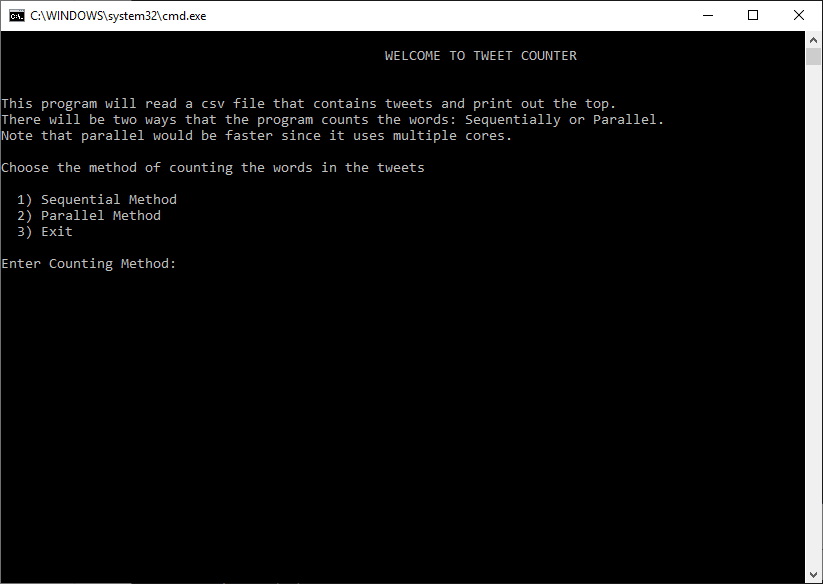
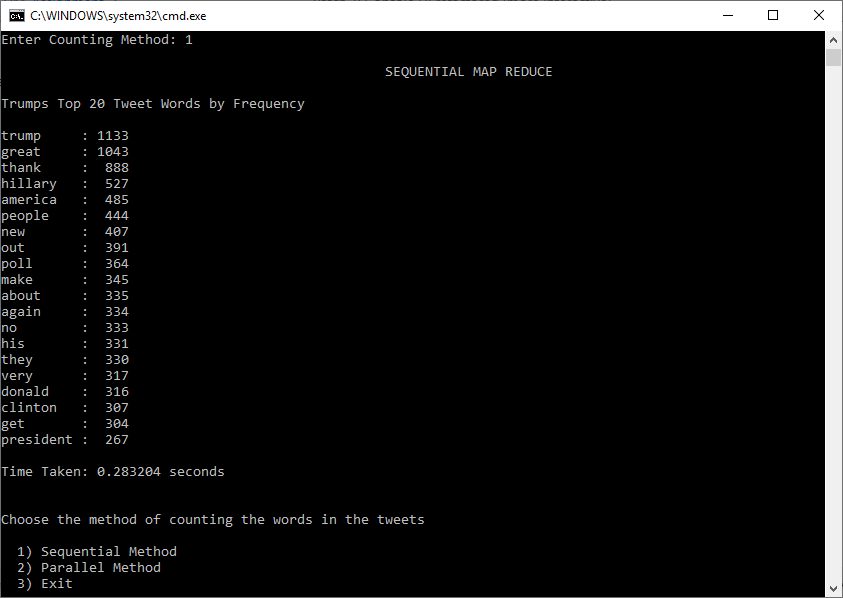
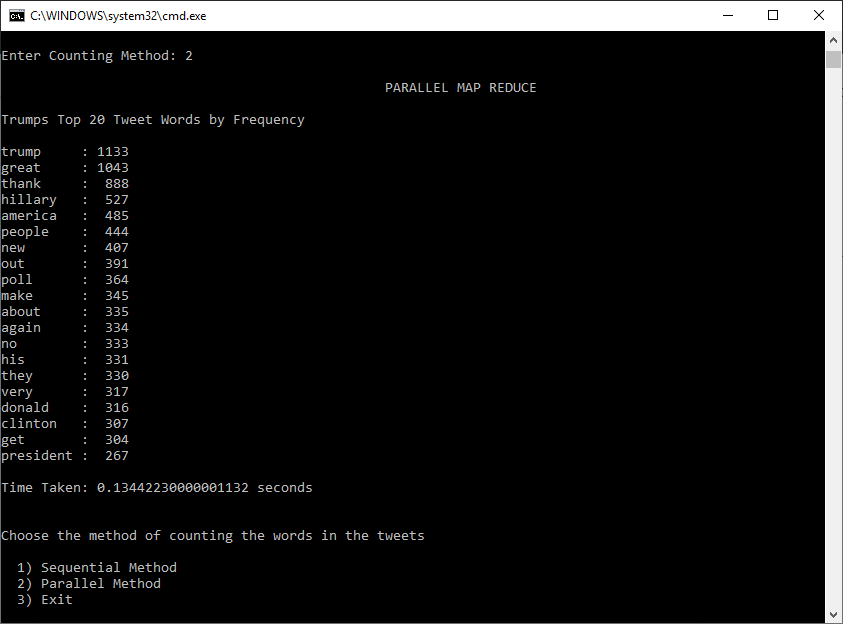
Overview: This program reads from a CSV file that contains tweets, in this case the local csv file contains Trump tweets (over 7000 tweets), and calculates the frequency of words that are used in all the tweets using a custom map reduce algorithm. There are two ways the algorithm counts the words: sequentially and in parallel (parallel method involves multiple cores performing the tasks). The user can choose which method to count the words.
Language used: Python for both sequential and distributed
Distributed Solution: I used multiprocessing for the parallel solution which involved importing the module and using the pool class to map the sublists. I used pool.imap_unordered instead of pool.map since it makes the processes independant and doesn't wait for the other processes' results to execute which makes it slightly faster than pool.map