![]()



Silk is a live profiling and inspection tool for the Django framework. Silk intercepts and stores HTTP requests and database queries before presenting them in a user interface for further inspection:
Silk has been tested with:
- Django: 3.2, 4.0, 4.1
- Python: 3.7, 3.8, 3.9, 3.10, 3.11
Via pip into a virtualenv:
pip install django-silkIn settings.py add the following:
MIDDLEWARE = [
...
'silk.middleware.SilkyMiddleware',
...
]
INSTALLED_APPS = (
...
'silk'
)Note: The middleware placement is sensitive. If the middleware before silk.middleware.SilkyMiddleware returns from process_request then SilkyMiddleware will never get the chance to execute. Therefore you must ensure that any middleware placed before never returns anything from process_request. See the django docs for more information on this.
Note: If you are using django.middleware.gzip.GZipMiddleware, place that before silk.middleware.SilkyMiddleware, otherwise you will get an encoding error.
If you want to use custom middleware, for example you developed the subclass of silk.middleware.SilkyMiddleware, so you can use this combination of settings:
# Specify the path where is the custom middleware placed
SILKY_MIDDLEWARE_CLASS = 'path.to.your.middleware.MyCustomSilkyMiddleware'
# Use this variable in list of middleware
MIDDLEWARE = [
...
SILKY_MIDDLEWARE_CLASS,
...
]To enable access to the user interface add the following to your urls.py:
urlpatterns += [path('silk/', include('silk.urls', namespace='silk'))]before running migrate:
python manage.py migrate
python manage.py collectstaticSilk will automatically begin interception of requests and you can proceed to add profiling
if required. The UI can be reached at /silk/
Via github tags:
pip install https://github.com/jazzband/silk/archive/<version>.tar.gzYou can install from master using the following, but please be aware that the version in master may not be working for all versions specified in requirements
pip install -e git+https://github.com/jazzband/django-silk.git#egg=django-silkSilk primarily consists of:
- Middleware for intercepting Requests/Responses
- A wrapper around SQL execution for profiling of database queries
- A context manager/decorator for profiling blocks of code and functions either manually or dynamically.
- A user interface for inspection and visualisation of the above.
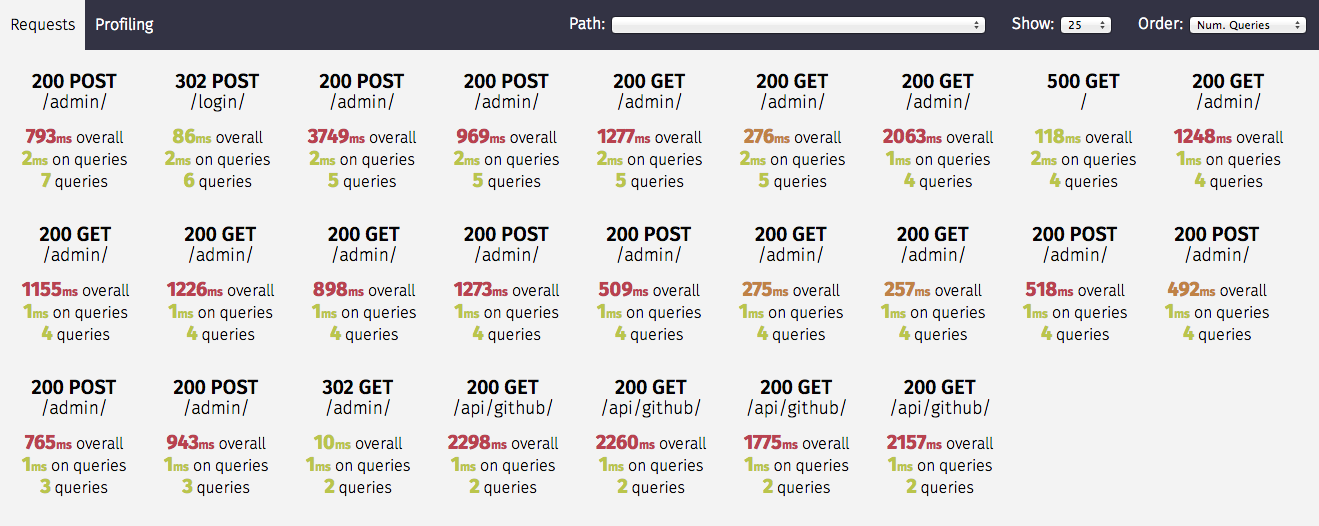
The Silk middleware intercepts and stores requests and responses in the configured database. These requests can then be filtered and inspecting using Silk's UI through the request overview:
It records things like:
- Time taken
- Num. queries
- Time spent on queries
- Request/Response headers
- Request/Response bodies
and so on.
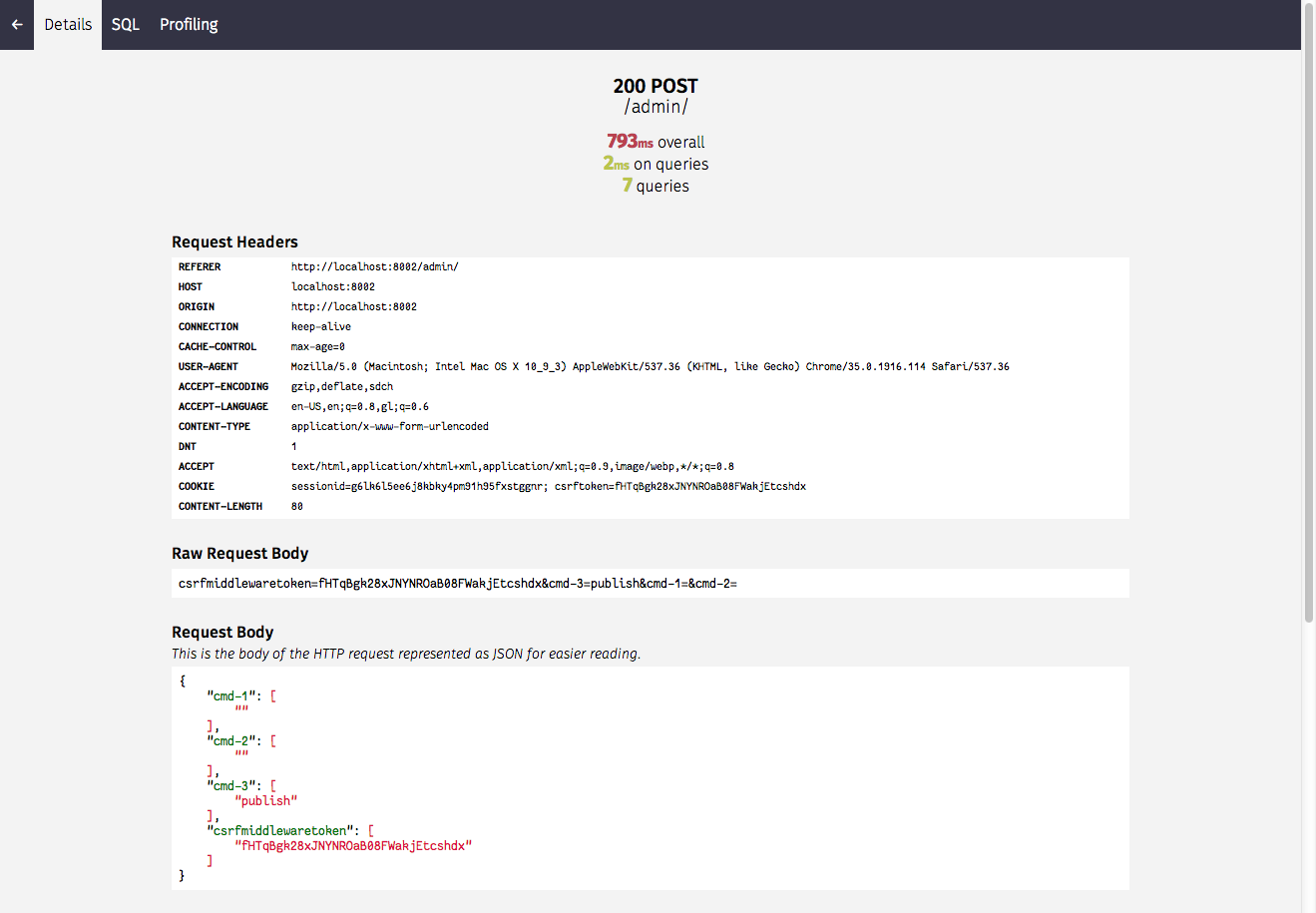
Further details on each request are also available by clicking the relevant request:
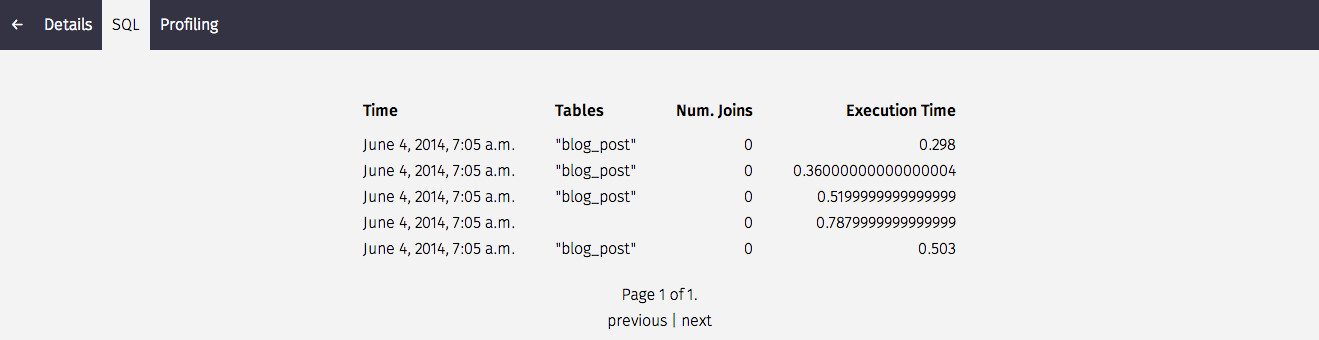
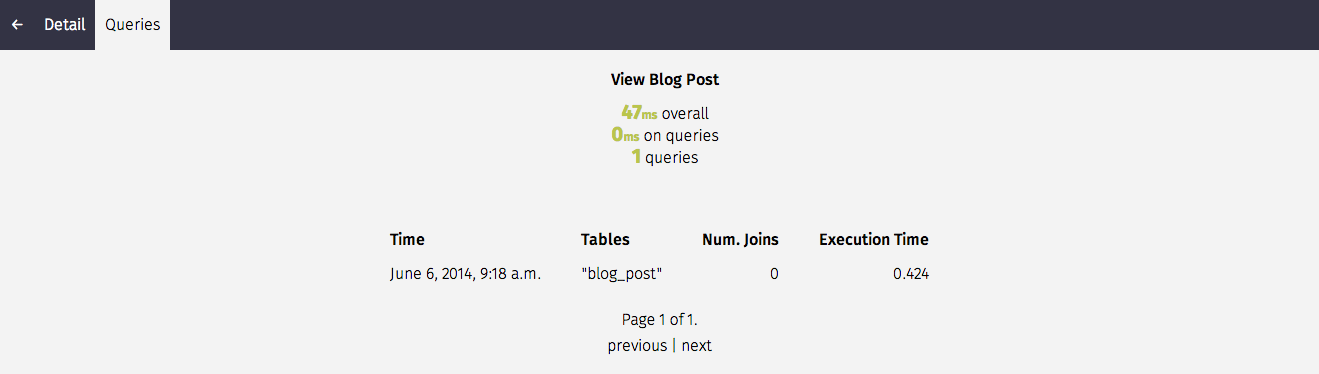
Silk also intercepts SQL queries that are generated by each request. We can get a summary on things like the tables involved, number of joins and execution time (the table can be sorted by clicking on a column header):
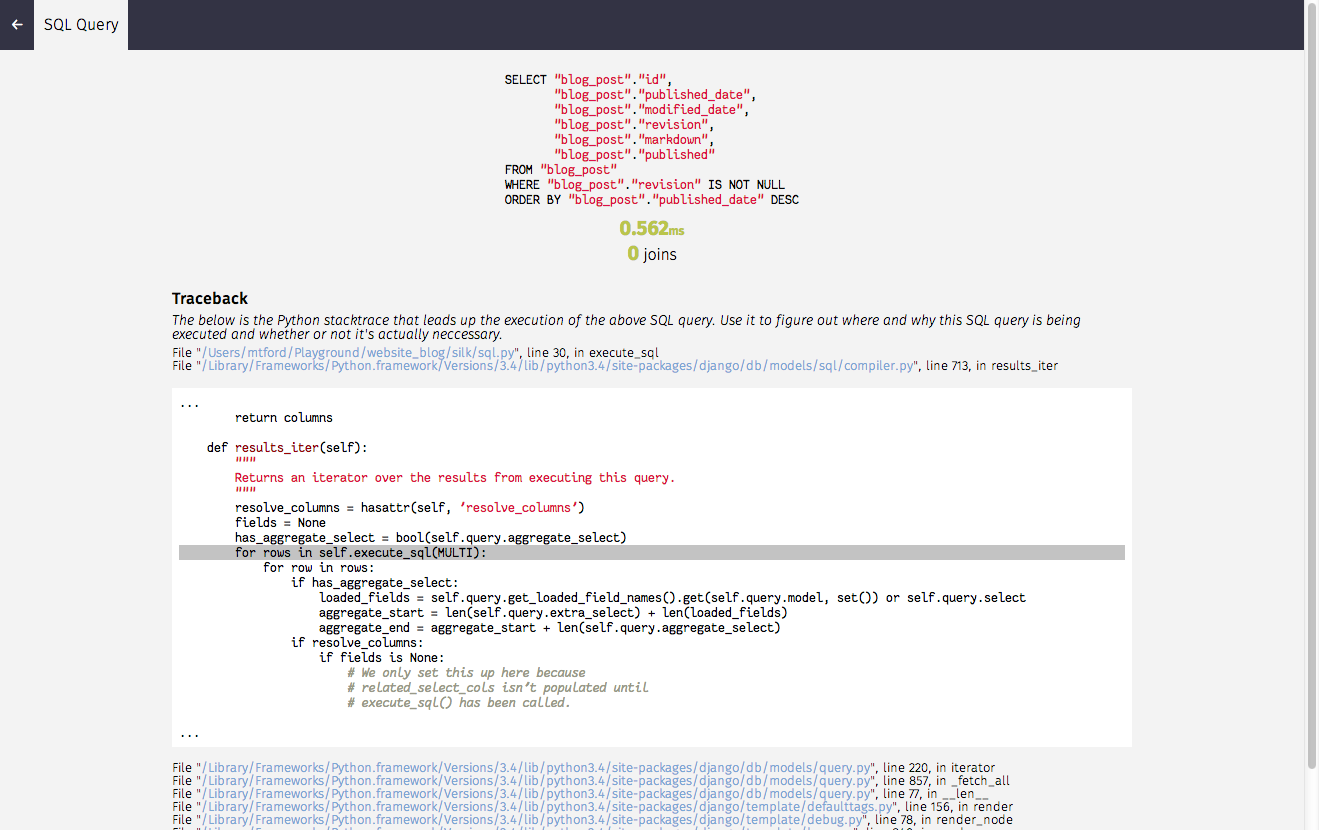
Before diving into the stack trace to figure out where this request is coming from:
Turn on the SILKY_PYTHON_PROFILER setting to use Python's built-in cProfile profiler. Each request will be separately profiled and the profiler's output will be available on the request's Profiling page in the Silk UI.
SILKY_PYTHON_PROFILER = TrueIf you would like to also generate a binary .prof file set the following:
SILKY_PYTHON_PROFILER_BINARY = TrueWhen enabled, a graph visualisation generated using gprof2dot and viz.js is shown in the profile detail page:

A custom storage class can be used for the saved generated binary .prof files:
SILKY_STORAGE_CLASS = 'path.to.StorageClass'The default storage class is silk.storage.ProfilerResultStorage, and when using that you can specify a path of your choosing. You must ensure the specified directory exists.
# If this is not set, MEDIA_ROOT will be used.
SILKY_PYTHON_PROFILER_RESULT_PATH = '/path/to/profiles/'A download button will become available with a binary .prof file for every request. This file can be used for further analysis using snakeviz or other cProfile tools
Silk can also be used to profile specific blocks of code/functions. It provides a decorator and a context manager for this purpose.
For example:
from silk.profiling.profiler import silk_profile
@silk_profile(name='View Blog Post')
def post(request, post_id):
p = Post.objects.get(pk=post_id)
return render(request, 'post.html', {
'post': p
})Whenever a blog post is viewed we get an entry within the Silk UI:
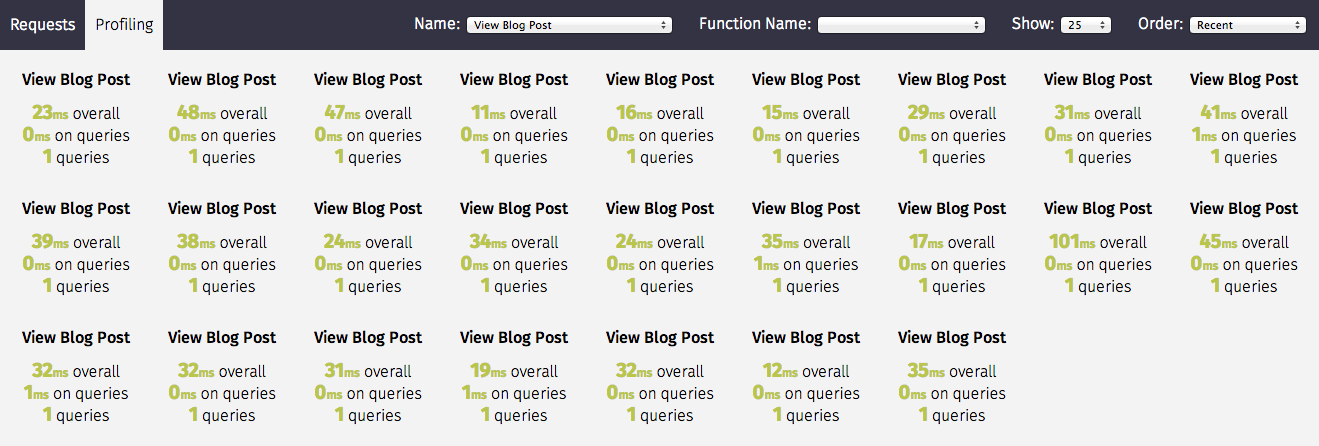
Silk profiling not only provides execution time, but also collects SQL queries executed within the block in the same fashion as with requests:
The silk decorator can be applied to both functions and methods
from silk.profiling.profiler import silk_profile
# Profile a view function
@silk_profile(name='View Blog Post')
def post(request, post_id):
p = Post.objects.get(pk=post_id)
return render(request, 'post.html', {
'post': p
})
# Profile a method in a view class
class MyView(View):
@silk_profile(name='View Blog Post')
def get(self, request):
p = Post.objects.get(pk=post_id)
return render(request, 'post.html', {
'post': p
})Using a context manager means we can add additional context to the name which can be useful for narrowing down slowness to particular database records.
def post(request, post_id):
with silk_profile(name='View Blog Post #%d' % self.pk):
p = Post.objects.get(pk=post_id)
return render(request, 'post.html', {
'post': p
})One of Silk's more interesting features is dynamic profiling. If for example we wanted to profile a function in a dependency to which we only have read-only access (e.g. system python libraries owned by root) we can add the following to settings.py to apply a decorator at runtime:
SILKY_DYNAMIC_PROFILING = [{
'module': 'path.to.module',
'function': 'MyClass.bar'
}]which is roughly equivalent to:
class MyClass:
@silk_profile()
def bar(self):
passThe below summarizes the possibilities:
"""
Dynamic function decorator
"""
SILKY_DYNAMIC_PROFILING = [{
'module': 'path.to.module',
'function': 'foo'
}]
# ... is roughly equivalent to
@silk_profile()
def foo():
pass
"""
Dynamic method decorator
"""
SILKY_DYNAMIC_PROFILING = [{
'module': 'path.to.module',
'function': 'MyClass.bar'
}]
# ... is roughly equivalent to
class MyClass:
@silk_profile()
def bar(self):
pass
"""
Dynamic code block profiling
"""
SILKY_DYNAMIC_PROFILING = [{
'module': 'path.to.module',
'function': 'foo',
# Line numbers are relative to the function as opposed to the file in which it resides
'start_line': 1,
'end_line': 2,
'name': 'Slow Foo'
}]
# ... is roughly equivalent to
def foo():
with silk_profile(name='Slow Foo'):
print (1)
print (2)
print(3)
print(4)Note that dynamic profiling behaves in a similar fashion to that of the python mock framework in that we modify the function in-place e.g:
""" my.module """
from another.module import foo
# ...do some stuff
foo()
# ...do some other stuff,we would profile foo by dynamically decorating my.module.foo as opposed to another.module.foo:
SILKY_DYNAMIC_PROFILING = [{
'module': 'my.module',
'function': 'foo'
}]If we were to apply the dynamic profile to the functions source module another.module.foo after
it has already been imported, no profiling would be triggered.
Sometimes you may want to dynamically control when the profiler runs. You can write your own logic for when to enable the profiler. To do this add the following to your settings.py:
This setting is mutually exclusive with SILKY_PYTHON_PROFILER and will be used over it if present. It will work with SILKY_DYNAMIC_PROFILING.
def my_custom_logic(request):
return 'profile_requests' in request.session
SILKY_PYTHON_PROFILER_FUNC = my_custom_logic # profile only session has recording enabled.You can also use a lambda.
# profile only session has recording enabled.
SILKY_PYTHON_PROFILER_FUNC = lambda request: 'profile_requests' in request.sessionSilk currently generates two bits of code per request:

Both are intended for use in replaying the request. The curl command can be used to replay via command-line and the python code can be used within a Django unit test or simply as a standalone script.
By default anybody can access the Silk user interface by heading to /silk/. To enable your Django
auth backend place the following in settings.py:
SILKY_AUTHENTICATION = True # User must login
SILKY_AUTHORISATION = True # User must have permissionsIf SILKY_AUTHORISATION is True, by default Silk will only authorise users with is_staff attribute set to True.
You can customise this using the following in settings.py:
def my_custom_perms(user):
return user.is_allowed_to_use_silk
SILKY_PERMISSIONS = my_custom_permsYou can also use a lambda.
SILKY_PERMISSIONS = lambda user: user.is_superuserBy default, Silk will save down the request and response bodies for each request for future viewing no matter how large. If Silk is used in production under heavy volume with large bodies this can have a huge impact on space/time performance. This behaviour can be configured with the following options:
SILKY_MAX_REQUEST_BODY_SIZE = -1 # Silk takes anything <0 as no limit
SILKY_MAX_RESPONSE_BODY_SIZE = 1024 # If response body>1024 bytes, ignoreSometimes it is useful to be able to see what effect Silk is having on the request/response time. To do this add
the following to your settings.py:
SILKY_META = TrueSilk will then record how long it takes to save everything down to the database at the end of each request:

Note that in the above screenshot, this means that the request took 29ms (22ms from Django and 7ms from Silk)
On high-load sites it may be helpful to only record a fraction of the requests that are made. To do this add the following to your settings.py:
Note: This setting is mutually exclusive with SILKY_INTERCEPT_FUNC.
SILKY_INTERCEPT_PERCENT = 50 # log only 50% of requestsOn high-load sites it may also be helpful to write your own logic for when to intercept requests. To do this add the following to your settings.py:
Note: This setting is mutually exclusive with SILKY_INTERCEPT_PERCENT.
def my_custom_logic(request):
return 'record_requests' in request.session
SILKY_INTERCEPT_FUNC = my_custom_logic # log only session has recording enabled.You can also use a lambda.
# log only session has recording enabled.
SILKY_INTERCEPT_FUNC = lambda request: 'record_requests' in request.sessionTo make sure silky garbage collects old request/response data, a config var can be set to limit the number of request/response rows it stores.
SILKY_MAX_RECORDED_REQUESTS = 10**4The garbage collection is only run on a percentage of requests to reduce overhead. It can be adjusted with this config:
SILKY_MAX_RECORDED_REQUESTS_CHECK_PERCENT = 10In case you want decouple silk's garbage collection from your webserver's request processing, set SILKY_MAX_RECORDED_REQUESTS_CHECK_PERCENT=0 and trigger it manually, e.g. in a cron job:
python manage.py silk_request_garbage_collectTo enable query analysis when supported by the dbms a config var can be set in order to execute queries with the analyze features.
SILKY_ANALYZE_QUERIES = TrueTo pass additional params for profiling when supported by the dbms (e.g. VERBOSE, FORMAT JSON), you can do this in the following manner.
SILKY_EXPLAIN_FLAGS = {'format':'JSON', 'costs': True}By default, Silk is filtering values that contains the following keys (they are case insensitive)
SILKY_SENSITIVE_KEYS = {'username', 'api', 'token', 'key', 'secret', 'password', 'signature'}But sometimes, you might want to have your own sensitive keywords, then above configuration can be modified
SILKY_SENSITIVE_KEYS = {'custom-password'}A management command will wipe out all logged data:
python manage.py silk_clear_request_log
This is a Jazzband project. By contributing you agree to abide by the Contributor Code of Conduct and follow the guidelines.
Silk features a project named project that can be used for silk development. It has the silk code symlinked so
you can work on the sample project and on the silk package at the same time.
In order to setup local development you should first install all the dependencies for the test project. From the
root of the project directory:
pip install -r requirements.txtYou will also need to install silk's dependencies. From the root of the git repository:
pip install -e .At this point your virtual environment should have everything it needs to run both the sample project and
silk successfully.
Before running, you must set the DB_ENGINE and DB_NAME environment variables:
export DB_ENGINE=sqlite3
export DB_NAME=db.sqlite3For other combinations, check tox.ini.
Now from the root of the sample project apply the migrations
python manage.py migrateNow from the root of the sample project directory start the django server
python manage.py runservercd project
python manage.py testHappy profiling!