Comparison of various GPU acceleration frameworks using matrix-vector multiplication as an example.
We compute:
-
$\mathbf{A} \mathbf{x} = \mathbf{b}$ with$\mathbf{A} \in \mathbb{R}^{m \times n}$ where$m = 512$ and$n = 1024$ . $b_i = \sum_j A_{i,j} x_j$
Or in code:
for (int i = 0; i < m; i++){
float sum = 0.0f;
for (int j = 0; j < n; j++){
sum += A[i * n + j] * x[j];
}
b[i] = sum;
}All experiments were run on an NVIDIA GeForce RTX 3060 Laptop GPU.
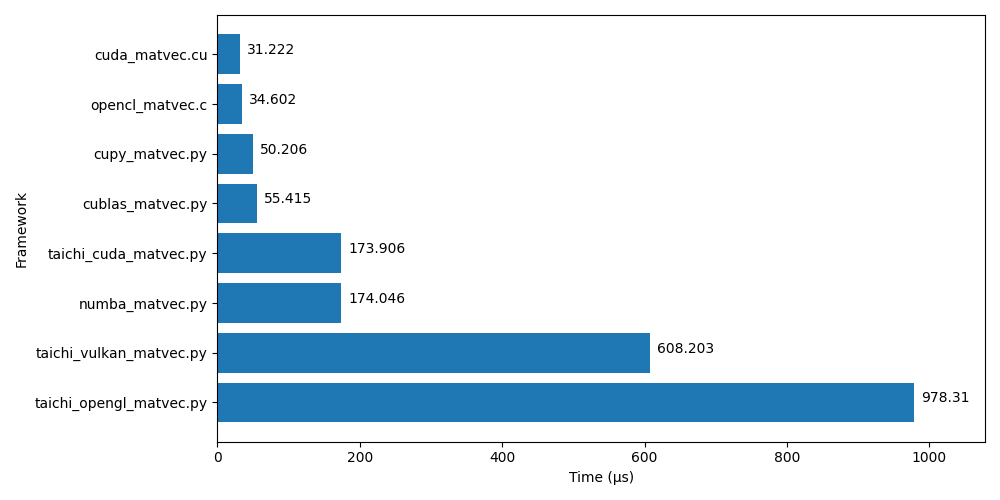
| Framework | Min Time [µs] | Median [µs] | Max [µs] |
|---|---|---|---|
| cuda_matvec.cu | 31.222 | 32.200 | 64.190 |
| opencl_matvec.c | 34.602 | 35.105 | 59.908 |
| cupy_matvec.py | 50.206 | 53.148 | 545.908 |
| cublas_matvec.py | 55.415 | 57.691 | 152.909 |
| taichi_cuda_matvec.py | 173.906 | 178.040 | 64770.521 |
| numba_matvec.py | 174.046 | 180.960 | 194117.546 |
| taichi_vulkan_matvec.py | 608.203 | 788.168 | 8638.188 |
| taichi_opengl_matvec.py | 978.310 | 986.743 | 11853.526 |
Note that the "Max [µs]" column usually shows the time of the first run, including JIT-compilation.
- The native frameworks (CUDA, OpenCL) are clearly fastest.
- Direct wrappers around CUDA are slightly slower, probably due to foreign function call overhead.
- Taichi and Numba (both with LLVM/CUDA backend) are roughly equally fast.
- The running time with Taichi's Vulkan backend varies greatly.
- Other Taichi GPU backends are quite slow, which is unfortunate, since they support a larger number of platforms.
To run the benchmark: