RCU is getting more popular in recent kernel version because it improve performance significantly if you use it correctly. Let us check what it is and how it is implemented.
Basically RCU makes one write-thread and many read-thread run concurrently. rwlock is similar to run many read-thread run at the same time but rwlock cannot run write-thread and read-thread at the same time. Of course, it would be best to have something being enable to run many write-thread and many read-thread but it does not exist at the moment. The best solution we have now is RCU to run one write-thread and many read-thread.
Unfortunately there are some constrains:
- read-thread cannot read the latest data that the write-thread just has written.
- write-thread waits for all read-lock to be unlocked.
- Only one write-thread can run when many read-thread are running. You must use spinlock to synchronize data for many write-thread.
References
- http://www2.rdrop.com/users/paulmck/RCU/
- http://www.cs.nyu.edu/~lerner/spring11/proj_rcu.pdf
- http://www.slideshare.net/vh21/yet-another-introduction-of-linux-rcu
For example, let us review how mybrd uses RCU.
Let us start with the simplest example. mybrd_lookup_page uses rcu_read_lock when it finds a page including the target sector.
static struct page *mybrd_lookup_page(struct mybrd_device *mybrd,
sector_t sector)
{
pgoff_t idx;
struct page *p;
rcu_read_lock(); // why rcu-read-lock?
// 9 = SECTOR_SHIFT
idx = sector >> (PAGE_SHIFT - 9);
p = radix_tree_lookup(&mybrd->mybrd_pages, idx);
rcu_read_unlock();
pr_warn("lookup: page-%p index-%d sector-%d\n",
p, p ? (int)p->index : -1, (int)sector);
return p;
}
As you can see with the name of the function, rcu_read_lock, you can call rcu_read_lock before reading a resource. It looks a little bit weird. So far locking is usually for preventing other threads from accessing the resource and makeing only one thread access the resource. How does the rcu_read_lock make many read-thread access the resource at the same time and?
Let us check the source code in kernel version 2.6.11. It would be the simplest implementation of RCU because RCU was just merged into the kernel.
/**
* rcu_read_lock - mark the beginning of an RCU read-side critical section.
*
* When synchronize_kernel() is invoked on one CPU while other CPUs
* are within RCU read-side critical sections, then the
* synchronize_kernel() is guaranteed to block until after all the other
* CPUs exit their critical sections. Similarly, if call_rcu() is invoked
* on one CPU while other CPUs are within RCU read-side critical
* sections, invocation of the corresponding RCU callback is deferred
* until after the all the other CPUs exit their critical sections.
*
* Note, however, that RCU callbacks are permitted to run concurrently
* with RCU read-side critical sections. One way that this can happen
* is via the following sequence of events: (1) CPU 0 enters an RCU
* read-side critical section, (2) CPU 1 invokes call_rcu() to register
* an RCU callback, (3) CPU 0 exits the RCU read-side critical section,
* (4) CPU 2 enters a RCU read-side critical section, (5) the RCU
* callback is invoked. This is legal, because the RCU read-side critical
* section that was running concurrently with the call_rcu() (and which
* therefore might be referencing something that the corresponding RCU
* callback would free up) has completed before the corresponding
* RCU callback is invoked.
*
* RCU read-side critical sections may be nested. Any deferred actions
* will be deferred until the outermost RCU read-side critical section
* completes.
*
* It is illegal to block while in an RCU read-side critical section.
*/
#define rcu_read_lock() preempt_disable()
/**
* rcu_read_unlock - marks the end of an RCU read-side critical section.
*
* See rcu_read_lock() for more information.
*/
#define rcu_read_unlock() preempt_enable()
So simple. It only enables/disables preemption. If one thread reads a resource, other threads on other CPUs also can read the resource. But any threads on the same CPU cannot read the resource.
Now let us check the implementation of kernel version 4.4.x. It becames more complicated but let us assume that we enable CONFIG_TREE_RCU and disable CONFIG_PREEMPT_RCU as arch/x86/configs/x86_64_defconfig sets. If we remove code for debugging and disabled options, it would be like following code.
static inline void rcu_read_lock(void)
{
__rcu_read_lock();
__acquire(RCU);
rcu_lock_acquire(&rcu_lock_map);
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_lock() used illegally while idle");
}
static inline void rcu_read_unlock(void)
{
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_unlock() used illegally while idle");
__release(RCU);
__rcu_read_unlock();
rcu_lock_release(&rcu_lock_map); /* Keep acq info for rls diags. */
}
static inline void __rcu_read_lock(void)
{
if (IS_ENABLED(CONFIG_PREEMPT_COUNT))
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
if (IS_ENABLED(CONFIG_PREEMPT_COUNT))
preempt_enable();
}
# define __acquire(x) (void)0
# define __release(x) (void)0
# define rcu_lock_acquire(a) do { } while (0)
# define rcu_lock_release(a) do { } while (0)
After removing extra code, only preempt_disable/enable remain.
Let us see how mybrd_insert_page function inserts a page into the radix tree with radix_tree_insert function. Please note which lock it uses.
static struct page *mybrd_insert_page(struct mybrd_device *mybrd,
sector_t sector)
{
pgoff_t idx;
struct page *p;
gfp_t gfp_flags;
p = mybrd_lookup_page(mybrd, sector);
if (p)
return p;
// must use _NOIO
gfp_flags = GFP_NOIO | __GFP_ZERO;
p = alloc_page(gfp_flags);
if (!p)
return NULL;
if (radix_tree_preload(GFP_NOIO)) {
__free_page(p);
return NULL;
}
// According to radix tree API document,
// radix_tree_lookup() requires rcu_read_lock(),
// but user must ensure the sync of calls to radix_tree_insert().
spin_lock(&mybrd->mybrd_lock);
// #sector -> #page
// one page can store 8-sectors
idx = sector >> (PAGE_SHIFT - 9);
p->index = idx;
if (radix_tree_insert(&mybrd->mybrd_pages, idx, p)) {
__free_page(p);
p = radix_tree_lookup(&mybrd->mybrd_pages, idx);
pr_warn("failed to insert page: duplicated=%d\n",
(int)idx);
} else {
pr_warn("insert: page-%p index=%d sector-%d\n",
p, (int)idx, (int)sector);
}
spin_unlock(&mybrd->mybrd_lock);
radix_tree_preload_end();
return p;
}
It uses spinlock to add a page into the radix tree. You must use spinlock to write data protected by RCU but there is no lock in code reading data. Therefore many threads can read data concurrently but only one thread can write data.
For your information, radix_tree_preload prepares some per-cpu data which will be uses when adding new node into the radix tree. preempt_disable/enable are enought to protect per-cpu data. That is why radix_tree_preload/end are necessary along with spinlock.
Actually radix-tree is not a good example for RCU because radix-tree functions are wrapping and hiding some code to show how to use RCU. The first module in the kernel applying RCU is the linked list. The linked list is so common in the kernel so that it gained big performance improvement after applying RCU. And code is simple and good to show how to use RCU.
With RCU, many read-thread can run in parallel. But write-thread calling list_add_rcu or list_del_rcu must access the list after locking with spinlock or mutexlock.
The most common function to read the linked list is list_for_each_entry. There is a RCU version of it: list_for_each_entry_rcu. It reads the list so that there could be many threads reading the lisk.
Let us see the code of RCU list in include/linux/rculist.h
static inline void INIT_LIST_HEAD_RCU(struct list_head *list)
{
WRITE_ONCE(list->next, list);
WRITE_ONCE(list->prev, list);
}
#define list_next_rcu(list) (*((struct list_head __rcu **)(&(list)->next)))
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new);
next->prev = new;
}
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
#define list_entry_rcu(ptr, type, member) \
container_of(lockless_dereference(ptr), type, member)
#define lockless_dereference(p) \
({ \
typeof(p) _________p1 = READ_ONCE(p); \
smp_read_barrier_depends(); /* Dependency order vs. p above. */ \
(_________p1); \
})
#define list_for_each_entry_rcu(pos, head, member) \
for (pos = list_entry_rcu((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry_rcu(pos->member.next, typeof(*pos), member))
#define rcu_assign_pointer(p, v) \
do { \
uintptr_t _r_a_p__v = (uintptr_t)(v); \
rcu_check_sparse(p, __rcu); \
\
if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) \
WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); \
else \
smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); \
} while (0)
There is a rcu version of INIT_LIST_HEAD: INIT_LIST_HEAD_RCU.
list_next_rcu is actually the same to list_next except __rcu attribute for compiler.
That is for sparse tool which does static analysis of kernel code and does nothing in runtime.
Let us ignore it at the moment.
First let us check list_add which directly call __list_add.
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
The first line set next->prev pointer to the new node. Let us assume that there is no lock, and one thread just sets next->prev to new while another thread is reading the list reversely, The second thread reads next->prev and new->prev. Reading new->prev would generate kernel panic because next->prev is not initialized yet.
Let us check how list_add_rcu is different.
list_add_rcu directly calls __list_add_rcu that is doing:
- initialize new node
- smp_store_release is a combination of smp_bm and WRITE_ONDE.
- insert memory barrier smp_mb to prevent re-ordering of new node setting and reading: reading new node is always executed after setting
- WRITE_ONCE(prev->next, new)
- If a thread was reading the list in order and accessing prev node, now it can access new node.
- The memory barrier guarantees that new node is always initialized correctly and has next and prev pointers.
- WRITE_ONCE macro forces compiler to write memory atomically.
- next->prev = new
- If a thread was reading the list in reverse order and accessing next node, it can access new node now.
- No smp_mb between
new->prev = prevandprev->next = new. It does not matter if two lines are done reversely.
It is not easy to understand at first. It could be good to draw some picture for each step and check how two threads reading in order and reverse order can read the list correctly. You need to understand the magic of the memory barrier and WRITE_ONCE macro which is just a volatile memory access of C language.
list_del_rcu is actually the same to list_del. list_del_rcu is implemented to make a pair of list_add_rcu.
* Note that the caller is not permitted to immediately free
* the newly deleted entry. Instead, either synchronize_rcu()
* or call_rcu() must be used to defer freeing until an RCU
* grace period has elapsed.
*/
static inline void list_del_rcu(struct list_head *entry)
{
__list_del_entry(entry);
entry->prev = LIST_POISON2;
}
But you must notice that there is something you must remember. As you see in the comment, you should not free the memory of removed node immediately after removing with list_del_rcu. The memory can be freed after calling synchronize_rcu or call_rcu.
Below is an example to show how to use list_del_rcu.
static void thin_dtr(struct dm_target *ti)
{
struct thin_c *tc = ti->private;
unsigned long flags;
spin_lock_irqsave(&tc->pool->lock, flags);
list_del_rcu(&tc->list);
spin_unlock_irqrestore(&tc->pool->lock, flags);
synchronize_rcu();
thin_put(tc);
wait_for_completion(&tc->can_destroy);
It gets lock and deletes a RCU-list node, and then calls synchronize_rcu before freeing memory of the deleted node. The thin_put function frees the memory of tc object.
RCU version of list_entry is list_entry_rcu. It reads a pointer of the node with memory barrier and READ_ONCE macro that are wrapped by lockless_dereference macro. Finally list_for_each_entry_rcu is implemented with list_entry_rcu.
You can see "grace period" in the comment of list_del_rcu. As below picture shows, the grace period is a time that there are some threads reading the RCU-protected object and a thread wanting to free the object waits all reading threads finish.
For example, thread-A calls list_del_rcu and move one node out of the list while some threads are traversing the list. Some reading thread are accessing the moved node but it is ok because the removed node is not freed. When all reading threads calls rcu_read_unlock the grace period ends and then thread-A can continue to free the removed node because no thread access the removed list. Some reading threads can start traversing the list after synchronize_rcu call of thread-A but it is ok because they will follow the changed list. So the grace period does not wait for the new reading threads arrived after synchronize_rcu.
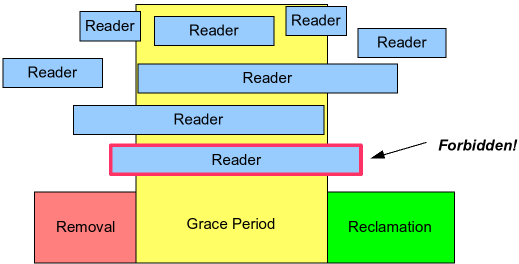
How does the synchronize_rcu detect all reading threads on other CPUs finish?
In kernl v2.6, rcu_read_unlock is enabling preemption so that there should be context-switching between processes or kernel lever and user level. RCU module registers a per-cpu tasklet executed by the context-switching. Each tasklet of each CPU marks that there is a context-switching of the CPU. When all CPUs execute the context-switching it means the grace period ends and it wakes up the thread calling synchronize_rcu.
Latest kernel versions have different and complicated RCU implementation. Kernel 2.6 has the simplest implementation of the RCU. You can start with kernel 2.6 to understand the implementation of the RCU.
Reference