Run 🤗 Transformers in your browser! We currently support BERT, DistilBERT, T5, GPT2, and BART models, for a variety of tasks including: masked language modelling, text classification, translation, summarization, question answering, and text generation.
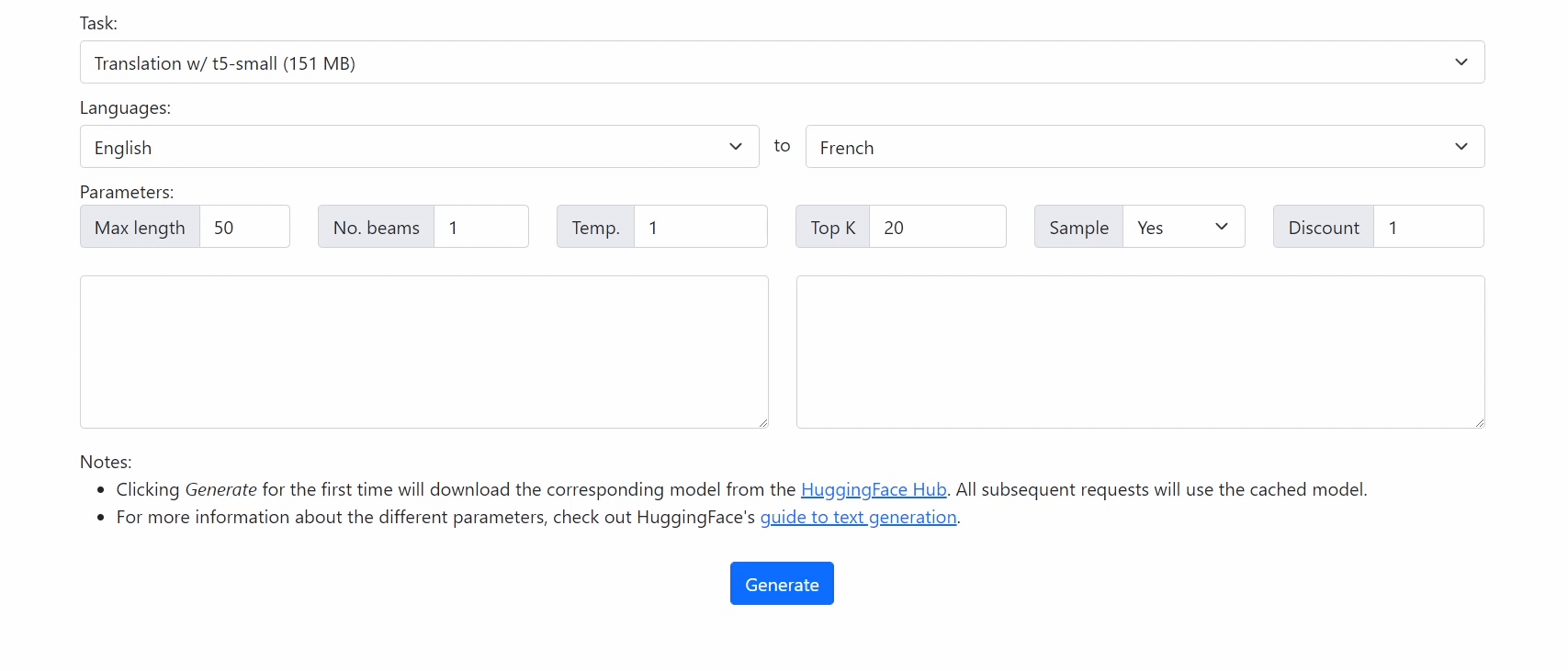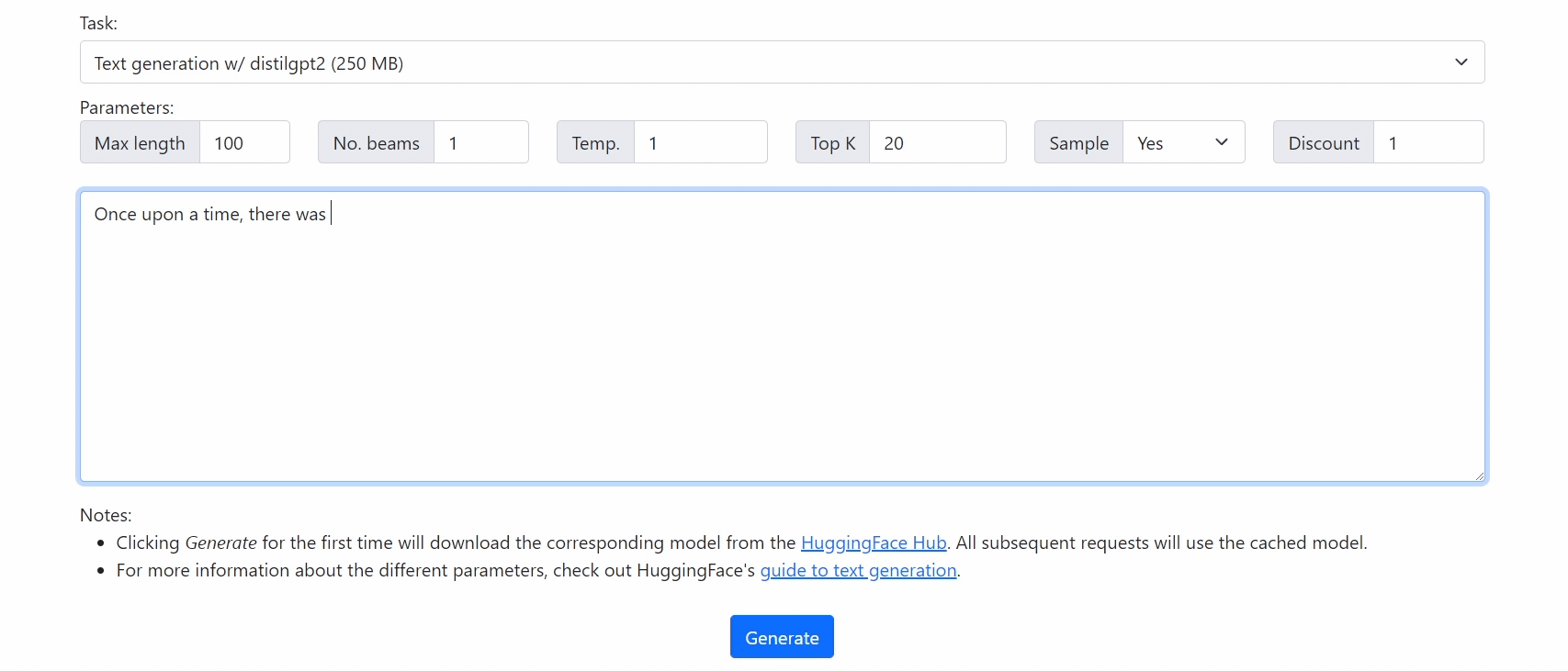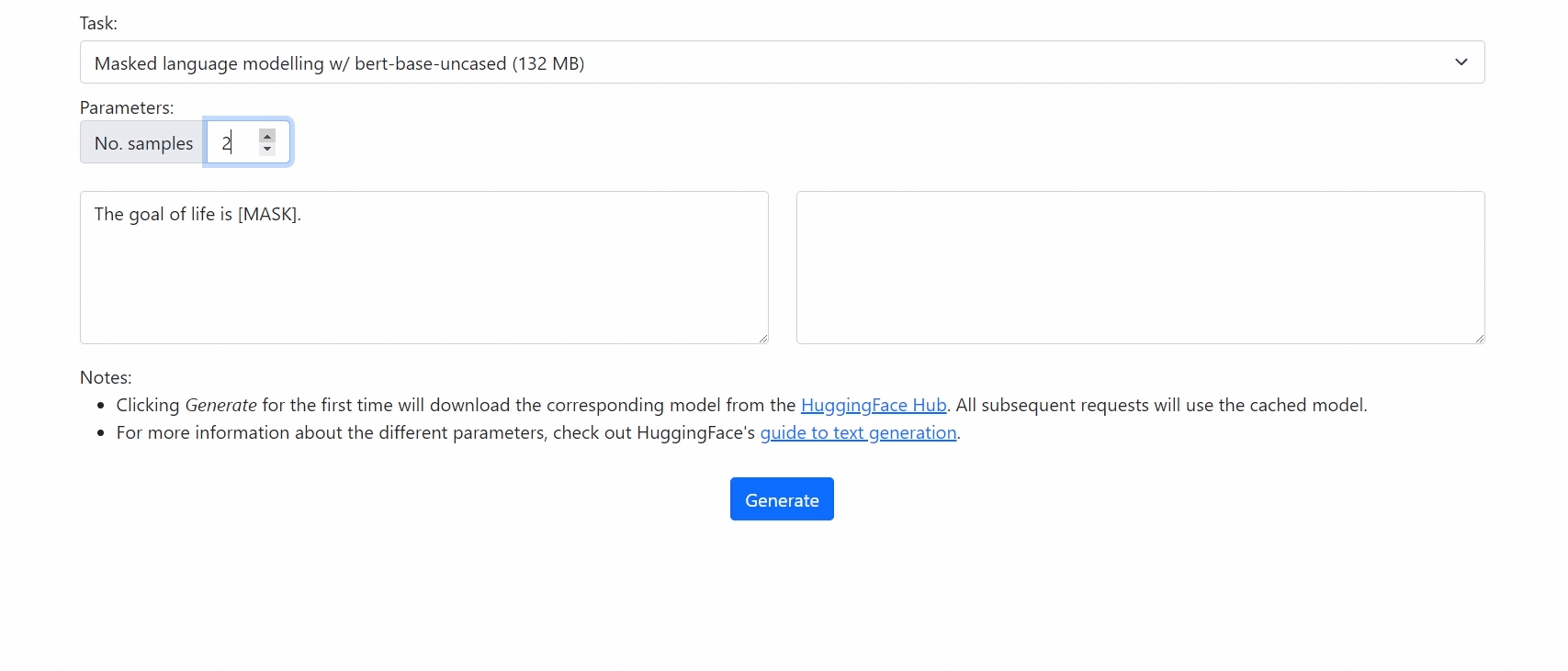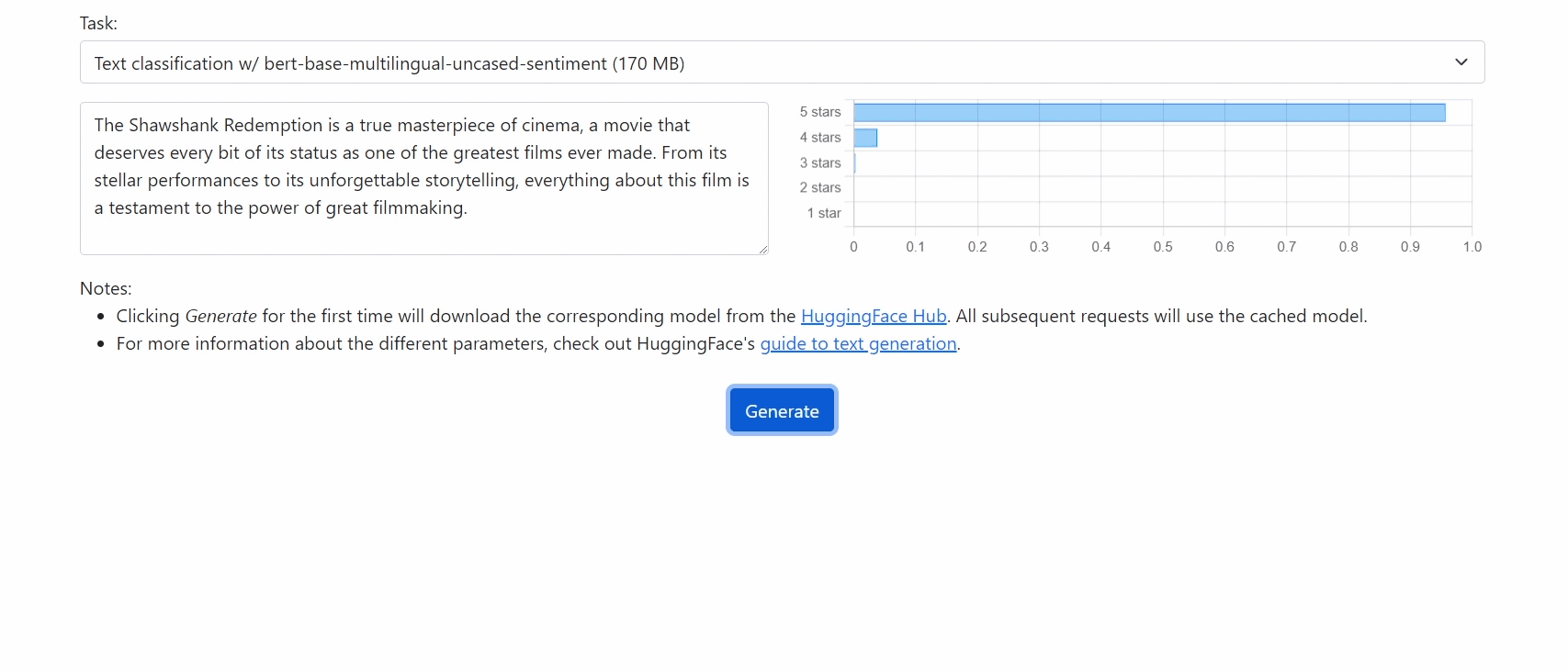
It's super easy to translate from existing code!
Python (original):
from transformers import (
AutoTokenizer,
AutoModelForSeq2SeqLM
)
path = './models/pytorch/t5-small'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForSeq2SeqLM.from_pretrained(path)
text = 'translate English to French: Hello, how are you?'
input_ids = tokenizer(text, return_tensors='pt').input_ids
output_token_ids = model.generate(input_ids)
output_text = tokenizer.decode(output_token_ids[0], True)
print(output_text) # "Bonjour, comment allez-vous?"Javascript (ours):
import {
AutoTokenizer,
AutoModelForSeq2SeqLM
} from "transformers.js";
let path = './models/onnx/t5-small';
let tokenizer = await AutoTokenizer.from_pretrained(path);
let model = await AutoModelForSeq2SeqLM.from_pretrained(path);
let text = 'translate English to French: Hello, how are you?';
let input_ids = tokenizer(text).input_ids;
let output_token_ids = await model.generate(input_ids);
let output_text = tokenizer.decode(output_token_ids[0], true);
console.log(output_text); // "Bonjour, comment allez-vous?"Check out our demo at https://xenova.github.io/transformers.js/. As you'll see, everything runs inside the browser!
We use ONNX Runtime to run the models in the browser, so you must first convert your PyTorch model to ONNX (which can be done using our conversion script). For the following examples, we assume your PyTorch models are located in the ./models/pytorch/ folder. To choose a different location, specify the parent input folder with --input_parent_dir /path/to/parent_dir/ (note: without the model id).
Here are some of the models we have already converted (along with the command used).
-
t5-small for translation/summarization.
python -m scripts.convert --quantize --model_id t5-small --task seq2seq-lm-with-past -
distilgpt2 for text generation.
python -m scripts.convert --quantize --model_id distilgpt2 --task causal-lm-with-past -
bert-base-uncased for masked language modelling.
python -m scripts.convert --quantize --model_id bert-base-uncased --task masked-lm -
bert-base-cased for masked language modelling.
python -m scripts.convert --quantize --model_id bert-base-cased --task masked-lm -
bert-base-multilingual-uncased for sequence classification (i.e., sentiment analysis).
python -m scripts.convert --quantize --model_id bert-base-multilingual-uncased --task sequence-classification -
distilbert-base-uncased-distilled-squad for question answering.
python -m scripts.convert --quantize --model_id distilbert-base-uncased-distilled-squad --task question-answering -
distilbart-cnn-6-6 for summarization.
python -m scripts.convert --quantize --model_id distilbart-cnn-6-6 --task seq2seq-lm-with-past
Note: We recommend quantizing the model (--quantize) to reduce model size and improve inference speeds (at the expense of a slight decrease in accuracy).
Coming soon...
Coming soon... In the meantime, check out the source code for the demo here.
Inspired by https://github.com/praeclarum/transformers-js