batch duration,window duration以及sliding duration的关系 #16
Comments
|
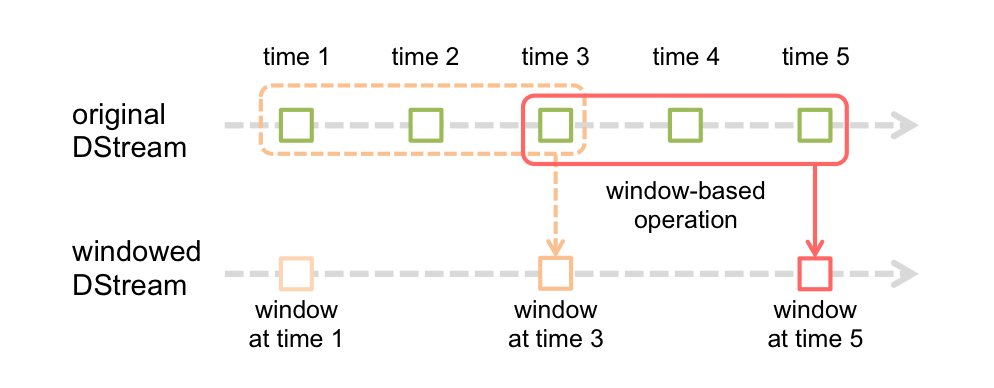
@cjuexuan 上图里 batch duration = 1, window length = 3, sliding interval = 2 |
|
@proflin 这也就是有些时候的input size 是0 events的原因么? |
|
@proflin thanks |
|
@proflin 每隔batch都会生成一个RDD,只是到windowDStream的时候做了合并,生成UnionRDD或者PartitionerAwareUnionRDD,最后输出一个RDD |
|
@luckuan 的解释更详细一些。对图中的 originalDStream,每个 batch 都生成了 RDD,对 windowedDStream,每隔 sliding interval 才去实际生成 RDD,而不是每个 batch 都生成 RDD。 |
|
@luckuan thanks,good job |
|
@proflin 请问spark stream支持几种window operation? 在论文上看到一种叫做session window的 |
|
如果你是指 Google Dataflow 对 Window 的定义(如下图)的话,那么 Spark Streaming 支持 Fixed 和 Sliding,原生并不支持 Sessions。
另一方面可以参考 Cloudera 的 Spark-Dataflow,可能基于 Spark Streaming 提供了 Sessions 支持,我不是特别清楚。 |

|
话说前两种window operation比较适合的场景是什么? 对了,我觉得像交易所这种数据对corretness的要求是极其高的,我一直觉得不适合用现在这些流失处理进行,感觉还是batch处理比较合理。 @proflin |
|
前两种就是通常意义下的 window;一般大家常见到的 window 操作都适合于这两种场景。另外实际上 Fixed 只是 Sliding 的一种特殊情况。 Watermark 的概念主要还是看 WheelMill 吧,DataFlow 以 WheelMill 为流引擎,DataFlow 的 watermark 是来自 WheelMill 的。WheelMill 的论文来自 VLDB 2013。 交易所的对实时性要求高的计算(高频交易等)都是针对特定业务的专有系统来支持的。这类系统专业、稳定、非常非常实时,但是不会具有通用性。现有流数据平台无法很好的支持交易所的需求。我还没听说过交易所也用 Batch 处理(如 MR、Spark 等)的,他们应该也是有专用系统。 |
|
@lw-lin 每隔 sliding interval 才去实际生成 RDD 这点有改进的空间么? 尤其是对接kafka的sliding window . 比如batch 5s , sliding interval 为15s 。 这样其实有10s时间 streaming流不去拉去kafka数据,只等待到15s 拉去 一次 浪费时间和带宽。 如果能安装batch时间 (5s)实际生产rdd数据,极大提高流的效率 |
|
@superwood @lw-lin 对图中的 originalDStream,每个 batch 都生成了 RDD。那么0,5,10,15s时都会去kafka拉取数据吧。只不过触发计算的时候获取的原始RDD范围会跨多个batch。 |
您能否抽时间讲一下这三个之间的关系,从doc上看貌似只是说window duration和sliding duration都应该设为batch duration的倍数,而job的submit到底是参照的batch duration还是sliding duration,请您为我解惑
The text was updated successfully, but these errors were encountered: