A list of applications that support MCP integrations
This page provides an overview of applications that support the Model Context Protocol (MCP). Each client may support different MCP features, allowing for varying levels of integration with MCP servers.
| Client | Resources | Prompts | Tools | Sampling | Roots | Notes |
|---|---|---|---|---|---|---|
| Claude Desktop App | ✅ | ✅ | ✅ | ❌ | ❌ | Full support for all MCP features |
| Zed | ❌ | ✅ | ❌ | ❌ | ❌ | Prompts appear as slash commands |
| Sourcegraph Cody | ✅ | ❌ | ❌ | ❌ | ❌ | Supports resources through OpenCTX |
| Firebase Genkit | ✅ | ✅ | ❌ | ❌ | Supports resource list and lookup through tools. | |
| Continue | ✅ | ✅ | ✅ | ❌ | ❌ | Full support for all MCP features |
| GenAIScript | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools. |
| Cline | ✅ | ❌ | ✅ | ❌ | ❌ | Supports tools and resources. |
| LibreChat | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools for Agents |
| TheiaAI/TheiaIDE | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools for Agents in Theia AI and the AI-powered Theia IDE |
| Superinterface | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools |
| 5ire | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools. |
| Bee Agent Framework | ❌ | ❌ | ✅ | ❌ | ❌ | Supports tools in agentic workflows. |
The Claude desktop application provides comprehensive support for MCP, enabling deep integration with local tools and data sources.
Key features:
- Full support for resources, allowing attachment of local files and data
- Support for prompt templates
- Tool integration for executing commands and scripts
- Local server connections for enhanced privacy and security
ⓘ Note: The Claude.ai web application does not currently support MCP. MCP features are only available in the desktop application.
Zed is a high-performance code editor with built-in MCP support, focusing on prompt templates and tool integration.
Key features:
- Prompt templates surface as slash commands in the editor
- Tool integration for enhanced coding workflows
- Tight integration with editor features and workspace context
- Does not support MCP resources
Cody is Sourcegraph's AI coding assistant, which implements MCP through OpenCTX.
Key features:
- Support for MCP resources
- Integration with Sourcegraph's code intelligence
- Uses OpenCTX as an abstraction layer
- Future support planned for additional MCP features
Genkit is Firebase's SDK for building and integrating GenAI features into applications. The genkitx-mcp plugin enables consuming MCP servers as a client or creating MCP servers from Genkit tools and prompts.
Key features:
- Client support for tools and prompts (resources partially supported)
- Rich discovery with support in Genkit's Dev UI playground
- Seamless interoperability with Genkit's existing tools and prompts
- Works across a wide variety of GenAI models from top providers
Continue is an open-source AI code assistant, with built-in support for all MCP features.
Key features
- Type "@" to mention MCP resources
- Prompt templates surface as slash commands
- Use both built-in and MCP tools directly in chat
- Supports VS Code and JetBrains IDEs, with any LLM
Programmatically assemble prompts for LLMs using GenAIScript (in JavaScript). Orchestrate LLMs, tools, and data in JavaScript.
Key features:
- JavaScript toolbox to work with prompts
- Abstraction to make it easy and productive
- Seamless Visual Studio Code integration
Cline is an autonomous coding agent in VS Code that edits files, runs commands, uses a browser, and more–with your permission at each step.
Key features:
- Create and add tools through natural language (e.g. "add a tool that searches the web")
- Share custom MCP servers Cline creates with others via the
~/Documents/Cline/MCPdirectory - Displays configured MCP servers along with their tools, resources, and any error logs
LibreChat is an open-source, customizable AI chat UI that supports multiple AI providers, now including MCP integration.
Key features:
- Extend current tool ecosystem, including Code Interpreter and Image generation tools, through MCP servers
- Add tools to customizable Agents, using a variety of LLMs from top providers
- Open-source and self-hostable, with secure multi-user support
- Future roadmap includes expanded MCP feature support
Theia AI is a framework for building AI-enhanced tools and IDEs. The AI-powered Theia IDE is an open and flexible development environment built on Theia AI.
Key features:
- Tool Integration: Theia AI enables AI agents, including those in the Theia IDE, to utilize MCP servers for seamless tool interaction.
- Customizable Prompts: The Theia IDE allows users to define and adapt prompts, dynamically integrating MCP servers for tailored workflows.
- Custom agents: The Theia IDE supports creating custom agents that leverage MCP capabilities, enabling users to design dedicated workflows on the fly.
Theia AI and Theia IDE's MCP integration provide users with flexibility, making them powerful platforms for exploring and adapting MCP.
Learn more:
Superinterface is AI infrastructure and a developer platform to build in-app AI assistants with support for MCP, interactive components, client-side function calling and more.
Key features:
- Use tools from MCP servers in assistants embedded via React components or script tags
- SSE transport support
- Use any AI model from any AI provider (OpenAI, Anthropic, Ollama, others)
5ire is an open source cross-platform desktop AI assistant that supports tools through MCP servers.
Key features:
- Built-in MCP servers can be quickly enabled and disabled.
- Users can add more servers by modifying the configuration file.
- It is open-source and user-friendly, suitable for beginners.
- Future support for MCP will be continuously improved.
Bee Agent Framework is an open-source framework for building, deploying, and serving powerful agentic workflows at scale. The framework includes the MCP Tool, a native feature that simplifies the integration of MCP servers into agentic workflows.
Key features:
- Seamlessly incorporate MCP tools into agentic workflows.
- Quickly instantiate framework-native tools from connected MCP client(s).
- Planned future support for agentic MCP capabilities.
Learn more:
If you've added MCP support to your application, we encourage you to submit a pull request to add it to this list. MCP integration can provide your users with powerful contextual AI capabilities and make your application part of the growing MCP ecosystem.
Benefits of adding MCP support:
- Enable users to bring their own context and tools
- Join a growing ecosystem of interoperable AI applications
- Provide users with flexible integration options
- Support local-first AI workflows
To get started with implementing MCP in your application, check out our Python or TypeScript SDK Documentation
This list is maintained by the community. If you notice any inaccuracies or would like to update information about MCP support in your application, please submit a pull request or open an issue in our documentation repository.
How to participate in Model Context Protocol development
We welcome contributions from the community! Please review our contributing guidelines for details on how to submit changes.
All contributors must adhere to our Code of Conduct.
For questions and discussions, please use GitHub Discussions.
Our plans for evolving Model Context Protocol (H1 2025)
The Model Context Protocol is rapidly evolving. This page outlines our current thinking on key priorities and future direction for the first half of 2025, though these may change significantly as the project develops.
The ideas presented here are not commitments—we may solve these challenges differently than described, or some may not materialize at all. This is also not an exhaustive list; we may incorporate work that isn't mentioned here.
We encourage community participation! Each section links to relevant discussions where you can learn more and contribute your thoughts.
Our top priority is enabling remote MCP connections, allowing clients to securely connect to MCP servers over the internet. Key initiatives include:
-
Authentication & Authorization: Adding standardized auth capabilities, particularly focused on OAuth 2.0 support.
-
Service Discovery: Defining how clients can discover and connect to remote MCP servers.
-
Stateless Operations: Thinking about whether MCP could encompass serverless environments too, where they will need to be mostly stateless.
To help developers build with MCP, we want to offer documentation for:
- Client Examples: Comprehensive reference client implementation(s), demonstrating all protocol features
- Protocol Drafting: Streamlined process for proposing and incorporating new protocol features
Looking ahead, we're exploring ways to make MCP servers more accessible. Some areas we may investigate include:
- Package Management: Standardized packaging format for MCP servers
- Installation Tools: Simplified server installation across MCP clients
- Sandboxing: Improved security through server isolation
- Server Registry: A common directory for discovering available MCP servers
We're expanding MCP's capabilities for complex agentic workflows, particularly focusing on:
-
Hierarchical Agent Systems: Improved support for trees of agents through namespacing and topology awareness.
-
Interactive Workflows: Better handling of user permissions and information requests across agent hierarchies, and ways to send output to users instead of models.
-
Streaming Results: Real-time updates from long-running agent operations.
We're also invested in:
- Community-Led Standards Development: Fostering a collaborative ecosystem where all AI providers can help shape MCP as an open standard through equal participation and shared governance, ensuring it meets the needs of diverse AI applications and use cases.
- Additional Modalities: Expanding beyond text to support audio, video, and other formats.
- [Standardization] Considering standardization through a standardization body.
We welcome community participation in shaping MCP's future. Visit our GitHub Discussions to join the conversation and contribute your ideas.
The latest updates and improvements to MCP
* Simplified, express-like API in the [TypeScript SDK](https://github.com/modelcontextprotocol/typescript-sdk) * Added 8 new clients to the [clients page](https://modelcontextprotocol.io/clients) * FastMCP API in the [Python SDK](https://github.com/modelcontextprotocol/python-sdk) * Dockerized MCP servers in the [servers repo](https://github.com/modelcontextprotocol/servers) * Jetbrains released a Kotlin SDK for MCP! * For a sample MCP Kotlin server, check out [this repository](https://github.com/modelcontextprotocol/kotlin-sdk/tree/main/samples/kotlin-mcp-server)Understand how MCP connects clients, servers, and LLMs
The Model Context Protocol (MCP) is built on a flexible, extensible architecture that enables seamless communication between LLM applications and integrations. This document covers the core architectural components and concepts.
MCP follows a client-server architecture where:
- Hosts are LLM applications (like Claude Desktop or IDEs) that initiate connections
- Clients maintain 1:1 connections with servers, inside the host application
- Servers provide context, tools, and prompts to clients
flowchart LR
subgraph " Host (e.g., Claude Desktop) "
client1[MCP Client]
client2[MCP Client]
end
subgraph "Server Process"
server1[MCP Server]
end
subgraph "Server Process"
server2[MCP Server]
end
client1 <-->|Transport Layer| server1
client2 <-->|Transport Layer| server2
The protocol layer handles message framing, request/response linking, and high-level communication patterns.
```typescript class Protocol { // Handle incoming requests setRequestHandler(schema: T, handler: (request: T, extra: RequestHandlerExtra) => Promise): void // Handle incoming notifications
setNotificationHandler<T>(schema: T, handler: (notification: T) => Promise<void>): void
// Send requests and await responses
request<T>(request: Request, schema: T, options?: RequestOptions): Promise<T>
// Send one-way notifications
notification(notification: Notification): Promise<void>
}
```
async def send_notification(
self,
notification: NotificationT
) -> None:
"""Send one-way notification that doesn't expect response."""
# Notification handling implementation
async def _received_request(
self,
responder: RequestResponder[ReceiveRequestT, ResultT]
) -> None:
"""Handle incoming request from other side."""
# Request handling implementation
async def _received_notification(
self,
notification: ReceiveNotificationT
) -> None:
"""Handle incoming notification from other side."""
# Notification handling implementation
```
Key classes include:
ProtocolClientServer
The transport layer handles the actual communication between clients and servers. MCP supports multiple transport mechanisms:
-
Stdio transport
- Uses standard input/output for communication
- Ideal for local processes
-
HTTP with SSE transport
- Uses Server-Sent Events for server-to-client messages
- HTTP POST for client-to-server messages
All transports use JSON-RPC 2.0 to exchange messages. See the specification for detailed information about the Model Context Protocol message format.
MCP has these main types of messages:
-
Requests expect a response from the other side:
interface Request { method: string; params?: { ... }; }
-
Results are successful responses to requests:
interface Result { [key: string]: unknown; }
-
Errors indicate that a request failed:
interface Error { code: number; message: string; data?: unknown; }
-
Notifications are one-way messages that don't expect a response:
interface Notification { method: string; params?: { ... }; }
sequenceDiagram
participant Client
participant Server
Client->>Server: initialize request
Server->>Client: initialize response
Client->>Server: initialized notification
Note over Client,Server: Connection ready for use
- Client sends
initializerequest with protocol version and capabilities - Server responds with its protocol version and capabilities
- Client sends
initializednotification as acknowledgment - Normal message exchange begins
After initialization, the following patterns are supported:
- Request-Response: Client or server sends requests, the other responds
- Notifications: Either party sends one-way messages
Either party can terminate the connection:
- Clean shutdown via
close() - Transport disconnection
- Error conditions
MCP defines these standard error codes:
enum ErrorCode {
// Standard JSON-RPC error codes
ParseError = -32700,
InvalidRequest = -32600,
MethodNotFound = -32601,
InvalidParams = -32602,
InternalError = -32603
}SDKs and applications can define their own error codes above -32000.
Errors are propagated through:
- Error responses to requests
- Error events on transports
- Protocol-level error handlers
Here's a basic example of implementing an MCP server:
```typescript import { Server } from "@modelcontextprotocol/sdk/server/index.js"; import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {
resources: {}
}
});
// Handle requests
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [
{
uri: "example://resource",
name: "Example Resource"
}
]
};
});
// Connect transport
const transport = new StdioServerTransport();
await server.connect(transport);
```
app = Server("example-server")
@app.list_resources()
async def list_resources() -> list[types.Resource]:
return [
types.Resource(
uri="example://resource",
name="Example Resource"
)
]
async def main():
async with stdio_server() as streams:
await app.run(
streams[0],
streams[1],
app.create_initialization_options()
)
if __name__ == "__main__":
asyncio.run(main)
```
-
Local communication
- Use stdio transport for local processes
- Efficient for same-machine communication
- Simple process management
-
Remote communication
- Use SSE for scenarios requiring HTTP compatibility
- Consider security implications including authentication and authorization
-
Request processing
- Validate inputs thoroughly
- Use type-safe schemas
- Handle errors gracefully
- Implement timeouts
-
Progress reporting
- Use progress tokens for long operations
- Report progress incrementally
- Include total progress when known
-
Error management
- Use appropriate error codes
- Include helpful error messages
- Clean up resources on errors
-
Transport security
- Use TLS for remote connections
- Validate connection origins
- Implement authentication when needed
-
Message validation
- Validate all incoming messages
- Sanitize inputs
- Check message size limits
- Verify JSON-RPC format
-
Resource protection
- Implement access controls
- Validate resource paths
- Monitor resource usage
- Rate limit requests
-
Error handling
- Don't leak sensitive information
- Log security-relevant errors
- Implement proper cleanup
- Handle DoS scenarios
-
Logging
- Log protocol events
- Track message flow
- Monitor performance
- Record errors
-
Diagnostics
- Implement health checks
- Monitor connection state
- Track resource usage
- Profile performance
-
Testing
- Test different transports
- Verify error handling
- Check edge cases
- Load test servers
Create reusable prompt templates and workflows
Prompts enable servers to define reusable prompt templates and workflows that clients can easily surface to users and LLMs. They provide a powerful way to standardize and share common LLM interactions.
Prompts are designed to be **user-controlled**, meaning they are exposed from servers to clients with the intention of the user being able to explicitly select them for use.Prompts in MCP are predefined templates that can:
- Accept dynamic arguments
- Include context from resources
- Chain multiple interactions
- Guide specific workflows
- Surface as UI elements (like slash commands)
Each prompt is defined with:
{
name: string; // Unique identifier for the prompt
description?: string; // Human-readable description
arguments?: [ // Optional list of arguments
{
name: string; // Argument identifier
description?: string; // Argument description
required?: boolean; // Whether argument is required
}
]
}Clients can discover available prompts through the prompts/list endpoint:
// Request
{
method: "prompts/list"
}
// Response
{
prompts: [
{
name: "analyze-code",
description: "Analyze code for potential improvements",
arguments: [
{
name: "language",
description: "Programming language",
required: true
}
]
}
]
}To use a prompt, clients make a prompts/get request:
// Request
{
method: "prompts/get",
params: {
name: "analyze-code",
arguments: {
language: "python"
}
}
}
// Response
{
description: "Analyze Python code for potential improvements",
messages: [
{
role: "user",
content: {
type: "text",
text: "Please analyze the following Python code for potential improvements:\n\n```python\ndef calculate_sum(numbers):\n total = 0\n for num in numbers:\n total = total + num\n return total\n\nresult = calculate_sum([1, 2, 3, 4, 5])\nprint(result)\n```"
}
}
]
}Prompts can be dynamic and include:
{
"name": "analyze-project",
"description": "Analyze project logs and code",
"arguments": [
{
"name": "timeframe",
"description": "Time period to analyze logs",
"required": true
},
{
"name": "fileUri",
"description": "URI of code file to review",
"required": true
}
]
}When handling the prompts/get request:
{
"messages": [
{
"role": "user",
"content": {
"type": "text",
"text": "Analyze these system logs and the code file for any issues:"
}
},
{
"role": "user",
"content": {
"type": "resource",
"resource": {
"uri": "logs://recent?timeframe=1h",
"text": "[2024-03-14 15:32:11] ERROR: Connection timeout in network.py:127\n[2024-03-14 15:32:15] WARN: Retrying connection (attempt 2/3)\n[2024-03-14 15:32:20] ERROR: Max retries exceeded",
"mimeType": "text/plain"
}
}
},
{
"role": "user",
"content": {
"type": "resource",
"resource": {
"uri": "file:///path/to/code.py",
"text": "def connect_to_service(timeout=30):\n retries = 3\n for attempt in range(retries):\n try:\n return establish_connection(timeout)\n except TimeoutError:\n if attempt == retries - 1:\n raise\n time.sleep(5)\n\ndef establish_connection(timeout):\n # Connection implementation\n pass",
"mimeType": "text/x-python"
}
}
}
]
}const debugWorkflow = {
name: "debug-error",
async getMessages(error: string) {
return [
{
role: "user",
content: {
type: "text",
text: `Here's an error I'm seeing: ${error}`
}
},
{
role: "assistant",
content: {
type: "text",
text: "I'll help analyze this error. What have you tried so far?"
}
},
{
role: "user",
content: {
type: "text",
text: "I've tried restarting the service, but the error persists."
}
}
];
}
};Here's a complete example of implementing prompts in an MCP server:
```typescript import { Server } from "@modelcontextprotocol/sdk/server"; import { ListPromptsRequestSchema, GetPromptRequestSchema } from "@modelcontextprotocol/sdk/types";const PROMPTS = {
"git-commit": {
name: "git-commit",
description: "Generate a Git commit message",
arguments: [
{
name: "changes",
description: "Git diff or description of changes",
required: true
}
]
},
"explain-code": {
name: "explain-code",
description: "Explain how code works",
arguments: [
{
name: "code",
description: "Code to explain",
required: true
},
{
name: "language",
description: "Programming language",
required: false
}
]
}
};
const server = new Server({
name: "example-prompts-server",
version: "1.0.0"
}, {
capabilities: {
prompts: {}
}
});
// List available prompts
server.setRequestHandler(ListPromptsRequestSchema, async () => {
return {
prompts: Object.values(PROMPTS)
};
});
// Get specific prompt
server.setRequestHandler(GetPromptRequestSchema, async (request) => {
const prompt = PROMPTS[request.params.name];
if (!prompt) {
throw new Error(`Prompt not found: ${request.params.name}`);
}
if (request.params.name === "git-commit") {
return {
messages: [
{
role: "user",
content: {
type: "text",
text: `Generate a concise but descriptive commit message for these changes:\n\n${request.params.arguments?.changes}`
}
}
]
};
}
if (request.params.name === "explain-code") {
const language = request.params.arguments?.language || "Unknown";
return {
messages: [
{
role: "user",
content: {
type: "text",
text: `Explain how this ${language} code works:\n\n${request.params.arguments?.code}`
}
}
]
};
}
throw new Error("Prompt implementation not found");
});
```
# Define available prompts
PROMPTS = {
"git-commit": types.Prompt(
name="git-commit",
description="Generate a Git commit message",
arguments=[
types.PromptArgument(
name="changes",
description="Git diff or description of changes",
required=True
)
],
),
"explain-code": types.Prompt(
name="explain-code",
description="Explain how code works",
arguments=[
types.PromptArgument(
name="code",
description="Code to explain",
required=True
),
types.PromptArgument(
name="language",
description="Programming language",
required=False
)
],
)
}
# Initialize server
app = Server("example-prompts-server")
@app.list_prompts()
async def list_prompts() -> list[types.Prompt]:
return list(PROMPTS.values())
@app.get_prompt()
async def get_prompt(
name: str, arguments: dict[str, str] | None = None
) -> types.GetPromptResult:
if name not in PROMPTS:
raise ValueError(f"Prompt not found: {name}")
if name == "git-commit":
changes = arguments.get("changes") if arguments else ""
return types.GetPromptResult(
messages=[
types.PromptMessage(
role="user",
content=types.TextContent(
type="text",
text=f"Generate a concise but descriptive commit message "
f"for these changes:\n\n{changes}"
)
)
]
)
if name == "explain-code":
code = arguments.get("code") if arguments else ""
language = arguments.get("language", "Unknown") if arguments else "Unknown"
return types.GetPromptResult(
messages=[
types.PromptMessage(
role="user",
content=types.TextContent(
type="text",
text=f"Explain how this {language} code works:\n\n{code}"
)
)
]
)
raise ValueError("Prompt implementation not found")
```
When implementing prompts:
- Use clear, descriptive prompt names
- Provide detailed descriptions for prompts and arguments
- Validate all required arguments
- Handle missing arguments gracefully
- Consider versioning for prompt templates
- Cache dynamic content when appropriate
- Implement error handling
- Document expected argument formats
- Consider prompt composability
- Test prompts with various inputs
Prompts can be surfaced in client UIs as:
- Slash commands
- Quick actions
- Context menu items
- Command palette entries
- Guided workflows
- Interactive forms
Servers can notify clients about prompt changes:
- Server capability:
prompts.listChanged - Notification:
notifications/prompts/list_changed - Client re-fetches prompt list
When implementing prompts:
- Validate all arguments
- Sanitize user input
- Consider rate limiting
- Implement access controls
- Audit prompt usage
- Handle sensitive data appropriately
- Validate generated content
- Implement timeouts
- Consider prompt injection risks
- Document security requirements
Expose data and content from your servers to LLMs
Resources are a core primitive in the Model Context Protocol (MCP) that allow servers to expose data and content that can be read by clients and used as context for LLM interactions.
Resources are designed to be **application-controlled**, meaning that the client application can decide how and when they should be used. Different MCP clients may handle resources differently. For example:- Claude Desktop currently requires users to explicitly select resources before they can be used
- Other clients might automatically select resources based on heuristics
- Some implementations may even allow the AI model itself to determine which resources to use
Server authors should be prepared to handle any of these interaction patterns when implementing resource support. In order to expose data to models automatically, server authors should use a model-controlled primitive such as Tools.
Resources represent any kind of data that an MCP server wants to make available to clients. This can include:
- File contents
- Database records
- API responses
- Live system data
- Screenshots and images
- Log files
- And more
Each resource is identified by a unique URI and can contain either text or binary data.
Resources are identified using URIs that follow this format:
[protocol]://[host]/[path]
For example:
file:///home/user/documents/report.pdfpostgres://database/customers/schemascreen://localhost/display1
The protocol and path structure is defined by the MCP server implementation. Servers can define their own custom URI schemes.
Resources can contain two types of content:
Text resources contain UTF-8 encoded text data. These are suitable for:
- Source code
- Configuration files
- Log files
- JSON/XML data
- Plain text
Binary resources contain raw binary data encoded in base64. These are suitable for:
- Images
- PDFs
- Audio files
- Video files
- Other non-text formats
Clients can discover available resources through two main methods:
Servers expose a list of concrete resources via the resources/list endpoint. Each resource includes:
{
uri: string; // Unique identifier for the resource
name: string; // Human-readable name
description?: string; // Optional description
mimeType?: string; // Optional MIME type
}For dynamic resources, servers can expose URI templates that clients can use to construct valid resource URIs:
{
uriTemplate: string; // URI template following RFC 6570
name: string; // Human-readable name for this type
description?: string; // Optional description
mimeType?: string; // Optional MIME type for all matching resources
}To read a resource, clients make a resources/read request with the resource URI.
The server responds with a list of resource contents:
{
contents: [
{
uri: string; // The URI of the resource
mimeType?: string; // Optional MIME type
// One of:
text?: string; // For text resources
blob?: string; // For binary resources (base64 encoded)
}
]
}MCP supports real-time updates for resources through two mechanisms:
Servers can notify clients when their list of available resources changes via the notifications/resources/list_changed notification.
Clients can subscribe to updates for specific resources:
- Client sends
resources/subscribewith resource URI - Server sends
notifications/resources/updatedwhen the resource changes - Client can fetch latest content with
resources/read - Client can unsubscribe with
resources/unsubscribe
Here's a simple example of implementing resource support in an MCP server:
```typescript const server = new Server({ name: "example-server", version: "1.0.0" }, { capabilities: { resources: {} } });// List available resources
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [
{
uri: "file:///logs/app.log",
name: "Application Logs",
mimeType: "text/plain"
}
]
};
});
// Read resource contents
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
const uri = request.params.uri;
if (uri === "file:///logs/app.log") {
const logContents = await readLogFile();
return {
contents: [
{
uri,
mimeType: "text/plain",
text: logContents
}
]
};
}
throw new Error("Resource not found");
});
```
@app.list_resources()
async def list_resources() -> list[types.Resource]:
return [
types.Resource(
uri="file:///logs/app.log",
name="Application Logs",
mimeType="text/plain"
)
]
@app.read_resource()
async def read_resource(uri: AnyUrl) -> str:
if str(uri) == "file:///logs/app.log":
log_contents = await read_log_file()
return log_contents
raise ValueError("Resource not found")
# Start server
async with stdio_server() as streams:
await app.run(
streams[0],
streams[1],
app.create_initialization_options()
)
```
When implementing resource support:
- Use clear, descriptive resource names and URIs
- Include helpful descriptions to guide LLM understanding
- Set appropriate MIME types when known
- Implement resource templates for dynamic content
- Use subscriptions for frequently changing resources
- Handle errors gracefully with clear error messages
- Consider pagination for large resource lists
- Cache resource contents when appropriate
- Validate URIs before processing
- Document your custom URI schemes
When exposing resources:
- Validate all resource URIs
- Implement appropriate access controls
- Sanitize file paths to prevent directory traversal
- Be cautious with binary data handling
- Consider rate limiting for resource reads
- Audit resource access
- Encrypt sensitive data in transit
- Validate MIME types
- Implement timeouts for long-running reads
- Handle resource cleanup appropriately
Understanding roots in MCP
Roots are a concept in MCP that define the boundaries where servers can operate. They provide a way for clients to inform servers about relevant resources and their locations.
A root is a URI that a client suggests a server should focus on. When a client connects to a server, it declares which roots the server should work with. While primarily used for filesystem paths, roots can be any valid URI including HTTP URLs.
For example, roots could be:
file:///home/user/projects/myapp
https://api.example.com/v1
Roots serve several important purposes:
- Guidance: They inform servers about relevant resources and locations
- Clarity: Roots make it clear which resources are part of your workspace
- Organization: Multiple roots let you work with different resources simultaneously
When a client supports roots, it:
- Declares the
rootscapability during connection - Provides a list of suggested roots to the server
- Notifies the server when roots change (if supported)
While roots are informational and not strictly enforcing, servers should:
- Respect the provided roots
- Use root URIs to locate and access resources
- Prioritize operations within root boundaries
Roots are commonly used to define:
- Project directories
- Repository locations
- API endpoints
- Configuration locations
- Resource boundaries
When working with roots:
- Only suggest necessary resources
- Use clear, descriptive names for roots
- Monitor root accessibility
- Handle root changes gracefully
Here's how a typical MCP client might expose roots:
{
"roots": [
{
"uri": "file:///home/user/projects/frontend",
"name": "Frontend Repository"
},
{
"uri": "https://api.example.com/v1",
"name": "API Endpoint"
}
]
}This configuration suggests the server focus on both a local repository and an API endpoint while keeping them logically separated.
Let your servers request completions from LLMs
Sampling is a powerful MCP feature that allows servers to request LLM completions through the client, enabling sophisticated agentic behaviors while maintaining security and privacy.
This feature of MCP is not yet supported in the Claude Desktop client.The sampling flow follows these steps:
- Server sends a
sampling/createMessagerequest to the client - Client reviews the request and can modify it
- Client samples from an LLM
- Client reviews the completion
- Client returns the result to the server
This human-in-the-loop design ensures users maintain control over what the LLM sees and generates.
Sampling requests use a standardized message format:
{
messages: [
{
role: "user" | "assistant",
content: {
type: "text" | "image",
// For text:
text?: string,
// For images:
data?: string, // base64 encoded
mimeType?: string
}
}
],
modelPreferences?: {
hints?: [{
name?: string // Suggested model name/family
}],
costPriority?: number, // 0-1, importance of minimizing cost
speedPriority?: number, // 0-1, importance of low latency
intelligencePriority?: number // 0-1, importance of capabilities
},
systemPrompt?: string,
includeContext?: "none" | "thisServer" | "allServers",
temperature?: number,
maxTokens: number,
stopSequences?: string[],
metadata?: Record<string, unknown>
}The messages array contains the conversation history to send to the LLM. Each message has:
role: Either "user" or "assistant"content: The message content, which can be:- Text content with a
textfield - Image content with
data(base64) andmimeTypefields
- Text content with a
The modelPreferences object allows servers to specify their model selection preferences:
-
hints: Array of model name suggestions that clients can use to select an appropriate model:name: String that can match full or partial model names (e.g. "claude-3", "sonnet")- Clients may map hints to equivalent models from different providers
- Multiple hints are evaluated in preference order
-
Priority values (0-1 normalized):
costPriority: Importance of minimizing costsspeedPriority: Importance of low latency responseintelligencePriority: Importance of advanced model capabilities
Clients make the final model selection based on these preferences and their available models.
An optional systemPrompt field allows servers to request a specific system prompt. The client may modify or ignore this.
The includeContext parameter specifies what MCP context to include:
"none": No additional context"thisServer": Include context from the requesting server"allServers": Include context from all connected MCP servers
The client controls what context is actually included.
Fine-tune the LLM sampling with:
temperature: Controls randomness (0.0 to 1.0)maxTokens: Maximum tokens to generatestopSequences: Array of sequences that stop generationmetadata: Additional provider-specific parameters
The client returns a completion result:
{
model: string, // Name of the model used
stopReason?: "endTurn" | "stopSequence" | "maxTokens" | string,
role: "user" | "assistant",
content: {
type: "text" | "image",
text?: string,
data?: string,
mimeType?: string
}
}Here's an example of requesting sampling from a client:
{
"method": "sampling/createMessage",
"params": {
"messages": [
{
"role": "user",
"content": {
"type": "text",
"text": "What files are in the current directory?"
}
}
],
"systemPrompt": "You are a helpful file system assistant.",
"includeContext": "thisServer",
"maxTokens": 100
}
}When implementing sampling:
- Always provide clear, well-structured prompts
- Handle both text and image content appropriately
- Set reasonable token limits
- Include relevant context through
includeContext - Validate responses before using them
- Handle errors gracefully
- Consider rate limiting sampling requests
- Document expected sampling behavior
- Test with various model parameters
- Monitor sampling costs
Sampling is designed with human oversight in mind:
- Clients should show users the proposed prompt
- Users should be able to modify or reject prompts
- System prompts can be filtered or modified
- Context inclusion is controlled by the client
- Clients should show users the completion
- Users should be able to modify or reject completions
- Clients can filter or modify completions
- Users control which model is used
When implementing sampling:
- Validate all message content
- Sanitize sensitive information
- Implement appropriate rate limits
- Monitor sampling usage
- Encrypt data in transit
- Handle user data privacy
- Audit sampling requests
- Control cost exposure
- Implement timeouts
- Handle model errors gracefully
Sampling enables agentic patterns like:
- Reading and analyzing resources
- Making decisions based on context
- Generating structured data
- Handling multi-step tasks
- Providing interactive assistance
Best practices for context:
- Request minimal necessary context
- Structure context clearly
- Handle context size limits
- Update context as needed
- Clean up stale context
Robust error handling should:
- Catch sampling failures
- Handle timeout errors
- Manage rate limits
- Validate responses
- Provide fallback behaviors
- Log errors appropriately
Be aware of these limitations:
- Sampling depends on client capabilities
- Users control sampling behavior
- Context size has limits
- Rate limits may apply
- Costs should be considered
- Model availability varies
- Response times vary
- Not all content types supported
Enable LLMs to perform actions through your server
Tools are a powerful primitive in the Model Context Protocol (MCP) that enable servers to expose executable functionality to clients. Through tools, LLMs can interact with external systems, perform computations, and take actions in the real world.
Tools are designed to be **model-controlled**, meaning that tools are exposed from servers to clients with the intention of the AI model being able to automatically invoke them (with a human in the loop to grant approval).Tools in MCP allow servers to expose executable functions that can be invoked by clients and used by LLMs to perform actions. Key aspects of tools include:
- Discovery: Clients can list available tools through the
tools/listendpoint - Invocation: Tools are called using the
tools/callendpoint, where servers perform the requested operation and return results - Flexibility: Tools can range from simple calculations to complex API interactions
Like resources, tools are identified by unique names and can include descriptions to guide their usage. However, unlike resources, tools represent dynamic operations that can modify state or interact with external systems.
Each tool is defined with the following structure:
{
name: string; // Unique identifier for the tool
description?: string; // Human-readable description
inputSchema: { // JSON Schema for the tool's parameters
type: "object",
properties: { ... } // Tool-specific parameters
}
}Here's an example of implementing a basic tool in an MCP server:
```typescript const server = new Server({ name: "example-server", version: "1.0.0" }, { capabilities: { tools: {} } });// Define available tools
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [{
name: "calculate_sum",
description: "Add two numbers together",
inputSchema: {
type: "object",
properties: {
a: { type: "number" },
b: { type: "number" }
},
required: ["a", "b"]
}
}]
};
});
// Handle tool execution
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "calculate_sum") {
const { a, b } = request.params.arguments;
return {
content: [
{
type: "text",
text: String(a + b)
}
]
};
}
throw new Error("Tool not found");
});
```
@app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="calculate_sum",
description="Add two numbers together",
inputSchema={
"type": "object",
"properties": {
"a": {"type": "number"},
"b": {"type": "number"}
},
"required": ["a", "b"]
}
)
]
@app.call_tool()
async def call_tool(
name: str,
arguments: dict
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "calculate_sum":
a = arguments["a"]
b = arguments["b"]
result = a + b
return [types.TextContent(type="text", text=str(result))]
raise ValueError(f"Tool not found: {name}")
```
Here are some examples of types of tools that a server could provide:
Tools that interact with the local system:
{
name: "execute_command",
description: "Run a shell command",
inputSchema: {
type: "object",
properties: {
command: { type: "string" },
args: { type: "array", items: { type: "string" } }
}
}
}Tools that wrap external APIs:
{
name: "github_create_issue",
description: "Create a GitHub issue",
inputSchema: {
type: "object",
properties: {
title: { type: "string" },
body: { type: "string" },
labels: { type: "array", items: { type: "string" } }
}
}
}Tools that transform or analyze data:
{
name: "analyze_csv",
description: "Analyze a CSV file",
inputSchema: {
type: "object",
properties: {
filepath: { type: "string" },
operations: {
type: "array",
items: {
enum: ["sum", "average", "count"]
}
}
}
}
}When implementing tools:
- Provide clear, descriptive names and descriptions
- Use detailed JSON Schema definitions for parameters
- Include examples in tool descriptions to demonstrate how the model should use them
- Implement proper error handling and validation
- Use progress reporting for long operations
- Keep tool operations focused and atomic
- Document expected return value structures
- Implement proper timeouts
- Consider rate limiting for resource-intensive operations
- Log tool usage for debugging and monitoring
When exposing tools:
- Validate all parameters against the schema
- Sanitize file paths and system commands
- Validate URLs and external identifiers
- Check parameter sizes and ranges
- Prevent command injection
- Implement authentication where needed
- Use appropriate authorization checks
- Audit tool usage
- Rate limit requests
- Monitor for abuse
- Don't expose internal errors to clients
- Log security-relevant errors
- Handle timeouts appropriately
- Clean up resources after errors
- Validate return values
MCP supports dynamic tool discovery:
- Clients can list available tools at any time
- Servers can notify clients when tools change using
notifications/tools/list_changed - Tools can be added or removed during runtime
- Tool definitions can be updated (though this should be done carefully)
Tool errors should be reported within the result object, not as MCP protocol-level errors. This allows the LLM to see and potentially handle the error. When a tool encounters an error:
- Set
isErrortotruein the result - Include error details in the
contentarray
Here's an example of proper error handling for tools:
```typescript try { // Tool operation const result = performOperation(); return { content: [ { type: "text", text: `Operation successful: ${result}` } ] }; } catch (error) { return { isError: true, content: [ { type: "text", text: `Error: ${error.message}` } ] }; } ``` ```python try: # Tool operation result = perform_operation() return types.CallToolResult( content=[ types.TextContent( type="text", text=f"Operation successful: {result}" ) ] ) except Exception as error: return types.CallToolResult( isError=True, content=[ types.TextContent( type="text", text=f"Error: {str(error)}" ) ] ) ```This approach allows the LLM to see that an error occurred and potentially take corrective action or request human intervention.
A comprehensive testing strategy for MCP tools should cover:
- Functional testing: Verify tools execute correctly with valid inputs and handle invalid inputs appropriately
- Integration testing: Test tool interaction with external systems using both real and mocked dependencies
- Security testing: Validate authentication, authorization, input sanitization, and rate limiting
- Performance testing: Check behavior under load, timeout handling, and resource cleanup
- Error handling: Ensure tools properly report errors through the MCP protocol and clean up resources
Learn about MCP's communication mechanisms
Transports in the Model Context Protocol (MCP) provide the foundation for communication between clients and servers. A transport handles the underlying mechanics of how messages are sent and received.
MCP uses JSON-RPC 2.0 as its wire format. The transport layer is responsible for converting MCP protocol messages into JSON-RPC format for transmission and converting received JSON-RPC messages back into MCP protocol messages.
There are three types of JSON-RPC messages used:
{
jsonrpc: "2.0",
id: number | string,
method: string,
params?: object
}{
jsonrpc: "2.0",
id: number | string,
result?: object,
error?: {
code: number,
message: string,
data?: unknown
}
}{
jsonrpc: "2.0",
method: string,
params?: object
}MCP includes two standard transport implementations:
The stdio transport enables communication through standard input and output streams. This is particularly useful for local integrations and command-line tools.
Use stdio when:
- Building command-line tools
- Implementing local integrations
- Needing simple process communication
- Working with shell scripts
const transport = new StdioServerTransport();
await server.connect(transport);
```
const transport = new StdioClientTransport({
command: "./server",
args: ["--option", "value"]
});
await client.connect(transport);
```
async with stdio_server() as streams:
await app.run(
streams[0],
streams[1],
app.create_initialization_options()
)
```
async with stdio_client(params) as streams:
async with ClientSession(streams[0], streams[1]) as session:
await session.initialize()
```
SSE transport enables server-to-client streaming with HTTP POST requests for client-to-server communication.
Use SSE when:
- Only server-to-client streaming is needed
- Working with restricted networks
- Implementing simple updates
const app = express();
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {}
});
let transport: SSEServerTransport | null = null;
app.get("/sse", (req, res) => {
transport = new SSEServerTransport("/messages", res);
server.connect(transport);
});
app.post("/messages", (req, res) => {
if (transport) {
transport.handlePostMessage(req, res);
}
});
app.listen(3000);
```
const transport = new SSEClientTransport(
new URL("http://localhost:3000/sse")
);
await client.connect(transport);
```
app = Server("example-server")
sse = SseServerTransport("/messages")
async def handle_sse(scope, receive, send):
async with sse.connect_sse(scope, receive, send) as streams:
await app.run(streams[0], streams[1], app.create_initialization_options())
async def handle_messages(scope, receive, send):
await sse.handle_post_message(scope, receive, send)
starlette_app = Starlette(
routes=[
Route("/sse", endpoint=handle_sse),
Route("/messages", endpoint=handle_messages, methods=["POST"]),
]
)
```
MCP makes it easy to implement custom transports for specific needs. Any transport implementation just needs to conform to the Transport interface:
You can implement custom transports for:
- Custom network protocols
- Specialized communication channels
- Integration with existing systems
- Performance optimization
// Send a JSON-RPC message
send(message: JSONRPCMessage): Promise<void>;
// Close the connection
close(): Promise<void>;
// Callbacks
onclose?: () => void;
onerror?: (error: Error) => void;
onmessage?: (message: JSONRPCMessage) => void;
}
```
```python
@contextmanager
async def create_transport(
read_stream: MemoryObjectReceiveStream[JSONRPCMessage | Exception],
write_stream: MemoryObjectSendStream[JSONRPCMessage]
):
"""
Transport interface for MCP.
Args:
read_stream: Stream to read incoming messages from
write_stream: Stream to write outgoing messages to
"""
async with anyio.create_task_group() as tg:
try:
# Start processing messages
tg.start_soon(lambda: process_messages(read_stream))
# Send messages
async with write_stream:
yield write_stream
except Exception as exc:
# Handle errors
raise exc
finally:
# Clean up
tg.cancel_scope.cancel()
await write_stream.aclose()
await read_stream.aclose()
```
Transport implementations should handle various error scenarios:
- Connection errors
- Message parsing errors
- Protocol errors
- Network timeouts
- Resource cleanup
Example error handling:
```typescript class ExampleTransport implements Transport { async start() { try { // Connection logic } catch (error) { this.onerror?.(new Error(`Failed to connect: ${error}`)); throw error; } } async send(message: JSONRPCMessage) {
try {
// Sending logic
} catch (error) {
this.onerror?.(new Error(`Failed to send message: ${error}`));
throw error;
}
}
}
```
```python
@contextmanager
async def example_transport(scope: Scope, receive: Receive, send: Send):
try:
# Create streams for bidirectional communication
read_stream_writer, read_stream = anyio.create_memory_object_stream(0)
write_stream, write_stream_reader = anyio.create_memory_object_stream(0)
async def message_handler():
try:
async with read_stream_writer:
# Message handling logic
pass
except Exception as exc:
logger.error(f"Failed to handle message: {exc}")
raise exc
async with anyio.create_task_group() as tg:
tg.start_soon(message_handler)
try:
# Yield streams for communication
yield read_stream, write_stream
except Exception as exc:
logger.error(f"Transport error: {exc}")
raise exc
finally:
tg.cancel_scope.cancel()
await write_stream.aclose()
await read_stream.aclose()
except Exception as exc:
logger.error(f"Failed to initialize transport: {exc}")
raise exc
```
When implementing or using MCP transport:
- Handle connection lifecycle properly
- Implement proper error handling
- Clean up resources on connection close
- Use appropriate timeouts
- Validate messages before sending
- Log transport events for debugging
- Implement reconnection logic when appropriate
- Handle backpressure in message queues
- Monitor connection health
- Implement proper security measures
When implementing transport:
- Implement proper authentication mechanisms
- Validate client credentials
- Use secure token handling
- Implement authorization checks
- Use TLS for network transport
- Encrypt sensitive data
- Validate message integrity
- Implement message size limits
- Sanitize input data
- Implement rate limiting
- Use appropriate timeouts
- Handle denial of service scenarios
- Monitor for unusual patterns
- Implement proper firewall rules
Tips for debugging transport issues:
- Enable debug logging
- Monitor message flow
- Check connection states
- Validate message formats
- Test error scenarios
- Use network analysis tools
- Implement health checks
- Monitor resource usage
- Test edge cases
- Use proper error tracking
A comprehensive guide to debugging Model Context Protocol (MCP) integrations
Effective debugging is essential when developing MCP servers or integrating them with applications. This guide covers the debugging tools and approaches available in the MCP ecosystem.
This guide is for macOS. Guides for other platforms are coming soon.MCP provides several tools for debugging at different levels:
-
MCP Inspector
- Interactive debugging interface
- Direct server testing
- See the Inspector guide for details
-
Claude Desktop Developer Tools
- Integration testing
- Log collection
- Chrome DevTools integration
-
Server Logging
- Custom logging implementations
- Error tracking
- Performance monitoring
The Claude.app interface provides basic server status information:
-
Click the <img src="https://mintlify.s3.us-west-1.amazonaws.com/mcp/images/claude-desktop-mcp-plug-icon.svg" style={{display: 'inline', margin: 0, height: '1.3em'}} /> icon to view:
- Connected servers
- Available prompts and resources
-
Click the <img src="https://mintlify.s3.us-west-1.amazonaws.com/mcp/images/claude-desktop-mcp-hammer-icon.svg" style={{display: 'inline', margin: 0, height: '1.3em'}} /> icon to view:
- Tools made available to the model
Review detailed MCP logs from Claude Desktop:
# Follow logs in real-time
tail -n 20 -F ~/Library/Logs/Claude/mcp*.logThe logs capture:
- Server connection events
- Configuration issues
- Runtime errors
- Message exchanges
Access Chrome's developer tools inside Claude Desktop to investigate client-side errors:
- Create a
developer_settings.jsonfile withallowDevToolsset to true:
echo '{"allowDevTools": true}' > ~/Library/Application\ Support/Claude/developer_settings.json- Open DevTools:
Command-Option-Shift-i
Note: You'll see two DevTools windows:
- Main content window
- App title bar window
Use the Console panel to inspect client-side errors.
Use the Network panel to inspect:
- Message payloads
- Connection timing
When using MCP servers with Claude Desktop:
- The working directory for servers launched via
claude_desktop_config.jsonmay be undefined (like/on macOS) since Claude Desktop could be started from anywhere - Always use absolute paths in your configuration and
.envfiles to ensure reliable operation - For testing servers directly via command line, the working directory will be where you run the command
For example in claude_desktop_config.json, use:
{
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/Users/username/data"]
}Instead of relative paths like ./data
MCP servers inherit only a subset of environment variables automatically, like USER, HOME, and PATH.
To override the default variables or provide your own, you can specify an env key in claude_desktop_config.json:
{
"myserver": {
"command": "mcp-server-myapp",
"env": {
"MYAPP_API_KEY": "some_key",
}
}
}Common initialization problems:
-
Path Issues
- Incorrect server executable path
- Missing required files
- Permission problems
- Try using an absolute path for
command
-
Configuration Errors
- Invalid JSON syntax
- Missing required fields
- Type mismatches
-
Environment Problems
- Missing environment variables
- Incorrect variable values
- Permission restrictions
When servers fail to connect:
- Check Claude Desktop logs
- Verify server process is running
- Test standalone with Inspector
- Verify protocol compatibility
When building a server that uses the local stdio transport, all messages logged to stderr (standard error) will be captured by the host application (e.g., Claude Desktop) automatically.
Local MCP servers should not log messages to stdout (standard out), as this will interfere with protocol operation.For all transports, you can also provide logging to the client by sending a log message notification:
```python server.request_context.session.send_log_message( level="info", data="Server started successfully", ) ``` ```typescript server.sendLoggingMessage({ level: "info", data: "Server started successfully", }); ```Important events to log:
- Initialization steps
- Resource access
- Tool execution
- Error conditions
- Performance metrics
In client applications:
- Enable debug logging
- Monitor network traffic
- Track message exchanges
- Record error states
-
Initial Development
- Use Inspector for basic testing
- Implement core functionality
- Add logging points
-
Integration Testing
- Test in Claude Desktop
- Monitor logs
- Check error handling
To test changes efficiently:
- Configuration changes: Restart Claude Desktop
- Server code changes: Use Command-R to reload
- Quick iteration: Use Inspector during development
-
Structured Logging
- Use consistent formats
- Include context
- Add timestamps
- Track request IDs
-
Error Handling
- Log stack traces
- Include error context
- Track error patterns
- Monitor recovery
-
Performance Tracking
- Log operation timing
- Monitor resource usage
- Track message sizes
- Measure latency
When debugging:
-
Sensitive Data
- Sanitize logs
- Protect credentials
- Mask personal information
-
Access Control
- Verify permissions
- Check authentication
- Monitor access patterns
When encountering issues:
-
First Steps
- Check server logs
- Test with Inspector
- Review configuration
- Verify environment
-
Support Channels
- GitHub issues
- GitHub discussions
-
Providing Information
- Log excerpts
- Configuration files
- Steps to reproduce
- Environment details
In-depth guide to using the MCP Inspector for testing and debugging Model Context Protocol servers
The MCP Inspector is an interactive developer tool for testing and debugging MCP servers. While the Debugging Guide covers the Inspector as part of the overall debugging toolkit, this document provides a detailed exploration of the Inspector's features and capabilities.
The Inspector runs directly through npx without requiring installation:
npx @modelcontextprotocol/inspector <command>npx @modelcontextprotocol/inspector <command> <arg1> <arg2>A common way to start server packages from NPM or PyPi.
```bash npx -y @modelcontextprotocol/inspector npx # For example npx -y @modelcontextprotocol/inspector npx server-postgres postgres://127.0.0.1/testdb ``` ```bash npx @modelcontextprotocol/inspector uvx # For example npx @modelcontextprotocol/inspector uvx mcp-server-git --repository ~/code/mcp/servers.git ```To inspect servers locally developed or downloaded as a repository, the most common way is:
```bash npx @modelcontextprotocol/inspector node path/to/server/index.js args... ``` ```bash npx @modelcontextprotocol/inspector \ uv \ --directory path/to/server \ run \ package-name \ args... ```Please carefully read any attached README for the most accurate instructions.

The Inspector provides several features for interacting with your MCP server:
- Allows selecting the transport for connecting to the server
- For local servers, supports customizing the command-line arguments and environment
- Lists all available resources
- Shows resource metadata (MIME types, descriptions)
- Allows resource content inspection
- Supports subscription testing
- Displays available prompt templates
- Shows prompt arguments and descriptions
- Enables prompt testing with custom arguments
- Previews generated messages
- Lists available tools
- Shows tool schemas and descriptions
- Enables tool testing with custom inputs
- Displays tool execution results
- Presents all logs recorded from the server
- Shows notifications received from the server
-
Start Development
- Launch Inspector with your server
- Verify basic connectivity
- Check capability negotiation
-
Iterative testing
- Make server changes
- Rebuild the server
- Reconnect the Inspector
- Test affected features
- Monitor messages
-
Test edge cases
- Invalid inputs
- Missing prompt arguments
- Concurrent operations
- Verify error handling and error responses
A list of example servers and implementations
This page showcases various Model Context Protocol (MCP) servers that demonstrate the protocol's capabilities and versatility. These servers enable Large Language Models (LLMs) to securely access tools and data sources.
These official reference servers demonstrate core MCP features and SDK usage:
- Filesystem - Secure file operations with configurable access controls
- PostgreSQL - Read-only database access with schema inspection capabilities
- SQLite - Database interaction and business intelligence features
- Google Drive - File access and search capabilities for Google Drive
- Git - Tools to read, search, and manipulate Git repositories
- GitHub - Repository management, file operations, and GitHub API integration
- GitLab - GitLab API integration enabling project management
- Sentry - Retrieving and analyzing issues from Sentry.io
- Brave Search - Web and local search using Brave's Search API
- Fetch - Web content fetching and conversion optimized for LLM usage
- Puppeteer - Browser automation and web scraping capabilities
- Slack - Channel management and messaging capabilities
- Google Maps - Location services, directions, and place details
- Memory - Knowledge graph-based persistent memory system
- EverArt - AI image generation using various models
- Sequential Thinking - Dynamic problem-solving through thought sequences
- AWS KB Retrieval - Retrieval from AWS Knowledge Base using Bedrock Agent Runtime
These MCP servers are maintained by companies for their platforms:
- Axiom - Query and analyze logs, traces, and event data using natural language
- Browserbase - Automate browser interactions in the cloud
- Cloudflare - Deploy and manage resources on the Cloudflare developer platform
- E2B - Execute code in secure cloud sandboxes
- Neon - Interact with the Neon serverless Postgres platform
- Obsidian Markdown Notes - Read and search through Markdown notes in Obsidian vaults
- Qdrant - Implement semantic memory using the Qdrant vector search engine
- Raygun - Access crash reporting and monitoring data
- Search1API - Unified API for search, crawling, and sitemaps
- Tinybird - Interface with the Tinybird serverless ClickHouse platform
A growing ecosystem of community-developed servers extends MCP's capabilities:
- Docker - Manage containers, images, volumes, and networks
- Kubernetes - Manage pods, deployments, and services
- Linear - Project management and issue tracking
- Snowflake - Interact with Snowflake databases
- Spotify - Control Spotify playback and manage playlists
- Todoist - Task management integration
Note: Community servers are untested and should be used at your own risk. They are not affiliated with or endorsed by Anthropic.
For a complete list of community servers, visit the MCP Servers Repository.
TypeScript-based servers can be used directly with npx:
npx -y @modelcontextprotocol/server-memoryPython-based servers can be used with uvx (recommended) or pip:
# Using uvx
uvx mcp-server-git
# Using pip
pip install mcp-server-git
python -m mcp_server_gitTo use an MCP server with Claude, add it to your configuration:
{
"mcpServers": {
"memory": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-memory"]
},
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/allowed/files"]
},
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<YOUR_TOKEN>"
}
}
}
}- MCP Servers Repository - Complete collection of reference implementations and community servers
- Awesome MCP Servers - Curated list of MCP servers
- MCP CLI - Command-line inspector for testing MCP servers
- MCP Get - Tool for installing and managing MCP servers
- Supergateway - Run MCP stdio servers over SSE
Visit our GitHub Discussions to engage with the MCP community.
Get started with the Model Context Protocol (MCP)
Kotlin SDK released! Check out what else is new.
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
- A growing list of pre-built integrations that your LLM can directly plug into
- The flexibility to switch between LLM providers and vendors
- Best practices for securing your data within your infrastructure
At its core, MCP follows a client-server architecture where a host application can connect to multiple servers:
flowchart LR
subgraph "Your Computer"
Host["Host with MCP Client\n(Claude, IDEs, Tools)"]
S1["MCP Server A"]
S2["MCP Server B"]
S3["MCP Server C"]
Host <-->|"MCP Protocol"| S1
Host <-->|"MCP Protocol"| S2
Host <-->|"MCP Protocol"| S3
S1 <--> D1[("Local\nData Source A")]
S2 <--> D2[("Local\nData Source B")]
end
subgraph "Internet"
S3 <-->|"Web APIs"| D3[("Remote\nService C")]
end
- MCP Hosts: Programs like Claude Desktop, IDEs, or AI tools that want to access data through MCP
- MCP Clients: Protocol clients that maintain 1:1 connections with servers
- MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol
- Local Data Sources: Your computer's files, databases, and services that MCP servers can securely access
- Remote Services: External systems available over the internet (e.g., through APIs) that MCP servers can connect to
Choose the path that best fits your needs:
Get started building your own server to use in Claude for Desktop and other clients Get started building your own client that can integrate with all MCP servers Get started using pre-built servers in Claude for Desktop Check out our gallery of official MCP servers and implementations View the list of clients that support MCP integrations Learn how to use LLMs like Claude to speed up your MCP development Learn how to effectively debug MCP servers and integrations Test and inspect your MCP servers with our interactive debugging toolDive deeper into MCP's core concepts and capabilities:
Understand how MCP connects clients, servers, and LLMs Expose data and content from your servers to LLMs Create reusable prompt templates and workflows Enable LLMs to perform actions through your server Let your servers request completions from LLMs Learn about MCP's communication mechanismWant to contribute? Check out our Contributing Guide to learn how you can help improve MCP.
Get started building your own client that can integrate with all MCP servers.
In this tutorial, you'll learn how to build a LLM-powered chatbot client that connects to MCP servers. It helps to have gone through the Server quickstart that guides you through the basic of building your first server.
[You can find the complete code for this tutorial here.](https://github.com/modelcontextprotocol/quickstart-resources/tree/main/mcp-client)## System Requirements
Before starting, ensure your system meets these requirements:
* Mac or Windows computer
* Latest Python version installed
* Latest version of `uv` installed
## Setting Up Your Environment
First, create a new Python project with `uv`:
```bash
# Create project directory
uv init mcp-client
cd mcp-client
# Create virtual environment
uv venv
# Activate virtual environment
# On Windows:
.venv\Scripts\activate
# On Unix or MacOS:
source .venv/bin/activate
# Install required packages
uv add mcp anthropic python-dotenv
# Remove boilerplate files
rm hello.py
# Create our main file
touch client.py
```
## Setting Up Your API Key
You'll need an Anthropic API key from the [Anthropic Console](https://console.anthropic.com/settings/keys).
Create a `.env` file to store it:
```bash
# Create .env file
touch .env
```
Add your key to the `.env` file:
```bash
ANTHROPIC_API_KEY=<your key here>
```
Add `.env` to your `.gitignore`:
```bash
echo ".env" >> .gitignore
```
<Warning>
Make sure you keep your `ANTHROPIC_API_KEY` secure!
</Warning>
## Creating the Client
### Basic Client Structure
First, let's set up our imports and create the basic client class:
```python
import asyncio
from typing import Optional
from contextlib import AsyncExitStack
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv() # load environment variables from .env
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.anthropic = Anthropic()
# methods will go here
```
### Server Connection Management
Next, we'll implement the method to connect to an MCP server:
```python
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server
Args:
server_script_path: Path to the server script (.py or .js)
"""
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
```
### Query Processing Logic
Now let's add the core functionality for processing queries and handling tool calls:
```python
async def process_query(self, query: str) -> str:
"""Process a query using Claude and available tools"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in response.tools]
# Initial Claude API call
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
tools=available_tools
)
# Process response and handle tool calls
tool_results = []
final_text = []
for content in response.content:
if content.type == 'text':
final_text.append(content.text)
elif content.type == 'tool_use':
tool_name = content.name
tool_args = content.input
# Execute tool call
result = await self.session.call_tool(tool_name, tool_args)
tool_results.append({"call": tool_name, "result": result})
final_text.append(f"[Calling tool {tool_name} with args {tool_args}]")
# Continue conversation with tool results
if hasattr(content, 'text') and content.text:
messages.append({
"role": "assistant",
"content": content.text
})
messages.append({
"role": "user",
"content": result.content
})
# Get next response from Claude
response = self.anthropic.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1000,
messages=messages,
)
final_text.append(response.content[0].text)
return "\n".join(final_text)
```
### Interactive Chat Interface
Now we'll add the chat loop and cleanup functionality:
```python
async def chat_loop(self):
"""Run an interactive chat loop"""
print("\nMCP Client Started!")
print("Type your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
async def cleanup(self):
"""Clean up resources"""
await self.exit_stack.aclose()
```
### Main Entry Point
Finally, we'll add the main execution logic:
```python
async def main():
if len(sys.argv) < 2:
print("Usage: python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
import sys
asyncio.run(main())
```
You can find the complete `client.py` file [here.](https://gist.github.com/zckly/f3f28ea731e096e53b39b47bf0a2d4b1)
## Key Components Explained
### 1. Client Initialization
* The `MCPClient` class initializes with session management and API clients
* Uses `AsyncExitStack` for proper resource management
* Configures the Anthropic client for Claude interactions
### 2. Server Connection
* Supports both Python and Node.js servers
* Validates server script type
* Sets up proper communication channels
* Initializes the session and lists available tools
### 3. Query Processing
* Maintains conversation context
* Handles Claude's responses and tool calls
* Manages the message flow between Claude and tools
* Combines results into a coherent response
### 4. Interactive Interface
* Provides a simple command-line interface
* Handles user input and displays responses
* Includes basic error handling
* Allows graceful exit
### 5. Resource Management
* Proper cleanup of resources
* Error handling for connection issues
* Graceful shutdown procedures
## Common Customization Points
1. **Tool Handling**
* Modify `process_query()` to handle specific tool types
* Add custom error handling for tool calls
* Implement tool-specific response formatting
2. **Response Processing**
* Customize how tool results are formatted
* Add response filtering or transformation
* Implement custom logging
3. **User Interface**
* Add a GUI or web interface
* Implement rich console output
* Add command history or auto-completion
## Running the Client
To run your client with any MCP server:
```bash
uv run client.py path/to/server.py # python server
uv run client.py path/to/build/index.js # node server
```
<Note>
If you're continuing the weather tutorial from the server quickstart, your command might look something like this: `python client.py .../weather/src/weather/server.py`
</Note>
The client will:
1. Connect to the specified server
2. List available tools
3. Start an interactive chat session where you can:
* Enter queries
* See tool executions
* Get responses from Claude
Here's an example of what it should look like if connected to the weather server from the server quickstart:
<Frame>
<img src="https://mintlify.s3.us-west-1.amazonaws.com/mcp/images/client-claude-cli-python.png" />
</Frame>
## How It Works
When you submit a query:
1. The client gets the list of available tools from the server
2. Your query is sent to Claude along with tool descriptions
3. Claude decides which tools (if any) to use
4. The client executes any requested tool calls through the server
5. Results are sent back to Claude
6. Claude provides a natural language response
7. The response is displayed to you
## Best practices
1. **Error Handling**
* Always wrap tool calls in try-catch blocks
* Provide meaningful error messages
* Gracefully handle connection issues
2. **Resource Management**
* Use `AsyncExitStack` for proper cleanup
* Close connections when done
* Handle server disconnections
3. **Security**
* Store API keys securely in `.env`
* Validate server responses
* Be cautious with tool permissions
## Troubleshooting
### Server Path Issues
* Double-check the path to your server script is correct
* Use the absolute path if the relative path isn't working
* For Windows users, make sure to use forward slashes (/) or escaped backslashes (\\) in the path
* Verify the server file has the correct extension (.py for Python or .js for Node.js)
Example of correct path usage:
```bash
# Relative path
uv run client.py ./server/weather.py
# Absolute path
uv run client.py /Users/username/projects/mcp-server/weather.py
# Windows path (either format works)
uv run client.py C:/projects/mcp-server/weather.py
uv run client.py C:\\projects\\mcp-server\\weather.py
```
### Response Timing
* The first response might take up to 30 seconds to return
* This is normal and happens while:
* The server initializes
* Claude processes the query
* Tools are being executed
* Subsequent responses are typically faster
* Don't interrupt the process during this initial waiting period
### Common Error Messages
If you see:
* `FileNotFoundError`: Check your server path
* `Connection refused`: Ensure the server is running and the path is correct
* `Tool execution failed`: Verify the tool's required environment variables are set
* `Timeout error`: Consider increasing the timeout in your client configuration
Get started building your own server to use in Claude for Desktop and other clients.
In this tutorial, we'll build a simple MCP weather server and connect it to a host, Claude for Desktop. We'll start with a basic setup, and then progress to more complex use cases.
Many LLMs (including Claude) do not currently have the ability to fetch the forecast and severe weather alerts. Let's use MCP to solve that!
We'll build a server that exposes two tools: get-alerts and get-forecast. Then we'll connect the server to an MCP host (in this case, Claude for Desktop):

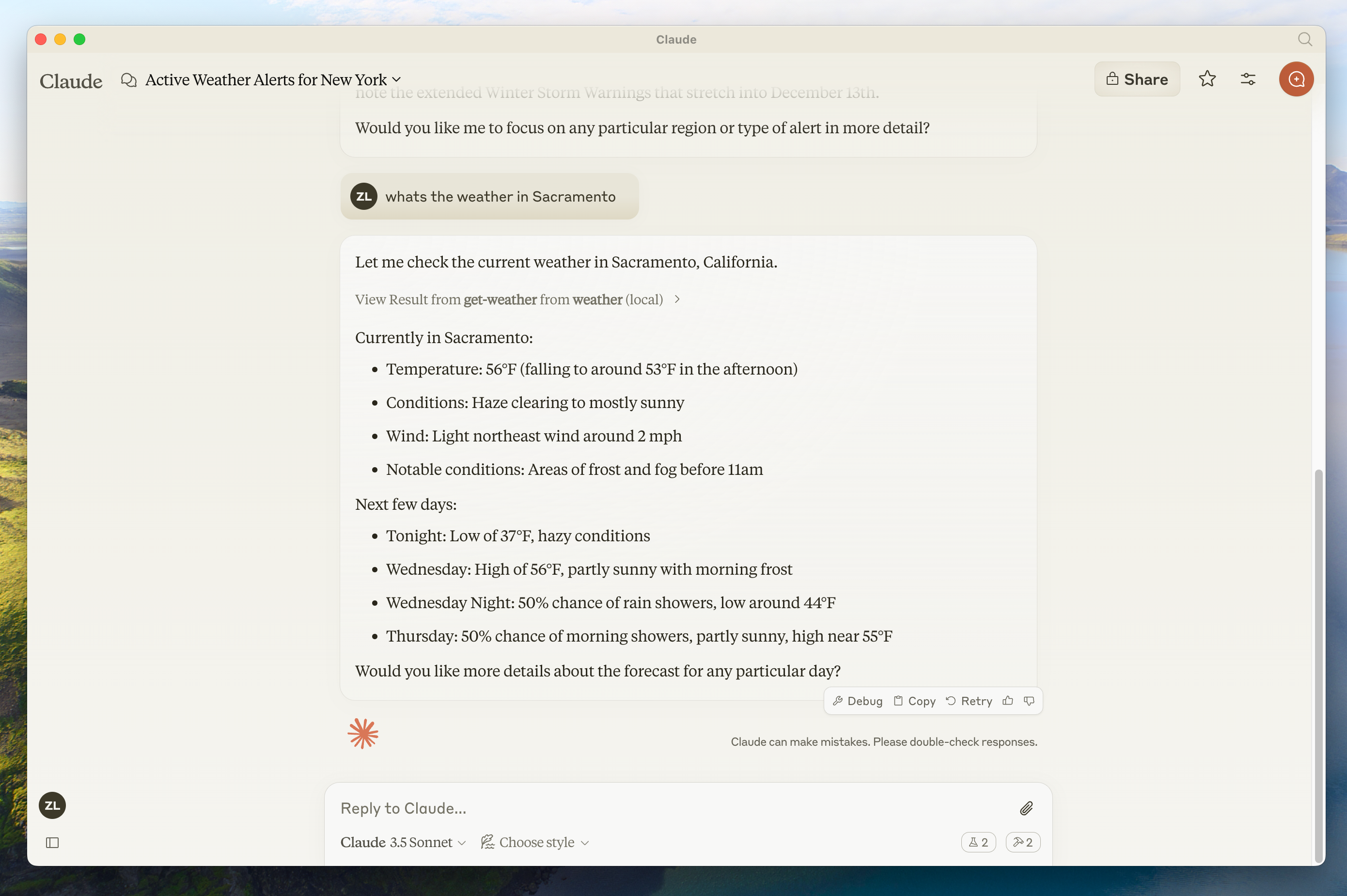
MCP servers can provide three main types of capabilities:
- Resources: File-like data that can be read by clients (like API responses or file contents)
- Tools: Functions that can be called by the LLM (with user approval)
- Prompts: Pre-written templates that help users accomplish specific tasks
This tutorial will primarily focus on tools.
Let's get started with building our weather server! [You can find the complete code for what we'll be building here.](https://github.com/modelcontextprotocol/quickstart-resources/tree/main/weather-server-python)### Prerequisite knowledge
This quickstart assumes you have familiarity with:
* Python
* LLMs like Claude
### System requirements
* Python 3.10 or higher installed.
* You must use the Python MCP SDK 1.2.0 or higher.
### Set up your environment
First, let's install `uv` and set up our Python project and environment:
<CodeGroup>
```bash MacOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
```
```powershell Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
</CodeGroup>
Make sure to restart your terminal afterwards to ensure that the `uv` command gets picked up.
Now, let's create and set up our project:
<CodeGroup>
```bash MacOS/Linux
# Create a new directory for our project
uv init weather
cd weather
# Create virtual environment and activate it
uv venv
source .venv/bin/activate
# Install dependencies
uv add "mcp[cli]" httpx
# Create our server file
touch weather.py
```
```powershell Windows
# Create a new directory for our project
uv init weather
cd weather
# Create virtual environment and activate it
uv venv
.venv\Scripts\activate
# Install dependencies
uv add mcp[cli] httpx
# Create our server file
new-item weather.py
```
</CodeGroup>
Now let's dive into building your server.
## Building your server
### Importing packages and setting up the instance
Add these to the top of your `weather.py`:
```python
from typing import Any
import httpx
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("weather")
# Constants
NWS_API_BASE = "https://api.weather.gov"
USER_AGENT = "weather-app/1.0"
```
The FastMCP class uses Python type hints and docstrings to automatically generate tool definitions, making it easy to create and maintain MCP tools.
### Helper functions
Next, let's add our helper functions for querying and formatting the data from the National Weather Service API:
```python
async def make_nws_request(url: str) -> dict[str, Any] | None:
"""Make a request to the NWS API with proper error handling."""
headers = {
"User-Agent": USER_AGENT,
"Accept": "application/geo+json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception:
return None
def format_alert(feature: dict) -> str:
"""Format an alert feature into a readable string."""
props = feature["properties"]
return f"""
Event: {props.get('event', 'Unknown')}
Area: {props.get('areaDesc', 'Unknown')}
Severity: {props.get('severity', 'Unknown')}
Description: {props.get('description', 'No description available')}
Instructions: {props.get('instruction', 'No specific instructions provided')}
"""
```
### Implementing tool execution
The tool execution handler is responsible for actually executing the logic of each tool. Let's add it:
```python
@mcp.tool()
async def get_alerts(state: str) -> str:
"""Get weather alerts for a US state.
Args:
state: Two-letter US state code (e.g. CA, NY)
"""
url = f"{NWS_API_BASE}/alerts/active/area/{state}"
data = await make_nws_request(url)
if not data or "features" not in data:
return "Unable to fetch alerts or no alerts found."
if not data["features"]:
return "No active alerts for this state."
alerts = [format_alert(feature) for feature in data["features"]]
return "\n---\n".join(alerts)
@mcp.tool()
async def get_forecast(latitude: float, longitude: float) -> str:
"""Get weather forecast for a location.
Args:
latitude: Latitude of the location
longitude: Longitude of the location
"""
# First get the forecast grid endpoint
points_url = f"{NWS_API_BASE}/points/{latitude},{longitude}"
points_data = await make_nws_request(points_url)
if not points_data:
return "Unable to fetch forecast data for this location."
# Get the forecast URL from the points response
forecast_url = points_data["properties"]["forecast"]
forecast_data = await make_nws_request(forecast_url)
if not forecast_data:
return "Unable to fetch detailed forecast."
# Format the periods into a readable forecast
periods = forecast_data["properties"]["periods"]
forecasts = []
for period in periods[:5]: # Only show next 5 periods
forecast = f"""
{period['name']}:
Temperature: {period['temperature']}°{period['temperatureUnit']}
Wind: {period['windSpeed']} {period['windDirection']}
Forecast: {period['detailedForecast']}
"""
forecasts.append(forecast)
return "\n---\n".join(forecasts)
```
### Running the server
Finally, let's initialize and run the server:
```python
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')
```
Your server is complete! Run `uv run weather.py` to confirm that everything's working.
Let's now test your server from an existing MCP host, Claude for Desktop.
## Testing your server with Claude for Desktop
<Note>
Claude for Desktop is not yet available on Linux. Linux users can proceed to the [Building a client](/quickstart/client) tutorial to build an MCP client that connects to the server we just built.
</Note>
First, make sure you have Claude for Desktop installed. [You can install the latest version
here.](https://claude.ai/download) If you already have Claude for Desktop, **make sure it's updated to the latest version.**
We'll need to configure Claude for Desktop for whichever MCP servers you want to use. To do this, open your Claude for Desktop App configuration at `~/Library/Application Support/Claude/claude_desktop_config.json` in a text editor. Make sure to create the file if it doesn't exist.
For example, if you have [VS Code](https://code.visualstudio.com/) installed:
<Tabs>
<Tab title="MacOS/Linux">
```bash
code ~/Library/Application\ Support/Claude/claude_desktop_config.json
```
</Tab>
<Tab title="Windows">
```powershell
code $env:AppData\Claude\claude_desktop_config.json
```
</Tab>
</Tabs>
You'll then add your servers in the `mcpServers` key. The MCP UI elements will only show up in Claude for Desktop if at least one server is properly configured.
In this case, we'll add our single weather server like so:
<Tabs>
<Tab title="MacOS/Linux">
```json Python
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather",
"run",
"weather.py"
]
}
}
}
```
</Tab>
<Tab title="Windows">
```json Python
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"C:\\ABSOLUTE\\PATH\\TO\\PARENT\\FOLDER\\weather",
"run",
"weather.py"
]
}
}
}
```
</Tab>
</Tabs>
<Warning>
You may need to put the full path to the `uv` executable in the `command` field. You can get this by running `which uv` on MacOS/Linux or `where uv` on Windows.
</Warning>
<Note>
Make sure you pass in the absolute path to your server.
</Note>
This tells Claude for Desktop:
1. There's an MCP server named "weather"
2. To launch it by running `uv --directory /ABSOLUTE/PATH/TO/PARENT/FOLDER/weather run weather`
Save the file, and restart **Claude for Desktop**.
### Prerequisite knowledge
This quickstart assumes you have familiarity with:
* TypeScript
* LLMs like Claude
### System requirements
For TypeScript, make sure you have the latest version of Node installed.
### Set up your environment
First, let's install Node.js and npm if you haven't already. You can download them from [nodejs.org](https://nodejs.org/).
Verify your Node.js installation:
```bash
node --version
npm --version
```
For this tutorial, you'll need Node.js version 16 or higher.
Now, let's create and set up our project:
<CodeGroup>
```bash MacOS/Linux
# Create a new directory for our project
mkdir weather
cd weather
# Initialize a new npm project
npm init -y
# Install dependencies
npm install @modelcontextprotocol/sdk zod
npm install -D @types/node typescript
# Create our files
mkdir src
touch src/index.ts
```
```powershell Windows
# Create a new directory for our project
md weather
cd weather
# Initialize a new npm project
npm init -y
# Install dependencies
npm install @modelcontextprotocol/sdk zod
npm install -D @types/node typescript
# Create our files
md src
new-item src\index.ts
```
</CodeGroup>
Update your package.json to add type: "module" and a build script:
```json package.json
{
"type": "module",
"bin": {
"weather": "./build/index.js"
},
"scripts": {
"build": "tsc && node -e \"require('fs').chmodSync('build/index.js', '755')\"",
},
"files": [
"build"
],
}
```
Create a `tsconfig.json` in the root of your project:
```json tsconfig.json
{
"compilerOptions": {
"target": "ES2022",
"module": "Node16",
"moduleResolution": "Node16",
"outDir": "./build",
"rootDir": "./src",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true
},
"include": ["src/**/*"],
"exclude": ["node_modules"]
}
```
Now let's dive into building your server.
## Building your server
### Importing packages and setting up the instance
Add these to the top of your `src/index.ts`:
```typescript
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const NWS_API_BASE = "https://api.weather.gov";
const USER_AGENT = "weather-app/1.0";
// Create server instance
const server = new McpServer({
name: "weather",
version: "1.0.0",
});
```
### Helper functions
Next, let's add our helper functions for querying and formatting the data from the National Weather Service API:
```typescript
// Helper function for making NWS API requests
async function makeNWSRequest<T>(url: string): Promise<T | null> {
const headers = {
"User-Agent": USER_AGENT,
Accept: "application/geo+json",
};
try {
const response = await fetch(url, { headers });
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return (await response.json()) as T;
} catch (error) {
console.error("Error making NWS request:", error);
return null;
}
}
interface AlertFeature {
properties: {
event?: string;
areaDesc?: string;
severity?: string;
status?: string;
headline?: string;
};
}
// Format alert data
function formatAlert(feature: AlertFeature): string {
const props = feature.properties;
return [
`Event: ${props.event || "Unknown"}`,
`Area: ${props.areaDesc || "Unknown"}`,
`Severity: ${props.severity || "Unknown"}`,
`Status: ${props.status || "Unknown"}`,
`Headline: ${props.headline || "No headline"}`,
"---",
].join("\n");
}
interface ForecastPeriod {
name?: string;
temperature?: number;
temperatureUnit?: string;
windSpeed?: string;
windDirection?: string;
shortForecast?: string;
}
interface AlertsResponse {
features: AlertFeature[];
}
interface PointsResponse {
properties: {
forecast?: string;
};
}
interface ForecastResponse {
properties: {
periods: ForecastPeriod[];
};
}
```
### Implementing tool execution
The tool execution handler is responsible for actually executing the logic of each tool. Let's add it:
```typescript
// Register weather tools
server.tool(
"get-alerts",
"Get weather alerts for a state",
{
state: z.string().length(2).describe("Two-letter state code (e.g. CA, NY)"),
},
async ({ state }) => {
const stateCode = state.toUpperCase();
const alertsUrl = `${NWS_API_BASE}/alerts?area=${stateCode}`;
const alertsData = await makeNWSRequest<AlertsResponse>(alertsUrl);
if (!alertsData) {
return {
content: [
{
type: "text",
text: "Failed to retrieve alerts data",
},
],
};
}
const features = alertsData.features || [];
if (features.length === 0) {
return {
content: [
{
type: "text",
text: `No active alerts for ${stateCode}`,
},
],
};
}
const formattedAlerts = features.map(formatAlert);
const alertsText = `Active alerts for ${stateCode}:\n\n${formattedAlerts.join("\n")}`;
return {
content: [
{
type: "text",
text: alertsText,
},
],
};
},
);
server.tool(
"get-forecast",
"Get weather forecast for a location",
{
latitude: z.number().min(-90).max(90).describe("Latitude of the location"),
longitude: z.number().min(-180).max(180).describe("Longitude of the location"),
},
async ({ latitude, longitude }) => {
// Get grid point data
const pointsUrl = `${NWS_API_BASE}/points/${latitude.toFixed(4)},${longitude.toFixed(4)}`;
const pointsData = await makeNWSRequest<PointsResponse>(pointsUrl);
if (!pointsData) {
return {
content: [
{
type: "text",
text: `Failed to retrieve grid point data for coordinates: ${latitude}, ${longitude}. This location may not be supported by the NWS API (only US locations are supported).`,
},
],
};
}
const forecastUrl = pointsData.properties?.forecast;
if (!forecastUrl) {
return {
content: [
{
type: "text",
text: "Failed to get forecast URL from grid point data",
},
],
};
}
// Get forecast data
const forecastData = await makeNWSRequest<ForecastResponse>(forecastUrl);
if (!forecastData) {
return {
content: [
{
type: "text",
text: "Failed to retrieve forecast data",
},
],
};
}
const periods = forecastData.properties?.periods || [];
if (periods.length === 0) {
return {
content: [
{
type: "text",
text: "No forecast periods available",
},
],
};
}
// Format forecast periods
const formattedForecast = periods.map((period: ForecastPeriod) =>
[
`${period.name || "Unknown"}:`,
`Temperature: ${period.temperature || "Unknown"}°${period.temperatureUnit || "F"}`,
`Wind: ${period.windSpeed || "Unknown"} ${period.windDirection || ""}`,
`${period.shortForecast || "No forecast available"}`,
"---",
].join("\n"),
);
const forecastText = `Forecast for ${latitude}, ${longitude}:\n\n${formattedForecast.join("\n")}`;
return {
content: [
{
type: "text",
text: forecastText,
},
],
};
},
);
```
### Running the server
Finally, implement the main function to run the server:
```typescript
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error("Weather MCP Server running on stdio");
}
main().catch((error) => {
console.error("Fatal error in main():", error);
process.exit(1);
});
```
Make sure to run `npm run build` to build your server! This is a very important step in getting your server to connect.
Let's now test your server from an existing MCP host, Claude for Desktop.
## Testing your server with Claude for Desktop
<Note>
Claude for Desktop is not yet available on Linux. Linux users can proceed to the [Building a client](/quickstart/client) tutorial to build an MCP client that connects to the server we just built.
</Note>
First, make sure you have Claude for Desktop installed. [You can install the latest version
here.](https://claude.ai/download) If you already have Claude for Desktop, **make sure it's updated to the latest version.**
We'll need to configure Claude for Desktop for whichever MCP servers you want to use. To do this, open your Claude for Desktop App configuration at `~/Library/Application Support/Claude/claude_desktop_config.json` in a text editor. Make sure to create the file if it doesn't exist.
For example, if you have [VS Code](https://code.visualstudio.com/) installed:
<Tabs>
<Tab title="MacOS/Linux">
```bash
code ~/Library/Application\ Support/Claude/claude_desktop_config.json
```
</Tab>
<Tab title="Windows">
```powershell
code $env:AppData\Claude\claude_desktop_config.json
```
</Tab>
</Tabs>
You'll then add your servers in the `mcpServers` key. The MCP UI elements will only show up in Claude for Desktop if at least one server is properly configured.
In this case, we'll add our single weather server like so:
<Tabs>
<Tab title="MacOS/Linux">
<CodeGroup>
```json Node
{
"mcpServers": {
"weather": {
"command": "node",
"args": [
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather/build/index.js"
]
}
}
}
```
</CodeGroup>
</Tab>
<Tab title="Windows">
<CodeGroup>
```json Node
{
"mcpServers": {
"weather": {
"command": "node",
"args": [
"C:\\PATH\\TO\\PARENT\\FOLDER\\weather\\build\\index.js"
]
}
}
}
```
</CodeGroup>
</Tab>
</Tabs>
This tells Claude for Desktop:
1. There's an MCP server named "weather"
2. Launch it by running `node /ABSOLUTE/PATH/TO/PARENT/FOLDER/weather/build/index.js`
Save the file, and restart **Claude for Desktop**.
Let's make sure Claude for Desktop is picking up the two tools we've exposed in our weather server. You can do this by looking for the hammer <img src="https://mintlify.s3.us-west-1.amazonaws.com/mcp/images/claude-desktop-mcp-hammer-icon.svg" style={{display: 'inline', margin: 0, height: '1.3em'}} /> icon:

After clicking on the hammer icon, you should see two tools listed:

If your server isn't being picked up by Claude for Desktop, proceed to the Troubleshooting section for debugging tips.
If the hammer icon has shown up, you can now test your server by running the following commands in Claude for Desktop:
- What's the weather in Sacramento?
- What are the active weather alerts in Texas?
When you ask a question:
- The client sends your question to Claude
- Claude analyzes the available tools and decides which one(s) to use
- The client executes the chosen tool(s) through the MCP server
- The results are sent back to Claude
- Claude formulates a natural language response
- The response is displayed to you!
Claude.app logging related to MCP is written to log files in `~/Library/Logs/Claude`:
* `mcp.log` will contain general logging about MCP connections and connection failures.
* Files named `mcp-server-SERVERNAME.log` will contain error (stderr) logging from the named server.
You can run the following command to list recent logs and follow along with any new ones:
```bash
# Check Claude's logs for errors
tail -n 20 -f ~/Library/Logs/Claude/mcp*.log
```
**Server not showing up in Claude**
1. Check your `claude_desktop_config.json` file syntax
2. Make sure the path to your project is absolute and not relative
3. Restart Claude for Desktop completely
**Tool calls failing silently**
If Claude attempts to use the tools but they fail:
1. Check Claude's logs for errors
2. Verify your server builds and runs without errors
3. Try restarting Claude for Desktop
**None of this is working. What do I do?**
Please refer to our [debugging guide](/docs/tools/debugging) for better debugging tools and more detailed guidance.
This usually means either:
1. The coordinates are outside the US
2. The NWS API is having issues
3. You're being rate limited
Fix:
* Verify you're using US coordinates
* Add a small delay between requests
* Check the NWS API status page
**Error: No active alerts for \[STATE]**
This isn't an error - it just means there are no current weather alerts for that state. Try a different state or check during severe weather.
Get started using pre-built servers in Claude for Desktop.
In this tutorial, you will extend Claude for Desktop so that it can read from your computer's file system, write new files, move files, and even search files.
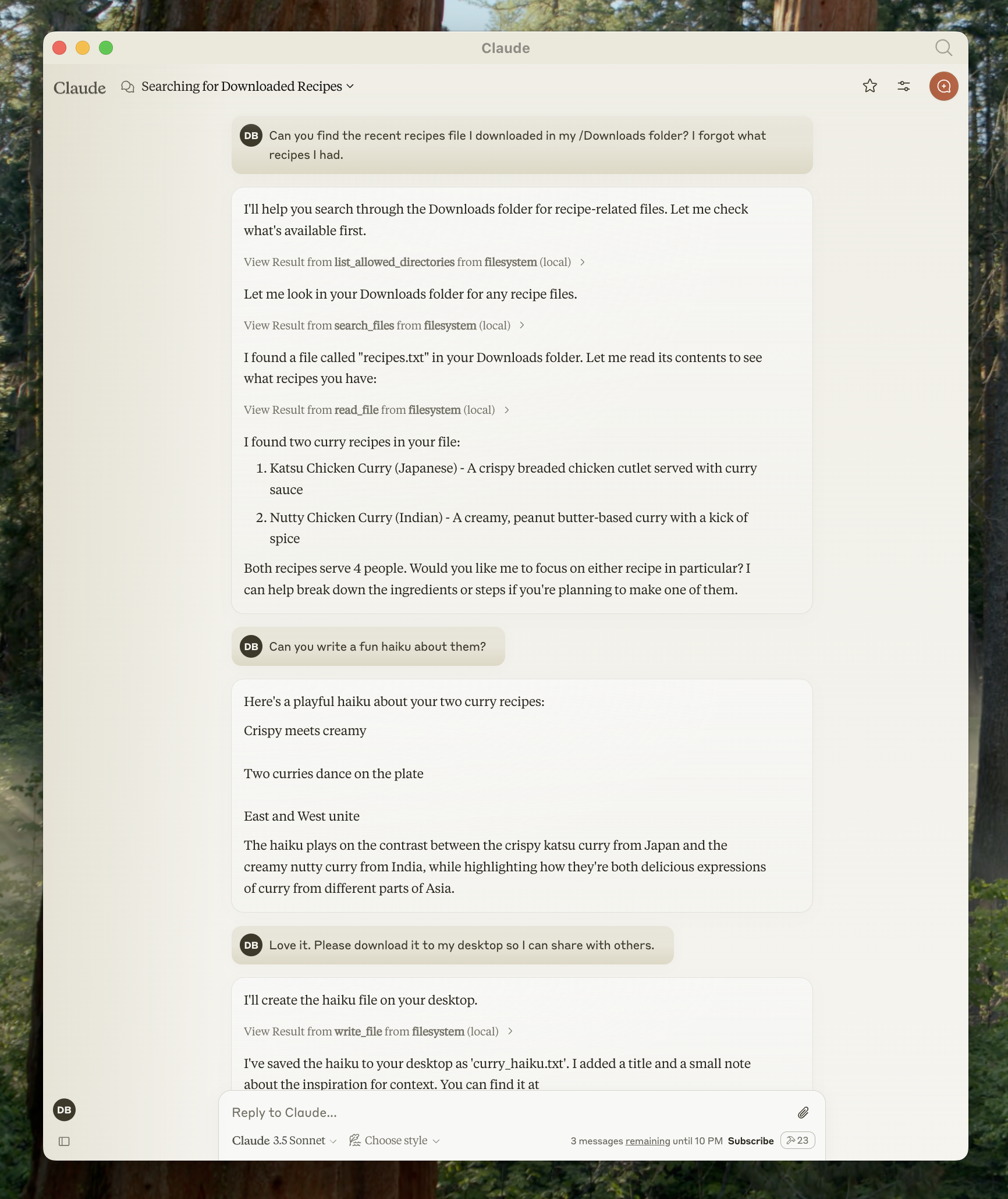
Don't worry — it will ask you for your permission before executing these actions!
Start by downloading Claude for Desktop, choosing either macOS or Windows. (Linux is not yet supported for Claude for Desktop.)
Follow the installation instructions.
If you already have Claude for Desktop, make sure it's on the latest version by clicking on the Claude menu on your computer and selecting "Check for Updates..."
Because servers are locally run, MCP currently only supports desktop hosts. Remote hosts are in active development.To add this filesystem functionality, we will be installing a pre-built Filesystem MCP Server to Claude for Desktop. This is one of dozens of servers created by Anthropic and the community.
Get started by opening up the Claude menu on your computer and select "Settings..." Please note that these are not the Claude Account Settings found in the app window itself.
This is what it should look like on a Mac:
Click on "Developer" in the lefthand bar of the Settings pane, and then click on "Edit Config":
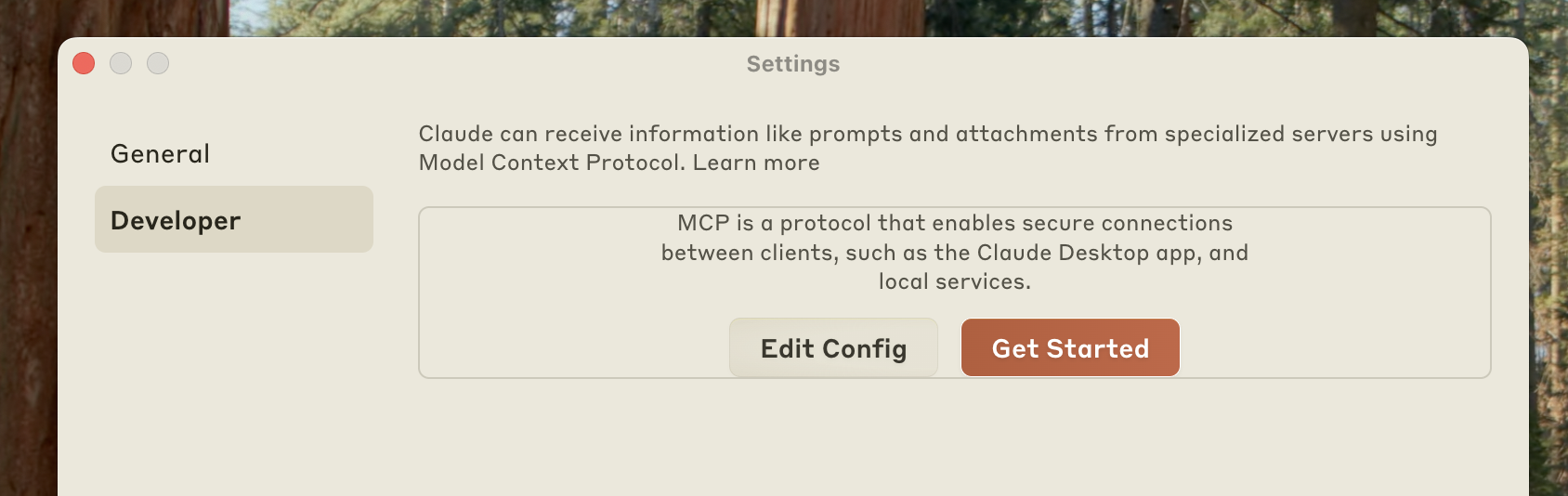
This will create a configuration file at:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
if you don't already have one, and will display the file in your file system.
Open up the configuration file in any text editor. Replace the file contents with this:
```json { "mcpServers": { "filesystem": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "/Users/username/Desktop", "/Users/username/Downloads" ] } } } ``` ```json { "mcpServers": { "filesystem": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "C:\\Users\\username\\Desktop", "C:\\Users\\username\\Downloads" ] } } } ```Make sure to replace username with your computer's username. The paths should point to valid directories that you want Claude to be able to access and modify. It's set up to work for Desktop and Downloads, but you can add more paths as well.
You will also need Node.js on your computer for this to run properly. To verify you have Node installed, open the command line on your computer.
- On macOS, open the Terminal from your Applications folder
- On Windows, press Windows + R, type "cmd", and press Enter
Once in the command line, verify you have Node installed by entering in the following command:
node --versionIf you get an error saying "command not found" or "node is not recognized", download Node from nodejs.org.
**How does the configuration file work?**This configuration file tells Claude for Dekstop which MCP servers to start up every time you start the application. In this case, we have added one server called "filesystem" that will use the Node npx command to install and run @modelcontextprotocol/server-filesystem. This server, described here, will let you access your file system in Claude for Desktop.
Claude for Desktop will run the commands in the configuration file with the permissions of your user account, and access to your local files. Only add commands if you understand and trust the source.
After updating your configuration file, you need to restart Claude for Desktop.
Upon restarting, you should see a hammer <img src="https://mintlify.s3.us-west-1.amazonaws.com/mcp/images/claude-desktop-mcp-hammer-icon.svg" style={{display: 'inline', margin: 0, height: '1.3em'}} /> icon in the bottom right corner of the input box:

After clicking on the hammer icon, you should see the tools that come with the Filesystem MCP Server:

If your server isn't being picked up by Claude for Desktop, proceed to the Troubleshooting section for debugging tips.
You can now talk to Claude and ask it about your filesystem. It should know when to call the relevant tools.
Things you might try asking Claude:
- Can you write a poem and save it to my desktop?
- What are some work-related files in my downloads folder?
- Can you take all the images on my desktop and move them to a new folder called "Images"?
As needed, Claude will call the relevant tools and seek your approval before taking an action:
{kind=link}
{kind=link}
<Tabs>
<Tab title="MacOS/Linux">
```bash
npx -y @modelcontextprotocol/server-filesystem /Users/username/Desktop /Users/username/Downloads
```
</Tab>
<Tab title="Windows">
```bash
npx -y @modelcontextprotocol/server-filesystem C:\Users\username\Desktop C:\Users\username\Downloads
```
</Tab>
</Tabs>
* macOS: `~/Library/Logs/Claude`
* Windows: `%APPDATA%\Claude\logs`
* `mcp.log` will contain general logging about MCP connections and connection failures.
* Files named `mcp-server-SERVERNAME.log` will contain error (stderr) logging from the named server.
You can run the following command to list recent logs and follow along with any new ones (on Windows, it will only show recent logs):
<Tabs>
<Tab title="MacOS/Linux">
```bash
# Check Claude's logs for errors
tail -n 20 -f ~/Library/Logs/Claude/mcp*.log
```
</Tab>
<Tab title="Windows">
```bash
type "%APPDATA%\Claude\logs\mcp*.log"
```
</Tab>
</Tabs>
1. Check Claude's logs for errors
2. Verify your server builds and runs without errors
3. Try restarting Claude for Desktop
Speed up your MCP development using LLMs such as Claude!
This guide will help you use LLMs to help you build custom Model Context Protocol (MCP) servers and clients. We'll be focusing on Claude for this tutorial, but you can do this with any frontier LLM.
Before starting, gather the necessary documentation to help Claude understand MCP:
- Visit https://modelcontextprotocol.io/llms-full.txt and copy the full documentation text
- Navigate to either the MCP TypeScript SDK or Python SDK repository
- Copy the README files and other relevant documentation
- Paste these documents into your conversation with Claude
Once you've provided the documentation, clearly describe to Claude what kind of server you want to build. Be specific about:
- What resources your server will expose
- What tools it will provide
- Any prompts it should offer
- What external systems it needs to interact with
For example:
Build an MCP server that:
- Connects to my company's PostgreSQL database
- Exposes table schemas as resources
- Provides tools for running read-only SQL queries
- Includes prompts for common data analysis tasks
When working with Claude on MCP servers:
- Start with the core functionality first, then iterate to add more features
- Ask Claude to explain any parts of the code you don't understand
- Request modifications or improvements as needed
- Have Claude help you test the server and handle edge cases
Claude can help implement all the key MCP features:
- Resource management and exposure
- Tool definitions and implementations
- Prompt templates and handlers
- Error handling and logging
- Connection and transport setup
When building MCP servers with Claude:
- Break down complex servers into smaller pieces
- Test each component thoroughly before moving on
- Keep security in mind - validate inputs and limit access appropriately
- Document your code well for future maintenance
- Follow MCP protocol specifications carefully
After Claude helps you build your server:
- Review the generated code carefully
- Test the server with the MCP Inspector tool
- Connect it to Claude.app or other MCP clients
- Iterate based on real usage and feedback
Remember that Claude can help you modify and improve your server as requirements change over time.
Need more guidance? Just ask Claude specific questions about implementing MCP features or troubleshooting issues that arise.