...menustart
...menuend

nginx把一个请求分成了很多阶段,这样第三方模块就可以根据自己行为,挂载到不同阶段进行处理达到目的。
| 阶段 | 说明 |
|---|---|
| set_by_lua | 流程分支处理判断变量初始化 |
| rewrite_by_lua | 转发、重定向、缓存等功能(例如特定请求代理到外网) |
| access_by_lua | IP准入、接口权限等情况集中处理(例如配合iptable完成简单防火墙) |
| content_by_lua | 内容生成 |
| header_filter_by_lua | 应答HTTP过滤处理(例如添加头部信息) |
| body_filter_by_lua | 应答BODY过滤处理(例如完成应答内容统一成大写) |
| log_by_lua | 回话完成后本地异步完成日志记录(日志可以记录在本地,还可以同步到其他机器) |
- 实际上我们只使用其中一个阶段content_by_lua,也可以完成所有的处理。
- 但这样 会让我们的代码比较臃肿,越到后期越发难以维护。把我们的逻辑放在不同阶段,分工明确,代码独立,后期发力可以有很多有意思的玩法。
Example:
如果在最开始的开发中,使用的是http明文协议,后面需要修改为aes加密协议,利用不同的执行阶段,我们可以非常简单的实现:
# 明文协议版本
location /mixed {
content_by_lua '...'; # 请求处理
}
# 加密协议版本
location /mixed {
access_by_lua '...'; # 请求加密解码
content_by_lua '...'; # 请求处理,不需要关心通信协议
body_filter_by_lua '...'; # 应答加密编码
}
- 内容处理部分都是在content_by_lua阶段完成,第一版本API接口开发都是基于明文。
- 为了传输体积、安全等要求,我们设计了支持压缩、加密的密文协议(上下行) -在access_by_lua完成密文协议解码,body_filter_by_lua完成应答加密编码。
- log_by_lua是一个请求阶段最后发生的,文件操作是阻塞的(FreeBSD直接无视)
- nginx为了实时高效的给请求方应答后,日志记录是在应答后异步记录完成的。由此可见如果我们有日志输出的情况,最好统一到log_by_lua阶段。
- 可能需要 ngx.ctx 来保存 content 或其他阶段的数据, 以便在 log 阶段使用
- 如果我们自定义放在content_by_lua阶段,那么将线性的增加请求处理时间。
- Nginx为了减少系统上下文切换,它的worker是用单进程单线程设计的,事实证明这种做法运行效率很高。
- Nginx要么是在等待网络讯号,要么就是在处理业务(请求数据解析、过滤、内容应答等),没有任何额外资源消耗。
官方有明确说明,Openresty的官方API绝对100% noblock,所以我们只能在她的外面寻找了。我这里大致归纳总结了一下,包含下面几种情况:
- 高CPU的调用(压缩、解压缩、加解密等)
- 高磁盘的调用(所有文件操作)
- 非Openresty提供的网络操作(luasocket等)
- 系统命令行调用(os.execute等)
这些都应该是我们尽量要避免的。理想丰满,现实骨感,谁能保证我们的应用中不使用这些类型的API?
没人保证,我们能做的就是把他们的调用数量、频率降低再降低,如果还是不能满足我们需要,那么就考虑把他们封装成独立服务,对外提供TCP/HTTP级别的接口调用,这样我们的Openresty就可以同时享受异步编程的好处又能达到我们的目的。
- 一个生产环境的缓存系统,需要根据自己的业务场景和系统瓶颈,来找出最好的方案,这是一门平衡的艺术。
- 一般来说,缓存有两个原则。
- 一是越靠近用户的请求越好,
- 比如能用本地缓存的就不要发送HTTP请求,
- 能用CDN缓存的就不要打到Web服务器,
- 能用nginx缓存的就不要用数据库的缓存;
- 二是尽量使用本进程和本机的缓存解决,因为跨了进程和机器甚至机房,缓存的网络开销就会非常大,在高并发的时候会非常明显。
- 一是越靠近用户的请求越好,
我们介绍下在 OpenResty 里面,有哪些缓存的方法。
使用 Lua shared dict:
我们看下面这段代码:
function get_from_cache(key)
local cache_ngx = ngx.shared.my_cache
local value = cache_ngx:get(key)
return value
end
function set_to_cache(key, value, exptime)
if not exptime then
exptime = 0
end
local cache_ngx = ngx.shared.my_cache
local succ, err, forcible = cache_ngx:set(key, value, exptime)
return succ
end
- ngx.shared.my_cache 要在 nginx.conf 中定义
lua_shared_dict my_cache 128m;
- nginx所有worker之间共享的,内部使用的LRU算法(最近最少使用)来判断缓存是否在内存占满时被清除。
使用Lua LRU cache:
直接复制下春哥的示例代码:
local _M = {}
-- alternatively: local lrucache = require "resty.lrucache.pureffi"
local lrucache = require "resty.lrucache"
-- we need to initialize the cache on the Lua module level so that
-- it can be shared by all the requests served by each nginx worker process:
local c = lrucache.new(200) -- allow up to 200 items in the cache
if not c then
return error("failed to create the cache: " .. (err or "unknown"))
end
function _M.go()
c:set("dog", 32)
c:set("cat", 56)
ngx.say("dog: ", c:get("dog"))
ngx.say("cat: ", c:get("cat"))
c:set("dog", { age = 10 }, 0.1) -- expire in 0.1 sec
c:delete("dog")
end
return _M
- shared.dict 使用的是共享内存,
- 每次操作都是全局锁,如果高并发环境,不同worker之间容易引起竞争。
- 所以单个shared.dict的体积不能过大。
- 丰富API add、replace、incr、get_stale(在key过期时也可以返回之前的值)、get_keys(获取所有key,虽然不推荐,但说不定你的业务需要呢)
- 内存占用比较少。
- lrucache是worker内使用的,
- 由于nginx是单进程方式存在,所以永远不会触发锁,效率上有优势,并且没有shared.dict的体积限制,内存上也更弹性,
- 不同worker之间数据不同享,同一缓存数据可能被冗余存储。
- 供的API比较少,现在只有get、set和delete
这是一个比较常见的功能,你会怎么做呢?Google一下,你会找到Lua的官方指南,里面介绍了10种sleep不同的方法,选择一个用,然后你就杯具了:( nginx高并发的特性不见了!
在OpenResty里面选择使用库的时候,有一个基本的原则:尽量使用ngx Lua的库函数,尽量不用Lua的库函数,因为Lua的库都是同步阻塞的。
# you do not need the following line if you are using
# the ngx_openresty bundle:
lua_package_path "/path/to/lua-resty-redis/lib/?.lua;;";
server {
location /non_block {
content_by_lua_block {
ngx.sleep(0.1)
}
}
}
- ngx.timer.at()
- 这个函数是在后台用nginx轻线程(light thread),在指定的延时后,调用指定的函数。
- 我们有机会做一些更有想象力的功能出来。比如 批量提交和cron任务。
- 特别注意:有一些ngx_lua的API不能在这里调用,
- 比如子请求、ngx.req.* 和向下游输出的API (ngx.print、ngx.flush之类),
- 原因是这些请求都需要绑定某个请求,但是对于 ngx.timer.at 自身的运行,是与当前任何请求都没关系的。
local delay = 5
local handler
handler = function (premature)
-- do some routine job in Lua just like a cron job
if premature then
return
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
-
不同的业务应用场景,会有完全不同的非法终端控制策略
- 常见的限制策略有终端IP、访问域名端口,这些可以通过防火墙等很多成熟手段完成。
- 也有一些特定限制策略,例如特定cookie、url、location,甚至请求body包含有特殊内容,这种情况下普通防火墙就比较难限制。
-
Nginx的是HTTP 7层协议的实现者
- 相对普通防火墙从通讯协议有自己的弱势,同等的配置下的性能表现绝对远不如防火墙,
- 但它的优势胜在价格便宜、调整方便,还可以完成HTTP协议上一些更具体的控制策略,与iptable的联合使用,让Nginx玩出更多花样。
列举几个限制策略来源:
- IP地址
- 域名、端口
- Cookie特定标识
- location
- body中特定标识
示例配置(allow、deny):
location / {
deny 192.168.1.1;
allow 192.168.1.0/24; #IPv4
allow 10.1.1.0/16; #IPv4
allow 2001:0db8::/32; #IPv6
deny all;
}
- The rules are checked in sequence until the first match is found.
- In this example, access is allowed only for IPv4 networks 10.1.1.0/16 and 192.168.1.0/24 excluding the address 192.168.1.1, and for IPv6 network 2001:0db8::/32.
- In case of a lot of rules, the use of the ngx_http_geo_module module variables is preferable.
目前为止所有的控制,都是用Nginx模块完成,执行效率、配置明确是它的优点。缺点也比较明显,修改配置代价比较高(reload服务)。并且无法完成与第三方服务的对接功能交互(例如调用iptable)。 在Openresty里面,这些问题就都容易解决,还记得access_by_lua么?推荐一个第三方库lua-resty-iputils。
- 在一些请求中,我们会做一些日志的推送、用户数据的统计等和返回给终端数据无关的操作。
- 这些操作,即使你用异步非阻塞的方式,在终端看来,也是会影响速度的。
- 这个和我们的原则:终端请求,需要用最快的速度返回给终端,是冲突的。
- 最理想的是,获取完给终端返回的数据后,就断开连接,后面的日志和统计等动作,在断开连接后,后台继续完成即可。
怎么做到呢?我们先看其中的一种方法:
local response, user_stat = logic_func.get_response(request)
ngx.say(response)
# 即时关闭连接,把数据返回给终端
# 后面的数据库操作还会运行
ngx.eof() # 最关键的一行代码
if user_stat then
local ret = db_redis.update_user_data(user_stat)
end
需要注意的是,你不能任性的把阻塞的操作加入代码,即使在ngx.eof()之后。 虽然已经返回了终端的请求,但是,nginx的worker还在被你占用。所以在keep alive的情况下,本次请求的总时间,会把上一次eof()之后的时间加上。 如果你加入了阻塞的代码,nginx的高并发就是空谈。 有没有其他的方法来解决这个问题呢?我们会在ngx.timer.at里面给大家介绍更优雅的方案。
- 关闭code cache
- 这个选项在调试的时候最好关闭。
- lua_code_cache off;
- 记录日志
- 看上去谁都会的东西,要想做好也不容易。
- QA发现了一个bug,开发说我修改代码加个日志看看,然后QA重现这个问题,发现日志不够详细,需要再加,反复...
- 你在写代码的时候,就需要考虑到调试日志
local response, err = redis_op.finish_client_task(client_mid, task_id)
if response then
put_job(client_mid, result)
ngx.log(ngx.WARN, "put job:", common.json_encode({channel="task_status", mid=client_mid, data=result}))
end
- 我们在做一个操作后,就把结果记录到nginx的error.log里面,等级是warn。
- 在生产环境下,日志等级默认为error,在我们需要详细日志的时候,把等级调整为warn即可。
- 在我们的实际使用中,我们会把一些很少发生的重要事件,做为error级别记录下来,即使它并不是nginx的错误。
- 与日志配套的,你需要 logrotate 来做日志的切分和备份。
使用FFI判断操作系统:
local ffi = require("ffi")
if ffi.os == "Windows" then
print("windows")
elseif ffi.os == "OSX" then
print("MAC OS X")
else
print(ffi.os)
end
调用zlib压缩库:
local ffi = require("ffi")
ffi.cdef[[
unsigned long compressBound(unsigned long sourceLen);
int compress2(uint8_t *dest, unsigned long *destLen,
const uint8_t *source, unsigned long sourceLen, int level);
int uncompress(uint8_t *dest, unsigned long *destLen,
const uint8_t *source, unsigned long sourceLen);
]]
local zlib = ffi.load(ffi.os == "Windows" and "zlib1" or "z")
local function compress(txt)
local n = zlib.compressBound(#txt)
local buf = ffi.new("uint8_t[?]", n)
local buflen = ffi.new("unsigned long[1]", n)
local res = zlib.compress2(buf, buflen, txt, #txt, 9)
assert(res == 0)
return ffi.string(buf, buflen[0])
end
local function uncompress(comp, n)
local buf = ffi.new("uint8_t[?]", n)
local buflen = ffi.new("unsigned long[1]", n)
local res = zlib.uncompress(buf, buflen, comp, #comp)
assert(res == 0)
return ffi.string(buf, buflen[0])
end
-- Simple test code.
local txt = string.rep("abcd", 1000)
print("Uncompressed size: ", #txt)
local c = compress(txt)
print("Compressed size: ", #c)
local txt2 = uncompress(c, #txt)
assert(txt2 == txt)
- Lua module 是 VM 级别共享的
- 各个请求的私有数据 , 只应通过你自己的函数参数来传递,或者通过 ngx.ctx 表。
- 前者是推荐 ,因为效率高得多。
- 进程间
- 所有Nginx的工作进程共享变量,使用指令lua_shared_dict定义
- 进程内 worker
- Lua源码中声明为全局变量,就是声明变量的时候不使用local关键字,这样的变量在同一个进程内的所有请求都是共享的
-
- ngx_lua使用LuaJIT编译,2. 声明全局变量的模块是require引用。LuaJIT会缓存模块中的全局变量, 高并发的情况下,很容易出错
- 每请求
- Lua源码中声明变量的时候使用local关键字,和ngx.ctx类似,变量的生命周期只存在同一个请求中
- 在OpenResty中,连接池在使用上如果不加以注意,容易产生数据写错地方,或者得到的应答数据异常以及类似的问题,
- 当然使用短连接可以规避这样的问题,但是在一些企业用户环境下,短连接+高并发对企业内部的防火墙是一个巨大的考验,因此,长连接自有其勇武之地,
- 使用长连接的时候要记住,长连接一定要保持其连接池中所有连接的正确性。
- 如果连接 出现错误,则不要将该连接加入连接池。
OpenResty 引用第三方 resty 库非常简单,只需要将相应的文件拷贝到 resty 目录下即可。
我们以 resty.http 库为例。
只要将 lua-resty-http/lib/resty/ 目录下的 http.lua 和 http_headers.lua两个文件拷贝到 /usr/local/openresty/lualib/resty 目录下即可(假设你的openresty安装目录为 /usr/local/openresty)。
content_by_lua_block {
local http = require "resty.http"
local httpc = http.new()
local res, err = httpc:request_uri("http://www.baidu.com")
if res.status == ngx.HTTP_OK then
ngx.say(res.body)
else
ngx.exit(res.status)
end
}
- 任何一个开发语言、开发框架,都有它存在的明确目的,重心是为了解决什么问题。
- OpenResty的存在也有其自身适用的应用场景。
- 在lua中混合处理不同nginx模块输出(proxy, drizzle, postgres, redis, memcached等)。
- 在请求真正到达上游服务之前,lua中处理复杂的准入控制和安全检查。
- 比较随意的控制应答头(通过Lua)。
- 从外部存储中获取后端信息,并用这些信息来实时选择哪一个后端来完成业务访问。
- 在内容handler中随意编写复杂的web应用,同步编写异步访问后端数据库和其他存储。
- 在rewrite阶段,通过Lua完成非常复杂的处理。
- 在Nginx子查询、location调用中,通过Lua实现高级缓存机制。
- 对外暴露强劲的Lua语言,允许使用各种Nginx模块,自由拼合没有任何限制。
- 有长时间阻塞调用的过程
- 例如通过 Lua 完成系统命令行调用
- 使用阻塞的Lua API完成相应操作
- 单个请求处理逻辑复杂,尤其是需要和请求方多次交互的长连接场景
- Nginx的内存池 pool 是每次新申请内存存放数据
- 所有的内存释放都是在请求退出的时候统一释放
- 如果单个请求处理过于复杂,将会有过多内存无法及时释放
- 内存占用高的处理
- 受制于Lua VM的最大使用内存 1G 的限制
- 这个限制是单个Lua VM,也就是单个Nginx worker
- 两个请求之间有交流的场景
- 例如你做个在线聊天,要完成两个用户之间信息的传递
- 当前OpenResty还不具备这个通讯能力(后面可能会有所完善)
- 与行业专用的组件对接
- 最好是 TCP 协议对接,不要是 API 方式对接,防止里面有阻塞 TCP 处理
- 由于OpenResty必须要使用非阻塞 API ,所以传统的阻塞 API ,我们是没法直接使用的
- 获取 TCP 协议,使用 cosocket 重写(重写后的效率还是很赞的)
- 每请求开启的 light thread 过多的场景
- 虽然已经是light thread,但它对系统资源的占用相对是比较大的
- 这些适合、不适合信息可能在后面随着 OpenResty 的发展都会有新的变化,大家拭目以待。
- cosocket 是 OpenResty 世界中技术、实用价值最高的部分。
- 可以用非常低廉的成本,优雅的姿势,比传统 socket 编程效率高好几倍的方式进行网络编程。
- 无论资源占用、执行效率、并发数等都非常出色
cosocket = coroutine + socket
- 需要协程特性支撑,
- 需要 nginx 非常最重要的一部分“事件循环回调机制”
在 Lua 世界中调用任何一个有关 cosocket 网络函数内部关键调用如图所示:
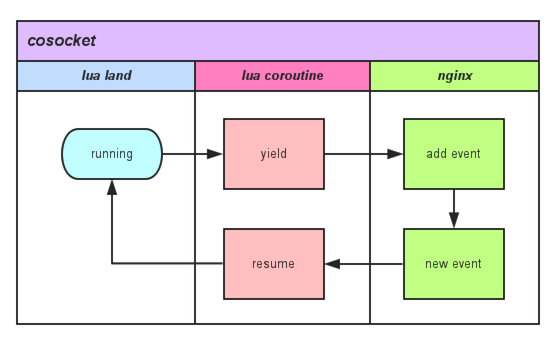
- 用户的 Lua 脚本每触发一个网络操作,都会触发一个协程的 yield 以及 resume,
- 因为每请求的 Lua 脚本实际上都运行在独享协程之上,可以在任何需要的时候暂停自己(yield),也可以在任何需要的时候被唤醒(resume)。 暂停自己,把网络事件注册到 Nginx 监听列表中,并把运行权限交给 Nginx。
- 当有 Nginx 注册网络事件达到触发条件时,唤醒对应的协程继续处理。
- 依此为蓝板,封装实现 connect、read、recieve 等操作,形成了大家目前所看到的 cosocket API。
- cosocket 对象是全双工的,也就是说,一个专门读取的 "light thread",一个专门写入的 "light thread",它们可以同时对同一个 cosocket 对象进行操作(两个 "light threads" 必须运行在同一个 Lua 环境中,原因见上)。
- 但是你不能让两个 "light threads" 对同一个 cosocket 对象都进行读(或者写入、或者连接)操作,否则当调用 cosocket 对象时,你将得到一个类似 "socket busy reading" 的错误。
特性:
- 它是异步的;
- 它是非阻塞的;
- 它是全双工的;
异步/同步是做事派发方式,阻塞/非阻塞是如何处理事情,两组概念不在同一个层面。
无论 ngx.socket.tcp()、ngx.socket.udp()、ngx.socket.stream()、ngx.req.socket(),它们基本流程都是一样的,只是一些细节参数上有区别(比如 TCP 和 UDP 的区别)。
下面这些函数,都是用来辅助完成更高级的 socket 行为控制:
- connect
- sslhandshake
- send
- receive
- close
- settimeout
- setoption
- receiveuntil
- setkeepalive
- getreusedtimes
它们不仅完整兼容 LuaSocket 库的 TCP API,而且还是 100% 非阻塞的。
show 一个例子,对 cosocket 使用有一个整体认识。
location /test {
resolver 114.114.114.114;
content_by_lua_block {
local sock = ngx.socket.tcp()
local ok, err = sock:connect("www.baidu.com", 80)
if not ok then
ngx.say("failed to connect to baidu: ", err)
return
end
local req_data = "GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n"
local bytes, err = sock:send(req_data)
if err then
ngx.say("failed to send to baidu: ", err)
return
end
local data, err, partial = sock:receive()
if err then
ngx.say("failed to recieve to baidu: ", err)
return
end
sock:close()
ngx.say("successfully talk to baidu! response first line: ", data)
}
}
- 这里的 socket 操作都是异步非阻塞的
官方默认绑定包有多少是基于 cosocket 的:
- ngx_stream_lua_module Nginx "stream" 子系统的官方模块版本(通用的下游 TCP 对话)。
- lua-resty-memcached 基于 ngx_lua cosocket 的库。
- lua-resty-redis 基于 ngx_lua cosocket 的库。
- lua-resty-mysql 基于 ngx_lua cosocket 的库。
- lua-resty-upload 基于 ngx_lua cosocket 的库。
- lua-resty-dns 基于 ngx_lua cosocket的库。
- lua-resty-websocket 提供 WebSocket 的客户端、服务端,基于 ngx_lua cosocket 的库。