360 0Kee-Team 的 crawlergo动态爬虫 结合 长亭XRAY扫描器的被动扫描功能 (其它被动扫描器同理)
https://github.com/0Kee-Team/crawlergo
https://github.com/chaitin/xray
注:若运行出现权限不足,请删除crawlergo空文件夹。
一直想找一个小巧强大的爬虫配合xray的被动扫描使用,曾经有过自己写爬虫的想法,奈何自己太菜写一半感觉还没有awvs的爬虫好用
360 0Kee-Teem最近公开了他们自己产品中使用的动态爬虫模块,经过一番摸索发现正合我意,就写了这个脚本
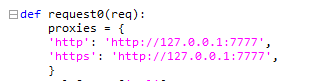
由于该爬虫并未开放代理功能并且有一些从页面抓取的链接不会访问,所以我采用的官方推荐的方法,爬取完成后解析输出的json再使用python的request库去逐个访问
大概逻辑为:
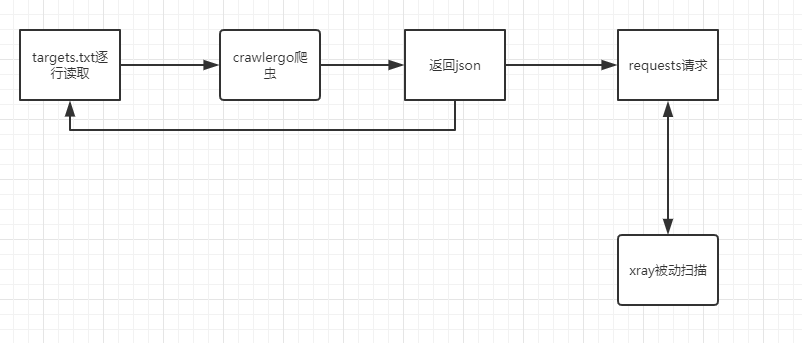
爬取和请求的过程使用了多线程和队列使得请求不会阻塞下一个页面的爬取
注意,是下载编译好的文件而不是git clone它的库

配置参数详见XRAY官方文档
./crawlergo -c C:\Program Files (x86)\Google\Chrome\Application\chrome.exe -t 20 -f smart --fuzz-path --output-mode json target

配置参数详见crawlergo官方文档