
An engineering and implementation prespective
Disclaimer: this document just collates, links and include work published across many articles and contributions. the respective credits (including of images extracted from these links) goes to the respective authors/developers of the work.
ps: Special thanks goes to Ethereum R & D discord (especially to @vbuterin and @piper ) for helping understand some of the aspects of Kate.
pps: This document was developed for the benefit of 🌟 lodestar team, an awesome ETH POS client in works based on typescript enabling ETH everywhere, but also to enable the author's understanding of the ETH ecosystem and innovations. Hopefully this will benefit other developers/techies from all around the world. All rights of this work waived through CC0
A wholesome guide to familiarize, summarize and provide pointers to deep dive into proposed used of Kate Commitments while staying in ethereum's context. Aim of the document is more summarization and less rigour, but please follow the links as they explain in detail what is being talked about.
Note-1: Hash is just a commitment to the value being hashed, proof is checking the integrity of Hash w.r.t data.
For e.g. h1=H(t1,t2,t3..), and give h1 to the verifier (for e.g. in a block header), and then give a tempered block (t1,t2',t3...), one would be able to fast calculate the integrity of the block and reject it as the tempered block.
Similarly root of a merkle tree is a commitment to the leaves and their indexes (paths), or in short to the map of indexes => values.

Proof here is the merkle branch and its sibling hashes which can be used to check the consistency all the way to the merkle root.

The map of indexes => values can be represented as a polynomial f(x) which takes the value f(index)=value courtesy of Lagrange Interpolation . This f(index)=value is called evaluation form and the more typical representation f(x)=a0+ a1.x + a2.x^2... is called coefficient form. Intuitively, we fit a polynomial on the (index,value) points.

For optimizations, and for one to one mapping between polynomial and data map, instead of just index as x in f(x), w^index is used i.e. f(w^index)=value where w is the dth root of unity where d is the degree of the polynomial (the maximum index value we are trying to represent), so that FFT can be deployed for efficient polynomial operations like multiplication and division which are of the O(d) in evaluation form and can be converted back into coefficient form in O(d*log(d)). So its still beneficial to keep d small.


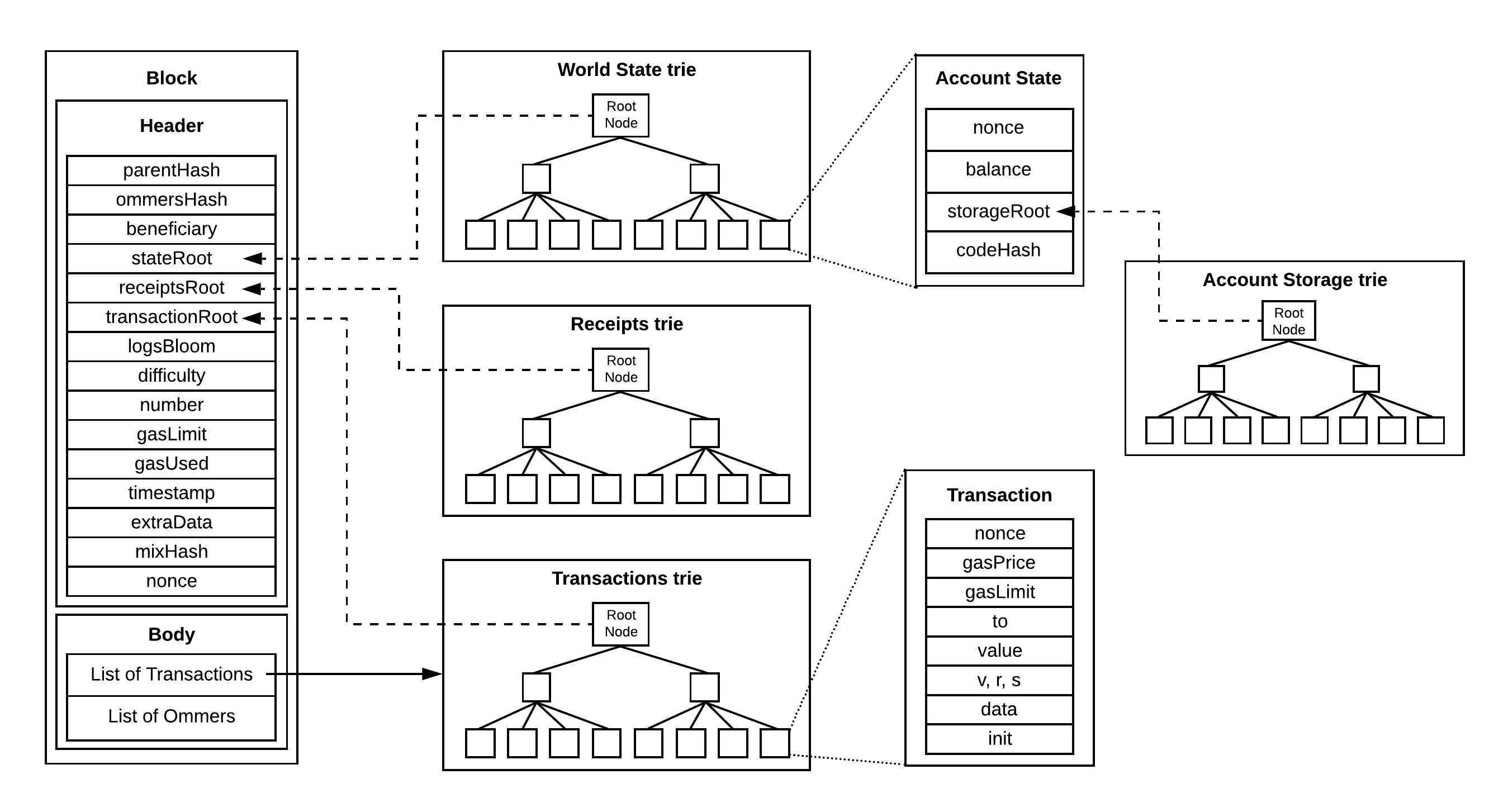
Ethereum currently use merkle trees and more specifically patricia merkle tries to commit to EVM data (EVM state, block transactions or transaction recepits and may be in near future contract code as well) , that can be
- inserted/updated block by block to arrive at the new root hash(commitment) in an incremental way
- inspected and proved block by block (or even transaction by transaction) by the verifier
Trie structure here gives that piece by piece capability.

Given a large d-ary trie with size N leaves, any leaf change will take O(log-d(N)) nodes updation (all the way to the root) to compute the new root reflecting new state, which requires additonal (d-1)*O(log-d(N)) sibling nodes Hashes/Commitments as witnesses for both time (and space if light clients are to be served). In a block, which is a batched update of lets say m random leaf updates where m<<N, only a very small percentage of nodes will be expected to share the witnesses and computations and hence the update Order wouldn't change much for per update.
This problem is compounded even further (because of size of the witness data) in following scenarios:
- a partly fast sync protocol like beam sync which can download and fast verify blockheaders to arrive to the latest canonical head of the chain (without building the state) and start partipiating in the network concensus while incrementally building its state by fetching witnesses of missed/not yet loaded state.
- to serve light nodes who only wants to concern themselves with a particular sliced view of the blockchain.
- going full stateless any transactions or contract operations will bundle their own witnesses to prove the correctness of the data input as well as output.
- blockchain sharding where the validators are shuffled between various shards and it would not be feasible to construct full state.
- code merklization where accessing code segments will need to bundle witnesses for those code chunks
- state expiry protocols where state witnesses for an address would need to be rebundeled to resurrect the state of an account.
In an experiment on stateless ethereum, the block proof sizes of 1MB were observed (of which majority of them were merkle proofs), which would even blow up in multiples in times of an attack.

One way to get around this is binary merkle trees taking d out of the picture but then the depth of tree would increase but it would still remain O log(N)

Following properties are desirable for any ideal commitment scheme to have for commiting to data in the block headers
- A small size (48 bytes) that can easily fit into block header but still has strong security guarantees.
- Easy to prove that commitment was created using a subset of chunkified data
- Very small and ideally constant proof size
- For tracking state it should be easy to make changes (to
index=>valuemap) in an incremental way
Kate commitment based constructions are the result of search of pursuing such an ideal scheme. Vanilla Kate excel at first three.

Kate commitment as such is just another Hashing scheme, but it doesn't Hash 'bytes', it hashes polynomials.
It actually is the evaluation of the polynomical f(x) at a secret (fixed) value s but represented on an elliptical curve i.e. [f(s)], which requires a trusted setup ( of the sorts of zcash genesis) to generate [s], [s^2], ... [s^d] (to plug into the polynomial wherever there is x^i as [f(s)] = f([s])) where d is the max degree we would deal in.

Here notation [t] means elliptical curve at point t which is basically t[1] i.e. generator [1] of the additive group on the elliptical curve added t times (modulo Fp). All operations on the curves are some modulo Fp where Fp imposes some field on the curve.
Note:3.0 any/every value in the indexes=>values map has also to be represented on an elliptical curve as curve element [value] to calculate commitment (as you will see later). This imposes restriction on size of value to be modulo Fp ~ BLS Curve order ~ somewhere between 31-32 bytes. For simplicity, it gets restricted to 31 bytes, any bigger value will need to be chunkified and appropriately represented with its index (or truncated).

Note3.1: [t] can be treated as Hash of t as obtaining t from [t] is discrete log problem known to be intractable for secure curves.
Note3.2: s is a secret and should be unknown forever to all/any but elliptical curve points [s], [s^2]...[s^d] as well as evaluation on another curve [s]' (whose generator is [1]', only [s]' is required) are generated, known, shared and public at trusted setup time, and are sort of system parameters.
As mentioned before, we represent our data map (index=>value) as f(w^index)=value i.e. evaluation form of the polynomial (or in other words we fitted a polynomial here on these (w^index,value) points).
So Kate commitment is just an evaluated point f(s) on the elliptical curve i.e. [f(s)]=f([s]) i.e. can be computed by plugging [s],[s^2] ... into expanded form of f(x).
So whats the good thing about this:
- Verification of the commitment can be done by providing another evaluation (provided by the block generator)
y=f(r)of the underlying polynomial at a random pointrand evaluation of the quotient polynomialq(x)=(f(x)-y)/(x-r))at[s]i.e.q([s])and comparing with the previously provided commitmentf([s])using a pairing equation (which is just a multiplication scheme for two points on curve) This is called opening the commitment atr, andq([s])is the proof. one can easily see thatq(s)is intutively the quotientp(s)-rdivided bys-rwhich is exactly what we check using the [pairing equation] i.e. check(f([s])-[y]) * [1]'= q([s]) * [s-r]' - In non interactive and deterministic version Fiat Shamir Heuristic provides a way for us to get that relative random point
ras randomness only matters with respect to inputs we are trying to prove. i.e. once commitmentC=f([s])has been provided,rcan be obtained by hashing all inputs (r=Hash(C,..)), where the commitment provider has to provide the opening and proof. - Using preccomputed Lagrange polynomials,
f([s]),q([s])can be directly computed from the evaluation form. To compute an opening atr, you would convert thef(x)to coefficient formf(x)=a0+ a1*x^1....(i.e. extracta0,a1,...) by doing the inverse FFT which isO(d log d), but even there is a substitue algorithm available to do it inO(d)without applying (inverse)FFT. - You can prove multiple evalutions of
f(x)at their respectiveindexs, i.e. multipleindex=>valuei.e.index1=>value1,index2=>value2...indexk=>valueki.e.kdata points using the single opening and proofq(x)the quotient polynomial (to calculate proof) is now the quotient if we dividef(x)by the zero polynomialz(x) =(x-w^index1)*(x-w^index2)...(x-w^indexk)- remainder
r(x)(r(x)is a max degreekpolynomial that interpolatesindex1=>value1,index2=>value2...indexk=valuek) - check
( f([s])-r([s]) )* [1] ' = q([s]) * z([s]')
In the sharded setup of the POS chain where the sharded data blobs will be represeted as a low degree polynomial (and extended for erasure coding into twice its size using the same fitted polynomial), the Kate commitment can be checked against random chunks to validate and establish availabily without needing siblings datapoints and hence enabling random sampling.
Now, for a state with possible 2^28 accounts, you would require a 2^28 degree polynomial for just a flat commitment construction. There are some downsides to that if updates and inserts are to be done. And any change in any one of those accounts will trigger the computation of the commitment (and more problematic witnesses/proofs)
- Any change into any of the lets say
kindex=>valuepoints, let say atindexk, will requirekto update the commitment again using the corresponding Lagrange polys ~O(1)per udate - However, since
f(x)has changed, all the witnessq_i([s])i.e. withness ofithindex=>valuewill need to be updated ~O(N)- If we don't maintain precomputed
q_i[s]witnesses, any witness calculation from scratch requiresO(N)
- If we don't maintain precomputed
- A construction to update Kate in amortized
sqrt(N)
Hence for the 4rth point of ideal commitment we need a special construction: Verkel tries
The ethereum state that needs to be represented is 2^28 ~= 16^7 ~= 250m size indexes=> values map (possible accounts). If we just build a flat commitment (d we would need will be ~2^28) then despite our proof still being O(1) of the size of elliptical curve element of 48 bytes, any insert or update will require either O(N) updates to all precomputed witnesses (the q_i(s) of all the points) or O(N) on the fly computation per witness.
Hence we need to move away from a flat structure to something called Verkle Trees which you will notice is also a trie like its merkle counterpart.

i.e. Build a commitment tree in same way as merkle, where we can keep d low at each node of the tree (but can still go as high as ~256 or 1024).
- Each parent is the commitment that encodes the commitment of their children as children are a map of
index => child valueswhereindexis the child'sindexat that particular parent node. - Actually the parent's commitment encode the Hashed child nodes as the input to the commitment is standarized
32bytes size values (check note on size). - The leaves encode the commitment to the chunk of
32byte hash of data that those leaves store or directly to data if its only32byte data as in case of proposed State Tree as mentioned in next section. (check note on size) - to provide the proof of a branch (analogous to merkle branch proofs), a multi-proof commitment
Dcan be generated along with its opening at point relatively random pointtagain using fiat shamir heruristic.
- for witness proof computation instead of
O ((d-1) * log-d(N))we will be doing better atO( log-d(N) )ridding ourselves from(d-1)factor.
Proposed ETH State Verkle Tree
A single trie structure for account header, code chunks as well as storage chunks with node commitments of degree d=256 polys
- combines address and header/storage slot to derive a 32 bytes
storageKeywhich essentially is a representation of the tuple(address,sub_key,leaf_key) - First 30 bytes of the derived key are used for normal verkle tree node pivots constructed
- Last 2 bytes are depth-2 subtrees to represent maximum
65536chunks of32bytes(check note on size) - For basic data, the dept-2 subtree has maximum 4 leaf commitments to cover header + code
- For storage a chunk of
65536*32bytes is represented as a single depth-2 subtree, there can be many such subtrees in the main trie for storage of an account. - Proposed GAS schedule
- access events of the type
(address, sub_key, leaf_key) WITNESS_CHUNK_COSTfor every unique access event- additonal
WITNESS_BRANCH_COSTfor every uniqueaddress,sub_keycombination
- access events of the type
Code will automatically become part of verkle trees as the part of unified state tree.
- header and code of a block are all part of a single depth-2 commitment tree
- at max 4 witnesses for chunks with
WITNESS_CHUNK_COSTand one mainWITNESS_BRANCH_COSTfor accessing account.
- Updates/inserts to the leaf
index=>valuewill requiredlog_d(N)commitment recomputes ~log_d(N) - To generate proof, prover would also require evaluting
f_i(X)/(X-z_i)for each of the branch commitment nodes ~O( log_d N ), each which would require ~dops ~O( d log_d(N) ) - proof size
O( log_d(N) )
One of the goals of ETH POS is to enable to commit 1.5MB/s of data (think this throughput as the state change throughput and hence transaction throughput that layer 2 rollups can use and eventually layer 1 EVM) into the chain. To achieve this, many parallel proposals will be done and verified at any given *12 second slot*, and hence multiple (~64) data shards will exists, each publising its own shard blob every slot. Beacon block will include the shard blobs which have >2/3 voting support, and the fork choice rule will determine if the beacon block is canonical based on the availability of all the blobs on that beacon block and its ancestors.
Note-3: shards are not chains here, any implied order will need to be interpreted by layer 2 protocols
Kate commitment can be used to create data validity and availability scheme without clients accesing full data published across shards by the shard proposer.

- Shard blob (without erasure coding) is
16384(32 bytecheck note on size) samples~512kBwith the shard header comprising mainly of corresponding max16384degree polynomial commitment to these samples- But the domain
Dof the evaluation representation of polynomial is2*16384size i.e.1,w^1,...w^,...w^32767wherewis the32768throot of unityand not16384. - This enables us to fit a max
16384degree polynomial on the data (f(w^i)=sample-ifori<16384), and then extend(evaluate) it to32768places (i.e. evaluatef(w^16384)...f(w^32767) as erasure coding samples - proofs of evaluations at each of these points are also calculated and bundeled along with samples
- Any of the
16384samples out of32768can be used to fully recoverf(x)and hence the original samples i.e.f(1),f(w^1),f(w^2)...f(w^16383)
- But the domain
2048chunks of these erasure coded32768samples (each chunk containing16samples i.e.512 bytechunks) are published by the shard proposer horizontally (ith chunk going to 'i'th vertical subnet along with their respective proof), plus globally publishing thecommitmentof the full blob.- Each validator downloads and checks chunks (and validates with the commitment of the respective blob) across the
k~20vertical subnets for the assigned(shard,slot)to establishavailability guarantees- We need to allocate enough validators to a (shard,slot) so that collaboratively half (or more) of the data is covered for these with some statistical bounds
~128committe per(shard,slot)out of which atleast~70+should attest to availability and validity i.e.2/3of the committe attesing for successful inclusion of shard blob in the beacon chain. ~262144validators (32slots *64shards *128minimum committee size)` required
- We need to allocate enough validators to a (shard,slot) so that collaboratively half (or more) of the data is covered for these with some statistical bounds
As we can see from the POC verkle go library after one time building of verkle for the size of state tree, the inserts and updates to verkle will be pretty fast.



{kind=link}
PS: this work has not been funded or granted by anyone. if you think this adds value to the ecosystem you could tip the author at: 0xb44ddd63d0e27bb3cd8046478b20c0465058ff04