





EdgarTools is a Python library for accessing SEC EDGAR filings as structured data. Parse financial statements, insider trades, fund holdings, proxy statements, and 20+ other filing types with a consistent Python API — in a few lines of code. Free and open source.
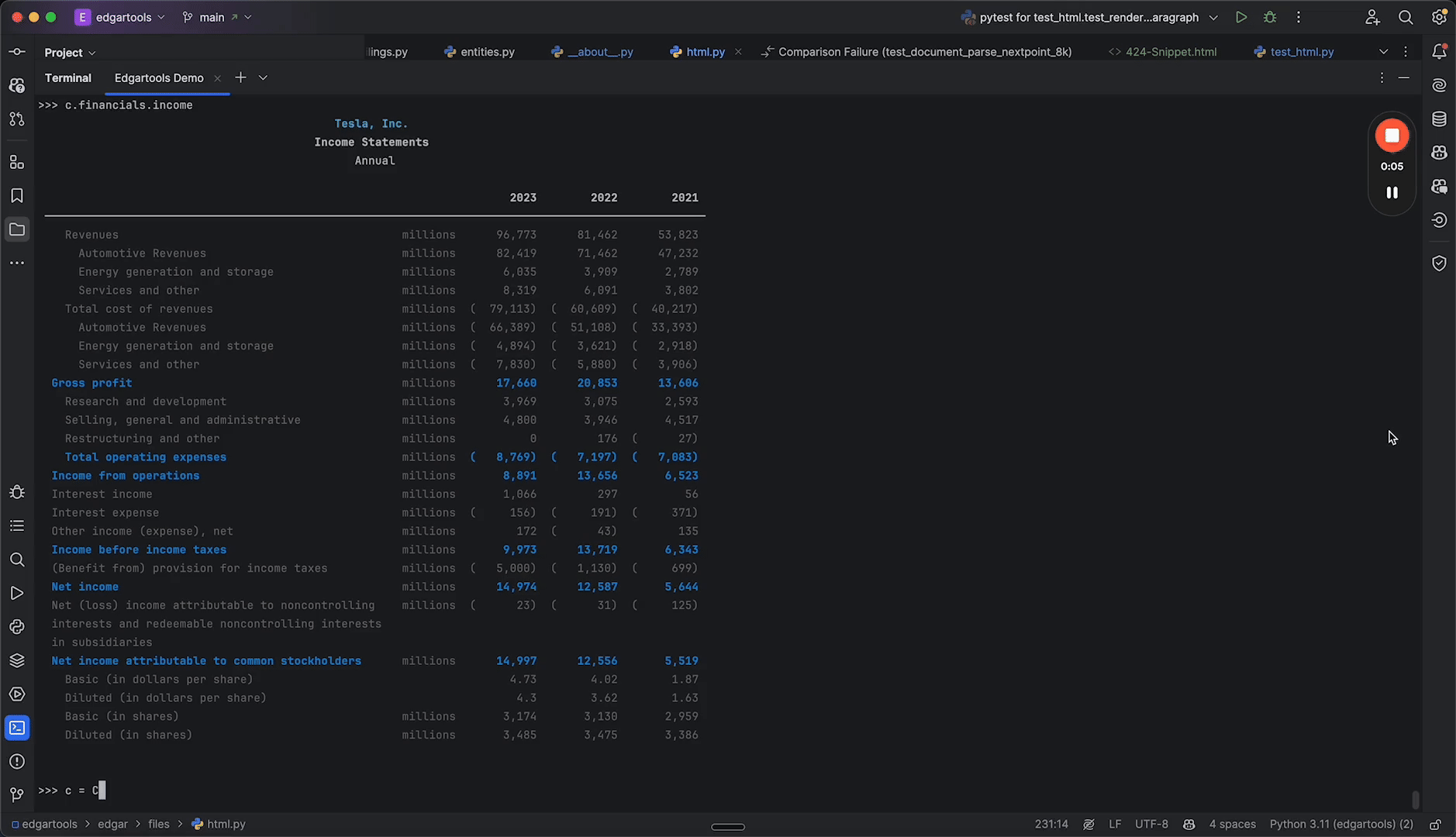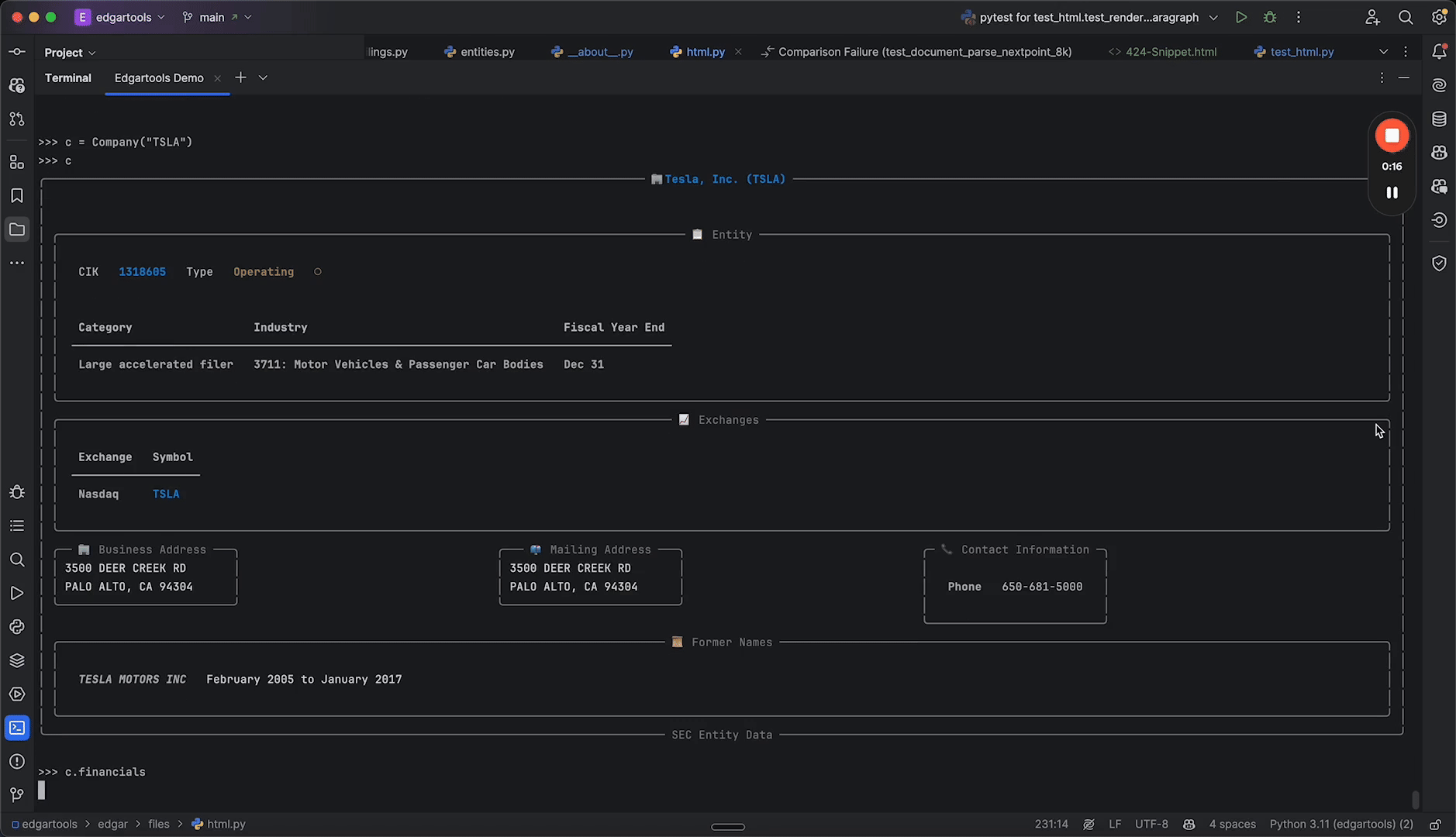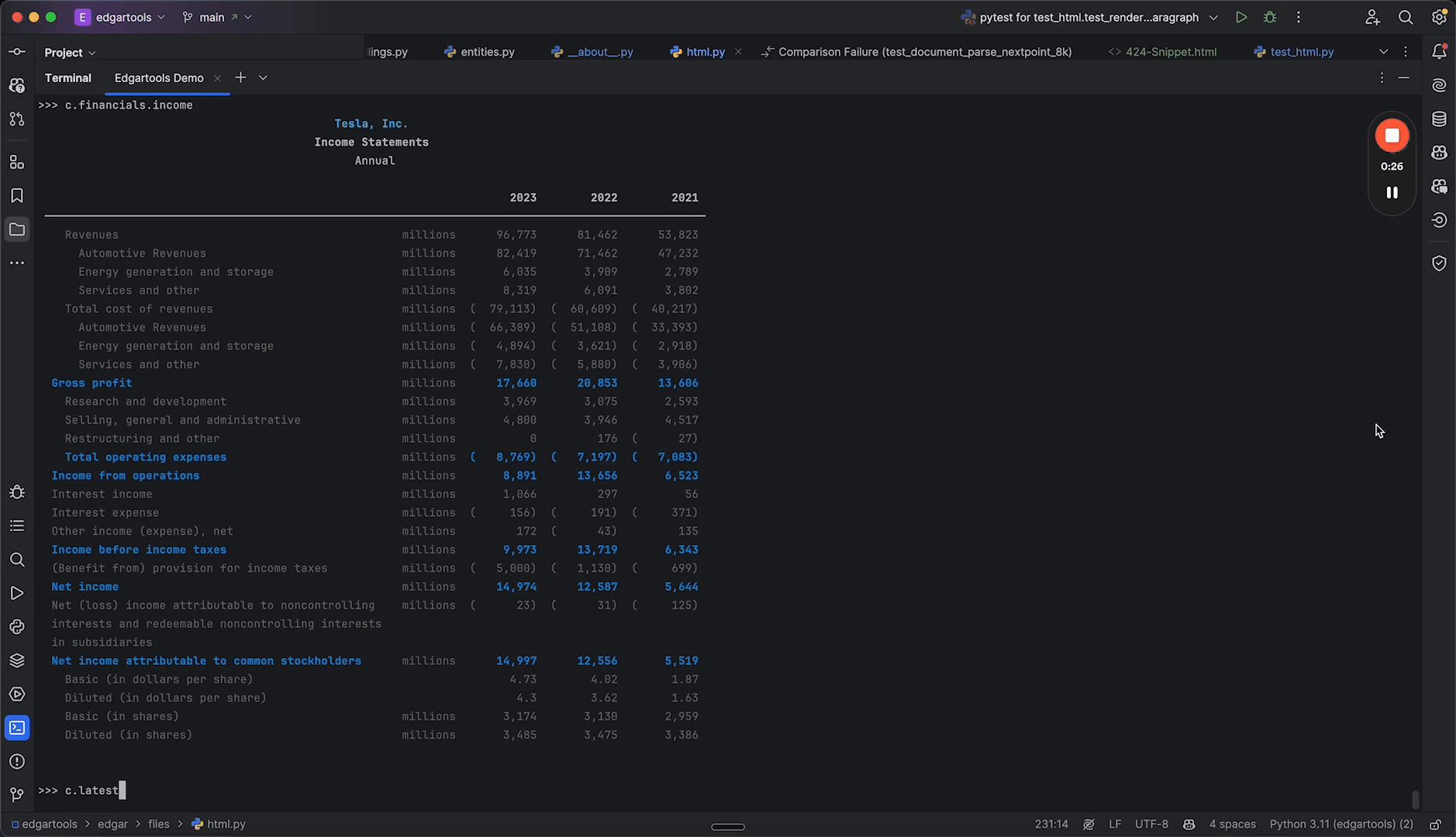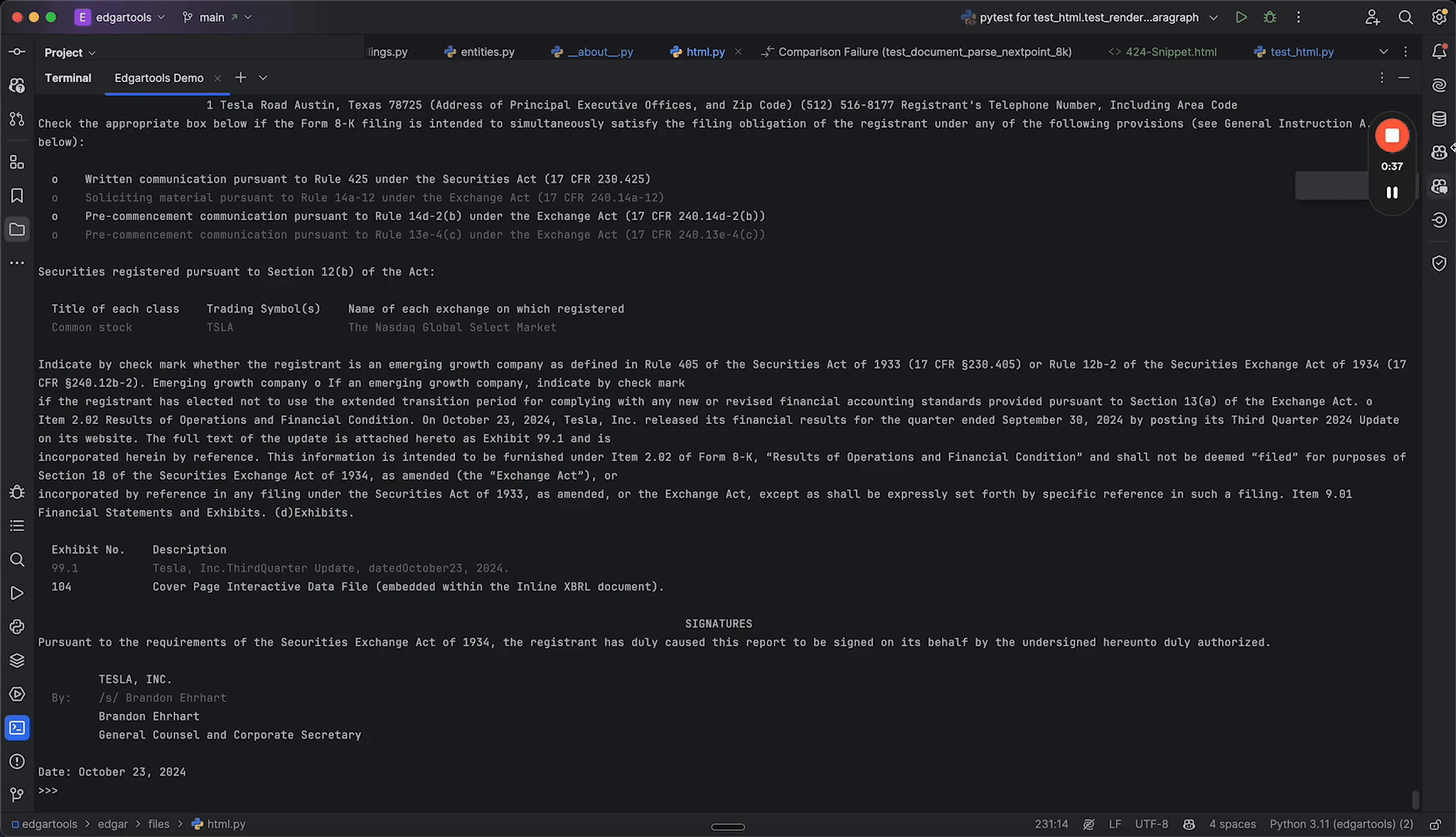
SEC EDGAR has every filing back to 1994, free — and almost none of it is ready to use. EdgarTools turns any filing into a typed Python object, so a 10-K's revenue is one line instead of an afternoon of XBRL parsing.
# Apple's latest income statement — rendered, standardized, done
from edgar import Company
Company("AAPL").get_financials().income_statement()|
Financial Statements Income, balance sheet, cash flow in one call XBRL-standardized for cross-company comparison |
Every Filing Type 13F holdings, Form 4 insiders, 8-K events, funds, proxies Typed objects + pandas DataFrames for 20+ forms |
Built for Pipelines & AI Rate-limit aware, smart caching, enterprise mirrors Built-in MCP server + LLM-ready text for RAG |
Everything starts with a Company or a Filing. Call .obj() and you get a typed object built for that form — its data ready as pandas DataFrames and clean text.

The same typed output that reads cleanly in a notebook drops straight into a pipeline: DataFrames for your warehouse, LLM-ready text and an MCP server for your AI stack, rate-limit and enterprise-mirror aware for scale.
1. Install
pip install edgartools2. Identify yourself to the SEC — EDGAR requires an email with every request. No key, no signup, no rate-limit tier; set it once:
from edgar import *
set_identity("your.name@example.com")3. Get data — every filing is now a few lines away:
# Standardized financial statements, straight from XBRL
Company("AAPL").get_financials().income_statement()
# The latest insider Form 4 as a structured object
Company("AAPL").get_filings(form="4").latest().obj()
Next: explore the Use Cases below, or dive into the documentation and Quick Guide.
financials = Company("MSFT").get_financials()
financials.balance_sheet() # all line items
financials.income_statement() # revenue, net income, EPSform4 = Company("TSLA").get_filings(form="4").latest().obj()
form4.to_dataframe() # insider buy/sell transactionsthirteenf = get_filings(form="13F-HR").latest().obj()
thirteenf.holdings # every portfolio position as a DataFrameInstitutional Holdings guide →
eightk = get_filings(form="8-K").latest().obj()
eightk.items # reported event itemsfacts = Company("AAPL").get_facts()
facts.query().by_concept("Revenue").to_dataframe() # revenue history as a DataFrame|
Financial data
Funds & ownership
|
Filings & text
Built for production
|
EdgarTools supports all SEC form types including 10-K annual reports, 10-Q quarterly filings, 8-K current reports, 13F institutional holdings, Form 4 insider transactions, proxy statements (DEF 14A), S-1 registration statements, N-CSR fund reports, N-MFP money market data, N-PORT fund portfolios, Schedule 13D/G ownership, Form D offerings, Form C crowdfunding, and Form 144 restricted stock. Parse XBRL financial data, extract text sections, and convert filings to pandas DataFrames.
EdgarTools is a Python library that talks directly to SEC EDGAR. sec-api is the best-known hosted API that returns JSON. Both parse filings — the difference is how you work with the data, and what it costs you.
| EdgarTools | sec-api | |
|---|---|---|
| Cost | Free, MIT | $49+/mo |
| Data format | Typed Python objects → DataFrames | JSON you parse yourself |
| Where it runs | In your process — no key, no quotas, no vendor lock-in | Hosted API — key + rate tiers |
| Filing coverage | 20+ typed forms (10-K, 8-K, 13F, N-PORT, proxy…) | 15+ structured endpoints |
| AI / MCP | ||
| Open source |
Bottom line: in Python, EdgarTools gives you typed objects, AI-native output, and the full SEC corpus — free, open, and inspectable, with no keys or bills. pip install edgartools and you're querying filings in two lines.
EdgarTools is the open-source library — SEC-filing primitives you compose in your own code, free and self-run.
edgar.tools is the hosted platform built on that same open engine: the full SEC corpus as a managed service, so your team gets the data without running the pipeline — and without the black box of a closed API.
Reach for the library when you want control in your own stack; reach for edgar.tools when you'd rather not operate it yourself.
EdgarTools includes an MCP server and AI skills for Claude Desktop and Claude Code. Ask questions in natural language and get answers backed by real SEC data.
- "Compare Apple and Microsoft's revenue growth rates over the past 3 years"
- "Which Tesla executives sold more than $1 million in stock in the past 6 months?"
Setup Instructions
Install the EdgarTools skill for Claude Code or Claude Desktop:
pip install "edgartools[ai]"
python -c "from edgar.ai import install_skill; install_skill()"This adds SEC analysis capabilities to Claude, including 3,450+ lines of API documentation, code examples, and form type reference.
Run EdgarTools as an MCP server for any AI client -- Claude Desktop, Cline, or your own containerized deployment.
Add to Claude Desktop config (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"edgartools": {
"command": "uvx",
"args": ["--from", "edgartools[ai]", "edgartools-mcp"],
"env": {
"EDGAR_IDENTITY": "Your Name your.email@example.com"
}
}
}
}Requires uv. Alternatively, pip install "edgartools[ai]" and use python -m edgar.ai.
See AI Integration Guide for complete documentation.
EdgarTools runs in production at hedge funds, fintechs, and research desks — MIT-licensed, no keys, no subscriptions, and maintained by one person.
The SEC amends filing formats every quarter and ships a new XBRL taxonomy every year. Sponsorship is what keeps 20+ parsers current and funds new extractors as fresh disclosure types appear.
Recurring sponsorship + corporate tiers via GitHub · One-time thanks via Buy Me a Coffee
If EdgarTools is in your data pipeline, GitHub Sponsors offers corporate tiers from $250 to $1,500/mo with:
- Response SLAs (24h–48h first response on critical issues)
- Quarterly strategy calls and roadmap input
- Logo placement in this README
- 7-day early access for internal regression testing
- Annual invoicing through GitHub — procurement-friendly
- GitHub Issues - Bug reports and feature requests
- Discussions - Questions and community discussions
Contributions welcome:
- Code: Fix bugs, add features, improve documentation
- Examples: Share interesting use cases and examples
- Feedback: Report issues or suggest improvements
- Spread the Word: Star the repo, share with colleagues
See our Contributing Guide for details.
Need help building production SEC data infrastructure? The creator of EdgarTools offers consulting for teams building financial AI products:
- SEC Data Sprint (1–3 days) — Working prototype on your data
- Architecture Review (1–2 weeks) — Pipeline audit with prioritized fixes
- Pipeline Build (2–4 weeks) — Production-ready code, tests, and handoff
EdgarTools is distributed under the MIT License