diff --git a/README.md b/README.md
index a9c0988adba..f92a6e6dca0 100644
--- a/README.md
+++ b/README.md
@@ -3,7 +3,7 @@
 -
- +
+


 @@ -13,7 +13,10 @@
### What is Modin?
-Modin is a drop-in replacement for [pandas](https://github.com/pandas-dev/pandas) that scales the single-threaded pandas to become multi-threaded, using all of your cores and offering instant speedup to your workflows. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs out of memory.
+Modin is a drop-in replacement for [pandas](https://github.com/pandas-dev/pandas). While pandas is
+single-threaded, Modin lets you instantly speed up your workflows by scaling pandas so it uses all of your
+cores. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs
+[out of memory](https://modin.readthedocs.io/en/latest/getting_started/why_modin/out_of_core.html).
Using modin is as simple as replacing the pandas import:
@@ -26,7 +29,7 @@ import modin.pandas as pd
#### From PyPI
-Modin can be installed with `pip`:
+Modin can be installed with `pip` on Linux, Windows and MacOS:
```bash
pip install modin[all] # (Recommended) Install Modin with all of Modin's currently supported engines.
@@ -43,8 +46,9 @@ Modin automatically detects which engine(s) you have installed and uses that for
#### From conda-forge
-Installing from conda forge using `modin-all` will install Modin and 3 engines: ([Ray](https://github.com/ray-project/ray),
-[Dask](https://github.com/dask/dask) and [Omnisci](https://modin.readthedocs.io/en/latest/UsingOmnisci/index.html))
+Installing from [conda forge](https://github.com/conda-forge/modin-feedstock) using `modin-all`
+will install Modin and three engines: [Ray](https://github.com/ray-project/ray),
+[Dask](https://github.com/dask/dask), and [Omnisci](https://www.omnisci.com/platform/omniscidb).
```bash
conda install -c conda-forge modin-all
@@ -58,30 +62,7 @@ conda install -c conda-forge modin-dask # Install Modin dependencies and Dask.
conda install -c conda-forge modin-omnisci # Install Modin dependencies and Omnisci.
```
-### Pandas API Coverage
-
-
@@ -13,7 +13,10 @@
### What is Modin?
-Modin is a drop-in replacement for [pandas](https://github.com/pandas-dev/pandas) that scales the single-threaded pandas to become multi-threaded, using all of your cores and offering instant speedup to your workflows. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs out of memory.
+Modin is a drop-in replacement for [pandas](https://github.com/pandas-dev/pandas). While pandas is
+single-threaded, Modin lets you instantly speed up your workflows by scaling pandas so it uses all of your
+cores. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs
+[out of memory](https://modin.readthedocs.io/en/latest/getting_started/why_modin/out_of_core.html).
Using modin is as simple as replacing the pandas import:
@@ -26,7 +29,7 @@ import modin.pandas as pd
#### From PyPI
-Modin can be installed with `pip`:
+Modin can be installed with `pip` on Linux, Windows and MacOS:
```bash
pip install modin[all] # (Recommended) Install Modin with all of Modin's currently supported engines.
@@ -43,8 +46,9 @@ Modin automatically detects which engine(s) you have installed and uses that for
#### From conda-forge
-Installing from conda forge using `modin-all` will install Modin and 3 engines: ([Ray](https://github.com/ray-project/ray),
-[Dask](https://github.com/dask/dask) and [Omnisci](https://modin.readthedocs.io/en/latest/UsingOmnisci/index.html))
+Installing from [conda forge](https://github.com/conda-forge/modin-feedstock) using `modin-all`
+will install Modin and three engines: [Ray](https://github.com/ray-project/ray),
+[Dask](https://github.com/dask/dask), and [Omnisci](https://www.omnisci.com/platform/omniscidb).
```bash
conda install -c conda-forge modin-all
@@ -58,30 +62,7 @@ conda install -c conda-forge modin-dask # Install Modin dependencies and Dask.
conda install -c conda-forge modin-omnisci # Install Modin dependencies and Omnisci.
```
-### Pandas API Coverage
-
-
-
-| pandas Object | Modin's Ray Engine Coverage | Modin's Dask Engine Coverage |
-|-------------------|:------------------------------------------------------------------------------------:|:---------------:|
-| `pd.DataFrame` |  | |
-| `pd.Series` |
| |
-| `pd.Series` |  | |
-| `pd.read_csv` | ✅ | ✅ |
-| `pd.read_table` | ✅ | ✅ |
-| `pd.read_parquet` | ✅ | ✅ |
-| `pd.read_sql` | ✅ | ✅ |
-| `pd.read_feather` | ✅ | ✅ |
-| `pd.read_excel` | ✅ | ✅ |
-| `pd.read_json` | [✳️](https://github.com/modin-project/modin/issues/554) | [✳️](https://github.com/modin-project/modin/issues/554) |
-| `pd.read_` | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) |
-
-
-
| |
-| `pd.read_csv` | ✅ | ✅ |
-| `pd.read_table` | ✅ | ✅ |
-| `pd.read_parquet` | ✅ | ✅ |
-| `pd.read_sql` | ✅ | ✅ |
-| `pd.read_feather` | ✅ | ✅ |
-| `pd.read_excel` | ✅ | ✅ |
-| `pd.read_json` | [✳️](https://github.com/modin-project/modin/issues/554) | [✳️](https://github.com/modin-project/modin/issues/554) |
-| `pd.read_` | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) |
-
-
-
-Some pandas APIs are easier to implement than other, so if something is missing feel
-free to open an issue!
-
-
-##### Choosing a Compute Engine
+#### Choosing a Compute Engine
If you want to choose a specific compute engine to run on, you can set the environment
variable `MODIN_ENGINE` and Modin will do computation with that engine:
@@ -94,94 +75,75 @@ export MODIN_ENGINE=dask # Modin will use Dask
This can also be done within a notebook/interpreter before you import Modin:
```python
-import os
+from modin.config import Engine
-os.environ["MODIN_ENGINE"] = "ray" # Modin will use Ray
-os.environ["MODIN_ENGINE"] = "dask" # Modin will use Dask
-
-import modin.pandas as pd
+Engine.put("ray") # Modin will use Ray
+Engine.put("dask") # Modin will use Dask
```
-Check [this Modin docs section](https://modin.readthedocs.io/en/latest/UsingOmnisci/index.html) for Omnisci engine setup.
+Check [this Modin docs section](https://modin.readthedocs.io/en/latest/development/using_omnisci.html) for Omnisci engine setup.
-**Note: You should not change the engine after you have imported Modin as it will result in undefined behavior**
+_Note: You should not change the engine after your first operation with Modin as it will result in undefined behavior._
-##### Which engine should I use?
+#### Which engine should I use?
-If you are on Windows, you must use Dask. Ray does not support Windows. If you are on
-Linux or Mac OS, you can install and use either engine. There is no knowledge required
+On Linux, MacOS, and Windows you can install and use either Ray or Dask. There is no knowledge required
to use either of these engines as Modin abstracts away all of the complexity, so feel
free to pick either!
-On Linux you also can choose [Omnisci](https://modin.readthedocs.io/en/latest/UsingOmnisci/index.html) which is an experimental
-engine based on [OmnisciDB](https://www.omnisci.com/platform/omniscidb) and included into [Intel® Distribution of Modin](https://software.intel.com/content/www/us/en/develop/tools/oneapi/components/distribution-of-modin.html) which is a part of [Intel® oneAPI AI Analytics Toolkit (AI Kit)](https://www.intel.com/content/www/us/en/developer/tools/oneapi/ai-analytics-toolkit.html)
-
-##### Advanced usage
-
-In Modin, you can start a custom environment in Dask or Ray and Modin will connect to
-that environment automatically. For example, if you'd like to limit the amount of
-resources that Modin uses, you can start a Dask Client or Initialize Ray and Modin will
-use those instances. Make sure you've set the correct environment variable so Modin
-knows which engine to connect to!
-
-For Ray:
-```python
-import ray
-ray.init(plasma_directory="/path/to/custom/dir", object_store_memory=10**10)
-# Modin will connect to the existing Ray environment
-import modin.pandas as pd
-```
-
-For Dask:
-```python
-from distributed import Client
-client = Client(n_workers=6)
-# Modin will connect to the Dask Client
-import modin.pandas as pd
-```
-
-This gives you the flexibility to start with custom resource constraints and limit the
-amount of resources Modin uses.
+On Linux you also can choose [Omnisci](https://modin.readthedocs.io/en/latest/development/using_omnisci.html), which is an experimental
+engine based on [OmnisciDB](https://www.omnisci.com/platform/omniscidb) and included in the
+[Intel® Distribution of Modin](https://software.intel.com/content/www/us/en/develop/tools/oneapi/components/distribution-of-modin.html),
+which is a part of [Intel® oneAPI AI Analytics Toolkit (AI Kit)](https://www.intel.com/content/www/us/en/developer/tools/oneapi/ai-analytics-toolkit.html).
+### Pandas API Coverage
-### Full Documentation
+
-Visit the complete documentation on readthedocs: https://modin.readthedocs.io
+| pandas Object | Modin's Ray Engine Coverage | Modin's Dask Engine Coverage |
+|-------------------|:------------------------------------------------------------------------------------:|:---------------:|
+| `pd.DataFrame` | | |
+| `pd.Series` | | |
+| `pd.read_csv` | ✅ | ✅ |
+| `pd.read_table` | ✅ | ✅ |
+| `pd.read_parquet` | ✅ | ✅ |
+| `pd.read_sql` | ✅ | ✅ |
+| `pd.read_feather` | ✅ | ✅ |
+| `pd.read_excel` | ✅ | ✅ |
+| `pd.read_json` | [✳️](https://github.com/modin-project/modin/issues/554) | [✳️](https://github.com/modin-project/modin/issues/554) |
+| `pd.read_` | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) | [✴️](https://modin.readthedocs.io/en/latest/supported_apis/io_supported.html) |
-### Scale your pandas workflow by changing a single line of code.
+
+Some pandas APIs are easier to implement than others, so if something is missing feel
+free to open an issue!
+### More about Modin
-```python
-import modin.pandas as pd
-import numpy as np
+For the complete documentation on Modin, visit our [ReadTheDocs](https://modin.readthedocs.io/en/latest/index.html) page.
-frame_data = np.random.randint(0, 100, size=(2**10, 2**8))
-df = pd.DataFrame(frame_data)
-```
-**In local (without a cluster) modin will create and manage a local (dask or ray) cluster for the execution**
+#### Scale your pandas workflow by changing a single line of code.
+_Note: In local mode (without a cluster), Modin will create and manage a local (Dask or Ray) cluster for the execution._
-To use Modin, you do not need to know how many cores your system has and you do not need
-to specify how to distribute the data. In fact, you can continue using your previous
+To use Modin, you do not need to specify how to distribute the data, or even know how many
+cores your system has. In fact, you can continue using your previous
pandas notebooks while experiencing a considerable speedup from Modin, even on a single
machine. Once you've changed your import statement, you're ready to use Modin just like
-you would pandas.
-
+you would with pandas!
#### Faster pandas, even on your laptop
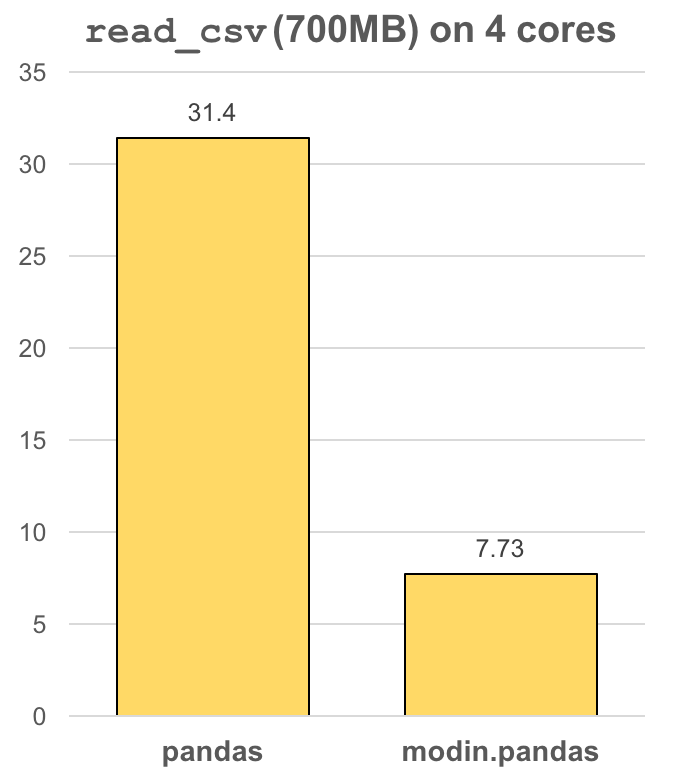 -The `modin.pandas` DataFrame is an extremely light-weight parallel DataFrame. Modin
-transparently distributes the data and computation so that all you need to do is
-continue using the pandas API as you were before installing Modin. Unlike other parallel
-DataFrame systems, Modin is an extremely light-weight, robust DataFrame. Because it is
-so light-weight, Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
+The `modin.pandas` DataFrame is an extremely light-weight parallel DataFrame.
+Modin transparently distributes the data and computation so that you can continue using the same pandas API
+while working with more data faster. Because it is so light-weight,
+Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
In pandas, you are only able to use one core at a time when you are doing computation of
-any kind. With Modin, you are able to use all of the CPU cores on your machine. Even in
-`read_csv`, we see large gains by efficiently distributing the work across your entire
-machine.
+any kind. With Modin, you are able to use all of the CPU cores on your machine. Even with a
+traditionally synchronous task like `read_csv`, we see large speedups by efficiently
+distributing the work across your entire machine.
```python
import modin.pandas as pd
@@ -189,36 +151,62 @@ import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
```
-#### Modin is a DataFrame designed for datasets from 1MB to 1TB+
-
-We have focused heavily on bridging the solutions between DataFrames for small data
-(e.g. pandas) and large data. Often data scientists require different tools for doing
-the same thing on different sizes of data. The DataFrame solutions that exist for 1KB do
-not scale to 1TB+, and the overheads of the solutions for 1TB+ are too costly for
-datasets in the 1KB range. With Modin, because of its light-weight, robust, and scalable
-nature, you get a fast DataFrame at small and large data. With preliminary [cluster](https://modin.readthedocs.io/en/latest/using_modin.html#using-modin-on-a-cluster)
-and [out of core](https://modin.readthedocs.io/en/latest/out_of_core.html)
-support, Modin is a DataFrame library with great single-node performance and high
+#### Modin can handle the datasets that pandas can't
+
+Often data scientists have to switch between different tools
+for operating on datasets of different sizes. Processing large dataframes with pandas
+is slow, and pandas does not support working with dataframes that are too large to fit
+into the available memory. As a result, pandas workflows that work well
+for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size
+of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably
+work with hundreds of GBs without worrying about substantial slowdown or memory errors.
+With [cluster](https://modin.readthedocs.io/en/latest/getting_started/using_modin/using_modin_cluster.html)
+and [out of core](https://modin.readthedocs.io/en/latest/getting_started/why_modin/out_of_core.html)
+support, Modin is a DataFrame library with both great single-node performance and high
scalability in a cluster.
#### Modin Architecture
-We designed Modin to be modular so we can plug in different components as they develop
-and improve:
+We designed [Modin's architecture](https://modin.readthedocs.io/en/latest/development/architecture.html)
+to be modular so we can plug in different components as they develop and improve:
+
+
-The `modin.pandas` DataFrame is an extremely light-weight parallel DataFrame. Modin
-transparently distributes the data and computation so that all you need to do is
-continue using the pandas API as you were before installing Modin. Unlike other parallel
-DataFrame systems, Modin is an extremely light-weight, robust DataFrame. Because it is
-so light-weight, Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
+The `modin.pandas` DataFrame is an extremely light-weight parallel DataFrame.
+Modin transparently distributes the data and computation so that you can continue using the same pandas API
+while working with more data faster. Because it is so light-weight,
+Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
In pandas, you are only able to use one core at a time when you are doing computation of
-any kind. With Modin, you are able to use all of the CPU cores on your machine. Even in
-`read_csv`, we see large gains by efficiently distributing the work across your entire
-machine.
+any kind. With Modin, you are able to use all of the CPU cores on your machine. Even with a
+traditionally synchronous task like `read_csv`, we see large speedups by efficiently
+distributing the work across your entire machine.
```python
import modin.pandas as pd
@@ -189,36 +151,62 @@ import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
```
-#### Modin is a DataFrame designed for datasets from 1MB to 1TB+
-
-We have focused heavily on bridging the solutions between DataFrames for small data
-(e.g. pandas) and large data. Often data scientists require different tools for doing
-the same thing on different sizes of data. The DataFrame solutions that exist for 1KB do
-not scale to 1TB+, and the overheads of the solutions for 1TB+ are too costly for
-datasets in the 1KB range. With Modin, because of its light-weight, robust, and scalable
-nature, you get a fast DataFrame at small and large data. With preliminary [cluster](https://modin.readthedocs.io/en/latest/using_modin.html#using-modin-on-a-cluster)
-and [out of core](https://modin.readthedocs.io/en/latest/out_of_core.html)
-support, Modin is a DataFrame library with great single-node performance and high
+#### Modin can handle the datasets that pandas can't
+
+Often data scientists have to switch between different tools
+for operating on datasets of different sizes. Processing large dataframes with pandas
+is slow, and pandas does not support working with dataframes that are too large to fit
+into the available memory. As a result, pandas workflows that work well
+for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size
+of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably
+work with hundreds of GBs without worrying about substantial slowdown or memory errors.
+With [cluster](https://modin.readthedocs.io/en/latest/getting_started/using_modin/using_modin_cluster.html)
+and [out of core](https://modin.readthedocs.io/en/latest/getting_started/why_modin/out_of_core.html)
+support, Modin is a DataFrame library with both great single-node performance and high
scalability in a cluster.
#### Modin Architecture
-We designed Modin to be modular so we can plug in different components as they develop
-and improve:
+We designed [Modin's architecture](https://modin.readthedocs.io/en/latest/development/architecture.html)
+to be modular so we can plug in different components as they develop and improve:
+
+ +
+### Other Resources
+
+#### Getting Started with Modin
+
+- [Documentation](https://modin.readthedocs.io/en/latest/)
+- [10-min Quickstart Guide](https://modin.readthedocs.io/en/latest/getting_started/quickstart.html)
+- [Examples and Tutorials](https://modin.readthedocs.io/en/latest/getting_started/examples.html)
+- [Videos and Blogposts](https://modin.readthedocs.io/en/latest/getting_started/examples.html#talks-podcasts)
+
+#### Modin Community
+
+- [Slack](https://join.slack.com/t/modin-project/shared_invite/zt-yvk5hr3b-f08p_ulbuRWsAfg9rMY3uA)
+- [Discourse](https://discuss.modin.org)
+- [Twitter](https://twitter.com/modin_project)
+- [Mailing List](https://groups.google.com/g/modin-dev)
+- [GitHub Issues](https://github.com/modin-project/modin/issues)
+- [StackOverflow](https://stackoverflow.com/questions/tagged/modin)
+
+#### Learn More about Modin
-
+- [Frequently Asked Questions (FAQs)](https://modin.readthedocs.io/en/latest/getting_started/faq.html)
+- [Troubleshooting Guide](https://modin.readthedocs.io/en/latest/getting_started/troubleshooting.html)
+- [Development Guide](https://modin.readthedocs.io/en/latest/development/index.html)
+- Modin is built on many years of research and development at UC Berkeley. Check out these selected papers to learn more about how Modin works:
+ - [Flexible Rule-Based Decomposition and Metadata Independence in Modin](https://people.eecs.berkeley.edu/~totemtang/paper/Modin.pdf) (VLDB 2021)
+ - [Dataframe Systems: Theory, Architecture, and Implementation](https://www2.eecs.berkeley.edu/Pubs/TechRpts/2021/EECS-2021-193.pdf) (PhD Dissertation 2021)
+ - [Towards Scalable Dataframe Systems](https://arxiv.org/pdf/2001.00888.pdf) (VLDB 2020)
-Visit the [Documentation](https://modin.readthedocs.io/en/latest/development/architecture.html) for
-more information, and checkout [the difference between Modin and Dask!](https://github.com/modin-project/modin/tree/master/docs/modin_vs_dask.md)
+#### Getting Involved
-**`modin.pandas` is currently under active development. Requests and contributions are welcome!**
+***`modin.pandas` is currently under active development. Requests and contributions are welcome!***
+For more information on how to contribute to Modin, check out the
+[Modin Contribution Guide](https://modin.readthedocs.io/en/latest/development/contributing.html).
-### More information and Getting Involved
+### License
-- Read the [documentation](https://modin.readthedocs.io/en/latest/) for more information.
-- Check out [our paper](http://www.vldb.org/pvldb/vol13/p2033-petersohn.pdf) to learn more about the theory underlying Modin.
-- Ask questions or participate in discussions on our [Discourse](https://discuss.modin.org).
-- Let us know how you're using Modin! Join our community [Slack](https://modin.org/slack.html) to discuss and ask questions.
-- Submit bug reports to our [GitHub Issues Page](https://github.com/modin-project/modin/issues).
-- Contributions are welcome! Open a [pull request](https://github.com/modin-project/modin/pulls).
+[Apache License 2.0](LICENSE)
diff --git a/docs/getting_started/faq.rst b/docs/getting_started/faq.rst
index 91b4c3024f2..dc0fb54ecbe 100644
--- a/docs/getting_started/faq.rst
+++ b/docs/getting_started/faq.rst
@@ -21,7 +21,7 @@ The :py:class:`~modin.pandas.dataframe.DataFrame` is a highly
scalable, parallel DataFrame. Modin transparently distributes the data and computation so
that you can continue using the same pandas API while being able to work with more data faster.
Modin lets you use all the CPU cores on your machine, and because it is lightweight, it
-often has less memory overhead than pandas. See this :doc:`page ` to
+often has less memory overhead than pandas. See this :doc:`page ` to
learn more about how Modin is different from pandas.
Why not just improve pandas?
@@ -54,7 +54,14 @@ with dataframes that don't fit into the available memory. As a result, pandas wo
for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size
of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably
work with hundreds of GBs without worrying about substantial slowdown or memory errors. For more information,
-see :doc:`out-of-memory support ` for Modin.
+see :doc:`out-of-memory support ` for Modin.
+
+How does Modin compare to Dask DataFrame and Koalas?
+""""""""""""""""""""""""""""""""""""""""""""""""""""
+
+TLDR: Modin has better coverage of the pandas API, has a flexible backend, better ordering semantics,
+and supports both row and column-parallel operations.
+Check out this :doc:`page ` detailing the differences!
How does Modin work under the hood?
"""""""""""""""""""""""""""""""""""
@@ -96,14 +103,12 @@ import with Modin import:
Which execution engine (Ray or Dask) should I use for Modin?
""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
-Whichever one you want! Modin supports Ray_ and Dask_ execution engines to provide an effortless way
-to speed up your pandas workflows. The best thing is that you don't need to know
-anything about Ray and Dask in order to use Modin and Modin will automatically
-detect which engine you have
-installed and use that for scheduling computation. If you don't have a preference, we recommend
-starting with Modin's default Ray engine. If you want to use a specific
-compute engine, you can set the environment variable ``MODIN_ENGINE`` and
-Modin will do computation with that engine:
+Modin lets you effortlessly speed up your pandas workflows with either Ray_'s or Dask_'s execution engine.
+You don't need to know anything about either engine in order to use it with Modin. If you only have one engine
+installed, Modin will automatically detect which engine you have installed and use that for scheduling computation.
+If you don't have a preference, we recommend starting with Modin's default Ray engine.
+If you want to use a specific compute engine, you can set the environment variable ``MODIN_ENGINE``
+and Modin will do computation with that engine:
.. code-block:: bash
@@ -113,6 +118,15 @@ Modin will do computation with that engine:
pip install "modin[dask]" # Install Modin dependencies and Dask to run on Dask
export MODIN_ENGINE=dask # Modin will use Dask
+This can also be done with:
+
+.. code-block:: python
+
+ from modin.config import Engine
+
+ Engine.put("ray") # Modin will use Ray
+ Engine.put("dask") # Modin will use Dask
+
We also have an experimental OmniSciDB-based engine of Modin you can read about :doc:`here `.
We plan to support more execution engines in future. If you have a specific request,
please post on the #feature-requests channel on our Slack_ community.
@@ -158,16 +172,16 @@ How can I contribute to Modin?
**Modin is currently under active development. Requests and contributions are welcome!**
-If you are interested in contributing please check out the :doc:`Getting Started`
-guide then refer to the :doc:`Development Documentation` section,
+If you are interested in contributing please check out the :doc:`Contributing Guide`
+and then refer to the :doc:`Development Documentation`,
where you can find system architecture, internal implementation details, and other useful information.
Also check out the `Github`_ to view open issues and make contributions.
.. _issue: https://github.com/modin-project/modin/issues
-.. _Slack: https://modin.org/slack.html
+.. _Slack: https://join.slack.com/t/modin-project/shared_invite/zt-yvk5hr3b-f08p_ulbuRWsAfg9rMY3uA
.. _Github: https://github.com/modin-project/modin
.. _Ray: https://github.com/ray-project/ray/
-.. _Dask: https://dask.org/
-.. _papers: https://arxiv.org/abs/2001.00888
-.. _guide: https://modin.readthedocs.io/en/stable/installation.html?#installing-on-google-colab
+.. _Dask: https://github.com/dask/dask
+.. _papers: https://people.eecs.berkeley.edu/~totemtang/paper/Modin.pdf
+.. _guide: https://modin.readthedocs.io/en/latest/getting_started/installation.html#installing-on-google-colab
.. _tutorial: https://github.com/modin-project/modin/tree/master/examples/tutorial
diff --git a/docs/getting_started/installation.rst b/docs/getting_started/installation.rst
index aabacc00667..754a401ee4e 100644
--- a/docs/getting_started/installation.rst
+++ b/docs/getting_started/installation.rst
@@ -24,7 +24,7 @@ To install the most recent stable release run the following:
pip install -U modin # -U for upgrade in case you have an older version
-Modin can be used with :doc:`Ray`, :doc:`Dask`, or :doc:`OmniSci` engines. If you don't have Ray_ or Dask_ installed, you will need to install Modin with one of the targets:
+Modin can be used with :doc:`Ray`, :doc:`Dask`, or :doc:`OmniSci` engines. If you don't have Ray_ or Dask_ installed, you will need to install Modin with one of the targets:
.. code-block:: bash
@@ -147,8 +147,8 @@ that these changes have not made it into a release and may not be completely sta
Windows
-------
-All Modin engines except :doc:`OmniSci` are available both on Windows and Linux as mentioned above.
-Default engine on Windows is :doc:`Ray`.
+All Modin engines except :doc:`OmniSci` are available both on Windows and Linux as mentioned above.
+Default engine on Windows is :doc:`Ray`.
It is also possible to use Windows Subsystem For Linux (WSL_), but this is generally
not recommended due to the limitations and poor performance of Ray on WSL, a roughly
2-3x worse than native Windows.
diff --git a/docs/getting_started/troubleshooting.rst b/docs/getting_started/troubleshooting.rst
index 2ad912f81e5..0476afc989d 100644
--- a/docs/getting_started/troubleshooting.rst
+++ b/docs/getting_started/troubleshooting.rst
@@ -20,7 +20,7 @@ Please note, that while Modin covers a large portion of the pandas API, not all
UserWarning: `DataFrame.asfreq` defaulting to pandas implementation.
-To understand which functions will lead to this warning, we have compiled a list of :doc:`currently supported methods `. When you see this warning, Modin defaults to pandas by converting the Modin dataframe to pandas to perform the operation. Once the operation is complete in pandas, it is converted back to a Modin dataframe. These operations will have a high overhead due to the communication involved and will take longer than pandas. When this is happening, a warning will be given to the user to inform them that this operation will take longer than usual. You can learn more about this :doc:`here `.
+To understand which functions will lead to this warning, we have compiled a list of :doc:`currently supported methods `. When you see this warning, Modin defaults to pandas by converting the Modin dataframe to pandas to perform the operation. Once the operation is complete in pandas, it is converted back to a Modin dataframe. These operations will have a high overhead due to the communication involved and will take longer than pandas. When this is happening, a warning will be given to the user to inform them that this operation will take longer than usual. You can learn more about this :doc:`here `.
If you would like to request a particular method be implemented, feel free to `open an
issue`_. Before you open an issue please make sure that someone else has not already
diff --git a/docs/getting_started/using_modin/using_modin_locally.rst b/docs/getting_started/using_modin/using_modin_locally.rst
index e24029aa32e..6c79e174c04 100644
--- a/docs/getting_started/using_modin/using_modin_locally.rst
+++ b/docs/getting_started/using_modin/using_modin_locally.rst
@@ -67,7 +67,7 @@ cluster for you:
Finally, if you already have an Ray or Dask engine initialized, Modin will
automatically attach to whichever engine is available. If you are interested in using
-Modin with OmniSci engine, please refer to :doc:`these instructions `. For additional information on other settings you can configure, see
+Modin with OmniSci engine, please refer to :doc:`these instructions `. For additional information on other settings you can configure, see
:doc:`this page ` for more details.
Advanced: Configuring the resources Modin uses
@@ -116,4 +116,4 @@ specify more processors than you have available on your machine; however this wi
improve the performance (and might end up hurting the performance of the system).
.. note::
- Make sure to update the ``MODIN_CPUS`` configuration and initialize your preferred engine before you start working with the first operation using Modin! Otherwise, Modin will opt for the default setting.
\ No newline at end of file
+ Make sure to update the ``MODIN_CPUS`` configuration and initialize your preferred engine before you start working with the first operation using Modin! Otherwise, Modin will opt for the default setting.
diff --git a/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst b/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
index 2dba23b65db..2ecdd92b005 100644
--- a/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
+++ b/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
@@ -84,4 +84,4 @@ Performance Comparison
**Modin provides substantial speedups even on operators not supported by other systems.** Thanks to its flexible partitioning schemes that enable it to support the vast majority of pandas operations — be it row, column, or cell-oriented - Modin provides benefits on operations such as ``join``, ``median``, and ``infer_types``. While Koalas performs ``join`` slower than Pandas, Dask failed to support ``join`` on more than 20M rows, likely due poor support for `shuffles `_. Details of the benchmark and additional join experiments can be found in `our paper `_.
.. _documentation: http://docs.dask.org/en/latest/DataFrame.html#design.
-.. _Modin's documentation: https://modin.readthedocs.io/en/latest/developer/architecture.html
+.. _Modin's documentation: https://modin.readthedocs.io/en/latest/development/architecture.html
diff --git a/docs/getting_started/why_modin/pandas.rst b/docs/getting_started/why_modin/pandas.rst
index a30b354f07c..872e77b0abd 100644
--- a/docs/getting_started/why_modin/pandas.rst
+++ b/docs/getting_started/why_modin/pandas.rst
@@ -66,6 +66,6 @@ smaller code footprint while still guaranteeing that it covers the entire pandas
Modin has an internal algebra, which is roughly 15 operators, narrowed down from the
original >200 that exist in pandas. The algebra is grounded in both practical and
theoretical work. Learn more in our `VLDB 2020 paper`_. More information about this
-algebra can be found in the :doc:`../development/architecture` documentation.
+algebra can be found in the :doc:`architecture ` documentation.
.. _VLDB 2020 paper: https://arxiv.org/abs/2001.00888
+
+### Other Resources
+
+#### Getting Started with Modin
+
+- [Documentation](https://modin.readthedocs.io/en/latest/)
+- [10-min Quickstart Guide](https://modin.readthedocs.io/en/latest/getting_started/quickstart.html)
+- [Examples and Tutorials](https://modin.readthedocs.io/en/latest/getting_started/examples.html)
+- [Videos and Blogposts](https://modin.readthedocs.io/en/latest/getting_started/examples.html#talks-podcasts)
+
+#### Modin Community
+
+- [Slack](https://join.slack.com/t/modin-project/shared_invite/zt-yvk5hr3b-f08p_ulbuRWsAfg9rMY3uA)
+- [Discourse](https://discuss.modin.org)
+- [Twitter](https://twitter.com/modin_project)
+- [Mailing List](https://groups.google.com/g/modin-dev)
+- [GitHub Issues](https://github.com/modin-project/modin/issues)
+- [StackOverflow](https://stackoverflow.com/questions/tagged/modin)
+
+#### Learn More about Modin
-
+- [Frequently Asked Questions (FAQs)](https://modin.readthedocs.io/en/latest/getting_started/faq.html)
+- [Troubleshooting Guide](https://modin.readthedocs.io/en/latest/getting_started/troubleshooting.html)
+- [Development Guide](https://modin.readthedocs.io/en/latest/development/index.html)
+- Modin is built on many years of research and development at UC Berkeley. Check out these selected papers to learn more about how Modin works:
+ - [Flexible Rule-Based Decomposition and Metadata Independence in Modin](https://people.eecs.berkeley.edu/~totemtang/paper/Modin.pdf) (VLDB 2021)
+ - [Dataframe Systems: Theory, Architecture, and Implementation](https://www2.eecs.berkeley.edu/Pubs/TechRpts/2021/EECS-2021-193.pdf) (PhD Dissertation 2021)
+ - [Towards Scalable Dataframe Systems](https://arxiv.org/pdf/2001.00888.pdf) (VLDB 2020)
-Visit the [Documentation](https://modin.readthedocs.io/en/latest/development/architecture.html) for
-more information, and checkout [the difference between Modin and Dask!](https://github.com/modin-project/modin/tree/master/docs/modin_vs_dask.md)
+#### Getting Involved
-**`modin.pandas` is currently under active development. Requests and contributions are welcome!**
+***`modin.pandas` is currently under active development. Requests and contributions are welcome!***
+For more information on how to contribute to Modin, check out the
+[Modin Contribution Guide](https://modin.readthedocs.io/en/latest/development/contributing.html).
-### More information and Getting Involved
+### License
-- Read the [documentation](https://modin.readthedocs.io/en/latest/) for more information.
-- Check out [our paper](http://www.vldb.org/pvldb/vol13/p2033-petersohn.pdf) to learn more about the theory underlying Modin.
-- Ask questions or participate in discussions on our [Discourse](https://discuss.modin.org).
-- Let us know how you're using Modin! Join our community [Slack](https://modin.org/slack.html) to discuss and ask questions.
-- Submit bug reports to our [GitHub Issues Page](https://github.com/modin-project/modin/issues).
-- Contributions are welcome! Open a [pull request](https://github.com/modin-project/modin/pulls).
+[Apache License 2.0](LICENSE)
diff --git a/docs/getting_started/faq.rst b/docs/getting_started/faq.rst
index 91b4c3024f2..dc0fb54ecbe 100644
--- a/docs/getting_started/faq.rst
+++ b/docs/getting_started/faq.rst
@@ -21,7 +21,7 @@ The :py:class:`~modin.pandas.dataframe.DataFrame` is a highly
scalable, parallel DataFrame. Modin transparently distributes the data and computation so
that you can continue using the same pandas API while being able to work with more data faster.
Modin lets you use all the CPU cores on your machine, and because it is lightweight, it
-often has less memory overhead than pandas. See this :doc:`page ` to
+often has less memory overhead than pandas. See this :doc:`page ` to
learn more about how Modin is different from pandas.
Why not just improve pandas?
@@ -54,7 +54,14 @@ with dataframes that don't fit into the available memory. As a result, pandas wo
for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size
of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably
work with hundreds of GBs without worrying about substantial slowdown or memory errors. For more information,
-see :doc:`out-of-memory support ` for Modin.
+see :doc:`out-of-memory support ` for Modin.
+
+How does Modin compare to Dask DataFrame and Koalas?
+""""""""""""""""""""""""""""""""""""""""""""""""""""
+
+TLDR: Modin has better coverage of the pandas API, has a flexible backend, better ordering semantics,
+and supports both row and column-parallel operations.
+Check out this :doc:`page ` detailing the differences!
How does Modin work under the hood?
"""""""""""""""""""""""""""""""""""
@@ -96,14 +103,12 @@ import with Modin import:
Which execution engine (Ray or Dask) should I use for Modin?
""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
-Whichever one you want! Modin supports Ray_ and Dask_ execution engines to provide an effortless way
-to speed up your pandas workflows. The best thing is that you don't need to know
-anything about Ray and Dask in order to use Modin and Modin will automatically
-detect which engine you have
-installed and use that for scheduling computation. If you don't have a preference, we recommend
-starting with Modin's default Ray engine. If you want to use a specific
-compute engine, you can set the environment variable ``MODIN_ENGINE`` and
-Modin will do computation with that engine:
+Modin lets you effortlessly speed up your pandas workflows with either Ray_'s or Dask_'s execution engine.
+You don't need to know anything about either engine in order to use it with Modin. If you only have one engine
+installed, Modin will automatically detect which engine you have installed and use that for scheduling computation.
+If you don't have a preference, we recommend starting with Modin's default Ray engine.
+If you want to use a specific compute engine, you can set the environment variable ``MODIN_ENGINE``
+and Modin will do computation with that engine:
.. code-block:: bash
@@ -113,6 +118,15 @@ Modin will do computation with that engine:
pip install "modin[dask]" # Install Modin dependencies and Dask to run on Dask
export MODIN_ENGINE=dask # Modin will use Dask
+This can also be done with:
+
+.. code-block:: python
+
+ from modin.config import Engine
+
+ Engine.put("ray") # Modin will use Ray
+ Engine.put("dask") # Modin will use Dask
+
We also have an experimental OmniSciDB-based engine of Modin you can read about :doc:`here `.
We plan to support more execution engines in future. If you have a specific request,
please post on the #feature-requests channel on our Slack_ community.
@@ -158,16 +172,16 @@ How can I contribute to Modin?
**Modin is currently under active development. Requests and contributions are welcome!**
-If you are interested in contributing please check out the :doc:`Getting Started`
-guide then refer to the :doc:`Development Documentation` section,
+If you are interested in contributing please check out the :doc:`Contributing Guide`
+and then refer to the :doc:`Development Documentation`,
where you can find system architecture, internal implementation details, and other useful information.
Also check out the `Github`_ to view open issues and make contributions.
.. _issue: https://github.com/modin-project/modin/issues
-.. _Slack: https://modin.org/slack.html
+.. _Slack: https://join.slack.com/t/modin-project/shared_invite/zt-yvk5hr3b-f08p_ulbuRWsAfg9rMY3uA
.. _Github: https://github.com/modin-project/modin
.. _Ray: https://github.com/ray-project/ray/
-.. _Dask: https://dask.org/
-.. _papers: https://arxiv.org/abs/2001.00888
-.. _guide: https://modin.readthedocs.io/en/stable/installation.html?#installing-on-google-colab
+.. _Dask: https://github.com/dask/dask
+.. _papers: https://people.eecs.berkeley.edu/~totemtang/paper/Modin.pdf
+.. _guide: https://modin.readthedocs.io/en/latest/getting_started/installation.html#installing-on-google-colab
.. _tutorial: https://github.com/modin-project/modin/tree/master/examples/tutorial
diff --git a/docs/getting_started/installation.rst b/docs/getting_started/installation.rst
index aabacc00667..754a401ee4e 100644
--- a/docs/getting_started/installation.rst
+++ b/docs/getting_started/installation.rst
@@ -24,7 +24,7 @@ To install the most recent stable release run the following:
pip install -U modin # -U for upgrade in case you have an older version
-Modin can be used with :doc:`Ray`, :doc:`Dask`, or :doc:`OmniSci` engines. If you don't have Ray_ or Dask_ installed, you will need to install Modin with one of the targets:
+Modin can be used with :doc:`Ray`, :doc:`Dask`, or :doc:`OmniSci` engines. If you don't have Ray_ or Dask_ installed, you will need to install Modin with one of the targets:
.. code-block:: bash
@@ -147,8 +147,8 @@ that these changes have not made it into a release and may not be completely sta
Windows
-------
-All Modin engines except :doc:`OmniSci` are available both on Windows and Linux as mentioned above.
-Default engine on Windows is :doc:`Ray`.
+All Modin engines except :doc:`OmniSci` are available both on Windows and Linux as mentioned above.
+Default engine on Windows is :doc:`Ray`.
It is also possible to use Windows Subsystem For Linux (WSL_), but this is generally
not recommended due to the limitations and poor performance of Ray on WSL, a roughly
2-3x worse than native Windows.
diff --git a/docs/getting_started/troubleshooting.rst b/docs/getting_started/troubleshooting.rst
index 2ad912f81e5..0476afc989d 100644
--- a/docs/getting_started/troubleshooting.rst
+++ b/docs/getting_started/troubleshooting.rst
@@ -20,7 +20,7 @@ Please note, that while Modin covers a large portion of the pandas API, not all
UserWarning: `DataFrame.asfreq` defaulting to pandas implementation.
-To understand which functions will lead to this warning, we have compiled a list of :doc:`currently supported methods `. When you see this warning, Modin defaults to pandas by converting the Modin dataframe to pandas to perform the operation. Once the operation is complete in pandas, it is converted back to a Modin dataframe. These operations will have a high overhead due to the communication involved and will take longer than pandas. When this is happening, a warning will be given to the user to inform them that this operation will take longer than usual. You can learn more about this :doc:`here `.
+To understand which functions will lead to this warning, we have compiled a list of :doc:`currently supported methods `. When you see this warning, Modin defaults to pandas by converting the Modin dataframe to pandas to perform the operation. Once the operation is complete in pandas, it is converted back to a Modin dataframe. These operations will have a high overhead due to the communication involved and will take longer than pandas. When this is happening, a warning will be given to the user to inform them that this operation will take longer than usual. You can learn more about this :doc:`here `.
If you would like to request a particular method be implemented, feel free to `open an
issue`_. Before you open an issue please make sure that someone else has not already
diff --git a/docs/getting_started/using_modin/using_modin_locally.rst b/docs/getting_started/using_modin/using_modin_locally.rst
index e24029aa32e..6c79e174c04 100644
--- a/docs/getting_started/using_modin/using_modin_locally.rst
+++ b/docs/getting_started/using_modin/using_modin_locally.rst
@@ -67,7 +67,7 @@ cluster for you:
Finally, if you already have an Ray or Dask engine initialized, Modin will
automatically attach to whichever engine is available. If you are interested in using
-Modin with OmniSci engine, please refer to :doc:`these instructions `. For additional information on other settings you can configure, see
+Modin with OmniSci engine, please refer to :doc:`these instructions `. For additional information on other settings you can configure, see
:doc:`this page ` for more details.
Advanced: Configuring the resources Modin uses
@@ -116,4 +116,4 @@ specify more processors than you have available on your machine; however this wi
improve the performance (and might end up hurting the performance of the system).
.. note::
- Make sure to update the ``MODIN_CPUS`` configuration and initialize your preferred engine before you start working with the first operation using Modin! Otherwise, Modin will opt for the default setting.
\ No newline at end of file
+ Make sure to update the ``MODIN_CPUS`` configuration and initialize your preferred engine before you start working with the first operation using Modin! Otherwise, Modin will opt for the default setting.
diff --git a/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst b/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
index 2dba23b65db..2ecdd92b005 100644
--- a/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
+++ b/docs/getting_started/why_modin/modin_vs_dask_vs_koalas.rst
@@ -84,4 +84,4 @@ Performance Comparison
**Modin provides substantial speedups even on operators not supported by other systems.** Thanks to its flexible partitioning schemes that enable it to support the vast majority of pandas operations — be it row, column, or cell-oriented - Modin provides benefits on operations such as ``join``, ``median``, and ``infer_types``. While Koalas performs ``join`` slower than Pandas, Dask failed to support ``join`` on more than 20M rows, likely due poor support for `shuffles `_. Details of the benchmark and additional join experiments can be found in `our paper `_.
.. _documentation: http://docs.dask.org/en/latest/DataFrame.html#design.
-.. _Modin's documentation: https://modin.readthedocs.io/en/latest/developer/architecture.html
+.. _Modin's documentation: https://modin.readthedocs.io/en/latest/development/architecture.html
diff --git a/docs/getting_started/why_modin/pandas.rst b/docs/getting_started/why_modin/pandas.rst
index a30b354f07c..872e77b0abd 100644
--- a/docs/getting_started/why_modin/pandas.rst
+++ b/docs/getting_started/why_modin/pandas.rst
@@ -66,6 +66,6 @@ smaller code footprint while still guaranteeing that it covers the entire pandas
Modin has an internal algebra, which is roughly 15 operators, narrowed down from the
original >200 that exist in pandas. The algebra is grounded in both practical and
theoretical work. Learn more in our `VLDB 2020 paper`_. More information about this
-algebra can be found in the :doc:`../development/architecture` documentation.
+algebra can be found in the :doc:`architecture ` documentation.
.. _VLDB 2020 paper: https://arxiv.org/abs/2001.00888