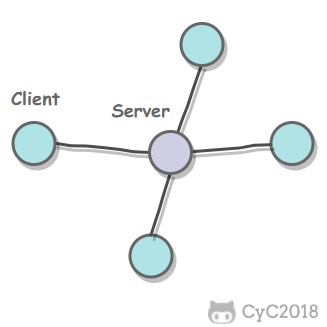
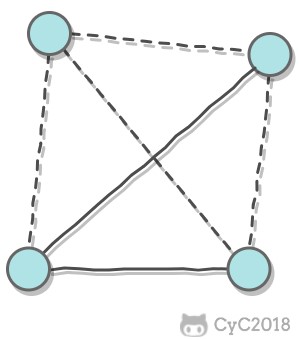
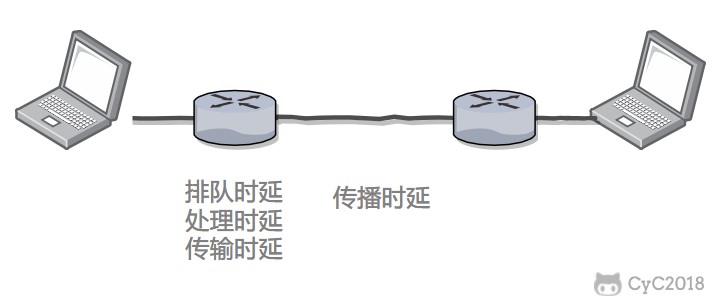
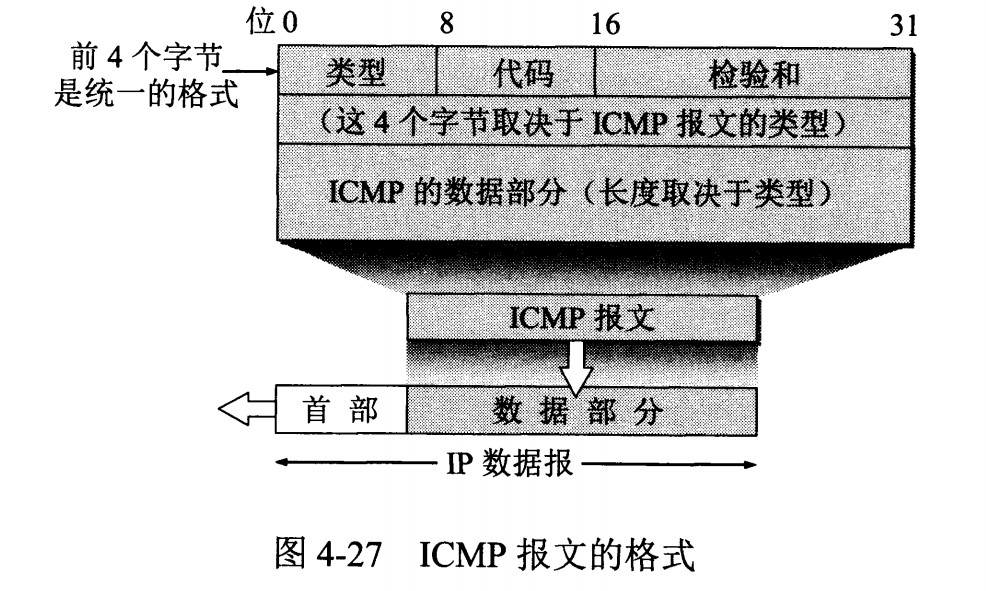
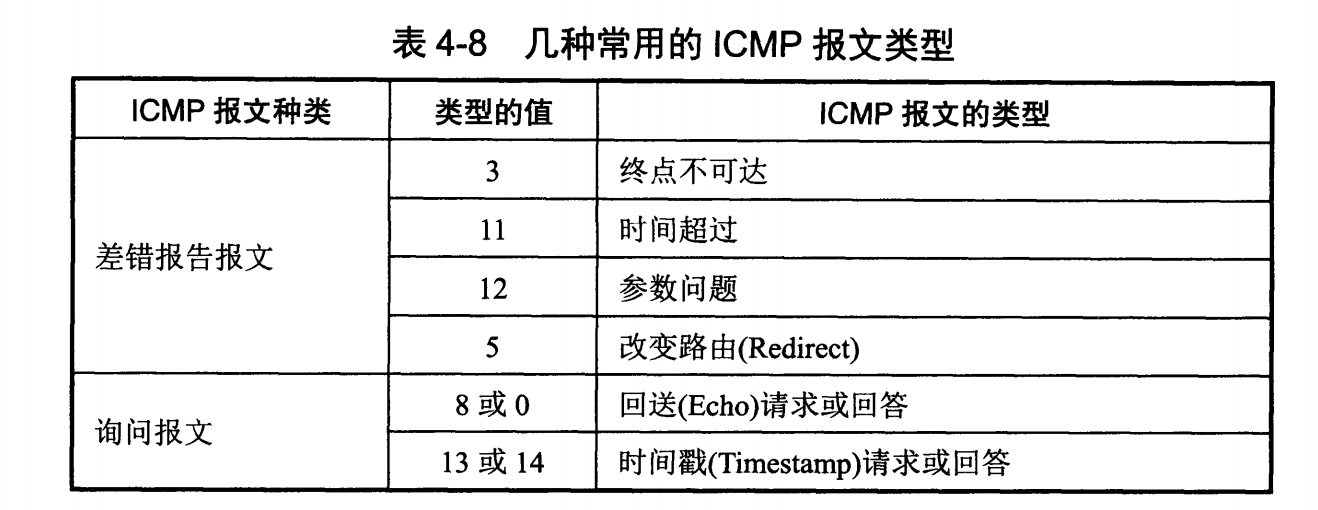
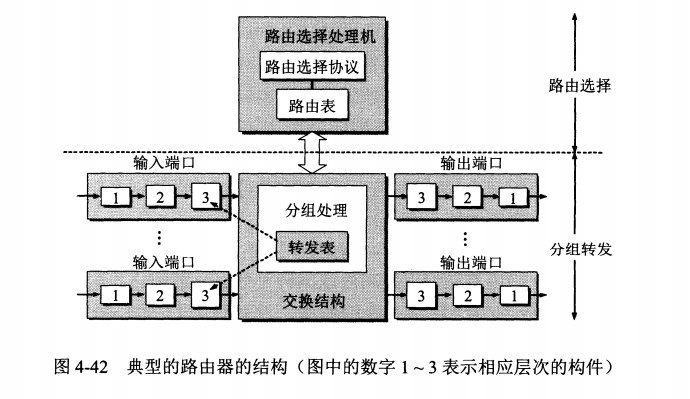
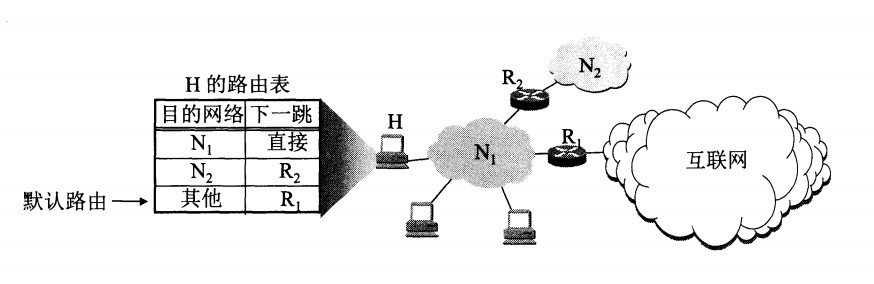
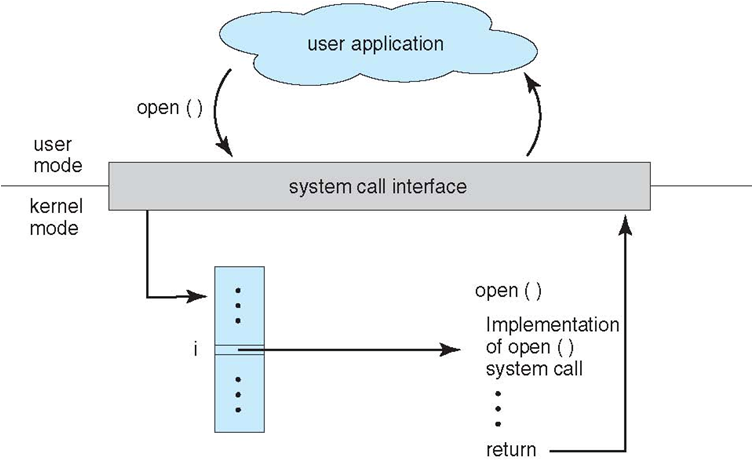
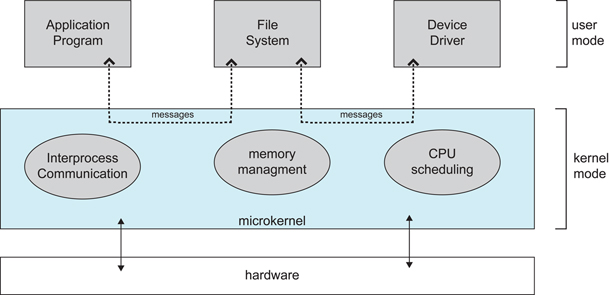
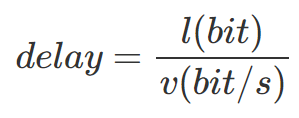diff --git "a/PART_1_\347\256\227\346\263\225\345\237\272\347\241\200/README.md" "b/PART_1_\347\256\227\346\263\225\345\237\272\347\241\200/README.md"
index 7830ca9d..b842adcd 100644
--- "a/PART_1_\347\256\227\346\263\225\345\237\272\347\241\200/README.md"
+++ "b/PART_1_\347\256\227\346\263\225\345\237\272\347\241\200/README.md"
@@ -1,4 +1,4 @@
-## PART I 算法基础
+## PART_1_算法基础
[下载 XMIND 完整版](https://www.cxyhub.com/all/programming/12460/)
diff --git "a/PART_2_\345\212\233\346\211\243\345\233\276\350\247\243/README.md" "b/PART_2_\345\212\233\346\211\243\345\233\276\350\247\243/README.md"
index e37ad915..55ce221e 100644
--- "a/PART_2_\345\212\233\346\211\243\345\233\276\350\247\243/README.md"
+++ "b/PART_2_\345\212\233\346\211\243\345\233\276\350\247\243/README.md"
@@ -1,4 +1,4 @@
-## PART II 算法图解题典
+## PART_2_力扣图解
| Title | 分类 | 难度 |
|---|---|---|
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/README.md" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/README.md"
new file mode 100644
index 00000000..dc9b7e8c
--- /dev/null
+++ "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/README.md"
@@ -0,0 +1,13 @@
+## PART_3_大厂面试
+
+考虑到现在网上面经实在太杂,很多都冠以 “BAT” 之名,重复率、错误率都非常高。所以我尽可能的挑选出了我认为比较好的 50 篇面经(基本不重复),并对内容做了分类。
+
+建议大家把这个页面收藏起来,防止后面需要的时候找不到了。
+
+希望大家可以点个 star 支持一下~
+
+- [系统设计-长文(非常建议读,我自己也看了)](https://github.com/donnemartin/system-design-primer/blob/master/README-zh-Hans.md)
+- [后端-社招(两年): 蚂蚁 头条 PingCAP](https://github.com/aylei/interview)
+- [后端-京东-JAVA](https://www.cnblogs.com/wupeixuan/p/8908524.html#%E4%B8%80%E3%80%81java)
+- [后端-百度-高并发抢红包设计](https://github.com/xbox1994/Java-Interview/blob/master/MD/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1-%E9%AB%98%E5%B9%B6%E5%8F%91%E6%8A%A2%E7%BA%A2%E5%8C%85.md)
+- [NLP(机器学习)-百度](https://www.e-learn.cn/topic/95743)
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\344\272\254\344\270\234\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\344\272\254\344\270\234\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\344\272\254\344\270\234\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\344\272\254\344\270\234\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\345\215\216\344\270\272\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\345\215\216\344\270\272\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\345\215\216\344\270\272\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\345\215\216\344\270\272\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\345\244\264\346\235\241\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\345\244\264\346\235\241\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\345\244\264\346\235\241\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\345\244\264\346\235\241\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\273\264\346\273\264\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\346\273\264\346\273\264\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\273\264\346\273\264\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\346\273\264\346\273\264\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\347\231\276\345\272\246\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\347\231\276\345\272\246\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\347\231\276\345\272\246\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\347\231\276\345\272\246\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\347\276\216\345\233\242\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\347\276\216\345\233\242\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\347\276\216\345\233\242\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\347\276\216\345\233\242\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\350\205\276\350\256\257\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\350\205\276\350\256\257\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\350\205\276\350\256\257\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\350\205\276\350\256\257\347\257\207.zip"
diff --git "a/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\351\230\277\351\207\214\347\257\207.zip" "b/PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\351\230\277\351\207\214\347\257\207.zip"
similarity index 100%
rename from "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\351\230\277\351\207\214\347\257\207.zip"
rename to "PART_3_\345\244\247\345\216\202\351\235\242\350\257\225/\346\261\207\346\200\273/\351\230\277\351\207\214\347\257\207.zip"
diff --git a/git b/git
new file mode 100644
index 00000000..e69de29b
diff --git a/hello-algorithm.iml b/hello-algorithm.iml
new file mode 100644
index 00000000..47ffbb0a
--- /dev/null
+++ b/hello-algorithm.iml
@@ -0,0 +1,82 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git "a/other/designpattern/\344\270\255\344\273\213\350\200\205\346\250\241\345\274\217.md" "b/other/designpattern/\344\270\255\344\273\213\350\200\205\346\250\241\345\274\217.md"
new file mode 100644
index 00000000..bd2d5190
--- /dev/null
+++ "b/other/designpattern/\344\270\255\344\273\213\350\200\205\346\250\241\345\274\217.md"
@@ -0,0 +1,185 @@
+## 中介者(Mediator)
+
+### 介绍
+
+中介者模式(Mediator Pattern)是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。中介者模式属于行为型模式。
+
+### Intent
+
+集中相关对象之间复杂的沟通和控制方式。
+
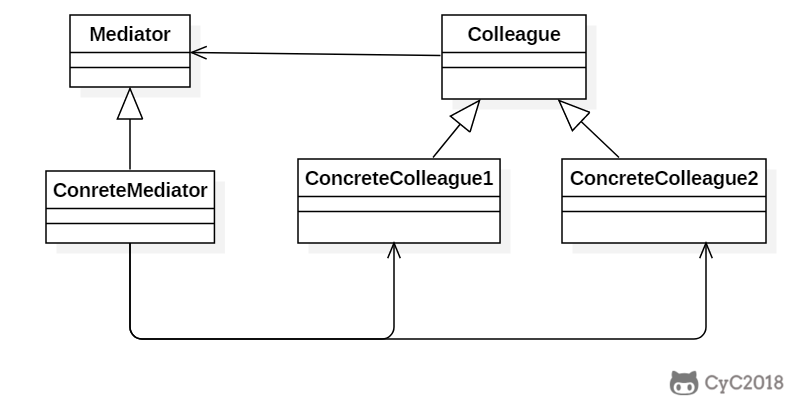
+### Class Diagram
+
+- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
+- Colleague:同事,相关对象
+
+
+
+### Implementation
+
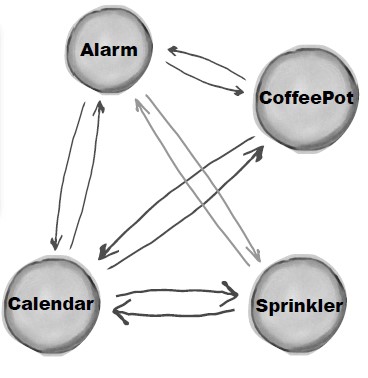
+Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:
+
+
+
+使用中介者模式可以将复杂的依赖结构变成星形结构:
+
+
+
+```java
+public abstract class Colleague {
+ public abstract void onEvent(Mediator mediator);
+}
+```
+
+```java
+public class Alarm extends Colleague {
+
+ @Override
+ public void onEvent(Mediator mediator) {
+ mediator.doEvent("alarm");
+ }
+
+ public void doAlarm() {
+ System.out.println("doAlarm()");
+ }
+}
+```
+
+```java
+public class CoffeePot extends Colleague {
+ @Override
+ public void onEvent(Mediator mediator) {
+ mediator.doEvent("coffeePot");
+ }
+
+ public void doCoffeePot() {
+ System.out.println("doCoffeePot()");
+ }
+}
+```
+
+```java
+public class Calender extends Colleague {
+ @Override
+ public void onEvent(Mediator mediator) {
+ mediator.doEvent("calender");
+ }
+
+ public void doCalender() {
+ System.out.println("doCalender()");
+ }
+}
+```
+
+```java
+public class Sprinkler extends Colleague {
+ @Override
+ public void onEvent(Mediator mediator) {
+ mediator.doEvent("sprinkler");
+ }
+
+ public void doSprinkler() {
+ System.out.println("doSprinkler()");
+ }
+}
+```
+
+```java
+public abstract class Mediator {
+ public abstract void doEvent(String eventType);
+}
+```
+
+```java
+public class ConcreteMediator extends Mediator {
+ private Alarm alarm;
+ private CoffeePot coffeePot;
+ private Calender calender;
+ private Sprinkler sprinkler;
+
+ public ConcreteMediator(Alarm alarm, CoffeePot coffeePot, Calender calender, Sprinkler sprinkler) {
+ this.alarm = alarm;
+ this.coffeePot = coffeePot;
+ this.calender = calender;
+ this.sprinkler = sprinkler;
+ }
+
+ @Override
+ public void doEvent(String eventType) {
+ switch (eventType) {
+ case "alarm":
+ doAlarmEvent();
+ break;
+ case "coffeePot":
+ doCoffeePotEvent();
+ break;
+ case "calender":
+ doCalenderEvent();
+ break;
+ default:
+ doSprinklerEvent();
+ }
+ }
+
+ public void doAlarmEvent() {
+ alarm.doAlarm();
+ coffeePot.doCoffeePot();
+ calender.doCalender();
+ sprinkler.doSprinkler();
+ }
+
+ public void doCoffeePotEvent() {
+ // ...
+ }
+
+ public void doCalenderEvent() {
+ // ...
+ }
+
+ public void doSprinklerEvent() {
+ // ...
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Alarm alarm = new Alarm();
+ CoffeePot coffeePot = new CoffeePot();
+ Calender calender = new Calender();
+ Sprinkler sprinkler = new Sprinkler();
+ Mediator mediator = new ConcreteMediator(alarm, coffeePot, calender, sprinkler);
+ // 闹钟事件到达,调用中介者就可以操作相关对象
+ alarm.onEvent(mediator);
+ }
+}
+```
+
+```java
+doAlarm()
+doCoffeePot()
+doCalender()
+doSprinkler()
+```
+
+### JDK
+
+- All scheduleXXX() methods of [java.util.Timer](http://docs.oracle.com/javase/8/docs/api/java/util/Timer.html)
+- [java.util.concurrent.Executor#execute()](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/Executor.html#execute-java.lang.Runnable-)
+- submit() and invokeXXX() methods of [java.util.concurrent.ExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ExecutorService.html)
+- scheduleXXX() methods of [java.util.concurrent.ScheduledExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ScheduledExecutorService.html)
+- [java.lang.reflect.Method#invoke()](http://docs.oracle.com/javase/8/docs/api/java/lang/reflect/Method.html#invoke-java.lang.Object-java.lang.Object...-)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+

+
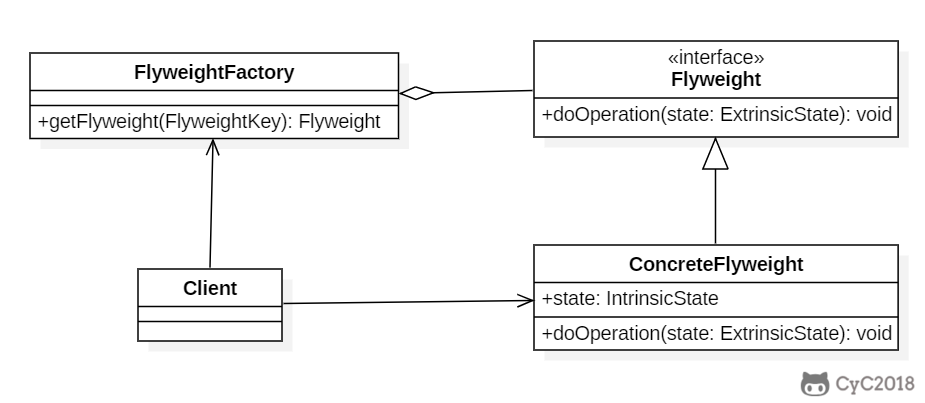
+
+### Implementation
+
+```java
+public interface Flyweight {
+ void doOperation(String extrinsicState);
+}
+```
+
+```java
+public class ConcreteFlyweight implements Flyweight {
+
+ private String intrinsicState;
+
+ public ConcreteFlyweight(String intrinsicState) {
+ this.intrinsicState = intrinsicState;
+ }
+
+ @Override
+ public void doOperation(String extrinsicState) {
+ System.out.println("Object address: " + System.identityHashCode(this));
+ System.out.println("IntrinsicState: " + intrinsicState);
+ System.out.println("ExtrinsicState: " + extrinsicState);
+ }
+}
+```
+
+```java
+public class FlyweightFactory {
+
+ private HashMap flyweights = new HashMap<>();
+
+ Flyweight getFlyweight(String intrinsicState) {
+ if (!flyweights.containsKey(intrinsicState)) {
+ Flyweight flyweight = new ConcreteFlyweight(intrinsicState);
+ flyweights.put(intrinsicState, flyweight);
+ }
+ return flyweights.get(intrinsicState);
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ FlyweightFactory factory = new FlyweightFactory();
+ Flyweight flyweight1 = factory.getFlyweight("aa");
+ Flyweight flyweight2 = factory.getFlyweight("aa");
+ flyweight1.doOperation("x");
+ flyweight2.doOperation("y");
+ }
+}
+```
+
+```html
+Object address: 1163157884
+IntrinsicState: aa
+ExtrinsicState: x
+Object address: 1163157884
+IntrinsicState: aa
+ExtrinsicState: y
+```
+
+### JDK
+
+Java 利用缓存来加速大量小对象的访问时间。
+
+- java.lang.Integer#valueOf(int)
+- java.lang.Boolean#valueOf(boolean)
+- java.lang.Byte#valueOf(byte)
+- java.lang.Character#valueOf(char)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
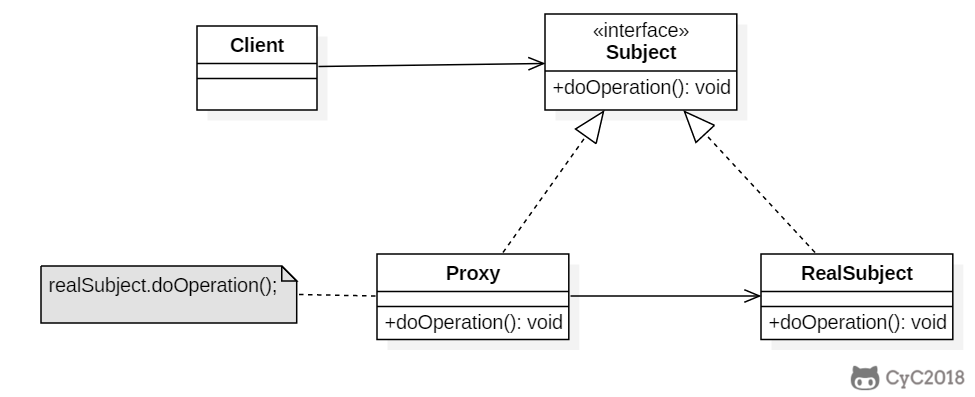
+### Implementation
+
+以下是一个虚拟代理的实现,模拟了图片延迟加载的情况下使用与图片大小相等的临时内容去替换原始图片,直到图片加载完成才将图片显示出来。
+
+```java
+public interface Image {
+ void showImage();
+}
+```
+
+```java
+public class HighResolutionImage implements Image {
+
+ private URL imageURL;
+ private long startTime;
+ private int height;
+ private int width;
+
+ public int getHeight() {
+ return height;
+ }
+
+ public int getWidth() {
+ return width;
+ }
+
+ public HighResolutionImage(URL imageURL) {
+ this.imageURL = imageURL;
+ this.startTime = System.currentTimeMillis();
+ this.width = 600;
+ this.height = 600;
+ }
+
+ public boolean isLoad() {
+ // 模拟图片加载,延迟 3s 加载完成
+ long endTime = System.currentTimeMillis();
+ return endTime - startTime > 3000;
+ }
+
+ @Override
+ public void showImage() {
+ System.out.println("Real Image: " + imageURL);
+ }
+}
+```
+
+```java
+public class ImageProxy implements Image {
+
+ private HighResolutionImage highResolutionImage;
+
+ public ImageProxy(HighResolutionImage highResolutionImage) {
+ this.highResolutionImage = highResolutionImage;
+ }
+
+ @Override
+ public void showImage() {
+ while (!highResolutionImage.isLoad()) {
+ try {
+ System.out.println("Temp Image: " + highResolutionImage.getWidth() + " " + highResolutionImage.getHeight());
+ Thread.sleep(100);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ highResolutionImage.showImage();
+ }
+}
+```
+
+```java
+public class ImageViewer {
+
+ public static void main(String[] args) throws Exception {
+ String image = "http://image.jpg";
+ URL url = new URL(image);
+ HighResolutionImage highResolutionImage = new HighResolutionImage(url);
+ ImageProxy imageProxy = new ImageProxy(highResolutionImage);
+ imageProxy.showImage();
+ }
+}
+```
+
+### JDK
+
+- java.lang.reflect.Proxy
+- RMI
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
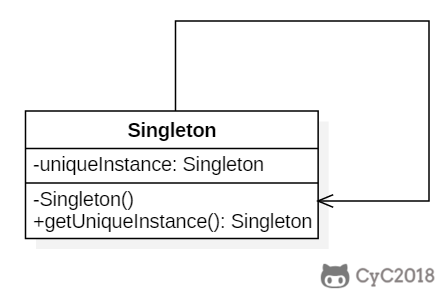
+### Implementation
+
+#### Ⅰ 懒汉式-线程不安全
+
+以下实现中,私有静态变量 uniqueInstance 被延迟实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
+
+这个实现在多线程环境下是不安全的,如果多个线程能够同时进入 `if (uniqueInstance == null)` ,并且此时 uniqueInstance 为 null,那么会有多个线程执行 `uniqueInstance = new Singleton();` 语句,这将导致实例化多次 uniqueInstance。
+
+```java
+public class Singleton {
+
+ private static Singleton uniqueInstance;
+
+ private Singleton() {
+ }
+
+ public static Singleton getUniqueInstance() {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+#### Ⅱ 饿汉式-线程安全
+
+线程不安全问题主要是由于 uniqueInstance 被实例化多次,采取直接实例化 uniqueInstance 的方式就不会产生线程不安全问题。
+
+但是直接实例化的方式也丢失了延迟实例化带来的节约资源的好处。
+
+```java
+private static Singleton uniqueInstance = new Singleton();
+```
+
+#### Ⅲ 懒汉式-线程安全
+
+只需要对 getUniqueInstance() 方法加锁,那么在一个时间点只能有一个线程能够进入该方法,从而避免了实例化多次 uniqueInstance。
+
+但是当一个线程进入该方法之后,其它试图进入该方法的线程都必须等待,即使 uniqueInstance 已经被实例化了。这会让线程阻塞时间过长,因此该方法有性能问题,不推荐使用。
+
+```java
+public static synchronized Singleton getUniqueInstance() {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ return uniqueInstance;
+}
+```
+
+#### Ⅳ 双重校验锁-线程安全
+
+uniqueInstance 只需要被实例化一次,之后就可以直接使用了。加锁操作只需要对实例化那部分的代码进行,只有当 uniqueInstance 没有被实例化时,才需要进行加锁。
+
+双重校验锁先判断 uniqueInstance 是否已经被实例化,如果没有被实例化,那么才对实例化语句进行加锁。
+
+```java
+public class Singleton {
+
+ private volatile static Singleton uniqueInstance;
+
+ private Singleton() {
+ }
+
+ public static Singleton getUniqueInstance() {
+ if (uniqueInstance == null) {
+ synchronized (Singleton.class) {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 `uniqueInstance = new Singleton();` 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句:第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作,而第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 uniqueInstance == null 时两个线程同时进行实例化操作。
+
+```java
+if (uniqueInstance == null) {
+ synchronized (Singleton.class) {
+ uniqueInstance = new Singleton();
+ }
+}
+```
+
+uniqueInstance 采用 volatile 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+
+1. 为 uniqueInstance 分配内存空间
+2. 初始化 uniqueInstance
+3. 将 uniqueInstance 指向分配的内存地址
+
+但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
+
+使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+
+#### Ⅴ 静态内部类实现
+
+当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
+
+这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
+
+```java
+public class Singleton {
+
+ private Singleton() {
+ }
+
+ private static class SingletonHolder {
+ private static final Singleton INSTANCE = new Singleton();
+ }
+
+ public static Singleton getUniqueInstance() {
+ return SingletonHolder.INSTANCE;
+ }
+}
+```
+
+#### Ⅵ 枚举实现
+
+```java
+public enum Singleton {
+
+ INSTANCE;
+
+ private String objName;
+
+
+ public String getObjName() {
+ return objName;
+ }
+
+
+ public void setObjName(String objName) {
+ this.objName = objName;
+ }
+
+
+ public static void main(String[] args) {
+
+ // 单例测试
+ Singleton firstSingleton = Singleton.INSTANCE;
+ firstSingleton.setObjName("firstName");
+ System.out.println(firstSingleton.getObjName());
+ Singleton secondSingleton = Singleton.INSTANCE;
+ secondSingleton.setObjName("secondName");
+ System.out.println(firstSingleton.getObjName());
+ System.out.println(secondSingleton.getObjName());
+
+ // 反射获取实例测试
+ try {
+ Singleton[] enumConstants = Singleton.class.getEnumConstants();
+ for (Singleton enumConstant : enumConstants) {
+ System.out.println(enumConstant.getObjName());
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+```html
+firstName
+secondName
+secondName
+secondName
+```
+
+该实现可以防止反射攻击。在其它实现中,通过 setAccessible() 方法可以将私有构造函数的访问级别设置为 public,然后调用构造函数从而实例化对象,如果要防止这种攻击,需要在构造函数中添加防止多次实例化的代码。该实现是由 JVM 保证只会实例化一次,因此不会出现上述的反射攻击。
+
+该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
+
+### Examples
+
+- Logger Classes
+- Configuration Classes
+- Accesing resources in shared mode
+- Factories implemented as Singletons
+
+### JDK
+
+- [java.lang.Runtime#getRuntime()](http://docs.oracle.com/javase/8/docs/api/java/lang/Runtime.html#getRuntime%28%29)
+- [java.awt.Desktop#getDesktop()](http://docs.oracle.com/javase/8/docs/api/java/awt/Desktop.html#getDesktop--)
+
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
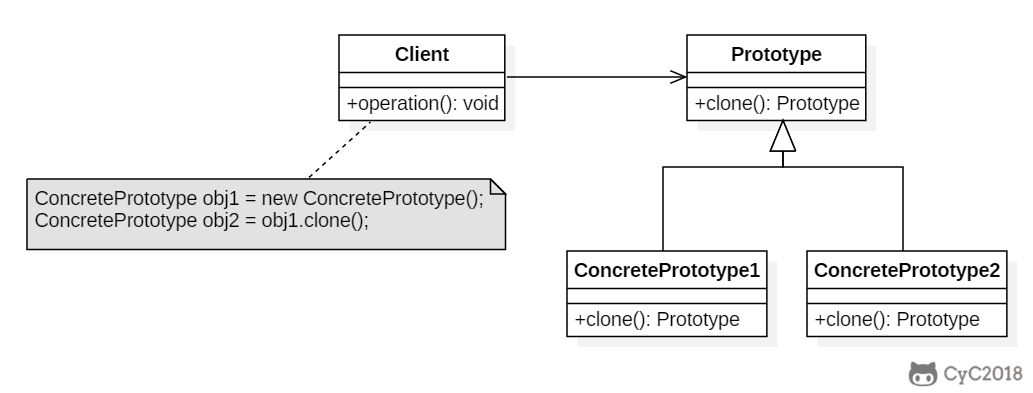
+### Implementation
+
+```java
+public abstract class Prototype {
+ abstract Prototype myClone();
+}
+```
+
+```java
+public class ConcretePrototype extends Prototype {
+
+ private String filed;
+
+ public ConcretePrototype(String filed) {
+ this.filed = filed;
+ }
+
+ @Override
+ Prototype myClone() {
+ return new ConcretePrototype(filed);
+ }
+
+ @Override
+ public String toString() {
+ return filed;
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Prototype prototype = new ConcretePrototype("abc");
+ Prototype clone = prototype.myClone();
+ System.out.println(clone.toString());
+ }
+}
+```
+
+```html
+abc
+```
+
+### JDK
+
+- [java.lang.Object#clone()](http://docs.oracle.com/javase/8/docs/api/java/lang/Object.html#clone%28%29)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
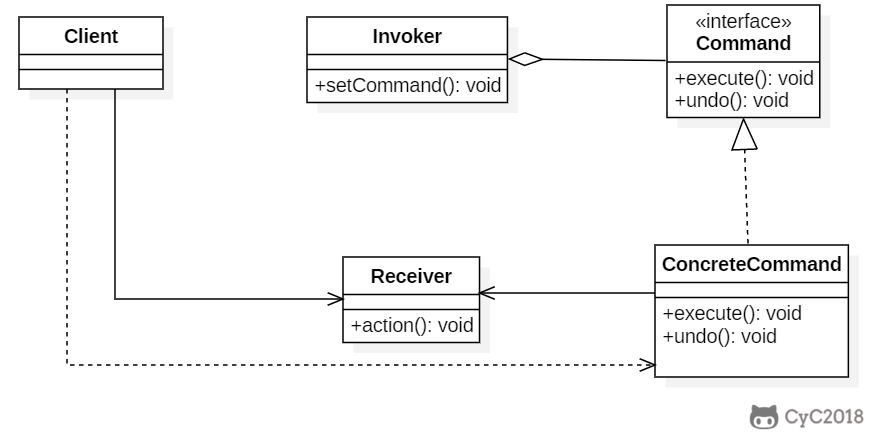
+### Implementation
+
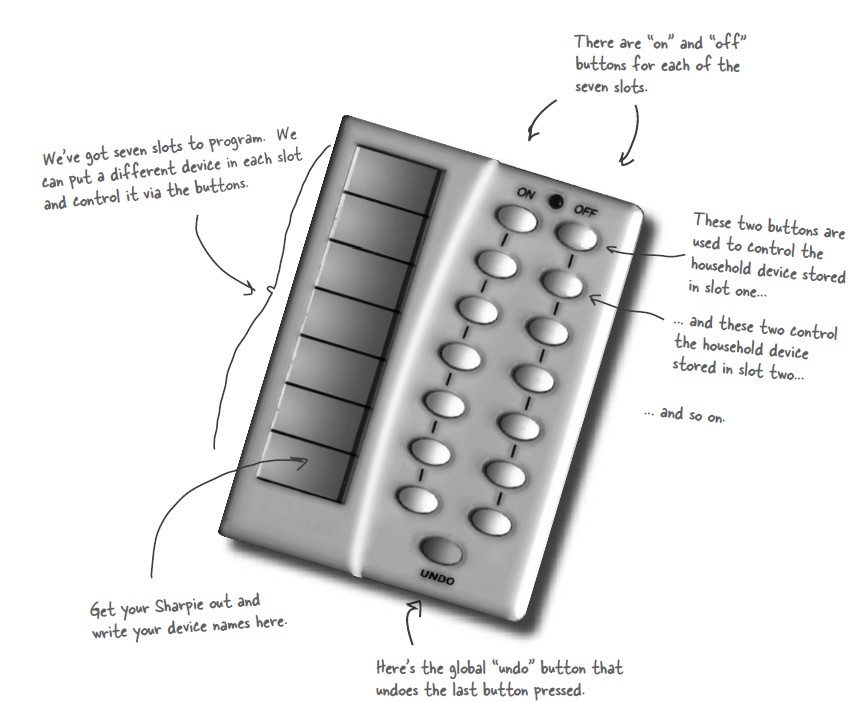
+设计一个遥控器,可以控制电灯开关。
+
+
+
+```java
+public interface Command {
+ void execute();
+}
+```
+
+```java
+public class LightOnCommand implements Command {
+ Light light;
+
+ public LightOnCommand(Light light) {
+ this.light = light;
+ }
+
+ @Override
+ public void execute() {
+ light.on();
+ }
+}
+```
+
+```java
+public class LightOffCommand implements Command {
+ Light light;
+
+ public LightOffCommand(Light light) {
+ this.light = light;
+ }
+
+ @Override
+ public void execute() {
+ light.off();
+ }
+}
+```
+
+```java
+public class Light {
+
+ public void on() {
+ System.out.println("Light is on!");
+ }
+
+ public void off() {
+ System.out.println("Light is off!");
+ }
+}
+```
+
+```java
+/**
+ * 遥控器
+ */
+public class Invoker {
+ private Command[] onCommands;
+ private Command[] offCommands;
+ private final int slotNum = 7;
+
+ public Invoker() {
+ this.onCommands = new Command[slotNum];
+ this.offCommands = new Command[slotNum];
+ }
+
+ public void setOnCommand(Command command, int slot) {
+ onCommands[slot] = command;
+ }
+
+ public void setOffCommand(Command command, int slot) {
+ offCommands[slot] = command;
+ }
+
+ public void onButtonWasPushed(int slot) {
+ onCommands[slot].execute();
+ }
+
+ public void offButtonWasPushed(int slot) {
+ offCommands[slot].execute();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Invoker invoker = new Invoker();
+ Light light = new Light();
+ Command lightOnCommand = new LightOnCommand(light);
+ Command lightOffCommand = new LightOffCommand(light);
+ invoker.setOnCommand(lightOnCommand, 0);
+ invoker.setOffCommand(lightOffCommand, 0);
+ invoker.onButtonWasPushed(0);
+ invoker.offButtonWasPushed(0);
+ }
+}
+```
+
+### JDK
+
+- [java.lang.Runnable](http://docs.oracle.com/javase/8/docs/api/java/lang/Runnable.html)
+- [Netflix Hystrix](https://github.com/Netflix/Hystrix/wiki)
+- [javax.swing.Action](http://docs.oracle.com/javase/8/docs/api/javax/swing/Action.html)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
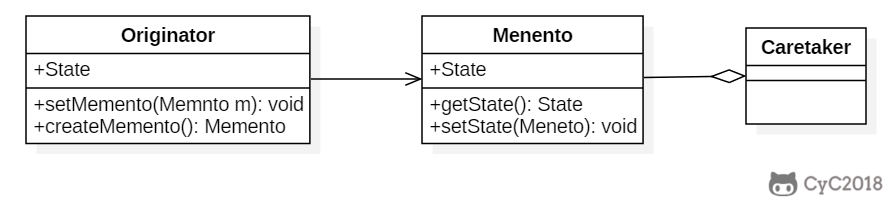
+
+### Implementation
+
+以下实现了一个简单计算器程序,可以输入两个值,然后计算这两个值的和。备忘录模式允许将这两个值存储起来,然后在某个时刻用存储的状态进行恢复。
+
+实现参考:[Memento Pattern - Calculator Example - Java Sourcecode](https://www.oodesign.com/memento-pattern-calculator-example-java-sourcecode.html)
+
+```java
+/**
+ * Originator Interface
+ */
+public interface Calculator {
+
+ // Create Memento
+ PreviousCalculationToCareTaker backupLastCalculation();
+
+ // setMemento
+ void restorePreviousCalculation(PreviousCalculationToCareTaker memento);
+
+ int getCalculationResult();
+
+ void setFirstNumber(int firstNumber);
+
+ void setSecondNumber(int secondNumber);
+}
+```
+
+```java
+/**
+ * Originator Implementation
+ */
+public class CalculatorImp implements Calculator {
+
+ private int firstNumber;
+ private int secondNumber;
+
+ @Override
+ public PreviousCalculationToCareTaker backupLastCalculation() {
+ // create a memento object used for restoring two numbers
+ return new PreviousCalculationImp(firstNumber, secondNumber);
+ }
+
+ @Override
+ public void restorePreviousCalculation(PreviousCalculationToCareTaker memento) {
+ this.firstNumber = ((PreviousCalculationToOriginator) memento).getFirstNumber();
+ this.secondNumber = ((PreviousCalculationToOriginator) memento).getSecondNumber();
+ }
+
+ @Override
+ public int getCalculationResult() {
+ // result is adding two numbers
+ return firstNumber + secondNumber;
+ }
+
+ @Override
+ public void setFirstNumber(int firstNumber) {
+ this.firstNumber = firstNumber;
+ }
+
+ @Override
+ public void setSecondNumber(int secondNumber) {
+ this.secondNumber = secondNumber;
+ }
+}
+```
+
+```java
+/**
+ * Memento Interface to Originator
+ *
+ * This interface allows the originator to restore its state
+ */
+public interface PreviousCalculationToOriginator {
+ int getFirstNumber();
+ int getSecondNumber();
+}
+```
+
+```java
+/**
+ * Memento interface to CalculatorOperator (Caretaker)
+ */
+public interface PreviousCalculationToCareTaker {
+ // no operations permitted for the caretaker
+}
+```
+
+```java
+/**
+ * Memento Object Implementation
+ *
+ * Note that this object implements both interfaces to Originator and CareTaker
+ */
+public class PreviousCalculationImp implements PreviousCalculationToCareTaker,
+ PreviousCalculationToOriginator {
+
+ private int firstNumber;
+ private int secondNumber;
+
+ public PreviousCalculationImp(int firstNumber, int secondNumber) {
+ this.firstNumber = firstNumber;
+ this.secondNumber = secondNumber;
+ }
+
+ @Override
+ public int getFirstNumber() {
+ return firstNumber;
+ }
+
+ @Override
+ public int getSecondNumber() {
+ return secondNumber;
+ }
+}
+```
+
+```java
+/**
+ * CareTaker object
+ */
+public class Client {
+
+ public static void main(String[] args) {
+ // program starts
+ Calculator calculator = new CalculatorImp();
+
+ // assume user enters two numbers
+ calculator.setFirstNumber(10);
+ calculator.setSecondNumber(100);
+
+ // find result
+ System.out.println(calculator.getCalculationResult());
+
+ // Store result of this calculation in case of error
+ PreviousCalculationToCareTaker memento = calculator.backupLastCalculation();
+
+ // user enters a number
+ calculator.setFirstNumber(17);
+
+ // user enters a wrong second number and calculates result
+ calculator.setSecondNumber(-290);
+
+ // calculate result
+ System.out.println(calculator.getCalculationResult());
+
+ // user hits CTRL + Z to undo last operation and see last result
+ calculator.restorePreviousCalculation(memento);
+
+ // result restored
+ System.out.println(calculator.getCalculationResult());
+ }
+}
+```
+
+```html
+110
+-273
+110
+```
+
+### JDK
+
+- java.io.Serializable
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
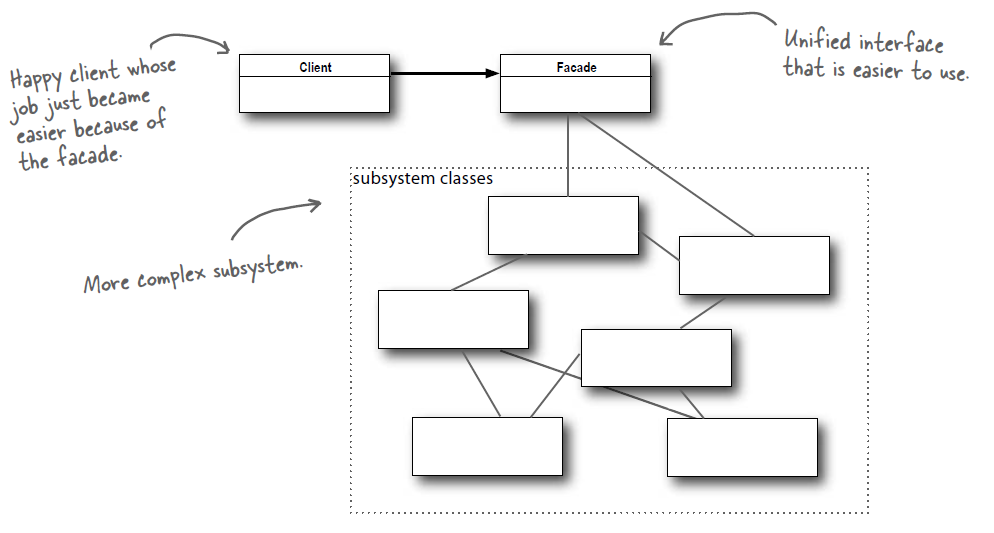
+### Implementation
+
+观看电影需要操作很多电器,使用外观模式实现一键看电影功能。
+
+```java
+public class SubSystem {
+ public void turnOnTV() {
+ System.out.println("turnOnTV()");
+ }
+
+ public void setCD(String cd) {
+ System.out.println("setCD( " + cd + " )");
+ }
+
+ public void startWatching(){
+ System.out.println("startWatching()");
+ }
+}
+```
+
+```java
+public class Facade {
+ private SubSystem subSystem = new SubSystem();
+
+ public void watchMovie() {
+ subSystem.turnOnTV();
+ subSystem.setCD("a movie");
+ subSystem.startWatching();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Facade facade = new Facade();
+ facade.watchMovie();
+ }
+}
+```
+
+### 设计原则
+
+最少知识原则:只和你的密友谈话。也就是说客户对象所需要交互的对象应当尽可能少。
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
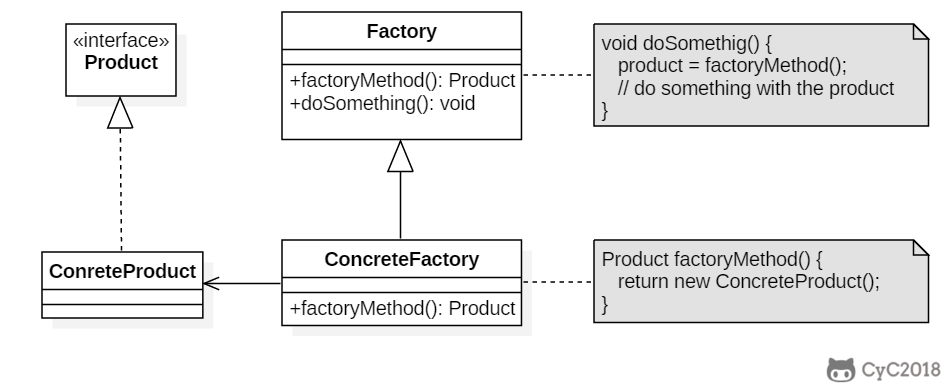
+```java
+public abstract class Factory {
+ abstract public Product factoryMethod();
+ public void doSomething() {
+ Product product = factoryMethod();
+ // do something with the product
+ }
+}
+```
+
+```java
+public class ConcreteFactory extends Factory {
+ public Product factoryMethod() {
+ return new ConcreteProduct();
+ }
+}
+```
+
+```java
+public class ConcreteFactory1 extends Factory {
+ public Product factoryMethod() {
+ return new ConcreteProduct1();
+ }
+}
+```
+
+```java
+public class ConcreteFactory2 extends Factory {
+ public Product factoryMethod() {
+ return new ConcreteProduct2();
+ }
+}
+```
+
+### JDK
+
+- [java.util.Calendar](http://docs.oracle.com/javase/8/docs/api/java/util/Calendar.html#getInstance--)
+- [java.util.ResourceBundle](http://docs.oracle.com/javase/8/docs/api/java/util/ResourceBundle.html#getBundle-java.lang.String-)
+- [java.text.NumberFormat](http://docs.oracle.com/javase/8/docs/api/java/text/NumberFormat.html#getInstance--)
+- [java.nio.charset.Charset](http://docs.oracle.com/javase/8/docs/api/java/nio/charset/Charset.html#forName-java.lang.String-)
+- [java.net.URLStreamHandlerFactory](http://docs.oracle.com/javase/8/docs/api/java/net/URLStreamHandlerFactory.html#createURLStreamHandler-java.lang.String-)
+- [java.util.EnumSet](https://docs.oracle.com/javase/8/docs/api/java/util/EnumSet.html#of-E-)
+- [javax.xml.bind.JAXBContext](https://docs.oracle.com/javase/8/docs/api/javax/xml/bind/JAXBContext.html#createMarshaller--)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
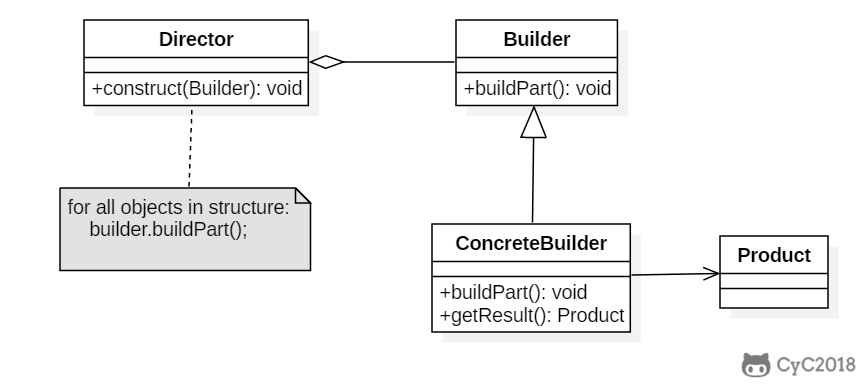
+### Implementation
+
+以下是一个简易的 StringBuilder 实现,参考了 JDK 1.8 源码。
+
+```java
+public class AbstractStringBuilder {
+ protected char[] value;
+
+ protected int count;
+
+ public AbstractStringBuilder(int capacity) {
+ count = 0;
+ value = new char[capacity];
+ }
+
+ public AbstractStringBuilder append(char c) {
+ ensureCapacityInternal(count + 1);
+ value[count++] = c;
+ return this;
+ }
+
+ private void ensureCapacityInternal(int minimumCapacity) {
+ // overflow-conscious code
+ if (minimumCapacity - value.length > 0)
+ expandCapacity(minimumCapacity);
+ }
+
+ void expandCapacity(int minimumCapacity) {
+ int newCapacity = value.length * 2 + 2;
+ if (newCapacity - minimumCapacity < 0)
+ newCapacity = minimumCapacity;
+ if (newCapacity < 0) {
+ if (minimumCapacity < 0) // overflow
+ throw new OutOfMemoryError();
+ newCapacity = Integer.MAX_VALUE;
+ }
+ value = Arrays.copyOf(value, newCapacity);
+ }
+}
+```
+
+```java
+public class StringBuilder extends AbstractStringBuilder {
+ public StringBuilder() {
+ super(16);
+ }
+
+ @Override
+ public String toString() {
+ // Create a copy, don't share the array
+ return new String(value, 0, count);
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ StringBuilder sb = new StringBuilder();
+ final int count = 26;
+ for (int i = 0; i < count; i++) {
+ sb.append((char) ('a' + i));
+ }
+ System.out.println(sb.toString());
+ }
+}
+```
+
+```html
+abcdefghijklmnopqrstuvwxyz
+```
+
+### JDK
+
+- [java.lang.StringBuilder](http://docs.oracle.com/javase/8/docs/api/java/lang/StringBuilder.html)
+- [java.nio.ByteBuffer](http://docs.oracle.com/javase/8/docs/api/java/nio/ByteBuffer.html#put-byte-)
+- [java.lang.StringBuffer](http://docs.oracle.com/javase/8/docs/api/java/lang/StringBuffer.html#append-boolean-)
+- [java.lang.Appendable](http://docs.oracle.com/javase/8/docs/api/java/lang/Appendable.html)
+- [Apache Camel builders](https://github.com/apache/camel/tree/0e195428ee04531be27a0b659005e3aa8d159d23/camel-core/src/main/java/org/apache/camel/builder)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
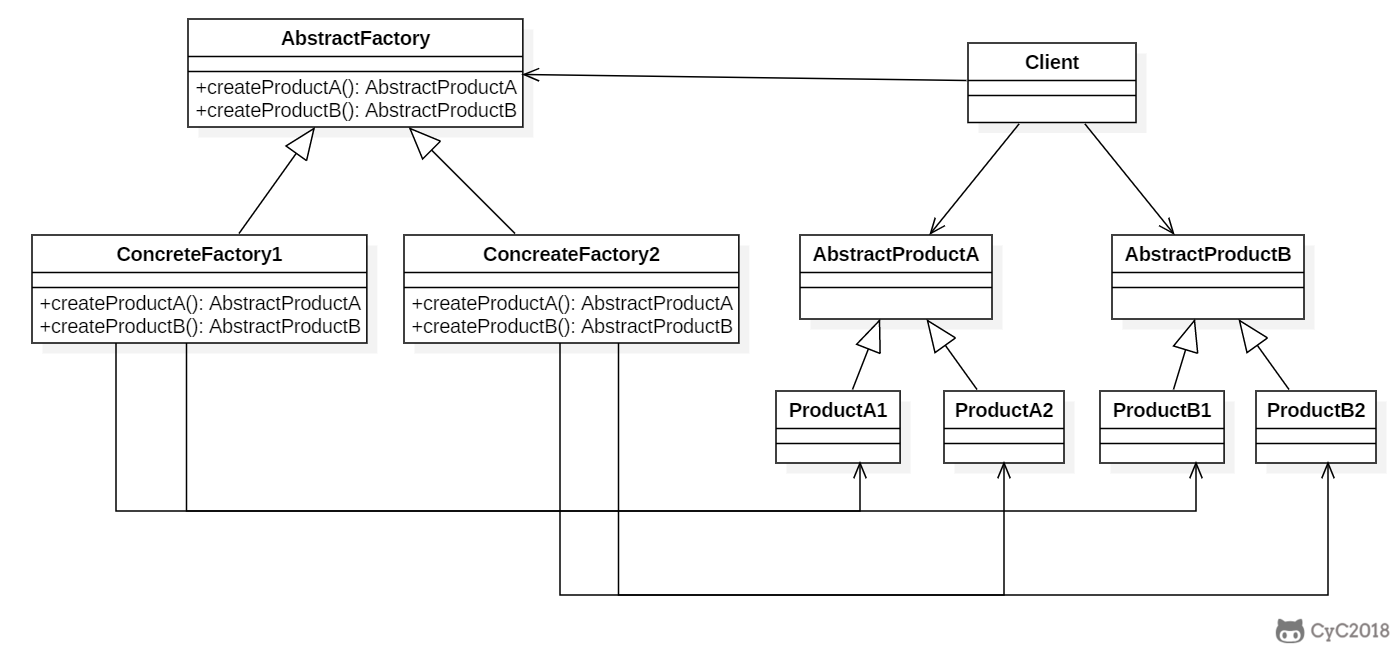
+### Implementation
+
+```java
+public class AbstractProductA {
+}
+```
+
+```java
+public class AbstractProductB {
+}
+```
+
+```java
+public class ProductA1 extends AbstractProductA {
+}
+```
+
+```java
+public class ProductA2 extends AbstractProductA {
+}
+```
+
+```java
+public class ProductB1 extends AbstractProductB {
+}
+```
+
+```java
+public class ProductB2 extends AbstractProductB {
+}
+```
+
+```java
+public abstract class AbstractFactory {
+ abstract AbstractProductA createProductA();
+ abstract AbstractProductB createProductB();
+}
+```
+
+```java
+public class ConcreteFactory1 extends AbstractFactory {
+ AbstractProductA createProductA() {
+ return new ProductA1();
+ }
+
+ AbstractProductB createProductB() {
+ return new ProductB1();
+ }
+}
+```
+
+```java
+public class ConcreteFactory2 extends AbstractFactory {
+ AbstractProductA createProductA() {
+ return new ProductA2();
+ }
+
+ AbstractProductB createProductB() {
+ return new ProductB2();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ AbstractFactory abstractFactory = new ConcreteFactory1();
+ AbstractProductA productA = abstractFactory.createProductA();
+ AbstractProductB productB = abstractFactory.createProductB();
+ // do something with productA and productB
+ }
+}
+```
+
+### JDK
+
+- [javax.xml.parsers.DocumentBuilderFactory](http://docs.oracle.com/javase/8/docs/api/javax/xml/parsers/DocumentBuilderFactory.html)
+- [javax.xml.transform.TransformerFactory](http://docs.oracle.com/javase/8/docs/api/javax/xml/transform/TransformerFactory.html#newInstance--)
+- [javax.xml.xpath.XPathFactory](http://docs.oracle.com/javase/8/docs/api/javax/xml/xpath/XPathFactory.html#newInstance--)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
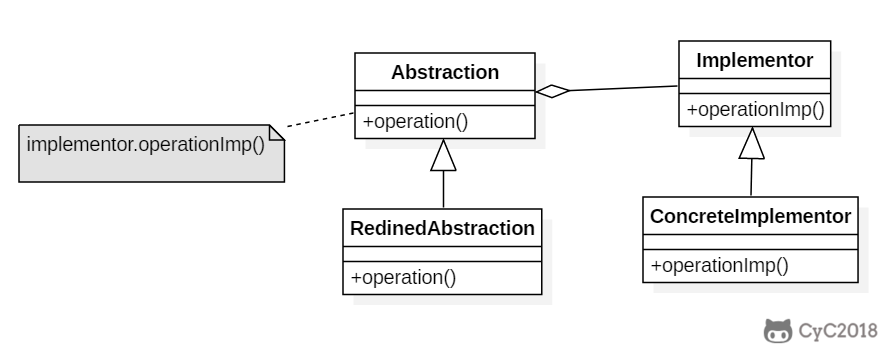
+### Implementation
+
+RemoteControl 表示遥控器,指代 Abstraction。
+
+TV 表示电视,指代 Implementor。
+
+桥接模式将遥控器和电视分离开来,从而可以独立改变遥控器或者电视的实现。
+
+```java
+public abstract class TV {
+ public abstract void on();
+
+ public abstract void off();
+
+ public abstract void tuneChannel();
+}
+```
+
+```java
+public class Sony extends TV {
+ @Override
+ public void on() {
+ System.out.println("Sony.on()");
+ }
+
+ @Override
+ public void off() {
+ System.out.println("Sony.off()");
+ }
+
+ @Override
+ public void tuneChannel() {
+ System.out.println("Sony.tuneChannel()");
+ }
+}
+```
+
+```java
+public class RCA extends TV {
+ @Override
+ public void on() {
+ System.out.println("RCA.on()");
+ }
+
+ @Override
+ public void off() {
+ System.out.println("RCA.off()");
+ }
+
+ @Override
+ public void tuneChannel() {
+ System.out.println("RCA.tuneChannel()");
+ }
+}
+```
+
+```java
+public abstract class RemoteControl {
+ protected TV tv;
+
+ public RemoteControl(TV tv) {
+ this.tv = tv;
+ }
+
+ public abstract void on();
+
+ public abstract void off();
+
+ public abstract void tuneChannel();
+}
+```
+
+```java
+public class ConcreteRemoteControl1 extends RemoteControl {
+ public ConcreteRemoteControl1(TV tv) {
+ super(tv);
+ }
+
+ @Override
+ public void on() {
+ System.out.println("ConcreteRemoteControl1.on()");
+ tv.on();
+ }
+
+ @Override
+ public void off() {
+ System.out.println("ConcreteRemoteControl1.off()");
+ tv.off();
+ }
+
+ @Override
+ public void tuneChannel() {
+ System.out.println("ConcreteRemoteControl1.tuneChannel()");
+ tv.tuneChannel();
+ }
+}
+```
+
+```java
+public class ConcreteRemoteControl2 extends RemoteControl {
+ public ConcreteRemoteControl2(TV tv) {
+ super(tv);
+ }
+
+ @Override
+ public void on() {
+ System.out.println("ConcreteRemoteControl2.on()");
+ tv.on();
+ }
+
+ @Override
+ public void off() {
+ System.out.println("ConcreteRemoteControl2.off()");
+ tv.off();
+ }
+
+ @Override
+ public void tuneChannel() {
+ System.out.println("ConcreteRemoteControl2.tuneChannel()");
+ tv.tuneChannel();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ RemoteControl remoteControl1 = new ConcreteRemoteControl1(new RCA());
+ remoteControl1.on();
+ remoteControl1.off();
+ remoteControl1.tuneChannel();
+ RemoteControl remoteControl2 = new ConcreteRemoteControl2(new Sony());
+ remoteControl2.on();
+ remoteControl2.off();
+ remoteControl2.tuneChannel();
+ }
+}
+```
+
+### JDK
+
+- AWT (It provides an abstraction layer which maps onto the native OS the windowing support.)
+- JDBC
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
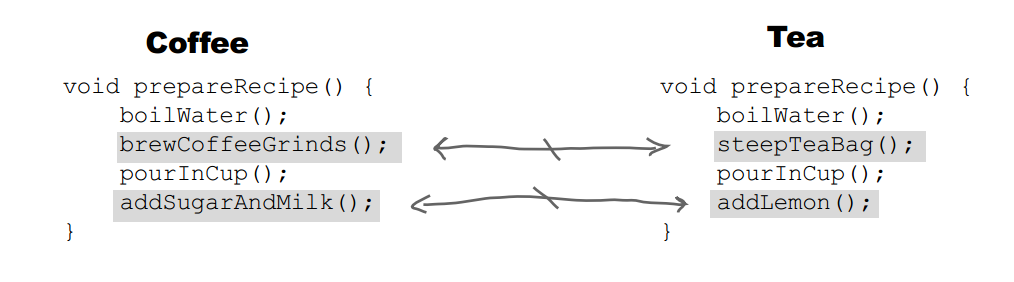
+### Implementation
+
+冲咖啡和冲茶都有类似的流程,但是某些步骤会有点不一样,要求复用那些相同步骤的代码。
+
+
+
+```java
+public abstract class CaffeineBeverage {
+
+ final void prepareRecipe() {
+ boilWater();
+ brew();
+ pourInCup();
+ addCondiments();
+ }
+
+ abstract void brew();
+
+ abstract void addCondiments();
+
+ void boilWater() {
+ System.out.println("boilWater");
+ }
+
+ void pourInCup() {
+ System.out.println("pourInCup");
+ }
+}
+```
+
+```java
+public class Coffee extends CaffeineBeverage {
+ @Override
+ void brew() {
+ System.out.println("Coffee.brew");
+ }
+
+ @Override
+ void addCondiments() {
+ System.out.println("Coffee.addCondiments");
+ }
+}
+```
+
+```java
+public class Tea extends CaffeineBeverage {
+ @Override
+ void brew() {
+ System.out.println("Tea.brew");
+ }
+
+ @Override
+ void addCondiments() {
+ System.out.println("Tea.addCondiments");
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ CaffeineBeverage caffeineBeverage = new Coffee();
+ caffeineBeverage.prepareRecipe();
+ System.out.println("-----------");
+ caffeineBeverage = new Tea();
+ caffeineBeverage.prepareRecipe();
+ }
+}
+```
+
+```html
+boilWater
+Coffee.brew
+pourInCup
+Coffee.addCondiments
+-----------
+boilWater
+Tea.brew
+pourInCup
+Tea.addCondiments
+```
+
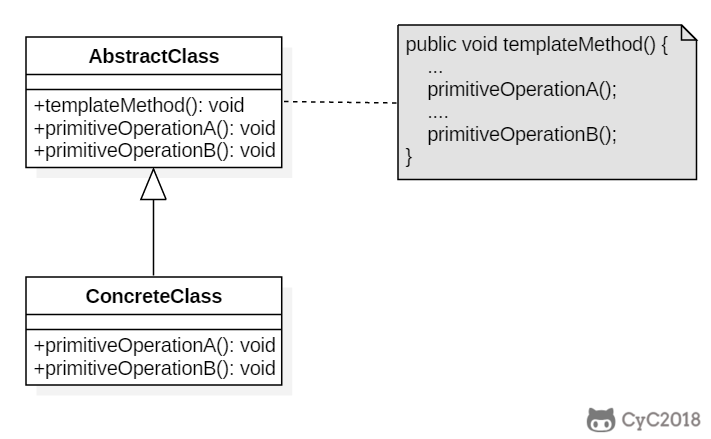
+### JDK
+
+- java.util.Collections#sort()
+- java.io.InputStream#skip()
+- java.io.InputStream#read()
+- java.util.AbstractList#indexOf()
+
+
+
+
+
+
+
diff --git "a/other/designpattern/\347\212\266\346\200\201\346\250\241\345\274\217.md" "b/other/designpattern/\347\212\266\346\200\201\346\250\241\345\274\217.md"
new file mode 100644
index 00000000..d2dbf6a0
--- /dev/null
+++ "b/other/designpattern/\347\212\266\346\200\201\346\250\241\345\274\217.md"
@@ -0,0 +1,318 @@
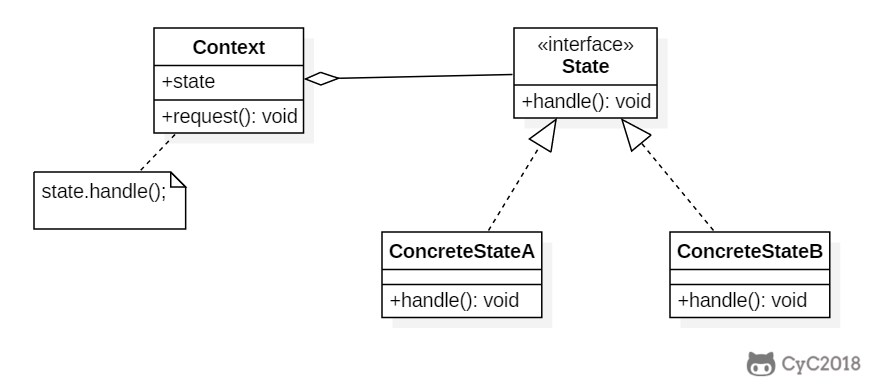
+## 状态(State)
+
+### 介绍
+
+在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。
+
+在状态模式中,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
+
+### Intent
+
+允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它所属的类。
+
+### Class Diagram
+
+
+
+### Implementation
+
+糖果销售机有多种状态,每种状态下销售机有不同的行为,状态可以发生转移,使得销售机的行为也发生改变。
+
+
+
+```java
+public interface State {
+ /**
+ * 投入 25 分钱
+ */
+ void insertQuarter();
+
+ /**
+ * 退回 25 分钱
+ */
+ void ejectQuarter();
+
+ /**
+ * 转动曲柄
+ */
+ void turnCrank();
+
+ /**
+ * 发放糖果
+ */
+ void dispense();
+}
+```
+
+```java
+public class HasQuarterState implements State {
+
+ private GumballMachine gumballMachine;
+
+ public HasQuarterState(GumballMachine gumballMachine) {
+ this.gumballMachine = gumballMachine;
+ }
+
+ @Override
+ public void insertQuarter() {
+ System.out.println("You can't insert another quarter");
+ }
+
+ @Override
+ public void ejectQuarter() {
+ System.out.println("Quarter returned");
+ gumballMachine.setState(gumballMachine.getNoQuarterState());
+ }
+
+ @Override
+ public void turnCrank() {
+ System.out.println("You turned...");
+ gumballMachine.setState(gumballMachine.getSoldState());
+ }
+
+ @Override
+ public void dispense() {
+ System.out.println("No gumball dispensed");
+ }
+}
+```
+
+```java
+public class NoQuarterState implements State {
+
+ GumballMachine gumballMachine;
+
+ public NoQuarterState(GumballMachine gumballMachine) {
+ this.gumballMachine = gumballMachine;
+ }
+
+ @Override
+ public void insertQuarter() {
+ System.out.println("You insert a quarter");
+ gumballMachine.setState(gumballMachine.getHasQuarterState());
+ }
+
+ @Override
+ public void ejectQuarter() {
+ System.out.println("You haven't insert a quarter");
+ }
+
+ @Override
+ public void turnCrank() {
+ System.out.println("You turned, but there's no quarter");
+ }
+
+ @Override
+ public void dispense() {
+ System.out.println("You need to pay first");
+ }
+}
+```
+
+```java
+public class SoldOutState implements State {
+
+ GumballMachine gumballMachine;
+
+ public SoldOutState(GumballMachine gumballMachine) {
+ this.gumballMachine = gumballMachine;
+ }
+
+ @Override
+ public void insertQuarter() {
+ System.out.println("You can't insert a quarter, the machine is sold out");
+ }
+
+ @Override
+ public void ejectQuarter() {
+ System.out.println("You can't eject, you haven't inserted a quarter yet");
+ }
+
+ @Override
+ public void turnCrank() {
+ System.out.println("You turned, but there are no gumballs");
+ }
+
+ @Override
+ public void dispense() {
+ System.out.println("No gumball dispensed");
+ }
+}
+```
+
+```java
+public class SoldState implements State {
+
+ GumballMachine gumballMachine;
+
+ public SoldState(GumballMachine gumballMachine) {
+ this.gumballMachine = gumballMachine;
+ }
+
+ @Override
+ public void insertQuarter() {
+ System.out.println("Please wait, we're already giving you a gumball");
+ }
+
+ @Override
+ public void ejectQuarter() {
+ System.out.println("Sorry, you already turned the crank");
+ }
+
+ @Override
+ public void turnCrank() {
+ System.out.println("Turning twice doesn't get you another gumball!");
+ }
+
+ @Override
+ public void dispense() {
+ gumballMachine.releaseBall();
+ if (gumballMachine.getCount() > 0) {
+ gumballMachine.setState(gumballMachine.getNoQuarterState());
+ } else {
+ System.out.println("Oops, out of gumballs");
+ gumballMachine.setState(gumballMachine.getSoldOutState());
+ }
+ }
+}
+```
+
+```java
+public class GumballMachine {
+
+ private State soldOutState;
+ private State noQuarterState;
+ private State hasQuarterState;
+ private State soldState;
+
+ private State state;
+ private int count = 0;
+
+ public GumballMachine(int numberGumballs) {
+ count = numberGumballs;
+ soldOutState = new SoldOutState(this);
+ noQuarterState = new NoQuarterState(this);
+ hasQuarterState = new HasQuarterState(this);
+ soldState = new SoldState(this);
+
+ if (numberGumballs > 0) {
+ state = noQuarterState;
+ } else {
+ state = soldOutState;
+ }
+ }
+
+ public void insertQuarter() {
+ state.insertQuarter();
+ }
+
+ public void ejectQuarter() {
+ state.ejectQuarter();
+ }
+
+ public void turnCrank() {
+ state.turnCrank();
+ state.dispense();
+ }
+
+ public void setState(State state) {
+ this.state = state;
+ }
+
+ public void releaseBall() {
+ System.out.println("A gumball comes rolling out the slot...");
+ if (count != 0) {
+ count -= 1;
+ }
+ }
+
+ public State getSoldOutState() {
+ return soldOutState;
+ }
+
+ public State getNoQuarterState() {
+ return noQuarterState;
+ }
+
+ public State getHasQuarterState() {
+ return hasQuarterState;
+ }
+
+ public State getSoldState() {
+ return soldState;
+ }
+
+ public int getCount() {
+ return count;
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ GumballMachine gumballMachine = new GumballMachine(5);
+
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+
+ gumballMachine.insertQuarter();
+ gumballMachine.ejectQuarter();
+ gumballMachine.turnCrank();
+
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+ gumballMachine.ejectQuarter();
+
+ gumballMachine.insertQuarter();
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+ gumballMachine.insertQuarter();
+ gumballMachine.turnCrank();
+ }
+}
+```
+
+```html
+You insert a quarter
+You turned...
+A gumball comes rolling out the slot...
+You insert a quarter
+Quarter returned
+You turned, but there's no quarter
+You need to pay first
+You insert a quarter
+You turned...
+A gumball comes rolling out the slot...
+You insert a quarter
+You turned...
+A gumball comes rolling out the slot...
+You haven't insert a quarter
+You insert a quarter
+You can't insert another quarter
+You turned...
+A gumball comes rolling out the slot...
+You insert a quarter
+You turned...
+A gumball comes rolling out the slot...
+Oops, out of gumballs
+You can't insert a quarter, the machine is sold out
+You turned, but there are no gumballs
+No gumball dispensed
+```
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
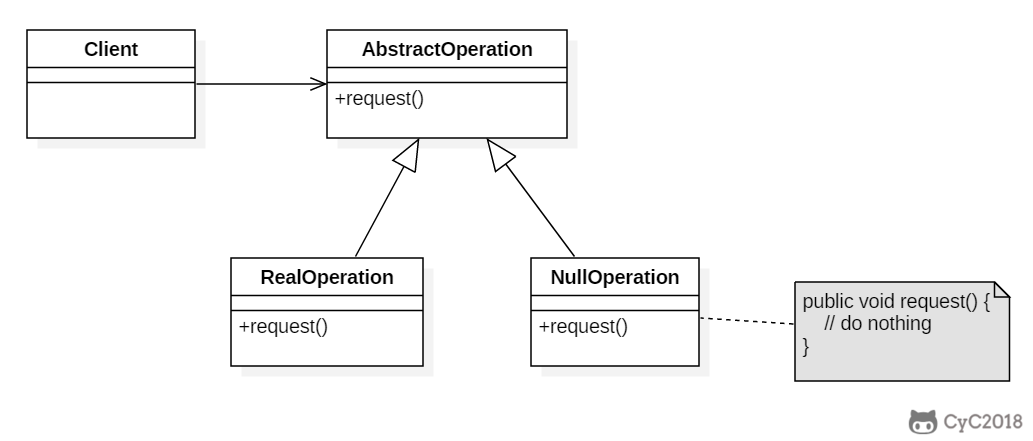
+### Implementation
+
+```java
+public abstract class AbstractOperation {
+ abstract void request();
+}
+```
+
+```java
+public class RealOperation extends AbstractOperation {
+ @Override
+ void request() {
+ System.out.println("do something");
+ }
+}
+```
+
+```java
+public class NullOperation extends AbstractOperation{
+ @Override
+ void request() {
+ // do nothing
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ AbstractOperation abstractOperation = func(-1);
+ abstractOperation.request();
+ }
+
+ public static AbstractOperation func(int para) {
+ if (para < 0) {
+ return new NullOperation();
+ }
+ return new RealOperation();
+ }
+}
+```
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
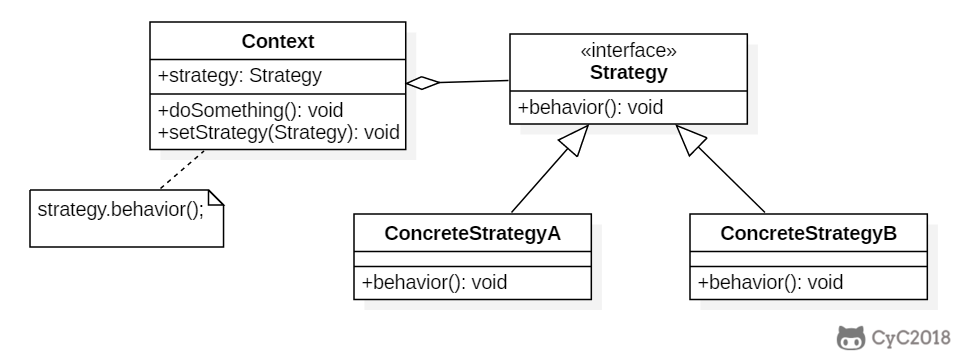
+### 与状态模式的比较
+
+状态模式的类图和策略模式类似,并且都是能够动态改变对象的行为。但是状态模式是通过状态转移来改变 Context 所组合的 State 对象,而策略模式是通过 Context 本身的决策来改变组合的 Strategy 对象。所谓的状态转移,是指 Context 在运行过程中由于一些条件发生改变而使得 State 对象发生改变,注意必须要是在运行过程中。
+
+状态模式主要是用来解决状态转移的问题,当状态发生转移了,那么 Context 对象就会改变它的行为;而策略模式主要是用来封装一组可以互相替代的算法族,并且可以根据需要动态地去替换 Context 使用的算法。
+
+### Implementation
+
+设计一个鸭子,它可以动态地改变叫声。这里的算法族是鸭子的叫声行为。
+
+```java
+public interface QuackBehavior {
+ void quack();
+}
+```
+
+```java
+public class Quack implements QuackBehavior {
+ @Override
+ public void quack() {
+ System.out.println("quack!");
+ }
+}
+```
+
+```java
+public class Squeak implements QuackBehavior{
+ @Override
+ public void quack() {
+ System.out.println("squeak!");
+ }
+}
+```
+
+```java
+public class Duck {
+
+ private QuackBehavior quackBehavior;
+
+ public void performQuack() {
+ if (quackBehavior != null) {
+ quackBehavior.quack();
+ }
+ }
+
+ public void setQuackBehavior(QuackBehavior quackBehavior) {
+ this.quackBehavior = quackBehavior;
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ Duck duck = new Duck();
+ duck.setQuackBehavior(new Squeak());
+ duck.performQuack();
+ duck.setQuackBehavior(new Quack());
+ duck.performQuack();
+ }
+}
+```
+
+```html
+squeak!
+quack!
+```
+
+### JDK
+
+- java.util.Comparator#compare()
+- javax.servlet.http.HttpServlet
+- javax.servlet.Filter#doFilter()
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
+```java
+public interface Product {
+}
+```
+
+```java
+public class ConcreteProduct implements Product {
+}
+```
+
+```java
+public class ConcreteProduct1 implements Product {
+}
+```
+
+```java
+public class ConcreteProduct2 implements Product {
+}
+```
+
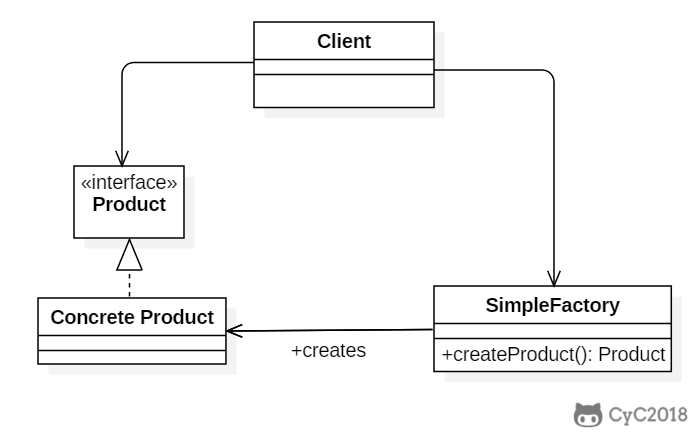
+以下的 Client 类包含了实例化的代码,这是一种错误的实现。如果在客户类中存在这种实例化代码,就需要考虑将代码放到简单工厂中。
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ int type = 1;
+ Product product;
+ if (type == 1) {
+ product = new ConcreteProduct1();
+ } else if (type == 2) {
+ product = new ConcreteProduct2();
+ } else {
+ product = new ConcreteProduct();
+ }
+ // do something with the product
+ }
+}
+```
+
+以下的 SimpleFactory 是简单工厂实现,它被所有需要进行实例化的客户类调用。
+
+```java
+public class SimpleFactory {
+
+ public Product createProduct(int type) {
+ if (type == 1) {
+ return new ConcreteProduct1();
+ } else if (type == 2) {
+ return new ConcreteProduct2();
+ }
+ return new ConcreteProduct();
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ SimpleFactory simpleFactory = new SimpleFactory();
+ Product product = simpleFactory.createProduct(1);
+ // do something with the product
+ }
+}
+```
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
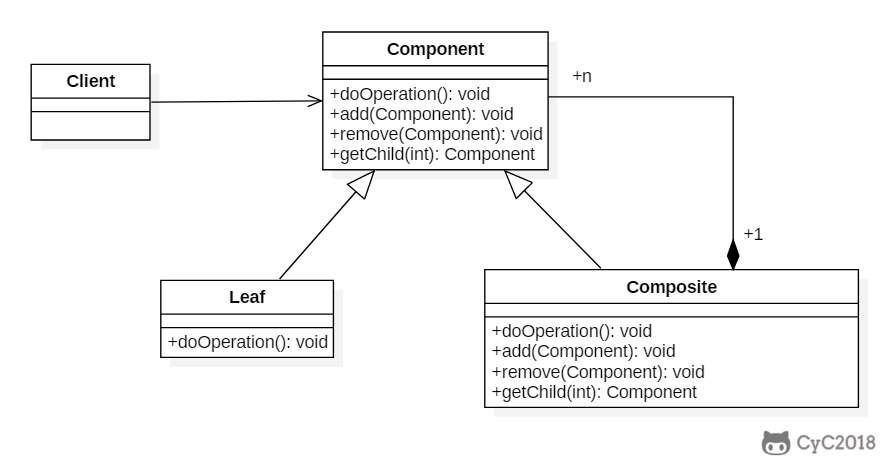
+
+### Implementation
+
+```java
+public abstract class Component {
+ protected String name;
+
+ public Component(String name) {
+ this.name = name;
+ }
+
+ public void print() {
+ print(0);
+ }
+
+ abstract void print(int level);
+
+ abstract public void add(Component component);
+
+ abstract public void remove(Component component);
+}
+```
+
+```java
+public class Composite extends Component {
+
+ private List child;
+
+ public Composite(String name) {
+ super(name);
+ child = new ArrayList<>();
+ }
+
+ @Override
+ void print(int level) {
+ for (int i = 0; i < level; i++) {
+ System.out.print("--");
+ }
+ System.out.println("Composite:" + name);
+ for (Component component : child) {
+ component.print(level + 1);
+ }
+ }
+
+ @Override
+ public void add(Component component) {
+ child.add(component);
+ }
+
+ @Override
+ public void remove(Component component) {
+ child.remove(component);
+ }
+}
+```
+
+```java
+public class Leaf extends Component {
+ public Leaf(String name) {
+ super(name);
+ }
+
+ @Override
+ void print(int level) {
+ for (int i = 0; i < level; i++) {
+ System.out.print("--");
+ }
+ System.out.println("left:" + name);
+ }
+
+ @Override
+ public void add(Component component) {
+ throw new UnsupportedOperationException(); // 牺牲透明性换取单一职责原则,这样就不用考虑是叶子节点还是组合节点
+ }
+
+ @Override
+ public void remove(Component component) {
+ throw new UnsupportedOperationException();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Composite root = new Composite("root");
+ Component node1 = new Leaf("1");
+ Component node2 = new Composite("2");
+ Component node3 = new Leaf("3");
+ root.add(node1);
+ root.add(node2);
+ root.add(node3);
+ Component node21 = new Leaf("21");
+ Component node22 = new Composite("22");
+ node2.add(node21);
+ node2.add(node22);
+ Component node221 = new Leaf("221");
+ node22.add(node221);
+ root.print();
+ }
+}
+```
+
+```html
+Composite:root
+--left:1
+--Composite:2
+----left:21
+----Composite:22
+------left:221
+--left:3
+```
+
+### JDK
+
+- javax.swing.JComponent#add(Component)
+- java.awt.Container#add(Component)
+- java.util.Map#putAll(Map)
+- java.util.List#addAll(Collection)
+- java.util.Set#addAll(Collection)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
+设计不同种类的饮料,饮料可以添加配料,比如可以添加牛奶,并且支持动态添加新配料。每增加一种配料,该饮料的价格就会增加,要求计算一种饮料的价格。
+
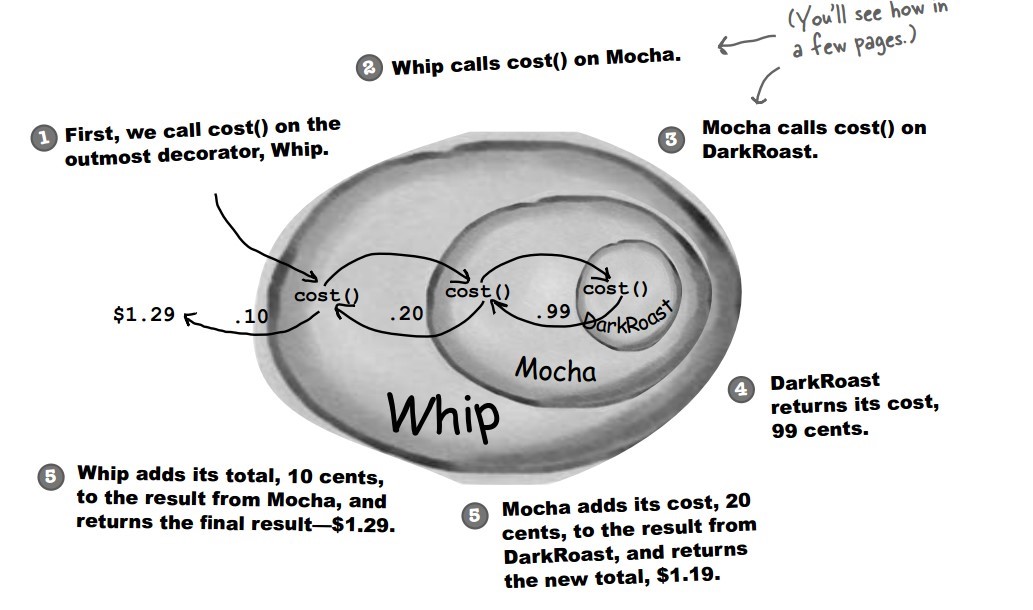
+下图表示在 DarkRoast 饮料上新增新添加 Mocha 配料,之后又添加了 Whip 配料。DarkRoast 被 Mocha 包裹,Mocha 又被 Whip 包裹。它们都继承自相同父类,都有 cost() 方法,外层类的 cost() 方法调用了内层类的 cost() 方法。
+
+
+
+```java
+public interface Beverage {
+ double cost();
+}
+```
+
+```java
+public class DarkRoast implements Beverage {
+ @Override
+ public double cost() {
+ return 1;
+ }
+}
+```
+
+```java
+public class HouseBlend implements Beverage {
+ @Override
+ public double cost() {
+ return 1;
+ }
+}
+```
+
+```java
+public abstract class CondimentDecorator implements Beverage {
+ protected Beverage beverage;
+}
+```
+
+```java
+public class Milk extends CondimentDecorator {
+
+ public Milk(Beverage beverage) {
+ this.beverage = beverage;
+ }
+
+ @Override
+ public double cost() {
+ return 1 + beverage.cost();
+ }
+}
+```
+
+```java
+public class Mocha extends CondimentDecorator {
+
+ public Mocha(Beverage beverage) {
+ this.beverage = beverage;
+ }
+
+ @Override
+ public double cost() {
+ return 1 + beverage.cost();
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ Beverage beverage = new HouseBlend();
+ beverage = new Mocha(beverage);
+ beverage = new Milk(beverage);
+ System.out.println(beverage.cost());
+ }
+}
+```
+
+```html
+3.0
+```
+
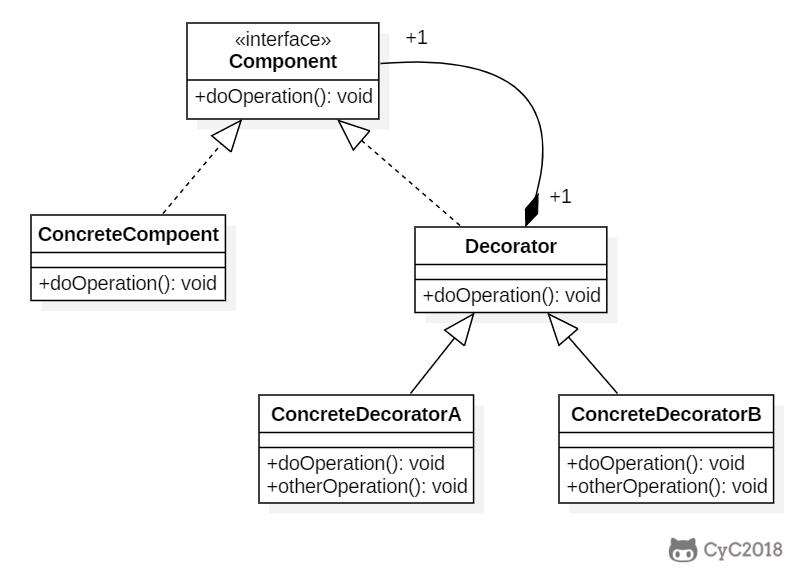
+### 设计原则
+
+类应该对扩展开放,对修改关闭:也就是添加新功能时不需要修改代码。饮料可以动态添加新的配料,而不需要去修改饮料的代码。
+
+不可能把所有的类设计成都满足这一原则,应当把该原则应用于最有可能发生改变的地方。
+
+### JDK
+
+- java.io.BufferedInputStream(InputStream)
+- java.io.DataInputStream(InputStream)
+- java.io.BufferedOutputStream(OutputStream)
+- java.util.zip.ZipOutputStream(OutputStream)
+- java.util.Collections#checked[List|Map|Set|SortedSet|SortedMap]()
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Class Diagram
+
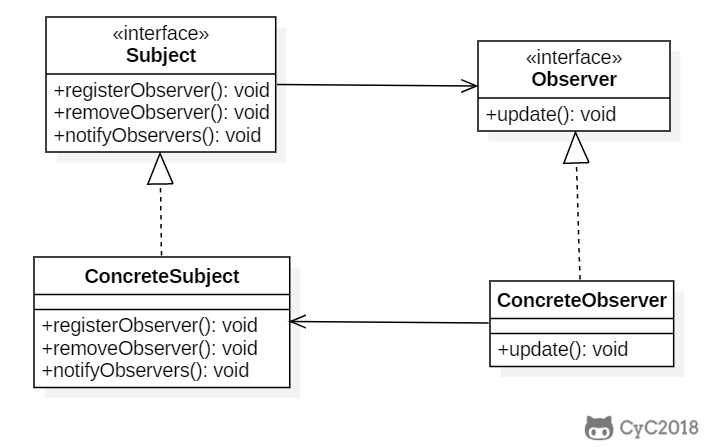
+主题(Subject)具有注册和移除观察者、并通知所有观察者的功能,主题是通过维护一张观察者列表来实现这些操作的。
+
+观察者(Observer)的注册功能需要调用主题的 registerObserver() 方法。
+
+ 
+
+### Implementation
+
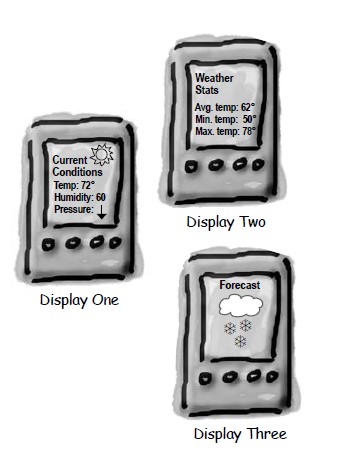
+天气数据布告板会在天气信息发生改变时更新其内容,布告板有多个,并且在将来会继续增加。
+
+ 
+
+```java
+public interface Subject {
+ void registerObserver(Observer o);
+
+ void removeObserver(Observer o);
+
+ void notifyObserver();
+}
+```
+
+```java
+public class WeatherData implements Subject {
+ private List observers;
+ private float temperature;
+ private float humidity;
+ private float pressure;
+
+ public WeatherData() {
+ observers = new ArrayList<>();
+ }
+
+ public void setMeasurements(float temperature, float humidity, float pressure) {
+ this.temperature = temperature;
+ this.humidity = humidity;
+ this.pressure = pressure;
+ notifyObserver();
+ }
+
+ @Override
+ public void registerObserver(Observer o) {
+ observers.add(o);
+ }
+
+ @Override
+ public void removeObserver(Observer o) {
+ int i = observers.indexOf(o);
+ if (i >= 0) {
+ observers.remove(i);
+ }
+ }
+
+ @Override
+ public void notifyObserver() {
+ for (Observer o : observers) {
+ o.update(temperature, humidity, pressure);
+ }
+ }
+}
+```
+
+```java
+public interface Observer {
+ void update(float temp, float humidity, float pressure);
+}
+```
+
+```java
+public class StatisticsDisplay implements Observer {
+
+ public StatisticsDisplay(Subject weatherData) {
+ weatherData.reisterObserver(this);
+ }
+
+ @Override
+ public void update(float temp, float humidity, float pressure) {
+ System.out.println("StatisticsDisplay.update: " + temp + " " + humidity + " " + pressure);
+ }
+}
+```
+
+```java
+public class CurrentConditionsDisplay implements Observer {
+
+ public CurrentConditionsDisplay(Subject weatherData) {
+ weatherData.registerObserver(this);
+ }
+
+ @Override
+ public void update(float temp, float humidity, float pressure) {
+ System.out.println("CurrentConditionsDisplay.update: " + temp + " " + humidity + " " + pressure);
+ }
+}
+```
+
+```java
+public class WeatherStation {
+ public static void main(String[] args) {
+ WeatherData weatherData = new WeatherData();
+ CurrentConditionsDisplay currentConditionsDisplay = new CurrentConditionsDisplay(weatherData);
+ StatisticsDisplay statisticsDisplay = new StatisticsDisplay(weatherData);
+
+ weatherData.setMeasurements(0, 0, 0);
+ weatherData.setMeasurements(1, 1, 1);
+ }
+}
+```
+
+```html
+CurrentConditionsDisplay.update: 0.0 0.0 0.0
+StatisticsDisplay.update: 0.0 0.0 0.0
+CurrentConditionsDisplay.update: 1.0 1.0 1.0
+StatisticsDisplay.update: 1.0 1.0 1.0
+```
+
+### JDK
+
+- [java.util.Observer](http://docs.oracle.com/javase/8/docs/api/java/util/Observer.html)
+- [java.util.EventListener](http://docs.oracle.com/javase/8/docs/api/java/util/EventListener.html)
+- [javax.servlet.http.HttpSessionBindingListener](http://docs.oracle.com/javaee/7/api/javax/servlet/http/HttpSessionBindingListener.html)
+- [RxJava](https://github.com/ReactiveX/RxJava)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
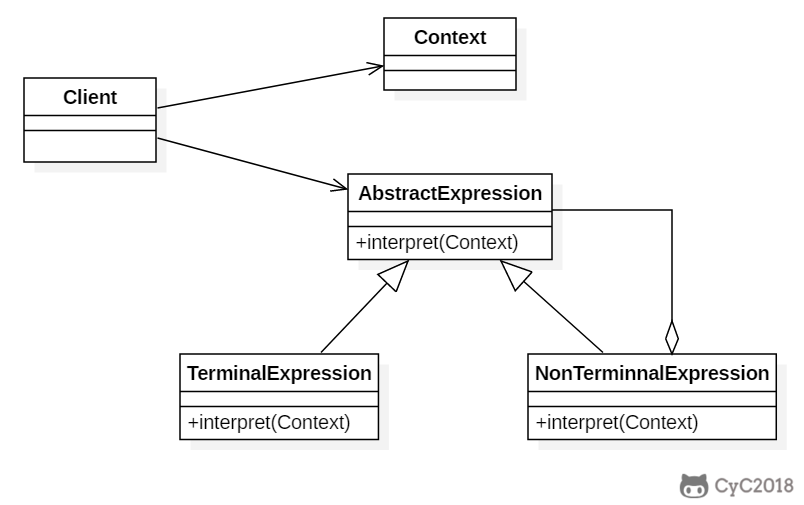
+以下是一个规则检验器实现,具有 and 和 or 规则,通过规则可以构建一颗解析树,用来检验一个文本是否满足解析树定义的规则。
+
+例如一颗解析树为 D And (A Or (B C)),文本 "D A" 满足该解析树定义的规则。
+
+这里的 Context 指的是 String。
+
+```java
+public abstract class Expression {
+ public abstract boolean interpret(String str);
+}
+```
+
+```java
+public class TerminalExpression extends Expression {
+
+ private String literal = null;
+
+ public TerminalExpression(String str) {
+ literal = str;
+ }
+
+ public boolean interpret(String str) {
+ StringTokenizer st = new StringTokenizer(str);
+ while (st.hasMoreTokens()) {
+ String test = st.nextToken();
+ if (test.equals(literal)) {
+ return true;
+ }
+ }
+ return false;
+ }
+}
+```
+
+```java
+public class AndExpression extends Expression {
+
+ private Expression expression1 = null;
+ private Expression expression2 = null;
+
+ public AndExpression(Expression expression1, Expression expression2) {
+ this.expression1 = expression1;
+ this.expression2 = expression2;
+ }
+
+ public boolean interpret(String str) {
+ return expression1.interpret(str) && expression2.interpret(str);
+ }
+}
+```
+
+```java
+public class OrExpression extends Expression {
+ private Expression expression1 = null;
+ private Expression expression2 = null;
+
+ public OrExpression(Expression expression1, Expression expression2) {
+ this.expression1 = expression1;
+ this.expression2 = expression2;
+ }
+
+ public boolean interpret(String str) {
+ return expression1.interpret(str) || expression2.interpret(str);
+ }
+}
+```
+
+```java
+public class Client {
+
+ /**
+ * 构建解析树
+ */
+ public static Expression buildInterpreterTree() {
+ // Literal
+ Expression terminal1 = new TerminalExpression("A");
+ Expression terminal2 = new TerminalExpression("B");
+ Expression terminal3 = new TerminalExpression("C");
+ Expression terminal4 = new TerminalExpression("D");
+ // B C
+ Expression alternation1 = new OrExpression(terminal2, terminal3);
+ // A Or (B C)
+ Expression alternation2 = new OrExpression(terminal1, alternation1);
+ // D And (A Or (B C))
+ return new AndExpression(terminal4, alternation2);
+ }
+
+ public static void main(String[] args) {
+ Expression define = buildInterpreterTree();
+ String context1 = "D A";
+ String context2 = "A B";
+ System.out.println(define.interpret(context1));
+ System.out.println(define.interpret(context2));
+ }
+}
+```
+
+```html
+true
+false
+```
+
+### JDK
+
+- [java.util.Pattern](http://docs.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html)
+- [java.text.Normalizer](http://docs.oracle.com/javase/8/docs/api/java/text/Normalizer.html)
+- All subclasses of [java.text.Format](http://docs.oracle.com/javase/8/docs/api/java/text/Format.html)
+- [javax.el.ELResolver](http://docs.oracle.com/javaee/7/api/javax/el/ELResolver.html)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
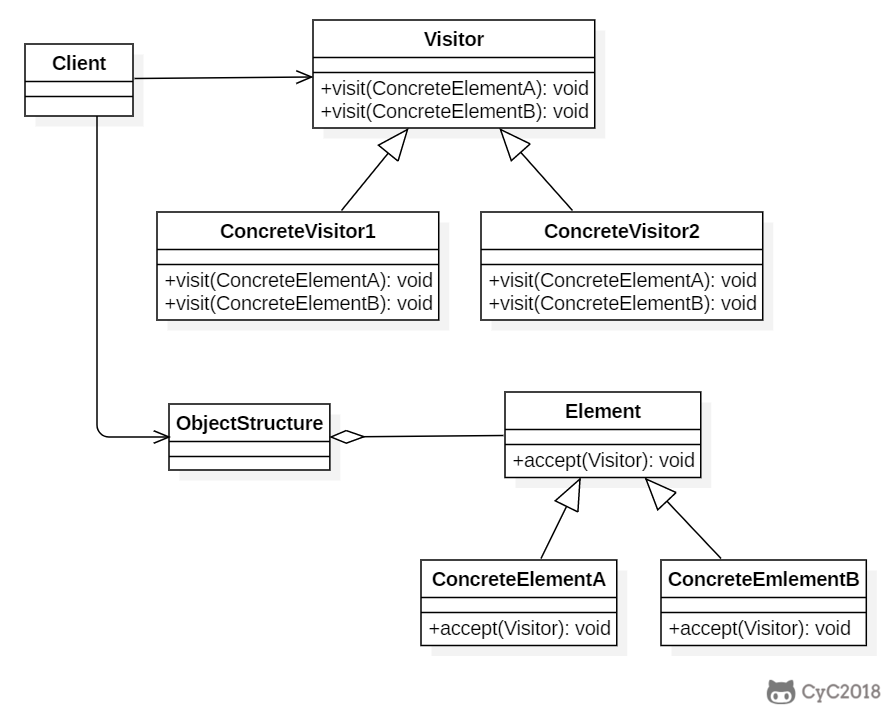
+
+### Implementation
+
+```java
+public interface Element {
+ void accept(Visitor visitor);
+}
+```
+
+```java
+class CustomerGroup {
+
+ private List customers = new ArrayList<>();
+
+ void accept(Visitor visitor) {
+ for (Customer customer : customers) {
+ customer.accept(visitor);
+ }
+ }
+
+ void addCustomer(Customer customer) {
+ customers.add(customer);
+ }
+}
+```
+
+```java
+public class Customer implements Element {
+
+ private String name;
+ private List orders = new ArrayList<>();
+
+ Customer(String name) {
+ this.name = name;
+ }
+
+ String getName() {
+ return name;
+ }
+
+ void addOrder(Order order) {
+ orders.add(order);
+ }
+
+ public void accept(Visitor visitor) {
+ visitor.visit(this);
+ for (Order order : orders) {
+ order.accept(visitor);
+ }
+ }
+}
+```
+
+```java
+public class Order implements Element {
+
+ private String name;
+ private List- items = new ArrayList();
+
+ Order(String name) {
+ this.name = name;
+ }
+
+ Order(String name, String itemName) {
+ this.name = name;
+ this.addItem(new Item(itemName));
+ }
+
+ String getName() {
+ return name;
+ }
+
+ void addItem(Item item) {
+ items.add(item);
+ }
+
+ public void accept(Visitor visitor) {
+ visitor.visit(this);
+
+ for (Item item : items) {
+ item.accept(visitor);
+ }
+ }
+}
+```
+
+```java
+public class Item implements Element {
+
+ private String name;
+
+ Item(String name) {
+ this.name = name;
+ }
+
+ String getName() {
+ return name;
+ }
+
+ public void accept(Visitor visitor) {
+ visitor.visit(this);
+ }
+}
+```
+
+```java
+public interface Visitor {
+ void visit(Customer customer);
+
+ void visit(Order order);
+
+ void visit(Item item);
+}
+```
+
+```java
+public class GeneralReport implements Visitor {
+
+ private int customersNo;
+ private int ordersNo;
+ private int itemsNo;
+
+ public void visit(Customer customer) {
+ System.out.println(customer.getName());
+ customersNo++;
+ }
+
+ public void visit(Order order) {
+ System.out.println(order.getName());
+ ordersNo++;
+ }
+
+ public void visit(Item item) {
+ System.out.println(item.getName());
+ itemsNo++;
+ }
+
+ public void displayResults() {
+ System.out.println("Number of customers: " + customersNo);
+ System.out.println("Number of orders: " + ordersNo);
+ System.out.println("Number of items: " + itemsNo);
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Customer customer1 = new Customer("customer1");
+ customer1.addOrder(new Order("order1", "item1"));
+ customer1.addOrder(new Order("order2", "item1"));
+ customer1.addOrder(new Order("order3", "item1"));
+
+ Order order = new Order("order_a");
+ order.addItem(new Item("item_a1"));
+ order.addItem(new Item("item_a2"));
+ order.addItem(new Item("item_a3"));
+ Customer customer2 = new Customer("customer2");
+ customer2.addOrder(order);
+
+ CustomerGroup customers = new CustomerGroup();
+ customers.addCustomer(customer1);
+ customers.addCustomer(customer2);
+
+ GeneralReport visitor = new GeneralReport();
+ customers.accept(visitor);
+ visitor.displayResults();
+ }
+}
+```
+
+```html
+customer1
+order1
+item1
+order2
+item1
+order3
+item1
+customer2
+order_a
+item_a1
+item_a2
+item_a3
+Number of customers: 2
+Number of orders: 4
+Number of items: 6
+```
+
+### JDK
+
+- javax.lang.model.element.Element and javax.lang.model.element.ElementVisitor
+- javax.lang.model.type.TypeMirror and javax.lang.model.type.TypeVisitor
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
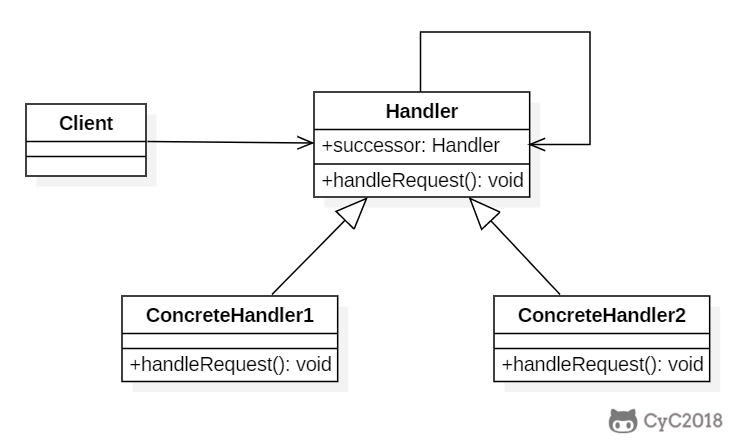
+```java
+public abstract class Handler {
+
+ protected Handler successor;
+
+
+ public Handler(Handler successor) {
+ this.successor = successor;
+ }
+
+
+ protected abstract void handleRequest(Request request);
+}
+```
+
+```java
+public class ConcreteHandler1 extends Handler {
+
+ public ConcreteHandler1(Handler successor) {
+ super(successor);
+ }
+
+
+ @Override
+ protected void handleRequest(Request request) {
+ if (request.getType() == RequestType.TYPE1) {
+ System.out.println(request.getName() + " is handle by ConcreteHandler1");
+ return;
+ }
+ if (successor != null) {
+ successor.handleRequest(request);
+ }
+ }
+}
+```
+
+```java
+public class ConcreteHandler2 extends Handler {
+
+ public ConcreteHandler2(Handler successor) {
+ super(successor);
+ }
+
+
+ @Override
+ protected void handleRequest(Request request) {
+ if (request.getType() == RequestType.TYPE2) {
+ System.out.println(request.getName() + " is handle by ConcreteHandler2");
+ return;
+ }
+ if (successor != null) {
+ successor.handleRequest(request);
+ }
+ }
+}
+```
+
+```java
+public class Request {
+
+ private RequestType type;
+ private String name;
+
+
+ public Request(RequestType type, String name) {
+ this.type = type;
+ this.name = name;
+ }
+
+
+ public RequestType getType() {
+ return type;
+ }
+
+
+ public String getName() {
+ return name;
+ }
+}
+
+```
+
+```java
+public enum RequestType {
+ TYPE1, TYPE2
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+
+ Handler handler1 = new ConcreteHandler1(null);
+ Handler handler2 = new ConcreteHandler2(handler1);
+
+ Request request1 = new Request(RequestType.TYPE1, "request1");
+ handler2.handleRequest(request1);
+
+ Request request2 = new Request(RequestType.TYPE2, "request2");
+ handler2.handleRequest(request2);
+ }
+}
+```
+
+```html
+request1 is handle by ConcreteHandler1
+request2 is handle by ConcreteHandler2
+```
+
+### JDK
+
+- [java.util.logging.Logger#log()](http://docs.oracle.com/javase/8/docs/api/java/util/logging/Logger.html#log%28java.util.logging.Level,%20java.lang.String%29)
+- [Apache Commons Chain](https://commons.apache.org/proper/commons-chain/index.html)
+- [javax.servlet.Filter#doFilter()](http://docs.oracle.com/javaee/7/api/javax/servlet/Filter.html#doFilter-javax.servlet.ServletRequest-javax.servlet.ServletResponse-javax.servlet.FilterChain-)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Implementation
+
+```java
+public interface Aggregate {
+ Iterator createIterator();
+}
+```
+
+```java
+public class ConcreteAggregate implements Aggregate {
+
+ private Integer[] items;
+
+ public ConcreteAggregate() {
+ items = new Integer[10];
+ for (int i = 0; i < items.length; i++) {
+ items[i] = i;
+ }
+ }
+
+ @Override
+ public Iterator createIterator() {
+ return new ConcreteIterator(items);
+ }
+}
+```
+
+```java
+public interface Iterator- {
+
+ Item next();
+
+ boolean hasNext();
+}
+```
+
+```java
+public class ConcreteIterator
- implements Iterator {
+
+ private Item[] items;
+ private int position = 0;
+
+ public ConcreteIterator(Item[] items) {
+ this.items = items;
+ }
+
+ @Override
+ public Object next() {
+ return items[position++];
+ }
+
+ @Override
+ public boolean hasNext() {
+ return position < items.length;
+ }
+}
+```
+
+```java
+public class Client {
+
+ public static void main(String[] args) {
+ Aggregate aggregate = new ConcreteAggregate();
+ Iterator iterator = aggregate.createIterator();
+ while (iterator.hasNext()) {
+ System.out.println(iterator.next());
+ }
+ }
+}
+```
+
+### JDK
+
+- [java.util.Iterator](http://docs.oracle.com/javase/8/docs/api/java/util/Iterator.html)
+- [java.util.Enumeration](http://docs.oracle.com/javase/8/docs/api/java/util/Enumeration.html)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+### Class Diagram
+
+
+
+### Implementation
+
+鸭子(Duck)和火鸡(Turkey)拥有不同的叫声,Duck 的叫声调用 quack() 方法,而 Turkey 调用 gobble() 方法。
+
+要求将 Turkey 的 gobble() 方法适配成 Duck 的 quack() 方法,从而让火鸡冒充鸭子!
+
+```java
+public interface Duck {
+ void quack();
+}
+```
+
+```java
+public interface Turkey {
+ void gobble();
+}
+```
+
+```java
+public class WildTurkey implements Turkey {
+ @Override
+ public void gobble() {
+ System.out.println("gobble!");
+ }
+}
+```
+
+```java
+public class TurkeyAdapter implements Duck {
+ Turkey turkey;
+
+ public TurkeyAdapter(Turkey turkey) {
+ this.turkey = turkey;
+ }
+
+ @Override
+ public void quack() {
+ turkey.gobble();
+ }
+}
+```
+
+```java
+public class Client {
+ public static void main(String[] args) {
+ Turkey turkey = new WildTurkey();
+ Duck duck = new TurkeyAdapter(turkey);
+ duck.quack();
+ }
+}
+```
+
+### JDK
+
+- [java.util.Arrays#asList()](http://docs.oracle.com/javase/8/docs/api/java/util/Arrays.html#asList%28T...%29)
+- [java.util.Collections#list()](https://docs.oracle.com/javase/8/docs/api/java/util/Collections.html#list-java.util.Enumeration-)
+- [java.util.Collections#enumeration()](https://docs.oracle.com/javase/8/docs/api/java/util/Collections.html#enumeration-java.util.Collection-)
+- [javax.xml.bind.annotation.adapters.XMLAdapter](http://docs.oracle.com/javase/8/docs/api/javax/xml/bind/annotation/adapters/XmlAdapter.html#marshal-BoundType-)
+
+你可以通过下方扫码回复【进群】,加入我们的高端计算机学习群!以及下载超过 100 张高清思维导图!
+
+
+
+
+
+
+
+- 一般指令模式(Command mode):VIM 的默认模式,可以用于移动游标查看内容;
+- 编辑模式(Insert mode):按下 "i" 等按键之后进入,可以对文本进行编辑;
+- 指令列模式(Bottom-line mode):按下 ":" 按键之后进入,用于保存退出等操作。
+
+在指令列模式下,有以下命令用于离开或者保存文件。
+
+| 命令 | 作用 |
+| :--: | :--: |
+| :w | 写入磁盘|
+| :w! | 当文件为只读时,强制写入磁盘。到底能不能写入,与用户对该文件的权限有关 |
+| :q | 离开 |
+| :q! | 强制离开不保存 |
+| :wq | 写入磁盘后离开 |
+| :wq!| 强制写入磁盘后离开 |
+
+## GNU
+
+GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操作系统,称为 GNU,其内容软件完全以 GPL 方式发布。其中 GPL 全称为 GNU 通用公共许可协议(GNU General Public License),包含了以下内容:
+
+- 以任何目的运行此程序的自由;
+- 再复制的自由;
+- 改进此程序,并公开发布改进的自由。
+
+## 开源协议
+
+- [Choose an open source license](https://choosealicense.com/)
+- [如何选择开源许可证?](http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html)
+
+# 二、磁盘
+
+## 磁盘接口
+
+### 1. IDE
+
+IDE(ATA)全称 Advanced Technology Attachment,接口速度最大为 133MB/s,因为并口线的抗干扰性太差,且排线占用空间较大,不利电脑内部散热,已逐渐被 SATA 所取代。
+
+
+
+### 2. SATA
+
+SATA 全称 Serial ATA,也就是使用串口的 ATA 接口,抗干扰性强,且对数据线的长度要求比 ATA 低很多,支持热插拔等功能。SATA-II 的接口速度为 300MB/s,而 SATA-III 标准可达到 600MB/s 的传输速度。SATA 的数据线也比 ATA 的细得多,有利于机箱内的空气流通,整理线材也比较方便。
+
+
+
+### 3. SCSI
+
+SCSI 全称是 Small Computer System Interface(小型机系统接口),SCSI 硬盘广为工作站以及个人电脑以及服务器所使用,因此会使用较为先进的技术,如碟片转速 15000rpm 的高转速,且传输时 CPU 占用率较低,但是单价也比相同容量的 ATA 及 SATA 硬盘更加昂贵。
+
+
+
+### 4. SAS
+
+SAS(Serial Attached SCSI)是新一代的 SCSI 技术,和 SATA 硬盘相同,都是采取序列式技术以获得更高的传输速度,可达到 6Gb/s。此外也通过缩小连接线改善系统内部空间等。
+
+
+
+## 磁盘的文件名
+
+Linux 中每个硬件都被当做一个文件,包括磁盘。磁盘以磁盘接口类型进行命名,常见磁盘的文件名如下:
+
+- IDE 磁盘:/dev/hd[a-d]
+- SATA/SCSI/SAS 磁盘:/dev/sd[a-p]
+
+其中文件名后面的序号的确定与系统检测到磁盘的顺序有关,而与磁盘所插入的插槽位置无关。
+
+# 三、分区
+
+## 分区表
+
+磁盘分区表主要有两种格式,一种是限制较多的 MBR 分区表,一种是较新且限制较少的 GPT 分区表。
+
+### 1. MBR
+
+MBR 中,第一个扇区最重要,里面有主要开机记录(Master boot record, MBR)及分区表(partition table),其中主要开机记录占 446 bytes,分区表占 64 bytes。
+
+分区表只有 64 bytes,最多只能存储 4 个分区,这 4 个分区为主分区(Primary)和扩展分区(Extended)。其中扩展分区只有一个,它使用其它扇区来记录额外的分区表,因此通过扩展分区可以分出更多分区,这些分区称为逻辑分区。
+
+Linux 也把分区当成文件,分区文件的命名方式为:磁盘文件名 + 编号,例如 /dev/sda1。注意,逻辑分区的编号从 5 开始。
+
+### 2. GPT
+
+扇区是磁盘的最小存储单位,旧磁盘的扇区大小通常为 512 bytes,而最新的磁盘支持 4 k。GPT 为了兼容所有磁盘,在定义扇区上使用逻辑区块地址(Logical Block Address, LBA),LBA 默认大小为 512 bytes。
+
+GPT 第 1 个区块记录了主要开机记录(MBR),紧接着是 33 个区块记录分区信息,并把最后的 33 个区块用于对分区信息进行备份。这 33 个区块第一个为 GPT 表头纪录,这个部份纪录了分区表本身的位置与大小和备份分区的位置,同时放置了分区表的校验码 (CRC32),操作系统可以根据这个校验码来判断 GPT 是否正确。若有错误,可以使用备份分区进行恢复。
+
+GPT 没有扩展分区概念,都是主分区,每个 LBA 可以分 4 个分区,因此总共可以分 4 * 32 = 128 个分区。
+
+MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 233 TB = 8 ZB。
+
+
+
+## 开机检测程序
+
+### 1. BIOS
+
+BIOS(Basic Input/Output System,基本输入输出系统),它是一个固件(嵌入在硬件中的软件),BIOS 程序存放在断电后内容不会丢失的只读内存中。
+
+
+
+BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可以开机的磁盘,并读取磁盘第一个扇区的主要开机记录(MBR),由主要开机记录(MBR)执行其中的开机管理程序,这个开机管理程序会加载操作系统的核心文件。
+
+主要开机记录(MBR)中的开机管理程序提供以下功能:选单、载入核心文件以及转交其它开机管理程序。转交这个功能可以用来实现多重引导,只需要将另一个操作系统的开机管理程序安装在其它分区的启动扇区上,在启动开机管理程序时,就可以通过选单选择启动当前的操作系统或者转交给其它开机管理程序从而启动另一个操作系统。
+
+下图中,第一扇区的主要开机记录(MBR)中的开机管理程序提供了两个选单:M1、M2,M1 指向了 Windows 操作系统,而 M2 指向其它分区的启动扇区,里面包含了另外一个开机管理程序,提供了一个指向 Linux 的选单。
+
+
+
+安装多重引导,最好先安装 Windows 再安装 Linux。因为安装 Windows 时会覆盖掉主要开机记录(MBR),而 Linux 可以选择将开机管理程序安装在主要开机记录(MBR)或者其它分区的启动扇区,并且可以设置开机管理程序的选单。
+
+### 2. UEFI
+
+BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
+
+# 四、文件系统
+
+## 分区与文件系统
+
+对分区进行格式化是为了在分区上建立文件系统。一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统。
+
+## 组成
+
+最主要的几个组成部分如下:
+
+- inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号;
+- block:记录文件的内容,文件太大时,会占用多个 block。
+
+除此之外还包括:
+
+- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
+- block bitmap:记录 block 是否被使用的位图。
+
+
+
+## 文件读取
+
+对于 Ext2 文件系统,当要读取一个文件的内容时,先在 inode 中查找文件内容所在的所有 block,然后把所有 block 的内容读出来。
+
+
+
+而对于 FAT 文件系统,它没有 inode,每个 block 中存储着下一个 block 的编号。
+
+
+
+## 磁盘碎片
+
+指一个文件内容所在的 block 过于分散,导致磁盘磁头移动距离过大,从而降低磁盘读写性能。
+
+## block
+
+在 Ext2 文件系统中所支持的 block 大小有 1K,2K 及 4K 三种,不同的大小限制了单个文件和文件系统的最大大小。
+
+| 大小 | 1KB | 2KB | 4KB |
+| :---: | :---: | :---: | :---: |
+| 最大单一文件 | 16GB | 256GB | 2TB |
+| 最大文件系统 | 2TB | 8TB | 16TB |
+
+一个 block 只能被一个文件所使用,未使用的部分直接浪费了。因此如果需要存储大量的小文件,那么最好选用比较小的 block。
+
+## inode
+
+inode 具体包含以下信息:
+
+- 权限 (read/write/excute);
+- 拥有者与群组 (owner/group);
+- 容量;
+- 建立或状态改变的时间 (ctime);
+- 最近读取时间 (atime);
+- 最近修改时间 (mtime);
+- 定义文件特性的旗标 (flag),如 SetUID...;
+- 该文件真正内容的指向 (pointer)。
+
+inode 具有以下特点:
+
+- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
+- 每个文件都仅会占用一个 inode。
+
+inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息。
+
+
+
+## 目录
+
+建立一个目录时,会分配一个 inode 与至少一个 block。block 记录的内容是目录下所有文件的 inode 编号以及文件名。
+
+可以看到文件的 inode 本身不记录文件名,文件名记录在目录中,因此新增文件、删除文件、更改文件名这些操作与目录的写权限有关。
+
+## 日志
+
+如果突然断电,那么文件系统会发生错误,例如断电前只修改了 block bitmap,而还没有将数据真正写入 block 中。
+
+ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件系统。
+
+## 挂载
+
+挂载利用目录作为文件系统的进入点,也就是说,进入目录之后就可以读取文件系统的数据。
+
+## 目录配置
+
+为了使不同 Linux 发行版本的目录结构保持一致性,Filesystem Hierarchy Standard (FHS) 规定了 Linux 的目录结构。最基础的三个目录如下:
+
+- / (root, 根目录)
+- /usr (unix software resource):所有系统默认软件都会安装到这个目录;
+- /var (variable):存放系统或程序运行过程中的数据文件。
+
+
+
+# 五、文件
+
+## 文件属性
+
+用户分为三种:文件拥有者、群组以及其它人,对不同的用户有不同的文件权限。
+
+使用 ls 查看一个文件时,会显示一个文件的信息,例如 `drwxr-xr-x 3 root root 17 May 6 00:14 .config`,对这个信息的解释如下:
+
+- drwxr-xr-x:文件类型以及权限,第 1 位为文件类型字段,后 9 位为文件权限字段
+- 3:链接数
+- root:文件拥有者
+- root:所属群组
+- 17:文件大小
+- May 6 00:14:文件最后被修改的时间
+- .config:文件名
+
+常见的文件类型及其含义有:
+
+- d:目录
+- -:文件
+- l:链接文件
+
+9 位的文件权限字段中,每 3 个为一组,共 3 组,每一组分别代表对文件拥有者、所属群组以及其它人的文件权限。一组权限中的 3 位分别为 r、w、x 权限,表示可读、可写、可执行。
+
+文件时间有以下三种:
+
+- modification time (mtime):文件的内容更新就会更新;
+- status time (ctime):文件的状态(权限、属性)更新就会更新;
+- access time (atime):读取文件时就会更新。
+
+## 文件与目录的基本操作
+
+### 1. ls
+
+列出文件或者目录的信息,目录的信息就是其中包含的文件。
+
+```html
+# ls [-aAdfFhilnrRSt] file|dir
+-a :列出全部的文件
+-d :仅列出目录本身
+-l :以长数据串行列出,包含文件的属性与权限等等数据
+```
+
+### 2. cd
+
+更换当前目录。
+
+```
+cd [相对路径或绝对路径]
+```
+
+### 3. mkdir
+
+创建目录。
+
+```
+# mkdir [-mp] 目录名称
+-m :配置目录权限
+-p :递归创建目录
+```
+
+### 4. rmdir
+
+删除目录,目录必须为空。
+
+```html
+rmdir [-p] 目录名称
+-p :递归删除目录
+```
+
+### 5. touch
+
+更新文件时间或者建立新文件。
+
+```html
+# touch [-acdmt] filename
+-a : 更新 atime
+-c : 更新 ctime,若该文件不存在则不建立新文件
+-m : 更新 mtime
+-d : 后面可以接更新日期而不使用当前日期,也可以使用 --date="日期或时间"
+-t : 后面可以接更新时间而不使用当前时间,格式为[YYYYMMDDhhmm]
+```
+
+### 6. cp
+
+复制文件。如果源文件有两个以上,则目的文件一定要是目录才行。
+
+```html
+cp [-adfilprsu] source destination
+-a :相当于 -dr --preserve=all
+-d :若来源文件为链接文件,则复制链接文件属性而非文件本身
+-i :若目标文件已经存在时,在覆盖前会先询问
+-p :连同文件的属性一起复制过去
+-r :递归复制
+-u :destination 比 source 旧才更新 destination,或 destination 不存在的情况下才复制
+--preserve=all :除了 -p 的权限相关参数外,还加入 SELinux 的属性, links, xattr 等也复制了
+```
+
+### 7. rm
+
+删除文件。
+
+```html
+# rm [-fir] 文件或目录
+-r :递归删除
+```
+
+### 8. mv
+
+移动文件。
+
+```html
+# mv [-fiu] source destination
+# mv [options] source1 source2 source3 .... directory
+-f : force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖
+```
+
+## 修改权限
+
+可以将一组权限用数字来表示,此时一组权限的 3 个位当做二进制数字的位,从左到右每个位的权值为 4、2、1,即每个权限对应的数字权值为 r : 4、w : 2、x : 1。
+
+```html
+# chmod [-R] xyz dirname/filename
+```
+
+示例:将 .bashrc 文件的权限修改为 -rwxr-xr--。
+
+```html
+# chmod 754 .bashrc
+```
+
+也可以使用符号来设定权限。
+
+```html
+# chmod [ugoa] [+-=] [rwx] dirname/filename
+- u:拥有者
+- g:所属群组
+- o:其他人
+- a:所有人
+- +:添加权限
+- -:移除权限
+- =:设定权限
+```
+
+示例:为 .bashrc 文件的所有用户添加写权限。
+
+```html
+# chmod a+w .bashrc
+```
+
+## 默认权限
+
+- 文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
+- 目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
+
+可以通过 umask 设置或者查看默认权限,通常以掩码的形式来表示,例如 002 表示其它用户的权限去除了一个 2 的权限,也就是写权限,因此建立新文件时默认的权限为 -rw-rw-r--。
+
+## 目录的权限
+
+文件名不是存储在一个文件的内容中,而是存储在一个文件所在的目录中。因此,拥有文件的 w 权限并不能对文件名进行修改。
+
+目录存储文件列表,一个目录的权限也就是对其文件列表的权限。因此,目录的 r 权限表示可以读取文件列表;w 权限表示可以修改文件列表,具体来说,就是添加删除文件,对文件名进行修改;x 权限可以让该目录成为工作目录,x 权限是 r 和 w 权限的基础,如果不能使一个目录成为工作目录,也就没办法读取文件列表以及对文件列表进行修改了。
+
+## 链接
+
+
+
+
+```html
+# ln [-sf] source_filename dist_filename
+-s :默认是实体链接,加 -s 为符号链接
+-f :如果目标文件存在时,先删除目标文件
+```
+
+### 1. 实体链接
+
+在目录下创建一个条目,记录着文件名与 inode 编号,这个 inode 就是源文件的 inode。
+
+删除任意一个条目,文件还是存在,只要引用数量不为 0。
+
+有以下限制:不能跨越文件系统、不能对目录进行链接。
+
+```html
+# ln /etc/crontab .
+# ll -i /etc/crontab crontab
+34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 crontab
+34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
+```
+
+### 2. 符号链接
+
+符号链接文件保存着源文件所在的绝对路径,在读取时会定位到源文件上,可以理解为 Windows 的快捷方式。
+
+当源文件被删除了,链接文件就打不开了。
+
+因为记录的是路径,所以可以为目录建立符号链接。
+
+```html
+# ll -i /etc/crontab /root/crontab2
+34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab
+53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
+```
+
+## 获取文件内容
+
+### 1. cat
+
+取得文件内容。
+
+```html
+# cat [-AbEnTv] filename
+-n :打印出行号,连同空白行也会有行号,-b 不会
+```
+
+### 2. tac
+
+是 cat 的反向操作,从最后一行开始打印。
+
+### 3. more
+
+和 cat 不同的是它可以一页一页查看文件内容,比较适合大文件的查看。
+
+### 4. less
+
+和 more 类似,但是多了一个向前翻页的功能。
+
+### 5. head
+
+取得文件前几行。
+
+```html
+# head [-n number] filename
+-n :后面接数字,代表显示几行的意思
+```
+
+### 6. tail
+
+是 head 的反向操作,只是取得是后几行。
+
+### 7. od
+
+以字符或者十六进制的形式显示二进制文件。
+
+## 指令与文件搜索
+
+### 1. which
+
+指令搜索。
+
+```html
+# which [-a] command
+-a :将所有指令列出,而不是只列第一个
+```
+
+### 2. whereis
+
+文件搜索。速度比较快,因为它只搜索几个特定的目录。
+
+```html
+# whereis [-bmsu] dirname/filename
+```
+
+### 3. locate
+
+文件搜索。可以用关键字或者正则表达式进行搜索。
+
+locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内存中,并且每天更新一次,所以无法用 locate 搜索新建的文件。可以使用 updatedb 来立即更新数据库。
+
+```html
+# locate [-ir] keyword
+-r:正则表达式
+```
+
+### 4. find
+
+文件搜索。可以使用文件的属性和权限进行搜索。
+
+```html
+# find [basedir] [option]
+example: find . -name "shadow*"
+```
+
+**① 与时间有关的选项**
+
+```html
+-mtime n :列出在 n 天前的那一天修改过内容的文件
+-mtime +n :列出在 n 天之前 (不含 n 天本身) 修改过内容的文件
+-mtime -n :列出在 n 天之内 (含 n 天本身) 修改过内容的文件
+-newer file : 列出比 file 更新的文件
+```
+
++4、4 和 -4 的指示的时间范围如下:
+
+
+
+**② 与文件拥有者和所属群组有关的选项**
+
+```html
+-uid n
+-gid n
+-user name
+-group name
+-nouser :搜索拥有者不存在 /etc/passwd 的文件
+-nogroup:搜索所属群组不存在于 /etc/group 的文件
+```
+
+**③ 与文件权限和名称有关的选项**
+
+```html
+-name filename
+-size [+-]SIZE:搜寻比 SIZE 还要大 (+) 或小 (-) 的文件。这个 SIZE 的规格有:c: 代表 byte,k: 代表 1024bytes。所以,要找比 50KB 还要大的文件,就是 -size +50k
+-type TYPE
+-perm mode :搜索权限等于 mode 的文件
+-perm -mode :搜索权限包含 mode 的文件
+-perm /mode :搜索权限包含任一 mode 的文件
+```
+
+# 六、压缩与打包
+
+## 压缩文件名
+
+Linux 底下有很多压缩文件名,常见的如下:
+
+| 扩展名 | 压缩程序 |
+| -- | -- |
+| \*.Z | compress |
+|\*.zip | zip |
+|\*.gz | gzip|
+|\*.bz2 | bzip2 |
+|\*.xz | xz |
+|\*.tar | tar 程序打包的数据,没有经过压缩 |
+|\*.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
+|\*.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
+|\*.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
+
+## 压缩指令
+
+### 1. gzip
+
+gzip 是 Linux 使用最广的压缩指令,可以解开 compress、zip 与 gzip 所压缩的文件。
+
+经过 gzip 压缩过,源文件就不存在了。
+
+有 9 个不同的压缩等级可以使用。
+
+可以使用 zcat、zmore、zless 来读取压缩文件的内容。
+
+```html
+$ gzip [-cdtv#] filename
+-c :将压缩的数据输出到屏幕上
+-d :解压缩
+-t :检验压缩文件是否出错
+-v :显示压缩比等信息
+-# : # 为数字的意思,代表压缩等级,数字越大压缩比越高,默认为 6
+```
+
+### 2. bzip2
+
+提供比 gzip 更高的压缩比。
+
+查看命令:bzcat、bzmore、bzless、bzgrep。
+
+```html
+$ bzip2 [-cdkzv#] filename
+-k :保留源文件
+```
+
+### 3. xz
+
+提供比 bzip2 更佳的压缩比。
+
+可以看到,gzip、bzip2、xz 的压缩比不断优化。不过要注意的是,压缩比越高,压缩的时间也越长。
+
+查看命令:xzcat、xzmore、xzless、xzgrep。
+
+```html
+$ xz [-dtlkc#] filename
+```
+
+## 打包
+
+压缩指令只能对一个文件进行压缩,而打包能够将多个文件打包成一个大文件。tar 不仅可以用于打包,也可以使用 gzip、bzip2、xz 将打包文件进行压缩。
+
+```html
+$ tar [-z|-j|-J] [cv] [-f 新建的 tar 文件] filename... ==打包压缩
+$ tar [-z|-j|-J] [tv] [-f 已有的 tar 文件] ==查看
+$ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
+-z :使用 zip;
+-j :使用 bzip2;
+-J :使用 xz;
+-c :新建打包文件;
+-t :查看打包文件里面有哪些文件;
+-x :解打包或解压缩的功能;
+-v :在压缩/解压缩的过程中,显示正在处理的文件名;
+-f : filename:要处理的文件;
+-C 目录 : 在特定目录解压缩。
+```
+
+| 使用方式 | 命令 |
+| :---: | --- |
+| 打包压缩 | tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 |
+| 查 看 | tar -jtv -f filename.tar.bz2 |
+| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
+
+# 七、Bash
+
+可以通过 Shell 请求内核提供服务,Bash 正是 Shell 的一种。
+
+## 特性
+
+- 命令历史:记录使用过的命令
+- 命令与文件补全:快捷键:tab
+- 命名别名:例如 ll 是 ls -al 的别名
+- shell scripts
+- 通配符:例如 ls -l /usr/bin/X\* 列出 /usr/bin 下面所有以 X 开头的文件
+
+## 变量操作
+
+对一个变量赋值直接使用 =。
+
+对变量取用需要在变量前加上 \$ ,也可以用 \${} 的形式;
+
+输出变量使用 echo 命令。
+
+```bash
+$ x=abc
+$ echo $x
+$ echo ${x}
+```
+
+变量内容如果有空格,必须使用双引号或者单引号。
+
+- 双引号内的特殊字符可以保留原本特性,例如 x="lang is \$LANG",则 x 的值为 lang is zh_TW.UTF-8;
+- 单引号内的特殊字符就是特殊字符本身,例如 x='lang is \$LANG',则 x 的值为 lang is \$LANG。
+
+可以使用 \`指令\` 或者 \$(指令) 的方式将指令的执行结果赋值给变量。例如 version=\$(uname -r),则 version 的值为 4.15.0-22-generic。
+
+可以使用 export 命令将自定义变量转成环境变量,环境变量可以在子程序中使用,所谓子程序就是由当前 Bash 而产生的子 Bash。
+
+Bash 的变量可以声明为数组和整数数字。注意数字类型没有浮点数。如果不进行声明,默认是字符串类型。变量的声明使用 declare 命令:
+
+```html
+$ declare [-aixr] variable
+-a : 定义为数组类型
+-i : 定义为整数类型
+-x : 定义为环境变量
+-r : 定义为 readonly 类型
+```
+
+使用 [ ] 来对数组进行索引操作:
+
+```bash
+$ array[1]=a
+$ array[2]=b
+$ echo ${array[1]}
+```
+
+## 指令搜索顺序
+
+- 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
+- 由别名找到该指令来执行;
+- 由 Bash 内置的指令来执行;
+- 按 \$PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
+
+## 数据流重定向
+
+重定向指的是使用文件代替标准输入、标准输出和标准错误输出。
+
+| 1 | 代码 | 运算符 |
+| :---: | :---: | :---:|
+| 标准输入 (stdin) | 0 | < 或 << |
+| 标准输出 (stdout) | 1 | > 或 >> |
+| 标准错误输出 (stderr) | 2 | 2> 或 2>> |
+
+其中,有一个箭头的表示以覆盖的方式重定向,而有两个箭头的表示以追加的方式重定向。
+
+可以将不需要的标准输出以及标准错误输出重定向到 /dev/null,相当于扔进垃圾箱。
+
+如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 2>&1 表示将标准错误输出转换为标准输出。
+
+```bash
+$ find /home -name .bashrc > list 2>&1
+```
+
+# 八、管道指令
+
+管道是将一个命令的标准输出作为另一个命令的标准输入,在数据需要经过多个步骤的处理之后才能得到我们想要的内容时就可以使用管道。
+
+在命令之间使用 | 分隔各个管道命令。
+
+```bash
+$ ls -al /etc | less
+```
+
+## 提取指令
+
+cut 对数据进行切分,取出想要的部分。
+
+切分过程一行一行地进行。
+
+```html
+$ cut
+-d :分隔符
+-f :经过 -d 分隔后,使用 -f n 取出第 n 个区间
+-c :以字符为单位取出区间
+```
+
+示例 1:last 显示登入者的信息,取出用户名。
+
+```html
+$ last
+root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in
+root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33)
+root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16)
+
+$ last | cut -d ' ' -f 1
+```
+
+示例 2:将 export 输出的信息,取出第 12 字符以后的所有字符串。
+
+```html
+$ export
+declare -x HISTCONTROL="ignoredups"
+declare -x HISTSIZE="1000"
+declare -x HOME="/home/dmtsai"
+declare -x HOSTNAME="study.centos.vbird"
+.....(其他省略).....
+
+$ export | cut -c 12-
+```
+
+## 排序指令
+
+**sort** 用于排序。
+
+```html
+$ sort [-fbMnrtuk] [file or stdin]
+-f :忽略大小写
+-b :忽略最前面的空格
+-M :以月份的名字来排序,例如 JAN,DEC
+-n :使用数字
+-r :反向排序
+-u :相当于 unique,重复的内容只出现一次
+-t :分隔符,默认为 tab
+-k :指定排序的区间
+```
+
+示例:/etc/passwd 文件内容以 : 来分隔,要求以第三列进行排序。
+
+```html
+$ cat /etc/passwd | sort -t ':' -k 3
+root:x:0:0:root:/root:/bin/bash
+dmtsai:x:1000:1000:dmtsai:/home/dmtsai:/bin/bash
+alex:x:1001:1002::/home/alex:/bin/bash
+arod:x:1002:1003::/home/arod:/bin/bash
+```
+
+**uniq** 可以将重复的数据只取一个。
+
+```html
+$ uniq [-ic]
+-i :忽略大小写
+-c :进行计数
+```
+
+示例:取得每个人的登录总次数
+
+```html
+$ last | cut -d ' ' -f 1 | sort | uniq -c
+1
+6 (unknown
+47 dmtsai
+4 reboot
+7 root
+1 wtmp
+```
+
+## 双向输出重定向
+
+输出重定向会将输出内容重定向到文件中,而 **tee** 不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee 指令,一个输出会同时传送到文件和屏幕上。
+
+```html
+$ tee [-a] file
+```
+
+## 字符转换指令
+
+**tr** 用来删除一行中的字符,或者对字符进行替换。
+
+```html
+$ tr [-ds] SET1 ...
+-d : 删除行中 SET1 这个字符串
+```
+
+示例,将 last 输出的信息所有小写转换为大写。
+
+```html
+$ last | tr '[a-z]' '[A-Z]'
+```
+
+ **col** 将 tab 字符转为空格字符。
+
+```html
+$ col [-xb]
+-x : 将 tab 键转换成对等的空格键
+```
+
+**expand** 将 tab 转换一定数量的空格,默认是 8 个。
+
+```html
+$ expand [-t] file
+-t :tab 转为空格的数量
+```
+
+**join** 将有相同数据的那一行合并在一起。
+
+```html
+$ join [-ti12] file1 file2
+-t :分隔符,默认为空格
+-i :忽略大小写的差异
+-1 :第一个文件所用的比较字段
+-2 :第二个文件所用的比较字段
+```
+
+**paste** 直接将两行粘贴在一起。
+
+```html
+$ paste [-d] file1 file2
+-d :分隔符,默认为 tab
+```
+
+## 分区指令
+
+**split** 将一个文件划分成多个文件。
+
+```html
+$ split [-bl] file PREFIX
+-b :以大小来进行分区,可加单位,例如 b, k, m 等
+-l :以行数来进行分区。
+- PREFIX :分区文件的前导名称
+```
+
+# 九、正则表达式
+
+## grep
+
+g/re/p(globally search a regular expression and print),使用正则表示式进行全局查找并打印。
+
+```html
+$ grep [-acinv] [--color=auto] 搜寻字符串 filename
+-c : 统计匹配到行的个数
+-i : 忽略大小写
+-n : 输出行号
+-v : 反向选择,也就是显示出没有 搜寻字符串 内容的那一行
+--color=auto :找到的关键字加颜色显示
+```
+
+示例:把含有 the 字符串的行提取出来(注意默认会有 --color=auto 选项,因此以下内容在 Linux 中有颜色显示 the 字符串)
+
+```html
+$ grep -n 'the' regular_express.txt
+8:I can't finish the test.
+12:the symbol '*' is represented as start.
+15:You are the best is mean you are the no. 1.
+16:The world Happy is the same with "glad".
+18:google is the best tools for search keyword
+```
+
+示例:正则表达式 a{m,n} 用来匹配字符 a m\~n 次,这里需要将 { 和 } 进行转义,因为它们在 shell 是有特殊意义的。
+
+```html
+$ grep -n 'a\{2,5\}' regular_express.txt
+```
+
+## printf
+
+用于格式化输出。它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
+
+```html
+$ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt)
+ DmTsai 80 60 92 77.33
+ VBird 75 55 80 70.00
+ Ken 60 90 70 73.33
+```
+
+## awk
+
+是由 Alfred Aho,Peter Weinberger 和 Brian Kernighan 创造,awk 这个名字就是这三个创始人名字的首字母。
+
+awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:\$n,n 为字段号,从 1 开始,\$0 表示一整行。
+
+示例:取出最近五个登录用户的用户名和 IP。首先用 last -n 5 取出用最近五个登录用户的所有信息,可以看到用户名和 IP 分别在第 1 列和第 3 列,我们用 \$1 和 \$3 就能取出这两个字段,然后用 print 进行打印。
+
+```html
+$ last -n 5
+dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
+dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 (03:22)
+dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 (06:12)
+dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 (00:14)
+dmtsai tty1 Fri May 29 11:55 - 12:11 (00:15)
+```
+
+```html
+$ last -n 5 | awk '{print $1 "\t" $3}'
+```
+
+可以根据字段的某些条件进行匹配,例如匹配字段小于某个值的那一行数据。
+
+```html
+$ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename
+```
+
+示例:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
+
+```text
+$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
+root 0
+bin 1
+daemon 2
+```
+
+awk 变量:
+
+| 变量名称 | 代表意义 |
+| :--: | -- |
+| NF | 每一行拥有的字段总数 |
+| NR | 目前所处理的是第几行数据 |
+| FS | 目前的分隔字符,默认是空格键 |
+
+示例:显示正在处理的行号以及每一行有多少字段
+
+```html
+$ last -n 5 | awk '{print $1 "\t lines: " NR "\t columns: " NF}'
+dmtsai lines: 1 columns: 10
+dmtsai lines: 2 columns: 10
+dmtsai lines: 3 columns: 10
+dmtsai lines: 4 columns: 10
+dmtsai lines: 5 columns: 9
+```
+
+# 十、进程管理
+
+## 查看进程
+
+### 1. ps
+
+查看某个时间点的进程信息。
+
+示例:查看自己的进程
+
+```sh
+# ps -l
+```
+
+示例:查看系统所有进程
+
+```sh
+# ps aux
+```
+
+示例:查看特定的进程
+
+```sh
+# ps aux | grep threadx
+```
+
+### 2. pstree
+
+查看进程树。
+
+示例:查看所有进程树
+
+```sh
+# pstree -A
+```
+
+### 3. top
+
+实时显示进程信息。
+
+示例:两秒钟刷新一次
+
+```sh
+# top -d 2
+```
+
+### 4. netstat
+
+查看占用端口的进程
+
+示例:查看特定端口的进程
+
+```sh
+# netstat -anp | grep port
+```
+
+## 进程状态
+
+| 状态 | 说明 |
+| :---: | --- |
+| R | running or runnable (on run queue)
正在执行或者可执行,此时进程位于执行队列中。|
+| D | uninterruptible sleep (usually I/O)
不可中断阻塞,通常为 IO 阻塞。 |
+| S | interruptible sleep (waiting for an event to complete)
可中断阻塞,此时进程正在等待某个事件完成。|
+| Z | zombie (terminated but not reaped by its parent)
僵死,进程已经终止但是尚未被其父进程获取信息。|
+| T | stopped (either by a job control signal or because it is being traced)
结束,进程既可以被作业控制信号结束,也可能是正在被追踪。|
+
+
+
+
+## SIGCHLD
+
+当一个子进程改变了它的状态时(停止运行,继续运行或者退出),有两件事会发生在父进程中:
+
+- 得到 SIGCHLD 信号;
+- waitpid() 或者 wait() 调用会返回。
+
+其中子进程发送的 SIGCHLD 信号包含了子进程的信息,比如进程 ID、进程状态、进程使用 CPU 的时间等。
+
+在子进程退出时,它的进程描述符不会立即释放,这是为了让父进程得到子进程信息,父进程通过 wait() 和 waitpid() 来获得一个已经退出的子进程的信息。
+
+
+
+## wait()
+
+```c
+pid_t wait(int *status)
+```
+
+父进程调用 wait() 会一直阻塞,直到收到一个子进程退出的 SIGCHLD 信号,之后 wait() 函数会销毁子进程并返回。
+
+如果成功,返回被收集的子进程的进程 ID;如果调用进程没有子进程,调用就会失败,此时返回 -1,同时 errno 被置为 ECHILD。
+
+参数 status 用来保存被收集的子进程退出时的一些状态,如果对这个子进程是如何死掉的毫不在意,只想把这个子进程消灭掉,可以设置这个参数为 NULL。
+
+## waitpid()
+
+```c
+pid_t waitpid(pid_t pid, int *status, int options)
+```
+
+作用和 wait() 完全相同,但是多了两个可由用户控制的参数 pid 和 options。
+
+pid 参数指示一个子进程的 ID,表示只关心这个子进程退出的 SIGCHLD 信号。如果 pid=-1 时,那么和 wait() 作用相同,都是关心所有子进程退出的 SIGCHLD 信号。
+
+options 参数主要有 WNOHANG 和 WUNTRACED 两个选项,WNOHANG 可以使 waitpid() 调用变成非阻塞的,也就是说它会立即返回,父进程可以继续执行其它任务。
+
+## 孤儿进程
+
+一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。
+
+孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作。
+
+由于孤儿进程会被 init 进程收养,所以孤儿进程不会对系统造成危害。
+
+## 僵尸进程
+
+一个子进程的进程描述符在子进程退出时不会释放,只有当父进程通过 wait() 或 waitpid() 获取了子进程信息后才会释放。如果子进程退出,而父进程并没有调用 wait() 或 waitpid(),那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。
+
+僵尸进程通过 ps 命令显示出来的状态为 Z(zombie)。
+
+系统所能使用的进程号是有限的,如果产生大量僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程。
+
+要消灭系统中大量的僵尸进程,只需要将其父进程杀死,此时僵尸进程就会变成孤儿进程,从而被 init 进程所收养,这样 init 进程就会释放所有的僵尸进程所占有的资源,从而结束僵尸进程。
+
+# 参考资料
+
+- 鸟哥. 鸟 哥 的 Linux 私 房 菜 基 础 篇 第 三 版[J]. 2009.
+- [Linux 平台上的软件包管理](https://www.ibm.com/developerworks/cn/linux/l-cn-rpmdpkg/index.html)
+- [Linux 之守护进程、僵死进程与孤儿进程](http://liubigbin.github.io/2016/03/11/Linux-%E4%B9%8B%E5%AE%88%E6%8A%A4%E8%BF%9B%E7%A8%8B%E3%80%81%E5%83%B5%E6%AD%BB%E8%BF%9B%E7%A8%8B%E4%B8%8E%E5%AD%A4%E5%84%BF%E8%BF%9B%E7%A8%8B/)
+- [What is the difference between a symbolic link and a hard link?](https://stackoverflow.com/questions/185899/what-is-the-difference-between-a-symbolic-link-and-a-hard-link)
+- [Linux process states](https://idea.popcount.org/2012-12-11-linux-process-states/)
+- [GUID Partition Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
+- [详解 wait 和 waitpid 函数](https://blog.csdn.net/kevinhg/article/details/7001719)
+- [IDE、SATA、SCSI、SAS、FC、SSD 硬盘类型介绍](https://blog.csdn.net/tianlesoftware/article/details/6009110)
+- [Akai IB-301S SCSI Interface for S2800,S3000](http://www.mpchunter.com/s3000/akai-ib-301s-scsi-interface-for-s2800s3000/)
+- [Parallel ATA](https://en.wikipedia.org/wiki/Parallel_ATA)
+- [ADATA XPG SX900 256GB SATA 3 SSD Review – Expanded Capacity and SandForce Driven Speed](http://www.thessdreview.com/our-reviews/adata-xpg-sx900-256gb-sata-3-ssd-review-expanded-capacity-and-sandforce-driven-speed/4/)
+- [Decoding UCS Invicta – Part 1](https://blogs.cisco.com/datacenter/decoding-ucs-invicta-part-1)
+- [硬盘](https://zh.wikipedia.org/wiki/%E7%A1%AC%E7%9B%98)
+- [Difference between SAS and SATA](http://www.differencebetween.info/difference-between-sas-and-sata)
+- [BIOS](https://zh.wikipedia.org/wiki/BIOS)
+- [File system design case studies](https://www.cs.rutgers.edu/\~pxk/416/notes/13-fs-studies.html)
+- [Programming Project #4](https://classes.soe.ucsc.edu/cmps111/Fall08/proj4.shtml)
+- [FILE SYSTEM DESIGN](http://web.cs.ucla.edu/classes/fall14/cs111/scribe/11a/index.html)
+
+
+
+
+
+
+
diff --git "a/other/mysql/21\345\210\206\351\222\237Mysql\345\210\235\345\255\246\350\200\205\346\225\231\347\250\213.docx" "b/other/mysql/21\345\210\206\351\222\237Mysql\345\210\235\345\255\246\350\200\205\346\225\231\347\250\213.docx"
new file mode 100644
index 00000000..4072be60
Binary files /dev/null and "b/other/mysql/21\345\210\206\351\222\237Mysql\345\210\235\345\255\246\350\200\205\346\225\231\347\250\213.docx" differ
diff --git "a/other/mysql/MySQL\347\264\242\345\274\225\350\203\214\345\220\216\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204\345\217\212\347\256\227\346\263\225\345\216\237\347\220\206.pdf" "b/other/mysql/MySQL\347\264\242\345\274\225\350\203\214\345\220\216\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204\345\217\212\347\256\227\346\263\225\345\216\237\347\220\206.pdf"
new file mode 100644
index 00000000..64d28c89
Binary files /dev/null and "b/other/mysql/MySQL\347\264\242\345\274\225\350\203\214\345\220\216\347\232\204\346\225\260\346\215\256\347\273\223\346\236\204\345\217\212\347\256\227\346\263\225\345\216\237\347\220\206.pdf" differ
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \344\274\240\350\276\223\345\261\202.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \344\274\240\350\276\223\345\261\202.md"
new file mode 100644
index 00000000..fdd2de8a
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \344\274\240\350\276\223\345\261\202.md"
@@ -0,0 +1,169 @@
+
+* [UDP 和 TCP 的特点](#udp-和-tcp-的特点)
+* [UDP 首部格式](#udp-首部格式)
+* [TCP 首部格式](#tcp-首部格式)
+* [TCP 的三次握手](#tcp-的三次握手)
+* [TCP 的四次挥手](#tcp-的四次挥手)
+* [TCP 可靠传输](#tcp-可靠传输)
+* [TCP 滑动窗口](#tcp-滑动窗口)
+* [TCP 流量控制](#tcp-流量控制)
+* [TCP 拥塞控制](#tcp-拥塞控制)
+ * [1. 慢开始与拥塞避免](#1-慢开始与拥塞避免)
+ * [2. 快重传与快恢复](#2-快重传与快恢复)
+
+
+
+网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。
+
+# UDP 和 TCP 的特点
+
+- 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
+
+- 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
+
+# UDP 首部格式
+
+
+
+首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。
+
+# TCP 首部格式
+
+
+
+- **序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
+
+- **确认号** :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
+
+- **数据偏移** :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
+
+- **确认 ACK** :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
+
+- **同步 SYN** :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
+
+- **终止 FIN** :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
+
+- **窗口** :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
+
+# TCP 的三次握手
+
+
+
+假设 A 为客户端,B 为服务器端。
+
+- 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
+
+- A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
+
+- B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
+
+- A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
+
+- B 收到 A 的确认后,连接建立。
+
+**三次握手的原因**
+
+第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
+
+客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会忽略服务器之后发送的对滞留连接请求的连接确认,不进行第三次握手,因此就不会再次打开连接。
+
+# TCP 的四次挥手
+
+
+
+以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
+
+- A 发送连接释放报文,FIN=1。
+
+- B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
+
+- 当 B 不再需要连接时,发送连接释放报文,FIN=1。
+
+- A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
+
+- B 收到 A 的确认后释放连接。
+
+**四次挥手的原因**
+
+客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
+
+**TIME_WAIT**
+
+客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
+
+- 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
+
+- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
+
+# TCP 可靠传输
+
+TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
+
+一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
+
+
+其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
+
+超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
+
+
+其中 RTTd 为偏差的加权平均值。
+
+# TCP 滑动窗口
+
+窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
+
+发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
+
+接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
+
+
+
+# TCP 流量控制
+
+流量控制是为了控制发送方发送速率,保证接收方来得及接收。
+
+接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+# TCP 拥塞控制
+
+如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
+
+
+
+TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
+
+发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
+
+为了便于讨论,做如下假设:
+
+- 接收方有足够大的接收缓存,因此不会发生流量控制;
+- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
+
+
+
+## 1. 慢开始与拥塞避免
+
+发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
+
+注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
+
+如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
+
+## 2. 快重传与快恢复
+
+在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
+
+在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
+
+在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
+
+慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
+
+
+
+
+
+
+
+
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \345\272\224\347\224\250\345\261\202.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \345\272\224\347\224\250\345\261\202.md"
new file mode 100644
index 00000000..213f43f8
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \345\272\224\347\224\250\345\261\202.md"
@@ -0,0 +1,173 @@
+
+* [域名系统](#域名系统)
+* [文件传送协议](#文件传送协议)
+* [动态主机配置协议](#动态主机配置协议)
+* [远程登录协议](#远程登录协议)
+* [电子邮件协议](#电子邮件协议)
+ * [1. SMTP](#1-smtp)
+ * [2. POP3](#2-pop3)
+ * [3. IMAP](#3-imap)
+* [常用端口](#常用端口)
+* [Web 页面请求过程](#web-页面请求过程)
+ * [1. DHCP 配置主机信息](#1-dhcp-配置主机信息)
+ * [2. ARP 解析 MAC 地址](#2-arp-解析-mac-地址)
+ * [3. DNS 解析域名](#3-dns-解析域名)
+ * [4. HTTP 请求页面](#4-http-请求页面)
+
+
+
+# 域名系统
+
+DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转换的服务。这里的分布式数据库是指,每个站点只保留它自己的那部分数据。
+
+域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
+
+ 
+
+DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用 UDP 进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
+
+- 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
+- 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
+
+# 文件传送协议
+
+FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
+
+- 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
+- 数据连接:用来传送一个文件数据。
+
+根据数据连接是否是服务器端主动建立,FTP 有主动和被动两种模式:
+
+- 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0\~1023 是熟知端口号。
+
+ 
+
+- 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。
+
+ 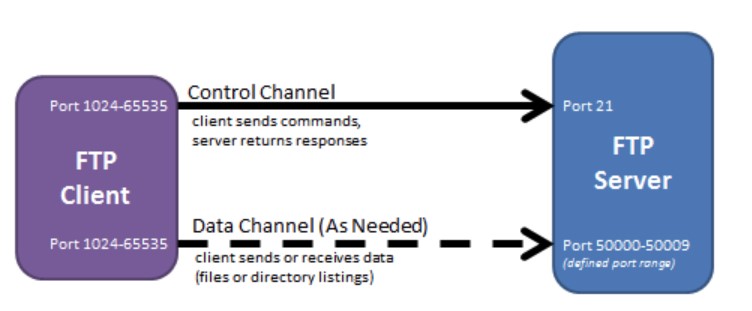
+
+主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
+
+# 动态主机配置协议
+
+DHCP (Dynamic Host Configuration Protocol) 提供了即插即用的连网方式,用户不再需要手动配置 IP 地址等信息。
+
+DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、网关 IP 地址。
+
+DHCP 工作过程如下:
+
+1. 客户端发送 Discover 报文,该报文的目的地址为 255.255.255.255:67,源地址为 0.0.0.0:68,被放入 UDP 中,该报文被广播到同一个子网的所有主机上。如果客户端和 DHCP 服务器不在同一个子网,就需要使用中继代理。
+2. DHCP 服务器收到 Discover 报文之后,发送 Offer 报文给客户端,该报文包含了客户端所需要的信息。因为客户端可能收到多个 DHCP 服务器提供的信息,因此客户端需要进行选择。
+3. 如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
+4. DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。
+
+ 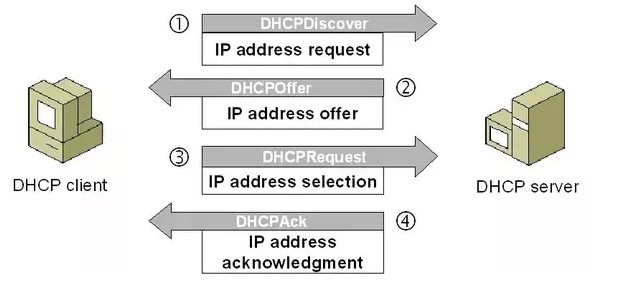
+
+# 远程登录协议
+
+TELNET 用于登录到远程主机上,并且远程主机上的输出也会返回。
+
+TELNET 可以适应许多计算机和操作系统的差异,例如不同操作系统系统的换行符定义。
+
+# 电子邮件协议
+
+一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件协议。
+
+邮件协议包含发送协议和读取协议,发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。
+
+ 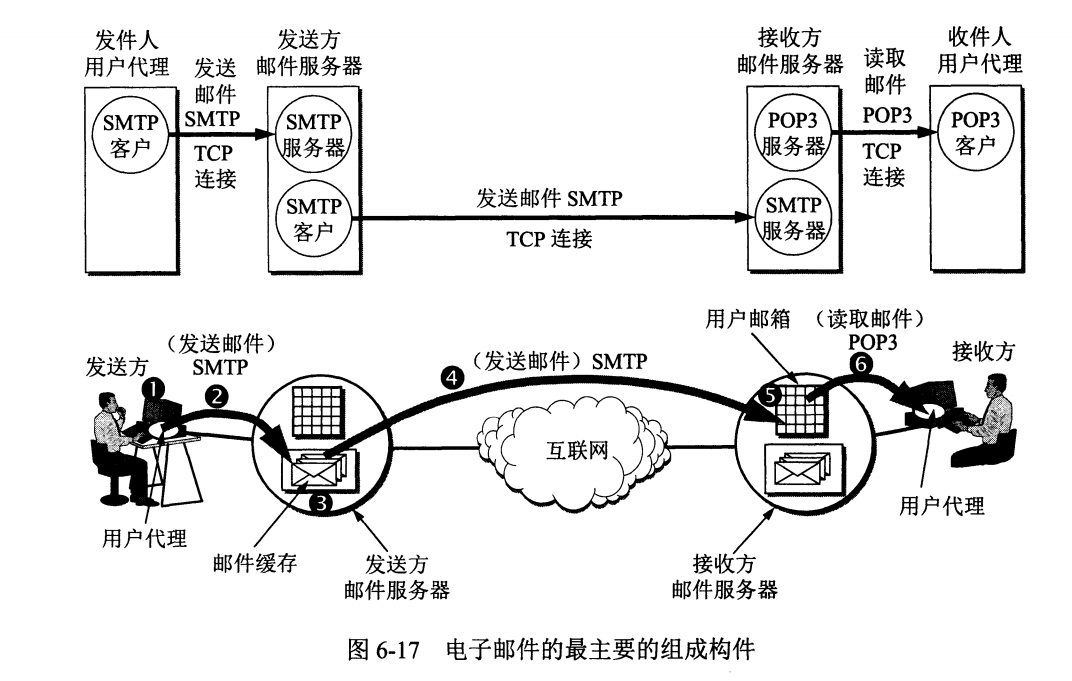
+
+## 1. SMTP
+
+SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。
+
+ 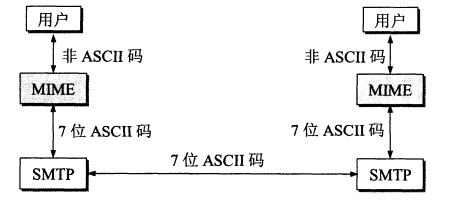
+
+## 2. POP3
+
+POP3 的特点是只要用户从服务器上读取了邮件,就把该邮件删除。但最新版本的 POP3 可以不删除邮件。
+
+## 3. IMAP
+
+IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地去访问服务器上的邮件。
+
+# 常用端口
+
+|应用| 应用层协议 | 端口号 | 传输层协议 | 备注 |
+| :---: | :--: | :--: | :--: | :--: |
+| 域名解析 | DNS | 53 | UDP/TCP | 长度超过 512 字节时使用 TCP |
+| 动态主机配置协议 | DHCP | 67/68 | UDP | |
+| 简单网络管理协议 | SNMP | 161/162 | UDP | |
+| 文件传送协议 | FTP | 20/21 | TCP | 控制连接 21,数据连接 20 |
+| 远程终端协议 | TELNET | 23 | TCP | |
+| 超文本传送协议 | HTTP | 80 | TCP | |
+| 简单邮件传送协议 | SMTP | 25 | TCP | |
+| 邮件读取协议 | POP3 | 110 | TCP | |
+| 网际报文存取协议 | IMAP | 143 | TCP | |
+
+# Web 页面请求过程
+
+## 1. DHCP 配置主机信息
+
+- 假设主机最开始没有 IP 地址以及其它信息,那么就需要先使用 DHCP 来获取。
+
+- 主机生成一个 DHCP 请求报文,并将这个报文放入具有目的端口 67 和源端口 68 的 UDP 报文段中。
+
+- 该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
+
+- 该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:FF:FF:FF:FF:FF,将广播到与交换机连接的所有设备。
+
+- 连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
+
+- 该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
+
+- 主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
+
+## 2. ARP 解析 MAC 地址
+
+- 主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
+
+- 主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
+
+- 该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
+
+- 该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
+
+- DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
+
+- 主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:FF:FF:FF:FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
+
+- 网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
+
+## 3. DNS 解析域名
+
+- 知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
+
+- 网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
+
+- 因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
+
+- 到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
+
+- 找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
+
+## 4. HTTP 请求页面
+
+- 有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
+
+- 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
+
+- HTTP 服务器收到该报文段之后,生成 TCP SYN ACK 报文段,发回给主机。
+
+- 连接建立之后,浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
+
+- HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将 Web 页面内容放入报文主体中,发回给主机。
+
+- 浏览器收到 HTTP 响应报文后,抽取出 Web 页面内容,之后进行渲染,显示 Web 页面。
+
+
+
+
+
+
+
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \346\246\202\350\277\260.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \346\246\202\350\277\260.md"
new file mode 100644
index 00000000..82aeffc0
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \346\246\202\350\277\260.md"
@@ -0,0 +1,139 @@
+
+* [网络的网络](#网络的网络)
+* [ISP](#isp)
+* [主机之间的通信方式](#主机之间的通信方式)
+* [电路交换与分组交换](#电路交换与分组交换)
+ * [1. 电路交换](#1-电路交换)
+ * [2. 分组交换](#2-分组交换)
+* [时延](#时延)
+ * [1. 排队时延](#1-排队时延)
+ * [2. 处理时延](#2-处理时延)
+ * [3. 传输时延](#3-传输时延)
+ * [4. 传播时延](#4-传播时延)
+* [计算机网络体系结构](#计算机网络体系结构)
+ * [1. 五层协议](#1-五层协议)
+ * [2. OSI](#2-osi)
+ * [3. TCP/IP](#3-tcpip)
+ * [4. 数据在各层之间的传递过程](#4-数据在各层之间的传递过程)
+
+
+
+# 网络的网络
+
+网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。而互联网(Internet)是全球范围的互连网。
+
+
+
+# ISP
+
+互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
+
+
+
+目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。
+
+
+
+# 主机之间的通信方式
+
+- 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。
+
+
+
+- 对等(P2P):不区分客户和服务器。
+
+
+
+# 电路交换与分组交换
+
+## 1. 电路交换
+
+电路交换用于电话通信系统,两个用户要通信之前需要建立一条专用的物理链路,并且在整个通信过程中始终占用该链路。由于通信的过程中不可能一直在使用传输线路,因此电路交换对线路的利用率很低,往往不到 10%。
+
+## 2. 分组交换
+
+每个分组都有首部和尾部,包含了源地址和目的地址等控制信息,在同一个传输线路上同时传输多个分组互相不会影响,因此在同一条传输线路上允许同时传输多个分组,也就是说分组交换不需要占用传输线路。
+
+在一个邮局通信系统中,邮局收到一份邮件之后,先存储下来,然后把相同目的地的邮件一起转发到下一个目的地,这个过程就是存储转发过程,分组交换也使用了存储转发过程。
+
+# 时延
+
+总时延 = 排队时延 + 处理时延 + 传输时延 + 传播时延
+
+
+
+## 1. 排队时延
+
+分组在路由器的输入队列和输出队列中排队等待的时间,取决于网络当前的通信量。
+
+## 2. 处理时延
+
+主机或路由器收到分组时进行处理所需要的时间,例如分析首部、从分组中提取数据、进行差错检验或查找适当的路由等。
+
+## 3. 传输时延
+
+主机或路由器传输数据帧所需要的时间。
+
+
+
+
+
+
+其中 l 表示数据帧的长度,v 表示传输速率。
+
+## 4. 传播时延
+
+电磁波在信道中传播所需要花费的时间,电磁波传播的速度接近光速。
+
+
+
+
+
+其中 l 表示信道长度,v 表示电磁波在信道上的传播速度。
+
+# 计算机网络体系结构
+
+
+
+## 1. 五层协议
+
+- **应用层** :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
+
+- **传输层** :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
+
+- **网络层** :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
+
+- **数据链路层** :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
+
+- **物理层** :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
+
+## 2. OSI
+
+其中表示层和会话层用途如下:
+
+- **表示层** :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
+
+- **会话层** :建立及管理会话。
+
+五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
+
+## 3. TCP/IP
+
+它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。
+
+TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
+
+
+
+## 4. 数据在各层之间的传递过程
+
+在向下的过程中,需要添加下层协议所需要的首部或者尾部,而在向上的过程中不断拆开首部和尾部。
+
+路由器只有下面三层协议,因为路由器位于网络核心中,不需要为进程或者应用程序提供服务,因此也就不需要传输层和应用层。
+
+
+
+
+
+
+
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\211\251\347\220\206\345\261\202.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\211\251\347\220\206\345\261\202.md"
new file mode 100644
index 00000000..7c6b8a16
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\211\251\347\220\206\345\261\202.md"
@@ -0,0 +1,26 @@
+
+* [通信方式](#通信方式)
+* [带通调制](#带通调制)
+
+
+
+# 通信方式
+
+根据信息在传输线上的传送方向,分为以下三种通信方式:
+
+- 单工通信:单向传输
+- 半双工通信:双向交替传输
+- 全双工通信:双向同时传输
+
+# 带通调制
+
+模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。
+
+
+
+
+
+
+
+
+
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\275\221\347\273\234\345\261\202.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\275\221\347\273\234\345\261\202.md"
new file mode 100644
index 00000000..36685f17
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \347\275\221\347\273\234\345\261\202.md"
@@ -0,0 +1,248 @@
+
+* [概述](#概述)
+* [IP 数据报格式](#ip-数据报格式)
+* [IP 地址编址方式](#ip-地址编址方式)
+ * [1. 分类](#1-分类)
+ * [2. 子网划分](#2-子网划分)
+ * [3. 无分类](#3-无分类)
+* [地址解析协议 ARP](#地址解析协议-arp)
+* [网际控制报文协议 ICMP](#网际控制报文协议-icmp)
+ * [1. Ping](#1-ping)
+ * [2. Traceroute](#2-traceroute)
+* [虚拟专用网 VPN](#虚拟专用网-vpn)
+* [网络地址转换 NAT](#网络地址转换-nat)
+* [路由器的结构](#路由器的结构)
+* [路由器分组转发流程](#路由器分组转发流程)
+* [路由选择协议](#路由选择协议)
+ * [1. 内部网关协议 RIP](#1-内部网关协议-rip)
+ * [2. 内部网关协议 OSPF](#2-内部网关协议-ospf)
+ * [3. 外部网关协议 BGP](#3-外部网关协议-bgp)
+
+
+
+# 概述
+
+因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
+
+使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
+
+
+
+与 IP 协议配套使用的还有三个协议:
+
+- 地址解析协议 ARP(Address Resolution Protocol)
+- 网际控制报文协议 ICMP(Internet Control Message Protocol)
+- 网际组管理协议 IGMP(Internet Group Management Protocol)
+
+# IP 数据报格式
+
+
+
+- **版本** : 有 4(IPv4)和 6(IPv6)两个值;
+
+- **首部长度** : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
+
+- **区分服务** : 用来获得更好的服务,一般情况下不使用。
+
+- **总长度** : 包括首部长度和数据部分长度。
+
+- **生存时间** :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
+
+- **协议** :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
+
+- **首部检验和** :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
+
+- **标识** : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
+
+- **片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
+
+
+
+# IP 地址编址方式
+
+IP 地址的编址方式经历了三个历史阶段:
+
+- 分类
+- 子网划分
+- 无分类
+
+## 1. 分类
+
+由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
+
+IP 地址 ::= {< 网络号 >, < 主机号 >}
+
+
+
+## 2. 子网划分
+
+通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
+
+IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
+
+要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
+
+注意,外部网络看不到子网的存在。
+
+## 3. 无分类
+
+无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
+
+IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
+
+CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
+
+CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
+
+一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 **构成超网** 。
+
+在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
+
+# 地址解析协议 ARP
+
+网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
+
+
+
+ARP 实现由 IP 地址得到 MAC 地址。
+
+
+
+每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
+
+如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
+
+
+
+# 网际控制报文协议 ICMP
+
+ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
+
+
+
+ICMP 报文分为差错报告报文和询问报文。
+
+
+
+## 1. Ping
+
+Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
+
+Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
+
+## 2. Traceroute
+
+Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
+
+Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
+
+- 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
+- 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
+- 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
+- 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
+
+# 虚拟专用网 VPN
+
+由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
+
+有三个专用地址块:
+
+- 10.0.0.0 \~ 10.255.255.255
+- 172.16.0.0 \~ 172.31.255.255
+- 192.168.0.0 \~ 192.168.255.255
+
+VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
+
+下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
+
+
+
+# 网络地址转换 NAT
+
+专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
+
+在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
+
+
+
+# 路由器的结构
+
+路由器从功能上可以划分为:路由选择和分组转发。
+
+分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
+
+
+
+# 路由器分组转发流程
+
+- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
+- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
+- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
+- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
+- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
+- 报告转发分组出错。
+
+
+
+# 路由选择协议
+
+路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
+
+互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
+
+可以把路由选择协议划分为两大类:
+
+- 自治系统内部的路由选择:RIP 和 OSPF
+- 自治系统间的路由选择:BGP
+
+## 1. 内部网关协议 RIP
+
+RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
+
+RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
+
+距离向量算法:
+
+- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
+- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
+ - 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
+ - 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
+- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
+
+RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
+
+## 2. 内部网关协议 OSPF
+
+开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
+
+开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
+
+OSPF 具有以下特点:
+
+- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
+- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
+- 只有当链路状态发生变化时,路由器才会发送信息。
+
+所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
+
+## 3. 外部网关协议 BGP
+
+BGP(Border Gateway Protocol,边界网关协议)
+
+AS 之间的路由选择很困难,主要是由于:
+
+- 互联网规模很大;
+- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
+- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
+
+BGP 只能寻找一条比较好的路由,而不是最佳路由。
+
+每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
+
+
+
+
+
+
+
+
diff --git "a/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \351\223\276\350\267\257\345\261\202.md" "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \351\223\276\350\267\257\345\261\202.md"
new file mode 100644
index 00000000..e7831ceb
--- /dev/null
+++ "b/other/netword/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234 - \351\223\276\350\267\257\345\261\202.md"
@@ -0,0 +1,202 @@
+
+* [基本问题](#基本问题)
+ * [1. 封装成帧](#1-封装成帧)
+ * [2. 透明传输](#2-透明传输)
+ * [3. 差错检测](#3-差错检测)
+* [信道分类](#信道分类)
+ * [1. 广播信道](#1-广播信道)
+ * [2. 点对点信道](#2-点对点信道)
+* [信道复用技术](#信道复用技术)
+ * [1. 频分复用](#1-频分复用)
+ * [2. 时分复用](#2-时分复用)
+ * [3. 统计时分复用](#3-统计时分复用)
+ * [4. 波分复用](#4-波分复用)
+ * [5. 码分复用](#5-码分复用)
+* [CSMA/CD 协议](#csmacd-协议)
+* [PPP 协议](#ppp-协议)
+* [MAC 地址](#mac-地址)
+* [局域网](#局域网)
+* [以太网](#以太网)
+* [交换机](#交换机)
+* [虚拟局域网](#虚拟局域网)
+
+
+
+# 基本问题
+
+## 1. 封装成帧
+
+将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
+
+
+
+## 2. 透明传输
+
+透明表示一个实际存在的事物看起来好像不存在一样。
+
+帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
+
+
+
+## 3. 差错检测
+
+目前数据链路层广泛使用了循环冗余检验(CRC)来检查比特差错。
+
+# 信道分类
+
+## 1. 广播信道
+
+一对多通信,一个节点发送的数据能够被广播信道上所有的节点接收到。
+
+所有的节点都在同一个广播信道上发送数据,因此需要有专门的控制方法进行协调,避免发生冲突(冲突也叫碰撞)。
+
+主要有两种控制方法进行协调,一个是使用信道复用技术,一是使用 CSMA/CD 协议。
+
+## 2. 点对点信道
+
+一对一通信。
+
+因为不会发生碰撞,因此也比较简单,使用 PPP 协议进行控制。
+
+# 信道复用技术
+
+## 1. 频分复用
+
+频分复用的所有主机在相同的时间占用不同的频率带宽资源。
+
+
+
+## 2. 时分复用
+
+时分复用的所有主机在不同的时间占用相同的频率带宽资源。
+
+
+
+使用频分复用和时分复用进行通信,在通信的过程中主机会一直占用一部分信道资源。但是由于计算机数据的突发性质,通信过程没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
+
+## 3. 统计时分复用
+
+是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。
+
+
+
+## 4. 波分复用
+
+光的频分复用。由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波。
+
+## 5. 码分复用
+
+为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片  和
和  有
+
+
+
+
有
+
+
+
+
+
+为了讨论方便,取 m=8,设码片 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
+
+在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到
+
+
+
+
+
+
+
+
+
+其中  为 的反码。
+
+利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
+
+码分复用需要发送的数据量为原先的 m 倍。
+
+
为 的反码。
+
+利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
+
+码分复用需要发送的数据量为原先的 m 倍。
+
+
+
+
+# CSMA/CD 协议
+
+CSMA/CD 表示载波监听多点接入 / 碰撞检测。
+
+- **多点接入** :说明这是总线型网络,许多主机以多点的方式连接到总线上。
+- **载波监听** :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
+- **碰撞检测** :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
+
+记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 **争用期** 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
+
+当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 **截断二进制指数退避算法** 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
+
+
+
+# PPP 协议
+
+互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。
+
+
+
+PPP 的帧格式:
+
+- F 字段为帧的定界符
+- A 和 C 字段暂时没有意义
+- FCS 字段是使用 CRC 的检验序列
+- 信息部分的长度不超过 1500
+
+
+
+# MAC 地址
+
+MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标识网络适配器(网卡)。
+
+一台主机拥有多少个网络适配器就有多少个 MAC 地址。例如笔记本电脑普遍存在无线网络适配器和有线网络适配器,因此就有两个 MAC 地址。
+
+# 局域网
+
+局域网是一种典型的广播信道,主要特点是网络为一个单位所拥有,且地理范围和站点数目均有限。
+
+主要有以太网、令牌环网、FDDI 和 ATM 等局域网技术,目前以太网占领着有线局域网市场。
+
+可以按照网络拓扑结构对局域网进行分类:
+
+
+
+# 以太网
+
+以太网是一种星型拓扑结构局域网。
+
+早期使用集线器进行连接,集线器是一种物理层设备, 作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离,之后再将这个比特发送到其它所有接口。如果集线器同时收到两个不同接口的帧,那么就发生了碰撞。
+
+目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
+
+以太网帧格式:
+
+- **类型** :标记上层使用的协议;
+- **数据** :长度在 46-1500 之间,如果太小则需要填充;
+- **FCS** :帧检验序列,使用的是 CRC 检验方法;
+
+
+
+# 交换机
+
+交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC 地址到接口的映射。
+
+正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
+
+下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
+
+
+
+# 虚拟局域网
+
+虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息。
+
+例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
+
+使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网。
+
+
+
+
+
+
+
+
+
diff --git "a/other/os/\345\206\205\345\255\230\347\256\241\347\220\206.md" "b/other/os/\345\206\205\345\255\230\347\256\241\347\220\206.md"
new file mode 100644
index 00000000..b0518efd
--- /dev/null
+++ "b/other/os/\345\206\205\345\255\230\347\256\241\347\220\206.md"
@@ -0,0 +1,144 @@
+
+* [虚拟内存](#虚拟内存)
+* [分页系统地址映射](#分页系统地址映射)
+* [页面置换算法](#页面置换算法)
+ * [1. 最佳](#1-最佳)
+ * [2. 最近最久未使用](#2-最近最久未使用)
+ * [3. 最近未使用](#3-最近未使用)
+ * [4. 先进先出](#4-先进先出)
+ * [5. 第二次机会算法](#5-第二次机会算法)
+ * [6. 时钟](#6-时钟)
+* [分段](#分段)
+* [段页式](#段页式)
+* [分页与分段的比较](#分页与分段的比较)
+
+
+
+# 虚拟内存
+
+虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
+
+为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
+
+从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0\~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
+
+
+
+# 分页系统地址映射
+
+内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
+
+一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
+
+下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
+
+
+
+# 页面置换算法
+
+在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
+
+页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
+
+页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
+
+## 1. 最佳
+
+> OPT, Optimal replacement algorithm
+
+所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
+
+是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
+
+举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
+
+```html
+7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
+```
+
+开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
+
+## 2. 最近最久未使用
+
+> LRU, Least Recently Used
+
+虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
+
+为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
+
+因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
+
+```html
+4,7,0,7,1,0,1,2,1,2,6
+```
+
+
+## 3. 最近未使用
+
+> NRU, Not Recently Used
+
+每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
+
+- R=0,M=0
+- R=0,M=1
+- R=1,M=0
+- R=1,M=1
+
+当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
+
+NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
+
+## 4. 先进先出
+
+> FIFO, First In First Out
+
+选择换出的页面是最先进入的页面。
+
+该算法会将那些经常被访问的页面换出,导致缺页率升高。
+
+## 5. 第二次机会算法
+
+FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
+
+当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
+
+
+
+## 6. 时钟
+
+> Clock
+
+第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
+
+
+
+# 分段
+
+虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
+
+下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
+
+
+
+分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
+
+
+
+# 段页式
+
+程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
+
+# 分页与分段的比较
+
+- 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
+
+- 地址空间的维度:分页是一维地址空间,分段是二维的。
+
+- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
+
+- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
+
+
+
+
+
diff --git "a/other/os/\346\255\273\351\224\201.md" "b/other/os/\346\255\273\351\224\201.md"
new file mode 100644
index 00000000..1346f087
--- /dev/null
+++ "b/other/os/\346\255\273\351\224\201.md"
@@ -0,0 +1,149 @@
+
+* [必要条件](#必要条件)
+* [处理方法](#处理方法)
+* [鸵鸟策略](#鸵鸟策略)
+* [死锁检测与死锁恢复](#死锁检测与死锁恢复)
+ * [1. 每种类型一个资源的死锁检测](#1-每种类型一个资源的死锁检测)
+ * [2. 每种类型多个资源的死锁检测](#2-每种类型多个资源的死锁检测)
+ * [3. 死锁恢复](#3-死锁恢复)
+* [死锁预防](#死锁预防)
+ * [1. 破坏互斥条件](#1-破坏互斥条件)
+ * [2. 破坏占有和等待条件](#2-破坏占有和等待条件)
+ * [3. 破坏不可抢占条件](#3-破坏不可抢占条件)
+ * [4. 破坏环路等待](#4-破坏环路等待)
+* [死锁避免](#死锁避免)
+ * [1. 安全状态](#1-安全状态)
+ * [2. 单个资源的银行家算法](#2-单个资源的银行家算法)
+ * [3. 多个资源的银行家算法](#3-多个资源的银行家算法)
+
+
+
+# 必要条件
+
+
+
+- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
+- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
+- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
+- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
+
+# 处理方法
+
+主要有以下四种方法:
+
+- 鸵鸟策略
+- 死锁检测与死锁恢复
+- 死锁预防
+- 死锁避免
+
+# 鸵鸟策略
+
+把头埋在沙子里,假装根本没发生问题。
+
+因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
+
+当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
+
+大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
+
+# 死锁检测与死锁恢复
+
+不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
+
+## 1. 每种类型一个资源的死锁检测
+
+
+
+上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
+
+图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
+
+每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
+
+## 2. 每种类型多个资源的死锁检测
+
+
+
+上图中,有三个进程四个资源,每个数据代表的含义如下:
+
+- E 向量:资源总量
+- A 向量:资源剩余量
+- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
+- R 矩阵:每个进程请求的资源数量
+
+进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
+
+算法总结如下:
+
+每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
+
+1. 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
+2. 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
+3. 如果没有这样一个进程,算法终止。
+
+## 3. 死锁恢复
+
+- 利用抢占恢复
+- 利用回滚恢复
+- 通过杀死进程恢复
+
+# 死锁预防
+
+在程序运行之前预防发生死锁。
+
+## 1. 破坏互斥条件
+
+例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
+
+## 2. 破坏占有和等待条件
+
+一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
+
+## 3. 破坏不可抢占条件
+
+## 4. 破坏环路等待
+
+给资源统一编号,进程只能按编号顺序来请求资源。
+
+# 死锁避免
+
+在程序运行时避免发生死锁。
+
+## 1. 安全状态
+
+
+
+图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
+
+定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
+
+安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
+
+## 2. 单个资源的银行家算法
+
+一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
+
+
+
+上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
+
+## 3. 多个资源的银行家算法
+
+
+
+上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
+
+检查一个状态是否安全的算法如下:
+
+- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
+- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
+- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
+
+如果一个状态不是安全的,需要拒绝进入这个状态。
+
+
+
+
+
+
+
diff --git "a/other/os/\347\243\201\347\233\230\350\260\203\345\272\246.md" "b/other/os/\347\243\201\347\233\230\350\260\203\345\272\246.md"
new file mode 100644
index 00000000..6a91822b
--- /dev/null
+++ "b/other/os/\347\243\201\347\233\230\350\260\203\345\272\246.md"
@@ -0,0 +1,65 @@
+
+* [磁盘结构](#磁盘结构)
+* [磁盘调度算法](#磁盘调度算法)
+ * [1. 先来先服务](#1-先来先服务)
+ * [2. 最短寻道时间优先](#2-最短寻道时间优先)
+ * [3. 电梯算法](#3-电梯算法)
+
+
+
+# 磁盘结构
+
+- 盘面(Platter):一个磁盘有多个盘面;
+- 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
+- 扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
+- 磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
+- 制动手臂(Actuator arm):用于在磁道之间移动磁头;
+- 主轴(Spindle):使整个盘面转动。
+
+
+
+# 磁盘调度算法
+
+读写一个磁盘块的时间的影响因素有:
+
+- 旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
+- 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
+- 实际的数据传输时间
+
+其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
+
+## 1. 先来先服务
+
+> FCFS, First Come First Served
+
+按照磁盘请求的顺序进行调度。
+
+优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
+
+## 2. 最短寻道时间优先
+
+> SSTF, Shortest Seek Time First
+
+优先调度与当前磁头所在磁道距离最近的磁道。
+
+虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
+
+
+
+## 3. 电梯算法
+
+> SCAN
+
+电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
+
+电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
+
+因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
+
+
+
+
+
+
+
+
diff --git "a/other/os/\350\277\233\347\250\213\347\256\241\347\220\206.md" "b/other/os/\350\277\233\347\250\213\347\256\241\347\220\206.md"
new file mode 100644
index 00000000..60d4951c
--- /dev/null
+++ "b/other/os/\350\277\233\347\250\213\347\256\241\347\220\206.md"
@@ -0,0 +1,601 @@
+
+* [进程与线程](#进程与线程)
+ * [1. 进程](#1-进程)
+ * [2. 线程](#2-线程)
+ * [3. 区别](#3-区别)
+* [进程状态的切换](#进程状态的切换)
+* [进程调度算法](#进程调度算法)
+ * [1. 批处理系统](#1-批处理系统)
+ * [2. 交互式系统](#2-交互式系统)
+ * [3. 实时系统](#3-实时系统)
+* [进程同步](#进程同步)
+ * [1. 临界区](#1-临界区)
+ * [2. 同步与互斥](#2-同步与互斥)
+ * [3. 信号量](#3-信号量)
+ * [4. 管程](#4-管程)
+* [经典同步问题](#经典同步问题)
+ * [1. 哲学家进餐问题](#1-哲学家进餐问题)
+ * [2. 读者-写者问题](#2-读者-写者问题)
+* [进程通信](#进程通信)
+ * [1. 管道](#1-管道)
+ * [2. FIFO](#2-fifo)
+ * [3. 消息队列](#3-消息队列)
+ * [4. 信号量](#4-信号量)
+ * [5. 共享存储](#5-共享存储)
+ * [6. 套接字](#6-套接字)
+
+
+
+# 进程与线程
+
+## 1. 进程
+
+进程是资源分配的基本单位。
+
+进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
+
+下图显示了 4 个程序创建了 4 个进程,这 4 个进程可以并发地执行。
+
+
+
+## 2. 线程
+
+线程是独立调度的基本单位。
+
+一个进程中可以有多个线程,它们共享进程资源。
+
+QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
+
+
+
+## 3. 区别
+
+Ⅰ 拥有资源
+
+进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
+
+Ⅱ 调度
+
+线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
+
+Ⅲ 系统开销
+
+由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
+
+Ⅳ 通信方面
+
+线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
+
+# 进程状态的切换
+
+
+
+- 就绪状态(ready):等待被调度
+- 运行状态(running)
+- 阻塞状态(waiting):等待资源
+
+应该注意以下内容:
+
+- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
+- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
+
+# 进程调度算法
+
+不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
+
+## 1. 批处理系统
+
+批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
+
+**1.1 先来先服务 first-come first-serverd(FCFS)**
+
+非抢占式的调度算法,按照请求的顺序进行调度。
+
+有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
+
+**1.2 短作业优先 shortest job first(SJF)**
+
+非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
+
+长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
+
+**1.3 最短剩余时间优先 shortest remaining time next(SRTN)**
+
+最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
+
+## 2. 交互式系统
+
+交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
+
+**2.1 时间片轮转**
+
+将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
+
+时间片轮转算法的效率和时间片的大小有很大关系:
+
+- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
+- 而如果时间片过长,那么实时性就不能得到保证。
+
+
+
+**2.2 优先级调度**
+
+为每个进程分配一个优先级,按优先级进行调度。
+
+为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
+
+**2.3 多级反馈队列**
+
+一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
+
+多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
+
+每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
+
+可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
+
+
+
+## 3. 实时系统
+
+实时系统要求一个请求在一个确定时间内得到响应。
+
+分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
+
+# 进程同步
+
+## 1. 临界区
+
+对临界资源进行访问的那段代码称为临界区。
+
+为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
+
+```html
+// entry section
+// critical section;
+// exit section
+```
+
+## 2. 同步与互斥
+
+- 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
+- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
+
+## 3. 信号量
+
+信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
+
+- **down** : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
+- **up** :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
+
+down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
+
+如果信号量的取值只能为 0 或者 1,那么就成为了 **互斥量(Mutex)** ,0 表示临界区已经加锁,1 表示临界区解锁。
+
+```c
+typedef int semaphore;
+semaphore mutex = 1;
+void P1() {
+ down(&mutex);
+ // 临界区
+ up(&mutex);
+}
+
+void P2() {
+ down(&mutex);
+ // 临界区
+ up(&mutex);
+}
+```
+
+ **使用信号量实现生产者-消费者问题**
+
+问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
+
+因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
+
+为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
+
+注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
+
+```c
+#define N 100
+typedef int semaphore;
+semaphore mutex = 1;
+semaphore empty = N;
+semaphore full = 0;
+
+void producer() {
+ while(TRUE) {
+ int item = produce_item();
+ down(&empty);
+ down(&mutex);
+ insert_item(item);
+ up(&mutex);
+ up(&full);
+ }
+}
+
+void consumer() {
+ while(TRUE) {
+ down(&full);
+ down(&mutex);
+ int item = remove_item();
+ consume_item(item);
+ up(&mutex);
+ up(&empty);
+ }
+}
+```
+
+## 4. 管程
+
+使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
+
+c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
+
+```pascal
+monitor ProducerConsumer
+ integer i;
+ condition c;
+
+ procedure insert();
+ begin
+ // ...
+ end;
+
+ procedure remove();
+ begin
+ // ...
+ end;
+end monitor;
+```
+
+管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
+
+管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
+
+ **使用管程实现生产者-消费者问题**
+
+```pascal
+// 管程
+monitor ProducerConsumer
+ condition full, empty;
+ integer count := 0;
+ condition c;
+
+ procedure insert(item: integer);
+ begin
+ if count = N then wait(full);
+ insert_item(item);
+ count := count + 1;
+ if count = 1 then signal(empty);
+ end;
+
+ function remove: integer;
+ begin
+ if count = 0 then wait(empty);
+ remove = remove_item;
+ count := count - 1;
+ if count = N -1 then signal(full);
+ end;
+end monitor;
+
+// 生产者客户端
+procedure producer
+begin
+ while true do
+ begin
+ item = produce_item;
+ ProducerConsumer.insert(item);
+ end
+end;
+
+// 消费者客户端
+procedure consumer
+begin
+ while true do
+ begin
+ item = ProducerConsumer.remove;
+ consume_item(item);
+ end
+end;
+```
+
+# 经典同步问题
+
+生产者和消费者问题前面已经讨论过了。
+
+## 1. 哲学家进餐问题
+
+ 
+
+五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
+
+下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
+
+```c
+#define N 5
+
+void philosopher(int i) {
+ while(TRUE) {
+ think();
+ take(i); // 拿起左边的筷子
+ take((i+1)%N); // 拿起右边的筷子
+ eat();
+ put(i);
+ put((i+1)%N);
+ }
+}
+```
+
+为了防止死锁的发生,可以设置两个条件:
+
+- 必须同时拿起左右两根筷子;
+- 只有在两个邻居都没有进餐的情况下才允许进餐。
+
+```c
+#define N 5
+#define LEFT (i + N - 1) % N // 左邻居
+#define RIGHT (i + 1) % N // 右邻居
+#define THINKING 0
+#define HUNGRY 1
+#define EATING 2
+typedef int semaphore;
+int state[N]; // 跟踪每个哲学家的状态
+semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
+semaphore s[N]; // 每个哲学家一个信号量
+
+void philosopher(int i) {
+ while(TRUE) {
+ think(i);
+ take_two(i);
+ eat(i);
+ put_two(i);
+ }
+}
+
+void take_two(int i) {
+ down(&mutex);
+ state[i] = HUNGRY;
+ check(i);
+ up(&mutex);
+ down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
+}
+
+void put_two(i) {
+ down(&mutex);
+ state[i] = THINKING;
+ check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
+ check(RIGHT);
+ up(&mutex);
+}
+
+void eat(int i) {
+ down(&mutex);
+ state[i] = EATING;
+ up(&mutex);
+}
+
+// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
+void check(i) {
+ if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
+ state[i] = EATING;
+ up(&s[i]);
+ }
+}
+```
+
+## 2. 读者-写者问题
+
+允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
+
+一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
+
+```c
+typedef int semaphore;
+semaphore count_mutex = 1;
+semaphore data_mutex = 1;
+int count = 0;
+
+void reader() {
+ while(TRUE) {
+ down(&count_mutex);
+ count++;
+ if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
+ up(&count_mutex);
+ read();
+ down(&count_mutex);
+ count--;
+ if(count == 0) up(&data_mutex);
+ up(&count_mutex);
+ }
+}
+
+void writer() {
+ while(TRUE) {
+ down(&data_mutex);
+ write();
+ up(&data_mutex);
+ }
+}
+```
+
+以下内容由 [@Bandi Yugandhar](https://github.com/yugandharbandi) 提供。
+
+The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
+
+```c
+int readcount, writecount; //(initial value = 0)
+semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
+
+//READER
+void reader() {
+
+ down(&readLock); // reader is trying to enter
+ down(&rmutex); // lock to increase readcount
+ readcount++;
+ if (readcount == 1)
+ down(&resource); //if you are the first reader then lock the resource
+ up(&rmutex); //release for other readers
+ up(&readLock); //Done with trying to access the resource
+
+
+//reading is performed
+
+
+ down(&rmutex); //reserve exit section - avoids race condition with readers
+ readcount--; //indicate you're leaving
+ if (readcount == 0) //checks if you are last reader leaving
+ up(&resource); //if last, you must release the locked resource
+ up(&rmutex); //release exit section for other readers
+}
+
+//WRITER
+void writer() {
+
+ down(&wmutex); //reserve entry section for writers - avoids race conditions
+ writecount++; //report yourself as a writer entering
+ if (writecount == 1) //checks if you're first writer
+ down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
+ up(&wmutex); //release entry section
+
+
+ down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
+ //writing is performed
+ up(&resource); //release file
+
+
+ down(&wmutex); //reserve exit section
+ writecount--; //indicate you're leaving
+ if (writecount == 0) //checks if you're the last writer
+ up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
+ up(&wmutex); //release exit section
+}
+```
+
+We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
+
+From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
+
+```source-c
+int readCount; // init to 0; number of readers currently accessing resource
+
+// all semaphores initialised to 1
+Semaphore resourceAccess; // controls access (read/write) to the resource
+Semaphore readCountAccess; // for syncing changes to shared variable readCount
+Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
+
+void writer()
+{
+ down(&serviceQueue); // wait in line to be servicexs
+ //
+ down(&resourceAccess); // request exclusive access to resource
+ //
+ up(&serviceQueue); // let next in line be serviced
+
+ //
+ writeResource(); // writing is performed
+ //
+
+ //
+ up(&resourceAccess); // release resource access for next reader/writer
+ //
+}
+
+void reader()
+{
+ down(&serviceQueue); // wait in line to be serviced
+ down(&readCountAccess); // request exclusive access to readCount
+ //
+ if (readCount == 0) // if there are no readers already reading:
+ down(&resourceAccess); // request resource access for readers (writers blocked)
+ readCount++; // update count of active readers
+ //
+ up(&serviceQueue); // let next in line be serviced
+ up(&readCountAccess); // release access to readCount
+
+ //
+ readResource(); // reading is performed
+ //
+
+ down(&readCountAccess); // request exclusive access to readCount
+ //
+ readCount--; // update count of active readers
+ if (readCount == 0) // if there are no readers left:
+ up(&resourceAccess); // release resource access for all
+ //
+ up(&readCountAccess); // release access to readCount
+}
+
+```
+
+# 进程通信
+
+进程同步与进程通信很容易混淆,它们的区别在于:
+
+- 进程同步:控制多个进程按一定顺序执行;
+- 进程通信:进程间传输信息。
+
+进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
+
+## 1. 管道
+
+管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
+
+```c
+#include
+int pipe(int fd[2]);
+```
+
+它具有以下限制:
+
+- 只支持半双工通信(单向交替传输);
+- 只能在父子进程或者兄弟进程中使用。
+
+ 
+
+## 2. FIFO
+
+也称为命名管道,去除了管道只能在父子进程中使用的限制。
+
+```c
+#include
+int mkfifo(const char *path, mode_t mode);
+int mkfifoat(int fd, const char *path, mode_t mode);
+```
+
+FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
+
+
+
+## 3. 消息队列
+
+相比于 FIFO,消息队列具有以下优点:
+
+- 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
+- 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
+- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
+
+## 4. 信号量
+
+它是一个计数器,用于为多个进程提供对共享数据对象的访问。
+
+## 5. 共享存储
+
+允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种 IPC。
+
+需要使用信号量用来同步对共享存储的访问。
+
+多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI 共享内存不是使用文件,而是使用内存的匿名段。
+
+## 6. 套接字
+
+与其它通信机制不同的是,它可用于不同机器间的进程通信。
+
+
+
+
+
+
+
diff --git "a/other/os/\351\241\265\351\235\242\347\275\256\346\215\242\347\256\227\346\263\225.md" "b/other/os/\351\241\265\351\235\242\347\275\256\346\215\242\347\256\227\346\263\225.md"
new file mode 100644
index 00000000..e0c6a7ac
--- /dev/null
+++ "b/other/os/\351\241\265\351\235\242\347\275\256\346\215\242\347\256\227\346\263\225.md"
@@ -0,0 +1,129 @@
+
+* [基本特征](#基本特征)
+ * [1. 并发](#1-并发)
+ * [2. 共享](#2-共享)
+ * [3. 虚拟](#3-虚拟)
+ * [4. 异步](#4-异步)
+* [基本功能](#基本功能)
+ * [1. 进程管理](#1-进程管理)
+ * [2. 内存管理](#2-内存管理)
+ * [3. 文件管理](#3-文件管理)
+ * [4. 设备管理](#4-设备管理)
+* [系统调用](#系统调用)
+* [大内核和微内核](#大内核和微内核)
+ * [1. 大内核](#1-大内核)
+ * [2. 微内核](#2-微内核)
+* [中断分类](#中断分类)
+ * [1. 外中断](#1-外中断)
+ * [2. 异常](#2-异常)
+ * [3. 陷入](#3-陷入)
+
+
+
+# 基本特征
+
+## 1. 并发
+
+并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
+
+并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
+
+操作系统通过引入进程和线程,使得程序能够并发运行。
+
+## 2. 共享
+
+共享是指系统中的资源可以被多个并发进程共同使用。
+
+有两种共享方式:互斥共享和同时共享。
+
+互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
+
+## 3. 虚拟
+
+虚拟技术把一个物理实体转换为多个逻辑实体。
+
+主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
+
+多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
+
+虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
+
+## 4. 异步
+
+异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
+
+# 基本功能
+
+## 1. 进程管理
+
+进程控制、进程同步、进程通信、死锁处理、处理机调度等。
+
+## 2. 内存管理
+
+内存分配、地址映射、内存保护与共享、虚拟内存等。
+
+## 3. 文件管理
+
+文件存储空间的管理、目录管理、文件读写管理和保护等。
+
+## 4. 设备管理
+
+完成用户的 I/O 请求,方便用户使用各种设备,并提高设备的利用率。
+
+主要包括缓冲管理、设备分配、设备处理、虛拟设备等。
+
+# 系统调用
+
+如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。
+
+
+
+Linux 的系统调用主要有以下这些:
+
+| Task | Commands |
+| :---: | --- |
+| 进程控制 | fork(); exit(); wait(); |
+| 进程通信 | pipe(); shmget(); mmap(); |
+| 文件操作 | open(); read(); write(); |
+| 设备操作 | ioctl(); read(); write(); |
+| 信息维护 | getpid(); alarm(); sleep(); |
+| 安全 | chmod(); umask(); chown(); |
+
+# 大内核和微内核
+
+## 1. 大内核
+
+大内核是将操作系统功能作为一个紧密结合的整体放到内核。
+
+由于各模块共享信息,因此有很高的性能。
+
+## 2. 微内核
+
+由于操作系统不断复杂,因此将一部分操作系统功能移出内核,从而降低内核的复杂性。移出的部分根据分层的原则划分成若干服务,相互独立。
+
+在微内核结构下,操作系统被划分成小的、定义良好的模块,只有微内核这一个模块运行在内核态,其余模块运行在用户态。
+
+因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。
+
+
+
+# 中断分类
+
+## 1. 外中断
+
+由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
+
+## 2. 异常
+
+由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
+
+## 3. 陷入
+
+在用户程序中使用系统调用。
+
+
+
+
+
+
+