|
| 1 | +# AgentJet Swarm Training |
| 2 | + |
| 3 | +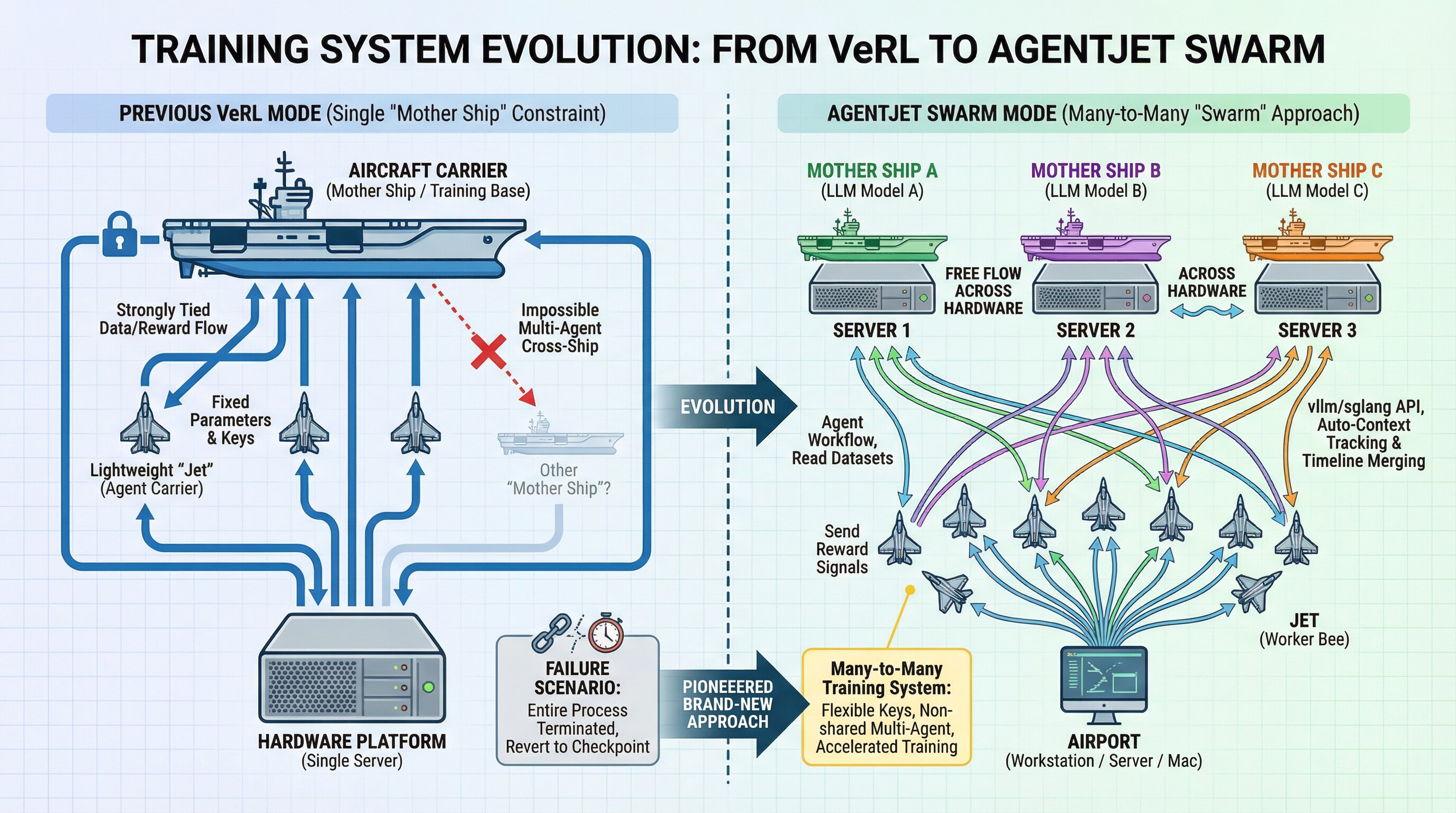 |
| 4 | + |
| 5 | +In previous training modes, the training base supported by VeRL could be likened to an "aircraft carrier". From this "mother ship", |
| 6 | +only lightweight "Jets" could take off as carriers for Agent operations, and all Jets were strongly tied to the "mother ship". |
| 7 | +This means it was impossible to use models from other "mother ships" for multi-agent training with non-shared parameters, nor could keys and reward parameters fixed in environment variables and code be switched conveniently, |
| 8 | +and they couldn't flow freely between multiple hardware platforms. Once any issue arose, the entire process had to be terminated and reverted to the previous checkpoint. |
| 9 | + |
| 10 | +However, the AgentJet Swarm mode has pioneered a brand-new training approach. Continuing with the previous metaphor, in swarm mode, |
| 11 | +you can freely launch multiple "mother ships" (corresponding to multiple LLM models to be trained) on one or more servers. |
| 12 | +Then, from an "airport" (e.g., your workstation, server, or even your Mac), you can "take off" any number of "Jets" to act as "worker bees" running the Agent workflow awaiting training, |
| 13 | +forming a many-to-many training system: |
| 14 | +- "Jets" are responsible for reading datasets, running the Agent workflow, and finally sending reward signals back to each "mother ship". |
| 15 | +- "Mother ships" are responsible for providing vllm/sglang API interfaces (with AgentJet’s automatic context tracking & timeline merging capabilities that significantly accelerate training), coordinating and computing samples. |
| 16 | + |
| 17 | + |
| 18 | +# Using AgentJet Swarm to Train Your Agents |
| 19 | + |
| 20 | +AgentJet Swarm opens infinite possibilities for both LLM Agent engineers and LLM researchers. It is very easy to use and understand. In fact, there is no need for verbose explaination, code explains itself: |
| 21 | + |
| 22 | +## (1/2) Launching a Swarm Server ("aircraft carrier") |
| 23 | + |
| 24 | +Simply run `ajet-swarm start` on a GPU server (or GPU cluster master), and we are done ✅. (You may ask: what about training config? Well, config will come from swarm client.) |
| 25 | + |
| 26 | +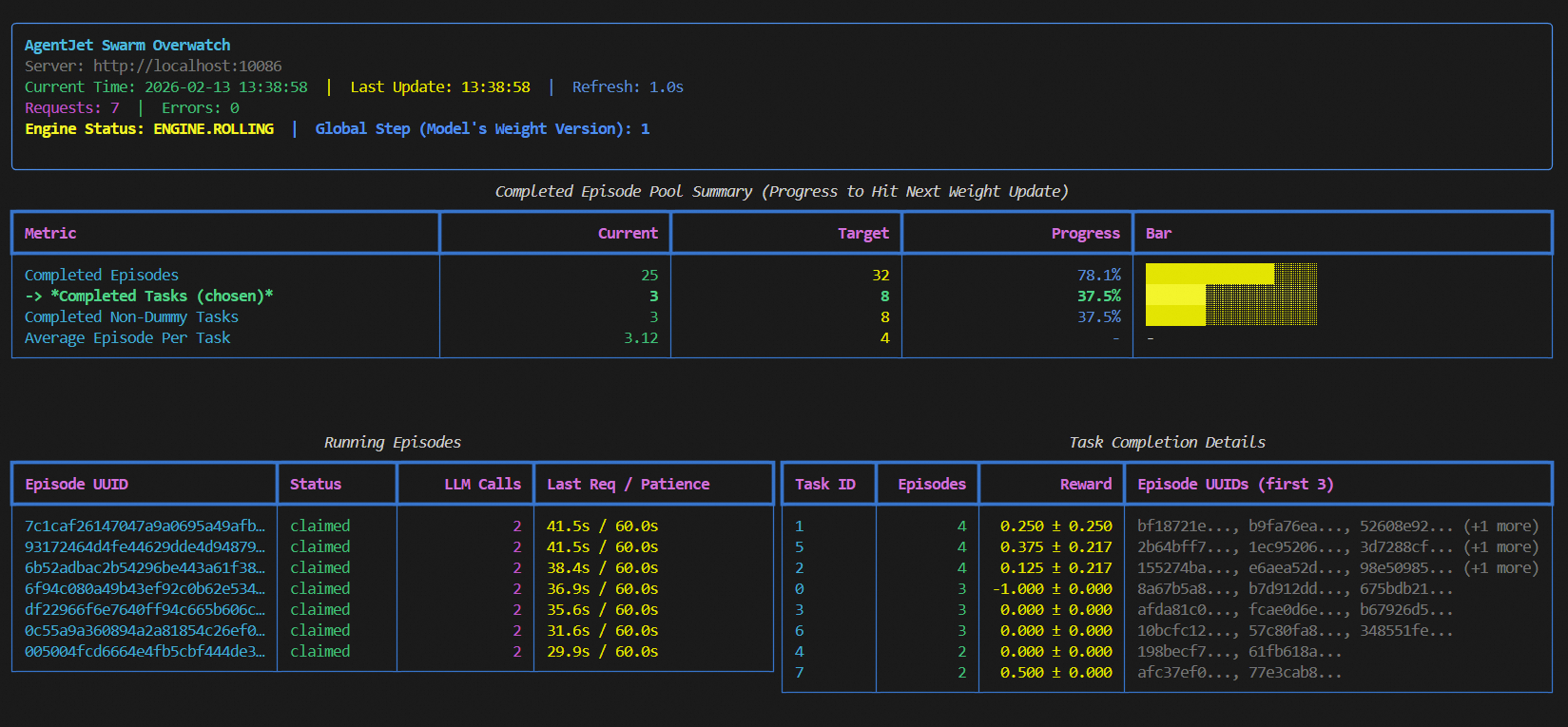 |
| 27 | + |
| 28 | +Notes: |
| 29 | +1. launch server together with a swarm monitor: |
| 30 | + ```bash |
| 31 | + (ajet-swarm start &> ajet-swarm-server.log) & (ajet-swarm overwatch) |
| 32 | + ``` |
| 33 | + |
| 34 | +2. overwatch swarm status with url: |
| 35 | + ```bash |
| 36 | + ajet-swarm overwatch --swarm-url=http://localhost:10086 |
| 37 | + ``` |
| 38 | + |
| 39 | +3. changing customized port (default port is 10086): |
| 40 | + ```bash |
| 41 | + ajet-swarm start --swarm-port=10086 |
| 42 | + ``` |
| 43 | + |
| 44 | +4. if you are using a multi-node cluster to train huge models, make sure you have already set up the ray cluster before you hit `ajet-swarm start`. |
| 45 | + |
| 46 | +## (2/2) Launching Swarm Clients ("jets") |
| 47 | + |
| 48 | +You can run any amount of swarm client: |
| 49 | +- on any devices (macbook, workstation, the same machine you run swarm-server, **wherever you want**). |
| 50 | +- at any time (before or in the middle of a training, **whenever you want**) |
| 51 | + |
| 52 | +But just remember: **ALL** swarm clients are equally authorized to order swarm server(s) **start or terminate** the training process. There is **no such role like Queen** in AgentJet Swarm. |
| 53 | + |
| 54 | +### 2-1. Connecting to a swarm server and make it rock&roll |
| 55 | + |
| 56 | +The primary objective of swarm client is to make sure network connection is good. |
| 57 | +Now, create a python script and start coding: |
| 58 | + |
| 59 | +```python |
| 60 | +from ajet.tuner_lib.experimental.as_swarm_client import SwarmClient |
| 61 | +REMOTE_SWARM_URL = "http://localhost:10086" # Change to your swarm remote url |
| 62 | +swarm_worker = SwarmClient(REMOTE_SWARM_URL) |
| 63 | +``` |
| 64 | + |
| 65 | +Secondly, generate a configuration (basically VeRL yaml, but slightly different), **connect** to swarm server and then tell the swarm server **which model to train**, etc. When configuration is ready, tell engine to read yaml and begin VeRL training cycles with `auto_sync_train_config_and_start_engine`. |
| 66 | + |
| 67 | +```python |
| 68 | +LOCAL_GRPO_N = 32 |
| 69 | +yaml_job = AgentJetJob( |
| 70 | + experiment_name="math_gsm8k_grpo", |
| 71 | + algorithm="grpo", |
| 72 | + n_gpu=4, |
| 73 | + model='/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2.5-3B-Instruct', |
| 74 | + batch_size=LOCAL_GRPO_N, |
| 75 | + num_repeat=4, |
| 76 | +) |
| 77 | +# hint: you can `yaml_job.dump_job_as_yaml('./config.yaml')` to take a look at the full configuration |
| 78 | +# hint: you can `yaml_job.build_job_from_yaml('./config.yaml')` to load yaml configuration as override. (there are some configurations that must be edited from yaml) |
| 79 | +swarm_worker.auto_sync_train_config_and_start_engine(yaml_job) |
| 80 | +``` |
| 81 | + |
| 82 | +The swarm server can be in the following states and transition between them as follows: |
| 83 | +- **OFFLINE**: The swarm server is started but does not load any models or perform any training. It enters this state directly after startup. Additionally, it transitions to this state upon receiving a `stop_engine` command from (any) client while in any other state. |
| 84 | +- **BOOTING**: The swarm server enters this state upon receiving a configuration followed by an explicit `begin_engine` command. In this state, it loads model parameters, initializes FSDP, and initializes vLLM. |
| 85 | +- **ROLLING**: The swarm server enters this state automatically after completing **BOOTING** or after finishing the **WEIGHT_SYNCING** state. This represents the sampling phase. |
| 86 | +- **ROLLING_POST**: When the swarm server determines that the sample pool is sufficient for proceeding to the next policy gradient step, it automatically transitions to this state. While in this state, ongoing episodes can still complete normally, but no new episodes can begin. |
| 87 | +- **WEIGHT_SYNCING**: After being in the **ROLLING_POST** state, once all computational resources and threads related to ongoing episodes are reclaimed and cleaned up, the swarm server transitions to this state. During this stage, VeRL completes the current policy gradient strategy update and then returns to the **ROLLING** state, repeating the cycle. |
| 88 | + |
| 89 | + |
| 90 | +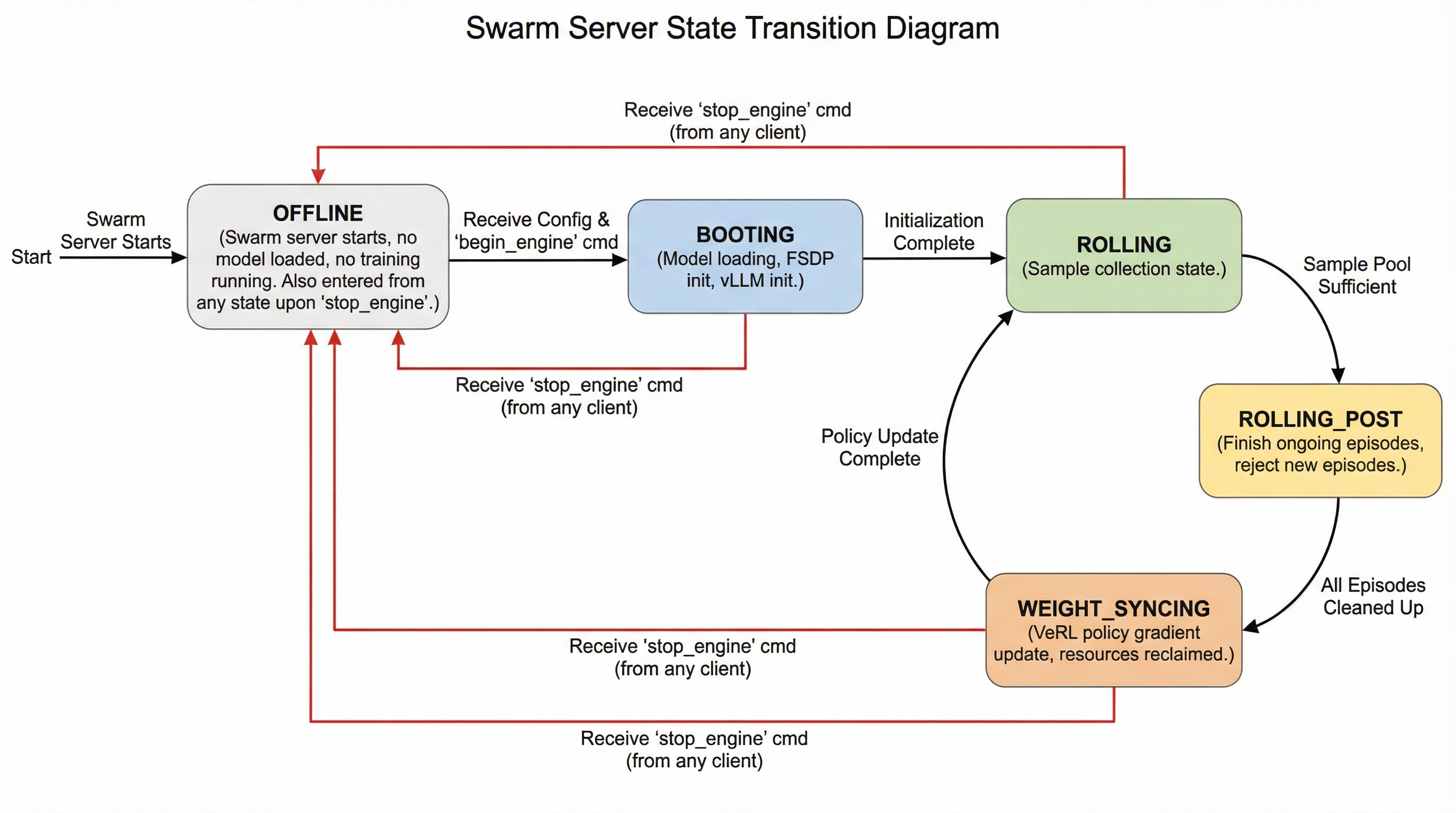 |
| 91 | + |
| 92 | +### 2-2. Read your dataset and create training epoch loop |
| 93 | + |
| 94 | +```python |
| 95 | +LOCAL_DATASET_PATH = "/mnt/data_cpfs/dataset/openai/gsm8k/main" |
| 96 | +dataset = RouterTaskReader( |
| 97 | + reader_type = "huggingface_dat_repo", |
| 98 | + reader_config = AjetTaskReader( |
| 99 | + huggingface_dat_repo = HuggingfaceDatRepo( |
| 100 | + dataset_path = LOCAL_DATASET_PATH |
| 101 | + ) |
| 102 | + ) |
| 103 | +) |
| 104 | +for epoch in range(LOCAL_NUM_EPOCH): |
| 105 | + for _, task in enumerate(dataset.generate_training_tasks()): |
| 106 | + for _ in range(LOCAL_GRPO_N): |
| 107 | + print(task) |
| 108 | + # executor.submit(rollout, task) # this is the place to begin a agent workflow / agent loop, we come back here later |
| 109 | +``` |
| 110 | +
|
| 111 | +You may ask: when does the policy gradient & llm weight update take place? |
| 112 | +The answer is simple: **the swarm server takes care of everything related to training, while the swarm clients do not need to worry about this process at all**. |
| 113 | +
|
| 114 | +By default, when enough amount (>=batch size) of samples (with reward) reach the swarm server, that when a llm weight update step begins. |
| 115 | +Please run `ajet-swarm overwatch` during training, this panel displays everything about the weight update timing, transparently. |
| 116 | +When opening this panel, you can see 3 modes which you can select from: "rollout_until_finish_enough_episodes"(only count episodes), "rollout_until_finish_enough_tasks" (+consider task group), "rollout_until_finish_enough_non_dummy_tasks" (+consider group reward) |
| 117 | +
|
| 118 | +
|
| 119 | +### 2-3. Intergrate with your agent loop. |
| 120 | +
|
| 121 | +Before intergrating your agent loop, we need to explain two concepts: **Episode** and **Task Group**. |
| 122 | +
|
| 123 | +The following process is called an "**Episode**": |
| 124 | +*<br/> |
| 125 | +(input task) -> (agent init and run task) -> (agent complete) -> (compute reward) |
| 126 | +<br/>* |
| 127 | +
|
| 128 | +And in comparison, we call a group of same-input episodes a **Task Group**: |
| 129 | +
|
| 130 | +*(input task 001) -> (agent init and run task) -> (agent complete) -> (compute reward 001-1) |
| 131 | +<br/> |
| 132 | +(input task 001) -> (agent init and run task) -> (agent complete) -> (compute reward 001-2) |
| 133 | +<br/> |
| 134 | +.............................. |
| 135 | +<br/> |
| 136 | +(input task 001) -> (agent init and run task) -> (agent complete) -> (compute reward 001-N)* |
| 137 | +
|
| 138 | +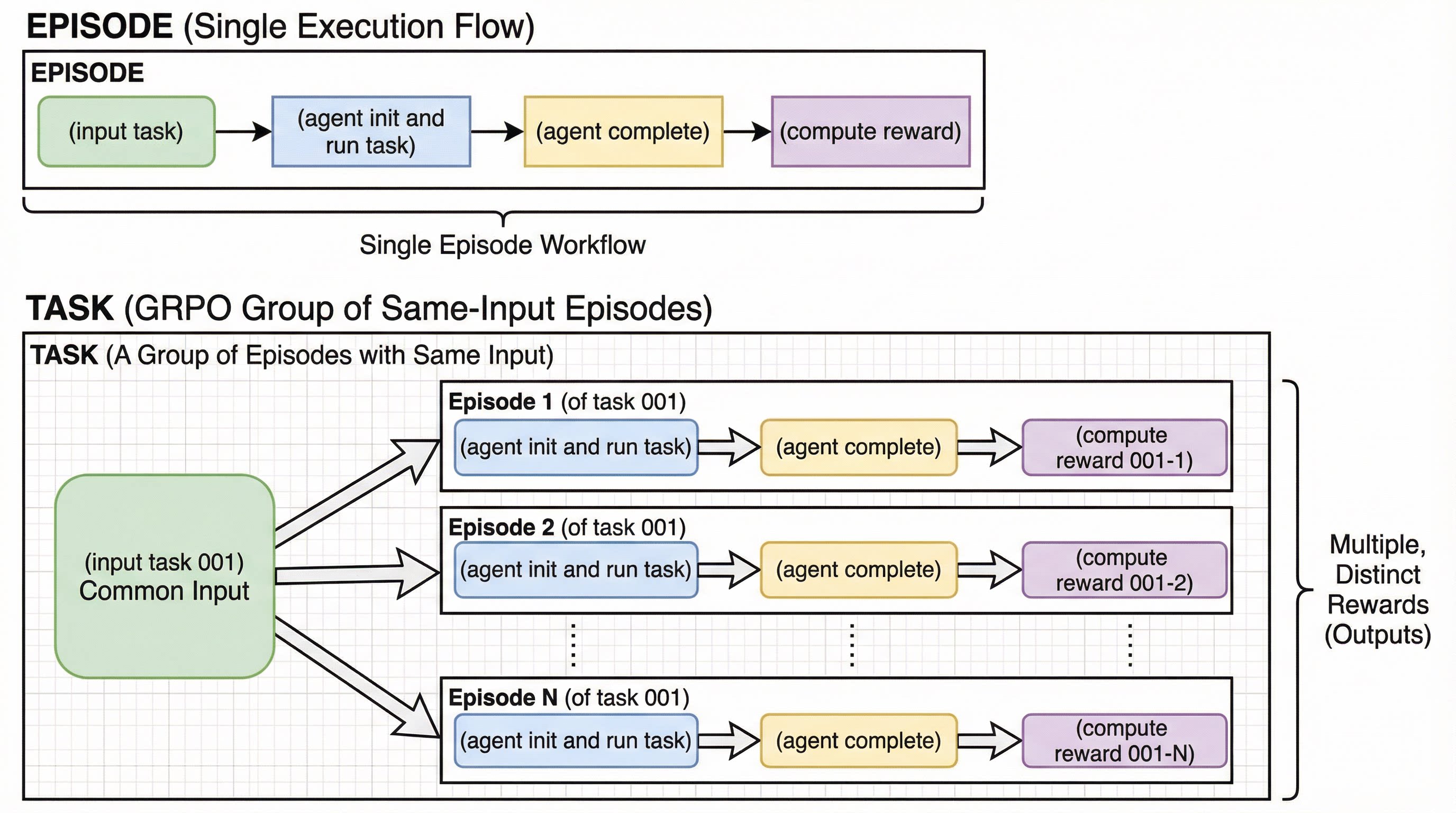 |
| 139 | +
|
| 140 | +With these two concepts in mind, we can write our training program (yes, this is training, NOT just inference): |
| 141 | +```python |
| 142 | +def rollout(task): |
| 143 | + try: |
| 144 | + # begin episode |
| 145 | + episode_uuid, api_baseurl_key = swarm_worker.begin_episode() |
| 146 | + # execute agent ( base_url = api_baseurl_key.base_url, api_key = api_baseurl_key.api_key ) |
| 147 | + workflow_output = execute_you_agent_here(task, api_baseurl_key) # reward is in `workflow_output` |
| 148 | + # report output back to swarm remote |
| 149 | + swarm_worker.end_episode(task, episode_uuid, workflow_output) |
| 150 | + return |
| 151 | + except: |
| 152 | + pass |
| 153 | +
|
| 154 | +executor = BoundedThreadPoolExecutor(max_workers=LOCAL_MAX_PARALLEL) |
| 155 | +for epoch in range(1024): |
| 156 | + # loop dataset epoch |
| 157 | + for _, task in enumerate(dataset.generate_training_tasks()): |
| 158 | + # loop dataset tasks |
| 159 | + for _ in range(LOCAL_GRPO_N): |
| 160 | + # loop episode |
| 161 | + executor.submit(rollout, task) |
| 162 | +swarm_worker.stop_engine() |
| 163 | +``` |
| 164 | +
|
| 165 | +Explaination: |
| 166 | +1. each agent workflow (each episode) must be started with `swarm_worker.begin_episode`, |
| 167 | +which take vLLM/SGLang computational resource from swarm server, and returns `api_baseurl_key`. |
| 168 | +2. take `base_url = api_baseurl_key.base_url` and `api_key = api_baseurl_key.api_key`, run your agent, compute reward, and return `workflow_output` to wrap the computed reward. |
| 169 | +3. call `end_episode` to report reward to swarm server. (or alternatively call `abort_episode` to give up this episode, hoping to rollout something else in next try) |
| 170 | +4. the whole `swarm_worker` thing is thread safe, go threading any way as you wish. |
| 171 | +5. you can kill this script in the middle from the training, move it to another computer(s), and resume training without losing any progress. |
| 172 | +6. you can **debug during training**, this is a crazy but very useful feature. Just change `end_episode` to `abort_episode` and remove `stop_engine`, and then you can copy the modified script to wherevery you want, and debug however you wish. |
0 commit comments