好好讀一次 Google SEO document
- 下面能看到蠻多重複的內容一直出現,是因為 document 就是這樣寫的
GA 是拿來看 User 瀏覽 Web 時的行為、逛哪些頁面、待多久的等等
GSC 是
- 看你 Web 的 SEO 表現如何
- 成效報表會顯示從 Google 搜尋獲得多少流量
- 偵測 Web 上有異常時,例如有很多頁面 404 等等
透過 submit Sitemap 給 google,讓 google 知道你的 Web、幫你 index
另外要確認 Google 有沒有辦法拜訪你的 web
- 行動裝置相容性測試: https://search.google.com/test/mobile-friendly?hl=zh-tw
- 為什麼是針對 mobile ? Google 認為,mobile 使用量多,有 mobile viwe 對 UX 好
找到 web 之後,Google 會嘗試解讀網頁內容,這稱為「建立索引」
- Google 會分析網頁內容、為嵌入網頁中的圖片和影片檔案編目,並以其他方式嘗試解讀網頁
- 然後將這些資訊儲存至「Google 索引」
如何提升網頁索引成效:
- 建立簡短而有意義的網頁標題
- 使用可傳達頁面主題的網頁標題
- 使用文字而非圖片來傳達內容
- Google 能夠解讀部分圖片和影片,但效果不如文字來得好
- 請至少使用替代文字和其他屬性,為影片和圖片加上適當註解
定義
index (索引)- Google 會將所有已知網頁儲存在「index」中
- 每個網頁的索引項目都會記錄網頁的內容及位置 (網址)
- 所謂的「建立索引」,是指 Google 擷取、讀取網頁,然後將網頁加入索引的過程
- 例句:Google 今天為我的網站建立了幾個網頁索引
Crawl (檢索)- 尋找新網頁或更新網頁的程序
- Google 會透過追蹤連結、讀取 Sitemap 等多種方法發掘網址
- 例句:Google 檢索網路,尋找新網頁,然後在適當情況下為這些網頁建立索引
Crawler 檢索器- 在網路上 crawls (fetch) 網頁並建立網頁索引的自動化軟體
- Googlebot:
- Google Crawler 的通稱。例句:Googlebot 會持續檢索網路。
你的網站在 Google 索引中嗎?判斷網站是否在 Google 索引中
- google
site:www.youtube.com就能判斷,若是有,應該要有結果出來
告訴 Google「不要」檢索哪些網頁
robots.txt檔案禁止系統檢索非機密資訊
# brandonsbaseballcards.com/robots.txt
# Tell Google not to crawl any URLs in the shopping cart or images in the icons folder,
# because they won't be useful in Google Search results.
User-agent: googlebot
Disallow: /checkout/
Disallow: /icons/
協助 Google (及使用者) 瞭解你的內容
- 為了最理想、順利建立索引,Googlebot 在檢索網頁時,應該和一般使用者看到完全相同的網頁
- 如果 robots.txt 檔案禁止檢索資源(JS, image),因而無法有效轉譯內容並為其建立索引,可能導致網站排名降低。
建議做法:
- 使用網址檢查工具: https://support.google.com/webmasters/answer/9012289
- 可讓你瞭解 Googlebot 所看到的內容以及實際轉譯結果
- 也能夠協助找出網站上存在的許多索引問題並進行修正
建立可準確傳達內容的獨特網頁標題
- 用
<title>讓使用者和搜尋引擎知道特定網頁的主題是什麼 - 將
<title>放在<head>,並為網站上的每個網頁建立獨一無二的標題 - 避免使用沒有相關的文字 or 多個頁面都是同樣的 title
- 如果文字太長或感覺不太相關,搜尋結果可能只顯示部分文字,或用演算法產生的標題連結
搜尋結果網頁中時,可能會使用 <title> 做為搜尋結果的標題連結

利用 <meta />
<meta />為 Google 和其他搜尋引擎提供網頁內容簡介- title 可能由幾個文字構成,而
<meta />則可能是句子或簡短段落 - 一樣放
<head> - Google 可能會將
<meta />當做摘要 - (根據搜尋方式及使用裝置的不同,使用者可能會看到不同長度的摘要)
<html>
<head>
<title>Brandon's Baseball Cards - Buy Cards, Baseball News, Card Prices</title>
<meta name="description" content="Brandon's Baseball Cards provides a large selection of vintage and modern baseball cards for sale. We also offer daily baseball news and events.">
</head>
<body>
結構化資料
- 搜尋引擎能根據網頁內容的說明,能以更為實用的方式在搜尋結果中呈現內容
- https://developers.google.com/search/docs/advanced/structured-data/intro-structured-data?hl=zh-tw
- https://developers.google.com/search/docs/advanced/structured-data/search-gallery?hl=zh-tw
- 檢查工具 Google 複合式搜尋結果測試
如果為網路商店的個別網頁加上了相關標記
- Google 就會知道這個網頁是用於販賣腳踏車,並且提供價格及客戶評論等資訊
- 結構化資料標記除了用於顯示複合式搜尋結果外,也會用於顯示其他格式的相關結果
- 例,營業時間
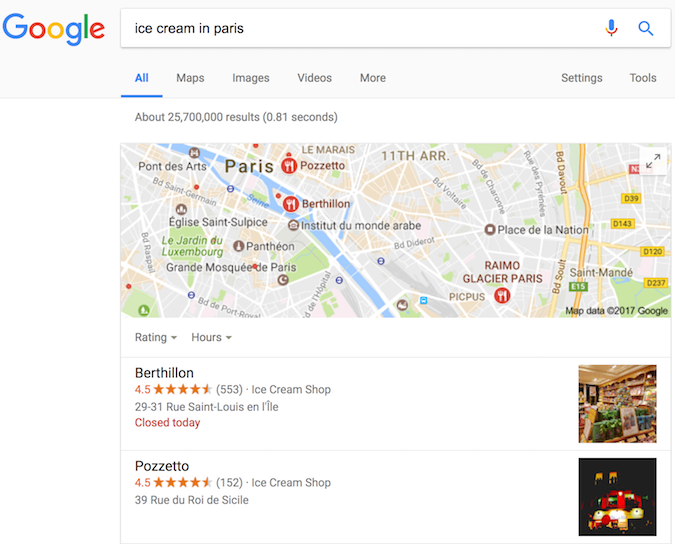
使用資料螢光筆和標記協助工具 想使用結構化標記,但不想改變網站的原始碼
- 可用 Data Highlighter。這工具已和 Search Console 整合,可支援部分內容類型
持續追蹤標記網頁的搜尋成效
- Rich result reports 中提供了各項複合式搜尋結果報告
- 顯示 Google 在網站中偵測到具備特定類型標記的網頁數量
- 這些網頁在搜尋結果中出現的次數
- 過去 90 天內使用者點選這些網頁的次數
- 還會顯示偵測到的錯誤
管理網站階層
網址通常可以分成幾部分:
protocol://hostname/path/filename?querystring#fragment
例如:
https://www.example.com/RunningShoes/Womens.htm?size=8#info
- 將
www和非 www視為不同版本,如www.example.com和example.com - 將網站加入 Search Console 時,建議同時加入
http://和https://的版本,以及www和非 www版本。 path、filename和querystring決定了系統會從你的 server 中存取的內容- 這三個部分會區分大小寫,
FILE和file會導向不同的網址
- 這三個部分會區分大小寫,
hostname和protocol不會區分大小寫- 搜尋引擎一般會忽略
#fragment hostname結尾是否有斜線符號,都會導向同樣的內容https://example.com/和https://example.com的內容相同path和filename結尾是否有斜線符號,會影響導向的網址- 因為關係到網址要表示是檔案或目錄
https://example.com/fish導向會和https://example.com/fish/的不同
透過文字進行 navigation
- 如果網站大部分都是文字連結,搜尋引擎就能更輕易檢索並瞭解網站
- 用 JS 建立網頁時,使用
<a />和href屬性值,並在網頁載入時就產生
為使用者建立 navigational page,為搜尋引擎建立 Sitemap
- 建立 XML Sitemap 檔案,確保搜尋引擎能夠發現網站上的新增網頁和更新網頁
- 這個檔案中要列出所有相關網址,以及主要內容的最近一次修改日期
custom 的 404 page
- 使用者有時會因開啟無效連結或輸入錯誤的網址,而連至網站中不存在的網頁,
- 用自訂 404 能幫助使用者返回網站上的有效網頁
- 可以透過 Google Search Console 瞭解造成「找不到網頁」錯誤的網址來源
留意連結的網站
- 當你的網站連結到其他網站,你網站的信譽可能會讓對方獲益
- 因此,有些使用者會將自己網站的連結放置在你的留言專區或留言板上,好沾你網站的光
- 另一方面,有時你可能會以負面方式提到某個網站,但不希望對方因為你網站的信譽而獲益
- 但是你當然不希望垃圾網站會因為你網站的信譽而獲益,這時用
nofollow屬性 - 如果想為網頁中所有的連結加上
nofollow屬性,在<head>中加入<meta name="robots" content="nofollow">
運用 nofollow 防範垃圾留言
- 告訴 Google 不要再追蹤連結的網頁,或是不要將你的網頁信譽傳遞給連結網頁
- 將連結的
rel設為nofollow或ugc(user custom content)<a href="http://www.example.com" rel="nofollow">Anchor text here</a>- https://developers.google.com/search/docs/advanced/guidelines/qualify-outbound-links?hl=zh-tw
圖片
- 用
<img>或<picture>- 語意式 HTML 可協助檢索器找到及處理圖片
- 用
<picture>能 response screen
- 避免用 CSS 顯示要建立索引的圖片
- 用
alt屬性- 在圖片因無法顯示時用替代文字
- 無障礙
- 如果把圖片設成連結,替代文字就有類似文字連結錨定文字的作用
協助搜尋引擎找到你的圖片
- 圖片 Sitemap
- 可以讓 Googlebot 更瞭解在網站上找到的圖片,並讓這些圖片更有機會顯示在 Google image 搜尋結果中
行動裝置
- 智慧型手機:「行動裝置」指的是智慧型手機,例如 iPhone or Android 系統的裝置
- 平板電腦:Google 認為平板電腦為一種獨立的裝置類型
- 因此當提到行動裝置時,基本上並不包括平板電腦
- 平板電腦螢幕較大,使用者在平板上瀏覽網站時,還是習慣看到與電腦瀏覽器類似的畫面,而不是手機
有許多方法能讓網站適合 mobile 瀏覽,Google 支援的實作方法如:
- 回應式網頁設計 (建議使用)
- 動態服務
- 獨立網址
無論選擇為 mobile 設置何種設定,都注意:
- 如果採用「動態服務」或擁有獨立的網站,無論是將網頁設為 mobile 專用格式,還是提供支援 mobile 格式的對應網頁
- 都必須讓 Google 得知這項設定。Google 就能在搜尋結果中將內容準確提供給使用 mobile 的搜尋者
- 如果採用「回應式網頁設計」,使用
meta name="viewport"標記指示瀏覽器如何調整內容 - 如果採用「動態服務」,請使用 Vary HTTP header,依據使用者代理程式指明變更
- 採用獨立網址時,加入含
rel="canonical"和rel="alternate"的<link>,指明兩個網址間的關係。
- 採用獨立網址時,加入含
- 封鎖網頁資源會讓 Google 無法完整解讀網站內容
- 這種情況,通常是因為
robots.txt封鎖了部分或所有網頁資源的存取權限
- 這種情況,通常是因為
- 避免出現會對 mobile 訪客造成困擾的常見錯誤,例如無法播放的影片。
- 如果 mobile 網頁無法提供令人滿意的搜尋體驗,在行動搜尋結果中的排名就會下滑
- 或者在搜尋結果中附帶顯示警告訊息
- 這類情形包括但不限於在 mobile 網頁上顯示妨礙使用體驗的整頁插頁式廣告
- 瞭解網站上的網頁是否符合標準,足以在 Google 搜尋結果網頁上標示為適合透過 mobile 瀏覽
- 修正對網站造成影響的 mobile 可用性問題
宣傳網站
- 如果你是當地商家的業主,用聲明商家檔案的擁有權,就能觸及使用 Google 地圖和 Google 搜尋功能的客戶
分析搜尋成效
- 分析特定網站在搜尋引擎中的搜尋成效的工具就是
Search Console - Search Console 提供了兩類重要資訊:
- Google 是否能找到我的內容?
- 網站在 Google 搜尋結果的成效表現如何?
網站擁有者可以利用這項服務:
- 查看 Googlebot 檢索網站的哪個部分時發生了問題
- 測試及提交 Sitemap
- 分析或產生 robots.txt 檔案
- 移除 Googlebot 已檢索的網址
- 指定偏好網域
- 找出 title 和 description 這兩個中繼標記的問題
- 瞭解使用者最常使用哪些搜尋關鍵字找到網站
- 瞭解 Googlebot 看到的網頁內容
- 在違反品質指南時收到通知,並提出網站重審要求
Microsoft 的 Bing 網站管理員工具也為網站擁有者提供了相關工具
主要 index/次要 index
Google 使用兩種 crawling 來 index 網站:mobile 和 desktop
- 每種 crawling 都會模擬使用者透過該類裝置造訪網頁的情況
- 目前,所有新網站的主要 crawling 都是 mobile
- 除此之外,Google 會使用 desktop 重新 crawling ,這就是所謂的「次要檢索」,目的是為了瞭解網站與另一種裝置類型的相容性
保持簡單的網址結構
- 網址結構盡可能簡單。試著組織網站內容,使用具有邏輯的網址結構,讓人容易理解。
- 如果可以,盡量使用具有意義的字詞,不要使用冗長的 ID
good
http://en.wikipedia.org/wiki/Aviation
example.com/lebensmittel/pfefferminz
視需要使用 UTF-8
bad
https://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
如果網站是多地區網站,考慮使用指定不同地理區域的網址結構
使用國家/地區專屬的網域
- 搭配 gTLD 使用國家/地區專屬子目錄:
example.de
example.com/de/
網址中使用連字號,讓使用者和搜尋引擎更容易瞭解網址中的概念
- 使用連字號
-,不要使用底線_
https://www.example.com/green-dress
https://www.example.com/summer-clothing/filter?color-profile=dark-grey
bad
https://www.example.com/greendress
https://www.example.com/summer_clothing/filter?color_profile=dark_grey
向 Google 說明你與連結網頁之間的關係
- 在
<a>加入其中一種rel屬性值即可 - 如果想 Google 無條件追蹤的一般連結,則不必加入 rel 屬性
rel="sponsored": 付費連結rel="ugc": 使用者自製內容 (UGC) 的連結,如指向評論和論壇文章的連結rel="nofollow"不想擔保連結網站的內容品質,不讓 Google 透過你的網站檢索連結的網頁- 如果是網站內部的連結,用
robots.txt的disallow
- 如果是網站內部的連結,用
- 多個值,用空格分隔或以半形逗號
rel="ugc nofollow"orrel="ugc,nofollow"
一般來說,Google 不會追蹤標有 rel 屬性的連結
- 不過 Google 可能會透過其他方式找到這些連結的網頁,例如 Sitemap 或是其他網站中的連結
- 因此 Google 仍有可能會檢索到這些連結
避免干擾性的插頁式廣告和對話方塊干擾性插頁式廣告示例
- 干擾性對話方塊和插頁式廣告會讓 Google 和其他搜尋引擎難以解讀內容,進而導致搜尋成效不佳
- 同樣,如果使用者覺得網站難以使用,很可能就不想再造訪網站
- (search engin 不知道會不會真的受影響)

以橫幅取代插頁式廣告
- 橫幅廣告範例,可提供更優質的使用者體驗
- 不占據整個網頁的插頁式廣告,只占用局部畫面的橫幅廣告來吸引使用者注意

除非法律規定,否則,對話方塊或插頁式廣告時,避免下列常見錯誤,以利 Google 能檢索及解讀內容
- 請勿以插頁式廣告遮蓋整個網頁
- 徵求使用者同意或要求提供資訊時,請勿將使用者重新導向至其他網頁
依法規定的插頁式內容
- 部分網站會因為發布的內容類型而需要顯示插頁式內容。例如
- 賭場網站可能需要顯示年齡驗證關卡,要求使用者先提供年齡才能瀏覽內容。
依法規定的插頁式內容不需遵守規範;不過,還是建議網站盡可能遵循下列做法:
- 確認內容與插頁式廣告重疊。這麼做可確保 Google 至少能夠檢索部分內容,並有機會顯示在搜尋結果中
- 勿為了收集同意聲明或提供資料,而將連入 HTTP 要求重新導向至其他網頁
- 如果將多個網址重新導向至單一網頁,會導致只有重新導向後的網頁能出現在搜尋結果中,因為 Googlebot 只會擷取該網頁。
將網站標記為兒童導向內容
- 如果網站或行動應用程式提供專為兒童設計的內容
- 兒童導向內容標記頁面為網站或服務加上標記
- 以要求 Google 根據《兒童網路隱私保護法》(COPPA),將該網站/服務的部分或整體內容視為兒童導向內容
- 尚未將網站新增至 Search Console,則必須先新增網站並驗證擁有權
標記為兒童導向內容
- 不會影響網站或應用程式在 Google 搜尋結果中的排名
- 可將整個網域或局部網域 (子網域或子目錄) 標記為兒童導向內容
- 標記網域或目錄後,其下的所有網頁都會納入標記的效力範圍
- 此操作需要經過一段時間才會在適用的 Google 服務中生效
- Google 隨時可對納入兒童導向標記的網域或子網域數量設限
如需進一步微調內容的處理方式
- 你可以將個別的廣告單元標記為兒童導向的內容
- 閱產品的說明中心,進一步瞭解正確的標記方式
- 注意:標記個別廣告單元後,會對放送的廣告產生立即影響
- 廣告單元標記的優先順序高於任何適用的網站層級設定
盡可能利用多個不同瀏覽器測試網站
- 可透過 Google Analytics,瞭解使用者瀏覽網站時最常使用哪些瀏覽器
避免建立重複的內容
- 通常是指一或多個網域中,完全或大致與其他同樣語言的內容相符的實質內容區塊
- 重複內容本身並不構成欺騙行為。非惡意的重複內容可能包括:
- 會產生一般網頁和行動裝置專用精簡網頁的論壇
- 在網路商店中,能透過多個不同網址顯示或連結的商品
- 列印專用的網頁
如果網站有許多內容大致相同的網頁,可以透過幾種不同的方式告知 Google 偏好網址,稱為「標準化」
某些情況下
- 有心人士會故意在多個網域中置入重複內容,試圖操控搜尋引擎的排名或贏得更多的流量
- 這種欺騙行為會讓訪客在多個搜尋結果中看到大致相同的內容,導致使用者體驗大打折扣
假設網站的每篇文章都有「普通」和「列印」版本,而且兩者都沒有使用 noindex 標記封鎖
- Google 會篩選,只在搜尋結果中列出其中一種版本
- 極少數情況下,Google 會發現有網站為了操控排名和欺騙使用者而顯示重複內容
- 針對涉嫌採取這些手段的網站,會對其索引和排名做出適當調整,會造成網站排名降低
- 或者可能導致網站從 Google 索引中完全移除,而不再出現於搜尋結果中
可透過以下幾項步驟主動處理重複內容問題,確保網站能向訪客顯示希望呈現的內容。
使用 301 重新導向機制:如果重新建構了網站,在.htaccess中使用301重新導向 (RedirectPermanent),即可巧為使用者、Googlebot 和其他自動尋檢程式進行重新導向。保持一致:盡量保持內部連結的一致性- 舉例來說,勿連結至
http://www.example.com/page/、http://www.example.com/page和http://www.example.com/page/index.htm
- 舉例來說,勿連結至
使用頂層網域:盡可能使用上層網域來處理國家/地區專屬內容。例如- 與
http://www.example.com/de或http://de.example.com相比,Google 更容易看出http://www.example.de中含有專為德國提供的內容。
- 與
謹慎使用聯合發布:如果以聯合發布方式在其他網站發布內容- 在每次相關搜尋中,Google 會一律顯示最適合使用者的版本,而這不一定是你偏好的版本
- 不過, 仍建議確保在聯合發布內容的每個網站上都有原始文章連結
- 也可以要求聯合發布內容的採用者在其網站上加入 noindex 標記,以免搜尋引擎為他們的內容版本建立索引。
盡量減少一成不變的重複內容:舉例,不要在每個網頁下方都放入冗長的版權文字- 建議改為提供簡短摘要,並附上詳細資料網頁的連結
避免發布不完整的內容:使用者不喜歡看到「空白」網頁,避免使用預留網頁- 例如,不要發布還沒有實際內容的網頁
- 如果需要建立預留網頁,用
noindex,避免 Google 為其建立索引
瞭解你的內容管理系統:請務必熟悉網站顯示內容的方式。網誌、論壇和相關系統通常會以多種格式顯示相同的內容,舉例來說,單篇網誌文章可能會顯示在網誌首頁和封存網頁中,也可能與標籤相同的其他文章出現在同一個網頁上。盡量減少相似內容:如果有許多相似的網頁,請考慮擴充各網頁的內容,或將其合併成一個網頁
Google 不建議透過 robots.txt 或其他方式禁止檢索器存取網站上的重複內容
- 因為,搜尋引擎無法檢索含有重複內容的網頁,就無法透過自動偵測發現這些網址指向相同內容
- 這樣會導致搜尋引擎誤將這些網址視為獨立的不重複網頁
- 較佳的做法是允許搜尋引擎檢索這些網址,但使用
rel="canonical"或301 重新導向等方式,將這些網址標示為重複內容 - 為避免系統因重複內容而過度檢索網站,也可以在 Search Console 中調整檢索頻率設定。
正確的 <a>
- Google 只能追蹤
<a>中含有href屬性的連結
Good
<a href="https://example.com">
<a href="/relative/path/file">Bad
<a routerLink="some/path">
<span href="https://example.com">
<a onclick="goto('https://example.com')">確認 Googlebot 未遭到封鎖
想知道網站上有哪些封鎖的網頁
- 請查看索引涵蓋範圍報表: https://support.google.com/webmasters/answer/7440203
- 或使用網址檢查工具測試特定網頁: https://support.google.com/webmasters/answer/9012289
在測試網站時保持 Google 搜尋排名的最佳做法
- 在測試不同版本的網頁內容或網址時,盡量減少對 Google 搜尋排名造成的影響
A/B 測試
- 為同個網頁建立多個版本來執行測試,而每個版本擁有獨立網址
- 當使用者存取原始網址時,將其中部分使用者重新導向到其他版本的網址,藉此比較各版使用者的行為
多變數測試:
- 使用即時變更網站的部分內容。可以測試網頁上多個部分的變更效果
- 例如標題、相片和「加入購物車」按鈕,測試軟體會向使用者顯示這些變更部分的不同組合
- 然後從統計角度分析哪個版本成效最佳
- 這種測試只會用到一個網址,測試會將變更的內容動態插入網頁
只是微幅調整按鈕、圖片或「行動號召」文字 (例如「加入購物車」和「立即購買!」) 等元素的大小、顏色或擺放位置
- 就可能會讓使用者與網頁互動的方式有出人意料的變化
- 但對搜尋結果摘要或排名的影響不大,甚至毫無影響。
不要偽裝測試網頁
- 勿對 Googlebot 和使用者顯示不同的網址組。這種行為稱為偽裝,已違反網站管理員指南
- 無論你是否在執行測試都不可使用。如果違反網站管理員指南,網站的排名可能會降低,甚至遭排除在 Google 搜尋結果之外
- 無論是利用伺服器邏輯、robots.txt 還是其他方法,只要涉及偽裝行為就不可行
使用 rel="canonical" 連結
- 如果運用多個網址進行
A/B 測試,可在所有替代網址上使用rel="canonical"屬性- 指明原始網址為偏好版本
- 之所以建議用
rel="canonical"而不是noindex中繼標記,前者更有助於達成測試目的- 舉例,在測試首頁的不同版本時,應該只想讓搜尋引擎瞭解各版本的本質,而不要建立索引 因為所有測試網址的內容其實都非常類似原始網址,或者只是變化版本,因此該歸納為同一組,並以原始網址為標準版本
使用 302 重新導向,非 301 重新導向
- 如果進行的
A/B 測試會將使用者從原始網址重新導向至其他版本的網址,使用302 (暫時性) 重新導向,不要使用 301 (永久性) 重新導向 - 這樣,搜尋引擎就會知道這只是測試期間的暫時性重新導向,應該將本來的網址保留在索引中,不要替換成重新導向目標的測試網頁。也可以使用 JS 進行重新導向,不會造成違規
提高內容在 Google image 中的曝光率,請以使用者為重:
提供優質關聯內容: 視覺內容與網頁主題相關。建議顯示原創圖片,為網頁增加原創性- 尤其不鼓勵在網頁中使用非原創的圖片或文字
選擇最佳顯示位置: 盡可能將圖片放置在相關文字附近- 考慮將最重要的圖片放置在網頁頂端附近
不要在圖片中嵌入重要文字: 避免在圖片中嵌入文字,尤其是網頁標題和選單項目等重要文字元素- 因為並非所有使用者都可存取文字,且網頁翻譯不支援圖片
- 讓更多人存取你的內容,透過 HTML 加入文字,並為圖片提供
alt
建立包含豐富資訊的優質網站: 對Google image來說,網頁上的優質內容和視覺內容同等重要- 前者可提供關聯的背景資訊,讓搜尋結果更為實用
- 網頁內容可用來產生與圖片相關的文字摘要,且 Google 會根據網頁內容品質為圖片排名。
建立適合透過裝置瀏覽的網站: 相比 desktop,使用者較常在 mobile 上使用 Google image 搜尋- 務必將網站設計成適合所有類型和大小的裝置瀏覽
為圖片建立良好的網址結構: Google 會使用網址路徑和檔案名稱來瞭解你的圖片- 以有邏輯的方式來架構網址
my-new-black-kitten.jpg比IMG00023.JPG更適合做檔名- 如要將圖片本地化,也翻譯檔案名稱
優化圖片/responsive: https://web.dev/fast/#optimize-webfonts高畫質 image: 高畫質 image 較能吸引使用者的目光- 清晰的圖片在結果縮圖中更為吸睛,可提高使用者造訪網站的機率
- Google 不會解析 CSS 裡的 image
<div style="background-image:url(puppy.jpg)" />
Google image
- 會自動產生標題和摘要,藉此概要說明各項結果的內容
- 可以根據 Google 的標題與摘要指南,改善
Google image顯示的網頁標題和摘要 - 新增結構化資料,只要加入結構化資料,
Google image就能以複合式搜尋結果顯示圖片
使用圖片 Sitemap 圖片是系統判斷網站內容為何的重要資訊來源
- 可以在
圖片 Sitemap中新增資訊,藉此將圖片的額外詳細資料提供給 Google - 並針對 Google 本來可能不會發現的圖片提供圖片網址
一般 Sitemap會強制實行 CORS 限制,但圖片 Sitemap不同,可包含其他網域的網址- 因此可使用 CDN 來代管圖片
- 建議透過 Search Console 驗證 CDN 的網域名稱,這樣 Google 在發現任何檢索錯誤時通知
- 因此可使用 CDN 來代管圖片
- https://youtu.be/1Zqkz8Y_kFw
- Google index 影片,指的是網頁中的 video
- 確保 video 是 public 的
- 影片能被 Google 存取的話,Google 還會建立動態的 preview,甚至分析影片段落,並標記
- 為了將影片盡可能呈現給使用者,請為每部影片建立專屬頁面
- 提交影片 Sitemap,讓 Google 更容易找到影片
- 支援的影片編碼: 3GP、3G2、ASF、AVI、DivX、M2V、M3U、M3U8、M4V、MKV、MOV、MP4、MPEG、OGV、QVT、RAM、RM、VOB、WebM、WMV、XAP
第三方內嵌播放器
- 如果網站嵌入了 YouTube、Vimeo 或 Facebook 等第三方平台的影片,Google 可能會為該影片建立兩筆索引記錄
- 一筆是你的網頁,另一筆則是第三方代管網站的對應網頁。這兩種版本都可能出現在 Google 的影片功能中
- 如果你嵌入了第三方播放器,仍建議提供結構化資料
- 此外也可以將這些網頁納入
影片 Sitemap - 聯絡影片代管商,確認允許 Google 擷取影片檔案
- 舉例,YouTube 上的公開影片就支援這項功能
- 此外也可以將這些網頁納入
提供高畫質的 thumbnail
- 影片必須具備有效的縮圖才能顯示在 Google video 功能中
- 否則即使網頁已編入索引,也只能顯示為一般的藍色連結
- 可以允許 Google 產生縮圖,或透過下列其中一種支援的方式提供縮圖
- 如果用
<video>,請指定poster屬性。 - 在
影片 Sitemap中指定<video:thumbnail_loc>標記 - 在
結構化資料中指定thumbnailUrl屬性。
- 如果用
- 如果允許 Google 擷取影片內容檔案,Google 可以產生縮圖
- 尺寸:至少 60x30 像素;Google 偏好較大的縮圖
- 此外,請使用穩定的網址提供檔案
影片預覽
- Google 會從影片中選取幾秒鐘的片段做為動態預覽,幫助使用者進一步瞭解影片提供的內容
- 為了讓影片能使用這項功能,請允許 Google 擷取影片內容檔案
- 可以使用 max-video-preview robots meta tag 設定這些影片預覽的時間長度上限

重要時刻 (Key moments)
- https://youtu.be/rsFLIewWSrI
- 「重要時刻」功能可將影片像書籍章節一樣分段,方便使用者瀏覽
- Google 搜尋就會自動嘗試偵測影片中的片段,並向使用者顯示重要時刻
- 或者,也可以自行告知 Google 影片的重點段落為何
- Google 會優先採用透過結構化資料或 YouTube 說明設定的重要時刻
- 如果影片由自己的網頁代管,可以透過下列兩種方式啟用重要時刻功能
Clip 結構化資料:指定每個片段確切的開始和結束時間,以及要顯示的片段標籤SeekToAction 結構化資料:告訴 Google 時間戳記通常位於網址結構中的哪個位置,讓 Google 自動識別重要時刻,並將使用者直接連結至影片中的段落
- 如果的影片由 YouTube 代管,在 YouTube 的影片說明中指定確切的時間戳記和標籤
- 如果要停用
Key moments,就使用 nosnippet meta tag
直播標記
- 如果是直播影片,可以透過 BroadcastEvent 結構化資料和 Indexing API
- 在該影片的搜尋結果中顯示紅色的「直播」標記

移除或限制影片的搜尋結果
- 如需盡快將影片網頁從搜尋結果中移除,對代管影片的網頁提出移除要求
- 如要永久移除影片的搜尋結果,就不能讓 Google 看到或存取影片所在網頁;回 404 錯誤、使用
noindex meta tag- 或要求進行伺服器端驗證
- 如果影片是嵌入其他網頁或網站,除非額外為每個網頁提交移除要求,否則 Google 不會移除這些網頁的搜尋結果
如要移除自家網站上影片的搜尋結果,執行下列其中一項:
- 如果到達網頁包含已移除或過期的影片,傳回 404 (Not found) HTTP statue code
- 除了 404,也可以傳回網頁的 HTML,讓大多數使用者瞭解內容已經變更。
- 如果到達網頁包含已移除或過期的影片,
noindex meta tag,避免系統為該到達網頁建立索引。 - 在 schema.org 結構化資料 (使用
expires屬性) 或影片 Sitemap(使用<video:expiration_date>元素) 中指定到期日 - 如果 Google 看到某部影片的到期日為過去日期,就不會將這部影片放在任何搜尋結果中
- 該影片的到達網頁仍然可以顯示為網頁搜尋結果,但不會顯示影片縮圖
- 這裡指的到期日包括透過
Sitemap、結構化資料和網站 header 中的 meta tag 的到期日
以下是影片到期日為 2009 年 11 月的影片 Sitemap 範例:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>http://www.example.com/videos/some_video_landing_page.html</loc>
<video:video>
<video:thumbnail_loc>
http://www.example.com/thumbs/123.jpg
</video:thumbnail_loc>
<video:title>
Grilling steaks for summer
</video:title>
<video:description>
Bob shows you how to grill steaks perfectly every time
</video:description>
<video:player_loc>
http://www.example.com/videoplayer?video=123
</video:player_loc>
<video:expiration_date>2009-11-05T19:20:30+08:00</video:expiration_date>
</video:video>
</url>
</urlset>根據使用者的位置限制影片的搜尋結果
- 可以根據搜尋者的位置限制影片的搜尋結果
- 如果使用
VideoObject 結構化資料來描述影片,設定regionsAllowed屬性 影片 Sitemap中使用<video:restriction>標記,能夠允許或拒絕影片出現在特定國家/地區的搜尋結果中- 每個影片項目只能使用一個
<video:restriction>標記 <video:restriction>標記必須包含一或多個以空格分隔的 ISO 3166 國家/地區代碼- 且必須使用 relationship 屬性指定限制的類型
relationship="allow":影片只能出現在指定國家/地區的搜尋結果中。如果沒有指定國家/地區,影片就不會出現在任何搜尋結果中。relationship="deny":除了指定的國家/地區以外,影片會出現在任何地方的搜尋結果中。如果沒有指定國家/地區,任何搜尋結果都能夠顯示這部影片。
- 每個影片項目只能使用一個
以下列影片 Sitemap 為例,影片只會出現在加拿大和墨西哥的搜尋結果中。
<url>
<loc>http://www.example.com/videos/some_video_landing_page.html</loc>
<video:video>
<video:thumbnail_loc>
http://www.example.com/thumbs/123.jpg
</video:thumbnail_loc>
<video:title>Grilling steaks for summer</video:title>
<video:description>
Bob shows you how to get perfectly done steaks every time
</video:description>
<video:player_loc>
http://www.example.com/player?video=123
</video:player_loc>
<video:restriction relationship="allow">ca mx</video:restriction>
</video:video>
</url>Google 能為很多類型的網頁與檔案建立 index
一般來說,搜尋引擎會以文字為作業基礎。也就是說,如果想要讓搜尋引擎檢索網頁內容並建立索引,內容就必須是文字格式
- 只在必要時使用互動式多媒體。建議使用 HTML 來建立網頁內容
- 如果首頁採用了非 HTML 啟動畫面,在其中加入可連向文字版網頁的一般 HTML 連結,讓使用者 (或 Googlebot) 即使不執行互動式多媒體,也能瀏覽網站
- 這不代表網站就無法使用互動式多媒體內容 (例如 Silverlight 或影片),只是嵌入這些檔案中的內容最好也能提供文字格式,以免部分搜尋引擎可能無法存取
iframe
- 透過 iframe 顯示的內容可能無法建立索引,無法出現在 Google 搜尋結果中
- 如果一定要這麼做,另外提供可連至 iframe 顯示內容的文字版連結,讓 Googlebot 能夠檢索
Flash
- Google 已不再支援 Flash,建議改用其他格式,如 HTML5。
利用 mete 指定網站為成人內容,這樣能讓 Google 調整搜尋結果,不會讓某些人看到
<meta name="rating" content="adult" />如果的網站只有相對少數的煽情露骨內容
- 上面是你一需要執行的操作
- 假設網站有數百個網頁,但只有少量網頁含有煽情露骨內容,標記這些網頁就夠,不需要將內容歸類到子網域
如果網站同時含有大量煽情露骨內容和非煽情露骨內容
- 除加入 meta 之外
- 建議將煽情露骨內容與網站上的非煽情露骨內容區隔開來
舉例
- 所有煽情露骨內容皆可移至其他網域或子網域
- 或者,將所有煽情露骨內容歸入其他目錄
https://explicit.example.com/page.html
https://explicit.example.com/image.jpg
https://explicit.example.com/video.mp4
https://example.com/explicit/page.html
https://example.com/explicit/image.jpg
https://example.com/explicit/video.mp4
如果未將內容分開
- Google 會將整個網站的性質判定為屬於煽情露骨網站
- 當安全搜尋功能開啟時,系統便會將整個網站濾除,即使某些內容可能並非煽情露骨
- 只須注意將這類內容歸到同一類,與非煽情露骨內容分開即可
如果已按照建議進行變更,但仍發現內容被誤標為煽情露骨內容,請考慮以下幾個因素:
- 如果才剛變更不久,分類器需要更多時間才能處理。最多可能需要 2 至 3 個月的時間
- 你對煽情露骨圖片進行模糊處理後,如果模糊效果能夠復原,或是網頁導向的圖片經過這類處理,系統可能仍會將該圖片視為煽情露骨圖片
- 不論是出於什麼原因而使用裸露內容 (即使是為了說明醫療程序),都無法抹滅這類內容的煽情露骨性質
- 如果含有煽情露骨的使用者自製內容,或是駭客利用偽裝關鍵字等其他技術在網站植入煽情露骨內容,網站可能會被視為含有煽情露骨內容
如果網站有網誌,而豐富、實用且原創的網誌內容則能鼓勵讀者回來造訪網站。以下幾個提示,協助發揮網誌的最大效用
- 用心撰寫內容,且經常更新
- 更新頻繁的網站能鼓勵人們再次瀏覽,但前提是內容必須要有連貫性
- 每週張貼一篇實用的文章,勝於每天張貼一篇品質欠佳的內容
- 將文章分類。使用標籤與標記是將內容分門別類的絕佳方式,還能鼓勵使用者瀏覽網誌
- 確保使用者 (和檢索器) 能夠輕易找到網誌
- 建議在首頁和網站的其他重要網頁上建立顯眼的網誌連結
- 考慮將網誌放在本來的網站上 (如
http://blog.example.com或www.example.com/blog
- 限制垃圾留言
- 在網誌上啟用留言的功能,有助建立社群歸屬感並激發討論。遺憾的是,有些人會濫用留言功能
- 每篇文章建立描述性的標題
- 讀者輕鬆瞭解文章的內容為何
- 文章標題常用來建立獨一無二的文章網址,且提供搜尋引擎關於網頁內容資訊
- 與線上社群交流互動
- 發布內容的動態消息
- 強烈建議發布內容動態消息,讓使用者在網誌更新時隨即收到通知
- RSS
- 能定期閱讀的訂閱者比偶爾光臨的訪客更有價值。
- 網誌新增到 Search Console 帳戶
- 驗證網誌
- 提交 Sitemap
- 如果會發布網站的 RSS 或 Atom 動態消息,可以提交動態消息的網址做為 Sitemap
- 針對電子商務,有這些地方有機會曝光
Google 搜尋

Google 圖片

Google 智慧鏡頭
- 如果希望產品現在 Google 智慧鏡頭的搜尋結果中,請將產品詳細資料上傳至 Google Merchant Center,加入產品資訊

Google 購物分頁
- 如果想讓產品顯示在 Google 購物分頁中,將產品資料上傳至 Google Merchant Center

商家檔案
- 如要 Google 提供你的商家詳細資料
- 聲明
商家檔案擁有權: https://www.google.com/business/ - 連結
商家檔案和 Merchant Center: https://support.google.com/merchants/answer/7454171
- 聲明

Google 地圖
- 要讓產品顯示在 Google 地圖搜尋結果中,將產品和商品目錄的庫存位置資料上傳至 Google Merchant Center

Google 如何使用結構化資料和 Google Merchant Center 資料
- (支援的功能可能會因國家/地區、裝置和其他因素而不同。)
Google 搜尋中的產品複合式搜尋結果
- 會使用
Product 結構化資料來顯示產品的複合式搜尋結果 - 可能會使用
Google Merchant Center資料來顯示產品的複合式搜尋結果。
含有產品註解的 Google 圖片搜尋結果
- 會使用
Product 結構化資料來顯示圖片上的產品註解 - 會使用
Google Merchant Center所列的圖片
Google 購物分頁
- 在某些情況下 (例如資料驗證期間),加入
結構化資料有助於Google Merchant Center作業 - 必須使用
Google Merchant Center,才能讓內容顯示在Google 購物分頁中。
Google 智慧鏡頭圖片搜尋結果
- 如果提供了
image 結構化資料屬性,Google 智慧鏡頭會使用這項屬性 Google 圖片會使用Google Merchant Center所列的圖片。
解決更新延遲問題
- Google 在整合你網站中的資料與
Google Merchant Center動態饋給時,可能會因為延遲而造成資料不一致的問題 - 舉例,某項產品已售完,網站會立即標示為無法購買,但
Google Merchant Center需要一些時間才會更新,這情況在使用動態饋給時特別容易發生
為避免價格和庫存供應情形等資料發生這種不一致的狀況 (這是同步處理問題的常見原因)
- 請在發現這類不一致問題時,指示 Google Merchant Center 根據網站內容自動更新 Merchant Center 中的產品資料
- 參考影片解說有哪些同步策略、手法: https://youtu.be/UQtdv_hoGuM
以下為與電子商務網站特別相關的結構化資料類型
- 購物者有時不僅想找到產品頁面,在購物歷程的不同階段,所需的資訊都可能不同
LocalBusiness
- 運用 LocalBusiness 結構化資料向 Google 提供商家詳細資訊,例如所在位置和營業時間
- 除此之外,也可以:
- 直接向 Google 我的商家註冊
- 註冊實體商店位置和商店代碼,以供
Google Merchant Center使用

Product
Product 結構化資料- 另外
Google Merchant Center中設定Merchant Center 的結構化資料

Review
- 評論摘錄, Google 瞭解你網站上的產品評論

HowTo
- 針對你網站上銷售的產品,要協助 Google 顯示與「操作說明」相關的複合式搜尋結果
- 結構化資料為操作說明網頁加上標記

FAQPage
- Google 提供的常見問題頁面
- 結構化資料標記常見問題

BreadcrumbList
- Google 顯示網站上的網頁階層
- 這項功能有助於 Google 在搜尋結果中顯示更有意義的導覽標記記錄。
- 導覽標記

WebSite
- Google 導入你的網站站內搜尋功能
- 網站連結搜尋框

VideoObject
- 有助於 Google 在搜尋結果中以適當方式顯示你的影片
- 結構定義標記讓 Google 顯示影片

為確保 Google 能在你推出電子商務網站時便找到該網站,向 Google 登錄你的新網站:
- 向 Google 驗證網站擁有權
- 要求 Google 將網站編入索引
- 追蹤 Google 搜尋將網站編入索引的情形
- Google Merchant Center 可能會驗證內容,並與 Google 搜尋索引進行交叉比對
- 為了避免出現錯誤的驗證警告,請確認網站已編入 Google 搜尋索引,而且產品處於可供購買狀態
- 可以運用索引涵蓋範圍報表查看索引建立進度
- 如果有實體商店,請透過 Google 提供商家詳細資料
- 申請使用 Google Merchant Center
- 可以藉此提供更多資訊,例如產品說明和特惠情報
如果想讓網站內容出現在 Google 購物分頁等介面中
- 申請使用 Google Merchant Center
- 申請使用這項服務還能讓產品適用其他豐富功能,比如在 Google 圖片中為產品的圖片加上產品徽章
推出網站後可以採取哪些策略來向 Google 提供網站內容,以及這些策略的優缺點
全面上線
- 在推出網站前,整個電子商務網站處於大眾和搜尋引擎都無法存取的狀態
- 仍然可以讓測試人員存取網站,確保一切運作正常後再對外公開網站
- 可以選擇何時要將網站「全面上線」,並同步展開其他行銷活動
- 推出網站後,立即按照上面電子商務網站的步驟行動。讓網站盡早出現在 Google 搜尋結果中
- 優點
- 內容在推出前完全對外保密,而這也許對你的行銷廣告活動至關重要
- 缺點
- 網站可能要經過較長時間才會顯示在 Google 搜尋結果和 Google 購物分頁中
推出首頁
- 推出網站時可以只讓 Google 存取首頁
- 首頁可以是包含商店說明文字的預留位置,用來傳達電子商務網站即將上線的資訊
- 預先驗證網站擁有權,等到產品在網站中上線後,再執行後續步驟
- 優點
- 可以登錄商店、提升網域名稱知名度,也可以開放其他人連結至你的網站
- 推出網站時,使用者就能在 Google 搜尋結果中找到,即使產品尚未上線也不影響
- 缺點
- 完整網站推出前,Google 搜尋結果和購物分頁不會顯示詳細資訊
推出網站但不開放購買產品
- 如果尚未準備好履行訂單,可以選擇先推出完整網站並停用購買功能
- 比如將產品標示為缺貨中。這樣一來,搜尋引擎就能建立所有網站產品內容的索引
- 建議在每個網頁中加入一則訊息,傳達網站正式上線的日期
- 請不要以停用「加入購物車」功能的方式來阻止使用者購買產品
- 因為 Google 可能會利用加入購物車功能來驗證最終價格詳細資訊,包括稅金和運費
- 完成推出電子商務網站的所有步驟,並在 Google Merchant Center 提供產品資料
- 使用
excluded_destination屬性標示沒有庫存 - 這樣就能及早發現與載入產品資料相關的驗證問題,但不必在 Google 購物等到達網頁上顯示產品可供購買
- 使用
- 在的網站推出後,Google 就會將內容編入索引
- 客戶可以在線上瀏覽網站,但無法下訂單
- 建議將網站尚未全面推出的訊息明確告知購物者
- 以免客戶因為無法完成購買交易而感到不滿
試營運
- 網站的各項功能就緒後就先啟用這些功能,日後再推出上線行銷活動
- 試營運可以轉化為「搶先體驗」活動,讓購物者可以在網站正式上線前展開探索
- 在網站上線後,盡快完成推出電子商務網站的所有步驟
- 試營運的優點是作業簡單,而且由於網站已完全上線,所以能進行低流量的真實使用者測試
- 使用者可能會在社群媒體上宣傳或提及你的網站,導致網站在預定推出的時間點前受到關注
如果網址結構不良,則可能導致下列問題:
- 內容可能缺漏:如果 Googlebot 誤認為某兩個網址傳回相同內容,檢索器只會擷取其中一個網址,並捨棄視為重複內容的另一個網址
- 如果 #fragment ID 來呈現不同內容,就可能會發生這種情形
- Google 建立索引時不會參考 fragment ID
- Google 會將
/product/t-shirt#black和/product/t-shirt#white視為相同網頁
- 檢索器可能會多次擷取相同的內容
- 如果 Google 認定某兩個網址不同,但卻都傳回相同網頁,可能導致檢索器重複擷取相同的內容
- 這會降低網站的檢索速度,server 也必須承擔不必要的額外負載
- 如
/product/black-t-shirt和/product?sku=1234可能傳回相同的產品頁面,但 Google 無法單就網址做出判斷
- 檢索器可能會認為網站含有無限數量的網頁
- 如果網址中含有時間戳記這類會持續變更的值,檢索器就可能會認為網站中有無限多的網頁
- 這麼 Google 可能需要更久才能找到網站上所有的實用內容
- 例如 Google 可能會將
/about?now=12:34am和/about?now=12:35am視為不同網址,但其實這兩個網址會顯示同樣的網頁。
網址建議
- 盡量減少傳回相同內容的替代網址數量
- 避免 Google 對網站發出不必要的要求
- 在實際擷取到網頁之前,Google 可能都無法判別哪兩個網址會傳回相同的網頁
- 如果你的 server 會忽略網址大小寫差異,請將所有文字都轉換成大寫或小寫,以利 Google 判斷網址參照的網頁是否相同
- 確保分頁結果中的每個網頁都擁有專屬網址,Google 最常在分頁網址結構中發現網址錯誤
- 網址路徑中加入說明文字,網址中的文字能夠協助 Google 進一步瞭解網頁內容。
- 建議
/product/black-t-shirt-with-a-white-collar - 不建議
/product/3243
- 建議
- 查詢參數能讓 Google 搜尋瞭解網站的結構,提高檢索與建立索引作業的效率
- 盡可能使用
?key=value參數/photo-frames?page=2、/t-shirt?color=green
- 而不用
?value/photo-frames?2、/t-shirt?green
- 避免重複使用相同參數,因為 Googlebot 可能會忽略重複使用的值
- 建議使用
?type=candy,sweet - 不建議使用
?type=candy&type=sweet
- 建議使用
- 盡可能使用
- 避免使用內部連結連至臨時參數網址,例如
- 工作階段 ID、追蹤程式碼
- 依據使用者變動的值 (location=nearby、time=last-week) 和目前時間等
- 這些值可能產生時效短暫或重複的網址。為了在 Google 搜尋中獲得最佳搜尋結果,請使用長期的永久性網址
- 建議使用
/t-shirt?location=UK - 不建議用
/t-shirt?location=nearby、/t-shirt?current-time=12:02、/t-shirt?session=123123123
- 建議使用
電子商務網站中的產品通常會提供多種尺寸或顏色
- 該採「產品子類」,Google 支援多種可用於產品子類的網址結構
- 如果選擇在單一網頁中呈現多個產品子類 (也就是讓這些子類共用相同的網址),請注意下列限制:
- 該網頁可能無法顯示為
產品複合式搜尋結果,因為這項功能只支援包含單一產品的網頁 - 且 Google 搜尋可能會將每個產品子類視為各自獨立的產品
- 由於 Google 購物等服務無法將使用者導向網站上的特定產品子類網頁
- 導致使用者必須先選取想要購買的子類,才能結帳
- 如果購物者已經在 Google 購物中選取了想要的子類,可能會造成使用者體驗不佳
- 該網頁可能無法顯示為
- 如果選擇為每種子類使用不同的網址,Google 建議使用下列其中一種做法
- 採用路徑區隔,如
/t-shirt/green - 採用查詢參數,如
/t-shirt?color=green
- 採用路徑區隔,如
為了協助 Google 瞭解哪個子類最適合顯示在搜尋結果中
- 請選擇其中一個產品子類的網址做為該產品的標準網址
如果選擇使用查詢參數來識別子類
- 省略查詢參數的網址做為標準網址。這有助於 Google 進一步瞭解產品子類之間的關係
- 舉例,如果某款 T 恤的 color 查詢參數預設值為 blue
- 使用
/t-shirt做為所有 T 恤子類的標準網址 - 藍色 T 恤使用
/t-shirt,不要用/t-shirt?color=blue - 綠色 T 恤的使用
/t-shirt?color=green
- 使用

如要協助 Google 搜尋和 Google 購物正確識別產品並瞭解產品子類之間的關係
- 在內部連結、
Sitemap和<link rel="canonical">標記中都使用相同的網址- 舉例,如果使用查詢參數來連結至分頁後序列網頁的第一頁,且第一頁就是預設網頁
- 那在整個網站的相同網址中統一加入或排除
?page=1
- 在所有可建立索引的網頁中使用自我參照的
<link rel="canonical">標記 (其中網址指向目前網頁的網址)- 並將這些網址加入 Sitemap
- 如果產品的每個子類都有專屬網址
- 用
<link rel="canonical">標記在所有子類的網頁上加入標準產品網址
- 用
- 用
<a href>在網頁上加入連結,不要用 JS 做為各網頁間的導覽機制- Googlebot 可能無法偵測 JS 程式碼中的導覽機制
- 盡可能在
<a href>和</a>標記之間加入有意義的文字- 例如要連結的產品名稱,不要使用「按這裡」等籠統的用語
- 避免連結到沒有實用內容的網頁,或至少避免這類網頁編入索引
- 如果某個類別中不含任何產品,用
noindexmeta - 如果網站會偵測類別是否沒有任何內容,並會自動將空白類別從站內搜尋中移除且不提供瀏覽,建議讓該網頁傳回 404 (not found) HTTP
- 如果某個類別中不含任何產品,用
不同類的 pagination,優缺點不一樣
分頁 (有著 1, 2, 3, 4 頁能切換的)
- 可讓使用者深入瞭解搜尋結果總數和目前所在的位置
- 使用者需使用較為複雜的控制項來瀏覽搜尋結果
- 內容會分散在多個網頁,而非單一的連續清單
- 必須載入新網頁才能查看更多內容 (depend)
載入更多 (lord more)
- 使用單一網頁就能顯示所有內容
- 可以讓使用者知道搜尋結果總數 (例如在按鈕上或按鈕附近)
- 因為所有搜尋結果都會顯示在單一網頁中,所以無法處理數量極為龐大的搜尋結果
Infinite scrolling
- 使用單一網頁就能顯示所有內容
- 直覺的使用方式,使用者只要持續捲動即可顯示更多內容
- 因為不清楚搜尋結果的總數,可能會導致結使用者陷入「捲動疲乏」
- 無法處理數量極為龐大的搜尋結果
分頁模式時,應該要
- 依序連結網頁
- 要確保搜尋引擎瞭解內容分頁後各網頁之間的關係,請在各個網頁連向下個網頁的連結中使用
<a href>。這有助於 Googlebot 找到接續的網頁。 - 此外,考慮將同一批搜尋結果中的每個網頁連結回清單的第一頁,藉此向 Google 強調整份清單的開頭
- 這麼做能告訴 Google,搜尋結果清單的第一頁比清單中其他頁面更適合做為到達網頁
- 一般,會建議為每個網頁提供不同的標題,以利區別,但分頁後的序列網頁不需要遵循這項建議
- 可以為序列中的所有網頁使用相同的標題和說明,Google 會試著辨識網頁在序列中的位置,並以此建立索引
- 要確保搜尋引擎瞭解內容分頁後各網頁之間的關係,請在各個網頁連向下個網頁的連結中使用
- 正確使用網址
- 為每網頁提供專屬網址。Google 會將分頁後序列中的每個網址視為個別網頁,因此請加上
?page=nquerystring - 請勿使用分頁後序列中的第一頁做為標準網頁。相反地,請讓每個網頁做為自身的標準網址
- 不要用 Fregment 網址作為頁碼,因為 Google 會忽略 fregmentId
- 如果 Googlebot 發現接續網頁的網址只有
#之後的文字不同,可能會判斷已擷取過接續網頁,也就不會瀏覽其連結
- 如果 Googlebot 發現接續網頁的網址只有
- 考慮使用預先載入、預先連結或預先擷取機制,讓使用者前往下一頁時能更快、UX 更好
- Google 以往會使用
<link rel="next" href="...">和<link rel="prev" href="...">來識別前後網頁之間的關係,現在已不再使用這些標記,不過其他搜尋引擎仍可能使用這類連結
- 為每網頁提供專屬網址。Google 會將分頁後序列中的每個網址視為個別網頁,因此請加上
- 避免系統為套用篩選器的網址或只是排列順序不同的網址建立索引
- 如果網站會產生較長的搜尋結果清單,可以選擇支援篩選器或不同的排序方式
- 舉例,在網址中加入
?order=price,傳回依照價格排序的同一份搜尋結果清單
- 舉例,在網址中加入
- 如要避免 Google 為同樣內容的搜尋結果清單建立索引,用
noindexmeta 來禁止不必要的網址索引作業,或是使用robots.txt檔案來要求 Google 不要檢索特定網址模式。
- 如果網站會產生較長的搜尋結果清單,可以選擇支援篩選器或不同的排序方式

Load more 和 Infinite scroll 時,通常會用 JS
- 當 Google 在檢索網站建立索引時,只會瀏覽 HTML 中具有
<a href>標記的網頁連結 - Google 不會點選按鈕 (除非使用
<a href>標記按鈕) - 也不會透過觸發 JS 來更新目前的網頁內容
如果使用 JS
除了這些最佳做法以外 (例如確保網站上的連結都可供檢索),也建議
- 使用 Sitemap 檔案或 Google Merchant Center 動態饋給,有助 Google 找到網站上的所有產品
針對 Infinite scroll search-friendly 的推薦做法
關於 infinite scroll,crawlers 始終無法模擬手動用戶行為(如 scroll 或按 load more)
- 如果 crawlers 無法訪問內容,則它不太可能出現在搜索結果中
- 為確保搜索引擎可以抓取從 infinite scroll page 鏈接的單個項目,請確保你或你的 CMS 產生一個分頁系列(component pages)以配合你的無限滾動。
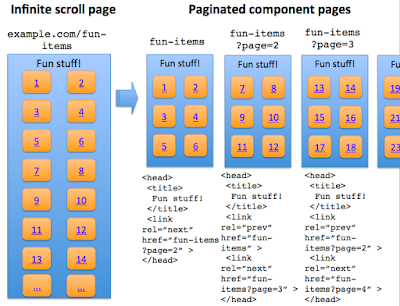
infinite scroll 在轉換為 paginated series 時變得 search-friendly
- 每個 component page 在 page 的
<head>標記中聲明了類似的<title>標記 - infinite scroll with pagination demo
上面這個 demo 展示了一些 key search-engine friendly points:
- Coverage: All individual items are accessible. With traditional infinite scroll, individual items displayed after the initial page load aren't discoverable to crawlers.
- No overlap: Each item is listed only once in the paginated series (for example, no duplication of items).
infinite scroll search-engine friendly points
- 將
infinite scroll內容分成 component,在禁用 JS 時可以訪問這些頁面 - 確定每頁包含多少內容
- 確保如果搜索者直接訪問此頁面,可以輕鬆找到他們想要的確切項目(例如,在找到所需內容之前無需大量滾動)。
- 保持合理的頁面載入時間
- 劃分內容,使系列中的組件頁面之間沒有重疊(緩衝除外)
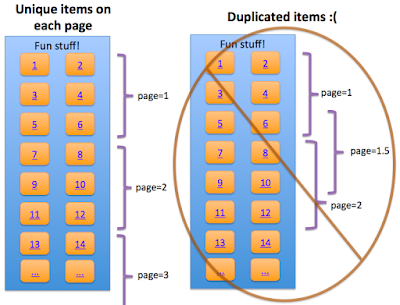
左邊是 search friendly,右邊的會導致重複內容的爬和索引
針對 infinite scroll 結構化的 URL
- 每個 component page 都包含完整的 URL
- good:
example.com/category?name=fun-items&page=1 - good:
example.com/fun-items?lastid=567 - bad:
example.com/fun-items#1
- good:
- 測試每個 component page(URL)是否可以將人直接帶到內容,並可以在沒有相同 cookie 或用戶歷史記錄的瀏覽器中訪問
- URL 參數都應遵循以下建議:
- 確保 URL 從現在起兩週後在概念上顯示相同的內容
- 避免基於相對時間的 URL 參數:
example.com/category/page.php?name=fun-items&days-ago=3
- 避免基於相對時間的 URL 參數:
- 創建可以向搜索者展示有價值內容的參數。避免將非搜索者有價值的參數作為訪問內容的主要方法:
example.com/fun-places?radius=5&lat=40.71&long=-73.40
- 確保 URL 從現在起兩週後在概念上顯示相同的內容
- URL 參數都應遵循以下建議:
在 infinite scroll 上實現replaceState and pushState
- 使用一個或兩個的決定取決於你網站的用戶行為。建議在以下情況下包含
pushState(單獨或與replaceState一起使用): - 任何類似於點擊或主動翻頁的用戶操作
- 為用戶提供通過最近分頁的內容進行連續備份的能力
測試 infinite scroll
- 檢查頁面值是否隨著用戶向上或向下滾動而調整
- 驗證系列中越界的頁面是否返回
404(例如,只有 p998,則example.com/category?name=fun-items&page=999應回404) - 調查潛在的無限滾動實現引入的可用性影響 (思考到底需不需要 infinite scroll)
如果發現 Google 搜尋結果顯示的內容與垃圾資訊、付費連結、惡意軟體或其他可能違反網站管理員指南的問題有關
- 利用相關連結提出檢舉
- Google 不會用檢舉資訊對違規做出直接處置,這些資訊仍相當重要,能協助 Google 瞭解如何改善垃圾內容偵測系統
垃圾內容 (需要 Google 帳戶)
- https://www.google.com/webmasters/tools/spamreportform
- 試圖在 Google 的搜尋結果中占有更好的位置
- 如隱藏的文字、入口網頁、偽裝或幕後重新導向
- 這些手段企圖降低搜尋結果品質,並造成全體使用者搜尋資訊時的不便與困擾
垃圾內容 (需要 Google 帳戶)
- https://www.google.com/webmasters/tools/paidlinks?pli=1
- 透過購買或販售連結來傳遞 PageRank,可能會降低搜尋結果的品質
- 這類連結配置不僅違反網站管理員指南,還可能降低網站在搜尋結果中的排名。
惡意軟體
網路詐騙
Sitemap 用來提供網站資訊的檔案
- 可以在其中列出網頁、影片和其他檔案的資訊,並呈現這些內容彼此間的關係
- Sitemap 會將網站上有哪些重要網頁和檔案告訴 Google,還針對這類檔案提供有價值的資訊
- 例如網頁上次更新的時間,以及是否有其他語言版本
- Google 會讀取網站的 Sitemap 檔案,藉此以更有效率的方式檢索網站
- 「影片條目」可以指定影片時間長度、類別和適齡分級
- 「圖片條目」可以包含圖片主題、類型和授權
- 「新聞項目」可以包含報導標題和發布日期
以下是可能會需要 Sitemap 的情況:
- 網站規模極大:Google 網路檢索器很可能會因此在檢索時遺漏某些新網頁或近期更新的網頁
- 網站有大量封存的內容網頁
- 但這些網頁彼此隔離或缺少適當連結
- 網站上的網頁並未適當彼此參照,在 Sitemap 中列出這些網頁,確保不會遺漏其中部分網頁
- 網站才剛建立,幾乎沒有外部連結
- Googlebot 和其他網路檢索器是透過網頁層層連結的方式來檢索網頁
- 因此如果沒有其他網站連往你的網頁,Google 可能找不到這些網頁
- 網站包含許多互動式多媒體內容 (影片、圖片),或是顯示在 Google 新聞中
- Google 就能在搜尋時視情況考量 Sitemap 提供的額外資訊
以下是可能「不」需要 Sitemap 的情況:
- 網站規模很「小」:「小」,指的是網站的網頁數不超過 500 個
- (以你認為有需要納入搜尋結果的網頁為準)
- 網站內部的連結完善:表示 Google 可以透過首頁的連結找出網站上所有的重要網頁
- 要顯示在搜尋結果中的媒體檔案 (影片、圖片) 或新聞網頁數量不多
- Sitemap 可協助 Google 在網站上找出影片和圖片檔或新聞報導,並加以解讀
- 如果不需要讓這些內容出現在圖片、影片或新聞搜尋結果中,可能就不需要 Sitemap
Google 支援所有格式的標準 Sitemap
- https://www.sitemaps.org/
- 但目前不支援在 Sitemap 中使用
<priority>屬性
單一 Sitemap
- 在未壓縮時的檔案大小上限為
50 MB,且最多只能包含50,000個網址 - 如果檔案較大或網址數量較多,必須將網址清單分割成數個 Sitemap
- 可以選擇建立 Sitemap 索引檔,也就是指向 Sitemap 清單的檔案,然後直接將這個索引檔案提交給 Google
- 也可以選擇提交多個 Sitemap
Sitemap 格式:
- XML
- RSS、mRSS 和 Atom 1.0
- 文字
XML:
- https://www.sitemaps.org/protocol.html 這邊有更完整的 doc
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/foo.html</loc>
<lastmod>2018-06-04</lastmod>
</url>
</urlset>RSS、mRSS 和 Atom 1.0
- 如果網誌含有
RSS或Atom動態消息,可以透過 Sitemap 提交動態消息的網址 - 大多數網誌軟體均可為你建立動態消息,需要注意的是,這類動態消息只會針對最近的網址提供資訊。
- Google 接受 RSS 2.0 和 Atom 1.0 動態消息
- 可以使用 mRSS (媒體 RSS) 動態消息將網站中影片內容的詳細資料提供給 Google
文字
- 如果你的 Sitemap 中只有網頁網址,可使用簡單的文字檔案將網址提供給 Google
- 檔案中,請將每個網址分行列出
UTF-8編碼- 勿在 Sitemap 檔案中加入網址以外的任何內容
- 文字檔沒有命名規則,不過必須使用
.txt副檔名,例如sitemap.txt
http://www.example.com/file1.html
http://www.example.com/file2.html
Sitemap 通用規範
- 使用一致且完整的網址。Google 會完全按照列出的網址進行檢索
- 舉例來說,如果網站為
https://www.example.com/,勿指定為https://example.com/- (缺少
www) 或./mypage.html(相對網址)
- (缺少
- 舉例來說,如果網站為
- 可在網站的任何位置張貼 Sitemap,但 Sitemap 的作用範圍僅限於上層目錄的子系
- 因此,建議將 Sitemap 張貼在網站根目錄,這樣便能涵蓋網站上的所有檔案
- 請勿在 Sitemap 中加入網址的工作階段 ID,以免系統重複檢索這些網址
- 使用 hreflang 註解將網址的替代語言版本告知 Google
- Sitemap 檔案必須使用 UTF-8 編碼,並且要有 URLs escaped
- 將大型 Sitemap 分割成較小的 Sitemap
- 每個 Sitemap 最多只能包含
50,000個網址 - 壓縮前的檔案大小不得大於
50 MB - 使用 Sitemap 索引檔,在其中列出所有個別 Sitemap
- https://developers.google.com/search/docs/advanced/sitemaps/large-sitemaps
- 每個 Sitemap 最多只能包含
- Sitemap 中只能列出標準網址
- 如果網頁有兩個版本,你只能將希望出現在搜尋結果中的版本列在 Sitemap 中
- 舉例來說,假如網站有
www和非www兩個版本,先決定要將哪個版本做為首要網站,並在其中張貼 Sitemap- 然後在另一個網站中新增
rel=canonical,或將該網站重新導向至首要網站
- 然後在另一個網站中新增
- mobile 和 desktop 的網址不同,建議只在 Sitemap 中指向其中一種版本
- 如果想同時指向這兩個網址,請為網址加上註解以指明電腦版和行動版
- 使用 Sitemap 擴充元素指向其他媒體類型,例如影片、圖片和新聞
- 針對不同語言或地區提供替代網頁,可以在 Sitemap 或 HTML 中用
hreflang指定替代網址 - 非英數字元和非拉丁字元,Sitemap 務必使用
UTF-8- 所有 XML 檔案一樣,下表所列字元的資料值 (包括網址) 都必須使用實體逸出碼
- 只能包含 ASCII 字元,不可包含延伸 ASCII 字元、特定控制碼或特殊字元,例如
*和{}- Sitemap 網址包含這些字元,就會在新增網址時收到錯誤訊息
- Sitemap 的作用是向 Google「建議」你認為重要的網頁
- Google 未必會檢索 Sitemap 中的每個網址
- Google 會忽略
<priority>和<changefreq>值 - Google 會使用
<lastmod>值,前提是該值必須始終保持準確且可供驗證- 例如將該值與網頁上次修改的版本進行比較時能得知目前的值較準確
- 網址在 Sitemap 中的位置並不重要,Google 不會按照網址在 Sitemap 中顯示的順序來檢索網址
| 符號 | Escape Code |
|---|---|
& |
& |
' |
' |
" |
" |
> |
> |
< |
< |
產生 Sitemap
- 如果用
WordPress、Wix或Blogger等 CMS- CMS 很可能已建立 Sitemap 並提供給搜尋引擎
- 嘗試搜尋 CMS 如何產生 Sitemap 的相關資訊
- 或搜尋 CMS 未自動產生 Sitemap 時該如何建立 Sitemap
- 舉例,如果用 Wix,請搜尋「wix Sitemap」
- 手動建立 Sitemap
- 如果 Sitemap 包含的網址少於幾十個,或許可以手動建立 Sitemap
- 自動產生 Sitemap
- 如果網址多於幾十個,就需要讓系統自動產生 Sitemap
- 雖然能產生 Sitemap 的工具有許多種,不過還是建議使用你的網站軟體自動產生
將 Sitemap 上傳給 Google
- Google 不會在每次檢索網站時檢查 Sitemap。除非透過連線偵測 (ping) 告知 Sitemap 有異動
- 否則 Google 只會在首次偵測到 Sitemap 時進行檢查
- 如果你並未新增或更新 Sitemap,請勿要求 Google 檢查 Sitemap
- 也不要重複提交相同的 Sitemap 或為其執行連線偵測 (ping)。
- Sitemap 中有經過更新的網頁,請用
<lastmod>標記這些網頁 - 可以透過下列幾種方式讓 Google 存取你的 Sitemap
- Sitemap 報告: https://support.google.com/webmasters/answer/7451001
- 使用連線偵測 (ping) 工具。在瀏覽器或指令列中對以下網址傳送 GET 要求,並在其中指明 Sitemap 的完整網址。請務必確保 Sitemap 檔案可供存取
- 在
robots.txt檔案中任一處插入指令,並在其中指明 Sitemap 的存取路徑- Google 會在下次檢索
robots.txt檔案時找到Sitemap
- Google 會在下次檢索
ping
https://www.google.com/ping?sitemap=FULL_URL_OF_SITEMAP
ping example
https://www.google.com/ping?sitemap=https://example.com/sitemap.xml
robots.txt 指出 Sitemap
Sitemap: https://example.com/my_sitemap.xml
分割大型 Sitemap
- 超過
50 MB,就必須分割成多個 Sitemap - 可用 Sitemap 索引檔一次提交多個 Sitemap
sitemapindex:用於整個檔案開頭與結尾的上層標記。sitemap:檔案中所列各個 Sitemap 的上層標記loc:Sitemap 的位置
- 索引檔所參照的 Sitemap 必須與 Sitemap 索引檔位於同一目錄中,或是位於網站階層更低的目錄中
- Search Console 帳戶中每個網站提交的 Sitemap 索引檔數量上限為 500 個
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://www.example.com/sitemap1.xml.gz</loc>
</sitemap>
<sitemap>
<loc>http://www.example.com/sitemap2.xml.gz</loc>
</sitemap>
</sitemapindex>如果擁有多個網站
- 可以建立一或多個包含所有已驗證網站網址的 Sitemap
- 將所有 Sitemap 儲存在同一個位置,藉此簡化建立及提交 Sitemap 的程序
- 所有網站都必須在 Search Console 中完成驗證
- 可以選擇下列方式:
- 單一 Sitemap 包含多個網站的網址,網站可以來自不同網域
- 如,於
http://host1.example.com/sitemap.xml的 Sitemap 可以包含下列網址:http://host1.example.comhttp://host2.example.comhttp://host3.example.comhttp://host1.example1.comhttp://host1.example.ch
- 如,於
- 以多個 Sitemap 分別代表不同網站,並將些檔案全部存放在同一個位置
http://host1.example.com/host1-example-sitemap.xmlhttp://host1.example.com/host2-example-sitemap.xmlhttp://host1.example.com/host3-example-sitemap.xmlhttp://host1.example.com/host1-example1-sitemap.xmlhttp://host1.example.com/host1-example-ch-sitemap.xml
- 單一 Sitemap 包含多個網站的網址,網站可以來自不同網域
- 或者將該 Sitemap 列入各網站所代管的
robots.txt
影片 Sitemap 和替代方案
- 影片 Sitemap 包含了網頁上代管影片的其他資訊
- 能協助 Google 找到網站上的影片並正確解讀影片內容
- 特別適合用於「最近新增」或是「無法透過一般檢索機制」找到的影片內容
- Google 影片 Sitemap 是 Sitemap 標準的延伸。
- Google 建議使用影片 Sitemap,不過也支援 mRSS 動態饋給
影片 Sitemap 的基本原則:
- 可專為影片建立個別的 Sitemap,也可在現有網頁的 Sitemap 中嵌入影片標記,端視何種方法對你較便利
- 單一網頁可代管多個影片
- Sitemap 中的每個項目皆為單一網頁的網址
- 而每個網頁可代管一或多部影片。每個 Sitemap 項目的結構參考下面
- 勿列出與代管網頁無關的影片
- 舉例,如果影片只是網頁的少許增補內容或與主要文字內容無關,不要加入影片 Sitemap 中
- Google 會驗證每部影片提供的資訊,確認是否與網站內容相符。如果不相符,可能不會為影片建立索引
- 影片 Sitemap 中的每個項目都包含一組由你提供的
必要值、建議值或選用值建議值和選用值可提供實用的中繼資料,讓 Google 強化影片搜尋結果,提升影片出現在搜尋結果中的機率- (較完整的標記定義清單在下面)
- 如果 Google 認為網頁文字比 Sitemap 中的資訊更實用,則可能會使用影片到達網頁上的文字,而非在 Sitemap 中提供的文字
- Google 索引演算法相當複雜,無法保證一定會為影片建立索引,也無法保證建立索引的時間
- 如果 Google 在提供的網址上找不到影片內容,就會忽略該 Sitemap 項目
- 每個 Sitemap 檔案最多只能包含 50,000 個網址
- 如果影片數量超過 50,000 部,可提交多個 Sitemap 和一個 Sitemap 索引檔
- 加入選用標記會增加檔案大小,即使影片數量尚未達到上限,未壓縮時的檔案仍有可能超過 50 MB
- Google 必須能夠存取來源檔案或播放器,檔案或播放器不得遭到
robots.txt封鎖、要求登入- 不支援需要透過串流通訊協定下載原始檔的中繼檔案
- 如要防範垃圾內容發布者 bot 存取位於
<player_loc>或<content_loc>網址的影片內容,可以透過驗證確認存取伺服器的漫遊器確實是 Googlebot
<url>
<loc>https://example.com/mypage</loc> <!-- URL of host page -->
<video> ... information about video 1 ... </video>
... as many additional <video> entries as you need ...
</url>使用單一網頁代管一部影片的影片 Sitemap 範例,其中包含 Google 使用的所有標記
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>http://www.example.com/videos/some_video_landing_page.html</loc>
<video:video>
<video:thumbnail_loc>http://www.example.com/thumbs/123.jpg</video:thumbnail_loc>
<video:title>Grilling steaks for summer</video:title>
<video:description>Alkis shows you how to get perfectly done steaks every
time</video:description>
<video:content_loc>
http://streamserver.example.com/video123.mp4</video:content_loc>
<video:player_loc>
http://www.example.com/videoplayer.php?video=123</video:player_loc>
<video:duration>600</video:duration>
<video:expiration_date>2021-11-05T19:20:30+08:00</video:expiration_date>
<video:rating>4.2</video:rating>
<video:view_count>12345</video:view_count>
<video:publication_date>2007-11-05T19:20:30+08:00</video:publication_date>
<video:family_friendly>yes</video:family_friendly>
<video:restriction relationship="allow">IE GB US CA</video:restriction>
<video:price currency="EUR">1.99</video:price>
<video:requires_subscription>yes</video:requires_subscription>
<video:uploader
info="http://www.example.com/users/grillymcgrillerson">GrillyMcGrillerson
</video:uploader>
<video:live>no</video:live>
</video:video>
</url>
</urlset>
影片 Sitemap 標記定義
- 可以在 rssboard.org 找到更多關於媒體 Sitemap 的說明文件
必要的標記
<url>: 網站中單一代管網頁的上層標記。基本 Sitemap 格式<loc>- 用於指定含有一或多部影片的特定代管網頁
- 當使用者在 Google 搜尋結果中點選影片時,系統就會將使用者導向這裡指定的網頁
- 這個網址在 Sitemap 中不能重複出現
- 如果單一網頁含有多部影片,請針對該網頁建立單一
<loc>標記- 並為網頁上的每部影片各新增一個
<video>子元素。
- 並為網頁上的每部影片各新增一個
<video:video>: 在<loc>標記指定的網頁中,單一影片所有資訊的上層元素<video:thumbnail_loc><video:title>- 影片的標題
- 所有 HTML 都必須 escape
- 或者包含在 CDATA 區塊中
- 建議讓這個值與網頁中顯示的影片標題相符
<video:description>- 影片說明,長度上限為 2048 個半形字元
- 所有 HTML 都必須 escape
- 或者包含在 CDATA 區塊中
- 這個值必須與網頁中顯示的說明相符,但不必完全一模一樣
<video:content_loc>- 指向實際影片媒體檔案的網址,檔案必須使用任一支援格式
- 必須提供
<video:content_loc>或<video:player_loc>- 建議盡可能提供
<video:content_loc>標記,讓 Google 擷取影片內容檔案,這是最有效的方法 - 如果無法用
<video:content_loc>,改提供<video:player_loc>
- 建議盡可能提供
- 這個值不得與
<loc>網址相同 - 這個標記相當於結構化資料中的
VideoObject.contentUrl - 如果要限制其他人存取內容,但仍要讓 Google 進行檢索,使用反向 DNS 查詢確保 Googlebot 可存取內容
<video:player_loc>- 指向特定影片的播放器。一般來說,這是
<embed>標記中src - 這個值不得與
<loc>網址相同 - 如果是 YouTube 影片,用這個值,不要使用
video:content_loc - 這個標記相當於結構化資料中的
VideoObject.embedUrl
- 指向特定影片的播放器。一般來說,這是
建議使用的標記
<video:duration>- 影片片長,以秒為單位。值必須介於 1 至 28800 (8 小時) 之間,含首尾值
<video:expiration_date>- 影片到期日,採 W3C 格式
- 在該日期後,搜尋結果中就不會再顯示這部影片
- 如有設定,Google 搜尋在指定日期之後就不會再顯示這部影片
- 如果影片不需設定有效期限,略過這個標記
- 支援的值為完整日期 (YYYY-MM-DD),或完整日期加上時、分、秒以及時區 (YYYY-MM-DDThh:mm:ss+TZD)
- 範例:
2012-07-16T19:20:30+08:00
- 範例:
選用標記
<video:rating>: 影片評等。值為0.0(最低) 到5.0(最高) 之間的浮點數,含首尾值<video:view_count>: 影片的觀看次數<video:publication_date>- 首次發布影片的日期,採 W3C 格式
- 支援的值為完整日期 (YYYY-MM-DD),或完整日期加上時、分、秒以及時區 (YYYY-MM-DDThh:mm:ss+TZD)
- 範例:2007-07-16T19:20:30+08:00
<video:family_friendly>- 使用者是否能在安全搜尋模式下找到這部影片
- 如果省略這個標記,安全搜尋模式開啟時也能搜尋到這部影片
yes:安全搜尋模式開啟時可搜尋到這部影片no:只有在關閉安全搜尋時才能搜尋到這部影片
<video:restriction>- 在指定國家/地區的搜尋結果中顯示或隱藏影片。
- 用 ISO 3166 格式指定以空格分隔的國家/地區代碼清單
- 每部影片僅限一個
<video:restriction>標記- 如果沒有
<video:restriction>標記,Google 會假設可以在所有地區顯示影片 - 這個標記只會影響搜尋結果,無法防止使用者在受限制的地區透過其他方式找到或播放影片。進一步瞭解如何套用國家/地區限制。
- 屬性:
relationship- 必要
- 值為
allow或deny
- 如果沒有
- 範例僅允許在加拿大和墨西哥顯示該影片的搜尋結果
<video:restriction relationship="allow">CA MX</video:restriction>
<video:platform>- 要在指定平台類型的搜尋結果中顯示或隱藏影片
- 這會是一份以空格分隔的平台類型清單
- 標記只會影響指定裝置類型的搜尋結果,無法防止使用者在遭到限制的平台上播放影片
- 每部影片只能顯示一個
<video:platform>標記。如果沒有標記,則會假設可在所有平台播放 - 支援的值:
web: 桌上型電腦和筆記型電腦上的傳統電腦瀏覽器mobile: 行動瀏覽器,例如手機或平板電腦上的瀏覽器tv: 電視瀏覽器,例如可透過 Google TV 裝置和遊戲主機使用的瀏覽器
- 屬性
relationship: (must) 是否允許在指定平台上播放影片,值為 allow 或 deny
- 範例:允許使用者透過電腦或電視播放影片,但禁止使用者透過行動裝置播放影片
<video:platform relationship="allow">web tv</video:platform>
<video:price>- 下載或觀看影片的價格。如果無須付費即可下載或觀看影片,請略過這個標記
- 可列出多個
<video:price>,例如用於指定多種貨幣、購買選項或解析度等 - 屬性
currency: (must) 用於指定貨幣,採 ISO 4217 格式type: (optional) 用於指定購買選項- 支援的值為
rent和own、預設值own
- 支援的值為
resolution: (optional) 指定購買版本的解析度,支援的值為hd和sd
<video:requires_subscription>: 是否必須訂閱才能觀看影片,允許的值為 yes 或 no<video:uploader>- 上傳者的名稱。每部影片僅可使用一個
- 字串值的長度上限為 255 個半形字元
- 屬性:
info- optional
- 用於指定某個網頁的網址,讓你透過該網頁提供上傳者的其他資訊
- 這個網址必須和 標記位於相同 domain
<video:live>: 影片是否為即時串流影片。支援的值為 yes 或 no。<video:tag>- 影片的任意字串標記,通常是一段簡短的敘述
- 用來說明影片或部分內容的主要概念。一部影片可以有多個標記
- 而且這些標記可能全都屬於同一類別
- 舉例,關於燒烤食物的影片屬於「燒烤」類別,但同時也可以加上「牛排」、「肉食」、「夏季」和「戶外」等標記
- 可以為與影片相關的每個標記都建立一個新的
<video:tag>元素 - 標記數量上限為 32 個。
<video:category>- 簡要說明影片概略類別的字串,長度上限為 256 個半形字元
- 一般而言,「類別」是指內容在主題上的概略分類,通常一部影片只屬於一個類別
- 例如,烹飪的網站可能會有「炙烤」、「烘烤」和「燒烤」等不同類別,影片屬於其中一個類別
<video:gallery_loc>: 目前未使用
Sitemap 替代方案:mRSS
- Google 建議用
影片 Sitemap和schema.org的VideoObject來標記影片,但也支援 mRSS 動態饋給 - mRSS 是 RSS 的延伸模組,可用來聯合發布多媒體檔案,提供比 RSS 標準更為詳盡的內容
- 每個 mRSS 動態饋給的未壓縮檔案大小不得超過 50 MB
- 最多只能包含 50,000 個影片項目
- 如果檔案大小超過 50 MB,或是影片數量超過 50,000 部,可提交多份 mRSS 動態饋給和一個 Sitemap 索引檔
- Sitemap 索引可以包含 mRSS 動態饋給
- https://www.rssboard.org/media-rss
mRSS 範例
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:media="http://search.yahoo.com/mrss/" xmlns:dcterms="http://purl.org/dc/terms/">
<channel>
<title>Example MRSS</title>
<link>http://www.example.com/examples/mrss/</link>
<description>MRSS Example</description>
<item xmlns:media="http://search.yahoo.com/mrss/" xmlns:dcterms="http://purl.org/dc/terms/">
<link>http://www.example.com/examples/mrss/example.html</link>
<media:content url="http://www.example.com/examples/mrss/example.flv" fileSize="405321"
type="video/x-flv" height="240" width="320" duration="120" medium="video" isDefault="true">
<media:player url="http://www.example.com/shows/example/video.swf?flash_params" />
<media:title>Grilling Steaks for Summer</media:title>
<media:description>Get perfectly done steaks every time</media:description>
<media:thumbnail url="http://www.example.com/examples/mrss/example.png" height="120" width="160"/>
<media:price price="19.99" currency="EUR" />
<media:price type="subscription" />
</media:content>
<media:restriction relationship="allow" type="country">us ca</media:restriction>
<dcterms:valid xmlns:dcterms="http://purl.org/dc/terms/">end=2020-10-15T00:00+01:00; scheme=W3C-DTF</dcterms:valid>
<dcterms:type>live-video</dcterms:type>
</item>
</channel>
</rss>圖片 Sitemap
- 將圖片加入 Sitemap 有助於 Google 發掘原本可能找不到的圖片 (例如用 JS 連結的圖片)
- 可以將圖片加入現有的 Sitemap,或另外建立一個圖片專屬的 Sitemap
示範
http://example.com/sample1.html這個網頁的 Sitemap- 網頁包含兩張圖片以及一個
http://example.com/sample2.html sample2中又包含一張圖片以及圖片 Sitemap 中所有可選用的中繼資料- (使用範例中的語法架構時,最多可以為每個網頁列出 1,000 張圖片)
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">
<url>
<loc>http://example.com/sample1.html</loc>
<image:image>
<image:loc>http://example.com/image.jpg</image:loc>
</image:image>
<image:image>
<image:loc>http://example.com/photo.jpg</image:loc>
</image:image>
</url>
<url>
<loc>http://example.com/sample2.html</loc>
<image:image>
<image:loc>http://example.com/picture.jpg</image:loc>
<image:caption>A funny picture of a cat eating cabbage</image:caption>
<image:geo_location>Lyon, France</image:geo_location>
<image:title>Cat vs Cabbage</image:title>
<image:license>http://example.com/image-license</image:license>
</image:image>
</url>
</urlset>必要標記
<image:image>- 包含單一圖片的所有資訊
- 每個
<url>最多可包含 1,000 個<image:image>
<image:loc>- 圖片的網址
- 某些情況下,圖片網址和主網站可能會相網域,Search Console 會同時驗證圖片和網站所在的網域
- 舉例,如果使用 Google 協作平台等內容傳遞聯播網來代管圖片,請確認代管網站已在 Search Console 中完成驗證
- 此外,確認
robots.txt檔案允許 Google 檢索要建立索引的任何內容
- 此外,確認
選用標記
<image:caption>: 圖片的說明文字。<image:geo_location>- 圖片所顯示的地理位置
- 例如
<image:geo_location>Limerick, Ireland</image:geo_location>
<image:title>: 圖片的標題<image:license>: 圖片授權所在的網址。如有需要,也可以改用圖片中繼資料
Google 新聞 Sitemap
建立 Google 新聞 Sitemap 時,請遵守下列規定:
- 請只在 Sitemap 中納入過去兩天內發布的報導網址
- 報導發布超過兩天後,請從新聞 Sitemap 中移除這些網址,或從舊網址中移除
<news:news>中繼資料 - 這些報導一般仍會在索引中保留 30 天
- 報導發布超過兩天後,請從新聞 Sitemap 中移除這些網址,或從舊網址中移除
- 發布新的報導後,請更新新聞 Sitemap
- Google 新聞檢索新聞 Sitemap 的頻率,與檢索網站上其他內容的頻率相同
- 每個新聞 Sitemap 中最多可以加入 1,000 個網址
- 如果同一個新聞 Sitemap 中超過 1,000 個網址,請分成數個較小的 Sitemap
- 並透過 Sitemap 索引檔管理 Sitemap 通訊協定中定義的這些 Sitemap
- 由於新聞 Sitemap 的檢索頻率高於網路 Sitemap,因此這項限制可確保網站不會超載
- 發布新報導後,請將新報導網址更新至目前的 Sitemap,而不要每次更新都建立新的 Sitemap。
- 使用新聞 Sitemap 並不代表網站的排名會因此提高
- 無論新聞網站有沒有新聞 Sitemap,Google 新聞都會使用正常的檢索方式搜尋所有新聞網站的首頁和版面,並為網頁加上標籤
Google 新聞 Sitemap 範例
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
<url>
<loc>http://www.example.org/business/article55.html</loc>
<news:news>
<news:publication>
<news:name>The Example Times</news:name>
<news:language>en</news:language>
</news:publication>
<news:publication_date>2008-12-23</news:publication_date>
<news:title>Companies A, B in Merger Talks</news:title>
</news:news>
</url>
</urlset>新聞必要標記
-
<publication>- 該篇報導的出版品。必須使用
<name>及<language>子標記<name>新聞出版品的名稱。這個標記必須與報導在news.google.com中顯示的名稱完全相同,除了括號中的內容之外。<language>出版品的語言,用兩個或三個英文字母組成的 ISO 639 code- 例外:如果是簡體中文,用
zh-cn;繁體中文,用zh-tw
- 該篇報導的出版品。必須使用
-
<publication_date>- 報導的發布日期,採用 W3C 格式 用「完整日期」格式 (YYYY-MM-DD),或者以「完整日期加上時、分、秒」格式搭配時區標誌符格式 (YYYY-MM-DDThh:mm:ssTZD)
- 請指定報導在網站上發布的原始日期和時間,而不是報導加入 Sitemap 的時間
- Google 新聞的檢索器接受下列任何格式:
- 完整日期:
YYYY-MM-DD (1997-07-16) - 完整日期加上時、分:
YYYY-MM-DDThh:mmTZD (1997-07-16T19:20+01:00) - 完整日期加上時、分、秒:
YYYY-MM-DDThh:mm:ssTZD (1997-07-16T19:20:30+01:00) - 完整日期加上時、分、秒及秒的小數位數:
YYYY-MM-DDThh:mm:ss.sTZD (1997-07-16T19:20:30.45+01:00)
- 完整日期:
-
<title>- 新聞報導的標題
- 如果版面不足,Google 新聞會縮短顯示的新聞報導標題
- 如實加入報導在網站上顯示的標題文字
- 不要在新聞 Sitemap 的
<title>中另外加入作者姓名、出版品名稱或發布日期
- robots.txt 檔案主要用於管理檢索器對網站造成的流量
- robots.txt 能夠告訴搜尋引擎檢索器,可存取網站上的哪些網址
- 主要用來避免網站因要求過多而超載,而不是讓特定網頁無法出現在 Google 搜尋結果
- 要防止自己的網頁出現在搜尋結果,請用
noindex,或使用密碼保護網頁
- 要防止自己的網頁出現在搜尋結果,請用
robots.txt 對不同檔案類型產生的影響
網頁- 如果 Google 檢索器提出的要求會讓伺服器不堪負荷,或想避免 Google 檢索網站上不重要或類似的網頁,可用 robots.txt 檔案管理網頁的檢索流量
- 適用的網頁類型包括 HTML、PDF 或其他 Google 可讀取的非媒體格式
- 如果透過 robots.txt 檔案禁止網頁出現在搜尋結果中
- 搜尋結果仍會顯示該網頁的網址
- 但不會提供網頁說明
- 系統會排除圖片檔、影片檔、PDF 和其他非 HTML 檔案
媒體檔案- 可以用 robots.txt 管理檢索流量,並防止圖片、影片和音訊檔案出現在 Google 搜尋結果中
- 不過,這麼做無法防止其他網頁或使用者連結至圖片、影片或音訊檔案
- 防止圖片顯示在 Google 搜尋結果中: https://developers.google.com/search/docs/advanced/crawling/prevent-images-on-your-page
- 移除或限制影片檔案顯示在 Google 搜尋結果中: https://developers.google.com/search/docs/advanced/guidelines/video#remove
資源檔案- 如果認為在載入網頁時略過不重要的圖片、指令碼或樣式檔案等資源,並不會造成太大的影響,那麼可以使用 robots.txt 檔案來封鎖這些資源檔案
- 但如果缺少這些資源會造成 Google 檢索器難以瞭解網頁內容,請不要封鎖這些資源,否則 Google 會無法正確分析仰賴這些資源的網頁
robots.txt 檔案的限制
- 並非所有搜尋引擎都能支援 robots.txt 指令
- robots.txt 檔案中的指示無法強制規範檢索器對網站所採取的行為
- Googlebot 和一些值得信任的網路檢索器都會遵循 robots.txt 檔案中的指示,但並非每個檢索器都是如此
- 因此,如要確保特定資訊不會受到網路檢索器存取,建議使用其他封鎖方式,例如用密碼保護伺服器上的私人檔案
- 各種檢索器解讀語法的方式有所不同
- 各種檢索器解讀指令的方式可能有些不同。有些網路檢索器可能無法理解特定指示,因此請對不同網路檢索器採用合適的語法
- 如果其他網站連結到 robots.txt 所封鎖的網頁,系統仍然可以為該網頁建立索引
- 雖然 Google 不會對 robots.txt 所封鎖的內容進行檢索或建立索引
- 但如果透過網路上其他網頁的連結發現封鎖的網址,仍然會建立這些網址的索引
- 在這種情況下,網頁網址或者網頁連結中的錨定文字這類公開資訊,仍會顯示在 Google 搜尋結果中
- 如要完全避免這種情形,建議用密碼保護伺服器上的檔案、使用 noindex,或是完全移除網頁
robots.txt 檔案位於網站的根目錄
www.example.com/robots.txt- 純文字檔案
範例
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
上面 robots.txt 表:
- 名為
Googlebot的使用者代理程式- 無法檢索任何以
http://example.com/nogooglebot/開頭的網址
- 無法檢索任何以
- 不是 Googlebot 的使用者代理程式
- 可以檢索整個網站
- 即使不指定這項規則,結果也會一樣;系統會預設允許使用者代理程式檢索整個網站
- 網站的 Sitemap 檔案位於 http://www.example.com/sitemap.xml
robots.txt 檔案
- 幾乎所有文字編輯器都能用來建立 robots.txt
- 但不要使用文書處理軟體,因為這類軟體通常會將檔案儲存為某種專有格式
- 有可能因此加上彎引號等不相容字元,或許會使檢索器發生問題
- 務必用
UTF-8- Google 會忽略不屬於 UTF-8 範圍的字元,進而導致 robots.txt 規則可能無法轉譯
- 檔案名稱必須是
robots.txt - 網站只能有一個
robots.txt - 檔案必須位於目標網站主機的根目錄
- 如要控制
https://www.example.com/下所有網址的檢索作業- 檔案就必須位於
https://www.example.com/robots.txt - 不能在子目錄 (如
https://example.com/pages/robots.txt)
- 檔案就必須位於
- 如果無法存取網站的根目錄,請改用其他封鎖方法,例如
noindex meta
- 如要控制
- 檔案適用於 Subdomain 或非標準通訊埠,如
https://website.example.com/robots.txthttp://example.com:8181/robots.txt
robots.txt 檔案規則:
- 包含一或多個群組。
- 每個群組都是由多項規則或指令 (指示) 組成,一項指令占一行
- 每個群組的開頭都會以
User-agent這一行指定群組適用的檢索器 - 群組包含以下資訊:
- 群組的適用對象 (使用者代理程式)
- 這個代理程式「可以」存取的目錄或檔案
- 這個代理程式「無法」存取的目錄或檔案
- 檢索器會依上到下的順序處理群組。每個使用者代理程式只能對應一組規則
- 也就是與其相應的第一組條件最明確的規則
- 根據預設,系統會假設使用者代理程式可以檢索未受 disallow 規則封鎖的網頁或目錄
- 規則區分大小寫,舉例,
disallow: /file.asp #用來標示註解
Google 檢索器支援以下 robots.txt 檔案中的指令:
user-agent- 必要
- 每個群組可指定一或多個
user-agent項目 - 這項指令會指定規則適用的自動化用戶端 (就是所謂的搜尋引擎檢索器) 名稱
- 也是每個規則群組的第一行內容
- Google user-agent 程式清單列出了各種 Google user-agent 程式的名稱
- 星號 (
*) 是 wildcard*表示各種 AdsBot 檢索器以外的所有檢索器;要比對 AdsBot 檢索器,必須特別指明User-agent: AdsBot-Google(AdsBot crawlers must be named explicitly)
disallow- 每項規則至少要有一個
disallow或allow - 禁止使用者代理程式在根網域下檢索的目錄或網頁
- 如果規則指向網頁,則必須提供瀏覽器中顯示的完整網頁名稱
- 規則必須以
/字元開頭,如果指向目錄,則必須以/結尾
- 每項規則至少要有一個
allow- 每項規則至少要有一個
disallow或allow項目 - 允許前述使用者代理程式在根網域下檢索的目錄或網頁
- 這個指令可用覆寫 disallow 指令
- 允許使用者代理程式在禁止檢索的目錄下檢索子目錄或網頁
- 如果是單一網頁,請指定瀏覽器中顯示的完整網頁名稱;如果是目錄,以
/做規則結尾
- 每項規則至少要有一個
sitemap- optional
- 每個檔案可包含零或多個 sitemap 項目
- 該網站的 Sitemap 所在位置
- Sitemap 網址必須為完整網址
- Google 不會假設或檢查是否有 http/https/www/ 非 www 等替代網址
- Allow 和 Disallow 的用途是指出 Google「可以」或「不可」檢索哪些內容,Sitemap 則適合用於指出 Google「應該」檢索哪些內容
- 除了 sitemap 以外,其餘指令都支援以
*萬用字元代表路徑前置字元、後置字元或整個字串 - 對於不符合以上任何指令的行,系統會加以忽略
- 在上傳並測試 robots.txt 檔案後,Google 檢索器會自動尋找並開始使用檔案
- 因此不必採取任何動作。如果更新了檔案,而且需要盡快重新整理 Google 的快取副本
# Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
# Example 2: Block Googlebot and Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# Example 3: Block all crawlers except AdsBot (AdsBot crawlers must be named explicitly)
User-agent: *
Disallow: /
Sitemap: https://example.com/sitemap.xml
Sitemap: http://www.example.com/sitemap.xml
測試 robots.txt 標記
- 測試新上傳的 robots.txt 檔案是否可公開存取,在私密瀏覽視窗,然後前往檔案位置
- 如
https://example.com/robots.txt - 能存取的話,表示可以開始測試標記
- 如
- Google 提供兩種測試 robots.txt 標記的方式:
- Search Console 中的 robots.txt 測試工具
- 只能針對網站已開放存取的 robots.txt 檔案使用這項工具
- https://support.google.com/webmasters/answer/6062598
- 如果是開發人員,參閱 Google 的開放原始碼 robots.txt 程式庫
- 這是 Google 搜尋使用的程式庫、
- 按照說明建立自己的程式庫。可以使用這項工具在本機上測試 robots.txt 檔案
- https://github.com/google/robotstxt
- Search Console 中的 robots.txt 測試工具
robots.txt 一些常見的實用規則:
禁止檢索整個網站
- 在某些情況下,未經檢索的網站網址仍可能會編入索引
- 這範例比對範圍不含各種 AdsBot 檢索器;如要比對 AdsBot 檢索器,必須特別指明
User-agent: *
Disallow: /
禁止檢索特定目錄及其中內容
- 在目錄後方附加正斜線,即可禁止檢索整個目錄
- 只要路徑中的任何位置出現設定的字串,就會視為禁止檢索的項目
Disallow: /junk/的結果會包含https://example.com/junk/和https://example.com/for-sale/other/junk/
User-agent: *
Disallow: /calendar/
Disallow: /junk/
Disallow: /books/fiction/contemporary/
允許單一檢索器存取網站內容
- 只有 googlebot-news 可檢索整個網站
User-agent: Googlebot-news
Allow: /
User-agent: *
Disallow: /
允許所有檢索器存取網站內容,但某一個檢索器除外
Unnecessarybot不得檢索網站,但其他漫遊器可以
User-agent: Unnecessarybot
Disallow: /
User-agent: *
Allow: /
禁止檢索單一網頁
- 例如,禁止
useless_file.html網頁
User-agent: *
Disallow: /useless_file.html
禁止 Google 圖片檢索特定圖片
- 例如,禁止 dogs.jpg 圖片。
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
禁止 Google 圖片檢索網站上的所有圖片
- Google 不得為未經檢索的圖片和影片建立索引
User-agent: Googlebot-Image
Disallow: /
禁止檢索特定類型的檔案
- 例如,禁止檢索所有的 .gif 檔案
User-agent: Googlebot
Disallow: /*.gif$
禁止檢索整個網站,但允許 Mediapartners-Google 進行檢索
- 這麼做會讓網頁無法顯示在搜尋結果中
- 但 Mediapartners-Google 網路檢索器仍可分析網頁,以決定要在網站上對訪客顯示哪些廣告
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /
使用 $ 比對以特定字串結尾的網址
- 例如,封鎖所有 .xls 檔案
User-agent: Googlebot
Disallow: /*.xls$
有效的 robots.txt 網址範例
Cache
- Google 會 cache robots.txt 檔案的內容,最多保留 24 小時
- 但如果在無法重新整理 cache 版本的情況下 (例如逾時或 5xx 錯誤),則會延長快取的保留時間
- 快取回應可由不同的檢索器共用
- Google 可能會依
max-ageCache-ControlHTTP header 增加或減少快取的效期
路徑比對範例
/: 比對根目錄以及所有層級較低的網址/*: 等同於/。結尾的萬用字元會遭到忽略/$: 僅比對根目錄。允許系統檢索任何較低層級的網址/fish: 比對所有以/fish開頭的路徑- 相符項目:
/fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anything
- 不相符: (進行比對時會區分大小寫)
/Fish.asp/catfish/?id=fish/desert/fish
- 相符項目:
/fish*: 等同於/fish。結尾的萬用字元會遭到忽略- 相符項目:
/fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anything
- 不相符:
/Fish.asp/catfish/?id=fish/desert/fish
- 相符項目:
/fish/: 比對/fish/資料夾中的所有項目- 相符項目:
/fish//animals/fish//fish/?id=anything/fish/salmon.htm
- 不相符:
/fish/fish.html/Fish/Salmon.asp
- 相符項目:
/*.php: 比對所有包含.php的路徑- 相符項目:
/index.php/filename.php/folder/filename.php/folder/filename.php?parameters/folder/any.php.file.html/filename.php/
- 不相符項目:
/(即使對應到 /index.php)/windows.PHP
- 相符項目:
/*.php$: 比對所有以.php結尾的路徑- 相符項目:
/filename.php/folder/filename.php
- 不相符:
/filename.php?parameters/filename.php//filename.php5/windows.PHP
- 相符項目:
/fish*.php: 依序比對所有包含/fish和.php的路徑。- 相符項目:
/fish.php/fishheads/catfish.php?parameters
- 不相符:
/Fish.PHP
- 相符項目:
規則的優先順序
- 檢索器會根據規則路徑長度,使用最明確的規則
- 如果規則發生衝突 (包括含有萬用字元的規則),則 Google 會使用限制最少的規則。
以下範例說明 Google 檢索器對特定網址套用哪些規則
http://example.com/pageallow: /pdisallow: /- 適用規則:
allow: /p,因規則較為明確
http://example.com/folder/pageallow: /folderdisallow: /folder- 適用規則:
allow: /folder,在規則發生衝突的情況下,Google 會使用限制最少的規則
http://example.com/page.htmallow: /pagedisallow: /*.htm- 適用的規則:
disallow: /*.htm,因規則路徑的長度較長,且網址中的更多字元相符,因此較明確
http://example.com/page.php5allow: /pagedisallow: /*.ph- 適用規則:
allow: /page,在規則發生衝突的情況下,Google 會使用限制最少的規則
http://example.com/allow: /$disallow: /- 適用規則:
allow: /$,因規則較為明確
http://example.com/page.htmallow: /$disallow: /- 適用規則:
disallow: /,因為allow規則僅適用於根網址
<meta />是向搜尋引擎提供網站相關資訊的絕佳途徑- 應置於
<head>中 - 除了
google-site-verification以外,大小寫無關緊要 - 如果網站需要使用下方沒有列出的標記,也沒有關係。如果 Google 無法解讀,便會選擇忽略
除了 meta,還可以將 HTML 網頁中的部分內容排除在網頁摘要之外,方法是在下列其中一個受支援的 HTML 標記中加入 data-nosnippet 屬性:
- span
- div
- section
例如:
<p>
This text can be included in a snippet
<span data-nosnippet>and this part would not be shown</span>.
</p>Google 能夠解讀的 meta
<meta name="description" content="A description of the page" />- 提供簡短的網頁說明。在某些情況下,這則說明會用於搜尋結果中所顯示的網頁摘要
<meta name="robots" content="..., ..." /><meta name="googlebot" content="..., ..." />- 這些可以控制搜尋引擎檢索及建立索引的行為
<meta name="robots">標記適用於所有搜尋引擎- 而
<meta name="googlebot">則為 Google 專用標記 - 當 robots 或 googlebot 之間有衝突時,會以限制較多的標記為準
- 舉例,如果網頁同時有
max-snippet:50和nosnippet,則會套用nosnippet
- 舉例,如果網頁同時有
- 預設值是
index,follow,不需要特別指定 - 也可以利用
X-Robots-TagHTTP header 指定這項資訊- 如果要防止 Google 為非 HTML 檔案 (如圖檔或其他類型文件) 建立索引,這指令就可以派上用場
<meta name="google" content="nositelinkssearchbox" />- 當使用者搜尋你的網站時,Google 搜尋結果有時會顯示網站的專用搜尋框,以及導向你網站的其他直接連結
- 這個標記會指示 Google 不要顯示網站連結搜尋框
- 解網站連結搜尋框: https://developers.google.com/search/docs/advanced/structured-data/sitelinks-searchbox
<meta name="googlebot" content="notranslate" />- 如果 Google 發現網頁內容可能不是使用者想要語言,可能會在搜尋結果中提供翻譯的標題連結和摘要
- 使用者點選翻譯的標題連結,後續與該網頁進行的互動都會透過 Google 翻譯進行,系統也會自動翻譯使用者隨後點選的任何連結網頁
- 一般來說,這會有更多機會將獨特且吸引人的內容,提供給更廣大的使用者族群
- 但是,也有可能因此遇到不樂見的狀況。可以使用這個中繼標記告訴 Google 不要為這個網頁提供翻譯
<meta name="google" content="nopagereadaloud" />- 禁止各種 Google 文字轉語音服務透過文字轉語音 (TTS) 程序朗讀網頁內容
<meta name="google-site-verification" content="..." />- 使用這個標記,向 Search Console 驗證你擁有這個網站
- 注意,雖然
name和content的屬性值必須完全符合 Google 提供給的內容 (包括大小寫) - 至於標記由 XHTML 改成 HTML,或者標記格式是否符合網頁的格式,則無關緊要。
<meta http-equiv="Content-Type" content="...; charset=..." /><meta charset="..." >- 能夠定義網頁的內容類型及字元集
- 務必在內容屬性值的前後加上引號,否則系統可能會以錯誤的方式解譯字元集屬性
- 建議盡量使用
Unicode/UTF-8
<meta http-equiv="refresh" content="...;url=..." />- 標記能夠在一段時間之後將使用者導向到新的網址,有時也被當成一種簡單的重新導向方式
- 不過,不是所有的瀏覽器都支援這個標記,所以這也可能對使用者造成困擾
- W3C 不建議使用這個標記。建議改用伺服器端 301 重新導向
<meta name="viewport" content="...">- 告訴瀏覽器如何在行動裝置上轉譯網頁
- Google 就會知道該網頁適合在行動裝置上瀏覽
<meta name="rating" content="adult" /><meta name="rating" content="RTA-5042-1996-1400-1577-RTA" />- 將網頁標為含有成人內容,表示安全搜尋應該要過濾這個網頁
noindex 禁止 Google 搜尋建立索引
- 想避免某個網頁或資源顯示在 Google 搜尋中,可在 HTTP response 中加入 noindex meta 或header
- Googlebot 下次檢索該網頁並看到 noindex meta 或 header 時,就會將該網頁完全排除在 Google 搜尋結果之外,不論是否有其他網站連結到該網頁,結果都一樣。
- 為了讓 noindex 指令生效,檢索器必須能夠存取網頁或資源,因此勿使用 robots.txt 檔案加以封鎖
- 如果網頁遭到 robots.txt 檔案封鎖,檢索器便無從發現 noindex 指令
- 該網頁仍可能出現在搜尋結果中。比方說,如果有其他網頁連結到該網頁
如要防止「大部分的搜尋引擎網路檢索器」將網站的特定網頁編入索引,在 <head>
<meta name="robots" content="noindex">如果「只想防止 Google 網路檢索器」將特定網頁編入索引
<meta name="googlebot" content="noindex">HTTP response header
- 可用於非 HTML 資源,例如 PDF、影片檔案和圖片檔
X-Robots-Tagheader
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
更多指令的說明
要求 Google 重新檢索網址
- 使用網址檢查工具要求 Google 檢索個別網址
- 如果網址的數量龐大,請改為提交 Sitemap
- 檢索程序需時幾天至幾週不等,你可以透過索引狀態報表或網址檢查工具掌握進度
- https://support.google.com/webmasters/answer/7440203
- https://support.google.com/webmasters/answer/9012289 多次要求重新檢索同一網址或 Sitemap 並不會加快檢索速度
降低 Googlebot 檢索頻率
- Google 的目標是在每次造訪網站時,盡可能檢索更多網頁,同時避免對伺服器頻寬造成太大影響
- 在某些情況下,可能會對基礎架構造成沉重負載,或在服務中斷期間產生不必要費用
- 為減輕影響,可以決定是否要減少 Googlebot 提出的要求數量
- 使用 Search Console 降低檢索頻率
- 要快速降低檢索頻率,在 Search Console 中變更 Googlebot 的檢索頻率
- 變更通常會在幾天內生效
- 進一步瞭解檢索預算對 Googlebot 會有什麼影響
如果需要緊急降低短時間內的檢索頻率
- 例如幾個小時或 1 到 2 天,回含有 500、503 或 429 HTTP 結果碼的資訊錯誤網頁,不要傳回所有網站內容
- Googlebot 檢索到大量含有 500、503 或 429 (例如當你停用網站時),便會降低檢索頻率
- 這項變更會同時反映在傳回這些錯誤的網址以及整個網站的檢索作業
- 一旦這些錯誤的數量減少,檢索頻率就會再次自動增加
- 警告:不建議長時間這麼做,最多不應超過 1 到 2 天
- 如果持續數天在同樣的網址上觀察到這些狀態碼,可能會將該網址從 Google 索引中移除
驗證 Google 檢索器:
- 手動:適用於一次性查詢,會使用指令列工具。在大多數情況下,這個方法就夠用了。
- 自動:適用於大規模查詢,會使用自動解決方案來比對檢索器的 IP 位址,檢查是否符合已發布的 Googlebot IP 位址清單
手動
- 找出記錄中存取伺服器的 IP 位址,使用 host 指令執行反向 DNS 查詢
- 確認網域名稱是否為 googlebot.com 或 google.com
- 針對在步驟 1 擷取到的網域名稱,使用 host 指令執行正向 DNS 查詢
- 確認查詢結果是否為本來記錄中存取伺服器的 IP 位址
host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
host 66.249.90.77
77.90.249.66.in-addr.arpa domain name pointer rate-limited-proxy-66-249-90-77.google.com.
host rate-limited-proxy-66-249-90-77.google.com
rate-limited-proxy-66-249-90-77.google.com has address 66.249.90.77
自動
- 可以比對檢索器的 IP 位址和 Googlebot IP 位址清單
- 針對其他可能存取網站的 Google IP 位址 (例如來自使用者要求或 Apps Script),請將進行存取的 IP 位址與 Google IP 位址清單進行比對
大型網站擁有者的檢索預算管理指南
- 如果網站沒有大量會經常變動的網頁,或者網頁檢索作業看起來都是在發布網頁的同一天完成,那就不需要這這段,只需要隨時保持 Sitemap 為最新狀態,並定期檢查索引涵蓋範圍即可
- 如果已上線一段時間,但卻從未建立索引,這屬於不一樣的問題,改用網址檢查工具找出網頁未建立索引的原因
這段指南適用於下列網站:
- 擁有超過 100 萬個不重複網頁,且內容變動頻率適中 (每週一次) 的大型網站
- 擁有超過 1 萬個不重複網頁,且內容變動極為頻繁 (每天) 的中型或大型網站
- 此處數字僅是為了方便判斷網站型態而提供的概略估計值,而非絕對門檻值
檢索容量上限
- Googlebot不希望對伺服器造成負擔
- Googlebot 會計算「檢索容量上限」,在檢索時可用的最大同時連線數量,以及擷取作業之間的延遲時間
- 計算出來的容量上限要能為所有重要內容建立索引,但又不會讓伺服器超過負荷
檢索容量上限可能因下列因素而有所起伏:
- 檢索健康狀態
- 如果網站連續一陣子的回應速度都很快,檢索容量上限就會提高
- 如果網站的回應速度變慢或出現伺服器錯誤,檢索容量上限則會降低,檢索次數也會隨之減少
- 網站有在 Search Console 中設定的限制
- 不過,設定較高的上限並不會使檢索次數自動增加
- Google 的檢索能力上限:Google 擁有許多硬體資源,但數量並非無限
以下是決定檢索需求的幾項重要因素:
- 系統對網址庫的判斷
- Googlebot 會在未經你說明的情況下,嘗試檢索網站上所有或大部分的已知網址
- 如果這當中存在許多重複網址,或者因為其他原因根本不需要檢索 (如網址已移除、內容不重要等等)
- 等於 Google 浪費許多時間檢索網站。這也是你最能主動控制的因素
- 熱門程度:為了盡可能在索引中提供最新的資訊,在網際網路上越熱門的網址,其檢索頻率也會越高
- 過時程度:系統希望能以足夠的頻率重新檢索文件,以便及時反映任何變更
- 此外,關聯到整個網站的事件 (例如網站遷移) 可能會使檢索需求增加,因為需要為新網址中的內容重新建立索引
提升檢索效率最佳做法
- 管理網址庫
- 使用適當的工具告訴 Google 要檢索哪些網頁,以及不要檢索哪些網頁
- 整合重複的內容。排除重複內容,讓系統能著重於檢索獨特的內容,而不只是網址不重複而已
- 用
robots.txt禁止 Google 檢索網址- 有些網頁對使用者可能很重要,但不見得希望出現在搜尋結果中
- 例如會重複連結網頁資訊的無限捲動頁面,或是相同網頁的不同排序版本
- 如果無法依上一條所說的方式進行整合,用
robots.txt封鎖不重要的網頁 - 透過 robots.txt 封鎖網址會大幅降低系統為網址建立索引的機率
- 勿用
noindex,Google 仍會送出檢索要求,直到看見 noindex 時才會捨棄該網頁- 白白浪費檢索時間
- 勿用
robots.txt將檢索預算重新分配給其他網頁,即使多出檢索預算可用,也不會轉移給其他網頁
- 如果網頁已永久移除,請傳回 404/410 錯誤
- Google 不會忘記已知的網址,但 404 是很強烈的信號
- 會告訴 Google 不要再檢索該網址
- 相較來說,系統會在檢索佇列中將遭到封鎖的網址保留較長一段時間,並在解除封鎖後重新進行檢索
- 排除轉址式 404 錯誤、會持續受到檢索,白白浪費預算。查看索引涵蓋範圍報表,確認是否有轉址式 404 錯誤
- 隨時保持 Sitemap 為最新狀態
- Google 會定期讀取 Sitemap
- 如果網站內容已經更新,建議加入
<lastmod>
- 避免使用過長的重新導向鏈結,因為這種做法會對檢索造成負面影響
- 確保網頁擁有良好的載入效率
- 監控網站的檢索作業,監控網站在檢索期間是否有任何可用性問題,並設法讓檢索作業更有效率
以下幾個重要步驟可協助監控網站的檢索情形:
- 查看 Googlebot 是否在網站上遇到可用性問題
- 透過檢索統計資料報告查看 Googlebot 檢索記錄
- 報告會顯示 Google 在網站上遇到可用性問題的時間
- 如果報告顯示網站出現可用性錯誤或警告
- 查看「主機可用性」圖表,找到 Googlebot 要求次數超過紅色限制線的部分
- 按下圖表,查看無法檢索的網址,嘗試找出這些網址與網站發生的問題之間有何關聯
- 處理方式:
- 封鎖不希望受到檢索的網頁
- 改散網頁的載入perf
- 提升伺服器負載量
- 透過檢索統計資料報告查看 Googlebot 檢索記錄
- 查看網站中是否有應檢索而未檢索的部分
- 如果認為 Googlebot 漏掉某個重要內容,可能是因為
- Googlebot 不知道該內容存在、該內容已對 Google 封鎖,或者是網站的可用性限制了的存取 (也有可能是因為 Google 試圖避免網站超載)
- 對大部分網站而言,Googlebot 至少要花上數天的時間才會注意到新網頁的存在
- 這些作業至少需要三天的時間
- 除「新聞網站」這類有時效性的網站之外,大部分網站都不應預期新網址能在發布的同一天受到檢索
- 處理方式:
- 更新 Sitemap 以反映新的網址
- 檢查 robots.txt,確認並未封鎖網頁
- 重新審視檢索的優先順序 (也就是謹慎使用檢索預算)
- 確認伺服器負載量並未用盡
- 如果 Googlebot 偵測到伺服器無法回應檢索要求,便會縮減檢索次數
- 注意,如果內容價值低落或沒有使用者要求存取該類內容,那即使檢索完成,也不會顯示在搜尋結果中
- 如果認為 Googlebot 漏掉某個重要內容,可能是因為
- 查看更新後內容的檢索速度是否符合需求
- 檢查網站記錄,查看 Googlebot 檢索特定網址的時間
- 建議做法:
- 如果網站有新聞內容,使用新聞 Sitemap
- 張貼或變更 Sitemap 時,請透過連線偵測 (ping) 工具通知 Google
- Sitemap 中使用
<lastmod>,指出網址在什麼時候更新了內容 - 使用簡單的網址架構,協助 Google 順利找到網頁
- 提供標準的可檢索
<a>連結,協助 Google 順利找到網頁
- 請避免:
- 每天多次提交相同且無變動的 Sitemap
- 預期 Googlebot 會檢索 Sitemap 中的所有內容或立即進行檢索
- Sitemap 是向 Googlebot 提出實用的建議做法,但並非必要
- 在 Sitemap 中加入不想在 Google 搜尋中顯示的網址
- 這會讓檢索預算浪費在不希望建立索引的網頁上
- 改善網站的檢索效率
- Google 的檢索成效受限於頻寬、時間和 Googlebot 執行個體的可用性
- 如果伺服器能更迅速地回應要求,或許就能在網站上檢索更多網頁
- 透過以下方式調整:
- robots.txt 禁止 Googlebot 載入不重要的大型資源。務必只封鎖非關鍵性的資源,例如裝飾性的圖片,這類資源不會影響 Googlebot 瞭解網頁內容的意義。
- 確保網頁能迅速載入
- 不要使用過長的重新導向,這對檢索作業造成負面影響
- 回應伺服器要求所花費的時間以及轉譯網頁所需的時間,兩者都相當重要,這其中也包括圖片和指令碼等內嵌資源的載入和執行時間。請特別留意需要建立索引的大型資源或慢速資源
- 隱藏不想在搜尋結果中顯示的網址
- 如果 Google 檢索到網站上有許多你不希望檢索的網址,可能會對網站的檢索和索引成效產生負面影響。這類網址有以下幾種:
- 多面向導覽和工作階段 ID:多面向導覽通常是網站內的重複內容;而工作階段 ID 和其他只會排序或篩選網頁的網址參數一樣,都不會提供新內容。用 robots.txt 封鎖多面向導覽網頁
- 重複的內容
- 轉址式 404 錯誤網頁:如果網頁已不存在,請傳回 404
- 遭入侵的網頁:請務必查看安全性問題報告,如果找到任何遭入侵網頁,請加以修正或移除。
- 無限空間網址和 Proxy:用 robots.txt 禁止 Google 檢索這些網址
- 劣質內容和垃圾內容
- 這類內容包括購物車頁面、無限捲動頁面,以及會執行動作的網頁 (例如「註冊」頁面或「立即購買」頁面)
- 建議做法:
- 如果完全不希望 Google 檢索某個資源或網頁,用 robots.txt 加以封鎖
- 如果有多個網頁都重複使用相同的資源 (例如共用圖片或 JavaScript 檔案),請在每個網頁中以相同網址的參照該資源,以便 Google 能快取同樣的資源並重複使用,不必對同一個資源發出多次要求
- 請避免:
- 請勿定期新增或移除 robots.txt 中的網頁或目錄,試圖藉此重新分配網站的檢索預算
- 請勿透過輪流抽換 Sitemap 內的項目或其他暫時隱藏機制,試圖重新分配預算
- 處理網站的過度檢索問題 (緊急情況時)
- 監控伺服器,確認 Googlebot 對你的網站是否提出過多檢索要求。
- 在情況緊急時,建議按照下列步驟減緩 Googlebot 的檢索頻率:
- 「暫時」針對 Googlebot 的要求傳回 503/429
- Googlebot 會在接下來的 2 天內持續嘗試重新檢索這些網址
- 請注意,傳回這類「無法使用」代碼如果超過數天,Google 永久降低網址的檢索頻率,甚至永久停止檢索,因此,請一併執行其他後續步驟
- 降低網站的 Googlebot 檢索頻率。這項作業最慢會在 2 天後生效
- 且你必須具備 Search Console 資源擁有者權限
- 先瀏覽檢索統計資料報告,查看「主機可用性」中的「主機使用率」圖表,如果圖表顯示 Google 過度檢索網站的問題在長時間內反覆發生,才執行這項作業
- 「暫時」針對 Googlebot 的要求傳回 503/429
- 一旦檢索頻率降低,請停止針對檢索要求傳回 503/429 結果碼
- 如果執行傳回 503 的時間超過 2 天,Google 會從索引中移除這些傳回 503 的網址
- 長期監控網站的檢索狀況和主機的負載量,視情況重新提高檢索頻率,或者允許預設的檢索頻率
- 如果出現問題的檢索器是其中一個 AdsBot 檢索器
- 起因很可能是你之前曾為網站建立動態搜尋廣告目標,而 Google 正試圖檢索這個網站
- 這作業每 2 週會進行一次
- 如果伺服器負載量不足以處理這些檢索要求,建議限制廣告目標數量,或是增加伺服器負載量
Search Console 會
- 針對 4xx–5xx 範圍中的狀態碼和失敗的重新導向 (3xx) 產生錯誤訊息
- 2xx 狀態碼回應,系統可能會將收到的回應內容納入索引
- HTTP 2xx (success) 不保證系統會對網頁建立索引
code
- 2xx (success)
- Google 會先查看網頁內容,再決定是否建立索引
- 如果內容疑似有誤 (例如空白網頁或錯誤訊息),Search Console 就會顯示轉址式 404 錯誤
- 200 (success), 201 (created)
- Googlebot 會將內容傳送至索引管道。索引系統可能會對內容建立索引(不保證)
- 202 (accepted)
- Googlebot 在檢索內容時會等候一小段時間,然後將收到的任何內容傳送至索引管道
- 逾時時間視使用者代理程式而定,如 Googlebot Smartphone 和 Googlebot Image 的逾時時間可能有所差異
- 204 (no content)
- Googlebot 會向索引管道發出信號,說明檢索器未收到任何內容
- Search Console 可能會在網站的索引涵蓋範圍報表中顯示轉址式 404 錯誤
- 3xx (redirection)
- Googlebot 最多採用 10 個重新導向躍點
- 如果未在 10 個躍點內收到內容,Search Console 會在索引涵蓋範圍報表中顯示重新導向錯誤
- 躍點數量視使用者代理程式而定,例如 Googlebot Smartphone 和 Googlebot Image 的值可能有所差異
- 在使用 robots.txt 的情況下,Google 會依據 RFC 1945 的定義允許至少五個重新導向躍點,之後便會停止並判定 robots.txt 檔案發生 404 錯誤
- 301 (moved permanently)
- Googlebot 會遵循重新導向,且索引管道會將重新導向當做表示重新導向目標應為標準網址的「強烈」信號
- 302 (found), 303 (see other)
- Googlebot 會遵循重新導向,且索引管道會將重新導向當做表示重新導向目標應為標準網址的「微弱」信號
- 304 (not modified)
- Googlebot 會向索引管道發出信號,說明當前內容與上次檢索的內容相同。索引管道可能會重新計算網址的信號,但狀態碼並不會對索引作業造成任何影響
- 307 (temporary redirect) 等同於 302
- 308 (moved permanently) 等同於 301
- 4xx (client errors)
- Google 的索引管道不會對傳回 4xx 狀態碼的網址建立索引
- 並且會將已建立索引並傳回 4xx 狀態碼的網址從索引中移除
- 400 (bad request), 401 (unauthorized), 403 (forbidden) , 404 (not found), 410 (gone), 411 (length required)
- 除了 429 以外,其餘 4xx 錯誤都會以同樣的方式處理
- Googlebot 會向索引管道發出信號,說明網頁內容不存在
- 索引管道會將先前已建立索引的網址從索引中移除,同時也不會處理新檢索的 404 網頁
- 檢索頻率會逐漸降低。
- 不要用 401, 403 來限制檢索頻率。除了 429 之外,其餘 4xx 狀態碼都不會對檢索頻率產生影響
- 429 (too many requests)
- Googlebot 會將 429 狀態碼視為伺服器超載的訊號,並判定為伺服器錯誤
- 5xx (server errors)
- 5xx 和 429 伺服器錯誤會促使 Google 檢索器暫時降低檢索頻率
- 系統會將已建立索引的網址保留在索引中,但最終會予以移除
- 如果 robots.txt 檔案超過 30 天才傳回伺服器錯誤狀態碼,Google 會使用 robots.txt 的最後一個快取副本。如果找不到快取資料,Google 則會假設沒有任何檢索限制
- 500 (internal server error), 502 (bad gateway), 503 (service unavailable)
- Googlebot 會降低網站檢索頻率。檢索頻率降低時,即表示傳回伺服器錯誤的個別網址數量增加
- Google 的索引管道會將持續傳回伺服器錯誤的網址從索引中移除。
網路錯誤和 DNS 錯誤
- 網路錯誤和 DNS 錯誤會對網址在 Google 搜尋中的排名產生負面影響,而且非常快速
- Googlebot 處理 5xx 伺服器錯誤的方式,與網路逾時、連線重設和 DNS 錯誤的處理方式相似
- 在發生網路錯誤的情況下,檢索器會立即降低檢索頻率
DNS 錯誤偵錯
- 最常見的原因是設定錯誤,不過也可能是因為防火牆規則封鎖了 Googlebot DNS 查詢所造成
檢查防火牆規則
- 確認 Google 使用的任何 IP 皆未遭到任何防火牆規則封鎖,且系統允許
UDP和TCP要求
查看你的 DNS 記錄。再次確認你的 A 和 CNAME 記錄是否分別指向正確的 IP 位址和主機名稱,例如:
dig +nocmd example.com a +noall +answer
dig +nocmd www.example.com cname +noall +answer
確認所有名稱伺服器是否都指向正確的網站 IP 位址,例如:
dig +nocmd example.com ns +noall +answer
example.com. 86400 IN NS a.iana-servers.net.
example.com. 86400 IN NS b.iana-servers.net.
dig +nocmd @a.iana-servers.net example.com +noall +answer
example.com. 86400 IN A 93.184.216.34
dig +nocmd @b.iana-servers.net example.com +noall +answer
...
如果在過去 72 小時內曾變更 DNS 設定
- 請等候一段時間,讓相關變更在全球 DNS 網路中全面生效。
- 如要加快更新速度,你可以清除 Google 的公用 DNS 快取
下表列出常見 Google crawlers,以及如何在 robots.txt、robots meta tags 和 X-Robots-Tag HTTP 指令中指定這些檢索器的相關資訊
user agent token: 在 robots.txt 的User-agent使用這個值Full user agent string: crawler 的完整描述、會出現在 HTTP request 裡面
(稍微列出,不把完整內容寫在這邊了: https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers)
Crawlers
APIs-Google- User agent token:
APIs-Google - Full user agent string:
APIs-Google (+https://developers.google.com/webmasters/APIs-Google.html)
- User agent token:
AdSense- User agent token:
Mediapartners-Google - Full user agent string: Mediapartners-Google
- User agent token:
AdsBot Mobile Web Android: (檢查 Android 裝置網頁廣告品質)- User agent token:
AdsBot-Google-Mobile - Full user agent string:
Mozilla/5.0 (Linux; Android 5.0; SM-G920A) AppleWebKit (KHTML, like Gecko) Chrome Mobile Safari (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html)
- User agent token:
AdsBotGooglebot ImageGooglebot NewsGooglebot VideoGooglebot DesktopGooglebot SmartphoneMobile AdSenseMobile Apps AndroidFeedfetcherGoogle Read AloudDuplex on the webGoogle FaviconWeb LightGoogle StoreBot
你可能會因為一些原因而希望對 Google 隱藏某些內容,例如:
- 保密資料
- 避免對目標對象顯示價值較低的內容
- 讓 Google 只檢索重要內容
如果想禁止 Google 顯示特定內容,以下是幾種主要方法:
- 移除內容: 所有內容類型
- 要確保特定內容不會出現在 Google 搜尋或其他地方,最好的方法就是移除。如果要移除的是 Google 已經顯示的資訊,可能必須採取額外步驟才能永久移除資訊(下面補充)
- 使用密碼保護檔案: 所有內容類型
- 如果用 Apache ,可編輯
.htaccess,用密碼保護 server 上的目錄。網路上有許多工具能完成此作業
- 如果用 Apache ,可編輯
- robots.txt 和/或緊急圖片移除要求: 圖片
- (下面補充)
noindex指令: 網頁- 選擇不顯示在特定 Google 資源中: 網頁
nosnippet中繼標記: 搜尋結果摘要<meta name="robots" content="nosnippet" />- Google 就不會在搜尋結果顯示該網頁的摘要
- 不過,這可能會讓搜尋結果產生令人疑惑的訊息,例如「沒有這個頁面的資訊」
- 網址參數工具: 網頁、網站區塊、網址模式
如要快速移除,請使用移除工具
- 這能在一天內,從 Google 搜尋結果中移除網站代管的網頁
- https://support.google.com/webmasters/answer/9689846
「移除工具」中提出要求後
- 效力大約可維持 6 個月
- 如要永久禁止網頁出現在 Google 搜尋結果中,請採取下列其中一種做法:
- 移除或更新網頁內容
- 使用密碼保護網頁
- 為網頁加上 noindex: noindex 標記只會禁止網頁出現在 Google 搜尋結果中,使用者和其他不支援 noindex 的搜尋引擎還是可以存取該網頁。
如何從他人的網站上移除內容?
- 要求 Google 移除特定資訊
- https://support.google.com/websearch/troubleshooter/3111061
如果圖片不需要立即移除
- 在 server 根目錄中加入封鎖圖片的 robots.txt 檔案
- 「移除工具」需要較長的時間才能將圖片從搜尋結果中移除
- 因為使用萬用字元或子路徑的封鎖方式,可更靈活的控管選擇。此外,這個做法適用於所有搜尋引擎 (「移除網址」僅適用於 Google)
假設要 Google 排除網站的 dogs.jpg 圖片 (位於 www.yoursite.com/images/dogs.jpg),在 robots.txt 中
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
如要將網站上的所有圖片從索引中移除
User-agent: Googlebot-Image
Disallow: /
如果要移除特定類型的所有檔案
User-agent: Googlebot-Image
Disallow: /*.gif$
如果你有某一個網頁可透過多個網址存取,或者不同網頁上存在相似的內容
- Google 會將這些網頁視為相同網頁的重複版本
- 從中選出一個網址做為「標準」版本進行檢索,然後將其他網址判定為「重複」網址並降低檢索頻率。
如果你未將標準網址明確告知 Google
- Google 會自行選擇標準網址,或是認定標準及重複網址的參考權重相同
- 這可能會導致某些非預期的行為
有許多合理因素可能造成網站出現不同的網址指向同一個網頁,或是內容重複或非常相似的網頁位於不同的網址。最常見的原因如下:
為了支援多種裝置類型:
https://example.com/news/koala-rampage
https://m.example.com/news/koala-rampage
https://amp.example.com/news/koala-rampage
為了支援搜尋參數或工作階段 ID 等元素而採用動態網址:
https://www.example.com/products?category=dresses&color=green
https://example.com/dresses/cocktail?gclid=ABCD
https://www.example.com/dresses/green/greendress.html
同一篇文章置於網誌的不同版面底下時,系統會自動儲存多個網址:
https://blog.example.com/dresses/green-dresses-are-awesome/
https://blog.example.com/green-things/green-dresses-are-awesome/
server 經過設定,會針對 www/非 www、http/https 版本的網址提供相同的內容:
http://example.com/green-dresses
https://example.com/green-dresses
http://www.example.com/green-dresses
基於以下原因,Google 建議在一系列重複或相似的網頁中明確選擇一個標準網頁:
- 為了指定要顯示在搜尋結果中的網址。例如
- 你可能想讓使用者透過
https://www.example.com/dresses/green/greendress.html進入商品網頁 - 而非 https://example.com/dresses/cocktail?gclid=ABCD。
- 你可能想讓使用者透過
- 為了整合相似或重複網頁的連結信號
- 這可協助搜尋引擎將個別網址的資訊 (例如造訪連結) 整合成偏好的單一網址
- 為了簡化單一產品或主題的追蹤指標
- 如果使用多個不同的網址,會難以針對某項特定內容取得整合性指標
- 為了管理聯合發布內容
- 如果你以聯合發布方式在其他網域發布內容,建議確保搜尋結果中顯示的是偏好的網址
- 為了避免耗時檢索重複網頁
- 盡量把時間花在檢索最新網頁或有更新內容的網頁,而不要檢索同一網頁的不同版本,例如電腦版和行動版
判斷 Google 認定的標準網頁
- 可以使用網址檢查工具來判斷 Google 認定的標準網頁
要為重複網址或相似網頁指定標準網址,請選擇下列其中一種方法
rel=canonical <link>: 在所有重複網頁的程式碼中加入<link>,指向標準網頁- 優點:可對應的重複網頁數量不限
- 缺點:
- 網頁檔案可能會因此變大
- 如網站規模較大,或是其中的網址經常變更,維護作業會變得複雜
- 僅適用於 HTML,不適用於 PDF 這類;可以針對這類檔案改用 rel=canonical HTTP header
rel=canonical HTTP: 在網頁回應中傳送rel=canonical- 優點:
- 網頁檔案不會變大
- 可對應的重複網頁數量不限
- 缺點:如果網站規模較大,或是其中的網址經常變更,維護作業會變得複雜
- 優點:
Sitemap: 在 Sitemap 指定標準網頁- 優點:易於實作及維護,特別是對大型網站
- 缺點:
- Googlebot 仍須根據 Sitemap 中宣告的所有標準網頁判別相關聯的重複網頁
- 對 Googlebot 來說,Sitemap 的信號效力不及
rel=canonical
301 重新導向: 使用 301 告知 Googlebot,重新導向的網址是優於指定網址的版本。只有在要淘汰重複的網頁時,才適用這個方法
所有標準化方法均適用以下一般指南:
- 勿將 robots.txt 檔案用於標準化
- 勿使用網址移除工具執行標準化,以免系統從搜尋結果中移除同一網址的「所有」版本。
- 無論採用單一或多種標準化做法,請勿為相同網頁指定不同的標準網址
- 舉例來說,勿在 Sitemap 中為網頁指定一個網址,卻又使用 rel="canonical" 為同樣的網頁指定另一網址。
- 勿使用 noindex 將網頁排除在標準網頁的選擇範圍之外
- 這指令禁止網頁編入索引,而不是用來管理標準網頁的選項
- 使用 hreflang 標記時,請指定同一種語言的標準網頁,如果沒有的話,則可指定最佳替代語言的標準網頁
- 與網站內部的網頁建立連結時,請連結至標準網址,而非重複網址
用 HTTPS (而非 HTTP) 做為標準網址
- 認定網頁的標準網址時,Google 偏好
HTTPS而非HTTP網頁,除非有下列問題或衝突情形:HTTPS含有無效的安全資料傳輸層 (SSL) 憑證HTTPS網頁含有不安全的相依關係 (圖片除外)HTTPS會將使用者重新導向HTTP網頁,或透過HTTP網頁重新導向使用者HTTPS網頁中含有指向HTTP網頁的rel="canonical"link
根據預設,Google 偏好 HTTPS 勝於 HTTP,不過仍可採取下列任一做法,確保這種行為不會遭到覆寫:
- 新增重新導向,從
HTTP指向HTTPS - 新增
rel="canonical"link,從HTTP指向HTTPS - 導入
HTTP嚴格傳輸安全性機制(Strict-Transport-Security)
勿採用下列做法,以免 Google 誤將 HTTP 當成標準網頁:
- 使用無效的傳輸層安全標準 (TLS)/安全資料傳輸層 (SSL) 憑證,以及
HTTPS至HTTP重新導向- 這些做法很有可能造成 Google 偏好
HTTP,即使導入HTTP Strict-Transport-Security也無法覆寫這項偏好設定
- 這些做法很有可能造成 Google 偏好
- 在
Sitemap或hreflang中加入HTTP網頁,而不是HTTPS版本 - 採用誤植主機名稱版本的安全資料傳輸層 (SSL)/傳輸層安全標準 (TLS) 憑證
- 例如在
example.com提供www.example.com的憑證 - 務必採用與完整網站網址相符的憑證,或是可供單一網域中多個子網域使用的萬用憑證
- 例如在
使用 rel="canonical" link tag
- 在 HTML 的
head中用<link>,指出該網頁與其他網頁重複。
假設有多個網址都能存取相同的內容,而你想將其中的 https://example.com/dresses/green-dresses 指定為標準網址
- 在重複網頁的
<head>區段中加入包含rel="canonical"屬性的<link>元素,指向標準網頁。例如:<link rel="canonical" href="https://example.com/dresses/green-dresses" />
- 如果標準網頁有行動版本,加入指向行動版網頁的
rel="alternate"link:<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/dresses/green-dresses">
- 為網頁加上
hreflang或其他適當的重新導向 - 搭配
rel="canonical"link 時請採用絕對路徑,不要使用相對路徑
(雖然不建議,但如何用 Javascript 插入 rel="canonical" link tag)
使用 rel="canonical" HTTP header
- 如果你能設定 server,就能使用
rel="canonical"HTTP header,為 Google 搜尋支援的文件 (包括 PDF 檔案等非 HTML 文件) 指定標準網址。 - 若你透過多個網址提供 PDF 檔案,可以傳回
rel="canonical"HTTP header,將 PDF 檔案的標準網址告知 Googlebot:Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"
rel="canonical"HTTP header 的使用建議與rel="canonical"link tag 的建議相同。根據RFC2616的規定,請只在rel="canonical"HTTP header 中使用雙引號
使用 Sitemap
- 可以為每個網頁挑選一個標準網址,然後透過
Sitemap提交 - Sitemap 中列出的所有網頁「都代表你建議的標準網頁」,Google 會根據內容相似度判斷是否有重複的網頁,以及哪些網頁發生重複
- Google「不保證」一定會將 Sitemap 中的網址視為標準網址,但 Sitemap 是為大型網站定義標準網址的簡易方法,也很適合用來告知 Google 你認為網站上的哪些網頁最重要。
- 請勿在 Sitemap 中加入非標準網頁。如果用了 Sitemap,其中只能指定標準網址
針對已停用的網址使用 301 重新導向
- 如果要淘汰現有的重複網頁,但必須確保在舊網址失效前能順利進行轉換,就採用這個方法
- 假設使用者可透過以下多個網址存取你的網頁:
https://example.com/homehttps://home.example.comhttps://www.example.com
- 選擇其中一個網址做為標準網址,然後使用 301 重新導向將其他網址的流量傳送到偏好的網址
- 使用 server side 301 重新導向,是確保使用者和搜尋引擎都能導向正確網頁的最佳方式
網址重新導向可有效讓 Google 搜尋和訪客得知網頁已移至新的位置。在下列情況特別實用:
- 你已經將網站遷移至新的網域,並希望這次轉移作業盡可能無縫接軌
- 使用者透過多個不同網址存取你的網站,建議你從中選取一個偏好 (標準) 網址,並透過重新導向將其他網址的流量傳送到那個網址。
- 你要合併兩個網站,希望把連到淘汰網址的連結都重新導向到正確網頁
- 移除了某個網頁,想要將使用者導向到新網頁。
重新導向類型總覽
- 永久重新導向:在搜尋結果中顯示新的重新導向目標。
- 如果確定重新導向不會還原,用永久重新導向
- 暫時重新導向:在搜尋結果中顯示來源網頁。
下表將說明幾種可用於設定永久及暫時重新導向的方法,並按照 Google 能夠正確解讀的機率將這些方法排序 (舉例來說,Google 正確解讀伺服器端重新導向的機率最高)
永久: (Googlebot 會遵循重新導向,而且索引管道會將重新導向視為強烈信號,表示重新導向目標應為標準網址)
- HTTP 301 (moved permanently) 設定 server side redirect
- HTTP 308 (moved permanently) 設定 server side redirect
- meta refresh (0 秒) 設定 meta refresh 重新導向
- HTTP 重新整理 (0 秒) 設定 meta refresh 重新導向
- JavaScript location 設定 JavaScript 重新導向
- (!!! 只在無法進行 server side 或 meta refresh 重新導向時,才使用 JavaScript 重新導向)
- Crypto 重新導向
- (!!! 如果有別的選擇,請勿仰賴以 crypto 重新導向讓搜尋引擎得知內容已移至其他位置。)
暫時: (Googlebot 會遵循重新導向,而且索引管道會將重新導向視為微弱信號,表示重新導向目標應為標準網址)
- HTTP 302 (found) 設定 server side redirect
- HTTP 303 (see other) 設定 server side redirect
- HTTP 307 (temporary redirect) 設定 server side redirect
- meta refresh (大於 0 秒) 設定 meta refresh 重新導向
- HTTP refresh (大於 0 秒) 設定 meta refresh 重新導向
meta refresh: Google 會區分以下兩種 meta refresh
- 即時 meta refresh 重新導向:在瀏覽器中載入網頁時立刻觸發。Google 搜尋會將即時 meta refresh 重新導向解讀為永久重新導向。
- 延遲 meta refresh 重新導向:只在網站擁有者任意設定的秒數過後觸發。Google 搜尋會將延遲 meta refresh 重新導向解讀為暫時重新導向。
即時
<!doctype html>
<html>
<head>
<meta http-equiv="refresh" content="0; url=https://example.com/newlocation" />
<title>Example title</title>
<!--...-->上面的跟這段 http header 有同樣效果
HTTP/1.1 200 OK
Refresh: 0; url=http://www.example.com/newlocation
如要建立 Google 會解讀為暫時重新導向的延遲重新導向,請將 content 屬性設為重新導向應延遲的秒數:
<!doctype html>
<html>
<head>
<meta http-equiv="refresh" content="5; url=https://example.com/newlocation" />
<title>Example title</title>
<!--...-->JavaScript location 重新導向
- 完成網址檢索後,Google 搜尋會運用網路轉譯服務來解讀及執行 JavaScript。
- 只在無法進行 server side 或 meta refresh 重新導向時,才使用 JavaScript 重新導向
- 雖然 Google 會嘗試轉譯 Googlebot 檢索的每個網址,仍有許多原因可能導致轉譯失敗
- 如果設定 JavaScript 重新導向,Google 或許會因為內容轉譯失敗而根本看不到該重新導向
如要設定 JavaScript 重新導向,在 HTML head 的 script 中將 location 屬性設為重新導向目標網址,例如:
<!doctype html>
<html>
<head>
<script>
window.location.href('http://www.example.com/newlocation')
</script>
<title>Example title</title>
<!--...-->Crypto 重新導向
- 即使無法實作任何傳統的重新導向方法,你還是應該努力讓使用者得知網頁或其中內容已移至其他位置。最簡單的做法是新增指向新網頁的連結並附上簡短說明
- 對於這種可協助使用者找到新網站的做法,Google 可能會視為 crypto 重新導向
<a href="https://newsite.example.com/newpage.html">We moved! Find the content on our new site!</a>在某些情況下,網站擁有者可能會想把網站遷移到其他網址,或是變更網站的基礎架構
「遷移」指的則是採取下列其中一種方式遷移現有的網頁:
適用於所有網站遷移作業的建議
- 如果你的網站適合這麼做,請將遷移作業拆分成多個步驟進行
- 建議先遷移部分網站內容,測試任何可能對流量和搜尋索引服務造成的影響。測試完成後,再一次或分批遷移剩餘的網站內容
- 在決定要從網站中的哪一個部分開始測試時,建議選擇不常變更,以及不會因為常見或無法預測的事件而受到顯著影響的部分
- 請盡可能在網站流量較低時進行遷移
- 如果網站流量會因為季節不同而出現變化,或是會固定在星期幾下滑,就可以在這些流量平緩的時段遷移網站
- 在網站遷移期間可能發生的問題會影響到的使用者較少
- 遷移作業期間網站排名可能出現短暫波動
- 當網站有任何重大異動時,在 Google 重新檢索網站及建立索引的期間,排名很可能出現變動
- 一般而言,需要數週的時間才能為中型網站完成大部分網頁的索引遷移作業,大型網站所需的時間則更長
- 系統找出並處理遷移網址所需的時間,取決於網址的數量和你的伺服器速度
- 提交 Sitemap 可以加快尋找作業
- 如果牽涉到網址變更,建議進行 A/B 版本測試或運作測試。
- 你可以規劃為期數週的測試,讓 Google 檢索及建立索引來反映異動內容,並且投入更多時間監控流量
這段再說明在遷移網站主機基礎架構時,該如何盡量減少對 Google 搜尋排名造成的影響
- 無論是要更換代管服務供應商或遷移至 CDN,都建議參考本文
將網站的備份版本上傳至新的代管服務供應商,然後從各方面測試使用者與網站的互動情形,確認網站是否如預期運作
- 在網路瀏覽器中開啟「新網站」,並檢查網站的所有元素:網頁、圖片、表單和下載 (如 PDF file)
- 建立測試環境,例如依照 IP 位址限制存取,以便在網站上線前測試所有功能
- 使用暫時性主機名稱 (如
beta.example.com) 對新的基礎架構進行公開測試,確認不同的瀏覽器是否都能順利存取網站- 暫時性主機名稱可協助測試 Googlebot 是否能找到網站
- 如果可以的話,引導網站少部分的即時流量去測試新網站
確認 Googlebot 能夠存取新的主機基礎架構
- 用 Search Console 中的網址檢查工具確認 Googlebot 能夠存取新的基礎架構
降低 DNS 記錄的存留時間值
- 降低網站 DNS 記錄的存留時間值可以加快網站遷移速度,讓網際網路服務供應商 (ISP) 更快取得新的設定
- DNS 設定通常是由 ISP 根據指定的存留時間 (TTL) 設定進行快取
- 建議提前在網站遷移前至少一週,將存留時間調降至較保守的數值 (例如數小時),以便加快重新整理 DNS 快取的速度
檢查 Search Console 的驗證狀態
- 遷移後,務必確認你的 Search Console 驗證狀態是否依然正常
- 如果使用 HTML 檔案在 Search Console 中驗證網站的擁有權,別忘了要在新版網站中加入目前的驗證檔案
- 同樣,如果驗證擁有權的方式是在內容管理系統範本中加入中繼標記或透過 GA (分析),請確認新的內容管理系統也包含這些項目
遷移流程如下:
- 移除任何暫時禁止檢索的設定
- 建立新版網站時,有些擁有者會使用
robots.txt檔案來禁止 Googlebot 和其他檢索器進行任何檢索 - 或是使用
noindex中繼標記或 HTTP 標頭來封鎖內容索引作業 - 務必在準備好遷移網站時,將這類禁止設定從新建的網站中全數移除
- 建立新版網站時,有些擁有者會使用
- 更新 DNS 設定
- 只要更新 DNS 記錄,讓網址指向新的主機供應商,系統就會開始遷移網站
- 具體做法,洽詢你的 DNS 供應商
- 由於系統已快取 DNS 快取設定,因此需要一段時間才能讓網際網路上的所有使用者都看見這些記錄
監控流量: 為了順利進行遷移,請執行下列三項操作:
- 注意新舊伺服器的記錄
- 在 DNS 設定生效及網站流量開始轉移後,舊伺服器記錄到的流量將會下降,新伺服器的流量則相應增加
- 使用不同的公用 DNS 檢查工具
- 確認全球的 ISP 都已順利更新為新的 DNS 設定
- 監控檢索行為:
- 監控 Search Console 中的索引涵蓋範圍圖表
- https://www.youtube.com/watch?v=L0UqvdHJaXE
Googlebot 檢索頻率須知
- Googlebot 的檢索頻率往往會在遷移開始後立即出現暫時性的下降,並在接下來幾週內穩定上升,甚至可能高於遷移前的頻率
- 會出現這樣的波動,是因為根據許多信號來決定檢索頻率,而這些信號會在主機改變時出現變化
- 只要 Googlebot 在存取新的服務基礎架構時沒有遇到嚴重問題或變慢,就會視需要盡快檢索網站
關閉舊的代管服務
- 查看舊供應商的伺服器記錄,等到舊供應商的流量降為零時,即可關閉舊的代管服務基礎架構,網站遷移作業就大功告成
這說明如何在變更網站上現有網頁的網址時,盡可能減少對 Google 搜尋結果造成的影響
舉例來說,以下幾種情況皆屬這類網站遷移作業:
- 從
HTTP變更為HTTPS - 將網域從
example.com變更為example.net,或者合併多個網域或主機名稱 - 變更網址路徑:從
example.com/page.php?id=1變為example.com/widgetor- 從
example.com/page.html變為example.com/page.htm
- 從
遷移網站並變更網址時的常見問題:
- Google 建議一次遷移所有內容,還是分段遷移?
- 可以採取分段遷移的方式
- 如何測得已建立索引的網頁數量?
- 在 Search Console 中分別驗證每項資源的資料
- 可以透過索引狀態報告掌握大致概況
- 也可從 Sitemap 報告瞭解透過 Sitemap 提交的網址有多少已建立索引
- Google 需要多久時間才能辨識網址的異動?
- Google 沒有固定的檢索頻率,辨識異動的時間長短會依網站規模和可能的檢索速度而定,因為遷移作業是以網址為單位逐一進行。
- 重新導向到新網址會影響連結評價嗎?
- 不會。301 或 302 重新導向不會導致 PageRank 下滑
從 HTTP 遷移至 HTTPS
- 參閱 HTTPS 最佳做法
- 務必將 HTTPS 資源新增到 Search Console
- Search Console 會分別處理
HTTP和HTTPS,不會共用這兩種資源的資料 - 因此,如果網頁同時使用這兩種通訊協定,就必須建立不同的 Search Console 資源
- Search Console 會分別處理
從 HTTP 遷移至 HTTPS 的常見問題:
- HTTPS 遷移作業會影響排名嗎?
- 就和所有遷移作業一樣,在遷移過程中,排名可能會有些許變動
HTTPS網站的排名可能會微幅提升,但不會出現明顯變化- 雖
HTTPS為正向的排名信號,但是這項信號只是影響排名的眾多因素之一,目前影響力也比不上提供優質的網站內容 - 因此在短期內,
HTTPS並不會為 SEO 帶來重大優勢
- 可只將部分網頁遷移到
HTTPS嗎?- 可以。可以按照自己的步調,先從一部分網頁開始著手,經過測試之後再遷移更多網頁
- 如果採取分批的做法,同時想避免處理中的網址提早被編入索引,建議使用
rel=canonical而不是重新導向。如果使用重新導向,將無法測試進行重新導向的網頁。
- 使用
rel=canonical標記是否能保證HTTP網址一定能編入索引?- 不能,但在我們選擇要將已建立索引的哪個網址提供給使用者時,這是很強勁的信號
- Google 建議使用哪個憑證?
- 凡是新式瀏覽器接受的新型憑證,Google 搜尋也都接受
- 搜尋關鍵字是否會在網站遷移至
HTTPS後有所變動?- 這部分不會因為改用
HTTPS而有任何改變,仍然可以在 Search Console 中查看搜尋查詢
- 這部分不會因為改用
- 如何測得已建立索引的網頁數量?
- 在 Search Console 中分別驗證
HTTP和HTTPS資源,然後使用索引涵蓋範圍報表查看哪些網頁已建立索引
- 在 Search Console 中分別驗證
- 從
HTTP遷移至HTTPS需要多久?- Google 沒有固定的檢索頻率,辨識異動的時間長短會依網站規模和可能的檢索速度而定,因為遷移作業是以網址為單位逐一進行
- 我們在
robots.txt中參照了HTTP Sitemap,應該更新robots.txt以加入新的HTTPS Sitemap嗎?- 建議更新
robots.txt,使其指向 Sitemap 檔案的HTTPS版本。建議在 Sitemap 中只列出HTTPS網址 - 提醒,如果將網站上每個網址都由
HTTP重新導向至HTTPS,檢索器還是只能存取一個robots.txt檔案。舉例,如果http://example.com/robots.txt會重新導向至https://example.com/robots.txt,Google 和其他搜尋引擎將無法瀏覽HTTP版本的內容
- 建議更新
- 哪一個 Sitemap 應該對應至試行
HTTPS的部分?- 可以針對網站中已更新的部分單獨建立一個 Sitemap,這樣能更準確地追蹤試行部分的索引編列情形
- 不過,務必確認這些網址並未重複出現在其他 Sitemap 中
- 如果們採用了重新導向 (從
HTTP到HTTPS或從HTTPS到HTTP),Sitemap 中應列出哪些網址?- 列出所有新的
HTTPS網址並移除舊的HTTP網址。如果偏好建立新的 Sitemap,只要列出新的HTTPS網址即可
- 列出所有新的
- 是否需要針對
HTTPS版本的robots.txt另外加入特定內容?- 不需要。
- 我們應該支援 HSTS 嗎?
- 雖然
HTTP嚴格傳輸安全性機制能夠提升安全性,但也會讓復原策略變得更為複雜 - 詳細資訊,參閱
HTTPS最佳做法
- 雖然
- 如果整個網站只使用一個 Google 新聞 Sitemap,該如何分段遷移網站?
- 如果想針對新遷移的
HTTPS部分使用 Google 新聞 Sitemap,請先與 Google 新聞團隊聯絡並告知通訊協定異動。等將網站各部分遷移至HTTPS時,再到 Search Console 的HTTPS資源中提交新的 Google 新聞 Sitemap
- 如果想針對新遷移的
- 對於 Google 新聞發布者中心的
HTTPS遷移作業,Google 有任何特別的建議嗎?- Google 新聞發布者中心會直接處理
HTTP遷移至HTTPS的相關作業 - 因此,除非同時使用了新聞 Sitemap,否則一般來說不必為 Google 新聞採取任何動作
- 如果使用了新聞 Sitemap,請與 Google 新聞團隊聯絡並告知異動。也可以向新聞團隊告知異動部分
- 舉例來說,如果是遷移至 HTTPS,可以指出自己正從
http://example.com/section遷移至https://example.com/section
- Google 新聞發布者中心會直接處理
每種遷移方式的事前準備細節各不相同,但通常都需要執行以下一或多項操作:
- 設定新的內容管理系統 (CMS) 並在其中新增內容。
- 轉移目前代管的圖片和下載項目,例如 PDF,這些可能已經有來自 Google 搜尋或連結的流量,將新位置告訴使用者和 Googlebot 會很有用
- 如要將網址遷移至 HTTPS,請取得必要的傳輸層安全標準 (TLS) 憑證並在伺服器上進行設定。
網站的 robots.txt 檔案
- 能夠控制 Googlebot 可以檢索的區域
- 確認新網站 robots.txt 檔案內的指令能正確反映要禁止檢索的部分
- 有時會在開發階段禁止任何檢索。如採取這個策略,務必在開始遷移網站時備妥完整的 robots.txt 檔案
- 同樣,如果開發階段使用
noindex指令,在開始遷移時,要移除noindex指令的網址清單
- 同樣,如果開發階段使用
- 對於不會從舊網站遷移至新網站的內容,請確認這些孤立網址可正確傳回 HTTP 404 或 410 錯誤回應代碼
- 可以透過新網站的設定面板讓舊的網址傳回錯誤回應碼,也可以為新網址建立重新導向,並讓該網址傳回 HTTP 錯誤代碼
勿將許多舊網址重新導向至不相關的相同目的地 (例如新網站的首頁)
- 這會造成使用者混淆
- 還可能遭 Google 視為轉址式 404 錯誤
- 如果將原先由多個網頁代管的內容整合到同一個新網頁上,就能夠把多個舊網址重新導向至整合後的新網頁,而不受此限制
網站遷移作業是否能成功,取決於 Search Console 的設定是否正確且符合現況
- 確認已在
Search Console中驗證新舊網站的擁有權,並務必驗證新舊網站的所有版本 - 舉例,請驗證
www.example.com和example.com的擁有權- 如有用
HTTPS網址,則還須驗證HTTPS和HTTP兩種版本的網站
- 如有用
網站遷移後,務必確認 Search Console 驗證狀態是否依然正常
- 如果用 HTML 檔案方法在 Search Console 中驗證網站的擁有權,別忘了要在新版網站中加入目前的驗證檔案
- 同樣地,如果用參照中繼標記的檔案來驗證擁有權,或者透過 Google Analytics (分析) 進行驗證,請確認新的 CMS 中也包含這些項目
如果曾經在 Search Console 中變更舊網站的部分設定,則必須讓新網站的設定也反映這些變更。例如:
- 網址參數:如果曾經設定網址參數來控制舊網址的檢索或索引作業,請確認也為新網站套用必要的相同設定
- 指定地理區域:舊網站可能已有明確的指定地理區域,例如指定地理區域網域或國家/地區代碼頂層網域 (例如
.co.uk)。如果要繼續指定相同區域,請為新網站套用相同設定- 不過,如果遷移網站的目的是為了協助公司進入國際市場,因此不希望網站與任何特定國家/地區建立關聯,請在「
網站設定」網頁的下拉式清單中選取[未選取]
- 不過,如果遷移網站的目的是為了協助公司進入國際市場,因此不希望網站與任何特定國家/地區建立關聯,請在「
- 檢索頻率:建議不要在 Search Console 中限制 Googlebot 檢索新舊網址的頻率
- 也不要設定特定的檢索頻率,除非已經知道網站無法承擔 Googlebot 的檢索量,才需要這麼做
- 如果已對 Googlebot 檢索舊網站的頻率設限,請考慮移除限制。Google 的演算法會自動偵測網站是否已經遷移,並且據此調整 Googlebot 的檢索行為,讓索引更快反映這項變更
- 禁止反向連結:如果曾經透過上傳檔案,禁止舊網站上的部分連結,建議使用新網站的 Search Console 帳戶重新上傳這個檔案
如果新網站將設在最近購買的網域上,建議先確認其中是否有前一位使用者遺留下的問題。請檢查下列設定:
- 先前垃圾內容導致的專人介入處理:Google 會對不遵循《網站管理員指南》的網站採取專人介入處理行動,例如降低網站排名,甚至將網站從搜尋結果中完全移除
- 查看 Search Console 的「專人介入處理」頁面,瞭解系統是否曾對新網站採取任何專人介入處理行動,並且解決其中列出的所有問題,「最後」再提出重審要求
- 已移除的網址:確認先前的擁有者沒有遺漏任何需要移除的網址,尤其是網站層級的網址。此外,在為內容提交移除網址要求前,請確認你已瞭解不該使用網址移除工具的情況
在遷移網站的過程中,分析新舊網站的使用量是一件很重要的事情,而網頁分析軟體能協助完成這項作業
- 一般設定網頁分析的方式是在各網頁上嵌入一段 JavaScript 片段。根據選用的分析軟體及其記錄、處理或篩選設定的不同,追蹤不同網站所獲得的詳細資料也會有所差異
- 如果使用 Google Analytics (分析),且希望能清楚區分內容報表,建議你為新網站建立新的設定檔
- 遷移完成後,Google 檢索新網站的頻率會比平常更為繁重,因為網站會將流量從舊網站重新導向新網站,而舊網站的所有檢索也會重新導向新網站
- 此外,新的網站還必須處理任何其他檢索作業。務必確認新網站有足夠的負載量能處理增加的 Google 流量
- 如果曾經使用資料螢光筆對應舊網頁中的資料,務必為新網站重新執行對應作業
- Google 搜尋結果顯示的某些應用程式連結會在應用程式中開啟你的網頁,請在 HTTPS 網頁準備就緒後更新這類連結,以便引導至新的 HTTPS 網址
- 這類連結不支援重新導向,因此除非更新了應用程式連結的處理方式,否則使用者在行動瀏覽器中點選連結後,只能在瀏覽器中開啟網頁,無法透過應用程式開啟
本節會針對如何正確評估兩個網站的網址及建立對應關係,說明一些常見做法
- 確定舊網址
- 在非常簡易的網站遷移作業中,可以不必建立舊網址的清單。舉例,如果要更換網站的網域 (從
example.com變更為example.net),只要使用萬用字元的伺服器端重新導向即可。 - 如果遷移較複雜,就需要為舊網址建立清單,然後一一對應到新的目的地網址。取得舊網址清單的方式會依目前的網站設定而異,以下列舉幾供參考:
- 優先處理重要網址:
- 查看 Sitemap,因為最重要的網址很可能都已透過這種方式提交至 Search Console
- 查看伺服器記錄或分析軟體,鎖定流量最大的網址
- 查看 Search Console 的「連至你網站的連結」功能,尋找包含內部和外部連結的網頁
- 使用內容管理系統,通常這樣就能輕鬆取得所有代管內容的網址清單
- 查看伺服器記錄,鎖定使用者近期至少造訪一次的網址。請注意季節性的流量變化,並依此為網站選擇適合的時段
- 找出包含圖片和影片的網址。確認網站遷移計畫中包含已嵌入影片、圖片、JavaScript、CSS 檔案等内容的網址。這些網址必須和網站上其他內容採用同樣的遷移方式
- 優先處理重要網址:
- 在非常簡易的網站遷移作業中,可以不必建立舊網址的清單。舉例,如果要更換網站的網域 (從
- 建立新舊網址間的對應關係
- 取得舊網址清單後,請決定每個網址要重新導向至的對應網址
- 儲存對應的方式取決於伺服器和遷移位置。可以用資料庫,也可以在系統中為常用的重新導向模式設定一些網址改寫規則
- 更新所有網址的詳細資料
- 決定網址對應關係後,可以執行以下三項操作,讓網頁做好遷移準備:
- 更新註解,指向每個網頁的 HTML 或 Sitemap 項目中的新網址:
- 每個到達網頁網址都應該要有自我參照的
rel="canonical"<link>標記 - 如果遷移的網站包含多語言或多地區版本的網頁,而且這些網頁含有
rel-alternate-hreflang註解,記得將註解更新為新的網址 - 如果遷移的網站有相應的行動裝置版本,務必更新
rel-alternate-media註解,以便使用新的網址- 詳情請參閱智慧型手機網站指南
- 更新內部連結:
- 變更新網站上的內部連結,由舊網址改成指向新網址。必要時,可以使用先前產生的對應檔案來找出連結並進行更新
- 請儲存下列清單以供最後遷移時使用:
- 包含新版對應網址的 Sitemap 檔案。請參閱建立 Sitemap 的說明文件。
- 連結至舊網址的網站清單。可以在 Search Console 中找到連至網站的連結。
- 決定網址對應關係後,可以執行以下三項操作,讓網頁做好遷移準備:
- 301 重新導向的準備工作
- 對應關係準備好之後,下一步就在伺服器上設定 HTTP 301 重新導向,依據對應關係將舊網址導向新網址
- 請留意以下事項:
- 使用 HTTP 301 重新導向。雖然 Googlebot 支援多種重新導向,但還是建議盡可能使用 HTTP 301 重新導向
- 避免連續重新導向。雖然 Googlebot 和瀏覽器可以追蹤多個重新導向的「鏈結」(例如:第 1 頁 > 第 2 頁 > 第 3 頁),還是建議直接重新導向至最終目的地
- 如果無法這麼做,盡量減少連續重新導向的次數,最好在 3 次以內,最多不超過 5 次。連續重新導向會增加使用者的等待時間,而且並非所有瀏覽器都支援多次連續重新導向。
- 測試重新導向。可以使用網址檢查工具來測試個別網址,或是使用指令列工具或指令碼來測試大量網址
只要網址對應正確且重新導向功能正常運作,即可開始遷移網站。
- 決定網站遷移方式:一次遷移完成或分段遷移?
- 小型或中型網站:建議一次完成網站上所有網址的遷移,不要分成好幾個部分遷移
- 可以促進使用者與新編排的網站產生良好互動
- 也讓 Google 的演算法能夠快速偵測到網站遷移行動,加快更新索引的速度
- 大型網站:可以選擇分幾部分來遷移大型網站的內容,以便監控、偵測並快速修正問題
- 小型或中型網站:建議一次完成網站上所有網址的遷移,不要分成好幾個部分遷移
- 更新 robots.txt 檔案:
- 在舊網站上,移除所有 robots.txt 指令。這個動作可以讓 Googlebot 發現所有指向新網站的重新導向,並據此更新索引
- 提醒,在啟用重新導向功能後,檢索器將無法看到舊的 robots.txt 檔案內容
- 新網站上,確認 robots.txt 檔案允許所有檢索,包括對圖片、CSS、JavaScript 和其他網頁資產的檢索 (不想開放檢索的網址除外)
- 在舊網站上,移除所有 robots.txt 指令。這個動作可以讓 Googlebot 發現所有指向新網站的重新導向,並據此更新索引
- 根據網址對應關係設定舊網站,將使用者和 Googlebot 從舊網站重新導向至新網站
- 在 Search Console 中為舊網站提交網址變更要求。
- 如果是將網站從 HTTP 遷移至 HTTPS,則不需要使用網址變更工具
- 盡可能保留重新導向連結,通常要保留至少 1 年。讓 Google 有時間將所有信號轉移至新網址,包括在舊網址上重新檢索,並重新指派其他網站上指向舊網址的連結
- 從使用者的角度來看,建議永久保留重新導向。不過,因為重新導向的速度對使用者而言仍較緩慢,建議更新自己網站的連結以及任何來自其他網站的高流量連結,將這些連結指向新的網址
- 在 Search Console 中提交新的 Sitemap
- 這可協助 Google 瞭解新網址。現階段,你可以移除舊的 Sitemap,Google 往後會使用新的 Sitemap
網站遷移之後
- Googlebot 需要一段時間才能找出並處理所有遷移的網址
- 時間的長度會視伺服器的速度和涉及網址的數量而定
- 一般需要數週的時間才能為中型網站完成大部分網頁的遷移作業,大型網站所需的時間則更長
- 遷移過程中,網站內容在網頁搜尋結果的能見度可能出現短暫波動。這是正常現象,網站排名在一段時間後就會穩定下來
開始遷移網站後,請盡量更新連入連結,以改善使用者體驗並降低伺服器負載。這些連結包括:
- 外部連結:你先前已儲存了一份連至目前內容的網站清單,請試試看能否與這些網站的管理員聯絡,請對方將原本的連結更新為指向新網站。建議根據每個連結導入的造訪次數來安排處理順序
- 來自 Facebook、Twitter 和 LinkedIn 的個人資料連結
- 指向新到達網頁的廣告活動
- 開始遷移後,可以監控使用者和檢索器的流量在新網站和舊網站上的變化
- 理想情況下,舊網站的流量會下降,新網站的流量則會上升
- 可以使用 Search Console 和其他工具來監控網站上的使用者和檢索器活動
Search Console 提供了許多實用功能,可協助監控網站的遷移情形,包括:
- Sitemap:提交先前為對應關係儲存的兩個 Sitemap
- 一開始,新網址 Sitemap 中沒有任何已建立索引的網頁,而舊網址 Sitemap 中的許多網頁都已建立索引
- 經過一段時間後,根據舊網址 Sitemap 建立索引的網頁數量將會逐漸歸零,新網址的索引數量則會相應增加
- 索引涵蓋範圍報表:這圖表會反映網站遷移的進展,顯示舊網站中已建立索引的網址數量逐漸下滑,而新網站中已建立索引的網址數量則會增加
- 定期查看這份報表,確認是否有任何非預期的檢索錯誤
- 搜尋查詢:隨著新網站有越來越多網頁編入索引並加入排名,搜尋查詢報告將會開始顯示新網站中網址獲得的搜尋曝光次數和點擊次數
- 隨時留意伺服器存取記錄和錯誤記錄,尤其要注意 Googlebot 的檢索記錄、任何非預期傳回 HTTP 錯誤狀態碼的網址,以及一般使用者的流量
- 如果已在網站上安裝任何網站分析軟體,或是內容管理系統 (CMS) 提供分析服務,也建議透過這些方式檢查流量,掌握流量從舊網站轉向新網站的進展。尤其是 Google Analytics (分析) 的即時報表功能,在網站遷移作業初期十分便利
- 一般應該會看到舊網站的流量逐漸減少,新網站的流量逐漸增加
網站遷移問題疑難排解 以下是遷移網站並變更網址時 (包括從 HTTP 遷移至 HTTPS) 常見的錯誤,這些錯誤可能會導致 Google 無法為新網站建立完整的索引。
noindex 或 robots.txt 封鎖
- 部分
noindex或robots.txt封鎖設定僅為遷移作業所需,記得在不需要時移除。 - 網站沒有
robots.txt檔案沒有關係,但務必在無法提供系統要求的robots.txt檔案時,盡速傳回正確的 404 錯誤碼 - 測試方法:
- 檢查 HTTPS 網站中的
robots.txt檔案,確認是否有任何需要修改的地方。 - 使用網址檢查工具檢查任何 Google 漏掉的新網站網頁
- 檢查 HTTPS 網站中的
重新導向有誤
- 檢查從舊網站到新網站的重新導向,常有使用者被導向至新網站上錯誤的網址 (不存在的網址)。
其他檢索錯誤
- 檢閱索引涵蓋範圍報表,確認新網站在遷移期間是否有其他錯誤數量增加的情況
負載量不足
- 遷移完成後,Google 檢索新網站的頻率會比平常更為繁重,因為網站會將流量從舊網站重新導向新網站,而舊網站的所有檢索也會重新導向新網站,除此之外,新的網站還必須處理任何其他檢索作業。請務必確認網站有足夠的負載量能處理增加的 Google 流量
未更新應用程式連結
- 如要在你的應用程式中開啟網頁,請先將應用程式連結更新為指向新網址
未更新 Sitemap
- 請確認已更新所有 Sitemap 並納入新網址
未更新資料螢光筆
- 如果曾經使用資料螢光筆對應舊網頁中的資料,就需要為新網站重新執行對應作業
假設你無法履行訂單或有許多產品缺貨
- 可以考慮暫時關閉線上商家
- 如果這是暫時性的情況,預計在接下來幾週或幾個月內就能恢復供貨,我們建議採取相關措施時,盡可能地維持網站在 Google 搜尋結果中的排名
下面說明如何安全地暫停線上業務
如果是暫時性的情況,且有再次營運線上業務的打算,建議繼續讓網站保持上線狀態,並且限制部分網站功能
- 對於網站的 Google 搜尋排名,這種做法造成的負面影響最小,所以才推薦
- 使用者依然可以找到你的產品、閱讀評論或新增願望清單以便日後購買
建議採取以下做法:
- 停用購物車功能:停用購物車功能是最簡單的方法,且不會影響網站在 Google 搜尋中的曝光率
- 顯示橫幅或彈出式視窗:在包括到達網頁的所有頁面上,顯示橫幅或彈出式視窗,協助使用者迅速瞭解網站現況
- 說明已知的所有異常延遲情形、送貨時間、取貨或送貨方式,讓使用者可以在抱有正確期望的情況下繼續瀏覽網站
- 如要避免橫幅或彈出式視窗中的內容顯示在搜尋結果的文字片段中,使用
data-nosnippetHTML 屬性
更新結構化資料:如果網站使用結構化資料 (例如 Product、Book 和 Event),請確定已將資訊調整到位- 例如正確顯示目前的產品供應情形,或是將活動變更為已取消狀態
- 如果有實體店面,請更新當地商家結構化資料,以便正確顯示目前的營業時間
- 檢查 Merchant Center 動態饋給:如果使用 Merchant Center,依照 availability [供應情形] 屬性最佳做法中的指示操作。
- 將更新內容告知 Google:如需 Google 重新檢索少量網頁 (例如首頁),用 Search Console。如果需要檢索的網頁數量較多 (例如所有產品頁面),用 Sitemap
警告:將網站從 Google 索引中完全移除是一項重大變更,需要相當長的時間才能復原
- 要恢復完全移除的網站,所需的時間並不固定,也沒有機制能加快恢復進度
- 因此,強烈建議採用限制網站功能的做法,不要將網站從 Google 搜尋中移除
你可以決定停用整個網站。這種極端措施應該僅使用非常短的時間 (最多幾天)
- 否則即使已正確進行設定,還是會在 Google 搜尋中對網站造成重大影響
以下是停用整個網站會帶來的負面影響,請務必納入考量:
- 客戶在網路上如果找不到你的商家,就無法得知業務狀態
- 客戶無法直接找到或查看商家資訊,也不能取得相關範例、評論、規格、維修指南和手冊等內容,這會影響客戶日後的購買意願
- 知識面板中的資訊可能會遺失,像是聯絡電話和網站標誌
- Search Console 將驗證失敗,會因此而無法透過 Google 搜尋找到你商家的相關資訊
- Search Console 中的匯總報表會因為索引中的網頁遭到捨棄而遺失資料
- 如果你的網站必須先重新編入索引,則在經過較長時間後,恢復作業的難度會大幅提升
- 此外,也無法確定恢復作業需要多久時間,以及之後網站在 Google 搜尋中顯示的情況是否相同
如果判斷自己確實有這樣的需求,可以採取以下這些做法:
- 如果需要緊急停用網站 1 到 2 天的時間,傳回含有
503HTTP 回應狀態碼的資訊錯誤網頁,不要傳回所有內容 - 如果需要停用網站的時間較長,請使用
200HTTP 狀態碼提供可建立索引的首頁做為預留位置,方便使用者在 Google 搜尋中查詢 - 如果還在思考要採取何種做法,但急需在 Google 搜尋中隱藏網站,可以先暫時從 Google 搜尋中移除網站
停用網站的最佳做法
- 注意,如果網頁傳回
503HTTP 回應狀態碼,Google 的系統就無法重新整理網站的標題、說明、中繼資料或結構化資料
如果你決定這麼做,請參考下列最佳做法:
- 勿在
robots.txt檔案中禁止所有檢索作業,可能會使系統從 Google 搜尋中移除網站的內容及網址 - 勿傳回
403、404、410HTTP 狀態碼,或使用noindex漫遊器中繼標記或x-robots-tagHTTP 標頭來封鎖網站。這會將網站的網址從 Google 搜尋中移除 - 勿在 Search Console 中使用臨時網站移除工具關閉網站。這麼做會導致使用者找不到你的網站,無法得知網站狀態
- 此外,你商家產品的潛在經銷商或關聯企業可能仍會繼續在 Google 搜尋中顯示。
- 勿使用
503HTTP 回應狀態碼封鎖你的 robots.txt 檔案 - 透過
robots.txt檔案繼續允許檢索網頁。請勿為robots.txt傳回503HTTP 回應狀態碼,以免封鎖所有網頁檢索作業 - 使用 curl 或類似工具在本機確認
503HTTP 回應狀態碼。例如:
curl -I -X GET "https://www.example.com/"
HTTP/1.1 503 Service Unavailable
Mime-Version: 1.0
Content-Type: text/html
(...)
為了將 503 錯誤網頁的伺服器端和用戶端負載降到最低,建議:
- 使用 retry-after HTTP 標頭設定最可能恢復網站的日期或持續時間
- 使用靜態 HTML。
- 盡量減少使用網頁外的資源,採用內嵌式 CSS 樣式表和 base-64 編碼的圖片
在錯誤網頁的內容中,讓使用者清楚瞭解後續步驟。這類資訊可能包括:
- 其他相關資訊的連結
- 預計的網站再次上線日期,或下次更新資訊的時間
- 客服人員的聯絡方式
如果網站會為不同語言、國家或地區的使用者提供不同內容,可以在 Google 搜尋為個別使用者呈現最適合的網站版本
多語言與多地區的差異為何?
- 多語言網站是指使用兩種以上語言提供內容的網站
- 舉例,假設加拿大公司的網站提供英文和法文兩種版本,Google 搜尋會嘗試尋找符合搜尋者語言的網頁版本
- 多地區網站是指明確以不同國家/地區的使用者做為目標的網站
- 舉例,假設某間產品製造商會出貨到美國與加拿大,Google 搜尋會嘗試為搜尋者找到適當的地區網頁
- 網站也可能同時具有多地區和多語言的屬性
針對不同的語言版本使用不同網址
- Google 建議為網頁的每種語言版本使用不同網址,不要使用 Cookie 或瀏覽器設定來調整網頁的內容語言
- 如果針對不同語言使用不同網址,運用 hreflang 註解協助 Google 搜尋結果連結至正確的網頁語言版本
如果偏好根據語言設定來動態變更內容或將使用者重新導向
- Google 不一定都能找到並檢索所有的變化版本
- 因為 Googlebot 檢索器通常源自美國,而且檢索器傳送 HTTP 要求時也不會在要求標頭中設定 Accept-Language
確保 Google 能明確判斷網頁使用的語言
- Google 會根據網頁顯示的內容來確定網頁使用何種語言,不會使用任何程式碼層級的語言資訊 (例如
lang屬性) 或網址進行判斷 - 只要確保每個網頁的內容和導覽介面都使用同一種語言,而且避免在網頁上提供對照翻譯,就能幫助 Google 正確判斷網頁語言
- 如果只翻譯網頁上的樣板文字,並以同一種語言顯示網頁的大部分內容 (這種情況在包含使用者自製內容的網頁中經常出現),就可能導致同樣的內容搭配不同的樣板語言重複出現在搜尋結果中,讓使用體驗大打折扣
- 可以使用
robots.txt防止搜尋引擎檢索網站上自動翻譯的網頁,畢竟自動翻譯有時詞不達義,可能會被視為垃圾內容
- 可以使用
如果擁有多個網頁版本:
- 建議新增其他語言版本網頁的超連結,以便使用者點選不同語言版本的網頁。
- 請避免自動判斷使用者所用語言並重新導向至該語言版本。這類重新導向動作可能會讓使用者 (以及搜尋引擎) 無法瀏覽你網站的所有版本
使用語言專屬的網址
- 可以在網址中使用本地化文字,也可以使用國際化網域名稱 (IDN)。但都請務必在網址中用
UTF-8編碼,並記得在連結時正確逸出網址。
可以指定網站的目標對象,專門將網站 (或其中某些部分) 提供給特定國家/地區中使用某種語言的使用者
這可以提高在目標國家/地區的網頁排名,但是目標使用者將無法看到其他語言或地區版本的結果
在 Google 上為網站指定地理區域:
- 網頁或網站層級:為網站或網頁使用地區的專屬網址
- 網頁層級:使用
hreflang或Sitemap向 Google 說明各個網頁適用的地區或語言 - 網站層級:如果網站使用一般頂層網域,例如
.com、.org或.eu,用「指定國際目標」報告設定網站的目標地區
如果網站有多個目標國家/地區,則請勿使用「指定國際目標」報告。舉例
- 如果某個網站會介紹蒙特婁當地餐廳,那麼將目標設定為加拿大使用者就很容易理解;但如果除了加拿大之外,法國、加拿大和馬利等地的法文使用者也是這個網站的目標讀者,那麼只以加拿大使用者為目標就不太合理。
- 請記得,指定地理區域不一定完全可靠,因此請務必設想當使用者瀏覽到「錯誤」的網站版本時,該如何處理。可行做法,就是在所有網頁上顯示每個版本的連結,讓使用者能夠自行選擇地區和/或語言
請勿根據 IP 分析調整提供的內容
- 分析 IP 位置資訊不僅困難、分析結果經常不可靠
- 更可能導致 Google 無法正確檢索網站的變化版本,大多數的檢索作業都是從美國執行
可以考慮採用方便為網站或其中部分內容指定不同地理區域的網址結構。下表介紹了各種可行選項:
國家/地區專屬網域: example.de
優點:
- 地理區域定位明確
- 伺服器位置沒有關聯
- 方便分隔網站
缺點:
- 昂貴 (可用性可能受限)
- 需要更多基礎架構
- ccTLD 規定嚴格 (有時候)
- 只能指定一個國家/地區
有 gTLD 的子網域: de.example.com
優點:
- 設定容易
- 可以使用 Search Console 的地理定位功能
- 允許不同的伺服器位置
- 方便分隔網站
缺點:
- 使用者可能無法從網址本身辨識地理定位 (無法辨別「de」代表語言還是國家/地區)
有 gTLD 的子目錄 example.com/de/
優點:
- 設定容易
- 可以使用 Search Console 的地理定位功能
- 減輕維護負擔 (同一部主機)
缺點:
- 使用者可能無法從網址本身辨識地理定位
- 單一伺服器位置
- 不容易分隔網站
網址參數: site.com?loc=de
- 不建議使用
缺點:
- 難以根據網址來區隔
- 使用者可能無法從網址本身辨識地理定位
- 無法在 Search Console 中進行地理定位
Google 會根據下列幾種指標來判斷網頁最適合的目標對象:
- 使用 Search Console「指定國際目標」報告設定的目標地區。假設
- 使用一般頂層網域 (gTLD),並採用其他國家/地區的主機供應商
- 如果要為網站指定地理區域,建議透過 Search Console 告知 Google 有意將網站關聯到哪個國家/地區
- 國家/地區代碼頂層網域名稱 (ccTLD)
- 這些名稱各自代表特定國家/地區,例如
.de代表德國、.cn代表中國 - 這類指標可讓使用者和搜尋引擎明確得知網站特別鎖定特定國家/地區的使用者
- 部分國家/地區會限制 ccTLD 的使用者資格,因此請務必先瞭解相關資訊
- Google 也會將部分虛名 ccTLD (例如
.tv和.me) 視為 gTLD,因為使用者和網站擁有者經常認為這些 ccTLD 比指定國家/地區用途更廣泛。如有需要,參閱 Google 的 gTLD 清單
- 這些名稱各自代表特定國家/地區,例如
- 標記、標頭或 Sitemap 中的 hreflang 陳述式
- 伺服器位置 (透過伺服器的 IP 位址判定)。伺服器的實際位置通常位於使用者附近,在某種程度上反映網站的目標對象
- 不過,由於某些網站用 CDN,或是在網路伺服器基礎架構較佳的國家/地區進行代管,因此伺服器的位置不一定具有指標性
- 其他指標。還可以從其他指標判斷網站可能的目標對象,包括:網頁上的當地住址和電話號碼、網站使用的語言種類和幣別、來自其他當地網站的連結,或者如果有商家檔案,該處也會有一些蛛絲馬跡可以用來當做判斷依據
Google「不會」採取的做法:
- Google 會從全球各地不同地點檢索網路,但不會為了找出某個網頁的所有變化版本,而改用其他地方的檢索器來檢索網站
- 務必採用本文列出的方式 (例如 hreflang 項目、ccTLD 或明確連結),將網站公開提供的任何地區版本或語言版本明白告知 Google
- Google 會忽略位置相關的中繼標記 (例如
geo.position或distribution) 或指定地理區域的 HTML 屬性。
如果多地區版本網站會在不同網址中以相同語言提供類似或重複的內容 (如在 example.de/ 和 example.com/de/ 上顯示相似的德文內容)
- 選出一個偏好版本,並加上
rel="canonical"元素和hreflang標記,以確保能為搜尋者提供正確語言或地區的網址
一般頂層網域(gTLD)
- gTLD 是未與特定地區建立關聯的網域。如果網站使用一般頂層網域 (例如
.com、.org),並且要指定特定地理位置的使用者,請使用上述其中一種方法明確設定國家/地區目標
如果網頁有多種語言或地區版本,向 Google 說明這些不同的變化版本。有助於 Google 搜尋根據語言或地區將使用者導向最適當的網頁版本
- 即使不採取任何行動,Google 也可能自行找到網頁的替代語言版本,但還是建議明確指明語言或區域的專屬網頁,一般來說這會是最好的做法
如果網站符合以下情形,就建議指明替代網頁:
- 如果只翻譯了網頁範本,例如導覽和頁尾,主要內容仍使用單一語言。對於大多數內容都是使用者自製內容的網頁來說,這是很普遍的情況,例如論壇網頁
- 如果網頁大部分內容都很類似,而且只使用了一種語言,但是少數內容有專屬的地區版本。舉例,網站上的英文網頁可能有不同版本,分別適用於美國、英國和愛爾蘭的使用者
- 如果網站內容已全部翻譯成多種語言。例如,每個網頁都分別提供了德文和英文版本
有三種方法可以向 Google 指明網頁有哪些語言/地區版本:
- HTML
- HTTP 標頭
- Sitemap
適用於所有方法的通用規範
- 每個語言版本都必須列出本身以及所有其他語言版本。
- 替代網址必須是包含傳輸方式 (http/https) 的完整網址,因此
- 使用
https://example.com/foo,「不要使用」//example.com/foo或/foo
- 使用
- 替代網址不一定要位於相同的網域。
- 如果為使用相同語言但來自不同地區的使用者指定了數個替代網址,建議同時提供一個總括性網址,以便服務使用該語言但沒有指定地理區域的使用者
- 舉例,如果分別為愛爾蘭 (
en-ie)、加拿大 (en-ca) 和澳洲 (en-au) 的英文使用者提供專屬網址,請另外提供一個通用的英文網頁 (en),供美國、英國及所有其他英語系地區的搜尋者使用 - 也可以選擇其中一個地區專屬網頁做為通用網頁
- 舉例,如果分別為愛爾蘭 (
- 如果兩個網頁並未同時指向對方,系統即會忽略標記。這是為了不讓其他網站的人任意建立標記並冒稱其網頁是你網頁的替代版本
- 如果很難針對每種語言維護一套完整的雙向連結,你可以省略某些網頁上的部分語言;Google 仍會處理指向對方的網頁
- 但務必在新擴充的語言頁面和原始/主要語言的頁面之間建立雙向連結
- 舉例來說,如果最初以法文建立網站,並將網址置於
.fr,在推出新的墨西哥文 (.mx) 和西班牙文 (.es) 網頁後,應該優先建立這兩者與主要.fr網頁間的雙向連結,而不是為這兩個同屬西班牙語系的新網頁 (.mx和.es) 建立彼此間的雙向連結。
- 請考慮為不相符的語言新增備用網頁,特別是在國家/地區或語言選取器或是有自動導向功能的首頁。請使用
x-default值- 如:
<link rel="alternate" href="https://example.com/" hreflang="x-default" />
- 如:
HTML 標記
- 在網頁標頭中新增
<link rel="alternate" hreflang="lang_code"... >元素,讓 Google 知道網頁的所有語言及地區變化版本 - 如果沒有 Sitemap 或無法指定網站的 HTTP 回應標頭,就可以採用這個方法
- 在網頁每個變化版本的
<head>加入一組<link>元素,其中每個連結代表一種網頁變化版本 - 該元素所在的變化版本也必須包括在內。換句話說,每個網頁版本中的這組連結都會是一樣的
每個 link 元素的語法如下:
lang_code此網頁版本鎖定的支援語言/地區代碼,或使用x-default來比對網頁上hreflang標記未明確列出的任何語言url_of_page此網頁專屬語言/地區版本的完整網址
<link rel="alternate" hreflang="lang_code" href="url_of_page" />範例
Example Widgets, Inc 的網站為美國、英國和德國地區的使用者提供服務。下列網址含有大量相同內容,但每個地區的版本都有部分差異:
https://en.example.com/page.html: 通用英文版首頁,其中包含美國至各國的運費資訊https://en-gb.example.com/page.html: 英國版首頁,以英鎊顯示價格https://en-us.example.com/page.html: 美國版首頁,以美元顯示價格https://de.example.com/page.html: 德文版首頁https://www.example.com/: 未指定任何目標語言或語言代碼的預設網頁,提供選取器讓使用者自行選擇語言和地區
Google 不會根據這些網址中的語言專屬子網域 (en、en-gb、en-us、de) 來判斷網頁的目標對象,你必須明確對應正確的目標對象。
在上述「包含地區變化版本的網址」表格中,所有列舉網頁的 <head> 部分都會包含以下這段 HTML 程式碼
- 這段程式碼會將美國、英國、一般英文使用者和德文使用者導向各自的本地化網頁
- 並將其餘使用者導向通用首頁。Google 搜尋會根據使用者的瀏覽器設定傳回適合的結果
<head>
<title>Widgets, Inc</title>
<link rel="alternate" hreflang="en-gb" href="https://en-gb.example.com/page.html" />
<link rel="alternate" hreflang="en-us" href="https://en-us.example.com/page.html" />
<link rel="alternate" hreflang="en" href="https://en.example.com/page.html" />
<link rel="alternate" hreflang="de" href="https://de.example.com/page.html" />
<link rel="alternate" hreflang="x-default" href="https://www.example.com/" />
</head>HTTP header
- 可以使用 GET 回應傳回 HTTP 標頭,向 Google 提供網頁的所有語言和地區變化版本。這種方法適用於非 HTML 檔案 (例如 PDF)
header 的格式如下:
<url_x>替代網頁的完整網址,對應至指派給相關 hreflang 屬性的語言代碼字串。網址前後須有<和>標記。例如:<https://www.google.com>lang_code_x此網頁版本指定的支援語言/地區代碼,或使用x-default來比對網頁上hreflang標記未明確列出的任何語言
Link: <url1>; rel="alternate"; hreflang="lang_code_1", <url2>; rel="alternate"; hreflang="lang_code_2", ...
必須為每個網頁版本指定一組 <url>、rel="alternate" 和 hreflang 的值,並用逗號分隔,如以下範例所示
假設有某個網站具備三種版本的 PDF 檔案,分別適用於英文使用者、瑞士地區的德文使用者,以及其他所有德文使用者,以下示範網站會傳回的 Link: header:
Link: <https://example.com/file.pdf>; rel="alternate"; hreflang="en",
<https://de-ch.example.com/file.pdf>; rel="alternate"; hreflang="de-ch",
<https://de.example.com/file.pdf>; rel="alternate"; hreflang="de"
Sitemap
- 做法是新增
<loc>元素來指定單一網址,並列出包含該網頁在內,每個語言/地區版本的<xhtml:link>子元素。因此,如果網頁有 3 種版本,Sitemap 就會有 3 個項目,而每個項目分別包含 3 個相同的子項目
Sitemap 規則:
- 請依照下列方式指定 xhtml 命名空間:
xmlns:xhtml="http://www.w3.org/1999/xhtml"
- 為每個網址單獨建立一個
<url>元素,做法和處理其他 Sitemap 時相同。 - 每個
<url>元素都必須包含指出網頁網址的<loc>子元素。 - 每個
<url>元素都必須包含子元素<xhtml:link rel="alternate" hreflang="supported_language-code">- 並在其中列出包括該網頁本身在內的每個替代版本。
<xhtml:link>子元素的順序並不重要,但建議採用同樣順序,方便檢查錯誤
- 並在其中列出包括該網頁本身在內的每個替代版本。
- 將 Sitemap 上傳至你網站上 Sitemap 適用的目錄中
範例 假設網站為全球英文使用者提供英文版網頁,並為全球德文使用者以及瑞士地區德文使用者提供兩種德文版網頁,且三者內容相同。那麼該網站的所有網址將如下所示:
www.example.com/english/page.html: 適用於英文使用者。www.example.de/deutsch/page.html: 適用於德文使用者。www.example.de/schweiz-deutsch/page.html: 適用於瑞士地區的德文使用者。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>https://www.example.com/english/page.html</loc>
<xhtml:link rel="alternate" hreflang="de" href="https://www.example.de/deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="de-ch" href="https://www.example.de/schweiz-deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="en" href="https://www.example.com/english/page.html" />
</url>
<url>
<loc>https://www.example.de/deutsch/page.html</loc>
<xhtml:link rel="alternate" hreflang="de" href="https://www.example.de/deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="de-ch" href="https://www.example.de/schweiz-deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="en" href="https://www.example.com/english/page.html" />
</url>
<url>
<loc>https://www.example.de/schweiz-deutsch/page.html</loc>
<xhtml:link rel="alternate" hreflang="de" href="https://www.example.de/deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="de-ch" href="https://www.example.com/schweiz-deutsch/page.html" />
<xhtml:link rel="alternate" hreflang="en" href="https://www.example.com/english/page.html" />
</url>
</urlset>支援的語言/地區代碼
- hreflang 屬性的值能夠識別替代網址的語言代碼 (採 ISO 639-1 格式)
- 也能識別地區代碼 (採 ISO 3166-1 Alpha 2 格式),如果僅指定一個代碼,Google 會假設該代碼為語言代碼。此外,語言不一定要與地區相對應
例如:
de:德文內容,不限地區en-GB:對英國使用者顯示的英文內容de-ES:對西班牙使用者顯示的德文內容
警告:不要單獨指定國家/地區代碼。Google 不會根據國家/地區代碼自動推測出網頁的語言
- 如果要簡化標籤作業,可以自行指定語言代碼。例如:
be:白俄羅斯文,與地理區域無關 (雖然be也是比利時的國家/地區代碼,但是 Google 不會將這個代碼解讀為比利時)
如要將網頁限定為特定地理區域,請在語言後方加上國家/地區代碼。例如:
nl-be:適用於比利時地區使用者的荷蘭文網頁fr-be:適用於比利時地區使用者的法文網頁
對於同種語言的不同文字版本,系統會根據國家/地區判斷正確的文字版本。例如
- 對台灣的使用者使用
zh-TW時,系統會自動判斷相應的語言文字版本 - 也可以使用 ISO 15924 格式明確指定文字版本,如下所示:
zh-Hant:中文 (繁體)zh-Hans:中文 (簡體)
- 如同其他語言代碼,也可以視需要指定地區。舉例,可以
zh-Hans-US為美國境內的使用者指定中文 (簡體)
針對不相符的語言使用 x-default 值
- 如果沒有其他語言/地區符合使用者的瀏覽器設定,保留
x-default值就會派上用場 - 建議用這個選用值,可以在沒有相符語言時控制網頁
- 無須為
x-default值指定語言代碼;網頁鎖定的是瀏覽器設定語言與你網站不同的使用者,與網頁本身的語言無關
<link rel="alternate" href="https://example.com/en-gb" hreflang="en-gb" />
<link rel="alternate" href="https://example.com/en-us" hreflang="en-us" />
<link rel="alternate" href="https://example.com/en-au" hreflang="en-au" />
<link rel="alternate" href="https://example.com/country-selector" hreflang="x-default" />「標題連結」指的是 Google 搜尋和其他資源 (例如 Google 新聞) 中搜尋結果的標題,能夠連結到搜尋結果代表的網頁
- Google 會參考不同來源的資訊,自動判斷標題連結
- 不過可以按照下面做法,指明偏好的標題連結

影響標題連結的最佳做法
- 確認已使用
<title>元素為網站上的所有網頁指定標題 - 在
<title>元素中使用簡明扼要的文字,避免籠統。例如,不要將首頁標題稱為「首頁」,或特定使用者的個人資料網頁標題稱為「個人資料」- 不宜過於冗長,以免無法在搜尋結果中完整顯示
- 避免在標題中濫填關鍵字。雖然在
<title>中提供具有描述性的字詞十分實用,但請勿重複使用相同的字詞或詞組。「Foobar, foo bar, foobars, foo bars」之類的標題文字對於使用者毫無助益- 且這種標題中濫填關鍵字的情形可能會讓 Google 和其他使用者認為這筆結果不可靠
- 避免在
<title>中使用重複或公式化的文字,務必為網站上各個網頁的<title>撰寫獨特且具有描述性的文字- 例如,將商務網站上每頁的標題都稱為「便宜商品大拍賣」,使用者就很難區分各網頁間有什麼不同
- 也不建議使用內容大同小異的冗長文字,這會讓標題過於「公式化」
- 舉例,如果將所有
<title>都設為「<樂團名稱> - 查看影片、歌詞、海報、專輯、評論和演唱會資訊」,導致包含許多不具說明效果的文字。
- 舉例,如果將所有
- 其中一種方法是以動態方式更新
<title>,使其更能充分反映網頁的實際內容,例如只在含有影片或歌詞的特定網頁上,才加入「影片」、「歌詞」等字詞- 另一種方法則是精簡
<title>中的文字,只使用樂團的實際名稱,然後搭配中繼說明來描述網頁內容
- 另一種方法則是精簡
- 以簡明扼要的方式在標題中宣傳品牌。網站首頁的
<title>相當適合用來提供網站的相關資訊,例如:<title>ExampleSocialSite 是結識各方好友的交流天地</title>- 但如果每個網頁都顯示這段文字,網站的可讀性就會降低,重複的感覺也會特別明顯。請考慮只在每個
<title>文字的開頭或結尾加入網站名稱,並以連字號、冒號或直立線做為分隔符號 <title>ExampleSocialSite:註冊新帳戶。</title>
- 明確指出哪些文字是網頁的主要標題。Google 會檢視建立標題連結時的各種不同來源
- 包括主要的視覺標題、標題元素,以及其他大型且顯眼的文字,如果多則廣告標題的視覺重量和醒目性都相同,就會讓使用者感到困惑
- 建議確保主要標題明顯與網頁上其他文字有所區別,並清楚出現在網頁上最顯眼的位置 (例如使用較大的字型、把標題文字放入網頁上第一個可見的
<h1>等)。
- 禁止搜尋引擎檢索網頁時請格外謹慎。
robots.txt可有效阻止 Google 檢索網頁,但無法完全禁止 Google 為這些網頁建立索引- 舉例,只要能從其他人的網站連至你的網頁,Google 就可為網頁建立索引;但如果無法存取網頁內容,就會以其他網站的錨定文字等站外內容做為標題連結。如要禁止網址編入索引,可以使用
noindex指令。
- 舉例,只要能從其他人的網站連至你的網頁,Google 就可為網頁建立索引;但如果無法存取網頁內容,就會以其他網站的錨定文字等站外內容做為標題連結。如要禁止網址編入索引,可以使用
- 使用與網頁主要內容相同的指令碼和語言。 Google 會嘗試顯示與網頁主要指令碼和語言相符的標題連結。 如果 Google 判定
<title>與網頁主要內容的指令碼或語言不符,可能就會選擇不同的文字做為標題連結
Google 搜尋會使用下列來源自動判斷標題連結:
<title>中的內容- 網頁上顯示的主要標題文字
- 標題元素,例如
<h1>元素
- 標題元素,例如
- 其他透過調整樣式而變得更大而顯眼的內容
- 網頁中的其他文字
- 網頁上的錨定文字
- 指向該網頁的連結中使用的文字
提醒: Google 必須重新檢索並重新處理網頁,才會注意到這些來源的更新內容,這個過程可能需要幾天到幾週的時間。如果內容有所變更,可以要求 Google 重新檢索網頁
「摘要」指的是在 Google 搜尋和其他資源 (例如 Google 新聞) 中,針對搜尋結果顯示的說明或摘要
- Google 會多方參考不同的資訊,自動判斷適當的摘要,來源包括每個網頁中繼標記的說明資訊
- 此外,也會使用網頁上找到的資訊,或是根據標記和網頁內容來建立複合式搜尋結果

網頁摘要的建立方式
- 網頁摘要是系統依網頁內容自動建立,以供使用者預覽
- Google 搜尋可能會根據不同筆搜尋,為同一個網頁顯示不同摘要。
網站擁有者可透過兩種主要方式建議我們使用哪些內容建立網頁摘要:
- 複合式搜尋結果
- 在網站中加入評論、食譜、業務或活動等結構化資料,協助 Google 瞭解網頁內容
- 中繼說明標記:Google 有時候會使用
<meta>標記內容來產生摘要
禁止顯示摘要或調整摘要長度的方式
- 你可以選擇不讓 Google 在搜尋結果中建立及顯示網站的摘要,用
nosnippet中繼標記 - 或是可以告訴 Google 希望的摘要長度上限。使用
max-snippet:[number]中繼標記 - 也可以使用
data-nosnippet屬性,禁止 Google 在摘要中顯示網頁的特定內容
meta description 的最佳做法
- 確認網站上的所有網頁皆具備中繼說明
- 為網站上的各個網頁建立獨一無二的說明
- 如果每個網頁都使用相同或類似的說明,當多個網頁同時出現在搜尋結果中時,這些說明並沒有實質的用途
- 盡可能建立正確的網頁描述說明,在主要首頁或其他彙整網頁上使用網站層級說明,並在其餘的網頁上使用網頁層級說明
- 在說明中加入與內容相關的資訊。中繼說明不必是完整的句子,也可以包含網頁的相關資訊
- 舉例,新聞和網誌文章可列出作者、發布日期或署名資訊
- 這可以讓潛在訪客看到不一定會出現在網頁摘要中、但與搜尋標的極其相關的資訊
- 同樣,商品網頁中關於價格、年齡或製造商等重要資訊可能四散在網頁各處
- 但利用良好的中繼說明就能將這些重要資訊整合在一起
例如,下列中繼說明便提供了一本書的詳細資訊。
<meta name="description" content="Written by A.N. Author,
Illustrated by V. Gogh, Price: $17.99,
Length: 784 pages">在此範例中,所有資訊都清楚標示並分隔開來。
利用程式產生說明
- 大型的資料庫型網站而言 (例如商品資訊整合目錄),透過程式為後者產生說明是比較建議的適當做法
- 特定網頁資料則非常適合藉由程式產生
- 記住,由一長串關鍵字所組成的中繼說明並不能讓使用者清楚瞭解網頁內容,也較不可能取代一般的網頁摘要
使用優質的說明
- 最後,確認說明能夠明確描述網頁的內容。由於中繼說明不會顯示在使用者看到的網頁上
- 良好的說明會顯示在 Google 的搜尋結果中,極有助於改善搜尋流量的質與量
Google 提供多種有趣的搜尋外觀元素,可套用至自己的網頁搜尋結果:
一般大致有以下幾種類別:
「基本藍色連結(plain blue link)」一詞並非官方用語,卻常用於非官方內容 (這種搜尋結果其實沒有官方名稱)

這種搜尋結果含有許多常見的元件:
- 標題連結:Google 搜尋中網頁搜尋結果的標題,Google 會根據多項特徵判定合適的網頁標題連結,可以在
<title>中指明 - 網址:網頁的網址。建議一併指定網頁的導覽標記
- 摘要:Google 搜尋網頁搜尋結果中的說明或摘要
可以透過多種強化項目讓基本或複合式搜尋結果看起來更豐富,包括
大部分強化項目都需要結構化資料才能用
搜尋結果中的導覽標記

搜尋結果中的網站連結搜尋框

搜尋結果中的標誌
「複合式搜尋結果」是含有圖像元素的搜尋結果
- 包括評論星等、縮圖或某種視覺強化項目
- 複合式搜尋結果可在搜尋結果中獨立顯示
某些類型的複合式搜尋結果可以包含在搜尋結果的輪轉介面中
複合式搜尋結果的種類繁多
- 大多都與搜尋結果顯示的特定內容類型 (書籍、電影、文章等等) 有所連結
- 實際外觀會隨著 Google 針對搜尋結果類型修正最佳版面配置和行為而改變
- 在使用體驗上更生動的複合式搜尋結果稱為多元化搜尋結果,具備各項進階互動功能
讓 Google 在檢索網頁時進行處理。一旦你針對網頁上的功能提供結構化資料,當特定功能或資訊能為使用者提供更好的搜尋體驗時
- 該功能或資訊就會顯示在 Google 搜尋結果、Google 助理、Google 地圖或其他 Google 產品中
結構化資料不只可用於指定搜尋功能
- 也能協助 Google 執行多項操作,包括:瞭解網站上的資訊並以嶄新而有趣的方式 (例如 Google 助理的動作) 呈現
- 提供更符合需求的搜尋結果 (例如讓使用者搜尋食材包含雞肉或熱量低於 500 大卡的食譜);或將資訊儲存在知識面板中
複合式搜尋結果類型的完整清單
Google 知識面板
- 來自單一或多個網頁的一組資訊
- 會在複合式搜尋結果中以帶有圖片、文字和連結的形式顯示
從外觀上並不容易分辨複合式資訊卡和知識面板搜尋結果
- 知識面板搜尋結果可包含識別資訊 (例如標誌、偏好的網站名稱)
- 也可能利用 schema.org 元素、甚至是本文未提及的元素來擷取資料
瞭解如何管理知識面板資料:
當使用者透過 Google 搜尋提出問題時,系統可能會在搜尋結果網頁頂端以特殊的「精選摘要」區塊顯示取自網站的搜尋結果

進一步瞭解精選摘要
OneBox 會在搜尋結果中顯示內嵌答案或工具
- 如當地時間 OneBox 或翻譯 OneBox
- 使用者無法將自訂的 OneBox 新增至搜尋結果
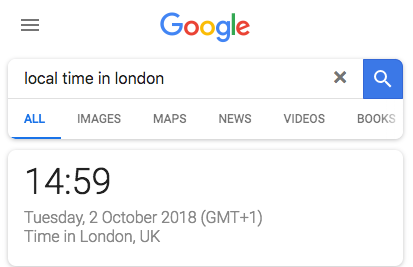
在 Android 的特殊檢視面板上,網頁可能會出現在捲動式的搜尋結果清單
- 每張搜尋結果資訊卡會列出單頁網頁摘要

進一步瞭解探索
為什麼要為網頁指定搜尋功能?
- 可提供對使用者更有吸引力的搜尋結果,也鼓勵使用者更常與網站互動
以下一些個案研究:
- 爛番茄將搜尋功能新增至 100,000 個不重複網頁,發現相較於不含結構化資料的網頁,透過結構化資料強化的網頁在點閱率上高出 25%。
- Food Network 將 80% 的網頁轉換為啟用搜尋功能,發現造訪次數提升 35%。
- 樂天發現,啟用搜尋功能的網頁在使用者瀏覽時間方面增加 1.5 倍
- 雀巢發現以複合式搜尋結果形式顯示的網頁,其點閱率比未啟用複合式搜尋結果的網頁高出 82%
更多詳細 case study:
哪些功能最適合我的網站?
- 下表會根據網站的內容列出可供使用的功能
- 其中某些功能可涵蓋整個網站,某些則是以單一網頁為套用單位
- 各項功能的詳細資料,請參閱資料庫頁面
文章/網誌 |
文章、AMP、事實查核、How-to、支援朗讀服務項目、訂閱和付費牆內容 |
書籍 |
書籍、評論 |
教育 |
課程、輪轉介面、資料集 |
娛樂/媒體/新聞 |
輪轉介面、活動、事實查核、直播、電影、評論、訂閱和付費牆內容、影片(和影片即時串流)、Podcast(另參閱影片最佳做法) |
商家與公司行號 |
企業或公司的識別資訊、當地商家(適用於有實體商店的企業)、熱門地點清單 |
活動 |
活動、影片、影片即時串流 |
食譜 |
食譜、輪轉介面、AMP、評論 |
產品 |
產品類型、評論、軟體應用程式、FAQ |
科學或研究機構 |
資料集 |
徵才相關內容 |
徵人啟事、職業、雇主累計評分 |
不限類型 |
導覽標記 網站連結搜尋框(適用於大型網站) Assistant:與 Google 助理整合的語音介面,可讓使用者透過語音互動。 要加入圖片,參閱圖片最佳做法 參閱 AMP 和行動裝置友善最佳做法,瞭解哪些做法和功能可讓網站適合 mobile。 使用問與答標記可指出網頁上有問答資訊 如果提供了需要訂閱才能存取的網站內容,或使用者需要註冊才能存取的內容建立索引,參閱這篇文章,進一步瞭解訂閱和付費牆內容的相關標記 |
Google 提供多種方式,讓你在搜尋結果中向使用者顯示重要的商家詳細資料
- 企業可透過公司識別資訊向 Google 標明特定資料,包括偏好的網站名稱、標誌以及其他公司資訊
- 也可以在知識面板中聲明企業或個人的資料擁有權並加以管理
- Google 也建議擁有實體商店的企業在識別資訊中納入實體商店資訊
- 此外,也可以聲明商家檔案的擁有權,以便讓當地商家資訊顯示在 Google 地圖以及 Google 搜尋的知識面板資訊卡中
- 注意:系統會將商家檔案資訊視為有公信力的資料
注意:
- 透過結構化資料來啟用強化搜尋功能,「並不保證」網頁一定透過指定的功能顯示
- 畢竟結構化資料只是用來讓網站「得以」使用某功能而已
- Google 致力於向使用者顯示最適當且最具吸引力的搜尋結果,但你的功能有可能在特定時間點並不適合某位使用者
實作搜尋功能的步驟如下:
- 看看上面的表格選擇適合網站的功能
- 其中部分功能適用於所有內容類型 (例如偏好的網站名稱可用於所有類型的網頁)
- 有些複合式搜尋結果則限制特定內容類型使用 (例如食譜複合式資訊卡僅適用於食譜)
- 閱讀各項外觀元素的相關詳細資訊,藉此確認是否適合使用
- 按照說明文件所述來實作功能
- 使用複合式搜尋結果測試工具驗證所有結構化資料,確保資料有效
- 務必確認網頁內容和使用結構化資料的方式皆符合結構化資料品質指南的規定,不符合規定將無法使用結構化資料
- 利用複合式搜尋結果狀態報告查看 Google 是否已找到結構化資料並可進行處理
- 定期透過
複合式搜尋結果狀態報告檢查錯誤。當變更網站範本或意外事件發生時,原本有效的結構化資料也可能突然出錯 - 針對啟用的搜尋元素監控點擊次數和曝光次數
Google I/O 大會上關於結構化資料的說明: Stand Out on Google Search Using Structured Data and Search Analytics (Google I/O '17)
- 可以透過成效報表直接追蹤部分搜尋功能的使用者流量
- 在報告中選取 [搜尋外觀] 即可進行監控
- 如果看不到特定功能的篩選器,則表示:
- Google 尚未的網站上偵測到該功能的任何例項
- 目前並非所有功能類型皆開放追蹤。如需瞭解可在 Search Console 追蹤的功能,請參閱說明文件
針對「啟用搜尋功能」和「未啟用搜尋功能」的網頁比較成效,以便確認是否值得採用
- 最好的做法就是在網站上針對幾個網頁執行功能啟用前後的測試
不過,由於單一網頁的瀏覽量會基於各種原因而有所不同,這項測試在執行上可能會有些困難
- 在網站上挑選一些已在 Search Console 中有數個月資料但尚未啟用任何結構化資料的網頁
- 務必選擇不受一年中特定時間影響且內容不具時效性的網頁
- 建議選用不會大幅變動但仍足以吸引使用者瀏覽的網頁,以便產生有意義的資料
- 將結構化資料或其他功能新增至網頁
- 然後在網頁上使用網址檢查工具,確認網頁程式碼有效且 Google 已找到新增的功能
- 在成效報表中累計數個月的成效資料,並依網址篩選資料內容以便比較網頁成效
- 精選摘要是一個特殊區塊
- 在呈現一般搜尋結果資訊時,會先顯示網頁的說明摘要,然後才顯示標題

如何選擇不採用精選摘要?兩種做法讓網頁不顯示精選摘要:
- 同時封鎖精選摘要和一般搜尋摘要
- 僅封鎖精選摘要
同時封鎖精選摘要和一般搜尋摘要
- 加上 nosnippet 標記的網頁不會顯示任何摘要,包括精選摘要和一般摘要
加上 data-nosnippet 標記的文字不會顯示在精選摘要或一般摘要
- 如果同時出現
nosnippet和data-nosnippet,系統會優先遵從 nosnippet 標記,也就是不顯示該網頁的任何摘要
- 如果同時出現
僅封鎖精選摘要
- 如果要保留一般格式的搜尋結果摘要,但不想顯示精選摘要,可利用 max-snippet 標記設定較短的摘要長度
- 因為,如果文字過短,系統根本無法產生實用的精選摘要,自然也就不會顯示精選摘要
- 如果仍持續顯示精選摘要,就進一步調降這個標記值。一般而言,max-snippet 標記設定的長度越短,網頁就越不容易顯示為精選摘要
- 對於網頁如何才能顯示為精選摘要,Google 並未規定確切的標記長度下限
- 因為長度下限會根據許多因素而改變,包括但不限於摘要中的資訊、語言和平台 (例如行動裝置、應用程式或電腦)
採用較低的 max-snippet 設定值無法保證網頁一定不會顯示為精選摘要
- 要絕對有效的解決方案,用
nosnippet
如何為網頁加上精選摘要標記?
- Google 並未提供這種功能
- Google 系統會根據使用者的搜尋要求來判斷網頁是否適合呈現為精選摘要,如果適合,就會自動顯示
使用者按一下精選摘要後會發生什麼事?
- 系統會將使用者直接引導至你網頁上精選摘要文字所顯示的段落
- 系統會自動捲動至精選摘要文字的所在位置
- 你無須在網站程式碼中附加任何額外標記
- 如果瀏覽器不支援所需基礎技術,或者系統無法確切判斷該將點擊引導至網頁中的哪個位置,那麼使用者在按下精選摘要後,便會前往來源網頁的頂端
- 「網站連結」是指統整到單一網頁搜尋結果底下的同網域連結
- 系統會分析網站的連結結構,找出捷徑,讓使用者快速找到想要的資訊
- 主要搜尋結果 2. 網站連結

只有在 Google 認為結果對使用者很實用時,才會顯示網站連結
- 如果網站架構不允許 Google 的演算法尋找優良的網站連結,或是 Google 認為網站連結和使用者的查詢不相關,則不會顯示網站連結
網站連結是由系統自動產生,有一些最佳做法可以協助提升網站連結的品質
- 務必在網頁標題和標題中使用言簡意賅且具相關性的文字來傳達資訊
- 建立使用者能夠輕鬆瀏覽的合理網站架構,並確實在重要網頁和其他相關網頁之間建立連結
- 確保內部連結的錨定文字簡明扼要,與指向的網頁具有關聯性
- 避免內容重複
如果 Google 可以判別網頁或影片的發布日期和更新日期,而且認定資訊對使用者有所助益,就會在結果中顯示這項資訊
- 可以主動提供這項資訊,協助 Google 判別發布日期和上次更新日期
由於每項因素都有可能導致問題發生
- 因此 Google 不會只根據單一因素判定日期
- 系統在判定網頁是何時發布或經過大幅更新時,一定會同時參考多項因素來決定最佳判斷結果

如要提供日期資訊給 Google,按照下列步驟:
- 遵循指南規範(在下面)
- 在網站上新增並醒目顯示使用者能看到的日期。為日期加上適當的文字標籤,例如「發布」或「上次更新」
- 以下列舉一些發布及更新日期:
- 張貼日期:2019 年 2 月 4 日
- 發布日期:2019 年 2 月 4 日
- 上次更新日期:2018 年 2 月 14 日
- 更新時間:2019 年 2 月 14 日晚上 8 點 (美國東部標準時間)
- 以下列舉一些發布及更新日期:
- 使用結構化資料指定日期
- 建議新增 CreativeWork 的子類型 (如 Article、BlogPosting,或 VideoObject)
- 指定
datePublished和/或dateModified欄位 - 遵循 Google 的結構化資料指南,讓檢索器解讀文章日期資訊
<html>
<head>
<title>Analyzing Google Search traffic drops</title>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": "Analyzing Google Search traffic drops",
"datePublished": "2021-07-20T08:00:00+08:00",
"dateModified": "2021-07-20T09:20:00+08:00"
}
</script>
</head>
<body>
<p>
Posted Tuesday, July 20, 2021
</p>
<p>
Suppose you open Search Console and find out that your Google Search traffic dropped. What should you do?
</p>
</body>
</html>日期資訊指南規範
- (無論是公開顯示日期或透過結構化資料提供日期,Google 都無法保證一定會顯示日期資訊,但遵循規範將有助於演算法順利找到及處理這些資訊)
- 日期為必要資訊,時間則為選填資訊: 無論採用可向使用者顯示的格式或結構化資料,時間部分都是選填資訊
- 如果選擇指定時間,請提供正確時區: 並視情況考量日光節約時間的影響
- 透過兩種方式提供的日期和時間資訊須保持一致:
- 比對可向使用者顯示的日期和相關結構化資料中的日期,確認兩者的值保持一致
- 如果選擇提供時間和時區,也一併確認
- 即使已在結構化資料中提供時間和時區資訊,也不一定要在可向使用者顯示的資料中列出時間和時區
- 勿指定未來的日期,也不要指定網頁中所述活動的日期: 日期資訊必須說明網頁的發布日期或更新日期,而非網頁中報導或活動的日期
- 如有需要,可以在網頁中加入活動標記來描述網頁中列出的活動
- 盡量避免網頁上出現其他日期: 如果按照最佳做法操作後,卻發現系統選用了不正確的日期,請考慮移除網頁上顯示的部分日期或其他所有日期
- 想讓網頁顯示在
Google 新聞搜尋結果中,請遵循這些額外規範
- 如果網站設有網站小圖示,該圖示可以顯示在網站的 Google 搜尋結果中

導入作業
- 遵循規範建立網站小圖示
- 在首頁 header 中加入
<link> - Google 每次檢索網站的首頁時,都會尋找並更新網站小圖示。如果想在變更網站小圖示後通知 Google,可以要求 Google 為網站首頁建立索引
- 這類更新可能需要幾天以上的時間才會顯示在搜尋結果中
<link rel="shortcut icon" href="/path/to/favicon.ico">rel: 將 rel 屬性設為下列其中一個字串:
shortcut icon,icon,apple-touch-icon,apple-touch-icon-precomposed
href: 網址可以是相對路徑 (/smile.ico) 或絕對路徑 (https://example.com/smile.ico),但必須與首頁位於同一網域
規範
- 必須遵守以下規範,才有資格在網站的搜尋結果旁顯示網站小圖示
- 每個網站只能有一個網站小圖示
- 網站的判斷標準以主機名稱為準。舉例
https://www.example.com/和https://code.example.com/是兩個不同的網站,可以有不同的圖示https://www.example.com/sub-site則是網站的子目錄,而你只能為https://www.example.com/設定一個網站小圖示,且該圖示會套用到整個網站及其子目錄
- 網站的判斷標準以主機名稱為準。舉例
- 網站小圖示檔案和首頁都必須可讓 Google 檢索: 也就是不得禁止 Google 存取
- 為方便使用者快速辨識網站,網站小圖示應以視覺化的方式呈現網站的品牌形象
- 網站小圖示必須是正方形:
- 且邊長為 48 像素的倍數,例如
48 x 48、96 x 96、144 x 144等 - SVG 則不限定尺寸。可以使用任何有效的網站小圖示格式
- 為了讓圖片能顯示在搜尋結果中,Google 會將圖片調整為 16 x 16,因此務必確認圖片在這個解析度下仍清晰可見
- 注意:勿直接提供 16 x 16 像素的網站小圖示
- 且邊長為 48 像素的倍數,例如
- 網站小圖示必須使用穩定的網址,切勿經常變更
- 如果 Google 認為圖示不妥當,包括含有色情內容或帶有仇恨意涵的符號 (例如納粹標誌),就不會顯示在搜尋結果中
- 如果在網站小圖示中發現這類圖像,Google 會改為顯示預設圖示
通常,使用者會使用各自的當地語言進行查詢,但搜尋結果呈現的內容不一定會使用相同語言
- 為了弭平語言落差,Google 有時會將搜尋結果的標題連結和摘要翻譯成搜尋查詢使用的語言
- 翻譯搜尋結果是 Google 搜尋的一項功能,可讓使用者以自己的語言查看其他語言的搜尋結果,協助發布者觸及更多使用者
- 目前,這項功能可以將英文搜尋結果翻譯成印尼文、北印度文、卡納達文、馬拉雅拉姆文、泰米爾文、泰盧固文
如果使用者點選翻譯後的標題連結
- 後續與該網頁進行的所有互動都會透過 Google 翻譯進行
- 系統也會自動翻譯使用者接續點選的任何連結網頁
- 使用者也可以展開搜尋結果,查看原本的標題連結和摘要,並以原始語言存取整個網頁
如果你是廣告聯播網供應商,可能需要採取其他操作,確保當使用者點選翻譯搜尋結果後,廣告聯播網的內容仍能正確顯示
- 進一步瞭解如何讓廣告聯播網能使用 Google 搜尋的翻譯相關功能,參閱這篇文章
透過 Search Console 監控成效
啟用或停用翻譯搜尋結果
- 這功能適用於所有網頁和搜尋結果,會依據使用者使用的語言自行啟用,你不必採取任何行動
- 翻譯搜尋結果功能就和 Google 搜尋中的其他翻譯相關功能一樣,如要選擇停用 Google 搜尋中的所有翻譯功能,請使用
notranslate指令
<meta name="robots" content="notranslate">
<meta name="googlebot" content="notranslate">HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
(…)
X-Robots-Tag: notranslate
(…)
Google 搜尋提供多種翻譯相關功能,如果你是廣告聯播網供應商,在遇到翻譯網頁無法正常顯示廣告的情形時,按照本指南,以確保廣告能正確顯示
Google 的做法
- 只要使用者點選經過翻譯的搜尋結果,Google 就會從發布者的網站上擷取該網頁,並重新編寫來源網址
將 Google 翻譯網址轉換為原始網址
如果廣告聯播網需要使用發布者的來源網址,就必須轉換 Google 翻譯後的網址,以確保廣告能正常顯示。請按照下列步驟,解碼發布者的主機名稱:
- 移除後置字元
.translate.goog,擷取主機名稱中的網域前置字元 - 以
,(半形逗號) 字元隔開_x_tr_enc參數,並儲存為encoding_list - 在網域前置字元前方加上
_x_tr_hp參數的值 (如果有的話) - 如果
encoding_list中包含1,且輸出內容的開頭為1-,從步驟2的輸出內容中移除1-前置字元 - 如果
encoding_list中包含0,且輸出內容的開頭為0-,從步驟3的輸出內容中移除0-前置字元- 如果移除了前置字元,將
is_idn設為true;否則,設為false
- 如果移除了前置字元,將
- 將
/\b-\b/(規則運算式) 替換為.(點) 字元 - 將
--(雙連字號) 字元替換成-(連字號) 字元 - 如果將
is_idn設為true,請加入國際化域名編碼前置字元xn-- - (選用) 轉換為萬國碼 (Unicode)
JavaScript 範例:從 Google 翻譯網址中解碼出主機名稱
function decodeHostname(proxyUrl) {
const parsedProxyUrl = new URL(proxyUrl);
const fullHost = parsedProxyUrl.hostname;
// 1. Extract the domain prefix from the hostname, by removing the ".translate.goog" suffix
let domainPrefix = fullHost.substring(0, fullHost.indexOf('.'));
// 2. Split _x_tr_enc parameter by "," (comma), save as encodingList
const encodingList = parsedProxyUrl.searchParams.has('_x_tr_enc')
? parsedProxyUrl.searchParams.get('_x_tr_enc').split(',')
: [];
// 3. Prepend value of _x_tr_hp parameter to the domain prefix, if it exists
if (parsedProxyUrl.searchParams.has('_x_tr_hp')) {
domainPrefix = parsedProxyUrl.searchParams.get('_x_tr_hp') + domainPrefix;
}
// 4. Remove '1-' prefix from the output of step 2 if encodingList contains
// '1' and the output begins with '1-'.
if (encodingList.includes('1') && domainPrefix.startsWith('1-')) {
domainPrefix = domainPrefix.substring(2);
}
// 5. Remove '0-' prefix from the output of step 3 if encodingList contains
// '0' and the output begins with '0-'.
// Set isIdn to true if removed, false otherwise.
let isIdn = false;
if (encodingList.includes('0') && domainPrefix.startsWith('0-')) {
isIdn = true;
domainPrefix = domainPrefix.substring(2);
}
// 6. Replace /\b-\b/ (regex) with '.' (dot) character.
// 7. Replace '--' (double hyphen) with '-' (hyphen).
let decodedSegment = domainPrefix
.replaceAll(/\b-\b/g, '.')
.replaceAll('--', '-');
// 8. If isIdn equals true, add the punycode prefix 'xn--'.
if (isIdn) {
decodedSegment = 'xn--' + decodedSegment;
}
return decodedSegment;
}
// decodeHostname("https://hbr-org.translate.goog/sponsored/2022/02/why-c-suite-leaders-get-passed-over-for-the-ceo-role?_x_tr_sl=en&_x_tr_tl=zh-TW&_x_tr_hl=zh-TW&_x_tr_pto=sc")
// // 'hbr.org'重建網址
- 使用原始的網頁網址,以經過解碼的主機名稱取代原本的主機名稱。
- 移除所有
_x_tr_*參數
測試程式碼
- Google 提供 test case ,為程式碼建立單元測試。對任一 proxyUrl 來說,decodeHostname 必須與預期的值相同
- 只能用於測試主機名稱解碼作業,請務必確保網址的路徑、片段和原始參數維持不變
- https://developers.google.com/search/docs/advanced/appearance/ad-network-and-translation#test-your-code
Structured data for web developers | Search Central Lightning Talks
結構化資料是一種標準化格式
- 是提供網頁相關資訊並將網頁內容分類
- 如在食譜網頁上,結構化資料就能分類材料、烹飪時間和溫度、熱量等內容。
JSON-LD 結構化資料,介紹食譜的名稱、作者以及其他詳細資料:
<html>
<head>
<title>Party Coffee Cake</title>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Party Coffee Cake",
"author": {
"@type": "Person",
"name": "Mary Stone"
},
"datePublished": "2018-03-10",
"description": "This coffee cake is awesome and perfect for parties.",
"prepTime": "PT20M"
}
</script>
</head>
<body>
<h2>Party coffee cake recipe</h2>
<p>
<i>by Mary Stone, 2018-03-10</i>
</p>
<p>
This coffee cake is awesome and perfect for parties.
</p>
<p>
Preparation time: 20 minutes
</p>
</body>
</html>Google 搜尋也會用結構化資料來提供特殊搜尋結果功能和強化項目
- 如,當食譜網頁提供了有效的結構化資料,就可以顯示在圖片搜尋結果中

複合式搜尋結果測試工具,可用來驗證結構化資料,在某些情況下也可用於預覽 Google 搜尋中的功能
除了此處列出的屬性和物件之外,通常 Google 也能運用 sameAs 屬性和其他 schema.org 結構化資料。若有需要,這些元素也可能在未來的搜尋功能中派上用場
Google 搜尋支援以下格式的結構化資料:
- JSON-LD (建議):
- 一種嵌入在網頁 header 或內文
<script>標記中的 JavaScript 標記法 - 標記不會與使用者可見的文字交錯,巢狀資料項目可透過更簡易的方式表達
- 如
Country > PostalAddress > MusicVenue > Event - 此外,Google 能夠解讀以動態方式植入網頁內容的
JSON-LD資料- 如透過 JavaScript 程式碼或內容管理系統中的內嵌小工具植入的資料
- 一種嵌入在網頁 header 或內文
- microdata
- RDFa
Article:多種複合式搜尋結果功能 (例如文章標題和比縮圖大的圖片) 中顯示的新聞、體育或網誌文章 |
 |
Book:讓使用者直接透過搜尋結果購買書籍 |
 |
導覽標記:導覽標記可表示該網頁在整個網站階層中的位置 |
 |
輪轉介面:複合式搜尋結果能以連續清單或圖片庫的形式,顯示來自單一網站的系列資訊卡。這功能必須與下列其中一種功能合併使用:食譜、課程、餐廳或電影。 |
 |
Course:提供教育課程。可包含課程名稱、提供單位和簡短說明等課程資料 |
 |
Dataset:在 Google 資料集搜尋中顯示的龐大資料集 |
 |
教育問與答:教育相關問題和解答,可協助學生在 Google 搜尋中探索學習卡 |
 |
EmployerAggregateRating:在 Google 工作機會搜尋服務中顯示的聘僱機構評估資訊,彙整自許多使用者提供的資訊 |
 |
預估薪酬:在 Google 求職服務中顯示的預估薪酬資訊,例如薪酬範圍以及某工作類型在特定區域的平均薪酬 |
 |
Event:顯示規劃活動清單的互動性複合式搜尋結果,例如會在特定時間或場所舉辦的演奏會或藝術節 |
 |
事實查核:具可信度的網站評估其他使用者的聲明事項後,提出的評估結果摘要 |
 |
FAQ:FAQ 是一種含有特定主題問答集的網頁類型 |
 |
居家活動:是種互動式複合式搜尋結果,可讓使用者探索能在家中從事的線上活動 |
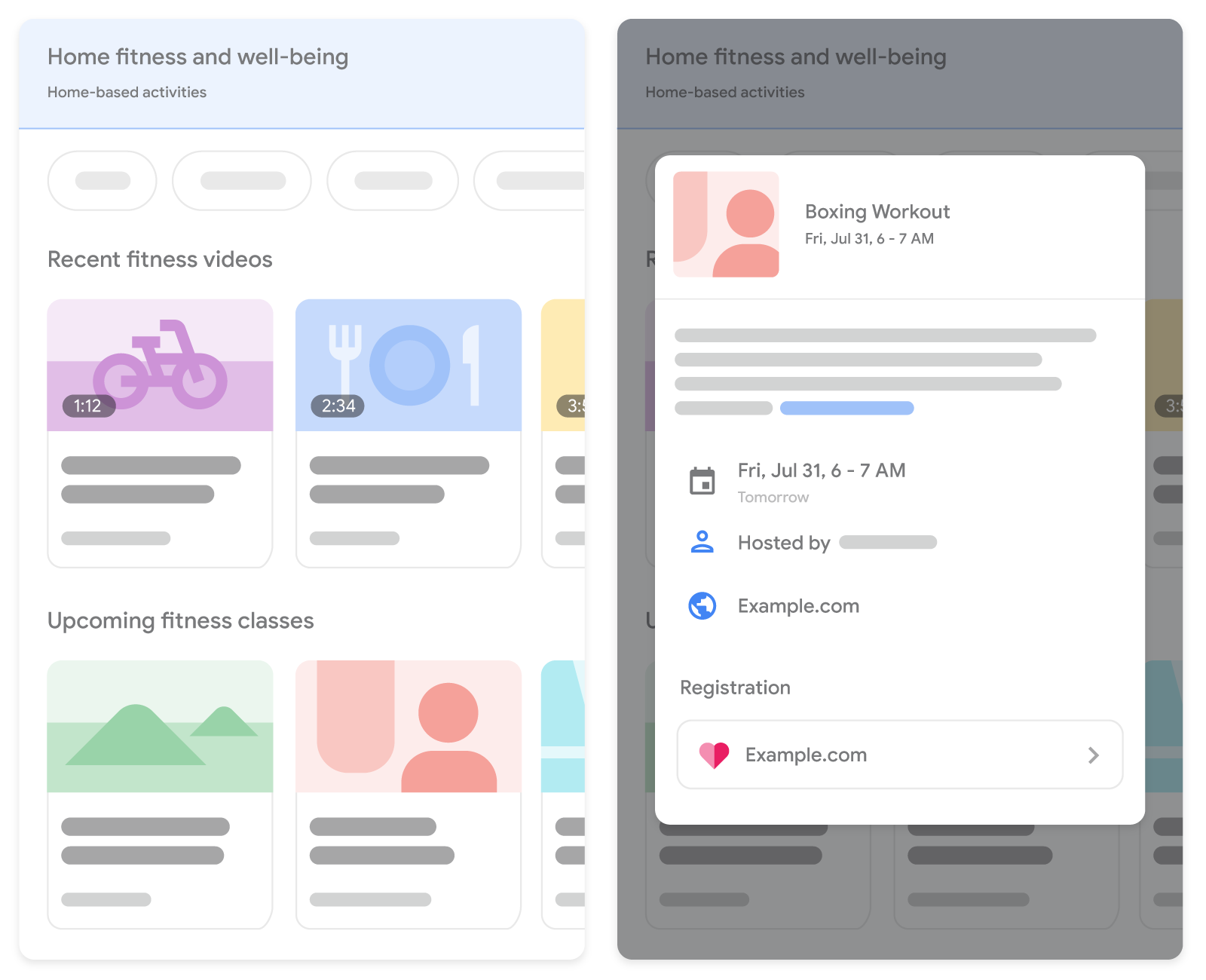 |
How-to:逐步引導使用者成功完成某件事,其中可包含影片、圖片和文字 |
 |
圖片授權:Google 圖片的「可申請授權」標記可讓使用者知道該圖片有可用的授權資訊,且能在圖片檢視器中提供授權連結,方便使用者瞭解詳細的圖片使用方式 |
 |
JobPosting:協助求職者找到工作的互動性複合式搜尋結果。可以在 Google 工作機會搜尋服務中顯示你的標誌、評論、評分和工作詳細資料 |
 |
教學影片:在教育影片中加入教學影片的結構化資料,就能協助師生探索及觀看教育影片 |
 |
當地商家:在 Google 知識面板中顯示的商家詳細資料,包括營業時間、評分、路線等,還能加入預約或訂購商品的操作選項 |
 |
Logo:在搜尋結果和 Google 知識面板中顯示標誌 |
|
數學解題工具:標示數學題型與特定數學題目解題步驟,幫助其他人解開數學問題 |
 |
Movie:電影輪轉介面可協助使用者在 Google 搜尋上探索電影清單 (例如「2019 年最好看的電影」)。可以提供這些電影的詳細資料,例如片名、導演相關資訊和圖片 |
 |
Podcast:讓 Podcast 在 Google 搜尋結果中顯示可播放的連結,或者顯示在 Google 播客應用程式、Google 助理等其他 Google 播客平台中 |
 |
Practice problem:新增有關數學和科學練習題的結構化資料,幫助其他人 |
 |
Product:產品資訊,包括價格、供貨情形和評分 |
 |
問與答:頁指的是以問答格式呈現資料的網頁,這種格式會先提出一個問題,緊接著提供問題的答案 |
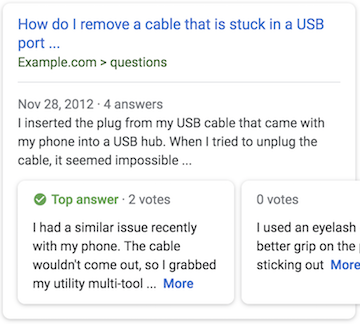 |
Recipe:以個別複合式搜尋結果呈現,或顯示於代管輪轉介面中的食譜 |
 |
評論摘錄:摘錄自評論網站的簡短評論或評分,通常是綜合眾多評論者的評分計算的平均值。評論摘錄的內容可涵蓋書籍、食譜、電影、產品、軟體應用程式和當地商家 |
 |
網站連結搜尋框 |
 |
軟體應用程式 (Beta 版):軟體應用程式的資訊,包括評分資訊、應用程式說明和應用程式的連結 |
 |
Speakable:讓搜尋引擎和其他應用程式在支援 Google 助理的裝置上,使用文字轉語音 (TTS) 功能辨識及朗讀新內容 |
 |
訂閱和付費牆內容:明確指出網站的付費牆內容,有助於我們判別網站是提供付費牆內容,還是採用了違反 Google 規範的偽裝手法 |
 |
Video: 影片資訊,附帶播放影片、指定影片片段和直播內容的選項 |
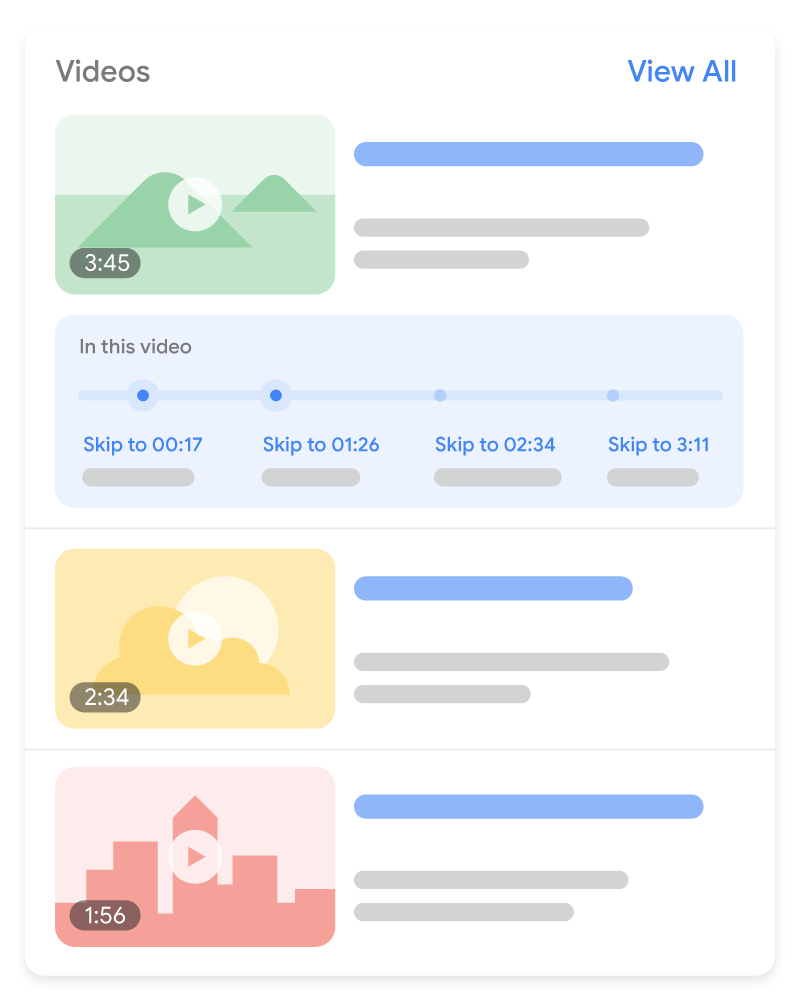 |
- 「單一網頁上有多個項目」表示同個網頁中有一種以上的事物
- 同個網頁中可能包含食譜、示範該食譜的烹飪影片,以及可讓使用者找到該食譜的導覽標記資訊
- 你能為使用者可見的所有資訊加上結構化資料標記,讓 Google 搜尋等搜尋引擎更容易理解網頁上的資訊
- 為網頁添加越多結構化資料標記,Google 搜尋越能清楚瞭解該網頁的內容,並以不同的搜尋功能顯示該網頁

無論是對項目採用巢狀結構或是個別指定每個項目,Google 搜尋都能瞭解這個網頁上有多個項目:
- 巢狀結構:
- 當網頁上有一個主要項目,而其他項目都歸類在這個主要項目之下時,就適合使用巢狀結構
- 在歸類相關項目 (例如含有影片和評論的食譜) 時,這種做法特別實用
- 注意:如果將某些項目連結起來能讓資訊更實用 (例如食譜和影片),一併對食譜和影片項目使用
@id,明確指出影片與網頁上的該食譜有關
- 個別項目:
- 當同一個網頁上每個項目都是獨立區塊時,就適合採用這種做法
以下示範巢狀結構:Recipe 為主要項目,aggregateRating 和 video 則以巢狀方式存在 Recipe 中
<html>
<head>
<title>How To Make Banana Bread</title>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Banana Bread Recipe",
"description": "The best banana bread recipe you'll ever find! Learn how to use up all those extra bananas.",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.7",
"ratingCount": "123"
},
"video": {
"@type": "VideoObject",
"name": "How To Make Banana Bread",
"description": "This is how you make banana bread, in 5 easy steps.",
"contentUrl": "http://www.example.com/video123.mp4"
}
}
</script>
</head>
<body>
</body>
</html>以下示範個別項目: 有兩個不同的項目 Recipe 和 BreadcrumbList
<html>
<head>
<title>How To Make Banana Bread</title>
<script type="application/ld+json">
[{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Banana Bread Recipe",
"description": "The best banana bread recipe you'll ever find! Learn how to use up all those extra bananas."
},
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "Recipes",
"item": "https://example.com/recipes"
},{
"@type": "ListItem",
"position": 2,
"name": "Bread recipes",
"item": "https://example.com/recipes/bread-recipes"
},{
"@type": "ListItem",
"position": 3,
"name": "How To Make Banana Bread"
}]
}]
</script>
</head>
<body>
</body>
</html>利用 JavaScript 產生結構化資料的最常見的方法如下:
- Google 代碼管理工具
- 自訂 JavaScript
使用 Google 代碼管理工具動態產生 JSON-LD
- 不必編輯程式碼,直接管理網站上的代碼
下列步驟操作:
- 在網站上設定及安裝 Google 代碼管理工具
- 在容器中新增自訂 HTML 標記。
- 將所需的結構化資料區塊貼到代碼內容中
- 前往容器管理選單的「安裝 Google 代碼管理工具」部分,按照其中的說明安裝容器
- 如要在網站上新增代碼,請透過 Google 代碼管理工具介面發布容器
- 測試
在 Google 代碼管理工具中使用變數
- Google 代碼管理工具 (GTM) 支援變數,能夠將網頁上的資訊當做結構化資料使用
- 因此,使用變數從網頁擷取結構化資料,不要直接複製 GTM 中的資訊
- 如果複製 GTM 中的資訊,網頁內容就更有可能與透過 GTM 插入的結構化資料不符
舉例,如要動態產生食譜 JSON-LD 區塊,並以網頁標題做為食譜名稱,則可以建立下列這個名為 recipe_name 的自訂變數:
function() { return document.title; }接著,就能在自訂 HTML 標記中使用 {{recipe_name}}
以下是自訂 HTML 標記內容的範例:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "{{recipe_name}}",
"image": [ "{{recipe_image}}" ],
"author": {
"@type": "Person",
"name": "{{recipe_author}}"
}
}
</script>注意:上述範例假設已在 GTM 中定義 recipe_name、recipe_image 和 recipe_author 變數了
利用自訂 JavaScript 產生結構化資料
- 另種產生結構化資料的方法是使用自訂 JavaScript
- 可以透過這種方式產生所有結構化資料,或者為伺服器端轉譯的結構化資料增添更多資訊
範例:
- 找出想採用的結構化資料類型。
- 編輯網站的 HTML,按照以下範例加入 JavaScript 程式碼片段
- 測試
fetch('https://api.example.com/recipes/123')
.then(response => response.text())
.then(structuredDataText => {
const script = document.createElement('script');
script.setAttribute('type', 'application/ld+json');
script.textContent = structuredDataText;
document.head.appendChild(script);
});測試實作成果:
- 開啟複合式搜尋結果測試
- 輸入要測試的網址。
- 按一下 [測試網址]
- 成功:如果確實完成所有操作,而且這項工具支援結構化資料類型,那麼系統就會顯示「網頁適合顯示複合式搜尋結果」訊息
- 如果複合式搜尋結果測試不支援測試的結構化資料類型,請查看轉譯後的 HTML。只要轉譯後的 HTML 含有結構化資料,Google 搜尋就能處理該資料
- 再試一次:如果系統顯示錯誤或警告,最有可能的原因是語法有誤或缺少屬性。請參閱相關結構化資料類型的說明文件,並確認已加所有屬性。如果問題持續發生,一併參閱這份指南,瞭解如何修正會影響搜尋體驗的 JavaScript 問題
在導網頁中加入 Article 結構化資料
- 有助於 Google 進一步瞭解網頁內容,有效提升文章標題文字、圖片和日期資訊在 Google 搜尋的搜尋結果和其他資源
- (例如 Google 新聞和 Google 助理)
- 可以加入 Article,明確向 Google 進一步指出內容的相關資訊 (舉例來說,指出這是新聞報導、作者是誰,或文章的標題是什麼)。
Article 結構化資料的頁面範例(複合式搜尋結果測試):
<html>
<head>
<title>Title of a News Article</title>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"headline": "Title of a News Article",
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"datePublished": "2015-02-05T08:00:00+08:00",
"dateModified": "2015-02-05T09:20:00+08:00",
"author": [{
"@type": "Person",
"name": "Jane Doe",
"url": "http://example.com/profile/janedoe123"
},{
"@type": "Person",
"name": "John Doe",
"url": "http://example.com/profile/johndoe123"
}]
}
</script>
</head>
<body>
</body>
</html>Article 物件必須以下列其中一種 schema.org 類型為基礎:
Article、NewsArticle、BlogPosting
建議屬性
author: 文章的作者- Person 或 Organization
- 為了讓 Google 更瞭解不同內容的作者,建議遵循作者標記最佳做法(在下面)
author.name: 作者的名稱author.url: 可明確識別文章作者的網頁連結,例如作者的社群媒體頁面、「關於我」頁面或簡介頁面- URL
- 也可以改用
sameAs,在分辨作者時,sameAs和url都是 Google 能解讀的資訊
dateModified: 文章最近修改的日期和時間,採 ISO 8601 格式- DateTime
- 這項屬性只有在你確定其適用於網站時才建議使用,複合式搜尋結果測試不會針對這項屬性顯示警告
datePublished: 文章首次發布的日期和時間,採 ISO 8601 格式- DateTime
- 這項屬性只有在你確定其適用於網站時才建議使用,複合式搜尋結果測試不會針對這項屬性顯示警告
headline: 文章的標題。不得超過 110 個字元- Text
image: 可代表文章的圖片網址。使用與文章相關的圖片,而非標誌或字幕- 重複的 ImageObject 或 URL
- 其他圖片規範:
- 每個網頁都必須包含至少一張圖片 (無論是否已加上標記)。Google 會根據顯示比例和解析度,選擇最適當的圖片顯示在搜尋結果中
- 圖片網址必須可供檢索和建立索引。如要測試 Google 能否存取網址,請使用網址檢查工具
- 圖片內容與標記的內容必須相符
- 圖片檔案必須使用 Google 圖片支援的格式
- 為獲得最佳效果,請提供多張高解析度圖片 (寬度乘以高度至少要 5 萬像素),長寬比分別為
16x9、4x3和1x1
ex
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
]{
"@context": "https://schema.org",
"@type": "NewsArticle",
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
]
}作者標記最佳做法: 為了讓 Google 更瞭解內容作者並以適當的方式呈現作者資訊
- 在標記中納入所有作者: 確定在網頁上顯示為作者的所有作者都納入標記中
- 指定多位作者: 指定多位作者時,請為每位作者使用專屬的
author欄位 - 使用其他欄位: 為了讓 Google 更瞭解作者是誰,強烈建議使用
type和url(或sameAs) 屬性- 為
url或sameAs使用有效的網址
- 為
- 僅在
author.name屬性中指定作者名稱: 在author.name中,僅指定作者的名稱。請勿新增任何其他資訊- 具體來說,勿加入下列資訊:
- 發布者的名稱。這資訊改用
publisher - 作者的職稱。這資訊,改用適當的屬性 (
jobTitle) - 前後或後置敬語。這資訊,改用適當的屬性 (
honorificPrefix或honorificSuffix) - 引導字詞 (例如「發文者」這類字詞就不應放入)
- 發布者的名稱。這資訊改用
- 具體來說,勿加入下列資訊:
- 請使用適當的
Type:- 對個人使用
Person類型 - 對機構使用
Organization類型 - 不要使用
Thing類型,也不要使用錯誤的類型 (例如對某個人使用Organization類型)
- 對個人使用
good:
"author": [
{"name": "Willow Lane"},
{"name": "Regula Felix"}
]bad:
"author": {
"name": "Willow Lane, Regula Felix"
}舉例來說,如果作者是某人,可以連結至作者網頁,提供作者詳細資訊:
"author": [
{
"@type": "Person",
"name": "Willow Lane",
"url": "http://www.example.com/staff/willow_lane"
}
]如果作者是某個機構,可以連結到該機構的首頁
"author":
[
{
"@type":"Organization",
"name": "Some News Agency",
"url": "https://www.example.com/"
}
]"author":
[
{
"name": "Echidna Jones",
"honorificPrefix": "Dr",
"jobTitle": "Editor in Chief"
}
],
"publisher":
[
{
"name": "Bugs Daily"
}
]
}以下為採用了作者標記最佳做法的範例:
"author":
[
{
"@type": "Person",
"name": "Willow Lane",
"jobTitle": "Journalist",
"url":"https://www.example.com/staff/willow-lane"
},
{
"@type":"Person",
"name": "Echidna Jones",
"jobTitle": "Editor in Chief",
"url":"https://www.example.com/staff/echidna-jones"
}
],
"publisher":
{
"name": "The Daily Bug",
"url": "https://www.example.com"
},
// + Other fields related to the article...
}書籍動作
- 可讓使用者透過 Google 搜尋書籍和作者
- 讓搜尋服務的使用者直接透過搜尋結果購買或借閱書籍
- 舉例,使用者可以搜尋《夏綠蒂的網》,並在搜尋的結果中購買或借閱這本書
- 結構化資料的規格提供兩種屬性:
ReadAction能讓使用者買書,BorrowAction能借書
作品和版本
- 這裡用兩種不同的詞彙來討論書籍:
- 作品 (
Work): 指一本書的抽象概念。具體來說,作品的屬性包括書名、作者和原文語言等中繼資料 - 版本 (
Edition): 書籍的實際版本。具體來說,版本的屬性包括出版年份、版本名稱和國際標準書號(ISBN) 等中繼資料
以《夏綠蒂的網》為例
- 這是一部「作品」
- 而它曾出版過的每種變體都是一種版本
- 這部作品可能會有初版、二版、節縮版、法文翻譯版等眾多版本
Book 實體分為兩種:
- Book (
Work) 是「頂層」的 Book 實體:workExample是 Work 的屬性之一,能指定一個獨一無二的 Book (Edition) 例項- 每個
Work必須有至少一個workExample
- Book (
Edition) 是「較低層級」的Book實體
一部「作品」可以有多個「版本」
- 建議盡可能將這些版本集合在一起
- Google 系統就能運用這本書的所有相關資訊,找到正確的書籍,並呈現在搜尋結果中
如果需要,可以將這些版本分割為多個作品記錄,但每個作品記錄都必須包含:
- 各自不同的
@id - 至少一個擁有
ISBN或其他支援 ID 的版本
圖書館系統和圖書館成員(僅適用於提供書籍借閱服務的供應商)
Library entity是「頂層」的Library實體類型- 包含一個
LibrarySystem實體以及該圖書館系統中每一個「較低層級」的Library(member) 實體
- 包含一個
LibrarySystem,代表由圖書館「成員」組成的合作網絡- 舉例,可將「奧斯汀公共圖書館」指定為
LibrarySystem實體 - 在其網站上,「奧斯汀公共圖書館」描述自己是為「德州奧斯汀地區」提供服務的公立圖書館「
系統」 - 而這套系統是由 20 個關聯圖書館 (或稱圖書館「成員」) 組成
- 舉例,可將「奧斯汀公共圖書館」指定為
每個 LibrarySystem 實體
- 必須擁有至少一個
Library(member) 實體 - 即使該圖書館實際上不屬於任何圖書館系統也一樣
- 面對這種情況時,為了順利導入書籍動作,請將這座圖書館視為其圖書館「系統」的唯一圖書館「成員」
對書籍動作導入作業而言
- 圖書館「成員」並非抽象的概念,因此會有實體地址,這點與圖書館「系統」不同
依照前面所述的邏輯
- 每個
Library(member) 實體都必須屬於至少一個LibrarySystem實體
ISBN 和其他支援的 ID
- Google 以 ISBN 為主要的核對信號
- 想在搜尋結果顯示書籍,就必須提供每本書的
ISBN或其他支援的 ID - Google 搜尋偏好採用
ISBN-13,但也可以提供下列 ID:- 國際線上圖書館電腦中心 (OCLC) 編號
- 美國國會圖書館控管編號 (LCCN)
- JP e-code
- 警告:Google 搜尋不接受
ISBN-10- 如果只有
ISBN-10,先透過 ISBN 轉換工具轉換為ISBN-13
- 如果只有
如果書籍沒有 ISBN
- 仍可在動態饋給中提供這些書籍,雖然使用者可能無法在 Google 搜尋中看到這些書,下列做法或許能協助獲得正確的比對結果:
- 將同一部作品的所有
Edition實體集合在同一個Work中,並確保至少其中一個版本擁有ISBN、OCLC 編號、LCCN或JP e-code - 這樣 Google 搜尋就能利用其他版本的 ISBN 或其他支援 ID 進行比對
- 將同一部作品的所有
- 加入第三方 ID。Google 搜尋目前支援兩種廣受使用的圖書館控管編號:
OCLC 編號和LCCN。如果有這兩項資訊,提供這些資訊
連結
- 為了確保使用者在尋找書籍時能獲得最佳使用體驗,動態饋給中的連結必須遵循下列規範:
- 如果有多個網頁會顯示相同的內容,則連結必須是包含書名和其他書籍資訊的標準網址
- 當使用者點選閱讀動作或借閱動作連結後,必須要連向直接支援購買或借閱該書的網頁
- 有些動作連結指向的網頁會要求使用者必須點擊更多連結,才能購買或借閱內容,特別注意不要這麼做
- 舉例,勿將使用者帶往搜尋結果網頁或產品摘要頁面
建立動態饋給
- 如果網站向使用者販售書籍,就必須上傳
Book動態饋給- 與 Google 代表聯絡,確認動態饋給的上傳方式和位置等詳細資訊
- 如果網站提供書籍借閱,就必須上傳兩個不同的動態饋給:
Book動態饋給和Library動態饋給- 與 Google 代表聯絡,確認動態饋給的上傳方式和位置等詳細資訊
動態饋給的檔案大小、數量和格式規定
動態饋給檔案大小相關規定:
- 未壓縮的動態饋給檔案不得大於 1 GB
- 要壓縮的動態饋給檔案不得大於 1 GB
- 如果未壓縮的動態饋給檔案大於 1 GB,必須將分割為多個檔案
- 壓縮格式必須為 zip, gz, tar, tar.gz, JAR, ar, arj, cpio 或傾印封存檔案(dump files)
- 多個動態饋給檔案,可以選擇直接原樣上傳,或是納入 Sitemap 索引檔中
- 單一動態饋給檔案的副檔名必須為
.json - 動態饋給不得含有過時的實體
- 過時實體是指
availabilityEnds設定為過去日期的實體,或網站已不再提供的實體
- 過時實體是指
- 動態饋給所包含的所有深層連結 (如
urlTemplate) 和所有網址 (如url),都必須是實際使用的網址- 勿使用開發網址或任何其他非實際使用的網址
- 所有網址 (例如
url) 都必須是標準網頁 - 動態饋給中的每個實體都必須指定下列屬性:
- 唯一識別碼:
@id - 專屬網址:
url - 專屬深層連結:
urlTemplate
- 唯一識別碼:
使用資料動態饋給驗證工具測試動態饋給
- 在資料動態饋給驗證工具上修正常見的錯誤和警告
- 確認「驗證日期」欄位中選取的是正確選項
- 為 Book 實體選取「書籍動作」q
- 確認
@type的值拼寫正確無誤 - 確認
@context的值設定正確- 將
ReadAction和BorrowAction都設定為"@context": "https://schema.org"
- 將
代管動態饋給檔案
- 準備好動態饋給檔案後,將檔案代管於安全的位置。Google 會定期擷取動態饋給,確保內容皆為最新資訊
系統支援下列幾種動態饋給代管方法:
| 代管 | 驗證支援 |
|---|---|
| Google Cloud Storage | Storage Object Viewer 權限 |
| HTTPS | 使用者名稱 + 密碼,或 HTTP 用戶端憑證 |
| 安全檔案傳輸通訊協定 | 密碼,或是金鑰 + 詞組,或兩者同時使用 |
| AWS S3 | 金鑰 ID + 存取金鑰 |
將動態饋給檔案送交審查
- 在 Google 搜尋收錄你的內容之前,Google 支援團隊會審查動態饋給中的深層連結品質
- 強烈建議你手動測試某些深層連結,確認這些連結開啟的網頁可供使用者購買或借閱書籍
- 注意:你必須是合作夥伴,才能順利使用這項功能以及提交動態饋給時必填的表單
- 如要提出動態饋給審查要求,要提供下列資訊:
- 代管位置:動態饋給檔案的網址
- 代管驗證 (如適用):讓 Google 能從代管位置取得動態饋給檔案的驗證憑證
視需要更新動態饋給
- 建議每天更新動態饋給,不過最終還是要依你目錄的變更頻率而定。留意下列情況和提示:
- Google 搜尋不支援即時更新
- Google 搜尋每天都會擷取你的動態饋給,擷取到的內容通常會在兩天內編入索引
- 如果已可預見某個版本的供應時間會有所變化,使用
availabilityStarts和availabilityEnds設定確切的供應日期 - 如果已停止供應,則完整移除該版本的實體
結構化資料類型定義:
- 你的內容必須包含下面列出的必要屬性,才能顯示在結構化搜尋結果中
- 建議屬性,為內容新增更多相關資訊,提供更優質的使用者體驗
DataFeed 實體:
- 每個傳送給 Google 的
schema.org資料動態饋給檔案,其根目錄層級都必須包含一個DataFeed實體 - 所有
Book和Library實體都必須列在DataFeed實體的dataFeedElement欄位下
必要屬性
@context:Text- 設為
https://schema.org
- 設為
@type:Text- 設為
DataFeed
- 設為
dataFeedElement:Book或LibrarySystem- 設定為單一
Book實體或LibrarySystem實體 or 為僅包含Book實體或LibrarySystem實體的陣列- 勿設定為同時包含
Book實體和LibrarySystem實體的陣列
- 勿設定為同時包含
- 設定為單一
dateModified:DateTime- 動態饋給上次更新的日期和時間,
ISO 8601格式
- 動態饋給上次更新的日期和時間,
在 Book 動態饋給中的使用範例:
{
"@context": "https://schema.org",
"@type": "DataFeed",
"dataFeedElement": [
{
"@context": "https://schema.org",
"@type": "Book",
"@id": "http://example.com/work/the_catcher_in_the_rye",
"url": "http://example.com/work/the_catcher_in_the_rye",
"name": "The Catcher in the Rye",
"author": {
"@type": "Person",
"name": "J.D. Salinger"
},
"sameAs": "https://en.wikipedia.org/wiki/The_Catcher_in_the_Rye",
"workExample": [
{
"@type": "Book",
"@id": "http://example.com/edition/the_catcher_in_the_rye_paperback",
"isbn": "9787543321724",
"bookEdition": "Mass Market Paperback",
"bookFormat": "https://schema.org/Paperback",
"inLanguage": "en",
...
},
...
]
}
],
"dateModified": "2018-09-10T13:58:26.892Z"
}在 LibrarySystem 動態饋給中的使用範例:
Book 實體
- schema.org/Book 已提供 Book 的完整定義
- 只需要考慮下列屬性即可
- 也可以定義建議的屬性,為內容新增更多相關資訊,提供更優質的使用者體驗
Book (Work)
Book實體是頂層的實體類型,代表一部「作品」
Book (Work) 必要屬性:
@context:Text- 設為
https://schema.org
- 設為
@id:Text- 書籍的全域唯一 ID
- 採網址形式,必須是你自己系統中的唯一值
- ID 應固定,不會隨著時間而改變
- 建議採用網址格式,但並非強制,且不一定要是有效連結
- 用於
@id值的網域必須由你們所擁有
@type:Text- 設為
Book
- 設為
author:Person或Organization- 書籍的作者
- 注意:如果書籍沒有作者,而是有一或多個「著作人」,照
schema.org/Book的定義加入這些著作人 - 如果書籍的作者是機構組織,照
schema.org/Organization的定義來定義作者
name:Text- 書籍的名稱
url:URL- 網站上介紹或描述該書籍資訊的網址
- 這個連結能協助系統準確比對動態饋給中的內容與 Google 資料庫中的內容
- 可以與
workExample.target.urlTemplate相同 - Google 搜尋會使用
workExample.target.urlTemplate中提供的網址做為實際的到達網頁
workExample:Book (Edition)- 作品的版本
Book (Work) 建議屬性
sameAs:URL- 可識別作品的參考網頁網址。舉例,可能是該本書在維基百科、維基數據、虛擬國際權威檔 (VIAF) 或美國國會圖書館的頁面
Book (Edition)
- 用於
workExample屬性,代表一部「作品」的其中一個「版本」
Book (Edition) 必要屬性
(我: 這些區塊是每個不同類別的「結構化資料」,這邊懶得繼續看了,下面列出標題,跳過)
- 導覽標記 (BreadcrumbList)
- 輪轉介面 (ItemList)
- 課程輪轉介面 (Course)
- COVID-19 公告 (SpecialAnnouncement)
- 資料集 (Dataset, DataCatalog, DataDownload)
- 教育問與答 (Quiz, Question, Answer)
- 雇主累計評分 (EmployerAggregateRating)
- 預估薪酬 (Occupation)
- 事件 (Event)
- 事實查核 (ClaimReview)
- 常見問題 (FAQPage, Question, Answer)
- 居家活動 (VirtualLocation)
- How-to (HowTo)
- Google 圖片中的圖片中繼資料
- 適用於工作搜尋的徵人啟事 (JobPosting)
- 教學影片 (LearningResource, VideoObject, Clip)
- 當地商家 (LocalBusiness)
- 標誌 (Organization)
- 數學解題工具 (MathSolver)
- 電影輪轉介面 (Movie)
- 練習題 (Quiz)
- 產品 (Product, Review, Offer)
- 問與答 (QAPage)
- 食譜 (Recipe, HowTo, ItemList)
- 評論摘錄 (Review, AggregateRating)
- 網站連結搜尋框 (WebSite)
- 軟體應用程式 (SoftwareApplication)
- Speakable (Article, WebPage)
- 訂閱和付費牆內容的結構化資料 (CreativeWork)
- 影片 (VideoObject, Clip, BroadcastEvent)
(我: 下面這些我也不打算細看了,記錄一些標題就先跳過)
「標題連結」指的是 Google 搜尋和其他資源 (例如 Google 新聞) 中搜尋結果的標題
- Google 會參考不同來源的資訊,自動判斷標題連結
- 不過你可以按照影響標題連結的最佳做法,指明偏好的標題連結
- https://developers.google.com/search/docs/appearance/title-link

- 片能夠出現在以下幾個不同的 Google 介面中,包括主要搜尋結果網頁、影片搜尋結果、Google 圖片和「探索」專區
- https://developers.google.com/search/docs/appearance/video

- 網路故事是廣受歡迎「故事」格式的網路版本,融合了影片、音訊、圖片、動畫和文字,打造出動態瀏的覽體驗
- 這種格式以視覺為主,可讓使用者透過輕觸或滑動,依自己的節奏逐步探索內容
- 如何將故事在 Google 搜尋、Google 探索和 Google 圖片等服務中的呈現方式,以及如何在這些服務中啟用網路故事外觀
- https://developers.google.com/search/docs/appearance/enable-web-stories
%EF%BC%8C%E5%9C%A8){kind=link}
(我: 現面這區塊是在把幾個 develop and debug 時會用到的工具介紹一下)
- Search Console
- 可協助任何網站擁有者瞭解自家網站在 Google 搜尋中的成效,以及如何改善網站在搜尋結果上的呈現方式,為網站帶來更相關的查詢流量
- https://developers.google.com/search/docs/monitor-debug/search-console-start
- https://search.google.com/search-console/welcome
- Search Console 中的報表
- 適合 SEO 專家、數位行銷人士以及網站系統管理員的實用報表
- https://developers.google.com/search/docs/monitor-debug/search-console-reports
- 使用搜尋運算子進行偵錯
- Google 搜尋支援數個搜尋運算子,可供您修正或指定搜尋目標
- https://developers.google.com/search/docs/monitor-debug/search-operators
- 防範及監控濫用情形
- 避免網站或平台使用者產生的垃圾內容
- 垃圾內容發布者經常利用開放留言表單和其他使用者原創內容輸入欄位,在不知情的網站上產生垃圾資訊內容。瞭解如何避免及監控您網站或平台上的濫用行為
- https://developers.google.com/search/docs/monitor-debug/prevent-abuse
- 惡意軟體和垃圾軟體
- 瞭解什麼是惡意軟體和垃圾軟體、避免發布垃圾軟體的相關規範,以及如何修正垃圾軟體相關問題
- https://developers.google.com/search/docs/monitor-debug/security/malware
- 杜絕惡意軟體感染
- 實用的提示和建議,可協助您杜絕惡意軟體感染
- https://developers.google.com/search/docs/monitor-debug/security/prevent-malware
- 社交工程 (網路詐騙和詐欺網站)
- Google 安全瀏覽累犯政策
- Google 安全瀏覽服務會針對危險的網站或不安全的下載檔案顯示警告訊息,協助保護使用者
- https://developers.google.com/search/docs/monitor-debug/security/safe-browsing-repeat-offenders
- 避免網站或平台使用者產生的垃圾內容
(我: 最後一區,針對幾個主題做專門介紹)
- 電子商務
- Google 搜尋中的電子商務網站最佳做法
- https://developers.google.com/search/docs/specialty/ecommerce
- 國際版和多語言版本網站相關主題總覽
- 如果網站內容因地而異,或包含不同語言,這篇文章將說明如何協助 Google 瞭解你的網站
- https://developers.google.com/search/docs/specialty/international
(最後一段有點偷懶,但實在太細了,不打算繼續花時間看這些細節,這些等實作時,當作 document 查,才是正確的做法)