The purpose of the scripts is to allow data in "flat" CSV tables to be converted to RDF triples in several serializations.
Link to current actual graph model for tang-song metadata.
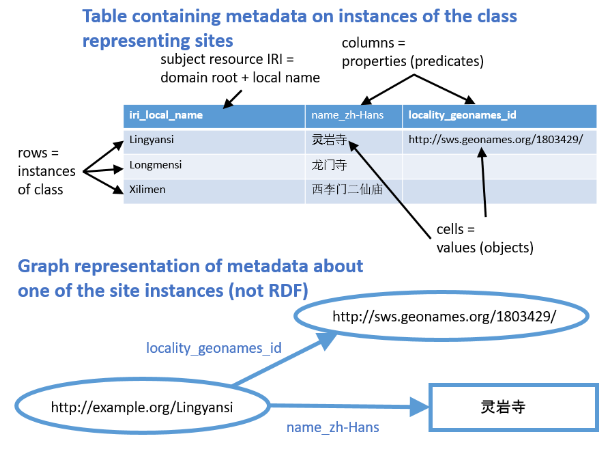
Fig. 1. Example metadata table for Chinese religious sites.
In the CSV table for the core class (in these examples named metadata.csv, with "metadata" serving as the core class prefix for related files), the rows represent data associated with a particular instance of the class of things that are described by the table. In the example above, the table describes religious sites in China. Each row represents a particular site. One column (headed: iri_local_name) contains the local name part of the IRI identifier for the particular instance of the root class for the table (in this case, the site). The full IRI of the subject resource is formed by concatenating the domain root ("http://example.org/" was used for the examples) and local name part. (See the "Other files required..." section below for information on how to set the domain root.) The other columns represent properties associated with the class described by the table, or other classes whose instances have a one-to-one relationship between instances of the root class.
Each cell in the table represents the value of the property represented by the column for the instance represented by the row. An RDF triple is formed from the subject IRI for the row, a predicate associated with the column property, and an object that is the value of the cell at the intersection of the column and row. The entire row represents an RDF graph of metadata associated with the resource represented by the row.

Fig. 2. Example table of classes represented by a row in the metadata table.
It is possible that all of the properties represented by the columns in the metadata.csv table are properties of the core class described by the table (the religious sites in the example). However, some properties (such as the description of dynasties represented at the site) aren't really properties of the site, but rather of another class that is associated with the core class. In the example, each site has a one-to-one association with a particular period of time over which buildings on the site were constructed. A second table, metadata-classes.csv, lists all of the classes linked in a one-to-one relationship in the metadata.csv table. (The general form of the file name is "[coreClassPrefix]-classes.csv") The id column in this table indicates how the subject IRI for the row should be modified to form an identifier for the instance of the linked class. If the value in the id column is "$root", the IRI for an instance of that class is the unmodified subject IRI. For instances of classes having a one-to-one relationship with the subject resource, the string in the id column is appended to the subject IRI as a fragment identifier (hash). If there is no desire to mint an IRI for the instance of the associated class, it can be a blank node. Each class whose instances are represented by a blank node must be identified by a different string following ":_".
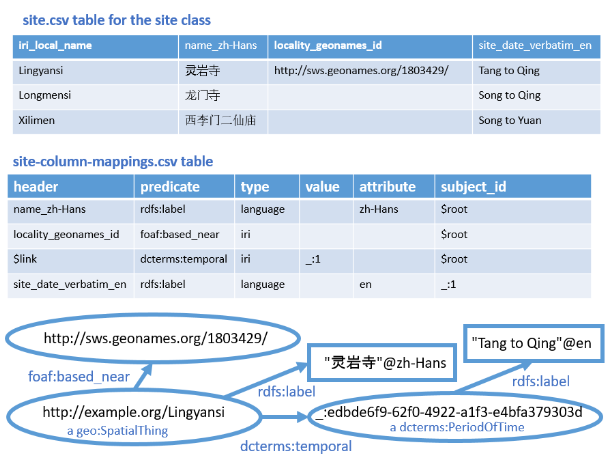
Fig. 3. Example mappings from the Chinese religious site metadata table to RDF graph
The file metadata-column-mappings.csv contains the mappings between RDF predicates to be used in the triples and the headers of the columns in the table for the property represented by the predicate. (The general form of the file name is "[coreClassPrefix]-column-mappings.csv") The table also indicates the kind of object that is represented by the cell in the row for that column. The properties are grouped according the subject resource to which they apply by the class listed in the subject_id column of the table.
The type of object can be one of three kinds of literals (plain, language-tagged, and datatyped), an IRI, or a blank node. A plain literal has "plain" in the type column, and empty value and attribute columns. A language-tagged literal has "language" in the type column, the ISO 639-1 language code (optionally with country and script suffixes) to be used for the tag in the attribute column, and an empty cell in the value column. A datatyped literal will have "datatype" in the type column, the datatype IRI in the attribute column, and an empty cell in the value column. The datatype IRI can be abbreviated and will usually be an XML datatype in the xsd: (a.k.a. xs:) namespace, e.g. xsd:integer.
If the object of the triple is an IRI, the type column has "iri". If the value and attribute columns have empty cells, the script assumes that the metadata table contains either a full, unabbreviated IRI, or a CURIE-abbreviated IRI (i.e. QName). If the value column in the mapping table contains a string, the script assumes that string should be prepended to the contents of the column in the metadata table. Optionally, a suffix can be appended if a string is present in the attribute column of the mapping table (but only if there is also a prefix present in the value column). For example, if the metadata table contains "1815582" in a column and the mapping table entry for that column contains "http://sws.geonames.org/" in the value column and "/" in the attribute column, the script will construct the IRI "http://sws.geonames.org/1815582/".
There are also cases where links need to be made without using data recorded in a column of the table. For example, if every instance in the table should have the same value of some property, the cell in the header column should contain "$constant". The constant value (literal or IRI) is listed in the value column. The type and attribute columns would contain entries appropriate for the kind of object that the value represents (e.g. language-tagged literal, IRI, etc.).
The final kind of entry in the metadata-column-mappings.csv file is a link between two classes whose properties are represented by columns in the table. Linking triples are generated by putting "$link" in the header column. The subject resource to be linked is indicated by the subject_id column. The id of the object resource is indicated by the value in the value column. This value must correspond to a value in the id column of the classes.csv file. For example, generating a geo:location link between the instances of the geo:SpatialThing and geo:Point classes shown in Fig. 2 would be accomplished by putting "$root" (the id of the geo:SpatialThing resource) in the subject_id column of the metadata-column-mappings.csv file, "geo:location" in the precicate column, and "point" (the id of the geo:Point resource) in the value column. If the link is to a blank node, use the same blank node placeholder as was used in the classes.csv table (Fig. 3).
Here is the RDF output in Turtle serialization that would result from applying the mapping table to the metadata table in Fig. 3.
<http://example.org/Lingyansi>
rdfs:label "灵岩寺"@zh-Hans;
rdfs:seeAlso <http://sws.geonames.org/1803429/>;
dcterms:temporal _:edbde6f9-62f0-4922-a1f3-e4bfa379303d;
a geo:SpatialThing.
_:edbde6f9-62f0-4922-a1f3-e4bfa379303d
rdf:value "Tang to Ching"@en;
a dcterms:PeriodOfTime.
In this example, each religious site may be linked to one or more buildings that are present at that site. Each site might also have been photographed one or more times. One possible approach would be to assign separate dereferenceable IRIs to each building and link each building instance to its containing site by the predicate schema:containedInPlace. Similarly, each photo could be assigned a separate dereferenceable IRI and linked by the predicate foaf:depicts to the particular site that was photographed.
However, it might be preferable to use the single dereferenceable IRI for the site along with fragment identifiers to distinguish the various buildings and photographs associated with the site. Then if, for example, a building hash IRI were dereferenced, the client would also retrieve all of the metadata about the site, other buildings at the site, and all photographs associated with the site in a single file.
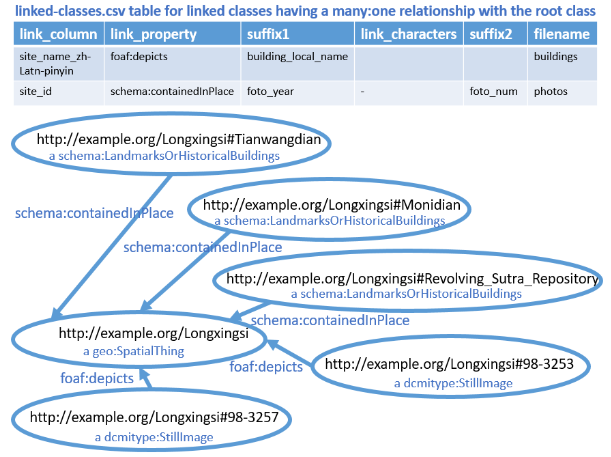
Fig. 4. Many-to-one relationships between buildings and photos of a Chinese religious site.
In order to accomplish that, a CSV table called linked-classes.csv should be created, with a row for each class that has a many-to-one relationship with the core class represented by the data in the metadata.csv file (Fig. 4). In the example, the string "buildings" is prepended to the CSV file names associated with the buildings. Thus buildings.csv for buildings corresponds to the metadata.csv file for sites, buildings-classes.csv for buildings corresponds to classes.csv for sites, and buildings-column-mappings.csv for buildings corresponds to cloumn-mappings.csv for sites. The formats and conventions previously described for the core class (e.g. sites) apply to the linked classes (e.g. buildings and photos) as well.
In the linked-classes.csv table (Fig. 4) the link_column indicates the column in the linked class table that acts as a foreign key to the primary key (found in the iri_local_name column) for a row in the metadata.csv file. There may be several rows in the linked class table whose value for the link_column column match primary key of a single row in the metadata.csv file.
The fragment identifiers for the linked resources can be formed from the values in one or two columns of the linked class metadata table. Alternatively, the linked resources can be blank nodes without identifiers. If the fragment identifier method is used, the string value of a single column or concatenated string values of two columns must uniquely identify the linked class instance from all other instances of that class in the database. In the example of Fig. 4, each building has a unique string in the building_name_zh-Latn-pinyin column, so appending that string as a hash to the site IRI results in a globally unique identifier for the building. In the case of the photos, there may be duplicate photo numbers within a given year, so a unique string for the photo is formed by concatenating a string for the year with a string for the photo. If the linked resource is to be a blank node, the value in the "suffix1" column should begin with the characters "_:" (the subsequent characters, if any, do not matter).
The link_property column contains the abbreviated IRI for the predicate used to make the link between the linked class and the root class of the metadata.csv file.
Here is how the RDF would look in Turtle serialization for the example in Fig. 4. For brevity, only a few properties of each linked resource are shown.
<http://example.org/Longxingsi>
rdfs:label "隆兴寺"@zh-Hans;
dcterms:temporal _:5dfe5ff8-1340-4eef-987c-f666ba92086c;
a geo:SpatialThing.
_:5dfe5ff8-1340-4eef-987c-f666ba92086c
rdf:value "initially built 586; now 宋 10th-11th century"@en;
a dcterms:PeriodOfTime.
<http://example.org/Longxingsi#Tianwangdian>
rdfs:label "天王殿"@zh-Hans;
schema:containedInPlace <http://example.org/Longxingsi>;
a schema:LandmarksOrHistoricalBuildings.
<http://example.org/Longxingsi#Monidian>
rdfs:label "摩尼殿"@zh-Hans;
schema:containedInPlace <http://example.org/Longxingsi>;
a schema:LandmarksOrHistoricalBuildings.
<http://example.org/Longxingsi#Revolving_Sutra_Repository>
rdfs:label "轉論藏閣"@zh-Hans;
schema:containedInPlace <http://example.org/Longxingsi>;
a schema:LandmarksOrHistoricalBuildings.
<http://example.org/Longxingsi##98-3253>
dcterms:description "Aerial overview over Longxingsi"@en;
foaf:depicts <http://example.org/Longxingsi>;
a dcmitype:StillImage.
<http://example.org/Longxingsi##98-3257>
dcterms:description "View from the main courtyard of Longxingsi"@en;
foaf:depicts <http://example.org/Longxingsi>;
a dcmitype:StillImage.
The file namespace.csv must be present in the same directory as the other CSV files. One column of the table must be headed "curie" and contain the compact IRI (CURIE, i.e. namespace abbreviation), without colon, for each IRI that is abbreviated in the metadata. The other column muse be headed "value" and contain the unabbreviated value of the IRI that is abbreviated by the CURIE.
CURIEs for several IRIs must be present in the table since the scripts themselves generate IRIs that use those CURIEs. Those CURIEs are: rdf (http://www.w3.org/1999/02/22-rdf-syntax-ns#), rdfs (http://www.w3.org/2000/01/rdf-schema#), xsd (http://www.w3.org/2001/XMLSchema#), and dc (http://purl.org/dc/elements/1.1/). It does not hurt to include CURIEs that are not represented in the data, but failing to include CURIEs that are represented in the data may result in errors.
The file constants.csv contains strings that may vary from user to user. They are include in this file to avoid hard-coding them in the scripts. The column header is an abbreviation for the constant and the first row below the headers contains the values. "domainRoot" is IRI to be appended to the local name part of resource IRIs. In Fig. 4, the domainRoot "http://example.org/" was appended to the local name "Longxingsi" to create the IRI for the site instance (geo:SpatialThing instance). If the column identifying the resource is a complete IRI, then the domainRoot value should be empty. "coreClassFile" is the name of the primary metadata CSV document for the core class (including file extension). The part of this name before the file extension forms the prefix for the "-classes.csv" and "-column-mapping.csv" files. "documentClass" is the rdf:type value for the RDF document that contains the serialized triples. The default is foaf:Document. The "creator" value is used as the value for the dc:creator property of the RDF document. "outputDirectory" is used to specify the directory where the output can be saved as a file. "outFileNameAfter" provides the delimiter within the resource identifier (IRI or local name) after which constitutes the file name. For example, if the resource identifier is "http://example.org/myThing" and the outFileNameAfter value is "/" then "myThing" would be used as the file name (with extension to be determined by the serialization). If the entire identifier is to be used, leave this empty. "Separator" provides the character used to separate items in the primary metadata CSV files (metadata.csv and [class]-metadata.csv where [class] is the class whose instances are linked in a many-to-one relationship with the primary class described by the metadata.csv file). Typically the value is "," although other characters may be used. For TAB separated values, use the escaped value "	". All of the other CSV files must be comma separated. The "baseIriColumn" is the header for the column containing the resource identifier (full IRI or local name). The "modifiedColumn" is the header for the column containing the last-modified value, which should be in xsd:dateTime format.