git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'模型链接:
- phi3-vision-128k-instruct: https://modelscope.cn/models/LLM-Research/Phi-3-vision-128k-instruct/summary
推理 phi3-vision-128k-instruct:
# Experimental environment: A10, 3090, V100, ...
# 16GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type phi3-vision-128k-instruct输出: (支持传入本地路径或URL)
"""
<<< Who are you?
I am Phi, an AI developed by Microsoft to assist with providing information, answering questions, and helping users find solutions to their queries. How can I assist you today?
--------------------------------------------------
<<< clear
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img><img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png</img>What is the difference between these two pictures?
The first picture shows a group of four cartoon sheep standing in a field, while the second picture is a close-up of a kitten with a blurred background. The main difference between these two pictures is the subject matter and the setting. The first picture features animals that are typically associated with farm life and agriculture, while the second picture focuses on a domestic animal, a kitten, which is more commonly found in households. Additionally, the first picture has a more peaceful and serene atmosphere, while the second picture has a more intimate and detailed view of the kitten.
--------------------------------------------------
<<< clear
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img>How many sheep are there in the picture?
There are four sheep in the picture.
--------------------------------------------------
<<< clear
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png</img>What is the result of the calculation?
The result of the calculation 1452 + 45304 is 46756.
--------------------------------------------------
<<< clear
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png</img>Write a poem based on the content of the picture.
In the tranquil night, a boat sails,
Through the darkened river, it sets sail.
A single candle flickers, casting light,
Guiding the way through the endless night.
The stars above, like diamonds bright,
Gleam down upon the boat's gentle flight.
The moon, a silent guardian in the sky,
Watches over the boat as it sails by.
The river, a mirror to the night,
Reflects the boat's journey, a beautiful sight.
The trees on either side, standing tall,
Whisper secrets to the boat, one and all.
In the stillness of the night, a sense of peace,
The boat, the river, the trees, all in their place.
A moment frozen in time, a scene so serene,
A journey through the night, a dream so unseen.
--------------------------------------------------
<<< clear
<<< <img>https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/ocr_en.png</img>Perform OCR on the image.
The image contains a text section with the heading 'Introduction'. It discusses the capabilities of SWIFT, which support training, inference, evaluation, and deployment of over 250 large language models (LLMs) and 35+ multimodal large models (MLLMs). It mentions that developers can apply this framework to their research and production environments, and that SWIFT supports lightweight training solutions provided by PEFT, as well as a complete Adapters library for various training techniques. It also highlights the availability of a Gradio web-ui for controlling training and inference, and the provision of deep learning courses and best practices for beginners. The text further states that SWIFT is expanding capabilities for other modalities, currently supporting full-parameter training and LoRA training for AnimateDiff. There are references to rich documentation and the availability of SWIFT web-ui on Huggingface space and ModelScope studio. The text is clear and fully visible in the image.
"""示例图片如下:
cat:

animal:

math:
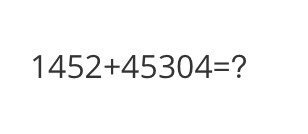
poem:

ocr_en:

单样本推理
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.phi3_vision_128k_instruct
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
query = """<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>How far is it from each city?"""
response, history = inference(model, template, query)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = 'Which city is the farthest?'
gen = inference_stream(model, template, query, history)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: Which city is the farthest?
response: Guangzhou is the farthest city, located 293km away.
history: [['<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>How far is it from each city?', 'The distances are as follows: Mata is 14km away, Yangjiang is 62km away, and Guangzhou is 293km away.'], ['Which city is the farthest?', 'Guangzhou is the farthest city, located 293km away.']]
"""示例图片如下:
road:

多模态大模型微调通常使用自定义数据集进行微调. 这里展示可直接运行的demo:
# Experimental environment: A10, 3090, V100, ...
# 16GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type phi3-vision-128k-instruct \
--dataset coco-en-mini \
# DDP Full
# Experimental environment: 2 * A100
# 2 * 50GB GPU memory
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 swift sft \
--model_type phi3-vision-128k-instruct \
--dataset coco-en-mini \
--sft_type full \
--ddp_find_unused_parameters true自定义数据集支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 支持每轮对话含多张图片或不含图片, 支持传入本地路径或URL)
[
{"conversations": [
{"from": "user", "value": "<img>img_path</img>11111"},
{"from": "assistant", "value": "22222"}
]},
{"conversations": [
{"from": "user", "value": "<img>img_path</img><img>img_path2</img><img>img_path3</img>aaaaa"},
{"from": "assistant", "value": "bbbbb"},
{"from": "user", "value": "<img>img_path</img>ccccc"},
{"from": "assistant", "value": "ddddd"}
]},
{"conversations": [
{"from": "user", "value": "AAAAA"},
{"from": "assistant", "value": "BBBBB"},
{"from": "user", "value": "CCCCC"},
{"from": "assistant", "value": "DDDDD"}
]}
]直接推理:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/phi3-vision-128k-instruct/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora并推理:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/phi3-vision-128k-instruct/vx-xxx/checkpoint-xxx \
--merge_lora true --safe_serialization false
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/phi3-vision-128k-instruct/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true