基础关系代数符号与操作如下所示:
-
传统的集合运算
-
并(∪)(union)
-
差(−)(except)
-
交(∩)(intersect)
-
笛卡尔积(×)
-
-
专门的关系运算
-
选择(σ)(where)
-
投影(π)(select)
-
连接(⋈θ)
-
除过传统的集合运算与专门的关系运算之外还有外连接、聚集、物化计算等,接下来会针对这些内容进行详细介绍。
使用选择操作符时的算法通常是 Scan,其中有线性扫描,也有索引扫描。通常对同一张表有多次选择的条件,应该将这多个条件优化到一次。
-
示例 1:合并多个选择。
该方法适合于对同一张表上有多个相同的选择条件而言,此时可以合并多次的选择,以减少多次过滤带来的消耗。比如条件
where T.a=T.b and T.b=T.c,这个条件是一个和的操作,需要过滤两次。因此在内部可以将它优化成一个过滤条件,直接判断T.a=T.b=T.c,而不是先判断T.a=T.b,再判断T.b=T.c。 -
示例 2:分解多个选择。
比如 SQL 语句
select * from T where T.a=3 OR T.b>8,假设 T 表的 a 和 b 组上都有各自的索引。这时候可以将这个 SQL 分解为两个 SQL(select * from T where T.a=3 UNION select * from T where T.b>8),各自利用索引加速进行查询,最后再合并结果,而不必因为 OR 导致索引失效。在实际应用中 OR 改写为 UNION 是一种非常经典的改写,感兴趣的同学可以搜索相关资料进行研究。
使用投影操作符能够减少列,从而减少中间临时关系的内存消耗,这里通过一个例子来帮助理解。
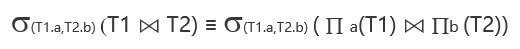
如上图所示,在这个示例中最终需要过滤出来的是表 T1 的 a 属性和表 T2 的 b 属性。假设表 T1 和表 T2 都是具有非常多属性的复杂表,在连接时做了全连接,导致产生的中间临时关系比较大。此时可以使用投影操作符提前进行列的投影,通过列投影操作生成的中间临时关系会比较小,并且连接操作的复杂度也会有所下降。
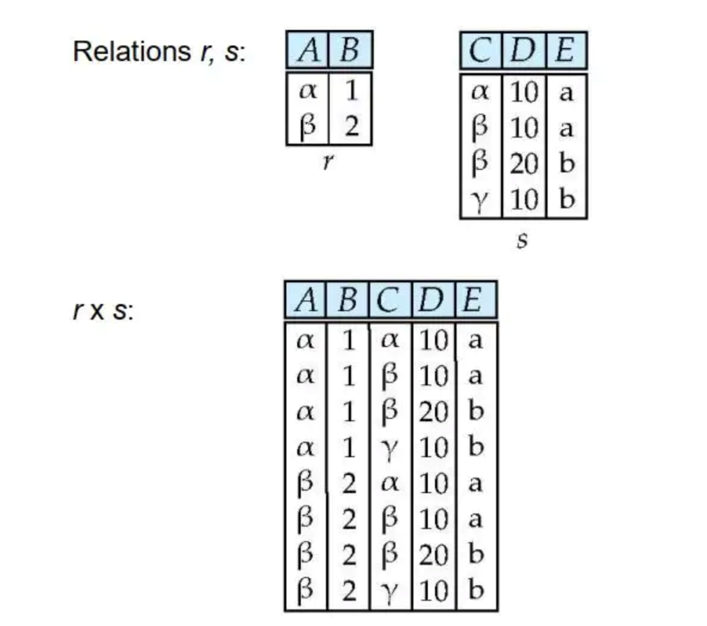
笛卡尔积不要求两个属性之间有公共属性,导致最终生成的结果集也会比较复杂。因为它是对两个关系中的每一条元素都一一进行连接,如下图所示,r 属性有两条元组,s 属性有四条元组,最后生成了八条元组,也就是乘积的关系。
在这个基础上,还有 inner join、left join、right join、full join。其中 inner join 称为内连接,其余三个称为外连接(out join)。
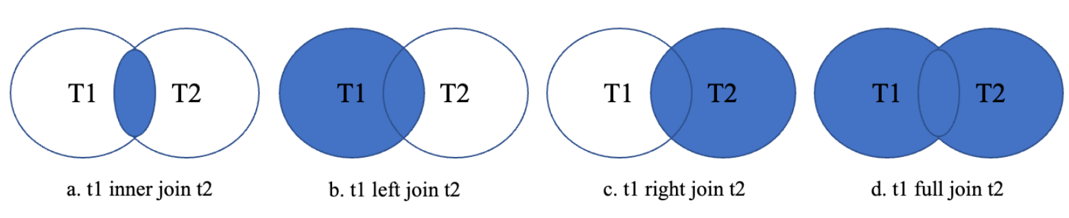
通常都会将 out join 改写为 inner join,因为内连接允许更多的连接顺序选择、基表谓词条件下压,有助于查询优化器选择到更好的查询执行计划,提升查询效率。之前 OceanBase 优化器团队出过一篇改写系列的文章,感兴趣的可以研究一下,博客链接:https://open.oceanbase.com/blog/10900347 《SQL 改写系列九:外连接转内连接的常见场景与错误》。
这里列举了几种连接算法的伪码,可以帮助理解每一种连接算法的原理。
-
Nest-loop join 算法的基本思想就是两个 for 循环。每次会迭代外表的一行,然后再以此为驱动去迭代内表的每一行 tuple,如果满足连接条件,就会加入结果集。这里有一个基本的优化思想,即可以将小表放在外层作为驱动表,这样会减少内表的循环次数,从而也会减少内表的遍历次数。
For t IN Rt: For s IN Rs: result.add(t,s)
-
Index Nest-loop join 算法是利用索引加速的一个嵌套循环算法。假设在内表有索引,且是一个等值的,每次驱动外表的一行,内表可以利用等值进行一个索引搜索,就不需要去遍历内表的全部元组,从而减少 IO 的消耗。
For t IN Rt: For s IN Rs using index: result.add(t,s)
-
Block Nest-loop join 算法的基本思想是每次的迭代不再是一行的 tuple,而是按块进行连接运算。先读取 Rt 表的一个 Block,再读遍读取 Rs 的一个 Block,然后将这两个表的元组进行连接。这个算法的基本思想就是不再以行为粒度,而是以块为粒度,从而减少 IO 的消耗。
For Bt IN Rt: For Bs IN Rs : For t IN Bt: For s IN Bs: result.add(t,s)
-
merge join 算法利用了归并排序的思想,先将两张关联表各自做排序,然后从各自的排序表中去抽取数据到另一个排序表中做一些条件匹配,从而生成结果集,示例中没有把它的伪码写的很详细,但可以说明基本的原理就是归并的思想。
Ra=Sort(Rt) Rb=Sort(Rs) Merge_join(Ra,Rb)--result.add(t,s)
-
hash join 算法是将其中一张表先在内存中建立一个哈希表,这张表通常是两张表中比较小的那一张表。需要注意的是,如果这个哈希表比较大,无法一次性构造在内存中,那就需要将这张表分多个 partition 写入磁盘,就会多一个写的拆架,也会降低效率。因此 hash join 算法通常适合于较小的表,可以完全存放在内存中。
HT=Build_hash(Rt) For s IN Rs: if hask_key(s) found in HT: result.add(t,s)
通常 merge join 的效率会比 hash join 差,但如果两张关联的表已经排序好了,此时就不需要做排序操作,这时 merge join 的效率就不一定比 hash join 差了。
交、并、差也是涉及到多表的运算,通常是用 merge join 或 hash join 的思想,只不过前面介绍的 merge join 和 hash join 是做连接,而交、并、差是在 merge 或 hash 的过程中做去重。
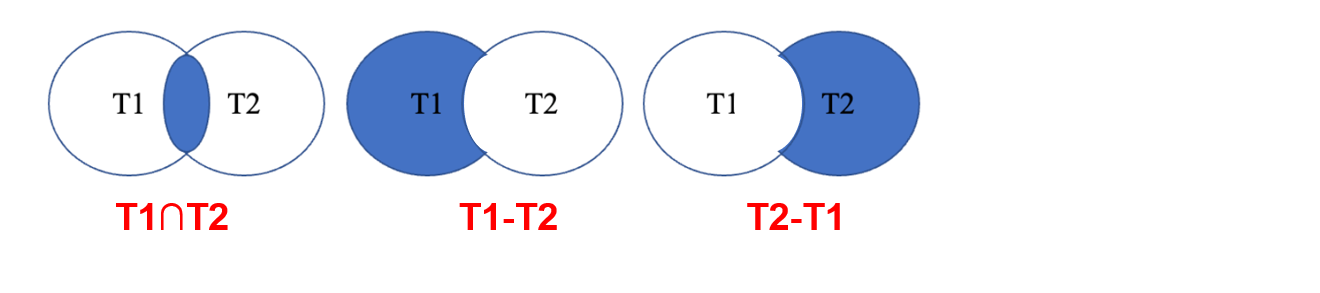
聚合操作也是用 merge 或 hash 的思想,通常通过 merge 或 hash 将同一组中的元组放在一起,然后在每个组内进行相应聚合函数的实现,这里列举了几个优化示例帮助理解。
-
部分聚合,对于 count、min、max 和 sum,可以保留组中目前找到的元组的聚合值。
-
当将部分聚合合并为计数时,将部分聚合相加。
-
对于 avg,保留 sum 和 count,并在最后用 sum 除以 count。
通过一个示例来介绍物化和流水线计算,SQL 语句 select max(c1) from test; 的语义是为了查询 test 表中 c1 的最大值。
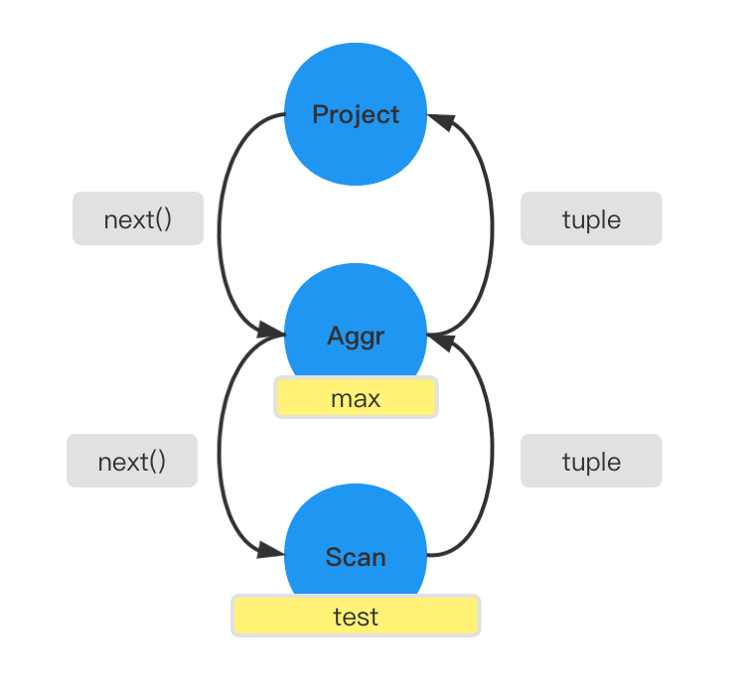
如上图所示这是火山引擎的一个执行流水线图。假设没有任何的潜在知识设想,那么一种比较自然的想法,就是对每一个操作都预先计算生成中间的临时关系。比如先扫描出 test 中的元组,放在内存缓冲块中,当投影操作向下驱动的时候,聚合算子可以直接读取已经扫描出来在缓冲块中的 test 元组的数据,然后直接去计算 c1 的最大值就可以了。但这样有个明显的缺点,如果申请的内存比较大(假设 test 比较大),那么这种代价的消耗是不划算的。
流水线计算的思想是把从上到下的多个算子,当成一体的算子。每次当投影算子向下驱动的时候,聚合算子会从扫描算子中取到一行元组,扫描算子每次只会向上驱动一行,然后聚合算子会马上根据这一行做运算,去判断是否是更大的值,然后进行更新。在整个过程中只需要消耗一行 tuple 大小的空间,而不需要去申请一个较大的内存缓存区块去存取物化的整个表的代价。
物化计算不一定比流水线计算效果差,这需要看具体的业务需求,只是在这个示例中,用流水线的计算方式更优。
希望通过以上知识的学习,在以后看到一条业务 SQL 的计划时,能够去注意这些计划中关系对应操作的基本原理,这也有助于判断查询计划是否更加高效。