(1)hibernate是全自动,而mybatis是半自动
hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。
(2)hibernate数据库移植性远大于mybatis
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(Oracle、MySQL等)的耦合性,而mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
(3)hibernate拥有完整的日志系统,mybatis则欠缺一些
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
(4)mybatis相比hibernate需要关心很多细节
hibernate配置要比mybatis复杂的多,学习成本也比mybatis高。但也正因为mybatis使用简单,才导致它要比hibernate关心很多技术细节。mybatis由于不用考虑很多细节,开发模式上与传统jdbc区别很小,因此很容易上手并开发项目,但忽略细节会导致项目前期bug较多,因而开发出相对稳定的软件很慢,而开发出软件却很快。hibernate则正好与之相反。但是如果使用hibernate很熟练的话,实际上开发效率丝毫不差于甚至超越mybatis。
(5)sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
(6)缓存机制上,hibernate要比mybatis更好一些
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
而Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
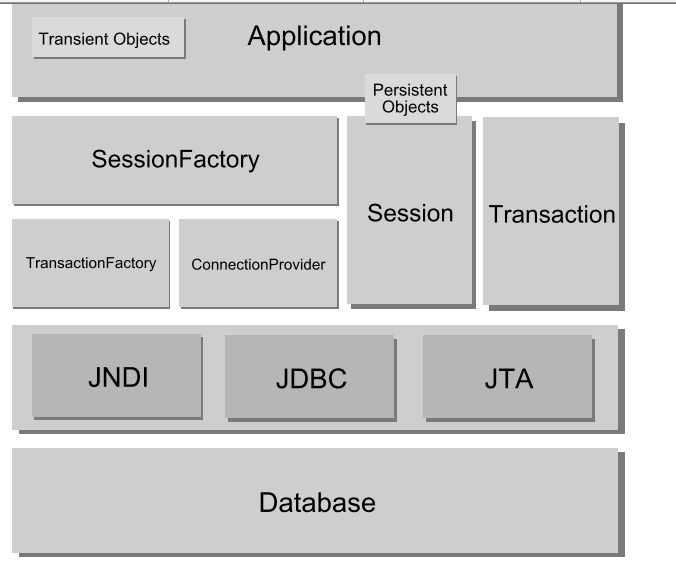
2) Session (org.hibernate.Session) 表示应用程序与持久储存层之间交互操作的一个单线程对象,此对象生存期很短。 其隐藏了JDBC连接,也是Transaction的工厂。其会持有一个针对持久化对象的必选(第一级)缓存,在遍历对象图或者根据持久化标识查找对象时会用到。
3) 事务Transaction (org.hibernate.Transaction) (可选的)应用程序用来指定原子操作单元范围的对象,它是单线程的,生命周期很短。 它通过抽象将应用从底层具体的JDBC、JTA以及CORBA事务隔离开。 某些情况下,一个Session之内可能包含多个Transaction对象。 尽管是否使用该对象是可选的,但无论是使用底层的API还是使用Transaction对象,事务边界的开启与关闭是必不可少的。
4) ConnectionProvider (org.hibernate.connection.ConnectionProvider) (可选的)生成JDBC连接的工厂(同时也起到连接池的作用)。 它通过抽象将应用从底层的Datasource或DriverManager隔离开。 仅供开发者扩展/实现用,并不暴露给应用程序使用。
5)TransactionFactory (org.hibernate.TransactionFactory) (可选的)生成Transaction对象实例的工厂。 仅供开发者扩展/实现用,并不暴露给应用程序使用。
6) 持久的对象及其集合 带有持久化状态的、具有业务功能的单线程对象,此对象生存期很短。 这些对象可能是普通的JavaBeans/POJO,唯一特殊的是他们正与(仅仅一个)Session相关联。 一旦这个Session被关闭,这些对象就会脱离持久化状态,这样就可被应用程序的任何层自由使用。 (例如,用作跟表示层打交道的数据传输对象。)
7) 瞬态(transient)和脱管(detached)的对象及其集合 那些目前没有与session关联的持久化类实例。他们可能是在被应用程序实例化后,尚未进行持久化的对象。也可能是因为实例化他们的Session已经被关闭而脱离持久化的对象。
参考: http://blog.sina.com.cn/s/blog_667fe4a501016awl.html
Hibernate的核心接口一共有5个,分别为:Session、SessionFactory、Transaction、Query和 Configuration。这5个核心接口在任何开发中都会用到。通过这些接口,不仅可以对持久化对象进行存取,还能够进行事务控制。下面对这五的核心 接口分别加以介绍。
1) Session接口: Session接口负责执行被持久化对象的CRUD操作(CRUD的任务是完成与数据库的交流,包含了很多常见的 SQL语句。)。但需要注意的是Session对象是非线程安全的。同时,Hibernate的session不同于JSP应用中的HttpSession。这里当使用session这个术语时,其实指的是Hibernate中的session,而以后会将HttpSesion对象称为用户session。
2) SessionFactory接口 SessionFactroy接口负责初始化Hibernate。它充当数据存储源的代理,并负责创建 Session对象。这里用到了工厂模式。需要注意的是SessionFactory并不是轻量级的,因为一般情况下,一个项目通常只需要一个SessionFactory就够,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
3) Configuration接口 Configuration接口负责配置并启动Hibernate,创建SessionFactory对 象。在Hibernate的启动的过程中,Configuration类的实例首先定位映射文档位置、读取配置,然后创建SessionFactory对象。
4) Transaction接口 Transaction接口负责事务相关的操作。它是可选的,开发人员也可以设计编写自己的底层事务处理代码。
5) Query和Criteria接口: Query和Criteria接口负责执行各种数据库查询。它可以使用HQL语言或SQL语句两种表达方式。
http://blog.csdn.net/martinmateng/article/details/50879436
特征:
- 不处于Session 缓存中
- 数据库中没有对象记录
Java如何进入临时状态:
- 通过new语句刚创建一个对象时
- 当调用Session 的delete()方法,从Session 缓存中删除一个对象时。
特征:
- 处于Session 缓存中
- 持久化对象数据库中设有对象记录
- Session 在特定时刻会保持二者同步
Java如何进入持久化状态
- Session 的save()把临时-》持久化状态
- Session 的load(),get()方法返回的对象
- Session 的find()返回的list集合中存放的对象
- session 的update(),saveOrupdate()使游离-》持久化
特征:
- 不再位于Session 缓存中
- 游离对象由持久化状态转变而来,数据库中可能还有对应记录。
Java如何进入持久化状态-》游离状态
- Session 的close()方法
- Session 的evict()方法,从缓存中删除一个对象。提高性能。少用。
(1)一级缓存就是Session级别的缓存,一个Session做了一个查询操作,它会把这个操作的结果放在一级缓存中,如果短时间内这个session(一定要同一个session)又做了同一个操作,那么hibernate直接从一级缓存中拿,而不会再去连数据库,取数据;
(2)二级缓存就是SessionFactory级别的缓存,顾名思义,就是查询的时候会把查询结果缓存到二级缓存中,如果同一个sessionFactory创建的某个session执行了相同的操作,hibernate就会从二级缓存中拿结果,而不会再去连接数据库;
3)Hibernate中提供了两级Cache,第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存由hibernate管理的,一般情况下无需进行干预;第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围或群集范围的缓存。这一级别的缓存可以进行配置和更改,并且可以动态加载和卸载。Hibernate还为查询结果提供了一个查询缓存,它依赖于第二级缓存;
http://www.open-open.com/lib/view/open1413527015465.html
在Hibernate框架中,当我们要访问的数据量过大时,明显用缓存不太合适, 因为内存容量有限,为了减少并发量,减少系统资源的消耗,这时Hibernate用懒加载机制来弥补这种缺陷,但是这只是弥补而不是用了懒加载总体性能就提高了。我们所说的懒加载也被称为延迟加载,它在查询的时候不会立刻访问数据库,而是返回代理对象,当真正去使用对象的时候才会访问数据库。
1、通过Session.load()实现懒加载
load(Object, Serializable):根据id查询。查询返回的是代理对象,不会立刻访问数据库,是懒加载的。当真正去使用对象的时候才会访问数据库。用load()的时候会发现不会打印出查询语句,而使用get()的时候会打印出查询语句。 使用load()时如果在session关闭之后再查询此对象,会报异常:could not initialize proxy - no Session。处理办法:在session关闭之前初始化一下查询出来的对象:Hibernate.initialize(user);使用load()可以提高效率,因为刚开始的时候并没有查询数据库。但很少使用。
2、one-to-one(元素)实现了懒加载。
在一对一的时候,查询主对象时默认不是懒加载。即:查询主对象的时候也会把从对象查询出来。需要把主对象配制成lazy="true" constrained="true" fetch="select"。此时查询主对象的时候就不会查询从对象,从而实现了懒加载。一对一的时候,查询从对象的是默认是懒加载。即:查询从对象的时候不会把主对象查询出来。而是查询出来的是主对象的代理对象。
3、many-to-one(元素)实现了懒加载。 多对一的时候,查询主对象时默认是懒加载。即:查询主对象的时候不会把从对象查询出来。
4、one-to-many(元素)懒加载:默认会懒加载,这是必须的,是重常用的。 一对多的时候,查询主对象时默认是懒加载。即:查询主对象的时候不会把从对象查询出来。
参考: http://blog.csdn.net/sanjy523892105/article/details/7071139 http://blog.csdn.net/yaorongwang0521/article/details/7074573
悲观锁 (Pessimistic Locking) 悲观锁,正如其名,他是对数据库而言的,数据库悲观了,他感觉每一个对他操作的程序都有可能产生并发。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
优点:数据的一致性保持得很好 缺点:不适合多个用户并发访问。
乐观锁 相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本(Version)记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个"version"字段来实现。乐观锁的工作原理:读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
个人公众号(欢迎关注):
