内存虚拟化技术是虚拟化技术中的基石,今天和同事聊到了内存虚拟化的实现问题,发现KVM虚拟化技术系列中少了一篇这方面的实现分析,特此补上。
内存虚拟化方案
- 纯软件模拟(SOFTMMU)—ShadowPage
- 硬件辅助实现 —EPT
- GVA - Guest虚拟地址
- GPA - Guest物理地址
- HVA - Host虚拟地址
- HPA -Host物理地址
- GVA->GPA Guest OS维护的页表进行传统的操作
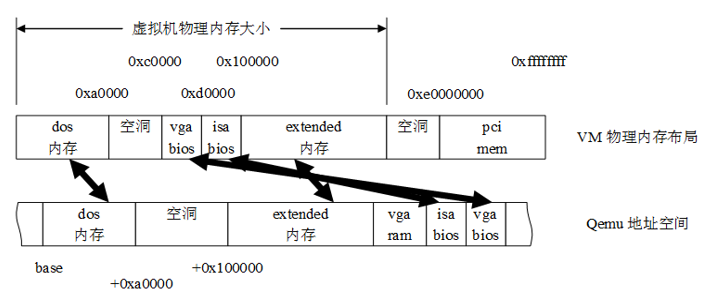
- GPA->HVA KVM的虚拟机实际上运行在Qemu的进程上下文中。于是,虚拟机的物理内存实际上是Qemu进程的虚拟地址。Kvm要把虚拟机的物理内存分成几个slot。这是因为,对计算机系统来说,物理地址是不连续的,除了bios和显存要编入内存地址,设备的内存也可能映射到内存了,所以内存实际上是分为一段段的。
kvm_set_phys_mem()->
kvm_set_user_memory_region()->
kvm_vm_ioctl() 进入kernel->
KVM_SET_USER_MEMORY_REGION->
kvm_vm_ioctl_set_memory_region()->
__kvm_set_memory_region()
QEMU对guest物理内存分段的的描述:
typedef struct KVMSlot
{
hwaddr start_addr; Guest物理地址块的起始地址
ram_addr_t memory_size; 大小
void *ram; QUMU用户空间地址
int slot; slot id
int flags;
} KVMSlot;指定了vm的物理地址,同时指定了Qemu分配的用户地址,前面一个地址是GPA,后 面一个地址是HVA。可见,一个memslot就是建立了GPA到HVA的映射关系。
内核态描述结构:
struct kvm_memslots {
int nmemslots; slot number
struct kvm_memory_slot memslots[KVM_MEMORY_SLOTS + KVM_PRIVATE_MEM_SLOTS];
};
struct kvm_memory_slot {
gfn_t base_gfn; 该块物理内存块所在guest 物理页帧号
unsigned long npages; 该块物理内存块占用的page数
unsigned long flags;
unsigned long *rmap; 分配该块物理内存对应的host内核虚拟地址(vmalloc分配)
unsigned long *dirty_bitmap;
struct {
unsigned long rmap_pde;
int write_count;
} *lpage_info[KVM_NR_PAGE_SIZES - 1];
unsigned long userspace_addr; 用户空间地址(QEMU)
int user_alloc;
};hva=base_hva+(gfn-base_gfn)*PAGE_SIZE
unsigned long gfn_to_hva(struct kvm *kvm, gfn_t gfn)
{
struct kvm_memory_slot *slot;
gfn = unalias_gfn_instantiation(kvm, gfn);
slot = gfn_to_memslot_unaliased(kvm, gfn);
if (!slot || slot->flags & KVM_MEMSLOT_INVALID)
return bad_hva();
return (slot->userspace_addr + (gfn - slot->base_gfn) * PAGE_SIZE);
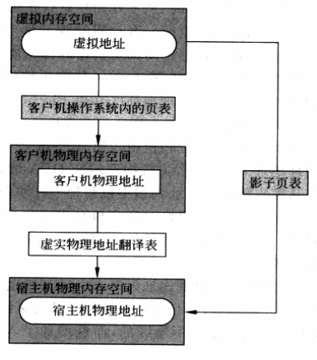
}Guest OS所维护的页表负责传统的从guest虚拟地址GVA到guest物理地址GPA的转换。如果MMU直接装载guest OS所维护的页表来进行内存访问,那么由于页表中每项所记录的都是GPA,MMU无法实现地址翻译。
解决方案:影子页表 (Shadow Page Table)
作用:GVA直接到HPA的地址翻译,真正被VMM载入到物理MMU中的页表是影子页表;
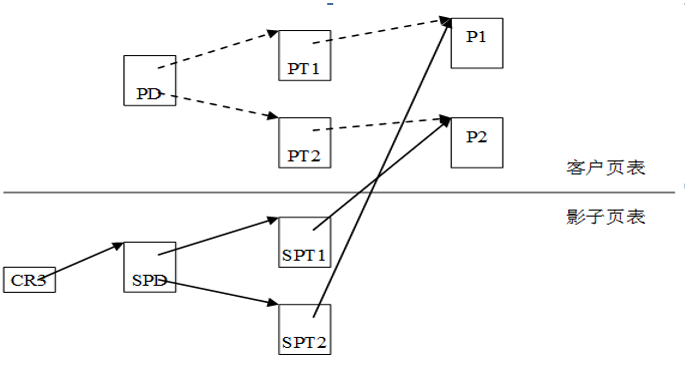
SPD是PD的影子页表,SPT1/SPT2是PT1/PT2的影子页表。由于客户PDE和PTE给出的页表基址和页基址并不是真正的物理地址,所以我们采用虚线表示PDE到GUEST页表以及PTE到普通GUEST页的映射关系。
-
开始时,VMM中的与guest OS所拥有的页表相对应的影子页表是空的;
-
而影子页表又是载入到CR3中真正为物理MMU所利用进行寻址的页表,因此开始时任何的内存访问操作都会引起缺页异常;导致vm发生VM Exit;进入handle_exception();
if (is_page_fault(intr_info)) { /* EPT won't cause page fault directly */ BUG_ON(enable_ept); cr2 = vmcs_readl(EXIT_QUALIFICATION); trace_kvm_page_fault(cr2, error_code); if (kvm_event_needs_reinjection(vcpu)) kvm_mmu_unprotect_page_virt(vcpu, cr2); return kvm_mmu_page_fault(vcpu, cr2, error_code, NULL, 0); }
获得缺页异常发生时的CR2,及当时访问的虚拟地址; 进入kvm_mmu_page_fault()(vmx.c)-> r = vcpu->arch.mmu.page_fault(vcpu, cr2, error_code);(mmu.c)-> FNAME(page_fault)(struct kvm_vcpu *vcpu, gva_t addr, u32 error_code)(paging_tmpl.h)-> FNAME(walk_addr)() 查guest页表,物理地址是否存在, 这时肯定是不存在的 The page is not mapped by the guest. Let the guest handle it. inject_page_fault()->kvm_inject_page_fault() 异常注入流程;
- Guest OS修改从GVA->GPA的映射关系填入页表;
- 继续访问,由于影子页表仍是空,再次发生缺页异常;
- FNAME(page_fault)->
- FNAME(walk_addr)() 查guest页表,物理地址映射均是存在->
- FNAME(fetch): 遍历影子页表,完成创建影子页表(填充影子页表); 在填充过程中,将客户机页目录结构页对应影子页表页表项标记为写保护,目的截获对于页目录的修改(页目录也是内存页的一部分,在页表中也是有映射的,guest对页目录有写权限,那么在影子页表的页目录也是可写的,这样对页目录的修改导致VMM失去截获的机会)
shadow_page = kvm_mmu_get_page(vcpu, table_gfn, addr, level-1, direct, access, sptep);
index = kvm_page_table_hashfn(gfn);
hlist_for_each_entry_safe
if (sp->gfn == gfn)
{……}
else
{sp = kvm_mmu_alloc_page(vcpu, parent_pte);}
为了快速检索GUEST页表所对应的的影子页表,KVM 为每个GUEST都维护了一个哈希 表,影子页表和GUEST页表通过此哈希表进行映射。对于每一个GUEST来说,GUEST 的页目录和页表都有唯一的GUEST物理地址,通过页目录/页表的客户机物理地址就 可以在哈希链表中快速地找到对应的影子页目录/页表。
- Guest OS修改从GVA->GPA的映射关系,为保证一致性,VMM必须对影子页表也做相应的维护,这样,VMM必须截获这样的内存访问操作;
- 导致VM Exit的机会
- INVLPG
- MOV TO CR3
- TASK SWITCH(发生MOV TO CR3 )
- 以INVLPG触发VM Exit为例:
- static void FNAME(invlpg)(struct kvm_vcpu *vcpu, gva_t gva)
- Paging_tmpl.h
- 影子页表项的内容无效
- GUEST在切换CR3时,VMM需要清空整个TLB,使所有影子页表的内容无效。在多进程GUEST操作系统中,CR3将被频繁地切换,某些影子页表的内容可能很快就会被再次用到,而重建影子页表是一项十分耗时的工作,这里需要缓存影子页表,即GUEST切换CR3时不清空影子页表。
内存虚拟化的两次转换: GVA->GPA (GUEST的页表实现) GPA->HPA (VMM进行转换)
影子页表将两次转换合一 根据GVA->GPA->HPA 计算出GVA->HPA,填入影子页表
优点: 由于影子页表可被载入物理 MMU 为客户机直接寻址使用,所以客户机的大多数内存访问都可以在没有 KVM 介入的情况下正常执行,没有额外的地址转换开销,也就大大提高了客户机运行的效率。
缺点: 1、KVM 需要为每个客户机的每个进程的页表都要维护一套相应的影子页表,这会带来较大内存上的额外开销; 2、客户在读写CR3、执行INVLPG指令或客户页表不完整等情况下均会导致VM exit,这导致了内存虚拟化效率很低 3、客户机页表和和影子页表的同步也比较复杂。
因此,Intel 的 EPT(Extent Page Table) 技术和 AMD 的 NPT(Nest Page Table) 技术都对内存虚拟化提供了硬件支持。这两种技术原理类似,都是在硬件层面上实现客户机虚拟地址到宿主机物理地址之间的转换。
VT-x提供了Extended Page Table(EPT)技术 硬件上直接支持GVA->GPA->HPA的两次地址转换 原理:
1. 在原有的CR3页表地址映射的基础上,EPT引入了EPT页表来实现另一次映射。
2. GVA->GPA->HPA两次地址转换都由CPU硬件来完成。
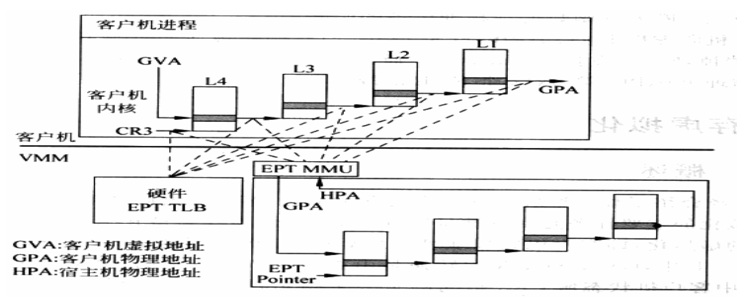
- Guest维护自身的客户页表:GVA->GPA
- EPT维护GPA->HPA的映射
- 处于非根模式的CPU加载guest进程的gCR3;
- gCR3是GPA,cpu需要通过查询EPT页表来实现GPA->HPA;
- 如果没有,CPU触发EPT Violation,由VMM截获处理;
- 假设客户机有m级页表,宿主机EPT有n级,在TLB均miss的最坏情况下,会产生m*n次内存访问,完成一次客户机的地址翻译;
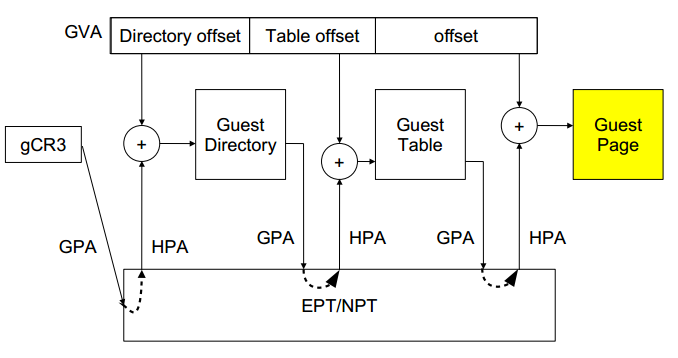
- 初始情况下:Guest CR3指向的Guest物理页面为空页面;
- Guest页表缺页异常,KVM采用不处理Guest页表缺页的机制,不会导致VM Exit,由Guest的缺页异常处理函数负责分配一个Guest物理页面(GPA),将该页面物理地址回填,建立Guest页表结构;
- 完成该映射的过程需要将GPA翻译到HPA,此时该进程相应的EPT页表为空,产生EPT_VIOLATION,虚拟机退出到根模式下执行,由KVM捕获该异常,建立该GPA到HOST物理地址HPA的映射,完成一套EPT页表的建立,中断返回,切换到非根模式继续运行。
- VCPU的mmu查询下一级Guest页表,根据GVA的偏移产生一条新的GPA,Guest寻址该GPA对应页面,产生Guest缺页,不发生VM_Exit,由Guest系统的缺页处理函数捕获该异常,从Guest物理内存中选择一个空闲页,将该Guest物理地址GPA回填给Guest页表;
- 此时该GPA对应的EPT页表项不存在,发生EPT_VIOLATION,切换到根模式下,由KVM负责建立该GPA->HPA映射,再切换回非根模式;
- 如此往复,直到非根模式下GVA最后的偏移建立最后一级Guest页表,分配GPA,缺页异常退出到根模式建立最后一套EPT页表。
- 至此,一条GVA对应在真实物理内存单元中的内容,便可通过这一套二维页表结构获得。
- VMCS的“VMCS-Execution”:Enable EPT字段,置位后EPT功能使能,CPU会使用EPT功能进行两次转换;
- EPT页表的基地址是VMCS的“VMCS-Execution”:Extended page table pointer字段;
vcpu_enter_guest()->
kvm_mmu_reload()->
kvm_mmu_load()->
vmx_set_cr3()
static void vmx_set_cr3(struct kvm_vcpu *vcpu, unsigned long cr3)
{
unsigned long guest_cr3;
u64 eptp;
guest_cr3 = cr3;
if (enable_ept) {
eptp = construct_eptp(cr3);
vmcs_write64(EPT_POINTER, eptp);
if (is_paging(vcpu) || is_guest_mode(vcpu))
guest_cr3 = kvm_read_cr3(vcpu);
else
guest_cr3 = vcpu->kvm->arch.ept_identity_map_addr;
ept_load_pdptrs(vcpu);
}
vmx_flush_tlb(vcpu);
vmcs_writel(GUEST_CR3, guest_cr3);
}
vmx_handle_exit()->
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation;
Handle_ept_violation()->
kvm_mmu_page_fault()->
tdp_page_fault()->
gfn_to_pfn(); GPA到HPA的转化分两步完成,分别通过gfn_to_hva、hva_to_pfn两个函数完成
__direct_map(); 建立EPT页表结构
```Guest运行过程中,首先获得gCR3的客户页帧号(右移PAGE_SIZE),根据其所在memslot区域获得其对应的HVA,再由HVA转化为HPA,得到宿主页帧号。若GPA->HPA的映射不存在,将会触发VM-Exit,KVM负责捕捉该异常,并交由KVM的缺页中断机制进行相应的缺页处理。kvm_vmx_exit_handlers函数数组中,保存着全部VM-Exit的处理函数,它由kvm_x86_ops的vmx_handle_exit负责调用。缺页异常的中断号为EXIT_REASON_EPT_VIOLATION,对应由handle_ept_violation函数进行处理。 tdp_page_fault是EPT的缺页处理函数,负责完成GPA->HPA转化.而传给tdp_page_fault的GPA是通过vmcs_read64函数(VMREAD指令)获得的. gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS);