![]()
Utilities for use with RxJava 2
Strings- create/manipulate streams ofString, conversions to and fromBytes- create/manipulate streams ofbyte[]StateMachine- a more expressive form ofscanthat can emit multiple events for each source eventonBackpressureBufferToFile- high throughput with memory-mapped filesFlowable TransformersObservable TransformersSerialized- tests pass on Linux, Windows 10, Solaris 10
- supports Java 1.8+
- requires rxjava 2.0.7+
Status: released to Maven Central
Maven site reports are here including javadoc.
Add this to your pom.xml:
<dependency>
<groupId>com.github.davidmoten</groupId>
<artifactId>rxjava2-extras</artifactId>
<version>VERSION_HERE</version>
</dependency>Or add this to your build.gradle:
repositories {
mavenCentral()
}
dependencies {
compile 'com.github.davidmoten:rxjava2-extras:VERSION_HERE'
}To use rxjava2-extras on Android you need these proguard rules.
- Primary target type is
Flowable(the backpressure supporting stream) - Operators will be implemented initially without fusion support (later)
- Where applicable
Single,MaybeandCompletablewill be used - To cross types (say from
FlowabletoMaybe) it is necessary to usetorather thancompose - Transformers (for use with
composeandto) are clustered within the primary owning class rather than bunched together in theTransformersclass. For example,Strings.join:
//produces a stream of "ab"
Maybe<String> o = Flowable
.just("a","b")
.to(Strings.join()); concat, join
decode
from(Reader),from(InputStream),from(File), ..
fromClasspath(String, Charset), ..
split(String), split(Pattern)
splitSimple(String)
toInputStream
trim
strings
splitLinesSkipComments
collect
from(InputStream), from(File)
unzip(File), unzip(InputStream)
Builder for .retryWhen()
serverSocket(port)
repeat
buffer with size and timeout
blockUntilWorkFinished
withThreadId
withThreadIdFromCallSite
fromNullable
doNothing
setToTrue
throwing
constant
throwing
alwaysTrue
alwaysFalse
throwing
constant
throwing
addLongTo
addTo
assertBytesEquals
close
decrement
doNothing
increment
printStackTrace
println
set
setToTrue
constant
identity
throwing
alwaysFalse
alwaysTrue
To buffer on maximum size and time since last source emission:
flowable.compose(
Transformers.buffer(maxSize, 10, TimeUnit.SECONDS));You can also make the timeout dependent on the last emission:
flowable.compose(
Transformers.buffer(maxSize, x -> timeout(x), TimeUnit.SECONDS));Accumulate statistics, emitting the accumulated results with each item.

Behaves as per toListWhile but allows control over the data structure used.

This operator supports request-one micro-fusion.
Performs an action only if a stream completes without emitting an item.
![]()
flowable.compose(
Transformers.doOnEmpty(action));This is a Flowable creation method that is aimed at supporting calls to a service that provides data in pages where the page sizes are determined by requests from downstream (requests are a part of the backpressure machinery of RxJava).

Here's an example.
Suppose you have a stateless web service, say a rest service that returns JSON/XML and supplies you with
- the most popular movies of the last 24 hours sorted by descending popularity
The service supports paging in that you can pass it a start number and a page size and it will return just that slice from the list.
Now I want to give a library with a Flowable definition of this service to my colleagues that they can call in their applications whatever they may be. For example,
- Fred may just want to know the most popular movie each day,
- Greta wants to get the top 20 and then have the ability to keep scrolling down the list in her UI.
Let's see how we can efficiently support those use cases. I'm going to assume that the movie data returned by the service are mapped conveniently to objects by whatever framework I'm using (JAXB, Jersey, etc.). The fetch method looks like this:
// note that start is 0-based
List<Movie> mostPopularMovies(int start, int size);Now I'm going to wrap this synchronous call as a Flowable to give to my colleagues:
Flowable<Movie> mostPopularMovies(int start) {
return Flowables.fetchPagesByRequest(
(position, n) -> Flowable.fromIterable(mostPopular(position, n)),
start)
// rebatch requests so that they are always between
// 5 and 100 except for the first request
.compose(Transformers.rebatchRequests(5, 100, false));
}
Flowable<Movie> mostPopularMovies() {
return mostPopularMovies(0);
}Note particularly that the method above uses a variant of rebatchRequests to limit both minimum and maximum requests. We particularly don't want to allow a single call requesting the top 100,000 popular movies because of the memory and network pressures that arise from that call.
Righto, Fred now uses the new API like this:
Movie top = mostPopularMovies()
.compose(Transformers.maxRequest(1))
.first()
.blockingFirst();The use of maxRequest above may seem unnecessary but strangely enough the first operator requests Long.MAX_VALUE of upstream and cancels as soon as one arrives. The take, elemnentAt and firstXXX operators all have this counter-intuitive characteristic.
Greta uses the new API like this:
mostPopularMovies()
.rebatchRequests(20)
.doOnNext(movie -> addToUI(movie))
.subscribe(subscriber);A bit more detail about fetchPagesByRequest:
- if the
fetchfunction returns aFlowablethat delivers fewer than the requested number of items then the overall stream completes.
Inserts zero or one items into a stream if the given Maybe succeeds before the next source emission.
Example:
Flowable
.interval(1, TimeUnit.SECONDS)
.compose(Transformers.insert(
Maybe.just(-1L).delay(500, TimeUnit.MILLISECONDS)))
.forEach(System.out::println);produces (with 500ms intervals between every emission):
0
-1
1
-1
2
-1
3
-1
4
-1
...
Modifies the last element of the stream via a defined Function.

Example:
Flowable
.just(1, 2, 3)
.compose(Transformers.mapLast(x -> x + 1))
.forEach(System.out::println);produces
1
2
4
Finds out-of-order matches in two streams.

You can use FlowableTranformers.matchWith or Flowables.match:
Flowable<Integer> a = Flowable.just(1, 2, 4, 3);
Flowable<Integer> b = Flowable.just(1, 2, 3, 5, 6, 4);
Flowables.match(a, b,
x -> x, // key to match on for a
x -> x, // key to match on for b
(x, y) -> x // combiner
)
.forEach(System.out::println);gives
1
2
3
4
Don't rely on the output order!
Under the covers elements are requested from a and b in alternating batches of 128 by default. The batch size is configurable in another overload.
Limits upstream requests.

- may allow requests less than the maximum
- serializes requests
- does not buffer items
- requests at start and just before emission of last item in current batch
flowable
.compose(Transformers.maxRequest(100));To constrain some requests then no constraint:
flowable
.compose(Transformers.maxRequest(100, 256, 256, 256, Long.MAX_VALUE);See also: minRequest, rebatchRequests

When you use Flowable.merge on synchronous sources the sources are completely consumed serially. As a consequence if you want to merge two infinite sources synchronously then you only get the first source and the second source is never read.
Flowables.mergeInterleaved round-robins the requests to the window of current publishers (up to maxConcurrent) so that two or more infinite streams can be merged without resorting to apply asynchronicity via an asynchronous scheduler.
There is a sacrifice made in that the operator is less performant than merging asynchronous streams because only one stream is requested from at a time. In addition the operator does not include micro- and macro-fusion optimisations.
Ensures requests are at least the given value(s).

- serializes requests
- may buffer items
- requests at start and just after emission of last item in current batch
flowable
.compose(Transformers.minRequest(10));To allow the first request through unconstrained:
flowable
.compose(Transformers.minRequest(1, 10));See also: maxRequest, rebatchRequests
With this operator you can offload a stream's emissions to disk to reduce memory pressure when you have a fast producer + slow consumer (or just to minimize memory usage).

If you have used the onBackpressureBuffer operator you'll know that when a stream is producing faster than the downstream operators can process (perhaps the producer cannot respond meaningfully to a slow down request from downstream) then onBackpressureBuffer buffers the items to an in-memory queue until they can be processed. Of course if memory is limited then some streams might eventually cause an OutOfMemoryError. One solution to this problem is to increase the effectively available memory for buffering by using off-heap memory and disk instead. That's why onBackpressureBufferToFile was created.
rxjava-extras uses standard file io to buffer serialized stream items. This operator can still be used with RxJava2 using the RxJava2Interop library.
rxjava2-extras uses fixed size memory-mapped files to perform the same operation but with much greater throughput.
Note that new files for a file buffered observable are created for each subscription and those files are in normal circumstances deleted on cancellation (triggered by onCompleted/onError termination or manual cancellation).
Here's an example:
// write the source strings to a
// disk-backed queue on the subscription
// thread and emit the items read from
// the queue on the io() scheduler.
Flowable<String> flowable =
Flowable
.just("a", "b", "c")
.compose(
Transformers
.onBackpressureBufferToFile()
.serializerUtf8())You can also use an Observable source (without converting to Flowable with toFlowable):
Flowable<String> flowable =
Observable
.just("a", "b", "c")
.to(
ObservableTransformers
.onBackpressureBufferToFile()
.serializerUtf8())Note that to is used above to cross types (Observable to Flowable).
This example does the same as above but more concisely and uses standard java IO serialization (normally it will be more efficient to write your own DataSerializer):
Flowable<String> flowable =
Flowable
.just("a", "b", "c")
.compose(Transformers
.<String>onBackpressureBufferToFile());An example with a custom serializer:
// define how the items in the source stream would be serialized
DataSerializer<String> serializer = new DataSerializer<String>() {
@Override
public void serialize(String s, DataOutput out) throws IOException {
output.writeUTF(s);
}
@Override
public String deserialize(DataInput in) throws IOException {
return input.readUTF();
}
@Override
public int sizeHint() {
// exact size unknown
return 0;
}
};
Flowable
.just("a", "b", "c")
.compose(
Transformers
.onBackpressureBufferToFile()
.serializer(serializer));
...You can configure various options:
Flowable
.just("a", "b", "c")
.compose(
Transformers
.onBackpressureBufferToFile()
.scheduler(Schedulers.computation())
.fileFactory(fileFactory)
.pageSizeBytes(1024)
.serializer(serializer));
....fileFactory(Func0<File>) specifies the method used to create the temporary files used by the queue storage mechanism. The default is a factory that calls Files.createTempFile("bufferToFile", ".obj").
There are some inbuilt DataSerializer implementations:
DataSerializers.utf8()DataSerializers.string(Charset)DataSerializers.bytes()DataSerializers.javaIO()- uses standard java serialization (ObjectOutputStreamand such)
Using default java serialization you can buffer array lists of integers to a file like so:
Flowable.just(1, 2, 3, 4)
//accumulate into sublists of length 2
.buffer(2)
.compose(Transformers
.<List<Integer>>onBackpressureBufferToFile()
.serializerJavaIO())In the above example it's fortunate that .buffer emits ArrayList<Integer> instances which are serializable. To be strict you might want to .map the returned list to a data type you know is serializable:
Flowable.just(1, 2, 3, 4)
.buffer(2)
.map(list -> new ArrayList<Integer>(list))
.compose(
Transformers
.<List<Integer>>onBackpressureBufferToFile()
.serializerJavaIO())Usual queue drain practices are in place but the queue this time is based on memory-mapped file storage. The memory-mapped queue borrows tricks used by Aeron. In particular:
- every byte array message is preceded by a header
message length in bytes (int, 4 bytes)
message type (1 byte) (0 or 1 for FULL_MESSAGE or FRAGMENT)
padding length in bytes (1 byte)
zeroes according to padding length
- high read/write throughput is achieved via minimal use of
Unsafevolatile puts and gets.
When a message is placed on the memory-mapped file based queue:
- The header and message bytes above are appended at the current write position in the file but the message length is written as zero (or in our case not written at all because the value defaults to zero).
- Only once all the message bytes are written is message length given its actual value (and this is done using
Unsafe.putOrderedInt). - When a read is attempted the length field is read using
Unsafe.getIntVolatileand if zero we do nothing (until the next read attempt).
Cancellation complicates things somewhat because pulling the plug suddenly on Unsafe memory mapped files means crashing the JVM with a sigsev fault. To reduce contention with cancellation checks, resource disposal is processed by the queue drain method (reads) and writes to the queue are serialized with cancellation via CAS semantics.
TODO Describe fragmentation handling.
Throughput is increased dramatically by using memory-mapped files.
rxjava2-extras can push through 800MB/s using 1K messages compared to rxjava-extras 43MB/s (2011 i7-920 @2.67GHz). My 2016 2 core i5 HP Spectre laptop with SSD pushes through up to 1.5GB/s for 1K messages.
Smaller messages mean more contention but still on my laptop I am seeing 6 million 40B messages per second.
To do long-running perf tests (haven't set up jmh for this one yet) do this:
mvn test -Dn=500000000Constrains requests to a range of values (rebatches).

rebatchRequests is the composition of the operators minRequest and maxRequest.
Example:
flowable
.compose(Transformers.rebatchRequests(5, 100));Allow the first request to be unconstrained by the minimum:
flowable
.compose(Transformers.rebatchRequests(5, 100, false));See also: minRequest, maxRequest
If a stream has elements and completes then the last element is repeated.

flowable.compose(
Transformers.repeatLast());A common use case for .retry() is some sequence of actions that are attempted and then after a delay a retry is attempted. RxJava does not provide
first class support for this use case but the building blocks are there with the .retryWhen() method. RetryWhen offers static methods that build a Function for use with Flowable.retryWhen().
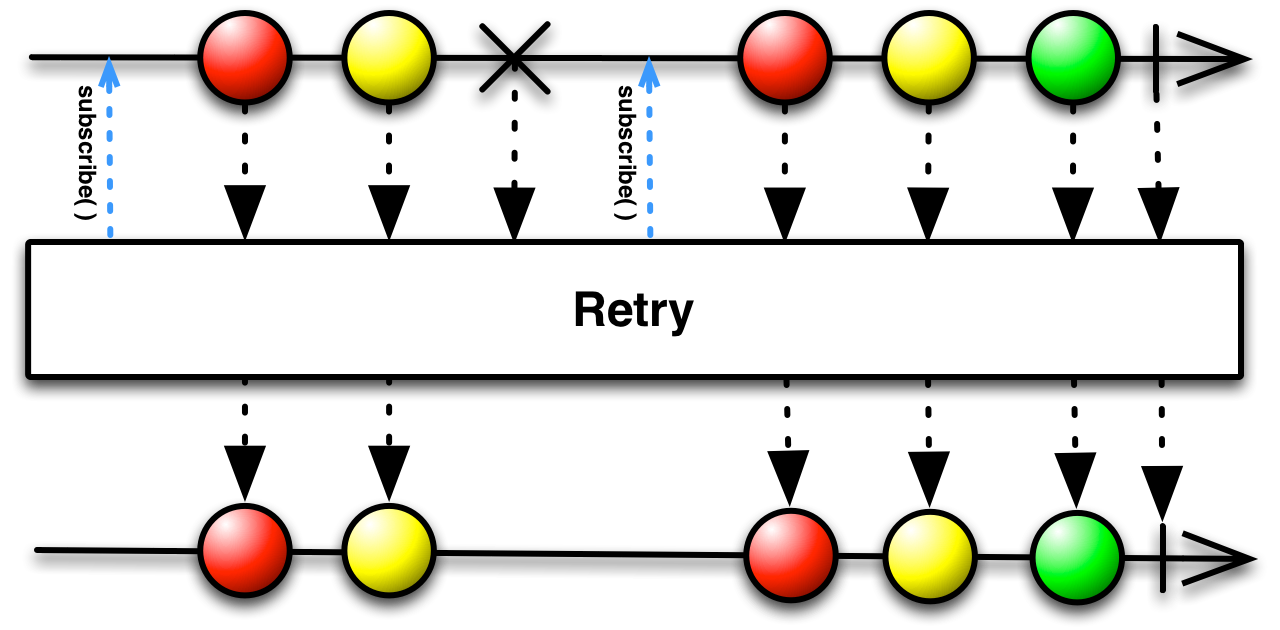
flowable.retryWhen(
RetryWhen.delay(10, TimeUnit.SECONDS).build());flowable.retryWhen(
RetryWhen.delay(10, TimeUnit.SECONDS)
.maxRetries(10).build());//the length of waits determines number of retries
Flowable<Long> delays = Flowable.just(10L,20L,30L,30L,30L);
flowable.retryWhen(
RetryWhen.delays(delays, TimeUnit.SECONDS).build());flowable.retryWhen(
RetryWhen.retryWhenInstanceOf(IOException.class)
.build());Reverses the order of emissions of a stream. Does not emit till source completes.

flowable.compose(
Transformers.reverse());Custom operators are difficult things to get right in RxJava mainly because of the complexity of supporting backpressure efficiently. Transformers.stateMachine enables a custom operator implementation when:
- each source emission is mapped to 0 to many emissions (of a different type perhaps) to downstream but those emissions are calculated based on accumulated state

An example of such a transformation might be from a list of temperatures you only want to emit sequential values that are less than zero but are part of a sub-zero sequence at least 1 hour in duration. You could use toListWhile above (when migrated!) but Transformers.stateMachine offers the additional efficiency that it will immediately emit temperatures as soon as the duration criterion is met.
To implement this example, suppose the source is half-hourly temperature measurements:
static class State {
final List<Double> list;
final boolean reachedThreshold;
State(List<Double> list, boolean reachedThreshold) {
this.list = list;
this.reachedThreshold = reachedThreshold;
}
}
int MIN_SEQUENCE_LENGTH = 2;
FlowableTransformer<Double, Double> trans = Transformers
.stateMachine()
.initialStateFactory(() -> new State(new ArrayList<>(), false))
.<Double, Double> transition((state, t, subscriber) -> {
if (t < 0) {
if (state.reachedThreshold) {
if (subscriber.isUnsubscribed()) {
return null;
}
subscriber.onNext(t);
return state;
} else if (state.list.size() == MIN_SEQUENCE_LENGTH - 1) {
for (Double temperature : state.list) {
if (subscriber.isUnsubscribed()) {
return null;
}
subscriber.onNext(temperature);
}
return new State(null, true);
} else {
List<Double> list = new ArrayList<>(state.list);
list.add(t);
return new State(list, false);
}
} else {
return new State(new ArrayList<>(), false);
}
}).build();
Flowable
.just(10.4, 5.0, 2.0, -1.0, -2.0, -5.0, -1.0, 2.0, 5.0, 6.0)
.compose(trans)
.forEach(System.out::println);To read serialized objects from a file:
Flowable<Item> items = Serialized.read(file);To write a Flowable to a file:
Serialized.write(flowable, file).subscribe();Serialized also has support for the very fast serialization library kryo. Unlike standard Java serialization Kryo can also serialize/deserialize objects that don't implement Serializable.
Add this to your pom.xml:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.0</version>
</dependency>For example,
To read:
Flowable<Item> items = Serialized.kryo().read(file);To write:
Flowable.write(flowable, file).subscribe();You can also call Serialized.kryo(kryo) to use an instance of Kryo that you have configured specially.
You may want to group emissions from a Flowable into lists of variable size. This can be achieved safely using toListWhile.

As an example from a sequence of temperatures lets group the sub-zero and zero or above temperatures into contiguous lists:
Flowable.just(10, 5, 2, -1, -2, -5, -1, 2, 5, 6)
.compose(Transformers.toListWhile(
(list, t) -> list.isEmpty()
|| Math.signum(list.get(0)) < 0 && Math.signum(t) < 0
|| Math.signum(list.get(0)) >= 0 && Math.signum(t) >= 0)
.forEach(System.out::println);produces
[10, 5, 2]
[-1, -2, -5, -1]
[2, 5, 6]
See also collectWhile. This operator supports request-one micro-fusion.
Sliding window minimum/maximum:

Flowable.just(3, 2, 5, 1, 6, 4)
.compose(Transformers.<Integer>windowMin(3))