diff --git a/Ouster_Yolo5_Demo.ipynb b/Ouster_Yolo5_Demo.ipynb
index 08cd1de..392bc00 100644
--- a/Ouster_Yolo5_Demo.ipynb
+++ b/Ouster_Yolo5_Demo.ipynb
@@ -3,8 +3,8 @@
{
"cell_type": "markdown",
"metadata": {
- "id": "view-in-github",
- "colab_type": "text"
+ "colab_type": "text",
+ "id": "view-in-github"
},
"source": [
" "
@@ -350,13 +350,36 @@
]
},
{
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "o997bW3ug20S"
+ },
+ "source": [
+ "## Step 4.1: Destaggering Frames\n",
+ "\n",
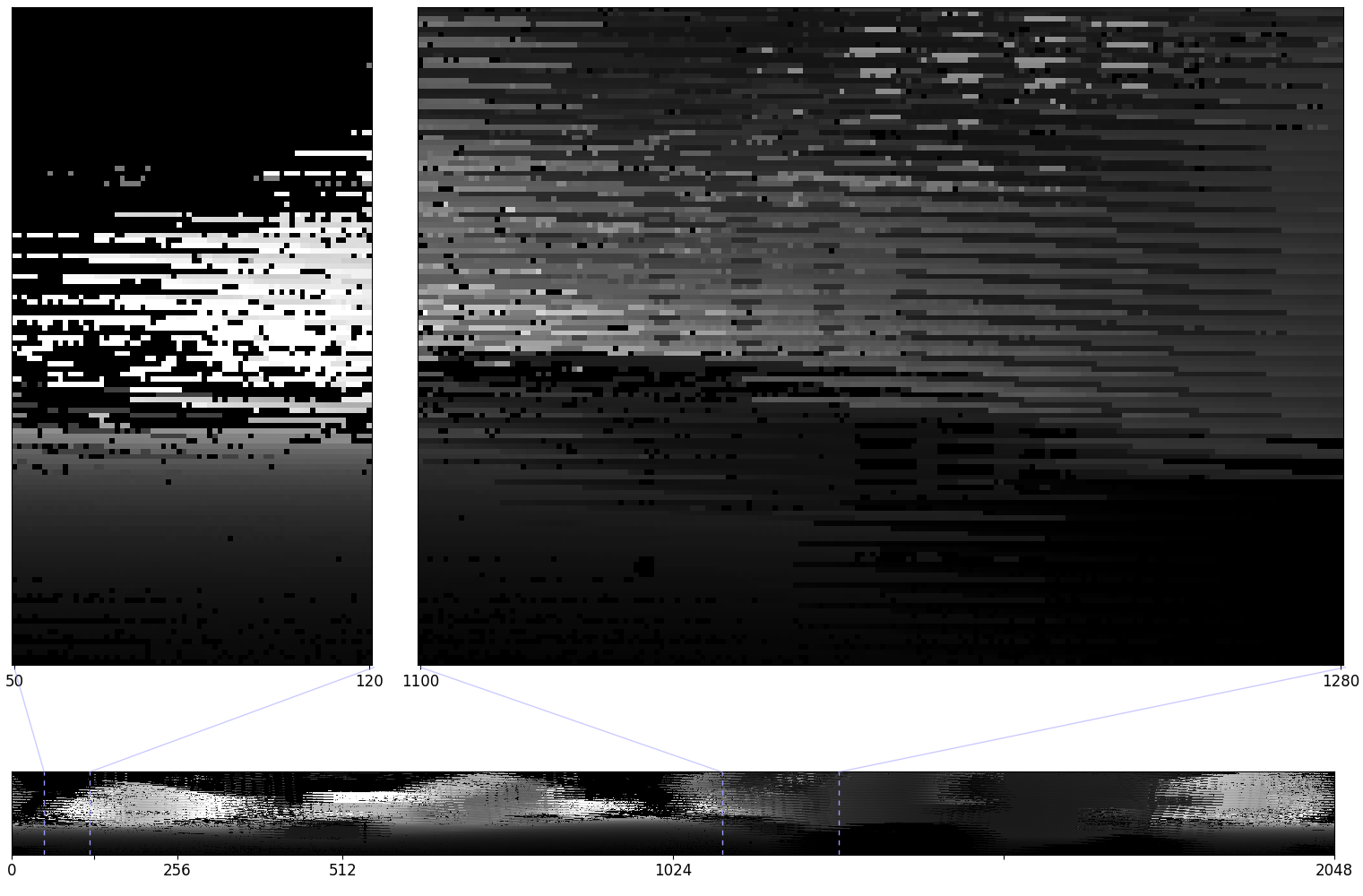
+ "In Ouster sensors, the point cloud is organized into staggered frames. This means that instead of capturing all the data points in one horizontal scan, the sensor captures every other data point in one scan and then captures the remaining data points in the next scan. This creates a staggered pattern in the point cloud, where every other row is shifted by half a scan angle relative to the previous row.\n",
+ "\n",
+ "The following image shows the raw representation of point clouds generated as captured by the sensor.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Evidently, the image does not seem very comprehensible. To actually view the content of the scan and run inference on the frame against the YOLOv5 model we need to perform an operation on it known as destaggering. The following image shows the outcome of applying destaggering on the above frame:\n",
+ "\n",
+ "\n",
+ "\n",
+ "For more information refer to [Staggering and Destaggering in Ouster Doc](https://static.ouster.dev/sdk-docs/reference/lidar-scan.html#staggering-and-destaggering)"
+ ]
+ },
+ {
+ "attachments": {},
"cell_type": "markdown",
"metadata": {
"id": "vZOGX4FCcpaE"
},
"source": [
- "## Step 4.1: Auto Leveling\n",
- "Before we proceed with reading sensor data and performing inference, we need to briefly explain the concept of auto leveling. Some of the values included in the point cloud represet very fine measurements like the distance which is measured in milimeters. The values could range between severl millimeters to thousands. These values can not fit within the typical range for image in computers which range between 0 and 255. Thus we need to perform an operation that performs mapping between the data emitted by the lidar sensor and fit it to range that can be represented using regular images. This process is known as **Auto Leveling** and for that we are going to use the **AutoExposure** class from the SDK. For more infromation refer to `https://static.ouster.dev/sdk-docs/cpp/ouster_client/image_processing.html`"
+ "## Step 4.2: Auto Leveling\n",
+ "Before we proceed with reading sensor data and performing inference, we need to briefly explain the concept of auto leveling. Some of the values included in the point cloud represet very fine measurements like the distance which is measured in milimeters. The values could range between severl millimeters to thousands. These values can not fit within the typical range for image in computers which range between 0 and 255. So we need to scale the range of values to fit this range. It may seem very straightforward to scale the image values by the factor of `image/np.max(image)*255` but simply scaling the value by a factor wouldn't work very well. Consider the case where the majority of values emitted by the sensor lie in the range of 50mm to 500mm but then you had few sparse values in the range of 10000mm or beyond. Performing the simple scalar conversion discussed ealier would result in a poor image (TODO give example image) due to dispropertionate scale of the image value. What would be a better approach to avoid the extreme values (outliers) that don't contribute much to the image. This can be achieved by taking the 3rd and 97th percentile of image values, drop any value that exceed them and then scale the remaining values with the reduce range. This process is known as **Auto Leveling**, the ouster-sdk implements this functionality through the **AutoExposure** interface. For more infromation refer to `https://static.ouster.dev/sdk-docs/cpp/ouster_client/image_processing.html`"
]
},
{
@@ -385,27 +408,6 @@
"}"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "o997bW3ug20S"
- },
- "source": [
- "## Step 4.2: Destaggering Frames\n",
- "\n",
- "In Ouster sensors, the point cloud is organized into staggered frames. This means that instead of capturing all the data points in one horizontal scan, the sensor captures every other data point in one scan and then captures the remaining data points in the next scan. This creates a staggered pattern in the point cloud, where every other row is shifted by half a scan angle relative to the previous row.\n",
- "\n",
- "The following image shows the raw representation of point clouds generated as captured by the sensor.\n",
- "\n",
- "\n",
- "\n",
- "Evidently, the image does not seem very comprehensible. To actually view the content of the scan and run inference on the frame against the YOLOv5 model we need to perform an operation on it known as destaggering. The following image shows the outcome of applying destaggering on the above frame:\n",
- "\n",
- "\n",
- "\n",
- "For more information refer to [Staggering and Destaggering in Ouster Doc](https://static.ouster.dev/sdk-docs/reference/lidar-scan.html#staggering-and-destaggering)"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -634,49 +636,7 @@
"outputs": [
{
"data": {
- "application/javascript": [
- "\n",
- " async function download(id, filename, size) {\n",
- " if (!google.colab.kernel.accessAllowed) {\n",
- " return;\n",
- " }\n",
- " const div = document.createElement('div');\n",
- " const label = document.createElement('label');\n",
- " label.textContent = `Downloading \"${filename}\": `;\n",
- " div.appendChild(label);\n",
- " const progress = document.createElement('progress');\n",
- " progress.max = size;\n",
- " div.appendChild(progress);\n",
- " document.body.appendChild(div);\n",
- "\n",
- " const buffers = [];\n",
- " let downloaded = 0;\n",
- "\n",
- " const channel = await google.colab.kernel.comms.open(id);\n",
- " // Send a message to notify the kernel that we're ready.\n",
- " channel.send({})\n",
- "\n",
- " for await (const message of channel.messages) {\n",
- " // Send a message to notify the kernel that we're ready.\n",
- " channel.send({})\n",
- " if (message.buffers) {\n",
- " for (const buffer of message.buffers) {\n",
- " buffers.push(buffer);\n",
- " downloaded += buffer.byteLength;\n",
- " progress.value = downloaded;\n",
- " }\n",
- " }\n",
- " }\n",
- " const blob = new Blob(buffers, {type: 'application/binary'});\n",
- " const a = document.createElement('a');\n",
- " a.href = window.URL.createObjectURL(blob);\n",
- " a.download = filename;\n",
- " div.appendChild(a);\n",
- " a.click();\n",
- " div.remove();\n",
- " }\n",
- " "
- ],
+ "application/javascript": "\n async function download(id, filename, size) {\n if (!google.colab.kernel.accessAllowed) {\n return;\n }\n const div = document.createElement('div');\n const label = document.createElement('label');\n label.textContent = `Downloading \"${filename}\": `;\n div.appendChild(label);\n const progress = document.createElement('progress');\n progress.max = size;\n div.appendChild(progress);\n document.body.appendChild(div);\n\n const buffers = [];\n let downloaded = 0;\n\n const channel = await google.colab.kernel.comms.open(id);\n // Send a message to notify the kernel that we're ready.\n channel.send({})\n\n for await (const message of channel.messages) {\n // Send a message to notify the kernel that we're ready.\n channel.send({})\n if (message.buffers) {\n for (const buffer of message.buffers) {\n buffers.push(buffer);\n downloaded += buffer.byteLength;\n progress.value = downloaded;\n }\n }\n }\n const blob = new Blob(buffers, {type: 'application/binary'});\n const a = document.createElement('a');\n a.href = window.URL.createObjectURL(blob);\n a.download = filename;\n div.appendChild(a);\n a.click();\n div.remove();\n }\n ",
"text/plain": [
""
]
@@ -686,9 +646,7 @@
},
{
"data": {
- "application/javascript": [
- "download(\"download_bd6fc902-d327-4332-bf86-0f81058a7d7f\", \"best.pt\", 14358689)"
- ],
+ "application/javascript": "download(\"download_bd6fc902-d327-4332-bf86-0f81058a7d7f\", \"best.pt\", 14358689)",
"text/plain": [
""
]
@@ -703,8 +661,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "provenance": [],
- "include_colab_link": true
+ "include_colab_link": true,
+ "provenance": []
},
"gpuClass": "standard",
"kernelspec": {
@@ -717,4 +675,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/yolo5_opencv.py b/yolo5_opencv.py
index f5d624a..82153ba 100644
--- a/yolo5_opencv.py
+++ b/yolo5_opencv.py
@@ -111,7 +111,6 @@ def run():
if not ret:
return True
-
fields = [ChanField.RANGE, ChanField.SIGNAL, ChanField.REFLECTIVITY, ChanField.NEAR_IR]
images = [None] * len(fields)
"
@@ -350,13 +350,36 @@
]
},
{
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "o997bW3ug20S"
+ },
+ "source": [
+ "## Step 4.1: Destaggering Frames\n",
+ "\n",
+ "In Ouster sensors, the point cloud is organized into staggered frames. This means that instead of capturing all the data points in one horizontal scan, the sensor captures every other data point in one scan and then captures the remaining data points in the next scan. This creates a staggered pattern in the point cloud, where every other row is shifted by half a scan angle relative to the previous row.\n",
+ "\n",
+ "The following image shows the raw representation of point clouds generated as captured by the sensor.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Evidently, the image does not seem very comprehensible. To actually view the content of the scan and run inference on the frame against the YOLOv5 model we need to perform an operation on it known as destaggering. The following image shows the outcome of applying destaggering on the above frame:\n",
+ "\n",
+ "\n",
+ "\n",
+ "For more information refer to [Staggering and Destaggering in Ouster Doc](https://static.ouster.dev/sdk-docs/reference/lidar-scan.html#staggering-and-destaggering)"
+ ]
+ },
+ {
+ "attachments": {},
"cell_type": "markdown",
"metadata": {
"id": "vZOGX4FCcpaE"
},
"source": [
- "## Step 4.1: Auto Leveling\n",
- "Before we proceed with reading sensor data and performing inference, we need to briefly explain the concept of auto leveling. Some of the values included in the point cloud represet very fine measurements like the distance which is measured in milimeters. The values could range between severl millimeters to thousands. These values can not fit within the typical range for image in computers which range between 0 and 255. Thus we need to perform an operation that performs mapping between the data emitted by the lidar sensor and fit it to range that can be represented using regular images. This process is known as **Auto Leveling** and for that we are going to use the **AutoExposure** class from the SDK. For more infromation refer to `https://static.ouster.dev/sdk-docs/cpp/ouster_client/image_processing.html`"
+ "## Step 4.2: Auto Leveling\n",
+ "Before we proceed with reading sensor data and performing inference, we need to briefly explain the concept of auto leveling. Some of the values included in the point cloud represet very fine measurements like the distance which is measured in milimeters. The values could range between severl millimeters to thousands. These values can not fit within the typical range for image in computers which range between 0 and 255. So we need to scale the range of values to fit this range. It may seem very straightforward to scale the image values by the factor of `image/np.max(image)*255` but simply scaling the value by a factor wouldn't work very well. Consider the case where the majority of values emitted by the sensor lie in the range of 50mm to 500mm but then you had few sparse values in the range of 10000mm or beyond. Performing the simple scalar conversion discussed ealier would result in a poor image (TODO give example image) due to dispropertionate scale of the image value. What would be a better approach to avoid the extreme values (outliers) that don't contribute much to the image. This can be achieved by taking the 3rd and 97th percentile of image values, drop any value that exceed them and then scale the remaining values with the reduce range. This process is known as **Auto Leveling**, the ouster-sdk implements this functionality through the **AutoExposure** interface. For more infromation refer to `https://static.ouster.dev/sdk-docs/cpp/ouster_client/image_processing.html`"
]
},
{
@@ -385,27 +408,6 @@
"}"
]
},
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "o997bW3ug20S"
- },
- "source": [
- "## Step 4.2: Destaggering Frames\n",
- "\n",
- "In Ouster sensors, the point cloud is organized into staggered frames. This means that instead of capturing all the data points in one horizontal scan, the sensor captures every other data point in one scan and then captures the remaining data points in the next scan. This creates a staggered pattern in the point cloud, where every other row is shifted by half a scan angle relative to the previous row.\n",
- "\n",
- "The following image shows the raw representation of point clouds generated as captured by the sensor.\n",
- "\n",
- "\n",
- "\n",
- "Evidently, the image does not seem very comprehensible. To actually view the content of the scan and run inference on the frame against the YOLOv5 model we need to perform an operation on it known as destaggering. The following image shows the outcome of applying destaggering on the above frame:\n",
- "\n",
- "\n",
- "\n",
- "For more information refer to [Staggering and Destaggering in Ouster Doc](https://static.ouster.dev/sdk-docs/reference/lidar-scan.html#staggering-and-destaggering)"
- ]
- },
{
"cell_type": "code",
"execution_count": null,
@@ -634,49 +636,7 @@
"outputs": [
{
"data": {
- "application/javascript": [
- "\n",
- " async function download(id, filename, size) {\n",
- " if (!google.colab.kernel.accessAllowed) {\n",
- " return;\n",
- " }\n",
- " const div = document.createElement('div');\n",
- " const label = document.createElement('label');\n",
- " label.textContent = `Downloading \"${filename}\": `;\n",
- " div.appendChild(label);\n",
- " const progress = document.createElement('progress');\n",
- " progress.max = size;\n",
- " div.appendChild(progress);\n",
- " document.body.appendChild(div);\n",
- "\n",
- " const buffers = [];\n",
- " let downloaded = 0;\n",
- "\n",
- " const channel = await google.colab.kernel.comms.open(id);\n",
- " // Send a message to notify the kernel that we're ready.\n",
- " channel.send({})\n",
- "\n",
- " for await (const message of channel.messages) {\n",
- " // Send a message to notify the kernel that we're ready.\n",
- " channel.send({})\n",
- " if (message.buffers) {\n",
- " for (const buffer of message.buffers) {\n",
- " buffers.push(buffer);\n",
- " downloaded += buffer.byteLength;\n",
- " progress.value = downloaded;\n",
- " }\n",
- " }\n",
- " }\n",
- " const blob = new Blob(buffers, {type: 'application/binary'});\n",
- " const a = document.createElement('a');\n",
- " a.href = window.URL.createObjectURL(blob);\n",
- " a.download = filename;\n",
- " div.appendChild(a);\n",
- " a.click();\n",
- " div.remove();\n",
- " }\n",
- " "
- ],
+ "application/javascript": "\n async function download(id, filename, size) {\n if (!google.colab.kernel.accessAllowed) {\n return;\n }\n const div = document.createElement('div');\n const label = document.createElement('label');\n label.textContent = `Downloading \"${filename}\": `;\n div.appendChild(label);\n const progress = document.createElement('progress');\n progress.max = size;\n div.appendChild(progress);\n document.body.appendChild(div);\n\n const buffers = [];\n let downloaded = 0;\n\n const channel = await google.colab.kernel.comms.open(id);\n // Send a message to notify the kernel that we're ready.\n channel.send({})\n\n for await (const message of channel.messages) {\n // Send a message to notify the kernel that we're ready.\n channel.send({})\n if (message.buffers) {\n for (const buffer of message.buffers) {\n buffers.push(buffer);\n downloaded += buffer.byteLength;\n progress.value = downloaded;\n }\n }\n }\n const blob = new Blob(buffers, {type: 'application/binary'});\n const a = document.createElement('a');\n a.href = window.URL.createObjectURL(blob);\n a.download = filename;\n div.appendChild(a);\n a.click();\n div.remove();\n }\n ",
"text/plain": [
""
]
@@ -686,9 +646,7 @@
},
{
"data": {
- "application/javascript": [
- "download(\"download_bd6fc902-d327-4332-bf86-0f81058a7d7f\", \"best.pt\", 14358689)"
- ],
+ "application/javascript": "download(\"download_bd6fc902-d327-4332-bf86-0f81058a7d7f\", \"best.pt\", 14358689)",
"text/plain": [
""
]
@@ -703,8 +661,8 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "provenance": [],
- "include_colab_link": true
+ "include_colab_link": true,
+ "provenance": []
},
"gpuClass": "standard",
"kernelspec": {
@@ -717,4 +675,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
diff --git a/yolo5_opencv.py b/yolo5_opencv.py
index f5d624a..82153ba 100644
--- a/yolo5_opencv.py
+++ b/yolo5_opencv.py
@@ -111,7 +111,6 @@ def run():
if not ret:
return True
-
fields = [ChanField.RANGE, ChanField.SIGNAL, ChanField.REFLECTIVITY, ChanField.NEAR_IR]
images = [None] * len(fields)