Executor 模块中最经典的模型是 Volcano Model(火山模型),它是一种基于行的流式迭代模型(Row-BasedStreaming Iterator Model),目前主流的关系数据库中都采用了这种模型,例如 Oracle、SQL Server、MySQL 等。
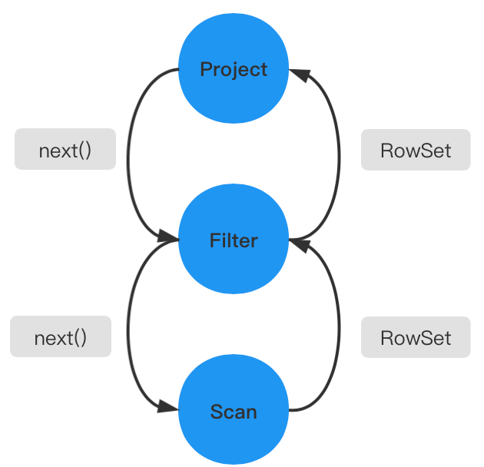
在火山模型中,所有的代数运算符(operator)都被看成是一个迭代器,它们都提供一组简单的接口:open()—next()—close(),查询计划树由一个个这样的关系运算符组成,每一次的 next() 调用,运算符就返回一行(Row),每一个运算符的 next() 都有自己的流控逻辑,数据通过运算符自上而下的 next() 嵌套调用而被动的进行拉取。
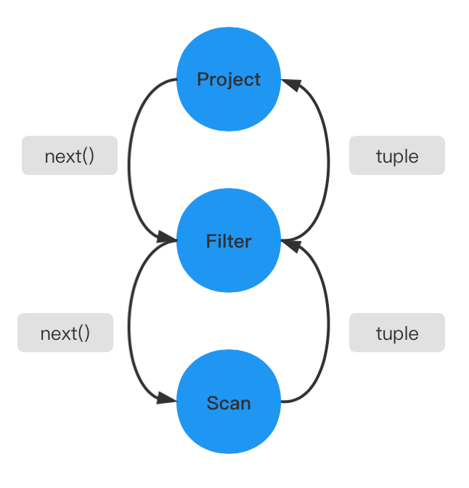
火山模型中每一个运算符都将下层的输入看成是一张表,next() 接口的一次调用就获取表中的一行数据,这样设计的优点是:每个运算符之间的代数计算是相互独立的,并且运算符可以伴随查询关系的变化出现在查询计划树的任意位置,这使得运算符的算法实现变得简单并且富有拓展性。
这种设计也会存在一些问题,如果没有一些阻塞性的操作,整个火山模型只需要很少的内存就能运作起来,每次只需要迭代一个 tuple 行。但有一些 Operator(如 sort),它是阻塞性的操作,要拿到所有的 tuple 之后,才能进行进行运算,这种操作符实际上是破坏了火山模型整体的流水性的运算。
另外一方面当处理的数据量增大时,也会有明显缺陷。因为每次只迭代一行,所以要向下调用很多层的 next() 函数,它导致了大量的虚函数开销,非常消耗 CPU 资源。
这个问题也是因为一些历史原因,火山模型最早于 1990 年 Goetz Graefe 在 Volcano,an Extensible and Parallel Query Evaluation System 这篇论文中提出的,在 90 年代早期,计算机的内存资源十分昂贵,相对于 CPU 的执行效率,IO 的效率要差得多。因此当时火山模型考虑的是将更多的内存资源用于 IO 的缓存设计,而没有考虑去优化这种结构导致的 CPU 方面执行效率的低下。从当时的条件来看,在硬件上它是一个非常合理的权衡。
经过多年的研究和发展,无论学术还是工业界都在火山模型的基础上不断改进,下面介绍几个示例:
-
RowSet 迭代
如下图所示,每次返回的不是一个 tuple,而是一个 RowSet。这种 RowSet 的迭代,它每一次的数据流传递不再是单行的模式,而是做单个 tuple 组成的集合。更多的运算就会停留在这个 next() 操作的内部,而不是在函数调用之间频繁的切换,可以减少 next() 的调用次数。同时这个局部的操作也有返回一个 tuple,变成了一个局部的循环操作。这种循环操作实际上是可以用现代的一些编译技术或 CPU 动态指定预测技术来进行优化的,也能够提升我们的查询效率。
-
操作符融合
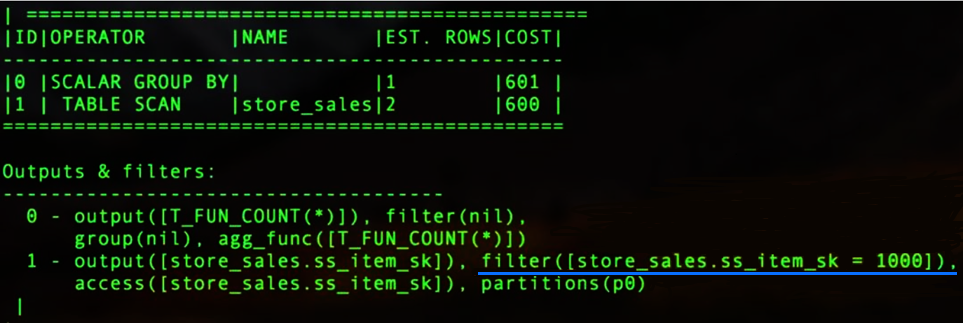
如下图所示,在做 TABLE SCAN 的时候,实际上做了一个过滤,过滤掉了
ss_item_sk=1000的操作。可以看到无论是第几步都有 Filter 操作,而实际上是把 Filter 的操作放到了投影和 Scan 里面,这样可以减少一层的调用。比如说这里的 Filter 下推到 Scan 里面去过滤掉,这在前面介绍的查询计划的优化中也有类似的操作。 -
拉取模型和推送模型
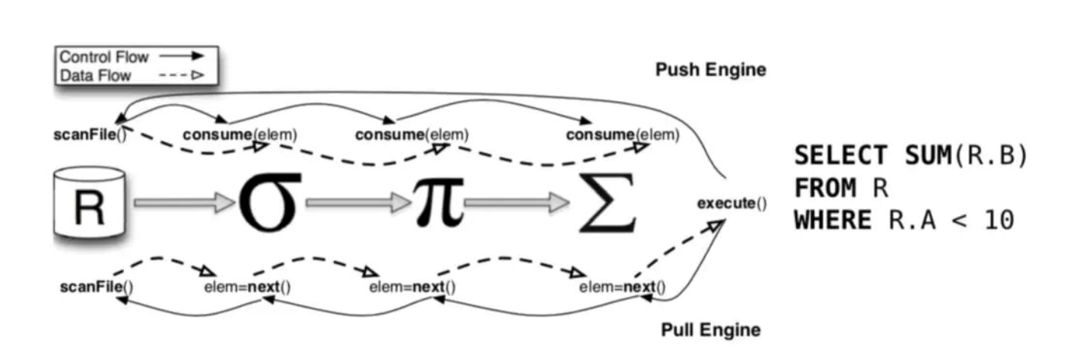
火山模型是一种被动的数据读取方式,它由上层的算子来驱动,当下层算子接受到上层算子的调用请求后,会返回符合条件的 tuple。但更方便的方式,应该是由下层算子主动将数据推送给上层算子。
为帮助大家理解拉取模型和推送模型的差异,接下来介绍一个示例。
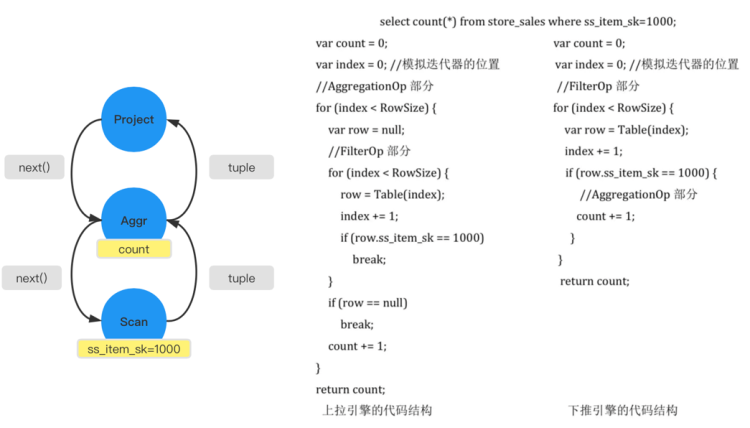
下图中所示 SQL ,语义是从 store_sales 中挑选符合条件的商品,并做聚合去计数。下图左边所示是对应的火山模型。挑选出符合条件的 tuple,然后返回给上层 Aggr 算子,再进行 count 操作去计数。
接下来分别来看一下上拉模型和下推模型的代码结构区别。
-
上拉引擎的代码结构
左边是经典的火山模型的一个伪代码,投影操作的代码这里没有列举出来。上拉模型是由上层的算子驱动,即从上层的 AggregationOp 去驱动,每次开始时,就会调用 FilterOp 的部分。FilterOp 遇到符合条件的时候,会结束自己的调用,然后将这条信息传回给上一层。当 row 不等于 null 时,就会将计数加一,这是外层 AggregationOp 的调用。
-
下推引擎的代码结构
推送模型的数据流动是从下层开始的一个 Scan 操作,也就是从它的 FilterOp 开始。即首先遍历他自己 Table,然后找到满足的行,推送给 AggregationOp 的部分,直接进行计数加一。可以看到下推引擎在代码的层次上相对上拉引擎简洁了许多,能够减少一些 CPU 资源的消耗。
-