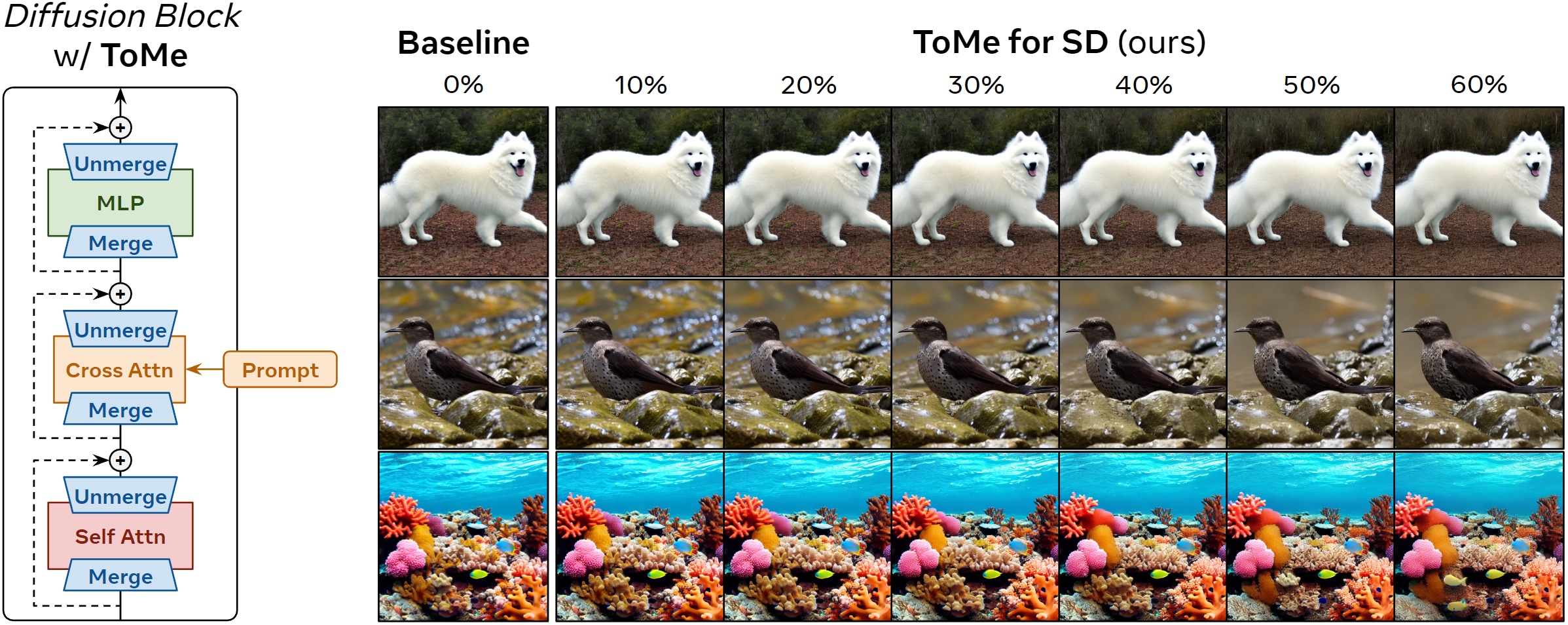
Token Merging for Fast Stable Diffusion 是一种 token 合并技术,它通过合并冗余的 token 从而可以减少 transformer 的计算量。该项技术可以应用到所有含有 transformer 结构的扩散模型中,比如:StableDiffusion、ControlNet 等模型。
ToMe for SD 生成的图像有着如下优势:
- 生成的结果能够接近原始图像;
- 生成速度提高了 2 倍;
- 即使合并了一半以上的token (60%),显存减少了约 5.7 倍。
Note: 下面是原作者repo中贴出的fid、时间和显存占用对比表。
| Method | r% | FID ↓ | Time (s/im) ↓ | Memory (GB/im) ↓ |
|---|---|---|---|---|
| Baseline (Original Model) | 0 | 33.12 | 3.09 | 3.41 |
| w/ ToMe for SD | 10 | 32.86 | 2.56 (1.21x faster) | 2.99 (1.14x less) |
| 20 | 32.86 | 2.29 (1.35x faster) | 2.17 (1.57x less) | |
| 30 | 32.80 | 2.06 (1.50x faster) | 1.71 (1.99x less) | |
| 40 | 32.87 | 1.85 (1.67x faster) | 1.26 (2.71x less) | |
| 50 | 33.02 | 1.65 (1.87x faster) | 0.89 (3.83x less) | |
| 60 | 33.37 | 1.52 (2.03x faster) | 0.60 (5.68x less) |
配置信息:
- GPU:4090
- 分辨率:512x512
- Scheduler:PLMS
- 精度:FP16
- 推理步数:50
- 数据集:ImageNet-1k
安装develop版本的ppdiffusers
pip install "ppdiffusers>=0.16.1"下面是 StableDiffusion + ToME 技术的例子
import paddle
from ppdiffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", safety_checker=None, paddle_dtype=paddle.float16)
# 我们可以开启 xformers
# pipe.enable_xformers_memory_efficient_attention()
# Apply ToMe with a 50% merging ratio
pipe.apply_tome(ratio=0.5) # Can also use pipe.unet in place of pipe here
generator = paddle.Generator().manual_seed(0)
image = pipe("a photo of an astronaut riding a horse on mars", generator=generator).images[0]
image.save("astronaut.png")下面是 ControlNet + ToME 技术的例子
import paddle
from ppdiffusers import ControlNetModel, StableDiffusionControlNetPipeline
from ppdiffusers.utils import load_image
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet, paddle_dtype=paddle.float16
)
# Apply ToMe with a 50% merging ratio
pipe.apply_tome(ratio=0.5) # Can also use pipe.unet in place of pipe here
# 我们可以开启 xformers
# pipe.enable_xformers_memory_efficient_attention()
generator = paddle.Generator().manual_seed(0)
prompt = "bird"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
)
image = pipe(prompt, image, generator=generator).images[0]
image.save("bird.png")测试代码参考自 huggingface/diffusers#2303
| Batch Size | Vanilla Attention | Vanilla Attention + TOME 0.5/0.749 | xFormers Cutlass + TOME 0.5/0.749 |
|---|---|---|---|
| 1 | 2.08 s | 2.15 s / 2.06 s | 1.99 s / 1.95 s |
| 10 | 14.15 s | 10.94 s / 10.04 s | 9.21 s / 8.87 s |
| 16 | 21.93 s | 16.73 s / 15.31 s | 13.98 s / 13.95 s |
| 32 | 42.93 s | 32.88 s / 29.48 s | 26.82 s / 29.08 s |
| 64 | OOM | 63.79 s / 58.21 s | 52.86 s / 50.8 s |
配置信息:
- GPU:A100
- 分辨率:512x512
- Scheduler:DPMSolverMultistepScheduler
- 精度:FP16
- 推理步数:50
If you use ToMe for SD or this codebase in your work, please cite:
@article{bolya2023tomesd,
title={Token Merging for Fast Stable Diffusion},
author={Bolya, Daniel and Hoffman, Judy},
journal={arXiv},
year={2023}
}
If you use ToMe in general please cite the original work:
@inproceedings{bolya2023tome,
title={Token Merging: Your {ViT} but Faster},
author={Bolya, Daniel and Fu, Cheng-Yang and Dai, Xiaoliang and Zhang, Peizhao and Feichtenhofer, Christoph and Hoffman, Judy},
booktitle={International Conference on Learning Representations},
year={2023}
}