A light, extensible agent framework built on Model Context Protocol that enables orchestration of AI workflows and tools in a straightforward, code-first manner.
This framework supports:
- MCP (Model Context Protocol) servers for standardized tool interfaces, prompts, memory, etc.
- An Agent abstraction that can seamlessly attach to multiple MCP servers, handle human input, signals, or additional specialized tasks.
- Common agent patterns, such as Swarm (by OpenAI), and Evaluator-Optimizer, Orchestrator, Router, and more from Anthropic’s Building Effective Agents blog, adapted for code-based control flow instead of rigid "graph-based" structures.
- Durable Execution with pluggable backends (e.g., Temporal) for advanced pause/resume, parallelization, and human-in-the-loop signals.
Why code-based control flow? In many agent frameworks, you must model nodes/edges, which adds an unnecessary layer of complexity. For conditionals, you have to craft subgraphs, or for loops, you must create cyclical edges. In mcp-agent, you just write regular Python control flow (loops, if/else conditionals) and let the executor handle concurrency, resiliency and orchestration.
We recommend using uv to manage your Python projects:
uv add "mcp-agent"Alternatively:
pip install mcp-agentThe examples directory has a number of example applications to get started with.
To run an example, clone this repo, update, then copy mcp_agent.secrets.yaml.example to mcp_agent.secrets.yaml and update with your API keys, and then:
uv run scripts/example.py run mcp_basic_agent # Replace with 'mcp_basic_agent' with any folder name under examples/Here is a basic "finder" agent that uses the fetch and filesystem servers to look up a file:
- Configure your application by creating an mcp_agent.config.yaml
mcp:
servers:
fetch:
command: "uvx"
args: ["mcp-server-fetch"]
filesystem:
command: "npx"
args:
[
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/saqadri/Desktop",
"<add other directories to give access to>",
]
anthropic:
# Secrets (api_key, etc.) can also be stored in an mcp_agent.secrets.yaml file which can be gitignored
api_key: claude-api-key
openai: ...import asyncio
import os
from mcp_agent.context import get_current_context
from mcp_agent.logging.logger import get_logger
from mcp_agent.agents.agent import Agent
from mcp_agent.workflows.llm.augmented_llm_openai import OpenAIAugmentedLLM
async def example_usage():
logger = get_logger("mcp_basic_agent.example_usage")
context = get_current_context()
logger.info("Current config:", data=context.config)
# This agent can read the filesystem or fetch URLs
finder_agent = Agent(
name="finder",
instruction="""You can read local files or fetch URLs.
Return the requested information when asked.""",
server_names=["fetch", "filesystem"],
)
async with finder_agent:
# List tools available to the finder agent
tools = await finder_agent.list_tools()
logger.info(f"Tools available:", data=tools)
# Attach an OpenAI-based LLM to the agent
llm = await finder_agent.attach_llm(OpenAIAugmentedLLM)
# Now we can do a prompt that might need the agent's capabilities
result = await llm.generate_str(
message="Show me what's in README.md verbatim"
)
logger.info(f"README.md contents: {result}")
result = await llm.generate_str(
message="Print the first two paragraphs from https://www.anthropic.com/research/building-effective-agents"
)
logger.info(f"Blog intro: {result}")
if __name__ == "__main__":
asyncio.run(example_usage())This framework provides a streamlined approach to building AI agents using capabilities exposed by MCP (Model Context Protocol) servers.
Simply put, MCP is quite low-level, and this framework handles the mechanics of connecting to servers, working with LLMs, handling external signals (like human input) and supporting persistent state via durable execution. That lets you, the developer, focus on the core business logic of your AI application.
Core benefits:
- Interoperability: MCP ensures that tools and servers can seamlessly plug in to your agent, forming a “server-of-servers.”
- Composability & Cutstomizability: Implements well-defined workflows, but in a composable way that enables compound workflows, and allows full customization across model provider, logging, orchestrator, etc.
- Programmatic control flow: Keeps things simple as developers just write code instead of thinking in graphs, nodes and edges. For branching logic, you write
ifstatements. For cycles, usewhileloops. - Human Input & Signals: Supports pausing workflows for external signals, such as human input, which are exposed as tool calls an Agent can make.
- Durable Execution: Supports persistent/long-running workflows (like with Temporal) for sophisticated async applications.
You can expose mcp-agent applications as MCP servers themselves, allowing MCP clients to interface with sophisticated AI workflows using the standard tools API of MCP servers. This is effectively a server-of-servers.
You can embed mcp-agent in an MCP client directly to manage the orchestration across multiple MCP servers.
You can use mcp-agent applications in a standalone fashion (i.e. they aren't part of an MCP client). The examples are all standalone applications.
The following are the building blocks of the mcp-agent framework:
- Context: global state and app configuration
- MCP server management:
gen_clientandMCPConnectionManagerto easily connect to MCP servers. - MCPAggregator: A server-of-servers that exposes multiple servers' capabilities behind a single MCP server interface.
- Agent: An MCPAggregator with a name and instruction, with the ability to customize behavior for tool calls and more.
- AugmentedLLM: An LLM that is attached to an Agent to achieve its task, exposing a
generatemethod.
Everything in the framework is a derivative of these core capabilities.
There is a global context that is initialized to manage application state, including configuration loaded from mcp_agent.config.yaml, such as the MCP server registry, logger settings, LLM API keys and more.
from mcp_agent.context import get_current_context
context = get_current_context()
server_registry = context.server_registry
config = context.configThis is the core building block of the entire framework
mcp-agent makes it trivial to connect to MCP servers. Create an mcp_agent.config.yaml to define server configuration under the mcp section:
mcp:
servers:
fetch:
command: "uvx"
args: ["mcp-server-fetch"]
description: "Fetch content at URLs from the world wide web"Manage the lifecycle of an MCP server within an async context manager:
from mcp_agent.mcp.gen_client import gen_client
async with gen_client("fetch") as fetch_client:
# Fetch server is initialized and ready to use
result = await fetch_client.list_tools()
# Fetch server is automatically disconnected/shutdownThe gen_client function makes it easy to spin up connections to MCP servers.
In many cases, you want an MCP server to stay online for persistent use (e.g. in a multi-step tool use workflow). For persistent connections, use:
connectanddisconnect
from mcp_agent.mcp.gen_client import connect, disconnect
fetch_client = None
try:
fetch_client = connect("fetch")
result = await fetch_client.list_tools()
finally:
disconnect("fetch")MCPConnectionManagerFor even more fine-grained control over server connections, you can use the MCPConnectionManager.
from mcp_agent.context import get_current_context
from mcp_agent.mcp.mcp_connection_manager import MCPConnectionManager
context = get_current_context()
connection_manager = MCPConnectionManager(context.server_registry)
async with connection_manager:
fetch_client = await connection_manager.get_server("fetch") # Initializes fetch server
result = fetch_client.list_tool()
fetch_client2 = await connection_manager.get_server("fetch") # Reuses same server connection
# All servers managed by connection manager are automatically disconnected/shut downMCPAggregator acts as a "server-of-servers".
It provides a single MCP server interface for interacting with multiple MCP servers.
This allows you to expose tools from multiple servers to LLM applications.
from mcp_agent.mcp.mcp_aggregator import MCPAggregator
aggregator = await MCPAggregator.create(server_names=["fetch", "filesystem"])
async with aggregator:
# combined list of tools exposed by 'fetch' and 'filesystem' servers
tools = await aggregator.list_tools()
# namespacing -- invokes the 'fetch' server to call the 'fetch' tool
fetch_result = await aggregator.call_tool(name="fetch-fetch", arguments={"url": "https://www.anthropic.com/research/building-effective-agents"})
# no namespacing -- first server in the aggregator exposing that tool wins
read_file_result = await aggregator.call_tool(name="read_file", arguments={})An Agent is an MCPAggregator with an name and instruction (or purpose).
Agents are the core building block of the mcp-agent framework. Agents expose tools and function to LLMs.
from mcp_agent.agents.agent import Agent
finder_agent = Agent(
name="finder",
instruction="You are an agent with filesystem + fetch access. Return the requested file or URL contents.",
server_names=["fetch", "filesystem"],
)AugmentedLLM is an LLM that has access to MCP servers and functions via Agents. Different LLM providers implement the AugmentedLLM interface to expose 3 functions:
generate: Generate message(s) given a prompt, possibly over multiple iterations and making tool calls as needed.generate_str: Returns the generated result as a string output.generate_structured: Uses Instructor to return the generated result as a Pydantic model.
Additionally, AugmentedLLM has memory, to keep track of long or short-term history.
from mcp_agent.agents.agent import Agent
from mcp_agent.workflows.llm.augmented_llm_anthropic import AnthropicAugmentedLLM
finder_agent = Agent(
name="finder",
instruction="You are an agent with filesystem + fetch access. Return the requested file or URL contents.",
server_names=["fetch", "filesystem"],
)
async with finder_agent:
llm = await finder_agent.attach_llm(AnthropicAugmentedLLM)
result = await llm.generate_str(
message="Print the first 2 paragraphs of https://www.anthropic.com/research/building-effective-agents",
# Can override model, tokens and other defaults
)
logger.info(f"Result: {result}")
# Multi-turn conversation
result = await llm.generate_str(
message="Summarize those paragraphs in a 128 character tweet",
)
logger.info(f"Result: {result}")Note: Notice the inversion of control. The Agent is the configuration of how you want the LLM to operate. You then attach an LLM to an Agent to operationalize your intent. This allows you to define agents once, and easily switch LLMs or LLM providers.
We provide implementations for every pattern in Anthropic’s Building Effective Agents, as well as the OpenAI Swarm pattern.
By design, each model and provider-agnostic, and exposed as an AugmentedLLM, making everything very composable (e.g. use an Evaluator-Optimizer as an Orchestrator's planner).
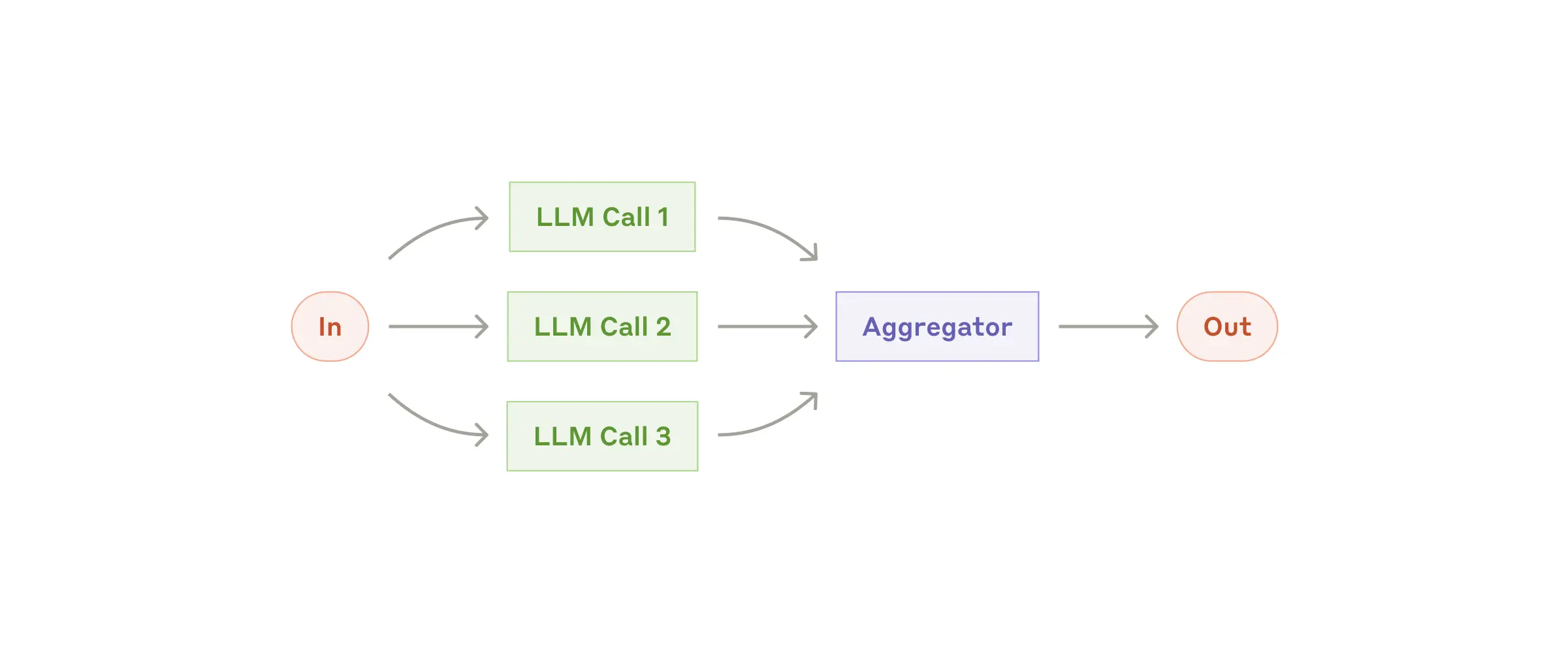
Fan-out tasks to multiple sub-agents and fan-in the results:
proofreader = Agent(name="proofreader", instruction="Review grammar...")
fact_checker = Agent(name="fact_checker", instruction="Check factual consistency...")
style_enforcer = Agent(name="style_enforcer", instruction="Enforce style guidelines...")
grader = Agent(name="grader", instruction="Combine feedback into a structured report.")
parallel = ParallelLLM(
fan_in_agent=grader,
fan_out_agents=[proofreader, fact_checker, style_enforcer],
llm_factory=OpenAIAugmentedLLM,
)
result = await parallel.generate_str("Student short story submission: ...", model="gpt-4o")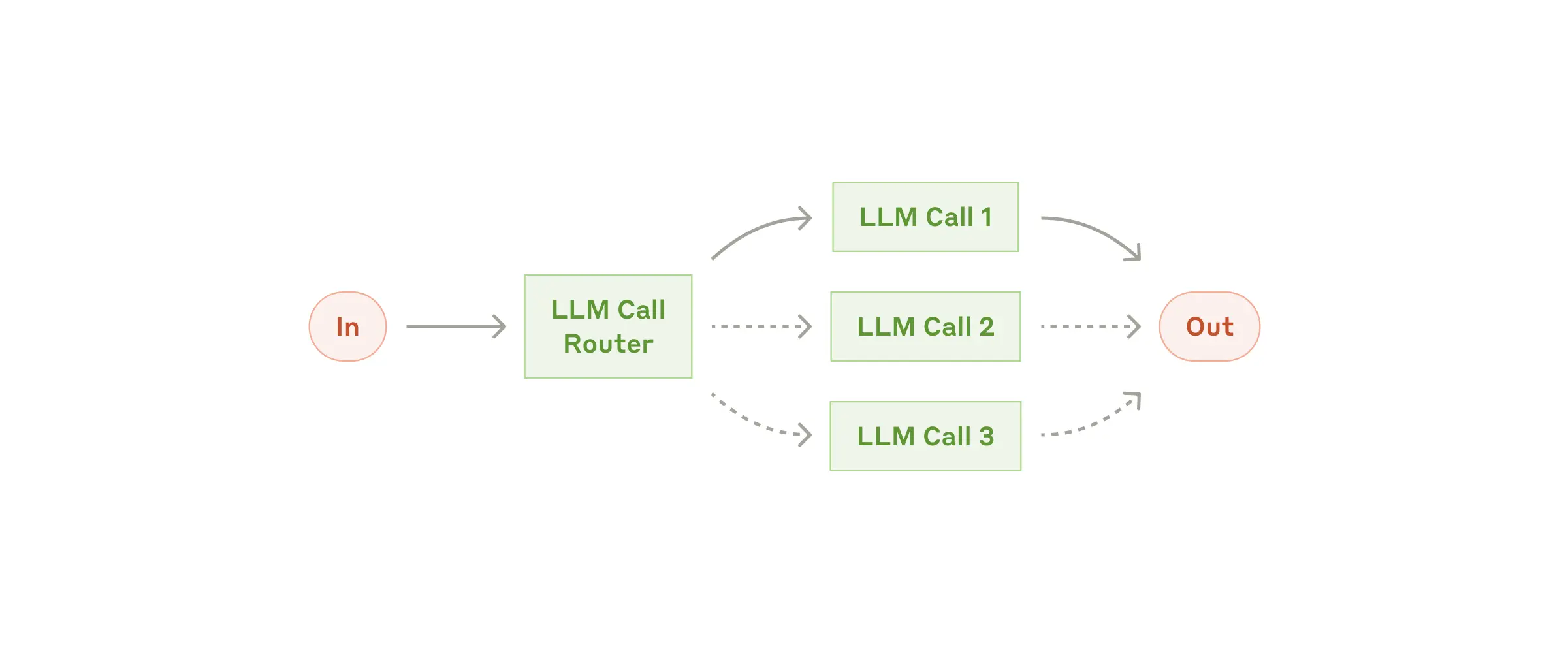
Given an input, route to the top_k most relevant categories. A category can be an Agent, a server or a regular function.
mcp-agent provides several router implementations, including:
EmbeddingRouter: uses embedding models for classificationLLMRouter: uses LLMs for classification
def print_hello_world:
print("Hello, world!")
finder_agent = Agent(name="finder", server_names=["fetch", "filesystem"])
writer_agent = Agent(name="writer", server_names=["filesystem"])
llm = OpenAIAugmentedLLM()
router = LLMRouter(
llm=llm,
agents=[finder_agent, writer_agent],
functions=[print_hello_world],
)
results = await router.route( # Also available: route_to_agent, route_to_server
request="Find and print the contents of README.md verbatim",
top_k=1
)
chosen_agent = results[0].result
async with chosen_agent:
...A close sibling of Router, the Intent Classifier pattern identifies the top_k Intents that most closely match a given input.
Just like a Router, mcp-agent provides both an embedding and LLM-based intent classifier.
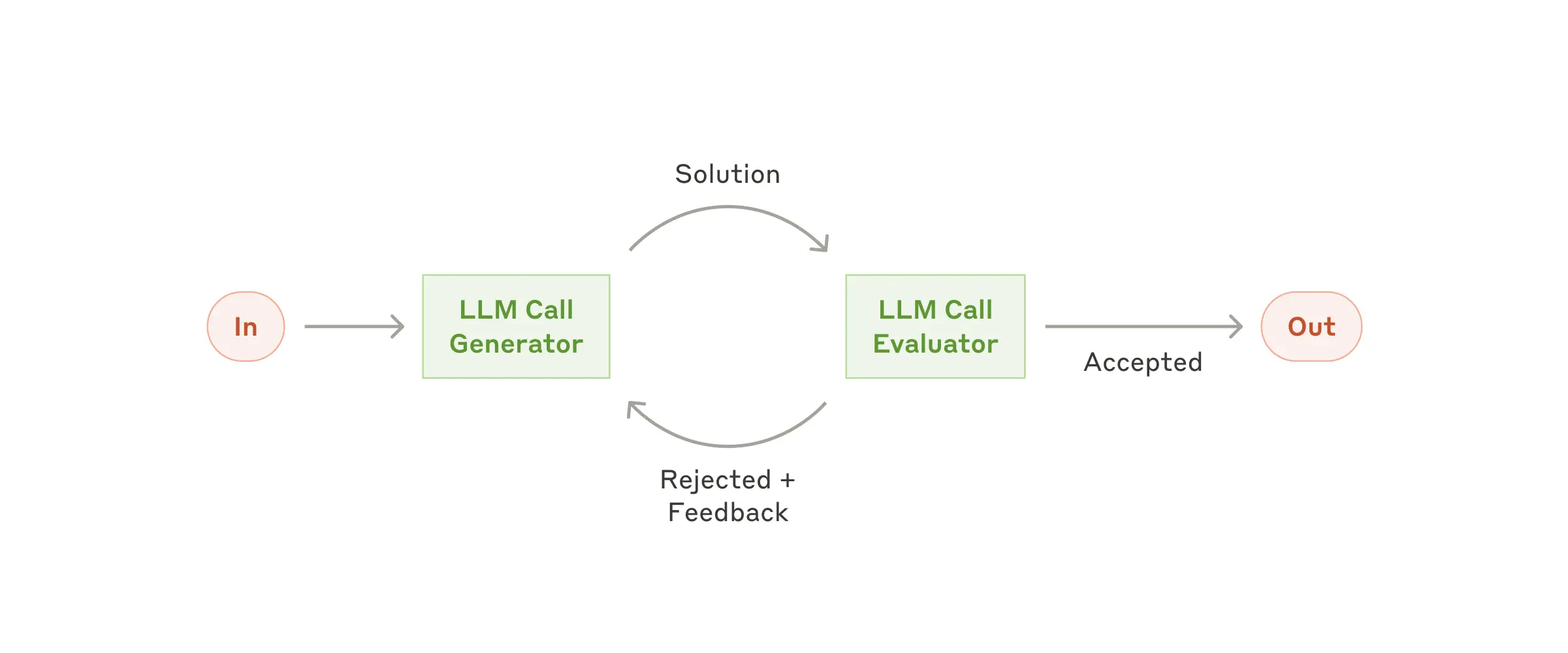
One LLM (the “optimizer”) refines a response, another (the “evaluator”) critiques it until we reach a threshold:
from mcp_agent.workflows.evaluator_optimizer.evaluator_optimizer import EvaluatorOptimizerLLM, QualityRating
optimizer = Agent(name="cover_letter_writer", server_names=["fetch"], instruction="Generate a cover letter ...")
evaluator = Agent(name="critiquer", instruction="Evaluate clarity, specificity, relevance...")
llm = EvaluatorOptimizerLLM(
optimizer=optimizer,
evaluator=evaluator,
llm_factory=OpenAIAugmentedLLM,
min_rating=QualityRating.EXCELLENT, # Keep iterating until the minimum quality bar is reached
)
result = await eo_llm.generate_str("Write a job cover letter for an AI framework developer role at LastMile AI.")
print("Final refined cover letter:", result)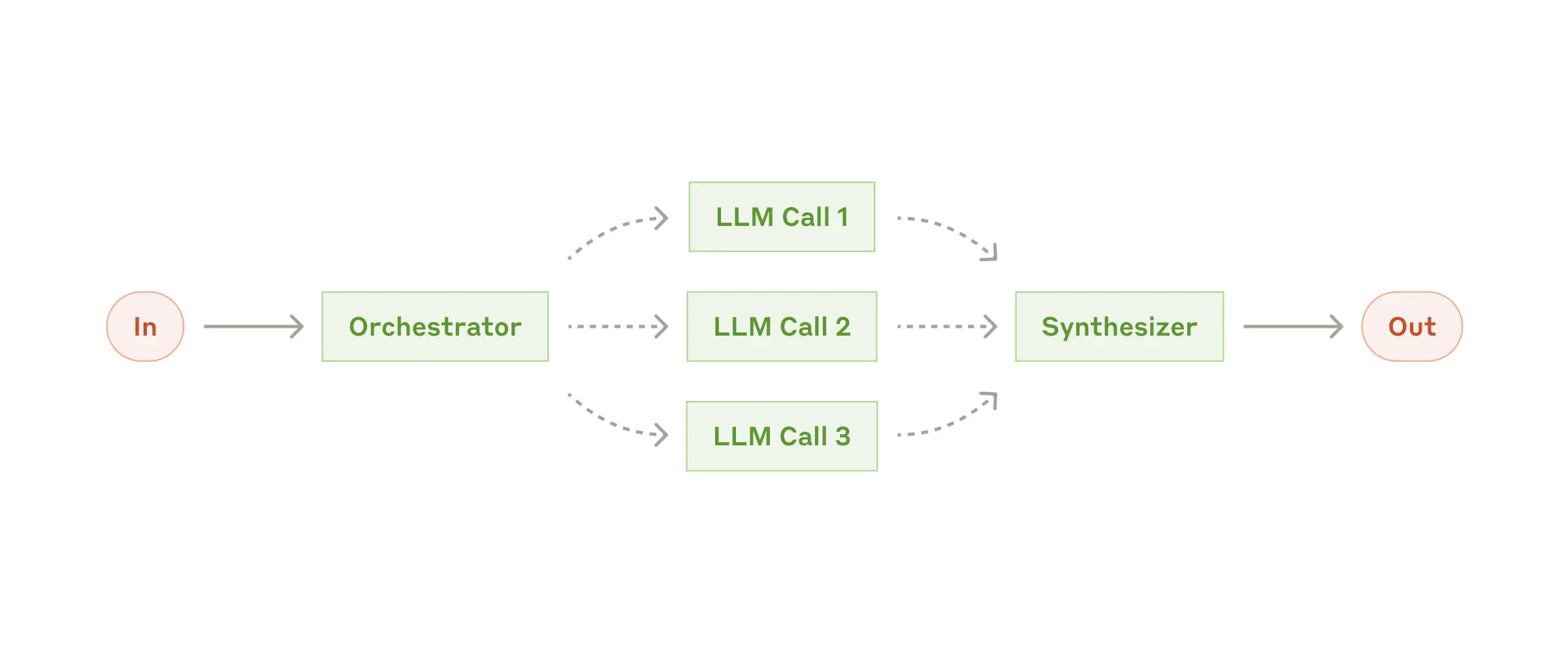
A higher-level LLM breaks tasks into steps, assigns them to sub-agents, and merges results. The Orchestrator workflow automatically parallelizes steps that can be done in parallel, and blocks on dependencies.
finder_agent = Agent(name="finder", server_names=["fetch", "filesystem"])
writer_agent = Agent(name="writer", server_names=["filesystem"])
proofreader = Agent(name="proofreader", ...)
fact_checker = Agent(name="fact_checker", ...)
style_enforcer = Agent(name="style_enforcer", instructions="Use APA style guide from ...", server_names=["fetch"])
orchestrator = Orchestrator(
llm_factory=AnthropicAugmentedLLM,
available_agents=[finder_agent, writer_agent, proofreader, fact_checker, style_enforcer],
plan_type="full", # Can also be "iterative", where the LLM thinks about the next set of parallel steps at a time.
)
task = "Load short_story.md, evaluate it, produce a graded_report.md with multiple feedback aspects."
result = await orchestrator.generate_str(task, model="gpt-4o")
print(result)OpenAI has an experimental multi-agent pattern called Swarm, which we provide a model-agnostic reference implementation for in mcp-agent.

The mcp-agent Swarm pattern works seamlessly with MCP servers, and is exposed as an AugmentedLLM, allowing for composability with other patterns above.
triage_agent = SwarmAgent(...)
flight_mod_agent = SwarmAgent(...)
lost_baggage_agent = SwarmAgent(...)
# The triage agent decides whether to route to flight_mod_agent or lost_baggage_agent
swarm = AnthropicSwarm(agent=triage_agent, context_variables={...})
test_input = "My bag was not delivered!"
result = await swarm.generate_str(test_input)
print("Result:", result)Signaling: The framework can pause/resume tasks (like in advanced Durable Execution modes). The agent or LLM might “signal” that it needs user input, so the workflow awaits. A developer may signal during a workflow to seek approval or review before continuing with a workflow.
Human Input: If an Agent has a human_input_callback, the LLM can call a __human_input__ tool to request user input mid-workflow.
The Swarm example shows this in action.
from mcp_agent.human_input.handler import console_input_callback
lost_baggage = SwarmAgent(
name="Lost baggage traversal",
instruction=lambda context_variables: f"""
{
FLY_AIR_AGENT_PROMPT.format(
customer_context=context_variables.get("customer_context", "None"),
flight_context=context_variables.get("flight_context", "None"),
)
}\n Lost baggage policy: policies/lost_baggage_policy.md""",
functions=[
escalate_to_agent,
initiate_baggage_search,
transfer_to_triage,
case_resolved,
],
server_names=["fetch", "filesystem"],
human_input_callback=console_input_callback, # Request input from the console
)You can configure global handlers on the application Context.
human_input_handler: Expose a handler for human input to AugmentedLLMs/Agents.signal_notification: Notification callback when a workflow is about to be blocked on a signal
By default, we use asyncio as the Executor. For advanced workflows, you can switch to Temporal (see src/mcp_agent/executor/temporal.py):
- Decorate tasks with @workflow_task
- Define a @workflow_run method for your workflow
- Let the system handle pause, resume, signals, concurrency, etc.
The key thing is separation of concerns. Your application code doesn't change, you simply pass a different Executor to change how the workflow is orchestrated.
There is support for distributed tracing, as well as basic logging via a logger interface.
Logger settings can be configured in mcp_agent.config.yaml.
Instead of using the standard Python logger, it is recommended to use the mcp-agent logger:
from mcp_agent.logging.logger import get_logger
logger = get_logger(__name__)This automatically integrates with distributed tracing (see @traced) as well as configuring custom transports (console, http, etc.).