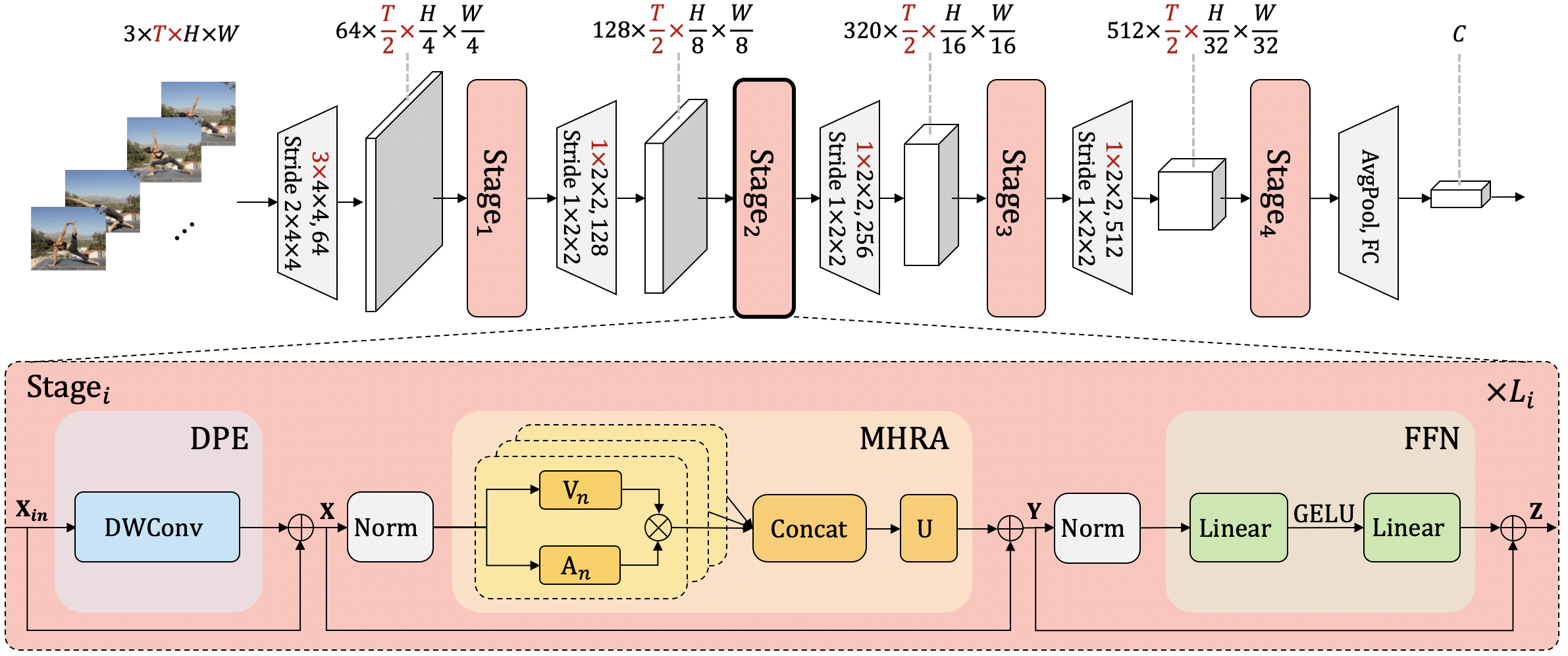
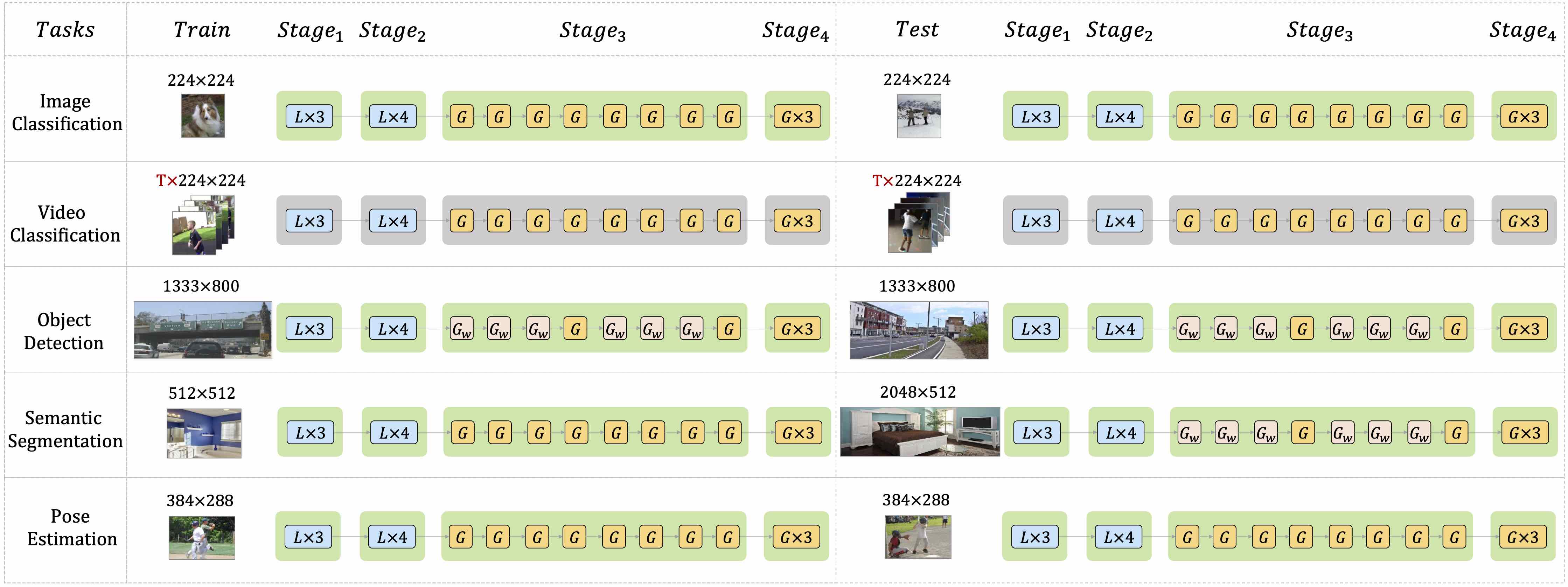
This project implements a topdown heatmap based human pose estimator, utilizing the approach outlined in UniFormer: Unifying Convolution and Self-attention for Visual Recognition (TPAMI 2023) and UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning (ICLR 2022).
- Setup Development Environment
- Python 3.7 or higher
- PyTorch 1.6 or higher
- MMEngine v0.6.0 or higher
- MMCV v2.0.0rc4 or higher
- MMDetection v3.0.0rc6 or higher
- MMPose v1.0.0rc1 or higher
All the commands below rely on the correct configuration of PYTHONPATH, which should point to the project's directory so that Python can locate the module files. In uniformer/ root directory, run the following line to add the current directory to PYTHONPATH:
export PYTHONPATH=`pwd`:$PYTHONPATH- Download Pretrained Weights
To either run inferences or train on the uniformer pose estimation project, you have to download the original Uniformer pretrained weights on the ImageNet1k dataset and the weights trained for the downstream pose estimation task. The original ImageNet1k weights are hosted on SenseTime's huggingface repository, and the downstream pose estimation task weights are hosted either on Google Drive or Baiduyun. We have uploaded them to the OpenMMLab download URLs, allowing users to use them without burden. For example, you can take a look at td-hm_uniformer-b-8xb128-210e_coco-256x192.py, the corresponding pretrained weight URL is already here and when the training or testing process starts, the weight will be automatically downloaded to your device. For the downstream task weights, you can get their URLs from the benchmark result table.
We have provided a inferencer_demo.py with which developers can utilize to run quick inference demos. Here is a basic demonstration:
python demo/inferencer_demo.py $INPUTS \
--pose2d $CONFIG --pose2d-weights $CHECKPOINT \
[--show] [--vis-out-dir $VIS_OUT_DIR] [--pred-out-dir $PRED_OUT_DIR]For more information on using the inferencer, please see this document.
Here's an example code:
python demo/inferencer_demo.py tests/data/coco/000000000785.jpg \
--pose2d projects/uniformer/configs/td-hm_uniformer-s-8xb128-210e_coco-256x192.py \
--pose2d-weights https://download.openmmlab.com/mmpose/v1/projects/uniformer/top_down_256x192_global_small-d4a7fdac_20230724.pth \
--vis-out-dir vis_resultsThen you will find the demo result in vis_results folder, and it may be similar to this:

- Data Preparation
Prepare the COCO dataset according to the instruction.
- To Train and Test with Single GPU:
python tools/test.py $CONFIG --auto-scale-lrpython tools/test.py $CONFIG $CHECKPOINT- To Train and Test with Multiple GPUs:
bash tools/dist_train.sh $CONFIG $NUM_GPUs --ampbash tools/dist_test.sh $CONFIG $CHECKPOINT $NUM_GPUs --ampHere is the testing results on COCO val2017:
| Model | Input Size | AP | AP50 | AP75 | AR | AR50 | Download |
|---|---|---|---|---|---|---|---|
| UniFormer-S | 256x192 | 74.0 | 90.2 | 82.1 | 79.5 | 94.1 | model | log |
| UniFormer-S | 384x288 | 75.9 | 90.6 | 83.0 | 81.0 | 94.3 | model | log |
| UniFormer-S | 448x320 | 76.2 | 90.6 | 83.2 | 81.4 | 94.4 | model | log |
| UniFormer-B | 256x192 | 75.0 | 90.5 | 83.0 | 80.4 | 94.2 | model | log |
| UniFormer-B | 384x288 | 76.7 | 90.8 | 84.1 | 81.9 | 94.6 | model | log |
| UniFormer-B | 448x320 | 77.4 | 91.0 | 84.4 | 82.5 | 94.9 | model | log |
Here is the testing results on COCO val 2017 from the official UniFormer Pose Estimation repository for comparison:
| Backbone | Input Size | AP | AP50 | AP75 | ARM | ARL | AR | Model | Log |
|---|---|---|---|---|---|---|---|---|---|
| UniFormer-S | 256x192 | 74.0 | 90.3 | 82.2 | 66.8 | 76.7 | 79.5 | ||
| UniFormer-S | 384x288 | 75.9 | 90.6 | 83.4 | 68.6 | 79.0 | 81.4 | ||
| UniFormer-S | 448x320 | 76.2 | 90.6 | 83.2 | 68.6 | 79.4 | 81.4 | ||
| UniFormer-B | 256x192 | 75.0 | 90.6 | 83.0 | 67.8 | 77.7 | 80.4 | ||
| UniFormer-B | 384x288 | 76.7 | 90.8 | 84.0 | 69.3 | 79.7 | 81.4 | ||
| UniFormer-B | 448x320 | 77.4 | 91.1 | 84.4 | 70.2 | 80.6 | 82.5 |
Note:
- All the original models are pretrained on ImageNet-1K without Token Labeling and Layer Scale, as mentioned in the official README . The official team has confirmed that Token labeling can largely improve the performance of the downstream tasks. Developers can utilize the implementation by themselves.
- The original implementation did not include the freeze BN in the backbone. The official team has confirmed that this can improve the performance as well.
- To avoid running out of memory, developers can use
torch.utils.checkpointin theconfig.pyby settinguse_checkpoint=Trueandcheckpoint_num=[0, 0, 2, 0] # index for using checkpoint in every stage - We warmly welcome any contributions if you can successfully reproduce the results from the paper!
If this project benefits your work, please kindly consider citing the original papers:
@misc{li2022uniformer,
title={UniFormer: Unifying Convolution and Self-attention for Visual Recognition},
author={Kunchang Li and Yali Wang and Junhao Zhang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao},
year={2022},
eprint={2201.09450},
archivePrefix={arXiv},
primaryClass={cs.CV}
}@misc{li2022uniformer,
title={UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning},
author={Kunchang Li and Yali Wang and Peng Gao and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao},
year={2022},
eprint={2201.04676},
archivePrefix={arXiv},
primaryClass={cs.CV}
}