-
Author: Sébastien Mosser mosser@i3s.unice.fr
-
Reviewer: Anne-Marie Déry pinna@polytech.unice.fr
-
Version: 02.2016
-
Prev.: Message interceptors to support the NTUI (Never Trust User Input) golden rule
We will rely on the Java Persistence API (JPA) to support relational database mappings. The version bundled in the OpenEJB stack is OpenJPA. JPA will enhance annotated classes to create persistence-aware versions of these classes that will be used instead of the one we wrote. This step must be triggered during the compilation process. To introduce this step in the build chain, we simply ask Maven to do so, in the pom.xml file. With the following configuration, it will process all the classes in the entities package (see the includes tag):
<plugin>
<groupId>org.apache.openjpa</groupId>
<artifactId>openjpa-maven-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<includes>**/entities/*.class</includes>
<addDefaultConstructor>true</addDefaultConstructor>
<enforcePropertyRestrictions>true</enforcePropertyRestrictions>
</configuration>
<executions>
<execution>
<id>enhancer</id>
<phase>process-classes</phase>
<goals>
<goal>enhance</goal>
</goals>
</execution>
</executions>
</plugin>A Persistence Unit (PU) is a logical set of entities that persists together and share common persistence properties. For CoD, we have to declare such a persistence Unit that contains the three following classes: Item, Customer and Order. Enumerations do not need to be declared in the unit, as they will not be persistent per se. The unit is defined in a file names resources/META-INF/persistence.xml. By declaring the unit as relying on the Java Transaction API (JTA) for transactions, the container will activate mechanisms that automatically support transactions, directly at the container level. This mechanism can obviously be bypassed manually when needed.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="tcf_persistence_unit" transaction-type="JTA">
<jta-data-source>TCFDataSource</jta-data-source>
<class>fr.unice.polytech.isa.tcf.entities.Customer</class>
<class>fr.unice.polytech.isa.tcf.entities.Item</class>
<class>fr.unice.polytech.isa.tcf.entities.Order</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<properties>
<property name="openjpa.jdbc.SynchronizeMappings" value="buildSchema(ForeignKeys=true)"/>
</properties>
</persistence-unit>
</persistence>Data sources are the concrete link between the data model defined at the application level and the physical database system that will store the related entities.
The CoD system needs two data sources: (i) a volatile database to be used for test purposes and (ii) a real one for production purpose. In this course, we will use HSQLDB, as the associated drivers are already included for free in the OpenEJB stack. One can use any JDBC compliant database (e.g., MySQL, Postgres, MongoDB, Derby), it is just a matter of configuring the container to load the right driver. We will simulate test and production environment using the following assumption: the test suite will be run against an in-memory database (stored directly inside the RAM), where the production environment will rely on a file-based one.
As Arquilian is used for testing purpose, it is quite logical that an Arquilian configuration is required for tshis very purpose. In the arquilian.xml configuration file, the following properties will configure the database to be used for test purposes.
- The
JdbcUrlwe used asks for an in-memory database with thememkeyword;- The
shutdown=trueoption will shutdown the database after the last connection;
- The
- The
JtaManagedoption will support transactions at the container level for the driver; - the
LogSqloption support the logging of the SQL queries generated by JPA on your behalf.
<property name="properties">
my-datasource = new://Resource?type=DataSource
my-datasource.JdbcUrl = jdbc:hsqldb:mem:TCFDB;shutdown=true
my-datasource.UserName = sa
my-datasource.Password =
my-datasource.JtaManaged = true
my-datasource.LogSql = true
</property>From the application server point of view, a data source is simply a kind of available external resources, among others. Such resources are defined in the WEB-INF/resources.xml file.
<resources>
<Resource id="production" type="DataSource">
JdbcDriver org.hsqldb.jdbcDriver
JdbcUrl jdbc:hsqldb:file:proddb
UserName sa
Password
LogSql true
JtaManaged true
</Resource>
</resources>The syntax is different as it is not loaded using the same mechanism than the one used by Arquilian, but the content is the very same. Excepting from the URL, which here refers to a local resource called proddb (actually not a single file but a bunch of related ones). This file will be handled by TomEE at runtime and will survive the termination of the TomEE process. According to our local setup, the files will be stored in the target/apache-tomee directory. Which obviously means that calling mvn clean will destroy the database contents.
Your favorite IDE can be used to access to the contents of the persistent database. It simply needs to configure a local HSQLDB source, with default login (sa). But be very careful, the file-based database cannot be accessed by two different applications at the very same time. As a consequence, the database is locked during the execution of the application that consumes it. If you forgot to disconnect your IDE from the file, you'll be able to start the application server but attempting to access to the storage layer will result in a timeout exception. Use with caution, and rely on tests instead of attempts. the first one are reproducible and ensure that you are not regressing, while the second ones ... does not worth a lot from a software engineering point of view.
If you really want to proceed, be sure to use the full path to reach your local file. Here is an example of configuration using IntelliJ 16 Ultimate Edition.
Now, our technical setup is complete, once and for all. We can focus on the business part, i.e., storing cookies, customers and related orders.
EJB Entities are very like EJB sessions, as they share the EJB philosophy, i.e., simple POJO with annotations. Excepting that the annotations here are related to persistences instead of functional concerns. Ad that entities needs a little bit more than simple annotations:
- An empty constructor
- A proper
equalsmethod that relies on business items - a proper
hashCodemethod to support objects identification in caches.
The equals and hashCode methods must relies on so-called business keys. It is extremely dangerous (and an hideous abstraction leak) to rely at the application level on elements generated by the database layer: you are losing control on object uniqueness. As a consequence, you must be able to define how two entities are equals from a business point of view (the architectural level), and not a technical one (the database one).
Let's take an example. You have a customer in your database, named "sebastien", with credit card number "1234567890", no orders, and a primary key identifier "42". A request to create a new customer named "sebastien", with credit card number "1234567890" is received by your system. Obviously, his order set is empty, and no primary key were assigned to this newcomer. Are these two entities equals? From a database point of view: the answer is no, their primary key differs. From a business point of view, i.e., the very purpose of the system, the answer is yes, they represent the very same person. So here is a simple golden rule: "never ever use a database primary key as part of your business object equality definition"
An Item does not exists by itself: it is part of a given cart, or a given order. As a consequence, it is an Embeddable entity. Its associated cookie is based on an enumeration, and thus declared as an Enumerated property. For clarity and log purposes, we prefer to use string literals (the cookie's name) instead of ordinals (the cookie's index in the enum) at the persistence level. The quantity cannot be null, so we simply add a validation constraint that will prevent to persist an entity with a null quantity of cookies. The cookie cannot be null too, so we use the same kind of constraints.
@Embeddable
public class Item implements Serializable {
@Enumerated(EnumType.STRING)
@NotNull
private Cookies cookie;
@NotNull
private int quantity;
//...
}The previously defined Order class relies on plain java UUIDs to identify orders among others. UUIDs are not part of the JPA specification, and cannot be used directly. We go here for the quick and dirty solution, i.e., altering our data model to store ids as numbers instead of strings.
- The
idfield is the refactored as an int; - The
orderStatusfield refers to an enumerated, this is the very same situation than the one encountered before for the cookie stored inside an item; - The
customerattribute refers to another entity, and considering that (i) an order will belong to a single customer and (ii) a customer will hopefully make multiple orders, we annotate this attribute as aManyToOne: many orders related to one single customer; - The
itemsfield is a collection of elements that cannot exists by themselves (as we defined an Item as an embeddable entity). We use the brand newElementCollectionannotation (available since JPA 2.0) that implement this intention.
We are still encountering a big issue. The Order class will be, like the others, automatically translated by OpenJPA into a SQL entity, i.e., a table named ORDER. You're not seeing the point? Imagine the query that will select the data associated to a given customer, and order her orders based on their status. Seeing it? Ordering the orders? ORDER is a SQL keyword, and thus cannot be used as a regular identifier! We need to adapt the way JPA will map the name, using the @Table annotation.
@Entity
@Table(name= "orders")
public class Order implements Serializable {
@Id
@GeneratedValue
private int id;
@ManyToOne
private Customer customer;
@ElementCollection
private Set<Item> items;
@Enumerated(EnumType.STRING)
private OrderStatus status;
// ...
}Customers were previously identified by their name. This is not reasonable anymore, so we add a primary key field to ensure better unicity. With respect to the other fields:
- The
namecannot be null; - The
creditCardfollows a regular pattern that we should verify to avoid storing inconsistent data. The pattern is defined as a regular expression (10 digits, i.e.,\\d{10}+in java words); - The
ordersfield is actually the counterpart of thecustomerone in theOrderentity. As a consequence it is defined as aOneToManyrelationship: one customer is linked to many orders. As the customer is the owner of the orders, it defines themappedByattribute needed to ensure the bidirectional relationship.
@Entity
public class Customer implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private int id;
@NotNull
private String name;
@NotNull
@Pattern(regexp = "\\d{10}+", message = "Invalid creditCardNumber")
private String creditCard;
@OneToMany(mappedBy = "customer")
private Set<Order> orders = new HashSet<>();
// ...
}When writing or when using the generated ones, be careful that your equals and hashcode methods do not introduce cyclic calls (symptom: StackOverflowError). For example, by default the generated hashcode methods for the Customer & Order classes looks like the following:
// Customer
public int hashCode() {
int result = getName() != null ? getName().hashCode() : 0;
result = 31 * result + (getCreditCard() != null ? getCreditCard().hashCode() : 0);
result = 31 * result + (getOrders() != null ? getOrders().hashCode() : 0);
return result;
}
// Order
public int hashCode() {
int result = getCustomer() != null ? getCustomer().hashCode() : 0;
result = 31 * result + (getItems() != null ? getItems().hashCode() : 0);
result = 31 * result + (getStatus() != null ? getStatus().hashCode() : 0);
return result;
}The previous code obviously triggers an infinite loops (this is the very same situation for the equals method). Be very careful when designing these methods, as the semantics of the operation must remain consistent while avoiding cyclic references. In this case, we simply break the cycle by calling getCustomer().getName().hashcode() instead of getCustomer().hashCode().
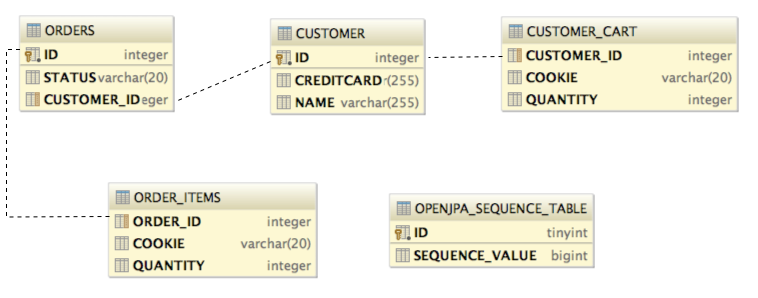
Based on these annotations, the JPA layer generates the following database schema.
An entity lives in the application container like a session component. The only difference is that we will need an EntityManager and a transactional context to access it. Tests are implemented as classical components tests, using Arquilian.
The entity manager will be injected by the container. One simply asks for a PersistenceContext, which will be provided by the container. As we are relying on JTA for transactional 'stuff', we can delegate it to the container thanks to the @Transactional annotation. It will ensure that a new transaction is created at the beginning of the test, and commited at the end, automatically.
@PersistenceContext
private EntityManager entityManager;
@Test
@Transactional(TransactionMode.COMMIT)
public void testCustomerStorage() throws Exception {
Customer c = new Customer(); // create an empty customer
c.setCreditCard("1234567890"); // setting up details
c.setName("John Doe");
assertEquals(0,c.getId()); // primary key is the default one, i.e., 0
entityManager.persist(c); // making the entity persistent
int id = c.getId();
assertNotEquals(0,id); // an id was assigned by the persistence layer
Customer stored = (Customer) entityManager.find(Customer.class, id);
assertEquals(c, stored); // The initial customer and the retrieved one are equals
}Sometimes it is necessary to manipulate transactions manually. For example, if a constraint is violated when trying to make an object persistent, the aborted transaction at the container level might hide the real reason. Here is an example where we need to manually rollback a given transaction before re-throwing the internal error. One should remark that transactions are also injected by the container, as it is not a developer's responsibility to take care of the transaction pool.
@Resource private UserTransaction manual;
@Test(expected = ConstraintViolationException.class)
public void constraintViolation() throws Exception {
Customer c = new Customer();
c.setName("Foo Bar");
c.setCreditCard("1234567890xxxx");
manual.begin(); // starting the transaction manually
try {
entityManager.persist(c);
manual.commit(); // commiting the transaction: everything went well
} catch(Exception e) {
manual.rollback(); // rollbacking the transaction is anything went wrong
throw e;
}
}Remark about Transactions (since EJB7):
- One can use both
@Injector@Resourceto obtain an instance of User Transaction - When using
@Beforeand@Afterannotations, the@Beforeis executed in the same transaction than the@Test, but the@Afteris not (considering that the transaction was committed at the end of the test). As a consequence, one must manually deal with transactional behaviour if needed
@Inject private UserTransaction utx;
@After
public void cleaningUp() throws Exception {
utx.begin();
john = entityManager.merge(john);
entityManager.remove(john);
john = null;
utx.commit();
}The entity manager is responsible for all the interactions between the domain and the persistence layer. It support id-based querying, SQL-based queries and object-based queries. Remember that an entity manager needs a transactional context (manual or container-based) to survive.
One cas ask the entity manager to retrieve an instance of a given Entity Class, given a relevant id. It will return a null if nothing is found in the database for the given key.
int id = 42;
Customer c = (Customer) entityManager.find(Customer.class, id);The entity manager can be used to talk directly to the database using SQL. This is possible but discouraged, as it introduce a strong coupling between the business layer and the storage one.
However, it is usual in test suite to wipe the database contents after the execution of a test to clean it up before the next one. This can be done easily:
entityManager.createQuery("DELETE FROM Customer").executeUpdate();
We consider here the implementation of the findByName operation exposed by the CustomerFinder interface.
The idea is to create a query that will return a Customer based on given Criteria. The root of this CriteriaQuery is made from the Customer class. We want to select using the previously defined root (i.e., from Customer) instances i where i.name matches the name given as argument. We then simply asks the entity manager to execute the query and get a single result. If there is one, it is wrapped inside an Optional, and if their is no result, we return the Empty value.
@Override
public Optional<Customer> findByName(String name) {
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Customer> criteria = builder.createQuery(Customer.class);
Root<Customer> root = criteria.from(Customer.class);
criteria.select(root).where(builder.equal(root.get("name"), name));
TypedQuery<Customer> query = entityManager.createQuery(criteria);
try {
return Optional.of(query.getSingleResult());
} catch (NoResultException nre){
return Optional.empty();
}
}Remark: one can argue that this is way too complex with respect to a simple SELECT * FROM CUSTOMER WHERE NAME = ? query. This is very true. But however, in front of complex queries, it is more safe to rely on the generations of engineers who worked on the java-to-sql transformation to optimize the query and the associated data loading to retrieve the results properly.
Let's consider tests built using a given customer, John. John must be the very same one for each tests, as the test framework does not ensure any execution order inside a test suite. To handle this issue, the easiest way is (i) to declare John as a private instance of the test suite, (ii) initialize him using an @Before method and finally (iii) destroy him using an @After method.
For the @Before method, one can simply rely on the registry to create a persistent version of John, and to the associated finder to retrieve it from the persistence layer. But as there is no way to delete a customer using the business operations, we need to use directly the entity manager to achieve this task. First, we use the finder to retrieve the persistent john from the database (in case of volatile changes made by the test we are cleaning up for). This version of John is detached, as it was retrieved in another transaction than ours: it was actually retrieved inside the boundary of the Finder. Returning the result make the object crossing the boundary of the component, and as a consequence detached it from its initial transaction. We need to attach it to our local persistence context before being allowed to remove it definitively: one cannot remove something that is not synchronized with the persistence layer, it might trigger consistency issues. Thus, we refresh it, obtaining as a result an attached version of John. This version can be safely removed using the entity manager.
private static final String NAME = "John";
private Customer john;
@Before
public void setUpContext() throws Exception {
registry.register(NAME, "1234567890");
john = finder.findByName(NAME).get();
}
@After
// cannot be annotated with @Transactional, as it is not a test method
public void cleaningUp() throws Exception {
transaction.begin();
Customer customer = finder.findByName(NAME).get();
entityManager.refresh(customer);
entityManager.remove(customer);
john = null;
transaction.commit();
}There is a containment relationship between Customers and Orders. As a consequence, deleting a Customer should delete the associated Orders transitively. If not, one can put the system into an inconsistent state by keeping Orders that are not related to a customer that exists. We consider here a customer john that contains a given order. The following specification must hold:
assertNotNull(entityManager.find(Customer.class, john.getId()));
assertNotNull(entityManager.find(Order.class, order.getId()));
entityManager.remove(john);
assertNull(entityManager.find(Customer.class, john.getId()));
assertNull(entityManager.find(Order.class, order.getId()));To asks JPA to transitively apply an operation through a given relation, we will rely on the cascading mechanism: the remove operation must be cascaded from Customer to Order. We simply have to declare it at the relation level:
public class Customer {
// ...
@OneToMany(cascade = {CascadeType.REMOVE}, mappedBy = "customer")
private Set<Order> orders = new HashSet<>();
// ...
}Warning: be very careful when cascading operations, especially the REMOVE one. Deleting an Order should not delete the associated customer...
The cascading relationship is used to propagate a persistence operation through relations. It does not automatically support the update of an object. If one wants to remove an order from a given customer, the order must be removed from the persistence layer, and also from the customer:
@Test
@Transactional(TransactionMode.COMMIT)
public void removingOrderInCustomer() throws Exception {
Customer john = new Customer("John Doe", "1234567890");
entityManager.persist(john);
Order o1 = new Order(john);
o1.setStatus(OrderStatus.IN_PROGRESS);
o1.addItem(new Item(Cookies.CHOCOLALALA, 3));
entityManager.persist(o1);
john.add(o1);
Order o2 = new Order(john);
o2.setStatus(OrderStatus.IN_PROGRESS);
o2.addItem(new Item(Cookies.DARK_TEMPTATION, 3));
entityManager.persist(o2);
john.add(o2);
int io1 = o1.getId();
john.getOrders().remove(o1);
entityManager.remove(o1);
assertNull(entityManager.find(Order.class, io1));
assertNotNull(entityManager.find(Order.class, o2.getId()));
assertEquals(1, john.getOrders().size());
assertEquals(o2, john.getOrders().toArray()[0]);
assertEquals(john, entityManager.find(Customer.class, john.getId()));
}When multiple relations are involved for a given persistent class, it might does not have any sense to load all the contents of the object if not necessary: large database query, big object, ... One can annotate a relation as lazy, and then the related element will only be loaded if accessed. For example, to lazy load the orders associated to a given customer:
@OneToMany(cascade = {CascadeType.REMOVE}, fetch = FetchType.LAZY, mappedBy = "customer")
private Set<Order> orders = new HashSet<>();Be careful, the laziness of a relationship is only automated within a given transaction. For example, in the following code, the first time we load the persistent entity we are in a given transaction, meaning that the system can access automatically to the orders, when needed. The second time, we are not in a transaction, and as a consequence the orders are null.
private Customer loadCustomer(int id) {
return entityManager.find(Customer.class, id);
}
@Test
public void lazyloadingDemo() throws Exception {
manual.begin();
Customer john = new Customer("John Doe", "1234567890");
entityManager.persist(john);
Order o1 = new Order(john, Cookies.CHOCOLALALA, 3); entityManager.persist(o1); john.add(o1);
Order o2 = new Order(john, Cookies.DARK_TEMPTATION, 1); entityManager.persist(o2); john.add(o2);
Order o3 = new Order(john, Cookies.SOO_CHOCOLATE, 2); entityManager.persist(o3); john.add(o3);
Customer sameTransaction = loadCustomer(john.getId()) ;
assertEquals(john, sameTransaction);
assertEquals(3, john.getOrders().size());
manual.commit();
Customer detached = loadCustomer(john.getId()) ;
assertNotEquals(john, detached);
assertNull(detached.getOrders());
}Remark: Within EJB sessions, a transaction is created each time a method is called. Objects are detached (cutting lazy-loading capabilities to null) each time a persistent object crosses the boundary of a transaction.