
数据的分组与聚合是关系型数据库中比较常见术语。使用数据库时,我们利用查询操作对各列或各行中的数据进行分组,可以针对其中的每一组数据进行各种不同的操作。
pandas的DataFrame数据结构也为我们提供了类似的功能,可以非常方便地对DataFrame进行变换。我们可以把生成的数据保存到python字典中,然后利用这些数据来创建一个python DataFrame,下面就开始练习pandans提供的聚合功能吧。
为了更直观的展示代码,我们用先代码后输出(截图)的方式呈现,每个部分为一个小节,方便大家查询。
在对数据处理的过程中,除了前期对数据的清洗,更多的工作是需要根据不同的分析需求对数据进行整合。比如需要统计某类数据的出现次数,或者需要按照不同级别来分别统计等等。为满足这些需求,比较常用的方法即分组和聚合。幸运的是,pandas中完美支持了这样的功能,掌握好pandas中这些功能,可以使数据处理的效率大大提高。这篇文章就通过一些基础而又十分扎实的例子带大家一起学习一下这些方法。
下面我们开始今天的学习之旅。
首先我们建立一个虚拟的数据。为了适应后续的实例,这里数据建立的稍微复杂一些。数据中除了比较正常的数据列以外,增加了建立双index的方法,同时数据中也特别地建立了一个日期列。建立数据的相关代码如下:
import pandas as pd
import numpy as np
data_dict = {'color' : ['black', 'white', 'black', 'white', 'black',
'white', 'black', 'white', 'black', 'white'],
'size' : ['S','M','L','M','L','S','S','XL','XL','M'],
'date':pd.date_range('1/1/2019',periods=10, freq='W' ),
'feature_1': np.random.randn(10),
'feature_2': np.random.normal(0.5, 2, 10)}
array=[['A','B','B','B','C','A','B','A','C','C'],['JP','CN','US','US','US','CN','CN','CA','JP','CA']]
index = pd.MultiIndex.from_arrays(array, names=['class', 'country'])
data_df = pd.DataFrame(data_dict,index=index)
data_df
简单展示一下我们的数据:

分组功能主要利用pandas的groupby函数。虽然分组功能用其他函数也可以完成,但是groupby函数是相对来说比较方便的。这个函数有很多神奇的功能,熟练后功能十分强大。groupby函数的官方参数说明如下:

我们首先进行简单分组,将创建的DataFrame实例data_df根据size进行分组,得到group_1。在这里我们将group_1转换成list类型后输出,代码如下:
group_1 = data_df.groupby('size')
for i in list(group_1):
print(i)
从print结果可见,转换后的list按照4种size(L,M,S,XL)生成了4个组:

在取得group_1分组后,对group_1进行分组运算(如sum),并对属性名称添加前缀sum_。
(注意:这里非数值数据则不会进行分组运算)
group_1.sum().add_prefix('sum_')
将计算得到的数据添加表头前缀后输出:

另外,可以进行分组计算的函数如下,这里就不一一展示用法了,各位读者可以自行尝试:

除了进行上述的运算,我们还可以用如下代码在group_1中获得所有size为M的行向量:
group_1.get_group('M')
结果如下:

pandas不仅可以按照单标签进行分组,还支持多重分组,这里我们将data_df根据size和color两个列标签进行多重分组,得到group_2:
group_2 = data_df.groupby(['size', 'color'])
for i in list(group_2):
print(i)
结果如下:

对分组后的数据,可以利用size函数获得组别个数:
print(group_1.size())
print(group_2.size())
得到结果:

此外,还可以利用函数进行分组,同时可以令groupby函数中的参数axis=1对列进行分组(axis=0对行进行分组)。用函数分组更加灵活,可以制定一些比较特殊的规则,比如下面例子中,我们就是将列名带有feature的划分为一组,其他的划分为另一组:
def get_letter_type(letter):
if 'feature' in letter:
return 'feature'
else:
return 'other'
for i in list(data_df.groupby(get_letter_type, axis=1)):
print(i)
得到结果如下:

分组对象除了列标签之外,还可以用索引进行分组。我们用不同level值来区分多重索引,其中0代表class,1代表country,这里也可以用索引的level进行分组(可以是一个list)。
for i in list(data_df.groupby(level=[0,1])):
print(i)
结果如下:

所谓聚合就是在对数据进行合理分组后,再根据需要对数据进行的一列操作,比如求和、转换等。聚合函数通常是数据处理的最终目的,数据分组很多情况下也是为更好聚合来服务的。
当GroupBy对象被建立后,我们也可以用agg函数对分组后的数据进行计算。下例中计算了group_2中feature_1的最大值和feature_2的均值。
group_2.agg({'feature_1' : np.min,'feature_2' : np.mean})
结果如下:

接下来我们使用transform函数对groupby对象进行变换,transform的计算结果和原始数据的形状保持一致。下例中我们自定义了函数data_range来获得根据size分组后各个值的范围。
data_range = lambda x: x.max() - x.min()
data_df.groupby('size').transform(data_range)
结果如下:

另外我们还常常通过transform函数将缺失值替换为组间平均值。
data_df.iloc[1, 3:5] = np.NaN
f = lambda x: x.fillna(x.mean())
df_trans = group_1.transform(f)
df_trans
结果如下:


根据列标签color进行分组后对列标签feature_1使用rolling方法,滚动计算最新三个值的平均值。这可能不太容易理解,这个rolling函数相当于定一个窗口(这里设为3),pandas从数据的第一列向前寻找最近的3个数据进行操作(这里是求平均),如果没有足够则返回NaN。rolling函数的具体用法可以查询官网。
data_df.groupby('color').rolling(3).feature_1.mean()
结果如下:

expanding函数相对rolling方法而言,不是固定的窗口而是扩展窗口,因此会对给定的操作进行叠加。如下例中的sum方法,其中的数值是不断叠加扩大的,也就是说窗口从3一直增加,rolling方法则是一直保持窗口大小为3不变。
data_df.groupby('color').expanding(3).feature_1.sum()
结果如下:
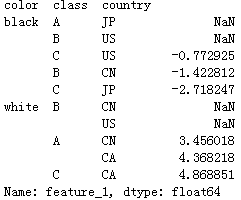
filter函数的参数是作用于整个组,返回值为True或False的函数。我们可以利用filter函数得到分组后的某些特定组别,如下例中元素数大于 3 的分组。
data_df.groupby('class').filter(lambda x: len(x) > 3)
结果如下:

有些分组数据用transform和aggregate都很难完成处理,这时候我们需要使用apply函数。在apply中可使用自定义函数,因此apply相较前两者更加灵活。例如如下代码输出feature_1的数据描述:
data_df.groupby('class')['feature_1'].apply(lambda x: x.describe())
结果如下:

又例如这里将每组的feature_1的数据进行提取运算,并变成了列数据original和demeaned。
def f(group):
return pd.DataFrame({'original' : group,'demeaned' : group - group.mean()})
data_df.groupby('class')['feature_1'].apply(f)
结果如下:

关于pandas分组与聚合方法的例子就暂时介绍这些,其实还有很多更具体和实用的用法,可以在具体的应用中逐步探索,如果各位有更好的应用例子也欢迎留言分享哦。
参考文献:无
- pandas toolkit
- https://cloud.tencent.com/developer/article/1193823
作者:周岩,王转转
责编:周岩,书生
审稿责编:周岩,书生