Trainable Tokenizer #2220
mosynaq
started this conversation in
New Features & Project Ideas
Trainable Tokenizer
#2220
Replies: 0 comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
-
Hi there! I am trying to train Persian models for spaCy and have done a lot so far. But the tokenization part suffers some deficiencies: It cannot recognize clitics and split them and since those clitics connect to a large number of words, this phenomenon cannot be described using RegEx. Conllu tree banks provide a good deal of information about tokens and their boundaries. See below for a good example
The above sample in picture:
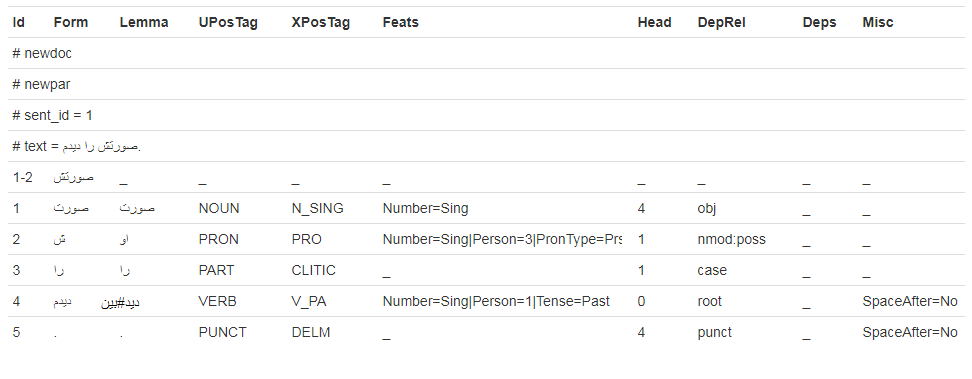
The sentence means literally : "His/her-face object-marker-token I-saw." meaning "I saw his/her face.".
In the first aolumn you can see "1-2" with the token and after that you can see the token properly tokenized. I believe this tree and others are a great source of information for a trainable tokenizer.
Questions
p.s.
Your Environment
Beta Was this translation helpful? Give feedback.
All reactions