Releases: wanghenshui/cppweeklynews
C++ 中文周刊 2024-03-30 第153期
本期文章由 HNY 赞助
最近博客内容较少,所以基本整合起来发
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-03-20 第246期
最近的热门事件无疑是xz被植入后门了,埋木马的哥们主动参与社区贡献,骗取信任拿到直接commit权限
趁主要维护人休假期间埋木马,但是木马有问题回归测试被安全人员发现sshd CPU升高,找到xz是罪魁祸首
无间道搁这
文章
How can I tell C++ that I want to discard a nodiscard value?
std::ignore 或者 decltype(std::ignore) _; 然后用 _,或者不自己写,等c++26
Step-by-Step Analysis of Crash Caused by Resize from Zero
resize 的参数为负数会异常(比如参数溢出意外负数)
有句讲句,标准库里的异常有时候很奇怪,大动干戈,副作用还是异常应该有明显的区分。但是目前来看显然是一股脑全异常了
比如stoi异常,这些场景里expect<T>更合适,或者c传统的返回值处理更合理一些
RDMA性能优化经验浅谈(一)
科普
GCC 14 Boasts Nice ASCII Art For Visualizing Buffer Overflows
告警更明显一些
Improvements to static analysis in the GCC 14 compiler
gcc14加了个-fanalyzer
包括上面的buffer溢出分析,死循环分析,比如 https://godbolt.org/z/vn55nn43z
void test (int m, int n) {
float arr[m][n];
for (int i = 0; i < m; i++)
for (int j = 0; j < n; i++)
arr[i][j] = 0.f;
/* etc */
}这里里面的循环条件一直没变,所以一直是死的
编译器能分析出问题
<source>: In function 'test':
<source>:5:23: warning: infinite loop [CWE-835] [-Wanalyzer-infinite-loop]
5 | for (int j = 0; j < n; i++)
| ~~^~~
'test': events 1-5
|
| 5 | for (int j = 0; j < n; i++)
| | ~~^~~ ~~~
| | | |
| | | (4) looping back...
| | (1) infinite loop here
| | (2) when 'j < n': always following 'true' branch...
| | (5) ...to here
| 6 | arr[i][j] = 0.f;
| | ~~~~~~~~~
| | |
| | (3) ...to here
|
ASM generation compiler returned: 0
<source>: In function 'test':
<source>:5:23: warning: infinite loop [CWE-835] [-Wanalyzer-infinite-loop]
5 | for (int j = 0; j < n; i++)
| ~~^~~
'test': events 1-5
|
| 5 | for (int j = 0; j < n; i++)
| | ~~^~~ ~~~
| | | |
| | | (4) looping back...
| | (1) infinite loop here
| | (2) when 'j < n': always following 'true' branch...
| | (5) ...to here
| 6 | arr[i][j] = 0.f;
| | ~~~~~~~~~
| | |
| | (3) ...to here
|
Execution build compiler returned: 0
Program returned: 255这个功能非常有用 gcc14已经发布,能体验到赶紧用起来,免费的静态检查了属于是
A case in API ergonomics for ordered containers
range的问题,如果range 的顺序颠倒,可能会产生未定义行为
举个例子,正常的范围使用
std::set<int> x=...;
// elements in [a,b]
auto first = x.lower_bound(a);
auto last = x.upper_bound(b);
while(first != last) std::cout<< *first++ <<" ";
// elements in [a,b)
auto first = x.lower_bound(a);
auto last = x.lower_bound(b);
// elements in (a,b]
auto first = x.upper_bound(a);
auto last = x.upper_bound(b);
// elements in (a,b)
auto first = x.upper_bound(a);
auto last = x.lower_bound(b);这里的用法的潜在条件是a < b,如果不满足,就完蛋了, 似乎没有办法预防写错,手动assert?
这也容易引起错误,能不能让使用者不要用接口有隐形成本?
boost multiindex设计了一种接口
template<typename LowerBounder,typename UpperBounder>
std::pair<iterator,iterator>
range(LowerBounder lower, UpperBounder upper);显然,不同的类型,隐含一层检查,看上去不好用,但是结合boost lambda2,非常直观
// equivalent to std::set<int>
boost::multi_index_container<int> x=...;
using namespace boost::lambda2;
// [a,b]
auto [first, last] = x.range(_1 >= a, _1 <= b);
// [a,b)
auto [first, last] = x.range(_1 >= a, _1 < b);
// (a,b]
auto [first, last] = x.range(_1 > a, _1 <= b);
// (a,b)
auto [first, last] = x.range(_1 > a, _1 < b);倾向于返回range处理,而不是手动拿到range,即使出现a>b的场景,顶多返回空range
这样要比上面的用法更安全一些
唉,API设计的问题还是有很多需要关注的地方
C++ left arrow operator
幽默代码一例(别这么写)
#include <iostream>
template<class T>
struct larrow {
larrow(T* a_) : a(a_) { }
T* a;
};
template <class T, class R>
R operator<(R (T::* f)(), larrow<T> it) {
return (it.a->*f)();
}
template<class T>
larrow<T> operator-(T& a) {
return larrow<T>(&a);
}
struct C {
void f() { std::cout << "foo\n"; }
};
int main() {
C x;
(&C::f)<-x;
}Upgrading the compiler: undefined behaviour uncovered
TLDR enum没指定默认值的bug,类似int不指定默认值
Trivial, but not trivially default constructible
一个例子
template<class T>
struct S {
S() requires (sizeof(T) > 3) = default;
S() requires (sizeof(T) < 5) = default;
};
static_assert(std::is_trivial_v<S<int>>);
static_assert(not std::is_default_constructible_v<S<int>>);是trivial的,但是构造函数有点多,就没法默认构造
你问这有什么用,确实没用。当不知道好了
今天也和读者聊天问push back T构造异常了咋办,
那我只能说这个T的实现很没有素质,除了bad alloc别的老子不想管
希望大家都做一个有素质的人
Understanding and implementing fixed point numbers
看不懂
Random distributions are not one-size-fits-all (part 1)
Random distributions are not one-size-fits-all (part 2)
随机数生成和场景关联程度太大了,lemire的算法省掉了取余% 但是部分场景性能并不能打败使用取余%的版本
How fast is rolling Karp-Rabin hashing?
其实就是滚动hash,比如这种
uint32_t hash = 0;
for (size_t i = 0; i < len; i++) {
hash = hash * B + data[i];
}
return hash;这个B可能是个质数,比如31,不过不重要
考虑一个字符串子串匹配场景,这种场景下得计算字串hash,比如长字符串内长度为N的子串,代码类似这样
for(size_t i = 0; i < len-N; i++) {
uint32_t hash = 0;
for(size_t j = 0; j < N; j++) {
hash = hash * B + data[i+j];
}
//...
}这个代码的问题是效率低,有没有什么优化办法?
显然这里面有重复计算,到N之前的hash计算完全可以提前算出来
后面变动的减掉就行
uint32_t BtoN = 1;
for(size_t i = 0; i < N; i++) { BtoN *= B; }
uint32_t hash = 0;
for(size_t i = 0; i < N; i++) {
hash = hash * B + data[i];
}
// ...
for(size_t i = N; i < len; i++) {
hash = hash * B + data[i] - BtoN * data[i-N];
// ...
}不知道你看懂没?
这样提前算好性能翻个五倍没啥问题
代码在这里 https://github.com/lemire/clhash/
还有这个 https://github.com/lemire/rollinghashcpp
视频
C++ Weekly - Ep 421 - You're Using optional, variant, pair, tuple, any, and expected Wrong!
不要直接从原类型返回optional这种盒子类型,会破坏RVO 手动make_optional就行了
C++ 中文周刊 2024-03-25 第152期
公众号

qq群 点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等,评论区留言
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-03-13 第245期
c++26 东京会议如火如荼,详情Mick235711已经发了,公众号也发了,这里不再赘述
文章
Introduction To Low Latency Programming: External Processing
其实就是提前算好,包括不限于利用编译期 利用脚本生成以及constexpr
异步拆分,让别人算
Condvars and atomics do not mix
用condvar 条件就要放到mutex下修改,即便这个变量是atomic,也要放到mutex下修改
Jumbled Protocol Buffer Message Layout
protoc会重排你定义的字段布局
static void OptimizeLayoutHelper(std::vector<const FieldDescriptor*>* fields,
const Options& options,
MessageSCCAnalyzer* scc_analyzer) {
if (fields->empty()) return;
// The sorted numeric order of Family determines the declaration order in the
// memory layout.
enum Family {
REPEATED = 0,
STRING = 1,
// Laying out LAZY_MESSAGE before MESSAGE allows a single memset to zero
// MESSAGE and ZERO_INITIALIZABLE fields together.
LAZY_MESSAGE = 2,
MESSAGE = 3,
ZERO_INITIALIZABLE = 4,
OTHER = 5,
kMaxFamily
};
作者观察到一个现象,本来字段很多,删掉一部份字段,性能应该有提升,结果并没有
message Stats {
int64 ts = 1;
int64 show = 2;
int64 click = 3;
int64 cost = 4;
int64 hour_show = 5;
int64 hour_click = 6;
int64 hour_cost = 7;
int64 acc_show = 8;
int64 acc_click = 9;
int64 acc_cost = 10;
repeated int64 bucket = 11;
repeated int64 hour_bucket = 12;
repeated int64 acc_bucket = 13;
}
优化成这样
// After remove the `hour_*` fields
message StatsOpt {
int64 ts = 1;
int64 show = 2;
int64 click = 3;
int64 cost = 4;
int64 acc_show = 5;
int64 acc_click = 6;
int64 acc_cost = 7;
repeated int64 bucket = 8;
repeated int64 acc_bucket = 9;
}
内存布局原来是这样
+------ 16 BYTE ------+- 8 BYTE -+------ 16 BYTE ------+- 8 BYTE -+------ 16 BYTE ------+
| (11)bucket | (11)size | (12)hour | (12)size | (13)acc_bucket |
+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+
| (13.a) | (1)ts | (2)show | (3)click | (4)cost | (5) | (6) | (7) |
+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+
| (8) | (9) | (10) | * | * | * | * | * |
+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+现在是这样
+------ 16 BYTE ------+- 8 BYTE -+------ 16 BYTE ------+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+
| (8)bucket | (8)size | (9)hour | (9)size | (13.a) | (1)ts |
+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+
| (2)show | (3)click | (4)cost | (5) | (6) | (7) | * | * |
+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+- 8 BYTE -+
生成文件是这样的
struct Impl_ {
::PROTOBUF_NAMESPACE_ID::RepeatedField< int64_t > bucket_;
mutable std::atomic<int> _bucket_cached_byte_size_;
::PROTOBUF_NAMESPACE_ID::RepeatedField< int64_t > acc_bucket_;
mutable std::atomic<int> _acc_bucket_cached_byte_size_;
int64_t ts_;
int64_t show_;
int64_t click_;
int64_t cost_;
int64_t acc_show_;
int64_t acc_click_;
int64_t acc_cost_;
mutable ::PROTOBUF_NAMESPACE_ID::internal::CachedSize _cached_size_;
};
union { Impl_ _impl_; };能看到ts和cost跨cacheline了。以前的字段虽然大,但不是夸cacheline的,优化后反而跨cacheline导致变慢
C++ exit-time destructors
介绍析构 runtime细节,非常细,值得一看
Daily bit(e) of C++ | Coroutines: step by step
又一个协程教程
C++23: Encoding related changes
介绍了一些编码方面的改进,包括多语言支持/unicode等等
std::locale::global(std::locale("Russian.1251"));
auto s = std::format("День недели: {}", std::chrono::Monday);
Bug hunting in Btrfs
调试代码发现了btrfs有bug,然后去找bug在哪里,很细,值得一看,这里标记TODO
C++20: Basic Chrono Terminology with Time Duration and Time Point
std::chrono::months 你猜是多少?30.436875
std::chrono::years 你猜是多少?365.2425
非常之令人无语,这种傻逼接口有存在的必要吗
Two handy GDB breakpoint tricks
gdb小技巧
工作招聘
金山招聘,感兴趣点击链接
互动环节
微信公众号终于有评论区了
最近有点卷,更新不太及时, 而且这几周没啥有营养的文章,非常可惜,有啥好玩的我单独发吧
C++ 中文周刊 2024-03-09 第151期
欢迎投稿,推荐或自荐文章/软件/资源等
请提交 issue 或评论区留言
本期文章由 不语 HNY {} 赞助
周末有点忙,内容不多,这周争取双更
话说看到了别人的知识星球真有一种这也能卖钱的感觉
c++知识普及还是很远,无论深度还是广度,优质内容还是太少了,这种稍微懂点就敢开知识星球开课了
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-02-28 第243期
文章
浅谈侵入式结构的应用
总结的的非常好
In C++/WinRT, you shouldn’t destroy an object while you’re co_awaiting it
co_wait对象如果被析构,可能有bug
struct MyThing : winrt::implements<MyThing, winrt::IInspectable>
{
winrt::IAsyncAction m_pendingAction{ nullptr };
winrt::IAsyncAction DoSomethingAsync() {
auto lifetime = get_strong();
m_pendingAction = LongOperationAsync();
co_await m_pendingAction;
PostProcessing();
}
void Cancel() {
if (m_pendingAction) {
m_pendingAction.Cancel();
m_pendingAction = nullptr;
}
}
};这段代码, 如果DoSomethingAsync的时候另一个线程Cancel了,pendingAction被析构了,co_await就会挂
解决方案,co_await副本,复制一份或者decay_copy auto{}
这种指针问题和co_await关系不大,但是容易忽略,普通函数也可以触发,比如异步调用lambda,然后lambda里reset指针,这种场景,可能需要copy这个对象
Borrow Checker, Lifetimes and Destructor Arguments in C++ Avanced compile-time validation with stateful
看得我眼睛疼 在线演示 https://godbolt.org/z/71qs619Ge
LLVM's 'RFC: C++ Buffer Hardening' at Google
安全加固 c buffer的 google内部测试加固完性能衰退也就%1 希望llvm合了
RAII all the things?
用unique_ptr来搞,以前讲过类似的。直接贴代码
struct fcloser {
void operator()(std::FILE* fp) const noexcept {
std::fclose(fp);
}
};
using file_ptr = std::unique_ptr<std::FILE, fcloser>;
struct mem_unmapper {
size_t length{};
void operator()(void* addr) const noexcept {
::munmap(addr, length);
}
};
using mapped_mem_ptr = std::unique_ptr<void, mem_unmapper>;
[[nodiscard]] inline mapped_mem_ptr make_mapped_mem(void* addr, size_t length, int prot, int flags, int fd, off_t offset) {
void* p = ::mmap(addr, length, prot, flags, fd, offset);
if (p == MAP_FAILED) { // MAP_FAILED is not NULL
return nullptr;
}
return {p, mem_unmapper{length}}; // unique_ptr owns a deleter, which remembers the length
}
// Intentionally non-RAII
class file_descriptor {
int fd_{-1};
public:
file_descriptor(int fd = -1): fd_(fd) {}
file_descriptor(nullptr_t) {}
operator int() const { return fd_; }
explicit operator bool() const { return fd_ != -1; }
friend bool operator==(file_descriptor, file_descriptor) = default; // Since C++20
};
struct fd_closer {
using pointer = file_descriptor; // IMPORTANT
void operator()(pointer fd) const noexcept {
::close(int(fd));
}
};
//using unique_fd = std::unique_ptr<int, fd_closer>; // Ok
using unique_fd = std::unique_ptr<file_descriptor, fd_closer>; // Ok
//using unique_fd = std::unique_ptr<void, fd_closer>; // Ok
其他场景自己拼一个defer或者scope_exit
How do I make an expression non-movable? What’s the opposite of std::move?
如何实现强制不move?
template<typename T>
std::remove_reference_t<T> const& no_move(T&& t)
{
return t;
}
std::vector<int> v = no_move(make_vector());Python3.13的JIT是如何实现的
这个也有点意思
不用指针实现pimpl
代码很短
class impl
{
public:
impl();
~impl();
int add(int x) const;
private:
alignas(private_align) unsigned char buffer[private_size];
};
class impl_private
{
public:
explicit impl_private(int y);
int add(int x) const;
private:
int _y;
};
template<typename T>
using impl_t = std::conditional_t<std::is_const_v<std::remove_pointer_t<T>>,
impl_private const,
impl_private>*;
#define IMPL std::launder(reinterpret_cast<impl_t<decltype(this)>>(buffer))
impl::impl()
{
(void)new (buffer) impl_private(1);
}
impl::~impl()
{
IMPL->~impl_private();
}
int impl::add(int x) const
{
return IMPL->add(x);
}核心是用buffer存实现类,然后硬转,看一乐
工作招聘
字节跳动图数据库有个招聘,友情推荐一下
字节图数据库 ByteGraph 团队招聘数据库研发工程师,参与 ByteGraph 存储引擎、查询引擎、数据库与计算融合引擎的核心代码开发。
实习、校招、社招均可,base 地北京/成都/杭州/新加坡均可,新加坡由于签证问题对级别有一定要求,细节可私聊。
可以加 微信 Expelidarmas或者邮件 huyingqian@bytedance.com
他们vldb发过论文的,字节的业务也很强
互动
还是缺少优质内容,大家给给点子
C++ 中文周刊 2024-02-24 第150期
本期文章由 黄亮Anthony Amnesia 赞助
最近沸沸扬扬的白宫发文,转向更安全的语言,明示c++不行
除了把NSA之前的观点重新提出来之外,没有任何新东西,
就像个想离婚的在这里埋怨不想过了,死鬼你也不改你看人家xx语言
要我说这就是美帝不行的原因,从上到下都没有耐性我靠
最近很忙视频都没来得及看。后面慢慢补吧,视频可能单独发总结
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-02-21 第242期
本台记者 kenshin报道,visual studio最近更新了非常有用的功能,分析编译时间之类,分析字段内存布局,分析include等等
感兴趣 可以更新一下 What’s New for C++ Developers in Visual Studio 2022 17.9
另外clang gcc有单独的工具,比如ftime-trace,比如 这个
xmake 2.8.7发布
boost新parser正在review中 https://lists.boost.org/Archives/boost/2024/02/255957.php
类似boost spirit,代码在这里 https://github.com/tzlaine/parser
think-cell出了个意见,他们在自己的库里维护了boost spirit,觉得重新造轮子不太合理,详情见 https://www.think-cell.com/en/career/devblog/parsers-vs-unicode
文章
Rage Against The Glue: Beyond Run-Time Media Frameworks with Modern C++
音视频领域有个 M x N问题
不同的media processors 在N种平台上导致api复杂度上升不可维护
考虑一种接口设计方法,让代码更简练
琢磨半天结果是concept + boost pfr之类的检测接口/策略模版
还有一些其他的想法 在这里
constexpr and consteval functions
记住这段代码就行了
// This is a pure compile-time function.
// Any evaluation is fully done at compile-time;
// no runtime code will be generated by the compiler, just like `static_assert`.
consteval size_t strlen_ct(const char* s) {
size_t n = 0;
for (; s[n] != '\0'; ++n);
return n;
}
// This is a pure runtime function, which can only be invoked at runtime.
size_t strlen(const char* s);
// This function can be invoked both at both compile-time and at runtime,
// depending on the context.
constexpr size_t strlen_dual(const char* s) {
if consteval {
return strlen_ct(s); // compile-time path
} else {
return strlen(s); // runtime path
}
}
constexpr最好两种分支都实现,避免意外的问题
How to debug C and C++ programs with rr
其实rr和gdb record差不多,感觉可以用这个文档例子做个视频,这里标记一个TODO
Undefined behavior in C and C++
讲UB产生的场景,以及如何避免,给的方案编译flag ubsan以及换个语言,我谢谢你
Measuring energy usage: regular code vs. SIMD code
lemire新活,只要你的代码足够快,即使是simd这种费电的指令相比而言整体费电也不多
值得复现一下
My late discovery of std::filesystem - Part I
介绍fs相关api,比如遍历之类的,我就不列出来了
How to write unit tests in C++ relying on non-code files?
介绍非代码文件怎么和代码编译到一起的,bazel/cmake都有类似configfile的方法。embed赶紧来吧
Navigating Memory in C++: A Guide to Using std::uintptr_t for Address Handling
为什么用它,用int32 int64之类的类型,reinterpret cast可能会有fpermissive报错,比如
#include <cstdint>
namespace HAL {
class UART {
public:
explicit UART(std::uint32_t base_address);
void write(std::byte byte);
std::byte read() const;
// ...
private:
struct Registers* const registers;
};
}
constexpr std::uint32_t com1_based_address = 0x4002'0000U;
int main() {
HAL::UART com1{com1_based_address};
com1.write(std::byte{0x5A});
auto val = com1.read();
...
}
namespace {
struct Registers // layout of hardware UART
{
std::uint32_t status; // status register
std::uint32_t data; // data register
std::uint32_t baud_rate; // baud rate register
...
std::uint32_t guard_prescaler; // Guard time and prescaler register
};
static_assert(sizeof(Registers) == 40, "Registers struct has padding");
Registers Mock_registers{};
}
// doctest
TEST_CASE("UART Construction") {
constexpr std::uint32_t baud_115k = 0x8b;
constexpr std::uint32_t b8_np_1stopbit = 0x200c;
HAL::UART com3 {reinterpret_cast<std::uint32_t>(&Mock_registers)}; // 不行
CHECK(Mock_registers.baud_rate == baud_115k);
CHECK(Mock_registers.ctrl_1 == b8_np_1stopbit);
}但如果把UART构造函数改成intptr就没问题
#include <cstdint>
namespace HAL {
class UART {
public:
explicit UART(std::uintptr_t base_addr);
...
};
}
// doctest
TEST_CASE("UART Construction") {
constexpr std::uint32_t baud_115k = 0x8b;
constexpr std::uint32_t b8_np_1stopbit = 0x200c;
HAL::UART com3 {reinterpret_cast<std::uintptr_t>(&Mock_registers)};
CHECK(Mock_registers.baud_rate == baud_115k);
CHECK(Mock_registers.ctrl_1 == b8_np_1stopbit);
}为什么不用intptr? 如果涉及到负数移动,或者做差有负数之类的,可以用intptr,其他场景还是uintptr更合适
Introduction To Low Latency Programming: Minimize Branching And Jumping
哥们出书了,120页卖10刀有点贵我靠,书在这里 https://a.co/d/0U6KOfb
这个文章是节选,大概思路就是降低跳转和分支
- 勤用 && || 利用短路特性
- 关注能生成cmov的写法,condition mov几乎和mov差不多,利用cmov替代jump test更好,什么能生成cmov? 冒号表达式
- 减少虚函数使用,你用variant模拟那也是虚函数,不要自欺欺人哈
- inline,可以用
[[gnu::always_inline]] - 善用 __builtin_expect
- 分支改switch
一个样例
void processThisString(std::string_view input)
{
if (input == "production") {
processProd(input);
} else if (input == "RC") {
processRC(input);
} else if (input == "beta")
processBeta(input);
}
}
void processThisString(std::string_view input)
{
constexpr auto i = 0;
switch (input[i]) {
case "production"[i]: processProd(input); break;
case "RC"[i]: processRC(input); break;
case "beta"[i]: processBeta(input); break;
}
}1 << n vs. 1U << n and a cell phone autofocus problem
#include <stdio.h>
static unsigned long set_bit_a(int bit) {
return 1 << bit;
}
static unsigned long set_bit_b(int bit) {
return 1U << bit;
}
int main() {
printf("sizeof(unsigned long) here: %zd\n", sizeof(unsigned long));
for (int i = 0; i < 32; ++i) {
printf("1 << %d : 0x%lx | 0x%lx\n", i, set_bit_a(i), set_bit_b(i));
}
return 0;
}64位机器 31会打印什么?https://gcc.godbolt.org/z/qa3o34hrW
非常幽默
1 << 0 : 0x1 | 0x1
1 << 1 : 0x2 | 0x2
1 << 2 : 0x4 | 0x4
1 << 3 : 0x8 | 0x8
1 << 4 : 0x10 | 0x10
1 << 5 : 0x20 | 0x20
...
1 << 29 : 0x20000000 | 0x20000000
1 << 30 : 0x40000000 | 0x40000000
1 << 31 : 0xffffffff80000000 | 0x80000000m32并没有这个问题
自底向上理解memory_order
理解理解
Using std::expected from C++23
不会的拖出去
#include <charconv>
#include <expected>
#include <string>
#include <system_error>
#include <iostream>
std::expected<int, std::string> convertToInt(const std::string& input) {
int value{};
auto [ptr, ec] = std::from_chars(input.data(), input.data() + input.size(), value);
if (ec == std::errc())
return value;
if (ec == std::errc::invalid_argument)
return std::unexpected("Invalid number format");
else if (ec == std::errc::result_out_of_range)
return std::unexpected("Number out of range");
return std::unexpected("Unknown conversion error");
}
int main() {
std::string userInput = "111111111111111";
auto result = convertToInt(userInput);
if (result)
std::cout << "Converted number: " << *result << '\n';
else
std::cout << "Error: " << result.error() << '\n';
}
c23有一种模拟的方法
#include <stdio.h>
struct { bool success; int value; } parse(const char* s) {
if (s == NULL)
return (typeof(parse(0))) { false, 1};
return (typeof(parse(0))) { true, 1 };
};
int main() {
auto r = parse("1");
if (r.success) {
printf("%d", r.value);
}
}不建议使用
LLVM 中的一致性分析框架详解 之 发散源和指令一致性判断
学点llvm
A story of a very large loop with a long instruction dependency chain
简单来说就是拆循环 loop fission + 降低数据buffur大小,小于l1 cacheline,提升性能
需要复现一下
如何发现是内存子系统的问题(buffer大于cacheline)? 使用likwid 查的。这个实验需要复现一下看看
When an instruction depends on the previous instruction depends on the previous instructions… : long instruction dependency chains and performance
简单来说就是通过 interleave 拆分任务,来加速,这个和loop fission还不太一样,loop fission就是单纯的拆循环,interleave又不同任务分发调度的感觉
Atomics And Concurrency
这个比较基础和cpprefence差不多
The Auto macro
#pragma once
template<class L>
class AtScopeExit {
L& m_lambda;
public:
AtScopeExit(L& action) : m_lambda(action) {}
~AtScopeExit() noexcept(false) { m_lambda(); }
};
#define TOKEN_PASTEx(x, y) x ## y
#define TOKEN_PASTE(x, y) TOKEN_PASTEx(x, y)
#define Auto_INTERNAL1(lname, aname, ...) ...C++ 中文周刊 2024-02-17 第149期
欢迎投稿,推荐或自荐文章/软件/资源等
请提交 issue 或评论区留言
本期文章由 不语 黄亮Anthony Tudou kenshin 赞助
勉强算半期吧,返程没时间了,简单更新一下
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-02-14 第241期
其实重点比较明朗,就execution reflect graph这些,剩下的基本都是修正
fiber_context也好久了
文章
Clang 出了 Bug 怎么办?来一起修编译器吧!
看一遍基本就把clang llvm这套东西串起来了。都学一下吧,llvm战未来朋友们
C++20的constexpr string为什么无法工作
感受抽象的gcc sso优化实现
另外clang本来是没做constexpr sso优化的,最近又给加上了
微信群里也讨论了,咨询了maskray老师意见,可能就是为了对齐libstdcxx的行为
我和这个想法相同,你都constexpr了,还sso干啥
C++ 中 constexpr 的发展史!
感觉有点不认识const了
Velox: Meta’s Unified Execution Engine
还挺有意思的
too dangerous for c++
对比rust c++的shared_ptr没有太限制生命周期,可能会用错,c++还是太自由了
On the virtues of the trailing comma
就是这种行尾的逗号,对于git merge也友好
// C, C++
Thing a[] = {
{ 1, 2 },
{ 3, 4 },
{ 5, 6 },
// ^ trailing comma
};
// C#
Thing[] a = new[] {
new Thing {
Name = "Bob",
Id = 31415,
// ^ trailing comma
},
new Thing {
Name = "Alice",
Id = 2718,
// ^ trailing comma
},
// ^ trailing comma
};
Dictionary d = new Dictionary<string, Thing>() {
["Bob"] = new Thing("Bob") { Id = 31415 },
["Alice"] = new Thing("Alice", 2718),
// ^ trailing comma
};
感觉这是个不成文规定实现
Formatting User-Defined Types in C++20
简单实现
#include <format>
#include <iostream>
class SingleValue {
public:
SingleValue() = default;
explicit SingleValue(int s): singleValue{s} {}
int getValue() const {
return singleValue;
}
private:
int singleValue{};
};
template<>
struct std::formatter<SingleValue> : std::formatter<int> { // (1)
auto format(const SingleValue& singleValue, std::format_context& context) const {
return std::formatter<int>::format(singleValue.getValue(), context);
}
};
int main() {
SingleValue singleValue0;
SingleValue singleValue2020{2020};
SingleValue singleValue2023{2023};
std::cout << std::format("{:*<10}", singleValue0) << '\n';
std::cout << std::format("{:*^10}", singleValue2020) << '\n';
std::cout << std::format("{:*>10}", singleValue2023) << '\n';
}Visual overview of a custom malloc() implementation
典型内存池实现介绍
Vectorizing Unicode conversions on real RISC-V hardware
哥们看不懂rsicv 不太懂
C++20 Concepts Applied – Safe Bitmasks Using Scoped Enums
直接贴代码吧
template<typename T>
constexpr std::
enable_if_t<
std::conjunction_v<std::is_enum<T>,
// look for enable_bitmask_operator_or
// to enable this operator ①
std::is_same<bool,
decltype(enable_bitmask_operator_or(
std::declval<T>()))>>,
T>
operator|(const T lhs, const T rhs) {
using underlying = std::underlying_type_t<T>;
return static_cast<T>(
static_cast<underlying>(lhs) |
static_cast<underlying>(rhs));
}
namespace Filesystem {
enum class Permission : uint8_t {
Read = 1,
Write,
Execute,
};
// Opt-in for operator| ②
constexpr bool
enable_bitmask_operator_or(Permission);
} // namespace Filesystem这个玩法就是针对部分提供enable_bitmask_operator_or 的enum class 提供 operator |
现在是2024了,有没有新的玩法
concept
template<typename T>
requires(std::is_enum_v<T>and requires(T e) {
// look for enable_bitmask_operator_or to
// enable this operator ①
enable_bitmask_operator_or(e);
}) constexpr auto
operator|(const T lhs, const T rhs) {
using underlying = std::underlying_type_t<T>;
return static_cast<T>(
static_cast<underlying>(lhs) |
static_cast<underlying>(rhs));
}
namespace Filesystem {
enum class Permission : uint8_t {
Read = 0x01,
Write = 0x02,
Execute = 0x04,
};
// Opt-in for operator| ②
consteval
void enable_bitmask_operator_or(Permission);
} // namespace Filesystem
c++23 有to_underlying了
template<typename T>
requires(std::is_enum_v<T>and requires(T e) {
enable_bitmask_operator_or(e);
}) constexpr auto
operator|(const T lhs, const T rhs)
{
return static_cast<T>(std::to_underlying(lhs) |
std::to_underlying(rhs));
}简洁一丢丢
开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- graphiz 一个图遍历演示库,挺好玩的
- mantis P2M: A Fast Solver for Querying Distance from Point to Mesh Surface 的实现
C++ 中文周刊 2024-02-09 第148期
qq群 点击进入
欢迎投稿,推荐或自荐文章/软件/资源等
请提交 issue 或评论区留言
本期文章由 黄亮Anthony HNY 不语 赞助
祝大家新年快乐
资讯
把from_chars搬到c++11,我建议放弃c++11 ,2024了bro 文档
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-01-31 第239期
What’s New in vcpkg January 2024
另外有个重写loki的活动哈,有点幽默,感兴趣可以点击直达
(重写loki不是已经做了吗,folly啊)
brpc发布1.8版本 release note
文章
使用 hugetlb 提升性能
redis 为啥不用?避免影响rdb生成?
另外这有个 hugetop命令
代码这里 https://gitlab.com/procps-ng/procps
C++异常的误用以及改进
群友翻译,非常干货,值得看看
不过异常设计的还是太傻呗了
[RFC] Upstreaming ClangIR https://discourse.llvm.org/t/rfc-upstreaming-clangir/76587/19
之前聊到的MLIR 在c/c++上的落地 CIR准备合入到LLVM
感觉clang明显更激进一些,而gcc还是一群老登
Option Soup: the subtle pitfalls of combining compiler flags https://hacks.mozilla.org/2024/01/option-soup-the-subtle-pitfalls-of-combining-compiler-flags/
傻逼locale问题,虽然你是静态连接libstdcxx-static,但是locale并不static
errno and libc https://dxuuu.xyz/errno.html
errno是内核设置还是libc设置?当然是libc
怎么验证? 简单来说就是同一个系统调用,调用syscall/通过汇编调用,观察errno变化
static int use_wrapper(int cmd, union bpf_attr *attr, unsigned int size) {
long ret;
errno = 0;
ret = syscall(__NR_bpf, cmd, attr, size);
if (ret < 0)
printf("wrapped syscall failed, ret=%d, errno=%d\n", ret, errno);
else
printf("wrapped syscall succeeded\n");
}asm
static int use_raw(int cmd, union bpf_attr *attr, unsigned int size) {
long ret;
errno = 0;
__asm__(
"movq %1, %%rax\n" /* syscall number */
"movq %2, %%rdi\n" /* arg1 */
"movq %3, %%rsi\n" /* arg2 */
"movq %4, %%rdx\n" /* arg3 */
"syscall\n"
"movq %%rax, %0\n"
/* retval */
: "=r"(ret)
/* input operands */
: "r"((long)__NR_bpf), "r"((long)cmd), "r"((long)attr), "r"((long)size)
/* clobbers */
: "rax", "rdi", "rsi", "rdx"
);
/* Check return value */
if (ret < 0)
printf("raw syscall failed, ret=%d, errno=%d\n", ret, errno);
else
printf("raw syscall succeeded\n");
}gcc 7.3 bug一例 class template argument deduction fails in new-expression
template <typename T1, typename T2>
struct Bar {
Bar(T1, T2) { }
};
int main() {
auto x = Bar(1, 2);
auto y = new Bar(3, 4);
auto z = new Bar{3, 4};
}低版本的gcc (现在低版本gcc指的是7/8了)用大括号绕过即可,为什么列这个呢,因为我遇到了
Unexpected Ways Memory Subsystem Interacts with Branch Prediction
int binary_search(int* array, int number_of_elements, int key) {
int low = 0, high = number_of_elements-1, mid;
while(low <= high) {
mid = (low + high)/2;
if (st == search_type::REGULAR) {
if(array[mid] < key)
low = mid + 1;
else if(array[mid] == key)
return mid;
else
high = mid-1;
}
if (st == search_type::CONDITIONAL_MOVE) {
int middle = array[mid];
if (middle == key) {
return mid;
}
int new_low = mid + 1;
int new_high = mid - 1;
__asm__ (
"cmp %[array_middle], %[key];"
"cmovae %[new_low], %[low];"
"cmovb %[new_high], %[high];"
: [low] "+&r"(low), [high] "+&r"(high)
: [new_low] "g"(new_low), [new_high] "g"(new_high), [array_middle] "g"(middle), [key] "g"(key)
: "cc"
);
}
if (st == search_type::ARITHMETIC) {
int middle = array[mid];
if (middle == key) {
return mid;
}
int new_low = mid + 1;
int new_high = mid - 1;
int condition = array[mid] < key;
int condition_true_mask = -condition;
int condition_false_mask = -(1 - condition);
low += condition_true_mask & (new_low - low);
high += condition_false_mask & (new_high - high);
}
}
return -1;
}| Array Size (in elements) | Original | Conditional Moves | Arithmetics |
|---|---|---|---|
| 4 K | Runtime: 0.22 sInstr: 434 M CPI: 1.96Mem. Data Volume: 0.45 GB | Runtime: 0.14 sInstr: 785 MCPI: 0.728Mem. Data Volume: 0.25 GB | Runtime: 0.19 sInstr: 1.102 MCPI: 0.69Mem. Data Volume: 0.32 GB |
| 16 K | Runtime: 0.26 sInstr: 511 MCPI: 2.01Mem. Data Volume: 0.49 GB | Runtime: 0.19 sInstr: 928 MCPI: 0.77Mem. Data Volume: 0.39 GB | Runtime: 0.24 sInstr: 1.308 MCPI: 0.72Mem. Data Volume: 0.46 GB |
| 64 K | Runtime: 0.32 sInstr: 584 MCPI: 2.143Mem. Data Volume: 0.48 GB | Runtime: 0.24 sInstr: 1.064 MCPI: 0.90Mem. Data Volume: 0.25 GB | Runtime: 0.31Instr: 1.504CPI: 0.82Mem. Data Volume: 0.26 GB |
| 256 K | Runtime: 0.43 sInstr: 646 MCPI: 2.59Mem. Data Volume: 0.36 GB | Runtime: 0.39 sInstr: 1.199 MCPI: 1.28Mem. Data Volume: 0.32 GB | Runtime: 0.47 sInstr: 1.698 MCPI: 1.09Mem. Data Volume: 0.36 GB |
| 1 M | Runtime: 0.56 sInstr: 727 MCPI: 3.05Mem. Data Volume: 0.67 GB | Runtime: 0.59 sInstr: 1.333 MCPI: 1.72Mem. Data Volume: 0.59 GB | Runtime: 0.70 sInstr: 1.891 MCPI: 1.42Mem. Data Volume: 0.68 GB |
| 4 M | Runtime: 1.127 sInstr: 798 MCPI: 4.65Mem. Data Volume: 9.94 GB | Runtime: 1.48 sInstr: 1.467 MCPI: 3.1Mem. Data Volume: 3.75 GB | Runtime: 1.59 sInstr: 2.084 MCPI: 2.45Mem. Data Volume: 3.9 GB |
| 16 M | Runtime: 1.65 sInstr: 870 MCPI: 6.26Mem. Data Volume: 18.48 GB | Runtime: 2.75 sInstr: 1.601CPI: 4.16Mem. Data Volume: 6.95 GB | Runtime: 2.90 sInstr: 2.277 MCPI: 3.18Mem. Data Volume: 7.05 GB |
课外阅读
快排代码
static int partition(std::vector<float>& vector, int low, int high) {
float pivot = vector[high];
int i = (low - 1);
for (int j = low; j < high; j++) {
if (vector[j] <= pivot) {
i++;
std::swap(vector[i], vector[j]);
}
}
i = i + 1;
std::swap(vector[i], vector[high]);
return i;
} static int partition(std::vector<float>& vector, int low, int high) {
float* vector_i = &vector[low];
float* vector_j = &vector[low];
float* vector_end = &vector[high];
__m128 pivot = _mm_load_ss(&vector[0] + high);
while(true) {
if (vector_j >= vector_end) break;
__m128 vec_i = _mm_load_ss(vector_i);
__m128 vec_j = _mm_load_ss(vector_j);
__m128 compare = _mm_cmplt_ss(vec_j, pivot); // if (vec_j < pivot)
__m128 new_vec_i = _mm_blendv_ps(vec_i, vec_j, compare);
__m128 new_vec_j = _mm_blendv_ps(vec_j, vec_i, compare);
int increment = _mm_extract_epi32(_mm_castps_si128(compare), 0) & 0x1;
_mm_store_ss(vector_i, new_vec_i);
_mm_store_ss(vector_j, new_vec_j);
vector_i += increment;
vector_j++;
}
std::swap(*vector_i, *vector_end);
return (vector_i - &vector[0]);
}
代码在这里 https://github.com/ibogosavljevic/johnysswlab/blob/master/2022-01-sort/
感觉值得展开讲讲。我找作者要了授权,后面还会继续介绍这个。本地也复现一下
constexpr number parsing
有句讲句 from_chars接口有点难用
auto res = std::from_chars(str.data() + start, str.data() + str.size(), result);
if (res.ec == std::errc{}) {...}可以用结构化绑定,更好看一点
c++26可以直接这么用
auto res = std::from_chars(str.data() + start, str.data() + str.size(), result);
if (res) { ... }converting string_view to time point
std::chrono::sys_seconds convertToTimePoint(std::string_view fmtstring)
{
std::chrono::sys_seconds syssec;
std::istringstream in{std::string{raw_data}};//raw_data is a string_view
in >> std::chrono::parse(fmtstring, syssec);
return syssec;
}没有std::chrono::parse?
std::chrono::sys_seconds convertToTimePoint(std::string_view fmtstring)
{
std::chrono::sys_seconds syssec;
std::istringstream in{std::string{raw_data}};//raw_data is a string_view
std::tm tm = {};
in >> std::get_time(&tm, fmtstring.data());
std::time_t time = std::mktime(&tm);
if(in.good())
syssec = std::chrono::time_point_cast< std::c...C++ 中文周刊 2024-01-26 第147期
qq群 点击进入
欢迎投稿,推荐或自荐文章/软件/资源等
本期文章由 不语 沧海 彩虹蛇皮虾 赞助
jetbrain发布了23年 c++ 生态回顾 https://blog.jetbrains.com/clion/2024/01/the-cpp-ecosystem-in-2023/
感兴趣的可以看看,没啥意思
资讯
标准委员会动态/ide/编译器信息放在这里
一月邮件
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2024/#mailing2024-01
文章
全新的构造函数,C++ 中的 relocate 构造函数
其实这个概念之前讨论了很久,老熟人Arthur O’Dwyer 提了很多相关的提案 patch。大家感兴趣的可以读一下。算是一个优化的点
之前也提到过,比如
讲trivial relocation的现状以及开源实现
| T.r. types | Non-t.r. types | Throwing-move types | Rightward motion (`insert`) | Leftward motion (`erase`) | Non-pointer iterators | ||
| STL Classic (non-relocating) | std::copy | N/A | N/A | ✓ | UB | ✓ | ✓ |
std::copy_n | N/A | N/A | ✓ | UB | UB | ✓ | |
std::copy_backward | N/A | N/A | ✓ | ✓ | UB | ✓ | |
| cstring | memcpy | ✓ | UB | ✓ | UB | UB | SFINAE |
memmove | ✓ | UB | ✓ | ✓ | ✓ | SFINAE | |
| Qt | q_uninitialized_relocate_n | ✓ | ✓ | ✓? | UB | UB | SFINAE |
q_relocate_overlap_n | ✓ | ✓ | ✓ | ✓ | ✓ | SFINAE | |
| BSL | destructiveMove | ✓ | ✓ | ✓ | UB | UB | SFINAE |
| P2786R0 | trivially_relocate | ✓ | SFINAE | SFINAE | ✓ | ✓ | SFINAE |
relocate | ✓ | ✓ | SFINAE | ✓ | ✓ | SFINAE | |
move_and_destroy | ✓ | ✓ | SFINAE | UB | ? | ✓ | |
| P1144R6 | uninitialized_relocate | ✓ | ✓ | ✓ | UB | ✓ | ✓ |
uninitialized_relocate_n | ✓ | ✓ | ✓ | UB | ✓ | ✓ | |
| P1144R7 | uninitialized_relocate_backward | ✓ | ✓ | ✓ | ✓ | UB | ✓ |
等等,周边信息很多
why gcc and clang sometimes emit an extra mov instruction for std::clamp on x86
直接贴代码 https://godbolt.org/z/rq9dsGxh5
#include <algorithm>
double incorrect_clamp(double v, double lo, double hi){
return std::min(hi, std::max(lo, v));
}
double official_clamp(double v, double lo, double hi){
return std::clamp(v, lo, hi);
}
double official_clamp_reordered(double hi, double lo, double v){
return std::clamp(v, lo, hi);
}
double correct_clamp(double v, double lo, double hi){
return std::max(std::min(v, hi), lo);
}
double correct_clamp_reordered(double lo, double hi, double v){
return std::max(std::min(v, hi), lo);
}对应的汇编
incorrect_clamp(double, double, double):
maxsd xmm0, xmm1
minsd xmm0, xmm2
ret
official_clamp(double, double, double):
maxsd xmm1, xmm0
minsd xmm2, xmm1
movapd xmm0, xmm2
ret
official_clamp_reordered(double, double, double):
maxsd xmm1, xmm2
minsd xmm0, xmm1
ret
correct_clamp(double, double, double):
minsd xmm2, xmm0
maxsd xmm1, xmm2
movapd xmm0, xmm1
ret
correct_clamp_reordered(double, double, double):
minsd xmm1, xmm2
maxsd xmm0, xmm1
ret为什么正确的代码多了一条 mov xmm?
浮点数 +-0的问题,标准要求返回第一个参数,比如 std::clamp(-0.0f, +0.0f, +0.0f)
如果配置了-ffinite-math-only -fno-signed-zeros 最终汇编是一样的 https://godbolt.org/z/esMY18a5z
Fuzzing an API with libfuzzer
举一个fuzz例子,大家都学一下
你看这个接口感觉可能无从下手
extern "C"
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size)我们要测试的接口长这样
template <typename T, size_t Capacity>
requires (std::is_nothrow_move_constructible_v<T> && std::is_nothrow_move_assignable_v<T>)
class fixed_stack
{
public:
T& push(T t) {
if (size() == capacity()) throw size_error("push on full stack");
return data_[++size_] = std::move(t);
}
T& back() {
if (empty()) throw size_error("back on empty stack");
return data_[size_];
}
T pop() {
if (empty()) throw size_error("pop on empty stack");
return std::move(data_[size_--]);
}
[[nodiscard]] bool empty() const { return size() == 0; }
[[nodiscard]] size_t size() const { return size_; }
[[nodiscard]] static size_t capacity() { return Capacity; }
private:
size_t size_ = 0;
std::array<T, Capacity> data_{};
};考虑一下测试代码
可能长这样
truct failure : std::string {
using std::string::string;
};
#define REQUIRE(...) if (__VA_ARGS__) {;} else throw failure #(__VA_ARGS__)
#define FAIL(...) throw failure(__VA_ARGS__)
int main() {
unsigned fail_count = 0;
struct test {
const char* name;
std::function<void()> f;
};
test tests[] {
{ "default constructed stack is empty",
[]{
fixed_stack<int, 8> s;
REQUIRE(s.size() == 0);
REQUIRE(s.empty());
}},
{ "Each push grows size by one",
[] {
fixed_stack<int, 8> s;
s.push(3);
REQUIRE(s.size() == 1);
s.push(2);
REQUIRE(s.size() == 2);
s.push(8);
REQUIRE(s.size() == 3);
}
},
{ "Pop returns the pushed elements in reverse order",
[]{
fixed_stack<int, 8> s;
s.push(3);
s.push(2);
s.push(8);
REQUIRE(s.pop() == 8);
REQUIRE(s.pop() == 2);
REQUIRE(s.pop() == 3);
}
},
{ "pop on empty throws",
[]{
fixed_stack<int, 8> s;
s.push(3);
s.pop();
try {
s.pop();
FAIL("didn't throw");
}
catch (const size_error&)
{
// good!
}
}}
};
for (auto& t : tests){
try {
std::cout << std::setw(60) << std::left << t.name << "\t";
t.f();
std::cout << "PASS!";
} catch (const failure& f) {
std::cout << "FAILED!\nError: " << f << '\n';
++fail_count;
} catch (...) {
std::cout << "FAILED!\nUnknown reason!";
++fail_count;
}
std::cout << '\n';
}
}现在咱们考虑怎么把这个测试代码改写成fuzz test?
简单来说输入的就是一段二进制,怎么根据这个二进制拆解出不同的动作,拆解出不同的输入?
struct exhausted {};
struct source {
std::span<const uint8_t> input;
template <typename T>
requires (std::is_trivial_v<T>)
T get() {
constexpr auto data_size = sizeof(T);
if (input.size() < data_size) throw exhausted{};
alignas (T) uint8_t buff[data_size];
std::copy_n(input.begin(), data_size, buff);
input = input.subspan(data_size);
return std::bit_cast<T>(buff);
}
};
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
source s{{data, size}};
std::vector<int> comparison;
std::optional<fixed_stack<std::unique_ptr<int>, 8>> stack;
try {
for (;;) {
if (!stack.has_value()) {
stack.emplace();
}
// 通过source 拿一个u8来枚举动作
const auto action = s.get<uint8_t>();
switch (action) {
case 0: // push
{
// 通过source拿到需要的输入数据
const int v = s.get<int>();
const auto size = stack->size();
try {
stack->push(std::make_unique<int>(v));
comparison.push_back(v);
assert(stack->size() == comparison.size());
assert(stack->b...C++ 中文周刊 第141期
qq群 手机qq点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
最近在找工作准备面试题,更新可能有些拖沓,见谅
本周内容比较少
本期文章由 黄亮Anthony HNY 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
clion新增AI助手 https://www.jetbrains.com/clion/whatsnew/
编译器信息最新动态推荐关注hellogcc公众号 OSDT Weekly 2023-12-06 第231期
文章
感兴趣的可以看一下。很短
抽出相同的二进制,节省二进制大小。和inline逻辑相反
可能会有性能衰退
原理?如何找出重复的二进制序列?后缀树爆搜
也可以从不同角度来做,比如IR层
具体很细节。感兴趣的可以看看
借助outline做冷热分离,有性能提升,还挺有意思的,算是PGO一部分吧,拿到profile来分析
stream就是垃圾 strstream没人用。有spanstream代替
lemire博士新活
常规
int parse_uint8_naive(const char *str, size_t len, uint8_t *num) {
uint32_t n = 0;
for (size_t i = 0, r = len & 0x3; i < r; i++) {
uint8_t d = (uint8_t)(str[i] - '0');
if (d > 9)
return 0;
n = n * 10 + d;
}
*num = (uint8_t)n;
return n < 256 && len && len < 4;
}
当然c++可以用from chars加速
int parse_uint8_fromchars(const char *str, size_t len, uint8_t *num) {
auto [p, ec] = std::from_chars(str, str + len, *num);
return (ec == std::errc());
}能不能更快?这是u8场景,考虑SWAR,组成一个int来处理
int parse_uint8_fastswar(const char *str, size_t len,
uint8_t *num) {
if(len == 0 || len > 3) { return 0; }
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x30303030lu;
digits.as_int <<= ((4 - len) * 8);
uint32_t all_digits =
((digits.as_int | (0x06060606 + digits.as_int)) & 0xF0F0F0F0)
== 0;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 24);
return all_digits
& ((__builtin_bswap32(digits.as_int) <= 0x020505));
}评论区bob给了个更快的
int parse_uint8_fastswar_bob(const char *str, size_t len, uint8_t *num) {
union { uint8_t as_str[4]; uint32_t as_int; } digits;
memcpy(&digits.as_int, str, sizeof(digits));
digits.as_int ^= 0x303030lu;
digits.as_int <<= (len ^ 3) * 8;
*num = (uint8_t)((0x640a01 * digits.as_int) >> 16);
return ((((digits.as_int + 0x767676) | digits.as_int) & 0x808080) == 0)
&& ((len ^ 3) < 3)
&& __builtin_bswap32(digits.as_int) <= 0x020505ff;
}感兴趣可以玩一玩
场景 完美hash,4bytes字符串做key,如何快速算hash?
直接把字符串当成int来算
#define SIZE 512
uint8_t lut[SIZE] = {};
// multiply, shift, mask
uint32_t simple_hash(uint32_t u) {
uint64_t h = (uint64_t) u * 0x43ff9fb13510940a;
h = (h >> 32) % SIZE;
return (uint32_t) h;
}
// generate, cast and hash
void build_lut() {
char strings[256*4];
memset(strings, 0, sizeof(strings));
char *iter = strings;
for (int i = 0; i < 256; ++i) {
sprintf(iter, "%d", i);
iter += 4;
}
iter = strings;
for (int i = 0; i < 256; ++i) {
unsigned c = *(unsigned*) iter;
iter += 4;
unsigned idx = simple_hash(c);
lut[idx] = i;
}
}视频
cppcon2023 工作日开始更新视频了,这周好玩的列一下
- A Long Journey of Changing std::sort Implementation at Scale - Danila Kutenin - CppCon 2023 https://www.youtube.com/watch?v=cMRyQkrjEeI
这个作者danlark在llvm比较活跃
这个视频非常值得一看,列举了sort的改进优化,各个系统的差异,以及nth_element的副作用问题
很多库写的median算法实际是错的!
https://godbolt.org/z/9xWoYTfMP
int median(std::vector<int>& v) {
int mid = v.size() / 2;
std::nth_element(v.begin(), v.begin() + mid, v.end());
int result = v[mid];
if (v.size() % 2 == 0) {
std::nth_element(v.begin(), v.begin() + mid - 1, v.end());
result = (v[mid] + v[mid-1])/2;
// result = (result + v[mid-1]) /2;
}
return result;
}
由于nth_element不保证整体有序,只保证n的位置是对的,所以第二次的计算可能改变第一次的结果
然而社区很多median实现都是错的
- Customization Methods: Connecting User and C++ Library Code - Inbal Levi - CppCon 2023 https://www.youtube.com/watch?v=mdh9GLWXWyY
介绍了一些查找逻辑的设计,从swap到ADL,到CPO tag_invoke 再到最近的讨论,有Custom function设计
还算有意思 。但有句讲句tag_invoke很扭曲,cpo也是
- Variable Monitoring with Declarative Interfaces - Nikolaj Fogh - Meeting C++ 2023 https://www.youtube.com/watch?v=AJDbu1kaj5g
auto myMonitor = Monitor([](int i){ return i > 0; }, [](bool valid){ std::cout << "Valid: " << valid << std::endl; }]);
int variable = 0;
myMonitor(variable); // Prints Valid: 0
variable = 1;
myMonitor(variable); // Prints Valid: 1不过不知道有啥用途。signal handler类似的玩意
比如监控内存,真到了瓶颈,直接在发现的位置条件判断也不是不行
或者类似bvar之类的玩意,把数据导出 回调交给别的组件
不知道什么场景能用上
招聘
字节的音视频团队,主要负责剪映上的音视频/非线性编辑相关工作,业务前景也比较好,目前有三个方向的岗位
- 桌面端音视频研发 https://job.toutiao.com/s/i8enPrw5
- 多端音视频引擎研发 https://job.toutiao.com/s/i8enr7Es
- C++工程基础架构研发 https://job.toutiao.com/s/i8enjTHT
base北上广深杭都可以,薪资open,有兴趣的同学可以通过链接投递
英伟达招llvm实习生
联系方式 vwei@nvidia.com
或微信 aoewqf1997 (请备注“LLVM实习生”
C++ 中文周刊 2024 01 19 第146期
qq群 点击进入
欢迎投稿,推荐或自荐文章/软件/资源等
本期文章由 黄亮Anthony Amnisia HNY CHENL 赞助
上周和朋友们吃饭耽误了,一直没空写
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-01-17 第237期
最近的最大热门就是Linux社区又有人讨论引入c++了,很多c宏实际上做的就是一部份concept工作,引入concept还是很爽的,不过linus有生之年应该不会引入,不过是又一次炒冷饭
祝linus健康
文章
The C++20 Naughty and Nice List for Game Devs
介绍一些对游戏开发比较好的c++20特性
- <=> 不错
coroutine不错std::bit_cast不错 复制转换,避免UB<numbers>不错,有PI可以用了- 新的同步原语
<barrier>,<latch>, and<semaphore> <span>可以- Designated initializers 非常好用,c一直都有,居然没兼容
struct Point {
float x;
float y;
float z;
};
Point origin{.x = 0.f, .y = 0.f, .z = 0.f};char8_t比较脑瘫,众所周知,char8_t是unsigned char,但u8 udl以前是修饰char的,c++20改成修饰char8_t了
破坏u8语义了,msvc可以/Zc:char8_t关掉,gcc也可以关 -fno-char8_t
https://en.cppreference.com/w/cpp/language/string_literal 第五条 六条
(5,6) UTF-8 string literal
const char[N](until C++20)
const char8_t[N](since C++20)
no_unique_address msvc有ABI问题,慎用
Modules没法用
ranges没屌用
format 二进制太大了
source_location 没易用性提升不说,std::source_location::file_name居然返回 const char*
怎么想的我真他妈服了
Why My Print Didn't Output Before a Segmentation Fault
#include <stdio.h>
int main(void)
{
printf("%s", "Hello!");
int *p = NULL;
*p = 5;
// Will not be reached due to crash above
printf("%s", "Another Hello!");
}
//$ gcc -Wall -Wextra -o hello hello.c && ./hello
//Segmentation fault (core dumped)经典buffer IO没刷buffer。怎么改成正常的?加\n 用stderr用fflush
C++ time_point wackiness across platforms
timepoint在mac上有精度损失,代码
#include <stdio.h>
#include <chrono>
int main() {
std::chrono::system_clock::time_point tp =
std::chrono::system_clock::from_time_t(1234567890);
// Okay.
tp += std::chrono::milliseconds(1);
// No problem here so far.
tp += std::chrono::microseconds(1);
// But... this fails on Macs:
// tp += std::chrono::nanoseconds(123);
// So you adapt, and this works everywhere. It slices off some of that
// precision without any hint as to why or when, and it's ugly too!
tp += std::chrono::duration_cast<std::chrono::system_clock::duration>(
std::chrono::nanoseconds(123));
// Something like this swaps the horizontal verbosity for vertical
// stretchiness (and still slices off that precision).
using std::chrono::duration_cast;
using std::chrono::system_clock;
using std::chrono::nanoseconds;
tp += duration_cast<system_clock::duration>(nanoseconds(123));
// This is what you ended up with:
auto tse = tp.time_since_epoch();
printf("%lld\n", (long long) duration_cast<nanoseconds>(tse).count());
// Output meaning when split up:
//
// sec ms us ns
//
// macOS: 1234567890 001 001 000 <-- 000 = loss of precision (246 ns)
//
// Linux: 1234567890 001 001 246 <-- 246 = 123 + 123 (expected)
//
return 0;
}Implementing the missing sign instruction in AVX-512
sign函数很常用, 大概长这样
function sign(a, b): # a and b are integers
if b == 0 : return 0
if b < 0 : return -a
if b > 0 : return a
很容易用sign实现abs
abs(a) = sign(a,a)
进入正题,写一个avx512 sign
#include <x86intrin.h>
__m512i _mm512_sign_epi8(__m512i a, __m512i b) {
__m512i zero = _mm512_setzero_si512();
__mmask64 blt0 = _mm512_movepi8_mask(b);
__mmask64 ble0 = _mm512_cmple_epi8_mask(b, zero);
__m512i a_blt0 = _mm512_mask_mov_epi8(zero, blt0, a);
return _mm512_mask_sub_epi8(a, ble0, zero, a_blt0);;
}如果单独处理0场景,可以这样
#include <x86intrin.h>
__m512i _mm512_sign_epi8_cheated(__m512i a, __m512i b) {
__m512i zero = _mm512_setzero_si512();
__mmask64 blt0 = _mm512_movepi8_mask(b);
return _mm512_mask_sub_epi8(a, blt0, zero, a);;
}
/*
function sign_cheated(a, b): # a and b are integers
if b < 0 : return -a
if b ≥ 0 : return a
*/What the func is that?
c++26咱们有四个function了 std::function std::move_only_function
std::copyable_function std::function_ref
都什么玩意?
std::function_ref好理解,就std::function的引用view版本,那他为啥不叫std::function_view?
另外两个是啥玩意?
回到function上,function的缺点是什么?看代码
struct Functor {
void operator()() { std::cout << "Non-const\n"; }
void operator()() const { std::cout << "Const\n"; }
};
const Functor ftor; // I'm const!
const std::function<void()> f = ftor; // So am I! Const all the way
f(); // Prints "Non-const"
问题就在于function的表现,复制的时候,用的是值,自然用的是non const版本
这是缺陷!如何变成正常的样子?也就是这样
std::function<void()> f = ftor; f(); // prints "Non-const"
const std::function<void()> f = ftor; f(); // prints "Const"为了修复这个const 问题,引入move_only_function 显然只能初始化一次
另外引入copyable_function 告诉大伙,function应该是copyable_function,大家注意语义
raymond chen环节,看不太懂
How do I prevent my C++/WinRT implementation class from participating in COM aggregation?
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 1
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 2
In C++/WinRT, how can I await multiple coroutines and capture the results?, part 3
视频
Taro: Task Graph-Based Asynchronous Programming Using C++ Coroutine – Dian-Lun Lin - CppCon 2023
他这个设计就是taskflow的coroutine版本!说实话我之前想到过这个点子,但人家费心思实现了,我就想想
热门库最近更新了什么
这个环节我会偶尔更新一下某些库最近的动态更新/代码讲解之类的
之前说想要搞但一直偷懒,这里更新一期seastar,下期folly/brpc之类的,也希望大家给点建议
seastar一直是非常积极跟进标准演进的库,代码新特性用的多,也和周边库配合的很好
比如配置fmt支持compile time string
最近的改动,他们给内置的内存池加了PROFILE配置
另外,有几个优化其实很小,比如判断内部peer已经用不到了,只clear但还占用内存,可以主动清掉
diff --git a/include/seastar/core/shared_future.hh b/include/seastar/core/shared_future.hh
index 0e1e31e6..4a2ea71f 100644
--- a/include/seastar/core/shared_future.hh
+++ b/include/seastar/core/shared_future.hh
@@ -168,6 +168,9 @@ class shared_future {
_peers.pop_front();
}
}
+ // _peer is now empty, but let's also make sure it releases any
+ // memory it might hold in reserve.
+ _peers = {};
_keepaliver.release();
}另外就是修复bug 同一个端口,同时listen同时accept场景应该抛异常
互动环节
最近甲流非常严重,周围很多得的进医院的,但一开始按照普通感冒治疗没用,得抗病毒多喝水
希望大家别得
啥也不是,散会!
C++ 中文周刊 第145期
qq群 点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等评论区留言
本期文章由 黄亮Anthony HNY 赞助
2024 01 07
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-01-03 第235期
文章
现代分支预测:从学术界到工业界
看个乐呵, 了解概念对于CPU运行还是有点理解的
LLVM中指令选择的流程是啥样的?
LLVM知识,学吧,都是知识,早晚碰到
【数据结构】Jemalloc中的Radix Tree
解析Jemalloc的关键数据结构
jemalloc最新知识,学吧
Optimizing the unoptimizable: a journey to faster C++ compile times
编译很慢,怎么抓?
#include <fmt/core.h>
int main() {
fmt::print("Hello, {}!\n", "world");
}
// c++ -ftime-trace -c hello.cc -I include -std=c++20ftime-trace的数据可以放到浏览器的tracing里,比如 chrome://tracing/
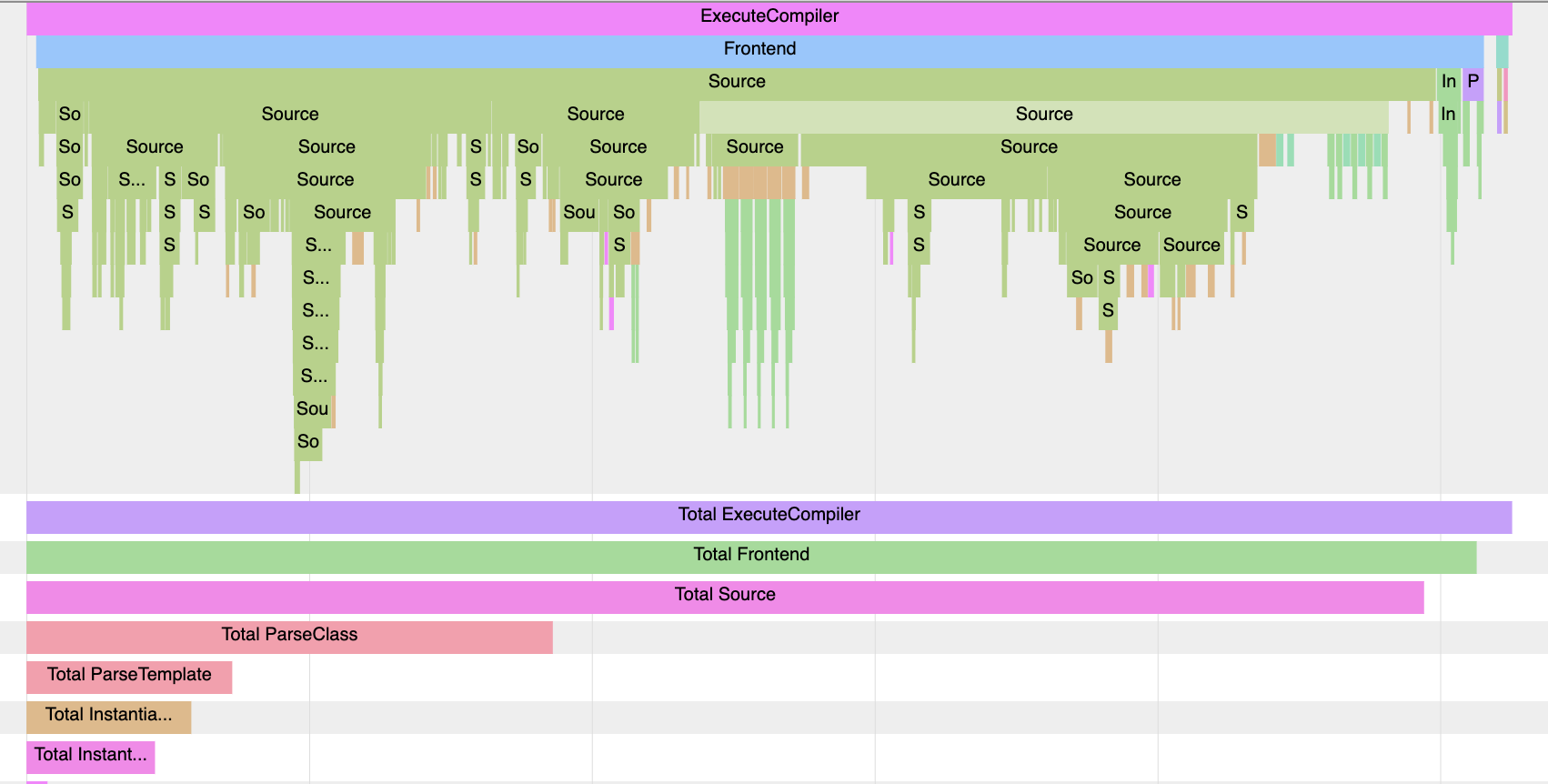
我没看懂他是怎么分析出头文件的耗时的,总之,把string前向声明一下
#ifdef FMT_BEGIN_NAMESPACE_STD
FMT_BEGIN_NAMESPACE_STD
template <typename Char>
struct char_traits;
template <typename T>
class allocator;
template <typename Char, typename Traits, typename Allocator>
class basic_string;
FMT_END_NAMESPACE_STD
#else
# include <string>
#endif但是这种接口编译不过
template <typename... T>
FMT_NODISCARD FMT_INLINE auto format(format_string<T...> fmt, T&&... args)
-> basic_string<char> {
return vformat(fmt, fmt::make_format_args(args...));
}因为basic_string<char>找不到实现,怎么破?
template <typename... T, typename Char = char>
FMT_NODISCARD FMT_INLINE auto format(format_string<T...> fmt, T&&... args)
-> basic_string<Char> {
return vformat(fmt, fmt::make_format_args(args...));
}
然后这个操作就省掉了大量编译时间
Why doesn’t my code compile when I change a shared_ptr(p) to an equivalent make_shared(p)?
结构是这样的
class WidgetContainer : IWidgetCallback
{
//
};
auto widget = std::shared_ptr<Widget>(new Widget(this));能不能换成make_shared?不能,因为是private继承
怎么破?
auto widget = std::make_shared<Widget>(
static_cast<IWidgetCallback*>(this));Did you know about C++26 static reflection proposal (2/N)?
struct foo {
int a{};
int b{};
int c{};
};
static_assert(3 == std::size(std::meta::nonstatic_data_members_of(^foo)));Inside STL: The deque, implementation
deque msvc实现有坑爹的地方
| gcc | clang | msvc | |
|---|---|---|---|
| Block size | as many as fit in 512 bytes but at least 1 element | as many as fit in 4096 bytes but at least 16 elements | power of 2 that fits in 16 bytes but at least 1 element |
| Initial map size | 8 | 2 | 8 |
| Map growth | 2× | 2× | 2× |
| Map shrinkage | On request | On request | On request |
| Initial first/last | Center | Start | Start |
| Members | block** map; size_t map_size; iterator first; iterator last; |
block** map; block** first_block; block** last_block; block** end_block; size_t first; size_t size; |
block** map; size_t map_size; size_t first; size_t size; |
| Map layout | counted array | simple_deque | counted array |
| Valid range | Pair of iterators | Start and count | Start and count |
| Iterator | T* current; T* current_block_begin; T* current_block_end; block** current_block; |
T* current; block** current_block; | deque* parent; size_t index; |
| begin()/end() | Copy first and last. | Break first and first + size into block index and offset. | Break first and first + size into block index and offset. |
| Spare blocks | Aggressively pruned | Keep one on each end | Keep all |
block size太小了
windows相关
- How to allocate address space with a custom alignment or in a custom address region
- How do I prevent my ATL class from participating in COM aggregation? DECLARE_NOT_AGGREGATABLE didn’t work
- The case of the vector with an impossibly large size
视频
What we've been (a)waiting for? - Hana Dusíková - Meeting C++ 2023
介绍协程并写了个co curl 有点意思,视频我也传B站了 https://www.bilibili.com/video/BV1NG411B7Fy/
代码在这里 https://github.sheincorp.cn/hanickadot/co_curl
开源项目更新/新项目介绍
- fmt 10.2更新,支持duration打印 %j 还支持这么玩
#include <fmt/chrono.h>
int main() {
fmt::print("{}\n", std::chrono::days(42)); // prints "42d"
}编译期物理计算的
- nanobind 一个python binding,速度性能都不错,群友kenshin推荐
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- Unilang deepin的一个通用编程语言,点子有点意思,也缺人,感兴趣的可以github讨论区或者deepin论坛看一看。这里也挂着长期推荐了
- gcc-mcf 懂的都懂
工作招聘
https://job.toutiao.com/s/i8Tv36Jf
字节杭州虚拟机v8研发
字节的音视频团队,主要负责剪映上的音视频/非线性编辑相关工作,业务前景也比较好,目前有三个方向的岗位
- 桌面端音视频研发 https://job.toutiao.com/s/i8enPrw5
- 多端音视频引擎研发 https://job.toutiao.com/s/i8enr7Es
- C++工程基础架构研发 https://job.toutiao.com/s/i8enjTHT
base北上广深杭都可以,薪资open,有兴趣的同学可以通过链接投递
互动环节
新的一年开始了,本周刊也走过了三个年头,希望大家都健康我也继续保持更新下去
如果有疑问评论最好在上面链接到评论区里评论,这样方便搜索,微信公众号有点封闭/知乎吞评论