Table of contents
- Cloud-Native Applications
- SOLID Principles
- Domain-driven Design (DDD)
- Resiliency Patterns
- CAP Therom
- Peer to Peer Choregraphy
- Microfrontends
- Chaos Engineering
- GraphQL
- Cache Strategies
Cloud native apps are designed and built to exploit scale, elasticity, resiliency, and flexibility provided by public, private, and hybrid clouds.
- Usually designed as self contained services or microservices, packed as containers for portability, deployed to immutable infrastructure.
- Microservices are the core of cloud native application architecture
- Cloud native microservices communicate with each other via APIs and use event-driven architecture, which makes them loosely coupled, serves to enhance the overall performance of each application.
- Adheres to 12-factor principles
12 Factor App is set of principles for building the scalable and performant, independent, and most resilient cloud native applications.
- Codebase (One codebase tracked in revision control, many deploys)
- Dependencies (Explicitly declare and isolate the dependencies)
- Config (Store configurations in an environment)
- Backing Services (treat backing resources as attached resources)
- Build, release, and Run (Strictly separate build and run stages)
- Processes (execute the app as one or more stateless processes)
- Port Binding (Export services via port binding)
- Concurrency (Scale out via the process model)
- Disposability (maximize the robustness with fast startup and graceful shutdown)
- Dev/prod parity (Keep development, staging, and production as similar as possible)
- Logs (Treat logs as event streams)
- Admin processes (Run admin/management tasks as one-off processes)
Domain-Driven Design (DDD) is about mapping 'business domain' concepts into software artifacts.
- It emphasizes on rich domain model over anemic domain model
- The domain concepts & logic is modeled as Entities, Value Objects, and Aggregates with clear boundaries.
- In anemic domain models, entities are represented by classes with data and connections to other entities. Business logic is absent in these classes and logic is usually placed in managers, services, utilities, helpers, etc.
- Traditonal anemic domain models, leads to a fat Service Layer where facade classes accumulate more business logic with time and domain objects become mere data carriers with getters and setters. Since proper responsibility boundaries are not defined, domain-specific business logic and responsibilities may leak into other components.
- DDD architecture promotes a rich model and thin services.
- Bounded contexts are a pattern in DDD that represent partitions in the domain model. Similar to subdomains, which are partitions in the domain, bounded contexts are partitions in the domain model.
- Bounded contexts are defined with explicit boundaries and the relationships
- In DDD, each aggregate requires one repository. This means we have fewer repositories in DDD than the number of DAOs required to load and persist entities in an application with an anemic model.
- In DDD, since the Order aggregate must contain all the business operations that can be performed on it, we need to move the logic to change the order status and to add an item, from the Service Layer to the Domain Layer
DDD Architecture Layers
- Domain Layer contains entities & value objects along with repository interface. All the business logic will live in this layer.
- UI Layer will contain the controller.
- Application Layer will contain the services. There is now a separate service for each operation that is performed on a specific area of the domain.
- Infrastructure Layer will contain the implementation of the interfaces defined in the domain, as well as classes that provide this implementation. Any operations that require our application to communicate with the outside world should be implemented in this layer too.
- S – Single Responsibility Principle
- O – Open-Closed Principle
- L – Liskov Substitution Principle
- I – Interface Segregation Principle
- D – Dependency Inversion Principle
Design Pattern - is like a cure against some disease. And Disease - is violation of S.O.L.I.D.
SOLID priciples implementation using Python
Single Responsibility Principle states that,
- A class should have only one primary responsibility and should not take other responsibilities.
- A class should have only one reason to change.
Open-Closed Principle states that,
-
Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification.
-
Following this principle ensures that a class is well defined to do what it is supposed to do. Adding any further features can be done by creating new entities that extend the existing class’s features and add more features to itself.
-
Strategy pattern is a good way to implementing Open-close is a principle, There are other patterns that help achieve OCP, like Abstract Factory. You can achieve OCP in a class by externalizing some of its responsibilities to a Strategy and writing new Strategies instead of modifying the class itself, but it is not the only way of respecting OCP.
-
Collections.sort works on any collection of objects that implement the Comparable interface, it is not limited to sorting just integers or just strings — it is not limited to any specific type. The sorting algorithm will work as it was designed, so we can say that it is closed to modification, but the sorting criteria will vary depending on the compareTo method implementation
-
Liskov Substitution Principle states that,
- Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.
Interface Segregation Principle states that,
- No client should be forced to depend on methods it does not use.
Dependency Inversion Principle states that,
- High level module should not depend on low level modules. Both should depend on abstractions
- Abstractions should not depend on details. Details should depend on abstractions.
Dependency Inversion Principle By Example
Other principles,
- Prefer composition to inheritance
- Encapsulate changes
- Do high cohesion and low coupling etc
CQRS — Command Query Response Segregation - allows to scale system read functions and write functions independently. It is often that a system handles more reads than writes.
CQRS is often DDD-oriented, associated with Event-Source and Eventual Consistency.
The patterns employs "One Write Model, N Read Models"
- One internal model it writes with: the write model, altered by Commands
- One or several read models it and other applications read from.
The Read Models can be read by front-ends or by APIs.
In a distributed system, failures can happen. Network can have transient failures, hardware can fail, storage disks can corrupt. Therefore, design an application to be self-healing when failures occur.
Resiliency is the capability to handle partial failures while continuing to execute and not crash. Applications that communicate with remote services and resources must be sensitive to transient faults.
This requires a three-pronged approach:
- Detect failures.
- Respond to failures gracefully.
- Log and monitor failures, to give operational insight.
Transient faults include the momentary loss of network connectivity to components and services, the temporary unavailability of a service, or timeouts that arise when a service is busy. These faults are often self-correcting, and if the action is repeated after a suitable delay it is likely to succeed.
We decorate network-bound calls with resiliency aspects in following order:
** Retry ( CircuitBreaker ( RateLimiter ( TimeLimiter ( Bulkhead ( Function ) ) ) ) ) **
The execution order: decorate a network call in order for resilience:
- RateLimiter (prevent a call if rate-limit exceeded)
- TimeLimiter (time-out a call)
- CircuitBreaker (fail-fast)
- Retry (retry on exceptions)
- Fallback (fallback as last resort)
Resilience4j is a lightweight fault tolerance designed for functional programming.
A technique to avoid cascading failures in an interdependent microservices environment, where dependent service has outage or degraded performance.
Circuit Breaker framework monitors communications for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error or with some alternative service or default message
It make sure system is responsive & resilient and threads are not waiting for an unresponsive call.
The circuit breaker has three distinct states: Closed, Open, and Half-Open:
- Closed – remains in the closed state and all calls pass through to the services. When the number of failures exceeds a predetermined threshold the breaker trips, and it goes into the Open state.
- Open – The circuit breaker returns an error for calls without executing the function.
- Half-Open – After a timeout period, the circuit switches to a half-open state to test if the underlying problem still exists. If a single call fails in this half-open state, the breaker is once again tripped. If it succeeds, the circuit breaker resets back to the normal, closed state.
Bulkhead for concurrency controller (limits concurrent handling) and circuit breaker to control constant overlaod.
Will protect from bursts & spikes. With bulkhead pattern, components of an application are isolated into pools so that if one fails, the others will continue to function.
The benefits of this pattern include:
- Isolates consumers and services from cascading failures. An issue affecting a consumer or service can be isolated within its own bulkhead, preventing the entire solution from failing.
- Allows you to preserve some functionality in the event of a service failure. Other services and features of the application will continue to work.
- Allows you to deploy services that offer a different quality of service for consuming applications. A high-priority consumer pool can be configured to use high-priority services.
References
Antifragility Vs. Resilency A resilience strategy seeks stability, survival or a "business as usual" outcome, while antifragility seeks an outcome of continuous improvement using a disruption as a catalyst for change.
Perform an operation multiple times without changing the result.
- Update the contact details of a user in the system.
- Delete a file.
Not idempotent operations - send payment, create orders. REST - POST, PATCH
Receives a request with the same idempotence key (could be UUID (or) request/reference id), it knows that it’s a retry.
CAP stands for Consistency, Availability and Partition Tolerance.
Partition Tolerance means, if there is a partition between nodes or the parts of the cluster in a distributed system are not able to talk to each other, the system should still be functioning.
A distributed system always needs to be partition tolerant, we shouldn’t be making a system where a network partition brings down the whole system.
CAP theorem means if there is network partition and if you want your system to keep functioning you can provide either Availability or Consistency and not both.
Consistency in CAP theorem is not same as Consistency in RDBMS ACID. CAP consistency talks about data consistency across cluster of nodes and not on a single server/node.
Consistency means, if you write data to the distributed system, you should be able to read the same data at any point in time from any nodes of the system or simply return an error if data is in an inconsistent state. Never return inconsistent data.
Availability in CAP theorem is not the same as the downtime we talk about in our day to day system. Example 99.9% availability of a microservice is not the same as CAP theorem Availability. CAP-Availibilty talks about if the cluster has network partition how the system will behave, whether it will start giving error or keep serving requests successfully.
Availability means the system should always perform reads/writes on any non-failing node of the cluster successfully without any error. This is availability is mainly associated with network partition. i.e. in the presence of network partition whether a node returns success response or an error for read/write operation.
A single leader based system that accepts reads and writes, should never be categorized under Availability. Making these kinds of system Consistent and not Available.
All RDBMS are Consistent as all reads and writes go to a single node/server.
Cassandra, any coordinator nodes can accept read or write requests and forwards requests to respective replicas based on the partition key. Cassandra is categorized as AP(Available and Partition Tolerant)
Peer to peer task choreography using Pub/sub model worked for simplest of the flows, but quickly highlighted some of the issues associated with the approach:
- Process flows are “embedded” within the code of multiple microservices
- As the number of microservices grow and the complexity of the processes increases, getting visibility into these distributed workflows becomes difficult without a central orchestrator.
- Tight coupling and assumptions around input/output, SLAs etc, making it harder to adapt to changing needs
- Cannot answer "How much are we done with process X"?
Central Orchestration Engine
- Orchestrate microservices-based process flows.
- Each task in process or business flows are implemented as microservices.
- A workflow blueprint defines a series of tasks that needs be executed. Each of the tasks are either a control task (e.g. fork, join, decision, sub workflow, etc.) or a worker task
- Workflow definitions are decoupled from the service implementations.


- Workflow engine is a state machine, As workflow events occur combines with workflow blueprint with current state, to identify next state and schedules tasks, updates states machine
- Task Workers are intended to be idempotent stateless functions. The polling model allows us to handle backpressure on the workers and provide auto-scalability based on the queue depth when possible.
- Workers are language agnostic, allowing each microservice to be written in the language most suited for the service.
References
- https://conductor.netflix.com/devguide/architecture/index.html
- https://netflixtechblog.com/netflix-conductor-a-microservices-orchestrator-2e8d4771bf40
The key building blocks in non-blocking IO are:
- Event Demultiplexer
- Event Queue
- Event Loop
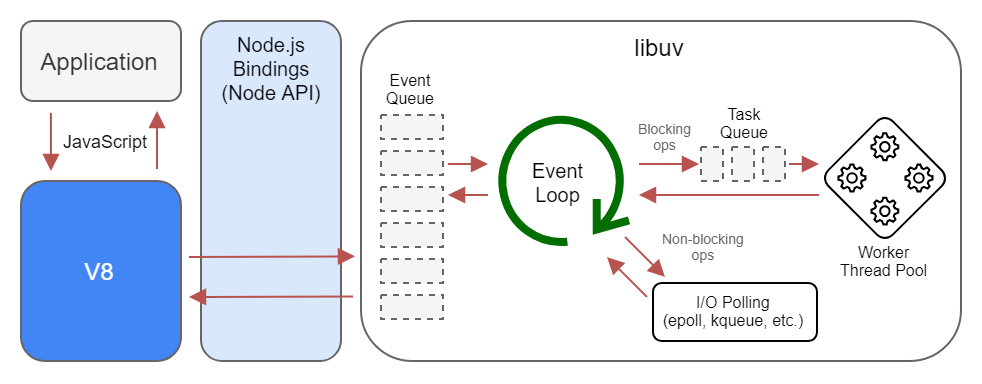

In this mechanism the system collects and queues I/O events coming from a set of watched resources. It blocks the process until new events are available. So no CPU time is wasted waiting for events.
IOC can be done using Dependency Injection (DI). It explains how to inject the concrete implementation into a class that is using abstraction, in other words an interface inside.
The IoC container creates an object of the specified class and also injects all the dependency objects through a constructor, a property or a method at run time and disposes it at the appropriate time.
BFF are a lightweight translation layers (aka backend services) that decouple individual clients from downstream services and serve only a single frontend. Adopt separate backend services for different types of clients, . That way, a single backend service doesn't need to handle the conflicting requirements of various client types. This pattern can help keep each microservice simple, by separating client-specific concerns.
https://blog.bitsrc.io/bff-pattern-backend-for-frontend-an-introduction-e4fa965128bf
Backend-as-a-Service allows to hook up mobile/webapps to the backend with a set of core app features, including authentication, authorization, managing users, sending push notifications, and connecting to third-party cloud providers.
GraphQL, I see it as query language for API
3 operation types:
- Query
- Mutation (Write and Get)
- Subscription
https://piotrminkowski.com/2023/08/29/introduction-to-grpc-with-spring-boot/
- Full-Duplex Protocol: WebSocket is a full-duplex protocol as it allows the application to send and receive data at the same time.
- Stateful Protocol: It means the connection between server and client will not be terminated until and unless closed by any one of them either by the client or by the server. Once the connection is terminated from one end it is also closed by another end.
- 3-way handshake: Websocket uses a 3-way handshake also known as TCP connection for establishing communication between a client and server.
Cache repeatedly access information held in a data store into memory to improve performance.
Cache-aside is also called as lazy caching, wherein first check item exist in cache. If the item exists in the cache, use that. If the item does not exist in the cache, query the data store, however on the way back you drop the item in the cache.
In cache-aside, application is responsible for reading and writing from the database and the cache doesn't interact with the database at all. Cache is "kept aside" as a faster and more scalable in-memory data store.
In read-through/write-through cache, application treats cache as the main data store and reads data from it and writes data to it. The cache is responsible for reading and writing this data to the database, thereby relieving the application of this responsibility.
- In read-through cache, the application always requests data from the cache. If cache has no data, it is responsible for retrieving the data from the DB using an underlying provider plugin. Compared to Cache-Aside, Read-Through moves the responsibility of getting the value from the datastore to the cache provider.
- In write-through cache, the cache is updated in real time when the database is updated. So, if a user updates his or her profile, the updated profile is also pushed into the cache. You can think of this as being proactive to avoid unnecessary cache misses. Similar to Read-Through but for writes, Write-Through moves the writing responsibility to the cache provider.
In the Write-Behind scenario, modified cache entries are asynchronously written to the data source.