這是 eugeneyan 的一篇關於做 Data Science Project 的事前、中 and 後的規劃
eugeneyan document 那篇,有提到這文章也是 one-pagers 的範例,所以我來看這篇
關於 part2 (druing) and part3 (after) 我預計不會去讀了,那比較偏 Data Science 的實作相關
以前每當有人找 eugeneyan 討論 data science problem 時,eugeneyan 總是直接鑽進去、研究 data,build 一些東西
在做了幾個專案之後,eugeneyan 開始懷疑。這樣直接栽進去,真的是快速的方法嗎?有更好的方法嗎?
eugeneyan 對工作進行了反思,並意識到在一些事情上損失了時間,比如。
- 登錯誤的山頭
- 當蒼蠅拍也可以用的時候卻用火箭筒
- 陷入兔子洞和死胡同
為了解決這個問題,eugeneyan 為自己制定了三個專案前任務
one-pagertime-boxbreakdown
- 地圖包括
意圖、預期結果、可交付成果和限制因素
- 要解決的問題是什麼?
- 或者我們想從中獲得的機會是什麼?
- 客戶將如何受益?
- 我們為什麼要這樣做,為什麼它很重要?
“Management is doing things right; leadership is doing the right things.” - Peter Drucker
,我們通常對能建造某樣東西感到如此興奮
- 以至於我們沒有停下來問 WHY?
- 我們只是假設建造它是一個好主意。
- 但,思考問題和意圖,可能會意識到
- 嘿,也許我們根本不需要解決它
- 也許它只影響到極少數的客戶,而這些客戶可能無論如何都會流失
無論如何,我們已經把不必要的專案扼殺在萌芽狀態
An unclear problem and intent also leads to another difficulty: How do we decide which solution is better? How do we know if we’re successful? By writing it down, we now have a point of reference. This can be used to compare across problems when prioritising, as well as to compare across solutions when designing.
不明確的問題和意圖也導致了另一個困難
- 如何決定哪個解決方案更好?
- 如何知道我們是否成功?
- 通過寫下來,我們現在有了一個參考點
- 這可以在確定優先次序時用於比較不同的問題,也可以在設計時用於比較不同的解決方案
有了 intent,我們可以討論成功是什麼樣子
- 我們應該多好地解決這個問題?
- 我們如何衡量它?
- 在
data science中,通常是個商業指標,如轉換率、減少欺詐所節省的費用、淨促銷員分數等
"如果你不能衡量它,你就不能改變它"。 - Peter Drucker
有了無限的資源,我們能完全解決任何問題
- 但是,我們沒有無限的資源
- 用可量化的術語來說明期望的結果,可以防止落入追逐移動目標的陷阱中
- 我們知道什麼時候我們已經過了終點線
這也有助於
- 決定哪些專案要繼續進行
- 解決一個問題到
95%可能需要3-4倍於解決到90%的努力 - 解決到
99%可能需要10-100倍努力 - 資源有限,我們會選擇不追求一個需要
99%準確率的問題(例如,臨床診斷),讓我們投資於其他更有價值的東西
現在,可以設計一個符合 intent 和 desired outcome 的可交付成果
- 我們應該如何解決這個問題?
- 解決方案的設計應該滿足意圖和期望的結果
- 同時牢記需要與現有系統集成
例如
- 電子商務平台的
intent是改善客戶發現和購買產品的方式 - 為了達到這個目的,我們應該改進搜尋?或者推薦?或電子郵件活動?
- 如果是推薦器,我們將如何部署它?
- 它將是一個每天更新的 cache 嗎?
- 還是一個接受客戶和/或產品作為輸入並返回一系列建議的服務?
這不需要特別詳細
- 現在不需要完整的架構和規格
- 但是,有一個粗略的草圖,以獲得業務、產品和技術團隊的前期支持,是很有用的
- 我們不需要一個有所有的鐘聲和口哨聲,但卻沒有結果的可交付成果
- 我們不希望建立一個無法整合的實時、多模態的深度學習推薦器
- 一定要得到這方面的反饋
「如何不解決一個問題」往往比如何解決這個問題更重要
- 這一點並沒有得到足夠的重視
- 為團隊提供界限和約束,會帶來更大的創造力和自由
- 沒有約束,我們不知道我們不能做什麼。因此,在漸進式中小心翼翼地穿行
- 相反,有了明確的約束,除了違反約束,我們可以做任何事情,這是一種解放,可以導致破壞性的創新
一個商業約束例子
- 以前,我的目標是在我們的搜尋和分類頁面上介紹新產品。其目的是增加他們(即新產品)的印象、點擊率和轉化率
做到這一點的明顯方法是
- 用新產品填充搜尋結果,而不考慮客戶體驗(像一個只有廣告的搜尋引擎)和整體業務指標
- 另一個極端是以微不足道的變化來謹慎行事(例如,每天一個新產品);這將對業務和目標沒有實際影響
- 這兩種方法都會是次優的
值得慶幸的是,我有一個單一的業務約束條件
- "
不要把轉換率降低 5% 以上" - 這提供了一個「預算」,以及在約束條件下進行試驗的自由
結果是
- 我們能夠迅速推出一個有效的解決方案
- (雖然我們預計轉換率會下降,但
A/B測試顯示,它實際上增加了,儘管不明顯)
為 production 構建 machine learning systems 時,技術限制是很常見的
- Front-end 可能會有 50-100ms 以下的延遲限制,以及吞吐量要求(例如,x 個並發請求)
- 我們可能必須遵守消費者期望的某種 interface、schema 或 format
還可能面臨著資源限制
- data science 和 machine learning pipelines 可能是計算和 memory 密集型的
- 模型訓練可能需要在 x 小時內完成,因為有 y 台機器的集群
- 這就為 pipelines 對資源的需求程度設定了界限,幫助我們專注於構建可以在 production 中部署的東西
"限制因素推動了創新,並迫使我們專注。與其試圖消除它們,不如利用它們來發揮你的優勢。" - 37Signals (Basecamp)
將 intent、desired outcome、deliverable 和 constraints 寫在 single-paged 上
- 這可以分享給利益相關者,讓他們審查、反饋和接受
- 對確保我們建立的東西會被使用,並且值得努力
這需要利益相關者有一定的紀律性
- 畢竟,這項工作對他們來說是沒有成本的
- 沒有什麼能阻止他們在專案進行到一半時改變主意
- 然而,一個令人信服的
intent和明確定義的結果和交付物可以減輕這種風險
- 然而,一個令人信服的
現在,寫 one-pagers 是我的必修課(雖然我可能不會傳閱)
- 我經常在研究、實驗和發展的森林中迷失方向
- 我很容易被新研究和技術分心,或者忘記它應該如何為客戶帶來好處
- 重新審視
one-pagers總是能讓我回到正軌
大多數專案都是從解決方案開始的
- 然後為每個組件和整體設計提出估算
- 我從不理解這一點,這就像開一張空白支票。
我傾向於做相反的事情
- 給出一個預算(
Time-Box),我們怎樣才能設計出合適的解決方案? intentanddesired outcome決定了Time-Box,而Time-Box決定了解決方案的設計- Basecamp 也是這樣做的,他們對各種問題有不同的胃口,並相應地確定解決方案的範圍
在專案的各個階段,時間框架會有所不同
- 開始的時候,還在探索和不確定性很高的時候,我們會希望有更嚴格的時間框架來限制野鵝的追逐
- 一旦有了進入 production 的確定性,我們就可以分配更大的時間框架
"工作擴展到填補可用於完成的時間"。 - Parkinson’s Law
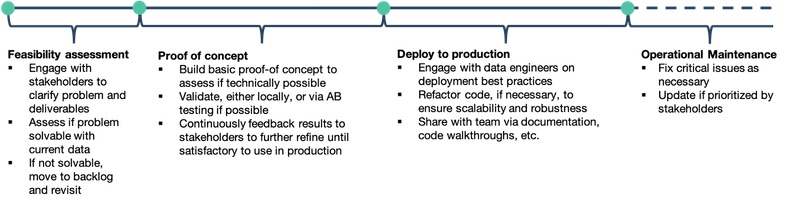
通常情況下
- 我們從可行性評估開始。利用現有的 data 和技術
- 我們是否能夠解決這個問題?如果是這樣,到什麼程度?
- 在這個階段,我們的目標是進行快速和骯髒的調查。通常在 1-2 週的時間內進行
在確定可行性後
- 我們進行概念驗證(POC)
- 這階段,我們把一個樣板放在一起,以評估我們的解決方案在技術上是否可以實現
- 理想情況下,還要測試與上游 data 供應商和下游消費者的集成點
- 能否滿足技術上的限制(如延遲、吞吐量)?模型性能是否令人滿意?這通常需要一兩個月的時間
如果一切順利
- 我們就為 production 開發
- 我們也要對這過程進行時間限制
- 過於寬鬆的時間表會導致非必要的功能被擠進去,以及無休止的開發
- 沒有實際的部署,沒有人從中受益
- 這通常需要3-6個月,包括基礎設施、工作協調、測試、監控、文件等
(上述每個階段列出數字取決於專案和組織。儘管如此,有了這些數字,就能感覺到我將在每個階段投入的相對努力了)
範例參考:
有了 one-pager and time-box,就能提高專案的成功機會
- 通常情況下,這就足夠了
- 然而,把它
break it Down來可能會有幫助 - 特別是當涉及到不熟悉的 data 或技術時
- 目的是為了儘早發現可能的兔子洞和死胡同,並減少在這些方面浪費的時間
正在使用一個新的 data source?
- 向 DBA 討論,了解 data 的完整性和 refresh 的頻率
- 如果 data source 只在午夜時分更新,就沒有必要在白天重新訓練模型
- 考慮使用一種新的技術來處理大 data ?就潛在的挑戰和障礙諮詢 senior data engineers
"預見性不是預測未來,而是最大限度地減少驚喜"。 - Karl Schroeder
理想情況下
break it Down能找出哪些 component 更難實現或風險更大- 這些通常涉及以前沒有做過的事情
- 我們希望把風險前置,先從這些可怕的部分開始
- 如果關鍵部分無法實施,我們應該在投資和完成專案的其他部分之前,儘早知道,而不是拖延
break it Down 的時候
- 我經常諮詢具有更多專業知識和經驗的前輩
- 他們通常對值得更多關注的潛在麻煩和障礙有更好的直覺
- 如果你是最資深的人,讓一雙新的眼睛看一下
break it Down,找出可能錯過的東西
知道兔子洞在哪里以及如何避免它們,為在執行階段節省了大量時間
這可能看起來是不必要的、額外的工作
- 但它並不花費很多時間,而且它減少了所做的總工作
- 一個
one-pager通常需要1-2天,最多一星期 - 在
one-pager上花的時間越多,節省的時間就越多 - 需要更多的時間表明問題
- 理想的解決方案還不清楚就開始 build,會導致浪費精力
同樣地,適當的 Time-Box 確保我們根據問題的大小謹慎地投資於一個解決方案
- 儘早發現兔子洞和死胡同有助於我們避免它們,減少努力的浪費