diff --git a/_posts/2018-06-02-linear-regression.md b/_posts/2018-06-02-linear-regression.md
deleted file mode 100644
index df991378e4b2..000000000000
--- a/_posts/2018-06-02-linear-regression.md
+++ /dev/null
@@ -1,357 +0,0 @@
----
-title: "Linear Regression for Starters"
-excerpt: "I was recently inspired by this following PyData London talk by
-[Vincent Warmerdam](http://koaning.io/). It's a great talk: he has a lot of
-great tricks to make simple, small-brain models really work wonders, and he
-emphasizes thinking about your problem in a logical way over trying to use
-_(Tensorflow)_ cutting-edge or _(deep learning)_ hyped-up methods just for the
-sake of using them…"
-tags:
- - mathematics
- - statistics
-header:
- overlay_image: /assets/images/cool-backgrounds/cool-background6.png
- caption: 'Photo credit: [coolbackgrounds.io](https://coolbackgrounds.io/)'
-mathjax: true
-last_modified_at: 2018-06-02
----
-
-I was recently inspired by this following PyData London talk by [Vincent
-Warmerdam](http://koaning.io/). It's a great talk: he has a lot of great tricks
-to make simple, small-brain models really work wonders, and he emphasizes
-thinking about your problem in a logical way over trying to use cutting-edge
-_(Tensorflow)_ or hyped-up _(deep learning)_ methods just for the sake of using
-them — something I'm amazed that people seem to need to be reminded of.
-
-
-
-One of my favorite tricks was the first one he discussed: extracting and
-forecasting the seasonality of sales of some product, just by using linear
-regression (and some other neat but ultimately simple tricks).
-
-That's when I started feeling guilty about not really
-[_grokking_](https://www.merriam-webster.com/dictionary/grok) linear regression.
-It sounds stupid for me to say, but I've never really managed to _really_
-understand it in any of my studies. The presentation always seemed very canned,
-each topic coming out like a sardine: packed so close together, but always
-slipping from your hands whenever you pick them up.
-
-So what I've done is take the time to really dig into the math and explain how
-all of this linear regression stuff hangs together, trying (and only partially
-succeeding) not to mention any domain-specific names. This post will hopefully
-be helpful for people who have had some exposure to linear regression before,
-and some fuzzy recollection of what it might be, but really wants to see how
-everything fits together.
-
-There's going to be a fair amount of math (enough to properly explain the gist
-of linear regression), but I'm really not emphasizing proofs here, and I'll even
-downplay explanations of the more advanced concepts, in favor of explaining the
-various flavors of linear regression and how everything hangs together.
-
-## So Uh, What is Linear Regression?
-
-The basic idea is this: we have some number that we're interested in. This
-number could be the price of a stock, the number of stars a restaurant has on
-Yelp… Let's denote this _number-that-we-are-interested-in_ by the letter
-$$y$$. Occasionally, we may have multiple observations for $$y$$ (e.g. we
-monitored the price of the stock over many days, or we surveyed many restaurants
-in a neighborhood). In this case, we stack these values of $$y$$ and consider
-them as a single vector: $${\bf y}$$. To be explicit, if we have $$n$$
-observations of $$y$$, then $${\bf y}$$ will be an $$n$$-dimensional vector.
-
-We also have some other numbers that we think are related to $$y$$. More
-explicitly, we have some other numbers that we suspect _tell us something_ about
-$$y$$. For example (in each of the above scenarios), they could be how the stock
-market is doing, or the average price of the food at this restaurant. Let us
-denote these _numbers-that-tell-us-something-about-y_ by the letter $$x$$.
-So if we have $$p$$ such numbers, we'd call them $$x_1, x_2, ..., x_p$$. Again,
-we occasionally have multiple observations: in which case, we arrange the $$x$$
-values into an $$n \times p$$ matrix which we call $$X$$.
-
-If we have this setup, linear regression simply tells us that $$y$$ is a
-weighted sum of the $$x$$s, plus some constant term. Easier to show you.
-
-$$ y = \alpha + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_p x_p + \epsilon $$
-
-where the $$\alpha$$ and $$\beta$$s are all scalars to be determined, and the
-$$\epsilon$$ is an error term (a.k.a. the **residual**).
-
-Note that we can pull the same stacking trick here: the $$\beta$$s will become a
-$$p$$-dimensional vector, $${\bf \beta}$$, and similarly for the $$\epsilon$$s.
-Note that $$\alpha$$ remains common throughout all observations.
-
-If we consider $$n$$ different observations, we can write the equation much more
-succinctly if we simply prepend a column of $$1$$s to the $${\bf X}$$ matrix and
-prepend an extra element (what used to be the $$\alpha$$) to the
-$${\bf \beta}$$ vector.
-
-Then the equation can be written as:
-
-$$ {\bf y} = {\bf X} {\bf \beta} + {\bf \epsilon} $$
-
-That's it. The hard part (and the whole zoo of different kinds of linear
-regressions) now comes from two questions:
-
-1. What can we assume, and more importantly, what _can't_ we assume about $$X$$ and $$y$$?
-2. Given $$X$$ and $$y$$, how exactly do we find $$\alpha$$ and $$\beta$$?
-
-## The Small-Brain Solution: Ordinary Least Squares
-
- -
-This section is mostly just a re-packaging of what you could find in any
-introductory statistics book, just in fewer words.
-
-Instead of futzing around with whether or not we have multiple observations,
-let's just assume we have $$n$$ observations: we can always set $$ n = 1 $$ if
-that's the case. So,
-
-- Let $${\bf y}$$ and $${\bf \beta}$$ be $$p$$-dimensional vectors
-- Let $${\bf X}$$ be an $$n \times p$$ matrix
-
-The simplest, small-brain way of getting our parameter $${\bf \beta}$$ is by
-minimizing the sum of squares of the residuals:
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-Our estimate for $${\bf \beta}$$ then has a “miraculous” closed-form
-solution[^1] given by:
-
-$$ {\bf \hat{\beta}} = ({\bf X}^T {\bf X})^{-1} {\bf X} {\bf y} $$
-
-This solution is so (in)famous that it been blessed with a fairly universal
-name, but cursed with the unimpressive name _ordinary least squares_ (a.k.a.
-OLS).
-
-If you have a bit of mathematical statistics under your belt, it's worth noting
-that the least squares estimate for $${\bf \beta}$$ has a load of nice
-statistical properties. It has a simple closed form solution, where the
-trickiest thing is a matrix inversion: hardly asking for a computational
-miracle. If we can assume that $$\epsilon$$ is zero-mean Gaussian, the least
-squares estimate is the maximum likelihood estimate. Even better, if the errors
-are uncorrelated and homoskedastic, then the least squares estimate is the best
-linear unbiased estimator. _Basically, this is very nice._ If most of that flew
-over your head, don't worry — in fact, forget I said anything at all.
-
-## Why the Small-Brain Solution Sucks
-
-[There are a ton of
-reasons.](http://www.clockbackward.com/2009/06/18/ordinary-least-squares-linear-regression-flaws-problems-and-pitfalls/)
-Here, I'll just highlight a few.
-
-1. Susceptibilty to outliers
-2. Assumption of homoskedasticity
-3. Collinearity in features
-4. Too many features
-
-Points 1 and 2 are specific to the method of ordinary least squares, while 3 and
-4 are just suckish things about linear regression in general.
-
-### Outliers
-
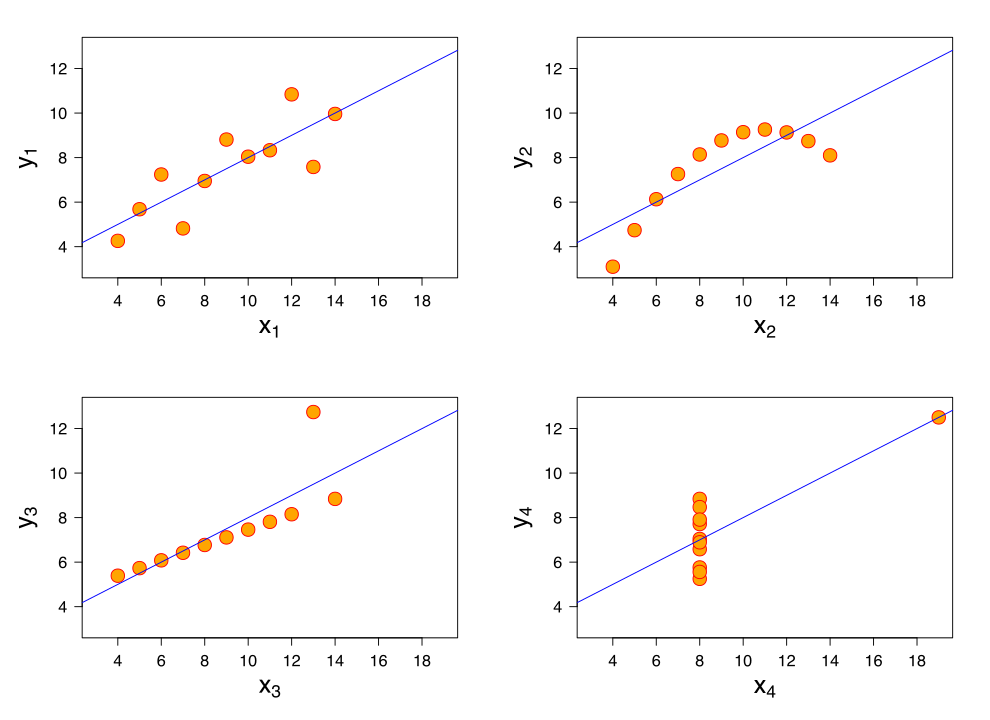
-The OLS estimate for $${\bf \beta}$$ is famously susceptible to outliers. As an
-example, consider the third data set in [Anscombe's
-quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet). That is, the data
-is almost a perfect line, but the $$n$$th data point is a clear outlier. That
-single data point pulls the entire regression line closer to it, which means it
-fits the rest of the data worse, in order to accommodate that single outlier.
-
-
-
-This section is mostly just a re-packaging of what you could find in any
-introductory statistics book, just in fewer words.
-
-Instead of futzing around with whether or not we have multiple observations,
-let's just assume we have $$n$$ observations: we can always set $$ n = 1 $$ if
-that's the case. So,
-
-- Let $${\bf y}$$ and $${\bf \beta}$$ be $$p$$-dimensional vectors
-- Let $${\bf X}$$ be an $$n \times p$$ matrix
-
-The simplest, small-brain way of getting our parameter $${\bf \beta}$$ is by
-minimizing the sum of squares of the residuals:
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-Our estimate for $${\bf \beta}$$ then has a “miraculous” closed-form
-solution[^1] given by:
-
-$$ {\bf \hat{\beta}} = ({\bf X}^T {\bf X})^{-1} {\bf X} {\bf y} $$
-
-This solution is so (in)famous that it been blessed with a fairly universal
-name, but cursed with the unimpressive name _ordinary least squares_ (a.k.a.
-OLS).
-
-If you have a bit of mathematical statistics under your belt, it's worth noting
-that the least squares estimate for $${\bf \beta}$$ has a load of nice
-statistical properties. It has a simple closed form solution, where the
-trickiest thing is a matrix inversion: hardly asking for a computational
-miracle. If we can assume that $$\epsilon$$ is zero-mean Gaussian, the least
-squares estimate is the maximum likelihood estimate. Even better, if the errors
-are uncorrelated and homoskedastic, then the least squares estimate is the best
-linear unbiased estimator. _Basically, this is very nice._ If most of that flew
-over your head, don't worry — in fact, forget I said anything at all.
-
-## Why the Small-Brain Solution Sucks
-
-[There are a ton of
-reasons.](http://www.clockbackward.com/2009/06/18/ordinary-least-squares-linear-regression-flaws-problems-and-pitfalls/)
-Here, I'll just highlight a few.
-
-1. Susceptibilty to outliers
-2. Assumption of homoskedasticity
-3. Collinearity in features
-4. Too many features
-
-Points 1 and 2 are specific to the method of ordinary least squares, while 3 and
-4 are just suckish things about linear regression in general.
-
-### Outliers
-
-The OLS estimate for $${\bf \beta}$$ is famously susceptible to outliers. As an
-example, consider the third data set in [Anscombe's
-quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet). That is, the data
-is almost a perfect line, but the $$n$$th data point is a clear outlier. That
-single data point pulls the entire regression line closer to it, which means it
-fits the rest of the data worse, in order to accommodate that single outlier.
-
- -
-### Heteroskedasticity and correlated residuals
-
-Baked into the OLS estimate is an implicit assumption that the $$\epsilon$$s all
-have the same variance. That is, the amount of noise in our data is independent
-of what region of our feature space we're in. However, this is usually not a
-great assumption. For example, harking back to our stock price and Yelp rating
-examples, this assumption states that the price of a stock fluctuates just as
-much in the hour before lunch as it does in the last 5 minutes before market
-close, or that Michelin-starred restaurants have as much variation in their Yelp
-ratings as do local coffee shops.
-
-Even worse: not only can the residuals have different variances, but they may
-also even be correlated! There's no reason why this can't be the case. Going
-back to the stock price example, we know that high-volatility regimes introduce
-much higher noise in the price of a stock, and volatility regimes tend to stay
-fairly constant over time (notwithstanding structural breaks), which means that
-the level of volatility (i.e. noise, or residual) suffers very high
-autocorrelation.
-
-The long and short of this is that some points in our training data are more
-likely to be impaired by noise and/or correlation than others, which means that
-some points in our training set are more reliable/valuable than others. We don’t
-want to ignore the less reliable points completely, but they should count less
-in our computation of $${\bf \beta}$$ than points that come from regions of
-space with less noise, or not impaired as much by correlation.
-
-### Collinearity
-
-Collinearity (or multi-collinearity) is just a fancy way of saying that our
-features are correlated. In the worst case, suppose that two of our columns in
-the $${\bf X}$$ matrix are identical: that is, we have repeated data. Then, bad
-things happen: the matrix $${\bf X}^T {\bf X}$$ no longer has full rank (or at
-least, becomes
-[ill-conditioned](https://en.wikipedia.org/wiki/Condition_number)), which means
-the actual inversion becomes an extremely sensitive operation and is liable to
-give you nonsensically large or small regression coefficients, which will impact
-model performance.
-
-### Too many features
-
-Having more data may be a good thing, but more specifically, having more
-_observations_ is a good thing. Having more _features_ might not be a great
-thing. In the extreme case, if you have more features than observations, (i.e.
-$$ n < p $$), then the OLS estimate of $${\bf \beta}$$ generally fails to be
-unique. In fact, as you add more and more features to your model, you will find
-that model performance will begin to degrade long before you reach this point
-where $$ n < p $$.
-
-## Expanding-Brain Solutions
-
-
-
-### Heteroskedasticity and correlated residuals
-
-Baked into the OLS estimate is an implicit assumption that the $$\epsilon$$s all
-have the same variance. That is, the amount of noise in our data is independent
-of what region of our feature space we're in. However, this is usually not a
-great assumption. For example, harking back to our stock price and Yelp rating
-examples, this assumption states that the price of a stock fluctuates just as
-much in the hour before lunch as it does in the last 5 minutes before market
-close, or that Michelin-starred restaurants have as much variation in their Yelp
-ratings as do local coffee shops.
-
-Even worse: not only can the residuals have different variances, but they may
-also even be correlated! There's no reason why this can't be the case. Going
-back to the stock price example, we know that high-volatility regimes introduce
-much higher noise in the price of a stock, and volatility regimes tend to stay
-fairly constant over time (notwithstanding structural breaks), which means that
-the level of volatility (i.e. noise, or residual) suffers very high
-autocorrelation.
-
-The long and short of this is that some points in our training data are more
-likely to be impaired by noise and/or correlation than others, which means that
-some points in our training set are more reliable/valuable than others. We don’t
-want to ignore the less reliable points completely, but they should count less
-in our computation of $${\bf \beta}$$ than points that come from regions of
-space with less noise, or not impaired as much by correlation.
-
-### Collinearity
-
-Collinearity (or multi-collinearity) is just a fancy way of saying that our
-features are correlated. In the worst case, suppose that two of our columns in
-the $${\bf X}$$ matrix are identical: that is, we have repeated data. Then, bad
-things happen: the matrix $${\bf X}^T {\bf X}$$ no longer has full rank (or at
-least, becomes
-[ill-conditioned](https://en.wikipedia.org/wiki/Condition_number)), which means
-the actual inversion becomes an extremely sensitive operation and is liable to
-give you nonsensically large or small regression coefficients, which will impact
-model performance.
-
-### Too many features
-
-Having more data may be a good thing, but more specifically, having more
-_observations_ is a good thing. Having more _features_ might not be a great
-thing. In the extreme case, if you have more features than observations, (i.e.
-$$ n < p $$), then the OLS estimate of $${\bf \beta}$$ generally fails to be
-unique. In fact, as you add more and more features to your model, you will find
-that model performance will begin to degrade long before you reach this point
-where $$ n < p $$.
-
-## Expanding-Brain Solutions
-
- -
-Here I'll discuss some add-ons and plugins you can use to upgrade your Ordinary
-Least Squares Linear Regression™ to cope with the four problems I described
-above.
-
-### Heteroskedasticity and correlated residuals
-
-To cope with different levels of noise, we can turn to *generalized least
-squares* (a.k.a. GLS), which is basically a better version of ordinary least
-squares. A little bit of math jargon lets us explain GLS very concisely. Instead
-of minimizing the _Euclidean norm_ of the residuals, we minimize its
-_Mahalanobis norm_: in this way, we take into account the second-moment
-structure of the residuals, and allows us to put more weight on the data points
-on more valuable data points (i.e. those not impaired by noise or correlation).
-
-Mathematically, the OLS estimate is given by
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-whereas the GLS estimate is given by
-
-$${\bf \hat{\beta}} = \text{argmin} ({\bf y} - {\bf X}{\bf \beta})^T {\bf \Sigma} ({\bf y} - {\bf X}{\bf \beta})$$
-
-where $${\bf \Sigma}$$ is the _known_ covariance matrix of the residuals.
-
-Now, the GLS estimator enjoys a lot of statistical properties: it is unbiased,
-consistent, efficient, and asymptotically normal. _Basically, this is very
-**very** nice._
-
-In practice though, since $$\Sigma$$ is usually not known, approximate methods
-(such as [weighted least
-squares](https://en.wikipedia.org/wiki/Least_squares#Weighted_least_squares), or
-[feasible generalized least
-squares](https://en.wikipedia.org/wiki/Generalized_least_squares#Feasible_generalized_least_squares))
-which attempt to estimate the optimal weight for each training point, are used.
-One thing that I found interesting while researching this was that these
-methods, while they attempt to approximate something better than OLS, may end up
-performing _worse_ than OLS! In other words (and more precisely), it's true that
-these approximate estimators are _asymptotically_ more efficient, for small or
-medium data sets, they can end up being _less_ efficient than OLS. This is why
-some authors prefer to just use OLS and find _some other way_ to estimate the
-variance of the estimator (where this _some other way_ is, of course, robust to
-heteroskedasticity or correlation).
-
-### Outliers
-
-Recall that OLS minimizes the sum of squares (of residuals):
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-A _regularized estimation_ scheme adds a penalty term on the size of the coefficients:
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 + P({\bf \beta}) $$
-
-where $$P$$ is some function of $${\bf \beta}$$. Common choices for $$P$$ are:
-
-- The $$l_1$$ norm: $$P({\bf \beta}) = \|{\bf \beta}\|_1$$
-
-- The $$l_2$$ norm: $$P({\bf \beta}) = \|{\bf \beta}\|_2$$
-
-- Interpolating between the the first two options:
- $$P({\bf \beta}) = a \|{\bf \beta}\|_1 + (1-a) \|{\bf \beta}\|_2$$, where $$0 < a < 1$$
-
-While regularized regression has empirically been found to be more resilient to
-outliers, it comes at a cost: the regression coefficients lose their nice
-interpretation of “the effect on the regressand of increasing this regressor by
-one unit”. Indeed, regularization can be thought of as telling the universe: “I
-don't care about interpreting the regression coefficients, so long as I get a
-reasonable fit that is robust to overfitting”. For this reason, regularization
-is usually used for prediction problems, and not for inference.
-
-An alternative solution would be to apply some pre-processing to our data: for
-example, some anomaly detection on our data points could remove outliers from
-the consideration of our linear regression. However, this method also comes with
-its own problems — what if it removes the wrong points? It has the potential to
-really mess up our model if it did.
-
-The main takeaway, then, is that _outliers kinda just suck_.
-
-### Collinearity
-
-Collinearity a problem that comes and goes — sometimes it's there, othertimes
-not, and it's better to always pretend it's there than it is to risk forgetting
-about it.
-
-There are many ways to [detect
-multicollinearity](https://en.wikipedia.org/wiki/Multicollinearity#Detection_of_multicollinearity),
-many ways to [remedy
-it](https://en.wikipedia.org/wiki/Multicollinearity#Remedies_for_multicollinearity)
-and [many consequences if you
-don't](https://en.wikipedia.org/wiki/Multicollinearity#Consequences_of_multicollinearity).
-The Wikipedia page is pretty good at outlining all of those, so I'll just point
-to that.
-
-An alternative that Wikipedia doesn't mention is principal components regression
-(PCR), which is literally just principal components analysis followed by
-ordinary least squares. As you can imagine, by throwing away some of the
-lower-variance components, you can usually remove some of the collinearity.
-However, this comes at the cost of interpretability: there is no easy way to
-intuit the meaning of a principal component.
-
-A more sophisticated approach would be a close cousin of PCR: [partial least
-squares
-regression](https://en.wikipedia.org/wiki/Partial_least_squares_regression).
-It's a bit more mathematically involved, and I definitely don't have the time to
-do it full justice here. Google!
-
-### Too many features
-
-Having too many features to choose from sounds like the first-world problem of
-data science, but it opens up the whole world of high-dimensional statistics and
-feature selection. There are a lot of techniques that are at your disposal to
-winnow down the number of features here, but the one that is most related to
-linear regression is [least angle
-regression](https://en.wikipedia.org/wiki/Least-angle_regression) (a.k.a. LAR or
-LARS). It's an iterative process that determines the regression coefficients
-according to which features are most correlated with the target, and increases
-(or decreases) these regression coefficients until some other feature looks like
-it has more explanatory power (i.e. more correlated with the target). Like so
-many other concepts in this post, I can't properly do LAR justice in such a
-short space, but hopefully the idea was made apparent.
-
-Of course, there are other methods for feature selection too: you can run a
-regularized regression to force most of the features to have zero or near-zero
-coefficients, or you could use any of the tools in
-[`sklearn.feature_selection`](http://scikit-learn.org/stable/modules/feature_selection.html).
-
-## Now What?
-
-So that was pretty rushed and a bit hand-wavy, but hopefully it gave you a
-high-level view of what linear regression is, and how all these other flavors of
-linear regression differ from the ordinary least squares, and how they were made
-to remedy specific shortcomings of OLS.
-
-And it should come as no surprise that there are even more directions to take
-the concept of linear regression: [generalized linear models (a.k.a.
-GLMs)](https://en.wikipedia.org/wiki/Generalized_linear_model) allow you to
-model different kinds of $$y$$ variables (e.g. what if $$y$$ is a binary
-response, instead of a continuous variable?), and [Bayesian linear
-regression](https://www.quantstart.com/articles/Bayesian-Linear-Regression-Models-with-PyMC3)
-offers an amazing way to quantify the uncertainty in your coefficients. Big
-world; happy hunting!
-
----
-
-[^1]: Insert obligatory footnote here about [the Moore–Penrose inverse a.k.a. the pseudoinverse](https://en.wikipedia.org/wiki/Moore%E2%80%93Penrose_inverse).
-
-Here I'll discuss some add-ons and plugins you can use to upgrade your Ordinary
-Least Squares Linear Regression™ to cope with the four problems I described
-above.
-
-### Heteroskedasticity and correlated residuals
-
-To cope with different levels of noise, we can turn to *generalized least
-squares* (a.k.a. GLS), which is basically a better version of ordinary least
-squares. A little bit of math jargon lets us explain GLS very concisely. Instead
-of minimizing the _Euclidean norm_ of the residuals, we minimize its
-_Mahalanobis norm_: in this way, we take into account the second-moment
-structure of the residuals, and allows us to put more weight on the data points
-on more valuable data points (i.e. those not impaired by noise or correlation).
-
-Mathematically, the OLS estimate is given by
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-whereas the GLS estimate is given by
-
-$${\bf \hat{\beta}} = \text{argmin} ({\bf y} - {\bf X}{\bf \beta})^T {\bf \Sigma} ({\bf y} - {\bf X}{\bf \beta})$$
-
-where $${\bf \Sigma}$$ is the _known_ covariance matrix of the residuals.
-
-Now, the GLS estimator enjoys a lot of statistical properties: it is unbiased,
-consistent, efficient, and asymptotically normal. _Basically, this is very
-**very** nice._
-
-In practice though, since $$\Sigma$$ is usually not known, approximate methods
-(such as [weighted least
-squares](https://en.wikipedia.org/wiki/Least_squares#Weighted_least_squares), or
-[feasible generalized least
-squares](https://en.wikipedia.org/wiki/Generalized_least_squares#Feasible_generalized_least_squares))
-which attempt to estimate the optimal weight for each training point, are used.
-One thing that I found interesting while researching this was that these
-methods, while they attempt to approximate something better than OLS, may end up
-performing _worse_ than OLS! In other words (and more precisely), it's true that
-these approximate estimators are _asymptotically_ more efficient, for small or
-medium data sets, they can end up being _less_ efficient than OLS. This is why
-some authors prefer to just use OLS and find _some other way_ to estimate the
-variance of the estimator (where this _some other way_ is, of course, robust to
-heteroskedasticity or correlation).
-
-### Outliers
-
-Recall that OLS minimizes the sum of squares (of residuals):
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 $$
-
-A _regularized estimation_ scheme adds a penalty term on the size of the coefficients:
-
-$${\bf \hat{\beta}} = \text{argmin} \|{\bf y} - {\bf X}{\bf \beta}\|^2 + P({\bf \beta}) $$
-
-where $$P$$ is some function of $${\bf \beta}$$. Common choices for $$P$$ are:
-
-- The $$l_1$$ norm: $$P({\bf \beta}) = \|{\bf \beta}\|_1$$
-
-- The $$l_2$$ norm: $$P({\bf \beta}) = \|{\bf \beta}\|_2$$
-
-- Interpolating between the the first two options:
- $$P({\bf \beta}) = a \|{\bf \beta}\|_1 + (1-a) \|{\bf \beta}\|_2$$, where $$0 < a < 1$$
-
-While regularized regression has empirically been found to be more resilient to
-outliers, it comes at a cost: the regression coefficients lose their nice
-interpretation of “the effect on the regressand of increasing this regressor by
-one unit”. Indeed, regularization can be thought of as telling the universe: “I
-don't care about interpreting the regression coefficients, so long as I get a
-reasonable fit that is robust to overfitting”. For this reason, regularization
-is usually used for prediction problems, and not for inference.
-
-An alternative solution would be to apply some pre-processing to our data: for
-example, some anomaly detection on our data points could remove outliers from
-the consideration of our linear regression. However, this method also comes with
-its own problems — what if it removes the wrong points? It has the potential to
-really mess up our model if it did.
-
-The main takeaway, then, is that _outliers kinda just suck_.
-
-### Collinearity
-
-Collinearity a problem that comes and goes — sometimes it's there, othertimes
-not, and it's better to always pretend it's there than it is to risk forgetting
-about it.
-
-There are many ways to [detect
-multicollinearity](https://en.wikipedia.org/wiki/Multicollinearity#Detection_of_multicollinearity),
-many ways to [remedy
-it](https://en.wikipedia.org/wiki/Multicollinearity#Remedies_for_multicollinearity)
-and [many consequences if you
-don't](https://en.wikipedia.org/wiki/Multicollinearity#Consequences_of_multicollinearity).
-The Wikipedia page is pretty good at outlining all of those, so I'll just point
-to that.
-
-An alternative that Wikipedia doesn't mention is principal components regression
-(PCR), which is literally just principal components analysis followed by
-ordinary least squares. As you can imagine, by throwing away some of the
-lower-variance components, you can usually remove some of the collinearity.
-However, this comes at the cost of interpretability: there is no easy way to
-intuit the meaning of a principal component.
-
-A more sophisticated approach would be a close cousin of PCR: [partial least
-squares
-regression](https://en.wikipedia.org/wiki/Partial_least_squares_regression).
-It's a bit more mathematically involved, and I definitely don't have the time to
-do it full justice here. Google!
-
-### Too many features
-
-Having too many features to choose from sounds like the first-world problem of
-data science, but it opens up the whole world of high-dimensional statistics and
-feature selection. There are a lot of techniques that are at your disposal to
-winnow down the number of features here, but the one that is most related to
-linear regression is [least angle
-regression](https://en.wikipedia.org/wiki/Least-angle_regression) (a.k.a. LAR or
-LARS). It's an iterative process that determines the regression coefficients
-according to which features are most correlated with the target, and increases
-(or decreases) these regression coefficients until some other feature looks like
-it has more explanatory power (i.e. more correlated with the target). Like so
-many other concepts in this post, I can't properly do LAR justice in such a
-short space, but hopefully the idea was made apparent.
-
-Of course, there are other methods for feature selection too: you can run a
-regularized regression to force most of the features to have zero or near-zero
-coefficients, or you could use any of the tools in
-[`sklearn.feature_selection`](http://scikit-learn.org/stable/modules/feature_selection.html).
-
-## Now What?
-
-So that was pretty rushed and a bit hand-wavy, but hopefully it gave you a
-high-level view of what linear regression is, and how all these other flavors of
-linear regression differ from the ordinary least squares, and how they were made
-to remedy specific shortcomings of OLS.
-
-And it should come as no surprise that there are even more directions to take
-the concept of linear regression: [generalized linear models (a.k.a.
-GLMs)](https://en.wikipedia.org/wiki/Generalized_linear_model) allow you to
-model different kinds of $$y$$ variables (e.g. what if $$y$$ is a binary
-response, instead of a continuous variable?), and [Bayesian linear
-regression](https://www.quantstart.com/articles/Bayesian-Linear-Regression-Models-with-PyMC3)
-offers an amazing way to quantify the uncertainty in your coefficients. Big
-world; happy hunting!
-
----
-
-[^1]: Insert obligatory footnote here about [the Moore–Penrose inverse a.k.a. the pseudoinverse](https://en.wikipedia.org/wiki/Moore%E2%80%93Penrose_inverse).