## + stories 1 0.951 85.121 -10519.3
## + leasing_rate 1 0.618 85.453 -10507.7
## + empl_gr 1 0.460 85.611 -10502.2
## + class_b 1 0.295 85.776 -10496.5
## + Gas_Costs 1 0.158 85.913 -10491.7
## + cd_total_07 1 0.059 86.012 -10488.3
## + hd_total07 1 0.059 86.012 -10488.3
## + renovated 1 0.019 86.052 -10486.9
## + Precipitation 1 0.005 86.067 -10486.4
## + net 1 0.004 86.068 -10486.4
## - total_dd_07 1 6.208 92.927 -10399.7
## - cluster_rent 1 12.182 98.901 -10212.7
## - Rent 1 133.488 220.206 -7811.4
#Step: AIC=-11140.9
not_green_rent ~ Rent + total_dd_07 + cluster_rent + Electricity_Costs +
age## not_green_rent ~ Rent + total_dd_07 + cluster_rent + Electricity_Costs +
## age
hist(not_green$Rent, 25)
mean(not_green$Rent)## [1] 28.26678
hist(green_only$Rent, 25)
mean(green_only$Rent)## [1] 30.01603
xbar = mean(green_only$Rent)
sig_hat = sd(green_only$Rent)
se_hat = sig_hat/sqrt(nrow(green_only))
xbar + c(-1.96,1.96)*se_hat## [1] 29.04623 30.98583
#normal confidence interval for sample meanmodel1 = lm(Rent ~ 1, data=green_only)
confint(model1, level=0.95)## 2.5 % 97.5 %
## (Intercept) 29.04453 30.98753
#bootstrapping
library(mosaic)## Warning: package 'mosaic' was built under R version 4.0.2
## Loading required package: dplyr
## Warning: package 'dplyr' was built under R version 4.0.2
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
## Loading required package: lattice
## Loading required package: ggformula
## Warning: package 'ggformula' was built under R version 4.0.2
## Loading required package: ggplot2
## Loading required package: ggstance
## Warning: package 'ggstance' was built under R version 4.0.2
##
## Attaching package: 'ggstance'
## The following objects are masked from 'package:ggplot2':
##
## geom_errorbarh, GeomErrorbarh
##
## New to ggformula? Try the tutorials:
## learnr::run_tutorial("introduction", package = "ggformula")
## learnr::run_tutorial("refining", package = "ggformula")
## Loading required package: mosaicData
## Warning: package 'mosaicData' was built under R version 4.0.2
## Loading required package: Matrix
## Registered S3 method overwritten by 'mosaic':
## method from
## fortify.SpatialPolygonsDataFrame ggplot2
##
## The 'mosaic' package masks several functions from core packages in order to add
## additional features. The original behavior of these functions should not be affected by this.
##
## Note: If you use the Matrix package, be sure to load it BEFORE loading mosaic.
##
## Have you tried the ggformula package for your plots?
##
## Attaching package: 'mosaic'
## The following object is masked from 'package:Matrix':
##
## mean
## The following object is masked from 'package:ggplot2':
##
## stat
## The following objects are masked from 'package:dplyr':
##
## count, do, tally
## The following objects are masked from 'package:stats':
##
## binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
## quantile, sd, t.test, var
## The following objects are masked from 'package:base':
##
## max, mean, min, prod, range, sample, sum
green_only_boot = resample(green_only)
mean(green_only_boot$Rent)## [1] 29.83156
model2 = lm(Rent ~ 1, data=not_green)
confint(model2, level=0.95)## 2.5 % 97.5 %
## (Intercept) 27.91459 28.61896
green_all_boot = resample(not_green)
mean(not_green$Rent)## [1] 28.26678
##Summary
Some exploratory data to get a feel for the dataset. We can understand here the relationship between rent for green buildings and rent for not buildings. It is confirmed here that the difference between the rent prices exists for green biuldings and not green buidlings. At a 97.5% confidence interval, we are able to see that the interval for rent prices for not green buildings does not overlap with the green interval rents, showing that there is a higher cost (or more revenue) from having a green building. However, is it because it is green, or some other variable in the background that is correlated with green buildings, that drives up rent prices?
To take a deeper look at this, I decided to do a stepwise regression model for: all buildings, green only, and not green buildings to see what variables impacted rent the most, and if there were any changes or patterns among these.
For all buildings, we had an AIC=-10971.86 rent_all ~ Rent + total_dd_07 + cluster_rent + Electricity_Costs + age
It seems for all buildings, what impacts rent the most would be: * the age of a building, which makes sense, the older the building, the more depreciated, and the less valued by customers and the market * cluster rent (a measure of average rent per square-foot per calendar year in the building’s local market) which makes sense, because if the market is in new york, it will be more expensive than texas * total.dd.07 the total number of degree days (either heating or cooling) in the building’s region in 2007, this one seemed not as obvious to me but, seeing electricity costs is also on here, the correlation between degrees and electricity costs has a correlation of 0.67, showing there is some correlation. the higher it is outside, the colder it will be inside and vice versa * electricity costs makese sense since it is a variable costs and is paid monthly just like rent, can determine the overall amount charged
For green buildings, we had an AIC=-1319.5
green_rent ~ Rent + total_dd_07 + Electricity_Costs + cluster_rent
As explained above, this contains everything but age
To measure if this is different than buildings that are not green we had an AIC=-11140.9 not_green_rent ~ Rent + total_dd_07 + cluster_rent
- Electricity_Costs + age
The only thing that varies from all buildings, not green buildings and the green buildings is that green buildings are not as impacted by age.
As we take the mean and median age for buildings, green_only has a mean age of 23.84526 and a median of 22 while not green buildings are much older with a mean of 49.46733 and a median of 37.
While measuring the correlation between rent price and age it shows only a 0.10, the prices could be determined another way (cluster rent and rent have a correlation of 0.7593399). Having such a big difference in age of buildings could suggest that since green buildings are often newer, they have nicer places and people usually pay more for newer buildings.
However, another reason could be electricity costs. Green buildings have a higher correlation with the total.dd.07 and electricity costs (-0.7178119) than all buildings (-0.657102) and not green buildings (0.6522979). This could suggest that green buildings are impacted more by the heat and therefore use electricity more or less accordingly. Green buildings also have a higher mean average for electricity costs (0.03158175) than non green buildings (0.03089946) showing they do on average spend more on electricity. More electricity usage, more electricity costs and bills, higher rent, and higher revenue. This makes sense because while green buildings try to lower costs such as water, lighting, disposal etc, this is coming from somewhere else (solar panels, different sources of heating) that could affect electricity in different ways or even cause their customers to seek to use more electricity.
I believe there is possibility of confounding variables for the relationship between rent and green status. Affirmed by our stepmodels, green status wasn’t even chosen as a significant variable in any of the samples, showing that it might not be the reason for rent prices.
Furthermore, there’s a lot that goes into rent prices, such as the area you live in, how old the building is, etc. When looking at green buildings, you are looking at newer buildings, and the fact that the building is new could affect the amount you charge for rent. When looking at the energy source changes for green buildings, there is always an effect of redirection of that energy, and that confounding variable could come from the electricity bills.
I believe that the developer should look further into resources to determine what exactly causes rent prices to be higher, and I believe it is not due to it being green, but the effects and attributes that being green has. You do not want to solely base your profit off being green, because following this model, each year you would make less due to the building getting older, or maybe higher electricity costs for the company to maintain being green. You need to see specifically what is causing a higher rent price, and not rely on just being green because background variables are at work here.
cor(green$total_dd_07, green$Electricity_Costs)## [1] -0.657102
mean(green_only$age)## [1] 23.84526
median(green_only$age)## [1] 22
mean(not_green$age)## [1] 49.46733
median(not_green$age)## [1] 37
cor(green$Rent, green$age)## [1] -0.1026638
cor(green$Rent, green$cluster_rent)## [1] 0.7593399
print(cor(green_only$Rent, green_only$Electricity_Costs))## [1] 0.399297
plot(green_only$Rent, green_only$Electricity_Costs)
cor(green$Rent, green$Electricity_Costs)## [1] 0.3916586
plot(green$Rent, green$Electricity_Costs)
print(cor(green_only$total_dd_07, green_only$Electricity_Costs))## [1] -0.7178119
plot(green_only$total_dd_07, green_only$Electricity_Costs)
print(cor(green$total_dd_07, green$Electricity_Costs))## [1] -0.657102
plot(green$total_dd_07, green$Electricity_Costs)
print(cor(not_green$total_dd_07, not_green$Electricity_Costs))## [1] -0.6522979
mean(green_only$Electricity_Costs)## [1] 0.03158175
mean(not_green$Electricity_Costs)## [1] 0.03089946
Going more in depth into the previous analysis, we did more data exploration to see if there were more patterns or other ones that strengthened our previous beliefs.
gb <- read.csv("https://raw.githubusercontent.com/jgscott/STA380/master/data/greenbuildings.csv")
head(gb)## CS_PropertyID cluster size empl_gr Rent leasing_rate stories age renovated
## 1 379105 1 260300 2.22 38.56 91.39 14 16 0
## 2 122151 1 67861 2.22 28.57 87.14 5 27 0
## 3 379839 1 164848 2.22 33.31 88.94 13 36 1
## 4 94614 1 93372 2.22 35.00 97.04 13 46 1
## 5 379285 1 174307 2.22 40.69 96.58 16 5 0
## 6 94765 1 231633 2.22 43.16 92.74 14 20 0
## class_a class_b LEED Energystar green_rating net amenities cd_total_07
## 1 1 0 0 1 1 0 1 4988
## 2 0 1 0 0 0 0 1 4988
## 3 0 1 0 0 0 0 1 4988
## 4 0 1 0 0 0 0 0 4988
## 5 1 0 0 0 0 0 1 4988
## 6 1 0 0 0 0 0 1 4988
## hd_total07 total_dd_07 Precipitation Gas_Costs Electricity_Costs
## 1 58 5046 42.57 0.01370000 0.02900000
## 2 58 5046 42.57 0.01373149 0.02904455
## 3 58 5046 42.57 0.01373149 0.02904455
## 4 58 5046 42.57 0.01373149 0.02904455
## 5 58 5046 42.57 0.01373149 0.02904455
## 6 58 5046 42.57 0.01373149 0.02904455
## cluster_rent
## 1 36.78
## 2 36.78
## 3 36.78
## 4 36.78
## 5 36.78
## 6 36.78
gb$green_rating = as.factor(gb$green_rating) There
is large variation and outliners in the dataset. The eco-friendly
building appears to have higher rental rate comparatively, looking at
the same cluster_rent level.
There
is large variation and outliners in the dataset. The eco-friendly
building appears to have higher rental rate comparatively, looking at
the same cluster_rent level.
What percentage of green buildings having a higher rental price than local market rental price? What about percentage of nongreen buildings?
d1 = gb %>%
group_by(green_rating ) %>%
summarize(good_performance = sum(Rent > cluster_rent)/n())## `summarise()` ungrouping output (override with `.groups` argument)
ggplot(data = d1) +
geom_bar(mapping = aes(x = green_rating, y = good_performance ), stat='identity') +
labs(title = "Percentage of Buildings with Higher Rental Rate than Local Market Rental Rate")+
coord_flip() Proportionally, more green buildings have higher than market rental
rate
Proportionally, more green buildings have higher than market rental
rate
gb_filtered = filter(gb, leasing_rate>.1)
gb_filtered %>%
group_by(green_rating) %>%
summarize(Rent.med = median(Rent))## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 2 x 2
## green_rating Rent.med
## <fct> <dbl>
## 1 0 25
## 2 1 27.6
So far the results support the EXCEL guru’s analysis, that green buildings have a higher rental price comparatively. Green Buildings have a 27.6 vs Nongreen Buildings’ 25, but we want to know if green or nongreen causes the difference in price. In another words, how other factors play in determining rental rate?
ggplot(data = gb) +
geom_point(mapping = aes(x = age, y = Rent, color = green_rating))+
labs(title = "Building Rent with different BUilding Age") The green building did not show a strong pattern in higher rent, given
the same building age
The green building did not show a strong pattern in higher rent, given
the same building age
gb %>%
group_by(green_rating) %>%
summarize(renovated.count = count(renovated > 0))## Warning: `data_frame()` is deprecated as of tibble 1.1.0.
## Please use `tibble()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.
## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 2 x 2
## green_rating renovated.count
## <fct> <int>
## 1 0 2850
## 2 1 146
gb_filtered = filter(gb, renovated>0)
ggplot(data = gb_filtered) +
geom_point(mapping = aes(x = cluster_rent, y = Rent, color = green_rating),stat='identity') +
labs(title = "Renovated Building in Local Market") If both are renovated, green buildings generally have a higher rental
price than the nongreen buildings in the same local market.
If both are renovated, green buildings generally have a higher rental
price than the nongreen buildings in the same local market.
hist(gb$stories)
hist(gb$age)
gb_filtered = filter(gb, 20 > stories, stories > 10, age < 25, age > 10)
ggplot(data = gb_filtered) +
geom_point(mapping = aes(x = cluster_rent, y = Rent, color = green_rating)) +
labs(title = "Rent per Square of Green Building and NonGreen Building in Similar Condition")
gb_filtered %>%
group_by(green_rating) %>%
summarize(Rent.med = median(Rent))## `summarise()` ungrouping output (override with `.groups` argument)
## # A tibble: 2 x 2
## green_rating Rent.med
## <fct> <dbl>
## 1 0 34.2
## 2 1 34.6
There is a small green building premium but it is not as high as the EXCEL Guru estimated.
So far we have seen how green building appear to have a higher rental rate, but we still cannot prove green building is having a higher rental rate. It could be an indirect results of others factors.
ABIA<- read.csv("https://raw.githubusercontent.com/jgscott/STA380/master/data/ABIA.csv")
View(ABIA)
dim(ABIA)
str(ABIA)##Check the correlation between each variables
library("GGally")
# ggcorr(): Plot a correlation matrix
ggcorr(data = ABIA, palette = "RdYlGn",
label = TRUE, label_color = "black") Carrier Delay and LateAircraf Delay with the 0.6 seem to be more
correlated with Departure Delay and Arrival Delay than any other kinds
of delay, why?
Carrier Delay and LateAircraf Delay with the 0.6 seem to be more
correlated with Departure Delay and Arrival Delay than any other kinds
of delay, why?
library(magrittr)
library(dplyr)
new=ABIA %>% replace(is.na(.), 0)
colMeans(new['CarrierDelay'])## CarrierDelay
## 3.061334
colMeans(new['WeatherDelay'])## WeatherDelay
## 0.4460911
colMeans(new['NASDelay'])## NASDelay
## 2.481251
colMeans(new['SecurityDelay'])## SecurityDelay
## 0.01412452
colMeans(new['LateAircraftDelay'])## LateAircraftDelay
## 4.569051
When we looked at the average delay minutes of each type, we noticed that LateAircraftDelay and CarrierDelay postpone more time. Whatever cause these two types of delay might require more time to deal with. That’s why they are high correlated to DepDelay amd ArrDelay.
##What is the most common reason of delay
new=ABIA %>% replace(is.na(.), 0)
a=colSums(new != 0)
a['CarrierDelay']## CarrierDelay
## 9787
a['WeatherDelay']## WeatherDelay
## 1116
a['NASDelay']## NASDelay
## 10831
a['SecurityDelay']## SecurityDelay
## 78
a['LateAircraftDelay']## LateAircraftDelay
## 10682
The most common reason of delay is actually NASDelay. NAS Delay refers to all airport operations, heavy traffic volume, and flight delays caused by aviation management. By comparison it can probably be solved in a short time.
##The most common reason of cancellation
cancel=dplyr::count(ABIA, CancellationCode, sort = TRUE)
#(A = carrier, B = weather, C = NAS, D = security)
cancel## CancellationCode n
## 1 97840
## 2 A 719
## 3 B 605
## 4 C 96
According to the count of cacellation code, Carrier Delay is the most common reason.The fligts delay due to reasons such as emergency maintenance of the aircraft, crew deployment, baggage storage, and aircraft filling in fuel.
So suprised the most common reason of delay was not weather.
##Flights each month
hist(x=ABIA$Month,
main="Flights each Month",
xlab="Month",
ylab="Frequency")  More flights during summer, probably because of the summer vacation.
(May~July)
More flights during summer, probably because of the summer vacation.
(May~July)
##Flights each weekdays
week <- group_by(ABIA, DayOfWeek)
count <- summarise(week,count = n())
count## # A tibble: 7 x 2
## DayOfWeek count
## <int> <int>
## 1 1 14798
## 2 2 14803
## 3 3 14841
## 4 4 14774
## 5 5 14768
## 6 6 11454
## 7 7 13822
hist(x=ABIA$DayOfWeek,
main="Flights each week day",
xlab="week",
ylab="Frequency")  More flights on wednesday.
More flights on wednesday.
##Flights to Austin
to_austin=ABIA[ABIA$Dest == 'AUS',]
dplyr::count(to_austin, Origin, sort = TRUE)## Origin n
## 1 DAL 5583
## 2 DFW 5508
## 3 IAH 3704
## 4 PHX 2786
## 5 DEN 2719
## 6 ORD 2515
## 7 HOU 2310
## 8 ATL 2255
## 9 LAX 1732
## 10 JFK 1356
## 11 ELP 1344
## 12 LAS 1232
## 13 SJC 968
## 14 EWR 939
## 15 MEM 835
## 16 BNA 795
## 17 BWI 728
## 18 SAN 715
## 19 MDW 713
## 20 LBB 690
## 21 CLT 660
## 22 CVG 653
## 23 MCO 632
## 24 IAD 631
## 25 SFO 609
## 26 SLC 550
## 27 FLL 481
## 28 MAF 471
## 29 MCI 459
## 30 MSY 443
## 31 ABQ 433
## 32 CLE 380
## 33 BOS 368
## 34 TPA 367
## 35 HRL 366
## 36 ONT 304
## 37 PHL 290
## 38 SNA 246
## 39 LGB 245
## 40 OAK 236
## 41 RDU 231
## 42 JAX 229
## 43 TUS 229
## 44 IND 218
## 45 SEA 147
## 46 STL 95
## 47 TUL 90
## 48 OKC 87
## 49 MSP 54
## 50 TYS 3
## 51 SAT 2
## 52 BHM 1
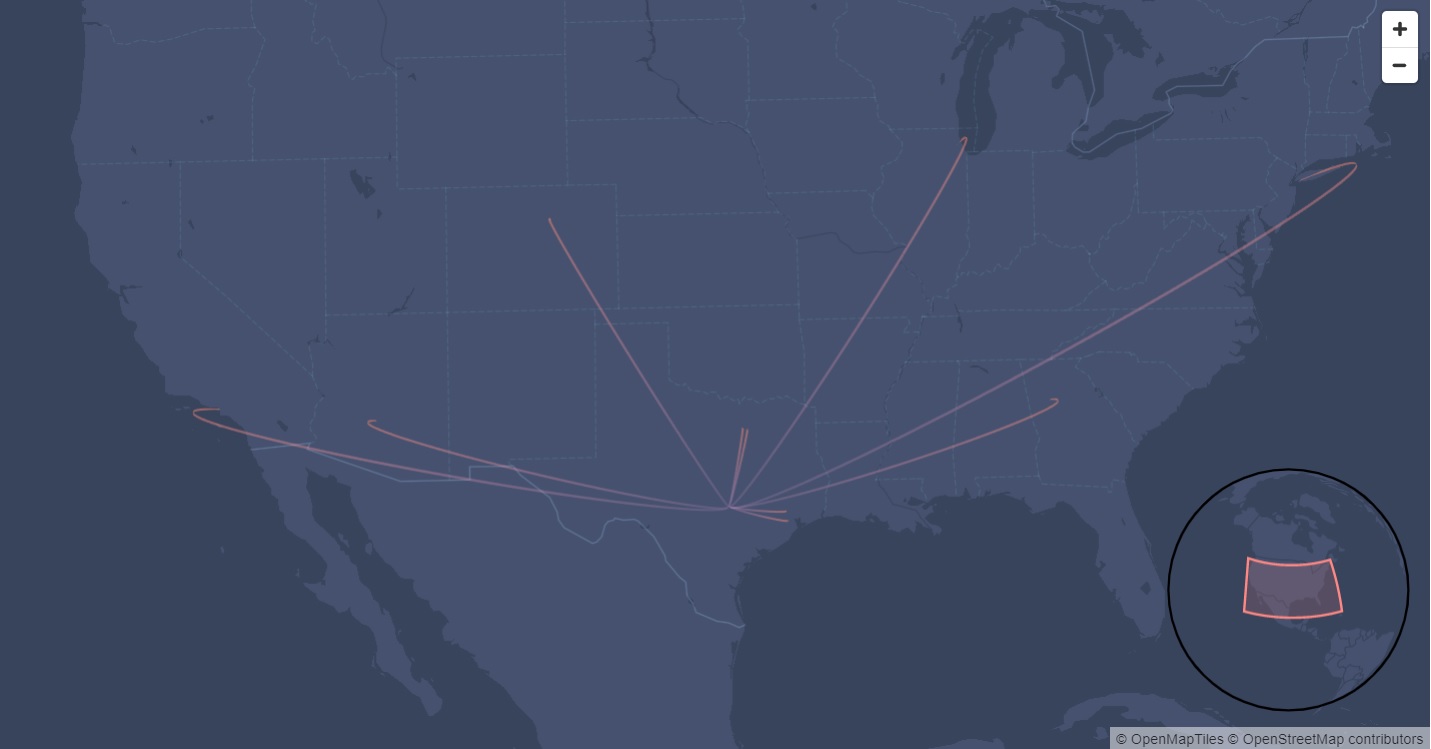
Top three numbers of flights are from two Dallas airports and Houston.
##fly from Austin
away_austin=ABIA[ABIA$Origin == 'AUS',]
dplyr::count(away_austin, Dest, sort = TRUE)## Dest n
## 1 DAL 5573
## 2 DFW 5506
## 3 IAH 3691
## 4 PHX 2783
## 5 DEN 2673
## 6 ORD 2514
## 7 HOU 2319
## 8 ATL 2252
## 9 LAX 1733
## 10 JFK 1358
## 11 ELP 1349
## 12 LAS 1231
## 13 SJC 968
## 14 EWR 949
## 15 MEM 834
## 16 BNA 792
## 17 BWI 730
## 18 SAN 719
## 19 MDW 712
## 20 LBB 692
## 21 IAD 670
## 22 CLT 659
## 23 CVG 653
## 24 MCO 632
## 25 SFO 610
## 26 SLC 548
## 27 FLL 481
## 28 MAF 470
## 29 MCI 459
## 30 MSY 444
## 31 ABQ 435
## 32 CLE 380
## 33 BOS 368
## 34 HRL 367
## 35 TPA 367
## 36 ONT 305
## 37 PHL 290
## 38 LGB 245
## 39 SNA 245
## 40 OAK 236
## 41 RDU 231
## 42 TUS 228
## 43 JAX 226
## 44 IND 218
## 45 SEA 149
## 46 STL 95
## 47 OKC 88
## 48 TUL 88
## 49 MSP 55
## 50 DSM 1
## 51 DTW 1
## 52 ORF 1
Top three for flghts fly from Austin remain the same.
densityplot( ~ Distance ,
data=ABIA
) Mostly are short distance flghts less than 500 miles
Mostly are short distance flghts less than 500 miles
boxplot(formula = AirTime ~ UniqueCarrier,
data = ABIA,
xlab = "Carriers code",
ylab = "Airtime(min)",
col ="blue")  B6 is JetBlue. This carrier seems to fly logner air time in minutes. Is
it because its destinations tend to be farer?
B6 is JetBlue. This carrier seems to fly logner air time in minutes. Is
it because its destinations tend to be farer?
b=summarise(group_by(new, UniqueCarrier), count(UniqueCarrier))## `summarise()` ungrouping output (override with `.groups` argument)
b## # A tibble: 16 x 2
## UniqueCarrier `count(UniqueCarrier)`
## <chr> <int>
## 1 9E 2549
## 2 AA 19995
## 3 B6 4798
## 4 CO 9230
## 5 DL 2134
## 6 EV 825
## 7 F9 2132
## 8 MQ 2663
## 9 NW 121
## 10 OH 2986
## 11 OO 4015
## 12 UA 1866
## 13 US 1458
## 14 WN 34876
## 15 XE 4618
## 16 YV 4994
##Average miles of each carriers
c=summarise(group_by(new, UniqueCarrier), sum(Distance))## `summarise()` ungrouping output (override with `.groups` argument)
c## # A tibble: 16 x 2
## UniqueCarrier `sum(Distance)`
## <chr> <int>
## 1 9E 1705226
## 2 AA 12786743
## 3 B6 6814746
## 4 CO 3867432
## 5 DL 1734942
## 6 EV 671015
## 7 F9 1652300
## 8 MQ 503307
## 9 NW 120286
## 10 OH 3041637
## 11 OO 3821947
## 12 UA 1979778
## 13 US 1271376
## 14 WN 21212992
## 15 XE 3611113
## 16 YV 5185040
m=merge(c, b, by.x="UniqueCarrier", by.y="UniqueCarrier")
m['frac']=m['sum(Distance)']/m['count(UniqueCarrier)']
m## UniqueCarrier sum(Distance) count(UniqueCarrier) frac
## 1 9E 1705226 2549 668.9784
## 2 AA 12786743 19995 639.4970
## 3 B6 6814746 4798 1420.3306
## 4 CO 3867432 9230 419.0067
## 5 DL 1734942 2134 813.0000
## 6 EV 671015 825 813.3515
## 7 F9 1652300 2132 775.0000
## 8 MQ 503307 2663 189.0000
## 9 NW 120286 121 994.0992
## 10 OH 3041637 2986 1018.6326
## 11 OO 3821947 4015 951.9171
## 12 UA 1979778 1866 1060.9743
## 13 US 1271376 1458 872.0000
## 14 WN 21212992 34876 608.2404
## 15 XE 3611113 4618 781.9647
## 16 YV 5185040 4994 1038.2539
JetBlue tends to fly longer distances. So its total Air time is longest among all carriers.
#Question 3: Portfolio Modeling
- We are buliding 3 different models with different risk levels.
Our chosen ETF’s include SPY, SVXY, QQQ, YYY
YYY - Amplify High Income ETF SPY - One of the safest ETFs SVXY - ProShares VIX Short-Term Futures ETF is high risk QQQ - Ivesco QQQ trust one of the largest IWF - iShares Russell 1000 Growth ETF LGLV -SPDR S TR/RUSSELL 1000 LOW VOLATILI
## Warning: package 'quantmod' was built under R version 4.0.2
## Loading required package: xts
## Warning: package 'xts' was built under R version 4.0.2
## Loading required package: zoo
## Warning: package 'zoo' was built under R version 4.0.2
##
## Attaching package: 'zoo'
## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric
##
## Attaching package: 'xts'
## The following objects are masked from 'package:dplyr':
##
## first, last
## Loading required package: TTR
## Warning: package 'TTR' was built under R version 4.0.2
## Registered S3 method overwritten by 'quantmod':
## method from
## as.zoo.data.frame zoo
## Version 0.4-0 included new data defaults. See ?getSymbols.
## Warning: package 'foreach' was built under R version 4.0.2
##
## Attaching package: 'foreach'
## The following objects are masked from 'package:purrr':
##
## accumulate, when
## 'getSymbols' currently uses auto.assign=TRUE by default, but will
## use auto.assign=FALSE in 0.5-0. You will still be able to use
## 'loadSymbols' to automatically load data. getOption("getSymbols.env")
## and getOption("getSymbols.auto.assign") will still be checked for
## alternate defaults.
##
## This message is shown once per session and may be disabled by setting
## options("getSymbols.warning4.0"=FALSE). See ?getSymbols for details.
## pausing 1 second between requests for more than 5 symbols
## pausing 1 second between requests for more than 5 symbols
## [1] "SPY" "SVXY" "QQQ" "YYY" "IWF" "LGLV"
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/SPY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/SPY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=div&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/QQQ?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/QQQ?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/YYY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/YYY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/IWF?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/IWF?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/LGLV?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/LGLV?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'






## ClCl.SPYa ClCl.SVXYa ClCl.QQQa ClCl.YYYa ClCl.IWFa
## 2007-01-03 NA NA NA NA NA
## 2007-01-04 0.0021221123 NA 0.018963898 NA 0.005618014
## 2007-01-05 -0.0079763183 NA -0.004766296 NA -0.006667922
## 2007-01-08 0.0046250821 NA 0.000684219 NA 0.004354173
## 2007-01-09 -0.0008498831 NA 0.005013605 NA 0.001264433
## 2007-01-10 0.0033315799 NA 0.011791406 NA 0.006855511
## ClCl.LGLVa
## 2007-01-03 NA
## 2007-01-04 NA
## 2007-01-05 NA
## 2007-01-08 NA
## 2007-01-09 NA
## 2007-01-10 NA




 The starting wealth value is $100,000
The starting wealth value is $100,000
Simulation 1: Modeling a safe portfolio
ETFs used: “SPY” , “QQQ”, “LGLV”
#### Now use a bootstrap approach
#### With more stocks
mystocks = c("SPY", "SVXY","QQQ","YYY","IWF","LGLV")
myprices = getSymbols(mystocks, from = "2014-01-01")## pausing 1 second between requests for more than 5 symbols
## pausing 1 second between requests for more than 5 symbols
# A chunk of code for adjusting all stocks
# creates a new object adding 'a' to the end
# For example, WMT becomes WMTa, etc
for(ticker in mystocks) {
expr = paste0(ticker, "a = adjustOHLC(", ticker, ")")
eval(parse(text=expr))
}## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/SPY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/SPY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=div&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/SVXY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/QQQ?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/QQQ?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/YYY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/YYY?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query2.finance.yahoo.com/v7/finance/download/IWF?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/IWF?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/LGLV?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
## Warning in read.table(file = file, header = header, sep = sep,
## quote = quote, : incomplete final line found by readTableHeader
## on 'https://query1.finance.yahoo.com/v7/finance/download/LGLV?
## period1=-2208988800&period2=1597708800&interval=1d&events=split&crumb=bIYuOOdYVRY'
head(SPYa)## SPY.Open SPY.High SPY.Low SPY.Close SPY.Volume SPY.Adjusted
## 2014-01-02 161.8579 161.9371 160.5383 160.9254 119636900 160.9254
## 2014-01-03 161.1981 161.5236 160.6703 160.8990 81390600 160.8990
## 2014-01-06 161.4269 161.4884 160.1864 160.4327 108028200 160.4327
## 2014-01-07 161.0749 161.6908 160.9518 161.4181 86144200 161.4181
## 2014-01-08 161.3917 161.7260 160.8990 161.4533 96582300 161.4533
## 2014-01-09 161.9723 161.9899 160.8198 161.5588 90683400 161.5588
# Combine all the returns in a matrix
all_returns = cbind( ClCl(SPYa),
ClCl(SVXYa),
ClCl(QQQa),
ClCl(YYYa),
ClCl(IWFa),
ClCl(LGLVa))
head(all_returns)## ClCl.SPYa ClCl.SVXYa ClCl.QQQa ClCl.YYYa ClCl.IWFa
## 2014-01-02 NA NA NA NA NA
## 2014-01-03 -0.0001640007 0.006050087 -0.007218953 0.0017323084 -0.001291092
## 2014-01-06 -0.0028979059 0.011952161 -0.003693433 0.0008647212 -0.005993584
## 2014-01-07 0.0061416703 0.023399265 0.009267875 0.0073434125 0.007803216
## 2014-01-08 0.0002180510 -0.001669529 0.002180842 -0.0042882075 0.001407825
## 2014-01-09 0.0006538524 -0.002617421 -0.003321510 0.0008613695 -0.000117186
## ClCl.LGLVa
## 2014-01-02 NA
## 2014-01-03 0.000000000
## 2014-01-06 0.000000000
## 2014-01-07 0.005466947
## 2014-01-08 0.000000000
## 2014-01-09 0.000000000
all_returns = as.matrix(na.omit(all_returns))
# Compute the returns from the closing prices
pairs(all_returns)
# Sample a random return from the empirical joint distribution
# This simulates a random day
return.today = resample(all_returns, 1, orig.ids=FALSE)
initial_wealth = 100000
sim1 = foreach(i=1:5000, .combine = rbind) %do% {
weights = c(0.4, 0.03, 0.3, 0.03, 0.02, 0.3)
total_wealth = initial_wealth
holdings = total_wealth * weights
n_days = 20
wealthtracker = rep(0, n_days)
for(today in 1:n_days){
return_today = resample(all_returns, 1, orig.ids=FALSE)
holdings = holdings * (1 + return_today)
total_wealth = sum(holdings)
wealthtracker[today] = total_wealth
# Rebalancing
holdings = total_wealth * weights
}
wealthtracker
}
head(sim1)## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## result.1 107950.7 116075.7 124604.8 134588.7 145299.1 157563.5 167637.8
## result.2 108409.8 116307.1 126746.0 136359.9 148119.6 160107.5 178557.3
## result.3 107588.1 115402.1 127550.0 140169.0 152510.6 164818.0 181181.5
## result.4 107422.9 116273.9 125779.1 135866.1 146712.1 155688.5 168101.5
## result.5 107978.8 116645.5 125167.9 133561.2 145122.6 157110.8 170868.2
## result.6 108278.3 116624.7 126011.9 137655.0 161104.3 174089.9 188506.7
## [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## result.1 180824.3 198009.8 215977.4 234298.1 253095.7 272996.3 297834.5
## result.2 192931.7 208178.1 227078.1 248015.1 267625.3 292354.6 315831.5
## result.3 197200.6 214066.2 230678.2 252583.8 271015.0 294481.4 318123.9
## result.4 181246.7 195835.5 210896.9 227264.2 247058.8 267934.2 296262.7
## result.5 185055.6 198594.8 215923.8 234618.9 253655.6 273830.7 297326.5
## result.6 202003.8 216977.6 236763.2 255888.8 278497.5 302848.2 324701.7
## [,15] [,16] [,17] [,18] [,19] [,20]
## result.1 318441.2 343625.2 369081.2 398270.7 435434.9 475923.1
## result.2 343894.9 363556.1 394495.9 426617.1 460327.1 498519.6
## result.3 344112.8 374213.7 408086.0 451108.1 487085.9 521251.1
## result.4 320205.2 347442.5 375886.9 404239.0 435426.9 468727.2
## result.5 326551.0 348577.9 376658.4 408209.3 443067.9 476183.3
## result.6 346656.7 381346.1 413040.3 443294.3 478804.3 515919.9
hist(sim1[,n_days], 50)
plot(density(sim1[,n_days]))
# Profit/loss
hist(sim1[,n_days]- initial_wealth, breaks=30)
conf_5Per = confint(sim1[,n_days]- initial_wealth, level = 0.90)$'5%'## Confidence Interval from Bootstrap Distribution (5000 replicates)
cat('\nAverage return of investement after 20 days', mean(sim1[,n_days]), "\n")##
## Average return of investement after 20 days 472008
cat('\n5% Value at Risk for safe portfolio-',conf_5Per, "\n")##
## 5% Value at Risk for safe portfolio- 332156.9




## Confidence Interval from Bootstrap Distribution (5000 replicates)
##
## Average return of investement after 20 days 472008
## NULL
##
## 5% Value at Risk for safe portfolio- 332156.9
##Model 2: High Risk Model
Using ETFs: SVXY, YYY, IWF
Distributed 90% of the total wealth among the low performing ETFs




## Confidence Interval from Bootstrap Distribution (5000 replicates)
##
## Average return of investement after 20 days 393022.5
##
## 5% Value at Risk for High portfolio- 237581.8
Model 3: Using equal weights for all ETFs



## Confidence Interval from Bootstrap Distribution (5000 replicates)
##
## Average return of investement after 20 days 142.0271
##
## 5% Value at Risk for High portfolio- -99874.04

##Summary
The Safe model gave the best return on investment and out of the 6 ETFs chosen, 3 of them were defined as the safe model ETFs. The next model used was a high risk model as the equity was distributed among 3 of out of 6 ETFs that were known for their level of risk.Finally a 3rd model was used which gave equal weights to all the different ETFs to see the returs over the time period.
The avg return on investment on Model 1 was 472560.3 with a VaR value of 333204.7 The avg return on investment on Model 2 was 391992.9 with a VaR value of 238154.8 The avg return on investment on Model 3 was 141.8352 with a VaR value of (-99874.28)
The model 1 was the safe model portfolio and as expected produced the highest return on investment then following with the high risk model and finally the diverse model (Model 3) seemed to have a negative return on investment. These values could have been different if we used different ETFs in building our models.
#Question 4: Market Segmentation

## V1 V2 V3 V4
## Min. :0.4193 Min. :0.2522 Min. : 0.3408 Min. :0.3933
## 1st Qu.:0.5957 1st Qu.:0.5928 1st Qu.: 0.5824 1st Qu.:0.7193
## Median :0.7777 Median :0.7768 Median : 0.8380 Median :1.0175
## Mean :0.9860 Mean :1.1913 Mean : 1.5891 Mean :1.5999
## 3rd Qu.:1.1998 3rd Qu.:1.1348 3rd Qu.: 1.2710 3rd Qu.:1.5344
## Max. :3.4128 Max. :6.8522 Max. :11.0950 Max. :6.1199
## V5 V6 V7 V8
## Min. :0.2432 Min. :0.545 Min. : 0.4351 Min. :0.4945
## 1st Qu.:0.5462 1st Qu.:0.805 1st Qu.: 0.7732 1st Qu.:0.6727
## Median :0.8671 Median :1.075 Median : 0.9052 Median :0.9709
## Mean :1.3236 Mean :1.381 Mean : 1.5799 Mean :1.4380
## 3rd Qu.:1.1655 3rd Qu.:1.383 3rd Qu.: 1.3495 3rd Qu.:1.5473
## Max. :6.7725 Max. :9.260 Max. :11.6825 Max. :7.1818
## V9 V10
## Min. : 0.4153 Min. :0.1762
## 1st Qu.: 0.6568 1st Qu.:0.3543
## Median : 0.8249 Median :0.4477
## Mean : 1.6967 Mean :0.5370
## 3rd Qu.: 1.3630 3rd Qu.:0.7063
## Max. :11.1836 Max. :1.2480











A lot variables are correlated to each other from the different clusters. An example can be seen online gaming and college university has a higher correlation and even personal fitness and health nutrition which makes sense that they are correlated. A possibility could be to use PCA to help create fewer uncorrelated variables.
The variables chatter, spam, adult were removed
Continuing onto futher PCA Analysis

cumsum(pca_var1)[10]## [1] 0.6337156
At 10th PC = 63.37% of the variation is explained.
Using Kaiser rule: https://docs.displayr.com/wiki/Kaiser_Rule
Picked 10 PC to use for futher analysis.

The code chunk above takes a while to run.
It is difficult to find the number of clusters from the plot as the within SS decreases with number of clusters.
We have decided to use a smaller number such as 5 cluster since it is easier to intrepret and identify market segments. Let’s also look at the where our points are using 5 clusters.

Some of the separation of the clusters seem intuitive enough to make more sense of them and figure out what they represent in the analysis.





Based on the K-Means clustering, we can identify distinct market segments that NutrientH20 can potentially leverage to design specific marketing campaigns.
Some of the Market Segments identified include: - Sports_Fandom, Travel, Outdoors - Small_Business, Current Events - Food, cooking, college_uni, Personal fitness - Cooking, Personal Fitness, Food, Shopping, Fashion - Travel, Outdoors, Business, cooking
Different clusters include some of the same interests and some unique ones. A lot of the interets are known to be related to each other such as travel and outdoors, small business rely on current events that impact their lives. College students are focused on personal fitness which aslo is related to cooking and food. There are many more that are closely related.
Market Segmentation allows us to find and target a defined audience while tracking what their interests are. Using the segmented insights companies can use the insights to derive resources towards areas that will lead to higher growth and more profits.
The Market segments however are not always the same once identified as over time they should be updated to match the audience as the audience which consists of users is always moving in and out of different segments.
#Question 5: Author Attribution
First you have to import all of the libraries needed for testing different models and visualization (tidyverse, arules, arulesViz, igrpah, etc)
library(tm) ## Loading required package: NLP
library(magrittr)
library(slam)
library(proxy)##
## Attaching package: 'proxy'
## The following objects are masked from 'package:stats':
##
## as.dist, dist
## The following object is masked from 'package:base':
##
## as.matrix
library(caret)## Loading required package: lattice
## Loading required package: ggplot2
##
## Attaching package: 'ggplot2'
## The following object is masked from 'package:NLP':
##
## annotate
library(plyr)
library(dplyr)##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:plyr':
##
## arrange, count, desc, failwith, id, mutate, rename, summarise,
## summarize
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
library(ggplot2)
library('e1071')We read in the data using the reader plain function.
# Read in the data
#Defining reader plain function
readerPlain = function(fname){
readPlain(elem=list(content=readLines(fname)),
id=fname, language='en') }#Reading all folders
train=Sys.glob('C:/Users/lucye/Downloads/UT MSBA/STA S380/Part 2/STA380/data/ReutersC50/C50train/*')We read in all of the files for the training variables.
We then create a null training dataset to store all of the strings from the files, attaching them to its respective author.
#Creating training dataset
comb_art=NULL
labels=NULL
for (name in train)
{
author=substring(name,first=50)#first= ; ensure less than string length
article=Sys.glob(paste0(name,'/*.txt'))
comb_art=append(comb_art,article)
labels=append(labels,rep(author,length(article)))
}We also clean the file by combing through the lines and making the titles more readable by replacing the ‘.txt’ part with the name of the file.
#Cleaning the file names
readerPlain <- function(fname)
{
readPlain(elem=list(content=readLines(fname)),
id=fname, language='en')
}
comb = lapply(comb_art, readerPlain)
names(comb) = comb_art
names(comb) = sub('.txt', '', names(comb))Code takes a while to run
corp_tr=Corpus(VectorSource(comb))We then have to preprocess the data and tokenism it using the tm_map function, this allows us to convert all of the letters to lower case, remove numbers,punctuation, excess space, and stop words This leaves us with 3394 words and 2500 documents. We then come up with a summary statistic to see the amount of sparse terms then remove them from the data set. We then apply a term frequency weighting to measure the relative frequency of the occurrence of each word to the lenght of the documents. Then we put all of these as a matrix, and keep them as a measurement of term frequency and help us in identifying the author based on these patterns.
#Pre-processing and tokenization using tm_map function:
corp_tr_cp=corp_tr #copy of the corp_tr file
corp_tr_cp = tm_map(corp_tr_cp, content_transformer(tolower)) #convert to lower case## Warning in tm_map.SimpleCorpus(corp_tr_cp, content_transformer(tolower)):
## transformation drops documents
corp_tr_cp = tm_map(corp_tr_cp, content_transformer(removeNumbers)) #remove numbers## Warning in tm_map.SimpleCorpus(corp_tr_cp, content_transformer(removeNumbers)):
## transformation drops documents
corp_tr_cp = tm_map(corp_tr_cp, content_transformer(removePunctuation)) #remove punctuation## Warning in tm_map.SimpleCorpus(corp_tr_cp,
## content_transformer(removePunctuation)): transformation drops documents
corp_tr_cp = tm_map(corp_tr_cp, content_transformer(stripWhitespace)) #remove excess space## Warning in tm_map.SimpleCorpus(corp_tr_cp,
## content_transformer(stripWhitespace)): transformation drops documents
corp_tr_cp = tm_map(corp_tr_cp, content_transformer(removeWords),stopwords("en")) #removing stopwords. Not exploring much on this, to avoid losing out on valuable information.## Warning in tm_map.SimpleCorpus(corp_tr_cp, content_transformer(removeWords), :
## transformation drops documents
DTM_train = DocumentTermMatrix(corp_tr_cp)
DTM_train # some basic summary statistics## <<DocumentTermMatrix (documents: 2500, terms: 32573)>>
## Non-/sparse entries: 545361/80887139
## Sparsity : 99%
## Maximal term length: 47
## Weighting : term frequency (tf)
#Removing sparse items
DTM_tr=removeSparseTerms(DTM_train,.99)
tf_idf_mat = weightTfIdf(DTM_tr)
DTM_trr<-as.matrix(tf_idf_mat) #Matrix
tf_idf_mat #3394 words, 2500 documents## <<DocumentTermMatrix (documents: 2500, terms: 3396)>>
## Non-/sparse entries: 382971/8107029
## Sparsity : 95%
## Maximal term length: 47
## Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
Then, we have to repeat the same for the test directory by reading in all of the files in the test directory.
test=Sys.glob('C:/Users/lucye/Downloads/UT MSBA/STA S380/Part 2/STA380/data/ReutersC50/C50test/*')Creating and appending all of the words in the articles to the corresponding author.
comb_art1=NULL
labels1=NULL
for (name in test)
{
author1=substring(name,first=50)#first= ; ensure less than string length
article1=Sys.glob(paste0(name,'/*.txt'))
comb_art1=append(comb_art1,article1)
labels1=append(labels1,rep(author1,length(article1)))
}Cleaning the file names for the test set by substituting ‘.txt’ by the name of the author as an easy identifier.
#Cleaning the file names!!
comb1 = lapply(comb_art1, readerPlain)
names(comb1) = comb_art1
names(comb1) = sub('.txt', '', names(comb1))Code takes a while to run
Then, creating a mining corpus of the files.
#Create a text mining corpus
corp_ts=Corpus(VectorSource(comb1))Then we have to tokenize the data again by converting all to lowercase, removing numbers, removing punctuation, white spaces, and stopwords to avoid losing out on valuable information. # Tokenization
#Pre-processing and tokenization using tm_map function:
corp_ts_cp=corp_ts #copy of the corp_tr file
corp_ts_cp = tm_map(corp_ts_cp, content_transformer(tolower)) #convert to lower case## Warning in tm_map.SimpleCorpus(corp_ts_cp, content_transformer(tolower)):
## transformation drops documents
corp_ts_cp = tm_map(corp_ts_cp, content_transformer(removeNumbers)) #remove numbers## Warning in tm_map.SimpleCorpus(corp_ts_cp, content_transformer(removeNumbers)):
## transformation drops documents
corp_ts_cp = tm_map(corp_ts_cp, content_transformer(removePunctuation)) #remove punctuation## Warning in tm_map.SimpleCorpus(corp_ts_cp,
## content_transformer(removePunctuation)): transformation drops documents
corp_ts_cp = tm_map(corp_ts_cp, content_transformer(stripWhitespace)) #remove excess space## Warning in tm_map.SimpleCorpus(corp_ts_cp,
## content_transformer(stripWhitespace)): transformation drops documents
corp_ts_cp = tm_map(corp_ts_cp, content_transformer(removeWords),stopwords("en")) #removing stopwords. Not exploring much on this, to avoid losing out on valuable information. ## Warning in tm_map.SimpleCorpus(corp_ts_cp, content_transformer(removeWords), :
## transformation drops documents
To validate that the preprocessing and tokenizing left us with the same amount of variables in test and train, we look at the column names from the train document and the TF matrix we created. this leaves us with 3394 words and 2500 documents.
#Ensuring same number of variables in test and train by specifying column names from the train document term matrix
DTM_ts=DocumentTermMatrix(corp_ts_cp,list(dictionary=colnames(DTM_tr)))
tf_idf_mat_ts = weightTfIdf(DTM_ts)## Warning in weightTfIdf(DTM_ts): unreferenced
## term(s): stadatareuterscctrainaaronpressmannewsmltxt
## stadatareuterscctrainalancrosbynewsmltxt
## stadatareuterscctrainalexandersmithnewsmltxt
## stadatareuterscctrainbenjaminkanglimnewsmltxt
## stadatareuterscctrainbernardhickeynewsmltxt
## stadatareuterscctrainbraddorfmannewsmltxt
## stadatareuterscctraindarrenschuettlernewsmltxt
## stadatareuterscctraindavidlawdernewsmltxt
## stadatareuterscctrainednafernandesnewsmltxt
## stadatareuterscctrainericauchardnewsmltxt
## stadatareuterscctrainfumikofujisakinewsmltxt
## stadatareuterscctraingrahamearnshawnewsmltxt
## stadatareuterscctrainheatherscoffieldnewsmltxt
## stadatareuterscctrainjanlopatkanewsmltxt
## stadatareuterscctrainjanemacartneynewsmltxt
## stadatareuterscctrainjimgilchristnewsmltxt
## stadatareuterscctrainjowinterbottomnewsmltxt
## stadatareuterscctrainjoeortiznewsmltxt
## stadatareuterscctrainjohnmastrininewsmltxt
## stadatareuterscctrainjonathanbirtnewsmltxt
## stadatareuterscctrainkarlpenhaulnewsmltxt
## stadatareuterscctrainkeithweirnewsmltxt
## stadatareuterscctrainkevindrawbaughnewsmltxt
## stadatareuterscctrainkevinmorrisonnewsmltxt
## stadatareuterscctrainkirstinridleynewsmltxt
## stadatareuterscctrainkouroshkarimkhanynewsmltxt
## stadatareuterscctrainlydiazajcnewsmltxt
## stadatareuterscctrainlynneodonnellnewsmltxt
## stadatareuterscctrainlynnleybrowningnewsmltxt
## stadatareuterscctrainmarcelmichelsonnewsmltxt
## stadatareuterscctrainmarkbendeichnewsmltxt
## stadatareuterscctrainmartinwolknewsmltxt
## stadatareuterscctrainmatthewbuncenewsmltxt
## stadatareuterscctrainmichaelconnornewsmltxt
## stadatareuterscctrainmuredickienewsmltxt stadatareuterscctrainnicklouthnewsmltxt
## stadatareuterscctrainpatriciacomminsnewsmltxt
## stadatareuterscctrainpeterhumphreynewsmltxt
## stadatareuterscctrainpierretrannewsmltxt
## stadatareuterscctrainrobinsidelnewsmltxt
## stadatareuterscctrainrogerfillionnewsmltxt
## stadatareuterscctrainsamuelperrynewsmltxt
## stadatareuterscctrainsarahdavisonnewsmltxt
## stadatareuterscctrainscotthillisnewsmltxt
## stadatareuterscctrainsimoncowellnewsmltxt stadatareuterscctraintaneelynnewsmltxt
## stadatareuterscctraintheresepolettinewsmltxt
## stadatareuterscctraintimfarrandnewsmltxt
## stadatareuterscctraintoddnissennewsmltxt
## stadatareuterscctrainwilliamkazernewsmltxt
DTM_tss<-as.matrix(tf_idf_mat_ts) #Matrix
tf_idf_mat_ts #3394 words, 2500 documents## <<DocumentTermMatrix (documents: 2500, terms: 3396)>>
## Non-/sparse entries: 379314/8110686
## Sparsity : 96%
## Maximal term length: 47
## Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
We use PCE to take relevant features from this dataset to focus on the important variables as well as take away the effect multicolinnearity has on the dataset but still retaining the information from the relevant correlated variables.
What we did here was to eliminate 0 entry columns and only use columns that correlated/intersected with each other, and extract the principal components for those columns.
DTM_trr_1<-DTM_trr[,which(colSums(DTM_trr) != 0)]
DTM_tss_1<-DTM_tss[,which(colSums(DTM_tss) != 0)]
DTM_tss_1 = DTM_tss_1[,intersect(colnames(DTM_tss_1),colnames(DTM_trr_1))]
DTM_trr_1 = DTM_trr_1[,intersect(colnames(DTM_tss_1),colnames(DTM_trr_1))]mod_pca = prcomp(DTM_trr_1,scale=TRUE)
pred_pca=predict(mod_pca,newdata = DTM_tss_1)Code takes a while to run
#Until PC724 - 74.5, almost 75% of variance explained. Hence stopping at 724 out of 2500 principal components
plot(mod_pca,type='line') 
var <- apply(mod_pca$x, 2, var)
prop <- var / sum(var)
#cumsum(prop)
plot(cumsum(mod_pca$sdev^2/sum(mod_pca$sdev^2)))
From this, we choose the right amount of principal components that explain almost 75% of the variance. Here we choose PC724 out of the 2500 principal components.
We then have to prepare the dataset so it can be classified. The classification procedures I have chosen to use is Random Forest, Naive Bayes, and KNN. Fitting a classifier like trees would be good to determine divides using features from the text. Naive Bayes was chosen because it is good at computing the probability that a new document falls into which class (‘bag of words’) and is class specific. KNN is good for measuring similarity in terms of distance measure and since we have the TF matrix (similar to cosine distance), this will be simpler (KNN often times gives us a high accuracy).
We make sure that the dataset only contains the relevant features for classifying the documents to the author. We have to scale some of the data as well as convert it to a dataframe for easier access.
tr_class = data.frame(mod_pca$x[,1:724])
tr_class['author']=labels
tr_load = mod_pca$rotation[,1:724]
ts_class_pre <- scale(DTM_tss_1) %*% tr_load
ts_class <- as.data.frame(ts_class_pre)
ts_class['author']=labels1##(A) Random Forest Technique
We set a seed so we will get similar results each time. We then apply the random forest model to predict author from all files from the training dataset.
library(randomForest)## randomForest 4.6-14
## Type rfNews() to see new features/changes/bug fixes.
##
## Attaching package: 'randomForest'
## The following object is masked from 'package:dplyr':
##
## combine
## The following object is masked from 'package:ggplot2':
##
## margin
set.seed(1)
mod_rand<-randomForest(as.factor(author)~.,data=tr_class, mtry=6,importance=TRUE)Then we try to predict this on the test dataset and convert it to a table. We are able to compare these predictions to the actual results for the authors. Then we merge these two into a temporary variable to compare the differences or similarities, and compute the percentage correct that using random forests allowed us to achieve.
pre_rand<-predict(mod_rand,data=ts_class)
tab_rand<-as.data.frame(table(pre_rand,as.factor(ts_class$author)))
predicted<-pre_rand
actual<-as.factor(ts_class$author)
temp<-as.data.frame(cbind(actual,predicted))
temp$flag<-ifelse(temp$actual==temp$predicted,1,0)
sum(temp$flag)## [1] 1875
sum(temp$flag)*100/nrow(temp)## [1] 75
1873 documents were classified with the right author giving an accuracy classification rate of 75%.
##(B) Naive Baye’s
For Naive Baye’s, we apply it to the training dataset and try to find the relationship between author and all of the documents. We then create a prediction variable using this model and the test set.
library('e1071')
mod_naive=naiveBayes(as.factor(author)~.,data=tr_class)
pred_naive=predict(mod_naive,ts_class)Using the predictions, we are able to compare it to the actual values for author. We again create and merge the two dataframes for actual and predictions to calculate the accuracy of Naive Bayes and how well it did on predicting the author based on a document.
library(caret)
predicted_nb=pred_naive
actual_nb=as.factor(ts_class$author)
temp_nb<-as.data.frame(cbind(actual_nb,predicted_nb))
temp_nb$flag<-ifelse(temp_nb$actual_nb==temp_nb$predicted_nb,1,0)
sum(temp_nb$flag)## [1] 809
sum(temp_nb$flag)*100/nrow(temp_nb)## [1] 32.36
809 documents were classified with the right author giving us an accuracy classification rate of 32.36%
pred_naive_tr=predict(mod_naive,tr_class)
tr_err_naive_pre<-pred_naiveWe then go on to compare the train vs test accuracy.
##KNN
For the KNN procedure, we take a subset from the training set and test set and factor it for author. We set a seed to just ensure we get smiliar results. We then apply the KNN to our subsets of test and training variables against the author.
train.X = subset(tr_class, select = -c(author))
test.X = subset(ts_class,select=-c(author))
train.author=as.factor(tr_class$author)
test.author=as.factor(ts_class$author)library(class)
set.seed(1)
knn_pred=knn(train.X,test.X,train.author,k=1)Then to caluclate the accuracy of the prediction model on the test set, we ssee if the knn classification for prediction matches the test set author value and calculate the accuracy.
temp_knn=as.data.frame(cbind(knn_pred,test.author))
temp_knn_flag<-ifelse(as.integer(knn_pred)==as.integer(test.author),1,0)
sum(temp_knn_flag)## [1] 844
sum(temp_knn_flag)*100/nrow(temp_knn) #802## [1] 33.76
844 documents were classified with the right author giving us an accuracy classification rate of 33.76%
library(ggplot2)
comp<-data.frame("Model"=c("Random Forest","Naive Baye's","KNN"), "Test.accuracy"=c(75,32.36,33.76))
comp## Model Test.accuracy
## 1 Random Forest 75.00
## 2 Naive Baye's 32.36
## 3 KNN 33.76
ggplot(comp,aes(x=Model,y=Test.accuracy))+geom_col() Comparing the 3 different classification techniques (KNN, random forest,
Naive bayes) we can see that random forest has the highest accuracy by
for for testing. The KNN had an accuracy of only 32.08, Naive Baye’s had
an accuracy of only 32.40, while Random Forest had a test accuracy for
74.90%. Therefore Random Forest is the best model predictor for this
dataset for predicting the author of an article on the basis of that
article’s textual context.
Comparing the 3 different classification techniques (KNN, random forest,
Naive bayes) we can see that random forest has the highest accuracy by
for for testing. The KNN had an accuracy of only 32.08, Naive Baye’s had
an accuracy of only 32.40, while Random Forest had a test accuracy for
74.90%. Therefore Random Forest is the best model predictor for this
dataset for predicting the author of an article on the basis of that
article’s textual context.
#Question 6: Association Rule Mining
## [1] "citrus fruit,semi-finished bread,margarine,ready soups"
## [2] "tropical fruit,yogurt,coffee"
## [3] "whole milk"
## [4] "pip fruit,yogurt,cream cheese ,meat spreads"
## [5] "other vegetables,whole milk,condensed milk,long life bakery product"
## [6] "whole milk,butter,yogurt,rice,abrasive cleaner"
## chr [1:9835] "citrus fruit,semi-finished bread,margarine,ready soups" ...
## Length Class Mode
## 9835 character character
We transform the data into a “transactions” class before applying the apriori algorithm. We are doing this as it is required by the apriori algorithm.
summary of the dataset: 1. There are total of 9835 transactions in our dataset 2. Whole milk is the present in 2513 baskets and is the most frequently bought item 3. More than half of the transactions have 4 or lesser items per basket
## transactions as itemMatrix in sparse format with
## 9835 rows (elements/itemsets/transactions) and
## 169 columns (items) and a density of 0.02609146
##
## most frequent items:
## whole milk other vegetables rolls/buns soda
## 2513 1903 1809 1715
## yogurt (Other)
## 1372 34055
##
## element (itemset/transaction) length distribution:
## sizes
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## 2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46
## 17 18 19 20 21 22 23 24 26 27 28 29 32
## 29 14 14 9 11 4 6 1 1 1 1 3 1
##
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.000 3.000 4.409 6.000 32.000
##
## includes extended item information - examples:
## labels
## 1 abrasive cleaner
## 2 artif. sweetener
## 3 baby cosmetics

Let’s explore rules with support > 0.05, confidence > 0.1 and length <= 2 using the ‘apriori’ algorithm
Support is measured by summing up the number of transactions of both “A” and “B” and dividing by the total number of transactions
Confidence is measured by summing up the number of transactions with both “A” and “B” and dividing by the total number of transactions with “A”
To get strong rulese increase the value of the ‘conf’ parameter and to get longer rules we increaes the ‘maxlen’ parameter.
There are only 6 rules generated because of the high support and low confidence level. We also notice that most relationships in this item set include whole milk, yogurt and rolls/buns which is in accordance with the transaction frequency plot we saw earlier. These are some of the most frequently bought items.
## lhs rhs support confidence coverage
## [1] {yogurt} => {whole milk} 0.05602440 0.4016035 0.1395018
## [2] {whole milk} => {yogurt} 0.05602440 0.2192598 0.2555160
## [3] {rolls/buns} => {whole milk} 0.05663447 0.3079049 0.1839349
## [4] {whole milk} => {rolls/buns} 0.05663447 0.2216474 0.2555160
## [5] {other vegetables} => {whole milk} 0.07483477 0.3867578 0.1934926
## [6] {whole milk} => {other vegetables} 0.07483477 0.2928770 0.2555160
## lift count
## [1] 1.571735 551
## [2] 1.571735 551
## [3] 1.205032 557
## [4] 1.205032 557
## [5] 1.513634 736
## [6] 1.513634 736

Let’s decrease support further and increase confidence slightly with support > 0.02, confidence > 0.2 and length <= 2
This item set contains 72 rules and includes a lot more items. However, whole milk still seems to be a common occurence.

Let us increase the confidence level and decrease the support further. Let’s explore rules with support > 0.0015, confidence > 0.8 and length <= 2

Lift=ConfidenceExpected Confidence=P(A∩B)P(A).P(B). Lift is the factor by which, the co-occurrence of A and B exceeds the expected probability of A and B co-occurring, had they been independent. So, higher the lift, higher the chance of A and B occurring together.The information to explain the concept has been take via http://r-statistics.co/Association-Mining-With-R.html
Summary
Association mining is commonly used for making product recommendations. This is done so by recommending products that are commonly bought together. However, in practical situations this is 100$% accurate and sometimes rules can give misleading results.
From the grocery.txt dataset, we can make some observations. If a person buys red or blush wine then they may also end up buying beer. This also holds for people that buy liquor. A different observation includes that people are more likely to buy vegetables if they are already buying fruit or vegetable based juice. There is also a commonalty in buying meat which is commonly bought with association to vegetables and it leads to other associations. One very easy observation to note was that whole milk was the most common item purchased by buyers. The different associations from the model are indicative of what happens in a practical grocery shopping scenario as people tend to shop for all these type of items.