Big science fix passing multiple tensors #1400
Conversation
…activation Avoid partitioning small activations
* removes repeated overflow log * pipe_replicated * _pipe_replicated -> ds_pipe_replicated * Adds send/recv fallback to bcast when torch version <= 1.8
…er (deepspeedai#1263) Co-authored-by: Olatunji Ruwase <olruwase@microsoft.com>
* Use mpu in DeepSpeedConfig() call * Improve argument naming
* FP16 fused and unfused grad norm query. * API for obtaining global unclipped gradient norm across parameter groups * Use global norm not group norms Co-authored-by: Shaden Smith <shaden.smith@microsoft.com>
* restore fp16 params if no zero ckpts available * formatting
Co-authored-by: Jeff Rasley <jerasley@microsoft.com>
 stas00
left a comment
stas00
left a comment
There was a problem hiding this comment.
Great work, Thomas!
I left a few small suggestions.
I think the only issue here is that this new code doesn't have a test, so unless we add one it's likely to break down the road.
I'm not an expert on DS test suite, I added a few tests following monkey-see-monkey-do but this one might be not so easy to add. Let's first see if this is in general acceptable by the DS team and then we can work on a test.
deepspeed/runtime/pipe/engine.py
Outdated
| group=self.grid.get_slice_parallel_group()) | ||
| inputs = tuple([part.to_meta(), part.data()]) | ||
|
|
||
| inputs = ([part.to_meta(), part.data(), *inputs_grad_tail]) |
There was a problem hiding this comment.
should this not be a tuple? it could be just fine, I was just comparing with the original and it was there...
There was a problem hiding this comment.
This is a tuple, in python you don't need to specifcy tuple, parenthesis work just fine.
There was a problem hiding this comment.
I think it will be list.
>>> list_ = [1, 2, 3]
>>> is_tuple = (list_)
>>> type(is_tuple)
<class 'list'>the following line means type casting. parenthesis can not cast list into tuple.
so you need to remain keyword tuple.
inputs = ([part.to_meta(), part.data()]) # list
inputs = tuple([part.to_meta(), part.data()]) # tupleThere was a problem hiding this comment.
ah well played I didn't notice, which now begs the question why it works ...
EDIT: It actually doesn't matter, because you end up looping over the elements of an iterable. But I'll make the desired changes.
|
@ShadenSmith, @jeffra - could you please have a look at the proposed changes - this is currently a blocker for our adding of prefix-lm to Meg-DS. Thank you! |
|
@thomasw21, also please run: to auto-format your code - as you can see the build CI failed. |
|
|
|
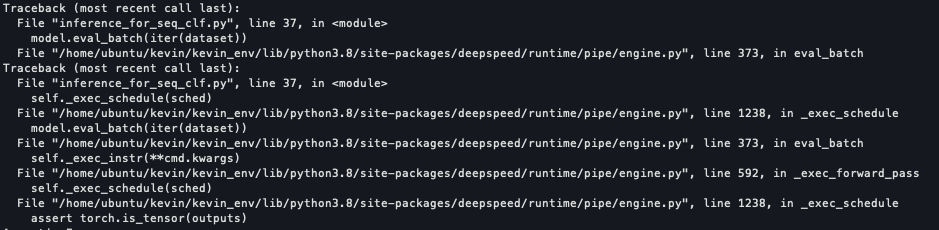
@thomasw21 I'll test your branch now. If it works, this will be a very great work. |
|
@thomasw21 I got error from this line. assert all([torch.is_tensor(elt) and elt.requires_grad is False for elt in outputs[1:]])Why all the output tensors except for first one must not be grad tensor when tuple was output? |
|
407ff0f#diff-26611f6be759237464a03bb1328cbc16555888836b3504dc3703e2e25d2a3ca3
|
|
Hey @hyunwoongko! Concerning the grad issue, i had two reasons:
|
|
I made un issue to make it more accessible for others. |
…sing-multiple-tensors
|
@stas00 Thanks ! I'll wait to get first general approval of the approach before writing tests I guess? Something important to note is that passing bool tensors works because we use torch 1.7+ (there was an issue with bool tensors not working in distributed setting using nccl) |
perhaps then it should check that @jeffra, what do you think? Do you have internal needs to support torch<1.7 for PP? Additionally, could one of you please confirm that this line of changes is agreeable to you? |
…:thomasw21/DeepSpeed into big-science-fix-passing-multiple-tensors
|
I should have fixed all the failing tests:
|

 ShadenSmith
left a comment
ShadenSmith
left a comment
There was a problem hiding this comment.
This is great, thanks a ton!
Fixes necessary for implementation of prefix lm:
torch.distributedfor pytorch > 1.7)