- ⚡ The Library to Build and Auto-optimize LLM Applications ⚡ + ⚡ Say Goodbye to Manual Prompting and Vendor Lock-In ⚡
+
-
+
![]()
- All Documentation | - Models | + View Documentation +
@@ -57,14 +58,21 @@
-+AdalFlow is a PyTorch-like library to build and auto-optimize any LM workflows, from Chatbots, RAG, to Agents. +
+ @@ -73,7 +81,24 @@ For AI researchers, product teams, and software engineers who want to learn the -->
+# Why AdalFlow
+
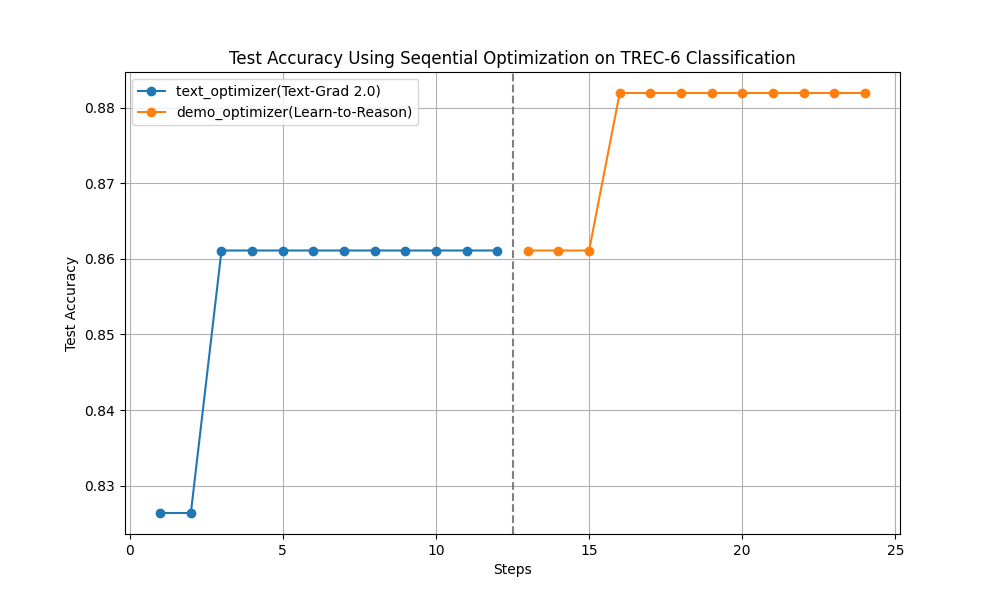
+1. **Say goodbye to manual prompting**: AdalFlow provides a unified auto-differentiative framework for both zero-shot optimization and few-shot prompt optimization. Our research, ``LLM-AutoDiff`` and ``Learn-to-Reason Few-shot In Context Learning``, achieve the highest accuracy among all auto-prompt optimization libraries.
+2. **Switch your LLM app to any model via a config**: AdalFlow provides `Model-agnostic` building blocks for LLM task pipelines, ranging from RAG, Agents to classical NLP tasks.
+
+
-->
+# Why AdalFlow
+
+1. **Say goodbye to manual prompting**: AdalFlow provides a unified auto-differentiative framework for both zero-shot optimization and few-shot prompt optimization. Our research, ``LLM-AutoDiff`` and ``Learn-to-Reason Few-shot In Context Learning``, achieve the highest accuracy among all auto-prompt optimization libraries.
+2. **Switch your LLM app to any model via a config**: AdalFlow provides `Model-agnostic` building blocks for LLM task pipelines, ranging from RAG, Agents to classical NLP tasks.
+
+
+  +
+
+  +
+
-
-
-
-
 + -->
-
-#
-
# Documentation
AdalFlow full documentation available at [adalflow.sylph.ai](https://adalflow.sylph.ai/):
-- [How We Started](https://www.linkedin.com/posts/li-yin-ai_both-ai-research-and-engineering-use-pytorch-activity-7189366364694892544-Uk1U?utm_source=share&utm_medium=member_desktop)
+
# AdalFlow: A Tribute to Ada Lovelace
diff --git a/adalflow/CHANGELOG.md b/adalflow/CHANGELOG.md
index 408f1da0..9d00ef54 100644
--- a/adalflow/CHANGELOG.md
+++ b/adalflow/CHANGELOG.md
@@ -1,3 +1,11 @@
+
+## [1.0.4] - 2025-02-13
+
+### Modified
+- `Embedder` and `BatchEmbedder` changed to `DataComponent`.
+
+### model_client (added)
+- `list_models` method.
## [1.0.2] - 2025-02-02
### Added
- Added `TogetherClient` to support the Together API.
diff --git a/adalflow/adalflow/__init__.py b/adalflow/adalflow/__init__.py
index 2e8513fa..e3065464 100644
--- a/adalflow/adalflow/__init__.py
+++ b/adalflow/adalflow/__init__.py
@@ -1,4 +1,4 @@
-__version__ = "1.0.3"
+__version__ = "1.0.4"
from adalflow.core.component import (
Component,
@@ -21,7 +21,7 @@
Document,
)
from adalflow.core.model_client import ModelClient
-from adalflow.core.embedder import Embedder
+from adalflow.core.embedder import Embedder, BatchEmbedder
# parser
from adalflow.core.string_parser import (
@@ -65,16 +65,15 @@
GroqAPIClient,
OllamaClient,
TransformersClient,
- AnthropicAPIClient,
CohereAPIClient,
BedrockAPIClient,
DeepSeekClient,
TogetherClient,
+ AnthropicAPIClient,
)
# data pipeline
from adalflow.components.data_process.text_splitter import TextSplitter
-from adalflow.components.data_process.data_components import ToEmbeddings
__all__ = [
"Component",
@@ -96,6 +95,7 @@
"ModelClient",
"Generator",
"Embedder",
+ "BatchEmbedder",
"Retriever",
"Parameter",
"AdalComponent",
@@ -146,4 +146,5 @@
"CohereAPIClient",
"BedrockAPIClient",
"TogetherClient",
+ "AnthropicAPIClient",
]
diff --git a/adalflow/adalflow/components/agent/react.py b/adalflow/adalflow/components/agent/react.py
index 7d2bb72e..9a302383 100644
--- a/adalflow/adalflow/components/agent/react.py
+++ b/adalflow/adalflow/components/agent/react.py
@@ -111,7 +111,6 @@
"kwargs": {{history.action.kwargs}}",
{% endif %}
"Observation": "{{history.observation}}"
-
------------------------
{% endfor %}
diff --git a/adalflow/adalflow/components/data_process/__init__.py b/adalflow/adalflow/components/data_process/__init__.py
index 4e8948e1..bfa78e3e 100644
--- a/adalflow/adalflow/components/data_process/__init__.py
+++ b/adalflow/adalflow/components/data_process/__init__.py
@@ -1,11 +1,11 @@
"""Components here are used for data processing/transformation."""
from .text_splitter import TextSplitter
-from .data_components import ToEmbeddings, RetrieverOutputToContextStr
+from .data_components import RetrieverOutputToContextStr, ToEmbeddings
from adalflow.utils.registry import EntityMapping
-__all__ = ["TextSplitter", "ToEmbeddings", "RetrieverOutputToContextStr"]
+__all__ = ["TextSplitter", "RetrieverOutputToContextStr", "ToEmbeddings"]
for name in __all__:
EntityMapping.register(name, globals()[name])
diff --git a/adalflow/adalflow/components/data_process/data_components.py b/adalflow/adalflow/components/data_process/data_components.py
index 700c4e5e..be8a906b 100644
--- a/adalflow/adalflow/components/data_process/data_components.py
+++ b/adalflow/adalflow/components/data_process/data_components.py
@@ -88,7 +88,7 @@ def __call__(self, input: ToEmbeddingsInputType) -> ToEmbeddingsOutputType:
# convert documents to a list of strings
embedder_input: BatchEmbedderInputType = [chunk.text for chunk in output]
outputs: BatchEmbedderOutputType = self.batch_embedder(input=embedder_input)
- # n them back to the original order along with its query
+ # put them back to the original order along with its query
for batch_idx, batch_output in tqdm(
enumerate(outputs), desc="Adding embeddings to documents from batch"
):
diff --git a/adalflow/adalflow/components/model_client/__init__.py b/adalflow/adalflow/components/model_client/__init__.py
index 224c9557..4fdd07c8 100644
--- a/adalflow/adalflow/components/model_client/__init__.py
+++ b/adalflow/adalflow/components/model_client/__init__.py
@@ -81,6 +81,10 @@
"adalflow.components.model_client.together_client.TogetherClient",
OptionalPackages.TOGETHER,
)
+AzureAIClient = LazyImport(
+ "adalflow.components.model_client.azureai_client.AzureAIClient",
+ OptionalPackages.AZURE,
+)
get_first_message_content = LazyImport(
"adalflow.components.model_client.openai_client.get_first_message_content",
OptionalPackages.OPENAI,
diff --git a/adalflow/adalflow/components/model_client/groq_client.py b/adalflow/adalflow/components/model_client/groq_client.py
index 9f0e723c..10e07b8a 100644
--- a/adalflow/adalflow/components/model_client/groq_client.py
+++ b/adalflow/adalflow/components/model_client/groq_client.py
@@ -163,3 +163,16 @@ def to_dict(self) -> Dict[str, Any]:
] # unserializable object
output = super().to_dict(exclude=exclude)
return output
+
+ def list_models(self):
+ return self.sync_client.models.list()
+
+
+if __name__ == "__main__":
+
+ from adalflow.utils import setup_env
+
+ setup_env()
+
+ client = GroqAPIClient()
+ print(client.list_models())
diff --git a/adalflow/adalflow/components/model_client/ollama_client.py b/adalflow/adalflow/components/model_client/ollama_client.py
index bd0f7571..c39a3d18 100644
--- a/adalflow/adalflow/components/model_client/ollama_client.py
+++ b/adalflow/adalflow/components/model_client/ollama_client.py
@@ -64,6 +64,13 @@ class OllamaClient(ModelClient):
- [Download Ollama app] Go to https://github.com/ollama/ollama?tab=readme-ov-file to download the Ollama app (command line tool).
Choose the appropriate version for your operating system.
+ One way to do is to run the following command:
+
+ .. code-block:: shell
+
+ curl -fsSL https://ollama.com/install.sh | sh
+ ollama serve
+
- [Pull a model] Run the following command to pull a model:
diff --git a/adalflow/adalflow/components/model_client/openai_client.py b/adalflow/adalflow/components/model_client/openai_client.py
index b483e666..0e77b1f7 100644
--- a/adalflow/adalflow/components/model_client/openai_client.py
+++ b/adalflow/adalflow/components/model_client/openai_client.py
@@ -574,3 +574,18 @@ def _prepare_image_content(
# model_client_dict = model_client.to_dict()
# from_dict_model_client = OpenAIClient.from_dict(model_client_dict)
# assert model_client_dict == from_dict_model_client.to_dict()
+
+
+if __name__ == "__main__":
+ import adalflow as adal
+
+ # setup env or pass the api_key
+ from adalflow.utils import setup_env
+
+ setup_env()
+
+ openai_llm = adal.Generator(
+ model_client=adal.OpenAIClient(), model_kwargs={"model": "gpt-3.5-turbo"}
+ )
+ resopnse = openai_llm(prompt_kwargs={"input_str": "What is LLM?"})
+ print(resopnse)
diff --git a/adalflow/adalflow/core/embedder.py b/adalflow/adalflow/core/embedder.py
index ca6d5cac..d968a045 100644
--- a/adalflow/adalflow/core/embedder.py
+++ b/adalflow/adalflow/core/embedder.py
@@ -12,7 +12,7 @@
BatchEmbedderInputType,
BatchEmbedderOutputType,
)
-from adalflow.core.component import Component
+from adalflow.core.component import DataComponent
import adalflow.core.functional as F
__all__ = ["Embedder", "BatchEmbedder"]
@@ -20,7 +20,7 @@
log = logging.getLogger(__name__)
-class Embedder(Component):
+class Embedder(DataComponent):
r"""
A user-facing component that orchestrates an embedder model via the model client and output processors.
@@ -39,14 +39,14 @@ class Embedder(Component):
model_type: ModelType = ModelType.EMBEDDER
model_client: ModelClient
- output_processors: Optional[Component]
+ output_processors: Optional[DataComponent]
def __init__(
self,
*,
model_client: ModelClient,
model_kwargs: Dict[str, Any] = {},
- output_processors: Optional[Component] = None,
+ output_processors: Optional[DataComponent] = None,
) -> None:
super().__init__(model_kwargs=model_kwargs)
@@ -192,7 +192,7 @@ def _extra_repr(self) -> str:
return s
-class BatchEmbedder(Component):
+class BatchEmbedder(DataComponent):
__doc__ = r"""Adds batching to the embedder component.
Args:
diff --git a/adalflow/adalflow/core/generator.py b/adalflow/adalflow/core/generator.py
index 3bd4ae95..863f47bd 100644
--- a/adalflow/adalflow/core/generator.py
+++ b/adalflow/adalflow/core/generator.py
@@ -94,8 +94,9 @@ class Generator(GradComponent, CachedEngine, CallbackManager):
trainable_params (Optional[List[str]], optional): The list of trainable parameters. Defaults to [].
Note:
- The output_processors will be applied to the string output of the model completion. And the result will be stored in the data field of the output.
+ 1. The output_processors will be applied to the string output of the model completion. And the result will be stored in the data field of the output.
And we encourage you to only use it to parse the response to data format you will use later.
+ 2. For structured output, you should avoid using `stream` as the output_processors can only be run after all the data is available.
"""
model_type: ModelType = ModelType.LLM
@@ -335,7 +336,7 @@ def _post_call(self, completion: Any) -> GeneratorOutput:
r"""Get string completion and process it with the output_processors."""
# parse chat completion will only fill the raw_response
output: GeneratorOutput = self.model_client.parse_chat_completion(completion)
- # Now adding the data filed to the output
+ # Now adding the data field to the output
data = output.raw_response
if self.output_processors:
if data:
@@ -1187,7 +1188,6 @@ def _extra_repr(self) -> str:
]
s += f"trainable_prompt_kwargs={prompt_kwargs_repr}"
- s += f", prompt={self.prompt}"
return s
def to_dict(self) -> Dict[str, Any]:
diff --git a/adalflow/adalflow/core/model_client.py b/adalflow/adalflow/core/model_client.py
index 320c34d7..a967ca67 100644
--- a/adalflow/adalflow/core/model_client.py
+++ b/adalflow/adalflow/core/model_client.py
@@ -119,3 +119,9 @@ def _track_usage(self, **kwargs):
def __call__(self, *args, **kwargs):
return super().__call__(*args, **kwargs)
+
+ def list_models(self):
+ """List all available models from this provider"""
+ raise NotImplementedError(
+ f"{type(self).__name__} must implement list_models method"
+ )
diff --git a/adalflow/adalflow/core/prompt_builder.py b/adalflow/adalflow/core/prompt_builder.py
index 71590205..87e8536f 100644
--- a/adalflow/adalflow/core/prompt_builder.py
+++ b/adalflow/adalflow/core/prompt_builder.py
@@ -223,3 +223,39 @@ def get_jinja2_environment():
return default_environment
except Exception as e:
raise ValueError(f"Invalid Jinja2 environment: {e}")
+
+
+if __name__ == "__main__":
+
+ import adalflow as adal
+
+ template = r"""
+ -->
-
-#
-
# Documentation
AdalFlow full documentation available at [adalflow.sylph.ai](https://adalflow.sylph.ai/):
-- [How We Started](https://www.linkedin.com/posts/li-yin-ai_both-ai-research-and-engineering-use-pytorch-activity-7189366364694892544-Uk1U?utm_source=share&utm_medium=member_desktop)
+
# AdalFlow: A Tribute to Ada Lovelace
diff --git a/adalflow/CHANGELOG.md b/adalflow/CHANGELOG.md
index 408f1da0..9d00ef54 100644
--- a/adalflow/CHANGELOG.md
+++ b/adalflow/CHANGELOG.md
@@ -1,3 +1,11 @@
+
+## [1.0.4] - 2025-02-13
+
+### Modified
+- `Embedder` and `BatchEmbedder` changed to `DataComponent`.
+
+### model_client (added)
+- `list_models` method.
## [1.0.2] - 2025-02-02
### Added
- Added `TogetherClient` to support the Together API.
diff --git a/adalflow/adalflow/__init__.py b/adalflow/adalflow/__init__.py
index 2e8513fa..e3065464 100644
--- a/adalflow/adalflow/__init__.py
+++ b/adalflow/adalflow/__init__.py
@@ -1,4 +1,4 @@
-__version__ = "1.0.3"
+__version__ = "1.0.4"
from adalflow.core.component import (
Component,
@@ -21,7 +21,7 @@
Document,
)
from adalflow.core.model_client import ModelClient
-from adalflow.core.embedder import Embedder
+from adalflow.core.embedder import Embedder, BatchEmbedder
# parser
from adalflow.core.string_parser import (
@@ -65,16 +65,15 @@
GroqAPIClient,
OllamaClient,
TransformersClient,
- AnthropicAPIClient,
CohereAPIClient,
BedrockAPIClient,
DeepSeekClient,
TogetherClient,
+ AnthropicAPIClient,
)
# data pipeline
from adalflow.components.data_process.text_splitter import TextSplitter
-from adalflow.components.data_process.data_components import ToEmbeddings
__all__ = [
"Component",
@@ -96,6 +95,7 @@
"ModelClient",
"Generator",
"Embedder",
+ "BatchEmbedder",
"Retriever",
"Parameter",
"AdalComponent",
@@ -146,4 +146,5 @@
"CohereAPIClient",
"BedrockAPIClient",
"TogetherClient",
+ "AnthropicAPIClient",
]
diff --git a/adalflow/adalflow/components/agent/react.py b/adalflow/adalflow/components/agent/react.py
index 7d2bb72e..9a302383 100644
--- a/adalflow/adalflow/components/agent/react.py
+++ b/adalflow/adalflow/components/agent/react.py
@@ -111,7 +111,6 @@
"kwargs": {{history.action.kwargs}}",
{% endif %}
"Observation": "{{history.observation}}"
-
------------------------
{% endfor %}
diff --git a/adalflow/adalflow/components/data_process/__init__.py b/adalflow/adalflow/components/data_process/__init__.py
index 4e8948e1..bfa78e3e 100644
--- a/adalflow/adalflow/components/data_process/__init__.py
+++ b/adalflow/adalflow/components/data_process/__init__.py
@@ -1,11 +1,11 @@
"""Components here are used for data processing/transformation."""
from .text_splitter import TextSplitter
-from .data_components import ToEmbeddings, RetrieverOutputToContextStr
+from .data_components import RetrieverOutputToContextStr, ToEmbeddings
from adalflow.utils.registry import EntityMapping
-__all__ = ["TextSplitter", "ToEmbeddings", "RetrieverOutputToContextStr"]
+__all__ = ["TextSplitter", "RetrieverOutputToContextStr", "ToEmbeddings"]
for name in __all__:
EntityMapping.register(name, globals()[name])
diff --git a/adalflow/adalflow/components/data_process/data_components.py b/adalflow/adalflow/components/data_process/data_components.py
index 700c4e5e..be8a906b 100644
--- a/adalflow/adalflow/components/data_process/data_components.py
+++ b/adalflow/adalflow/components/data_process/data_components.py
@@ -88,7 +88,7 @@ def __call__(self, input: ToEmbeddingsInputType) -> ToEmbeddingsOutputType:
# convert documents to a list of strings
embedder_input: BatchEmbedderInputType = [chunk.text for chunk in output]
outputs: BatchEmbedderOutputType = self.batch_embedder(input=embedder_input)
- # n them back to the original order along with its query
+ # put them back to the original order along with its query
for batch_idx, batch_output in tqdm(
enumerate(outputs), desc="Adding embeddings to documents from batch"
):
diff --git a/adalflow/adalflow/components/model_client/__init__.py b/adalflow/adalflow/components/model_client/__init__.py
index 224c9557..4fdd07c8 100644
--- a/adalflow/adalflow/components/model_client/__init__.py
+++ b/adalflow/adalflow/components/model_client/__init__.py
@@ -81,6 +81,10 @@
"adalflow.components.model_client.together_client.TogetherClient",
OptionalPackages.TOGETHER,
)
+AzureAIClient = LazyImport(
+ "adalflow.components.model_client.azureai_client.AzureAIClient",
+ OptionalPackages.AZURE,
+)
get_first_message_content = LazyImport(
"adalflow.components.model_client.openai_client.get_first_message_content",
OptionalPackages.OPENAI,
diff --git a/adalflow/adalflow/components/model_client/groq_client.py b/adalflow/adalflow/components/model_client/groq_client.py
index 9f0e723c..10e07b8a 100644
--- a/adalflow/adalflow/components/model_client/groq_client.py
+++ b/adalflow/adalflow/components/model_client/groq_client.py
@@ -163,3 +163,16 @@ def to_dict(self) -> Dict[str, Any]:
] # unserializable object
output = super().to_dict(exclude=exclude)
return output
+
+ def list_models(self):
+ return self.sync_client.models.list()
+
+
+if __name__ == "__main__":
+
+ from adalflow.utils import setup_env
+
+ setup_env()
+
+ client = GroqAPIClient()
+ print(client.list_models())
diff --git a/adalflow/adalflow/components/model_client/ollama_client.py b/adalflow/adalflow/components/model_client/ollama_client.py
index bd0f7571..c39a3d18 100644
--- a/adalflow/adalflow/components/model_client/ollama_client.py
+++ b/adalflow/adalflow/components/model_client/ollama_client.py
@@ -64,6 +64,13 @@ class OllamaClient(ModelClient):
- [Download Ollama app] Go to https://github.com/ollama/ollama?tab=readme-ov-file to download the Ollama app (command line tool).
Choose the appropriate version for your operating system.
+ One way to do is to run the following command:
+
+ .. code-block:: shell
+
+ curl -fsSL https://ollama.com/install.sh | sh
+ ollama serve
+
- [Pull a model] Run the following command to pull a model:
diff --git a/adalflow/adalflow/components/model_client/openai_client.py b/adalflow/adalflow/components/model_client/openai_client.py
index b483e666..0e77b1f7 100644
--- a/adalflow/adalflow/components/model_client/openai_client.py
+++ b/adalflow/adalflow/components/model_client/openai_client.py
@@ -574,3 +574,18 @@ def _prepare_image_content(
# model_client_dict = model_client.to_dict()
# from_dict_model_client = OpenAIClient.from_dict(model_client_dict)
# assert model_client_dict == from_dict_model_client.to_dict()
+
+
+if __name__ == "__main__":
+ import adalflow as adal
+
+ # setup env or pass the api_key
+ from adalflow.utils import setup_env
+
+ setup_env()
+
+ openai_llm = adal.Generator(
+ model_client=adal.OpenAIClient(), model_kwargs={"model": "gpt-3.5-turbo"}
+ )
+ resopnse = openai_llm(prompt_kwargs={"input_str": "What is LLM?"})
+ print(resopnse)
diff --git a/adalflow/adalflow/core/embedder.py b/adalflow/adalflow/core/embedder.py
index ca6d5cac..d968a045 100644
--- a/adalflow/adalflow/core/embedder.py
+++ b/adalflow/adalflow/core/embedder.py
@@ -12,7 +12,7 @@
BatchEmbedderInputType,
BatchEmbedderOutputType,
)
-from adalflow.core.component import Component
+from adalflow.core.component import DataComponent
import adalflow.core.functional as F
__all__ = ["Embedder", "BatchEmbedder"]
@@ -20,7 +20,7 @@
log = logging.getLogger(__name__)
-class Embedder(Component):
+class Embedder(DataComponent):
r"""
A user-facing component that orchestrates an embedder model via the model client and output processors.
@@ -39,14 +39,14 @@ class Embedder(Component):
model_type: ModelType = ModelType.EMBEDDER
model_client: ModelClient
- output_processors: Optional[Component]
+ output_processors: Optional[DataComponent]
def __init__(
self,
*,
model_client: ModelClient,
model_kwargs: Dict[str, Any] = {},
- output_processors: Optional[Component] = None,
+ output_processors: Optional[DataComponent] = None,
) -> None:
super().__init__(model_kwargs=model_kwargs)
@@ -192,7 +192,7 @@ def _extra_repr(self) -> str:
return s
-class BatchEmbedder(Component):
+class BatchEmbedder(DataComponent):
__doc__ = r"""Adds batching to the embedder component.
Args:
diff --git a/adalflow/adalflow/core/generator.py b/adalflow/adalflow/core/generator.py
index 3bd4ae95..863f47bd 100644
--- a/adalflow/adalflow/core/generator.py
+++ b/adalflow/adalflow/core/generator.py
@@ -94,8 +94,9 @@ class Generator(GradComponent, CachedEngine, CallbackManager):
trainable_params (Optional[List[str]], optional): The list of trainable parameters. Defaults to [].
Note:
- The output_processors will be applied to the string output of the model completion. And the result will be stored in the data field of the output.
+ 1. The output_processors will be applied to the string output of the model completion. And the result will be stored in the data field of the output.
And we encourage you to only use it to parse the response to data format you will use later.
+ 2. For structured output, you should avoid using `stream` as the output_processors can only be run after all the data is available.
"""
model_type: ModelType = ModelType.LLM
@@ -335,7 +336,7 @@ def _post_call(self, completion: Any) -> GeneratorOutput:
r"""Get string completion and process it with the output_processors."""
# parse chat completion will only fill the raw_response
output: GeneratorOutput = self.model_client.parse_chat_completion(completion)
- # Now adding the data filed to the output
+ # Now adding the data field to the output
data = output.raw_response
if self.output_processors:
if data:
@@ -1187,7 +1188,6 @@ def _extra_repr(self) -> str:
]
s += f"trainable_prompt_kwargs={prompt_kwargs_repr}"
- s += f", prompt={self.prompt}"
return s
def to_dict(self) -> Dict[str, Any]:
diff --git a/adalflow/adalflow/core/model_client.py b/adalflow/adalflow/core/model_client.py
index 320c34d7..a967ca67 100644
--- a/adalflow/adalflow/core/model_client.py
+++ b/adalflow/adalflow/core/model_client.py
@@ -119,3 +119,9 @@ def _track_usage(self, **kwargs):
def __call__(self, *args, **kwargs):
return super().__call__(*args, **kwargs)
+
+ def list_models(self):
+ """List all available models from this provider"""
+ raise NotImplementedError(
+ f"{type(self).__name__} must implement list_models method"
+ )
diff --git a/adalflow/adalflow/core/prompt_builder.py b/adalflow/adalflow/core/prompt_builder.py
index 71590205..87e8536f 100644
--- a/adalflow/adalflow/core/prompt_builder.py
+++ b/adalflow/adalflow/core/prompt_builder.py
@@ -223,3 +223,39 @@ def get_jinja2_environment():
return default_environment
except Exception as e:
raise ValueError(f"Invalid Jinja2 environment: {e}")
+
+
+if __name__ == "__main__":
+
+ import adalflow as adal
+
+ template = r""" pip install -U adalflow
+
+ Setup `OPENAI_API_KEY` in your `.env` file or pass the `api_key` to the client.
+
+ import adalflow as adal
+
+ # setup env or pass the api_key to client
+ from adalflow.utils import setup_env
+ setup_env()
-3. Load environment variables
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ openai_llm = adal.Generator(
+ model_client=adal.OpenAIClient(), model_kwargs={"model": "gpt-3.5-turbo"}
+ )
+ resopnse = openai_llm(prompt_kwargs={"input_str": "What is LLM?"})
+ Setup `GROQ_API_KEY` in your `.env` file or pass the `api_key` to the client.
-.. code-block:: python +
+ import adalflow as adal
+ # setup env or pass the api_key to client
from adalflow.utils import setup_env
setup_env()
-Or, you can load it yourself with ``python-dotenv``:
+ llama_llm = adal.Generator(
+ model_client=adal.GroqAPIClient(), model_kwargs={"model": "llama3-8b-8192"}
+ )
+ resopnse = llama_llm(prompt_kwargs={"input_str": "What is LLM?"})
-.. code-block:: python
- from dotenv import load_dotenv
- load_dotenv() # This loads the environment variables from `.env`.
+ Setup `ANTHROPIC_API_KEY` in your `.env` file or pass the `api_key` to the client.
+
+ import adalflow as adal
-4. Install Optional Packages
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-
-AdalFlow currently has built-in support for (1) OpenAI, Groq, Anthropic, Google, and Cohere, and (2) FAISS and Transformers.
-You can find all optional packages at :class:`OptionalPackages`.
-Make sure to install the necessary SDKs for the components you plan to use.
-Here is the list of our tested versions:
+ # setup env or pass the api_key to client
+ from adalflow.utils import setup_env
+ setup_env()
-.. code-block::
+ anthropic_llm = adal.Generator(
+ model_client=adal.AnthropicAPIClient(), model_kwargs={"model": "claude-3-opus-20240229"}
+ )
+ resopnse = anthropic_llm(prompt_kwargs={"input_str": "What is LLM?"})
+
+ Ollama is one option. You can also use `vllm` or HuggingFace `transformers`.
+
+ # Download Ollama command line tool
+ curl -fsSL https://ollama.com/install.sh | sh
+
+ # Pull the model to use
+ ollama pull llama3
+ Use it in the same way as other providers.
+
+ import adalflow as adal
+
+ llama_llm = adal.Generator(
+ model_client=adal.OllamaClient(), model_kwargs={"model": "llama3"}
+ )
+ resopnse = llama_llm(prompt_kwargs={"input_str": "What is LLM?"})
+ For other providers, check the official documentation.
+
+ pip install -U adalflow
+LM apps often relys on other cloud or local model services and each of them often has their own Python SDKs.
+AdalFlow handles all of them as optional packages, so that developers only need to install the ones they need.
-
- ![]() -
-
-
-
+ import adalflow as adal
+ from adalflow.utils import setup_env
+ setup_env()
-.. raw:: html
+ openai_llm = adal.Generator(
+ model_client=adal.OpenAIClient(), model_kwargs={"model": "gpt-3.5-turbo"}
+ )
+ resopnse = openai_llm(prompt_kwargs={"input_str": "What is LLM?"})
-
-.. AdalFlow helps developers build and optimize Retriever-Agent-Generator pipelines.
-.. Embracing a design philosophy similar to PyTorch, it is light, modular, and robust, with a 100% readable codebase.
-..
 + Open Source Code
+
+
+ Open Source Code
+
+
+ Open Source Code
+
+
+
+ Open Source Code
+
+
+ Open Source Code
+
+
+ Open Source Code
+
+
+ Open Source Code
+
+
+
+ Open Source Code
+
+ 

