Useful data
Newer and older results showing the average depth for games at fishtest conditions
| New | Old |
|---|---|
 |
 |
We measure the influence of Hash on the playing strength, using games of SF15.1 at LTC (60+0.6s) and VLTC (240+2.4s) on the UHO book. Hash is varied between 1 and 64 MB and 256MB in powers of two, leading to as average hashfull between 100 and 950 per thousand. The data suggests that keeping hashfull below 30% is best to maintain strength.
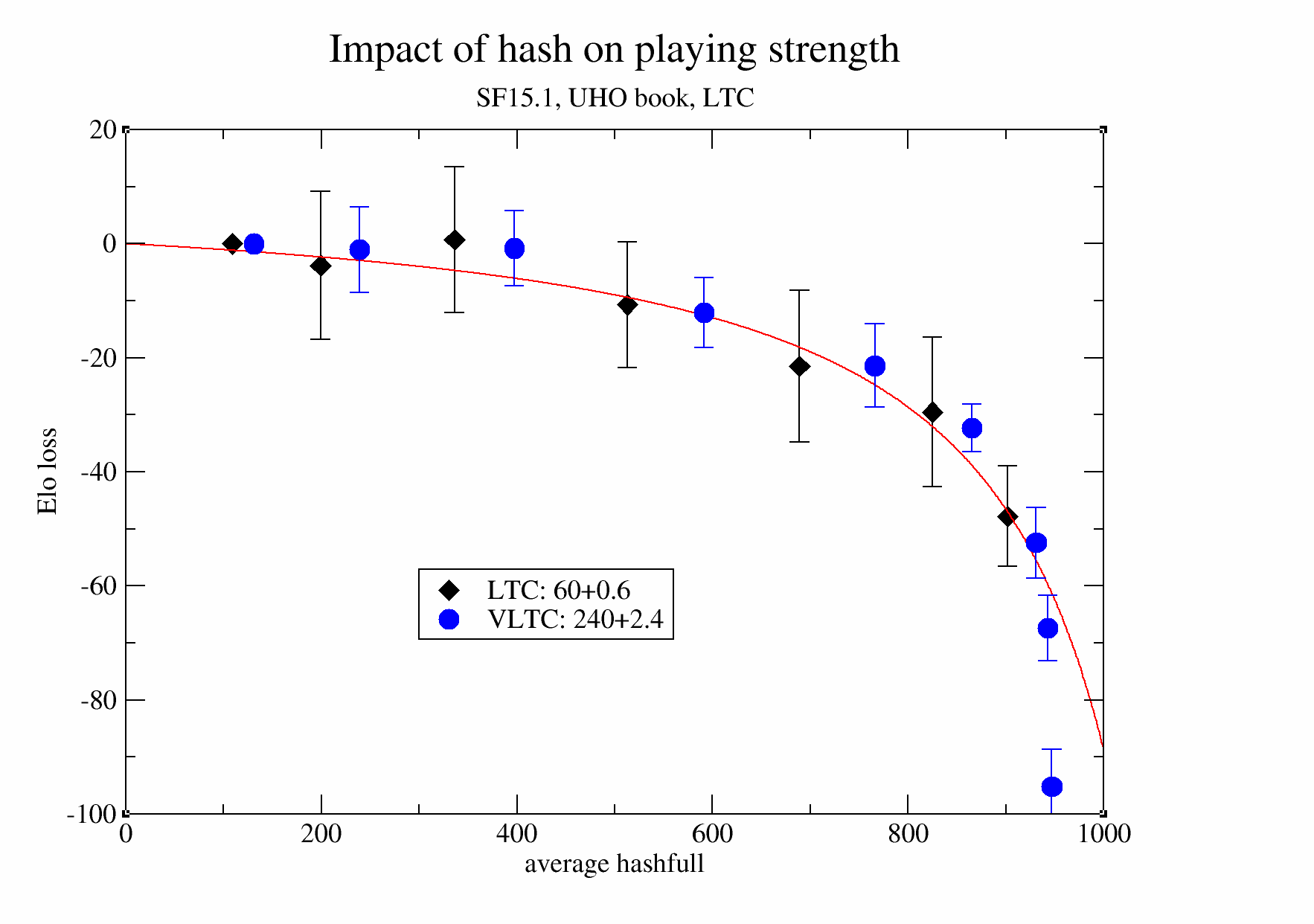
Raw data for the above graph
| Hash | Hashfull | Elo | Elo-err |
|---|---|---|---|
| 64 | 109 | 0.00 | 0.00 |
| 32 | 199 | -3.80 | 13.00 |
| 16 | 336 | 0.70 | 12.80 |
| 8 | 513 | -10.70 | 11.00 |
| 4 | 689 | -21.50 | 13.30 |
| 2 | 825 | -29.50 | 13.10 |
| 1 | 902 | -47.80 | 8.80 |
| Hash | Hashfull | Elo | Elo-err |
|---|---|---|---|
| 256 | 131 | 0.00 | 0.00 |
| 128 | 239 | -1.00 | 7.50 |
| 64 | 397 | -0.80 | 6.60 |
| 32 | 591 | -12.10 | 6.10 |
| 16 | 766 | -21.40 | 7.30 |
| 8 | 865 | -32.30 | 4.20 |
| 4 | 931 | -52.40 | 6.20 |
| 2 | 943 | -67.40 | 5.70 |
| 1 | 947 | -95.20 | 6.60 |
MultiPV provides the N best moves, and their associated principal variation. This is a great tool to understand the options available in a given position. However, this information does not come for free, and the computational cost computing it reducing the quality of the bestmove found relative to a search that only needs to find a single line.
| MultiPV | Elo | Elo-err |
|---|---|---|
| 1 | 0.0 | 0.0 |
| 2 | -97.2 | 2.1 |
| 3 | -156.7 | 2.8 |
| 4 | -199.3 | 2.9 |
| 5 | -234.5 | 2.8 |
Engine: Stockfish 15.1
Time control: 60s+0.6s
Book: UHO
| MultiPV | Elo | Elo-err | Points | Played |
|---|---|---|---|---|
| 1 | 0.0 | 13496.5 | 30614 | |
| 2 | 45.7 | 3.1 | 15388.0 | 30697 |
| 3 | 53.9 | 3.5 | 15732.5 | 30722 |
| 4 | 59.5 | 3.2 | 15862.5 | 30479 |
| 5 | 63.7 | 3.6 | 16078.5 | 30604 |
Time control: 580s+5.8s
Depth: 18
Consistent measurement of Elo gain (syzygy 6men vs none) for various SF versions:
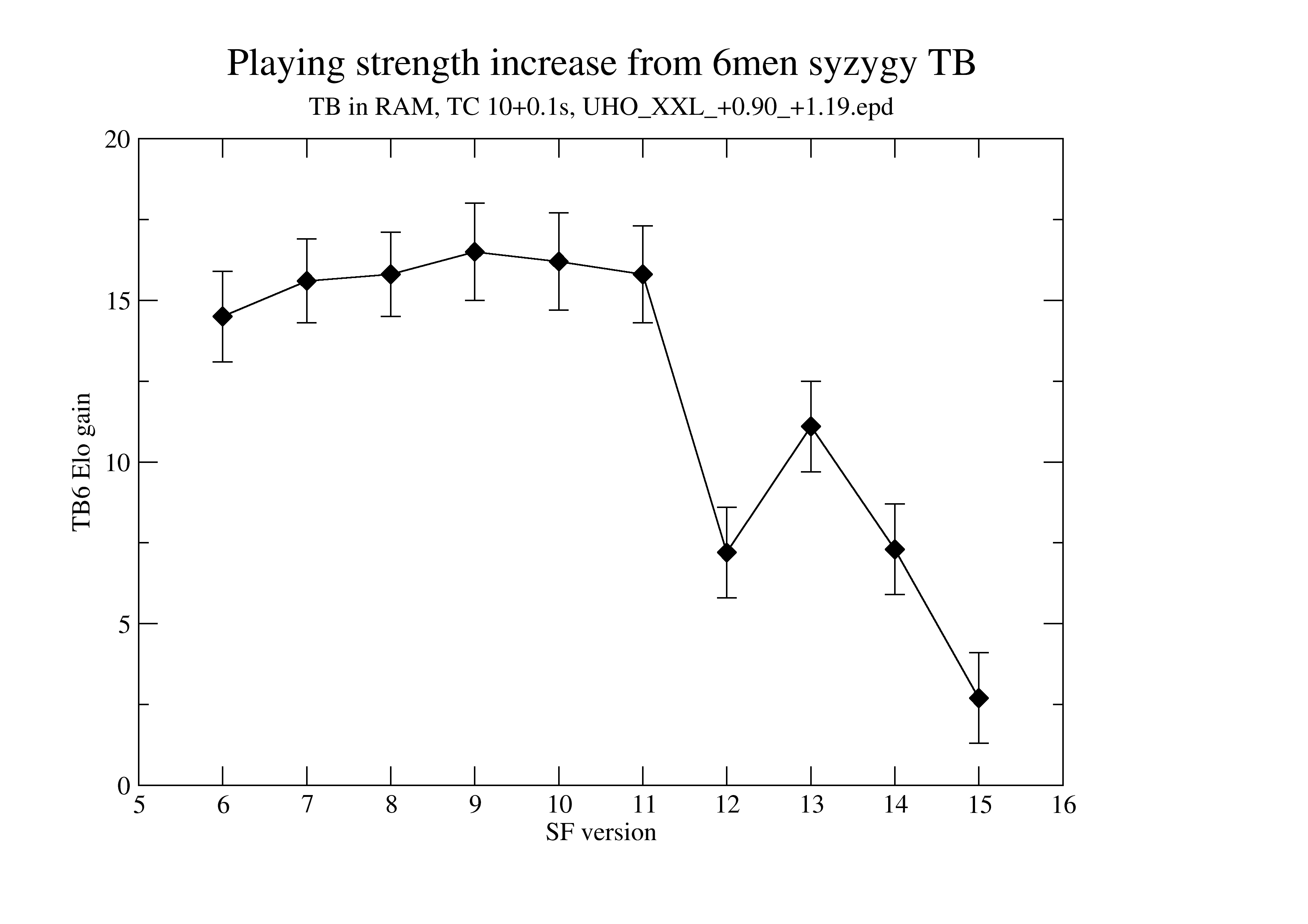
TB are in RAM (so fast access), TC is 10+0.1s (STC), book UHO_XXL_+0.90_+1.19.epd. No adjudication. The introduction of NNUE (with SF12) is clearly visible. With SF15, there is just 2.7 Elo gain.
Raw data for the above graph
| SF | Elo | Elo-err |
|---|---|---|
| 6 | 14.5 | 1.4 |
| 7 | 15.6 | 1.3 |
| 8 | 15.8 | 1.3 |
| 9 | 16.5 | 1.5 |
| 10 | 16.2 | 1.5 |
| 11 | 15.8 | 1.5 |
| 12 | 7.2 | 1.4 |
| 13 | 11.1 | 1.4 |
| 14 | 7.3 | 1.4 |
| 15 | 2.7 | 1.4 |
Tested at 10+0.1, with all syzygy WDL files on tmpfs (i.e. RAM), testing using none(0), 4, 5, and 6 man TB in a round-robin tournament (SF10dev).
| Rank | Name | Elo | +/- | Games | Score | Draws |
|---|---|---|---|---|---|---|
| 1 | syzygy6 | 13 | 2 | 82591 | 51.8% | 59.5% |
| 2 | syzygy5 | 2 | 2 | 82590 | 50.3% | 59.4% |
| 3 | syzygy4 | -7 | 2 | 82591 | 49.0% | 59.3% |
| 4 | syzygy0 | -7 | 2 | 82592 | 48.9% | 59.4% |
Tested at 60+0.6, with all syzygy WDL files on tmpfs (i.e. RAM), testing using none(0) against 6 man TB:
Score of syzygy6 vs syzygy0: 4084 - 3298 - 18510 [0.515] 25892 Elo difference: 10.55 +/- 2.25
Here we look at the threading efficiency of the lazySMP parallelization scheme. To focus on the algorithm we play games with a given budget of nodes rather than at a given TC. In principle, lazySMP has excellent scaling of the nps with cores, but practical measurement is influenced by e.g. frequency adjustments, SMT/hyperthreading, and sometimes hardware limitation.
In these tests, matches are played at a fixed nodes budget (using the nodestime feature of SF), and equivalence in strength between the serial player and the threaded player (for x threads in the graph below) is found by adjusting the number of nodes given to the threaded player (e.g. with 16 threads, the threaded player might need 200% of the nodes of the serial player to match the strength of the serial player). This 'equivalent nodestime' is determined for various number of threads and various nodes budgets (60+0.6Mnodes/game is somewhat similar to our usual LTC at 60+0.6s/game, if we assume 1Mnps).
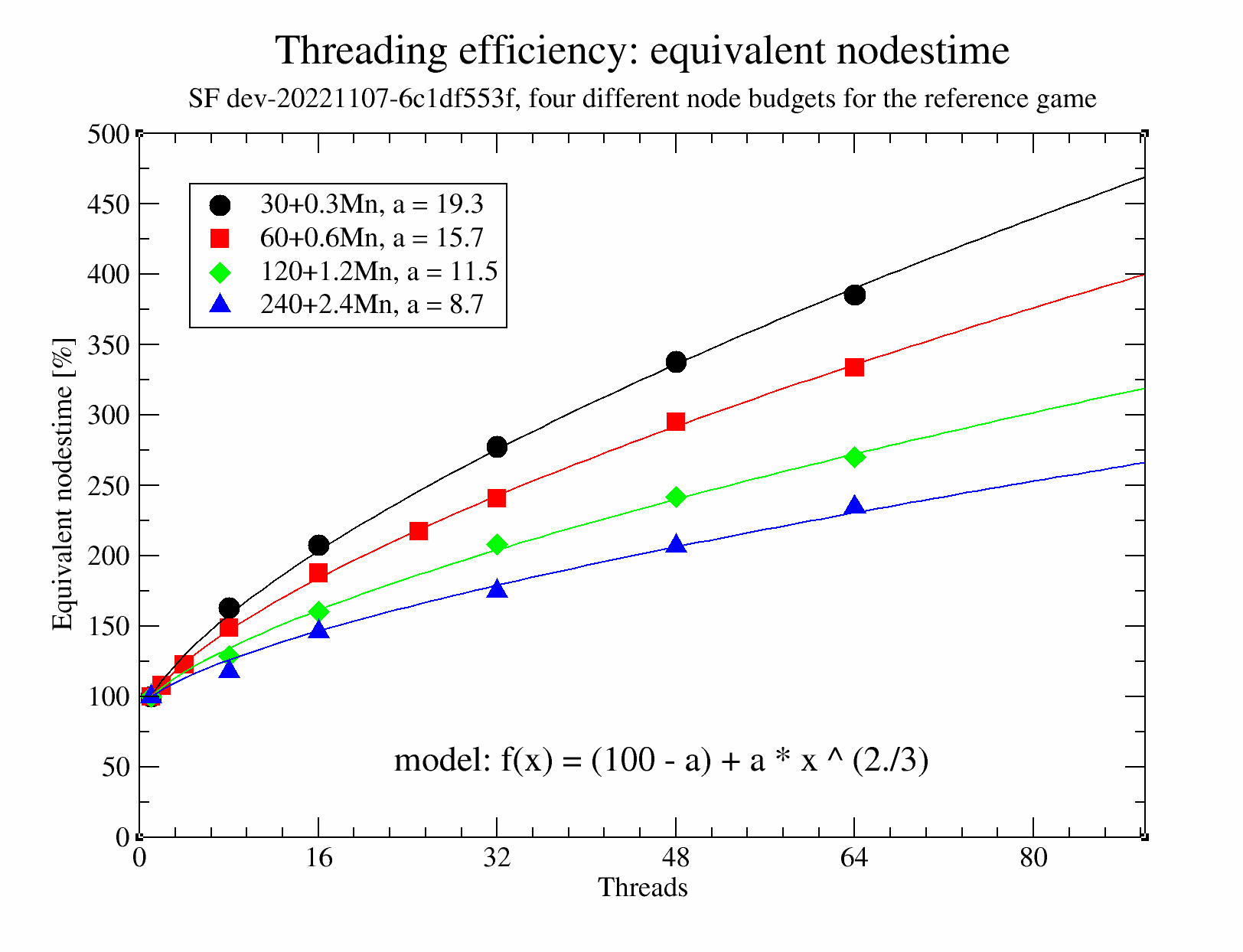
The interesting observation one can make immediately is that this 'equivalent nodestime' grows with the number of threads, but not too steeply, and further more that the 'equivalent nodestime' decreases with increasing nodes budget. The data shows that with 64 threads, the equivalent nodestime is about 200% for a node budget of 240+2.4Mn, i.e. despite such games being much faster than STC (10+0.1s), efficiency is still around 50%.
The curves are sufficiently smooth to be fitted with a model having 1 parameter that is different between the curves (f(x), parameter a, see caption). A smaller value of a means a higher efficiency.
The above parameter a from the model, can be fit as a function of nodes budget, this allows for extrapolating the parameter, and to arrive at and estimate for the 'equivalent nodestime' at large TC / nodes budgets:
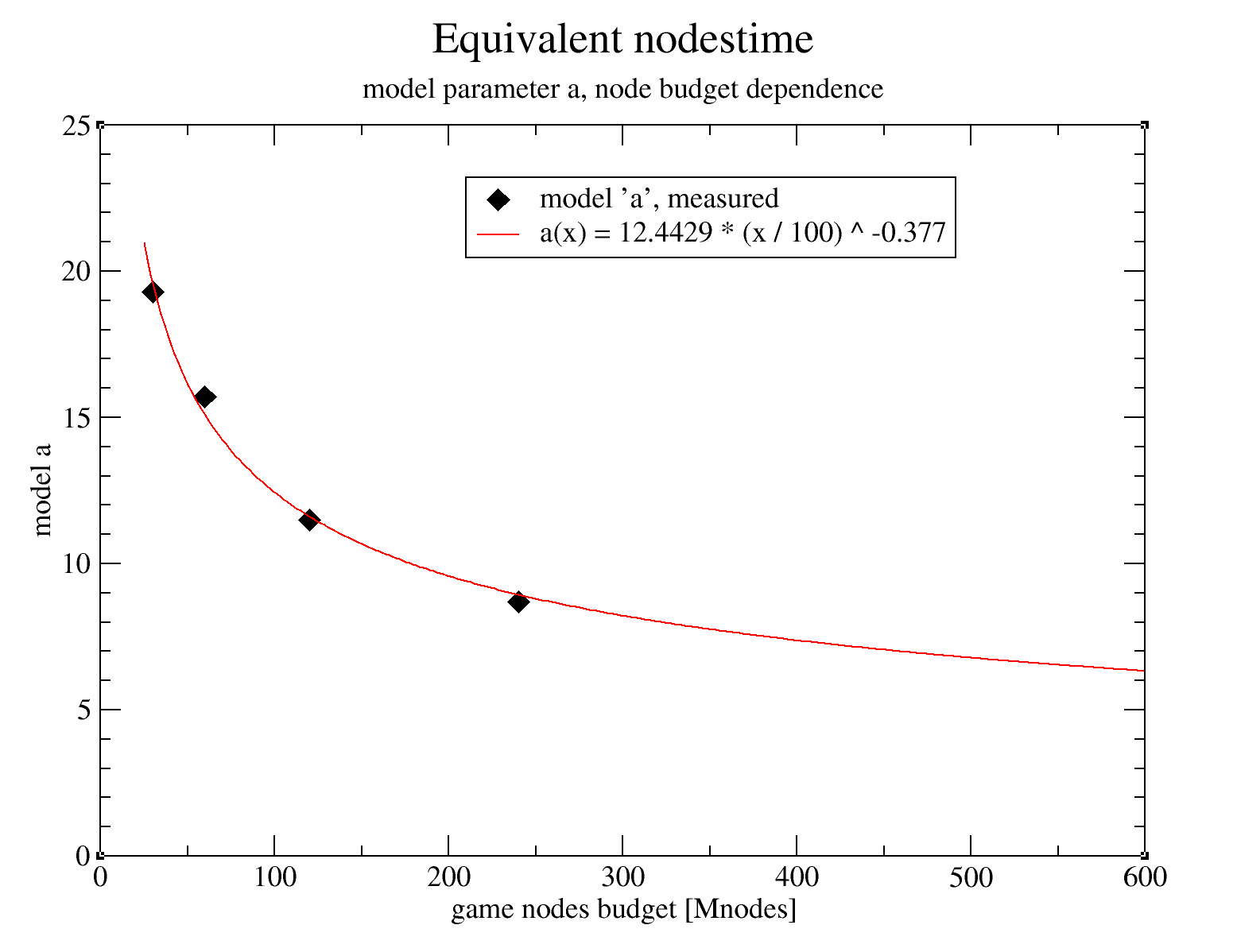
The fit is again fairly good. Taking a leap of faith, these measurements at up to 240+2.4Mn can be extrapolated to node budgets typical of TCEC or CCC (up to 500Gn). This allows us to predict speedup and/or efficiency.
| Speedup | Efficiency |
|---|---|
 |
 |
These extrapolations suggest that even at thread counts of >300, at TCEC TCs efficiency could be 80% or higher, provided the nps scales with the number of threads.
Playing 8 threads vs 1 thread at LTC (60+0.6, 8moves_v3.pgn):
Score of t8 vs seq: 476 - 3 - 521 [0.737] 1000
Elo difference: 178.6 +/- 14.0, LOS: 100.0 %, DrawRatio: 52.1 %
Playing 1 thread at 8xLTC (480+4.8) vs (60+0.6) (8moves_v3.pgn):
Score of seq8 vs seq: 561 - 5 - 434 [0.778] 1000
Elo difference: 217.9 +/- 15.8, LOS: 100.0 %, DrawRatio: 43.4 %
Which is roughly 82% efficiency (178/218).
Playing 8 threads vs 1 thread at STC (10+0.1):
Score of threads vs serial: 1606 - 15 - 540 [0.868] 2161
Elo difference: 327.36 +/- 14.59
Playing 8 threads @ 10+0.1 vs 1 thread @ 80+0.8:
Score of threads vs time: 348 - 995 - 2104 [0.406] 3447
Elo difference: -66.00 +/- 7.15
So, 1 -> 8 threads has about 83% scaling efficiency (327 / (327 + 66)) using this test.
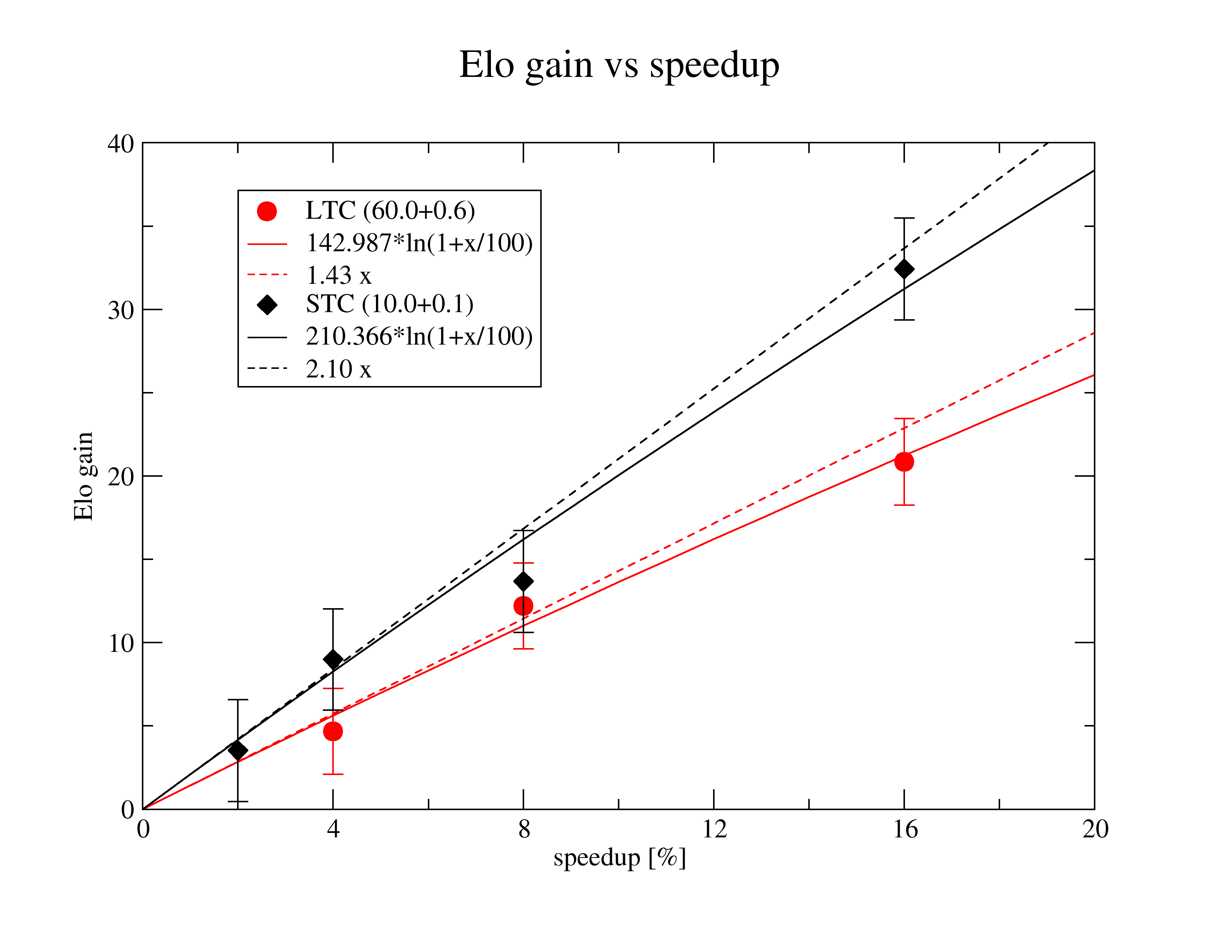
For small speedups (<~5%) the linear estimate can be used that gives Elo gain as a function of speedup percentage (x) as:
Elo_stc(x) = 2.10 x
Elo_ltc(x) = 1.43 x
To have 50% passing chance at STC<-0.5,1.5>, we need a 0.24% speedup, while at LTC<0.25,1.75> we need 0.70% speedup. A 1% speedup has nearly 85% passing chance at LTC.
Raw data:
tc 10+0.1:
16 32.42 3.06
8 13.67 3.05
4 8.99 3.04
2 3.52 3.05
tc 60+0.6:
16 20.85 2.59
8 12.20 2.57
4 4.67 2.57
Note: Numbers will depend on the precise hardware. The model was verified quite accurately on fishtest see https://github.com/locutus2/Stockfish/commit/82958c97214b6d418e5bc95e3bf1961060cd6113#commitcomment-38646654
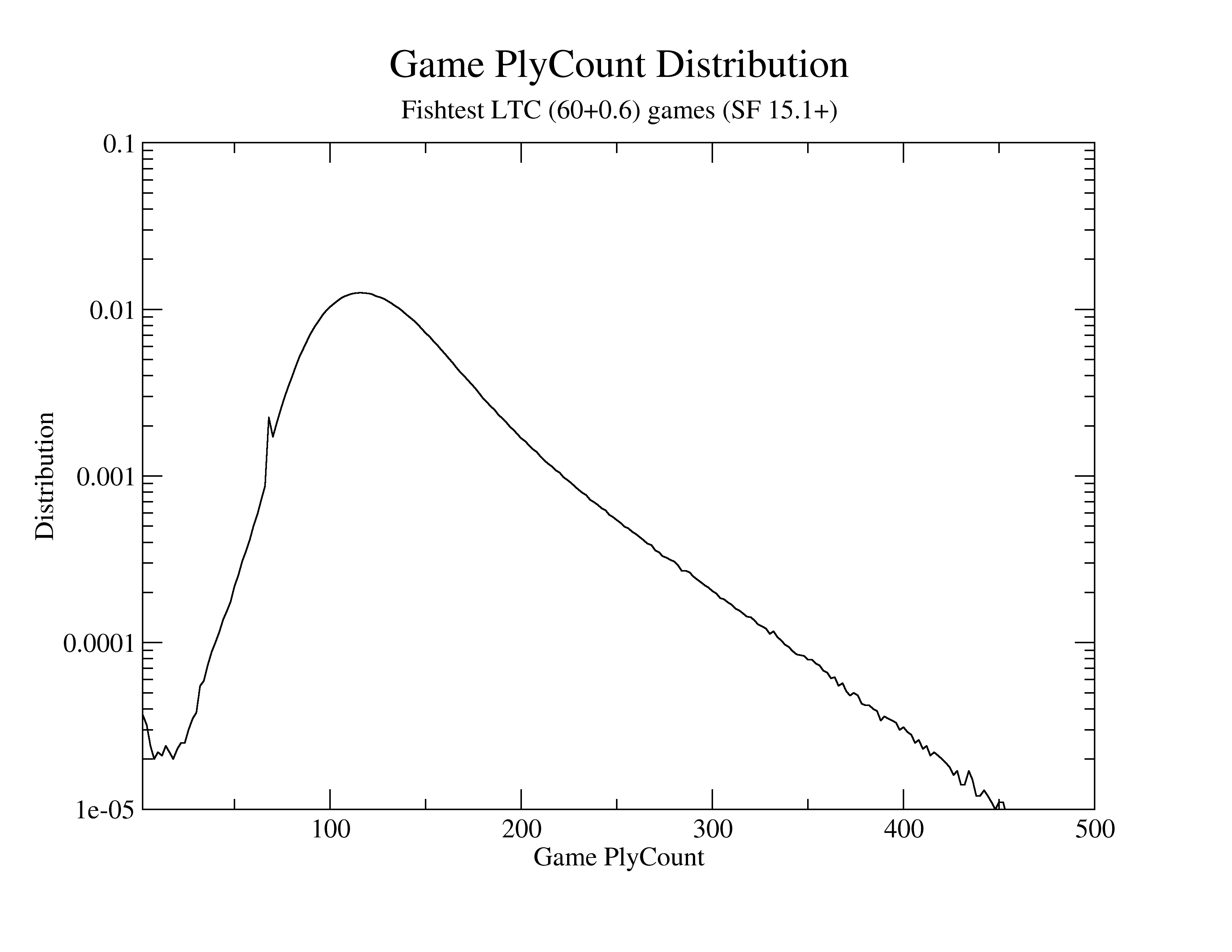
In a collection of a few million games, the longest was 902 plies.
The following graph give information on the Win-Loss-Draw (WLD) statistics, relating them to score and move number. It answers the question 'What fraction of positions that have a given score + (move number) in fishtest LTC, have a Win a Loss or a Draw ?'.

This model is used when Stockfish provides WLD statistics during analysis with the UCI_ShowWDL option set to True.
See also: https://github.com/official-stockfish/Stockfish/discussions/3402
| New | Old |
|---|---|
 |
 |
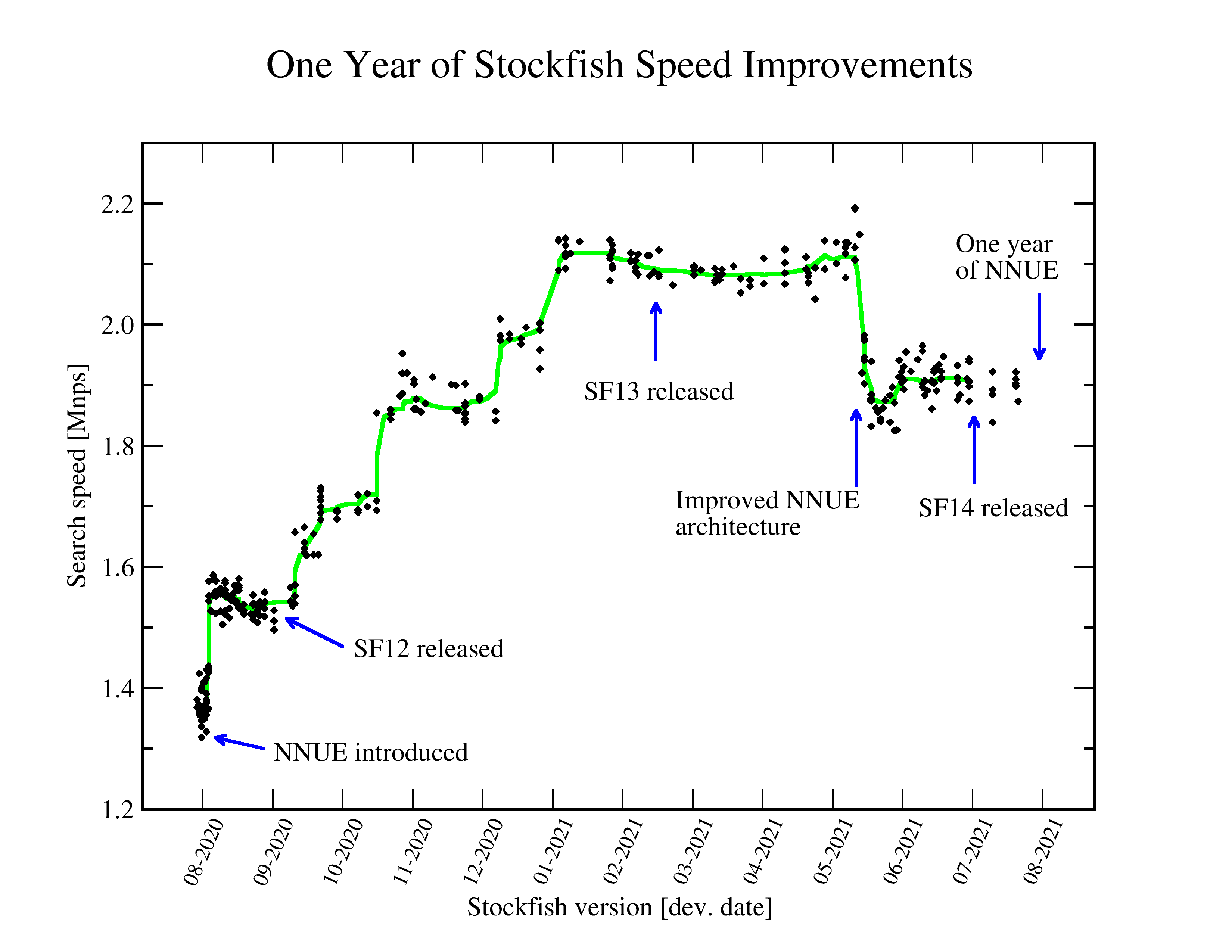
Presents nodes per second (nps) measurements for all SF version between the first NNUE commit (SF_NNUE, Aug 2th 2020) and end of July 2021 on a AMD Ryzen 9 3950X compiled with make -j ARCH=x86-64-avx2 profile-build. The last nps reported for a depth 22 search from startpos using NNUE (best over about 20 measurements) is shown in the graph. For reference, the last classical evaluation (SF_classical, July 30 2020) has 2.30 Mnps.
Measured playing games of 5+0.05s, with SF 7 - 15, using the three different books. Each version plays once with the base TC, and once with 20% time odds.
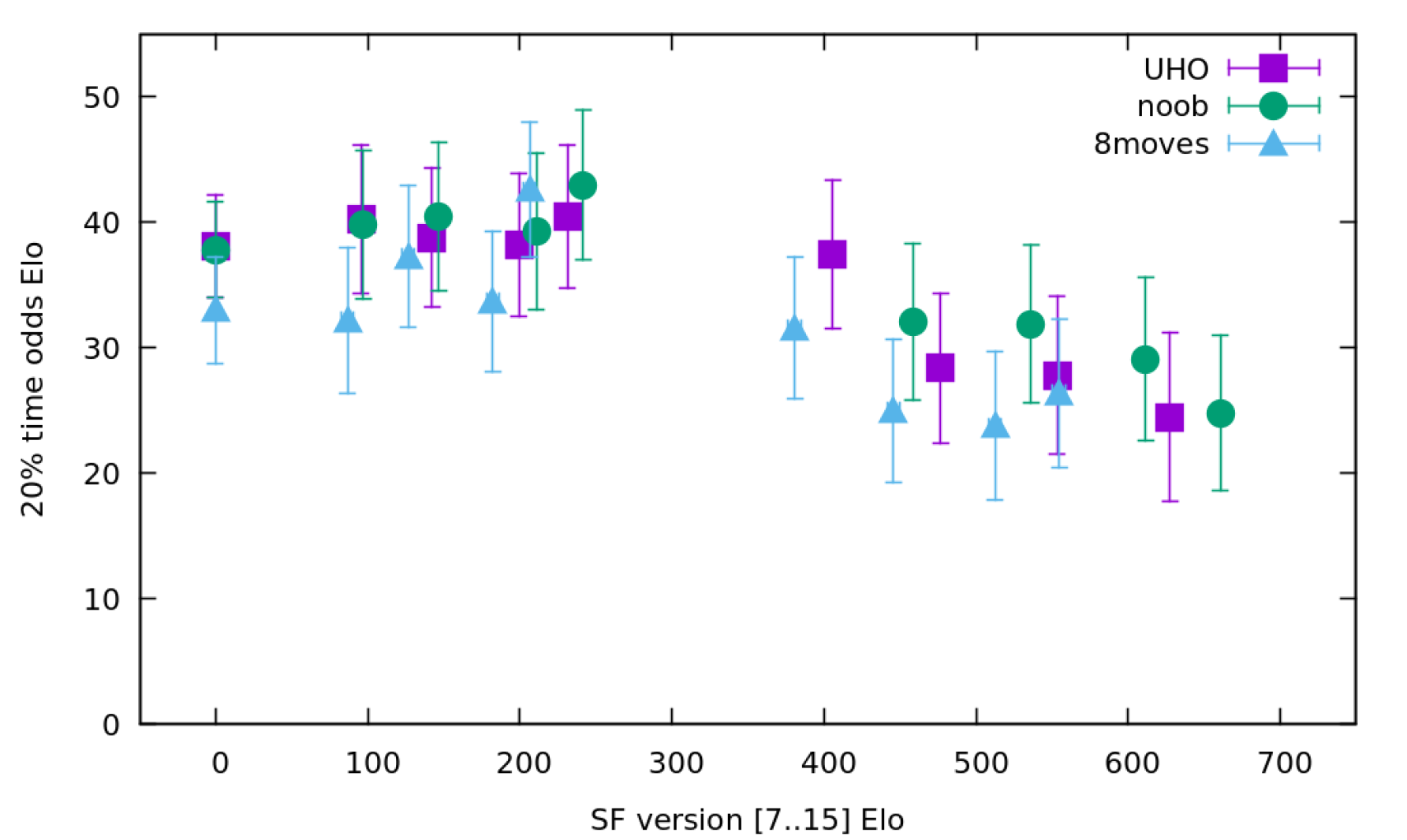
Raw data for the above graph
| SF | Elo | 20%-odds | Elo-err | Odds-err |
|---|---|---|---|---|
| SF7 | 0.0 | 38.1 | 0.0 | 4.1 |
| SF8 | 95.8 | 40.3 | 4.2 | 5.9 |
| SF9 | 142.3 | 38.8 | 3.9 | 5.5 |
| SF10 | 199.5 | 38.2 | 4.0 | 5.7 |
| SF11 | 231.2 | 40.5 | 4.3 | 5.7 |
| SF12 | 405.6 | 37.5 | 4.0 | 5.9 |
| SF13 | 476.5 | 28.4 | 4.2 | 6.0 |
| SF14 | 553.4 | 27.8 | 4.5 | 6.3 |
| SF15 | 627.6 | 24.5 | 4.6 | 6.7 |
| SF | Elo | 20%-odds | Elo-err | Odds-err |
|---|---|---|---|---|
| SF7 | 0.0 | 37.8 | 0.0 | 3.8 |
| SF8 | 97.2 | 39.8 | 4.3 | 5.9 |
| SF9 | 146.8 | 40.5 | 3.9 | 5.9 |
| SF10 | 211.1 | 39.3 | 4.3 | 6.2 |
| SF11 | 241.8 | 43.0 | 4.4 | 6.0 |
| SF12 | 458.4 | 32.1 | 4.3 | 6.2 |
| SF13 | 536.2 | 31.9 | 4.2 | 6.3 |
| SF14 | 611.3 | 29.1 | 4.5 | 6.5 |
| SF15 | 660.9 | 24.8 | 4.3 | 6.2 |
| SF | Elo | 20%-odds | Elo-err | Odds-err |
|---|---|---|---|---|
| SF7 | 0.0 | 33.0 | 0.0 | 4.2 |
| SF8 | 86.7 | 32.2 | 4.2 | 5.8 |
| SF9 | 126.7 | 37.3 | 4.0 | 5.6 |
| SF10 | 182.3 | 33.7 | 4.3 | 5.6 |
| SF11 | 206.5 | 42.6 | 4.0 | 5.4 |
| SF12 | 380.7 | 31.6 | 4.1 | 5.6 |
| SF13 | 445.8 | 25.0 | 4.0 | 5.7 |
| SF14 | 512.4 | 23.8 | 4.1 | 5.9 |
| SF15 | 554.5 | 26.4 | 4.1 | 5.9 |
The branching factor (bf) of Stockfish is defined here such that nodes = bf ** rootDepth or equivalently bf = exp(log(nodes)/rootDepth). Here, this has been measured with a single search from the starting position.

The trend is the deeper one searches the lower the branching factor, and newer versions of SF have a lower branching factor. A small difference in branching factor leads to very large differences in number of nodes searched. For example, SF10 needs about 143x more nodes than SF15.1 to reach depth 49.
Older SF (around SF10) had contempt that worked rather well. This data shows the dependence of Elo difference between SFdev of October 2018 and older versions of Stockfish depending on contempt value (The SFdev used is approx. 40Elo above SF9). Upper and lower bounds represent value with maximum error.
| Opponent | STC | LTC |
|---|---|---|
| 7 |  |
 |
| 8 |  |
 |
| 9 |  |
 |
Full data with values https://docs.google.com/spreadsheets/d/1R_eopD8_ujlBbt_Q0ygZMvuMsP1sc4UyO3Md4qL1z5M/edit#gid=1878521689
Here is the result of some scaling tests with the 2moves book. 40000 games each (STC=10+0.1, LTC=60+0.6)
| SF7 -> SF8 | SF8 -> SF9 | SF9 -> SF10 | |
|---|---|---|---|
| Elo STC | 95.91 +-2.3 | 58.28 +-2.3 | 71.03 +-2.4 |
| Elo LTC | 100.40 +-2.1 | 68.55 +-2.1 | 65.55 +-2.2 |
So we see that the common wisdom that increased TC causes elo compression is not always true.
See https://github.com/official-stockfish/Stockfish/issues/1859#issuecomment-449624976
Discussed here https://github.com/official-stockfish/Stockfish/pull/2401#issuecomment-552768526
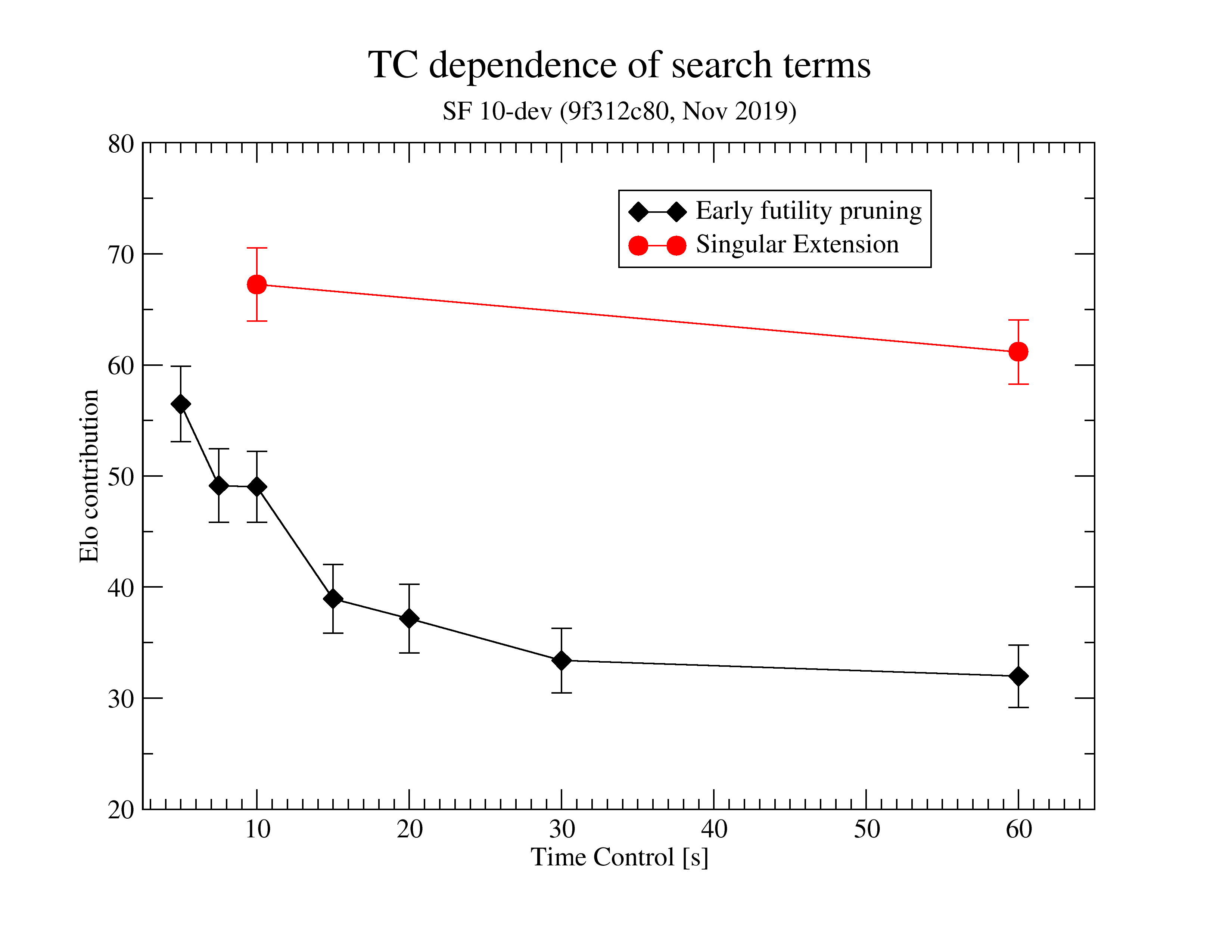
See spreadsheet at: https://github.com/official-stockfish/Stockfish/files/3828738/Stockfish.Feature.s.Estimated.Elo.worth.1.xlsx
Note: The estimated elo worth for various features might be outdated, or might get outdated soon.