Deployment & Documentation & Stats


Build Status & Code Coverage & Maintainability


PyOD is a comprehensive and scalable Python toolkit for detecting outlying objects in multivariate data. This exciting yet challenging field is commonly referred as Outlier Detection or Anomaly Detection. Since 2017, PyOD has been successfully used in various academic researches and commercial products [9] [16] [20] [21] [22] [23]. It is also well acknowledged by the machine learning community with various dedicated posts/tutorials, including Analytics Vidhya, KDnuggets, Computer Vision News, and awesome-machine-learning.
PyOD is featured for:
- Unified APIs, detailed documentation, and interactive examples across various algorithms.
- Advanced models, including Neural Networks/Deep Learning and Outlier Ensembles.
- Optimized performance with JIT and parallelization when possible, using numba and joblib.
- Compatible with both Python 2 & 3 (scikit-learn compatible as well).
Important Notes: PyOD has multiple neural network based models, e.g., AutoEncoders, which are implemented in Keras. However, PyOD would NOT install Keras and/or TensorFlow for you. This reduces the risk of interfering your local copies. If you want to use neural-net based models, please make sure Keras and a backend library, e.g., TensorFlow, are installed. An instruction is provided: neural-net FAQ. Similarly, the models depend on xgboost, e.g., XGBOD, would NOT enforce xgboost installation by default.
Citing PyOD:
If you use PyOD in a scientific publication, we would appreciate citations to the following paper:
@article{zhao2019pyod,
title={PyOD: A Python Toolbox for Scalable Outlier Detection},
author={Zhao, Yue and Nasrullah, Zain and Li, Zheng},
journal={arXiv preprint arXiv:1901.01588},
year={2019},
url={https://arxiv.org/abs/1901.01588}
}
or:
Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD: A Python Toolbox for Scalable Outlier Detection. arXiv preprint arXiv:1901.01588.
PyOD paper is accepted at JMLR (machine learning open-source software track) with minor revisions (to appear). See arxiv preprint.
Key Links and Resources:
Table of Contents:
- Quick Introduction
- Installation
- API Cheatsheet & Reference
- Algorithm Benchmark
- Quick Start for Outlier Detection
- Quick Start for Combining Outlier Scores from Various Base Detectors
- How to Contribute and Collaborate
PyOD toolkit consists of three major groups of functionalities:
(i) Individual Detection Algorithms :
| Type | Abbr | Algorithm | Year | Ref |
|---|---|---|---|---|
| Linear Model | PCA | Principal Component Analysis (the sum of weighted projected distances to the eigenvector hyperplanes) | 2003 | [19] |
| Linear Model | MCD | Minimum Covariance Determinant (use the mahalanobis distances as the outlier scores) | 1999 | [6] [18] |
| Linear Model | OCSVM | One-Class Support Vector Machines | 2003 | [14] |
| Proximity-Based | LOF | Local Outlier Factor | 2000 | [4] |
| Proximity-Based | CBLOF | Clustering-Based Local Outlier Factor | 2003 | [7] |
| Proximity-Based | LOCI | LOCI: Fast outlier detection using the local correlation integral | 2003 | [15] |
| Proximity-Based | HBOS | Histogram-based Outlier Score | 2012 | [5] |
| Proximity-Based | kNN | k Nearest Neighbors (use the distance to the kth nearest neighbor as the outlier score | 2000 | [17] |
| Proximity-Based | AvgKNN | Average kNN (use the average distance to k nearest neighbors as the outlier score) | 2002 | [3] |
| Proximity-Based | MedKNN | Median kNN (use the median distance to k nearest neighbors as the outlier score) | 2002 | [3] |
| Probabilistic | ABOD | Angle-Based Outlier Detection | 2008 | [10] |
| Probabilistic | FastABOD | Fast Angle-Based Outlier Detection using approximation | 2008 | [10] |
| Probabilistic | SOS | Stochastic Outlier Selection | 2012 | [8] |
| Outlier Ensembles | IForest | Isolation Forest | 2008 | [12] |
| Outlier Ensembles | Feature Bagging | 2005 | [11] | |
| Outlier Ensembles | LSCP | LSCP: Locally Selective Combination of Parallel Outlier Ensembles | 2019 | [23] |
| Outlier Ensembles | XGBOD | Extreme Boosting Based Outlier Detection (Supervised) | 2018 | [22] |
| Neural Networks | AutoEncoder | Fully connected AutoEncoder (use reconstruction error as the outlier score) | [1] [Ch.3] | |
| Neural Networks | SO_GAAL | Single-Objective Generative Adversarial Active Learning | 2019 | [13] |
| Neural Networks | MO_GAAL | Multiple-Objective Generative Adversarial Active Learning | 2019 | [13] |
(ii) Outlier Ensembles & Outlier Detector Combination Frameworks:
| Type | Abbr | Algorithm | Year | Ref |
|---|---|---|---|---|
| Outlier Ensembles | Feature Bagging | 2005 | [11] | |
| Outlier Ensembles | LSCP | LSCP: Locally Selective Combination of Parallel Outlier Ensembles | 2019 | [23] |
| Combination | Average | Simple combination by averaging the scores | 2015 | [2] |
| Combination | Weighted Average | Simple combination by averaging the scores with detector weights | 2015 | [2] |
| Combination | Maximization | Simple combination by taking the maximum scores | 2015 | [2] |
| Combination | AOM | Average of Maximum | 2015 | [2] |
| Combination | MOA | Maximization of Average | 2015 | [2] |
(iii) Utility Functions:
| Type | Name | Function | Documentation |
|---|---|---|---|
| Data | generate_data | Synthesized data generation; normal data is generated by a multivariate Gaussian and outliers are generated by a uniform distribution | generate_data |
| Stat | wpearsonr | Calculate the weighted Pearson correlation of two samples | wpearsonr |
| Utility | get_label_n | Turn raw outlier scores into binary labels by assign 1 to top n outlier scores | get_label_n |
| Utility | precision_n_scores | calculate precision @ rank n | precision_n_scores |
It is recommended to use pip for installation. Please make sure the latest version is installed, as PyOD is updated frequently:
pip install pyod
pip install --upgrade pyod # make sure the latest version is installed!
pip install --pre pyod # or include pre-release version for new featuresAlternatively, install from github directly (NOT Recommended)
git clone https://github.com/yzhao062/pyod.git
python setup.py installRequired Dependencies:
- Python 2.7, 3.5, 3.6, or 3.7
- numpy>=1.13
- numba>=0.35
- scipy>=0.19.1
- scikit_learn>=0.19.1
Optional Dependencies (see details below):
- Keras (optional, required for AutoEncoder)
- Matplotlib (optional, required for running examples)
- Tensorflow (optional, required for AutoEncoder, other backend works)
- XGBoost (optional, required for XGBOD)
Known Issue 1: Running examples needs Matplotlib, which may throw errors in conda virtual environment on mac OS. See reasons and solutions issue6.
Known Issue 2: Keras and/or TensorFlow are listed as optional. However, they are both required if you want to use neural network based models, such as AutoEncoder. See reasons and solutions neural-net installation
Known Issue 3: xgboost is listed as optional. However, it is required to run XGBOD. Users are expected to install xgboost to use XGBOD model.
Full API Reference: (https://pyod.readthedocs.io/en/latest/pyod.html). API cheatsheet for all detectors:
- fit(X): Fit detector.
- fit_predict(X): Fit detector first and then predict whether a particular sample is an outlier or not.
- fit_predict_score(X, y): Fit the detector, predict on samples, and evaluate the model by predefined metrics, e.g., ROC.
- decision_function(X): Predict raw anomaly score of X using the fitted detector.
- predict(X): Predict if a particular sample is an outlier or not using the fitted detector.
- predict_proba(X): Predict the probability of a sample being outlier using the fitted detector.
Key Attributes of a fitted model:
- decision_scores: The outlier scores of the training data. The higher, the more abnormal. Outliers tend to have higher scores.
- labels_: The binary labels of the training data. 0 stands for inliers and 1 for outliers/anomalies.
Full package structure can be found below:
- http://pyod.readthedocs.io/en/latest/genindex.html
- http://pyod.readthedocs.io/en/latest/py-modindex.html
Comparison of all implemented models are made available below:
(Figure, compare_all_models.py, Interactive Jupyter Notebooks):
For Jupyter Notebooks, please navigate to "/notebooks/Compare All Models.ipynb"
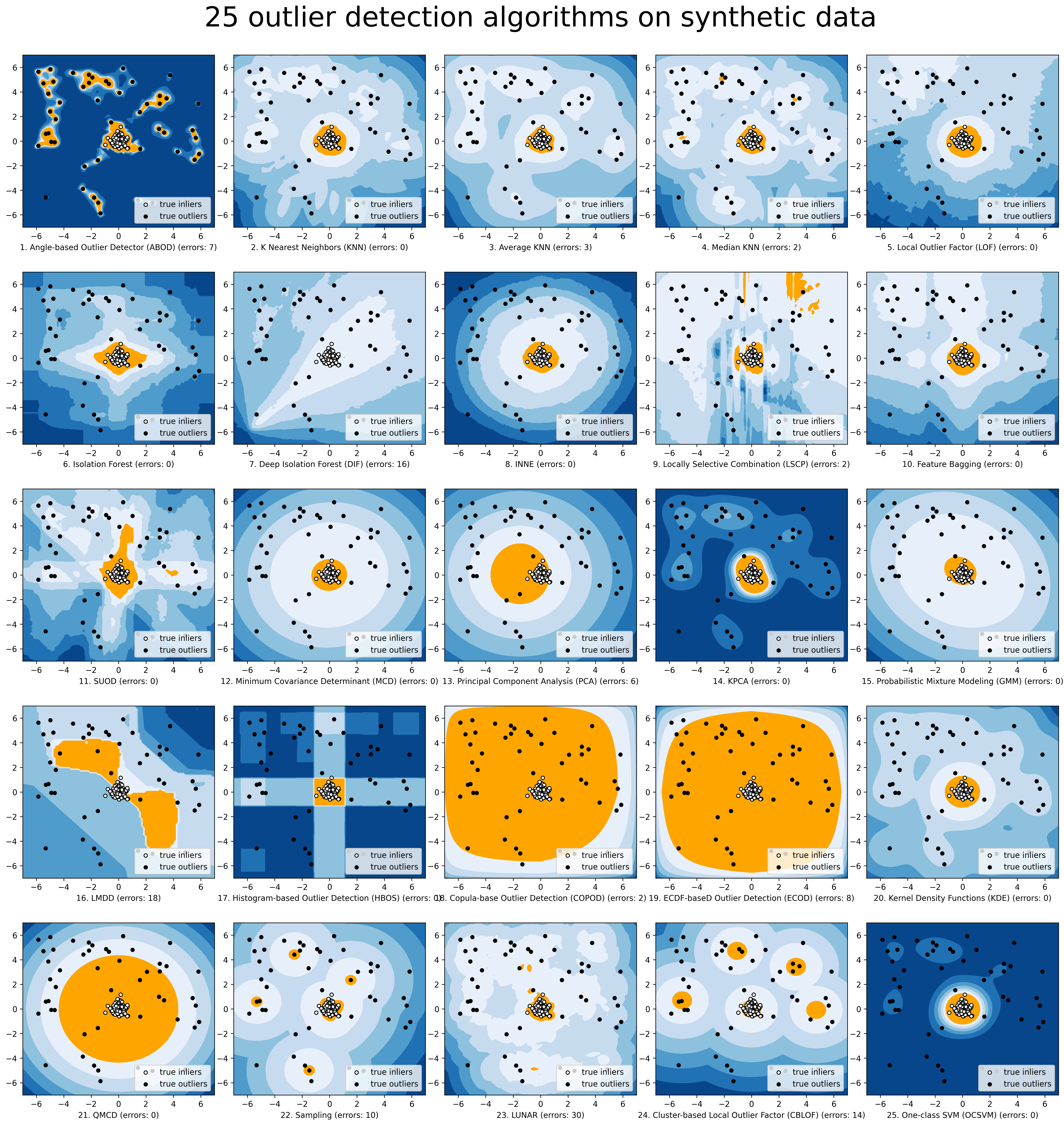
To provide an overview and quick guidance of the implemented models, a benchmark is supplied. In total, 17 benchmark data are used for comparision, all datasets could be downloaded at ODDS.
For each dataset, it is first split into 60% for training and 40% for testing. All experiments are repeated 20 times independently with different samplings. The mean of 20 trials are taken as the final result. Three evaluation metrics are provided:
- The area under receiver operating characteristic (ROC) curve
- Precision @ rank n (P@N)
- Execution time
Check the latest result benchmark. You are welcome to replicate this process by running benchmark.py.
PyOD has been well acknowledged by the machine learning community with a few featured posts and tutorials.
Analytics Vidhya: An Awesome Tutorial to Learn Outlier Detection in Python using PyOD Library
KDnuggets: Intuitive Visualization of Outlier Detection Methods
Computer Vision News (March 2019): Python Open Source Toolbox for Outlier Detection
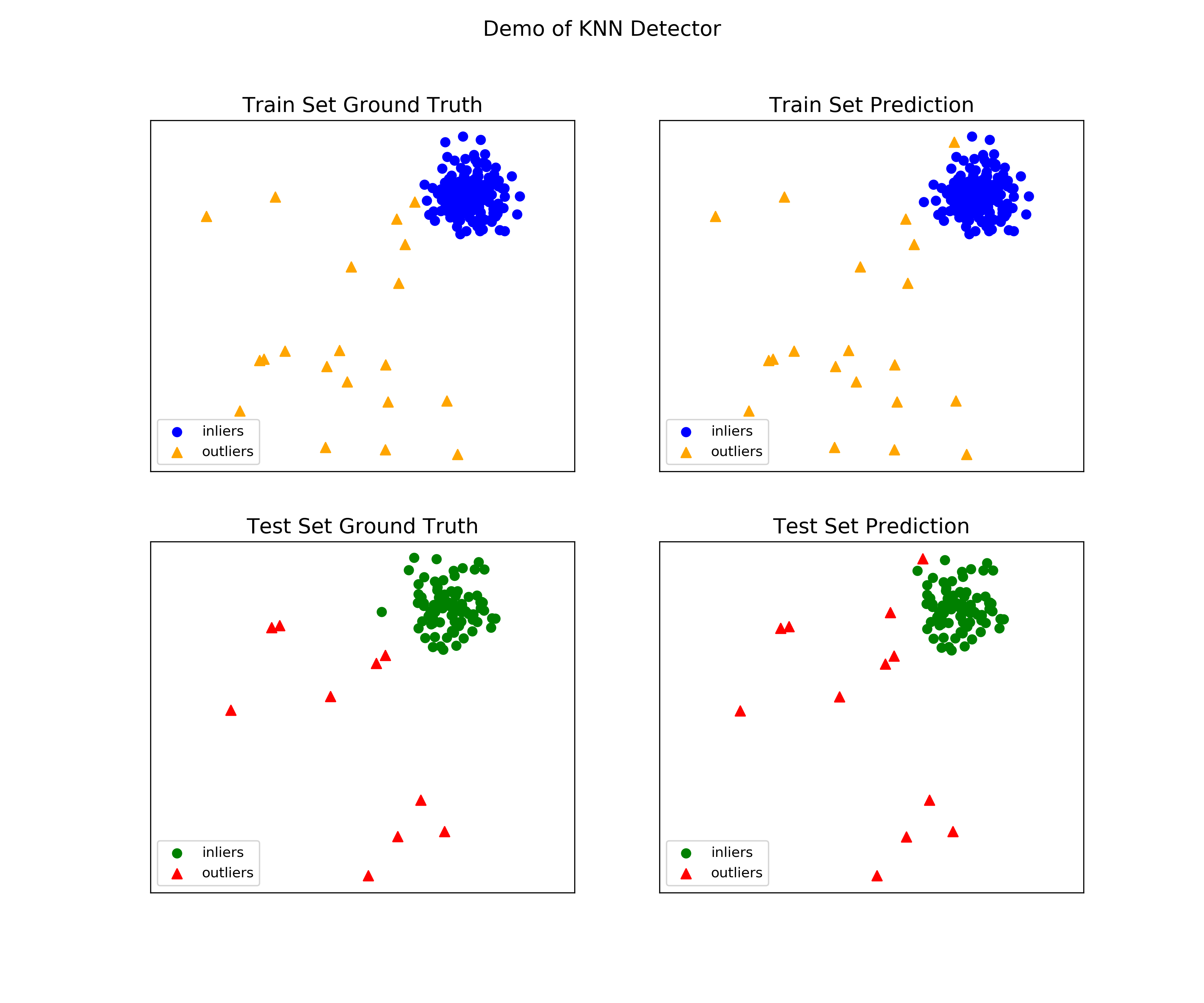
"examples/knn_example.py" demonstrates the basic APIs of PyOD using kNN detector.
See examples directory for more demos and more detailed instructions. It is noted the APIs for other algorithms are consistent/similar.
Initialize a kNN detector, fit the model, and make the prediction.
from pyod.models.knn import KNN # kNN detector # train kNN detector clf_name = 'KNN' clf = KNN() clf.fit(X_train) # get the prediction label and outlier scores of the training data y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores # get the prediction on the test data y_test_pred = clf.predict(X_test) # outlier labels (0 or 1) y_test_scores = clf.decision_function(X_test) # outlier scores
Evaluate the prediction by ROC and Precision@rank n (p@n):
# evaluate and print the results print("\nOn Training Data:") evaluate_print(clf_name, y_train, y_train_scores) print("\nOn Test Data:") evaluate_print(clf_name, y_test, y_test_scores)
See a sample output & visualization
On Training Data: KNN ROC:1.0, precision @ rank n:1.0 On Test Data: KNN ROC:0.9989, precision @ rank n:0.9
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False)
Visualization (knn_figure):
"examples/comb_example.py" illustrates the APIs for combining multiple base detectors (comb_example.py, Jupyter Notebooks).
For Jupyter Notebooks, please navigate to "/notebooks/Model Combination.ipynb"
Given we have n individual outlier detectors, each of them generates an individual score for all samples. The task is to combine the outputs from these detectors effectively Key Step: conducting Z-score normalization on raw scores before the combination. Four combination mechanisms are shown in this demo:
- Average: take the average of all base detectors.
- maximization : take the maximum score across all detectors as the score.
- Average of Maximum (AOM): first randomly split n detectors in to p groups. For each group, use the maximum within the group as the group output. Use the average of all group outputs as the final output.
- Maximum of Average (MOA): similarly to AOM, the same grouping is introduced. However, we use the average of a group as the group output, and use maximum of all group outputs as the final output. To better understand the merging techniques, refer to [6].
The walkthrough of the code example is provided:
Import models and generate sample data
from pyod.models.knn import KNN from pyod.models.combination import aom, moa, average, maximization from pyod.utils.data import generate_data X, y = generate_data(train_only=True) # load data
First initialize 20 kNN outlier detectors with different k (10 to 200), and get the outlier scores:
# initialize 20 base detectors for combination k_list = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200] train_scores = np.zeros([X_train.shape[0], n_clf]) test_scores = np.zeros([X_test.shape[0], n_clf]) for i in range(n_clf): k = k_list[i] clf = KNN(n_neighbors=k, method='largest') clf.fit(X_train_norm) train_scores[:, i] = clf.decision_scores_ test_scores[:, i] = clf.decision_function(X_test_norm)
Then the output scores are standardized into zero mean and unit variance before combination.
from pyod.utils.utility import standardizer train_scores_norm, test_scores_norm = standardizer(train_scores, test_scores)
Then four different combination algorithms are applied as described above:
comb_by_average = average(test_scores_norm) comb_by_maximization = maximization(test_scores_norm) comb_by_aom = aom(test_scores_norm, 5) # 5 groups comb_by_moa = moa(test_scores_norm, 5)) # 5 groups
Finally, all four combination methods are evaluated with ROC and Precision @ Rank n:
Combining 20 kNN detectors Combination by Average ROC:0.9194, precision @ rank n:0.4531 Combination by Maximization ROC:0.9198, precision @ rank n:0.4688 Combination by AOM ROC:0.9257, precision @ rank n:0.4844 Combination by MOA ROC:0.9263, precision @ rank n:0.4688
You are welcome to contribute to this exciting project:
- Please first check Issue lists for "help wanted" tag and comment the one you are interested. We will assign the issue to you.
- Fork the master branch and add your improvement/modification/fix.
- Create a pull request and follow the pull request template PR template
To make sure the code has the same style and standard, please refer to models, such as abod.py, hbos.py, or feature bagging for example.
You are also welcome to share your ideas by opening an issue or dropping me an email at yuezhao@cs.toronto.edu :)
| [1] | Aggarwal, C.C., 2015. Outlier analysis. In Data mining (pp. 237-263). Springer, Cham. |
| [2] | (1, 2, 3, 4, 5) Aggarwal, C.C. and Sathe, S., 2015. Theoretical foundations and algorithms for outlier ensembles.ACM SIGKDD Explorations Newsletter, 17(1), pp.24-47. |
| [3] | (1, 2) Angiulli, F. and Pizzuti, C., 2002, August. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery pp. 15-27. |
| [4] | Breunig, M.M., Kriegel, H.P., Ng, R.T. and Sander, J., 2000, May. LOF: identifying density-based local outliers. ACM Sigmod Record, 29(2), pp. 93-104. |
| [5] | Goldstein, M. and Dengel, A., 2012. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In KI-2012: Poster and Demo Track, pp.59-63. |
| [6] | Hardin, J. and Rocke, D.M., 2004. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Computational Statistics & Data Analysis, 44(4), pp.625-638. |
| [7] | He, Z., Xu, X. and Deng, S., 2003. Discovering cluster-based local outliers. Pattern Recognition Letters, 24(9-10), pp.1641-1650. |
| [8] | Janssens, J.H.M., Huszár, F., Postma, E.O. and van den Herik, H.J., 2012. Stochastic outlier selection. Technical report TiCC TR 2012-001, Tilburg University, Tilburg Center for Cognition and Communication, Tilburg, The Netherlands. |
| [9] | Kalayci, İ. and Ercan, T., 2018, October. Anomaly Detection in Wireless Sensor Networks Data by Using Histogram Based Outlier Score Method. In 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), pp. 1-6. IEEE. |
| [10] | (1, 2) Kriegel, H.P. and Zimek, A., 2008, August. Angle-based outlier detection in high-dimensional data. In KDD '08, pp. 444-452. ACM. |
| [11] | (1, 2) Lazarevic, A. and Kumar, V., 2005, August. Feature bagging for outlier detection. In KDD '05. 2005. |
| [12] | Liu, F.T., Ting, K.M. and Zhou, Z.H., 2008, December. Isolation forest. In International Conference on Data Mining, pp. 413-422. IEEE. |
| [13] | (1, 2) Liu, Y., Li, Z., Zhou, C., Jiang, Y., Sun, J., Wang, M. and He, X., 2018. Generative Adversarial Active Learning for Unsupervised Outlier Detection. arXiv preprint arXiv:1809.10816. |
| [14] | Ma, J. and Perkins, S., 2003, July. Time-series novelty detection using one-class support vector machines. In IJCNN' 03, pp. 1741-1745. IEEE. |
| [15] | Papadimitriou, S., Kitagawa, H., Gibbons, P.B. and Faloutsos, C., 2003, March. LOCI: Fast outlier detection using the local correlation integral. In ICDE '03, pp. 315-326. IEEE. |
| [16] | Ramakrishnan, J., Shaabani, E., Li, C. and Sustik, M.A., 2019. Anomaly Detection for an E-commerce Pricing System. arXiv preprint arXiv:1902.09566. |
| [17] | Ramaswamy, S., Rastogi, R. and Shim, K., 2000, May. Efficient algorithms for mining outliers from large data sets. ACM Sigmod Record, 29(2), pp. 427-438). |
| [18] | Rousseeuw, P.J. and Driessen, K.V., 1999. A fast algorithm for the minimum covariance determinant estimator. Technometrics, 41(3), pp.212-223. |
| [19] | Shyu, M.L., Chen, S.C., Sarinnapakorn, K. and Chang, L., 2003. A novel anomaly detection scheme based on principal component classifier. MIAMI UNIV CORAL GABLES FL DEPT OF ELECTRICAL AND COMPUTER ENGINEERING. |
| [20] | Weng, Y., Zhang, N. and Xia, C., 2019. Multi-Agent-Based Unsupervised Detection of Energy Consumption Anomalies on Smart Campus. IEEE Access, 7, pp.2169-2178. |
| [21] | Zhao, Y. and Hryniewicki, M.K. DCSO: Dynamic Combination of Detector Scores for Outlier Ensembles. ACM SIGKDD Workshop on Outlier Detection De-constructed (ODD v5.0), 2018. |
| [22] | (1, 2) Zhao, Y. and Hryniewicki, M.K. XGBOD: Improving Supervised Outlier Detection with Unsupervised Representation Learning. IEEE International Joint Conference on Neural Networks, 2018. |
| [23] | (1, 2, 3) Zhao, Y., Hryniewicki, M.K., Nasrullah, Z., and Li, Z. LSCP: Locally Selective Combination of Parallel Outlier Ensembles. SIAM International Conference on Data Mining (SDM). 2019. Accepted, to appear. |