diff --git a/.github/workflows/release.yml b/.github/workflows/release.yml
index 21b568d..59cb0a9 100644
--- a/.github/workflows/release.yml
+++ b/.github/workflows/release.yml
@@ -86,7 +86,7 @@ jobs:
env:
CMAKE_BUILD_TYPE: Release # do not compile with debug symbol to reduce wheel size
run: |
- bash -x .github/workflows/scripts/build.sh ${{ matrix.python-version }} ${{ matrix.cuda-version }}
+ bash -x .github/workflows/scripts/build.sh ${{ matrix.python-version }} ${{ matrix.cuda-version }} bdist_wheel
wheel_name=$(ls dist/*whl | xargs -n 1 basename)
asset_name=${wheel_name//"linux"/"manylinux1"}
echo "wheel_name=${wheel_name}" >> $GITHUB_ENV
@@ -106,24 +106,58 @@ jobs:
with:
name: ${{ env.asset_name }}
path: ./dist/${{ env.wheel_name }}
+ publish_package:
+ name: Publish Python 🐍 distribution 📦 to PyPI
+ needs: [release]
+ runs-on: ${{ matrix.os }}
+ environment:
+ name: pypi
+ url: https://pypi.org/project/minference/
+ permissions:
+ id-token: write
+
+ strategy:
+ fail-fast: false
+ matrix:
+ os: ['ubuntu-20.04']
+ python-version: ['3.10']
+ pytorch-version: ['2.3.0'] # Must be the most recent version that meets requirements-cuda.txt.
+ cuda-version: ['12.1']
+
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v4
+
+ - name: Setup ccache
+ uses: hendrikmuhs/ccache-action@v1.2
+ with:
+ create-symlink: true
+ key: ${{ github.job }}-${{ matrix.python-version }}-${{ matrix.cuda-version }}
+
+ - name: Set up Linux Env
+ if: ${{ runner.os == 'Linux' }}
+ run: |
+ bash -x .github/workflows/scripts/env.sh
+
+ - name: Set up Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+
+ - name: Install CUDA ${{ matrix.cuda-version }}
+ run: |
+ bash -x .github/workflows/scripts/cuda-install.sh ${{ matrix.cuda-version }} ${{ matrix.os }}
- # publish-to-pypi:
- # name: >-
- # Publish Python 🐍 distribution 📦 to PyPI
- # if: startsWith(github.ref, 'refs/tags/') # only publish to PyPI on tag pushes
- # needs: wheel
- # runs-on: ubuntu-latest
- # permissions:
- # id-token: write # IMPORTANT: mandatory for trusted publishing
-
- # steps:
- # - name: Download all the dists
- # uses: actions/download-artifact@v4
- # with:
- # path: dist/
- # - name: Pick the whl files
- # run: for file in dist/*;do mv $file ${file}1; done && cp dist/*/*.whl dist/ && rm -rf dist/*.whl1 && rm -rf dist/*+cu*
- # - name: Display structure of downloaded files
- # run: ls -R dist/
- # - name: Publish distribution 📦 to PyPI
- # uses: pypa/gh-action-pypi-publish@release/v1
+ - name: Install PyTorch ${{ matrix.pytorch-version }} with CUDA ${{ matrix.cuda-version }}
+ run: |
+ bash -x .github/workflows/scripts/pytorch-install.sh ${{ matrix.python-version }} ${{ matrix.pytorch-version }} ${{ matrix.cuda-version }}
+
+ - name: Build core package
+ run: |
+ bash -x .github/workflows/scripts/build.sh ${{ matrix.python-version }} ${{ matrix.cuda-version }} sdist
+ - name: Display structure of dist files
+ run: ls -R dist/
+ - name: Publish distribution 📦 to PyPI
+ uses: pypa/gh-action-pypi-publish@release/v1
+ with:
+ print-hash: true
diff --git a/.github/workflows/scripts/build.sh b/.github/workflows/scripts/build.sh
index 43b6ee4..908bd83 100644
--- a/.github/workflows/scripts/build.sh
+++ b/.github/workflows/scripts/build.sh
@@ -16,4 +16,4 @@ export MAX_JOBS=1
# Make sure release wheels are built for the following architectures
export TORCH_CUDA_ARCH_LIST="7.0 7.5 8.0 8.6 8.9 9.0+PTX"
# Build
-$python_executable setup.py bdist_wheel --dist-dir=dist
+$python_executable setup.py $3 --dist-dir=dist
diff --git a/README.md b/README.md
index cb5ec8c..c3a9472 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
-  +
+ 
@@ -8,7 +8,7 @@
| Project Page |
- Paper |
+ Paper |
HF Demo |
@@ -21,13 +21,13 @@ https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-
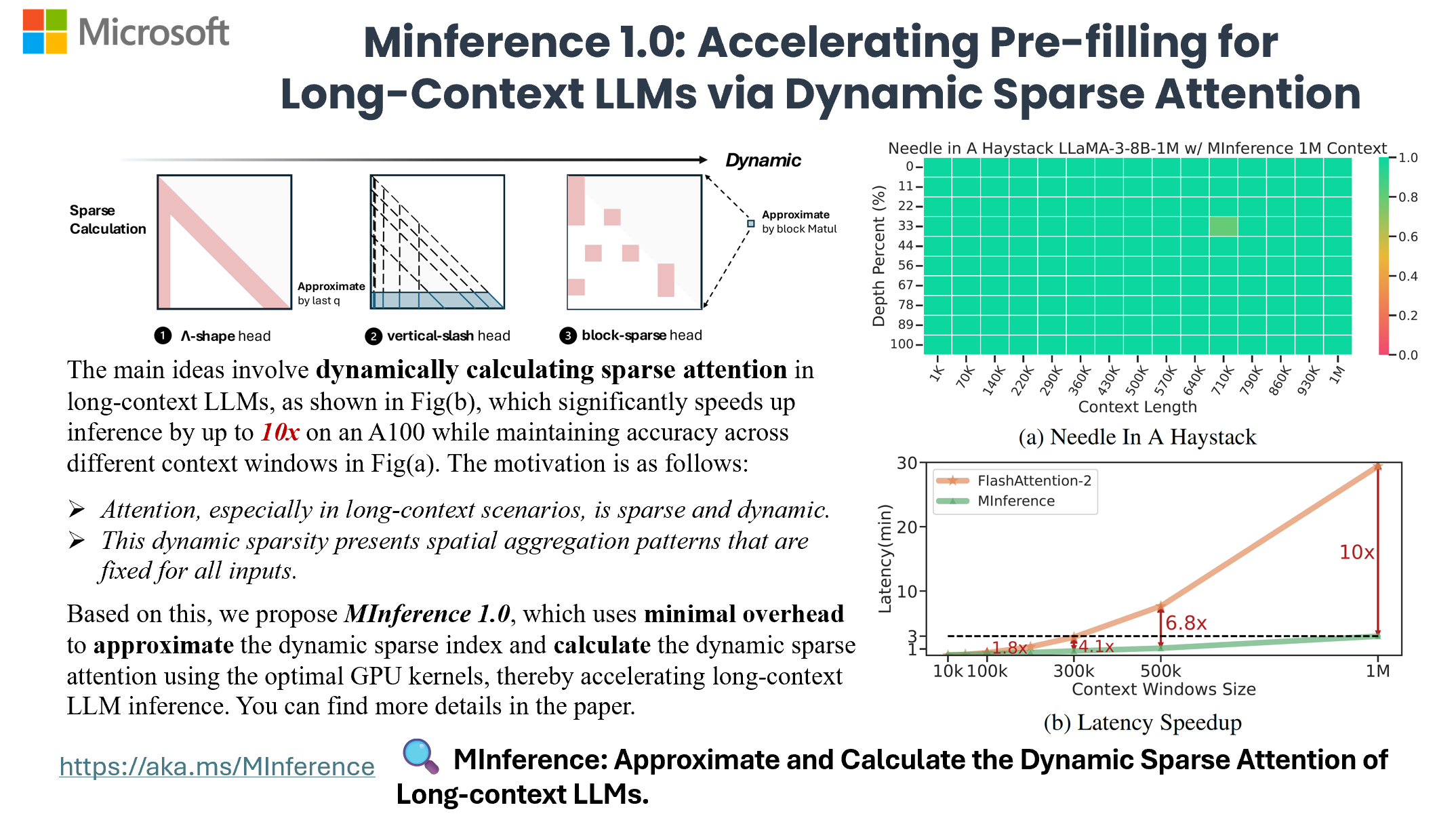
**MInference 1.0** leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a **10x speedup** for pre-filling on an A100 while maintaining accuracy.
-- [MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention](https://arxiv.org/abs/2407.) (Under Review, ES-FoMo @ ICML'24)
+- [MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention](https://arxiv.org/abs/2407.02490) (Under Review, ES-FoMo @ ICML'24)
_Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu_
## 🎥 Overview
-
+
## 🎯 Quick Start
@@ -47,7 +47,7 @@ pip install minference
General *MInference* **supports any decoding LLMs**, including LLaMA-style models, and Phi models.
We have adapted nearly all open-source long-context LLMs available in the market.
-If your model is not on the supported list, feel free to let us know in the issues, or you can follow [the guide](./experiments/) to manually generate the sparse heads config.
+If your model is not on the supported list, feel free to let us know in the issues, or you can follow [the guide](https://github.com/microsoft/MInference/blob/main/experiments) to manually generate the sparse heads config.
You can get the complete list of supported LLMs by running:
```python
@@ -102,11 +102,11 @@ attn_output = block_sparse_attention(q, k, v, topk)
attn_output = streaming_forward(q, k, v, init_num, local_window_num)
```
-For more details, please refer to our [Examples](./examples/) and [Experiments](./experiments/).
+For more details, please refer to our [Examples](https://github.com/microsoft/MInference/tree/main/examples) and [Experiments](https://github.com/microsoft/MInference/tree/main/experiments).
## FAQ
-For more insights and answers, visit our [FAQ section](./Transparency_FAQ.md).
+For more insights and answers, visit our [FAQ section](https://github.com/microsoft/MInference/blob/main/Transparency_FAQ.md).
**Q1: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?**
@@ -124,7 +124,7 @@ Similar vertical and slash line sparse patterns have been discovered in BERT[1]
[1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.
[2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.
-  +
+ 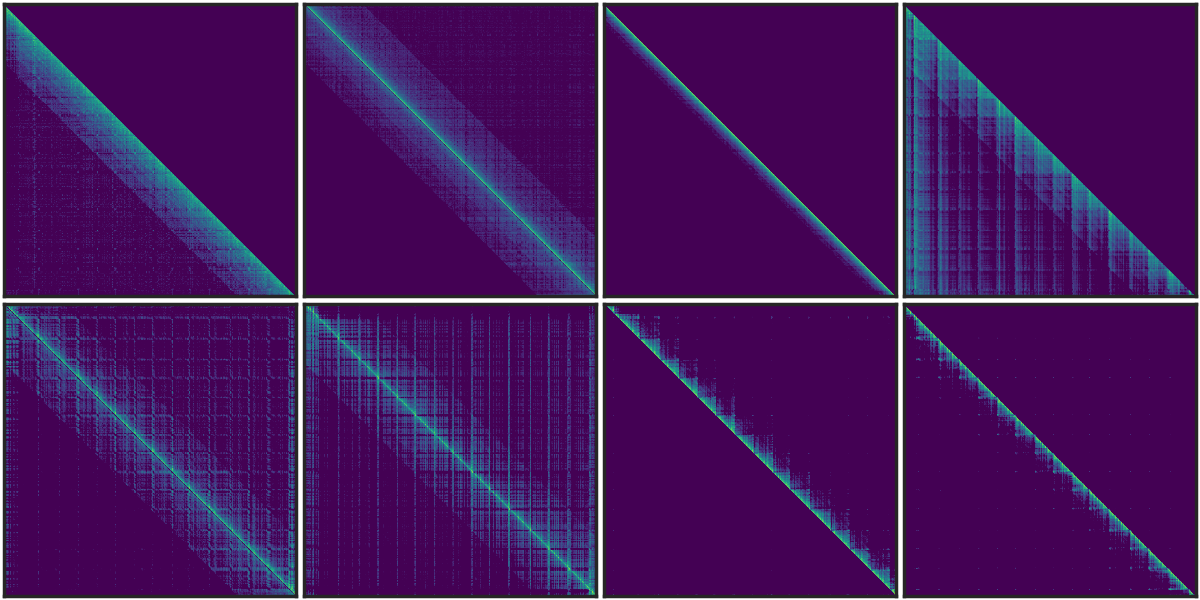
Figure 1. The sparse pattern in T5 Encoder.
@@ -140,7 +140,7 @@ If you find MInference useful or relevant to your project and research, please k
@article{jiang2024minference,
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
- journal={arXiv},
+ journal={arXiv preprint arXiv:2407.02490},
year={2024}
}
```