DJL serving is a high performance universal model serving solution. You can use djl-serving serve the following models out of the box:
- PyTorch TorchScript model
- TensorFlow SavedModel bundle
- Apache MXNet model
You can install extra extensions to enable the following models:
- ONNX model
- PaddlePaddle model
- TFLite model
- Neo DLR (TVM) model
- XGBoost model
- Sentencepiece model
- fastText/BlazingText model
DJL serving is built on top of Deep Java Library. You can visit DJL github repository to learn more about DJL.
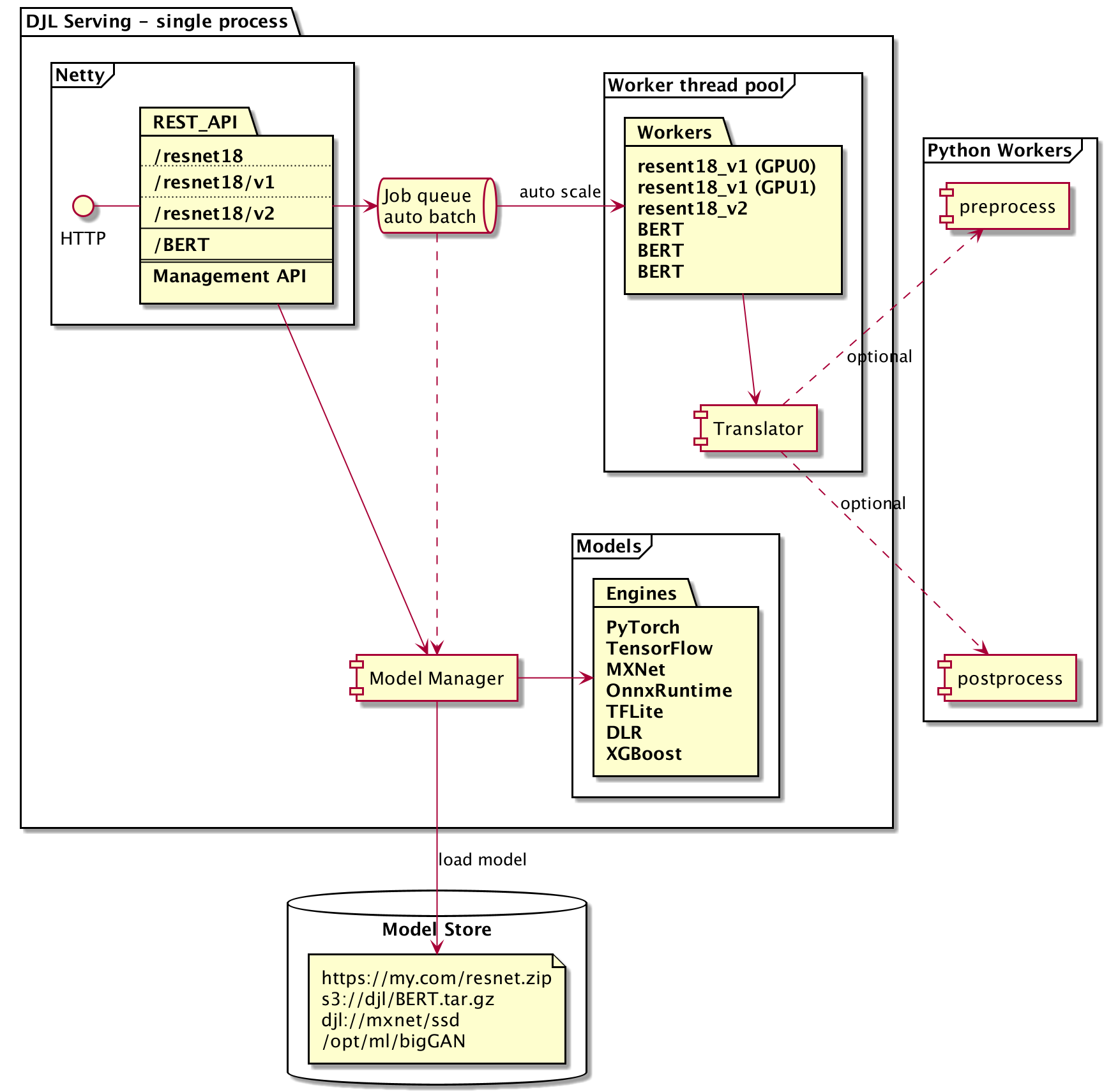
- Performance, DJL serving running multithreading inference in a single JVM. Our benchmark shows DJL serving has higher throughput than most of C++ based model server on the market.
- Ease of use, DJL serving can serve most of the models out of box.
- Easy to extend, DJL serving plugins make it easy for user to add their own extensions.
- Auto-scale, DJL serving automatically scales up/down worker threads based on the load.
- Dynamic batching, DJL serving supports dynamic batching to increase throughput.
- Model versioning, DJL allows user to load different version of a model on a single endpoint.
- Multi-engine support, DJL allows user to serve models from different engines at the same time.
For macOS
brew cask install djl-serving
# Start djl-serving as service:
brew services start djl-serving
# Stop djl-serving service
brew services stop djl-serving
For Ubuntu
curl -O https://publish.djl.ai/djl-serving/djl-serving_0.12.0-1_all.deb
sudo dpkg -i djl-serving_0.12.0-1_all.deb
For Windows
We are considering to create a chocolatey package for Windows. For the time being, you can
download djl-serving zip file from here.
You can also use docker to run DJL Serving:
docker run -itd -p 8080:8080 deepjavalibrary/djl-serving
Use the following command to start model server locally:
djl-servingThe model server will be listening on port 8080. You can also load a model for serving on start up:
djl-serving -m "https://resources.djl.ai/demo/mxnet/resnet18_v1.zip"Open another terminal, and type the following command to test the inference REST API:
curl -O https://resources.djl.ai/images/kitten.jpg
curl -X POST http://localhost:8080/predictions/resnet18_v1 -T kitten.jpg
or:
curl -X POST http://localhost:8080/predictions/resnet18_v1 -F "data=@kitten.jpg"
[
{
"className": "n02123045 tabby, tabby cat",
"probability": 0.4838452935218811
},
{
"className": "n02123159 tiger cat",
"probability": 0.20599420368671417
},
{
"className": "n02124075 Egyptian cat",
"probability": 0.18810515105724335
},
{
"className": "n02123394 Persian cat",
"probability": 0.06411745399236679
},
{
"className": "n02127052 lynx, catamount",
"probability": 0.010215568356215954
}
]For more command line options:
djl-serving --help
usage: djl-serving [OPTIONS]
-f,--config-file <CONFIG-FILE> Path to the configuration properties file.
-h,--help Print this help.
-m,--models <MODELS> Models to be loaded at startup.
-s,--model-store <MODELS-STORE> Model store location where models can be loaded.DJL Serving use RESTful API for both inference and management calls.
When DJL Serving startup, it starts two web services:
By default, DJL Serving listening on 8080 port and only accessible from localhost. Please see DJL Serving Configuration for how to enable access from remote host.
DJL Serving supports plugins, user can implement their own plugins to enrich DJL Serving features. See DJL Plugin Management for how to install plugins to DJL Serving.
you can set the logging level on the command-line adding a parameter for the JVM
-Dai.djl.logging.level={FATAL|ERROR|WARN|INFO|DEBUG|TRACE}